BAB II
LANDASAN TEORI
Pada dasarnya, ilmu pengukuran psikologis memiliki dua pendekatan, yaitu pendekatan classical test theory (selanjutnya akan disebut CTT) dan item response theory (selanjutnya akan disebut IRT). Pendekatan CTT adalah metode pertama yang dikembangkan untuk pengukuran. Teori-teori CTT mendominasi pengembangan rumus reliabilitas dan validitas yang dikenal dewasa ini (Suryabrata, 2005).
A. Classical Test Theory (CTT)
1. Pengertian CTT
2. Asumsi-asumsi dalam CTT
Asumsi-asumsi CTT pada dasarnya merupakan hubungan matematis antara skor tampak yang disimbolkan dengan huruf X, skor murni yang dilambangkan dengan huruf T, dan eror pengukuran yang diberi simbol huruf E. Skor tampak merupakan nilai performansi subjek yang diungkap melalui pengukuran yang dinyatakan dalam bentuk angka yang merupakan nilai total dari jawaban subjek terhadap aitem atau pernyataan dalam tes tersebut. Skor murni menjelaskan bahwa performansi subjek sesungguhnya yang tidak mungkin dapat diungkap secara langsung oleh tes. Eror pengukuran merupakan besaran eror subjek dalam setiap tes yang angkanya juga tidak dapat diketahui dengan pasti (Azwar, 2005).
Pendekatan CTT terdiri dari asumsi-asumsi yang berkaitan dengan skor tampak, skor murni dan komponen eror pengukuran. Allen & Yen (dalam Azwar, 2005) menjabarkan asumsi-asumsi hubungan antara skor tampak, eror pengukuran dan skor murni sebagai berikut:
Asumsi 1: X = T + E (1)
Asumsi 2: ε(X) = T (2) Asumsi ini menyatakan bahwa T sama dengan nilai harapan dari X-nya yang dilambangkan dengan ε(X). Jadi, T merupakan harga rata-rata dari distribusi teoretik X apabila orang yang sama dikenai tes yang sama berulangkali dengan asumsi pengulangan tes itu dilakukan tidak terbatas banyaknya dan setiap pengulangan tes adalah independen satu sama lain.
Asumsi 3: = 0 (3)
Asumsi ini menyatakan bahwa bagi populasi subjek yang dikenai tes, distribusi E pengukuran dan distribusi T tidak berkorelasi satu sama lain. Implikasinya, skor murni yang tinggi tidak selalu berarti mengandung eror yang selalu positif ataupun selalu negatif atau mempunyai E lebih tinggi dibanding subjek yang T-nya rendah.
Asumsi 4: = 0 (4)
Asumsi ini menyatakan bahwa eror pada dua tes ( yang dimaksud untuk mengukur hal yang sama) tidak saling berkorelasi. Artinya besarnya E pada suatu tes tidak tergantung pada E tes lainnya. Asumsi ini akan tidak terpenuhi sekiranya skor tampak dipengaruhi kondisi testing, seperti misalnya kelelahan, efek latihan, suasana hati, atau faktor-faktor dari lingkungan (Suryabrata, 2005).
Asumsi 5 : = 0 (5)
Selain lima asumsi yang telah diuraikan, terdapat dua asumsi lagi yang dijelaskan oleh Suryabrata (2005), yaitu:
Asumsi 6
Jika ada dua tes yang dimaksudkan untuk mengukur atribut yang sama mempunyai skor tampak X dan X’ yang memenuhi asumsi 1 sampai 5, dan untuk setiap populasi subjek T = T’ serta varians eror kedua tes tersebut sama, maka kedua tes tersebut disebut sebagai tes yang paralel.
Asumsi 7
Jika ada dua tes yang dimaksudkan untuk mengukur atribut yang sama mempunyai skor tampak X dan X’ yang memenuhi asumsi 1 sampai 5, dan apabila untuk setiap populasi subjek T1 = T2 + C, dengan C sebagai suatu bilangan konstan, maka kedua tes tersebut dapat disebut sebagai tes yang setara (equivalent test).Dua tes yang setara dapat memiliki varians eror yang berbeda karena keduanya belum tentu merupakan tes yang paralel, namun dua tes yang paralel tentu memenuhi syarat sebagai tes yang setara (Azwar, 2005).
B. Analisis Karakteristik Psikometri
1. Indeks Kesukaran Aitem
a. Pengertian Indeks Kesukaran Aitem
Indeks kesukaran aitem adalah rasio antara subjek yang menjawab aitem dengan benar dan total subjek yang menjawab aitem tersebut. Indeks kesukaran aitem ditentukan oleh seberapa banyak peserta tes berhasil menjawab aitem dengan benar. Semakin banyak peserta tes menjawab dengan benar, berarti semakin mudah aitem tersebut dan sebaliknya semakin sedikit peserta menjawab dengan benar, maka semakin sulit aitem tersebut (Azwar, 2007).
