BAB 2
TINJAUAN PUSTAKA
2.1.Rough Set
TeoriRough setsampai saat ini pendekatan lain untuk ketidakjelasan (Pawlak, 1982). Demikian pula untuk teori himpunan fuzzy bukan merupakan alternatif untuk teori himpunan klasik tetapi tertanam di dalamnya. Teori Rough Set dapat dilihat sebagai implementasi khusus dari gagasan G. Frege (1983) tentang ketidakjelasan, yaitu ketidaktepatan dalam pendekatan ini dinyatakan oleh batas wilayah dari suatu
himpunan, dan bukan oleh keanggotaan parsial, seperti dalam teori himpunan fuzzy. Konsep Rough Set dapat didefinisikan cukup umum dengan cara operasi topologi,
interior dan penutupan, yang disebut pendekatan.
Tujuan analisisRough Setadalah untuk mendapatkanruleyang klasifikasi setelah dilakukan pengumpulan data (Maharani, 2008). Rule disini sudah dikalsifikasikan setelah mendapatkanreduct.
Sebagai contoh, pasien yang menderita penyakit flu, memiliki gejala yang sama tetapi tak terlihat dan dapat dianggap sebagai unit penyakit pengetahuan medis. Pengetahuan medis ini disebut set dasar (konsep). Konsep dasar ini dapat dikombinasikan menjadi konsep majemuk, yaitu konsep yang unik ditentukan dalam hal konsep dasar pengetahuan. Set dasar disebut set renyah (set awal), dan set selain set dasar disebut set kasar (samar-samar, tidak tepat). Perbeadaan set dasar dan set kasar adalah dilihat dari batas wilayahnya, set dasar merupakan eleman yang ada didalam set yang pasti milik set, sementara set kasar adalah elemen yang berada diluar set yang mungkin milik set.
6
Fungsi keanggotaan merupakan pemetaan titik-titik yang didapat dari himpunan
fuzzy kedalam keanggotaan yang memiliki interval antara 0 sampai dengan 1. Salah
satu cara untuk mendapatkan nilai keanggotaan adalah dengan pendekatan fungsi.
2.1.1. Sistem Informasi dan Klasifikasi
Data awal yang didapatkan dalam Rough Setadalah data yang disusun didalam tabel atau bisa disebut juga sebagai database atau sistem informasi. Dasar-dasar untuk menentukan Rough Set adalah menentukan perkiraan atas dan perkiraan bawah data yang berada didalam tabel tersebut sehingga diklasifikasikan sehingga membentuk data yang lebih kecil inilah merupakan konsep Rough Set yang diharapkan. Secara umum AlgoritmaRough Setadalah sebagai berikut: (Hasherni, dkk, 1997).
• Langkah 1- Mengurangi sistem informasi vertikal dan horizontal (sistem reduksi).
• Langkah 2- Menghasilkan bagian dan klasifikasi.
• Langkah 3- Menghasilkan ruang perkiraan bawah dan atas.
• Langkah 4- Ekstrak aturan lokal (tertentu, mungkin, dan perkiraan). • Langkah 5- End.
2.1.2. Sistem Informasi dan HubunganIndiscernibility
Sistem informasi yang didapat dari database akan diinformasikan menjadi Rough Set. Dan sistem informasi ada dua, yaitu conditional attribute dan decision system. Tiap-tiap baris dikatakanobjectsedangkan tiap kolom dikatakanattribute.
Dimana U adalahsetterhingga yang tidak kosong dari objek yang disebut dengan
universedan Asetterhingga tidak kosong dari atribut dimana (Nurhayati, 2014):
IS = {U,A} (2.1)
Untuk tiap A. Set V disebutvalue setdari a.
