3.1 Kerangka Penelitian
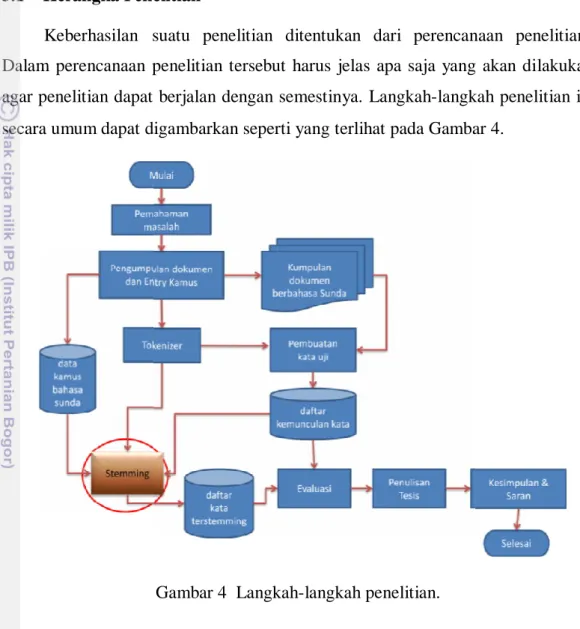
Keberhasilan suatu penelitian ditentukan dari perencanaan penelitian. Dalam perencanaan penelitian tersebut harus jelas apa saja yang akan dilakukan agar penelitian dapat berjalan dengan semestinya. Langkah-langkah penelitian ini secara umum dapat digambarkan seperti yang terlihat pada Gambar 4.
Gambar 4 Langkah-langkah penelitian. 3.2 Prosedur Penelitian
Berdasarkan langkah-langkah penelitian pada Gambar 4, tahapan penelitian yang dilakukan pada tiap langkah diuraikan pada pembahasan selanjutnya.
3.2.1 Tahap Pemahaman Masalah
Untuk dapat menyelesaikan penelitian ini, masalah yang ada harus dipahami dengan baik. Permasalahan yang ada digali dengan cara studi literatur dari sumber-sumber yang berkaitan dengan permasalahan penelitian ini. Selain itu, permasalahan dalam tentang tata bahasa Sunda dilakukan dengan cara melakukan
wawancara dengan nara sumber yang kompeten yaitu Bapak Dr. Yayat Sudaryat, M.Hum. (dosen Sastra Sunda Universitas Pendidikan Indonesia)
3.2.2 Tahap Pengumpulan Dokumen dan Pemasukan Data Kamus
Dokumen-dokumen dalam bahasa Sunda digunakan untuk pengujian pada tahap evaluasi stemming. Dokumen uji yang terkumpul adalah sebanyak 130 dokumen berbahasa Sunda dengan topik yang beragam. Topik dokumen berisi tentang sejarah, budaya, agama, berita dan lain-lain. Seluruh dokumen yang terkumpul, format penulisan dokumen kemudian diubah menjadi bentuk teks. Hal ini untuk memudahkan pembacaan dokumen oleh tokenizer.
Data kamus diperlukan untuk pembandingan kata pada proses stemming. Untuk memasukan data kamus, sumber data didapat dari Kamus Lengkep Sunda- Indonesia Indonesia Sunda Sunda-Sunda (Tamsyah 1996) dan dilengkapi dengan kamus Sunda – Indonesia (Satjadibrata 2011). Dari hasil pemasukan data kamus tersebut didapat 8 234 kata.
3.2.3 Tahap Perancangan Tokenizer
Tokenizer akan membaca kata per kata dari dokumen. Modul tokenizer
akan menerima masukan berupa dokumen dan keluarannya adalah kumpulan kata atau token. Tokenizer akan mengabaikan tanda baca, dan tanda-tanda lainnya yang tidak diperlukan. Tokenizer akan membaca dokumen dalam bentuk teks atau HTML. Program selengkapnya tokenizer dapat dilihat pada Lampiran 1.
