185
Pembentukan Prototype Data Dengan Metode
Means Untuk Klasifikasi dalam Metode
K-Nearest Neighbor (K-NN)
Khairul Umam Syaliman
Magister Teknik Informatika Fasilkom - TI USU [email protected]
Adli Abdillah Nababan
Magister Teknik Informatika Fasilkom - TI USU [email protected]
Nadia Widari Nasution
Magister Teknik Informatika Fasilkom - TI USU [email protected]
Abstrak
Metode K-Nearest Neighbor (K-NN) adalah metode klasifikasi yang sederhana. K-NN menentukan kelas suatu data berdasarkan mayoritas label dari K tetangga terdekat untuk mengklasifikasikan data tersebut. Permasalahan yang sering terjadi dalam metode ini adalah menentukan nilai K yang paling baik untuk digunakan dalam klasifikasi. Selain nilai K, model jarak yang digunakan untuk menghitung kedekatan data juga menjadi hal yang penting untuk diperhatikan. Karena termasuk dalam lazy learner, dalam mengklasifikasikan data yang baru K-NN akan menghitung kemiripan data baru keseluruh basis pengetahuna yang mengakibatkan proses klasifikasi menjadi lama. Untuk mengatasi permasalah tersebut, dalam penelitian ini penulis menciptakan prototype data dari setiap class data dengan menggunakan algoritma K-Means. Model jarak yang digunakan adalah Euclidean dengan nilai lamda 3. Penelitian ini berfokus pada pembentukan prototype data berdasarkan banyaknya data yang dapat diklasifikasikan.
Kata kunci : klasifikasi, K-Means, K-Nearest Neighbor, prototype data, Euclidean
I. LATARBELAKANG
K-Nearest Neighbor adalah metode untuk melakukan klasifikasi objek berdasarkan data pembelajaran yang terletak paling dekat dengan objek[1]. K-NN diperkenalkan pertama kali pada awal tahun 1950-an[2].
Meski K-NN tergolong metode yang sederhana dan mudah, K-NN tetap termasuk salah satu dalam top 10 algorithm[3]. Meskipun begitu K-NN juga memiliki masalah yang menarik untuk didiskusikan, antara lain adalah pemilihan K yang
186
paling sesuai untuk mengklassifikasikan suatu data. Hal ini dikarenakan metode ini hanya mengandalkan label mayoritas dari K tetangga terdekat.
Dalam mencari tetangga terdekat K-NN menggunakan model jarak, ada beberapa model jarak yang sering digunakan, antara lain manhattan, euclidean, dan lain-lain.
Dari beberapa model jarak yang dapat digunakan, model jarak euclidean menjadi model jarak yang paling sering digunakan, karena model jarak euclidean cocok untuk menentukan jarak terdekat (lurus) antara dua data[1]. Dalam penelitian kali ini akan dilakukan perhitungan dengan model jarak Euclidean.
Selain model jarak, pemilihan jumlah K juga menjadi permasalahan dalam algoritma ini. Maka dari itu, untuk mempermudah dan memfokuskan tujuan penelitian ini jumlah K yang akan digunakan untuk melakukan pengujian dimulai dari K=1 sampai K=10.
Pemilihan nilai K yang besar dapat mengakibatkan distorsi data yang besar pula, hal ini disebabkan karena setiap tetangga memiliki bobot yang sama terhadap data uji, sedangkan nilai K yang terlalu kecil bisa menyebabkan algoritma terlalu sensitive terhadap noise.
Karena termasuk kedalam Algoritma lazy learner, K-NN dalam pengklasifikasiannya akan menghitung jarak data baru ke seluruh data latih, yang mengakibatkan proses klasifikasi menjadi relative lebih lama.
Mengatasi kekurangan tersebut penelitian kali ini mencoba melakukan modifikasi sebelum melakukan klasifikasi dalam metode K-NN dengan menggunakan metode clustering K-Means yang bertujuan untuk menciptakan prototype data yang diharapkan dapat mewakali data dari setiap class data. Dimana gabungan dari dua algoritma ini selanjutnya disebut dengan K-MeansNN.
II. TINJAUANPUSTAKA
a. Klasifikasi
Secara harfiah, klasifikasi adalah pembagian sesuatu menurut kelas-kelas.