Dimana : IS adalahInformation System
7
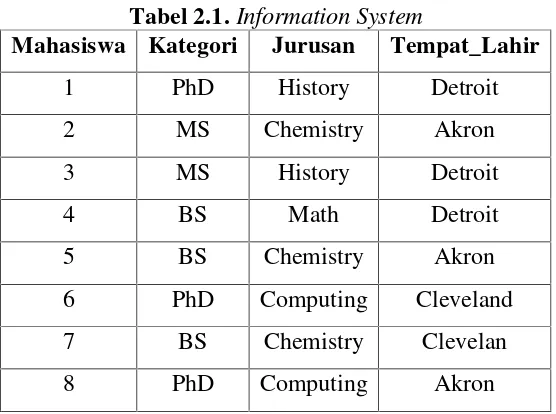
Tabel 2.1.Information System
Mahasiswa Kategori Jurusan Tempat_Lahir
1 PhD History Detroit
2 MS Chemistry Akron
3 MS History Detroit
4 BS Math Detroit
5 BS Chemistry Akron
6 PhD Computing Cleveland
7 BS Chemistry Clevelan
8 PhD Computing Akron
Tiap-tiap baris mempresentasikan objek, terdiri dari m example, seperti E1, E2, ..., Em. Sedangkan kolom mempresentasikan atribut, terdiri dari kategori, Jurusan, dan Tempat_Lahir.
Dalam penggunaan Information System terdapat outcome dari klasifikasi yang telah diketahui yang disebut dengan atribut keputusan. Information System tersebut
dapat disebut dengandecision system.
Decision systemdapat dilihat sebagai:
IS = (U,{A,C}) (2.2)
Dimana : IS adalahInformation System
U = {x1, x2, ...., xm}, yang merupakan sekumpulanexample. A = {a1, a2, ..., an}, sekumpulan atribut kondisi secara berurutan. C =decission attribute(keputusan)
Penjelasan dapat dilihat Tabel 2.2 (Chan, 2007):
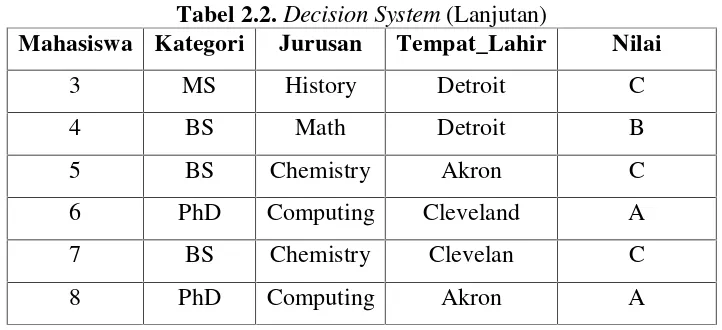
Tabel 2.2.Decision System
Mahasiswa Kategori Jurusan Tempat_Lahir Nilai
1 PhD History Detroit A
8
Tabel 2.2.Decision System(Lanjutan)
Mahasiswa Kategori Jurusan Tempat_Lahir Nilai
3 MS History Detroit C
4 BS Math Detroit B
5 BS Chemistry Akron C
6 PhD Computing Cleveland A
7 BS Chemistry Clevelan C
8 PhD Computing Akron A
Tiap-tiap baris mempresentasikan objek, terdiri dari m example, seperti E1, E2, ..., Em. Sedangkan kolom mempresentasikan atribut, terdiri dari kategori, Jurusan, Tempat_Lahir, dan Nilai.
