PENGKLASIFIKASI TEKS MULTI-DOMAIN PENDUKUNG TRANSLASI BAHASA
ALAMI MENGGUNAKAN METODE TOPOLOGICAL TAXONOMY TERM
STATISTICAL RATIO (T3SR)
Victor PhoaProgram Pascasarjana Ilmu Komputer, Universitas Gadjah Mada Gedung SIC Lt.3 FMIPA UGM, Sekip Utara Bulaksumur Yogyakarta 55281
Program Studi Fisika, Universitas Pattimura Gedung FMIPA Unpatti, Jl Ir. M. Putuhena, Poka Ambon
E-mail: [email protected]
ABSTRACT
During the observations in the last decade of the machine translation results, there is still a problem in terms of the quality of the translation. Based on observations, some machines already have complementary features as the disambiguation support (morphological variation unit) through the domains selections. Unfortunately, these methods usually are static or as single domain because user must determine the domain of corpus, while on the other hand, flat classification didn’t provide the good results. Under such constraints and conditions, the authors have developed new method and approach to automatically classify the text called Topological Taxonomy Term Statistical Ratio (T3SR) which based on taxonomy topology and utilize statistical feature, distributional properties (based on the golden ratio), heuristics, and relativity.This T3SR method has been tested on 10 (ten) corpus and compared with the flat method; Nearest Statistical Term Ratio (NTSR) and Normalized Ratio Nearest Statistical Term (NNTSR). Based on the results, the T3SR method outperformed the flat methods (which only obtained 60% score of feasibility). T3SR method gives very good indexing results, rank patterns, and the relevance of the logic (100% score of feasibility), so it is considered very feasible to be applied in the disambiguation preprocess of machine translation.
Kata Kunci: text classification, machine translation, natural language, disambiguation, golden ratio
ABSTRAK
Selama pengamatan dalam dekade terakhir terhadap hasil Penerjemahan Mesin, masih terdapat masalah dari segi kualitas terjemahannya. Berdasarkan sejumlah pengamatan, beberapa mesin telah memiliki fitur pelengkap sebagai pendukung disambiguasi (unit variasi morfologi) melalui penyediaan pemilihan domain keilmuan. Sayangnya, metode ini biasanya bersifat statis atau berdomain tunggal karena pengguna harus menentukan sendiri domain korpusnya, sedangkan di lain sisi, penglasifikasian dengan metode flat memberikan hasil yang tidak maksimal. Berdasarkan kendala dan kondisi sedemikian, maka penulis telah mengembangkan suatu metode dan pendekatan baru untuk menglasifikasikan teks secara otomatis yang disebut Topological Taxonomy Term Statistical Ratio (T3SR) yang berdasar pada topologi taksonomi dan memanfaatkan fitur statistik kata, sifat distibutif (berdasarkan rasio emas), heuristik, dan relativitas.Metode T3SR ini telah diujicobakan pada 10 (sepuluh) korpus dan dibandingkan dengan metode flat yaitu Nearest Term Statistical Ratio (NTSR) dan Normalized Nearest Term Statistical Ratio (NNTSR). Berdasarkan hasil, metode T3SR mengungguli metode flat (yang hanya memperoleh skor kelayakan 60%). Metode T3SR memberikan hasil pengindeksan, pola perangkingan, dan relevansi kelogisan yang sangat baik (dengan skor kelayakan 100%) sehingga dianggap layak untuk dapat diterapkan dalam praproses disambiguasi pada penerjemahan mesin.
Kata Kunci: klasifikasi teks, penerjemahan mesin, bahasa alami, disambiguasi, rasio emas
1. PENDAHULUAN
1.1 Latar Belakang
Selama pengamatan dalam dekade terakhir terhadap hasil Penerjemahan Mesin (Machine
Translation) ternyata masih terdapat masalah dari
segi kualitas translasinya. Terjemahan mesin sering belum begitu baik. Hal ini, terutama banyak pada terjadi untuk penerjemahan bahasa yang memiliki perbedaan rumpun. Menurut Hawkins dan Blakeslee (2004), masalah kualitas seperti ini disebabkan karena sejumlah pengembangan masih memanfaatkan metode yang belum dapat menyukseskan kualitas translasi dengan pendekatan sekali jalan. Dari sisi lain, kebenaran gramatikalitas
semata bukanlah pemandu utama bagi sintaksis, akan ada sangat banyak hal yang memberi peran dalam penerjemahan (Moss, 2009). ElShiekh (2012), yang melakukan investigasi pada mesin translasi juga menemukan ada kararakteristik pada seluruh mesin translasi, yakni adanya ketidakmampuan mesin untuk menangani fenomena ambiguitas semantis. Disamping hal tersebut, ternyata masih terdapat banyak kesalahan identifikasi pada seluruh tingkatan komponen translasinya.
Beberapa mesin sebenarnya telah memiliki fitur pelengkap sebagai pendukung disambiguasi (unit variasi morfologi). Fitur ini melalui penyediaan pemilihan domain disiplin keilmuan. Sayangnya,
metode ini umumnya masih bersifat statis (tunggal dan harus ditentukan sendiri oleh pengguna). Pengguna awam akan kesulitan menentukan domain yang tepat. Domain bersifat tunggal juga condong untuk tidak melakukan improvisasi translasi terhadap bidang terkait lainnya Kasus seperti ini banyak terlihat dalam mesin penerjemah lokal. Banyak yang mengeluhkan kualitas translasi dalam berbagai bidang tersebut.
Selain itu, pengalaman penulis dalam mengembangkan prototipe penerjemah mesin menemukan bahwa kualitas translasi mesin penerjemah sangat bergantung dari kemampuan penglasifikasian domain. Ini didasarkan untuk menghasilkan perangkingan domain yang logis, saling terkait serta berelasi secara dinamis. Penglasifikasian dengan metode flat memberikan hasil yang tidak maksimal. Berdasarkan adanya kendala dan kondisi sedemikian, penulis tertarik dan berinisiatif untuk melakukan penelitian untuk mengembangkan metode atau pendekatan untuk menglasifikasikan teks secara otomatis yang diharapkan lebih sesuai untuk mendukung proses translasi bahasa alami.
1.2 Hipotesis
Bolshakov dan Gelbukh (2004) mengungkapkan bahwa fungsi bahasa adalah seperti enkoder-dekoder untuk mentransfer arti dari satu orang ke orang lain. Pentransferan secara langsung tidak memungkinkan karena arti merupakan struktur otak yang tertuang dalam bentuk ide dan pikiran. Teori dari makna yang diekspresikan berada pada jalur yang berupa teka-teki (Modrak, 2001). Naturalisme diperlukan untuk memberikan kebenaran perhitungan yang memadai. Secara kontras dalam bahasa alami, relasi antara gagasan dan keadaan akan merepresentasikan kealamiannya. Eksplorasi ilmiah yang difokuskan realitas alam dan individu akan mengonstruksi kelogisan dan keilmiahan yang secara komprehensif menjelaskan data yang dikoleksikan (Campbell, 2007).
