LANDASAN TEORI
Bab ini memberikan penjelasan dasar mengenai konsep representasi sinyal ucapan, fonem, karakteristik dan cara kerja sistem pengenalan ucapan berbasis HMM. Juga dijelaskan mengenai HTK sebagai perkakas pembuatan model akustik, Julius sebagai mesin pengenal ucapan, konsep bahasa pemrograman C++, dan pustaka Qt, serta Sistem Operasi GNU/Linux.
2.1 Representasi Sinyal Ucapan
2.1.1 Sinyal Ucapan
Sinyal ucapan merupakan sinyal yang berubah terhadap waktu dengan kece-patan perubahan yang relatif lambat. Sinyal ucapan memiliki karakteristik yang tetap jika diamati pada rentang waktu yang pendek (antara 5 sampai 100 ms). Namun dalam rentang waktu yang lama (0,2 sekon atau lebih) karakteristiknya terlihat berubah-ubah sesuai bunyi ucapannya [8].
Ada berbagai cara untuk mengklasifikasikan komponen-komponen sinyal ucapan. Salah satu cara yang sederhana adalah dengan mengklasifikasikannya menjadi tiga keadaan yang berbeda, yaitu (1) silence (S), keadaan pada saat tidak ada ucapan yang diucapkan; (2) unvoiced (U), keadaan pada saat pita suara tidak melakukan vibrasi, sehingga suara yang dihasilkan bersifat tidak periodik; (3) voiced (V), keadaan pada saat terjadinya vibrasi pada pita suara, sehingga menghasilkan suara yang bersifat kuasi periodik.
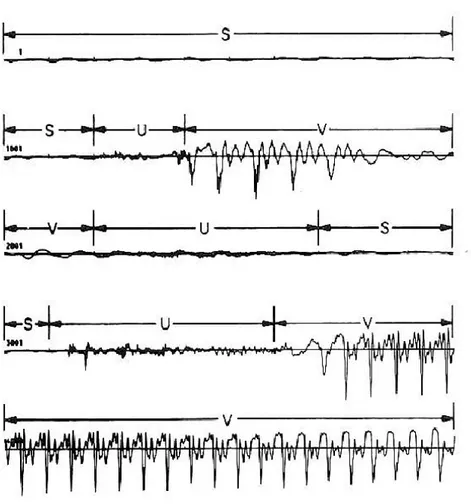
Gambar 2.1 Contoh Sinyal Ucapan “It's time”.
Gambar 2.1 Menunjukkan contoh sinyal ucapan dari ujaran bahasa inggris “It's time” yang diucapkan seorang pria. Kelima baris bersama pada gambar tersebut memperlihatkan sinyal ucapan sepanjang 500 ms dimana setiap baris memperli-hatkan potongan sinyal selama 100 ms. Pada Gambar 2.1 tercantum label-label S, U, dan V yang dapat mempermudah pengamatan perbedaan keadaan. Baris pertama dan awal baris kedua ditandai dengan silence (S) yang merepresentasikan keadaan diam dimana pembicara belum mengucapkan apapun. Amplitudo kecil yang tampak pada periode tersebut merupakan noise latar belakang yang ikut terekam.
Suatu periode singkat unvoiced (U) tampak mendahului vocal pertama dalam kata “It's”. Selanjutnya diikuti oleh daerah voiced (V) yang cukup panjang, merepresentasikan vokal “i”. Berikutnya diikuti oleh daerah unvoiced (U) yang merepresentasikan daerah pelemahan pengucapan “i”. Setelah itu diikuti oleh silence (S) sebelum pengucapan fonem “t” pada kata "It's", dan seterusnya.
Dari contoh tersebut jelas bahwa segmentasi ucapan menjadi S, U dan V tidak bersifat eksak, artinya ada daerah-daerah yang tidak dapat dikategorikan dengan tegas ke dalam salah satu dari tiga kategori tersebut. Salah satu penyebabnya adalah perubahan dari keadaan-keadaan alat ucap manusia yang tidak bersifat diskrit dari satu keadaan ke keadaan lainnya, sehingga bunyi transisi dari satu segmen ke segmen lainnya menghasilkan bentuk yang tidak mudah ditentukan. Selain itu, ada segmen-segmen ucapan yang mirip atau bahkan mengandung silence didalamnya.
2.1.2 Fonem
Fonem merupakan konsep penting dalam hal representasi ucapan. Fonem adalah unit bunyi terkecil yang dapat dibedakan oleh manusia. Fonem berbeda dengan abjad dimana fonem diklasifikasikan menurut pendengaran manusia. Satu abjad bisa saja memiliki beberapa fonem, atau sebaliknya.
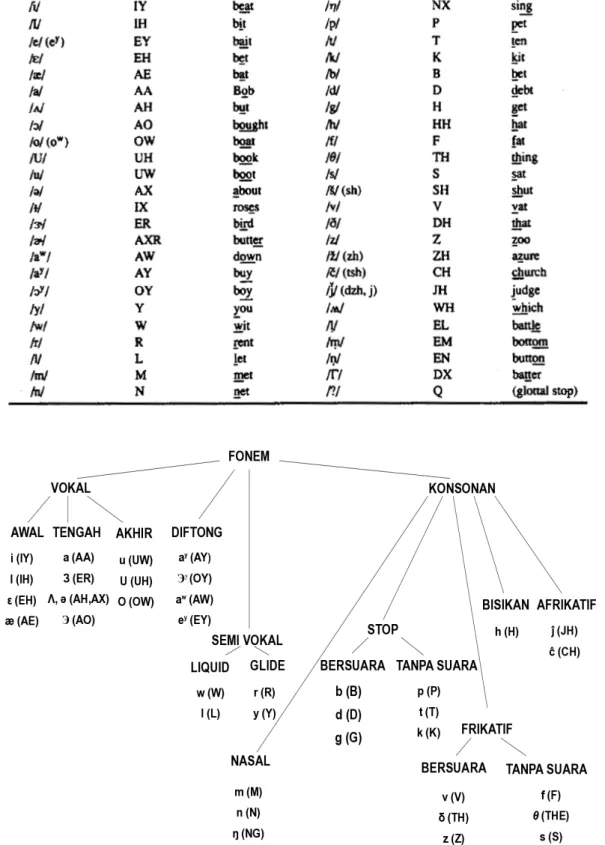
Setiap fonem memiliki ciri-ciri yang berbeda. Gambar 2.2 memperlihatkan daftar fonem bahasa Inggris-Amerika dan representasi ARPABET1
1. ARPABET merupakan kode transkripsi yang dibangun oleh Advanced Research Projects
Agency (ARPA) sebagai bagian dari proyek Speech Understanding (1971-1976). ARPABET
Tabel 2.1 Daftar Simbol Fonetik untuk Bahasa Inggris-Amerika.
