`
Implementasi Algoritma Naïve Bayes
dalam Proses Analisis Efisiensi Jasa Servis
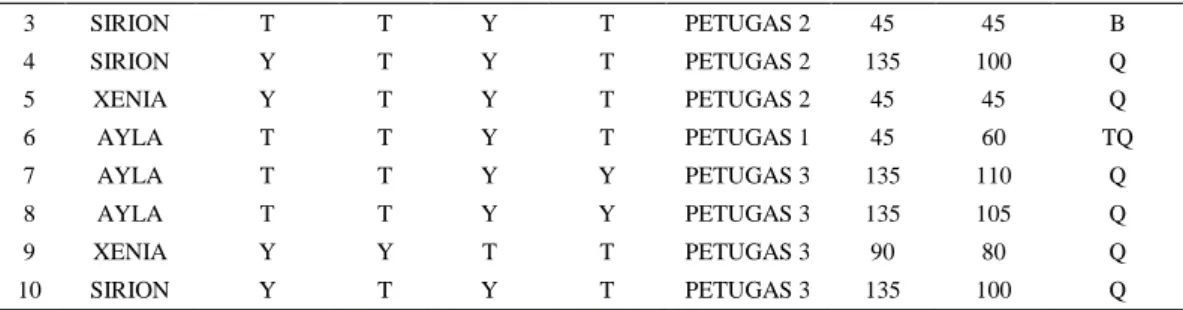
Bengkel Daihatsu Cabang Salatiga
Artikel Ilmiah
Peneliti:
Taufiq Jatmikanto (672009269) Magdalena A. Ineke Pakereng, M.Kom.
Program Studi Teknik Informatika
Fakultas Teknologi Informasi
Universitas Kristen Satya Wacana
Salatiga
Agustus 2016
`1 1. Pendahuluan
Pengetahuan tentang pelanggan merupakan aset yang kritikal. Usaha untuk mengumpulkan, mengelola dan membagi pengetahuan tentang pelanggan dapat menjadi kegiatan yang penting bagi suatu usaha kecil menengah [1]. Semakin ketatnya persaingan dalam dunia bisnis saat ini menuntut pengusaha untuk cepat dan tanggap dalam mengambil keputusan agar perusahaan yang didirikan dapat tetap bertahan di tengah situasi dan keadaan yang demikian. Salah satu langkah yang dapat dilakukan adalah dengan memberikan kepuasan kepada pelanggan secara maksimal, karena pada dasarnya tujuan dari suatu bisnis adalah menciptakan rasa puas pada pelanggan. Salah satu tindakan untuk memuaskan konsumen adalah bagaimana dan seberapa tinggi kualitas pelayanan yang diberikan terhadap konsumen [2].
Salah satu solusi yang dapat dilakukan oleh perusahaan untuk menjaga agar kinerja usahanya selalu berada dalam posisi baik adalah dengan menganalisis dan mengetahui faktor-faktor yang dapat menjaga kinerja usaha itu sendiri berada dalam posisi baik. Analisis dapat dilakukan dengan mengumpulkan data layanan yang bersifat historis dan kemudian menggali informasi yang dapat digunakan dari kumpulan data tersebut. Di dalam data tersebut dapat terlihat banyak komponen yang terkait dengan pelayanan terhadap pelanggan di antaranya hubungan antara jenis layanan, petugas/teknisi yang menangani, dan durasi waktu penyelesaian masalah.
Data mining dapat memberikan informasi yaitu petugas tertentu cocok
untuk menyelesaikan jenis masalah tertentu. Melalui informasi ini, maka ketika terdapat permintaan layanan yang masuk, maka sistem dapat memberikan rekomendasi petugas yang paling cocok untuk menyelesaikan jenis pekerjaan itu. Pada penelitian ini dirancang aplikasi data mining dengan algoritma Naïve Bayes, yang berfungsi untuk menganalisis efisiensi jasa servis pada bengkel Daihatsu cabang Salatiga.
