Fakultas Ilmu Komputer
Peramalan Jumlah Pemakaian Air di PT Pembangkit Jawa Bali Unit
Gresik dengan
Extreme Learning Machine
dan
Ant Colony Optimization
Anim Rofi’ah1, Imam Cholissodin2, Candra Dewi3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
PT. PJB Unit Gresik memanfaatkan air laut sebagai tenaga pembangkit listrik tenaga uap. Air memiliki kelebihan mudah didapat dan lebih ramah lingkungan. Namun air laut membutuhkan proses pemurnian terlebih dahulu agar dapat digunakan. Penggunaan air laut dalam pembangkit listrik sering mengalami masalah pengurangan air yang diakibatkan masalah-masalah tertentu seperti kebocoran pipa, adanya tempering, dan pembuangan gas-gas yang masih mengandung air sehingga siklus membutuhkan penambahan air agar turbin tetap bekerja. Untuk mengantisipasi kekurangan air yang dapat menghambat proses tersebut dibutuhkan suatu sistem cerdas yang dapat memperkirakan jumlah air yang dibutuhkan oleh proses pembangkitan. Salah satu metode peramalan adalah Extreme Learning Machine (ELM), untuk memaksimalkan hasil peramalan dilakukan optimasi dengan algoritme Ant Colony Optimization
yang dapat digunakan dalam optimasi input weight dan bias sebagai parameter ELM. Setelah melakukan optimasi untuk parameter ELM maka dilakukan proses training dan testing untuk mendapatkan hasil peramalan. Penelitian ini menggunakan 103 data. Berdasarkan penelitian yang telah dilakukan, didapatkan parameter optimal yaitu jumlah semut 30, batas parameter bobot awal adalah 0 sampai 1, jumlah data training dan data testing 82 data dan 21 data (80%:20%), serta iterasi maksimum adalah 500. Dari parameter tersebut didapatkan nilai MAPE untuk ELM-ACO sebesar 0.170% dengan waktu komputasi selama 3799.200 ms dan untuk algoritme ELM menghasilkan nilai MAPE 4.851% dnegan waktu komputasi selama 162.400 ms, sehingga optimasi parameter ELM mampu meningkatkan hasil peramalan.
Kata kunci: peramalan, pemakaian air, extreme learning machine, optimasi, ant colony optimization
Abstract
PT. PJB Unit Gresik using seawater as a steam power plant. Water has advantages such as it is high availability and environmentally friendly. However, seawater requires a refining process in order to be used. Using seawater as a power plant often experiences water-reduction problems caused by certain problems, such a pipeline leakage, tempering, and removal of gases that still contain water so that additional water is required to keep the turbin working. To anticipate the lack of water that can inhibit the process, an intelligent system required to estimate the amount of water that generation process needed. One of forecasting method is Extreme Learning Machine (ELM), to maximize forecasting results with optimization algorithm Ant Colony Optimization that can be used in the optimization input weight and bias of ELM parameters. After optimization process for ELM parameters, then the next process is training and testing to get forecasting result. This study uses 103 data. Based on the research, the optimal parameter number of ants is 40, the parameter range of the input weight is 0 to 1, the using 82 of training data and 21 testing data (80%: 20%), and the maximum iteration is 500. From these parameters obtained the MAPE value for ELM-ACO is 0.170% with 3799.200 ms running time and for the ELM algorithm the MAPE value is 4.851% with 162.400 ms, so the optimization of ELM parameters can improve the forecasting results.
1. PENDAHULUAN
Air memiliki memiliki berbagai manfaat dalam kehidupan. Salah satu pemanfaatan air untuk penghematan energi yaitu dengan menggunakan air sebagai tenaga pembangkit listrik. Penggunaan air sebagai pembangkit listrik dapat menghasilkan besaran energi yang disesuaikan dengan besaran aliran air (debit) (Harjanto, et al., 2014). Air dapat diunakan dalam pembangkit listrik tenaga air (PLTA) atau pembangkit listrik tenaga ualp (PLTU).
Penggunaan air sebagai energi pembangkit
memiliki lebih banyak keuntungan
dibandingkan bahan bakar minyak, karena air lebih ramah lingkungan dan juga lebih mudah didapat. Air laut yang digunakan untuk pembangkitan tenaga tidak dapat langsung digunakan, sehingg air laut membutuhkan proses pemurnian air (make-up water) agar dapat digunakan. Air yang telah dimurnikan tersebut akan digunakan untuk menggerakan turbin dalam proses pembangkitan listrik.
Penggunaan air sebagai pembangkit tenaga listrik sudah diterapkan pada PT. Pembangkit Jawa Bali (PJB) Unit Gresik sebagai tenaga pembangkit uap. Namun jumlah pemakaian air sering tidak terawasi dikarenakan sering terjadinya kebocoran pada pipa, spray atau
tempering, dan pembuangan gas yang masih mengandung air menyebabkan air yang telah diubah menjadi uap sering melebihi jumlah yang seharusnya dan menjadikan perusahaan kekurangan air murni sebagai tenaga pembangkit listrik. Penambahan air sangat perlu dilakukan untuk memenuhi kebutuhan air yang hilang karena masala-masalah dalam sistem tersebut. Untuk itu PT. PJB perlu melakukan perkiraan jumlah air yang dibutuhkan agar proses terus berjalan.