Klasifikasi teks merupakan hal yang penting dalam bagian pengolahan bahasa alami dan penelitian ekstraksi ciri (Cox & Worsley, 2010). Bidang keilmuan umum memiliki beberapa sub-disiplin atau cabang, dan garis yang membedakannya dengan yang lain sering tumpang tindih dan bersifat ambigu (Abbott, 2001). Dalam kompleksitas seperti ini klasifikasi hirarki bisa ditemukan (Pels, 2006). Taksonomi yang bersumber dari teks dapat menawarkan teknik penyingkapan secara komprehensif dan ringkas (Liu, Loh & Lu, 2008), dan yang teks yang terspesifikasikan dan diobservasi dalam suatu kelompok dapat dipahami dan ditingkatkan kualitasnya (Castilho dkk, 2008).
Dari berbagai pernyataan, menyiratkan perlunya proses disambiguasi (word-sense disambiguation) yang bergantung dari morfologi domain yang melihat secara komprehensif pada klasifikasi
sub-domain atau kekerabatannya. Karenanya, adalah sangat baik jika menelaah secara taksonomis atau melalui konsep hirarki dan naturalisme agar dapat meningkatkan kualitas translasi secara dinamis.
Pada tinjauan lanjutan didapati bahwa tiap leksikal mengandung informasi tentang perangai kata dalam suatu kalimat dan juga maknnya (Cook & Newson, 2007). Dapat diketahui secara umum perangai makna sangat dipengaruhi atau dikarakterisasi dari judul dan topiknya (Kondo dkk, 2011), dan kata-kata kunci (keywords) yang digunakan (Palomino & Wuytack, 2011).
Dengan demikian, ditarik hipotesa bahwa kata kunci dan judul dapat menjadi pembentuk morfologi makna dalam teks. Kata kunci dan judul merupakan manifestasi dari istilah teknis (terms) yang dipakai dalam teks. Makna dan perangai kata dalam korpus dapat dikarakterisasi dari sertaan domain dan sub-domainnya. Dengan demikian, untuk membangun mesin translasi yang lebih baik, terdapat kebutuhan untuk membuat mesin yang mengetahui domain yang tidak mengabaikan sub-domain dari suatu teks. Observasi ini dilakukan atas struktur hirarki keilmuan yang komprehensif seperti topologi taksonomi dan adalah sangat baik jika fitur didalamnya memiliki sifat-sifat naturalisme.
1.3 Perumusan Masalah
Salah satu masalah dasar yang perlu diselesaikan adalah kemampuan mesin translasi dalam analisa morfologis dan leksikal untuk menyukseskan disambiguasi. Bagian daripada analisa morfologis harus menemukan kategori yang memungkinkan, dan analisa leksikal kemudian mencoba menentukan arti yang benar sesuai konteks. Contoh dari masalah ini misalnya timbul pada proses terjemahan pada kutipan paragraf tabel 1.3.1.
Tabel 1.3.1 Kutipan Physics of magnetic resonance
imaging (Wikipedia, 2013)
MRI is used to image every part of the body, and is particularly useful for neurological conditions, for disorders of the muscles and joints, for evaluating tumors, and for showing abnormalities in the heart and blood vessels.
In MRI, the static magnetic field is caused to vary across the body (by using a field gradient), so that different spatial locations become associated with different precession frequencies. Usually these field gradients are pulsed, and it is the almost infinite variety of RF and gradient pulse sequences that gives MRI its versatility. Application of field gradient destroys the FID signal, but this can be recovered and measured by a refocusing gradient (to create a so‐called "gradient echo"), or by a radio frequency pulse (to create a so‐called "spin‐echo"). The whole process can be repeated when some T1‐relaxation has occurred and the thermal equilibrium of the spins has been more or less restored.
Typically, in soft tissues T1 is around one second while T2 and T*2 are a few tens of milliseconds. However, these values can vary widely between different tissues, as well as between different external magnetic fields.
Kata-kata yang digarisbawahi merupakan istilah teknis (terms) dari domain (lihat tabel 1.3.2), sedangkan yang bercetak tebal merupakan bagian
kata yang bersifat ambigu (lihat tabel 1.3.3). Dari perbendaharaan ini, kemudian dapat dilakukan beberapa cara untuk melakukan translasi.
Tabel 1.3.2 Pengelompokan istilah
Domain Daftar istilah
Fisika magnetic field, radio frequency, spin-echo, thermal equilibrium
Medis neurological conditions, tumors, blood vessels
Tabel 1.3.3 Glosarium bilingual untuk kata yang bersifat ambigu
Kata Asing Domain Terjemahan field Umum lapangan
Fisika medan tissues Umum Medis tisyu jaringan
Cara yang pertama dalam menentukan translasi tanpa memperhatikan domain seperti terlihat pada gambar 1.3.1. Kata “field” dan “tissues” menghasilkan terjemahan kata yang tidak sesuai dengan yang dimaksudkan oleh konteks karena mengambil dari terjemahan umum saja.
leksikal:
field → domain: umum → lapangan
tissues → domain: umum →tisyu
Gambar 1.3.1 Contoh terjemahan tanpa memperhatikan domain
Cara kedua menggunakan analisis leksikal berdasarkan referensi dari domain tunggal (Fisika atau Medis). Terdapat kata yang telah dapat diterjemahkan sesuai dengan konteksnya, namun pada kata yang lainnya masih tidak sesuai (lihat gambar 1.32 dan 1.3.3). Ini dikarenakan pada teks yang akan diterjemahkan sebenarnya bersifat multi-domain.
Domain Tunggal Fisika
↓ leksikal:
field → domain: fisika → medan tissues → domain: umum →tisyu
Gambar 1.3.2 Contoh terjemahan dengan pemilihan domain fisika (domain tunggal)
Domain Tunggal Medis
↓ leksikal:
field → domain: umum → lapangan
tissues → domain: medis →jaringan
Gambar 1.3.3 Contoh terjemahan dengan pemilihan domain medis (domain tunggal)
Cara yang ketiga adalah menggunakan analisis leksikal berdasarkan referensi multi-domain (Fisika diikuti Medis, atau sebaliknya. Dengan cara ini, hasil terjemahan dapat berkesesuaian dengan konteksnya (lihat gambar 1.3.4). Cara ini lebih baik karena komprehensif melihat domain-domain yang ada dalam teks.
Multi-domain Fisika Medis
↓ leksikal:
field → domain: fisika → medan tissues → domain: medis →jaringan
Gambar 1.3.4 Contoh terjemahan dengan pemilihan domain fisika diikuti dengan domain medis (multi-domain)
Dapat dilihat terdapat masalah pada kualitas penerjemahan yang tidak melibatkan analisis domain atau melibatkan domain tunggal saja. Dengan metode tersebut, akurasi translasi kurang memadai. Dengan demikian diperlukan analisis multi-domain. Dalam praktek, analisis multi-domain dapat diperoleh melalui penglasifikasi teks multi-domain. Dengan demikian perlu dibangun metode penglasifikasi multi-domain yang tepat ditujukan untuk mendukung proses translasi.