Berdasarkan permasalahan dalam hal pencapaian efisiensi jasa servis, dan kegunaan data mining dalam hal penggalian informasi, maka diajukan penelitian
data mining untuk analisis efisiensi kinerja pelayanan keluhan pada bengkel
Daihatsu cabang Salatiga. 2. Tinjauan Pustaka
Ridwan, Suyono dan Sarosa [3] menerapkan data mining dengan algoritma Naïve Bayes untuk mengevaluasi kinerja akademik mahasiswa. Penelitian tersebut difokuskan untuk mengevaluasi kinerja akademik mahasiswa pada tahun ke-2 dan diklasifikasikan dalam kategori mahasiswa yang dapat lulus tepat waktu atau tidak. Kemudian dari klasifikasi tersebut, sistem akan memberikan rekomendasi solusi untuk memandu mahasiswa lulus dalam waktu yang paling tepat dengan nilai optimal berdasarkan histori nilai yang telah ditempuh mahasiswa. Input dari sistem ini adalah data induk mahasiswa dan data akademik mahasiswa. Sampel mahasiswa angkatan 2005-2009 yang sudah dinyatakan lulus akan digunakan sebagai data training dan testing. Sedangkan
`2
data mahasiswa angkatan 2010-2011 dan belum lulus akan digunakan sebagai data target. Data input akan diproses menggunakan teknik data mining algoritma
Naïve Bayes Classifier (NBC) untuk membentuk tabel probabilitas sebagai dasar
proses klasifikasi kelulusan mahasiswa. Output dari sistem ini berupa klasifikasi kinerja akademik mahasiswa yang diprediksi kelulusannya dan memberikan rekomendasi untuk proses kelulusan tepat waktu atau lulus dalam waktu yang paling tepat dengan nilai optimal. Hasil pengujian menunjukkan bahwa faktor yang paling berpengaruh dalam penentuan klasifikasi kinerja akademik mahasiswa yaitu Indeks Prestasi Komulatif (IPK), Indeks Prestasi (IP) semester 1, IP semester 4, dan jenis kelamin.
Pada penelitian Via, Nugroho dan Syafrizal [4], digunakan algoritma
Naïve Bayes untuk membangun sistem pendukung keputusan klasifikasi tingkat
keganasan kanker payudara. Kanker payudara merupakan salah satu jenis kanker yang sering ditemukan pada kebanyakan wanita. Kanker ini ditandai dengan sel-sel abnormal yang tumbuh di luar kendali pada payudara. Hal ini menunjukkan bahwa kanker payudara adalah penyakit yang sangat ganas dan karenanya memerlukan pemeriksaan intensif dengan mendeteksi dini tingkat keganasan kanker payudara. Penelitian tersebut menganalisis tentang pengelompokan data kanker payudara untuk mengetahui kanker tersebut termasuk kanker jinak atau kanker ganas. Penelitian tersebut menggunakan 9 atribut sebagai masukan sistem dan data set yang digunakan adalah data set publik Breast Cancer Wisconsin
Original (WBCO) yang diambil dari UCI Machine Learning. Untuk
mengklasifikasi tingkat keganasan dapat dilakukan dengan pemanfaatan
bioinformatic dengan menggunakan teknik data mining salah satunya adalah
algoritma Naïve Bayes Classifier (NBC). Berdasarkan hasil pengujian dengan
confusion matrix diketahui bahwa NBC yang diterapkan untuk melakukan
klasifikasi tingkat keganasan kanker payudara memiliki akurasi pola yang cukup besar yaitu 97,82%, sedangkan error rate yang dihasilkan sebesar 2,18%. Hasil penelitian tersebut menunjukan bahwa dengan error rate yang cukup kecil maka algoritma Naïve Bayes Classifier terbukti cukup bagus untuk melakukan klasifikasi pada data WBCO.
Berdasarkan penelitian-penelitian yang telah dilakukan tentang data
mining terutama Naïve Bayes dalam membentuk sistem pendukung keputusan,
maka dilakukan penelitian ini. Penelitian ini menggunakan algoritma Naïve Bayes untuk menganalisis efisiensi jasa servis pada bengkel Daihatsu cabang Salatiga. Tujuan dari penelitian yang dilakukan adalah untuk merancang data mining untuk proses analisis efisiensi dalam jasa servis pada bengkel Daihatsu cabang Salatiga. Manfaat dari penelitian ini adalah untuk menghasilkan sebuah sistem rekomendasi penanganan jasa servis pada bengkel Daihatsu cabang Salatiga. Batasan masalah dalam penelitian ini adalah sebagai berikut: (1) Data yang dianalisis adalah data jenis-jenis jasa servis, pengerjaan servis oleh petugas, dan data petugas yang menangani pekerjaan tersebut; (2) Algoritma data mining yang digunakan adalah
Naïve Bayes; (3) Analisis dilakukan terhadap efisiensi waktu kerja, dan tidak pada
kualitas kerja.
Algoritma Naïve Bayes adalah klasifikasi statistik. Algoritma Naïve Bayes dapat memprediksi kelas anggota probabilitas. Klasifikasi Naïve Bayes
`3
dikembangkan berdasarkan teorema Bayes. Studi perbandingan algoritma-algoritma klasifikasi dapat menemukan sebuah klasifikasi Bayes sederhana yang dikenal sebagai “Naïve Bayes”. Algoritma Naïve Bayes berasumsi bahwa efek suatu nilai variabel di sebuah kelas yang ditentukan adalah tidak terkait pada nilai-nilai variabel lain. Asumsi ini disebut kelas kondisi bebas/tidak terikat. Itu dibuat untuk menyederhanakan perhitungan dan dalam hal ini dianggap sebagai “Naïve”. Algoritma Naïve Bayes memungkinkan secara cepat membuat model yang mempunyai kemampuan untuk prediksi dan juga menyediakan sebuah method baru dalam mengeksplorasi dan mengerti data. Bayes menyediakan metode yang digunakan untuk pembelajaran berdasarkan bukti (evidence) yang ada. Algoritmanya mempelajari bukti yang ada dengan menghitung korelasi di antara variabel yang diinginkan dan semua variabel yang lain.