Sistem peramalan serupa pernah dilakukan dalam prediksi penutupan harga saham harian Bank BRI dengan ELM, namun dalam penelitian ini mendapakan hasil yang belum optimal. Hal ini dibuktikan dengan nilai RMSE yang dihasilkan sebesar 21.58. Untuk menghasilkan peramalan yang baik perlu dilakukan optimasi pada parameter ELM, karena hasil yang kurang baik bisa kadi diakibatkan karena pemilihan nilai parameter yang kurang tepat. Algoritme Ant Cololony Optimization dapat digunakan untuk menemukan jalur terbaik. Kelebihan ACO yaitu
mudah dipahami dan diimplemntasikan (Deng, et al., 2015) serta memiliki natural self learning
yang sangat kuat (Tianshi & Yalei, 2014) sehingga sangat tepat digunakan dalam optimasi parameter ELM.
Berdasarkan permasalahan tersebut, perlu diterapkan suatu peramalan jumlah pemakaian air pada PT. PJB Unit Gresik menggunakan potensial dan energi kinetik. Kebutuhan air adalah jumlah air yang di energi yang dimiliki air dapat dimanfaatkan dan di gunakan dalam wujud energi mekanis dan energi listrik (Jatmiko, et al., 2012). Pembangkit Listrik Tenaga Uap (PLTU) merupakan pembangkit listrik yang mengendalikan energi kinetik dari uap air untuk menghasilkan tenaga listrik. Bentuk dari PLTU terdiri dari generator yang dihubungkan dengan turbin, untuk memutar turbin diperlukan suatu energi kinetik dari uap panas atau kering. Konsumsi energi pada peralatan dalam PLTU berasal dari putaran turbin karena uap panas. Untuk menghasilkan uap, perlu adanya proses pemanasan air dengan melakukan pembakaran. Untuk menghasilkan uap panas itu, diperlukan air yang diproses dengan cara boiling. Air yang digunakan adalah air yang memiliki standar tertentu.
2.2 Extreme Learning Machine (ELM)
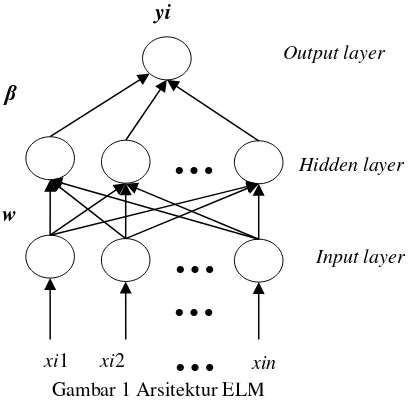
Extreme Learning Machine (ELM) adalah suatu metode pembelajaran feedforward
Gambar 1 Arsitektur ELM
Langkah-langkah algoritme ELM (Liang, et al., 2006):
A. Proses Training
1. Inisialisasi input bobot dan bias dengan nilai random [0,1]
2. Menghitung semua keluaran di hidden layer dengan fungsi aktivasi
𝑓(𝑥) = 1
1+𝑒−𝑥 (1)
Keterangan:
𝑓(𝑥) = fungsi aktivasi sigmoid 𝑒−𝑥 = eksponen pangkat minus data
ke- x luaran hidden layer
𝐻𝑖𝑛𝑖𝑡 𝑖𝑗 = (∑𝑛𝑘=1𝑤𝑗𝑘× 𝑥𝑖𝑘) + 𝑏𝑗 (2) Keterangan:
𝐻𝑖𝑛𝑖𝑡 = matriks keluaran hidden layer 𝑖 = [1,2,..,N], N adalah jumlah
data
𝑗 = [1,2,..,M], M adalah jumlah hidden neuron
𝑛 = jumlah input neuron
𝑤 = bobot bias
𝑥 = input
3. Menghitung Moore-Penrose Generalized Invers
𝛽 = 𝐻 × 𝑇
(3)
𝑦 = 𝐻 × 𝛽
(4)
Keterangan:
𝛽 = matriks output bobot dari hidden layer ke output layer
𝐻 = matiks keluaran hidden layer
𝐻+ = matriks Moore-Penrose Generalized
Invers dari matriks 𝐻 𝑇 = matriks target 𝑦 = hasil peramalan
B. Proses Testing
1.
Menghitung nilai matriks keluaran padahidden layer
𝐻 =
1+exp (−(𝑥 1𝑡𝑒𝑠𝑡𝑤𝑇+𝑏(𝑜𝑛𝑒𝑠(𝑖𝑡𝑒𝑠𝑡,1)))
(5)
Keterangan:
𝐻 = matriks keluaran hidden layer 𝑥𝑡𝑒𝑠𝑡 = matriks input yang telah
dinormalisasi
𝑤𝑇 = matriks transpose dari bobot 𝑖𝑡𝑒𝑠𝑡 = jumlah data uji
𝑏 = matriks bias
2.