Fonem vokal pada umumnya memiliki durasi yang lebih panjang dibandingkan dengan konsonan, dan spektrum frekuensinya lebih mudah dikenali. Fonem diftong adalah fonem yang bunyinya dimulai dengan vokal, dan berakhir dengan vokal lainnya [8]. Beberapa jenis diftong dalam bahasa Inggris-Amerika adalah /ay/, /oy/, /aw/, dan /ey/. Semivokal adalah fonem-fonem yang bunyinya mirip dengan vokal, namun sebenarnya bukan. Contoh fonem dalam kategori ini adalah /w/, /l/, /r/, dan /y/.
Klasifikasi fonem untuk setiap bahasa tidaklah jauh berbeda. Pada bahasa Indonesia terdapat 32 fonem [2] yang terdiri dari /a/, /e/, /E/, /i/, /o/, /u/, /b/, /p/, /d/, /t/, /g/, / k/, /kh/, /j/, /c/, /v/, /f/, /z/, /s/, /sy/, /h/, /r/, /l/, /m/, /n/, /ny/, /ng/, /w/ dan /y/ serta tiga buah diftong, yaitu : /ai/, /au/ dan /ou/.
2.2 Pengenalan Ucapan
Pengenalan ucapan merupakan proses penerjemahan sinyal akustik menjadi pesan linguistik. Proses pengenalan ucapan dilakukan oleh komponen perangkat lunak yang disebut sebagai mesin pengenal ucapan. Fungsi utama dari mesin pengenal adalah memproses masukan ucapan dan menerjemahkannya menjadi teks yang dikenali aplikasi. Aplikasi kemudian dapat melakukan salah satu dari dua tindakan berikut:
1. Aplikasi mengartikan hasil dari pengenalan sebagai perintah. Pada kasus ini, aplikasi merupakan aplikasi perintah dan kontrol. Salah satu contohnya adalah saat pengujar mengatakan "matikan komputer", aplikasi akan memberikan perintah kepada sistem untuk mematikan komputer. 2. Jika aplikasi menangani teks ucapan yang dikenali hanya sebagai teks,
maka ia dianggap sebagai aplikasi diktasi. Pada aplikasi diktasi, jika pengujar mengatakan "matikan komputer", aplikasi tidak akan mengartikan hasil sebagai perintah, tetapi hanya memberikan hasil teks "matikan komputer".
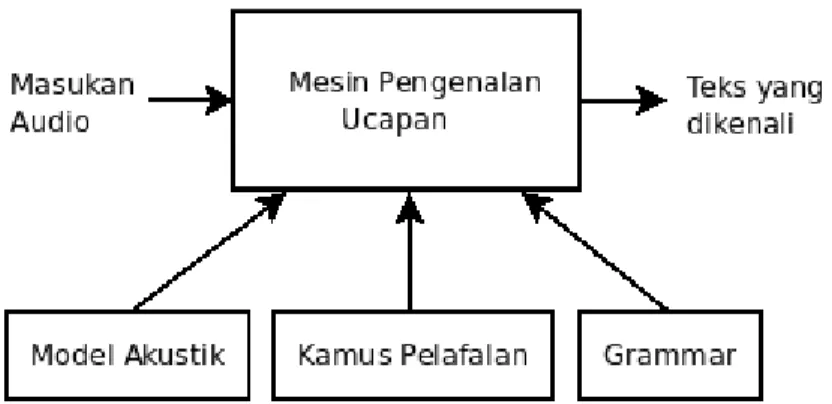
Proses pengenalan melibatkan beberapa komponen yang ditunjukkan pada Gambar 2.3 yakni:
Gambar 2.3 Pengenal Ucapan.
1. Masukan audio
Masukan audio merupakan masukan berupa ucapan dari pengujar dan noise yang dihasilkan pada lingkungan pengenalan.
2. Grammar
Grammar menggunakan sintaks tertentu, atau beberapa aturan, untuk mendefinisikan kata dan frasa yang dapat dikenali mesin pengenalan ucapan. Grammar dapat hanya berupa daftar kata-kata, atau dapat juga berupa aturan yang cukup fleksibel sehingga memampukan keragaman kata dan frasa yang dapat diucapkan seperti pada bahasa natural. Grammar
digunakan untuk memprediksikan kemungkinan urutan-urutan kata yang muncul dalam bahasa.
3. Model akustik
Model akustik dibuat dengan mengambil data rekaman ucapan dan transkripsi teksnya yang kemudian digunakan untuk membuat representasi statistikal dari tiap bunyi yang membentuk kata yang terdapat pada data. Model akustik menunjukkan bagaimana sebuah kata atau sebuah fon dilafalkan.
4. Kamus Pelafalan
Kamus elektronik dari transkripsi kata yang mengandung pelafalan fonetik dari keseluruhan kosakata yang digunakan pada proses pengenalan ucapan. 5. Teks yang dikenali
Keluaran berupa string teks yang didapat dari ucapan yang dikenali oleh mesin pengenalan ucapan.
Pada saat masukan audio datang ke mesin pengenal, biasanya ia tidak hanya mengandung ucapan tetapi juga noise latar belakang. Noise ini dapat menginter-ferensi proses pengenalan, sehingga mesin pengenal harus mengatasi (dan mungkin juga beradaptasi) lingkungan di mana ucapan diujarkan.
Dalam melakukan tugasnya, mesin pengenal ucapan menggunakan bermacam data, statistik, dan algoritma perangkat lunak. Tugas pertamanya adalah memproses sinyal audio yang datang dan mengubahnya ke dalam format yang cocok untuk analisis selanjutnya. Setelah data ucapan telah berada dalam format yang tepat, mesin akan mencari kecocokan yang paling baik. Ia melakukan ini
dengan cara memanfaatkan kata dan frasa yang dikenalnya (grammar), bersamaan dengan pengetahuannya tentang lingkungan di mana ia beroperasi. Pengetahuan tentang lingkungannya disediakan dalam bentuk model akustik. Setelah ia mengidentifikasi kemungkinan kecocokan terbaik dari ucapan, ia akan memberikan hasil pengenalan berupa string teks.