Berdasarkan bentuk permasalahan seperti ini disertai hal-hal yang disampaikan pada latar belakang dan hipotesa, maka dapat dirumuskan ada permasalahan utama. Perlu suatu metode penglasifikasi teks multi-domain yang tepat ditujukan untuk pentranslasian mesin, yakni:
Penglasifikasi yang dibuat harus bersifat multi-domain, yaitu klasifikasi yang dapat menghasilkan kumpulan domain berkait lebih dari satu.
Penglasifikasi harus dapat menyeleksi domain yang turut berperan.
Metode penglasifikasi teks yang dikembangkan harus memenuhi beberapa kaidah dari hipotesa, yakni: menggunakan topologi taksonomi, menggunakan pengalkulasian term frequency, memiliki sifat naturalisme, dan komponen pendukung kelogisan lain.
1.4 Batasan Masalah
Dalam penelitian dibatasi pada lingkup sebagai berikut:
Penyusunan data domain berdasarkan struktur disiplin akademik (Wikipedia, 2013) yang kemudian dilengkapi oleh penulis.
Domain yang diujicoba dalam penelitian sebanyak 10 (sepuluh) domain, yaitu Artificial
Intelligence, Astronomy, Business, Dance, Geography, Mathematics, Nursing, Physics, Political Theory, dan Theater.
Korpus, sumber istilah, dan rasio statistik yang digunakan berasal dari Microsoft Encarta 2009. Indeks kedekatan domain yang diperoleh
menggunakan pendekatan yang dikembangkan, yakni Topological Taxonomy Term Statistical
Ratio (T3SR) dan dibandingkan dengan
Penelitian sampai pada tinjauan kelogisan dan kelayakan penglasifikasian, tidak dilakukan pengimplementasian pada mesin penerjemah. 1.5 Tujuan Penelitian
Penelitian ini bertujuan untuk mengembangkan metode Topological Taxonomy Term Statistical
Ratio (T3SR) yang dapat dipakai untuk menentukan
Indeks Kedekatan bidang keilmuan (domain). Metode ini menjadi suatu teknik penglasifikasi teks yang bersifat multi-domain. Output dari metode ini berisi informasi domain yang berguna sebagai analisa domain. Dari hasil ini, kemudian dapat dipakai dalam analisa morfologis dan leksikal pada pentranslasian.
Dari teknis pengembangan, tujuannya adalah untuk mengembangkan metode penglasifikasi berbasis topologi taksonomi. Penglasifikasi menggunakan pola distribusi rasio emas dalam sebaran bobotnya, serta bersifat heuristik. Pengguna metode ini ditujukan untuk para peneliti/ pengembang mesin translasi, praktisi dalam pengolahan bahasa alami ataupun text mining sebagai alat penglasifikasi dan analisa domain. 1.6 Manfaat Penelitian
Penelitian ini diharapkan memberikan manfaat pada pengembangan mesin translasi. Metode yang didesain nantinya dapat digunakan untuk meningkatkan kualitas hasil terjemahan. Lebih spesifiknya, metode T3SR dapat dipakai sebagai acuan informasi pada proses analisis morfologis dan leksikal (berisi informasi analisa domain). Dengan demikian, diharapkan hasil disambiguasi pada terjemahan akan menjadi lebih akurat.
Dilain sisi, dengan proses penglasifikasian secara otomatis, dapat dimanfaatkan untuk meniadakan proses pemilihan domain secara manual. Praktisi yang berkecimpung dalam text mining dapat menggunakan metode ini untuk memperoleh informasi terkait analisis domain pada suatu korpus. Penelitian ini memberikan metode atau pendekatan baru, menjadi sudut pandang dan wawasan, dan referensi dalam penelitian-penelitian selanjutnya. 1.7 Keaslian Penelitian
Penelitian yang mengarah pada metode penglasifikasi teks memang telah banyak dilakukan, namun tidak banyak yang dikhususkan dan terdokumentasi sebagai metode untuk pendukung translasi multi-domain. Penglasifikasi sebelumnya sama sekali belum spesifik mengangkat riset penggunaan pola khusus dalam topologi taksonomi bidang keilmuan. Belum ditemukan satupun penelitian yang mencoba menggunakan rasio emas sebagai pola propagasi ideal dalam perelasian domain yang seragam dan terpola secara adaptif.
Teknik terdahulu (seperti diilustrasi pada gambar 1.7.1 a) cenderung menggunakan susunan hirarki sebagai percabangan selektif yang mendistribusikan
propagasi atau penyeleksian dari atas ke bawah
(top-down approach). Klasifikasi dilakukan dengan
menyebarkan pembobotan/perambatan yang menurun ke anak. Bobot propagasi umumnya ditentukan secara berbeda-beda atau tidak dengan aturan seragam.
Gambar 1.7.1 Pola sebaran dalam struktur pohon. (a) pendekatan top-down, (b) pendekatan mix dipadu graf.
Perbedaan pada pendekatan yang dibuat penulis adalah menggunakan topologi taksonomi dimana seluruh node dapat menjadi keputusan klasifikasi serta memiliki pusat sebaran relatif. Tiap node mampu menjadi pusat sebaran (dilustrasikan gambar 1.7.1 b). Distribusi bobot propagasi memiliki pola seragam dan adaptif baik ke atas (parent), ke atas (child), atau dengan node-node lainnya yang berelasi.
1.8 Metode Penelitian
Tahap-tahap yang akan dilakukan dalam penelitian ini dilakukan melalui metode penelitian sebagai berikut:
Pengembangan konsep, rancang acuan dan metode penglasifikasi teks.
Pengembangan representasi pengetahuan (knowledge representation).
Pengembangan tool penglasifikasi teks.
Menggunakan tool penglasifikasi teks yang telah dibuat untuk pengujian.
Penyusunan laporan hasil penelitian.
2. TINJAUAN PUSTAKA
Cukup banyak penelitian yang membahas penelitian penglasifikasian teks multi-domain, namun terdapat sangat sedikit yang menggunakan metode hirarki. Berdasarkan tinjauan litelatur yang telah dikumpulkan, maka penelitian yang paling dekat kaitannya dengan penelitian ini dapat dijabarkan sebagai berikut:
Granitzer (2003) melakukan penelitian penglasifikasian teks berbasis hirarki dengan menggunakan algoritma CentroidBooster dan BoosTexter. Hasil perangkingan tidak jauh berbeda dengan struktur flat, namun terdapat kesalahan yang muncul dikarenakan kesalahan perambatan pada anak node. Presisinya kurang disebabkan oleh adanya error propagasi.
Sevillano, Alías & Socoró (2004) melakukan penelitian penglasifikasian teks berbasis hirarki dengan menggunakan metode ICA (Independent
Text-to-Speech. Metode ini mampu
mengorganisasikan konten data teks dalam bentuk hirarki untuk dievaluasikan terhadap korpus teks bergaya jurnalistik. Klasifikasi pada dokumen
society memiliki ciri akurasi yang buruk karena
heterogenitas konten, sementara akurasi yang lebih tinggi diperoleh pada domain lainnya.