Menurut Sulistyo Basuki, klasifikasi adalah proses pengelompokan/ pengumpulan benda atau entitas yang sama, serta memisahkan benda atas entitas yang tidak sama.
Proses klasifikasi menggunakan metode K-Nearest Neighbor (K-NN) dan K-Means untuk clustering.
b. K-Nearest Neighbor
K-Nearest Neighbor (K-NN) merupakan sebuah metode untuk melakukan klasifikasi terhadap objek berdasarkan data pembelajaran yang jaraknya paling dekat dengan objek tersebut. K-NN termasuk algoritma supervised learning dimana hasil dari query instance yang baru diklasifikan berdasarkan mayoritas dari kategori pada K-NN. Kelas yang paling banyak muncul itu yang akan menjadi kelas hasil klasifikasi. Tujuan dari algoritma ini adalah mengklasifikasikan objek baru berdasarkan atribut dan training sample.
Algoritma K- Nearest Neighbor menggunakan klasifikasi ketetanggaan (neighbor) sebagai nilai prediksi dari query instance yang baru. Algoritma ini sederhana, bekerja berdasarkan jarak terpendek dari query instance ke training sample untuk menentukan ketetanggaannya [4].
Langkah-langkah untuk menghitung metode K-Nearest Neighbor antara lain:
1. Menentukan parameter k
2. Menghitung jarak antara data yang akan dievaluasi dengan semua pelatihan 3. Mengurutkan jarak yang terbentuk
4. Menentukan jarak terdekat sampai urutan k 5. Memasangkan kelas yang bersesuaian 6. Mencari jumlah kelas dari tetangga yang
terdekat dan tetapkan kelas tersebut sebagai kelas data yang akan dievaluasi
p i i i ix
x
d
1 2 1 2)
(
Keterangan: x1 = Sampel datax2 = Data uji atau data testing i = Variabel data
d = Jarak p = Dimensi data c. K-Means
K-means untuk clustering menggunakan metrik jarak untuk menemukan yang tetangga terdekat dan sebagian besar jarak Euclidean telah digunakan.
187
Fungsi objektif K-Means dapat direpresentasikan sebagai berikut:
k j n i j j ic
x
J
1 1 2 Algoritma K-Means1. Tetapkan jumlah awal centroid secara acak atau berurutan
2. Hitung jarak antara setiap titik data dan cluster pusat
3. Ulangi:
Tetapkan titik data jarak minimum ke cluster pusat yang jaraknya minimum untuk titik itu. 4. Hitung ulang cluster center dengan
menggunakan:
mi j i i ix
i
m
m
c
1
1(
);
mewakili jumlah data poin dalam (i) cluster5. Menghitung ulang jarak antara setiap titik data dan pusat cluster yang baru didapat
sampai:
Tidak ada titik data yang ditugaskan kembali.
d. Model Jarak
Model Jarak digunakan untuk menghitung jumlah kemiripan atau kedekatan suatu data.
Umam dan Labellapansa melakukan analisis terhadap model jarak Minkowski untuk menentukan jurusan yang tepat pada sekolah tinggi dengan nilai lamda 1, 2 dan 3. Jumlah data yand digunakan adalah 500 data dengan nilai lamda yang paling akurat adalah lamda 1[8].
Ause Labellapansa dkk melakukan penelitian untuk menentukan penyakit Schizophrenia dengan menggunakan model jarak minkowski dengan nilai lamda 1, 2, dan 3. Hasil yang didapati dari penelitian ini adalah saat lamda bernilai 3 hasil prediksi lebih akurat dari lamda yang bernilai 1 dan 2 [9].
Ada banyak model pengukuran jarak, dan yang paling sering digunkan antara lain model jarak Euclidea, Manhattan, Chebyshev, dan Minkowsky[1].
Pengukuran jarak pada ruang jarak Euclidean menggunakan formula :
( ) √∑
Pengukuran jarak pada ruang jarak Manhattan menggunakan formula :
( ) ∑
Pengukuran jarak pada ruang jarak Chebyshev menggunakan formula :
( ) √∑
Pengukuran jarak pada ruang jarak Minkowsky menggunakan formula :
( ) √∑
D adalah jarak antara data x dan y, N adalah jumlah fitur (dimensi) data. adalah parameter jarak Minkowsky, secara umum Minkowsky adalah generalisasi dari Euclidean dan Manhattan. merupakan parameter penentu, jika nilai λ = 1 maka ruang jarak Minkowsky sama dengan Manhattan, dan jika λ = 2 ruang jaraknya sama dengan Euclidean[6] dan jika λ= ∞ sama dengan ruang jarak Chebyshev[7].
