Fakultas Ilmu Komputer
3086
Analisis Perbandingan Kinerja Algoritme
Fair Share Scheduling
Dengan
Capacity Scheduling
Terhadap Pengiriman
Job
Pada Hadoop
Cluster
Multinode
Friska Anggia Nurlita Sari1, Adhitya Bhawiyuga2, Achmad Basuki3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3a[email protected]
Abstrak
Hadoop merupakan sebuah framework berbasis open-source digunakan untuk pengolahan data dengan skala besar dan tersimpan dalam sekelompok komputer yang saling terhubung dalam suatu jaringan secara terdistribusi. Hadoop terdapat beberapa algoritme penjadwalan untuk mengatur antrian job yang masuk, job yang telah dikirimoleh pengguna akan saling berkompetisi untuk merebutkan suatu resource
yang tersedia. Sehingga perlu adanya algoritme penjadwalan yang bertugas mengatur jalannya job pada sebuah resource serta mengelola pemrosesan data agar hasil yang dikeluarkan sesuai dengan apa yang diharapkan. Penelitian ini dilakukan untuk mengetahui perbandingan dari kinerja algoritme Fair Share Scheduling dan Capacity Scheduling pada pengiriman job pada Hadoop multinode untuk mengetahui nilai dari parameter Job Fail Rate, Latency, dan Throughput. Capacity Scheduling mendukung antrian secara hirarki yaitu dapat membagi resource yang tersedia pada cluster ke beberapa antrian. Fair Share Scheduling adalah metode alokasi pembagian resource pada antrian secara adil untuk seluruh job yang masuk pada antrian. Berdasarkan hasil pengujian yang telah dilakukan, memiliki nilai minimal Job Fail Rate yang lebih baik dibandingkan Fair Share Scheduling sebesar 0,99%. Fair Share Scheduling
memiliki nilai minimal Latency yang lebih baik sebesar 19,25 menit. Sedangkan nilai Throughput pada
Fair Share Scheduling lebih cepat sebesar 0,47 Mbit/s.
Kata kunci: Hadoop, Hadoop Multinode, Fair Share Scheduling, Capacity Scheduling, Job Fail Rate, Latency,
dan Throughput.
Abstract
Hadoop is a framework based on an open-source which is used for a data processing in a large scale and stored in a group of interconnected computers that are connected in a network which are distributed.Hadoop there are several scheduling algorithms to set the incoming job queue, jobs that have been submitted by the user will compete for a resource available. So the need for a scheduling algorithm in charge of managing the job on a resource and managing the data processing so that output issued in accordance with what is expected. This research was conducted to find out the comparison of performance of Fair Share Scheduling and Capacity Scheduling algorithm on job delivery on Hadoop multinode to know the value of Job Fail Rate, Latency, and Throughput parameters. Capacity Scheduling supports the queue in a hierarchy that is able to divide the available resources in the cluster into multiple queues. Fair Share Scheduling is a fair allocation of resource allocation methods for queues for all jobs that enter the queue. Based on the results of tests that have been done, has a minimum value of Job Failed Rate is better than Fair Share Scheduling of 0.99%. Fair Share Scheduling has a minimum value of better Latency of 19.25 minutes. While the value of Throughput on Fair Share Scheduling faster by 0.47 Mbit/s.
Keywords: Hadoop, Hadoop Multinode, Fair Share Scheduling, Capacity Scheduling Job Fail Rate, Latency, dan
Throughput.
1. PENDAHULUAN
Dengan besarnya kebutuhan data yang digunakan pada saat ini maka terjadi
diolah dan diproses. Dengan semakin rumitnya pengelolahan data dalam jumlah yang sangat besar tersebut, dapat diatasi dengan menggunakan Hadoop. Hadoop merupakan sebuah framework yang digunakan untuk pengolahan data dengan skala besar dan tersimpan dalam sekelompok komputer yang saling terhubung dalam suatu jaringan secara terdistribusi dan berjalan diatas cluster.
Big data merupakan sekumpulan data yang kompleks dan berskala besar melebihi kapasitas pemrosesan sistem database sehingga sangat sulit untuk diproses dengan cara pemrosesan data secara konvesional (Edd Dumbill,2012). Pada Big Data dikenal istilah 3V yaitu Volume, Variety, dan Velocity. Volume disini mengacu pada jumlah ukuran data, Variety yaitu jenis atau tipe data yang akan dikelola kompleksitasnya, sedangan pada Velocity yaitu kecepatan pada pemrosesan data (Azzeddine, 2015).
