BAB II
LANDASAN TEORI
2.1. Pengertian Data dan Informasi
Pengertian informasi ialah data. Data adalah kenyataan yang menggambarkan
suatu kejadian dan kesatuan nyata dan merupakan bentuk baku yang harus diolah
untuk menghasilkan informasi. Sedangkan informasi adalah data yang diolah menjadi
bentuk yang lebih berguna dan lebih berarti bagi yang menerimanya dan bermanfaat
dalam mengambil keputusan saat ini dan mendatang1.
Hubungan antara data dengan informasi adalah seperti bahan baku sampai
menjadi bahan jadi. Data merupakan bahan baku yang diolah untuk memberikan
informasi agar informasi dapat dianggap lebih tinggi nilai aktifnya daripada data.
1. HM. Jogiyanto. Analisa dan Disain Sistem Informasi: Pendekatan Terstruktur,
2.2. Arti dan Definisi Statistik
Dahulu statistik hanyalah merupakan kumpulan dari angka-angka mengenai
penduduk dan pendapatan suatu masyarakat serta angka-angka lain yang diperlukan
oleh pemerintah. Angka-angka yang menerangkan keadaan penduduk itu diperlukan
oleh pemerintah untuk menentukan jumlah pajak yang akan dipungut dan cara
pemungutannya, demikian juga untuk menaksir kekuatan potensiil negara yang
bersangkutan di dalam keadaan perang. Tetapi, lama-kelamaan pemerintah
mencampuri bidang-bidang yang lebih luas dari perekonomian suatu masyarakat dan
angka-angka yang diperlukan dan dikumpulkan pun bertambah banyak macamnya.
Dengan demikian macam dan jumlah angka-angka yang harus diolah bertambah
banyak dan cara-cara pengolahan baru pun ditemukan.
Dengan uraian singkat di atas, kita tidaklah akan heran melihat kenyataan
bahwa statistik sudah sejak lama menjadi bahan pelajaran yang sangat berguna bagi
orang-orang yang mempelajari ilmu-ilmu masyarakat (social sciences). Tentu hal ini
tidaklah berarti bahwa statistik hanyalah dipelajari oleh orang-orang dari ilmu sosial
saja, di dalam ilmu-ilmu lain pun pemakaian statistik itu dilakukan oleh banyak
orang.
Pada waktu belakangan ini, di negara kita sangat terasa pentingnya hasil-hasil
penelitian ilmiah, yang di zaman penjajahan sangat kurang sekali dilakukan. Dengan
bertambahnya kebutuhan akan hasil penelitian ilmiah di negara kita yang sedang
berkembang ini, makin terasa pulalah kebutuhan akan pelajaran statistik yang lebih
perekonomian negara, data dari waktu yang lampau haruslah dianalisa dan dipelajari,
di masa yang akan datang haruslah diramalkan. Di dalam kedua hal itu statistik
memegang peranan yang sangat penting. Dengan perkataan lain, baik di dalam
menilai dan menginterpretasi data dari masa yang lampau maupun di dalam mencoba
meramalkan keadaan di tahun-tahun yang akan datang. Statistik itu merupakan alat
yang sangat menolong, bahkan sering merupakan alat yang harus ada.
Tentu bukanlah di negara kita saja statistik itu semakin penting kedudukannya
dan bukanlah di negara-negara yang sedang berkembang saja. Kebutuhan akan
pengetahuan yang lebih baik mengenai statistik makin terasa di seluruh dunia, baik di
negara sosialis maupun di negara kapitalis, baik di negara yang sedang berkembang
maupun yang sudah berkembang.
Bagi kebanyakan orang, “statistik” itu merupakan seonggokan atau
sekumpulan angka-angka yang menerangkan sesuatu, baik yang sudah tersusun di
dalam daftar-daftar yang sudah teratur atau grafik-grafik maupun belum2.
2. Dr. Amudi Pasaribu, M.Sc., Ph.D, Pengantar Statistik, Jakarta: Ghalia Indonesia,
Pengertian kedua ialah bahwa “statistik” itu adalah kumpulan dari cara-cara
dan aturan-aturan mengenai pengumpulan data (keterangan mengenai sesuatu),
penganalisaan dan interpretasi data yang berbentuk angka-angka3.
Pengertian ketiga yang merupakan pengertian terakhir dari urutan arti
perkataan “statistik” itu, ialah pengertian bahwa statistik itu adalah bilangan-bilangan
yang menerangkan sifat (characteristic) dari sekumpulan data (pengamatan)4.