Hasil pengenalan dapat berupa salah satu dari keadaan: Penerimaan atau peno-lakan. Penerimaan dan penolakan ditandai oleh mesin pengenalan ucapan pada tiap pemrosesan ucapan. Ujaran yang diterima akan mengakibatkan mesin memberikan hasil teks yang dikenali. Tidak semua ujaran yang diproses oleh mesin pengenalan diterima.
Apapun yang dikatakan pengujar, mesin pengenal ucapan akan berusaha keras untuk mencari kecocokan ujaran dengan kata atau frasa yang ada pada grammar. Terkadang kecocokan yang dihasilkan buruk karena pengujar mengatakan sesuatu di mana aplikasi tidak mengharapkannya, atau pengujar berbicara sayup-sayup. Pada kasus ini, mesin pengenal akan menghasilkan kecocokan yang paling mendekati, yang mungkin tidak tepat.
Dari perspektif pengguna, sistem pengenalan ucapan dapat diklasifikasikan oleh kriteria berikut:
• Apakah sistem dapat digunakan oleh satu orang pengguna (speaker dependent) atau dapat digunakan oleh banyak pengguna (speaker independent)
• Apakah sistem memerlukan jeda waktu antara pengucapan tiap kata (isolated word recognition) atau dapat mengenali ucapan natural manusia,
dimana beberapa kata berhubungan dan diartikulasikan secara berkelanjutan (continuous speech recognition)
• Apakah ukuran dari kosakata yang dapat dikenali kecil (puluhan atau paling banyak ratusan kata) atau besar (ribuan kata). Pada kasus kosakata besar, ketika sistem dapat menerima ucapan yang kontinu, sistem tersebut dinamakan large vocabulary continuous speech recognition (LVSCR). Sistem pengenalan ucapan biasanya dapat dioperasikan dalam dua mode [3]:
1. Mode pelatihan
Pada mode ini, sistem dilatih menggunakan sejumlah kata atau kalimat yang memenuhi kriteria tertentu. Setiap contoh kata atau kalimat latih tersebut akan menghasilkan pola tertentu yang akan dipelajari oleh sistem dan disimpan sebagai template atau referensi.
2. Mode produksi atau pengenalan ucapan
Pada mode ini, setiap kalimat yang ingin dikenali akan dianalisis polanya lalu dibandingkan dengan template atau referensi. Kata atau kalimat yang diucapkan akan diidentifikasi oleh sistem.
Semua sistem pengenalan ucapan memiliki inti yang terdiri dari kumpulan model-model statistik yang merepresentasikan beragam ucapan pada bahasa yang ingin dikenali. Karena ucapan memiliki struktur temporal dan dapat dienkodekan sebagai urutan vektor spektral pada daerah frekuensi audio, maka Hidden Markov Model (HMM)2 tepat dipakai untuk membangun model-model tersebut [7].
Dalam sistem pengenalan ucapan, satu model HMM mewakili model penget-ahuan dari satu fonem tertentu. HMM digunakan untuk memfasilitasi
lahan proses stokastik yang dideskripsikan dengan fungsi probabilitas yang terb-entuk dalam Markov Chain3. Dalam penggunaan HMM, Markov Chain yang terdapat di dalamnya tidak pernah secara langsung bisa dianalisis atau diamati, oleh karena itu disebut Hidden Markov Model.
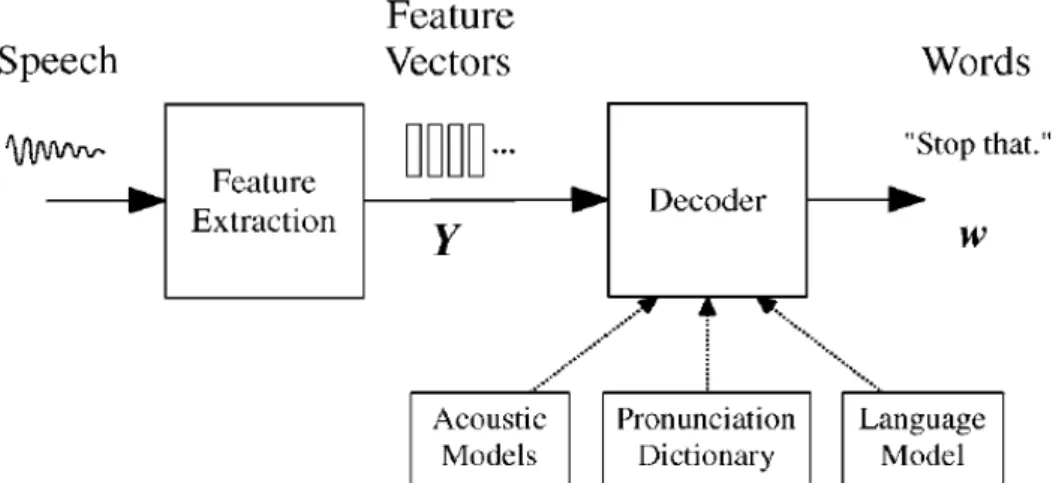
Komponen utama pada sistem pengenalan ucapan berbasis HMM ditunjukkan pada Gambar 2.4.
Gambar 2.4 Arsitektur Sistem Pengenalan.
Masukan gelombang audio dari mikrofon dikonversikan menjadi urutan vektor fitur akustik berukuran tetap Y1:T = y1,..., yT dengan proses yang disebut ekstraksi fitur. Vektor fitur pada dasarnya adalah representasi parametrik dari sinyal ucapan yang mengandung informasi terpenting dan disimpan dalam bentuk yang kompak. Proses ekstraksi fitur umumnya menggunakan skema encoding yang berdasarkan Mel-Frequency Cepstral Coefficient (MFCC). Pada skema ini digunakan skala non-linier yang disebut sebagai Mel-scale yang memimikkan jangkauan akustik dari pendengaran manusia. Mel-scale dapat diaproksimasi dengan:
Mel f =2595log101 f
700 (2.1)
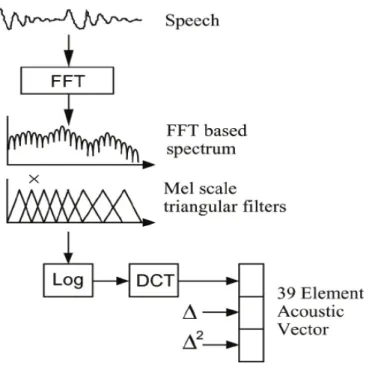
Pada proses ekstraksi yang menggunakan MFCC yang ditunjukkan pada Gambar 2.5, pertama sekali sinyal ditransformasikan ke domain spektral dengan transformasi fourier. Spektrum sinyal ucapan yang didapatkan kemudian dihaluskan dengan mengintegrasikan koefisien spektral dengan bin frekuensi yang disusun dalam Mel-scale. Kemudian kompresi log diterapkan pada keluaran bank filter untuk membuat statistik dari spektrum power ucapan yang diestimasi dalam aproksimasi Gaussian. Discrete cosine transform (DCT) diterapkan pada akhir proses.