b. Analisis Indeks Kesukaran Aitem
Taraf kesukaran suatu aitem dinyatakan oleh suatu indeks yang dinamakan indeks kesukaran aitem yang disimbolkan dengan huruf p, dengan rumus :
p = ni / N (6)
Keterangan:
p = Derajat kesukaran aitem
ni = Banyak peserta tes yang menjawab benar
N = Banyak peserta tes yang menjawab aitem
Tes disusun untuk melihat perbedaan subjek sehingga jika tidak ada seorang pun yang menjawab pertanyaan dengan benar, dalam artian aitem sangat susah (p = 0), atau sebaliknya, jika soal sangat gampang sehingga semua dapat menjawab pertanyaan dengan benar (p= 1) maka tujuan alat tes tidak dapat dipenuhi (Murphy & Davidshofer, 2003). Gregory (2000) mengkategorikan nilai p sebagai berikut:
Tabel 1. Kategori Batasan Nilai p
No. P Kategori
1 p < 0,3 Sulit 2 0.3 <p< 0,7 Sedang 3 p > 0,7 Mudah
2. Indeks Diskriminasi Aitem
a. Pengertian Indeks Diskriminasi Aitem
b. Analisis Indeks Diskriminasi Aitem
Diskriminasi aitem yang maksimal akan dicapai ketika seluruh subjek kelompok tinggi dapat menjawab aitem dengan benar dan seluruh subjek kelompok rendah tidak mampu untuk menjawabnya. Perbedaan proporsi penjawab aitem dengan benar antara kelompok tinggi dengan kelompok rendah dapat dirumuskan sebagai berikut :
d = niT / NT – niR / NR (7)
Keterangan:
niT = Jumlah peserta dari kelompok tinggi yang menjawab aitem dengan benar
NT = Jumlah peserta dari kelompok tinggi
niR = Jumlah peserta dari kelompok rendah yang menjawab item dengan benar
NR = Jumlah peserta dari kelompok rendah
Karena ni / N= p, maka dapat juga dirumuskan dengan:
d = pT - pR (8)
Keterangan:
pT = Indeks kesukaran item kelompok tinggi
pR = Indeks kesukaran item kelompok rendah
Indeks diskriminasi aitem yang ideal adalah yang mendekati angka 1, semakin besar indeks diskriminasi (semakin mendekati 1) berarti aitem tersebut mampu membedakan antara subjek yang menguasai materi yang diujikan dengan yang tidak menguasainya. Semakin kecil diskriminasi aitem (semakin mendekati 0) berarti semakin tidak jelaslah fungsi aitem yang bersangkutan dalam membedakan mana subjek yang menguasai materi yang diujikan dan subjek yang tidak tahu apa-apa (Azwar,2007).
Ebel (dalam Azwar, 2007) memberikan suatu panduan dalam evaluasi indeks diskriminasi aitem, yaitu :
Tabel 2. Evaluasi Indeks Diskriminasi Aitem
d Evaluasi
0,4 atau lebih Bagus sekali
0,3 - 0,39 Lumayan bagus, tidak membutuhkan revisi 0,2 – 0,29 Belum memuaskan, perlu revisi
d < 0,20 Jelek dan harus dibuang
Thorndike (dalam Azwar, 2007) mengatakan bahwa dalam proses seleksi aitem, aitem-aitem yang memiliki nilai diskriminasi aitem di atas 0,50 akan langsung dianggap baik sedangkan aitem-aitem dengan indeks diskriminasi di bawah 0,20 dapat langsung dibuang dan dianggap jelek.
Menurut Murphy dan Davidshofer (2003) ada tiga cara statsistik yang dapat digunakan untuk mengukur indeks diskriminasi aitem, yaitu:
1)Metode kelompok ekstrim
(25-35 % nilai terendah dalam kelompok). Aitem yang memiliki indeks diskriminasi yang baik akan dijawab benar oleh upper group dan dijawab salah oleh lower group.
2)Korelasi aitem-total
Korelasi aitem-total memberikan informasi tentang apakah aitem mengukur hal yang sama dengan tes. Korelasi aitem-total untuk aitem yang diskor 1 jika benar dan 0 jika salah sering juga disebut korelasi poin biserial. Korelasi poin biserial digunakan apabila aitem-aitem dalam tes berbentuk dikotomi. Nilai positif menunjukkan bahwa aitem dan tes mengukur hal yang sama, nilai mendekati nol menunjukkan bahwa bahwa aitem tidak memiliki indeks diskriminasi yang baik sehingga upper group menjawab pertayaan dengan salah dan lower group menjawab pertanyaan dengan benar.
3)Korelasi inter-aitem
Korelasi inter-aitem digunakan untuk memahami indeks diskriminasi aitem. Korelasi inter-aitem tidak menjelaskan mengapa beberapa aitem menunjukkan nilai yang tinggi atau rendah karena sangat jelas bahwa aitem yang memiliki nilai korelasi aitem total yang positif akan menunjukkan nilai yang positif juga pada kebanyakan aitemnya. Namun korelasi aitem total tidak dapat menjelaskan mengapa korelasi aitem total dapat bernilai negatif tetapi hal ini dapat dijelaskan dengan menggunakan korelasi inter-aitem.
Korelasi inter-aitem yang bernilai rendah dapat memiliki dua arti, kemungkinan pertama adalah aitem tidak mengukur hal yang sama dengan tes, sehingga aitem harus dibuang atau dibuat ulang, kemungkinan kedua adalah aitem memang mengukur atribut yang berbeda dengan tes dikarenakan tes memang disusun untuk mengukur dua atribut yang berbeda.