Sedangkan metode statistik diartikan dengan prosedur-prosedur yang
digunakan dalam pengumpulan, penyajian, analisis dan penafsiran data5.
3. Dr. Amudi Pasaribu, M.Sc., Ph.D, Pengantar Statistik, Jakarta: Ghalia Indonesia,
Cetakan keempat, 1981, hal. 18
4. Dr. Amudi Pasaribu, M.Sc., Ph.D, Pengantar Statistik, Jakarta: Ghalia Indonesia,
Cetakan keempat, 1981, hal. 18
5. Ronald, E. Walpole, Pengantar Statistika, PT. Gramedia Pustaka Utama, Jakarta,
Setelah memberikan pengertian-pengertian statistik diatas, dapatlah diberikan
definisi yang lebih tegas bagi ilmu statistik. Definisi tersebut dapatlah disusun
sebagai berikut:
Definisi: Ilmu Statistik adalah kumpulan dari cara-cara dan aturan-aturan
mengenai pengumpulan, pengolahan, penafsiran, dan penarikan
kesimpulan dari data berupa angka-angka6.
Sama halnya dengan definisi ilmu-ilmu lain, definisi ini tidaklah diharapkan
dapat memberi keterangan yang sempurna dan lengkap mengenai apa sebenarnya
ilmu statistik itu. Jika seseorang hendak mengetahui atau mempelajari suatu ilmu,
tidaklah cukup dia membaca sebuah definisi yang hanya terdiri dari satu kalimat saja.
2.3. Statistik Deskriptif dan Induktif
Statistik dapat dibagi atas dua bagian menurut tingkat pekerjaan yang dapat
dilakukan dengan cara-cara yang disediakan oleh setiap bagian itu. Kedua bagian dari
ilmu statistik itu ialah statistik deskriptif dan statistik induktif.
6. Dr. Amudi Pasaribu, M.Sc., Ph.D, Pengantar Statistik, Jakarta: Ghalia Indonesia,
Yang dimaksud dengan statistik deskriptif ialah bagian dari statistik yang
membicarakan mengenai penyusunan data ke dalam daftar-daftar atau jadwal,
pembuatan grafik-grafik, dan lain-lain yang sama sekali tidak menyangkut penarikan
kesimpulan7.
Definisi yang lain yaitu metode-metode yang berkaitan dengan pengumpulan
penyajian suatu gugus data sehingga memberikan informasi yang berguna8.
Dapat juga diartikan sebagai metode statistikal yang digunakan untuk
membuat tabel, grafik dan/atau rangkuman numerik dari data9.
Di samping penyusunan ke dalam daftar-daftar dan penggambaran
grafik-grafik dari data, kepada statistik deskriptif termasuk juga pengolahan yang bersifat
analisa dan interpretasi data, selama hal itu tidak menyangkut penarikan kesimpulan
yang berlaku umum atau pembuatan generalisasi
7. Dr. Amudi Pasaribu, M.Sc., Ph.D, Pengantar Statistik, Jakarta: Ghalia Indonesia,
Cetakan keempat, 1981, hal. 19
8. Ronald, E. Walpole, Pengantar Statistika, PT. Gramedia Pustaka Utama, Jakarta,
Edisi ke-3, 1992, hal. 1
9. Bambang, Suryoatmojo, Statistika dan Probabilitas, Fakultas Teknik Universitas
Statistik Induktif adalah bagian lain dari statistika yaitu semua aturan-aturan
dan cara-cara yang dapat dipakai sebagai alat di dalam mencoba menarik kesimpulan
yang berlaku umum dari data yang sudah tersusun dan diolah sebelumnya10.
Statistik Induktif mencakup semua metode yang berhubungan dengan analisis
sebagian data untuk kemudian sampai pada peramalan atau penarikan kesimpulan
mengenai keseluruhan data induknya11.
Statistik Induktif dapat diartikan pula proses penggunaan data dari sampel
untuk menarik kesimpulan tentang populasi12.
Jadi, di dalam statistik induktif itu kita akan mencoba mencari keterangan
yang berlaku umum yaitu membuat generalisasi dari data yang sedang kita hadapi
dan, biasanya sengaja dikumpulkan untuk tujuan itu. Di samping itu, statistik induktif
menyediakan juga alat-alat untuk pembuatan peramalan (prediction), penaksiran
(estimation), dan sebagainya.