Menghitung hasil keluaran hidden layerdengan Persamaan (1).
3.
Menghitung nilai evaluasi dengan MAPE.2.3 Ant Colony Optimization (ACO)
Ant Colony Optimization (ACO) pertama kali diperkenalkan oleh Dorigo dan Stuzzle di awal tahun 1990 yang didasarkan pada perilaku dari koloni semut. ACO adalah strategi optimasi yang bersifat stochastic. ACO adalah populasi semut yang bergerak secara independen. Komunikasi antar semut dalam suatu koloni menggunakan jejak yang ditinggalkan berupa
pheromone. Pheromone adalah zat yang seiring waktu berjalan akan menguap (Ariyasingha & Fernando, 2015). Langkah-langkah metode ACO (Dorigo, et al., 2006):
1. Inisialisasi parameter ACO 2. Menentukan node semut
a.
Menentukan posisi node semut pertama (𝑟) secara acak dengan nilai 0 sampai 9.b.
Menentukan nilai (𝑞) secara acakdengan nilai [0,1] (Hong, et al., 2011).
c.
Menentukan node selanjutnya Jika 𝑞 ≤ 𝑞0,
yi
w
β
Hidden layer
xin xi2
xi1
…
…
…
…
Output layer
𝑃(𝑟, 𝑢) = arg max𝑢∈𝐽(𝑟){[𝜏(𝑟, 𝑢)]𝛼× [𝜏(𝑟, 𝑢)]𝛽} (6)
Jika 𝑞 > 𝑞0, Tentukan nilai 𝑆
Keterangan:
𝑞 = nilai random antara 0 sampai 1 𝑞0 = nilai tetapan siklus semut
𝜏 = nilai intensitas feromon 𝑟 = node awal
𝑢 = node selanjutnya
𝛼 = tetapan pengendali intensitas feromon
𝛽 = tetapan pengendali visibilitas Nilai 𝑆 ditentukan secara acak sesuai dengan batas yang telah ditentukan.
Jika 𝑆 𝜖 𝐽(𝑟),
𝑃(𝑟, 𝑠) = { [𝜏(𝑟,𝑢)]
𝛼×[𝜏(𝑟,𝑢)]𝛽
∑𝑢𝜖𝐽(𝑟)[𝜏(𝑟,𝑢)]𝛼×[𝜏(𝑟,𝑢)]𝛽
0, 𝑙𝑎𝑖𝑛𝑛𝑦𝑎
(7)
Jika 𝑆 ∉ 𝐽(𝑟), 𝑃(𝑟, 𝑢) = 0 (8)
Keterangan:
𝜏 = nilai intensitas feromon 𝑟 = node awal
𝑢 = node selanjutnya
𝛼 = tetapan pengendali intensitas feromon
𝛽 = tetapan pengendali visibilitas
d.
Update nilai pheromone lokal𝜏(𝑟, 𝑢) = (1 − 𝑝) × (𝜏(𝑟, 𝑢)) + 𝜌𝜏0 (9)
Keterangan: 𝑟 = node awal
𝑢 = node selanjutnya
𝜌 = penguapan jejak feromon lokal 𝜏 = nilai intensitas feromon 𝜏0 = nilai intensitas feromon awal
e.
Perbarui node awal dengan node yang didapat. Ulangi langkah b sampai seluruh node semut terlewati. Pada 3. Konversi nilai parameter ELM4. Update pheromone global pada semut dengan nilai MAPE terkecil
𝜏(𝑟, 𝑠) = (1 − 𝛿) × (𝜏(𝑟, 𝑠)) + 𝛿∆𝜏(𝑟, 𝑠) (10)
Dimana ada kondisi:
Jika 𝜏(𝑟, 𝑢)𝜖 𝑔𝑙𝑜𝑏𝑎𝑙 𝑏𝑒𝑠𝑡 𝑡𝑜𝑢𝑟, maka
∆𝜏(𝑟, 𝑢) =
1𝐿 (11) Jika 𝜏(𝑟, 𝑢) ∉ 𝑔𝑙𝑜𝑏𝑎𝑙 𝑏𝑒𝑠𝑡 𝑡𝑜𝑢𝑟, maka
∆𝜏(𝑟, 𝑢) = 0
Keterangan:𝑟 = node awal 𝑢 = node selanjutnya 𝜏 = nilai intensitas feromon
∆𝜏(𝑟, 𝑢) = matriks perubahan intensitas
feromon global
𝐿 = MAPE global best tour
5. Kosongkan jalur kunjungan setiap semut
6. Menentukan stoping condition
2.4 Normalisasi
Normalisasi dilakukan dengan tujuan menyelaraskan data agar jarak antar data tidak terlalu besar, normalisasi dilakukan dengan min-max normalization dengan range [0, 1] (Saranya & Manikandani, 2013).