Untuk mulai menggunakan Naïve Bayes, perlu diketahui sebuah aturan dasar dalam algoritma ini. Rumus aturan Naïve Bayes ditunjukkan pada Rumus 1 dan Rumus 2.
P(a | b) = ( P(b | a) P(a) ) / P(b) (1)
Posterior = (Likehood * Prior) / Evidence (2)
Dimana, a adalah hal yang menyebabkan suatu hal terjadi (cause) dan b adalah akibatnya (effect), mengacu pada Rumus 1. P(a|b) sering disebut juga dengan istilah likehood dari b terhadap a, dari sini didapatkan probabilitas
posterior P(a|b), mengacu pada Rumus 2, dimana P(a|b) menyatakan probabilitas
munculnya a jika diketahui b.
Untuk menjelaskan teorema Naïve Bayes, perlu diketahui bahwa proses klasifikasi memerlukan sejumlah petunjuk untuk menentukan kelas apa yang sesuai bagi sampel yang dianalisis tersebut. Karena itu, teorema bayes tersebut disesuaikan sebagai berikut [5]:
C: Kelas. Dalam kasus penelitian ini berarti TQ, B, dan Q.
F1-FN: karakteristik. Dalam penelitian ini berarti jenis-jenis
pekerjaan, seperti tune up, service KM, dll.
P: Peluang/Posterior. Angka yang menunjukkan kemungkinan keberhasilan. Disajikan dalam persen.
(3)
Variabel C merepresentasikan kelas, sementara variabel F1...Fn merepresentasikan karakteristik petunjuk yang dibutuhkan untuk melakukan klasifikasi. Maka rumus tersebut menjelaskan bahwa peluang masuknya sampel karakteristik tertentu dalam kelas C (Posterior) adalah peluang munculnya kelas C (sebelum masuknya sampel tersebut, seringkali disebut prior), dikali dengan peluang kemunculan karakteristik karakteristik sampel pada kelas C (disebut juga
likelihood), dibagi dengan peluang kemunculan karakteristik-karakteristik sampel
secara global (disebut juga evidence). Karena itu, Rumus 3 dapat pula ditulis secara sederhana sebagai berikut [5]:
`4
Nilai Evidence selalu tetap untuk setiap kelas pada satu sampel. Nilai dari
posterior tersebut nantinya akan dibandingkan dengan nilai-nilai posterior kelas
lainnya untuk menentukan ke kelas apa suatu sampel akan diklasifikasikan. Penjabaran lebih lanjut rumus Naïve Bayes tersebut dilakukan dengan menjabarkan menggunakan aturan perkalian sebagai berikut [5]:
(5)
3. Metode dan Perancangan Sistem
Penelitian yang dilakukan, diselesaikan melalui tahapan penelitian yang terbagi dalam lima tahapan, yaitu: (1) Identifikasi masalah dan studi literatur, (2) Perancangan sistem, (3) Implementasi sistem, (4) Pengujian sistem dan analisis hasil pengujian, (5) Penulisan laporan.
Identifikasi Masalah dan Studi Literatur Perancangan Sistem
Implementasi Sistem
Pengujian Sistem dan Analisis Hasil Pengujian Penulisan Laporan
Gambar 1 Tahapan Penelitian
Tahapan penelitian pada Gambar 1, dapat dijelaskan sebagai berikut.
Tahap pertama yaitu melakukan identifikasi masalah yang terjadi pada Bengkel
Daihatsu cabang Salatiga. Masalah yang ditemukan dari hasil identifikasi yaitu layanan pada Bengkel Daihatsu dapat ditingkatkan, dengan memanfaatkan data riwayat pelayanan servis kendaraan. Berdasarkan studi literatur, diketahui bahwa dengan mengolah data riwayat pelayanan dengan algoritma data mining, dapat diperoleh informasi yang tersembunyi di dalamnya, dan dapat menjadi pendukung pengambilan keputusan. Tahap kedua yaitu melakukan perancangan sistem yang meliputi perancangan database dan perancangan antarmuka. Database yang dirancang berfungsi untuk menyimpan informasi data riwayat pelayanan. Struktur tabel ditunjukkan pada Tabel 1, dirancang berdasarkan data yang ada pada Bengkel Daihatsu cabang Salatiga. Antarmuka sistem dirancang untuk menghubungkan antara database dan hasil dari proses analisis Naïve Bayes, dengan pengguna sistem. Database berfungsi untuk menyimpan data saja. Proses analisis dirancang untuk berada di dalam program, bukan berada di database.
