BAB III TEORI DASAR
3.1 Konsep Dasar Seismik Refleksi
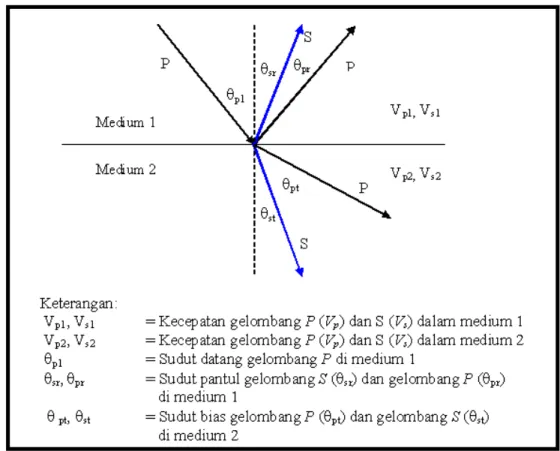
Penjalaran gelombang seismik mengikuti hukum snellius dimana gelombang datang akan dipantulkan dan di transmisikan jika melewati suatu reflektor.
Gambar 3.1 Penjalaran Gelombang Melalui Batas Dua medium Menurut Hukum Snellius
Kemampuan dari batuan untuk melewatkan gelombang akustik disebut Impedansi Akustik. Impedansi Akustik (IA) adalah produk dari densitas (ρ) dan kecepatan gelombang kompresional (V) (Badley,1985) dimana :
Perubahan Impedansi Akustik dapat digunakan sebagai indikator perubahan litologi, porositas, kekerasan, dan kandungan fluida. AI berbanding lurus dengan kekerasan batuan dan berbanding terbalik dengan porositas.
Refleksi seismik terjadi bila ada perubahan atau kontras pada AI. Untuk Koefisien Refleksi pada sudut datang nol derajat dapat dihitung menggunakan persamaan berikut:
1 2 1 2 AI AI AI AI Rc + − = (3.2)
Wavelet adalah sinyal transien yang mempunyai interval waktu dan amplitudo
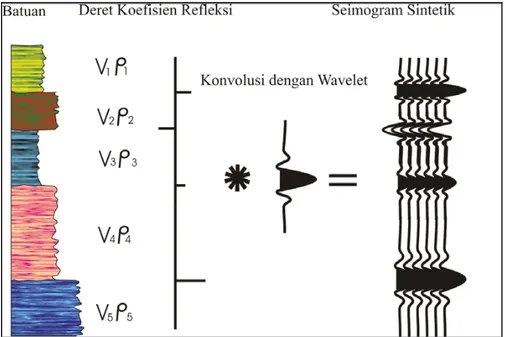
yang terbatas. Ada empat jenis wavelet yang umum diketahui, yaitu zero phase, minimum phase, maximum phase, dan mixed phase. Seismogram sintetik adalah rekaman seismik
buatan yang dibuat dari data log kecepatan dan densitas. Data kecepatan dan densitas membentuk fungsi koefisien refleksi yang selanjutnya dikonvolusikan dengan wavelet untuk mendapatkan seismogram sintetik seperti terlihat pada Gambar 3.2.
3.2 Metode Seismik Inversi
Pengertian secara lebih spesifik tentang seismik inversi dapat didefiniskan sebagai suatu teknik pembuatan model bawah permukaan dengan menggunakan data seismik sebagai input dan data sumur sebagai kontrol (Sukmono, 2000). Definisi tersebut menjelaskan bahwa metoda inversi merupakan kebalikan dari pemodelan dengan metoda ke depan (forward modelling) yang berhubungan dengan pembuatan seismogram sintetik berdasarkan model bumi. Russel (1988) membagi metoda seismik inversi dalam dua kelompok, yaitu inversi pre-stack dan inversi post-stack. Pada penelitian ini akan dibahas
inversi post-stack yang berhubungan dengan inversi amplitudo, dimana dalam inversi ini terdiri dari beberapa algoritma, yaitu inversi bandlimited (rekursif), inversi berbasis model (blocky) dan inversi sparse spike (maximum likelihood).