Pada Hadoop terdapat tiga komponen utama didalamnya yaitu MapReduce, Hadoop
Distributed File System (HDFS) dan Yet Another Resource Negotiator (YARN). MapReduce merupakan model pemrograman yang digunakan untuk melakukan pemrosesan data dengan skala besar. HDFS merupakan sistem file terdistribusi yang digunakan sebagai tempat penyimpanan dan pengolahan data berukuran besar. YARN digunakan untuk mengatur sumber daya komputasi dalam cluster
dan scheduling Hadoop. Untuk melakukan pengolahan data yang besar diperlukan sebuah pemrosesan terhadap job. Jumlah job yang harus dieksekusi harus lebih besar dari jumlah mesin yang tersedia. Sehingga kondisi ini harus membutuhkan sebuah antrian. Untuk memilih salah satu job yang harus dieksekusi dalam sebuah antrian maka diperlukan scheduling.
Penelitian ini akan membandingan dua algoritme penjadwalan yaitu Fair Share Scheduling dan Capacity Scheduling. Fair Share Scheduling adalah metode alokasi pembagian
resource pada antrian secara adil untuk seluruh
job yang masuk pada antrian. Capacity Scheduling mendukung antrian secara hirarki yaitu dapat membagi resource yang tersedia pada cluster ke beberapa antrian dan terdapat fitur prediksi job sehingga dapat meminimalkan nilai failed pada job yang akan dijalankan (Tom White, 2015). Dengan melakukan perbandingan tersebut bertujuan untuk mengetahui kinerja terbaik diantara kedua algoritme penjadawalan tersebut pada pengiriman job pada cluster
Hadoop berdasarkan pada parameter pengujian
yang telah digunakan.
Pengujian ini dilakukan dengan 3 skenario pengujian yang berbeda berdasarkan pada variabel bebas dan variabel tetap. Untuk skenario pengujian pertama menggunakan variabel bebas yaitu variasi ukuran data dan variabel tetap yaitu jumlah job dan jenis job. Skenario pengujian kedua menggunakan variabel bebas yaitu variasi jumlah job dan variabel tetap yaitu ukuran data dan jenis job. Skenario pengujian ketiga menggunakan variabel bebas yaitu variasi jenis job dan variabel tetap yaitu ukuran data dan jumlah job. Pada pengujian ini akan menggunakan parameter pembanding yaitu Job Fail Rate, Latency, dan Throughput sebagai acuan perhitungan kinerja sistem untuk mendapatkan hasil berupa grafik nilai yang dilakukan untuk perbandingan kinerja antara kedua algoritme tersebut.
2. TINJAUAN KEPUSTAKAAN 2.1 Hadoop
Hadoop merupakan suatu framework open source berbasis java dibawah lisensi Apache yang digunakan sebagai pengolah data yang berukuran besar dan desain sistem file secara terdistribusi. Hadoop ini berjalan diatas cluster
yang saling terhubung dengan beberapa komputer lainnya. Hadoop disebut juga sebagai
analytic engine yang digunakan seseorang untuk melakukan pembuatan penulisan perintah (write) dan menjalankan (run) aplikasi pemrosesan data dalam jumlah besar. Ada 3 komponen penyusun Hadoop yaitu Hadoop Distributed File System (HDFS), MapReduce, dan Yet Another Resource Negotiator (YARN).
2.1.1 HDFS (Hadoop Distributed File System)
HDFS sebagai direktori komputer dimana data Hadoop disimpan. HDFS umumnya diklasifikasikan menjadi dua bagian yang disebut dengan namenode dan datanode.
Namenode terletak pada server induk yang digunakan untuk mengelola sistem file
namespace seperti membuka, menutup, mengganti nama file atau direktori dan juga digunakan untuk mengatur akses file yang dilakukan oleh slave. Datanode digunakan untuk menyimpan data atau file. Pada datanode dalam satu file dibagi menjadi beberapa blok file
biasanya setiap blok file berukuran 128 MB. Setiap blok file akan direplikasi di datanodes,
replica ini diwakili oleh dua file dalam file
2.1.2 MapReduce
MapReduce merupakan model pemrograman untuk pemrosesan data berskala besar. MapReduce sebagai sistem yang mendasari untuk melakukan partisi input data, membuat jadwal eksekusi program di beberpa mesin,
handling kegagalan mesin, dan mengatur komunikasi yang diperlukan antar mesin. Komponen utama dari MapReduce adalah Job Tracker dan TaskTracker. Job Tracker adalah
master dari TaskTracker yang mengatur jadwal serta mengkoordinasi semua job yang telah di
submit oleh slave dan juga menangani distribusi
job ke TaskTracker. TaskTracker untuk menerima job dari Job Tracker dan memutuskan
job tersebut kedalam mapreduce task. TaskTracker juga melakukan eksekusi tugas dan melaporkan status terbaru kepada Job Tracker
dengan mengirimkan pesan heartbeat dan mengirimkan hasil terakhirnya (Ruchi, 2015).
