SENTIMENT ANALYSIS
TERHADAP TULISAN
MENGENAI UNIVERSITAS PERTAMINA DI MEDIA
SOSIAL TWITTER
LAPORAN TUGAS AKHIR
Oleh:
M. Rizky Widyayulianto 105216026
FAKULTAS SAINS DAN ILMU KOMPUTER
PROGRAM STUDI ILMU KOMPUTER
UNIVERSITAS PERTAMINA
OKTOBER 2020
SENTIMENT ANALYSIS
TERHADAP TULISAN
MENGENAI UNIVERSITAS PERTAMINA DI MEDIA
SOSIAL TWITTER
LAPORAN TUGAS AKHIR
Oleh:
M. Rizky Widyayulianto 105216026
FAKULTAS SAINS DAN ILMU KOMPUTER
PROGRAM STUDI ILMU KOMPUTER
UNIVERSITAS PERTAMINA
OKTOBER 2020
LEMBAR PENGESAHAN
Judul Tugas Akhir : Sentiment Analysis Terhadap Tulisan Mengenai Universitas Pertamina di Media Sosial Twitter Nama Mahasiswa : M. Rizky Widyayulianto
Nomor Induk Mahasiswa : 105216026
Program Studi : Ilmu Komputer
Fakultas : Sains dan Ilmu Komputer
Tanggal Lulus Sidang Tugas Akhir :
MENGESAHKAN
Pembimbing 1 Pembimbing 2
Meredita Susanty, M.Sc. Ade Irawan, Ph.D
116020 116130
MENGETAHUI, Ketua Program Studi
Muhamad Koyimatu, Ph.D NIP. 116108
3 September 2020
LEMBAR PERNYATAAN
Dengan ini saya menyatakan bahwa Tugas Akhir berjudulSentiment AnalysisTerhadap Tulisan Mengenai Universitas Pertamina di Media Sosial Twitter ini adalah benar-benar merupakan hasil karya saya sendiri dan tidak mengandung materi yang ditulis oleh orang lain kecuali telah dikutip sebagai referensi yang sumbernya telah dituliskan secara jelas sesuai dengan kaidah penulisan karya ilmiah.
Apabila dikemudian hari ditemukan adanya kecurangan dalam karya ini, saya bersedia mene-rima sanksi dari Universitas Pertamina sesuai dengan peraturan yang berlaku.
Demi pengembangan ilmu pengetahuan, saya menyetujui untuk memberikan kepada Univer-sitas Pertamina hak bebas royalti noneksklusif (non-exclusive royalty-free right) atas Tugas Akhir ini beserta perangkat yang ada. Dengan hak bebas royalti noneksklusif ini Universitas Pertamina berhak menyimpan, mengalih media/format-kan, mengelola dalam bentuk pangkatan data (database), merawat, dan mempublikasikan Tugas Akhir saya selama tetap mencantumkan nama saya sebagai penulis/pencipta dan sebagai pemilik Hak Cipta.
Demikian pernyataan ini saya buat dengan sebenarnya
Jakarta, 19 Agustus 2020 Yang membuat pernyataan,
ABSTRAK
M. Rizky Widyayulianto. 105216026. Sentiment AnalysisTerhadap Tulisan Mengenai Uni-versitas Pertamina di Media Sosial Twitter.
Konsepbranding mulai diterapkan di perusahaan yang tidak bergerak di sektor bisnis. Banyak universitas yang telah menerapkanbrandinguntuk menjagabrand imagedari universitas terse-but sehingga dapat menarik minat calon mahasiswa. Sentiment analysis adalah salah satu kegiatan yang dapat dilakukan untuk memantau brand imageuniversitas di mata masyarakat. Penelitian ini menerapkan konsep machine learning untuk melakukan sentiment analysis di media sosial Twitter. Dataset yang digunakan terdiri dari 4323tweetberbahasa Indonesia yang mengandung kata ”Universitas Pertamina”. Setiaptweetkemudian dikelompokkan ke 3 kelas berbeda berdasarkan sentimentweettersebut, yaitu negatif, netral dan positif.
Penelitian ini menggunakan 3 jenis modelmachine learning, yaituConvolutional Neural Net-work(CNN),Long Short Term Memory(LSTM) dan CNN-LSTM. Prosestrainingketiga model tersebut menggunakan teknik stratified 5-fold cross validation. Performa model kemudian diukur dengan menggunakanlearning curvedan mengukur parameter sepertiaccuracy, weighted-f1dan balanced accuracy. Model CNN-LSTM mendapatkan nilaiaccuracy tertinggi dengan 76.92%dan weighted-f1tertinggi dengan 76.78%. Sementara model LSTM mendapatkan ni-laibalanced accuracytertinggi dengan 66.05%. Berdasarkanlearning curvedari ketiga model tersebut, didapatkan bahwa dataset yang digunakan kurang representatif untuksentiment anal-ysis
ABSTRACT
M. Rizky Widyayulianto. 105216026. Sentiment Analysis Towards Post About Universitas Pertamina on Social Media Twitter.
The branding concept has begun to be applied in companies that are not engaged in the business sector. Many universities have implemented branding to maintain the brand image of the uni-versity so that it can attract prospective students. Sentiment analysis is one of the activities that can be carried out to monitor the university’s brand image in the eyes of the community. This re-search applies the concept of machine learning to conduct social media analysis of Twitter. The dataset used consists of 4323 tweets containing the word ”Universitas Pertamina”. Each tweet is then grouped into 3 different classes based on the sentiment of the tweet, namely negative, neutral and positive.
This study uses 3 types of machine learning models, namely Convolutional Neural Net-work (CNN), Long Short Term Memory (LSTM) and CNN-LSTM. The procedure for the three mod-els uses the stratified 5-fold cross validation technique. Model performance is then measured using a learning curve and measuring parameters such as accuracy, weighted-f1 and balanced accuracy. The CNN-LSTM model record the highest accuracy value with 76.92%and the high-est weighted-f1 with 76.78%. Meanwhile, the LSTM model gets the highest balanced accuracy value with 66.05%. Based on the learning curve of the three models, it was found that the dataset used was less representative for the sentiment analysis.
KATA PENGANTAR
Puji syukur penulis haturkan kehadirat Allah SWT yang telah menganugerahkan rahmat serta inayah-Nya, yang karena-Nya, penulis diberikan kekuatan dan kesabaran untuk menyelesaikan laporan Tugas Akhir yang berjudul “Sentiment Analysis Terhadap Tulisan Mengenai Universi-tas Pertamina di Media Sosial Twitter”.
Adapun pengajuan tugas akhir ini ditujukan sebagai pemenuhan ketentuan kelulusan pada jen-jang perkuliahan Strata I Universitas Pertamina. Lewat penyusunan tugas akhir ini penulis telah mengalami beberapa hambatan, tantangan seta kesulitan, namun karena binaan dan dukungan baik dari keluarga, dosen, dan teman - teman sekalian, akhirnya semua hambatan tersebut dapat teratasi.
Dalam penulisan tugas akhir ini penulis sadar akan ditemukan banyak kekurangan pada laporan ini, Baik itu dari segi kualitas maupun dari segi kuantitas bahan observasi yang penulis gunakan pada tugas akhir ini. Karenanya, penulis memerlukan saran serta kritik yang membangun untuk menjadikan tugas akhir ini lebih baik dari sebelumnya.
Selanjutnya penulis mengucapkan terima kasih yang sebanyak-banyaknya kepada segenap pi-hak yang telah memberikan dukungan, baik itu berupa bantuan, doa maupun dorongan dan beragam pengalaman selama proses penyelesaian penulisan tugas akhir ini. Semoga laporan ini dapat memberikan manfaat dan berguna bagi siapapun yang membaca laporan Tugas Akhir.
