R
GB-D cameras, such as Microsoft Kinect, are active sensors that provide high-resolution dense color and depth information at real-time frame rates. The wide availability of affordable RGB-D cameras is causing a revolution in perception and changing the landscape of robotics and related fields. RGB-D perception has been the focus of a great deal of attention and many research efforts by various fields in the last three years. In this article, we summarize and discuss our ongoing research on the promising uses of RGB-D in three-dimensional (3-D) mapping and 3-D recognition. Combining the strengths of optical cameras and laser rangefinders, the joint use of color and depth in RGB-D sensing makes visual perception more robust and efficient, leading to practical systems that build detailed 3-D models of large indoor spaces, as well as systems that reliably recognize everyday objects in complex scenes. RGB-D perception is yet a burgeoning technology: a rapidly growing number of research projects are being conducted on or using RGB-D perception while RGB-D hardware quickly improves. We believe that RGB-D perception will be on the center stage of perception and, by making robots see much better than before, will enable a variety of perception-based research and applications.Perception, the ability to sense and understand the envi-ronment, is fundamental to any intelligent system, whether human or robot. The capabilities and applications of modern robots are largely limited by how well they perceive. Although industrial robots get around the perception problem by work-ing in highly constrained environments, it becomes increas-ingly clear that perception will assume a central role as robots start to move into unconstrained everyday environments to perform tasks alongside humans.
While robots may have access to a wide variety of sensors, general-purpose robot perception usually relies on either tra-ditional optical cameras or laser rangefinders, each having advantages and disadvantages. Cameras are fundamentally limited by the loss of 3-D structure in the 3-D or two-dimen-sional (2-D) projection and by their dependency on lighting conditions. It is possible to recover 3-D structures from images (such as in the photo tourism line of work), but such a process requires high-quality images, is computationally demanding, and is brittle in many cases. On the other hand, laser rangefinders allow much more robust sensing at long range and have great success in applications such as autono-mous driving, but they are bulky and expensive and typically provide depth only at sparse scanlines. It remains a difficult and unsolved problem to develop robust perception solutions using either type of sensors.
The newly emerging RGB-D cameras, which combine the strengths of optical cameras and laser rangefinders, may enable a complete perception solution much faster and easier Digital Object Identifier 10.1109/MRA.2013.2253409
Date of publication: 6 December 2013
By Xiaofeng Ren, Dieter Fox, and Kurt Konolige
© ISTOCKPHOTO.COM/LINDAMARIEB
Change
T heir
Perception
Change
T heir
Perception
RGB-D Cameras for
than previously thought possible. RGB-D cameras are quickly evolving modern depth cameras that provide high-resolution (640 # 480 and above) dense depth and color
information, aligned and synchronized at real-time (30 frames/s and above). Typically being active cameras that project infrared (IR) signals and determine depth through stereo or time-of-flight, RGB-D cameras are both robust and rich in details. Like laser rangefinders, these cameras can compute 3-D measurements almost indepently of environ-ment lighting, providing depth maps that are much more robust than (passive) stereo rigs. Three-dimensional model-ing is much easier with dense depth measurements. Dense depth also allows the segmentation of scenes into layers, making object (and people) detection and tracking much easier than before. The combination of depth with high-reso-lution color in these cameras provides details that are much needed for real-world object and scene recognition.
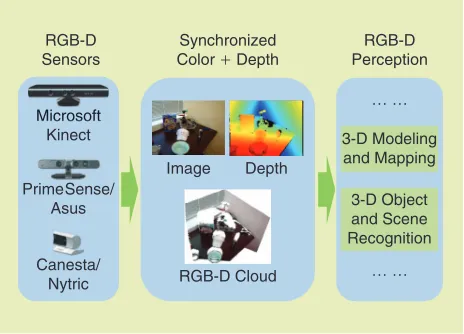
Although the ideas and prototypes of RGB-D cameras have been around for a long time, and there have been many proposals and designs for jointly processing depth and color, they were previously limited in impact largely due to the high cost of the hardware. The broader RGB-D revolution started only with the release of such consumer depth cameras as the Microsoft Kinect and the related PrimeSense cameras and the OpenKinect and Open Natural Interaction (Open NI) proj-ects that provided research communities access to these cam-eras (Figure 1). At US$150 each, these affordable RGB-D cameras have seized the attention of not only the developer communities but also robotics and vision researchers. Many research groups around the world, under a wide variety of contexts, have quickly delved into the studies of both funda-mental research questions on RGB-D perception and its prac-tical applications. The surge of research interests and the
broad range of topics are clearly shown in the latest work-shops that we and our colleagues coorganized, including the RGB-D workshops at RSS [1], and the consumer depth cam-era workshops at the International Conference on Computer Vision and the European Conference on Computer Vision (ICCV/ECCV)[2].
Having early access to consumer depth cameras, we have been working on RGB-D perception since late 2009, together with colleagues at the University of Washington, Intel Labs, Willow Garage, Technical University of Munich, Germany, and the École Polytechnique Fédérale de Lausanne, Switzerland. We have examined the properties of RGB-D camera hardware, designed local descriptors for RGB-D frames, collected labeled data sets for large-scale object rec-ognition, and developed near-real-time systems for 3-D mapping of large-scale environments. We are strongly encouraged by our experiences with RGB-D, finding that the combination of color and depth leads to robust and/or effi-cient solutions to many challenging perception problems. In this article, we will summarize and discuss our RGB-D research projects, the lessons we have learned, and what we look forward to in the near future, as interests and efforts in RGB-D perception continue to grow at a rapid pace.