3. Reliabilitas Alat Ukur a. Pengertian Reliabilitas
Menurut Oslterlind (2010), reliabilitas mengarah pada ketepatan dalam pengukuran mental yang ditentukan oleh kekonsistenan dari pengukuran paralel secara acak dari beberapa pengukuran. Pengertian reliabilitas diterapkan dalam dua konteks. Pertama, reliabilitas mengungkap ketepatan instrumen pengukuran, sebagaimana dalam indeks reliabilitas (dikalkulasi sebagai koefisien reliabilitas), dan kedua, reliabilitas diterapkan dalam antar-subjekal untuk testee, sebagaimana dispesifikasi dalam standar error pengukuran (SEM). Reliabilitas juga menandai konsep untuk mengestimasi seberapa baik sampel aitem mewakili keseluruhan aitem untuk konstruk laten atau konten domain. Semakin reliabel sebuah pengukuran, semakin kecil error yang diungkap dalam skor dan semakin terpercaya interpretasi yang dihasilkan.
Reliabilitas bergantung pada konteks penggunaan reliabilitas itu sendiri. Terdapat banyak perspektif pada reliabilitas, tergantung pada defenisi error yang digunakan dan defenisi konstruk laten maupun konten domain yang telah ditentukan sebelumnya.
Menurut Azwar (2005), reliabilitas merupakan terjemahan dari kata
konsistensi dan sebagainya, namun pada intinya konsep reliabilitas memiliki makna sejauh mana hasil suatu pengukuran dapat dipercaya. Menurut Anastasi & Urbina (2006) reliabilitas suatu tes merujuk pada konsistensi skor yang di peroleh oleh subjek yang sama ketika diberikan tes ulang yang sama atau seperangkat tes yang ekivalen dengan tes sebelumnya pada kondisi yang berbeda. Suryabrata (2005) menyatakan bahwa reliabilitas alat ukur menunjukkan sejauh mana hasil pengukuran dengan alat tersebut dapat dipercaya, yang mana hal ini ditunjukkan oleh taraf konsistensi skor yang diperoleh para subjek yang diukur dengan alat yang sama atau minimal setara, dalam kondisi yang berbeda. Oleh sebab itu, konsepsi mengenai reliabilitas berkaitan dengan derajat konsistensi antara dua perangkat skor tes, maka rumus reliabilitas selalu dinyatakan dalam bentuk koefisien korelasi (Azwar, 2005).
Lord dan Novick (dalam Osterlind, 2010), memberikan defenisi reliabilitas sebagai “reliabilitas sebuah tes didefenisikan sebagai kuadrat korelasi antara skor tampak dan skor murni”, sebagaimana dalam rumus :
ρ
2XT (9)
Menurut Osterlind (2010), reliabilitas juga dievaluasi dengan konsistensi pengukuran ketika pengukuran diulang terhadap subjek atau kelompok dari sebuah populasi. Semakin konstan pengukuran tersebut dalam pengukuran-pengukuran yang diulang, maka semakin tinggi reliabilitasnya.
ρ
XT (10)adalah antara dua skor-skor tampak atau kumpulan-kumpulan skor. Hal ini ditunjukkan dalam rumus:
ρ
x1x2 (11)b. Metode Estimasi Reliabilitas
Reliabilitas alat ukur juga menunjukkan eror pengukuran yang tidak dapat ditentukan secara pasti, hanya dapat diestimasi (Suryabrata, 2005). Estimasi reliabilitas dapat dibagi ke dalam tiga bentuk metode, yaitu pendekatan tes ulang, pendekatan tes paralel, dan pendekatan konsistensi internal (Azwar, 2005 dan Suryabrata, 2005).
1) Pendekatan tes ulang
Pendekatan ini dilakukan dengan cara menyajikan tes yang sama dua kali pada suatu kelompok yang sama dalam rentang waktu tertentu, minsalnya dua minggu (Suryabrata, 2005). Asumsinya adalah suatu tes yang reliabel akan menghasilkan skor tampak yang relatif sama apabila diberikan dua kali tes dalam waktu yang berbeda pada sekelompok subjek yang sama (Azwar, 2005).
Pendekatan tes ulang ini dapat dikatakan baik secara teori, namun dalam prakteknya mengandung kelemahan, yaitu kondisi subjek pada tes kedua tidak lagi sama dengan kondisi subjek pada tes pertama baik dari proses belajar, perubahan motivasi, pengalaman, sehingga pendekatan ini lebih baik digunakan bila objek ukur berupa keterampilan, terutama keterampilan fisik (Suryabrata, 2005). Menurut Azwar (2005), pendekatan tes ulang cocok digunakan hanya bagi tes yang mengukur aspek psikologis yang relatif stabil dan tidak mudah berubah. Rumus yang dapat digunakan untuk menentukan reliabilitas tes ulang adalah
2) Pendekatan tes paralel
Pendekatan reliabilitas bentuk paralel dilakukan dengan memberikan dua bentuk tes yang paralel pada sekelompok subjek, yaitu tes yang memiliki tujuan ukur yang sama dan isi aitem yang setara secara kualitas maupun kuantitas (Azwar, 2005). Pendekatan ini disebut juga sebagai alternate form yang digunakan untuk mengatasi kelemahan pendekatan tes ulang (Kumar, 2009). Menurut Azwar (2005), dua tes yang paralel hanya ada secara teoritis, tidak benar-benar paralel secara empirik. Rumus yang dapat digunakan untuk menentukan reliabilitas tes ulang adalah korelasi Pearson product moment
(Azwar, 2005)
3) Pendekatan konsistensi internal
(a). Pembelahan cara random
Membelah tes menjadi dua bagian secara random dapat dilakukan dengan cara undian sederhana guna menentukan aitem-aitem nomor berapa sajakah yang dimasukkan menjadi belahan pertama dan yang mana menjadi belahan kedua. Pembelahan secara random hanya boleh dilakukan bila tes yang akan dibelah berisi aitem-aitem yang homogen baik dari segi konten maupun segi indeks kesukaran aitem, namun jika aitem tersebut heterogen dapat juga menggunakan cara pembelahan ini asalkan aitem tersebut jumlahnya sangat besar (Azwar, 2005).
