IDENTIFIKASI JENIS MANGGA BERDASARKAN WARNA DAN
BENTUK DAUN MENGGUNAKAN METODE ANN VOTED
PERCEPTRON
Nur HidayatullahTeknik Informatika, Fakultas Teknik , Universitas Bhayangkara Surabaya, Surabaya, Indonesia
Email : [email protected]
ABSTRAK
Bagi sebagian masyarakat, membedakan jenis bibit mangga merupakan hal yang sulit dilakukan mengingat bentuk daun dan fisik tanaman yang hampir sama. Masyarakat baru bisa mengenali jenis mangga ketika mangga sudah berbuah dan itu masih harus menunggu minimal 6 bulan untuk berbuah. Voted Perceptron adalah salah satu metode klasifikasi linier yang arsitekturnya menggunakan layer input dan layer output dengan nilai vektor bobot tertentu untuk memaksimalkan margin antara dua kelas data. Penelitian ini menggunakan nilai Mean, momen nth, dan standart deviasi dari fitur warna green serta nilai compactness dan circularity untuk deskripsi bentuk dari citra daun. Dengan data latih sejumlah 30 data untuk masing masing kelas dengan perbandingan 20 data latih dan 10 sebagai data uji. Hasil penelitian ini didapat nilai akurasi sebesar 60% dan error sebesar 40% serta nilai precission untuk kelas mangga curut sebesar 0, kelas mangga gadung sebesar .6428, kelas mangga manalagi sebesar 0, kelas mangga madu sebesar . , kelas mangga golek sebesar . , kelas tidak terdaftar sebesar . . Sedangkan nilai recall untuk kelas mangga curut sebesar 0, kelas mangga gadung sebesar 0.9, kelas mangga manalagi sebesar 0, kelas mangga madu sebesar 1.0, kelas mangga golek sebesar 0.7, kelas tidak terdaftar sebesar 1.0.
Kata Kunci: voted perceptron, mangga, citra, golek, gadung, madu, manalagi, curut
1. PENDAHULUAN
Kemajuan dunia penelitian saat ini telah melahirkan berbagai produk unggulan termasuk di bidang pertanian. Saat ini terdapat berbagai jenis varietas tanaman hasil dari penelitian dan juga varietas asli termasuk juga jenis jenis mangga. Bagi sebagian masyarakat, membedakan jenis bibit mangga merupakan hal yang sulit dilakukan mengingat bentuk daun dan fisik tanaman yang hampir sama. Saat ini, masyarakat masih kesulitan menentukan jenis mangga ketika umur pohon masih kecil. Masyarakat baru bisa mengenali jenis mangga ketika mangga sudah berbuah dan itu masih harus menunggu minimal 6 bulan untuk berbuah. Masyarakat sering salah pilih memilih jenis pohon mangga yang hendak ditanam karena kesulitan menentukan jenis mangga ketika pohon masih kecil.
Oleh karena itu, penulis berinisiatif untuk melakukan penelitian klasifikasi jenis pohon mangga berdasarkan tekstur daun. Dengan
sistem yang dikembangkan ini, diharapkan dapat membantu masyarakat dalam mengenali jenis mangga yang akan ditanamnya, sehingga tidak merasa tertipu atau kecewa pada jenis mangga yang ditanamnya.
Sistematika dalam paper ini terbagi menjadi 5 bagian : bagian 1 memuat pendahuluan, bagian 2 membahas teori yang melandasi dalam melakukan penelitian, bagian 3 adalah desain sistem yang digunakan, bagian 4 adalah membahas skenario pengujian, dan analisis hasil pengujian, sedangkan bagian 5 membahas kesimpulan yang didapat dari penelitian.
2. LANDASAN TEORI 2.1. Analisa Citra
translasi, skala, transformasi geometrik), melakukan pemilihan citra ciri (feature images) yang optimal untuk tujuan analisis, melakukan proses penarikan informasi atau deskripsi objek atau pengenalan objek yang terkandung pada citra, melakukan kompresi atau reduksi data untuk tujuan penyimpanan data, transmisi data, dan waktu proses data.
2.1.1. Segmentasi Citra
Segmentasi citra bertujuan membagi citra kedalam sejumlah region dan objek. Pemisahan background dengan objek daun dilakukan untuk mendapatkan area citra daun yang terpisah dari background. Pemisahan background dan objek menggunakan nilai Treshold sehingga didapat objek citra yang diharapkan.
Deteksi tepi dari objek dilakukan untuk mendapatkan nilai keliling dari objek. Deteksi tepi menggunakan deteksi tepi sobel
� = √� + � yang mengunakan mask untuk memperkirakan nilai turunan Gx dan Gy.