RGB-D: Sensors
We use the term RGB-D cameras to refer to the emerging class of consumer depth cameras that provide both color and dense depth values at high resolution and real-time frame rates. To reliably measure depth, RGB-D cameras use active sensing techniques, based on projected texture stereo, struc-tured light, or time of flight. The technology from PrimeSense, used in the Microsoft Kinect and Asus Xtion, depends on structured light, which projects a known IR pat-tern into the environment and uses the stereo principle to triangulate and compute depth. Alternative designs, such as from Canesta, use the time-of-flight principle of measuring phase shift in an RF carrier. RGB-D cameras are superior to earlier generations of depth cameras and laser rangefinders in resolution and speed and/or accuracy. They are compact, lightweight, and easy to use. Most importantly, however, they are being mass produced and are available at a price that is reasonable for consumers, orders of magnitude cheaper than their predecessors.
Depth from Active Stereo
Stereo cameras have long been used for depth sensing, emu-lating how humans perceive distance. Passive stereo has major limitations and is fragile for indoor depth sensing for the fol-lowing reasons: 1) stereo relies on matching appearance and fails at textureless regions, and 2) passive cameras are at the mercy of lighting conditions, which are often poor indoors.
Active stereo approaches solve these problems by project-ing a pattern, effectively paintproject-ing the scene with a texture that is largely independent of the ambient lighting. There are two basic techniques: using a random or semirandom pattern with standard stereo (projected texture stereo) and using a
RGB-D Sensors
Synchronized Color + Depth
RGB-D Perception
Image Depth
RGB-D Cloud
3-D Modeling and Mapping
3-D Object and Scene Recognition
gg gg
Microsoft Kinect
PrimeSense/ Asus
Canesta/ Nytric
Microsoft
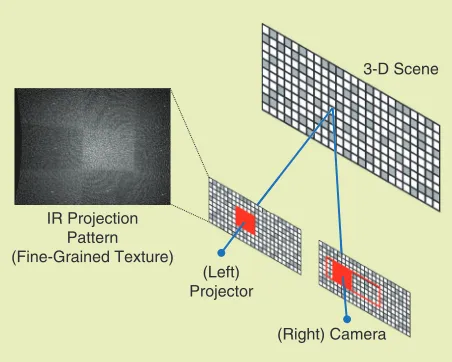
known, memorized pattern to substitute for one of the stereo cameras (structured light stereo). Figure 2 shows the basics of the structured light setup. One of the two cameras is replaced by an IR projector. The IR pattern is generated by an IR laser dispersed by a proprietary dual-stage diffraction grating. The IR camera knows the locally unique projection pattern and how the pattern shifts with distance, so a local search can determine the shift (disparity), and depth can be computed through triangulation. The advantage of the structured light approach is that it tends to generate fewer false positives since the pattern is known. On the other hand, projected texture stereo can potentially work outdoors, taking advantage of nat-ural as well as projected texture.
While the PrimeSense designs of the IR pattern are propri-etary, the analysis of Kinect by Willow Garage [3] and Konolige’s work on projected texture stereo [4] shed light on the design of projection patterns and the stereo algorithms needed. Konolige showed that Hamming distance patterns work better than De Bruijn or random patterns and can be further optimized through simulated annealing. With pro-jected patterns, stereo correspondence becomes easy: a stan-dard sum-of-absolute-difference block-matching algorithm works well enough. Figure 3 shows an example of active versus passive stereo from [4]. Using a standard real-time stereo algo-rithm, the difference in depth density is dramatic. Although passive stereo fails in most parts of the scene [Figure 3(a) and (b)], active stereo manages to recover depth almost every-where [Figure 3(c) and (d)]. The PrimeSense devices appear to use a similar block-matching algorithm with 9 # 9 blocks, with
the pattern most likely optimized for local disambiguity. The output depth is at 640 # 480 resolution and 30 frames/s,
rea-sonably accurate between the range of 0.8–4 m. As it is a stereo camera, the depth accuracy diminishes quadratically with dis-tance, about 2–5 mm at 0.8-m distance and about 1–2 cm at 2 m, sufficient for many applications.
Depth and RGB-D Calibration
A stereo setup must be calibrated internally (to eliminate lens distortion and to find the principal points) and externally (to find the offset between the cameras). For the PrimeSense devices, both the projector and the IR camera exhibit low dis-tortion. The projector is based on a laser and diffraction grat-ing and has inherently excellent distortion characteristics. The IR camera also exhibits low intrinsic distortion (see [3]), probably from careful lens selection. The external correspon-dence between the camera and the projector is probably determined by a factory calibration, but this is a conjecture. In any event, a rigid mount ensures that the devices do not have to be recalibrated during use.
Another calibration area is the relationship between the IR and RGB cameras, to map the depth image into corre-spondence with the RGB image (called registration by the OpenNI drivers). The cameras are placed close together (about 2.5-cm offset) to reduce parallax. Again there appears to be a factory calibration that is particular to each device. Given a known offset between the IR and RGB images, the IR image is mapped to a corresponding RGB point by first converting it to 3-D coordinates, transforming from the IR camera frame to the RGB frame using the known offset, and then reprojecting the 3-D points to the RGB image (with Z-buffering). This mapping can be done either on the device (ASUS Xtion Pro) or in the PC driver (Kinect). It is worth noting that the PrimeSense devices have the ability to syn-chronize the capture time of the IR and RGB images, but time synchronization is only available on the ASUS Xtion Pro, as it is turned off on the Kinect.
(Left) Projector
(Right) Camera 3-D Scene
IR Projection Pattern (Fine-Grained Texture)
Figure 2. The active structured light principle behind representative RGB-D cameras. The IR projector and camera form a stereo pair: the projector shoots a fixed, locally unique pattern and paints the scene with IR texture; the camera, calibrated to the projector and with the pattern memorized, computes stereo disparity and depth for each of the scene points. (Adapted from [4])
(a)
(c)
(b)
(d)
RGB-D: 3-D Mapping and Modeling
RGB-D cameras are well suited for 3-D mapping in that they capture a scene in 3-D point clouds without the loss of 3-D information that occurs in (optical) cameras. It is no surprise that 3-D mapping and modeling is one of the first areas in which RGB-D cameras have been successfully adopted. A challenge for either image-based or laser-based methods, large-scale 3-D mapping becomes feasible and efficient with RGB-D input, which is accessible to everyone with a Kinect. Building rich 3-D maps of environments has far-reaching implications in navigation, manipulation, semantic mapping, and telepresence.
