IMPLEMENTASI RSHINY DENGAN METODE LEXICON BASED DAN NAIVE BAYES CLASSIFIER TERHADAP RESTORAN NAMAAZ DINING
JAKARTA
1
Fanny Ardiansyah,
2Dewi Agushinta R.
Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Gunadarma
Jl. Margonda Raya No. 100, Depok 16424, Jawa Barat
1
[email protected],
2[email protected]
Abstrak
Namaaz Dining adalah restoran yang menerapkan konsep Gastronomi molekular pertama di Indonesia. Setiap pengunjung yang ingin mengunjungi restoran Namaaz Dining, pasti ingin mengetahui reaksi dari pengunjung yang sebelumnya telah mengunjungi Namaaz Dining. Hal tersebut diperlukan untuk mengetahui respon pengunjung apakah restoran ini layak untuk dikunjungi atau tidak dengan menerapkan analisis sentimen. Bahasa pemrograman R adalah bahasa untuk komputasi dan grafik statistik R merupakan proyek GNU yang serupa dengan Bahasa S yang telah dikembangkan di Bell Laboratorium oleh John Chambers dan rekan-rekannya. RShiny merupakan salah satu paket dalam bahasa R yang digunakan untuk membuat tampilan berbasis website. Hasil dari setiap tahapan analisis sentimen dan hasil akurasi sentimen yang divisualisasikan ke dalam tampilan halaman berbasis web server meliputi data keluaran pre-processing, proses metode Lexicon Based dan Naïve Bayes Classifier. Data tersebut divisualisasikan bentuk histogram, diagram pie dan wordcloud.
Kata Kunci: Analisis Sentimen, Lexicon Based, Naïve Bayes Classifier, Namaaz Dining, RShiny
Abstract
Namaaz Dining is a restaurant that applies the concept of the first molecular gastronomy in Indonesia. Every visitor who wants to visit the Namaaz Dining restaurant, definitely wants to know the reactions of visitors who have previously visited Namaaz Dining. This is needed to determine the response of visitors whether this restaurant is worth visiting or not by applying sentiment analysis. The R programming language is a language for computing and statistical graphics R is a GNU project similar to the S Language that has been developed at Bell Laboratories by John Chambers and his colleagues. RShiny is a package in the R language that is used to create website-based views. The results of each stage of sentiment analysis and sentiment accuracy results that are visualized into a web server-based page display include pre- processing output data, the Lexicon Based method process and the Naïve Bayes Classifier. The data are visualized in the form of histograms, pie charts and wordcloud.
Keywords: Analisis Sentimen, Lexicon Based, Naïve Bayes Classifier, Namaaz Dining, RShiny
PENDAHULUAN
Perkembangan teknologi yang sangat pesat memudahkan dalam pencarian segala informasi yang dibutuhkan melalui internet. Berbagai informasi seperti lokasi tempat makan dan tempat
wisata yang paling popular saat ini sangat mudah didapatkan. Informasi yang telah didapatkan melalui internet bisa dijadikan pertimbangan sebelum mengunjungi suatu tempat. Salah satu informasi yang biasanya dicari adalah lokasi restoran yang paling popular di suatu kota tertentu.
Analisis sentimen atau penggalian opini digunakan untuk mendapatkan sebuah uraian umum tentang kualitas sebuah layanan, apakah layanan tersebut cenderung mendapatkan nilai positif, negatif maupun netral [1]. Analisis sentimen digunakan untuk mengelompokkan opini- opini positif atau negatif dari pengunjung restoran Namaaz Dining sehingga mempercepat dan mempermudah tugas pengelola Namaaz Dining untuk meninjau kembali kekurangan dari tempat wisata Namaaz Dining dari segala aspek.
Bahasa pemrograman R adalah bahasa untuk komputasi dan grafik statistik R merupakan proyek GNU yang serupa dengan Bahasa S yang telah dikembangkan di Bell Laboratorium (sebelumnya AT & T, sekarang Lucent Technologies) oleh John Chambers dan rekan-rekannya.