Setelah ekstraksi fitur, decoder kemudian mencoba untuk mencari urutan kata w1:L = w1,...,wL dimana decoder kemungkinan besar telah menghasilkan Y:
w=arg max
w
{p w∣Y }
(2.2) Namun, karena P(w|Y) sangat susah untuk dimodelkan secara langsung, maka aturan Bayes digunakan untuk mentransformasikan persamaan 2.2 menjadi masalah pencarian yang ekivalen:
w=arg max
w
{P Y∣w P w} (2.3)
Kemungkinan P(Y|w) ditentukan oleh model akustik dan P(w) sebelumnya ditentukan oleh model bahasa.
2.3 Hidden Markov Model Toolkit
HTK (Hidden Markov Model Toolkit) merupakan kumpulan dari perkakas pemrograman untuk membuat dan memanipulasi Hidden Markov Model (HMM). HTK dikembangkan oleh Speech Vision and Robotics Group di Cambridge University Engineering Department (CUED) untuk membangun sistem pengen-alan ucapan berkosakata besar. Hak untuk menjual HTK diperoleh Entropic Research Laboratory Inc. pada tahun 1993 dan pengembangan penuh HTK ditransfer ke Entropic Cambridge Research Laboratory Ltd. saat didirikan pada tahun 1995. Microsoft® membeli Entropic pada tahun 1999 dan melisensikan HTK kembali ke CUED pada tahun 2000. Microsoft® menguasai hak cipta kode HTK, meskipun demikian HTK disediakan bebas untuk tujuan penelitian.
2.3.1 Arsitektur perangkat lunak HTK
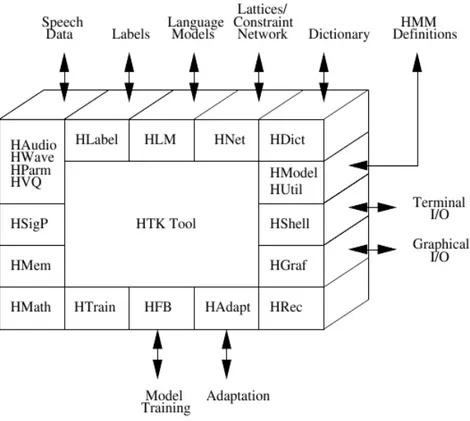
Kebanyakan fungsionalitas HTK dibangun dalam bentuk modul-modul pustaka. Modul-modul ini memastikan setiap perkakas memiliki pengantaraan yang sama ke dunia luar. Modul-modul ini juga menyediakan akses ke fungsi yang umum digunakan. Gambar 2.6 menunjukkan struktur perangkat lunak dari perkakas HTK dan pengantaraan masukan/keluarannya.
Gambar 2.6 Arsitektur Perangkat Lunak HTK.
Masukan/keluaran dan interaksi dengan sistem operasi diatur oleh modul HShell dan semua manajemen memori diatur oleh HMem. Dukungan matematika disediakan oleh HMath dan operasi pemrosesan sinyal yang dibutuhkan pada analisis ucapan disediakan oleh HSigP. Tiap jenis berkas yang dibutuhkan oleh
HTK memiliki modul pengantaraan tersendiri. HLabel memberikan pengantaraan untuk berkas label, HLM untuk berkas model bahasa, HNet untuk word network dan lattice, HDict untuk kamus, HVQ untuk VQ (Vector Quantisizer) codebook dan HModel untuk definisi HMM.
Masukan dan keluaran ucapan dikontrol oleh HWave pada tingkat waveform dan oleh HParm pada tingkat parameter. Masukan audio langsung didukung oleh HAudio dan interaksi grafis interaktif sederhana disediakan oleh HGraf. HUtil menyediakan fungsionalitas untuk memanipulasi HMM sedangkan HTrain dan HFB menyediakan dukungan untuk perkakas pelatihan HTK. HAdapt memberikan dukungan untuk perkakas adaptasi HTK. HRec mengandung fungsi utama proses pengenalan.
2.3.2 Toolkit (Perkakas)
Perkakas HTK dibagi ke dalam 4 kategori yang berhubungan dengan tiga tahap yang terkait dalam pembangunan pengenalan ucapan yakni:
1. Persiapan data 2. Pelatihan
3. Evaluasi (Pengujian dan analisis)
Beragam perkakas HTK dan tahap pemrosesannya ditunjukkan pada Gambar 2.7.
Gambar 2.7 Tahap-tahap Penggunaan Perkakas HTK [11].
2.3.2.1 Perkakas Persiapan Data
Untuk membangun sebuah pengenal ucapan dibutuhkan sejumlah berkas data ucapan dan transkripsinya. Korpus yaitu basis data dari berkas audio dapat digun-akan sebagai berkas data. Namun sebelum dapat digundigun-akan, korpus harus dikon-versi ke dalam bentuk parametrik yang sesuai dan transkripsinya harus dikondikon-versi ke format yang tepat dan menggunakan label yang diperlukan. HTK menyediakan perkakas HSlab untuk merekam data audio dan menganotasinya secara manual dengan transkripsi yang sesuai.
Untuk memparameterisasi audio digunakan HCopy. Secara mendasar, HCopy melakukan operasi penyalinan berkas audio dan mengkonversinya menjadi bentuk
parametrik yang dibutuhkan disaat proses penyalinan. Selain menyalin keselur-uhan berkas, HCopy memperbolehkan ekstraksi dari segmen yang relevan dan penyambungan berkas dengan menentukan parameter konfigurasi yang tepat. Perkakas HList dapat digunakan untuk mengecek isi dari berkas ucapan dan konversi parametrik.