𝑥′ =𝑥𝑚𝑎𝑥−𝑥𝑚𝑖𝑛𝑥−𝑥𝑚𝑖𝑛 (12)
Keterangan:
𝑥′ = data hasil normalisasi 𝑥 = data yang akan dinormalisasi 𝑥𝑚𝑎𝑥 = data terbesar dataset
𝑥𝑚𝑖𝑛 = data terkecil dataset
Jika dilakukan proses normalisasi, maka setelah selesai melakukan perhitungan ELM perlu dilakukan proses denormalisasi. Berikut merupakan rumus denormalisasi:
𝑥 = 𝑥′(𝑚𝑎𝑥 − 𝑚𝑖𝑛) + 𝑚𝑖𝑛 (13)
2.6 Nilai Evaluasi
Nilai evaluasi adalah nilai yang digunakan untuk mengukur kesalahan dalam peramalan. Dalam penelitian ini menggunakan evaluasi
Mean Absolute Percentage Error (MAPE). Berikut adalah rumus MAPE (Bratu, 2012):
𝑀𝐴𝑃𝐸 =∑𝑛𝑖=1((𝑦𝑡−𝑦′𝑡)𝑦𝑡 )×100
𝑛
(14)
Keterangan:
3. METODE
3.1 Data Penelitian
Data yang digunakan dalam penelitian ini adalah data historis jumlah pemakaian air harian sebagai tenaga pembangkit listrik pada PT. Pembangkit Jawa Bali Unit Gresik dari tanggal 1 Januari 2017 sampai dengan 31 Juli 2017. Data jumlah air per dua hari berjumlah sebanyak 103 data. Penelitian ini menggunakan 3 buah fitur yaitu X1, X2, dan X3. Fitur X1 merupakan data jumlah pemakaian air 6 hari sebelumnya, fitur X2 merupakan jumlah pemakaian air 4 hari sebelumnya, dan fitur X3 merupakan jumlah pemakaian air 2 hari sebelumnya.
3.2 Perancangan Algoritme
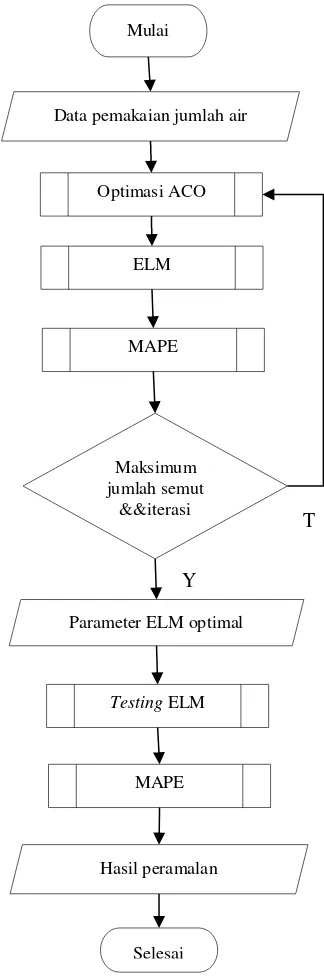
Tahapan- tahapan proses ELM-ACO adalah optimasi parameter bobot awal dan bias ELM, proses training dan proses teseting.
Langkah-langkah peramalan dengan ELM dan ACO dapat dijabarkan sebagai berikut:
1. Normalisasi data
Normalisasi data bertujuan untuk menyelaraskan data agar memiliki batasan yang sama, yaitu 0 sampai 1 dengan menggunakan Persamaan 16.
2. Optimasi ACO
Optimasi ACO digunakan untuk
mengoptimasi parameter input weight dan bias pada ELM, sehingga peramalan yang dihasilkan oleh ELM lebih optimal. Proses optimasi ELM terbagi menjadi:
Inisialisasi parameter ACO, yaitu jumlah semut, ordinate [0, 9], maksimum iterasi, tetapan penguapan pheromone, tetapan pengendali visibilitas, tetapan pengendali
pheromone, pheromone awal, dan tetapan siklus semut.
Menentukan node semut awal dengan memilih acak salah satu node
Menentukan node yang akan dikunjungi oleh semut dengan fungsi Roulette Wheel
dengan menggunakan Persamaan 7 atau Persamaan 8
Update pheromone local, yaitu perubahan feromon pada vertex yang telah dilaui semut menggunakan Persamaan 9
Memperbaharui node awal dengan node yang dikunjungi, setelah memperbarui node awal ulangi langkah tersebut sampai
seluruh node dilewati.
Konversi nilai parameter bobot awal dan bias sesuai batas yang telah ditentukan.