Salah satu kekuatan R adalah kemudahan plot kualitas publikasi yang dirancang dengan baik, termasuk simbol dan formula matematis jika diperlukan. R merupakan fasilitas perangkat muda terpadu untuk data manipulasi, kalkulasi, dan tampilan grafis. R [2]. Dalam pembuatan website, aplikasi yang digunakan adalah RStudio. RStudio adalah alat pemrograman atau Integrated Development Environment (IDE) bahasa R yang memiliki antar muka lebih baik daripada RGUI. RStudio memiliki 2 (dua) versi lisensi, yaitu Open Source Edition dan Commercial Edition [3]. Dalam melakukan simulasi R melalui RShiny bekerja di server (belakang layar) sedangkan pengguna disuguhi menu yang ramah dan interaktif berbasis web, sehingga pengguna tidak disyaratkan menguasai program R. Oleh karena itu RShiny sangat baik digunakan sebagai pelengkap pembelajaran statistika dimana penguna bisa lebih focus pada konsep statistika tanpa terkendala kemampuan penguasaan software statistika. Jika paket simulasi yang disediakan cukup memadai, maka situs ini dapat berfungsi sebagai laboratorium pembelajaran virtual. Visualisasi menggunakan R yang pada dasarnya merupakan software pengolah data, memiliki kelebihan dibandingkan dengan visualisasi menggunakan software bukan pengolah data (misalnya applet java). Dengan menggunakan R sebagai mesin pengolah, simulasi dan visualisasi bisa dilakukan pada semua aspek analisis data (simulasi data, estimasi, dan pemeriksaan goodnes of fit) [4].
Pada penelitian ini digunakan metode Lexicon Based dengan tujuan untuk menentukan sentimen awal dari suatu kalimat berdasarkan jumlah proporsi kata positif atau negatif yang menjadi penyusun kalimat, dan Naïve Bayes Classifier ditujukan untuk mengolah dan mengklasifikasikan komentar sehingga akan diketahui hasil klasifikasi dari data komentar dalam bentuk proporsi sentimen positif dan negatif. Pengujian akurasi proses klasifikasi antara sentimen prediksi dan sentimen aktual berdasarkan hasil perhitungan dengan Naïve Bayes
Classifier dihitung menggunakan Confusion Matrix. Hasil analisis sentimen divisualisasikan dalam bentuk histogram, diagram pie dan wordcloud.
Penelitian ini dilakukan dengan mempelajari penelitian-penelitian terdahulu yang memiliki keterkaitan tentang analisis sentimen, metode Lexicon Based dan Naïve Bayes Classifier, yaitu yang pertama adalah penelitian yang berjudul “Analisis Sentimen Pada Review Konsumen Menggunakan Metode Naïve Bayes Dengan Seleksi Fitur Chi Square Untuk Rekomendasi Lokasi Makanan Tradisional” memiliki kelebihan yaitu terdapat hasil rekomendasi lokasi makanan tradisional yang menampilkan nilai sentimen positif atau negatif dan memiliki kekurangan yaitu perbedaan dari nilai akurasi antara menggunakan seleksi fitur dan tanpa menggunakan seleksi fitur tidak terlalu signifikan. Penelitian tersebut dilakukan oleh Novan Dimas Pratama, Yuita Arum Sari dan Putra Pandu Adikara pada tahun 2018. Penelitian yang kedua yaitu berjudul “Analisis Sentimen Terhadap Tempat Wisata Dari Komentar Pengunjung Dengan Menggunakan Metode Naïve Bayes Classifier Studi Kasus Jawa Barat”
memiliki kelebihan yaitu algoritma Naïve Bayes Classifier dapat mengklasifikasikan suatu opini berupa komentar ke dalam dua kelas yaitu positif dan negatif dengan akurat, serta memiliki kekurangan yaitu tingkat akurasi yang tidak dicantumkan. Penelitian tersebut dilakukan oleh Lio Wilianto, Tacbir Hendro Pudjiantoro dan Fajri Rakhmat Umbara pada tahun 2017.
METODE PENELITIAN
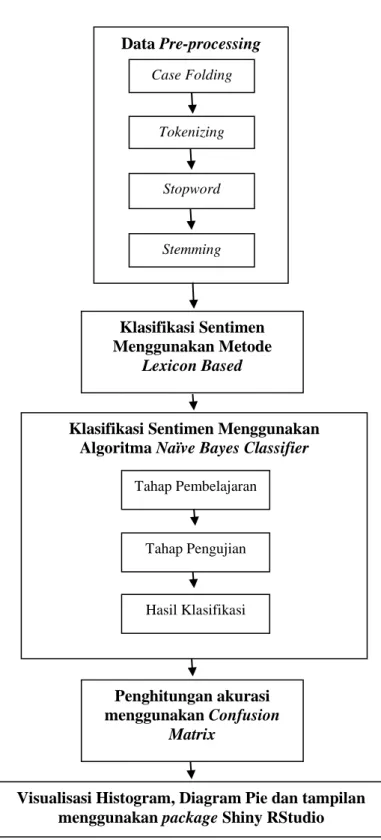
Tahap-tahap yang akan dilaksanakan pada tahap implementasi menggunakan RShiny diilustrasikan pada diagram di gambar 1.