2.1.3.SetdanSet Approximation
Menetapkan TeoriRough Setharus dikalsifikasikan kedalam satu set dan membuatnya menjadi bagian dari himpunan. Pendekatan yang lebih rendah, pendekatan atas, wilayah negatif, dan batas setXtentangI, masing-masing adalah :
P(X) = {x U:I(x) X} (2.3)
P(X) = {x U:I(x)∩X ≠ } (2.4)
BndP(X) = P(X) - P(X) (2.5)
Keterangan : P (X) adalah Pendekatan yg lebih rendah dari set X sehubungan dengan P(X tentu sehubungan dengan P)
P (X) adalah Pendekatan yg lebih tinggi dari set X sehubungan dengan P (yang mungkin X dalam p P)
BndP (X) adalah diklasifikasikan baik sebagai X atau tidak X sehubungan dengan P
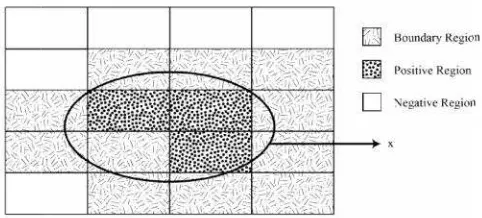
Gambar 2.1.Posi
Dari Tabel 2.2 diatas da • U\{kategori} = {(1, 6, 8 • U\{jurusan} = {(1, 3) • U\{tempat_lahir} = • U\{nilai} = {(1, 2, 6, 8 • Set X = {(nilai A)} = • Set B = {jurusan, t
U\B = {{1, 3}, {2, 5}, {4 • (X)= {6, 8}
• (X)= {1, 2, 3, 5, 6, 8} • Bnd(X) = {1, 2, 3, 5}
2.1.4. Quality of Approxi
Untuk mengukur keterga
X= {X1, X2, ..., Xn} ada
salah satu kelasX, dan
P(X) =
( ) | |
Keterangan : P(X) a
( ) U adalah se
Positive, boundary, and negative regionspada se (sumber :Yao, dkk, 1997)
s dapat dijelaskan bagaimana menghitungapprox
{(1, 6, 8)}, {(2, 3)}, {(4, 5, 7)}
{(1, 3)}, {(2, 5, 7)}, {(4)}, {(6, 8)}
r} = {(2, 5, 8)}, {(1, 3, 4)}, {(6, 7)}
1, 2, 6, 8)}, {(4)}, {(3, 5, 7)}
)} = {1, 2, 6, 8}
n, tempat_lahir}
{{1, 3}, {2, 5}, {4}, {6}, {7}, {8}}
(X)
(X) {1, 2, 3, 5, 6, 8} {1, 2, 3, 5}
pproximation and Reduct
tergantungan pengetahuan, kualitas klasifikasi ha } adalah partisi alam semesta U, di manaXi (i =
anP A, maka kualitas perkiraanXadalah
( ) | |
) adalahquality of approximationP terhadap X
adalah sigma atau jumlah, dimana i= 1,2,..., n
( )adalah pendekatan yang lebih rendah lah sekumpulan example
9
da sebuahsetx
approximation.
(X) (X)
si harus didefinisikan.
i = 1, 2, ...,n) adalah
( )
| | (2.6)
p X
1,2,..., n
10
2.1.5. Perhitungan Reduct dan Information System Berdasarkan Discernable Matrix
Showeron mengajukan metode untuk mengekspresikan pengetahuan dengan matriks
discernable pada tahun 1991, yang memiliki banyak keuntungan. Secara khusus,
dengan mudah dapat menjelaskan dan menghitung inti dan reduct dari information system. Maka fungsidiscernibilitydidefinisikan sebagai :
f(A) = Σa(x, y) (2.7)
(x, y) U x U
Keterangan : f(A) adalah fungsidiscernibility
` adalah pi
Σadalah sigma
aadalah variabel boolean (x, y) adalah objek x dan y U adalah sekumpulanexample
Sebuah matriks discernable dapat digunakan untuk mencari atribut bagian minimal (mengecil) untuk menurunkan gangguan data yang sama seperti pada atribut himpunan A. Untuk menemukan atribut bagian mini, perlu untuk membangun fungsi
discernibility yang merupakan fungsi Boolean dan dapat dibangun dalam metode berikut. Untuk setiap atribut yang dapat mengidentifikasi dua set elemen, seperti a1, a2, a3menunjuk Boolean konstanta, bentuk fungsi Boolean adalah a1+ a2+ a3atau (a1
a2 a3).