3.2.4 Tahap Pembuatan Kata Uji dari Dokumen
Pada tahap ini, dokumen yang terkumpul akan dicari token atau kata yang ada dalam dokumen tersebut. Pembuatan kata uji ini akan menggunakan tokenizer yang dirancang pada Bab 3.2.3. Kata atau token yang terkumpul akan disimpan dalam sebuah tabel dalam database yang berisi daftar kemunculan kata dalam dokumen. Kata yang disimpan dalam database adalah kata yang unik, artinya tidak akan ada kata yang sama.
Kata uji ini akan digunakan untuk pengujian algoritme stemming yang dirancang. Selanjutnya kata hasil stemming akan dievaluasi apakah hasil stemming sesuai dengan kata yang diharapkan.
3.2.5 Tahap Pembuatan Stoplist
Pada tahapan ini akan dibuang semua kata-kata dalam bahasa Sunda yang kurang memiliki arti. Pembuatan daftar stoplist dibuat secara manual. Kata-kata yang kurang berarti yang ditemukan, akan dimasukan dalam database stoplist. Daftar stoplist ini dikelompokan dalam kelompok sepeti terlihat pada Tabel 1.
Tabel 1 Daftar stoplist
Jenis Kata Contoh
Kata Tanya saha, naon, mana, naha, iraha, kumaha, sabaraha
Kata Penunjuk ieu, eta, dieu, kieu
Kata Sambung jeung, sareng, nepi, jaba, lian, nu, lamun, tapi, atawa, atanapi, tuluy, terus, teras, yen, majar, nu, anu, matak, majar
teh, mah, seug, heug, mun, boa, ketah, ketang, pisan,
Kata Lainnya sok, nu, anu
Kata Pangwates bae, be, wae, we, weh, mung, ngan, ukur, keur, nuju,
masih, keneh, pikeun, kanggo
Kata Sabab/Slesan da, kapan, kapanan, apan, pan, apanan
Kata Wengkuan deui, deuih, ge, oge,ongkoh
Kata Matotoskeun nya, nyah, enya, lain, sanes
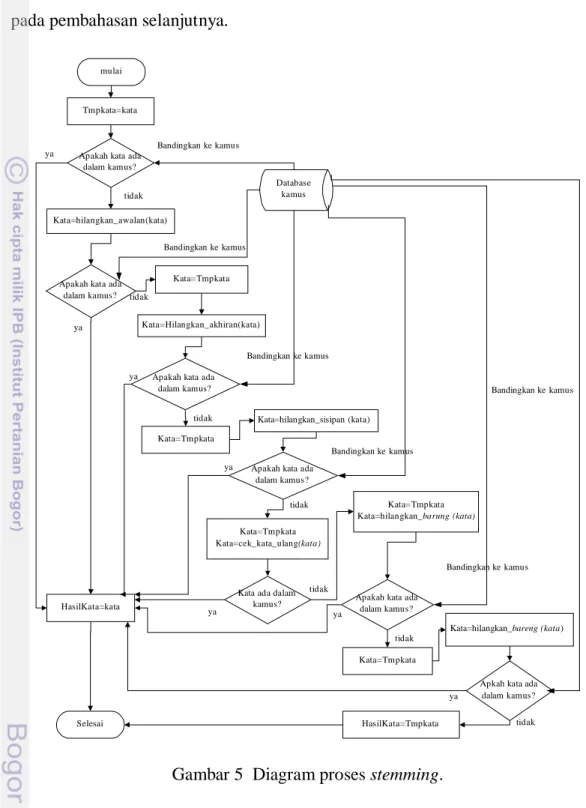
3.2.6 Tahap Perancangan Stemming
Proses stemming akan menghilangkan awalan (rarangken hareup), sisipan (rarangken tengah), akhiran (rarangken tukang), kata imbuhan terbelah (rarangken barung), dan kata gabungan (rarangken bareng). Selain itu algoritme
stemming juga akan menguji apakah kata adalah kata ulang. Algoritme stemming
yang dirancang berbentuk flowchart, seperti yang ada pada Gambar 5. Pada
flowchart tersebut terlihat inti dari algoritme tersebut adalah pada proses
penghilangan imbuhan, yaitu modul/fungsi: Hilangkan_Awalan(), Hilangkan_Akhiran(), Hilangkan_Sisipan(), Hilangkan_Barung(), Hilangkan_ Bareng() dan Cek_Kata_Ulang().