Jakarta, 19 Agustus 2020
DAFTAR ISI
ABSTRAK i
ABSTRACT ii
KATA PENGANTAR iii
DAFTAR ISI iv
DAFTAR TABEL vi
DAFTAR GAMBAR vii
BAB I PENDAHULUAN 1 1.1 Latar Belakang . . . 1 1.2 Rumusan Masalah . . . 2 1.3 Batasan Masalah . . . 2 1.4 Tujuan Penelitian . . . 2 1.5 Manfaat Penelitian . . . 2
BAB II TINJAUAN PUSTAKA 3 2.1 Machine Learning . . . 3
2.1.1 Tipemachine learning . . . 3
2.1.2 Neural network . . . 3
2.1.3 Convolutional neural network . . . 5
2.1.4 Recurrent neural network . . . 6
2.1.5 Long short-term memory . . . 6
2.1.6 Machine learningpada teks . . . 7
2.1.7 Bias, variance, overfitdanunderfit . . . 9
2.1.8 Mengukur performa model . . . 10
2.1.9 Learning Curve . . . 11
2.2 Sentiment Analysis . . . 14
2.3 Penelitian TerkaitSentiment Analysisdengan Bahasa Indonesia . . . 15
BAB III METODE PENELITIAN 16 3.1 Data Gathering . . . 16
3.2 Data Preprocessing . . . 16
3.3 Create and Training Model . . . 17
3.4 Analisis . . . 17
BAB IV HASIL DAN PEMBAHASAN 19 4.1 Data Gathering . . . 19
4.2 Data Preprocessing . . . 20
4.3 Create and Training Model . . . 22
4.3.1 Model CNN . . . 22
4.3.2 Model LSTM . . . 30
4.3.3 Model CNN-LSTM . . . 38
4.4 Analisis . . . 46
BAB V KESIMPULAN DAN SARAN 50 5.1 Kesimpulan . . . 50
5.2 Saran . . . 50
DAFTAR TABEL
Tabel 2.1 Contoh PenerapanBag of Words . . . 7
Tabel 4.1 Contoh Tweet dan Sentimen yang Diberikan . . . 19 Tabel 4.2 Contoh Kata yang Dinormalisasi . . . 21 Tabel 4.3 PerbandinganTweetyang Dihasilkan pada Setiap Tahapdata preprocessing . 21 Tabel 4.4 Data Epoch,Loss, danTrainingdari Setiap Fold pada ProsesTrainingModel
CNN dengan 5-Fold CrossValidationBeserta Rata-rata (mean) . . . 29 Tabel 4.5 Rata-rata nilaiTrue Positive, True Negative, False Positive, False Negative,
Precision,Recalldanf1-ScoreMasing-masing Label pada Model CNN . . . 29 Tabel 4.6 Data Epoch,Loss, danTrainingdari Setiap Fold pada ProsesTrainingModel
LSTM dengan 5-Fold Cross Validation Beserta Rata-rata (mean) . . . 37 Tabel 4.7 Rata-rata nilaiTrue Positive, True Negative, False Positive, False Negative,
Precision,Recalldanf1-ScoreMasing-masing Label pada Model LSTM . . . 37 Tabel 4.8 Data Epoch,Loss, danTrainingdari Setiap Fold pada ProsesTrainingModel
CNN-LSTM dengan 5-FoldCross ValidationBeserta Rata-rata (mean) . . . . 45 Tabel 4.9 Rata-rata nilaiTrue Positive, True Negative, False Positive, False Negative,
DAFTAR GAMBAR
Gambar 2.1 Ilustrasi Neuron padaNeural Network . . . 4
Gambar 2.2 IlustrasiFeed Forward Neural Network . . . 4
Gambar 2.3 IlustrasiConvolutional Layer . . . 5
Gambar 2.4 IlustrasiPooling Layer . . . 6
Gambar 2.5 Ilustrasi Neuron Pada RNN, dengan Neuron A,InputKe-tXtdanOutputht 6 Gambar 2.6 Ilustrasi One-Hot Encoding . . . 8
Gambar 2.7 Pembagian KelasTrue Positive,True Negative,False PositivedanFalse Neg-ative . . . 10
Gambar 2.8 Learning CurveuntukLoss(Brownlee, 2019) . . . 12
Gambar 2.9 Learning CurveuntukLosspada Model yang MengalamiOverfitting (Brown-lee, 2019) . . . 12
Gambar 2.10 Learning CurveuntukLosspada Model yang MengalamiUnderfit (Brown-lee, 2019) . . . 13
Gambar 2.11 Learning CurveuntukLossuntuk Dataset yang Tidak Representatif Secara Statistik (Brownlee, 2019) . . . 13
Gambar 2.12 Ilustrasi Pembagian Dataset pada K-fold Cross Validation . . . 14
Gambar 4.1 Pembagian Label pada Dataset . . . 20
Gambar 4.2 Distribusi Kata Unik per Label . . . 20
Gambar 4.3 Distribusi Kata Unik per Label Setelah TahapData Preprocessing . . . 22
Gambar 4.4 Struktur Model CNN . . . 23
Gambar 4.5 Hasil Proses Training, Confusion Matrix, dan Learning Curve dari model CNN pada Fold 1 . . . 24
Gambar 4.6 Hasil Proses Training, Confusion Matrix, dan Learning Curvedari Model CNN pada Fold 2 . . . 25
Gambar 4.7 Hasil prosestraining,Confusion Matrix, danlearning curvedari model CNN pada Fold 3 . . . 26
Gambar 4.8 Hasil Proses Training, Confusion Matrix, dan Learning Curvedari Model CNN pada Fold 4 . . . 27
Gambar 4.9 Hasil Proses Training, Confusion Matrix, dan Learning Curvedari Model CNN pada Fold 5 . . . 28 Gambar 4.10 Rata - rataWeighted f1,AccuracydanBalanced Accuracydari Model CNN 29
Gambar 4.11 Struktur Model LSTM . . . 31 Gambar 4.12 Hasil Proses Training, Confusion Matrix, dan Learning Curvedari Model
LSTM pada Fold 1 . . . 32 Gambar 4.13 Hasil Proses training, Confusion Matrix, dan Learning Curve dari Model
LSTM pada Fold 2 . . . 33 Gambar 4.14 Hasil Proses Training, Confusion Matrix, dan Learning Curvedari Model
LSTM pada Fold 3 . . . 34 Gambar 4.15 Hasil Proses Training, Confusion Matrix, dan Learning Curvedari Model
LSTM pada Fold 4 . . . 35 Gambar 4.16 Hasil Proses Training, Confusion Matrix, dan Learning Curvedari Model
LSTM pada Fold 5 . . . 36 Gambar 4.17 HasilWeighted f1,AccuracydanBalanced Accuracydari Model LSTM . . 37 Gambar 4.18 Struktur Model CNN-LSTM . . . 39 Gambar 4.19 Hasil Proses Training, Confusion Matrix, dan Learning Curvedari Model
CNN-LSTM pada Fold 1 . . . 40 Gambar 4.20 Hasil Proses Training, Confusion Matrix, dan Learning Curvedari Model
CNN-LSTM pada Fold 2 . . . 41 Gambar 4.21 Hasil Proses Training, Confusion Matrix, dan Learning Curvedari Model
CNN-LSTM pada Fold 3 . . . 42 Gambar 4.22 Hasil Proses Training, Confusion Matrix, dan Learning Curvedari Model
CNN-LSTM pada Fold 4 . . . 43 Gambar 4.23 Hasil Proses Training, Confusion Matrix, dan Learning Curvedari Model
CNN-LSTM pada Fold 5 . . . 44 Gambar 4.24 HasilWeighted f1,AccuracydanBalanced accuracydari Model CNN-LSTM
. . . 45 Gambar 4.25 Perbandingan Performa Model CNN, LSTM dan CNN-LSTM Berdasarkan
Accuracy,weighted f1, danBalanced Accuracydalam Persen (%) . . . 46 Gambar 4.26 Perbandingan f1-scoreModel CNN, LSTM dan CNN-LSTM Berdasarkan
Label Dataset dalam Persen (%) . . . 47 Gambar 4.27 PerbandinganPrecisiondanRecallModel CNN, model LSTM dan, model
CNN-LSTM dalam Persen (%) . . . 48 Gambar 4.28 PerbandinganLearning Curveyang Dihasilkan oleh ProsesTraining Fold5
BAB I
PENDAHULUAN
1.1 Latar BelakangSetiap konsumen memiliki arti atau definisi masing - masing terhadap produk atau merek yang mereka konsumsi atau gunakan, dimana persepsi ini berhubungan langsung dengan memori dari kon-sumen terhadap produk atau merek tersebut. Persepsi ini disebut juga sebagaibrand image(Gensler et al., 2015). Brand imagemerupakan bagian penting daribrand equity, yaitu persepsi konsumen terhadap merek tersebut. Apabila sebuah merek dapat mengontrol persepsi dan sikap konsumen mengenai merek tersebut, maka hal itu secara tidak langsung mempengaruhi konsumen untuk mem-beli produk dengan merek tersebut sehingga dapat meningkatkan penjualan dari perusahaan yang bersangkutan (Zhang et al., 2015).
Konsep brand image tidak hanya diterapkan untuk meningkatkan kinerja perusahaan di sektor bisnis, beberapa lembaga yang bergerak di sektor publik, seperti kepolisian Kota London (Lon-don metropolitan police), Gereja Katolik Roma, hingga beberapa universitas juga mulai melakukan kegiatanbranding(Marsh and Fawcett, 2011). Kegiatan brandingyang dilakukan oleh universitas, atau disebut jugauniversity branding, adalah kegiatan yang dilakukan untuk memberikan identitas bagi universitas serta untuk menyampaikan aspek - aspek yang dimiliki oleh universitas, seperti kual-itas pendidikan, sejarah, dan budaya kepada publik (Zhang and Zhao, 2009). Seperti halnya kegiatan
brandingyang dilakukan perusahaan untuk meningkatkan penjualan,university brandingdilakukan untuk mendapat keunggulan kompetitif dari universitas lainnya. Keunggulan ini nantinya dapat men-jadi pertimbangan bagi para calon mahasiswa untuk melanjutkan pendidikannya.
Selain melakukanbranding,brand monitoring, yaitu pemantauan mengenai apa yang diperbin-cangkan oleh orang - orang mengenai instansi tersebut, juga perlu dilakukan untuk mengetahui apakah
brand imageinstansi sesuai dengan targetbrandingyang dilaksanakan. Universitas yang membang-gakan kualitas mahasiswa yang dimilikinya tentu tidak ingin adanya berita atau pembicaraan men-genai perilaku mahasiswa yang tidak sesuai dengan aturan atau norma moral yang ada, yang dapat berujung pada rusaknyabrand imageuniversitas itu sendiri.Brand monitoringdapat dilakukan pada media sosial. Jumlah pengguna media sosial di seluruh dunia pada tahun 2019 mencapai 3,484 miliar orang, atau sekitar 45%dari keseluruhan populasi manusia (Lambert, 2020). Diantara sekian banyak media sosial yang ada, Twitter memiliki keunggulan dalam akses API yang memudahkan pengem-bang (developer) atau pihak yang berkepentingan untuk mengakses setiap tulisan (tweet) di Twitter. Twitter juga merupakan media sosial terbesar ke-8 berdasarkan jumlah pengguna aktif setiap bulan, dengan 326 juta pengguna (Lambert, 2020). Setiap harinya, pengguna Twitter membuat 500 juta
tweet, atau sekitar 6000tweetper detik.