The goal of RGB-D mapping is to robustly and efficiently create models of large-scale indoor environments that are accurate in both geometry (shape) and appearance (color). The RGB-D mapping work of Henry et al. [5], using Kinect-style cameras, developed the first RGB-D mapping system that allowed users to freely move an RGB-D camera through large spaces. Although a single RGB-D frame has limitations with range, noise, and missing depth, it was demonstrated that stitching together a stream of RGB-D frames in a consistent way could lead to large-scale maps (40-m long and wide) with accuracy up to 1 cm.
The flow diagram in Figure 4 shows their approach, in which a combination of image-based and shape-based matching techniques are used to align RGB-D frames. As in 2-D mapping, there are two issues to address for frame alignment: 1) visual odometry: how to align two
consecutive RGB-D frames, and 2) loop closure: how to detect loop closures and adjust camera poses so that they are globally consistent.
Visual Odometry and RGB-D ICP
The odometry problem considers two consecutive frames in an RGB-D video, where the relative motion is small. Frame-to-frame alignment is well studied for both the image-based case and the shape-based case. Image-based alignment is typically based on sparse feature matching [such as using the Scale-Invariant Feature Transform (SIFT)] and epipolar geometry, and shape-based alignment typically uses a ver-sion of the iterative closest point (ICP) algorithm on the dense point clouds. In the RGB-D case, color and depth information are jointly available, aligned (and synchronized in the PrimeSense case) at every pixel. For sparse feature matching, knowing the depth of feature points means that there is no scale ambiguity, and the full six-dimensional rela-tive transform can be computed from a pair of RGB-D frames. For ICP matching, knowing the color of 3-D points means that data association can be improved by using both distance and color similarity (although, in our experience, this benefit is limited).
How should we combine sparse feature matching and shape-based ICP into a single RGB-D ICP algorithm? Henry et al. [5] explored several variants of a jointly defined RGB-D cost function. The best choice found is the RE-RANSAC algorithm (see [5] for details), a linear combination of a reprojection cost for sparse features and a point-to-plane cost for dense ICP:
where T is the relative transform between frames s and .t The first term is the sparse feature matching cost, Af is the set of associations between features fs and ,ft and Proj is the ste-reo projection function that maps a 3-D point , ,^x y zh to
, , , u v d
^ h where ,^u vh are image coordinates and d is the dis-parity. The second term is the point-to-plane ICP cost func-tion, Ad is the dense correspondences between point clouds,
nj is the 3-D surface normal at point ,j and the weight wj is used to discard a fixed percentage of outliers with high errors.
b is a balancing parameter that is set heuristically.
This RGB-D ICP cost in (1) is optimized in two stages: 1) RANSAC is used to find the best set of sparse feature cor-respondences, and 2) RANSAC correspondences are fixed, and the ICP cost is iteratively optimized using Levenberg-Marquardt. Empirically, if a sufficiently large number of sparse features can be matched between frames (common when the scene contains many features), then the ICP cost term only provides marginal improvements at a high compu-tational cost. In such a case, the algorithm directly returns the RE-RANSAC solution.
Loop Closure Detection and Global Pose Optimization
Frame-to-frame alignment using RGB-D ICP is more robust and accurate than either image- or shape-based alignment. Nonetheless, a large environment could take thousands of frames to cover, and alignment errors accumulate. As in 2-D mapping, we need to solve the loop closure problem and compute globally consistent camera poses and maps.
The RGB-D solution to loop closure in [5] is heavily based on sparse features, as they are more distinctive and easier to match over large viewpoint changes. To detect loop closure, it follows a standard image-based approach and runs RE-RANSAC to find geometrically consistent feature matches between a subset of keyframes, prefiltering potential closures using vocabulary trees. To find globally consistent camera poses, it uses two strategies, one using the fast pose optimizer tree-based network optimizer (TORO) and one solving stereo-based sparse bundle adjustment (SBA).
SBA is a well-studied problem in image-based 3-D recon-struction that simultaneously optimizes camera poses and 3-D positions of feature points in the map. The following cost function is minimized:
( ) ( , , ) , proj
vij c pi j u v d c C
2
p P
i j
-! !
r r r
^ h
/
/
(2)where the summation is over cameras ^ hci and map points pj
^ h, and Proj is the stereo projection that maps a 3-D point to image coordinates ,^u vh and disparity ,d and vij are indicators of whether pj is observed in .ci This stereo SBA problem is solved using the fast algorithm that Konolige developed [6]. One of the large maps has about 1,500 camera poses, 80,000 3-D points projected to 250,000 2-D points; it has only 74 loop closure links and can be opti-mized in less than 10 s.
In RGB-D mapping, constraints between two consecu-tive frames are given by not only sparse feature correspon-dences but also by the ICP matching between point clouds. To incorporate the dense ICP part into SBA, 3-D points are sampled from one frame, and corresponding points in the other frame are found using the optimal relative pose. These point pairs are filtered using distance and normal, and are added to (2). Without this modification, if any consecutive frames have few feature pairs and are aligned with dense ICP, the SBA system would be disconnected and unsolvable.
Figure 4 shows an example of the 3-D map obtained with RGB-D mapping. A user carries a PrimeSense camera in-hand and walks through the indoor space of the Intel Seattle lab, about 40 # 40 m. The RGB-D mapping system
successfully aligns 1,500 RGB-D frames and merges them into a large consistent 3-D map using surfels, an incremen-tal and adaptive 3-D surface representation developed in computer graphics. The resulting map is geometrically cor-rect compared with 2-D maps and floor plans (see [5]) and full of 3-D and photometric details.
Real-Time and Interactive Mapping
Using efficient algorithms, such as fast feature detection and SBA, the RGB-D mapping pipeline of [5] can run close to real time on a laptop computer. Combining real-time processing with the compactness of the RGB-D sensor, it is conceivable that, in the near future, we will be able to build real-time 3-D mapping systems that a user can easily carry around and use to scan large environments.