Gambar 1 mask 3x3 2.1.2. Ekstraksi Fitur
Ekstraksi fitur bertujuan untuk mengambil nilai tertentu dari citra menjadi data sheet yang kemudian digunakan dalam peroses selanjutnya.
Pendekatan yang sering digunakan untuk analisis tekstur didasarkan pada properti statistik histogram intensitas. Satu kelas pengukuran didasarkan pada moment statistik. Untuk menghitung moment nth terhadap mean diberikan oleh:
��= ∑�−�= �− �� �
di mana zi adalah variabel random yang mengindikasikan intensitas, p(z) adalah histogram level intensitas dalam region, L adalah jumlah level intensitas yang tersedia,
mean (rata-rata) intensitas dihitung dengan formula:
= ∑�−�= �� �
Standart deviasi digunakan untuk menghitung ukuran rata rata contrass suatu citra. Nilai standart deviasi dihitung dengan rumus
σ=√�
Keterangan:
� = standart deviasi
� = varian
Compactness dan Circularity digunakan untuk deskriptor bentuk. Area, adalah jumlah piksel dalam obyek (luas). Perimeter, adalah jumlah piksel sepanjang boundary (keliling). Rasio compactness, adalah rasio antara (perimeter)2 / area.
Compactness = �2
�
Keterangan:
P = jumlah piksel sepanjang boundary (keliling)
A = jumlah piksel dalam obyek (luas) Rasio circularity, adalah rasio antara area dari obyek terhadap area lingkaran (bentuk paling compact) dengan panjang perimeter yang sama.
Circularity = 4�� �2
2.2.ANN Voted Perceptron
vektor perceptron beserta bobotnya yang dihasilkan dalam proses training ini disimpan untuk digunakan dalam proses klasifikasi, dengan menggunakan persamaan:
̃ = sign(� . )
Nilai ̃ merupakan hasil dari perkalian antara input dengan vektor � yang dibandingkan dengan nilai Treshold, yaitu jika nilai hasil perkalian dibawah Treshold,
maka ̃ = -1 dan jika sebaliknya maka nilai ̃ = 1.
Apabila dalam proses training dengan menggunakan vektor perceptron � salah dalam memprediksi maka vektor perceptron baru akan diperbarui dengan menggunakan persamaan:
��+ = ��+ �. �
Untuk proses klasifikasi, proses voting perceptron ini memanfaatkan vektor perceptron dan bobot { � , � , … . , ��, �� } yang tersimpan dari proses training yang didefinisikan dengan persamaan sebagai berikut:
y = sign ∑��= �� ��� ��.
Berikut adalah algoritma Voted Perceptron dan penjelasannya
1. Input : Training set beserta labelnya{ , , … . . , �, � }, inisialisasi nilai epoch dan Treshold. 2. Inisialisasi nilai vektor perceptron
training set yaitu
� = [ ], nilai bobot yaitu � = 1 , dan nilai k = 1
3. Lakukan sebanyak nilai epoch
a) Melakukan prediksi label pada training set dengan menggunakan persamaan :
̃ = ��� � .
b) Jika antara nilai ̃dan y mempunyai nilai yang sama, maka update nilai c menjadi �� = ��+
dan k tetap, sebaliknya jika nilainya berbeda maka lakukan proses mencari vektor perceptron baru dengan persamaan :
��+ = ��+ � . �
selain itu lakukan proses update pada nilai c dan nilai k yaitu:
��+ = ��+ dan k = k + 1
4. Output :
Beberapa nilai vektor perceptron dan bobot { � , � , … , ��, �� } yang selanjutnya digunakan dalam klasifikasi dengan menggunakan persamaan sebagai berikut :
y = sign ∑��= �� ��� ��.
3. DESAIN SISTEM
Sistem untuk melakukan klasifikasi jenis pohon mangga berdasarkan tekstur daun ini menggunakan sistem kerja adalah sebagai berikut :
I. Preprocessing
Pada bagian ini dilakukan pekerjaan awal sebelum pemrosesan citra lebih lanjut, seperti: resizing dan perbaikan intensitas.
II. Segmentasi
Segmentasi menggunakan metode Treshold.
III. Ekstraksi fitur
Pada bagian ini, dilakukan pengambilan komponen warna hijau pada citra daun yang sudah disegmentasi. Kemudian mengekstrak fitur yaitu: mean Green, momen nth Green, deviasi Green, compactness dan circularity.