3.2.1 Inversi Seismik Rekursif/Bandlimited
Inversi rekursif (bandlimited) adalah algoritma inversi yang mengabaikan efek wavelet seismik dan memperlakukan seolah-olah trace seismik merupakan kumpulan koefisien refleksi yang telah difilter oleh wavelet fasa nol. Metoda ini paling awal digunakan untuk menginversi data seismik dengan persamaan dasar (Russel, 1988) :
i i i i i i i i i i i i i Z Z r Z Z V V V V 1 1 1 1 1 1 + − = + − = + + + + + + ρ ρ ρ ρ (3.3)
dengan r = koefisien refleksi, (ρ = densitas, V=kecepatan gelombang P dan Z = Impedansi Akustik ). Dimulai dari lapisan pertama, impedansi lapisan berikutnya ditentukan secara rekursif dan tergantung nilai impedansi akustik lapisan di atasnya dengan perumusan sebagai berikut :
⎥ ⎦ ⎤ ⎢ ⎣ ⎡ + Π = + i i i i Z r 1 r 1 * Z 1 (3.4)
3.2.2 Inversi Seismik Model Based
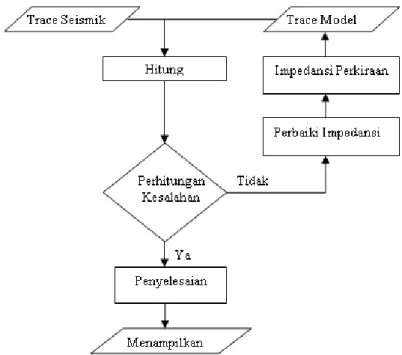
Prinsip metoda ini adalah membuat model geologi dan membandingkannya dengan data rill seismik. Hasil perbandingan tersebut digunakan secara iteratif memperbaharui model untuk menyesuaikan dengan data seismik . Metode ini dikembangkan untuk mengatsi masalah yang tidak dapat dipecahkan menggunakan metode rekursif. Teknik ini dapat dijelaskan melalui diagram alur berikut.
Gambar 3.3 Metoda Inversi Model Based
Keuntungan penggunaan metoda inversi berbasiskan model adalah metode ini tidak menginversi langsung dari seismik melainkan menginversi model geologinya. Sedangkan Permasalahan potensial menggunakan metoda inversi berbasis model adalah Sifat sensitif
terhadap bentuk waveletdan Sifat ketidak-unikan (non-uniqueness) untuk wavelet tertentu.
3.2.3 Inversi Seismik Sparse Spike
Metode Sparse-spike ini mengasumsikan bahwa reflektivitas yang sebenarnya dapat diasumsikan sebagai seri dari spike besar yang bertumpukan dengan spike-spike yang lebih kecil sebagai background. Kemudian dilakukan estimasi wavelet
berdasarkan asumsi model tersebut. Sparse-spike mengasumsikan bahwa hanya spike yang besar yang penting. Inversi ini mencari lokasi spike yang besar dari tras seismik. Spike-spike tersebut terus ditambahkan sampai tras dimodelkan secara cukup akurat. Amplitudo dari blok impedansi ditentukan dengan menggunakan algoritma inversi Model Based. Input parameter tambahan pada metoda ini adlah menentukan jumlah maksium spike yang akan dideteksi pada tiap tras seismik dan treshold pendeteksian seismik.