Masing-masing modul inti dari stemming tersebut akan dibahas secara rinci pada pembahasan selanjutnya.
mulai
Tmpkata=kata
ya Apakah kata ada dalam kamus? tidak Bandingkan ke kamus Database kamus Kata=hilangkan_awalan(kata) Bandingkan ke kamus Apakah kata ada
dalam kamus? tidak
Kata=Tmpkata
ya Kata=Hilangkan_akhiran(kata)
Bandingkan ke kamus ya Apakah kata ada
dalam kamus? Bandingkan ke kamus
tidak Kata=Tmpkata
Kata=hilangkan_sisipan (kata) Bandingkan ke kamus ya Apakah kata ada
dalam kamus? tidak Kata=Tmpkata Kata=cek_kata_ulang(kata) Kata=Tmpkata Kata=hilangkan_barung (kata) HasilKata=kata
Kata ada dalam kamus? ya
tidak ya
Apakah kata ada dalam kamus?
tidak
Bandingkan ke kamus
Kata=hilangkan_bareng (kata) Kata=Tmpkata
Apkah kata ada ya dalam kamus?
Selesai HasilKata=Tmpkata tidak
Gambar 5 Diagram proses stemming. 3.2.6.1 Modul/fungsi Hilangkan_Awalan()
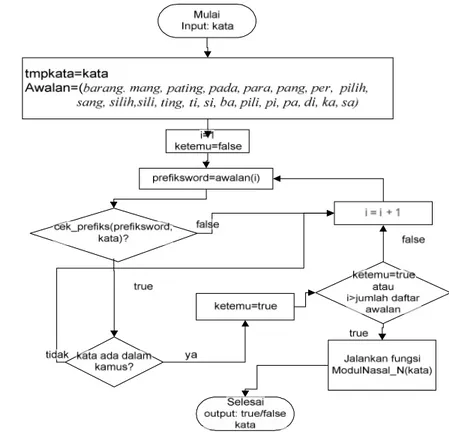
Modul/fungsi Hilangkan_Awalan() membutuhkan sebuah modul/fungsi lain yang berfungsi untuk menguji apakah suatu kata yang akan di-stem memiliki kata awalan: ba-, barang-, di-, ka-, N-, pa,- pada-, pang-, para-, per-, pi- sa-, sang-,
si-, silih/sili, ti-, ting-/pating-. Modul/fungsi pengujian ini diberi nama
Cek_Prefiks().
Fungsi Cek_Prefiks() ini akan mendapat masukan berupa kata awalan dan kata yang akan diuji. Keluarannya adalah berupa tipe data boolean true/benar atau
false/salah. Jika kata yang akan di-stem mengandung awalan yang disebut di atas,
maka fungsi Cek_Prefiks() akan bernilai true/benar dan keluaran lainnya adalah, variabel kata akan berisi kata yang sudah dihilangkan awalannya. Sebagai contoh diberikan kata barangbeuli (sesuatu untuk dibeli). Fungsi Cek_Prefiks() akan berbentuk Cek_Prefiks(“barang”,kata). Parameter pada fungsi Cek_prefiks() yaitu prefiksword akan berisi “barang” dan kata akan berisi “barangbeuli”. Selanjutnya fungsi Cek_Prefiks(“barang”, kata) akan menguji apakah awalan dari kata tersebut adalah “barang”, jika ya maka akan dihilangkan awalan tersebut sehingga sekarang variabel kata berisi “beuli”. Bentuk modul/fungsi Cek_Prefiks() ini seperti terlihat pada Gambar 6.
Fungsi Cek_Prefiks(prefiksword As String, kata As String) : Boolean n = Length(kata)
i = Length(prefiksword)
kt = Left(kata, i) //kt = Awalan dari kata
If (kt = prfiksword) Then //Dibandingkan antara kt dengan awalan
kata= Right(kata, n - i) //Jika benar kata=kata yang sdh
// dihilangkan akhirannya Cek_Prefiks = True Else Cek_Prefiks = False End If End Fungsi
Gambar 6 Fungsi Cek_Prefiks().