Teknologi machine learning memungkinkan komputer untuk mengklasifikasikan kalimat ber-dasarkan polaritasnya. Terdapat beberapa algoritma untuk mengimplementasikan modelsentiment analysissepertinaive-bayes,linear regression,Support Vector Machines(SVM) serta algoritmadeep
learningsepertiLong Short Term Memory(LSTM) danConvolutional Neural Network (CNN). Be-berapa penelitian lain sudah melakukansentiment analysisdengan teks berbahasa Indonesia dengan menggunakan algoritmaNaive-Bayesmaupun SVM. (Saputri et al., 2018) melakukansentiment anal-ysisdengan mengklasifikasikan tweetberdasarkan emosi ke dalam 5 kelas. Penelitian tersebut di-lakukan dengan menggunakan beberapafeaturesepertiBag of Wordsdanword embeddingdan dikom-binasikan untuk mendapatkan model terbaik dari metodelogistic regression, SVM, danrandom forest. (Iswanto and Poerwoto, 2018) melakukan sentiment analysis menggunakan modelnaive-bayes, SVM danmaximum entropypada tweet yang berhubungan dengan pemilihan presiden tahun 2014. Namun masih sedikit penelitian serupa untuk algoritmadeep learningPenelitian ini menggunakan algoritma CNN, LSTM dan CNN-LSTM untuk melakukansentiment analysis.
1.2 Rumusan Masalah
Penelitian ini mengusulkan metode interpretasi tulisan mengenai Universitas Pertamina di media sosial menjadi tulisan yang positif, negatif atau netral menggunakan model yang dibangun dengan algoritma CNN, LSTM, dan CNN-LSTM. penelitian ini adalah algoritma manakah antara LSTM, CNN, dan LSTM+CNN yang memiliki performa akurasi interpretasi yang terbaik dengan dataset yang jumlah data tiap labelnya tidak seimbang dan relatif sedikit ?
1.3 Batasan Masalah
Batasan masalah dalam penelitian ini adalah data yang digunakan didapat dari tulisan di media sosial Twitter
1.4 Tujuan Penelitian
Tujuan yang ingin dicapai dalam penelitian ini adalah:
1. Teridentifikasinya akurasi proses Sentiment Analysis dari model CNN, LSTM dan CNN-LSTM untuk topik Universitas Pertamina
2. Terciptanya model untuk mengidentifikasi sentimen tulisan mengenai Universitas Pertamina
1.5 Manfaat Penelitian
Model yang dihasilkan dari penelitian ini dapat digunakan untuk kegiatanbrand monitoringuntuk Universitas Pertamina. Dengan memanfaatkan model ini diharapkan dapat meningkatkan efektifitas daribrand monitoringyang dilakukan Universitas Pertamina.
BAB II
TINJAUAN PUSTAKA
2.1 Machine LearningMachine Learningadalah sebuah disiplin ilmu dari perancangan dan pembuatan algoritma yang memungkinkan sebuah sistem komputer untuk meningkatkan performa sistem tersebut dengan me-manfaatkan data yang dimiliki atau didapat oleh sistem tersebut (Mitchell et al., 1997). Sesuai de-ngan namanya,learning, sistem dapat belajar dengan cara melakukan komputasi (training) dengan data yang dimiliki dan menggunakan hasil komputasi tersebut untuk meningkatkan kinerja sistem. Tujuan dari penerapanmachine learningadalah untuk menghasilkan sebuah prediksi atau keputusan berdasarkan data yang ada.
2.1.1 Tipemachine learning
Berdasarkan cara pembelajaran yang dilakukan oleh sistem, machine learning terbagi menjadi tiga, yaitusupervised,unsupervised, danreinforcement.
1. Supervised machine learning, dimana setiap data masukan (input) diberikan sebuah label yang berfungsi sebagai hasil (output) yang seharusnya dihasilkan oleh datainput. Tujuan dari su-pervised machine learningadalah untuk menghasilkan model yang dapat memprediksioutput
berdasarkaninputyang diterima.
2. Unsupervised machine learning, dimana datainputtidak memiliki label. Tujuan dari unsuper-vised machine learningadalah untuk menghasilkan model dari datainputyang ada. Dengan tidak adanya label yang dapat menjadi indikator keberhasilan dari sistem, unsupervised ma-chine learning dapat menghasilkan sesuatu yang tidak diketahui sebelumnya, seperti pola -pola tertentu pada data.
3. Reinforcement machine learning, sistem dihadapkan langsung dengan lingkungan dinamis, di-mana sistem diminta untuk mengambil keputusan berdasarkan stimulus yang diterima sistem dari lingkungan, dan sekumpulan aturan yang dimiliki oleh sistem. Contoh darireinforcement machine learningadalah fiturself-driving car.
2.1.2 Neural network
Neural Networkadalah salah satu modelmachine learningberupa kumpulan elemen yang disebut neuron dan terhubung satu sama lain layaknya sistem saraf pada makhluk hidup (Gurney, 1997). Ide untuk neural network pertama kali dicetuskan oleh McCulloch and Pitts (1943), dimana mereka mencetuskan bahwa perilaku neuron dapat dimodelkan dengan propositional logic. Setiap neuron
melakukan komputasi denganinputyang diterima menggunakan fungsi aktivasi untuk menghasilkan
output. Setiap neuron dapat menerima 1 atau lebih input, dan setiap input dapat memiliki bobot (weight) dan bias yang berbeda - beda.
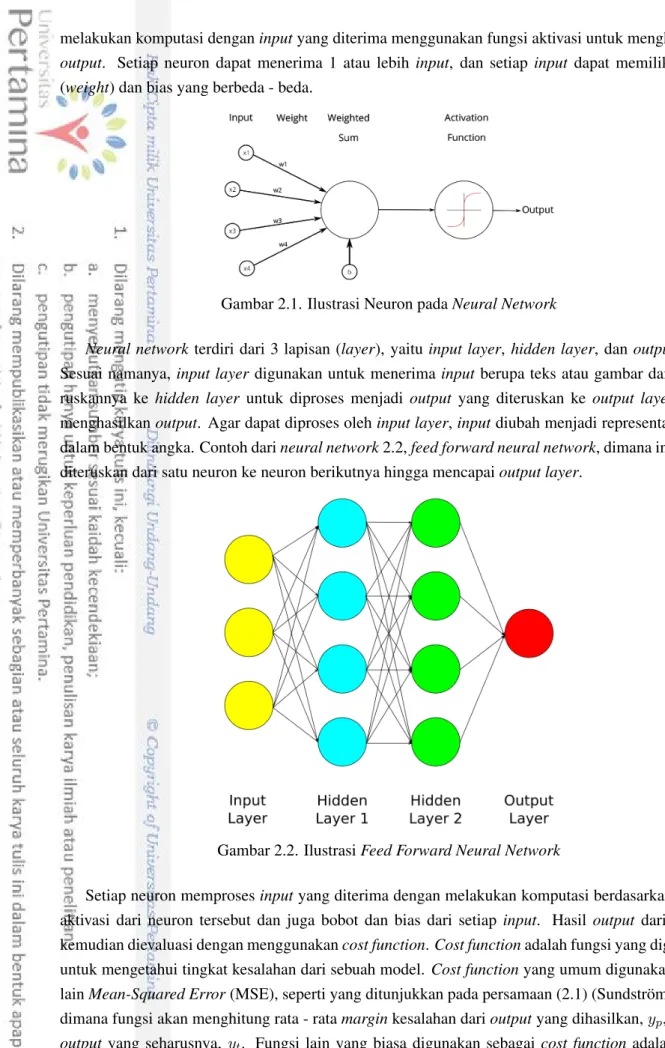
Gambar 2.1. Ilustrasi Neuron padaNeural Network
Neural network terdiri dari 3 lapisan (layer), yaitu input layer, hidden layer, dan output layer. Sesuai namanya,input layerdigunakan untuk menerima inputberupa teks atau gambar dan mene-ruskannya ke hidden layer untuk diproses menjadi output yang diteruskan ke output layer untuk menghasilkanoutput. Agar dapat diproses olehinput layer,inputdiubah menjadi representasiinput
dalam bentuk angka. Contoh darineural network2.2,feed forward neural network, dimana informasi diteruskan dari satu neuron ke neuron berikutnya hingga mencapaioutput layer.
Gambar 2.2. IlustrasiFeed Forward Neural Network
Setiap neuron memprosesinputyang diterima dengan melakukan komputasi berdasarkan fungsi aktivasi dari neuron tersebut dan juga bobot dan bias dari setiap input. Hasil output dari neuron kemudian dievaluasi dengan menggunakancost function.Cost functionadalah fungsi yang digunakan untuk mengetahui tingkat kesalahan dari sebuah model. Cost functionyang umum digunakan antara lainMean-Squared Error(MSE), seperti yang ditunjukkan pada persamaan (2.1) (Sundstr¨om, 2018), dimana fungsi akan menghitung rata - ratamarginkesalahan darioutputyang dihasilkan,yp, dengan
outputyang seharusnya, yt. Fungsi lain yang biasa digunakan sebagai cost function adalahCross
menghitung berapa selisih antaraypdanytdalam satuan bit dengan menggunakan logaritma basis 2. M SE= 1 N N X i=1 (yp−yt)2 (2.1) CE= 1 N N X i=1 ytlog(yp) (2.2)
Untuk meminimalisir kesalahan dari outputyang dihasilkan oleh sebuahneural network, bobot setiap input dapat diubah dengan menggunakan metodebackpropagation. Backpropagation adalah metode untuk untuk mengubah nilai parameter pada neuron (bobot dan bias) dengan cara menghitung gradien daricost function. Selain itu, perubahan bobot pada node juga dapat bergantung padalearning rate, dimanalearning ratemenentukan seberapa besar nilai bobot dapat diubah.
2.1.3 Convolutional neural network
Convolutional Neural Network(CNN) merupakan modelneural networkyang umumnya diguna-kan untuk klasifikasi gambar (Valueva et al., 2020). CNN dapat dibagi menjadi 3 bagian, yaitu con-volutional layer,pooling layer, danfully connected layer. Masukan pada CNN dapat digambarkan sebagai sebuah matriks angka.