Model dasar trace seismik didefinisikan oleh :
s(t) = w (t) * r (t) + n (t) (3.5)
Persamaan mengandung tiga variabel yang tidak diketahui sehingga sulit untuk menyelesaikan persamaan tersebut, namun dengan menggunakan asumsi tertentu permasalahan dekonvolusi dapat diselesaikan dengan beberapa teknik dekonvolusi yang dikelompokkan dalam metoda sparse-spike. Teknik-teknik tersebut meliputi :
1. Inversi dan dekonvolusi maximum-likelihood 2. Inversi dan dekonvolusi norm-L1
3.3 Metoda Multi-Atribut
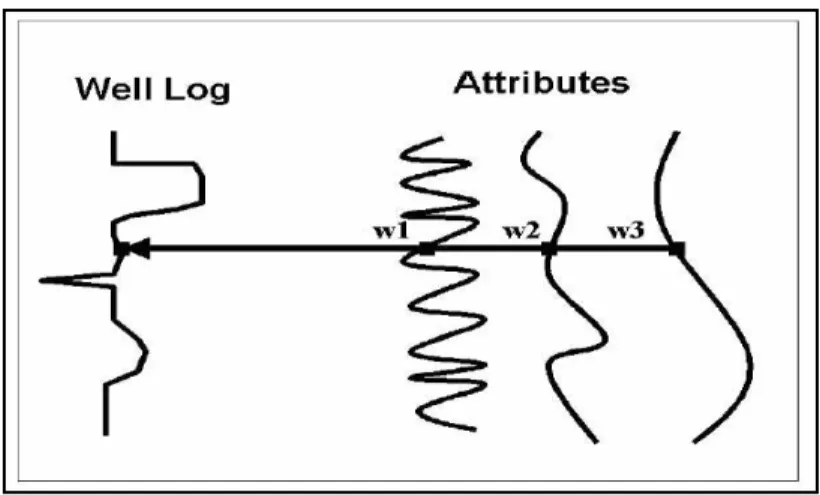
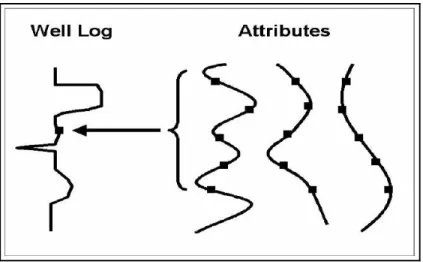
Analisis seismik multi-attrribute adalah salah satu metode statistik menggunakan lebih dari satu atribut untuk memprediksi beberapa properti fisik dari bumi. Pada analisa ini dicari hubungan antara log dengan data seismik pada lokasi sumur dan menggunakan hubungan tersebut untuk memprediksi atau mengestimasi volum dari properti log pada semua lokasi pada volum seismik.
Statistik dalam karakteristik reservoar digunakan untuk mengestimasi dan mensimulasikan hubungan spasial variabel pada nilai yang diinginkan pada lokasi yang tidak mempunyai data sampel terukur. Hal ini didasarkan pada kenyataan yang sering terjadi di alam bahwa pengukuran suatu variabel di suatu area yang berdekatan adalah sama. Kesamaan antara dua pengukuran tersebut akan menurun seiring dengan bertambahnya jarak pengukuran.
Schultz et al. (1994) mengidentifikasi tiga sub-kategori utama pada teknik analisa multi-atribut geostatistik, yaitu:
1. Perluasan dari co-kriging untuk melibatkan lebih dari satu atribut sekunder untuk memprediksi parameter utama.
2. Metode yang menggunakan matriks kovariansi untuk memprediksi suatu parameter dari atribut input yang telah diberi bobot secara linear.
3. Metode yang menggunakan Artificial Neural Networks (AANs) atau teknik optimisasi non-linear untuk mengkombinasikan atribut-atribut menjadi perkiraan dari parameter yang diinginkan.
Analisa multi-atribut pada penelitian ini menggunakan kategori yang kedua. Prosesnya sendiri melibatkan pembuatan dari volum pseudolog yang nantinya akan digunakan untuk memetakan penyebaran batupasir dan batulempung.