Algoritme dari modul/fungsi Hilangkan_ Awalan() ini dapat dilihat pada Gambar 7. Pada algoritme tersebut terlihat ada modul/fungsi yang berguna untuk menguji apakah kata mengandung nasal (N-), yaitu ModulNasal_N(). Algoritme untuk ModulNasal_N adalah sebagai berikut:
- Apakah kata mengandung prefiks “nga”, jika ya maka bandingkan dengan kamus jika tidak ketemu maka uji lagi apakah prefiks=”ng”. Bandingkan lagi dengan kamus, jika tidak ketemu maka beri tambahan di awal huruf “k” dan bandingkan lagi dengan kamus.
Gambar 7 Fungsi Hilangkan_Awalan().
- Jika tidak mengandung prefiks “nga”, uji lagi apakah mengandung prefiks “nge”, bandingkan lagi dengan kamus.
- Jika tidak mengandung “nge” uji apakah huruf awalnya adalah “m”, jika ya maka ganti huruf awal dengan huruf “b” atau “p” masing-masing penggantian huruf hasilnya dibandingkan dengan kamus.
- Jika tidak mengandung huruf awal “m”, maka uji lagi apakah dua huruf awal = “ny”, jika ya maka ganti huruf awal dengan huruf “c” atau “s” masing- masing penggantian huruf hasilnya dibandingkan dengan kamus.
- Jika tidak mengandung dua huruf “ny” maka uji apakah huruf awal = “n” jika ya ganti huruf awal dengan “t” dan bandingkan dengan kamus.
3.2.6.2 Modul/fungsi Hilangkan_Akhiran()
Sama seperti modul/fungsi Hilangkan_Awalan(), modul/fungsi Hilangkan_Akhiran() juga memerlukan fungsi pembantu lain untuk menguji apakah suatu kata mengandung akhiran. Akhiran yang akan diuji adalah: -an, -
eun, -keun, -na, -ing/-ning.
Modul/fungsi pengujian akhiran ini diberi nama Cek_Sufiks(). Modul ini menerima masukan berupa kata akhiran seperti yang disebut di atas dan kata yang akan dihilangkan akhirannya. Sebagai contoh akan diuji kata acukna (bajunya), yang mempunyai kata dasar acuk (baju) dan diberi akhiran -na. Fungsi Cek_Sufiks() akan berbentuk: Cek_Sufiks(“na”,”acukna”). Tugasnya membandingkan apakah ada akhiran -na pada kata “acukna”. Fungsi Cek_Sudiks akan menghasilkan true (benar) jika ada akhiran -na, serta menghilangkan akhiran -na pada kata acukna sehingga didapat kata dasar acuk. Bentuk algoritme Cek_Sufiks() ini adalah seperti terlihat pada Gambar 8.
Fungsi Cek_Sufiks(sufiksword As String, kata As String) : Boolean n = Length(kata)
i = Length(sufiksword)
kt = Right(kata, i) //kt = akhiran dari kata
If (kt = sufiksword)Then //Dibandingkan antara kt dengan akhiran kata= Left(kata, n - i) //Jika benar kata=kata yang sdh
// dihilangkanakhirannya Cek_Sufiks = True Else Cek_Sufiks = False End If End Fungsi
Gambar 8 Fungsi Cek_Sufiks().
Algoritme Hilangkan_Akhiran() akan menguji satu per satu apakah kata yang mempunyai akhiran seperti dalam daftar akhiran. Jika kata mempunyai akhiran maka akhiran pada kata tersebut akan dihilangkan. Algoritme Hilangkan_Akhiran() selengkapnya dapat dilihat pada Lampiran 2.
2) 3) 4) 5) 6) 7) 3.2.6.3 Modul/fungsi Hilangkan_Sisipan()
Pada modul/fungsi Hilangkan_Sisipan() ini terdapat aturan-aturan seperti yang dibahas pada Bab 2. Aturan-aturan tersebut diterapkan dalam algoritme seperti pembahasan di bawah ini:
1) Digunakan pada kata dasar yang diawali konsonan “l”, contoh: kata lieur menjadi lalieur (pusing-pusing), leuleus menjadi laleuleus (lemas-lemas). Algoritme untuk aturan tersebut terlihat pada Gambar 9.