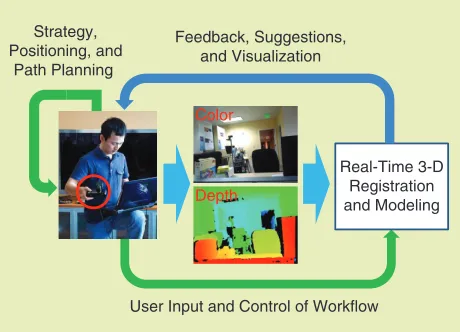
The work of Du et al. [7] developed and demonstrated a prototype of such an interactive system for dense 3-D map-ping, as illustrated in Figure 5. The mobile system runs at about 4 frames/s on a laptop using a PrimeSense camera pow-ered by the laptop’s USB connection. Unlike the offline sce-nario, where a user blindly collects an RGB-D video and hopes that there will no alignment failure and that the video will cover all the spots, the user can now:
● pause and resume, monitor the mapping progress and
check the partial map any time
● detect mapping failures (e.g., fast motion or lack of
fea-tures) and alert the user, rewind to recover from failures
● view automatic suggestions where the map is incomplete.
The same advantages would hold true for an interactive system in a robot mapping scenario, where the robot can plan and update its actions based on the mapping progress, or in a human–robot collaboration scenario where a robot works with a user to model the environment. Being able to access the map and interact with the system on fly opens up many possibilities in the areas of human–computer interaction and human–robot interaction.
Discussion
Three-dimensional mapping has been a long-standing chal-lenge for both image- and shape-based techniques. Indoor settings are particularly demanding due to lighting conditions and textureless areas. RGB-D cameras, which preserve both 3-D structures and photometric details in the input, provide a
Color
Depth
Feedback, Suggestions, and Visualization
Real-Time 3-D Registration and Modeling
User Input and Control of Workflow Strategy,
Positioning, and Path Planning
natural and easy solution to the problem. Our studies show that not only can we reliably scan large environments with RGB-D, we can do so efficiently in near real time. This is con-firmed in the work of Engelhard et al. [8], whose open-source RGBD SLAM (simultaneous localization and mapping) pack-age in the robot operating system (ROS) has been used in a number of robotics projects.
One problem closely related to environment mapping is the modeling of 3-D objects. Krainin et al. [9] showed an example in the context of robot manipulation, where a robot rotates and studies a novel object in its hand, incre-mentally building and updating a 3-D model of the object. Robot hand motion is guided by next-best-view selection based on information gain computed from a volumetric model of the object. If needed, the robot places the object back on the table and regrasps it in order to enable new viewpoints. With knowledge of its own arm/hand, and computing articulated ICP tracking of the arm and the object jointly, the robot can acquire a good 3-D model of the object using an RGB-D camera. Such autonomous object modeling is a first step toward enabling robots to adapt to unconstrained environments.
It is interesting to compare the RGB-D mapping system of Henry et al. [5] to KinectFusion [10], a more recent system developed at Microsoft that shows fine details for modeling room-size spaces. KinectFusion uses a depth-only solution to visual odometry, partly because the color and depth frames in Kinect are not time synchronized. Running a highly optimized version of ICP on graphics processing units, KinectFusion, along with its open-source implementation [in the point cloud library (PCL)], can run in real time near 30 frames/s. The robustness of ICP is greatly improved by aligning an incoming RGB-D frame to the partial 3-D model in a volumetric repre-sentation (instead of to the previous frame). In comparison, the RGB-D mapping system targets mapping at a much larger scale, as it has stronger loop closure capabilities and a less detailed 3-D representation.
The ability to build and update 3-D maps of environ-ments can have major impacts on robotics research and applications, not only in navigation and telepresence but also in semantic mapping and manipulation. A detailed 3-D map serves as a solid basis for a robot to understand its surroundings with higher level semantic concepts. As an example, Herbst et al. used RGB-D mapping and scene dif-ferencing for object discovery, using scene changes over time to detect movable objects [11]. Discovering and mod-eling unknown objects is a crucial skill if a robot is to be deployed in any real-world environment. Three-dimensional mapping has also been used in 3-D scene understanding and labeling [12], [13], which is further dis-cussed in the next section.
RGB-D: 3-D Object and Scene Recognition
Modeling an environment in terms of 3-D geometry and color is only the first step toward understanding it. For a robot to interact with the environment, object recognition is the
key; the robot needs to know what and where the objects are in a complex environment and what to do with them.
Our studies show that RGB-D perception has many advan-tages for object recognition. Comparing with image-only rec-ognition, RGB-D provides 3-D shape data and makes it feasi-ble to detect objects in a cluttered background [16]. Comparing with point cloud recognition, RGB-D uses color in addition to shape, leading to richer and more distinctive fea-tures especially for object instance recognition [17]. Combining robustness and discriminative power with effi-ciency, RGB-D object recognition achieves high accuracy clas-sifying hundreds of objects [15] and is quickly becoming prac-tical for analyzing complex scenes in real-world settings [18].
Recognition of Everyday Objects
For a robot to operate in the same environment where people live, its recognition task is mainly to find and classify objects that people use in their daily activities. The recognition task also spans multiple levels of specificity, such as category recog-nition (Is this a coffee mug?), instance recogrecog-nition (Is this Kevin’s coffee mug?), and pose recognition (Is the mug with the handle facing left?). A robot would need to be able to answer all these questions.