Tugasconvolutional layer adalah untuk mengubah matriks tersebut menjadi matriks yang lebih mudah untuk diproses oleh model, tanpa kehilangan fitur/nilai dari matriks masukan. Convolutional layermelakukan ini dengan melakukan operasi perkalian dot pada matriks masukan dengan matriks filter yang berisi nilai weight dan menghasilkan matriks berisiconvolved features. Nilaiweightdapat diubah dengan metodebackpropagation. Tujuan dari perkalian ini adalah untuk mengambilhigh-level featuresyang ada pada masukan, contohnya sisi atau titik tertentu pada gambar.
Gambar 2.3. IlustrasiConvolutional Layer
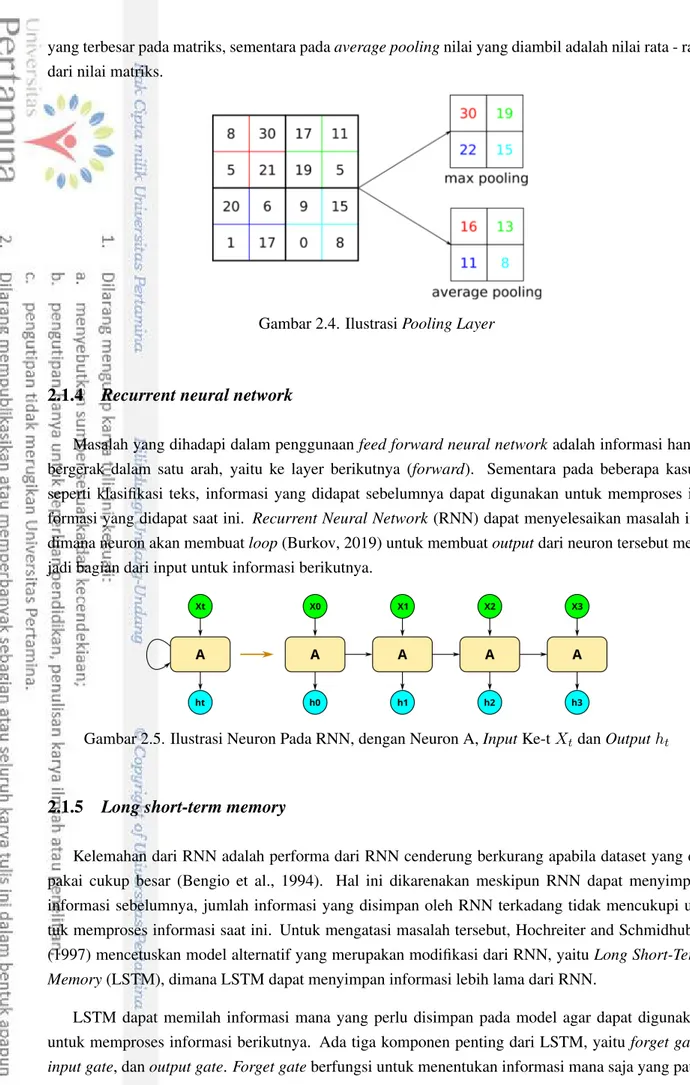
Matriks convolved features kemudian masuk ke pooling layer, dimana pada layer ini ukuran matriks kembali dikurangi dengan menggunakan metodesub-sampling. Tujuan dari pengurangan ini adalah untuk mengurangi waktu komputasi dan mengambil fitur dominan pada matriks. Ada 2 jenis
yang terbesar pada matriks, sementara padaaverage poolingnilai yang diambil adalah nilai rata - rata dari nilai matriks.
Gambar 2.4. IlustrasiPooling Layer
2.1.4 Recurrent neural network
Masalah yang dihadapi dalam penggunaanfeed forward neural networkadalah informasi hanya bergerak dalam satu arah, yaitu ke layer berikutnya (forward). Sementara pada beberapa kasus, seperti klasifikasi teks, informasi yang didapat sebelumnya dapat digunakan untuk memproses in-formasi yang didapat saat ini. Recurrent Neural Network(RNN) dapat menyelesaikan masalah ini, dimana neuron akan membuatloop(Burkov, 2019) untuk membuatoutputdari neuron tersebut men-jadi bagian dari input untuk informasi berikutnya.
Gambar 2.5. Ilustrasi Neuron Pada RNN, dengan Neuron A,InputKe-tXtdanOutputht
2.1.5 Long short-term memory
Kelemahan dari RNN adalah performa dari RNN cenderung berkurang apabila dataset yang di-pakai cukup besar (Bengio et al., 1994). Hal ini dikarenakan meskipun RNN dapat menyimpan informasi sebelumnya, jumlah informasi yang disimpan oleh RNN terkadang tidak mencukupi un-tuk memproses informasi saat ini. Unun-tuk mengatasi masalah tersebut, Hochreiter and Schmidhuber (1997) mencetuskan model alternatif yang merupakan modifikasi dari RNN, yaituLong Short-Term Memory(LSTM), dimana LSTM dapat menyimpan informasi lebih lama dari RNN.
LSTM dapat memilah informasi mana yang perlu disimpan pada model agar dapat digunakan untuk memproses informasi berikutnya. Ada tiga komponen penting dari LSTM, yaituforget gate,
untuk disimpan dalamnode. Hal ini dilakukan dengan memproses informasi yang diterima dengan informasi dari state sebelumnya menggunakan fungsi sigmoid. Hasil dari fungsi sigmoid berkisar antara 0 dan 1. Jika hasil lebih dekat ke 0, maka informasi akan dihapus/dilupakan (forget).Input gate
berfungsi untuk menentukan informasi mana yang akan disimpan, sementaraoutput gatemenentukan informasi apa yang dibutuhkan berikutnya.
2.1.6 Machine learningpada teks
Modelmachine learning tidak dapat mengolah data berupa teks (string). Agar data teks dapat diproses oleh modelmachine learning, data teks perlu direpresentasikan ke data dengan tipe angka (integer) [9]. Berikut adalah beberapa cara yang dapat digunakan untuk membuat representasi data teks menjadi data dengan tipeinteger.
Bag of words
MetodeBag of wordsmerupakan metode paling sederhana untuk merepresentasikan teks sebagai angka. Setiap kata pada teks digantikan dengan frekuensi kemunculan kata tersebut di dalam dataset secara keseluruhan. Contoh penerapanbag of wordsdapat dilihat pada Tabel 2.1
Tabel 2.1 Contoh PenerapanBag of Words
No Teks Text dalamBag of Words
1 saya sedang bermain game sepak bola 2 2 2 1 1 1 2 adik sedang bermain dengan saya 1 2 2 1 2 0
Pada instansi 1, kata “saya”, “sedang” dan “bermain” digantikan dengan angka 2. Hal ini dikare-nakan ketiga kata tersebut muncul sekali di instansi 1 dan 2, sedangkan kata lainnya hanya muncul sekali sehingga kata - kata tersebut diganti dengan angka 1. Karena instansi 2 mempunyai jumlah kata yang lebih sedikit dari instansi 1, instansi 2 diberikan angka tambahan yaitu 0 agar semua instansi memiliki jumlah kata yang sama.
TF-IDF
Kelemahan dari metodebag of wordsadalah setiap kata memiliki bobot yang sama, dimana se-harusnya kata yang lebih jarang muncul dapat menjadi indikator yang bagus untuk mengklasifikasikan teks (Rajaraman and Ullman, 2011). Metode TF-IDF (Terms Frequency - Inverse Document Fre-quency) memberikan nilai pada setiap kata dengan cara menghitung nilai TF dan IDF dari kata terse-but. Nilai TF, seperti yang ditunjukkan pada persamaan (2.3) (Rajaraman and Ullman, 2011), didapat dengan mengetahui frekuensi kemunculan kata i pada teks j (fij), dan mengetahui jumlah dari kata dengan kemunculan terbanyak pada teks tersebut. Sedangkan nilai IDF, seperti yang ditunjukkan pada persamaan (2.4) (Rajaraman and Ullman, 2011), yaitu dengan mengetahui logaritma basis 2 pada jumlah teks keseluruhan (N) dibagi dengan jumlah teks yang mengandung kata tersebut (Ni).
T F = fij maxkfkj (2.3) IDF = log2(N Ni ) (2.4)
Dari persamaan (2.3) dan (2.4) terlihat nilai sebuah kata di satu instansi dapat berbeda dengan nilai kata yang sama di instansi lainnya, dikarenakan setiap kata dapat memiliki frekuensi kemunculan yang berbeda - beda di setiap instansi dan setiap instansi dapat memiliki jumlah kata yang berbeda.
One-hot encoding
One-hot encodingbiasa digunakan untuk merepresentasikan label untuk model klasifikasi, baik itu teks maupun angka, menjadi kolom baru. Sebagai contoh, sebuah dataset untuk klasifikasi bi-natang mempunyai label “kucing”, “anjing” dan “kelinci”. Denganone-hot encoding, kolom label diganti dengan 3 kolom baru yaitu “kucing”, “anjing” dan “kelinci”. Nilai pada masing - masing kolom tersebut menunjukkan label dari instansi tersebut. One-hot encoding juga dapat dilakukan pada label dengan tipe angka, karena modelmachine learningmenganggap angka yang lebih besar memiliki bobot yang lebih besar, sehingga label “1” dapat dianggap bernilai lebih tinggi dari label “0”.
Gambar 2.6. Ilustrasi One-Hot Encoding
Word embedding
Padaword embedding, setiap kata direpresentasikan sebagai sebagai vektor berdimensi-n, dimana kata yang mempunyai arti yang serupa dapat direpresentasikan dengan vektor yang serupa. Word embeddingmemiliki keunggulan dibanding metode lain seperti bag of words dan TF-IDF, dimana representasi menggunakanword embeddingmembutuhkan dimensi yang lebih kecil dari metodebag of wordsdan TF-IDF. Selain itu,word embeddingdapat menyimpan hubungan antar kata yang memi-liki arti yang serupa atau sering digunakan berdekatan, sehingga mempunyai konteks yang sama. Pada tahun 2013, Google meluncurkan word2vec, sebuahword embedding toolkityang dapat digu-nakan untuk membuatword embeddingdengan waktu yang lebih singkat dari metode yang sudah ada sebelumnya.