If Cek_Prefiks("l", kata) Then //Jika huruf pertama adalah huruf //“l” maka
If Cek_Prefiks("al",kata) Then //diuji lagi apakah huruf //berikutnya=al
gab = "l" + kata //jika ya ganti al dengan huruf “l”
If ReadKamus(gab)Then //bandingkan dengan kamus kata = gab infiks = True Else kata = dummy infiks = False End If .... End if ... End If
Gambar 9 Bagian algoritme Hilangkan_Sisipan() untuk aturan kata yang diawali dengan huruf “l”.
Untuk lebih jelasnya diberi contoh sebagai berikut. Misalnya akan diuji untuk kata lalieur. Pengujian Cek_Prefiks("l", kata) akan memberikan hasil
true dan kata berubah menjadi “alieur”. Pengujian berikutnya yaitu
Cek_Prefiks("al", kata) maka akan memberikan nilai true juga dan kata akan menjadi “ieur”. Perintah gab = "l" + kata akan menambahkan huruf “l” pada kata “ieur” sehingga didapat kata “lieur” yang selanjutnya akan dibandingkan dengan kamus.
2) Digunakan pada kata dasar yang diakhiri konsonan “r” contoh: bageur menjadi balageur (banyak yang baik hati), pinter menjadi palinter (banyak yang pintar). Algoritme untuk aturan ini terlihat seperti pada Gambar 10.
4) 5)
If Cek_Sufiks("r", kata)Then //Apakah huruf terkahir adalah “r”
kata = dummy //kata dikembalikan ke bentuk semula
If InStr(kata, "al") Then //uji apakah kata mengandung “al” kata = Replace(kata, "al", "") //hilangkan “al” dalam kata
If ReadKamus(kata) Then //Bandingkan dengan kamus
infiks = True Else kata = dummy infiks = False End If End If ... End if
Gambar 10 Bagian algoritme Hilangkan_Sisipan() untuk aturan kata yang diawali dengan huruf “r”.
Pada modul ini terdapat sebuah variabel yang disebut dummy, yang fungsinya untuk mencatat kata sebelum diubah bentuknya. Variebel dummy ini berfungsi untuk mengembali kata menjadi bentuk semula jika diperlukan. Kata yang diberikan akan diuji apakah mempunyai huruf akhir “r” jika ya maka kata=dummy dan diuji lagi apakah kata mengandung suku kata “al”. Jika ya maka hilangkan suku kata “al” dan cari kata dalam kamus. Jika kata tidak ditemukan dalam kamus maka variabel infiks akan bernilai false dan variabel kata dikembalikan menjadi bentuk semula.
3) Digunakan pada kata dasar yang mengandung konsonan gabung br, tr, cr, kr,
pr, jr, dan dr, contoh: kempreng menjadi kalempreng (tangan-tangan yang
kaku), gombrang menjadi galombrang (pakaian yang kedodoran). Algoritme untuk aturan ini terlihat seperti pada Gambar 11.
If infiks_ar("tr br cr kr pr jr dr", kata) Then gab = Replace(kata, "al", "")
kata = gab infiks = True ....
End if
Gambar 11 Bagian algoritme Hilangkan_Sisipan() untuk aturan kata yang mengandung suku kata "tr”, “br”, “ cr”, “kr”, “ pr”, “ jr”, “dr”.
Kata yang diberikan, akan diuji apakah mengandung gabungan huruf "tr”, “br”, “ cr”, “kr”, “ pr”, “ jr”, “dr” Jika ya maka hilangkan suku kata “al” dari kata yang diberikan.
4) Rarangken tengah -ar- berubah menjadi ar- apabila digunakan pada kata dasar yang diawali huruf vokal, contoh: asup menjadi arasup (banyak yang masuk), ulin menjadi arulin (banyak yang main). Selain itu juga untuk mengatasi rarangken tengah “-ar-” yang berada di tengah seperti misalnya
barudak (anak-anak), diperlukan fungsi pembantu untuk menguji apakah
suatu kata mengandung suku kata “ar”. Fungsi tersebut memiliki bentuk seperti yang ditunjukkan pada Gambar 12.