2.1.3 YARN (Yet Another Resource Negotiator)
YARN merupakan salah satu komponen tambahan yang terdapat pada Hadoop versi 2. YARN merupakan sebuah platform pengolahan data yang secara umum disediakan oleh Hadoop untuk meningkatkan kemampuan MapReduce. Komponen dalam YARN adalah
Resourcemanager dan Nodemanager. Pada
resource manager mempunyai schedulercluster
yang digunakan untuk mengalokasikan resource
ke berbagai job yang sedang berjalan sesuai dengan batasan kapasitas antrian, batas pengguna. Pada node manager yang berjalan pada semua node yang terdapat pada cluster
untuk memulai dan memantau container,
memantau penggunaan resource (cpu, memori,
disk, jaringan) dan melaporkan ke
ResourceManager.
2.2 Hadoop Multinode
Hadoop multinode menggunakan gabungan dari 2 mesin server single node, 1 mesin untuk komputer master dan 1 mesin untuk komputer
slave. Pada Hadoop multi node ini, komputer
slave menggunakan 5 buah komputer. Sehingga pada Hadoop multinode ini dapat melakukan pengiriman job oleh beberapa pengguna secara bersama-sama. Pada HDFS, komputer master ini menjalankan namenode, jps, SecondaryNameNode, dan ResourceManager.
Sedangkan pada komputer slave menjalankan
datanode, jps, dan NodeManager.
2.3 Algoritme Fair Share Scheduling
Fair Share Scheduling merupakan metode yang digunakan untuk membagi setiap job agar mendapatkan resource yang sama dengan job
yang lainnya dari waktu ke waktu.. Dalam Fair Share Scheduling memungkinkan untuk job
dijalankan secara default, tetapi juga memungkinkan untuk melakukan pembatasan pengguna yang sedang menjalankan job melalui
file yang telah dikonfigurasi. Pembatasan job
tersebut berguna jika pengguna yang mengirimkan job kedalam cluster dengan jumlah yang sangat banyak. Karena terlalu banyak data dan konteks-switching sehingga mengakibatkan kinerja dari Fair Share Scheduling semakin melambat. Dengan melakukan pembatasan job
ini tidak menyebabkan job tersebut gagal, hanya saja harus menunggu dalam antrian sampai beberapa job dari pengguna sebelumnya telah selesai dilakukan (Apache,2016).
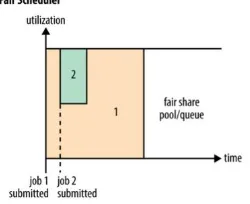
Pada gambar tersebut terdapat satu jenis
pool atau queue. Fair Share Scheduling adalah metode alokasi pembagian resource pada antrian secara adil untuk seluruh job yang masuk pada antrian. Ketika pengguna men-submit job 1, maka job tersebut akan menggunakan semua
resource yang tersedia karena tidak terdapat permintaan pada job lain. Kemudian pengguna mensubmit job 2 pada antrian meskipun job 1 masih berjalan, maka setelah beberapa saat pada masing-masing job akan menggunakan setengah dari resource yang tersedia. Jadi setiap job pada
queue akan mendapat setengah dari total keseluruhan resource yang ada pada cluster
tersebut.
Gambar 1. Sistem kerja job Fair Share Scheduling
Sumber : Tom White (2015)
2.4 Algoritme Capacity Scheduling
Capacity Scheduling merupakan sebuah algoritme penjadwalan pada YARN yang terdapat fitur queuing priority, sub-queue, dan dan prediksi kesalahan pada job. Pada suatu
queue memiliki prioritas untuk mengakses
resource dalam cluster. Ketika slot dalam queue
menggunakan queue tersebut meskipun queue
tersebut tidak memiliki prioritas job. Kemudian ketika pengguna melakukan submit job dengan
queue priority, maka queue yang memiliki prioritas tersebut akan langsung mendapatkan slot dari slot queue yang telah dipakai oleh job
yang tidak memiliki prioritas dengan menghentikan layanan terhadap job tersebut (Jagmohan, 2012).
Capacity Scheduling mendukung antrian secara hirarki untuk memastikan bahwa resource
tersebut dibagi di antara sub-antrian sebelum antrian lain yang diperbolehkan untuk menggunakan resource yang kosong. Dalam mengatur cluster membutuhkan dukungan yang sangat kuat dalam multi-tenancy karena untuk menjamin kapasitas yang tersedia. Capacity Scheduling menyediakan batas slot untuk memastikan bahwa suatu antrian tidak dapat memakan jumlah resource yang tidak sesuai dalam sebuah cluster. Selain itu, Capacity Scheduling dapat memberikan batas antrian yang diinisialisasi pada pengguna untuk menjamin stabilitas cluster. Untuk memberikan control lebih lanjut, maka Capacity Scheduling ini mendukung konsep antrian secara hierarki untuk memastikan resource yang dibagi antara sub-antrian dari sebuah slot sebelum sub-antrian lain dijalankan (Divya,2015).
Pada gambar 2 menunjukkan proses pengiriman job yang masuk dalam suatu antrian pada pada algoritme Capacity Scheduling
.