(b). Pembelahan gasal-genap
Pembelahan gasal-genap dilakukan dengan cara mengelompokkan seluruh aitem yang bernomor urut gasal menjadi belahan pertama dan seluruh aitem yang bernomor urut genap dijadikan satu kelompok belahan kedua. Cara pembelahan ini selain mudah dilakukan juga dapat menghindari kemungkinan terjadinya pengelompokkan aitem-aitem tertentu ke dalam salah satu belahan saja (Azwar, 2005).
(c). Pembelahan matched-random subtes
Selain beberapa cara pembelahan tes telah diuraikan, reliabilitas berdasarkan konsistensi internal juga dapat diestimasi dengan beberapa rumus (Azwar, 2005).
(a). Spearman-Brown
Rumus Spearman-Brown digunakan untuk metode split-half atau belah dua (Kumar, 2009 dan Crocker & Algina, 2003). Rumus komputasi Spearman-Brown merupakan rumus koreksi terhadap koefisien korelasi antara dua bagian tes dan dirumuskan sebagai beikut (Azwar, 2005):
S-B = rxx’= (12)
Keterangan:
rxx’ =Koefisien reliabilitas Spearman-Brown
r1.2 = Koefisien korelasi antara dua belahan
(b). Koefisien Alpha
Cara-cara pembelahan dapat diperluas pemakaiannya untuk membagi tes menjadi beberapa belahan. Bahkan suatu tes yang akan diestimasi reliabilitasnya dapat dibelah menjadi bagian-bagian sebanyak jumlah aitemnya sehingga setiap bagian hanya berisi satu aitem saja. Koefisien Alpha akan lebih baik jika pembelahan paralel satu sama lain atau setidaknya dapat memenuhi asumsi τ
-equivalent. Rumusan rumus Alpha adalah sebagai berikut (Azwar, 2005):
α = (13)
Keterangan :
= varians skor tes
Rumus ini dapat digunakan jika aitem dikotomi ataupun politomi, setiap belahan memiliki aitem yang relatif setara, paralel atau setidaknya memenuhi asumsi τ-equivalent. Selain itu, aitem-aitem dalam tes haruslah homogen agar estimasi yang diperoleh dapat mendekati reliabilitas yang sebenarnya.
(c). Kuder-Richardson 20 (KR-20)
KR 20 merupakan rata-rata estimasi reliabilitas dari semua cara belah-dua yang mungkin dilakukan. Rumus ini juga disebut sebagai koefisien α-20. Koefisien ini mencerminkan sejauhmana kesetaraan isi aitem-aitem dalam tes. Rumusan rumus KR-20 adalah (Azwar, 2005):
(14)
Keterangan :
= banyaknya aitem dalam tes
= varians skor tes
p = proporsi subjek yang mendapat angka 1 pada suatu aitem, yaitu banyaknya subjek yang mendapat angka 1 dibagi oleh banyaknya seluruh subjek yang menjawab aitem tersebut.
(d). Kuder-Richardson 21
Perhitungan KR-21 menggunakan rata-rata harga p dari keseluruhan aitem, Hal inilah yang membedakan antara KR-20 dengan KR-21. Rumusan KR-21 adalah (Azwar, 2005):
(15) Keterangan :
= banyaknya aitem dalam tes
= rata-rata p yaitu,
= varians skor tes
Rumus ini dapat digunakan jika aitem dikotomi, jumlah aitem sedikit dan membelahan tes sebanyak jumlah aitem. Indeks kesukaran aitem haruslah setara satu sama lain agar estimasi reliabilitas mendekati nilai yang sesungguhnya. Jadi, indeks kesukaran aitem yang sangat bervariasi mengakibatkan estimasi reliabilitas akan lebih rendah dari pada menggunakan KR-20.
(e). Rulon
Rulon mengusulkan suatu formula komputasi untuk mengestimasi reliabilitas skor dengan pendekatan belah dua tanpa perlu berasumsi bahwa kedua belahan tersebut mempunyai sifat t-equivalent sepanjang jumlah aitem pada kedua belahan adalah sama. Formula Rulon dirumuskan sebagai :
2 x 2
d S
S 1
rxx' = − / (16)
Keterangan : 2
d
S = Varians perbedaan skor kedua belahan 2
x
S = Varians skor tes
d = Perbedaan skor kedua belahan (c). Reliabilitas Skor Komposit
Ada kalanya skor tes sebagai deskripsi kuantitatif atribut dalam diri subjek tidak diperoleh langsung dari sekedar penjumlahan skor aitem-aitemnya, melainkan didapat dari komposisi atau penggabungan dari bebrapa skor. Beberapa skor tersebut dapat berupa skor dari bagian-bagian tes itu sendiri, yaitu komponen atau subtesnya, dapat pula berasal dari tes-tes yang berbeda sebagai suatu baterai instrumen. Dalam hal ini masing-masing komponen atau bagian tes akan memeberikan bobot yang tersendiri dalam menentukan skor tes (Azwar, 2012).