`5
Tahap ketiga yaitu mengimplementasikan rancangan yang telah dibuat di tahap
dua ke dalam sebuah aplikasi/program sesuai kebutuhan sistem. Aplikasi yang dikembangkan pada penelitian ini berbentuk aplikasi desktop untuk dijalankan pada sistem operasi Microsoft Windows, seperti yang digunakan oleh komputer-komputer yang ada di Bengkel Daihatsu cabang Salatiga. Tahap keempat yaitu melakukan pengujian terhadap sistem yang telah dibuat. Hasil pengujian dianalisis untuk dilihat apakah aplikasi yang telah dibuat sudah sesuai dengan yang diharapkan atau tidak, jika belum sesuai maka akan dilakukan perbaikan. Tahap
kelima yaitu melakukan penulisan laporan penelitian. Laporan penelitian
diharapkan dapat menjadi acuan bagi penelitian selanjutnya, terutama di bidang
data mining.
Gambar 2 Prototype Model [6]
Metode perancangan sistem dilakukan dengan menggunakan metodologi pengembangan perangkat lunak prototype model [6], ditunjukkan dengan diagram pada Gambar 2. Pada proses implementasi dihasilkan beberapa prototype yang dapat dijelaskan sebagai berikut. Tahap pertama: mendengarkan atau wawancara
customer atau user. Pada tahap ini diperoleh data pencatatan log kerja beserta
struktur data tersebut. Selain itu, diketahui kebutuhan user yaitu sebuah sistem yang dapat memberikan rekomendasi pemilihan teknisi dalam mengerjakan tugas
service kendaraan; Tahap kedua; merancang program kemudian membuat
perbaikan terhadap hasil yang diperoleh. Tahap ini menghasilkan sebuah
prototype, yang dibuat sesuai hasil wawancara pada tahap pertama; Tahap ketiga:
melakukan evaluasi prototype ke customer atau user. Evaluasi menghasilkan perbaikan-perbaikan atau tambahan-tambahan pada prototype yang diujikan kepada customer/user. Pada tahap ini proses akan kembali lagi ke tahap pertama.
Pada proses pengembangan dengan metode prototype, dihasilkan tiga prototype. Tiap prototype dihasilkan pada akhir siklus. Siklus pertama
`6
menghasilkan prototype yang berfungsi untuk mengolah data log kerja. Siklus kedua merupakan hasil pengembangan dari revisi prototype pertama. Protoype kedua berfungsi untuk mengolah log kerja, dan mengelompokkan waktu kerja ke dalam kategori Tidak Qualifed (TQ), Baik (B), dan Qualifed (Q). Siklus ketiga, menghasilkan prototype tiga yang memiliki fungsi tambahan yaitu analisis dengan naïve bayes.
Database Log Kerja
Log Kerja Data Uji
Analisis dengan Naive Bayes Rekomendasi Mulai Selesai
Gambar 3 Proses Rekam Data dan Analisis dengan Naïve Bayes.
Proses analisis dilakukan terhadap catatan kerja yang dilakukan oleh teknisi di bengkel Daihatsu cabang Salatiga. Catatan kerja (log) ini memiliki struktur yang ditunjukkan pada Tabel 1.
Tabel 1 Kriteria Data yang Digunakan
No Kolom Keterangan
1 Jenis Kendaraan Jenis Kendaran yang ditangani. Contoh: Alya, Luxio, Grand Max, Xenia
2 Ganti Oli Ganti oli mesin 3 Overhaul Bongkar mesin
4 Tune Up Perbaikan performa kendaraan 5 Service KM 5000 Service berjangka 5000 kilometer
6 Service KM
10000
Service berjangka 10000 kilomeer
7 Service > 10000
KM
Service untuk kilometer tempuh lebih dari 10000
Langkah perhitungan dengan Naïve Bayes dijelaskan dengan langkah-langkah berikut. Untuk dapat menghasilkan sebuah rekomendasi, maka diperlukan suatu data training set.
Tabel 2 Contoh Data Training Set No JENIS KENDA RAAN TUNE UP OVE RHA UL GANTI OLI SERVI CE KM 5000 PETUGAS Waktu Target Waktu Kerja Kualifika si Kerja 1 XENIA Y Y T Y PETUGAS 1 300 230 Q 2 XENIA Y Y T Y PETUGAS 2 300 280 Q
`7 3 SIRION T T Y T PETUGAS 2 45 45 B 4 SIRION Y T Y T PETUGAS 2 135 100 Q 5 XENIA Y T Y T PETUGAS 2 45 45 Q 6 AYLA T T Y T PETUGAS 1 45 60 TQ 7 AYLA T T Y Y PETUGAS 3 135 110 Q 8 AYLA T T Y Y PETUGAS 3 135 105 Q 9 XENIA Y Y T T PETUGAS 3 90 80 Q 10 SIRION Y T Y T PETUGAS 3 135 100 Q
Target kerja untuk Tune Up adalah 90 menit, Overhaul 120 menit, Ganti Oli 45 menit, dan Service KM 5000 adalah 90 menit. Pada Tabel 1, nomor 1, waktu target 300 menit diperoleh dari waktu Tune Up ditambah waktu Overhaul ditambah waktu Service KM 5000, yaitu 90+120+90 = 300 menit. Pekerjaan yang dilakukan kurang dari target waktu, maka dianggap Qualified (Q), lebih dari waktu target dianggap Tidak Qualified (TQ), dan jika tepat waktu maka dianggap Baik (B). Jika ada SATU pekerjaan untuk JENIS KENDARAAN XENIA, dengan layanan yang harus dikerjakan adalah Tune Up dan Overhaul, maka petugas yang dapat mengerjakan paling cepat dapat direkomendasikan dengan langkah berikut.