𝑊 = [(𝐴𝑚𝑎𝑥−𝐴𝑚𝑖𝑛𝐴−𝐴𝑚𝑖𝑛 ) × (𝑊𝑚𝑎𝑥 − 𝑊𝑚𝑖𝑛)] + 𝑊𝑚𝑖𝑛 (15)
𝑏 = [(𝐴𝑚𝑎𝑥−𝐴𝑚𝑖𝑛𝐴−𝐴𝑚𝑖𝑛 ) × (𝑏𝑚𝑎𝑥 − 𝑏𝑚𝑖𝑛)] + 𝑏𝑚𝑖𝑛 (16)
Keterangan:
𝐴 = hasil optimasi ACO
𝐴𝑚𝑖𝑛 = nilai minimal optimasi ACO 𝐴𝑚𝑎𝑥 = nilai maksimal optimasi ACO 𝑊𝑚𝑎𝑥 = batas atas parameter input weight 𝑊𝑚𝑖𝑛 = batas bawah parameter input weight 𝑏𝑚𝑎𝑥 = batas atas parameter bias
𝑏𝑚𝑖𝑛 = batas bawah parameter bias
3. Training ELM
Training ELM digunakan sebagai proses
learning dalam mengenali pola dari data.
Menggunakan parameter yang didapat dari optimasi ACO
Menghitung keluaran hidden layer
dengan menggunakan Persamaan 2.
Menghitung output weight
menggunakan Persamaan 3 dan Persamaan 4.
Menghitung tingkat error menggunakan MAPE.
Memperbaharui feromon global
menggunakan Persamaan 10
Cek kondisi berhenti
4. Testing ELM
Testing ELM digunakan dalam melakukan pengujian seberapa baik ELM dapat menghasilkan peramalan
Menghitung matriks keluaran hidden
layer dengan menggunakan
Persamaan2.
Menghitung bobot output
5. Denormalisasi hasil peramalan
Denormalisasi hasil peramalan mengunakan
min-max denormalization dengan Persamaan 17, setelah mendapat hasil peramalan dapat melakukan evaluasi dengan MAPE menggunakan Persamaan 18.
Gambar 2 Diagram alir ELM-ACO
Contoh representasi jalur yang dilalui salah satu semut yang optimal untuk optimasi bobot awal dan bias dengan jumlah node yang dikunjungi sebanyak 36 node dapat dilihat pada Gambar 3. Parameter-parameter ACO yang digunakan diantaranya maksimum iterasi = 300, jumlah semut = 35 nilai 𝛼 = 0.1 dan 𝛽 = 0.9 serta node yang dikunjungi sebanyak 36. Node yang dikunjungi oleh semut teresbut akan dikonversi menjadi nilai parameter input weight dan bias sebagai parameter awal dari ELM.
Gambar 3 Representasi jalur semut optimal
Pada Gambar 3 menunjukkan bahwa semut mengunjungi ordinate 5 sebagai node awal yang dilalui, kemudian semut mengunjungi ordinate 0 sebagai node yang terpilih untuk dikunjungi semut berdasarkan nilai probabilitas. Selanjutnya ordinate 0 akan menjadi node awal semut untuk menuju node selanjutnya yang akan dikunjungi hingga seluruh node dikunjungi sampai dengan node terakhir yaitu node ke-36. Hasil dari Grafik tersebut jalur yang terbentuk adalah 5, 0, 7, 1, 6, 4, 8, 7, 2, 5, 7, 1, 2, 7, 1, 2, 4, 5, 0, 6, 0, 7, 8, 8, 7, 2, 5, 8, 2, 2, 3, 4, 0, 4, 6, 8. Sehingga jika dikonversi menjadi parameter bobot input untuk 𝑤11 menggunakan node ke-1 sampai node ke-3, yaitu ordinate 5, 0, dan 7. Dengan menggunakan Persamaan 15 maka didapatkan hasil 𝑤11= 0.507.
4. PENGUJIAN DAN ANALISIS
Terdapat 4 pengujian yang dilakukan dalam penelitian ini. Penelitian tersebut meliputi pengujian iterasi ACO, pengujian jumlah semut, pengujian batas parameter ELM, dan pengujian jumlah data latih. Setiap pengujian dilakukan percobaan sebanyak 10 kali untuk mendapatkan nilai rata-rata MAPE.
4.1 Pengujian Jumlah Semut
Pengujian jumlah semut digunakan untuk mengetahui jumlah semut yang dapat menghasilkan paramater input weight dan bias yang paling optimal untuk menghasilkan nilai peramalan yang paling tepat. Pada pengujian ini jumlah semut yang digunakan dalam pengujian adalah 5, 10, 15, 20, 25, 35, dan 40. Nilai parameter lain yang digunakan pada pengujian ini yaitu 500 iterasi, range input weight [0, 1], banyak data training dan tetsting 80%:20%. Grafik hasil pengujian jumlah semut ditunjukkan pada Gambar 4.