IV. Pemisahan data
Metode pemilihan data dalam ujicoba sistem ini menggunakan metode Hold-Out, yaitu dengan membagi data menjadi data training dan data uji dengan perbandingan 20 data untuk data latih dan 10 data untuk data uji untuk masing masing kelas. Sehingga didapat 100 data latih dan 60 data uji yang terdiri dari 50 data kelas yang tersedia dan 10 data untuk kelas diluar kelas yang tersedia.
V. Training dengan ANN Voted Perceptron
Training dengan ANN Voted Perceptron dilakukan pada data training dengan label kelas yang sudah diberikan pada setiap data training.
VI. Klasifikasi
Kemudian hasilnya dilakukan pencocokan dengan kelas yang sesungguhnya sehingga
diketahui akuransi sistem dalam melakukan klasifikasi.
4. PENGUJIAN SISTEM
Uji coba terdiri dari dua proses, yaitu proses pelatihan dan proses uji coba. Proses pelatihan dilakukan untuk mendapatkan nilai vektor v dan nilai bobot c yang akan digunakan dalam proses uji coba atau klasifikasi. Metode pemilihan data dalam ujicoba sistem ini
menggunakan metode Hold-Out, yaitu dengan membagi data menjadi data training dan data uji dengan perbandingan 20 data untuk data latih dan 10 data untuk data uji untuk masing masing kelas. Sehingga didapat 100 data latih dan 60 data uji yang terdiri dari 50 data kelas yang tersedia dan 10 data untuk kelas diluar kelas yang tersedia.
Tabel 1 data latih sebelum normalisasi
No.
Mean Green
Momen nth Green
Deviasi
Green Circularity Compactness Kelas
1 93,1295 458,5595 21,414 0,1118 112,3163 Curut
2 56,2499 339,3081 18,4203 0,0199 630,7201 Curut
3 27,8049 578,0714 24,0431 0,2677 46,9259 Gadung
4 31,4087 731,9515 27,0546 0,2408 52,1491 Gadung
5 56,6315 784,1428 28,0025 0,2806 44,769 Golek
6 80,3845 926,5176 30,4388 0,2592 48,458 Golek
7 50,8432 1394,1996 37,339 0,2346 53,5391 Madu
8 54,2618 1325,4217 36,4063 0,2246 55,9197 Madu
9 88,6224 245,9413 15,6825 0,2207 56,9015 Manalagi
10 84,4245 295,7135 17,1963 0,1909 65,8098 Manalagi
Sebelum digunakan, data dinormalisasi terlebih dahulu agar jangkauan nilai fitur menjadi lebih merata dan seimbang menggunakan persamaan :
′= − �
− �
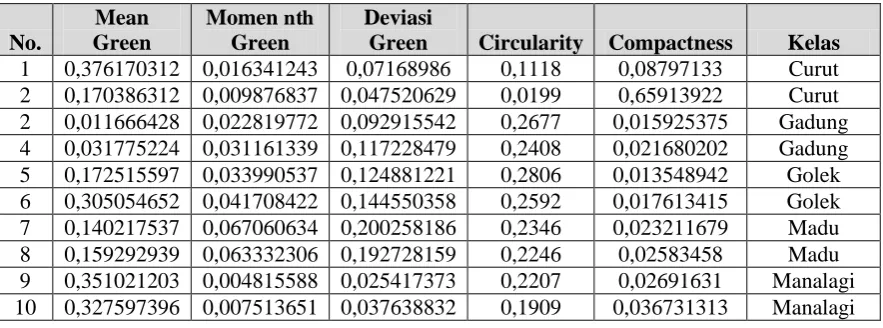
Tabel 2 data latih setelah dinormalisasi
No.
Mean Green
Momen nth Green
Deviasi
Green Circularity Compactness Kelas 1 0,376170312 0,016341243 0,07168986 0,1118 0,08797133 Curut 2 0,170386312 0,009876837 0,047520629 0,0199 0,65913922 Curut 2 0,011666428 0,022819772 0,092915542 0,2677 0,015925375 Gadung 4 0,031775224 0,031161339 0,117228479 0,2408 0,021680202 Gadung 5 0,172515597 0,033990537 0,124881221 0,2806 0,013548942 Golek 6 0,305054652 0,041708422 0,144550358 0,2592 0,017613415 Golek 7 0,140217537 0,067060634 0,200258186 0,2346 0,023211679 Madu 8 0,159292939 0,063332306 0,192728159 0,2246 0,02583458 Madu 9 0,351021203 0,004815588 0,025417373 0,2207 0,02691631 Manalagi 10 0,327597396 0,007513651 0,037638832 0,1909 0,036731313 Manalagi
Tabel 3 Hasil ujicoba
Dari penelitian ini, didapat kesimpulan sebagai berikut:
a. Sistem yang dibangun sudah mampu untuk mengenali jenis mangga berdasarkan warna dan bentuk daun namun error yang dihasilkan masih tinggi yaitu 40%.