Dalam kasus yang paling umum, kita mencari sebuah fungsi yang akan mengkonversi m atribut yang berbeda ke dalam properti yang diinginkan, ini dapat ditulis sebagai :
P(x,y,z) = F[A1(x,y,z),…, Am(x,y,z)] (3.6) dimana :
P = properti log, sebagai fungsi dari koordinat x,y,z
F = fungsi yang menyatakan hubungan antara atribut seismik dan properti log
Ai = atribut m, dimana i = 1,...,m.
Untuk kasus yang paling sederhana, hubungan antara log properti dan atribut seismik dapat ditunjukkan oleh persamaan jumlah pembobotan linier.
P = w0 + w1A1 + ... + wmAm (3.7) dimana :
wi = nilai bobot dari m+1, dimana 1 = 0,...,m
Atribut input dalam Analisa Multi-attribute (Internal Attribute) Atribut-seismik dapat dibagi kedalam dua kategori :
• Horizon-based attributes : dihitung sebagai nilai rata-rata antara dua horizon.
• Sample-based attributes : merupakan transformasi dari tras input untuk menghasilkan
tras output lainnya dengan jumlah yang sama dengan tras input (nilainya dihitung sampel per sampel).
Hubungan linier antara log target dan atribut ditunjukkan oleh sebuah garis lurus yang memenuhi persamaan:
Koefisien a dan b pada persamaan ini diperoleh dengan meminimalisasikan mean-square prediction error :
dimana penjumlahan dilakukan pada setiap titik di cross-plot. Dengan mengaplikasikan
garis regresi tersebut kita dapat memberikan prediksi untuk atribut target. Lalu dihitung kovariansi yang didefinisikan dalam persamaan:
Dimana mean nya adalah:
Nilai Kovariansi yang sudah dinormalisasi adalah:
Nilai ini merupakan prediksi eror, yaitu hasil pengukuran kecocokan untuk garis regresi. Prediksi eror ini merupakan perbedaan RMS antara target log sebenarnya dan target log prediksi.
Nilai korelasi terkadang dapat diperbaiki dengan mengaplikasikan transform non-linear untuk variabel target, variabel atribut, ataupun keduanya.
∑
= − − = N 1 i 2 i i 2 (y a b*x ) N 1 E∑
= − − = N 1 i i x i y xy N (x m )(y m ) 1 σ∑
= = N 1 i i x N x 1 m∑
= = N 1 i i y y N 1 m xy x y ρσ
σ σ
=x
b
a
y
=
+
∗
(3.8) (3.9) (3.10) (3.11) (3.12) (3.13)3.3.1 Regresi Linear Multi-Attribute
Pengembangan dari Cross-plot konvensional adalah dengan menggunakan
multiple-attribute
(a) (b)
Gambar 3.4 Ilustrasi Cross-plot dengan menggunakan (a) satu atribut dan (b) dua atribut
Dalam metoda ini, tujuan kita adalah untuk mencari sebuah operator, yang dapat memprediksi log sumur dari data seismik didekatnya. Pada kenyataannya, kita menganalisa data atribut seismik dan bukan data seismik itu sendiri. Salah satu alasan kenapa kita melakukan hal ini karena menggunakan data atribut seismik lebih menguntungkan dari pada data seismik itu sendiri, banyak dari atribut ini bersifat non linier, sehingga mampu meningkatkan kemampuan prediksi.
Pengembangan (extension) analisa linier konvensional terhadap multiple atribut (regresi linier multivariat) dilakukan secara langsung.
Gambar 3.5 Contoh kasus tiga atribut seismik, tiap sampel log target dimodelkan sebagai kombinasi linier dari sampel atribut pada interval waktu yang sama.
Pada tiap sampel waktu, log target dimodelkan oleh persamaan linier :
(t) A w (t) A w (t) A w w L(t)= 0 + 1 1 + 2 2 + 3 3
Pembobotan (weights) pada persamaan ini dihasilkan dengan meminimalisasi mean-squared prediction error.