Transkripsi biasanya memerlukan persiapan lebih lanjut karena sumber asli transkripsi tidak akan tepat seperti yang dibutuhkan, contohnya, karena perbedaan set fonem yang telah digunakan. HLed dapat digunakan untuk mengkonversi transkripsi menjadi format label HTK. HLed merupakan editor label yang digerakkan oleh script dan dapat menghasilkan keluaran berkas transkripsi ke sebuah berkas label master atau Master Label File (MLF).
Perkakas persiapan data lainnya mencakup HLStats, yang dapat mengum-pulkan dan menampilkan statistik pada berkas label, dan HQuant yang dapat digunakan untuk membangun sebuah VQ codebook untuk membangun sistem HMM probabilitas diskrit.
2.3.2.2 Perkakas Pelatihan
Langkah selanjutnya dalam membangun pengenal ucapan adalah mendefin-isikan topologi dari tiap HMM pada definisi prototip. HTK memperbolehkan HMM dibangun dengan topologi sembarang. Definisi prototip disimpan sebagai berkas teks dan dapat diedit dengan editor teks sederhana. Definisi prototip hanya ditujukan untuk menentukan karakteristik keseluruhan dan topologi HMM, sedangkan parameter aktual akan dikomputasi oleh perkakas pelatihan.
Pelatihan HMM berlangsung dalam beberapa tahap, seperti ditunjukkan pada Gambar 2.8. Tahap pertama adalah membangun set inisial model. Jika ada beberapa data pelatihan tersedia di mana batasan fon telah ditranskripsikan, data ini dapat digunakan sebagai bootstrap data. Dalam hal ini, perkakas HInit dan HRest menyediakan pelatihan kata-terisolasi menggunakan bootstrap data. HMM dihasilkan secara individual. HInit membaca semua bootstrap data dan memotong contoh fon yang dibutuhkan, setelah set inisial dari parameter dikomputasi secara iteratif menggunakan prosedur segmental k-means.
Pada iterasi pertama, data pelatihan disegmentasi secara seragam, setiap keadaan dicocokkan dengan segmen data yang berkaitan dan means dan variance-nya diestimasi. Pada iterasi selanjutnya segmentasi seragam digantikan dengan viterbi alignment. Setelah HInit selesai mengkomputasi nilai inisial parameter, nilai-nilai ini dire-estimasi lebih lanjut dengan HRest. HRest juga menggunakan boot-strap data, tetapi prosedur segemental k-means digantikan dengan re-estimasi Baum-Welch. Jika tidak ada bootstrap data tersedia, maka sebuah flat start dapat dibuat. Pada kasus ini, HMM diinisialisasi secara identikal dan memiliki mean dan variance keadaan sama dengan mean dan variance ucapan global. Perkakas HCompV dapat digunakan untuk hal ini.
Setelah set inisial model telah dibuat, perkakas HERest digunakan untuk melakukan embedded training menggunakan keseluruhan set pelatihan. HERest melakukan satu re-estimasi Baum-Welch dari keseluruhan set model fon HMM secara simultan. Untuk setiap ujaran, model fon yang berkorespondensi digabungkan dan kemudian algoritma forward-backward digunakan untuk mengumpulkan statistik relevan dari okupasi keadaan, means, variance dan seba-gainya untuk tiap HMM pada urutan. Setelah semua data pelatihan telah diproses, statistik yang terakumulasi digunakan untuk re-estimasi parameter HMM.
HTK memperbolehkan HMM untuk direfinasi secara inkremental. Pada umumnya, Gaussian tunggal, model context-independent dibuat pertama sekali. HMM ini dapat direfinasi secara iteratif dengan memperluasnya untuk memas-ukkan context-dependency (contohnya, biphone dan triphone) dan memakai komponen campuran multipel distribusi gaussian. Perkakas HHed dapat
digun-akan untuk mengganddigun-akan model ke dalam set context-dependent dan menaikkan jumlah komponen campuran. Kinerja dari pengujar spesifik dapat diperbaiki dengan mengadaptasi HMM menggunakan sejumlah kecil data adaptasi.
Salah satu masalah besar dalam pembuatan HMM context-dependent adalah kekurangan data pelatihan. Semakin kompleks set model, semakin banyak data pelatihan yang diperlukan, sehingga keseimbangan terjebak di antara kompleks-itas dan ketersediaan data. Keseimbangan ini dapat dicapai dengan mengikat para-meter bersama-sama, yang memperbolehkan data dikumpulkan untuk mengesti-masi secara kokoh parameter yang dibagi. HTK juga mendukung campuran terikat dan sistem probabilitas diskrit. Perkakas HSmooth dapat digunakan pada kasus ini untuk mengatasi kekurangan data.
2.3.2.3 Perkakas Pengujian
Perkakas pengenalan yang disediakan HTK adalah HVite. HVite menggunakan algoritma yang disebut token passing algorithm untuk melakukan pengenalan ucapan berbasis Viterbi. Sebagai masukan, HVite memerlukan word network yang mendeskripsikan urutan kata yang diperbolehkan, kamus yang mendefinisikan bagaimana tiap kata dilafalkan dan set HMM. HVite akan mengubah word network menjadi phone network dan mencantumkan definisi HMM yang tepat pada tiap instance fon, setelah itu pengenalan dapat dilakukan terhadap masukan audio atau pada sebuah daftar berkas ucapan yang disimpan.
Word network yang dibutuhkan HVite dapat berupa loop kata sederhana atau sebuah grammar kerja finite-state yang direpresentasikan oleh directed graphs. Pada loop word network sederhana, tiap kata dapat mengikuti kata apapun dan
probabilitas bigram secara normal dicantumkan ke transisi kata. Berkas network disimpan dalam format standar lattice HTK yang berbasis teks. HTK menye-diakan dua perkakas untuk membantu pembangunan network yakni HBuild dan HParse. HBuild memperbolehkan pembuatan sub-network yang dapat digunakan pada network di level yang lebih tinggi dan dapat memfasilitasi generasi loop kata. HParse merupakan perkakas yang dapat mengubah network yang ditulis dengan notasi grammar pada level yang lebih tinggi menjadi format standar lattice HTK. Notasi grammar pada level yang lebih tinggi didasarkan pada Extended Backus Naur Form (EBNF).