2.1.7 Bias, variance, overfitdanunderfit
Kesalahan (error) dari hasil prediksi sebuah model machine learningberasal dari dua jenis er-ror, yaitubiasdanvariance. Biasadalah asumsi yang digunakan oleh model untuk mempermudah proses menghasilkanoutput. Nilai bias yang tinggi (high bias) menandakan model dapat mempelajari data yang digunakan dengan cepat, namun cenderung memiliki performa yang semakin buruk seiring dengan kompleksitas masalah yang ingin diselesaikan.
Varianceadalah nilai yang mengestimasi perubahan dari model jika terjadi perubahan pada train-ing data. Nilaivariance yang tinggi menandakan model tidak dapat mengenali pola yang ada pada datatraining(generalisasi), sehingga performa model pada data yang berbeda cenderung menurun.
Errordari sebuah modelmachine learningmerupakan jumlah daribias danvariance, sehingga se-makin tinggi nilaibias, maka semakin rendah nilaivariance, dan sebaliknya. Hubungan antarabias
danvariance ini disebut jugabias-variance tradeoff. Idealnya, model machine learning yang di-hasilkan mempunyai nilaibiasdanvarianceserendah mungkin (low biasdanlow variance), namun
bias-variance tradeoff mengakibatkan jika nilai bias dari model dibuat serendah mungkin, maka model tersebut akan memiliki nilaivarianceyang tinggi.
Overfit adalah kondisi dimana model yang terlalu bergantung pada data yang digunakan saat
training, dimana model ini memiliki performa yang baik saat training, namun memiliki performa yang jelek ketika diujicobakan dengan data selain datatraining(Burkov, 2019). Hal ini dikarenakan model mempelajari detail dannoisepada datatrainingyang berdampak negatif pada performa model, dimana model tidak mampu untuk melakukan generalisasi dengan data yang digunakan saattraining. Model yang mengalamioverfitditandai dengan nilaivarianceyang tinggi (high variance). Underfit
adalah kondisi dimana model tidak dapat memetakan baik data testing maupun datatraining(Burkov, 2019). Kondisi ini dapat terjadi ketika model yang digunakan terlalu sederhana sehingga kurang memadai untuk memproses informasi yang diterima, atau jumlah proses training yang dilakukan (epoch) kurang banyak.Underfitditandai dengan nilaibiasyang tinggi (high bias).
Overfit pada modelneural networkdapat dicegah dengan melakukan proses yang disebut regu-larisasi, yaitu proses untuk mengurangi tingkat kompleksitas dari modelneural network. Beberapa proses regularisasi yang umum adalah sebagai berikut:
1. Early Stopping, yaitu menghentikan prosestraining model ketika performa dari model sudah tidak mengalami peningkatan saat prosestraining
2. Dropout, dimana beberapa unit neuron akan dinonaktifkan (drop) untuk menjaga nilai dari neuron tersebut agar tidak berubah terlalu drastis saat proses training.
3. L1&L2 Regularization, dimanacost functionpada model diubah dengan mempertimbangkan bobot dari semuafeature
2.1.8 Mengukur performa model
Hasil dari modelmachine learningdapat dikategorikan menjadi 4 kelas berbeda, yaituTrue Pos-itive,True Negative,False PositivedanFalse Negative.True Positive(TP) berarti model memprediksi bahwaoutputadalah kelas A danoutputseharusnya adalah kelas A.True Negative(TN) berarti model memprediksi bahwaoutputadalah bukan kelas A sedangkan outputseharusnya adalah bukan kelas A.False Positive(FP) berarti hasiloutputdari model adalah kelas A, sementaraoutputseharusnya adalah bukan kelas A. Sebaliknya, False Negative (FN) berarti model memprediksi output adalah bukan kelas A, tetapioutputsebenarnya adalah kelas A. Gambar 2.7 merupakan diagram yang me-nunjukkan nilai dari hasil prediksi dibandingkan dengan hasil sebenarnya. Diagram ini disebut juga
confusion matrix.
Gambar 2.7. Pembagian KelasTrue Positive,True Negative,False PositivedanFalse Negative
Performa sebuah model machine learning dapat diukur dengan menggunakan keempat kelas tersebut untuk menentukanaccuracy, precision, recalldanf1-score. Accuracy, seperti yang ditun-jukkan pada persamaan (2.5), didapat dengan membandingkan jumlah prediksi model yang benar, yaituTrue PositivedanTrue Negative, dengan jumlah prediksi model secara keseluruhan (Burkov, 2019).Precision, seperti yang ditunjukkan pada persamaan (2.6), adalah perbandingan antara prediksi positif yang tepat dengan prediksi positif keseluruhan (Burkov, 2019). Recall, seperti yang ditun-jukkan pada persamaan (2.7), adalah perbandingan kasus positif yang dapat diprediksi oleh model dengan benar (Burkov, 2019).F1-score, seperti yang ditunjukkan pada persamaan (2.8), dapat dihi-tung dengan menggunakanprecisiondanrecall(Burkov, 2019).
Accuracy = T P +T N T P +T N +F P +F N (2.5) P recision= T P T P +F P (2.6) Recall= T P T P +F N (2.7) f1 = 2 P recision·Recall P recision+Recall (2.8) Idealnya, model yang baik memiliki nilaiprecisiondan nilairecallyang tinggi. Apabila model memiliki nilaiprecision yang tinggi dan nilai recallyang rendah, maka model dapat memprediksi kasus positif sebenarnya dengan baik, namun hanya dapat mendeteksi sebagian kecil dari kasus positif sebenarnya. Model seperti ini disebutunder-predicting. Sebaliknya, model yang memilikiprecision
positif sebenarnya, namun tidak dapat memprediksi kasus positif sebenarnya dengan baik, dimana banyak kasus negatif yang dikenali model sebagai kasus negatif. Model seperti ini disebut over-predicting.
Jika dataset yang digunakan tidak berimbang, dimana ada satu kelas yang jumlah datanya jauh lebih banyak dari kelas lainnya,accuracykurang tepat untuk dijadikan pengukur karena dapat menye-babkan kesalahan dalam interpretasi (Akosa, 2017). Misalnya, ada 80%data dengan label kelas A di dataset, dan 20%dengan label bukan kelas A. Jika model mendapatkan akurasi sebesar 75%, ada kemungkinan bahwa nilai tersebut didapat hanya dengan memprediksi kelas A saja. Untuk mengan-tisipasi hal itu, ada 3 parameter yang digunakan untuk mengukur performa model dalam penelitian ini, yaituweighted f1-scoredanbalanced accuracy.
Weighted f1-scoredidapat dengan membagi nilai f1 setiap label dengan support atau jumlah data dengan label tersebut. Balanced accuracy, seperti yang ditunjukkan pada persamaan (2.10), dida-pat dengan menentukan specificity (Akosa, 2017), yaitu perbandingan antara jumlah nilai negatif yang diprediksi dengan tepat (False Positive) dan jumlah nilai negatif yang diprediksi (Akosa, 2017), seperti yang ditunjukkan pada persamaan (2.9).
Specif icity= F P
F P +T N (2.9)
BalancedAccuracy= recall+specif icity
2 (2.10)
2.1.9 Learning Curve
Menurut Anzanello and Fogliatto (2011),learning Curveadalah representasi matematis dari per-forma model dalam mengerjakan sebuah task yang dilakukan berulang kali. Umumnya learning curvedigambarkan sebagai sebuah grafik, dimana sumbu-x menunjukkan pengalaman (experience) atau berapa kalitask telah dilakukan pada model dan sumbu-y menunjukkan performa dari model. Satuan yang umum ditunjukkan padalearning curveuntuk model machine learningadalah akurasi danloss.Lossmenunjukkan selisih antaraoutputyang dihasilkan oleh model danoutputsebenarnya. Performa model yang baik ditunjukkan dengan nilailossyang kecil, yang menandakan model dapat memprediksi nilaioutputmendekati nilaioutputsebenarnya. Terdapat 2learning curveyang umum digunakan, yaitutraining learning curve, yaitu kurva yang menggambarkan performa model saat prosestraining, danvalidation learning curveyang menunjukkan performa model sesungguhnya.
Learning curve dapat digunakan untuk mengetahui apakah model yang digunakan mengalami
overfittingatauunderfitting. Learning curvepada Gambar 2.8 menunjukkan model yang tidak men-galamioverfittingmaupununderfitting(good fit). Pada Gambar 2.8, baik nilaitraining loss(warna biru) maupunvalidation loss(warna jingga) mengalami penurunan hingga hampir tidak ada perbe-daan diantara kedua nilai tersebut.
Model yang mengalamioverfitditandai dengan penurunan baik padatraining lossdanvalidation loss, namun seiring dengan semakin banyaktrainingyang dilakukan, nilaivalidation lossmengalami
Gambar 2.8.Learning CurveuntukLoss(Brownlee, 2019)
Gambar 2.9.Learning CurveuntukLosspada Model yang MengalamiOverfitting(Brownlee, 2019)
peningkatan sementaratraining loss tetap mengalami penurunan. Hal ini merupakan tanda model mengalamioverfit, dimana model hanya dapat melakukan generalisasi dan pada datatraining. Pada gambar 2.9 dapat dilihat pada suatu titik tertentu nilaivalidation lossmengalami peningkatan setelah sebelumnya mengalami penurunan, sedangkan nilaitraining lossterus mengalami penurunan.