∑
= − − − − = N j i 2 i 3 3 i 2 2 i 1 1 o 2 ) A w A w A w w Li ( N 1 ESolusi untuk empat pembobotan menghasilkan persamaan normal standar :
⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ = ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡
∑
∑
∑
∑
∑
∑
∑
∑
∑
∑
∑
∑
∑
∑
∑
∑
∑
∑
∑
− i i 3 i i 2 i i 1 i 1 i 3 2 i 3 i 2 i 3 i 1 i 3 i 3 i 2 i 2 2 i 2 i 1 i 2 i 3 i 1 i 2 i 1 i 1 2 i 1 i 3 i 2 i 1 3 2 1 0 L A L A L A L A A A A A A A A A A A A A A A A A A A A A N w w w wSeperti pada kasus atribut tunggal, mean-squared error yang dihitung
menggunakan pembobotan, merupakan pengukuran kesesuaian untuk transformasi tersebut, dimana sekarang koordinat x merupakan nilai log yang diprediksi dan koordinat y merupakan nilai real dari data log.
(3.14)
(3.15)
Lalu bagaimana caranya memilih kombinasi atribut yang paling baik untuk memprediksi log target? Dilakukan sebuah proses yang dinamakan step-wise regression:
1. Dicari atribut tunggal pertama yang paling baik dengan menggunakan trial and error. Untuk setiap atribut yang terdapat pada software dihitung error prediksinya.
Atribut terbaik adalah atribut yang memberikan eror prediksi terendah. Atribut ini selanjutnya akan disebut atribut-a
2. Dicari pasangan atribut yang paling baik dengan mengasumsikan anggota pasangan yang pertama adalah atribut-a. Pasangan yang paling baik adalah pasangan yang memberikan eror paling kecil. Atribut ini selanjutnya akan disebut atribut-b.
3. Dicari tiga buah atribut yang berpasangan paling baik, dengan mengasumsikan dua buah anggota yang pertama atribut-a dan atribut-b. Tiga buah atribut yang paling baik adalah yang memberikan eror prediksi paling kecil.
Prediksi ini berlangsung terus sebanyak yang diinginkan.
Eror prediksi, En, untuk n atribut selalu lebih kecil atau sama dengan En-1 untuk n-1 atribut, tidak peduli atribut mana yang digunakan.
3.3.2 Validasi
Pertanyaan selanjutnya yang harus dijawab adalah kapan kita harus berhenti menambahkan jumlah atribut. Bagaimanapun juga transformasi multi-atribut dengan jumlah atribut N+1 selalu mempunya prediksi eror lebih kecil atau sama dengan transformasi dengan N atribut. Menambah jumlah atribut, serupa dengan mencari kurva
regresi yang cocok untuk sebuah plot data, dengan menggunakan polinomial yang ordenya semakin besar.
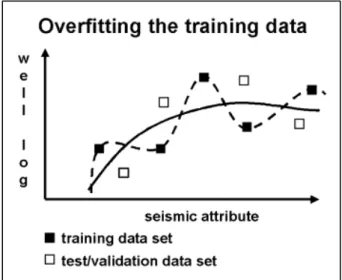
Apabila jumlah atribut yang digunakan semakin banyak, maka eror prediksi akan semakin berkurang. Masalah yang kemudian timbul adalah, biasanya data yang dihasilkan akan buruk bila diterapkan pada data baru (yang tidak termasuk dalam data training), karena atribut tersebut terlalu dicocokan dengan data training. Hal ini biasa disebut dengan over-training.
Gambar 3.6 Ilustrasi cross-validasi. Kedua kurva digunakan untuk mencocokkan
data. Kurva putus-putus menunjukkan korelasi yang baik dengan data training. Namun buruk jika kemudian digunakan set data validasi.