III.HASILDANPEMBAHASAN
a. Data Yang Digunakan
Dalam penelitian ini menggunakan dua data set yang diunduh dari UCI Repository Data Set. Data yang pertama adalah berupa data iris dan data yang kedua berupa data wine.
Setiap data dibagi menjadi dua, yaitu data latih sebesar 80% dan data uji sebesar 20%. Data tersebut akan digunakan untuk menguji gabungan metode K-means dan K-NN.
Jumlah masing-masing data subset dapat dilihat pada table dibawah ini :
Tabel 1. Jumlah Setiap Data Subset
Data
Subset Latih Uji Total
Iris 120 30 150
Wine 142 36 178
188
Iris-Setosa
Iris-Versicolor Virginica Total
40 40 40 120
Tabel 3. Detail Sebaran Data Latih Wine Setiap Class
Class 1 Class 2 Class 3 Total
42 58 42 142
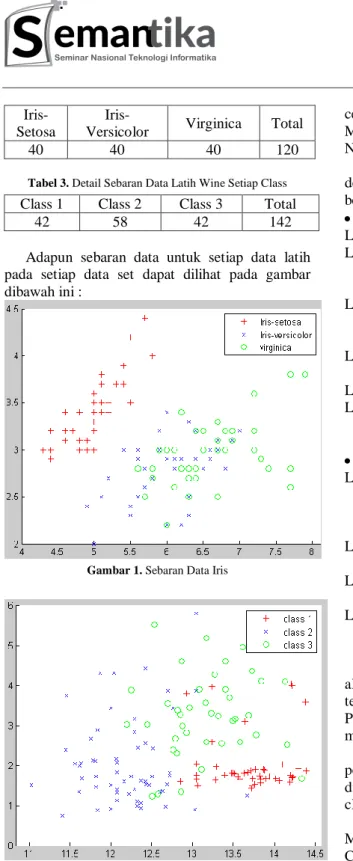
Adapun sebaran data untuk setiap data latih pada setiap data set dapat dilihat pada gambar dibawah ini :
Gambar 1. Sebaran Data Iris
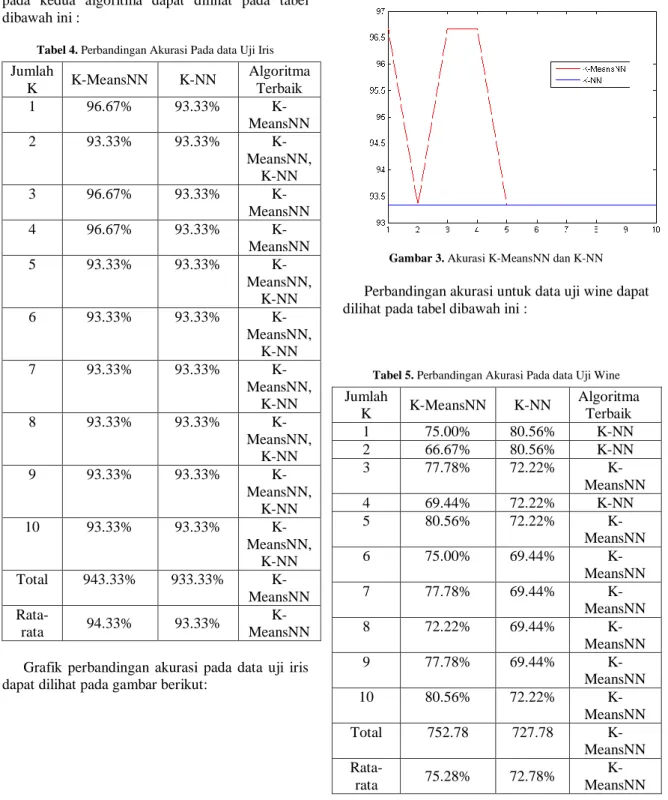
Gambar 2. Sebaran Data Wine
b. Proses K-MeansNN
Untuk melihat apakah pembentukan prototype ini berhasil atau tidak, maka akan dilihat berdasarkan perbandingan hasil klasifikasi yang dilakukan algoritma K-NN berdasarkan nilai
centroid akhir yang didapati dari algoritma Means sebagai prototype data dengan algoritma K-NN konvensional.
