using Convolutional Neural Network
Anhar Risnumawan1, Indra Adji Sulistijono2, Jemal Abawajy3, and Younes Saadi4
1
Mechatronics Engineering Division, 2
Graduate School of Engineering Technology, Politeknik Elektronika Negeri Surabaya (PENS), Kampus PENS, Surabaya, Indonesia
{anhar,indra}@pens.ac.id
3
School of Information Technology, Deakin University, Australia
4
Faculty of Computer Science & Information Technology, University of Malaya, Kuala Lumpur, Malaysia
Abstract. Text detection on scene images has increasingly gained a lot of interests, especially due to the increase of wearable devices. However, the devices often acquire low resolution images, thus making it difficult to detect text due to noise. Notable method for detection in low resolution images generally utilizes many features which are cleverly integrated and cascaded classifiers to form better discriminative system. Those methods however require a lot of hand-crafted features and manually tuned, which are difficult to achieve in practice. In this paper, we show that the notable cascaded method is equivalent to a Convolutional Neural Network (CNN) framework to deal with text detection in low resolution scene images. The CNN framework however has interesting mutual interaction between layers from which the parameters are jointly learned without requiring manual design, thus its parameters can be better optimized from training data. Experiment results show the efficiency of the method for detecting text in low resolution scene images.
Keywords: Scene text detection, low resolution images, cascaded
clas-sifiers, Convolutional Neural Network, mutual interaction, joint learning.
1
Introduction
In most embedded-systems-based platforms such as robotics and mobile de-vices, low resolution images are often acquired from low resolution camera since it has small size, modularity with the platforms, and its compatibility with low processing power of most embedded systems. Ranging from robot localization applications using road signs as a GPS alternative, wearable-devices-based scene text detection such as Google Goggles5
, vOICe6
, and Sypole7
to help visually impaired people.
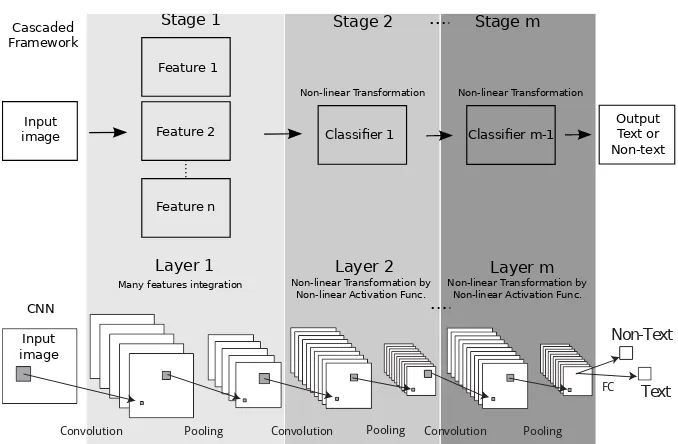
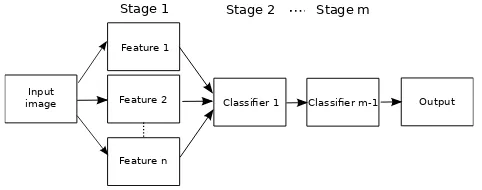
Dealing with low resolution images for detection is generally solved using many features which are cleverly integrated followed by cascaded classifiers to get better discriminative system as compared to the high-resolution-images-based systems [5, 11–13, 18–20]. Many features integration and cascaded classifier are extremely important to reduce misclassification rate due to the noise caused by low resolution images. The features are however prone to error due to imperfec-tion from manual design, while the cascaded classifiers require tedious jobs of hand-tuning before preparing another classifier to be cascaded, as shown in Fig. 1.
Feature 1
Feature 2
Feature n
Classifier 1 Classifier m-1 Stage 1 Stage 2 Stage m
Input
image Output
Fig. 1: General cascaded framework for detection in low resolution images, where there is no mutual interaction between stages. Each stage usually needs careful design and tune before working on another stage to be cascaded.