Cox & Worsley (2010) melakukan penglasifikasian multi-domain dengan menggunakan pendekatan ektraksi fitur N-gram umum. Hasil ektraksi kemudian dikombinasikan dengan perhitungan multinomial Naïve Bayes. Penglasifikasian teks dengan pendekatan ini memiliki hasil performa yang kurang baik. Hasil akurasi rata-rata yang diperoleh adalah 67% untuk books, 57.2% untuk electronics, 50% untuk hotels, dan 45.3% untuk restaurants.
Khan dkk. (2010) melakukan peninjauan pada berbagai metode penglasifikasi teks baik yang telah ada. Tinjauan ini menyimpulkan bahwa teknik statistik saja tidak cukup untuk text mining. Konsep representasi semantik dan ontologi dikatakan dapat menghasilkan klasifikasi yang lebih baik, tapi memerlukan riset yang lebih jauh.
Li dkk. (2012) melakukan penelitian penglasifikasian teks berbasis Multi-Domain Active
Learning berdasarkan optimasi framework
multi-domain SVM (Support Vector Machines). Penglasifikasian ini untuk menggantikan pelabelan secara manual pada aplikasi penglasifikasi sentimen, penglasifikasi Newsgroups, dan filter spam email. Hasil pendekatan ini memiliki keefektifan 33.2%, 42.9% dan 68.7%. Metode ini diverifikasi efesien untuk aplikasi skala besar. Penulisnya memiliki ketertarikan untuk melakukan pengembangan dengan pembagian fitur dalam susunan hirarkis untuk domain yang berjumlah banyak.
3. LANDASAN TEORI
3.1 Konsep dan Rancang Acuan Pendekatan
Penglasifikasi Teks
Tiap kata memiliki personalitas dan identitas. Tiap personalitas bisa serupa, tapi tak pernah sama karena urutan, tipe, polanya tidak pernah identik. Personalitas merupakan fitur yang membuat kita dapat mengidentifikasi kealamiahan dan melakukan perubahan dalam pola berpikir. Dalam suatu konteks teks. Untuk menyimpulkan pengenalan makna (identitas) diantara keseluruhan reaksi psikologis (personalitas) adalah melalui pencarian ciri. Salah satu alat bantu untuk melakukan penglasifikasian (identifikasi) ini adalah melalui domain yang berasal dari teks. Domain memungkinkan manusia untuk menangkap informasi (menelusur menuju identifikasi) yang hendak disampaikan secara tepat.
Maka, untuk dapat mengartikannya secara tepat suatu translasi adalah perlu untuk menentukan bidang keilmuan atau domainnya terlebih dahulu. Penentuan domain membantu proses disambiguasi kata yang hendak ditranslasikan dan membantu
untuk memprediksi personalitas dan identitas suatu kata. Dari pengasumsian sedemikian, maka dapatlah disusun metode-metode atau formulasi pendekatan yang dapat digunakan untuk menentukan bidang keilmuan. Penglasfikasian ini didasarkan pada statistik istilah teknis (term) yang berada dalam korpus.
3.2 Term Statistical Ratio (TSR)
Metode ini dirancang untuk tidak melihat pada potensi perulangan kata yang sama, tetapi melakukan pendekatan berdasarkan perbandingan istilah terhadap rasio kemunculan istilah pada teks. Spesifiknya dengan asumsi bahwa masing-masing teks dari berbagai domain dapat memiliki rasio kemunculan term yang berbeda-beda.
3.2.1 Nearest Term Statistical Ratio (NTSR) Pendekatan ini merupakan yang paling sederhana, yaitu dengan mengalkulasi kedekatan berdasarkan dengan perbandingan rasio kemunculan term. Rumusan yang dibentuk dapat dilihat pada formula 3.2.1. Teknik ini terlihat similar terhadap teknik umum yang dipakai dalam Term Frequency (Khan dkk, 2010). i i i i i
k
N
n
k
N
n
R
.
(3.2.1)
Ri = Indeks kedekatan lingkup di domain i
ni = Jumlah istilah (term) berkaitan dengan
domain i yang ditemukan
Ni = Jumlah kata relatif dalam teks terkait
klasifikasi pada domain i
ki = Rasio kemunculan istilah (term) pada
domain i
Jumlah kata relatif (Ni) ditentukan berdasarkan
populasi dimana term yang berupa kata majemuk berdiri sebagai sebuah kesatuan kata ketika klasifikasi dilakukan di domain i. Rasio kemunculan istilah (k) diperoleh dari jumlah istilah yang ditemukan pada korpus dibagi dengan jumlah kata relatifnya. Nilai ini dapat didasari oleh rasio minimum, rata-rata, atau maksimum.
3.2.2 Normalized Nearest Term Statistical Ratio (NNTSR)
Pada Nearest Term Statistical Ratio dapat terjadi masalah jika ada nilai indeks kedekatan (scope
proximity index) yang cukup rendah dibanding
domain utama sehingga cenderung dapat diabaikan. Untuk mengatasinya, dapat dilakukan melalui normalisasi, diharapkan dapat meningkatkan nilai indeks kedekatan. Normalisasi dilakukan dengan dengan memanfaatkan jarak euclidian dari setiap nilai indeks kedekatan domain-domain sebagai bilangan pembagi kemudian diakarkan (persamaan 3.2.2).
Teknik ini merupakan suatu bentuk gabungan dari norm dan logika mendekati domain. Teknik
norm euclidian umumnya dikenal dalam
perangkingan retrieval berdasarkan Vector Space
Model (Büttcher, Clarke & Cormack, 2011).
Sementara, fungsi logika mendekati umumnya diaplikasikan untuk membentuk set dalam logika samar (Wang, 1997).
M j j i i R R Rn 1 2 (3.2.2)Rni = Indeks kedekatan lingkup di domain i
yang dinormalisasi
M = Jumlah domain yang didefinisikan 3.3 Topological Taxonomy Term Statistical
Ratio (T3SR)
Pada pendekatan-pendekatan sebelumnya, pencarian kedekatan indeks hanya cocok diterapkan pada superdomain dengan struktur flat. Namun, set domain atau disiplin ilmu sebenarnya membentuk topologi taksonomi yang terdiri dari susunan konsep hirarki induk (parent) dan anak (child).
Bentuk topologi dapat diwakilkan menjadi bentuk takson berciri seperti yang diilustrasikan pada gambar 3.3.1. Pengalamatan node dapat menggunakan identitas simbolik (id) ataupun uniform untuk menandai hubungan. Misalnya, dapat dituliskan sebagai X, X:1, X:2, X:1:1, dsb, dan dapat pula dituliskan secara uniform logis seperti DISCIPLINES:natural_sciences:earth_sciences, dsb. Set pada orde nol (root) menjadi tag atau label pengenal yang mendeskripsikan isi taksonnya. Dalam bentuk umum, maka dapat dituliskan sebagai X:a:b:c:…:dst.