Tahapan proses K-MeansNN dapat dilakukan dengan mengikuti langkah-langkah sebagai berikut.
Pembentukan prototype data :
Langkah 1 : Tentukan banyak cluster (K) Langkah 2 : Untuk setiap kelompok data (Ci)
tentukan titik pusat cluster sebanyak K
Langkah 3 : Hitung jarak antara setiap data ke pusat cluster dengan menggunakan model jarak euclidean
Langkah 4 : Kelompokkan data ke cluster terdekat
Langkah 5 : Hitung pusat cluster baru
Langkah 6 : Lakukan Langkah 3 sampai Langkah 6 hingga konvergen
Klasifikasi data uji :
Langkah 7 : Hitung jarak antara data baru ke setiap pusat cluster pada setiap kelompok data (Ci) menggunakan model jarak Euclidean
Langkah 8 : Urutkan data dari pusat cluster berdasarkan jarak terdekat
Langkah 9 : Jadikan kelompok mayoritas menjadi kelompok untuk data baru Langkah 10 : Lakukan langkah 7 sampai 9 untuk
seluruh data uji
Secara sederhana, apabila dibandingkan antara algoritma K-MeansNN dan K-NN konvensional terletak pada pembelajaran dan klasifikasinya. Pada K-NN konvensional, algoritma tersebut tidak melakukan pembelajaran sama sekali.
Sedangkan K-MeansNN akan melakukan pembelajaran sehingga membentuk prototype data, dimana prototype data tersebut didapati dari pusat cluster pada setiap kelompok data.
Perbedaan dalam melakukan klasifikasinya, K-MeansNN hanya akan menghitung jarak sebanyak Ci x K untuk setiap data yang akan diklasifikasi. Sedangkan K-NN akan menghitung keseluruh data latih untuk setiap data baru.
Dalam penelitian ini, penulis menggunakan nilai K=1 sampai K=10 dengan model jarak euclidean. Dengan mengikuti langkah-langkah pada bagian III (B), maka perbandingan akurasi
189
pada kedua algoritma dapat dilihat pada tabel dibawah ini :
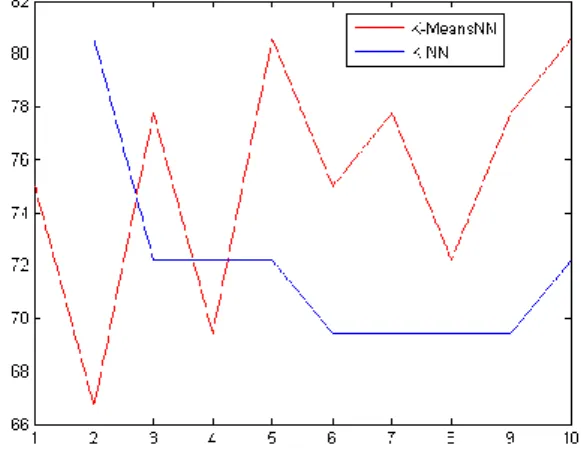
Tabel 4. Perbandingan Akurasi Pada data Uji Iris
Jumlah K K-MeansNN K-NN Algoritma Terbaik 1 96.67% 93.33% K-MeansNN 2 93.33% 93.33% K-MeansNN, K-NN 3 96.67% 93.33% K-MeansNN 4 96.67% 93.33% K-MeansNN 5 93.33% 93.33% K-MeansNN, K-NN 6 93.33% 93.33% K-MeansNN, K-NN 7 93.33% 93.33% K-MeansNN, K-NN 8 93.33% 93.33% K-MeansNN, K-NN 9 93.33% 93.33% K-MeansNN, K-NN 10 93.33% 93.33% K-MeansNN, K-NN Total 943.33% 933.33% K-MeansNN Rata-rata 94.33% 93.33% K-MeansNN Grafik perbandingan akurasi pada data uji iris dapat dilihat pada gambar berikut:
Gambar 3. Akurasi K-MeansNN dan K-NN
Perbandingan akurasi untuk data uji wine dapat dilihat pada tabel dibawah ini :
Tabel 5. Perbandingan Akurasi Pada data Uji Wine
Jumlah K K-MeansNN K-NN Algoritma Terbaik 1 75.00% 80.56% K-NN 2 66.67% 80.56% K-NN 3 77.78% 72.22% K-MeansNN 4 69.44% 72.22% K-NN 5 80.56% 72.22% K-MeansNN 6 75.00% 69.44% K-MeansNN 7 77.78% 69.44% K-MeansNN 8 72.22% 69.44% K-MeansNN 9 77.78% 69.44% K-MeansNN 10 80.56% 72.22% K-MeansNN Total 752.78 727.78 K-MeansNN Rata-rata 75.28% 72.78% K-MeansNN Grafik perbandingan akurasi pada data uji wine dapat dilihat pada gambar berikut :