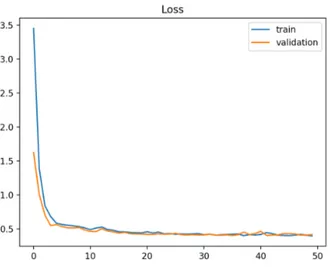
Model yang mengalamiunderfitditandai dengantraining learning curve yang cenderung datar, seperti pada Gambar 2.10a Tidak adanya penurunan padatraining loss menunjukkan model tidak dapat melakukan generalisasi pada data yang digunakan pada prosestraining. Hal ini disebabkan oleh kurangnya jumlah data yang digunakan.Underfitjuga dapat disebabkan oleh model yang masih dapat melakukan proses generalisasi yang lebih baik, yang ditandai dengan penurunan padatraining learning curvehingga grafik berakhir (Gambar 2.10b), yang berarti performa model dapat menjadi lebih baik apabila prosestrainingdilanjutkan.
(a) (b)
Gambar 2.10.Learning CurveuntukLosspada Model yang MengalamiUnderfit(Brownlee, 2019)
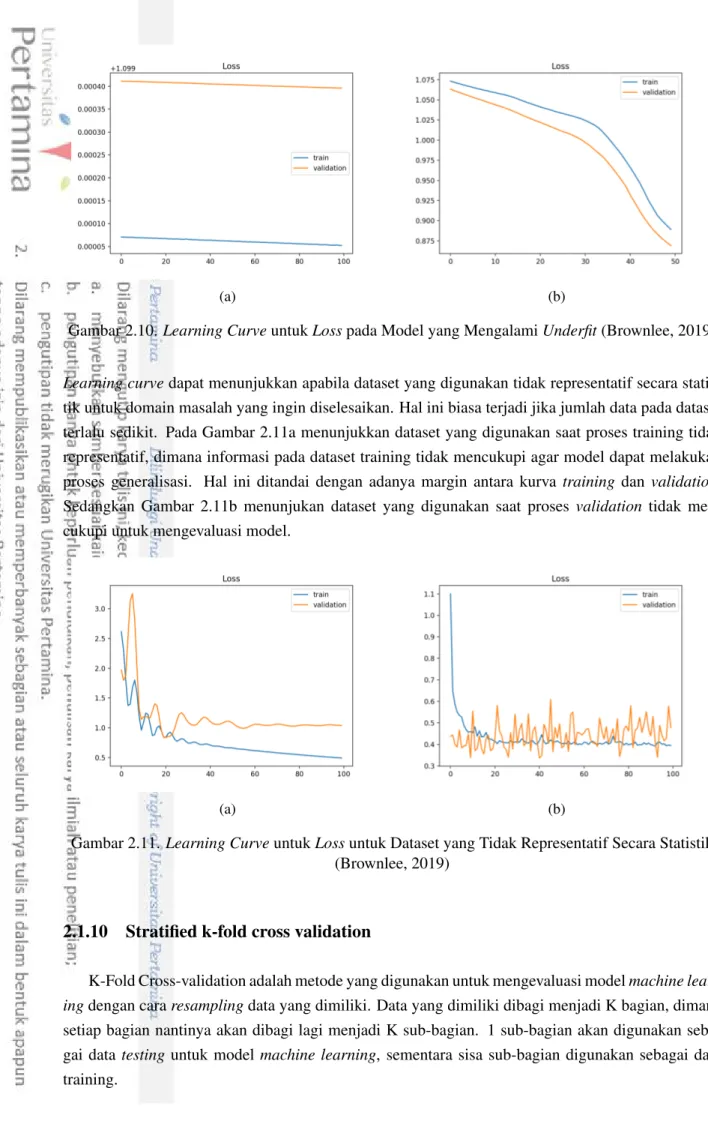
Learning curvedapat menunjukkan apabila dataset yang digunakan tidak representatif secara statis-tik untuk domain masalah yang ingin diselesaikan. Hal ini biasa terjadi jika jumlah data pada dataset terlalu sedikit. Pada Gambar 2.11a menunjukkan dataset yang digunakan saat proses training tidak representatif, dimana informasi pada dataset training tidak mencukupi agar model dapat melakukan proses generalisasi. Hal ini ditandai dengan adanya margin antara kurva training dan validation. Sedangkan Gambar 2.11b menunjukan dataset yang digunakan saat proses validation tidak men-cukupi untuk mengevaluasi model.
(a) (b)
Gambar 2.11.Learning CurveuntukLossuntuk Dataset yang Tidak Representatif Secara Statistik (Brownlee, 2019)
2.1.10 Stratified k-fold cross validation
K-Fold Cross-validation adalah metode yang digunakan untuk mengevaluasi modelmachine learn-ingdengan cararesamplingdata yang dimiliki. Data yang dimiliki dibagi menjadi K bagian, dimana setiap bagian nantinya akan dibagi lagi menjadi K sub-bagian. 1 sub-bagian akan digunakan seba-gai datatestinguntuk model machine learning, sementara sisa sub-bagian digunakan sebagai data training.
Gambar 2.12. Ilustrasi Pembagian Dataset pada K-fold Cross Validation
Kekurangan dari K-Fold Cross Validation adalah pembagian data untuk setiapfoldtidak memper-hitungkan distribusi kelas darioutput, sehingga apabila dataset yang digunakan memiliki distribusi kelas yang tidak seimbang (imbalance), ada kemungkinan salah satufoldtidak memiliki data dengan kelas tertentu. Untuk mengatasi hal ini, pembagian datafolddisesuaikan dengan distribusi kelas out-putdari dataset tersebut, sehingga setiapfoldmemiliki distribusi kelas yang serupa dengan distribusi kelas dataset. Hal ini dapat dilakukan dengan menggunakan variasi dari K-Fold Cross Validation, yaitu Stratified K-Fold Cross Validation (Pedregosa et al., 2011).
2.2 Sentiment Analysis
Menurut Liu et al. (2010) Sentiment analysis adalah studi komputasional terhadap opini, sen-timen, maupun emosi yang tertulis di dalam teks. Beberapa ahli menyebutkan bahwa sentiment analysisberbeda denganopinion mining, dimanaopinion mining berfungsi untuk menganalisis dan mengekstraksi opini penulis terhadap sebuah objek, sedangkansentiment analysisdigunakan untuk mengidentifikasi dan menganalisis sentimen yang ada pada sebuah teks (Medhat et al., 2014). Ada beberapa jenissentiment analysisyang umum dilakukan, yaitu:
1. Fine-grained sentiment analysis, dimana setiap teks dibagi menjadi 5 kelas, yaitu sangat nega-tif, neganega-tif, netral, posinega-tif, dan sangat positif.
2. Emotion detection, dilakukan untuk mengetahui emosi atau perasaan dari penulis teks tersebut. Cara yang dapat digunakan adalah dengan menggunakan lexicon, sebuah daftar kata dimana dari daftar kata tersebut dapat diketahui setiap kata terasosiasi dengan emosi apa.
3. Aspect-based sentiment analysis, yang merupakan versi sederhana darifine-grained sentiment analysis, dimana aspect-based sentiment analysis mengklasifikasikan teks ke 3 kelas, yaitu negatif, netral, dan positif.
4. Multilingual sentiment analysis, dimana data teks yang diteliti bisa berasal dari beberapa ba-hasa. Hal ini menimbulkan tantangan tersendiri karena beberapa bahasa tidak mempunyai re-sourceyang cukup untuk melakukansentiment analysis.
2.3 Penelitian TerkaitSentiment Analysisdengan Bahasa Indonesia
Beberapa penelitian sebelumnya telah melakukansentiment analysis dengan tweetdengan Ba-hasa Indonesia. Saputri et al. (2018) melakukansentiment analysisdengan mengklasifikasikantweet
berdasarkan emosi pada tahun 2018. Pada penelitian initweetakan diklasifikasikan menjadi 5 ke-las berdasarkan emosi dari penulistweettersebut. Saputri dan Mahendra membuat sendiri dataset yang digunakan pada penelitian ini, yaitu 4.403 tweet yang terbagi menjadi 5 kelas. Penelitian ini dilakukan dengan menggunakan beberapa feature seperti Bag of Words dan word embedding dan dikombinasikan untuk mengetahui kombinasifeatureyang dapat menghasilkan model terbaik. Pen-gukuran performa dilakukan dengan menggunakanf1-score. Penelitian ini menggunakan 3 model dengan algoritma yang berbeda untuk mengklasifikasikan tweet. Ketiga metode tersebut adalah lo-gistic regression,support vector machine, danrandom forest. Model yang dihasilkan pada penelitian ini mendapatkanf1-scoresebesar 69.74%. Penelitian ini menyerupai penelitian yang penulis lakukan, dimana penelitian yang dilakukan penulis juga akan melakukanmulticlass classificationpadatweet
berbahasa Indonesia. Namun pada penelitian ini penulis akan mengklasifikasikantweetberdasarkan sentimen daritweetitu sendiri menjadi 3 kelas berbeda, yaitu negatif, netral dan positif.
Iswanto and Poerwoto (2018) melakukansentiment analysismenggunakan modelNaive-Bayes,
Support Vector MachinedanMaximum Entropypadatweetyang berhubungan dengan pemilihan pres-iden tahun 2014 dan mendapatkan angka mencapai 85.5%untukprecisiondanrecall. Penelitian ini menyerupai penelitian yang penulis buat dimana penelitian ini adalahsentiment analysispada tweet dengan Bahasa Indonesia, dengan perbedaan terletak pada modelmachine learningyang digunakan, dimana penelitian ini menggunakanneural network. Selain itu, label yang digunakan sebagaioutput
dari penelitian ini hanya memiliki 2 kemungkinan, yaitu negatif dan positif, sedangkan pada peneli-tian yang penulis lakukan, ada 3 kemungkinanoutput, yaitu negatif, netral dan positif.