Jika atribut set kosong, maka konstan Boolean adalah 1 Misalnya, dalam kaitannya dengan matriks discernable menunjukkan pada Tabel 2.3 fungsi
discernibilityadalah :
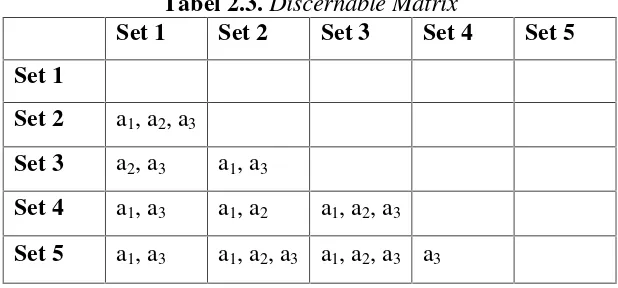
Tabel 2.3.Discernable Matrix
Set 1 Set 2 Set 3 Set 4 Set 5
Set 1
Set 2 a1, a2, a3
Set 3 a2, a3 a1, a3
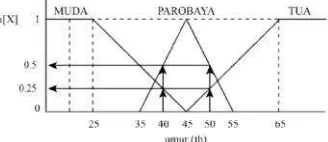
• Apabila seseorang TIDAK PAROBA • Apabila seseorang
PAROBAYA(µPAR • Apabila seseorang be
Dari sini bisa dije tidak cocok. Adanya signifikan dalam hal pe
Gambar 2.4 menunj
Gamb Pada Gambar 2.4, dapa • Seseorang yang be
µMUDA(40) = 0,25; dengan µPAROBAYA • Seseorang yang b
µTUA(50) = 0,25; na µPAROBAYA(50) = 0,5.
Disini terlihat jela himpunan crisp, nilai himpunanfuzzynilai ke
Berbeda lagi kita memiliki nilai pada i rentang terhadap hasil k nilai 0 sampai 1 sering MUDA adalah 0,9; m diulang secara individua
ang berusia 35 tahun kurang dari 1 tahun, m AYA (µPAROBAYA(35 tahun–1hr) = 0);
ang berusia 35 tahun lebih dari 1 tahun, m
AROBAYA(35) = 1);
ng berusia 55 tahun, maka ia dikatakan TUA (µ dijelaskan bahwa pemakaian himpunan crisp unt
a perubahan kecil saja sudah mengakibatka pemilihan himpunan.
nunjukkan himpunanfuzzyuntuk variabel umur.
mbar 2.4.HimpunanFuzzyuntuk Variabel umur pat dilihat bahwa:
berumur 40 tahun, termasuk dalam himpuna 0,25; namun dia juga termasuk dalam himpuna
A(40) = 0,5.
berumur 50 tahun, termasuk dalam himpuna
0,25; namun dia juga termasuk dalam himpunan PA 0,5.
elas perbedaan antara himpunan crisp dan him ai keanggotaan hanya ada 2 kemungkinan, ya i keanggotaan terletak pada rentang 0 sampai 1.
kita lihat perbedaan antara fuzzy dan proba da interval [0,1]. Keanggotaan fuzzy memberi sil keputusan. Sedangkan probabilitas memberika
ng muncul. Misalnya jika nilai keanggotaan sua maka tidak perlu dipermasalahkan berapa s vidual untuk mengharapkan suatu hasil yang ham
13
hun, maka ia dikatakan
hun, maka ia dikatakan
(µTUA(55) = 1);
sp untuk umur sangat kan perbedaan yang
ur.
umur
punan MUDA dengan punan PAROBAYA
punan TUA dengan
PAROBAYA dengan
himpunan fuzzy. Pada n, yaitu 0 dan 1, pada
1.
obabilitas. Keduanya berikan suatu ukuran rikan seberapa sering suatu himpunan fuzzy
14
Dilain pihak, nilai probabilitas 0,9 MUDA berarti 10% dari himpunan tersebut diharapkan TIDAK MUDA.