10. Dr. Amudi Pasaribu, M.Sc., Ph.D, Pengantar Statistik, Jakarta: Ghalia Indonesia,
Cetakan keempat, 1981, hal. 19
11. Ronald, E. Walpole, Pengantar Statistika, PT. Gramedia Pustaka Utama, Jakarta,
Edisi ke-3, 1992, hal. 2
12. Bambang, Suryoatmojo, Statistika dan Probabilitas, Fakultas Teknik Universitas
2.4. Ukuran Penyebaran
Ukuran penyebaran (ukuran penyimpangan) dapat dibedakan menjadi 2
macam, yaitu ukuran penyebaran mutlak (absolute dispersion) dan ukuran
penyebaran relatif (relative dispersion).
Pengukuran dispersi absolut hanya dapat digunakan bagi penggambaran
dispersi nilai-nilai observasi sebuah distribusi secara definitif. Sedangkan pengukuran
dispersi relatif digunakan bila kita ingin melakukan perbandingan tingkat dispersi
antara 2 atau beberapa distribusi dan bila jumlah nilai-nilai observasi dari dua atau
beberapa distribusi ialah tidak sama.
Ukuran penyebaran mutlak (absolute dispersion) dinyatakan di dalam satuan
yang sama dengan satuan data asli (misalnya: orang, tahun, kilogram, meter, rupiah,
dan sebagainya). Sedangkan ukuran bagi penyebaran relatif (relative dispersion)
dinyatakan di dalam bilangan tanpa satuan.
2.5. Ukuran Penyebaran Mutlak (Absolute Dispersion)
Harga rata-rata adalah merupakan suatu bilangan atau suatu nilai sekitar mana
nilai-nilai yang lain tersebar13.
13. Dr. Amudi Pasaribu, M.Sc., Ph.D, Pengantar Statistik, Jakarta: Ghalia Indonesia,
Dikatakan juga bahwa harga rata-rata dapat dipakai mewakili sekumpulan
data atau memberikan keterangan mengenai sekumpulan data. Akan tetapi keterangan
yang diberikannya mengenai kumpulan data yang diwakilinya adalah sangat kabur,
dan sering tidak banyak artinya. Kekaburan keterangan demikian itu bukanlah oleh
karena adanya bermacam-macam harga rata-rata saja, akan tetapi, walaupun kita
hanya memperhatikan satu macam harga rata-rata saja, keterangan itu masih tetap
tidak lengkap.
Sebagai contoh, marilah kita misalkan sekumpulan bilangan yang harga
rata-rata hitungnya (arithmetic mean) sama dengan 50. Misalkan pula lebih lanjut bahwa
di dalam kumpulan itu terdapat lima buah bilangan. Apakah yang dapat kita katakan
mengenai kelima bilangan itu? yang dapat kita katakan hanyalah bahwa beberapa dari
bilangan itu lebih besar dan beberapa lebih kecil dari 50 dan jumlah dari
selisih-selisih bilangan itu dengan 50 akan sama dengan nol. Hanya inilah yang dapat kita
katakan, tidak lebih tidak kurang.
Dari uraian diatas jelaslah bahwa harga rata-rata, baik berupa harga rata-rata
hitung, median, maupun berupa modus atau harga rata-rata lainnya, tidaklah
merupakan “wakil” yang sempurna dari sekumpulan data. Harga rata-rata itu, berdiri
sendiri, hanya dapat memberi gambaran yang kabur dan sepintas lalu saja dari
sekumpulan data. Untuk memperjelas keterangan tersebut, maka kepada keterangan
yang diberikan oleh harga rata-rata itu- biasanya kita memakai harga rata-rata hitung-
yang dapat dipakai untuk penyebaran itu antara lain adalah range, simpangan rata-rata
(average deviation atau mean deviation) dan simpangan standar (standard deviation).
Range merupakan suatu bilangan hasil selisih antara nilai yang tertinggi dan
nilai yang terendah di dalam sekumpulan data14. Pemakaian keterangan yang diberikan oleh range sebagai tambahan bagi keterangan yang telah diberikan oleh
harga rata-rata mengenai sekumpulan data, dapat memberi gambaran yang lebih
terang mengenai kumpulan data itu.
Pemakaian range sebagai ukuran penyebaran tidak memasukkan ke dalam
pertimbangan nilai-nilai yang lain di dalam sekumpulan data, selain dari kedua nilai
ekstrimnya. Inilah kelemahan utama daripada pemakaian range itu sebagai ukuran
penyebaran. Untuk melepaskan diri dari persoalan ini, kita dapat memakai ukuran
yang lain, ukuran yang memperhatikan setiap nilai di dalam kumpulan data yang
bersangkutan. Ukuran-ukuran yang demikian adalah simpangan rata-rata (average
deviation atau mean deviation) dan simpangan standar (standard deviation).