Gambar 1. Tahapan Penelitian
HASIL DAN PEMBAHASAN
Setelah melakukan tahap analisis dan perancangan, tahap berikutnya adalah merepresentasikan hasil dari tahap-tahap yang sudah dilakukan sebelumnya. Tahap ini
Data Pre-processing Case Folding
Tokenizing
Stopword
Stemming
Klasifikasi Sentimen Menggunakan Metode
Lexicon Based
Klasifikasi Sentimen Menggunakan Algoritma Naïve Bayes Classifier
Tahap Pembelajaran
Tahap Pengujian
Hasil Klasifikasi
Penghitungan akurasi menggunakan Confusion
Matrix
Visualisasi Histogram, Diagram Pie dan tampilan menggunakan package Shiny RStudio
menjelaskan hasil dari setiap tahapan proses analisis sentimen dan hasil akurasi sentimen yang divisualisasikan ke dalam tampilan halaman berbasis web server dengan menggunakan paket Shiny dari perangkat lunak RStudio.
1. Tampilan Menu Utama
Gambar 2. Tampilan Halaman Menu Utama
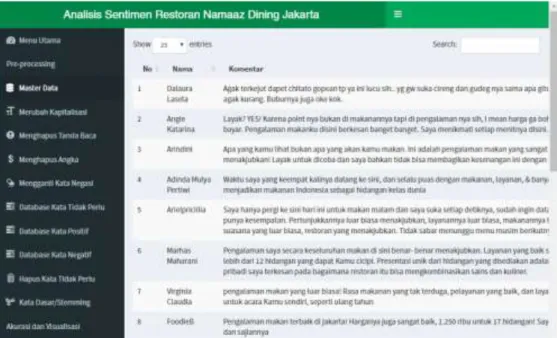
2. Tampilan Menu Pre-processing
Gambar 3. Tampilan Halaman Master Data
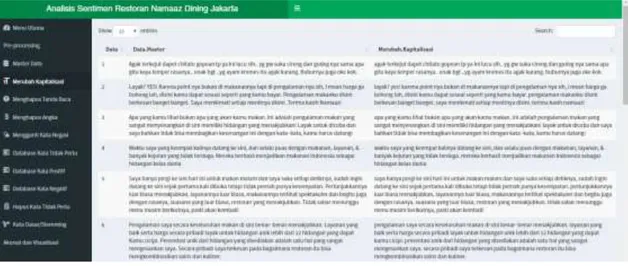
Gambar 4. Tampilan Halaman Menghapus Kapitalisasi
Gambar 5. Tampilan Halaman Menghapus Tanda Baca
Gambar 6. Tampilan Halaman Menghapus Angka
Gambar 7. Tampilan Halaman Mengganti Kata Negasi
Gambar 8. Tampilan Halaman Daftar Kata Tidak Perlu
Gambar 9. Tampilan Halaman Daftar Kata Positif
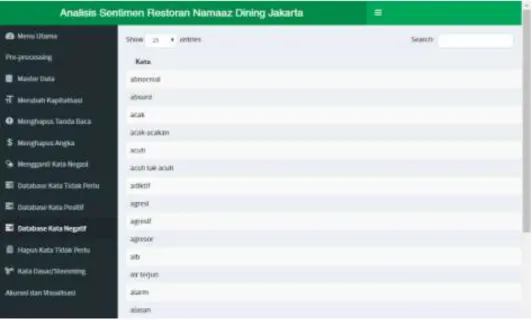
Gambar 10. Tampilan Halaman Daftar Kata Negatif
Gambar 11. Tampilan Halaman Menghilangkan Kata Tidak Perlu
Gambar 12. Tampilan Halaman Stemming
3. Tampilan Menu Visualisasi dan Akurasi
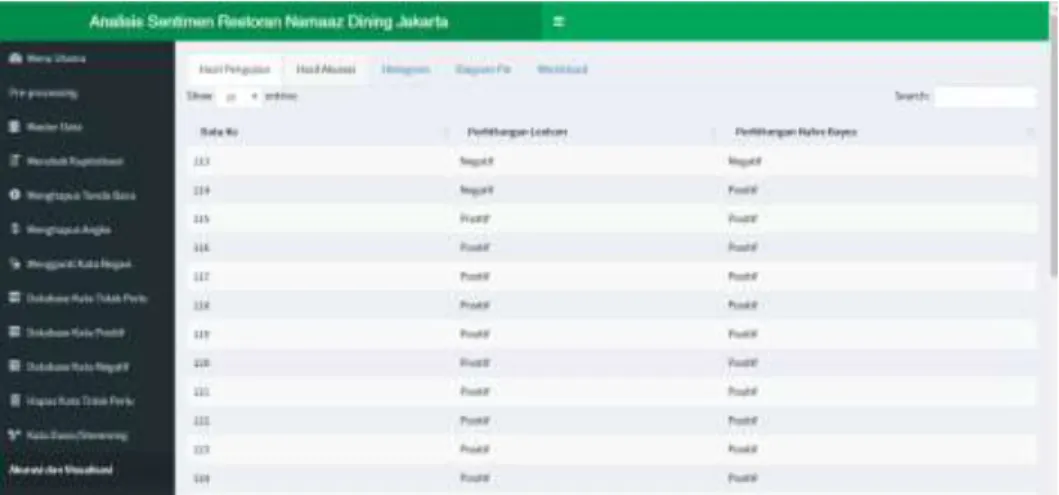
Gambar 13. Tampilan Halaman Hasil Pengujian
Gambar 14. Tampilan Halaman Akurasi Sistem
Gambar 15. Tampilan Halaman Visualisasi Data Histogram
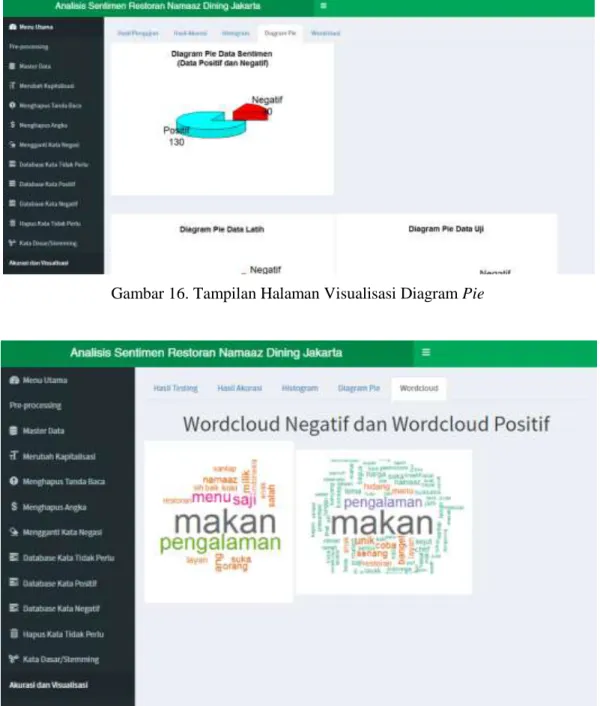
Gambar 16. Tampilan Halaman Visualisasi Diagram Pie
Gambar 17. Tampilan Halaman Visualisasi Wordcloud
KESIMPULAN DAN SARAN A. Kesimpulan