Perkakas HSGen dapat digunakan untuk melihat contoh jalur yang mungkin dikandung dalam sebuah network. HSGen mengambil network sebagai masukan dan secara acak menjelajahinya lalu menghasilkan keluaran berupa string-string kata. String ini dapat diperiksa untuk memastikan network sesuai dengan spesi-fikasi rancangannya.
Konstruksi kamus yang besar dapat mencakup penggabungan sumber-sumber berbeda dan melakukan transformasi pada sumber-sumber ini. Perkakas HDMan dapat membantu dalam proses ini.
2.3.2.4 Perkakas Analisis
Analisis kinerja pengenal berbasis HMM biasanya dilakukan dengan mencocokkan keluaran set transkripsi pengenal dengan transkripsi referensi yang tepat. Perkakas HResults dapat digunakan untuk melakukan perbandingan ini. Perkakas ini menggunakan Dynamic Programming untuk menyusun dengan benar distribusi transkripsi dan distiribusi hitung, penghapusan dan penyisipan.
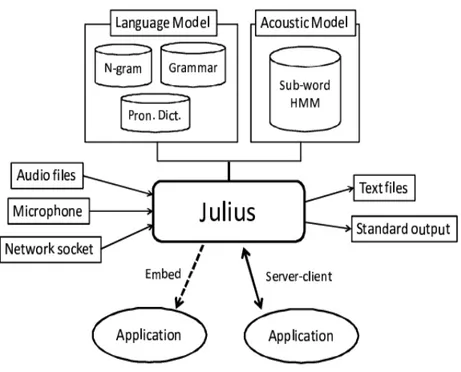
2.4 Julius [1]
Julius merupakan decoder open-source pengenalan ucapan berkinerja tinggi yang digunakan baik pada penelitian akademik maupun aplikasi-aplikasi industri. Julius menggabungkan teknik canggih utama pengenalan ucapan dan dapat melakukan pekerjaan LVCSR secara efektif pada pengolahan real-time dengan jejak memori yang relatif kecil.
Julius ditulis dengan bahasa C. Berjalan pada sistem operasi Linux, Windows, Mac OS X, Solaris, dan varian Unix lainnya.
Dengan memiliki model bahasa dan model akustik, Julius akan berfungsi sebagai Speech Recognition Engine (SRE) atau mesin pengenalan ucapan sesuai dengan tugas yang diberikan. Gambaran umum dari Julius diilustrasikan pada Gambar 2.9.
Julius mendukung pemrosesan berkas audio dan live audio stream. Untuk masukan berkas, Julius mengasumsikan satu ujaran kalimat per berkas masukan. Julius juga mendukung pemenggalan otomatis masukan dengan long pause, dimana deteksi pause akan dikerjakan berdasarkan tingkatan dan zero cross thresholds. Masukan audio melalui stream jaringan juga didukung.
Diperlukan model bahasa dan model akustik untuk menjalankan Julius. Model bahasa mencakup kamus pengucapan kata dan batasan sintaksis. Julius mendukung beragam jenis model bahasa: model kata N-gram, rule-base grammar, dan daftar kata sederhana untuk pengenalan kata-terisolasi. Model akustik untuk unit-unit sub-kata harus didefinisikan menurut HMM. Julius mendukung penuh berkas definisi HMM HTK.
Gambar 2.9 Gambaran Umum Julius.
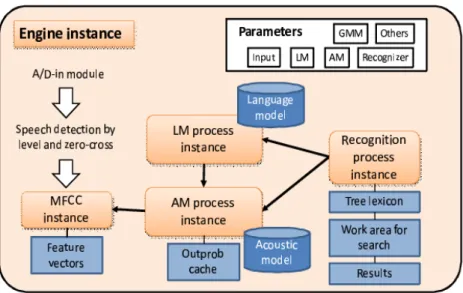
2.4.1 Arsitektur Sistem
Struktur modul internal Julius ditunjukkan pada Gambar 2.10. Struktur teratas merupakan Engine Instance yang mengandung semua modul yang dibutuhkan untuk sistem pengenalan, yakni model masukan audio, deteksi suara, ekstraksi fitur, model bahasa, model akustik dan proses pencarian.
Gambar 2.10 Struktur Internal Julius.
AM (Acoustic Model) process instance menangani HMM akustik dan area kerja komputasi akustik. MFCC (Mel-Frequency Cepstral Coefficients) instance dihasilkan dari AM process instance untuk mengekstrak urutan vektor fitur dari masukan gelombang ucapan. LM (Language Model) process instance menangani model bahasa dan area kerja komputasi linguistik. Recognition process instance merupakan proses pengenalan utama yang menggunakan AM process instance dan LM process instance. Modul-modul ini akan diciptakan di Engine instance sesuai dengan parameter konfigurasi yang diberikan. Untuk efisiensi saat melakukan pengenalan multi-model, model dapat dibagikan di antara beberapa instance yang lebih tinggi.
2.4.2 Algoritma Decoding
Julius melakukan pencarian dengan algoritma two-pass forward-backward pada saat decoding. Gambaran umum dari algoritma decoding ini ditunjukkan pada Gambar 2.11.
Gambar 2.11 Algoritma Decoding.
Pada pass pertama, sebuah leksikon berstruktur pohon yang ditetapkan dengan batasan model bahasa diterapkan dengan algoritma pencarian standar frame synchronous beam. Untuk efesiensi decoding, pada pass ini digunakan batasan model bahasa yang tereduksi yang hanya berkenaan dengan koneksi kata ke kata dengan mengabaikan konteks selanjutnya. Batasan aktual bergantung pada jenis model bahasa: saat menggunakan model N-gram, probabilitas bigram akan diap-likasikan pada pass ini. Saat memakai rule-based grammar, batasan pasangan kata yang diekstrak dari grammar yang diberikan akan digunakan. Banyak aproksimasi lain yang diterapkan pada pass pertama ini untuk decoding yang cepat dan handal. Dependensi konteks kata-silang diatasi dengan aproksimasi yang menerapkan model terbaik untuk history terbaik.