Tabel 3 Contoh Kasus
JENIS KENDARAAN
TUNE UP OVERHAUL GANTI OLI SERVICE
KM 5000 PETUGAS Kualifikasi Kerja XENIA Y Y T T PETUGAS 1 ? XENIA Y Y T T PETUGAS 2 ? XENIA Y Y T T PETUGAS 3 ?
Data training pada Tabel 3, menunjukkan bahwa ada 3 petugas: PETUGAS 1, PETUGAS 2, PETUGAS 3. Naïve Bayes akan digunakan untuk menghitung persentase waktu penyelesaian pekerjaan untuk tiap petugas. Rekomendasi diberikan untuk petugas yang memiliki persentase terbesar untuk waktu kerja yang paling kecil.
Langkah 1: variabel WAKTU (TQ, B, Q) P(TQ) = 1 / 10
P(B) = 1 / 10 P(Q) = 8 / 10
Langkah 2: variabel WAKTU dipasangkan dengan variabel-variabel yang lain JENIS KENDARAAN
Karena pekerjaan yang dicari ada di JENIS KENDARAAN XENIA, maka dihitung khusus yang JENIS KENDARAAN = XENIA
P(XENIA | TQ) = 0 / 1 P(XENIA | B) = 0 / 1 P(XENIA | Q) = 4 / 8 TUNE UP
Cari khusus yang TUNE UP=Y P(Y| TQ) = 0 / 1
P(Y| B) = 0 / 1 P(Y| Q) = 6 / 8
`8 OVERHAUL
Cari khusus yang OVERHAUL=Y P(Y | TQ) = 0 / 1
P(Y | B) = 0 / 1 P(Y | Q) = 3 /8 GANTI OLI
Cari khusus yang GANTI OLI= T P(T | TQ) = 0 / 1
P(T | B) = 0 / 1 P(T | Q) = 3 / 8 SERVICE KM 5000
Cari khusus yang SERVICE KM 5000=T P(T | TQ) = 1 / 1
P(T | B) = 1 / 1 P(T | Q) = 4 / 8 PETUGAS
Untuk menghitung petugas, dilakukan ke semua petugas yang ada. P(PETUGAS 1 | TQ) = 1 / 1 P(PETUGAS 1 | B) = 0 / 1 P(PETUGAS 1 | Q) = 1 / 1 P(PETUGAS 2 | TQ) = 0 / 1 P(PETUGAS 2 | B) = 1 / 1 P(PETUGAS 2 | Q) = 3 / 8 P(PETUGAS 3 | TQ) = 0 / 1 P(PETUGAS 3 | B) = 0 / 1 P(PETUGAS 3 | Q) = 4 / 8 Langkah 3: HITUNG KEMUNGKINAN
PETUGAS 1
Kemungkinan untuk PETUGAS 1 dalam waktu TQ:
=P(PETUGAS 1 | TQ) x P(SERVICE KM 5000=T | TQ) x P(GANTI OLI=T | TQ) x P(OVERHAUL=Y | TQ) x P(TUNE UP= TAMBAH | TQ) x P(JENIS KENDARAAN=XENIA | TQ) x P(TQ)
`9
Kemungkinan untuk PETUGAS 1 dalam waktu B:
= P(PETUGAS 1 | B) x P(SERVICE KM 5000=T | B) x P(GANTI OLI=T | B) x P(OVERHAUL=Y | B) x P(TUNE UP= TAMBAH | B) x P(JENIS KENDARAAN=XENIA | B) x P(B)
=0/1 x 1/1 x 0/1 x 0/1 x 0/1 x 0/1 x 1/10 = 0
Kemungkinan untuk PETUGAS 1 dalam waktu Q:
= P(PETUGAS 1 | Q) x P(SERVICE KM 5000=T | Q) x P(GANTI OLI=T | Q) x P(OVERHAUL=Y | Q) x P(TUNE UP= TAMBAH | Q) x P(JENIS KENDARAAN=XENIA | Q) x P(Q)
=1 / 1 x 4 / 8 x 3 / 8 x 3 /8 x 3 / 8 x 4 / 8 x 8 / 10 = 0.010546
PETUGAS 2
Kemungkinan untuk PETUGAS 2 dalam waktu TQ:
= P(PETUGAS 2 | TQ) x P(SERVICE KM 5000=T | TQ) x P(GANTI OLI=T | TQ) x P(OVERHAUL=Y | TQ) x P(TUNE UP= TAMBAH | TQ) x P(JENIS KENDARAAN=XENIA | TQ) x P(TQ)
=0 / 1 x 1/1 x 0/1 x 0/1 x 0/1 x 0/1 x 1/10 = 0
Kemungkinan untuk PETUGAS 2 dalam waktu B:
= P(PETUGAS 2 | B) x P(SERVICE KM 5000=T | B) x P(GANTI OLI=T | B) x P(OVERHAUL=Y | B) x P(TUNE UP= TAMBAH | B) x P(JENIS KENDARAAN=XENIA | B) x P(B)
=1 / 1 x 1/1 x 0/1 x 0/1 x 0/1 x 0/1 x 1/10 = 0
Kemungkinan untuk PETUGAS 2 dalam waktu Q:
= P(PETUGAS 2 | Q) x P(SERVICE KM 5000=T | Q) x P(GANTI OLI=T | Q) x P(OVERHAUL=Y | Q) x P(TUNE UP= TAMBAH | Q) x P(JENIS KENDARAAN=XENIA | Q) x P(Q)
=3 / 8 x 4 / 8 x 3 / 8 x 3 /8 x 3 / 8 x 4 / 8 x 8 / 10 = 0.00791
PETUGAS 3
Kemungkinan untuk PETUGAS 3 dalam waktu TQ:
= P(PETUGAS 3 | TQ) x P(SERVICE KM 5000=T | TQ) x P(GANTI OLI=T | TQ) x P(OVERHAUL=Y | TQ) x P(TUNE UP= TAMBAH | TQ) x P(JENIS KENDARAAN=XENIA | TQ) x P(TQ)
=0 / 1 x 1/1 x 0/1 x 0/1 x 0/1 x 0/1 x 1/10 = 0
Kemungkinan untuk PETUGAS 3 dalam waktu B:
= P(PETUGAS 3 | B) x P(SERVICE KM 5000=T | B) x P(GANTI OLI=T | B) x P(OVERHAUL=Y | B) x P(TUNE UP= TAMBAH | B) x P(JENIS KENDARAAN=XENIA | B) x P(B)
`10
Kemungkinan untuk PETUGAS 3 dalam waktu Q:
= P(PETUGAS 3 | Q) x P(SERVICE KM 5000=T | Q) x P(GANTI OLI=T | Q) x P(OVERHAUL=Y | Q) x P(TUNE UP= TAMBAH | Q) x P(JENIS KENDARAAN=XENIA | Q) x P(Q)
=4 / 8 x 4 / 8 x 3 / 8 x 3 /8 x 6 / 8 x 4 / 8 x 8 / 10 = 0.105468
Tabel 4 Kesimpulan Akhir
Petugas Waktu Nilai Kemungkinan Persentase (kalikan 100%)
PETUGAS 1 TQ 0 (tidak terpakai)
PETUGAS 1 B 0 (tidak terpakai)
PETUGAS 1 Q 0.010546 1.05%
PETUGAS 2 TQ 0 (tidak terpakai)
PETUGAS 2 B 0 (tidak terpakai)
PETUGAS 2 Q 0.00791 0.79 %
PETUGAS 3 TQ 0 (tidak terpakai)
PETUGAS 3 B 0 (tidak terpakai)
PETUGAS 3 Q 0.105468 10.54% (tertinggi dari semua)
PETUGAS 1, PETUGAS 2, dan PETUGAS 3 sama-sama masuk kategori
Qualified (Q), tapi dari 3 orang tersebut, persentasi tertinggi adalah PETUGAS 3
(5%). Jadi yang dipilih untuk tugas tersebut adalah PETUGAS 3 karena memiliki nilai kemungkinan terbesar untuk menyelesaikan waktu lebih dari waktu target. 4. Hasil dan Pembahasan
Aplikasi yang dirancang pada penelitian ini dikembangkan dalam bentuk aplikasi desktop. Aplikasi ini terhubung dengan database server (SQL Server Express 2008).
`11
Gambar 4 Form Log Kerja
Pada form log kerja (Gambar 4), dicatat setiap tugas yang dilaksanakan oleh teknisi Bengkel Daihatsu cabang Salatiga. Tiap detail pekerjaan, telah ditentukan waktu target sebelumnya. Berdasarkan waktu ini, dapat diketahui apakah seorang petugas masuk kualifikasi TQ (Tidak Qualified), B (Baik), atau Q (Qualified). Pekerjaan yang dilakukan kurang dari target waktu, maka dianggap
Qualified (Q), lebih dari waktu target dianggap Tidak Qualified (TQ), dan jika
tepat waktu maka dianggap Baik (B).