Bobor relatif suatu komponen ditentukan oleh besarnya sumbangan komponen tersebut dalam menentukan skor akhir, misalnya suatu komponen yang berisi lebih banyak aitem akan lebir besar bobotnya. Begitu pula suatu komponen yang mungkin aitemnya tidak banyak akan tetapi karena mempunyai tingkat kesukaran yang tinggi akan dapat diberi bobot yang besar. Skor akhir tes seperti itu merupakan suatu komposit, yaitu penggabungan skor beberapa komponen setelah melalui prosedur atau penyetaraan skor (Azwar, 2012).
yang tinggi (Azwar, 2012). Bila diinginkan untuk memperoleh estimasi tunggal terhadap skor komposit, dapat digunakan formula yang disarankan oleh Mosier (dalam Azwar, 2012), yaitu:
[
]
rjj’ = koefisien reliabilitas tiap komponen
rjk = koefisien relatif antara dua komponen yang berbeda
c. Standar Error Pengukuran dan Interpretasi Koefisien Reliabilitas
Menurut Osterlind (2010), standar error pengukuran (SEM) mengindikasikan kesenjangan antara skor tampak dan skor murni. Standar error pengukuran juga didefenisikan sebagai standar deviasi sebuah distribusi dari keseluruhan skor untuk semua subjek. Karena teori mengasumsikan distribusi yang setara dan normal untuk semua subjek dalam populasi, standar error pengukuran bisa dipandang sebagai rata-rata standar deviasi pada keseluruhan mean skor.
pengukuran sering dimengerti sebagai analogi dari indeks reliabilitas. Indeks reliabilitas adalah pengukuran yang mengidikasikan kekurangan error, kebalikan dari SEM. Indeks reliabilitas didefenisikan sebagai korelasi sederhana antara bentuk-bentuk paralel sebuah tes (Osterlind, 2010).
Standar error pengukuran merupakan fungsi dari reliabilitas (dan sebaliknya) ketika standar deviasi sebuah tes telah diketahui. Hubungan ini, dalam CTT, antara standar error pengukuran dan reliabilitas sudah terlihat ketika standar deviasi tetap konstan pada seluruh rentang skor sebuah tes. Standar deviasi yang konstan juga terlihat ketika skor ditunjukkan sebagai skor standar dalam unit-unit standar deviasi (Osterlind, 2010).
Secara teoritik, koefisien reliabilitas berkisar antara 0 sampai 1, namun secara empirik koefisien reliabilitas tidak pernah mencapai 1. Artinya terdapat ketidakkonsistenan skor antara dua tes yang paralel yang disebabkan oleh eror yang mempengaruhi performa subjek dalam mengikuti tes atau perbedaan antara skor tampak dan skor murni subjek (Crocker & Algina, 2005). Penafsiran terhadap koefisien reliabilitas dapat dilakukan melalui penafsiran standar eror pengukuran (SEm), dengan rumusan sebagai berikut:
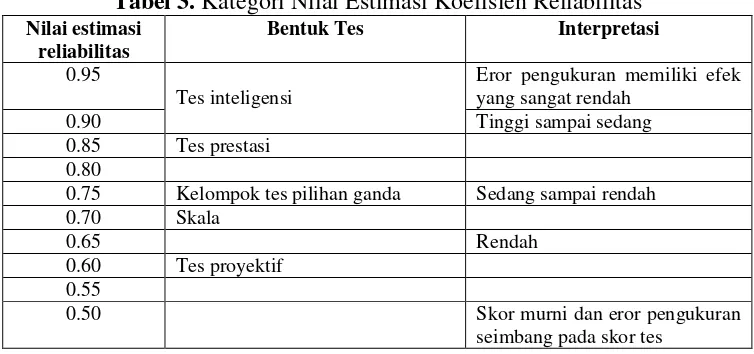
Murphy dan Davidshofer (2003) menjelaskan bahwa makna tinggi atau rendahnya koefisien reliabilitas tergantung pada tipe dari tes yang dikategorikan sebagai berikut:
Tabel 3. Kategori Nilai Estimasi Koefisien Reliabilitas
Nilai estimasi reliabilitas
Bentuk Tes Interpretasi
0.95
Tes inteligensi
Eror pengukuran memiliki efek yang sangat rendah
0.90 Tinggi sampai sedang
0.85 Tes prestasi 0.80
0.75 Kelompok tes pilihan ganda Sedang sampai rendah 0.70 Skala
0.65 Rendah
0.60 Tes proyektif 0.55
0.50 Skor murni dan eror pengukuran seimbang pada skor tes
d. Faktor-faktor yang Mempengaruhi Koefisien Reliabilitas
Crocker & Algina (2005) menjelaskan bahwa ada 3 hal utama yang secara tidak langsung mempengaruhi tinggi rendahnya koefisien reliabilitas suatu instrumen tes, yaitu:
1) Homogenitas Kelompok
Koefisien reliabilitas suatu tes akan dipengaruhi oleh variasi antara skor murni dan eror kelompok subjek atau skor tampak kelompok subjek. Semakin besar homogenitas kelompok semakin rendah nilai koefisien reliabilitas suatu tes dibandingkan dengan kelompok subjek yang heterogen.
2) Batasan Waktu dalam Tes
lebih pendek, performansi subjek akan sangat ditentukan oleh banyak faktor, termasuk kelelahan dan performansi subjek lain yang mengikuti tes tersebut. 3) Panjang Tes
Panjang dari suatu tes sangat bergantung dengan seberapa banyaknya aitem-aitem yang menyusun tes tersebut. Semakin banyak aitem yang memiliki kualitas baik dalam suatu tes, maka semakin tinggi pula indeks reliabilitas tes tersebut.