Fungsi in_str_ar(kata) : Boolean ar1 = Left(kata, 2)
ar2 = Mid(kata, 2, 2)
If ar1 = "ar" Or ar2 = "ar" Then in_str_ar = True
Else
in_str_ar = False End If
End Fungsi
Gambar 12 Fungsi in_str_ar().
Sedangkan penggalan algoritme untuk mengatasi rarangken tengah “ar” ini adalah seperti yang terlihat pada Gambar 13.
If in_str_ar(kata) Then kata = dummy
kata = Replace(kata, "ar", "") If ReadKamus(kata) Then Hilangkan_Sisipan = True Else ... Endif .... End if
Gambar 13 Bagian algoritme Hilangkan_Sisipan() untuk aturan kata yang mengandung suku kata “ar”.
5) Rarangken tengah -ar- berubah menjadi ra- apabila digunakan pada kata dasar yang hanya terdiri dari satu suku kata dan diawali huruf konsonan contoh: cleng menjadi racleng (berloncatan), beng menjadi rabeng
(berterbangan). Algoritme untuk aturan tersebut terlihat seperti pada Gambar 14.
If Cek_Prefiks("ra", kata) Then kata = Replace(kata, "ra", "") If ReadKamus(kata) Then infiks = True Else infiks = False kata = dummy End If .... End if
Gambar 14 Bagian algoritme Hilangkan_Sisipan() untuk aturan kata yang mengandung suku kata “ra”.
6) Rarangken tengah -in-, contoh: tulis menjadi tinulis (tertulis/ditulis), panggih menjadi pinanggih (bertemu), sareng menjadi sinareng (bersama).
Rarangken tengah -in- ini juga memerika fungsi pembantu yang berfungsi
untuk menguji apakah sutu kata mengandung suku kata “in”. Fungsi tersebut memiliki bentuk seperti terlihat pada Gambar 15.
Fungsi infiks_in(kata As String) : Boolean
in1 = Mid(kata, 2, 2) //ambil huruf kedua kata sebanyak 2 //huruf
If in1 = "in" Then infiks_in = True Else
infiks_in = False End If
End Fungsi
Gambar 15 Fungsi infiks_in().
Penggalan algoritme untuk mencari apakah kata mengandung suku kata “in” adalah seperti terlihat pada Gambar 16.
If infiks_in(kata) Then
kata = Replace(kata, "in", "") If ReadKamus(kata) Then Hilangkan_Sisipan = True Else Hilangkan_Sisipan = False kata = dummy End If End if
Gambar 16 Bagian algoritme Hilangkan_Sisipan() untuk aturan kata yang mengandung suku kata “in”.
Rarangken tengah -um-, contoh: sujud menjadi sumujud (bersujud), gantung
menjadi gumantung (tergantung), lengis menjadi lumengis (memelas-melas) Pada
Rarangken tengah -um- terdapat alomorf um-, yang terjadi apabila digunakan
pada kata dasar yang diawali huruf vokal, contoh: amis menjadi umamis (macam- macam manis), aing menjadi umaing (egois). Untuk mengatasi rarangken tengah “-um-“ ini juga diperlukan fungsi pembantu yang bertugas untuk menguji apakah kata mengandung suku kata “um” baik di awal kata maupun di tengah kata. Bentuk dari fungsi tersebut seperti terlihat pada Gambar 17. Sedangkan penggalan algoritme untuk rarangken tengah “-um-” seperti yang ditunjukkan pada Gambar 18. Algoritme selengkapnya untuk modul/fungsi Hilangkan_Sisipan() dapat dilihat pada Lampiran 2.
Fungsi In_Str_Um(kata As String) As Boolean um1 = Left(kata, 2)
um2 = Mid(kata, 2, 2)
If um1 = "um" Or um2 = "um" Then In_Str_Um = True
Else
In_Str_Um = False End If
End Fungsi
Gambar 17 Fungsi in_str_um().