BAB III
METODE PENELITIAN
Penelitian dilakukan dengan menggunakan bahasa pemrograman Python dan menggunakan Goo-gle Collaboratory (Bisong, 2019) sebagai compiler. Metode yang digunakan pada penelitian ini adalah metode penelitian kuantitatif. Alur pada penelitian ini adalah sebagai berikut:
3.1 Data Gathering
Data yang dibutuhkan pada tahap ini adalahtweetyang membahas Universitas Pertamina. Tweet
yang dipakai adalahtweetyang mengandung kata “Universitas Pertamina”, “Univ Pertamina”, atau
tweet yang dikirimkan kepada akun @UnivPertamina. Tweet yang digunakan dibuat pada tang-gal 10 April 2016 hingga 4 Mei 2020. Pengambilan data dilakukan dengan menggunakan library GetOldTweets31dari Python, dimana library ini dapat digunakan untuk mengambil tweet dan meny-impan informasi dari tweet tersebut seperti nama user, isi tweet, hingga tanggal tweet tersebut dibuat [23]. Jenis sentiment analysis yang dilakukan adalahaspect-based sentiment analysis. Setiap tweet akan diberikan label sesuai dengan sentimen yang terkandung dari teks tersebut, dengan label bernilai 0 untuk sentimen negatif, 1 untuk sentimen netral, dan 2 untuk sentimen positif. Proses pemberian label dilakukan secara manual, dimana pemberian label sentimen tidak memperhitungkan kalimat dengan makna sindiran dan/atau ironi.
3.2 Data Preprocessing
Data teks yang telah diperoleh kemudian diolah agar data tersebut dapat diproses oleh model
machine learning. Pengolahan data juga dilakukan untuk mengurangi dimensi dari data itu sendiri, sehingga model dapat memproses data lebih cepat. Pengurangan dimensi dilakukan dengan mengha-pus bagian teks yang dinilai tidak berpengaruh dalam prosessentiment analysis.
Tahapandata preprocessingyang dilakukan pada penelitian ini adalah sebagai berikut:
1. Data cleaning, yaitu menghapus bagian - bagian teks yang tidak diperlukan untuksentiment analysis seperti username (diawali dengan ‘@’), topic (diawali dengan ‘#’), alamat email, alamat situs, angka, spasi yang berlebihan, tanda baca, dan mengubah semua huruf menjadi huruf kecil.
2. Normalisasi, proses untuk merubah kata - kata dengan ejaan yang tidak baku dalam Bahasa Indonesia menjadi kata baku. Proses ini dilakukan juga untuk mengurangi dimensi dari data 3. Stemming.Stemmingadalah proses untuk mengubah kata berimbuhan menjadi kata dasar. 4. Stopword removal. Stopword adalah kata - kata yang umumnya sering muncul pada, contohnya
kata - kata penghubung seperti “dan”, “atau”. “di”. Kata - kata ini perlu dihapus karena pada
umumnya kata - kata ini tidak memiliki informasi tambahan untuk proses klasifikasi. Daftar kata stopwords berasal dari library Sastrawi2
5. Menghapustweetyang sama (duplikat)
6. one-hot encodingpada label, agar label dapat diproses oleh modelmachine learning
3.3 Create and Training Model
Pada penelitian ini ada 3 tipe neural network yang diujicobakan, yaitu LSTM, CNN, dan CNN-LSTM. Model LSTM dipilih karena model ini umumnya digunakan untuk proses klasifikasi teks dikarenakan kemampuannya untuk mengolah deretan kata [11]. Sementara model CNN dipilih karena walaupun lebih umum digunakan untuk proses klasifikasi gambar, model CNN dapat menghasilkan performa yang baik dalam klasifikasi teks (Kim, 2014). Sementara model CNN-LSTM merupakan gabungan dari kedua model tersebut dan diketahui dapat menghasilkan performa yang lebih baik dari model CNN maupun model LSTM (Zhou et al., 2015).
Setiap model menggunakanembedding layer sebagaiinput layer, dimana masukan tweet yang diterima akan diproses dengan metodeword embedding. Selain itu, metodeone-hot encoding juga digunakan untuk memproses kolom label, sehingga nantinya akan ada 3 kolom label yaitu “negatif”, “netral”, dan “positif”.
Karena label yang digunakan sebagaioutputbersifat kategorikal, dimana ada lebih dari 2 kemu-ngkinanoutput, makaloss functionyang digunakan pada proses training adalahcategorical crossen-tropy. Proses training (epoch) dilakukan sebanyak 200 kali, dimana angka 200 merupakan angka yang dipilih secara acak, sebanyak 20 kali untuk mengetahui jumlah epoch maksimal ketika nilai
validation/test losstidak menurun (N). Selama 20 percobaan, jumlah epoch ditambahkan sebanyak 30 jika nilaivalidation/test losstidak pernah naik untuk mengantisipasiunderfitting. Pada percobaan selanjutnya digunakan fungsiearly stoppingpada parametervalidation loss, dimana apabila nilai val-idation losstidak mengalami penurunan dalam N epoch (nilai yang telah didapatkan dari percobaan sebelumnya), maka prosestrainingakan dihentikan. Jumlah epoch yang digunakan pada percobaan ke-21 dan selanjutnya adalah jumlah maksimal epoch yang didapatkan dari 10 percobaan selanjutnya karena N bisa terjadi pada epoch yang berbeda pada setiap percobaan.
Setiap model kemudian akan di-trainingdengan menggunakan teknik stratified k-fold cross val-idation untuk melihat akurasi dan loss dari datasettraining danvalidation. Stratified k-fold dipilih untuk memastikan perbandingan antar kelas pada setiap bagian fold tetap sama. Nilai k yang digu-nakan pada penelitian ini adalah 5, dimana menurut Rodriguez (Rodriguez et al., 2010), nilai k yang dianjurkan adalah 5 atau 10. Diantara kedua nilai tersebut, nilai 5 dipilih karena jumlah data yang digunakan termasuk sedikit untuk algoritma yang digunakan. Pembagian data yang digunakan pada
trainingdantestingpada setiapfoldadalah 8:2.
3.4 Analisis
Performa setiap model yang kemudian akan dievaluasi dengan mengukur accuracy, balanced accuracy, danweighted f1 yang didapat dengan menggunakan validasi stratified k-fold. accuracy,
balanced accuracy, danweighted f1memiliki nilai terendah 0 dan nilai tertinggi 1.
Selain menggunakan parameter sepertiaccuracy,balanced accuracy, danweighted f1, performa model juga akan dianalisis menggunakanlearning curveyang dihasilkan selama proses training dari setiap model.Learning curvedapat menunjukkan apakah model mengalamioverfitmaupununderfit.
BAB IV
HASIL DAN PEMBAHASAN
4.1 Data GatheringDataset dalam penelitian ini diperoleh dari Twitter menggunakan library GetOldTweets3, dengan jumlah 4323tweet. Tweetyang digunakan sebagai data penelitian dibuat dari tanggal 10 April 2016 hingga 4 Mei 2020. Setiaptweetrata-rata memiliki panjang 114 karakter dan 16 kata. Secara keselu-ruhan dataset terdiri dari 70.348 kata yang tersusun dari 15.522 kata yang berbeda.
Proses pemberian label pada tweetdilakukan dengan pertimbangan yang didasari pada bahasa yang digunakan pada tweet (Mohammad, 2016) sebagai berikut:
1. Negatif jika tweetmenggunakan makna negatif, contohnya kritik, ketidakpuasan, kegagalan, mempertanyakan validasi/kompetensi
2. Positif jikatweetmenggunakan makna positif, contohnya dukungan, kekaguman, sikap positif, kesuksesan
3. Netral jikatweettidak termasuk dalam label negatif maupun label positif
Tabel 4.1 Contoh Tweet dan Sentimen yang Diberikan
Isi Tweet Sentimen
Penjual: Keluhkan Sistem Pembayaran Digital di Kantin
Univer-sitas Pertamina Negatif
Lebih mahal univ pertamina.ggg Negatif
@UnivPertamina kaa untuk pendaftaran ulang bagi maba up
ka-pan yaa? Netral
Hi Rum! Universitas Pertamina memiliki 4 program studi yang terdiri dari Ilmu Komunikasi, Hubungan Internasional, Manaje-men, dan Ilmu Ekonomi.
Netral Dosen Universitas Pertamina Terima Hibah Penelitian Rp 345
Juta http://po.st/0ab5lP via @po st @UnivPertamina Positif Ini adalah video keseruan di booth UP selama hari Kamis kemarin
sob! #universitasperamina #campusexpo #campusexpo2018 Positif
Dengan menggunakan pertimbangan tersebut, didapatkantweetdengan label netral mendominasi dengan 3169 (73.3%)tweet, sementaratweetdengan label negatif berjumlah 638 (14.8%)tweet, dan
tweetdengan label positif berjumlah 516 (11.9%). Berdasarkan kata - kata yang terdapat pada sebuah
tweet, pembagian kata - kata pada dataset berdasarkan kata yang berbeda per label dapat dilihat pada Gambar 4.2
Gambar 4.2 menunjukkan perbandingan antar label berbanding lurus dengan jumlah kata berbeda yang dimiliki oleh masing-masing label. Kata berbeda yang hanya ada di label positif (1.830 kata)
Gambar 4.1. Pembagian Label pada Dataset
lebih sedikit jika dibandingkan dengan kata berbeda yang ada di label positif dan ada di label lainnya (2.387 kata), dengan jumlah kata berbeda yang ada di label positif dan label netral berjumlah 2.276 kata.
Gambar 4.2. Distribusi Kata Unik per Label
4.2 Data Preprocessing
Datatweetyang didapat kemudian diproses untuk menghilangkannoiseatau bagian dari data yang dapat mengganggu performa dari model apabila dimasukkan ke modelmachine learning. Adapun proses yang dilakukan untuk menghilangkan noise pada teks adalah sebagai berikut
1. Data cleaning, dilakukan menggunakanRegular Expression(Thompson, 1968) untuk mengha-pus angka, tanda baca,topic, email, hyperlink. Hasil dari proses ini adalah pengurangan jumlah kata pada dataset, dimana sebelumnya dataset memiliki 70.348 kata, setelah proses cleaning data jumlah kata pada dataset menjadi 66.985 kata, atau pengurangan sebanyak 4,78%. Sedan-gkan jumlah kata yang berbeda pada dataset berkurang dari 15.522 kata menjadi 8.701 kata, berkurang sebanyak 43,9%.