Gambar 2. Sistem kerja job Capacity Scheduling
Sumber : Tom White (2015)
2.5 Pengujian
Pengujian ini menggunakan parameter
Job Fail Rate, Latency, dan Throughput yang dipakai untuk membandingkan kinerja dari algoritme Fair Share Scheduling dan Capacity Scheduling.
2.5.1 Job Fail Rate
Pada parameter Job Failed Rate ini digunakan untuk melakukan pengukuran jumlah
job yang mengalami kegagalan. Job yang gagal tersebut akan terus diulang kembali prosesnya.
Berikut adalah rumus yang digunakan untuk menghitung nilai fail rate yaitu (Yang XIA, 2011) :
Fail rate = 𝜆1 𝑥 𝑡𝑖𝑚𝑒𝑜𝑢𝑡 + 𝜆2 𝑥 𝑒𝑟𝑟𝑜𝑟 𝑠𝑢𝑚
Dimana 𝜆1 merupakan bobot dari
timeout dengan nilai 0,5. Timeout merupakan jumlah waktu dimana job mengalami kegagalan.
𝜆2 merupakan bobot dari error dengan nilai 1.
Error merupakan jumlah job yang gagal dan diulang kembali. Sedangkan sum merupakan jumlah keseluruhan dari job yang telah dimasukan dalam server Hadoop.
2.5.2 Latency
Pada parameter ini digunakan untuk mengukur rata-rata waktu yang dibutuhkan suatu
job untuk dikerjakan dari client ke server dalam suatu antrian. Nilai yang dihasilkan untuk
Latency ini diperoleh dari waktu awal suatu job
dikerjakan sampai waktu job selesai dikerjakan dan dibagi oleh jumlah job yang telah ditentukan. Satuan yang digunakan dalam
Latency ini adalah menit.
2.5.3 Throughput
Pada parameter ini digunakan untuk mengukur kecepatan rata-rata data yang diterima oleh suatu node dalam selang waktu tertentu. Parameter ini akan diperoleh dari ukuran data yang dikirim dibagi dengan waktu pengiriman data secara keseluruhan. Satuan yang digunakan untuk menghitung nilai Througput adalah bit/sec.
Throughput = Ukuran data yang diterima (Bytes) Waktu pengiriman data (sec)
3 METODOLOGI
Gambar 3. Diagram alir metode penelitian
3.1 Topologi Jaringan
Pada pembangunan sistem Hadoop diperlukan infrastruktur jaringan yang dibutuhkan untuk membangun komunikasi antar
node yang bersifat multinode.
Perancangan
topologi jaringan dapat dilihat pada gambar
4.
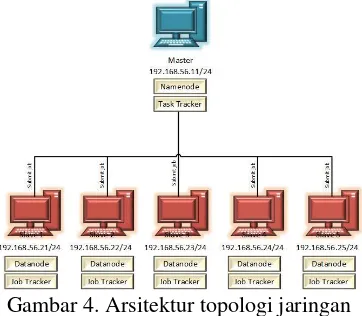
Gambar 4. Arsitektur topologi jaringan
Pada gambar 4 arsitektur perancangan sistem terdiri 1 komputer head master dan 5 komputer virtual yang digunakan sebagai komputer slave. Kemudian akan dilakukan konfigurasi Hadoop multi node cluster, dimana nantinya keenam komputer tersebut akan saling terhubung. Kelima komputer slave tersebut digunakan untum mengirim job ke komputer
master. Jenis job yang digunakan untuk distribusi data berupa job wordcount dan job wordmean.
3.2 Pengujian
Tahap pengujian pada penelitian ini dilakukan pada Hadoop multinode yang terdiri dari 3 skenario pengujian yang berbeda pada masing-masing algoritme Fair Share Scheduling
dan Capacity Scheduling. Pada masing-masing algortima scheduling akan dilakukan pengiriman
job dari slave ke master Hadoop berdasarkan skenario pengujian yang ditentukan. Pengujian ini dilakukan dengan 3 skenario pengujian yang berbeda berdasarkan pada variabel bebas dan variabel tetap. Untuk skenario pengujian pertama menggunakan variabel bebas berupa variasi ukuran data dan variabel tetap yaitu jumlah job dan jenis job. Skenario pengujian kedua menggunakan variabel bebas berupa variasi jumlah job dan variabel tetap yaitu ukuran data dan jenis job. Skenario pengujian ketiga menggunakan variabel bebas berupa variasi jenis job dan variabel tetap yaitu ukuran
data dan jumlah job.
Tabel 1. Skenario Penujian
4 IMPLEMENTASI DAN PENGUJIAN
Pada tahap implementasi, akan dijelaskan langkah-langah yang akan dilakukan dalam proses analisis kinerja algoritme fair scheduling
dengan capacity scheduling pada Hadoop cluster multinode dengan melakukan konfigurasi pada kedua algoritme penjadwalan.
4.1 Implementasi Hadoop
Berikut langkah-langkah untuk melakukan konfigurasi pada Hadoop.