If In_Str_Um(kata) <> 0 Then kata = Replace(kata, "um", "") If ReadKamus(kata) Then Hilangkan_Sisipan = True Else Hilangkan_Sisipan = False kata = dummy End If Else ... Endif
Gambar 18 Bagian algoritme Hilangkan_Sisipan() untuk aturan kata yang mengandung suku kata “um”.
3.2.6.4 Modul/fungsi Hilangkan_Barung()
Pada modul/fungsi Hilangkan_Barung() ini juga harus memenuhi aturan- aturan seperti yang dibahas pada Bab 2. Misalnya untuk aturan yang berakhiran “eun”, ternyata akhiran “-eun” ini mempunyai banyak aturan pada awalannya, contohnya: Rarangken barung sa- -eun (contoh: satujueun = setuju, sahandapeun = lebih bawah, samobileun = untuk satu mobil), Rarangken barung pika- -eun (contoh: pikabungaheun = membuat gembira, pikasebeleun = menyebalkan, pikanyaaheun = membuat jadi sayang), Rarangken barung pi- -eun (contoh:
pibajueun = bahan baju, pigeuliseun = akan cantik, pigedeeun = akan besar)
Algoritme untuk rarangken barung yang memiliki pola seperti di atas, mula-mula akan diuji apakah akhiran dari kata yang diberikan adalah “eun”. Jika ya, maka selanjutnya diuji satu per satu apakah kata memiliki awalan pi-, pika- atau sa-. Sehingga algoritme dengan pola seperti ini adalah penggalan algoritme yang terlihat seperti pada Gambar 19. Algoritme selengkapnya untuk modul/fungsi Hilangkan_Barung() ini dapat dilihat pada Lampiran 2.
If (Cek_Sufiks("eun", kata)) Then
If Cek_Prefiks("pika", kata) Then 'jika barung = pika- -eun Hilangkan_Barung = True
Else
If Cek_Prefiks("pi", kata) Then 'jika barung = pi- -eun Hilangkan_Barung = True
Else
If Cek_Prefiks("sa", kata) Then 'jika barung = sa- -eun Hilangkan_Barung = True
Else
If Cek_Sufiks("an", kata) Then Hilangkan_Barung = True Else Hilangkan_Barung = False End If End If End If End If End if
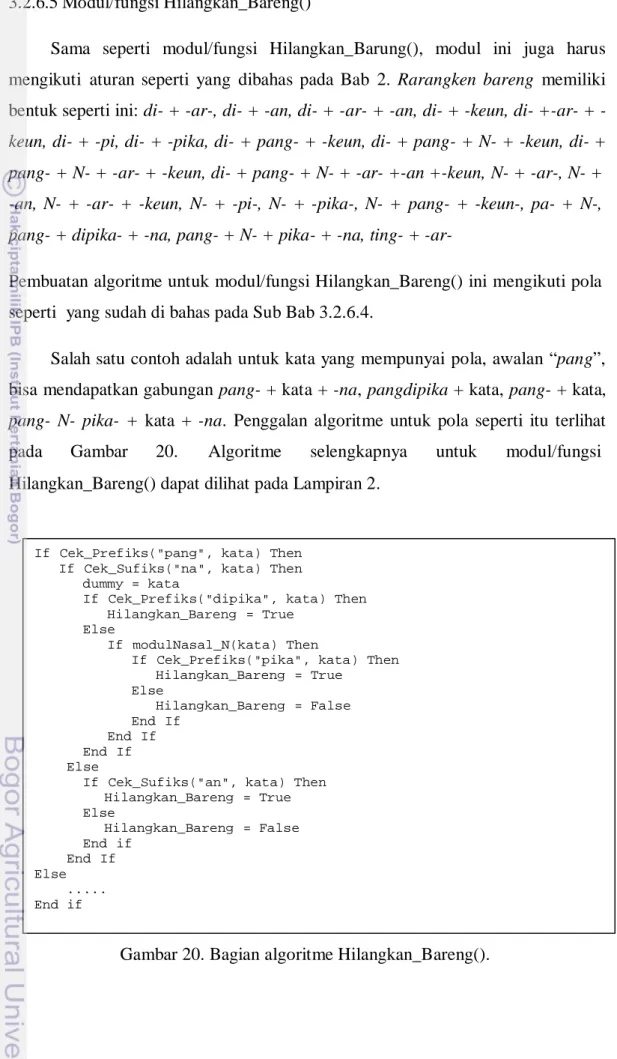
3.2.6.5 Modul/fungsi Hilangkan_Bareng()
Sama seperti modul/fungsi Hilangkan_Barung(), modul ini juga harus mengikuti aturan seperti yang dibahas pada Bab 2. Rarangken bareng memiliki bentuk seperti ini: di- + -ar-, di- + -an, di- + -ar- + -an, di- + -keun, di- +-ar- + -
keun, di- + -pi, di- + -pika, di- + pang- + -keun, di- + pang- + N- + -keun, di- + pang- + N- + -ar- + -keun, di- + pang- + N- + -ar- +-an +-keun, N- + -ar-, N- + -an, N- + -ar- + -keun, N- + -pi-, N- + -pika-, N- + pang- + -keun-, pa- + N-, pang- + dipika- + -na, pang- + N- + pika- + -na, ting- + -ar-
Pembuatan algoritme untuk modul/fungsi Hilangkan_Bareng() ini mengikuti pola seperti yang sudah di bahas pada Sub Bab 3.2.6.4.