Himpuananfuzzymemiliki 2 atribut, yaitu:
a. Linguistik, yaitu bahasa yang digunakan sehari-hari yang berupa kata-kata, bukan angka seperti MUDA, PAROBAYA, TUA.
b. Numeris, yaitu suatu nilai (angka) yang menunjukkan ukuran dari suatu variabel seperti: 40, 25, 50, dsb.
Ada beberapa hal yang perlu diketahui dalam memahami sistemfuzzy, yaitu:
a. VariabelFuzzy
Merupakan suatu variabel yang nilainya tidak pasti/relatif. Seperti: umur, temperatur, permintaan, dsb.
b. HimpunanFuzzy
Merupakan suatu himpunan yang terdapat didalam variabel fuzzy. Seperti: umur {MUDA, PAROBAYA, TUA}, Temperatur {dingin, sejuk, normal, hangat, panas}. c. Semesta Pembicaraan
Merupakan nilai yang diperbolehkan untuk dioperasikan dalam variabel fuzzy. Misalkan: umur batas variabel [0 +∞], dan temperatur batas variabel [0 100].
d. Domain
Merupakan batas nilai yang diizinkan dalam himpunanfuzzy. Contoh domain himpunanfuzzy:
• MUDA = [0 45]
• PAROBAYA = [35 55]
• TUA = [45 +∞]
• DINGIN = [0 20]
• SEJUK = [15 25]
• NORMAL = [20 30]
• HANGAT = [25 35]
Pada penjelasan diatas, diizinkan 0 sampai 45. dst.
2.4. Fungsi Keanggotaan Merupakan pemetaan t keanggotaan yang mem mendapatkan nilai kean a. Representasi Kurva Kurva segitiga pada da Gambar 2.5.
Fungsi Keanggotaan:
µ[x]=
0; x a atau x c
(x a) (b a) ; a x b
(b x) )c b); b x c
Keterangan :µ adala x adala
‘a’adal
‘b’adal
‘c’adala
b. Representasi Kurva Kurva Segitiga pada da
tas, dapat dilihat bahwa untuk variabel MUDA 45. Untuk PAROBAYA batas nilai yang diizinka
ggotaan
n titik-titik kurva yang didapat dari himpunanf
emiliki interval antara 0 sampai dengan 1. Sal keanggotaan adalah dengan pendekatan fungsi, y
rva Segitiga
dasar merupakan gabungan antar 2 garis (li
Gambar 2.5.Kurva Segitiga
:
x ≤ a atau x ≥ c − a) ; a ≤ x ≤ b c − b); b ≤ x ≤ c
dalah fungsi keanggotaan
dalah variabel
dalah batas awal, dengan derajat keanggotaan 0
dalah batas kedua, dengan derajat keanggotaan 1
‘ dalah batas ketiga, dengan derajat keanggotaan 0
rva Trapesium
dasarnya seperti bentuk segitiga, hanya saja ada
15
DA batas nilai yang zinkan 35 sampai 55,
nfuzzy kedalam nilai Salah satu cara untuk si, yaitu:
(linear) terlihat pada
(2.8)
0
n 1
‘ n 0
Fungsi Keanggotaan:
µ[x] = ( − )⁄
1;
( − ) ( −⁄
Keterangan :µ adala x adala
‘ a’ adal
‘b’ adal
‘c’adal
‘d’ adal
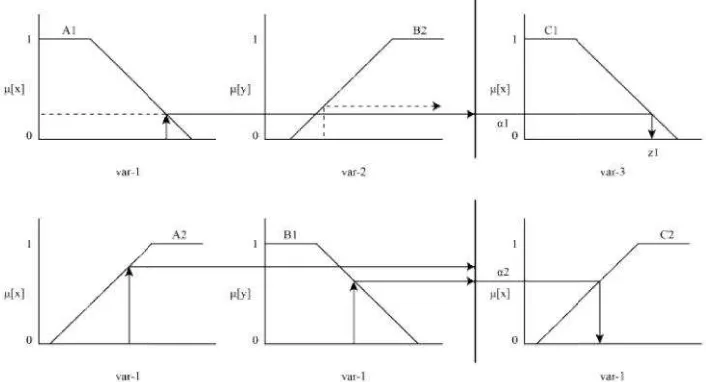
2.5. MetodeTsukamot
Secara umum bentuk m If (X IS A) and (Y IS B