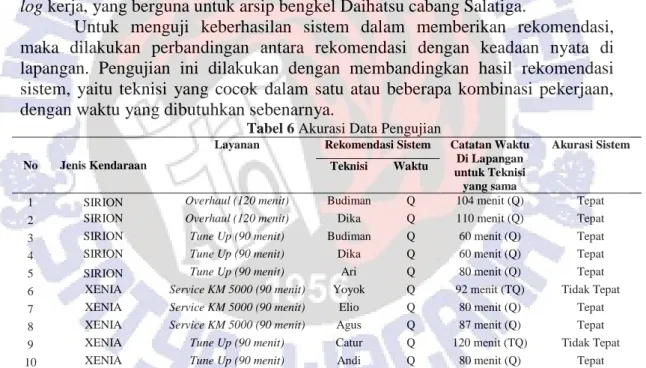
Gambar 5 Form Hasil Rekomendasi dengan Naïve Bayes
Analisis dan rekomendasi dengan algoritma Naïve Bayes memberikan hasil seperti ditunjukkan pada Gambar 5. Proses analisis bertujuan untuk memberikan rekomendasi petugas yang memiliki persentase terbesar dalam hal menyelesaikan pekerjaan. Pada Gambar 5, diberikan contoh hasil rekomendasi sistem. Kasus yang digunakan (uji data) adalah jenis kendaraan Xenia, dengan layanan yang diminta oleh pelanggan adalah Tune Up. Hasil rekomendasi sistem yaitu urutan teknisi/petugas berdasarkan persentase keberhasilannya dalam menyelesaikan pekerjaan tersebut dalam kategori waktu tertentu. Sebagai contoh, petugas “BUDIMAN” memiliki kemungkinan 0.38 persen untuk menyelesaikan tugas tersebut dalam kategori waktu “Q” (Qualified), yang berarti lebih cepat dari pada waktu yang ditargetkan. Petugas “DIKA” juga memiliki angka persentase yang sama, sedangkan “ARI” memiliki persentase tepat dibawahnya.
Pengujian beta berfungsi untuk mengetahui apakah sistem dapat diterima oleh pengguna sistem. Pengujian Beta merupakan pengujian yang dilakukan secara objektif dimana diuji secara langsung ke lapangan yaitu yang bersangkutan dengan membuat kuesioner mengenai kepuasan user, untuk selanjutnya dibagikan kepada sebagian user dengan mengambil sampel sebanyak 5 orang. Jawaban dikelompokkan pada 5 tingkatan, yaitu Sangat Setuju (SS), Setuju (S), Cukup (C), Tidak Setuju (TS), Sangat Tidak Setuju (STS). Responden berjumlah 5 orang yang terdiri dari kepala cabang, wakil kepala cabang, dan beberapa kepala bengkel/teknisi. Responden
`12
tersebut dipilih karena memiliki peran dalam pengambilan keputusan layanan servis kendaraan.
Tabel 5 Hasil Pengujian Beta
No Pertanyaan Jawaban
SS S C TS STS
1
Sistem memudahkan menganalisis efisiensi dalam penanganan service kendaraan
5
2 Sistem mudah untuk digunakan. 3 2 3 Sistem memberikan informasi yang
jelas dan bermanfaat 5
4
Sistem memberikan rekomendasi yang dapat berguna bagi kemajuan layanan di bengkel Daihatsu cabang Salatiga
3 2
Berdasarkan hasil pengujian beta, disimpulkan bahwa sistem dapat membantu pihak manajerial bengkel Daihatsu cabang Salatiga, dalam memberikan rekomendasi pemilihan petugas. Sistem mempermudah pencatatan
log kerja, yang berguna untuk arsip bengkel Daihatsu cabang Salatiga.
Untuk menguji keberhasilan sistem dalam memberikan rekomendasi, maka dilakukan perbandingan antara rekomendasi dengan keadaan nyata di lapangan. Pengujian ini dilakukan dengan membandingkan hasil rekomendasi sistem, yaitu teknisi yang cocok dalam satu atau beberapa kombinasi pekerjaan, dengan waktu yang dibutuhkan sebenarnya.
Tabel 6 Akurasi Data Pengujian No Jenis Kendaraan
Layanan Rekomendasi Sistem Catatan Waktu Di Lapangan untuk Teknisi
yang sama
Akurasi Sistem Teknisi Waktu
1 SIRION Overhaul (120 menit) Budiman Q 104 menit (Q) Tepat 2 SIRION Overhaul (120 menit) Dika Q 110 menit (Q) Tepat 3 SIRION Tune Up (90 menit) Budiman Q 60 menit (Q) Tepat 4 SIRION Tune Up (90 menit) Dika Q 60 menit (Q) Tepat 5 SIRION Tune Up (90 menit) Ari Q 80 menit (Q) Tepat 6 XENIA Service KM 5000 (90 menit) Yoyok Q 92 menit (TQ) Tidak Tepat 7 XENIA Service KM 5000 (90 menit) Elio Q 80 menit (Q) Tepat 8 XENIA Service KM 5000 (90 menit) Agus Q 87 menit (Q) Tepat 9 XENIA Tune Up (90 menit) Catur Q 120 menit (TQ) Tidak Tepat 10 XENIA Tune Up (90 menit) Andi Q 80 menit (Q) Tepat
Kategori waktu “Q” berarti penyelesaian pekerjaan lebih cepat dari target waktu yang disarankan, dan “TQ” berarti lebih lama dari target waktu. Berdasarkan Tabel 6, terdapat 2 dari 10 data pengujian, yang memberikan hasil rekomendasi yang tidak tepat.