Gambar 3.3.1 Bentuk hirarki umum dalam cabang disiplin ilmu.
Pada susunan hirarki seperti ini, dapat terjadi hubungan kekerabatan. Hubungan ini menyatakan relasi keterlibatan domain dan terjadi dalam satu arah maupun dua arah. Hubungan antar induk-anak (vertikal) umumnya selalu erat, tidak terpisah, dan sering berkaitan secara langsung. Sedangkan, hubungan antar anggota dengan orde setara (horisontal) dan hubungan lintas (cross) yang berbeda induk maupun orde umumnya terjadi secara relatif.
Dengan melihat keunikan hubungan yang terjadi secara vertikal (antara anak dan induk). Diasumsikan
hubungan ini secara ideal saling berkembang, berkontribusi, atau saling mendukung. Hubungan ini diadopsi sebagai model pendistribusian secara statistik. Penambahan istilah (term) pada suatu domain turut mendistribusikan porsi atau bobot pada domain turunan dan parentalnya.
Untuk mengakomodasi distribusi, konsep perkembangan ideal berdasarkan rasio emas (Tung, 2007) kemudian diadopsikan sebagai pola distribusinya (berdasarkan nilai konjugat). Dengan demikian, diasumsikan distribusi kepada anak maupun induknya akan memiliki porsi distribusi seragam sebesar Φ. Pada hubungan vertikal, pembobotan distribusi kumulatifnya kemudian dapat dirumuskan sebagai berikut.
h id a id a b a w id Max nD nD k k k W . ( ,0).( / ). 1
(3.3.1) dimanaWid = bobot distribusi ideal pada domain id.
nDa = jumlah term yang muncul pada anggota
Da.
nDid = jumlah term yang muncul pada anggota
Did.
b = orde tertinggi dalam pohon hirarki
kid = rasio kemunculan istilah pada domain id.
Jika nilai rasio yang jika tidak didefinisikan maka dapat diambil berdasarkan rasio maksimum, rata-rata, minimum, atau aturan khusus lainnya berdasarkan kalkulasi rasio parent atau
child.
ka = rasio kemunculan istilah pada domain a.
kh = koefisien heuristik.
w
= koefisien bobot, dimanaw
= wDa(id) untuk anggota Da yang bukanturunan atau parental dari id.
w
= Φ untuk anggota Da yang merupakanturunan atau parental dari id.
wDa(id) = bobot distribusi terhadap domain id
pada set Da.
Koefisien heuristik (kh) digunakan untuk
memperbaiki prioritas perangkingan. Nilai kh dapat
ditentukan melalui eksponensial efesiensi terhadap nilai absolut dari selisih orde antar domain. Dengan
parent dianggap lebih berperan dalam memberikan
konsep, maka kh dirumuskan melalui pendekatan
sebagai berikut.
k
h= μ
|x-y| + [(x-y) / Max(b-1, 1)] (3.3.2)dimana
μ = konstanta kepercayaan logis diantara 0…1 (contohnya, nilai konstanta yang lumrah adalah disekitar 0.94…0.98).
y = orde domain a.
Selanjutnya, indeks kedekatan pada lingkup domain dapat diperoleh melalui persamaan berikut.
id id id id N k W Rh . (3.3.3) dimana:
Rhid = Indeks kedekatan lingkup hirarkis di
domain id.
Nid = Jumlah kata relatif dalam teks terkait
klasifikasi pada domain id.
4. PERANCANGAN SISTEM
4.1 Komponen Sistem
Suatu sistem dalam mesin translasi yang umum terdiri dari komponen-komponen atau unit pendukung seperti yang terlihat pada gambar 4.1.1.
Gambar 4.1.1 Diagram sistem pada translasi mesin Unit analisis domain merupakan bagian yang diperlukan pada unit analisis morfologis dan kategorisasi leksikal. Unit analis domain (dalam petak bergaris titik-titik pada gambar 4.1.1) yang akan dirancang sistemnya dalam penelitian. Analisa domain dilakukan dengan menggunakan perantara penglasifikasi teks yang telah dikembangkan. 4.1.1 Unit Analisis Domain
Gambar 4.1.1.1 merupakan spesifik detil sistem yang digunakan sebagai penganalisa domain. Analisa domain ini berdasarkan penglasifikasi teks dengan metode NTSR, NNTSR, dan T3SR (dalam petak bergaris titik-titik pada gambar 4.1.1.1). Detil proses dan cara kerja unit ini adalah sebagai berikut:
Gambar 4.1.1.1 Diagram penglasifikasi teks yang digunakan sebagai analisa domain
Source (sumber teks) sebagai input diteruskan ke unit parser.
Parser memisahkan kata-kata yang terdapat dalam sumber teks. Untai kata-kata ini kemudian diteruskan ke unit Classifier.
Dalam classifier, akan dilakukan perhitungan statistik istilah (terms statistics calculaction). Proses ini menghitung jumlah kata dan istilah yang ditemukan per tiap domain.
Selanjutnya, classifier akan menghitung nilai indeks NTSR, NNTSR, dan T3SR untuk tiap domain (dalam gambar 4.1.1.1 ditunjukan
sebagain NTSR calculation, NNTSR
calculation, dan T3SR calculation).
Nilai indeks per tiap domain ini kemudian menjadi informasi domain yang diperlukan dalam pengolahan morfologis dan leksikal pada mesin translasi. Dalam penulisan ini, tujuannya untuk mengkaji kelayakannya. 4.1.2 Desain Antarmuka Penglasifikasi
Penglasifikasi didesain menggunakan antarmuka grafis yang tampilannya didasarkan oleh preliminary
screen pada gambar 4.1.2.1.
Gambar 4.1.2.1 Preliminary Screen aplikasi penglasifikasi teks
4.1.3 Diagram Komponen Penglasifikasi
Agar pengimplementasian menjadi fleksibel, maka digunakan pendekatan berorientasi objek (Shoval, 2007). Komponen penglasifikasi teks dirancang mengikuti diagram komponen pada gambar 4.1.3.1 dengan rincian komponen dan prosesnya adalah sebagai berikut:
Gambar 4.1.3.1 Diagram komponen penglasifikasi teks
Komponen user request handler didesain dalam bentuk perantara GUI (objek pada
window) yang tugasnya menangani antarmuka
4.1.2.1). User request handler menangani keutuhan proses penglasifikasian.
Data handler menggunakan data yang dimuat dari dokumen dan kemudian memprosesnya menjadi objek data node, membuat link yang diperlukan dan menginterpolasi rasio kid.
Parser merupakan unit yang berperan dalam memisahkan teks menjadi array kata dan simbol, dan memodifikasi simbol agar tidak terpengaruh oleh ragam penulisan.
Unit Classifier memiliki dua tahapan proses, yaitu inisiasi Create untuk mengindeks terms pada tiap node domain, melacak kata terpanjang, dan melacak orde tertinggi. Fungsi kedua adalah melaksanakan proses klasifikasi. Disini, terms dilacak dan dihitung, kemudian dilanjutkan proses kalkulasi indeks NTSR, NNTSR, dan T3SR berdasarkan input yang telah di-parser.