1. Siapkan virtual machine Ubuntu dengan menggunakan virtual box.
2. Melakukan konfigurasi alamat ip pada setiap node.
3. Melakukan instalasi java pada setiap node dengan printah “sudo apt-get install
default-jdk”.
4. Membuat grup user dengan printah”sudo
adduser –ingroup Hadoop hduser”.
5. Melakukan instalasi ssh dengan perintah
“sudo apt-get install ssh”.
6. Lalu konfigurasi id rsa dengan perintah “ssh -keygen -t rsa -P "" “. Kemudian ketik “cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/
authorized_keys”.
7. Download Hadoop dengan menggunakan Hadoop versi 2.7.3 “wget http:// mirror.wanxp.id/apache/hadoop/ common/ hadoop-2.7.3/hadoop-2.7.3.tar. gz”.
8. Lakukan konfigurasi pada file Hadoop dengan merubah beberapa parameter yang terdapat dalam dokumen yaitu pada file
hadoop-env.sh, core-site.xml, mapred-site.xml, hdfs-mapred-site.xml, dan yarn-site.xml.
4.2 Implementasi Fair Share Scheduling
Untuk menerapkan Fair Share Scheduling, administrator perlu melakukan konfigurasi pada
file yarn-site.xml dan fair-scheduler.xml untuk menempatkan job yang diajukan kedalam antrian sesuai dengan pengujian yang dilakukan.
Tambahkan parameter “yarn.resource
yarn-site.xml konfigurasi untuk mengelola scheduling
Hadoop pada resource manager. <property>
<name>yarn.resourcemanager.scheduler.class </name>
<value>org.apache.hadoop.yarn.server.resourc emanager.scheduler.fair.FairScheduler</value> </property>
Selain melakukan konfigurasi pada file yarn-site.xml, administrator juga melakukan konfigurasi pada file fair-scheduler.xml.
Pada Fair Share Scheduling untuk melihat informasi pada daftar antrian bisa dilakukan dengan membuka antarmuka dari YARN
resourcemanager.
Gambar 5. Daftar antrian fair share scheduling
pada Resource Manager
4.3 Implementasi Capacity Scheduling
Dalam melakukan konfigurasi pada Capacity Scheduling, administrator perlu melakukan pengaturan konfigurasi pada file yarn-site.xml dan capacity-scheduler.xml.
pada komputer master seorang administrator harus menambahkan parameter
“yarn.resourcemanager.scheduler.class”.Namun secara default pada Hadoop versi 2 telah menggunakan Capacity Scheduling, jadi bisa langsung menentukan antrian pada cluster.
<property>
<name> yarn.resourcemanager.scheduler.class </name>
<value>org.apache.hadoop.yarn.server.resource
manager.scheduler.capacity.CapacityScheduler </value>
</property>
Selain itu, administrator juga melakukan konfigurasi pada file capacity-scheduler.xml. Administrator perlu menentukan struktur antrian yang digunakan pada pengujian untuk pengiriman job.
Pada Capacity Scheduling untuk melihat informasi pada daftar antrian bisa dilakukan dengan membuka antarmuka dari YARN
resourcemanager.
Gambar 6. Daftar antrian capacity scheduling
pada Resource Manager
4.4 Pengujian
Pengujian pada algoritme penjadwalan
Fair Share Scheduling dan Capacity Scheduling
ini dilakukan untuk mengetahui perbandingan kinerja dari kedua algoritme tersebut berdasarkan pada pengiriman job yang diajukan pada cluster Hadoop. Pengujian ini dilakukan dengan 3 skenario pengujian yang berbeda.
4.4.1 Pengujian Variasi Ukuran Data
Pada skenario pengujian ini dilakukan dengan menggunakan variabel bebas berupa variasi ukuran data, sedangkan variabel tetap berupa jenis job dan jumlah job. Variasi ukuran data yang digunakan adalah 1,5 GB, 286,81 MB, dan 20 MB. Sedangkan jenis job yang digunakan adalah jobwordcount dan jumlah job sebanyak 5 job. Pada skenario pengujian ini menggunakan 5 buah nodeslave untuk melakukan pengiriman
job pada masing-masing algoritme Fair Share Scheduling dan Capacity Scheduling.
4.4.2 Pengujian Variasi Jumlah Job
Pada skenario pengujian ini dilakukan dengan menggunakan variabel bebas berupa variasi jumlah job, sedangkan variabel tetap berupa jumlah ukuran data dan jenis job. Variasi jumlah job yang digunakan adalah 5 job, 10 job, dan 15 job. Sedangkan jumlah ukuran data yang digunakan adalah 1,5 GB dan jenis job yang digunakan adalah job wordcount. Pada skenario pengujian ini menggunakan 5 buah node slave
untuk melakukan pengiriman job pada masing-masing algoritme Fair Share Scheduling dan
Capacity Scheduling.