190 Gambar 4. Akurasi K-MeansNN dan K-NN
IV. KESIMPULAN
Berdasarkan hasil penelitian dapat dilihat dari tabel dan gambar grafik akurasi yang telah dipaparkan maka dapat disimpulkan bahwa algoritma K-Means dapat digunakan sebagai suatu cara untuk menciptakan prototype data yang pada akhirnya prototype data tersebut dapat digunakan untuk melakukan klasifikasi dalam algoritma K-NN.
Pengujian dengan menggunakan data subset iris, diperoleh bahwa K-MeansNN berhasil mendapati nilai akurasi lebih tinggi saat nilai K=1 dengan nilai akurasi 96.67%, K=3 dengan nilai akurasi 96.67%, dan K=4 dengan nilai akurasi 96.67%, selebihnya nilai akurasi yang didapati oleh kedua algoritma adalah sama, sebesar 93.33%. Sedangkan pengujian dengan menggunakan data subser wine, diperoleh bahwa K-NN memiliki nilai akurasi yang tinggi saat nilai K=1 dengan nilai akurasi 80.56%, K=2 dengan nilai akurasi 80.56% dan K=4 dengan nilai akurasi 72.22%, selebihnya K-MeansNN mendapati nilai akurasi yang lebih tinggi.
DAFTARPUSTAKA
[1] Prasetyo, Eko. 2012. DATA MINING- Konsep dan Apliksai Menggunakan MATLAB. Andi Offset: Yogyakarta.
[2] Han, Jiawei ; Kamber, Micheline. 2007. Data Mining: Concepts and Techniques. Elsevier.
[3] Xindong, Wu., Vipin Kumar. 2009. The Top Ten Algorithms in Data Mining. Taylor & Francis Group. United States of America.
[4] Rizal Yepriyanto, dkk. Sistem Diagnosa Kesuburan Sperma Dengan Metode K-Nearest Neighbor (K-NN). Jurnal Ilmiah SINUS ISSN : 1693 – 1173
[5] Zhang, H and Guan, X. 2017. Iris Recognition Based on Grouping KNN and Rectangle Conversion. International Journal of IEEE Xplorer.
[6] Mergio, J.M., dan Casanovas, M., 2008, The Induced Minkowski Ordered Weighted Averaging Distance Operator, ESTYLF08, Cuencas Mineras (Mieres-Langreo), Congreso Espanol sobre Tecnologiasy Logica Fuzzy, pp 35-41.
[7] Rao, M.K., Swamy, K.V., seetha, K.A., dan Mohan, B.C., 2012, Face Recognition Using Different Local Feature with Different Distance Techniques, International Journal of Computer Science, Engineering and Information Technology (IJCSEIT), Vol.2, No.1, pp 67-74, DOI: 10.5121/ijcseit.2012.2107
[8] Bin Lukman, Khairul Umam Syaliman, and Ause Labellapansa. "Analisa Nilai Lamda Model Jarak Minkowsky Untuk Penentuan Jurusan SMA (Studi Kasus di SMA Negeri 2 Tualang)." Jurnal Teknik Informatika dan Sistem Informasi 1.2 (2015).
[9] Ause Labellapansa etc., 2016, Lambda Value Analysis on Weighted Minkowski Distance Model in CBR of Schizophrenia Type Diagnosis, Fourth International Conference on Information and Communication Technologies (ICoICT)