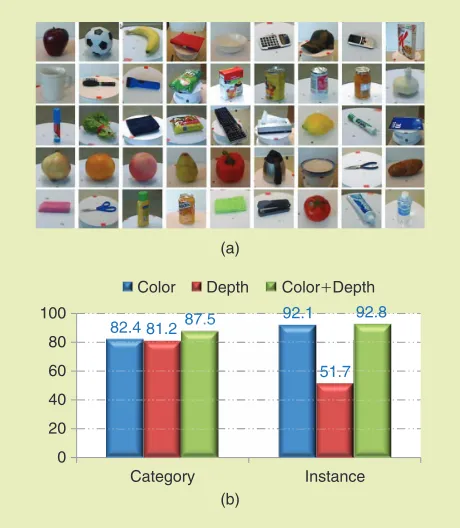
There were few object data sets in robotics or computer vision that covered a large number of household objects, and none existed for RGB-D data. The first task was to create such a data set on which features and algorithms could be evalu-ated. Lai et al. [14] collected an RGB-D object data set that captured 51 object categories and 300 object instances using a turntable, with a total of 250,000 RGB-D frames. Figure 6(a) shows some of the objects included. This data set allowed them to carry out empirical studies of state-of-the-art fea-tures, such as SIFT, histogram of oriented gradients (HOG), and Spin Images and classifiers including linear support vec-tor machine (SVM), kernel SVM, and random forest [14].
What image and depth features should we use for RGB-D recognition? Comparing with well-studied image features, depth features for recognition were underdeveloped; standard features such as Spin Images were not designed for view-based recognition. The work of Bo et al. [17] extended kernel descriptors, previously developed for image classification, to the depth domain. Kernel descriptors are a flexible frame-work that constructs a local descriptor from any pixelwise similarity function using kernel approximation. Five different depth kernel descriptors were developed, based on gradient, local binary pattern, surface normal, size, and kernel signature (using eigenvalues in kernel PCA). These kernel descriptors were shown to perform much better than standard features.
associated sparse code matrix X=6x1,f,xn@ by minimiz-ing the reconstruction error:
s.t. , ,
min Y DX i x K
,
D X F i
2
0
6 #
- (3)
where $ F is the Frobenius norm, xi are the columns of ,X the zero-norm $ 0 counts the nonzero entries in the sparse code xi, and K is the predefined sparsity level of the nonzero entries. Once the dictionary, ,D is learned, for a new test image, the sparse codes X can be efficiently computed using the greedy algorithm of orthogonal matching pursuit.
The beauty of this feature-learning approach is that it applies without change to images of grayscale, RGB color, and depth as well as surface normal. Figure 7 shows examples of the RGB-D dictionaries learned for the four types of data listed. In addition to these local features, Bo et al. also showed that a hierarchical sparse coding scheme unified the processes of both, extracting patch representations from pixels and extracting image representations from patches, hence com-prising a complete feature-learning pipeline for image classification.
Figure 6(b) shows a summary of the state-of-the-art results on the RGB-D data set using hierarchical sparse coding, as reported in [15]. There are two experimental set-ups, object category recognition, where object instances are left out for testing, and object instance recognition, where
one of the three camera heights are left out for testing. In both category and instance cases, combining color and depth features significantly improves the recognition accu-racy, clearly demonstrating the benefits of using RGB-D data. Depth-based recognition is almost as good as based recognition for the category case. Meanwhile, color-based recognition is much better than depth for the instance case. The category recognition accuracy is almost 90%, and the instance accuracy is at 93%. These results are encouraging and show promise for practical object recogni-tion at a large scale.
How can a robot efficiently recognize objects among hun-dreds and thousands of candidates? How can a robot solve the multitude of recognition problems, such as category and instance, in one framework? Lai et al. [19] developed a scal-able solution using an object-pose tree, making sequential decisions in the natural hierarchy defined by categories, instances, and (discrete and continuous) poses. This hierar-chical approach is shown in Figure 8. It is shown that the object-pose tree greatly improved efficiency while maintain-ing accuracy, and a large-margin tree model can be trained jointly at multiple levels using stochastic gradient descent. This makes it feasible to both recognize objects and estimate their poses (orientations) fast enough for interactive settings.
Object Detection and Scene Labeling
The RGB-D object data set discussed in the “Recognition of Everyday Objects” section mainly consists of views of iso-lated objects, on which the experiments in the same section are based. In many cases, such as a tabletop scenario, RGB-D segmentation can be used to extract objects from a scene. Simultaneously, in many other cases, objects cannot be easily isolated, and we need to address the object detection prob-lem, locating and recognizing objects from a complex scene with occlusions and clutter.
Hinterstoisser et al. [16] developed an RGB-D object detection approach that can locate object instances in near real time within complex scenes. The near-real-time perfor-mance is based on the linearizing memory with modalities (LINEMOD) algorithm, a template-matching approach opti-mized for SSE instructions and cache lines in modern central
(a) (b) (c) (d)
Figure 7. The dictionaries learned for 5#5 RGB-D patches using K-SVD. (a) Grayscale intensity and RGB (b) color, (c) depth, and (d) 3-D surface normal (three normal dimensions color-coded as RGB) [15].
82.481.2 92.1
51.7
87.5 92.8
0 20 40 60 80 100
Category Instance
Color Depth Color+Depth
(b) (a)
82.4 81.287.587.5
51.7 51 7
processing units (CPUs). Using a data set of six videos with large illumination and viewpoint changes, it showed that the RGB-D multimodal LINEMOD algorithm can detect multi-ple objects, low-textured or textureless, much more robustly than using either color or depth, and the detections are nearly perfect even for heavily cluttered scenes.
An example of the scene setup and detection results is shown in Figure 9. The key feature of this algorithm is the combination of gradient information from RGB images with normal vector information from depth images to form templates at a set of viewpoints of an object. LINEMOD works well on textureless objects by using both normal vec-tors from the object interior and color gradients from the object outline. Typically, several hundred templates are needed to cover a full set of poses; the algorithm can apply several thousand templates to a test image at over 10 Hz, which allows for near-real-time recognition of small sets of objects.