4. Validitas
a. Pengertian Validitas
Menurut Osterlind (2010), validitas merupakan inti dari pengujian mental. Validitas berarti bahwa informasi yang diungkap oleh sebuah tes adalah informasi yang sesuai, bermakna, dan berguna untuk pengambilan keputusan yang merupakan tujuan pengukuran mental. Standards Text (dalam Osterlind, 2010) mendeskripsikan bahwa validitas adalah pertimbangan yang paling fundamental dalam mengembangkan dan mengevaluasi tes dimana validitas mengarah pada sejauh mana bukti dan teori mendukung interpretasi skor tes berdasarkan tujuan penggunaan tes. Garrett (dalam Osterlind, 2010) mengatakan bahwa validitas suatu tes merupakan tingkat dimana suatu alat tes mengukur apa yang hendak diukurnya.
dapat dikatakan memiliki validitas yang tinggi apabila alat tersebut menjalankan fungsi ukurnya, atau memberikan hasil ukur yang sesuai dengan maksud dilakukannnya pengukuran tersebut, sehingga pengertian validitas terlihat berkaitan sangat erat dengan tujuan pengukuran. Suatu alat ukur biasanya hanya merupakan ukuran yang valid untuk satu tujuan yang spesifik. Pernyataan valid terhadap suatu pengukuran harus diikuti oleh keterangan yang menunjuk kepada tujuan awal pengukuran serta kelompok subjek yang mana yang hendak diukur (Azwar, 2005).
b. Sumber-sumber Bukti Validitas
Bukti-bukti validitas harus terkumpul dari banyak sumber ketika akan mengevaluasi validitas. Sumber-sumber ini memberikan informasi mengenai tingkat kepercayaan untuk membuat kesimpulan-kesimpulan berdasarkan skor dalam situasi tertentu (Osterlind, 2010). Beberapa bukti yang mendukung dalam mengevaluasi validitas diberikan dalam Standards for Educational and Psychological Testing/Standards text (American Educational Research Association, dkk, 1999, dalam Osterlind 2010).
1) Bukti Validitas Berdasarkan Isi Tes
tentang inteligensi manusia penuh dengan pemikiran dan teori yang berlainan tentang apa yang termasuk dan tidak termasuk. Dalam hal ini spesifikasi konstruk dibutuhkan dalam tujuan yang berbeda. Ketika membangun sebuah instrumen, seringkali orang yang mengembangkan tes mengkombinasikan deskripsi isi tes dan jenis proses respon dalam sebuah blueprint tes, dimana blueprint ini bisa menjadi dokumen yang sangat berguna bagi pengguna tes ketika akan mengevaluasi validitas berdasarkan isi tes. Menurut Azwar (2005), Validitas isi menunjukkan sejauhmana aitem-aitem dalam tes mencakup keseluruhan kawasan isi objek atau ciri atribut yang hendak diukur. Validitas isi ini diestimasi lewat pengujian terhadap isi tes dengan analisis rasional atau lewat professional judgement. Dengan kata lain validitas isi sangat tergantung pada penilaian subjektif subjekal dan tidak melibatkan perhitungan statistik.
2) Bukti Validitas Berdasarkan Proses Respon
Pengujian mental atau proses kognitif digunakan untuk mengungkap respon terhadap stimulus pengukuran adalah sumber lain untuk bukti validitas. Beberapa metode berdasarkan variabel-variabel laten dan proses kausal sebuah konstruk mungkin memasukkan analisis variabel laten, structural equation modeling (SEM), Hierarchical linear modeling(HLM), dan beberapa meta-analisis. Metode-metode ini juga bisa mengungkap informasi penting mengenai proses respon subjek.
3) Bukti Validitas Berdasarkan Struktur Internal
tetapi tidak ada satu metode pun yang dianggap terbaik secara umum. Kesesuaian metode yang digunakan tergantung pada konteks dimana tes dikembangkan, bagaimana tes tersebut digunakan dan keputusan apa yang ingin diinformasikan. Beberapa cara yang relevan untuk mempelajari pengukuran struktur internal sebagai berikut :Analisis faktor, analisis kluster, analisis komponen prinsipal, konfirmasi teori psikologi: faktor analisis konfirmatori, multitrait-multimethod matrix, teknik estimasi parameter kemampuan (IRT), strategi-strategi yang melibatkan teori kemampuan-generalisasi.
Model faktor umum (common factor model) adalah teori satu faktor dari Charles Spearman mengenai sebuah tes berisi aitem-aitem yang umum dan memiliki pengaruh yang unik. Dalam situasi praktis untuk validasi tes, model faktor umum diukur dengan menggunakan analisis faktor (factor analysis) atau analisis komponen prinsipal (principal component analysis, PCA). Inti prosedur ini adalah untuk mengurangi varians total diantara aitem-aitem dalam sebuah matriks kovarians sehingga jumlahnya bisa diestimasi.
Sebuah faktor adalah kombinasi aitem-aitem tes yang diyakini sebagai suatu kumpulan. Aitem-aitem yang berhubungan membentuk sebagian dari konstruk dan dikelompokkan bersama, aitem-aitem yang tidak berhubungan tidak membentuk bagian dari konstruk dan harus dikeluarkan dari kelompoknya (Munro, dalam Azwar, 2012).