Implementasi menggunakan RShiny pada analisis sentimen menggunakan metode Lexicon Based dan Naïve Bayes Classifier terhadap restoran Namaaz Dining Jakarta telah dilakukan. Tahapan yang diimplementasikan meliputi tahapan pre-processing (merubah kapitalisasi, menghapus tanda baca dan angka, menghapus kata tidak perlu dan mengubah kata menjadi kata dasar), tahapan klasifikasi Lexicon Based dalam menentukan ulasan apakah
termasuk ke dalam sentimen positif atau negatif serta tahapan klasifikasi Naïve Bayes Classifier yang meliputi tahap pembelajaran dan pengujian.
Keluaran yang ditampilkan pada halaman website berupa tabel hasil dari tahapan proses analisis sentimen. Hasil datanya kemudian divisualisasikan ke dalam bentuk histogram, diagram pie dan wordcloud.
B. Saran
Penelitian ini masih diperlukan pengembangan seperti pengambilan data objek untuk analisis sentimen berupa ulasan harus memiliki struktur kalimat yang sesuai dengan kaidah bahasa Indonesia dan memiliki makna sentimen. Selain itu pengembangan fitur yang diperlukan yakni proses pengambilan data dapat menggunakan fitur crawling supaya bisa mendapatkan data yang diinginkan berdasarkan objek penelitian dengan mudah dan cepat. Metode klasifikasi lain dapat digunakan untuk analisis sentimen secara dinamis. Fitur unduh database kata positif, negatif dan kata tidak perlu dapat ditambah sehingga memudahkan pengguna jika ingin melakukan analisis sentimen.
DAFTAR PUSTAKA
[1] Istiqomah, S. M., Maharani, W. Adiwijaya, 2014. Opinion Mining pada Twitter Menggunakan Klasifikasi Sentimen pada Hashtag berbasis Graf.
[2] Norman Matloff, 2009. The Art of R Programming.
[3] Faisal, M. R, 2017. Seri Belajar Data Science: Klasifikasi dengen Bahasa Pemrograman R, Volume 1.
[4] Sanchez, G., 2013. PLS Path Modeling with R. Trowchez Editions. Berkeley,
[5] RStudio and Inc. Shiny Widget Gallery. http://shiny.rstudio.com/gallery/widgetgallery.html.