4.2 Perancangan Representasi Pengetahuan Untuk memfasilitasi pembentukan data dan pendokumentasian penelitian, representasi berbentuk klasifikasi (Granitzer, 2003). Bentuk representasi menggunakan bentuk seperti ini diperlihatkan pada gambar 4..2.1 dengan konsistensi logis yang sama terhadap bentuk pohon (Wiley & Lieberman, 2011).
Gambar 4.2.2 Bentuk representasi klasifikasi dalam pendokumentasian
Pada penabelan, attribut Ratio mewakili (ki dan
kid ) yaitu jumlah kemunculan istilah per jumlah kata
dalam teks dalam suatu domain. Terms mewakili istilah dalam domain. Link mewakili wDa(id) yaitu
bobot distribusi terhadap domain id pada set Da.
Contoh penabelan (attribut) dapat dilihat pada tabel 4.2.1.
Tabel 4.2.1 Contoh pendokumentasian attribut
Tabel 1 (Computer sciences) SubKey Value
<null> Name Ratio Type Double Value 0.01234 Tag <null> <null> Name Terms
Type Multi-String
Value computer, computation, algorithms, theory of computation, computational systems, programming language, digital, turing test, digital logic, operating systems
Tag <null>
Link Name Computer engineering Type String atau Double Value Phi
Tag DISCIPLINES/Professions and Applied sciences/Child/Engineering/Child/Computer
engineering
Konstanta yang dipakai dalam penelitian adalah; konstanta kepercayaan logis (μ) = 0.97, dan Phi = 0.61803398875. Apabila rasio kemunculan terms (ki
atau kid) tidak didefinisikan, maka interpolasi
dilakukan dengan mengambil rasio maksimum terlebih dahulu dari anak domain. Jika tidak juga menemukan, maka diambil rasio minimum yang dimiliki oleh induk domain.
4.2.1 Rancangan Basis Data
Bentuk susunan data yang dipakai didesain menggunakan pendekatan object oriented design (OOD). Struktur rancangan objek sesuai gambar 4.2.1.1.
Gambar 4.2.1.1 OOD dari representasi pengetahuan
5. IMPLEMENTASI
5.1 Implementasi
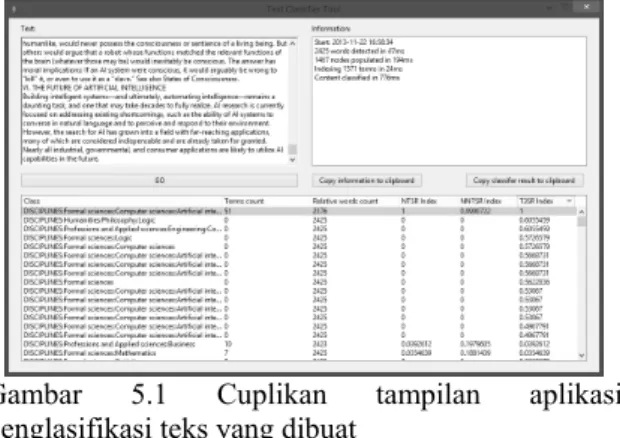
Pembuatan aplikasi penglasifikasi merupakan kelanjutan dari tahap perancangan sistem, dan implementasi didasarkan pada perancangan yang telah dilaksanakan sebelumnya. Adapun, aplikasi penglasifikasi dibuat dengan menggunakan Xojo/Realstudio 2012. Untuk representasi data, penyusunannya dibuat menggunakan basis data RML (Phoa & Liwang, 2013) melalui aplikasi Data Composer. Cuplikan tampilan aplikasi yang telah dibuat dapat dilihat pada gambar 5.1
Gambar 5.1 Cuplikan tampilan aplikasi penglasifikasi teks yang dibuat
5.2 Implementasi Perangkat Lunak
Penglasifikasi mempunyai 4 buah komponen perangkat lunak. Komponen ini yaitu Data handler,
Parser, Classifier, dan User request handler. Dalam
Class Object, dimana penamaan dari masing-masing class yang digunakan dapat dilihat pada Tabel 5.3.1. Tabel 5.3.1 Daftar Komponen Implementasi
N
o Komponen Class Object
Layanan (Interface
Method) 1 Data handler ClassifierLoader Create 2 Parser ClassifierParserLatin Parse 3 Classifier ClassifierTermControl Create
Classify 4 User request
handler WindowClassifier (GUI) PushButton1.Action Classify
User request handler merupakan class GUI
(objek window), komponen utama yang menangani antarmuka permintaan pengguna akan proses klasifikasi dan kemudian menampilkan informasi hasil penglasifikasian. Algoritma yang digunakan dapat dilihat pada tabel 5.3.2.
Tabel 5.3.2 Algoritma User request handler
ALGORITMA PROSEDUR/FUNGSI PushButton1.Action(); me.Enabled ← False; me.Refresh; Classify(); me.Enabled ← True; Classify(); {Parse} parser ← new(ClassifierParserLatin); parsed ← parser.Parse(TextAreaSample.Text); {Create classifier} f ← GetFolderItem(‘Resources’).Child(‘dev-x.crickets’); b ← rmldoc.OpenBinaryFile(f, s);
classer ← clsdoc.Create(rmldoc, ‘DISCIPLINES’); TermControl ← new(ClassifierTermControl); TermControl.Create(classer);
{Classify}
TermControl.Classify(parsed); {Show the results} ListboxResult.DeleteAllRows; m ← TermControl.NodeList.Ubound; FOR (i = 0 to m STEP 1) node ← TermControl.NodeList[i]; ss[0] ← node.VirtualAddress; ss[1] ← Cstr(node.StatTermFoundCount); ss[2] ← Cstr(node.StatWordCountRelative); ss[3] ← CStr(node.MethodProperty(0).ProximityIndex); ss[4] ← CStr(node.MethodProperty(1).ProximityIndex); ss[5] ← CStr(node.MethodProperty(2).ProximityIndex); ListboxResult.AddRow(ss); ENDFOR. 5.3 Pelaksanaan Pengujian
Pengujian tool penglasifikasi yang telah diimplementasi dilakukan dengan menggunakan 10 (sepuluh) korpus dari Microsoft Encarta 2009 sesuai yang telah direncanakan. Hasil dari penglasifikasi teks kemudian dirangkingkan. Hasil ini kemudian dianalisa dan dibahas pada bab 6.