Analisis faktor memiliki dua jenis prosedur yang dilandasi oleh dasar pemikiran yang agak berbeda, yaitu analisis faktor eksploratori (exploratory factor analysis, EFA) dan analisis faktor konfirmatori (confirmatory factor analysis, CFA). Prosedur faktor analisis eksploratori membantu pengembang tes dalam mengenali dan mengidentifikasi berbagai faktor yang membentuk suatu konstruk dengan cara menemukan varians skor terbesar dengan jumlah faktor yang paling sedikit yang dinyatakan dalam bentuk eigenvalue > 1,0 (Azwar, 2012). Prosedur analisis faktor konfirmatori biasanya akan menindaklanjuti hasil EFA dengan menyertakan dasar teori yang melandasi bangunan tes tersebut agar dapat menguji validitas konstruknya lebih lanjut. Jadi, CFA menguji sejauhmana model statistik yang dipakai sesuai dengan data empirik (Waltz dkk., dalam Azwar, 2012). Analisis faktor konfirmatori hampir selalu digunakan dalam proses pengembangan instrument untuk menguji struktur laten suatu tes, dalam hal ini CFA digunakan untuk memverifikasi banyaknya dimensi yang mendasari bangunan suatu tes dan pola hubungan antara aitem dengan faktor (factor loading
atau yang disebut muatan faktor)(Brown, dalam Azwar, 2012).
koefisien korelasi. Bila faktor-faktor tidak berkorelasi satu sama lain maka muatan faktor bukanlah koefisien korelasi akan tetapi seringkali diinterpretasikan seakan-akan koefisien korelasi (Azwar, 2012).
Analisis struktur faktor dilakukan untuk melihat struktur internal tes sebagai dukungan terhadap validitas model persamaan structural yang digunakan dalam konstruksi tes yang bersangkutan (Azwar, 2012). Untuk tujuan tersebut digunakan prosedur common factor analysis sebagai salahsatu metode pengujian model, terutama yang mengikuti anggapan bahwa satu konstruk dasar akan menghasilkan skor tampak (Aneshensel, dalam Azwar 2012). Bila model yang diajukan ternyata cocok dengan data skor subjek, berarti struktur internal tes adalah valid (Azwar, 2012)
korelasi di antara hasil pengukuran terhadap beberapa trait yagn berbeda sekalipun diukur menggunakan metode yang serupa (discriminant validity).
4) Bukti Validitas Berdasarkan Hubungan dengan Variabel Lain
Hubungan antara skor tes dan kriteria yang diuji sering diidentifikasi dengan melabel bukti kriteria sebagai bukti prediktif atau konkuren dalam validitas. Kedua jenis bukti ini menunjukkan kemunculan hubungan antara tes dan sebuah kriteria eksternal, perbedaanya hanya waktu kapan pengukuran hubungan korelasional. Bukti prediktif juga adalah sebuah indikator yang muncul dari perbandingan antara sebuah tes dengan tes di masa depan atau kriteria administrasi posttest. Dalam mengevaluasi validitas, masalah muncul ketika sebuah hubungan korelasional adalah sumber utama dalam bukti validitas. Kesulitan muncul dari fakta bahwa dalam CTT, skor murni hanya bisa didapat secara teoritis dan tidak bisa diketahui secara pasti. Dalam dunia praktis, terbukti bahwa reliabilitas korelasional sebagai bukti kriteria untuk validitas tes, ditekan oleh derajat eror pengukuran dalam kriteria. Keadaan ini disebut sebagai masalah kriteria. Masalah kriteria adalah ketika reliabilitas kriteria bergantung pada hubungan korelasional dengan kriteria eksternalnya.
5) Bukti Validitas Berdasarkan Pertimbangan-pertimbangan Eksternal Validitas Tampang sebagai Sumber Bukti
tidak bisa diuji dengan metode statistik, bukan berarti validitas tampang bisa dianggap rendah. Memberikan sebuah instrumen tes yang memiliki tampilan profesional pada peserta tes adalah tanggung jawab validitas pembuat tes.
c. Interpretasi Koefisien Validitas
Interpretasi koefisien validitas bersifat relatif. Tidak ada batasan universal yang mengarah kepada angka minimal yang harus dipenuhi agar suatu tes dikatakan valid. Menurut Cronbach (dalam Azwar, 2005) koefisien validitas yang baik adalah yang tertinggi yang bisa didapatkan. Jadi tidak ada batasan. Hal yang menjadi pertimbangan adalah sejauh mana tes tersebut dapat bermanfaat dalam pengambilan keputusan. Tes yang berfungsi untuk memprediksi hasil suatu prosedur seleksi dapat dikatakan memberikan kontribusi yang baik jika koefisien validitas berkisar antara 0,3 sampai dengan 0,5. Menurut Azwar (2005) koefisien validitas yang tidak begitu tinggi, sekitar 0,5 akan lebih dapat diterima dan dianggap memuaskan dan koefisien validitas yang kurang dari 0,3 biasanya dianggap tidak memuaskan. Sedangkan dalam penggunaan analisis faktor konfirmatori dengan bantuan program Lisrel 8.30, suatu aitem dikatakan memiliki validitas yang baik jika memenuhi dua nilai muatan faktor, yaitu t-values dan
C. Analisis Karakteristik Psikometri Alat Ukur
Alat ukur terdiri dari aitem-aitem yang dirancang untuk tujuan tertentu. Aitem dapat dikatakan memiliki kualitas yang baik jika aitem memiliki karakteristik psikometri yang baik pula (Azwar, 2007). Aitem berkualitas baik atau tidak dapat kita ketahui melalui analisis karakteristik psikometri terhadap aitem tersebut. Analisis terhadap aitem-aitem dalam suatu alat ukur pada awalnya akan memberikan tiga informasi, yaitu informasi tentang distraktor, indeks kesukaran aitem dan indeks diskriminasi aitem (Murphy & Davidshofer, 2003). Ketiga karakteristik tersebut akan saling mempengaruhi terhadap reliabilitas dan valididtas alat ukur. Tetapi penelitian ini hanya memberi informasi karakteristik indeks kesukaran aitem dan indeks diskriminasi aitem.