b. Tingkat error yang masih tinggi dipengaruhi beberapa faktor, antara lain pemilihan kriteria, intensitas cahaya pada citra input, dan metode pengumpulan citra input.
c. Dari dua kali percobaan yang dilakukan, didapat hasil sebagai berikut :
a) Pada percobaan pertama, sistem hanya mampu mengenali jenis mangga golek dengan akurasi sebesar 16 % dan tingkat error sebesar 84 % sehingga sistem belum layak digunakan untuk melakukan klasifikasi jenis mangga.
b) Pada percobaan kedua, sistem mampu mengenali jenis mangga dengan akurasi sebesar 60 % dan tingkat error sebesar 40 %. Meskipun akurasi sistem sudah lebih baik, sistem belum layak digunakan untuk melakukan klasifikasi jenis mangga dikarenakan tingkat error yang masih tinggi dan sistem hanya mengenali mangga jenis gadung, madu dan golek, tetapi belum mampu untuk mengenali mangga jenis curut dan manalagi.
c) Pada percobaan ketiga, didapat akurasi sebesar 60 % dan tingkat error sebesar 40 % dan rata rata
hasil yang didapat sama dengan ujicoba kedua.
d. Dari tiga kali percobaan, dengan melakukan normalisasi pada data latih maupun data uji didapat hasil yang lebih baik.
e. Data yang digunakan dalam penelitian ini merupakan data dari citra hasil tangkapan kamera. Oleh karena itu, kualitas citra sangat mempengaruhi hasil dari penelitian.
DAFTAR PUSTAKA
[1]. Arieshanti, Isye dan Purwananto, Yudhi. (2011), Model Prediksi Kebangkrutan Berbasis Neural Network dan Particle Swarm Optimation, Institut Teknologi Sepuluh November, Surabaya, Indonesia. [2]. Collins, Michael. (2002), Ranking
Algorithms for Named–Entity Extraction:Boosting and the Voted Perceptron, Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL), AT&T Labs-Research, Florham Park, New Jersey.
[3]. Collins, Michael. dan Duffy, Nigel. ( 2002 ), New Ranking Algorithms for Parsing and Tagging: Kernels over Discrete Structures, and the Voted Perceptron, Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL), AT&T
Labs-Research, Florham Park, New Jersey. [4]. Freund, Yoav. E Scapire, Robert. ( 1999 ),
Large Margin Clasification Using the Perceptron Algorithm, Machine Learning 37(3):277-296, AT&T Labs, Shannon Laboratory.
Klasifikasi Voted Perceptron, Institut Teknologi Sepuluh November, Surabaya, Indonesia.
[6]. Palgunadi, Sarngadi dan Almandatya, Yulandita. (2014), Klasifikasi Kualitas Daun Mangga Berdasarkan Warna Citra Daun, Universitas Sebelas Maret, Surakarta.
[7]. Prasetyo, Eko. (2012), Data mining – Konsep dan Aplikasi Menggunakan Matlab, edisi 1 Andi Offset:Yogyakarta.
[8]. Prasetyo, Eko. (2014), Data Mining Mengolah Data Menjadi Informasi Menggunakan Matlab, andi Offset:Yogyakarta.
[9]. Prasetyo, Eko. (2011), Pengolahan Citra Digital dan Aplikasinya menggunakan Matlab, Andi Offset:Yogyakarta.
[10]. Prasetyo, Eko dan Agustin, Soffiana. (2011), Klasifikasi Jenis Pohon Mangga Gadung dan Curut Berdasarkan Tekstur Daun, SESINDO 2011 - Jurusan Sistem Informasi ITS, Indonesia.
[11]. Riza Hermawan, Andrian. E Wibowo, Andriano. Fetiria Ningrum, Dwi. dan Sancho Liman, Nando. (2011), Klasifikasi daun Mangga, Daun Salam dan Sawo Menggunakan Metode Naive Bayes, Universitas Brawijaya, Malang.
[12]. Sassano Manabu, An Experimental of the Voted Perceptron and Support Vector Machines in Japanese Analysis Tasks, Yahoo Japan Corporation, Tokyo, Japan [13]. Sutoyo, T, dkk. (2009), Teori