4.4.3 Pengujian Variasi Jenis Job
Pada skenario pengujian ini dilakukan dengan menggunakan variabel bebas berupa variasi jenis job, sedangkan variabel tetap berupa jumlah ukuran data dan jumlah job. Variasi jenis
job wordmean. Sedangkan jumlah ukuran data yang digunakan sebesar 1,5 GB dan jumlah job
yang digunakan sebanyak 5 job. Pada skenario pengujian ini menggunakan 5 buah node slave
untuk melakukan pengiriman job pada masing-masing algoritme Fair Share Scheduling dan
Capacity Scheduling.
5. HASIL DAN ANALISIS
5.1 Nilai Job Failed Rate pada skenario variasi ukuran data
Gambar 7. Grafik Perbandingan Job Failed Rate pada skenario variasi ukuran data
Hasil nilai dari parameter Job Fail Rate
terlihat bahwa pada Fair Share Scheduling dan
Capacity Scheduling memiliki nilai Fail rate
maksimum pada pengiriman job dengan ukuran
dataset sebesar 1,5 GB kemudian semakin menurun seiring dengan semakin kecilnya ukuran dataset yang digunakan. Semakin besar ukuran data set yang digunakan maka proses pembacaan maps akan semakin lama dan mengakibatkan nilai failed dan nilai timeout
semakin besar. Untuk perbandingan besar nilai
Job Fail Rate pada algoritme Capacity Scheduling memiliki nilai maksimal sebesar 2.95%, sedangkan pada algoritme Fair Share Scheduling memiliki nilai maksimal sebesar 3.45% pada pengiriman job dengan ukuran data 1,5 GB.
5.2 Nilai Latency pada skenario variasi ukuran data
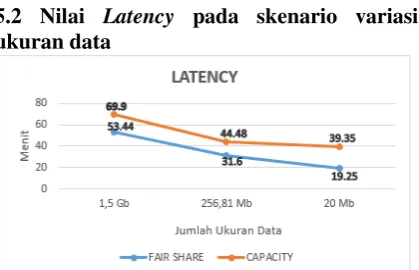
Gambar 8. Grafik Perbandingan Latency pada Skenario 1
Hasil nilai dari parameter Latency, dapat
dilihat bahwa rata-rata waktu yang dibutuhkan
Fair Share Scheduling dari masing-masing jumlah job yang telah dieksekusi kedalam antrian memiliki waktu pengerjaan yang lebih cepat dengan nilai maksimal sebesar 53,44 menit, sedangkan pada algoritme Capacity Scheduling memiliki nilai maksimal sebesar 69,9 menit. Pada Fair Share Scheduling dapat melakukan running job sebanyak 3 job pada waktu yang bersamaan dengan membagi
resource secara adil antara job satu dengan job
lainnya, sehingga proses pengerjaan job akan lebih cepat selesai jika dibandingkan dengan
Capacity Scheduling.
5.3 Skenario 1 pengujian pada response time
Gambar 9. Grafik Perbandingan Throughput
pada skenario variasi ukuran data
Pada variasi ukuran data dengan pengiriman job wordcount berdasarkan pengaruh pada jumlah ukuran dataset yang digunakan. Jika dilihat dari gambar tersebut grafik akan semakin menurun setiap berkurangnya jumlah ukuran data yang digunakan. Hal ini dikarenakan semakin kecil ukuran data yang digunakan, maka semakin kecil juga ukuran data yang diterima. Interval waktu selama job dikerjakan juga memengaruhi nilai throughput. Semakin besar jumlah ukuran data yang digunakan maka semakin lama waktu yang dibutuhkan job untuk menyelesaikannya.
Untuk perbandingan kecepatan pengiriman data pada algoritme Capacity Scheduling memiliki nilai maksimal sebesar 0,36 Mbit/s, sedangkan pada algoritme Fair Share Scheduling memiliki nilai maksimal sebesar 0,47 Mbit/s. Hal ini dikarenakan nilai
timeout pada Capacity Scheduling lebih rendah sehingga untuk melakukan pengiriman data akan semakin cepat jika dibandingkan dengan Fair Share Scheduling.
Gambar 10. Grafik Perbandingan Job Failed Rate pada variasi jumlah job
Hasil dari parameter Job Failed Rate
terlihat bahwa pada Fair Share Scheduling dan
Capacity Scheduling memiliki nilai Fail rate
manimum pada pengiriman job ke 5 pertama kemudian semakin meningkat seiring dengan bertambahnya jumlah job yang telah dieksekusi. Semakin banyak jumlah job yang dikerjakan maka antrian yang terjadi akan semakin banyak. Dengan semakin banyaknya antrian tersebut, job
akan semakin lama menunggu hingga proses eksekusi dilakukan. Dengan semakin lama proses eksekusi job tersebut maka akan menimbulkan nilai failed yang dapat menghambat waktu pengerjaan job. Pada algoritme Capacity Scheduling memiliki nilai minimal sebesar 2.05%, sedangkan pada algoritme Fair Share Scheduling memiliki nilai minimal sebesar 2.65%. Jadi algoritme Capacity Scheduling memiliki nilai fail rate yang lebih rendah jika dibandingkan dengan algoritme Fair Share Scheduling.