Indeks kesukaran aitem secara langsung akan mempengaruhi indeks diskriminasi aitem. Ketika aitem sangat susah (p = 0) atau aitem sangat mudah (p = 1), maka aitem tidak akan dapat membedakan antara subjek yang memiliki pengetahuan dan subjek yang tidak memiliki pengetahun sehingga indeks diskriminasi aitem menjadi rendah (Murphy & Davidshofer, 2003). Menurut Kumar (2009), indeks diskriminasi yang rendah dapat mempengaruhi validitas aitem tersebut yang kemudian akan mempengaruhi validitas tes secara keseluruhan. Ketika aitem mengukur fungsi ukur dengan tepat, maka aitem akan dapat membedakan antara kelompok yang memiliki atribut yang hendak diukur dan yang tidak memiliki atribut yang hendak diukur sehingga aitem dapat dikatakan valid.
setara satu sama lain atau sangat bervariasi maka koefisien reliabilitas akan rendah (Azwar, 2005). Pada beberapa kondisi, tes yang reliabel belum tentu valid, karena reliabilitas tes juga dipengaruhi oleh eror, tetapi tes yang valid sudah pasti reliabel (Azwar, 2005).
D. Culture Fair Intelligence Test (CFIT) Skala 3B 1. Sejarah dan Perkembangan CFIT
Spearman (1927) menyusun faktor analisis pertama terhadap kemampuan-kemampuan dan mengatakan bahwa kemampuan-kemampuan-kemampuan-kemampuan tersebut dapat dijelaskan dalam sebuah faktor umum (general factor) yang disebut “g” yang mengarah pada kecerdasan umum (Coaley, 2010). Menurut Spearman, kecerdasan terdiri dari satu faktor umum ditambah sejumlah faktor-faktor spesifik di dalamnya (Kaplan & Saccuzo, 2005). Dalam perkembangannya, Cattel menemukan bahwa kecerdasan bukan merupakan satu konsep tunggal tetapi terdiri dari dua komponen. Cattel membenarkan bahwa kecerdasan umum (general intelligence) memang ada tetapi dia mengatakan bahwa kecerdasan umum terdiri dari dua hal yang berhubungan tetapi berbeda, yaitu fluid intelligence dan crystallized intelligence.Fluid intelligence lebih ditentukan secara genetis sehingga lebih bebas budaya. Cattel memandang bahwa fluid intelligence
sebagai kemampuan logika primer yang berhubungan dengan masalah-masalah abstrak dan lebih terlibat dalam proses adaptasi. Sebaliknya, crystallized intelligence berkembang dari latihan terhadap fluid intelligence dalam lingkungan tertentu. (Coaley, 2010).
yang berhubungan dengan pengaruh budaya sehingga bisa diukur kecerdasan yang bebas dari proses belajar, budaya, dan sebagainya (Kaplan & Saccuzo, 2005).
Culture Fair Intelligence Test adalah pengukuran nonverbal terhadap fluid intelligence yang diciptakan oleh Raymond B. Cattel. Tujuan dari CFIT adalah untuk mengukur fluid intelligence (kemampuan analisis dalam situasi abstrak) dalam pola yang sebebas mungkin dari pengaruh budaya (Gregory, 2000). Culture Fair Intelligence Test dirancang untuk memberikan sebuah estimasi kecerdasan yang relatif bebas dari pengaruh bahasa dan budaya (Kaplan & Saccuzo, 2005) Salah satu tujuan tes instrument CFIT ini adalah untuk meminimalisir pengaruh-pengaruh yang tidak relevan dari pembelajaran budaya dan sosial sehingga dihasilkan pemisahan yang lebih bersih terhadap kemampuan alami dari pembelajaran yang spesifik (IPAT dalam Gregory, 2000). Awalnya tes ini dinamakan Culture Free Intelligence Test. Nama tes ini berubah setelah diketahui bahwa pengaruh budaya tidak bisa dihilangkan seutuhnya dari tes inteligensi (Gregory, 2000).
berisi 4 subtes : Seri, Klasifikasi, Matriks, dan Kondisi/topologi. Tiap subtes memiliki batasan waktu. CFIT merupakan speed test, dengan waktu 30 menit untuk skala 2 dan 3, tetapi hanya diberikan 12,5 menit pada tes sebenarnya (Gregory, 2000).
Reliabilitas CFIT melalui tes-retes, bentuk alternatif, dan konsitensi internal pada umumnya 0,70an pada skala 2 dan 3. Dalam hal validitas, CFIT berkorelasi sekitar 0,80an dengan faktor umum inteligensi dan menunjukkan hubungan yang kuat sekitar 0,70an dan 0,80an dengan alat ukur inteligensi yang umum dipakai seperti: WAIS, WISC, Raven PM, Stanford-Binet, Otis, dan