Untuk mengukur validitas dari jumlah atribut yang digunakan, dilakukan prosedur sebagai berikut. Misalnya, terdapat tiga buah atribut dan lima buah well. Untuk perhitungan pertama, sumur pertama tdak diikutkan. Lalu dihitung koefisien regresinya, tanpa menggunakan data dari sumur pertama. Dengan nilai koefisien yang dihasilkan, lalu dihitung prediksi eror dari sumur satu dengan rumus:
∑
= − − − − = N 1 i 2 i 3 i 2 i 1 0 i 2 ( w w *I w *E w *F) N 1 E ϕ (3.17)Ini adalah eror validasi untuk sumur satu. Proses ini kemudian diulang untuk sumur 2, sumur 3, dan sumur 4. Eror rata-ratanya dihitung dengan:
3.3.3 Convolutional Multi-Attribute
Analisa muli-atribut yang telah dijelaskan di atas melakukan korelasi dari setiap sampel target dengan sampel seismik atribut pada titik yang sama. Pendekatan ini sangat terbatas karena tidak mengindahkan kenyataan bahwa terdapat perbedaan kandungan frekuensi antara data seismik dengan data log.
Gambar 3.7 Perbedaan frekuensi antara data seismik dan data log
Alternatif lain untuk menyelesaikan masalah ini yaitu dengan mengasumsikan tiap sampel pada log target berhubungan dengan sejumlah sampel yang berdekatan pada atribut seismik.
(
)
5 5 4 3 2 1 E E E E E EA + + + + = (3.18)Gambar 3.8 Pengunaan 5 titik operator konvolusi untuk menghubungkan atribut seismik dengan log target.
Pengembangan dengan melibatkan operator konvolusi adalah :
3 3 2 2 1 1 0 w * A w * A w * A w L= + + +
dimana * operator konvolusi, dan w1 adalah operator jarak tertentu. Perlu dicatat jumlah koefisien bertambah menjadi :
(jumlah waktu atribut panjang operator) + 1
Koefisien operator dihasilkan dengan meminimalisaskan mean-squared
prediction error :
L
=
w
0+
w
1*
A
1+
w
2*
A
2+
w
3*
A
3 2 2 1 1 2 2 3 3 1 ( * * * ) N o i i i i j E Li w w A w A w A N = =∑
− + + + (3.19) (3.20) (3.21)3.4 Neural Network
Regresi Multi attribute dapat berjalan dengan baik apabila ada relasi linear fungsional yang baik di antara log yang di prediksi dan atribut seismik. Pada kasus hubungan yang non-linear kita dapat mengaplikasikan transformasi tersebut dengan metoda neural network sebagai algoritma prediksi. Dalam pengertian umum artificial neural network (ANN) adalah sekumpulan kumpulan komponen elektronik atau program komputer yang di desain untuk memodelkan kerja sistem otak. Otak manusia dideskripsikan sebagai suatu system yang kompleks, tidak linear dan mempunyai system informasi dan proses yang pararel. Komponen struktural otak manusia adalah sel-sel syaraf yang disebut neuron yang tersambung dengan jumlah besar koneksi yang disebut sinapsis. Sistem yang kompleks ini mempunyai kemampuan yang luar biasa untuk membangun cara kerjanya dan menyimpan informasi.
Neural Network meniru cara kerja otak dalam dua aspek : • Pengetahuan atau data di dapatkan dari proses training.
• Kekuatan koneksi inter-neuron diketahui sebagai bobot sinaptik yang digunakan untuk menyimpan pengetahuan tersebut.
Prosedur yang digunakan dalam proses training disebut algoritma training. Algoritma ini berfungsi untuk memodifikasi bobot sinaptik dari sebuah network untuk mendesain sebuah objek yang diinginkan. Meskipun neural network tergolong baru dalam dunia industri perminyakan, secara sejarah algoritma ini sudah dikenal sejak tahun 1940 dimana pada saat itu para psikolog mencoba untuk memodelkan cara otak manusia dalam belajar. Seiring dengan penemuan computer, peneliti mengembangkan sebuah program untuk melihat simulasi kerja otak manusia yang kompleks. Pada tahun 1969 Marvin Minsky menemukan satu metode perceptron yang dapat menyelesaikan beberapa masalah sederhana. Tahun 1986 Rumelhart dan McClelland mempublikasi sebuah algoritma Back-Propagation yang kemudian dikenal sebagai MLFN saat ini. Tahun 1990 Donald specht menemukan PNN dan metoda ini menjadi popular di lingkungan geofisika sebagai aplikasi yang cukup sukses (Huang et al., 1996; Todorov et al., 1998).