5.5 Nilai Latency pada skenario variasi jumlah job
Gambar 11. Grafik perbandingan Latency pada variasi jumlah job
Secara keseluruhan perbandingan besar nilai Latency pada algoritme Capacity Scheduling memiliki nilai maksimal sebesar 118,69 menit, sedangkan pada algoritme Fair Share Scheduling memiliki nilai maksimal sebesar 99,89 menit. Pada Fair Share Scheduling dan Capacity Scheduling memiliki
nilai Latency minimum pada pengiriman job ke 5 pertama kemudian semakin meningkat seiring dengan bertambahnya jumlah job yang telah dieksekusi. Hal ini disebabkan karena pengaruh nilai failed yang semakin banyak seiring dengan bertambahnya job yang dieksekusi maka akan menghambat proses pengerjaan job dan nilai
timeout yang diperoleh juga semakin lama sehingga tidak dapat memaksimalkan waktu pengerjaan job.
5.6 Nilai throughput pada skenario variasi jumlah job
Gambar 12. Grafik Perbandingan Throughput
pada Variasi jumlah job
Dari data tersebut semakin besar jumlah
job yang digunakan dalam skenario ini maka semakin kecil kecepatan pengiriman data yang di dapat. Hal ini dikarenakan semakin besar jumlah job yang digunakan maka akan bertambah banyak antrian suatu job, sehingga akan menyebabkan timeout. Semakin besar nilai
timeout maka semakin lama waktu pengerjaan suatu job sehingga akan memperkecil nilai throughput. Semakin besar nilai Throughput
semakin besar kecepatan pengiriman data suatu jaringan, maka semakin baik jaringan tersebut. Algoritme Capacity Scheduling memiliki nilai maksimal sebesar 0,36 Mbit/s, sedangkan pada algoritme Fair Share Scheduling memiliki nilai maksimal sebesar 0,47 Mbit/s.
5.7 Nilai Job Failed Rate pada skenario variasi jenis job
Hasil dari parameter Job Fail Rate terlihat bahwa pada jobwordmean memiliki perbedaan nilai Fail rate yang cukup kecil jika dibandingkan dengan job wordcount. Hal ini dikarenakan karena job wordmean melakukan proses pengerjaan job yang sederhana yaitu hanya melakukan proses perhitungan jumlah panjang kata dalam suatu file, sehingga pada eksekusi maps yang dijalankan akan semakin cepat dibandigkan dengan job wordcount yang akan menghitung kemiripan jumlah kata yang terdapat pada file. Dengan semakin cepat proses eksekusi maps tersebut maka akan meminimalisir munculnya failed pada saat dilakukannya proses pengiriman, sehingga akan berpengaruh pada nilai fail rate. Untuk perbandingan besar nilai Job Fail Rate pada algoritme Capacity Scheduling memiliki nilai minimal sebesar 1.81%, sedangkan pada algoritme Fair Share Scheduling memiliki nilai minimal sebesar 2.92% pada pengiriman job
wordmean. Jadi algoritme Capacity Scheduling
memiliki nilai fail rate yang lebih rendah jika dibandingkan dengan algoritme Fair Share Scheduling.
5.8 Nilai Latency pada skenario variasi jenis job
Gambar 14. Grafik Perbandingan Latency pada Variasi jenis job
Secara keseluruhan hasil dari parameter
Latency dapat dilihat bahwa bahwa rata-rata waktu yang dibutuhkan Fair Share Scheduling
dari masing-masing jenis job memiliki waktu pengerjaan yang lebih cepat jika dibandingkan dengan Capacity Scheduling. Pada job wordmean memiliki perbedaan nilai Latency
lebih cepat jika dibandingkan dengan job wordcount. Karena pada proses pengerjaan dengan menggunakan job wordmean memiliki nilai timeout yang lebih sedikit dibandingkan dengan job wordcount. Pada nilai timeout
tersebut akan berpengaruh pada cepat dan lamanya job untuk dieksekusi. Pada algoritme
Capacity Scheduling memiliki nilai minimal sebesar 65,3 menit, sedangkan pada algoritme
Fair Share Scheduling memiliki nilai minimal
sebesar 50,2 menit pada pengiriman job
wordmean. Jadi algoritme Fair Share Scheduling memiliki rata-rata nilai Latency yang lebih rendah jika dibandingkan dengan algoritme
Fair Share Scheduling
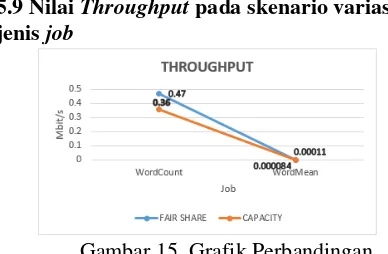
5.9 Nilai Throughput pada skenario variasi jenis job
Gambar 15. Grafik Perbandingan
Throughput pada Variasi jenis job
Secara keseluruhan hasil dari parameter
Throughput dapat dilihat bahwa bahwa kecepatan pengiriman data yang dibutuhkan
pada job wordcount dari masing-masing memiliki kecepatan pengiriman data yang lebih cepat jika dibandingkan dengan job wordmean.