Lai et al. [12] went beyond per-frame instance detection and labeled object types in 3-D scenes (i.e., labeling every point on the objects in the point cloud) by combining RGB-D mapping with object detection and segmentation. Given an RGB-D video, the RGB-D mapping system [5] is used to reconstruct a 3-D scene. This provides 3-D align-ments of the frames and a way to integrate object detections from multiple views. Object detection scores are projected into a voxel representation as follows:
, lnp yv v 1 lnp y x
v x
v v X
X
=
!X
^ h
/
^ h (4)where yv is a random variable representing the label of a voxel ,v Xv is the set of 3-D points x inside ,v where each x comes from a pixel in a particular view (RGB-D frame), which are aligned through mapping. For each object being searched, p y x^ v ) is a score computed using sliding-window detection in the frame containing .x The key observation of the approach is that it is much more robust, and efficient, to detect potential objects in each of the RGB-D frames and then integrate the scores than a direct 3-D shape matching on the merged 3-D point cloud. A Markov random field (MRF) is used to smooth the integrated scores using pairwise poten-tials that respect convex/concave surface connections. Figure 10 shows this detection-based approach to 3-D object labeling, where an example is taken from one of the multiob-ject scenes in the RGB-D obmultiob-ject data set.
In addition to detecting and labeling individual objects in a scene, Ren et al. [18] studied the dense scene labeling prob-lem, i.e., using RGB-D data to label every point in the scene into semantic classes such as walls, tables, and cabinets. This approach used the RGB-D kernel descriptors [17] as the underlying local features, which are shown to outperform standard features such as SIFT or TextonBoost for the scene-labeling task. The local features are aggregated at multiple scales using segmentation trees: 1) each segment at each level of a segmentation tree is classified into the semantic classes, 2) the features along each path from a leaf to the root are con-catenated and reclassified, and 3) a standard MRF is used at the bottom level for further smoothing of the labels. Some examples of the dense labeling results are shown in Figure 11. Evaluated using the New York University (NYU) depth data set [20], this approach utilized powerful features in efficient linear SVM classification and improved the labeling accuracy from 56% (in [20]) to 76%, a large step toward solving the challenging indoor scene understanding problem.
Discussion
Object recognition is crucial to a robot’s understanding of the environment and how it can interact with it. Our
Category
Cereal
Instance
View
Pose
Chex Bran Flakes
Striped Bowl BowlBlue
Apple Stapler Bowl
Category: Cereal Instance: Bran Flakes Pose: 18°
Figure 8. The object-pose tree for scalable recognition [19]. Object categories, instances, and poses are organized into a semantic hierarchy. The system makes a series of decisions by going down multiple levels in the tree, which is highly efficient while maintaining recognition accuracy.
Cup Car
Duck
Ape
Cam
Hole Punch
RGB-D features and their validations on large-scale RGB-D object data sets have quantified the benefits of combining color and depth, and we are able to develop robust and efficient solutions for hundreds of everyday objects for joint category, instance, and pose recognition. As we move from isolated objects into full scene understanding, we find great synergies between 3-D mapping and
recognition, combining low-level scene matching with high-level semantic reasoning.
Such a synergy was also found in the semantic labeling work of Koppula et al. [13]. They used the RGBD SLAM soft-ware to merge multiple Kinect frames into a single 3-D scene, and constructed 52 scenes of home and office environments. They developed semantic labeling algorithms that directly operate on the merged point clouds, modeling contextual relations such as object cooccurrence in 3-D. They achieved reasonably high accuracy (about 80% for 17 semantic classes) and demonstrated the use of semantic mapping by making a mobile robot find objects in cluttered environments.
The NYU depth data set, recently released by Silberman and Fergus [20], and used in [18], was a similar effort to benchmark RGB-D scene understanding, focusing on
single-view labeling of a large variety of scene types and layouts. It covered seven types of 64 real-world scenes in over 2,000 RGB-D frames, each labeled through Mechanical Turk, containing a large set of semantic classes. The encouraging results in [18] showed that unconstrained indoor scene understanding can potentially be solved to a large degree using RGB-D data, which will provide valuable semantic context for robot operations.
In the related field of human–computer interaction, the LEGO Oasis work of Ziola et al. [21] showed an interesting application of robust object recognition using RGB-D (Figure 12). It uses RGB-D data to segment objects from a table surface and runs the hierarchical recognition algo-rithm of Lai et al. [19] to recognize objects (LEGO and other types) in real time. Once the system knows the
Bed Sofa
Blind (1)
(2)
(3)
(4)
Table
Bookshelf Television
Cabinet Wall
Ceiling Window
Floor Picture
Background
Figure 11. The examples of the dense scene labeling approach [18] on the NYU depth data set for 13 semantic classes. The four rows are: 1) RGB frame, 2) depth frame, 3) results, and 4) groundtruth. Evaluated on a wide variety of scenes and scene layouts, these dense labeling results show promise for solving indoor semantic labeling using RGB-D, providing rich contexts for robot operations.
Multiobject Scenes in RGB-D Dataset 3-D Object Labeling Combining Recognition and Mapping Per-Frame
Recognition
Voxel Labeling
V
V
V
objects and their orientations on the table, it can perform interesting interactions using an overhead projector, such as projecting fire to simulate a dragon breathing fire onto a house. The success of this demo, shown at various places, including the Consumer Electronics Show, illustrates the robustness of RGB-D recognition and what possibilities real-world object recognition could open up.
To Get Started Using RGB-D
One major advantage of using RGB-D cameras is that the hardware is available to everyone, with a consumer price tag that makes it practically appealing. While the focus of this article is algorithm research, ease-of-use software develop-ment has also been at the center of attention for RGB-D per-ception. The PCL [22] is a central place where open-source RGB-D software packages are being developed. They are eas-ily accessible and closely integrated with the ROS platform and the OpenNI framework. The basics of PCL can be found in a recent tutorial published in IEEE Robotics and Automation Magazine [23].
For RGB-D mapping and 3-D modeling, the RGB-D mapping software of Henry et al. [5] has been made avail-able as an ROS stack at the authors’ Web site at the University of Washington, enabling 3-D mapping of large environments at the floor scale with a freely moving RGB-D camera. The RGBD SLAM package from Freiburg has simi-lar functions and is a part of ROS. The KinectFusion system [10] has a real-time open-source implementation, available in the trunk version of PCL, which allows highly detailed modeling at the room scale.