Setelah selesai pass pertama akan dihasilkan sebuah “word trellis index” yang merupakan set node kata akhir per frame yang bertahan, dengan score-nya dan starting frame-nya. Word trellis index ini digunakan untuk mencari kandidat kata dan score-nya pada pass selanjutnya secara efisien. Tidak seperti word-graph rescoring konvensional, pass kedua dapat melakukan Viterbi scoring yang lebih lebar dan ekspansi kata yang lebih lebar, yang akan memampukan pass ini mengatasi kehilangan akurasi akibat aproksimasi.
Pada pass kedua, model bahasa lengkap dan dependensi konteks silang-kata diaplikasikan untuk re-scoring. Pencarian dilakukan dengan arah yang berkeba-likan sehingga sentence-dependent Viterbi score yang tepat bisa didapatkan dengan decoding pencarian word-level stack. Masukan ucapan dievaluasi lagi dengan menghubungkannya dengan forward trellis sebagai hasil dari pass pertama.
Julius pada dasarnya mengasumsikan satu ujaran kalimat per masukan. Tetapi pada ucapan spontan alami seperti pada perkuliahan atau pertemuan, segmen masukan terkadang tidak tentu dan sering sekali panjang. Untuk mengatasinya, Julius memiliki fungsi untuk melakukan decoding suksesif dengan segmentasi short-pause yakni dengan memotong masukan yang panjang pada saat pengenalan dengan short pause secara otomatis. Ketika short pause dideteksi, Julius mengakhiri pencarian saat ini pada titik tersebut dan memulai kembali pengenalan dari titik tersebut.
2.4.3 Pengantaraan Modul
Agar dapat bertindak sebagai modul dari sistem pengenalan ucapan, mesin pengenalan perlu memiliki pengantaraan yang sederhana dan mudah dengan modul lainnya. Untuk itu Julius mengadopsi format standar dan umum pada pengantaraan untuk mempertahankan generalitas dan modularitas terhadap model yang beragam. Pengantaraan, masukan ucapan, dan keluaran dari Julius dijelaskan sebagai berikut.
A. Model Akustik
Julius mendukung HMM monophone dan triphone dengan campuran, keadaan-keadaan dan unit fon sembarang. Julius juga dapat menangani model-model campuran terikat dan model-model fonetik campuran terikat.
Format berkas model akustik harus dalam bentuk HTK ASCII. Format ini dapat diubah menjadi berkas biner Julius dengan perkakas mkbinhmm untuk pemuatan lebih cepat pada saat start-up.
B. Kamus
Format kamus pelafalan yang digunakan adalah format umum pada setiap jenis model bahasa yang berdasarkan pada format kamus HTK. Setiap pelafalan harus merupakan urutan sub-kata unit nama seperti yang didefinisikan pada model akustik. Pelafalan lebih dari satu untuk sebuah kata dapat dibuat sebagai sebuah entri terpisah.
C. Model Bahasa
Julius mendukung pengenalan ucapan berbasis model N-gram, rule-based grammar, dan hanya kamus.
1. N-gram: Sembarang panjang N-gram didukung. Class N-gram juga didukung, dimana probabilitas kata in-class harus diberikan di kamus bukannya di model bahasa.
2. Rule-based Grammar: Julius dapat melakukan pengenalan berdasarkan grammar tertulis. Format berkasnya dalam bentuk Backus–Naur Form (BNF) dimana sintaks category-level penulisan dan entri leksikal per-kategori dibuat dalam berkas berbeda. Berkas-berkas ini harus dikompilasi menggunakan script “mkdfa.pl” menjadi finite state automaton (FSA)
dan sebuah kamus pengenalan. Multipel grammar dapat digunakan pada satu waktu. Dalam hal ini, Julius akan mengeluarkan hipotesis terbaik dari antara semua grammar.
3. Pengenalan terisolasi: Julius akan melakukan pengenalan kata-terisolasi saat hanya digunakan sebuah kamus tanpa model bahasa. Karena pengenalan tidak memerlukan aproksimasi antar kata maka pengenalan akan berakhir pada pass pertama.
Model bahasa atau grammar pengenalan ucapan pada Julius dipisahkan ke dalam dua berkas:
1. Berkas ".grammar" yang mendefinisikan kumpulan aturan kata yang dapat diantisipasi oleh mesin pengenalan ucapan; daripada mendaftarkan semua kata di berkas .grammar, berkas grammar Julius menggunakan "Kategori Kata" yang merupakan nama dari daftar kata-kata yang ingin dikenali (yang didefinisikan pada berkas ".voca" yang terpisah).
2. Berkas ".voca" yang mendefinisikan "Kandidat Kata" yang sebenarnya di tiap kategori kata dan informasi pelafalannya (fonem yang membentuk informasi pelafalan ini harus sama dengan yang digunakan pada pelatihan model akustik).
D. Masukan/Keluaran
Julius mendukung masukan suara berupa berkas waveform (16 bit PCM) atau berkas vektor pola (format HTK) dan masukan live mikrofon.
Decoding pada pass pertama dilakukan secara paralel dengan masukan ucapan. Julius memulai pemrosesan segera setelah segmen masukan dimulai, saat pause panjang dideteksi, Julius akan mengakhiri pass pertama dan melanjutkan pass kedua. Karena pass kedua diselesaikan dalam waktu singkat maka keterlambatan keluaran hasil pengenalan sangat kecil.
Keluaran merupakan hasil pengenalan dalam bentuk urutan kata. Hasil N-best dapat menjadi keluaran. Urutan fonem, log kemungkinan score dan beberapa stat-istik pencarian juga dapat dihasilkan. Hasil parsial dapat juga muncul secara suksesif sebagai keluaran disaat proses pass pertama meskipun hasil akhir belum dapat dipastikan hingga pass kedua berakhir.
2.5 Bahasa Pemrograman C++
C++ adalah salah satu bahasa pemrograman komputer yang bersifat statically typed, bebas-bentuk, multi paradigma, kompilasi, dan general purpose. Dianggap sebagai bahasa pemrograman tingkat menengah karena mencakup gabungan dari bahasa tingkat tinggi dan bahasa tingkat rendah. Awalnya dikembangkan oleh Bjarne Stroustrup pada tahun 1979 pada Bell Labs sebagai perbaikan pada bahasa
pemrograman C, yang dinamakan “C dengan Kelas-kelas”. Kemudian pada tahun 1983 dinamakan sebagai C++.
C++ banyak digunakan pada industri perangkat lunak. Beberapa bidang aplikasinya mencakup perangkat lunak sistem, perangkat lunak aplikasi, driver peranti, perangkat lunak sistem tertanam, aplikasi client dan server berkinerja tinggi, dan perangkat lunak hiburan seperti video game.