The cascaded framework as shown in Fig. 1 has no mutual interaction be-tween stages. More specifically, the parameter on each stage is individually de-signed and tuned during learning, which is then the parameters become fixed when a new stage is designed. For example, the Histogram of Oriented Gradi-ent (HOG) feature is individually designed with its parameters manually tuned given the linear SVM classifier being used in [1]. Then HOG feature become fixed when new classifiers are designed [6].
In this paper, we show that the most notable cascaded framework that is using many integrated features and cascaded classifiers is equivalent to a deep convolutional neural network (CNN) [3], to deal with text detection on low res-olution scene images. The method mainly differs from the existing manually
hand-crafted features and explicitly learn each classifier, the method implicitly integrates many features and has mutual interaction between stages. This mu-tual interaction can be seen as the stages are connected and jointly learned for which the back-propagation technique is employed to obtain parameters simul-taneously.
2
Text detection using CNN
Overview of the system is shown in Fig. 2. Given a low resolution input scene image, response map is computed from CNN, and bounding boxes are formed to indicate the detected text lines. One can see the noise caused by low resolution from the zoomed image in Fig. 2b. These for example, the characters are not smooth as in high resolution images, touching between characters may be clas-sified as non-text, missing characters due to imperfect geometrical properties, and non-text may be classified as text due to noise.
(a) Low resolution image, 250x138 pixels (b) Zoomed image patch
(c) Response map from CNN (d) Bounding boxes formation
Notable works which solve text detection on low resolution images are Mirme-hdi et al. [7] and Nguyen et al. [10], but it only works for document which is differ from scene images. Sanketi et al. [14] used several stages to localize text on low resolution scene images. However, the method is just a proving concept. It is also noted that several stages system could hardly be maintained as the error from the first stage could be propagated due to imperfect tuning, and requires manually hand-crafted features.
Classifier is the main part of scene text detection system. It has been proven that increasing the performance of the classifier could increase the accuracy of detection, for example the works by [8, 9] applied cascaded classifiers to boost the accuracy.
Conventionally, in order to classify an image patchu whether it is text or non-text, a set of features Q(u) = (Q1(u), Q2(u), . . . , QN(u)) are extracted and
a binary classifier kl for each text and non-text label l is learned. From the
probabilistic point of view, this means classifiers are learned to yield a posterior probability distribution p(l|u) = kl(Q(u)) over labels given the inputs. The
objective is then to maximize to recognize the labelslcontained in image patch
u such thatl∗ = argmax
l∈Lp(l|u), where L ={text,non-text}. Those features Q often require hand-crafted manual design and optimized through a tedious jobs of trial-and-error cycle from which adjusting the features and re-learning the classifiers are needed. In this work, CNN is applied instead to learn the representation, jointly optimizing the features as well as the classifiers.
Multiple layers of features are stacked in CNN. A convolutional layer consist of N linear filters which is then followed by a non-linear activation functionh. A feature map fm(x, y) is an input to a convolutional layer, where (x, y)∈ Sm
are spatial coordinates on layer m. The feature map fm(x, y) ∈ RC contains C channels or fc
m(x, y) to indicate c-th channel feature map. The output of
convolutional layer is a new feature mapfn
m+1 such that,
fmn+1=hm(Wmn
O
fm+bmn) (1)
where Wmn and bmn denote the n-th filter kernel and bias, respectively and
N
denotes convolution operator. An activation layer hm such as the Rectified
Linear Unit (ReLU)hm(f) = max{0, f} is used in this work. In order to build
translation invariance in local neighborhoods, convolutional layers can be in-tertwined with normalization, subsampling, and pooling layers. Pooling layer is obtained by performing operation such as taking maximum or average over local neighborhood contained in channel c of feature maps. The process starts withf1 equal to input image patchu, performs convolution layer by layer, and ends by connecting the last feature map to a logistic regressor for classification to get the probability of the correct label. All the parameters of the model are jointly learned from the training data. This is achieved by minimizing the classi-fication loss over a training data using Stochastic Gradient Descent (SGD) and back-propagation.