0 1 2 3 4 5 6 7 8 9
0 3 6 9 12 15 18 21 24 27 30 33 36
o
rd
in
at
e
Kunjungan Node ke-Mulai
Optimasi ACO Data pemakaian jumlah air
ELM
T
Y Maksimum jumlah semut
&&iterasi
Parameter ELM optimal
Testing ELM
Selesai Hasil peramalan
MAPE
Gambar 4 Grafik pengujian jumlah semut
Berdasarkan Gambar 4, hasil pengujian jumlah semut menunjukkan bahwa variasi jumlah semut dapat berpengaruh pada nilai MAPE yang dihasilkan. Semakin banyak jumlah semut yang digunakan maka nilai MAPE yang dihasilkan juga semakin kecil, yang berarti bahwa nilai kesalahan peramalan juga semakin kecil. Hal ini disebabkan karena semakin banyak jumlah semut maka titik yang dieksplorasi semakin besar sehingga kemungkinan menghasilkan solusi optimasi yang terbaik semakin besar. Dari percobaan tersebut didapatkan bahwa rata-rata nilai MAPE terkecil didapatkan pada jumlah semut ke-40 dengan nilai MAPE 0.170.
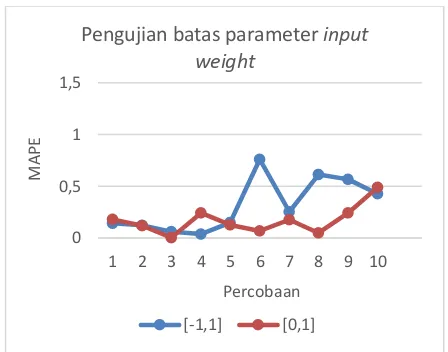
4.2 Pengujian batas parameter input weight
Pengujian batas parameter input weight digunakan untuk menentukan batas parameter yang paling optimal dalam peramalan ELM. Pada pengujian ini batas nilai parameter yang digunakan sebagai range dari input weight
adalah [-1, 1] dan [0, 1],
pengujian ini
dilakukan dikarenakan pada beberapa
penelitian terkait
extreme learning machine
yang pernah dilakukan menggunakan
range
antara 0 sampai 1, dan ada beberapa peneliti
yang menggunakan
range
-1 sampai 1.
Sehingga pengujian ini dilakukan untuk
mendapatkan batas bobot awal yang paling
optimal diantara kedua batas tersebutNilai
parameter lain yang digunakan pada pengujian ini yaitu 500 iterasi, 30 jumlah semut, serta perbandingan data training dan tetsting adalah 80%:20%. Grafik hasil pengujian batas parameter input weight ditunjukkan pada Gambar 5.Gambar 5 Grafik Pengujian batas parameter input weight
Berdasarkan Gambar 5, hasil pengujian batas parameter input weight didapatkan bahwa batas parameter mempengaruhi rata-rata nilai MAPE hasil peramalan. Dari percobaan ini didapatkan bahwa batas parameter [0, 1] menghasilkan hasil peramalan yang lebih optimal dengan nilai kesalahan 0.170%, dibandingkan dengan hasil yang didapat dengan batas [-1, 1] dengan nilai MAPE sebesar 0.313%. Hal ini dapat disebabkan karena fungsi aktivasi yang digunakan yaitu sigmoid biner. Pemilihan fungsi aktivasi berpotensi mempengaruhi batas parameter yang digunakan.
4.3 Pengujian Jumlah Iterasi
Pengujian jumlah iterasi bertujuan untuk mengetahui banyak iterasi yang menghasilkan parameter bobot dan bias yang paling optimal untuk menghasilkan nilai error yang paling terbaik. Pada pengujian ini banyak iterasi yang diuji adalah 30, 50, 100, 150, 200, 300, 400 dan 500 iterasi. Nilai parameter lain yang digunakan pada pengujian ini yaitu 40 jumlah semut, range input weight [0, 1], banyak data training 82 dan 21 data tetsting. Grafik hasil pengujian jumlah iterasi ditunjukkan pada Gambar 6.
Gambar 6 Grafik pengujian jumlah iterasi
0 Pengujian batas parameter input
Berdasarkan Gambar 6, menunjukkan bahwa jumlah maksimum iterasi berpengaruh pada nilai error yang dihasilkan dari proses peramalan. Pengujian jumlah iterasi dapat menunjukkan maksimum iterasi yang menghasilkan nilai parameter input weight yang paling optimal untuk melakukan proses peramalan. Berdasarkan pengujian yang telah dilakukan, jumlah maksimum iterasi yang baik adalah 500 dengan nilai rata-rata MAPE 0.161%. Semakin banyak iterasi yang ditetapkan hasil MAPE yang didapatkan juga semakin kecil, hal ini dikarenakan eksploitasi solusi optimal juga semakin besar sehingga kemungkinan ditemukannya terbaik juga semakin besar.