C++ memperbaiki sebagian besar fitur dari C dan memberikan kemampuan pemrograman berbasis objek atau object-oriented-programming (OOP) sehingga memberikan peningkatan produktivitas perangkat lunak, kualitas, dan reusability.
Pada pemrograman berbasis objek, data (atribut) dan fungsi (behaviour) dien-kapsulasi ke dalam paket yang disebut kelas-kelas dimana data dan fungsi sebuah kelas sangat berhubungan erat. Sebuah kelas seperti sebuah cetak biru. Dari sebuah cetak biru, perancang dapat membangun sebuah rumah. Dari sebuah kelas, programmer dapat membuat sebuah objek. Sebuah cetak biru dapat digunakan berulang kali untuk membuat banyak rumah. Sebuah kelas dapat digunakan berulang kali untuk membuat banyak objek dari kelas yang sama.
Kelas-kelas memiliki properti penyembunyian data. Ini berarti, meskipun objek kelas dapat berkomunikasi dengan kelas lain melalui pengantaraan yang telah ditentukan, kelas-kelas normalnya tidak diperbolehkan untuk mengetahui bagaimana kelas lain dimplementasikan karena detail implementasinya disem-bunyikan dari kelas itu sendiri.
Programmer C++ berkonsentrasi pada pembuatan tipe user-defined yang disebut kelas. Kelas juga disebut sebagai tipe programmer-defined. Setiap kelas
mengandung data dan kumpulan dari fungsi untuk memanipulasi data. Komponen data dari sebuah kelas disebut data member. Komponen fungsi dari sebuah kelas disebut member function atau method. Instance dari sebuah tipe built-in seperti int disebut sebagai variabel, dan instance dari sebuah tipe user-defined (yakni kelas) disebut sebagai sebuah objek. C++ lebih berfokus kepada kelas-kelas dibanding fungsi.
2.6 Pustaka Qt [5]
Pustaka Qt merupakan framework pengembangan aplikasi cross-platform yang banyak digunakan dalam pengembangan program Graphical User Interface (GUI), dikenal sebagai perkakas widget toolkit, dan juga digunakan dalam mengembangkan program non-GUI seperti perangkat konsol dan server. Diproduksi oleh divisi Pengembangan framework Qt milik Nokia.
Qt menggunakan standar C++, tetapi memanfaatkan penggunaan C prepro-cessor secara ekstensif untuk memperkaya bahasa pemrograman tersebut. Qt dapat juga digunakan dalam beberapa bahasa pemrograman lainnya melalui binding bahasa pemrograman. Dapat berjalan pada semua platform utama, dan memiliki dukungan internasionalisasi yang luas. Fitur non-GUI mencakup akses basis data SQL, parsing XML, manajemen thread, dukungan jaringan dan satu kesatuan API cross-platform untuk penanganan berkas.
2.7 Sistem Operasi GNU/Linux®
Sistem operasi GNU/Linux® merupakan kumpulan program dasar dan utilitas yang membuat komputer dapat bekerja yang menggunakan kernel (inti dari sistem
operasi) Linux® dan perkakas dari GNU Project. Kernel Linux® mulanya ditulis oleh Linus Torvalds pada tahun 1991. GNU Project dimulai pada tahun 1983 oleh Richard Stallman, memiliki tujuan untuk membuat "Sistem perangkat lunak Unix-compatible lengkap" yang keseluruhannya dibentuk dari Free Software. Proyek ini mulai dikerjakan tahun 1984. Kemudian, pada tahun 1985, Stallman memulai Free Software Foundation dan menulis GNU General Public License (GNU GPL) pada tahun 1989. Pada tahun 1990, sejumlah besar program yang dibutuhkan dalam sebuah sistem operasi (seperti pustaka, kompiler, editor teks, shell Unix, dan sistem windowing) telah selesai dikembangan namun elemen-elemen tingkat-rendah seperti device driver, daemon, dan kernel berhenti perkembangannya dan belum lengkap. Disinilah kernel Linux® mengisi kekosongan kernel yang dimiliki oleh GNU Project sehingga Linux® menjadi kernel dari GNU Project ini. Gabungan GNU Project dan kernel Linux® disebut sebagai GNU/Linux® oleh Free Software Foundation.
GNU/Linux® dapat dipasang pada banyak jenis perangkat keras komputer, mulai dari telepon genggam, komputer tablet, konsol video game, hingga main-frame dan superkomputer.
Pengembangan GNU/Linux® dilakukan dengan kolaborasi Free and Open Source Software (FOSS) dimana biasanya semua kode sumbernya dapat digun-akan, bebas dimodifikasi, dan distribusikan, baik secara komersial maupun non-komersial, oleh siapa saja dengan lisensi seperti GNU General Public License (GNU GPL). GNU/Linux® biasanya dipaketkan ke dalam bentuk yang dikenal sebagai distribusi GNU/Linux® atau umumnya dikenal dengan istilah distro
GNU/Linux®. Distribusi ini mencakup kernel Linux® dan semua perangkat lunak pendukung yang dibutuhkan untuk menjalankan sistem operasi yang lengkap seperti utilitas, pustaka, Sistem X Window, dan perkakas sistem user space serta pustaka utama yang mendukung yang berasal dari GNU Project.
Perbedaan utama antara GNU/Linux® dengan sistem operasi kontemporer populer lainnya adalah bahwa kernel Linux® dan komponen lainnya merupakan perangkat lunak gratis dan berkode sumber terbuka (FOSS) dan sebagian besar berlisensi GNU GPL. Sedangkan kelebihan GNU/Linux® terhadap sistem operasi lainnya adalah keamanan yang tinggi, reliabilitas, harga yang rendah, dan kebebasan dari vendor lock-in.
![Gambar 2.7 Tahap-tahap Penggunaan Perkakas HTK [11].](https://thumb-ap.123doks.com/thumbv2/123dok/4438317.3224600/15.892.264.681.170.603/gambar-tahap-tahap-penggunaan-perkakas-htk.webp)
![Gambar 2.8 Proses Pelatihan HMM [11].](https://thumb-ap.123doks.com/thumbv2/123dok/4438317.3224600/17.892.215.704.537.1038/gambar-proses-pelatihan-hmm.webp)