Keterangan :A, B, d X, Y, da
Misalkan duketahui 2rul
IF (x is A1) AN IF (x is A2) AN Dalam inferensinya, me 1. Fuzzyfkasi
2. Pembentukan basis pe 3. Mesininferensi
Gambar 2.6.Kurva Trapesium n:
0; ≤ ≥
) ( − );⁄ ≤ ≤
≤ ≤
− ); ≥
dalah fungsi keanggotaan
dalah variabel
dalah batas awal, dengan derajat keanggotaan 0
dalah batas kedua, dengan derajat keanggotaan 1
‘ dalah batas ketiga, dengan derajat keanggotaan 1
dalah bataskeempat, dengan derajat keanggotaa
kamoto
uk modelFuzzy Tsukamotoadalah: S B) Then (Z IS C)
, dan C adalah himpunanfuzzy.
, dan Z adalah variabel
2ruleberikut.
ND (y is B1) THEN (z is C1) ND (y is B2) THEN (z is C2)
, metodeTsukamotomenggunakan tahapan berikut
n basis pengetahuanfuzzy(ruledalam bentuk IF … TH
16
(2.9)
0
n 1
‘ n 1
taan 0
n berikut.
Menggunakan fun predikat tiap-tiap r
Kemudian masing keluaran hasil infe
4. Defuzzyfikasi
Menggunakan met
Z*=∑α
∑α
Keterangan :Z*adal ∑ adal
αi adal zjadal
Gambar 2.7 me
defuzzyfikasidilakukan de
Gambar 2.7
2.6. Penelitian Terdah Menurut Beberapa pene pada Tabel 2.4.
ungsi implikasi MIN (Gambar 2.8) untuk me p rule (α1, α2,α3, ….,αn).
sing-masing nilai α-predikat ini digunakan unt nferensi secara tegas (crisp) masing-masing rule
etode rata-rata (average)
dalah rata-rata (average) alah sigma atau jumlah
dalah alpha, i = 1, 2, ..., n
dalah fungsi keanggotaan, j = 1, 2, ..., n
menunjukkan skema penalaran fungsi implikasi kukan dengan cara mencari nilai rata-ratanya.
2.7.Inferensidengan Menggunakan MetodeTsuk
(Sumber:Jang, 1997)
dahulu
enelitian yang telah dilakukan sebagai aturan p
17
mendapatkan nilai α
-n u-ntuk me-nghitu-ng ule (z1, z2, z3, …., zn)
(2.10)
kasi MIN dan proses
Tsukamoto
18
Tabel 2.4.Penelitian Terdahulu
No. Judul Nama &
Tahun
Algoritma /
Metode Hasil Penelitian
1. Thyroid Diagnosis based Technique on Rough Set with Modified Similarity Relation
Radwan, Elsayed dan Adel M. A. Assiri. 2013
Rough Set hasil statistik menunjukkan bahwa algoritma ini klasifikasi evolusi adalah yang terbaik dalam mengurangi ukuran pohon, waktu, atribut dan
meningkatkan akurasi. 2. Effective Anomaly
Intrusion Detection System based on Neural Network with Indicator Variable and Rough set Reduction
Hasil penelitian menunjukkan bahwa algoritma yang diusulkan memberikan representasi yang lebih baik dan kuat dari hasil menunjukkan bahwa
algoritma yang diusulkan adalah handal dan efisien dalam deteksi intruksi.