3.4.1 Multi Layer Feed Forward Neural Network
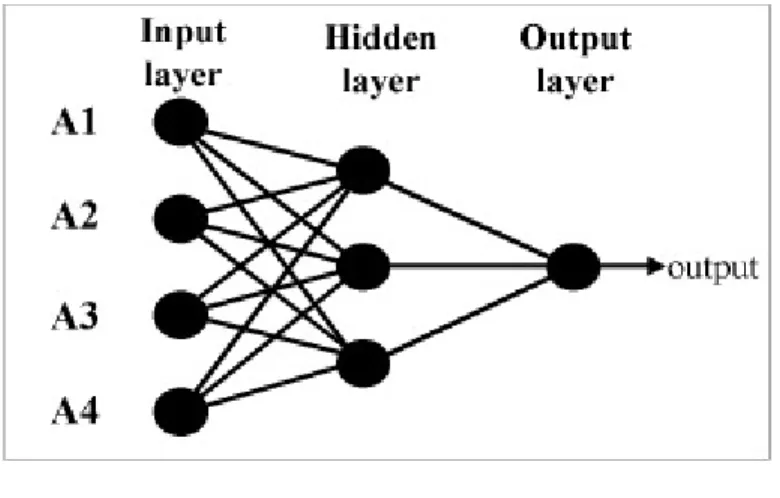
Gambar menunujukkan secara skematik arsitektur dasar dari MLFN. Algoritma ini terdiri dari beberapa set layer yang di desain menjadi dua layer atau lebih. Ada layer input dan output, dimana masing-masing layer terdiri atas paling sedikit satu neuron. Di antara dua layer tersebut terdapat ”hidden layer”. Neuron terkoneksi melalui sistem dimana neuron input untuk masing-masing layer berasal dari layer sebelumnya. Pada contoh di gambar ini ditunjukkan kita mempunyai empat atribut seismik dengan dengan hidden layer mempunyai tiga neuron dan satu output neuron, berarti ada 15 koneksi dan ini berarti skema ini punya 15 bobot.
Gambar 3.9. Ilustrasi MLFN
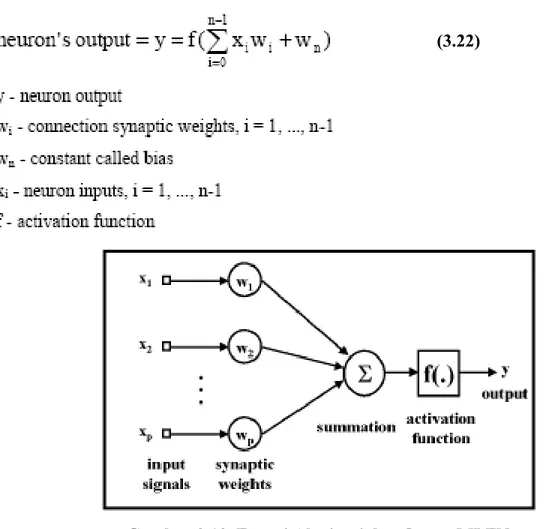
Neuron adalah unit informasi yang sangat penting dalam operasi algoritma neural network. Model neuron di tunjukkan oleh gambar 3. . Kita dapat mengidentifikasi 3 proses dasar dari model neuron :
• Setiap sinyal masukan Xi dikalikan dengan bobot Wi • Sinyal input yang sudah berbobot dijumlahkan
• Fungsi non-linear yaitu fungsi aktivasi di aplikasikan pada hasil penjumlahan tersebut.