Akurasi = (8/10) * 100% = 80%. Kesalahan = (2/10) * 100% = 20%.
Perlu diperhatikan bahwa catatan waktu di lapangan dapat dipengaruhi oleh faktor-faktor lain seperti kondisi kesehatan teknisi, semangat kerja teknisi, kondisi ruang kerja, dan lain sebagainya. Faktor-faktor ini tidak menjadi perhitungan dalam data mining di penelitian ini. Proses perhitungan Naïve Bayes menggunakan variabel jenis kendaraan dan jenis pekerjaan/layanan yang dilakukan.
`13
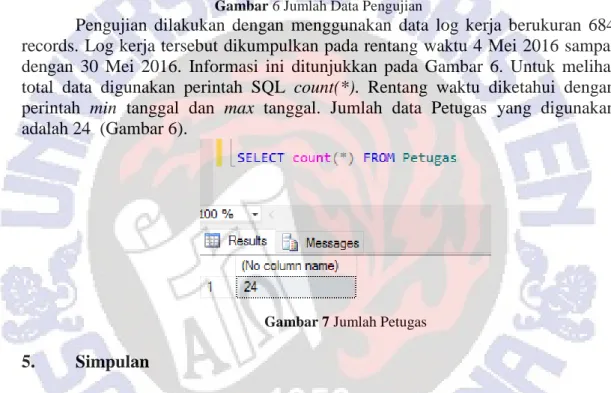
Gambar 6 Jumlah Data Pengujian
Pengujian dilakukan dengan menggunakan data log kerja berukuran 684 records. Log kerja tersebut dikumpulkan pada rentang waktu 4 Mei 2016 sampai dengan 30 Mei 2016. Informasi ini ditunjukkan pada Gambar 6. Untuk melihat total data digunakan perintah SQL count(*). Rentang waktu diketahui dengan perintah min tanggal dan max tanggal. Jumlah data Petugas yang digunakan adalah 24 (Gambar 6).
Gambar 7 Jumlah Petugas
5. Simpulan
Berdasarkan penelitian, pengujian dan analisis terhadap sistem, maka dapat diambil kesimpulan yaitu: 1) Sistem dapat membantu dalam hal pencatatan
log kerja bengkel Daihatsu cabang Salatiga; 2) Sistem memudahkan menganalisis
efisiensi dalam penanganan keluhan pelanggan; 3) Hasil analisis naïve bayes pada
log kerja penanganan keluhan pelanggan, berguna bagi pihak manajerial bengkel
Daihatsu cabang Salatiga, untuk peningkatan layanan kepada pelanggan; 4) Sistem dapat memberikan rekomendasi dengan tingkat akurasi 80%. Saran yang dapat diberikan untuk penelitian dan pengembangan selanjutnya adalah: analisis dapat diperluas tidak hanya terbatas pada komponen waktu, namun juga kepuasan pelanggan, dan biaya yang diperlukan. Algoritma untuk proses analisis juga dapat menggunakan algoritma data mining yang lain, sehingga diperoleh perbandingan hasil analisis antara Naïve Bayes, dengan algoritma yang lain seperti ID3.
`14 6. Daftar Pustaka
[1]. Winer, R. S. 2001. A Framework for Customer Relationship Management. California Management Review 43, 89–105. (doi:10.2307/41166102) [2]. Garcia-Murillo, M. & Annabi, H. 2002. Customer knowledge management.
Journal of the Operational Research Society 53, 875–884. (doi:10.1057/palgrave.jors.2601365)
[3]. Ridwan, M., Suyono, H. & Sarosa, M. 2013. Penerapan Data Mining
Untuk Evaluasi Kinerja Akademik Mahasiswa Menggunakan Algoritma Naive Bayes Classifier. Jurnal EECCIS 7, pp–59.
[4]. Via, Y. V., Nugroho, B. & Syafrizal, A. 2015. Sistem Pendukung
Keputusan Klasifikasi Tingkat Keganasan Kanker Payudara Dengan Metode Naive Bayes Classifier. SCAN-Jurnal Teknologi Informasi dan
Komunikasi 10, 63–68.
[5]. Bustami, B. 2014. Penerapan Algoritma Naïve Bayes Untuk Mengklasifikasi Data Nasabah Asuransi. Techsi 3.
[6]. Pressman, R. S. & Jawadekar, W. S. 1987. Software engineering. New York 1992

![Gambar 2 Prototype Model [6]](https://thumb-ap.123doks.com/thumbv2/123dok/4449249.2974848/10.892.148.761.312.795/gambar-prototype-model.webp)