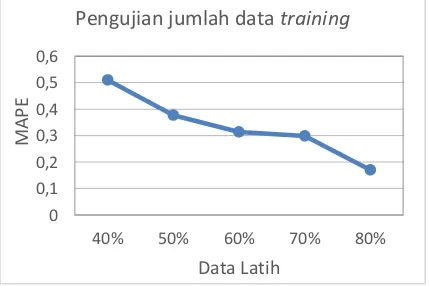
4.4 Pengujian Jumlah Data Training
Pengujian perbandingan jumlah data latih digunakan untuk mengetahui jumlah data latih yang paling optimal dalam melakukan pembelajaran untuk melakukan peramalan dengan nilai error yang kecil Pada percobaan
ini perbandingan yang digunakan adalah
perbandingan data latih dengan data uji
sebanyak 41, 52, 62, 72, dan 82 dari jumlah
data sebanyak 103 dengan persentase 40% :
20%, 50% : 20%, 60% : 20%, 70% : 20%
dan 80% : 20% . Nilai parameter lain yang
digunakan pada pengujian ini yaitu 40 jumlah semut, range input weight [0, 1], dan 500 iterasi. Grafik hasil pengujian pebandingan datatraining ditunjukkan pada Gambar 6.
Gambar 7 Grafik pengujian jumlah data training
Berdasarkan Gambar 7, hasil perbandingan jumlah data latih didapatkan bahwa perbandingan data latih mempengaruhi hasil peramalan. Data latih digunakan dalam proses
training atau proses pembelajaran dan proses dalam mengenali pola dalam metode ELM. Berdasarkan percobaan didapatkan bahwa nilai
data latih sebanyak 82 dengan nilai rata-rata MAPE 0.170%. Hal ini membuktikan bahwa semakin banyak data latih maka kesalahan akan semakin kecil, ini dikarenakan data training
digunakan sebagai metode pembelajaran, sehingga semakin banyak pola yang dikenali maka semakin akurat juga peramalan yang dihasilkan.
4.5 Analisis Global Hasil Pengujian
Berdasarkan pengujian yang telah dilakukan didapatkan parameter-parameter optimal dengan nilai MAPE terbaik. Pada pengujian pertama terkait pengaruh jumlah semut yang digunakan pada proses komputasi menunjukkan bahwa jumlah semut mempengaruhi hasil peramalan, dengan nilai MAPE terkecil yang didapatkan 0.170%. Pada pengujian kedua terkait batas parameter input weight, dari percobaan ditemukan bahwa nilai range bobot awal yang paling optimal adalah anatara 0 sampai 1, dengan nilai rata-rata MAPE 0.170%. Pengujian ketiga terkait pengujian maksimum iterasi pada ACO. Pada percobaan ini didapatkan bahwa iterasi berpengaruh dalam menghasilkan optimasi bobot awal dan bobot bias parameter ELM, hal ini dibuktikan dengan adanya penurunan nilai MAPE pada setiap peningkatan iterasi dan didapatkan nilai MAPE terendah pada iterasi 500 dengan nilai 0.161%. Pengujian keempat adalah pengujian jumlah data latih, dari percobaan dihasilkan bahwa semakin banyak jumlah data latih maka hasil peramalan juga semakin baik. Jumlah data latih optimal dari pengujian jumlah data latih adalah menggunakan 82 data latih dengan nilai rata-rata MAPE 0.170%. Perbandingan algoritme ELM dengan ELM-ACO ditunjukkan pada Tabel 1, dan grafik hasil perbandingan ELM dengan ELM-ACO ditunjukkan pada Gambar 8.
Tabel 1. Perbandingan ELM dengan ELM-ACO Percobaan
ke-i
Nilai MAPE Waktu Komputasi
ELM
Gambar 8 Perbandingan ELM dengan ELM-ACO
Dari 10 kali percobaan yang dilakukan didapatkan rata-rata nilai MAPE masing-masing algoritme adalah 4.373% untuk algoritme ELM dan 1.863% untuk algoritme ELM-ACO. Sedangkan untuk perbandingan dengan data aktual kesalahan yang dihasilkan dari peramalan ELM-ACO lebih kecil yaitu 110565.7 liter dibandingkan dengan peramalan dengan ELM dengan kesalahan sebesar 256552.9 liter. ELM-ACO menghasilkan peramalan yang lebih baik karena adanya optimasi input weight dan bias sehingga hasil yang didapat merupakan parameter ELM terbaik, sedangkan pada algoritme ELM input weight dan bias didapat secara acak. Sehingga optimasi parameter dengan ACO memberikan hasil yang lebih baik dibandingkan ELM tanpa optimasi. Untuk
perbandingan data aktual dengan hasil peramalan ditunjukkan pada Gambar 9 dan Gambar 10.