For RGB-D object recognition, the RGB-D kernel descriptor software [17] is available in both MATLAB and C++ at the authors’ Web site, producing state-of-the-art
accuracies on the RGB-D object data set [14], a publicly available benchmark with densely sampled RGB-D views of 300 everyday objects. The real-time LINEMOD object detec-tor is included in Open Source Computer Vision Library (OpenCV), making use of both color and depth data. PCL
and OpenCV also include a variety of other recognition algorithms such as Speeded-Up Robust Features (SURF) for color and Viewpoint Feature Histogram for depth.
There are a number of other growing software platforms for RGB-D perception in addition to PCL and OpenNI. The Microsoft Kinect software development kit (SDK) [24] brings Kinect cameras and their capabilities to Windows developers, such as the Xbox skeleton tracking [25] and speech recognition. The Intel Perceptual Computing SDK [26] is another hardware-software initiative that features RGB-D-based gesture recognition and hand tracking among other things, with a million-dollar call for creative usage. Both platforms, backed by large corporations, pro-vide an extensive set of basic functionalities and have been attracting more and more software developers, redefining the future of perceptual computing.
Conclusions
In this article we have discussed our recent work on RGB-D perception: jointly using color and depth data in affordable depth cameras for large-scale 3-D mapping and recognition. Our efforts are part of a much bigger picture of utilizing RGB-D devices for visual perception across multiple research domains. Much progress has been made since the release of Kinect, showing the great potential of RGB-D perception for a wide range of problems, from 3-D mapping and recognition to manipulation and human–robot interaction. Combining color and dense depth at real time, with a consumer price tag, RGB-D cameras provide numerous advantages over optical cameras and laser rangefinders.
We have found that RGB-D perception is much more robust and often more efficient than using RGB alone. An RGB-D camera is fundamentally better than a traditional optical camera with the same resolution in that: 1) it largely recovers the 3-D structure of the world without losing the structure in the projection to 2-D images, and 2) its depth channel is largely independent of ambient lighting. Although ultimately every perception problem is solvable using an optical camera (or a stereo pair), in practice, RGB-D cam-eras make it much easier to develop robust real-time solu-tions that roboticists can use as building blocks to explore their own research problems.
We have also found that RGB-D perception is more dis-criminating, providing richer information than obtained using depth alone. The Kinect pose tracker and the KinectFusion 3-D modeler do not use color; such depth-only approaches could be attractive if depth alone contained sufficient cues. On the other hand, the color channel typically has higher resolu-tion and higher granularity, is not limited by range, and is much easier to improve in hardware than the depth channel. Color and depth channels are time synchronized in the PrimeSense/Asus cameras and possibly in future versions of Kinect. We expect more and more color + depth approaches
as we target harder problems that require richer inputs. The field of RGB-D perception is quickly evolving, and so are the cameras themselves. Depth resolution, accuracy,
range, size, weight, and power consumption will all continue to improve. A large number of novel usages and applications are emerging in both robotics and related fields such as human–computer interaction and augmented reality, as evidenced in recent conferences, workshops, and startup companies. These are exciting times, and we expect RGB-D perception to grow quickly and to likely become the de facto choice for general-purpose robot perception.
Acknowledgments
The majority of the RGB-D research discussed in this article is the joint work between the authors and their colleagues and students Liefeng Bo, Marvin Cheng, Cedric Cagniart, Hao Du, Dan B. Goldman, Peter Henry, Evan Herbst, Stefan Hinterstoisser, Stefan Holzer, Slobodan Ilic, Mike Krainin, Kevin Lai, Vincent Lepetit, Nassir Navab, and Steve Seitz. We thank all of them for the productive and enjoyable collabora-tions. The work was funded in part by the Intel Science and Technology Center for Pervasive Computing (ISTC-PC), by ONR MURI (N00014-07-1-0749 and N00014-09-1-105), and by the National Science Foundation (contract number IIS-0812671). Part of this work was also conducted through col-laborative participation in the Robotics Consortium spon-sored by the U.S. Army Research Laboratory under the CTA Program (Cooperative Agreement W911NF-10-2-0016).
References
[1] (2010). RGB-D workshop @ RSS: Advanced reasoning with depth cameras. [Online]. Available: http://www.cs.washington.edu/ai/Mobile Robotics/ rgbd-workshop-2012/
[2] (2013). IEEE workshop on consumer depth cameras for computer vision. [Online]. Available: http://www.vision.ee.ethz.ch/CDC4CV/
[3] (2011). Kinect technical. [Online]. Available: http://wiki.ros.org/kinect_ calibration/technical
[4] K. Konolige, “Projected texture stereo,” in Proc. IEEE Int. Conf. Robotics Automation, pp. 148–155, 2010.
[5] P. Henry, M. Krainin, E. Herbst, X. Ren, and D. Fox, “RGB-D mapping: Using Kinect-style depth cameras for dense 3D modeling of indoor environ-ments,” Int. J. Robot. Res., vol. 31, no. 5, pp. 647–663, 2012.
[6] K. Konolige, “Sparse sparse bundle adjustment,” in Proc. British Machine Vision Conf., 2010, pp. 1–11.
[7] H. Du, P. Henry, X. Ren, M. Cheng, D. Goldman, S. Seitz, and D. Fox, “Interactive 3D modeling of indoor environments with a consumer depth camera,” in Proc. Int. Conf. Ubiquitous Computing, 2011, pp. 75–84.
[8] N. Engelhard, F. Endres, J. Hess, J. Sturm, and W. Burgard, “Real-time 3D visual SLAM with a hand-held RGB-D camera,” in Proc. RGB-D Workshop 3D Perception Robotics at EURON, 2011.
[9] M. Krainin, P. Henry, X. Ren, and D. Fox, “Manipulator and object track-ing for in hand 3D object modeltrack-ing,” Int. J. Robot. Res., vol. 30, no. 11, pp. 1311–1327, 2011.