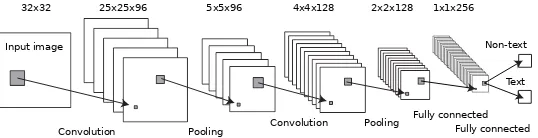
Input image
Convolution Pooling Convolution Pooling
Text Non-text
Fully connected 32x32 25x25x96
Fully connected 5x5x96 4x4x128 2x2x128 1x1x256
Fig. 3: CNN structure for this work.
normalized input then becomes an input to two convolutional and pooling layers. We found that the normalization is important to reduce the loss as the input is now centered and bounded to [0,1]. We use the number of first filtersN1= 96 and the secondN2= 128. After each convolutional layer and the first fully-connected (FC) layer we intertwine with ReLu activation layer. ReLu is simply passing all the feature maps if it is not less than zero hm(f) = max{0, f}. In practice we
found that ReLu will increase the convergence rate of learning process instead of using sigmoid function as it could easily deteriorate the gradient.
After the last fully-connected layer we apply sigmoid activation function followed by softmax loss layer. In our experiments, it was found empirically that sigmoid function after last fully-connected layer yields superior performance. This can be thought as bounded the output to be within the labels which are {0,1}for non-text and text labels, respectively. During testing, the output is the probability value of each label.
In order to form bounding boxes from the response maps, we apply non-maximal suppression (NMS) as in [15]. In particular, for each row in the response maps, we scan the possible overlapping line-level bounding boxes. Each bounding box is then scored by the mean value of probability contained in response maps. Then NMS is applied again to remove overlapping bounding boxes.
3
Relationship to the Existing Cascaded Framework
We show that the cascaded framework can be seen as a Convolutional Neural Network. Fig. 4 shows an illustration.
In the cascaded framework, many features are extracted from the input im-age. Those features are used to provide rich information to the classifier for better input representation. The classifier then decide the correct label of the input. The classifiers generally contain non-linear transformation such as in Sup-port Vector Machine (SVM) from which the input features space are projected or mapped onto higher dimension to apply linear operations. In order to make better discriminative system, several classifiers are usually cascaded.
Feature 1
Feature 2
Feature n
Classifier 1 Classifier m-1
Stage 1 Stage 2 Stage m
Input
Layer 1 Layer 2 Layer m
Non-linear Transformation Non-linear Transformation
Input image
Pooling Convolution Pooling Convolution Pooling FC
Fig. 4: Analogy between cascaded framework and Convolutional Neural Network structure.
However, in the CNN, many features integration, non-linear transformation, to-gether with maximum or average pooling, are all involved in a layer. It is fully feed-forward and can be computed efficiently. So the method able to optimize an end-to-end mapping that consists of all operations. In addition, the last fully-connected layer (FC) can be thought as pixel-wise non-linear transformation. A new stage or layer could be easily cascaded to make better discriminative system.
4
Experimental Results
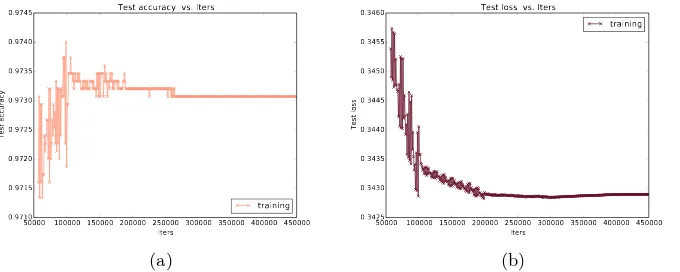
We train the CNN using ICDAR 2003 training set and synthetic data from [16]. Some of the training data is used as validation set. The learning rate of SGD parameters is set to 0.05 and decreases by multiplication of 0.1 for every 100,000 iterations. Maximum iteration is set to 450,000. Momentum parameter is 0.9. The validation set is tested for every 1000 iterations. Using a standard PC core i5 4Gb RAM running GPU 1Gb memory the training takes about 1 week. These validation test curves for every 1000 iteration during training as shown in Fig. 5.