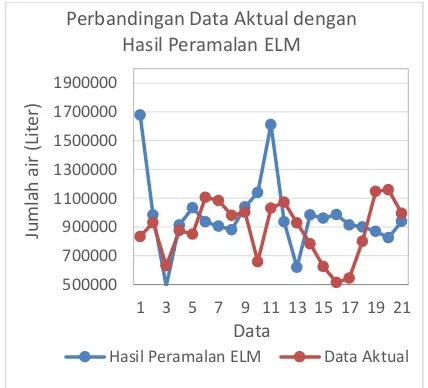
Gambar 9 Grafik perbandingan data aktual dengan hasil peramalan ELM-ACO
Gambar 10 Grafik perbandingan data aktual dengan hasil peramalan ELM
5. KESIMPULAN
Berdasarkan hasil penelitian peramalan jumlah pemakaian air dengan metode Extreme Learning Machine dan Ant Colony Optimization,
maka didapatkan kesimpulan sebagai berikut: 1. Untuk menerapkan metode Extreme
Learning Machine dan Ant Colony Optimization untuk peramalan jumlah pemakaian air adalah dengan melakukan optimasi pada parameter ELM, yaitu input weight dan bias, melakukan pelatihan ELM dan melakukan testing ELM. Proses diawali dengan menentukan parameter-parameter ACO, kemudian semua semut akan memilih titik yang akan dilewati oleh semut. Setelah seluruh jalur dilewati, langkah selanjutnya adalah mengubah nilai tersebut sesuai batasan yang ditentukan untuk parameter
input weight dan bias yang digunakan dalam
training ELM. Kemudian menghitung nilai
error menggunakan MAPE, bagi semut yang memiliki nilai error terkecil dilakukan
pembaruan pheromone. Setalah
mendapatkan input weight dan bias paling optimal maka proses selanjutnya adalah
tetsing ELM untuk menghasilkan peramalan jumlah pemakaian air
2. Berdasarkan pengujian dan analisis yang telah dilakukan, didapatkan bahwa parameter optimal untuk jumlah semut adalah 40, jumlah iterasi 500, batas parameter bobot terbaik adalah antara 0 sampai 1, dan data training yang digunakan 82 data serta 21 data testing dengan persentase 80% : 20%. Hasil dari penelitian mendapatkan nilai error yang cukup rendah
0
Perbandingan Data Aktual dengan Hasil Peramalan ELM-ACO
Hasil Peramalan ELM-ACO Data Aktual
500000
Perbandingan Data Aktual dengan Hasil Peramalan ELM
dengan algoritme Ant Colony Optimization
yang dapat memberikan solusi yang lebih baik dalam melakukan optimasi parameter pada peramlan jumlah pemakaian air dengan
Extreme Learning Machine. Kesalahan pada metode ELM-ACO yang dihitung dengan MAPE menghasilkan nilai MAPE sebesar 0.170% yang mana lebih rendah dibandingkan dengan metode ELM sendiri dengan nilai MAPE 4.851%.
3. Hasil dari pengujian menunjukkan bahwa metode ELM-ACO membutuhkan waktu komputasi yang lebih lama yaitu dengan waktu 3799.200 milisecoond dibandingkan
dengan metode ELM yang hanya
membutuhkan waktu 162.400 milisecoond . Namun hasil dari peramalan ELM-ACO lebih baik dibandingkan dengan ELM saja.
DAFTAR PUSTAKA
Ariyasingha, I. & Fernando, T., 2015. Performance Analisys of The Multi-Objective Ant Colony Optimization Algorithms for The Traveling Salesman Problem. Swarm and Evolutionary Computation, Volume 23, pp. 11-26. Bratu, M., 2012. The Reduction of Uncertainty
in Making Decision by Evaluating the Macroeconomic Forecasts Performance in Romania. Econimic Research, pp. 239-262.
Deng, X., Zhang, L., Lin, H. & Luo, L., 2015.
Pheromone Mark Ant Colony
Optimization with a Hybrid Node Based
Pheromone Update Strategy.
Neurocomputing, Volume 148, pp. 46-53.
Dorigo, M., Birattari, M. & Stutzle, T., 2006. Ant Colony Optimization: Artifical Ants as A Computational Intelegence Technique. IEEE Computational, pp. 28-39.
Harjanto, S., L., L. M. & Purwati, E., 2014. Studi Perencanaan Pembangkit Listrik Tenaga Air Tipe Run Off River Di Sungai Kladen Pacitan Menggunakan Metode Flow Duraton Cuvre Majemuk.
Hong, W. C., Dong, Y., Chen, L. Y. & Lai, C. Y., 2011. SVR with Hybrid Chaotic Genetic Algorithm for Tourism Demand Forecasting. Applied Soft Computing,
Volume 11, pp. 1881-1890.
Jatmiko, Asy’ari, H. & P., A. H., 2012.
Pemanfaatan Pemandian Umum Untuk Pembangkit Tenaga Listrik Mikrohidro ( PLTMh ) Menggunakan Kincir Tipe Overshot. Jurnal Emitor, 12(11), pp. 50-58.
Liang, N. Y. et al., 2006. A Fast and Accurate Onine Sequential Learning Algorithm for Feedforward Networks. IEE Transaction on Neural Networks, 17(6), pp. 1411-1423.
Saranya, C. & Manikandani, G., 2013. A Study on Normalization Techniques for Privacy Preserving Data Mining. International Journal of Engineering and Technology (IJET), 5(3).
Sun, Z. L., Choi, T. M., Au, K. F. & Yu, Y., 2008. Sales Forecasting using Extreme Learning Machine with Application in Fashion Reatiling. Elsevier Decision Support System, Issue 46, pp. 411-419. Tianshi, L. & Yalei, M., 2014. Improved Ant