[10] R. Newcombe, S. Izadi, O. Hilliges, D. Molyneaux, D. Kim, A. Davison, P. Kohli, J. Shotton, S. Hodges, and A. Fitzgibbon, “KinectFusion: Real-time dense surface mapping and tracking,” in Proc. IEEE Mixed Augmented Reality 10th Int. Symp., 2011, pp. 127–136.
[11] E. Herbst, X. Ren, and D. Fox, “RGB-D object discovery via multi scene analysis,” in Proc. IEEE/RSJ Int. Conf. Intelligent Robots Systems, 2011, pp. 4850–4856.
[12] K. Lai, L. Bo, X. Ren, and D. Fox, “Detection-based object labeling in 3D scenes,” in Proc. IEEE Int. Conf. Robotics Automation, 2012, pp. 1330–1337. [13] H. Koppula, A. Anand, T. Joachims, and A. Saxena, “Semantic labeling of 3D point clouds for indoor scenes,” in Proc. Neural Information Processing System, 2011, pp. 244–252.
[14] K. Lai, L. Bo, X. Ren, and D. Fox, “A large-scale hierarchical multiview RGB-D object dataset,” in Proc. IEEE Int. Conf. Robotics Automation, 2011, pp. 1817–1824. [15] L. Bo, X. Ren, and D. Fox, “Unsupervised feature learning for RGB-D based object recognition,” in Proc. Int. Symp. Experimental Robotics, 2012, pp. 387–402. [16] S. Hinterstoisser, S. Holzer, C. Cagniart, S. Ilic, K. Konolige, N. Navab, and V. Lepetit, “Multimodal templates for real-time detection of textureless objects in heavily cluttered scenes,” in Proc. Int. Conf. Computer Vision, 2011, pp. 858–865.
[17] L. Bo, X. Ren, and D. Fox, “Depth kernel descriptors for object recogni-tion,” in Proc. Int. Conf. Intelligent Robots Systems, 2011, pp. 821–826. [18] X. Ren, L. Bo, and D. Fox, “RGB-(D) scene labeling: Features and algo-rithms,” in Proc. IEEE Conf. Vision Pattern Recognition, 2012, pp. 2759–2766. [19] K. Lai, L. Bo, X. Ren, and D. Fox, “A scalable tree-based approach for joint object and pose recognition,” in Proc. AAAI Conference on Artificial Intelligence, 2011, pp. 1474–1480.
[20] N. Silberman and R. Fergus, “Indoor scene segmentation using a structured light sensor,” in Proc. IEEE Workshop 3D Representation Recognition, 2011. [21] R. Ziola, S. Grampurohit, N. Landes, J. Fogarty, and B. Harrison, “Examining interaction with general-purpose object recognition in LEGO OASIS,” in Proc. Visual Languages and Human-Centric Computing IEEE Symp., 2011, pp. 65–68.
[22] (2013). Point cloud library. [Online]. Available: http://pointclouds.org/ [23] A. Aldoma, Z. Marton, F. Tombari, W. Wohlkinger, C. Potthast, B. Zeisl, R. Rusu, S. Gedikli, and M. Vincze, “Point cloud library: Three-dimensional object recognition and 6 DOF pose estimation,” IEEE Robot. Autom. Mag., vol. 19, no. 3, pp. 80–91, 2012.
[24] (2013). Kinect for Windows. [Online]. Available: http://www.microsoft. com/en-us/kinectforwindows/
[25] J. Shotton, A. Fitzgibbon, M. Cook, T. Sharp, M. Finocchio, R. Moore, A. Kipman, and A. Blake, “Real-time human pose recognition in parts from sin-gle depth images,” in Proc. IEEE Conf. Computer Vision Pattern Recognition, 2011, vol. 2, pp. 1297–1304.
[26] (2013). Intel perceptual computing SDK. [Online]. Available: http://soft-ware.intel.com/enus/vcsource/tools/perceptual-computing-sdk//
Xiaofeng Ren, Amazon.com, Seattle, Washington. This work was done while Xiaofeng was at the Intel Science and Techonology Center (ISTC) for Pervasive Computing, Intel Labs. E-mail: xiaofenr@amazon.com.
Dieter Fox, Department of Computer Science and Engineering, University of Washington, Seattle. E-mail: fox@cs.washington.edu.
![Figure 4. (a) The RGB-D mapping algorithm in Henry et al. [5], combines sparse feature matching and dense ICP matching in both frame-to-frame odometry and loop closure](https://thumb-ap.123doks.com/thumbv2/123dok/3123647.1728039/4.567.47.276.413.626/figure-algorithm-combines-feature-matching-matching-odometry-closure.webp)
![Figure 9. Object detection using RGB-D [16]. Based on the LINE model that optimizes template matching for modern CPU architectures, both textured and textureless objects can be detected in real time in highly cluttered scenes.](https://thumb-ap.123doks.com/thumbv2/123dok/3123647.1728039/8.567.47.274.51.294/detection-optimizes-template-matching-architectures-textureless-detected-cluttered.webp)
![Figure 10. The detection-based object labeling using RGB-D mapping, 2) detect possible objects in each RGB-D frame, 3) project detection scores from [12], consisting of four stages: 1) construct a 3-D scene multiple frames into the scene, and 4) enforce label consistency through a voxel MRF on the point cloud.](https://thumb-ap.123doks.com/thumbv2/123dok/3123647.1728039/9.567.173.521.56.176/detection-labeling-possible-detection-consisting-construct-multiple-consistency.webp)
![Figure 12. The LEGO Oasis demo using RGB-D recognition [21]. Near-real-time object recognition allows interesting human–computer interactions using an overhead projector: a LEGO fire truck putting out a virtual fire on a house.](https://thumb-ap.123doks.com/thumbv2/123dok/3123647.1728039/10.567.45.277.51.214/figure-recognition-recognition-interesting-computer-interactions-overhead-projector.webp)