50000 100000 150000 200000 250000 300000 350000 400000 450000
Test accuracy vs. Iters
training
(a)
50000 100000 150000 200000 250000 300000 350000 400000 450000 Iters
Test loss vs. Iters
training
(b)
Fig. 5: Test accuracy (a) and loss (b) using validation set during training.
boxes could be easily formed using NMS as the non-text responses do not have regular pattern (such as horizontal alignment).
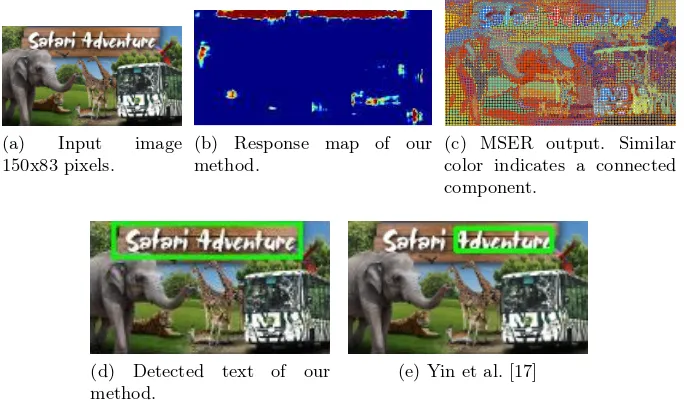
On the contrary, the well known methods based on connected components analysis such as Maximally Stable Extremal Regions (MSER)-based show many components are extracted as shown in Fig. 6c including non-text and fews are text. Moreover, note that some of the characters are touching its neighborhood, e.g., character S-a, r-i in the word ’Safari’, and the characters stroke width are relatively small. These could hardly be classified as text since most of the con-nected components analysis investigate geometrical structure of each component. We compare with the result from Yin et. al [17] as a representation from other cascaded-framework-like methods, since their method achieved the best perfor-mance on ICDAR competition dataset, it is also similar with the definition of the cascaded framework in this work, online demo is provided thus easy to make comparison, and more importantly it used connected components analysis using MSER-based. As can be seen the whole text line could not be detected as in Fig. 6e due to imperfect geometrical structure of the components because of noise.
(a) Input image 150x83 pixels.
(b) Response map of our method.
(c) MSER output. Similar color indicates a connected component.
(d) Detected text of our method.
(e) Yin et al. [17]
Fig. 6: Result and comparison with low resolution input image. Best viewed in color.
5
Conclusion
In this paper, we have presented a framework that has mutual interaction be-tween stages or layers using CNN to deal with text detection problems in low resolution images. The framework can be viewed as the conventional cascaded framework to build better discriminative system. Interestingly, many features integration, non-linear transformation, together with maximum or average pool-ing, are all involved in a layer. It is fully feed-forward and can be computed effi-ciently. Thus it is able to jointly optimize an end-to-end mapping that consists of all existing cascaded operations. The experiments show encouraging results that it would be beneficial for the future works on text detection in low resolution scene images.
6
Acknowledgements
The authors would like to thank Pusat Penelitian dan Pengabdian Masyarakat (P3M) of Politeknik Elektronika Negeri Surabaya (PENS) for supporting this research by Local Research Funding FY 2016.
References
1. Navneet Dalal and Bill Triggs. Histograms of oriented gradients for human
150x83
150x150
200x121
300x199
350x197
150x112
100x75
2. Keechul Jung, Kwang In Kim, and Anil K Jain. Text information extraction in
images and video: a survey. Pattern recognition, 37(5):977–997, 2004.
3. Yann LeCun, Bernhard Boser, John S Denker, Donnie Henderson, Richard E Howard, Wayne Hubbard, and Lawrence D Jackel. Backpropagation applied to
handwritten zip code recognition. Neural computation, 1(4):541–551, 1989.