Secara matematika :
Gambar 3.10. Fungsi Akstivasi dan Ouput MLFN
Fungsi aktivasi menentukan output dari neuron sesuai dengan inputnya. Fungsi sigmoid adalah salah satu fungsi aktivasi yang disunakan dalam konstruksi atifisial neural network. Fungsi yang membuat optimasi dari smoothness dan hubungan asimtotik di berikan oleh :
Fungsi Logistik mempunyai interval 0 sampai 1. Pada kasus fungsi anti simetrik, fungsi aktivasi juga bisa bernilai -1 sampai 1. Contohnya fungsi tangensial hiperbolik
(3.22)
(3.23)
Neural network didefinisi sebagai beberapa layer yang berisi neuron di setiap layer dan factor koneksi bobot. Proses estimasi bobot disebut training. Selama proses training neural network membangun model dengan menggunakan sampel. Setiap sampel terdiri dari input sinyal dan respon keluaran dari neural network. Set dari sampel merepresentasikan data. Untuk beberapa sampel kita akan membandingkan output dari netwoek dengan output dari model.
Misalnya y=[y1,y2,…yp] adalah vector yang mencakup output dengan p adalah jumlah neuron, dan d=[d1,d2,…,dp] adalah vector yang mencakup respon kita dapat menghitung error dari k :
Dan jika mempunyai beberapa sampel, maka errornya :
Tujuan algoritma neural network ini adalah untuk meminimalkan error. Ini dilakukan dengan terus memperbaharui faktor bobot. Masters (1995) mengkombinasikan conjugate-gradient algorithm dengan simulated annealing untuk mencari fungsi error global yang paling minimum. Jika kita menggunakan polynomial derajat tinggi, kemungkinan kita akan dapat mencocokkan fungsi dengan tepat.
3.4.2 Probabilistic Neural Network 3.4.3
Ide dasar dibalik PNN adalah menggunakan satu data atau lebih yang disebut variable independen untuk memprediksi variable dependen tunggal. Variable independen di representasikan sebagai vector x = [x1,x2,..,xp] dimana p adalah jumlah variable independen. Sedangkan variable dependen adalah y. Tujuan algoritma ini adalah untuk memprediksi variable y' yang tidak diketahui. Estimasi ini didasarkan pada persamaan fundamental dari regresi umum PNN :
(3.25)
Dimana n adalah jumlah dari sampel dan D(x,xi) :
D adalah jarak yang di skalakan diantara poin yang akan di estimasi, jarak tersebut yang disebut "smoothing" parameter. Untuk sampel ke m, prediksinya :
Jadi nilai yang di prediksi dari sampel ke m adalah y'm. Jika tahu nilai ym, kita dapat memprediksi error validasi
Dan total error prediksinya adalah :
(3.27)
(3.28)
(3.29)
(3.30)
3.4.3 Radial Basis Function
Misalnya kita mempunyai sampel seismik atribut dan sampel log kita dapat membuat ilustrasi skematik mengenai perbedaan antara training vektor.
Gambar 3.11 Ilustrasi Skematik tentang training vektor
Gambar 3.12 Grafik Skematik dari vektor si,sj,xk
Algoritma RBF dapat kita mengerti jika kita memahami algoritma PNN. Algoritma ini berdasarkan pada konsep jarak dalam spasi atribut. Jarak pada ilustrasi yang diberikan adalah amplitudo atribut dan kita dapat menghitung tiga kemungkinan jarak diantara vektor tersebut, yaitu ;
Pada RBF kita akan menggunakan fungsi dari jarak yang disebut basis fungsi, kita menggunakan fungsi Gaussian, yaitu :
Kemudian kita mengihitung nilai bobot dari data training menggunakan persamaan :
Setelah bobot dihitung kita dapat mengaplikasikannya pada set data menggunakan persamaan :
(3.33)
(3.34)