Dapat dibuktikan pada algoritme Fair Share Scheduling dengan Capacity Scheduling yang memiliki selisih nilai Throughput pada job wordcount sebesar 0,11 Mbit/s sedangkan pada
jobwordmean memiliki selisih nilai Throughput
sebesar 0.000026 Mbit/s. Karena pada proses pengerjaan dengan menggunakan job wordcount
lebih cepat jika dibandingkan dengan job wordmean. Dengan menggunakan job wordmean maka kecepatan pengiriman data juga akan semakin tinggi, meskipun kedua jenis job
tersebut menggunakan ukuran dataset yang sama.
6 PENUTUP
6.1 Kesimpulan
Berdasarkan dari pengujian, maka dapat ditarik kesimpulan sebagai berikut.
1. Algoritma Fair Share Scheduling dan
Capacity Scheduling dirancang dan disimulasikan menggunakan framework Hadoop dengan versi 2.7.3. Pengujian sistem yang dilakukan pada penelitian ini dilakukan dengan tiga skenario berbeda yaitu berdasarkan pada variasi ukuran data, variasi jumlah job, dan variasi jenis job. 2. Nilai dari parameter Job Fail rate pada
Capacity Scheduling lebih baik jika dibandingkan dengan Fair Share Scheduling
Karena
Capacity Scheduling
semakin
bertambahnya
job
yang dijalankan maka
semakin memperkecil nilai
timeout
sehingga dapat mengalami penurunan
pada nilai
failed rate
.
Nilai dari parameterLatency pada Fair Share Scheduling lebih baik jika dibandingkan dengan Capacity Scheduling dengan nilai minimal sebesar 19,25%.
Karena pada
Fair Share
Scheduling
dapat melakukan
running
job
sebanyak 3
job
pada waktu yang
bersamaan dengan membagi
resource
secara adil antara
job
satu dengan
job
lainnya, sehingga proses pengerjaan
job
akan lebih cepat selesai.
Nilai dari parameter Throughput pada Fair Share Scheduling memiliki kecepatan pengiriman data yang lebih baik jika dibandingkan dengan Capacity Scheduling dengan nilai maksimal sebesar 0,47Mbit/s.6.2 Saran
Berikut ini saran untuk para peneliti yang ingin melakukan pengembangan pada penelitian ini yaitu.
1. Mengganti algoritme job scheduling Hadoop lain pada server Hadoop.
2. Melakukan modifikasi pada jenis job yang berbeda dengan penelitian ini.
3. Menambahkan jumlah job sesuai kebutuhan.
4. Melakukan modifikasi pada parameter pengujian yang berbeda pada penelitian ini.
DAFTAR PUSTAKA
Apache Software Foundation, 2016. Hadoop :Fair Scheduler. ApacheHadoop, [online] Tersedia di : <https://Hadoop. apache.org/docs/r2.7.3/Hadoop-yarn/ Hadoop-yarn-site/Fair Scheduler.html> [Diakses 21 Maret 2017]
Apache Software Foundation, 2016. Hadoop :
Capacity Scheduling. ApacheHadoop, [online] Tersedia di : <https://Hadoop. apache.org/docs/r2.7.2/Hadoop-yarn/ Hadoop-yarn-site/CapacityScheduler. html> [Diakses 21 Maret 2017]
Azzeddine and Sara, August 2015, “The Big Data Revolution, Issues and
Applications”, International Journal of
Advanced Research in Komputer Science and Software Enggineering Vol. 5, Issue 8, pp.167-173.
Divya S, Kanya Rajesh, et al, 2015, “Big Data Analysis and Its Scheduling Policy – Hadoop”, IOSR Journal of Komputer Engineering Vol.17, Ver. IV, pp.36-40. Edd Dumbill, 2012, Planning for Big Data : A
CIO’s Handbook to the Changing Data
Landscape. 1005 Gravenstein Highway North, Sebastopol, CA 95472.
Jagmohan, C., Dwight, M., dan Winfried, G., 2012, The Impact of Capacity Scheduling Configuration Settings on MapReduce Jobs. Journal International Conference, Xiangtan, China.
Ruchi Mittal dan Ruhi Bagga, 2015, “
Performance Analysis of Multi-Node Hadoop Clusters using Amazon EC2
Instances” International Journal of
Science and Research (IJSR), Vol.4, Issue.10, pp.1646-1650.
Tom White, 2015. Hadoop: The Definitive Guide, Third Edition. O’REILLY, E -Book 4th Edition, pp.1-805.
Yang XIA, Lei WANG,et al, 2011, “Research on