Salah satu contoh adalah untuk kata yang mempunyai pola, awalan “pang”, bisa mendapatkan gabungan pang- + kata + -na, pangdipika + kata, pang- + kata,
pang- N- pika- + kata + -na. Penggalan algoritme untuk pola seperti itu terlihat
pada Gambar 20. Algoritme selengkapnya untuk modul/fungsi Hilangkan_Bareng() dapat dilihat pada Lampiran 2.
If Cek_Prefiks("pang", kata) Then If Cek_Sufiks("na", kata) Then
dummy = kata
If Cek_Prefiks("dipika", kata) Then Hilangkan_Bareng = True
Else
If modulNasal_N(kata) Then
If Cek_Prefiks("pika", kata) Then Hilangkan_Bareng = True Else Hilangkan_Bareng = False End If End If End If Else
If Cek_Sufiks("an", kata) Then Hilangkan_Bareng = True Else Hilangkan_Bareng = False End if End If Else ... End if
3.2.6.5 Modul/fungsi Cek_Kata_Ulang()
Pada modul/fungsi kata ulang, akan memisahkan dua hal, yaitu kata ulang yang berbentuk gembleng (seluruhnya) dan kata ulang yang berbentuk sabagian (sebagian). Kata ulang gembleng (seluruhnya) memiliki ciri setiap kata yang diulang dipisahkan dengan tanda “-“. Jika kata berbentuk gembleng (seluruhnya) maka kata yang diambil adalah kata terakhir setelah tanda “-“, setelah itu dicoba untuk menghilangkan imbuhan dari kata tersebut. Untuk kata ulang yang berbentuk sabagian (sebagian), kata ulang yang diberikan akan dihilangkan dahulu imbuhannya baru setelah itu dihilangkan unsur kata ulangnya. Bentuk dari algoritme untuk kata ulang ini dapat dilihat pada Lampiran 2.
3.2.7 Tahap Evaluasi Stemming
Pada proses evaluasi stemming ini akan coba dibandingkan antara daftar kata yang muncul dalam dokumen dan daftar kata yang sudah dilakukan proses
stemming. Pada tahap ini akan dilihat apakah kata yang ada dalam daftar kata
yang muncul dalam dokumen sudah terstemming seperti yang diharapkan. Proses evaluasi dilakukan dengan mengamati secara manual.
3.2.8 Tahap Penulisan Tesis
Setelah semua tahapan di atas selesai dilakukan, tahapan berikutnya adalah penulisan dokumen tesis. Penulisan dokumen tesis ini ditulis berdasarkan hasil yang sudah diuji coba dan penulisannya mengikuti standar yang sudah diberikan oleh Institut Pertanian Bogor.
3.2.9 Tahap Pembuatan Kesimpulan
Tahapan terakhir adalah tahapan pembuatan kesimpulan. Tahapan ini akan coba disimpulkan bagaimana hasil dari penelitian ini. Dari penelitian ini juga akan ditulis saran-saran untuk penelitian ke depan.