6. HASIL DAN PEMBAHASAN
6.1 Hasil keluaran sistem
Korpus diujicobakan pada penglasifikasi teks dan menghasilkan sejumlah informasi yang nantinya dapat digunakan sebagai analisis domain. Informasi analisa domain dari input korpus terbagi dalam 3 kelompok metode yang telah diimplementasikan, yaitu NTSR, NNTSR, dan T3SR. Informasi yang diperoleh adalah kelas domain, jumlah istilah (ni,
nDid), jumlah kata relatif (Ni, Nid), nilai indeks
NTSR (Ri), NNTSR (Rni), dan T3SR (Rhid),
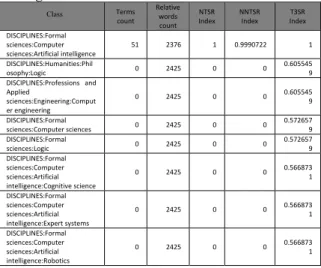
misalnya yang dapat dilihat pada tabel 6.1.1. Dari hasil ini, kemudian dilanjutkan dengan proses pengriteriaan untuk analisa kelayakan secara offline. Tabel 6.1.1 Perangkingan T3SR untuk Artificial
Intelligence Class Terms count Relative words count NTSR Index NNTSR Index T3SR Index DISCIPLINES:Formal sciences:Computer sciences:Artificial intelligence 51 2376 1 0.9990722 1 DISCIPLINES:Humanities:Phil osophy:Logic 0 2425 0 0 0.605545 9 DISCIPLINES:Professions and Applied sciences:Engineering:Comput er engineering 0 2425 0 0 0.6055459 DISCIPLINES:Formal sciences:Computer sciences 0 2425 0 0 0.572657 9 DISCIPLINES:Formal sciences:Logic 0 2425 0 0 0.572657 9 DISCIPLINES:Formal sciences:Computer sciences:Artificial intelligence:Cognitive science 0 2425 0 0 0.566873 1 DISCIPLINES:Formal sciences:Computer sciences:Artificial intelligence:Expert systems 0 2425 0 0 0.5668731 DISCIPLINES:Formal sciences:Computer sciences:Artificial intelligence:Robotics 0 2425 0 0 0.566873 1 6.2 Analisa Kelayakan
Setelah hasil penglasifikasian diperoleh, diperlukan analisa kelayakan agar dapat mengetahui dan menyimpulkan tingkat kelayakan dari metode yang telah dibuat. Analisa kelayakan ini menjadi alat ukur refleksi atas kelogisan dan keperluan fungsi analisis domain yang baik dalam penerjemahan mesin. Analisa dilakukan manual atau offline. Dari tiap hasil perangkingan dilakukan pengriteriaan perangkingan dan pengriteriaan nilai indeks. Dari kedua hasil pengriteriaan tadi barulah dilakukan analisa dan disimpul kelayakannya. Untuk jelasnya, dapat dilihat pada gambar 6.2.1.
Gambar 6.2.1 Alur proses analisa kelayakan 6.2.1 Pengriteriaan dan penilaian
Sistem skoring atau skala penilaian yang digunakan adalah skala 0-4. Adapun syarat dari jumlah kesertaan sub-domain (untuk domain lain yang berhubungan setelah domain di peringkat pertama) menggunakan skala yang dibatasi oleh deret yang dibatasi sampai pada tempat ke-empat dengan nilai [0, 1, 3, 5]. Deret ini diacu karena pengriteriaan linear dengan beda deret tetap atau berselisih 1 (satu) dapat memberikan bias penilaian yang kurang signifikan atau persepsi yang terlalu berdekatan. Ragam skala berdasar deret ini sering disebut juga skala tala Phytagoras dengan
pembulatan integer (Milne, Sethares & Plamondon, 2007), atau skala Neapolitan (Dave, 1992).
Pemilihan nilai ambang atau threshold untuk penilaian indeks adalah 0,5 sebagai gambaran umum domain yang berarti atau kuat relasinya terhadap korpus. Susunan kriteria penilaian lengkapnya dapat dilihat pada tabel 6.2.1.1 dan 6.2.1.2. Hasil pengriteriaannya dapat dilihat pada tabel 6.2.1.3. Tabel 6.2.1.1 Kriteria Penilaian Perangkingan
Penilaian Skor Kriteria
Sangat
Buruk 0 Hasil perangkingan tidak tepat dengan domainnya Buruk 1 Hasil pada rangking pertama sesuai dengan
domain, rangking setelahnya tidak berketerkaitan. Cukup
Baik 2
Hasil pada rangking pertama sesuai dengan domain, dengan minimal 1 rangking setelahnya memiliki keterkaitan dengan domain atau subdomain.
Baik
3 Hasil pada rangking pertama sesuai dengan domain, dengan minimal 3 rangking setelahnya memiliki keterkaitan logis secara berurutan. Sangat
Baik 4
Hasil pada rangking pertama sesuai dengan domain, dengan minimal 5 rangking setelahnya memiliki keterkaitan logis secara berurutan.
Tabel 6.2.2.2 Kriteria Penilaian Nilai Indeks
Penilaian Skor Kriteria
Sangat
Buruk 0
Domain utama memiliki indeks ≤ 0,5 Buruk 1 Domain utama memiliki indeks > 0,5.
Domain berikutnya memiliki indeks ≤ 0,5. Cukup
Baik 2 Domain utama memiliki indeks > 0,5 Minimal 1 domain yang terkait berikutnya memiliki indeks ≥ 0,5.
Baik
3 Domain utama memiliki indeks > 0,5 Minimal 3 domain yang terkait berikutnya memiliki indeks ≥ 0,5.
Sangat
Baik 4
Domain utama memiliki indeks > 0,5
Minimal 5 domain yang terkait berikutnya memiliki indeks ≥ 0,5.
Tabel 6.2.1.3 Penilaian Klasifikasi
Korpus
Penilaian NTSR Penilaian NNTSR Penilaian T3SR Skor Perang-kingan Skor Nilai Indeks Skor Perang-kingan Skor Nilai Indeks Skor Perang-kingan Skor Nilai Indeks Artificial Intelligence 1 1 1 1 4 4 Astronomy 3 1 3 1 4 4 Business 3 1 3 1 4 4 Dance 3 2 3 2 4 4 Geography 2 1 2 1 4 4 Mathematics 4 1 4 1 4 4 Nursing 2 1 2 1 4 4 Physics 3 1 3 1 4 4 Political Theory 2 1 2 1 4 4 Theater 1 1 1 2 4 4 Rata-rata 24/10 = 2,4 (60%) (Cukup Baik) 11/10 = 1,1 (27,5%) (Buruk) 24/10 = 2,4 (60%) (Cukup Baik) 12/10 = 1,2 (30%) (Buruk) 40/10 = 4 (100%) (Sangat Baik) 40/10 = 4 (100%) (Sangat Baik) 6.2.2 Bahasan
Dari penilaian-penilaian yang ada, dapat terlihat dari rata-ratanya bahwa metode T3SR mampu mengungguli metode flat (NTSR dan NNTSR). Metode NTSR memperoleh 60% kriteria kelayakan perangkingan dan 27,5% kriteria kelayakan indeks. Metode NNTSR sedikit memperbaiki kelayakan indeks namun tidaklah memperbaiki perangkingan. NNTSR memperoleh 60% kelayakan perangkingan dan 30% kelayakan indeks. Dengan metode T3SR, diperoleh 100% kelayakan perangkingan dan 100% kelayakan indeks.