4. Jian Liang, David Doermann, and Huiping Li. Camera-based analysis of text and
documents: a survey.International Journal of Document Analysis and Recognition
(IJDAR), 7(2-3):84–104, 2005.
5. Mirko M¨ahlisch, Matthias Oberl¨ander, Otto L¨ohlein, Dariu Gavrila, and Werner
Ritter. A multiple detector approach to low-resolution fir pedestrian recognition. InProceedings of the IEEE Intelligent Vehicles Symposium (IV2005), Las Vegas, NV, USA, 2005.
6. Subhransu Maji, Alexander C Berg, and Jitendra Malik. Classification using
in-tersection kernel support vector machines is efficient. InCVPR, pages 1–8. IEEE,
2008.
7. Majid Mirmehdi, Paul Clark, and Justin Lam. Extracting low resolution text with
an active camera for ocr. InSpanish Symposium on Pattern Recognition and Image
Processing IX, pages 43–48, 2001.
8. Lukas Neumann and JirıMatas. Real-time scene text localization and recognition.
InCVPR, pages 3538–3545. IEEE, 2012.
9. Lukas Neumann and Jiri Matas. On combining multiple segmentations in scene
text recognition. ICDAR, 2013.
10. Minh Hieu Nguyen, Soo-Hyung Kim, and Gueesang Lee. Recognizing text in
low resolution born-digital images. In Ubiquitous Information Technologies and
Applications, pages 85–92. Springer, 2014.
11. Anhar Risnumawan and Chee Seng Chan. Text detection via edgeless stroke width
transform. InISPACS, pages 336–340. IEEE, 2014.
12. Anhar Risnumawan, Palaiahankote Shivakumara, Chee Seng Chan, and Chew Lim
Tan. A robust arbitrary text detection system for natural scene images. Expert
Systems with Applications, 41(18):8027–8048, 2014.
13. Samir Sahli, Yueh Ouyang, Yunlong Sheng, and Daniel A Lavigne. Robust vehicle
detection in low-resolution aerial imagery. InSPIE Defense, Security, and Sensing,
pages 76680G–76680G. International Society for Optics and Photonics, 2010. 14. Pannag Sanketi, Huiying Shen, and James M Coughlan. Localizing blurry and
low-resolution text in natural images. In Applications of Computer Vision (WACV),
2011 IEEE Workshop on, pages 503–510. IEEE, 2011.
15. Kai Wang, Boris Babenko, and Serge Belongie. End-to-end scene text recognition.
InICCV, pages 1457–1464. IEEE, 2011.
16. Tao Wang, David J Wu, Andrew Coates, and Andrew Y Ng. End-to-end text
recognition with convolutional neural networks. InICPR, pages 3304–3308. IEEE,
2012.
17. Xu-Cheng Yin, Xuwang Yin, Kaizhu Huang, and Hong-Wei Hao. Robust text
detection in natural scene images. IEEE Transactions on Pattern Analysis and
Machine Intelligence, 36(5):970–983, May 2014.
18. Jianguo Zhang and Shaogang Gong. People detection in low-resolution video with
non-stationary background. Image and Vision Computing, 27(4):437–443, 2009.
19. Tao Zhao and Ram Nevatia. Car detection in low resolution aerial images. Image
and Vision Computing, 21(8):693–703, 2003.
20. Jiejie Zhu, Omar Javed, Jingen Liu, Qian Yu, Hui Cheng, and Harpreet Sawhney. Pedestrian detection in low-resolution imagery by learning multi-scale intrinsic
![Fig. 2: Overview of the system using low resolution input image. Response mapis shown as the probability output [0, 1] from CNN, ranging from blue(lowest)- yellow - red(highest)](https://thumb-ap.123doks.com/thumbv2/123dok/2363263.1637745/3.595.137.482.493.601/overview-resolution-response-probability-output-ranging-lowest-highest.webp)