14. Dr. Amudi Pasaribu, M.Sc., Ph.D, Pengantar Statistik, Jakarta: Ghalia Indonesia,
Jadi, jelaslah bahwa untuk menerangkan sekumpulan data, yang telah tersusun
di dalam sebuah pencaran frekuensi ataupun belum kita paling sedikit memerlukan
keterangan mengenai harga rata-rata (yang biasanya harga rata-rata hitung) dan
keterangan mengenai penyebaran data itu. Gabungan dari 2 macam keterangan ini
pun sering tidak cukup memberi keterangan yang memberi gambaran yang jelas
mengenai kumpulan data itu.
2.6. Simpangan Rata-rata dari Data Tak Tersusun
Dengan memisalkan bahwa x1, x2, ………., xn sebagai nilai-nilai di dalam
kumpulan data dan X sebagai harga rata-rata hitung dari kumpulan data itu, maka
simpangan-simpangan antara nilai-nilai itu dengan harga rata-rata hitungnya adalah:
( x1 - x ), ( x2 - x ), ………( xn - x )
dan harga-harga mutlaknya adalah:
x1 - x , x2 - x , ……… xn - x
penjumlahan dari harga-harga mutlak simpangan-simpangan itu menghasilkan:
x1 - x + x2 - x + …………..+ xn - x = ∑ xi - x
maka rumus-definisi dari simpangan rata-rata itu dapat dituliskan sebagai
(menyatakan simpangan rata-rata dengan SR):
n
SR = ( 1/n ) ∑ xi - x
Pemakaian harga mutlak disini adalah sangat penting, karena kalau harga
mutlak itu tidak dipakai, maka jumlah dari simpangan-simpangan itu akan sama
dengan nol. Akan tetapi, dengan mengambil harga rata-rata hitung dari jumlah harga
mutlak daripada simpangan-simpangan itu, pada umumnya, nilai nol tidak terdapat.
Jika nilai itu sama dengan nol, maka hal itu hanyalah kebetulan saja.
Sebagai contoh, marilah kita memperlihatkan deretan bilangan yang berikut;
70, 65, 45, 40, 30
dengan mudah dapat ditentukan bahwa harga rata-rata hitungnya adalah sama dengan
50. Jika dari setiap bilangan yang terdapat di dalam deretan ini kita mengurangkan
50, maka kita akan memperoleh simpangan-simpangan antara nilai-nilai itu dengan
harga rata-rata hitung, yaitu:
20, 15, -5, -10, -20
Setiap bilangan di dalam deretan yang terakhir ini merupakan simpangan
antara nilai di dalam kumpulan data dengan harga rata-rata hitung dari kumpulan data
itu. Kalau kita tidak memperhatikan tanda dari simpangan-simpangan itu- atau lebih
tepat lagi, kalau kita mengambil harga mutlak dari simpangan-simpangan tersebut-
maka kita akan memperoleh deretan:
20, 15, 5, 10, 20
yang semuanya berjumlah 70. Jadi harga mutlak dari simpangan-simpangan antara
data asli dengan harga rata-rata hitungnya, berjumlah 70. Maka, simpangan rata-rata
dari harga rata-rata hitung dari simpangan-simpangan antara data asli dengan harga
rata-rata hitung kumpulan data itu.
2.7. Simpangan Standar dari Data Tak Tersusun
Di dalam perhitungan simpangan rata-rata, kita mengambil harga mutlak dari
setiap simpangan. Kemudian, harga mutlak itu kita jumlahkan seluruhnya lalu dibagi
dengan n. Pengambilan harga mutlak simpangan-simpangan itu bertujuan
menghindarkan terdapatnya nilai yang sama dengan nol sebagai jumlahnya. Di dalam
ilmu pasti, kita mengenal juga sebuah cara lain untuk menghilangkan tanda, yaitu
dengan memangkatduakan bilangan yang positif maupun negatif kita selalu mendapat
bilangan positif sebagai hasilnya. Sehubungan dengan ukuran penyebaran, kita dapat
juga memakai cara itu. Sebagai pengganti penarikan tanda harga mutlak dari
simpangan-simpangan, kita memakai pangkatduanya. Dengan demikian
( xi - x )2
kita memperoleh nilai-nilai untuk setiap pengamatan (nilai) yang terdapat di dalam
kumpulan data yang bersangkutan. Pangkat-dua dari simpangan-simpangan itu
kemudian dijumlahkan seluruhnya dan dibagi dengan n. Nilai yang diperoleh itu
dinamakan variance dari kumpulan data tersebut.