Dari hasil analisa dan pembahasan,metode T3SR mampu untuk memberikan pola kriteria perangkingan dan kriteria nilai indeks yang sangat
baik untuk nantinya dapat diterapkan dalam keperluan disambiguasi dalam mesin penerjemah. Kemampuan heuristik menjadi nilai tambah yang sangat baik. Berdasar dari kelayakan/kelogisan perangkingan dan nilai indeksnya, maka metode T3SR dapat dianggap sangat layak untuk nantinya diimplementasikan sebagai alat analisis domain dalam mesin penerjemah.
7. KESIMPULAN DAN SARAN
7.1 Kesimpulan
Kesimpulan yang dapat diambil dalam penelitian ini adalah sebagai berikut:
Metode T3SR memiliki kriteria perangkingan dan kriteria nilai indeks yang sangat baik dibandingkan dengan metode flat (NTSR dan NNTSR).
Metode T3SR dianggap sangat layak untuk nantinya diimplementasi dalam mesin penerjemah.
Metode T3SR mengungguli metode penglasifikasi flat (NTSR dan NNTSR) dalam hal relevansi kelogisan berdasarkan kriteria perangkingan dan kriteria nilai indeks.
7.2 Saran
Saran-saran yang dapat diberikan melalui penelitian adalah sebagai berikut:
Peninjauan metode T3SR dalam penelitian ini masih bersifat melihat kelayakan perangkingan dan indeksnya dan belum diimplementasikan pada mesin penerjemah. Bagi peneliti yang berminat diharapkan kedepan dapat mengimplementasikannya dalam mesin penerjemah agar dapat dianalisa pula pengaruhnya terhadap akurasi terjemahan.
Mengingat dalam penelitian masih menggunakan ujicoba 10 (sepuluh) domain, maka kedepannya diharapkan dapat menggunakan jumlah domain uji yang lebih banyak serta jumlah terms yang lebih komprehensif.
Masih terbuka cara untuk lebih komprehensif dalam menghasilkan pola perangkingan. Metode T3SR masih memungkinkan untuk dimodifikasi agar menghasilkan penglasifikasian yang jauh lebih baik.
PUSTAKA
Abbott, A., 2001, Chaos of disciplines. University of Chicago Press, Chicago And London.
Bolshakov, I.A. and Gelbukh, A., 2004, Computational Linguistics, Mexico.
Büttcher, S., Clarke, C.L.A. and Cormack, G.V., 2011, Information Retrieval: Implementing and Evaluating Search Engines, The MIT Press, Massachusetts.
Campbell, T., 2007, My Big TOE, Lightning Strike books, USA.
Castilho, W.F., Filho, G.J.L., Prado, H.A and Ferneda, E., 2008, An Interpretation Process for Clustering Analysis Based on the Ontology of Language, Emerging Technologies of Text
Mining: Techniques and Applications, Information Science Reference, 1, 14, 297-320.
Cook, V.J. and Newson, M., 2007, Chomsky's Universal Grammar: An Introduction (Third Edition), Wiley, New York.
Cox, E. and Worsley M., 2010, In Pursuit of an Efficient Multi-Domain Text Classification Algorithm, Final Projects from CS 224N, Ling 284 for Spring 2009/2010, Learning Sciences and Technology Design Stanford University, Stanford.
Dave, C., 1992, Monster Scales and Modes, CentreStream, Canada.
ElShiekh, A.A.A., 2012, Google Translate Service: Transfer of Meaning, Distortion or Simply a New Creation? : An Investigation into the Translation Process & Problems at Google,
English Language and Literature Studies, 2, 1,
56-68.
Granitzer, M., 2003, Hierarchical Text Classification using Methods from Machine Learning, Master's Thesis, Institute of Theoretical Computer Science (IGI), Graz University of Technology, Austria.
Hawkins, J. and Blakeslee, S., 2004, On Intelligence, Levine Greenberg Literary Agency, New York.
Khan, A., Baharudin, B., Lee, L.H., Khan, K., 2010, A Review of Machine Learning Algorithms for Text-Documents Classification, Journal of
Advances in Information Technology, 1, 1, 4-20.
Kondo, T., Nanba, H., Takezawa, T. and Okumura, M., 2011, Technical Trend Analysis by Analyzing Research Papers’ Titles, Human
Language Technology: Challenges For Computer Science and Lingusitics, 1, 4, 512–
521.
Li, L., Jin, X., Pan, S.J. and Sun, J.T., 2012, Multi-Domain Active Learning for Text Classification,
ACM SIGKDD conference on Knowledge Discovery and Data Mining, Beijing, China,
August 12–16, 2012.
Liu, Y., Loh, H.T. and Lu, W.F., 2008, Deriving Taxonomy from Documents at Sentence Level,
Emerging Technologies of Text Mining: Techniques and Applications, Information Science Reference, 1, 5, 99-119.
Milne, A., Sethares, M. and Plamondon, J., 2007, Isomorphic Controllers and Dynamic Tuning: Invariant Fingering over a Tuning Continuum,
Computer Music Journal, Massachusetts
Institute of Technology, 31, 4, 15-32.
Modrak, D.K.W., 2001, Aristotle's Theory of Language and Meaning, Cambridge University Press, United Kingdom.
Moss, L.S., 2009, Natural Logic and Semantics,
Logic, Language and Meaning, 17, 9, 84–93.
Palomino, M.A. and Wuytack, T., 2011, Unsupervised Extraction of Keywords from News Archives, Human Language Technology:
Challenges For Computer Science and Lingusitics, 1, 4, 544–555.
Pels, H.J., 2006, Classification hierarchies for product data modelling, Production Planning &
Control, 17, 4, 367–377.
Phoa, V. dan Liwang, R., 2013, Model Sistem Informasi Geografis untuk Statistik Data-data Umum Negara Dunia, Seminar Nasional
Teknologi Informasi dan Komunikasi 2013 (SENTIKA 2013), 9 Maret 2013, 247-252.
Sevillano, X., Alías, F., and Socoró, 2004, J.C., ICA-based hierarchical text classification for multi-domain text-to-speech synthesis,
Acoustics, Speech, and Signal Processing, 2004 IEEE International Conference, 5, 5, 697-700.
Shoval, P., 2007, Functional and Object Oriented Analysis and Design, Idea Group Publishing, United State of America.
Tung, K.K., 2007, Topics in Mathematical Modeling, Princeton University Press, New Jersey.
Wang, Li-Xin, 1997, A Course in Fuzzy Systems and Control, Prentice-Hall International, New Jersey.
Wikipedia. 2013. List of academic disciplines, (Online),_(http://en.wikipedia.org/wiki/List_of_a cademic_disciplines, diakses 12 Agustus 2013). Wikipedia. 2013. Physics of magnetic resonance
imaging,_(Online),_(http://en.wikipedia.org/wiki /Physics_of_magnetic_resonance_imaging, diakses 26 November 2013).
Wiley, E.O. and Lieberman, B.S., 2011, Phylogenetics: theory and practice of phylogenetic systematics, Wiley-Blackwell, Singapore.