3. Fuzzy rough sets, and a granular neural network for unsupervised feature selection.
Kelemahan FRGNN diusulkan adalah bahwa dibutuhkan waktu komputasi yang lebih tinggi daripada metode terkait untuk tugas-tugas pilihan fitur. Tapi tetap t - hasil tes menunjukkan bahwa akurasi dari FRGNN lebih signifikan dibandingkan SFS di beberapa kasus.
4. Reduksi Parameter
Quality-Of-Service
bahwa parameter QoS dapat direduksi dengan teori RS sehingga memperoleh parameter QoS yang lebih sedikit sehingga akan menghasilkan jalur terbaik berdasarkan bobotnya pada topologi jaringan menggunakan algoritmaDijkstra.
5. Analisis Performansi Algoritma Rough
Jaringan RANFIS yang melibatkan JST, sistem fuzzy dan Rough Set, mampu membangun suatu sistem peramalan yang baik dengan performansi yang dihasilkan dalam RMSE yaitu 0.9836.
6. Klasterisasi Teks Menggunakan Metode O Siahaan, dan Isye
Hasil yang diperoleh menunjukkan bahwa metode ini dapat meningkatkan kualitas hasil klasterisasi rata-rata sebesar 30,28% dibandingkan hasil metodeK-Meansdengan pembobotan.
7. Feature Space
Reductions Using Rough Sets for a Rough-Neuro Hybrid Approach Based Pattern Classifier.
19
Tabel 2.4.Penelitian Terdahulu (Lanjutan)
No. Judul Nama &
Tahun
Algoritma /
Metode Hasil Penelitian
8. Thyroid Diagnosis based Technique on Rough Set with Modified Similarity Relation
Radwan, Elsayed dan Adel M. A. Assiri. 2013
Rough Set hasil statistik menunjukkan bahwa algoritma ini klasifikasi evolusi adalah yang terbaik dalam mengurangi ukuran pohon, waktu, atribut dan
meningkatkan akurasi.
Beberapa penelitian terdahulu menurut (Radwan, 2013) data yang tidak konsisten pada pasien, fitur yang tidak relevan, berlebihan, hilang, dan besar. Dalam tulisannya,
Rough set teori yang digunakan untuk mencoba untuk menghitung set minimal
reducts, yang digunakan untuk mengekstrak set minimal aturan keputusan yang menjelaskan hubungan kesamaan antara aturan. Menurut (Sadek, 2013) NNIV-RS (Neural Network dengan Indikator Variabel menggunakan Rough Set untuk pengurangan atribut) algoritma digunakan untuk mengurangi jumlah sumber daya komputer seperti memori dan CPU waktu yang diperlukan untuk mendeteksi serangan. Teori Rough Set digunakan untuk memilih keluar fitur
reducts. Indikator Variabel digunakan untuk mewakili dataset yang lebih efisien. Menurut (Maharani, 2008) dalam jurnalnya Rangkaian Jaringan Syaraf Tiruan berbasisneuron roughmemiliki kemampuanlearningberdasarkan data-data masukan, dan membantu sistem fuzzydalam menentukan rule yang terbaik dalam memprediksi data, sedangkan rough set sendiri akan mengklasifikasikan data acak yang melewatinya. Metode RANFIS ini digunakan untuk menemukan suatu pola perubahan tertentu, dan akan selalu belajar dari kesalahan atau error sebelumnya, sehingga akan didapatkan nilai akurasi yang sangat baik. Menurut (Arief, dkk, 2010) dalam jurnalnya Klasterisasi teks mempunyai salah satu permasalahan utama dalam
mengklasifikasikan jenis teks yang mempunyai sifatuncertainatau sulit dikategorikan pada data berdimensi yang tinggi dan menyebar. Pada penelitian ini diperkenalkan metode baru dalam penyusunan klasterisasi teks berbasis Roughset untuk persamaan kata. Metode yang diusulkan dalam penelitian ini bernama Max-max Roughness
(MMR). Roughset dipilih karena terbukti mampu mengatasi permasalahan data
20