Jadi, di dalam bentuk rumus, dapat kita tuliskan:
n
Variance = ( 1/n ) ∑ (xi - x )2
dimana n menunjukkan banyaknya pengamatan yang termasuk di dalam kumpulan
data itu.
Variance ini dapat dianggap sebagai ukuran daripada penyebaran atau lebih
tepat, ukuran penyimpangan antara nilai-nilai dengan harga rata-rata hitungnya. Akan
tetapi, di dalam definisi di atas tadi, variance itu adalah harga rata-rata hitung dari
pangkat-dua simpangan-simpangan antara nilai-nilai pengamatan dengan harga
rata-rata hitung dari kumpulan data itu. Jadi dapat kita katakan bahwa variance itu
bukanlah ukuran dari simpangan, melainkan ukuran dari pangkat-dua simpangan.
Benar, kalau simpangan-simpangan itu besar, pangkat-duanya pun besar dan jika
simpangan-simpangan itu kecil, pangkat-duanya pun kecil juga. Tetapi, walaupun
demikian, pangkat-dua adalah pangkat-dua, dan bukanlah ukuran dari pangkat-dua
simpangan yang kita inginkan.
Untuk mengembalikan variance itu kepada ukuran simpangan- jadi bukan
ukuran pangkat-dua simpangan,- kita dapat menarik akar-pangkat-dua ( √ ) daripada
variance itu. Nilai yang diperoleh dengan menarik akar-pangkat-dua dari variance
dinamakan simpangan standar atau standard deviation.
Biasanya orang memakai tanda S2 untuk menyatakan variance secara singkat. Oleh karena hubungan yang ada antara variance dengan standard deviation seperti
baru saja kita uraikan, maka standard deviation itu dinyatakan orang dengan S.
Dengan demikian, dari rumus variance di atas, dapatlah kita menyusun rumus untuk
n
S = ( 1/n ) ∑ ( xi - x )2
i = 1
Kalau kumpulan data itu hanya merupakan sampel, jadi bukan population,
maka biasanya kita memakai tanda x dan S untuk harga rata-rata hitung dan
standard deviation. Kalau data kita meliputi seluruh population, maka harga rata-rata
hitung dan standard deviation itu kita nyatakan dengan memakai μ dan σ,
masing-masing.
Sebenarnya, standard deviation itu boleh saja dianggap sebagai ukuran
simpangan antara nilai-nilai data dengan sembarang harga rata-rata, jadi tidaklah
harus merupakan simpangan antara nilai-nilai data dengan harga rata-rata hitung saja.
Jadi x di dalam rumus di atas dapat kita ganti dengan median, modus, atau harga
rata-rata lainnya. Kalau harga rata-rata sembarang itu kita nyatakan dengan R, maka
standard deviation itu dapat kita definisikan sebagai:
S = n
( 1/n ) ∑ (xi - R )2 i = 1
Marilah kita mengambil sebuah contoh yang sederhana untuk menunjukkan
perhitungan dari standard deviation dari data yang tak tersusun (ungrouped data).
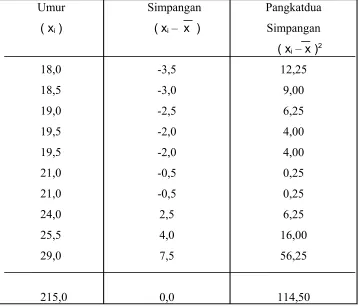
Misalkan kita mengumpulkan angka-angka yang menunjukkan umur dari 10
orang mahasiswa di tingkat pertama suatu fakultas. Dari bilangan-bilangan yang
deviation. Misalkan bahwa mereka berumur, berturut-turut 18,0 tahun, 18,5 tahun,
19,0 tahun, 19,5 tahun, 19,5 tahun, 21,0 tahun, 21,0 tahun, 24,0 tahun, 25,5 tahun,
dan 29,0 tahun. Jumlah umur mereka adalah sama dengan 215,0 tahun. Maka harga
rata-rata hitung umur mereka adalah 21,5 tahun.
Dengan mudah dapat kita hitung simpangan antara umur setiap mahasiswa
dengan umur rata-rata tadi. Perhitungan ini dilakukan di dalam kolom kedua dari
tabel 2.1. Pada kolom ketiga kita telah memasukkan pangkat-dua dari
simpangan-simpangan itu. Dengan memakai rumus dari standard deviation di atas, kita peroleh:
Jadi sepuluh orang mahasiswa itu mempunyai umur rata-rata sama dengan 21,5 tahun
dengan standard deviation sama dengan 3,38 tahun.