2. Normalisasi dilakukan dengan menggunakanRegular ExpressiondanlexiconBahasa Indonesia sehari - hari (Salsabila et al., 2018). Tercatat ada 5.206 kata yang dinormalisasi, atau sekitar 7,83%dari keseluruhan dataset, dimana 5.206 kata tersebut terdiri dari 611 kata yang berbeda. Jumlah kata yang berbeda berkurang 6,45% dari 8.701 kata menjadi 8.139 kata, sedangkan jumlah kata keseluruhan bertambah dari 65.985 kata menjadi 66.165 kata.
Tabel 4.2 Contoh Kata yang Dinormalisasi
Kata sebelum normalisasi Kata sesudah normalisasi
univ universitas
yg yang
aja saja
udah sudah
3. Stemming dilakukan dengan menggunakan library Sastrawi danRegular Expression. Dalam proses ini tercatat 11793 kata yang terdiri dari 2590 kata yang berbeda diubah menjadi bentuk kata dasar. Jumlah kata pada dataset bertambah dari 66.165 kata menjadi 66.499 kata, sedan-gkan jumlah kata yang berbeda berkurang dari 8.139 kata menjadi 6.046 kata.
4. Stopword removal dilakukan dengan menggunakan library Sastrawi danRegular Expression. Hasil dari tahap ini adalah pengurangan jumlah kata pada dataset dari 66.165 kata menjadi 52.561 kata, dan jumlah kata yang berbeda berkurang menjadi 6029 kata.
Tabel 4.3 PerbandinganTweetyang Dihasilkan pada Setiap Tahapdata preprocessing
Tahap Tweet
- Penjual: Keluhkan Sistem Pembayaran Digital di Kantin Univ Pertamina
Cleaning penjual keluhkan sistem pembayaran digital di kantin univ pertamina Normalisasi penjual keluhkan sistem pembayaran digital di kantin universitas pertamina
Stemming jual keluh sistem bayar digital di kantin universitas pertamina
Stopword removal jual keluh sistem bayar digital kantin universitas pertamina
5. Menghapustweetduplikat, dimana terdapat 71tweetyang merupakan duplikat daritweet lain-nya. tweettersebut kemudian dihapus dengan menggunakanlibrarypandas (McKinney, 2012)
Setelah diproses dataset memiliki 4.269 tweet, dengan pembagian 634 label negatif, 3.120 data dengan label netral, dan 515 data memiliki label positif. Jumlah kata secara keseluruhan adalah 52.065 kata dari sebelumnya 70.348 kata (berkurang 25.99%), dengan 6.029 kata yang berbeda dari sebelumnya 15.522 kata (berkurang 61,16%). Distribusi kata unik berdasarkan label dataset ditun-jukkan pada Gambar 4.3:
Sebelum diproses, jumlah kata unik di label netral mencapai 8.229 kata, setelah proses dilakukan jumlah tersebut berkurang 66,86%menjadi 2.729 kata. Jumlah kata unik di label negatif juga men-galami pengurangan yang serupa, dari 2.324 kata menjadi 791 kata (berkurang 65.96%). Begitu juga dengan jumlah kata unik yang hanya ada di label positif, dari 1830 kata menjadi 620 kata (berkurang 66.12%).
Gambar 4.3. Distribusi Kata Unik per Label Setelah TahapData Preprocessing
Walaupun sudah dilakukan tahap normalisasi, masih banyak kata yang tidak termasuk pada ba-hasa Indonesia baku. Tercatat ada 11.011 kata yang terdiri dari 3.251 kata unik yang tidak termasuk pada kata dasar yang tercatat pada Kamus Besar Bahasa Indonesia. Sebagian dari kata-kata ini adalah nama orang, tempat, maupun kata-kata dalam bahasa Inggris. Selain itu, terdapat juga bentuk kata informal yang tidak ada dalamlexiconyang digunakan.
4.3 Create and Training Model
Penelitian ini menggunakan tiga jenis model, yaitu CNN, LSTM, dan CNN-LSTM. Pada tahap sebelumnya telah dijelaskan adanya ketidakseimbangan pada jumlah data di masing-masing label, dimana data pada label netral (73,3%) lebih banyak dari data pada label lainnya. Hal ini dapat mempengaruhi performa model yang dihasilkan. Untuk mengatasi ketidakseimbangan tersebut, se-tiap model akan menggunakan parameterclass weightpada masing-masing label, dimana nilaiclass weightditentukan berdasarkan jumlah data pada masing-masing label. Nilai class weight didapat dengan menggunakan fungsi compute class weight dari library Scikit Learn. Hasil nilaiclass weight
yang didapat adalah negatif 2.244, netral 0.456, dan positif 2.763. Semakin tinggi nilaiclass weight
berarti semakin sedikit jumlah data pada label tersebut. Setiap model menggunakanembedding layer
untuk memproses masukan berupatweetyang telah diproses dengan teknikword embedding. Berdasarkan 20 kali percobaan didapatkan nilai N = 5 epoch terjadi sebelum 200 epoch. Artinya pada percobaan selanjutnya apabila nilaivalidationloss tidak mengalami penurunan dalam 10 epoch, maka prosestrainingakan dihentikan. Semua model dijalankan dengan optimizer RMSProp, epoch 200, batch size 64, dan class weight sesuai dengan nilai class weight yang telah didapatkan sebelum-nya.
4.3.1 Model CNN
Model CNN yang digunakan pada penelitian ini menggunakan embedding layer sebagai input layerModel ini menggunakan 2layerConv1D dan 2 layerMaxPooling1D untuk memproses input
yang diterima olehinput layer Setiaplayer Conv1D terdiri dari 256 hidden node. Fungsi aktivasi yang digunakan padalayerConv1D adalah ELU, sementara fungsi aktivasi padalayerDense adalah softmax.
Gambar 4.4. Struktur Model CNN
Model CNN yang digunakan pada penelitian ini menggunakan embedding layer sebagai input layerModel ini menggunakan 2layerConv1D dan 2 layerMaxPooling1D untuk memproses input
yang diterima olehinput layerSetiaplayerConv1D terdiri dari 256hidden node.
Prosestrainingmodel CNN dilakukan dengan teknik stratified 5-fold cross validation. Hasil dari prosestrainingtersebut dapat dilihat pada Gambar 4.5-4.9
Gambar 4.5. Hasil ProsesTraining,Confusion Matrix, danLearning Curvedari model CNN pada Fold 1
Gambar 4.6. Hasil ProsesTraining,Confusion Matrix, danLearning Curvedari Model CNN pada Fold 2
Gambar 4.7. Hasil prosestraining,Confusion Matrix, danlearning curvedari model CNN pada Fold 3
Gambar 4.8. Hasil ProsesTraining,Confusion Matrix, danLearning Curvedari Model CNN pada Fold 4
Gambar 4.9. Hasil ProsesTraining,Confusion Matrix, danLearning Curvedari Model CNN pada Fold 5
Learning curvemenunjukkan pada setiap prosestrainingdengan 5-fold cross validation, proses
trainingdihentikan sebelum nilai epoch mencapai 200, dimana prosestrainingdihentikan lebih awal (early stopping) dikarenakan performa model tidak mengalami peningkatan setelah melewati 5 epoch. Tabel 4.4 menunjukkan rata-rata prosestraining dihentikan setelah melewati 40 epoch. Selain itu,
train-ingdanaccuracy, dimana Tabel 4.4 menunjukkan adanya jarak sebesar 0.57978 antaratraining loss
danvalidation losssecara rata-rata. Hal ini menunjukkan bahwa dataset yang digunakan dalam proses
trainingkurang representatif untuk masalah yang ingin diselesaikan.
Tabel 4.4 Data Epoch,Loss, danTrainingdari Setiap Fold pada ProsesTrainingModel CNN dengan 5-Fold CrossValidationBeserta Rata-rata (mean)
1 2 3 4 5 Mean Epoch 42 41 27 41 49 40 Training loss 0.2203 0.2416 0.4095 0.2300 0.1872 0.25772 Training Accuracy 0.9619 0.9638 0.9008 0.9641 0.9788 0.95388 Validation loss 0.7295 0.9270 0.8896 0.7581 0.8833 0.8375 Validation accuracy 0.7994 0.6794 0.6896 0.7687 0.7295 0.73332
Rata-rataweighted-f1,accuracydanbalanced accuracydari prosestrainingmodel CNN dengan menggunakan 5-fold cross validation ditunjukkan pada Gambar 4.10. Model CNN menghasilkan nilaiweighted f1 dan accuracymasing-masing sebesar 0.7303 dan 0.7222. Namun nilai balanced accuracydari model CNN lebih rendah daripada nilaiaccuracy, yaitu 0.6276. Hal ini menunjukkan model CNN dapat mengenali suatu label pada dataset lebih baik daripada label lainnya. Hal ini dapat dibuktikan dengan melihat f1 score dari masing-masing label. Tabel 4.5 menunjukkan rata-rata nilai
f1-scoremasing-masing label dari prosestrainingdengan model CNN.
Gambar 4.10. Rata - rataWeighted f1,AccuracydanBalanced Accuracydari Model CNN
Dari nilai f1-scorepada masing-masing label, terlihat bahwa performa model CNN untuk me-ngenali data dengan label netral jauh lebih baik daripada data dengan label negatif maupun positif, dengan adanya perbedaan sebesar 0.398 dari label netral yang mendapatf1-scoretertinggi, dengan label positif yang mendapatf1-scoreterendah.
Tabel 4.5 Rata-rata nilaiTrue Positive,True Negative,False Positive,False Negative,Precision,
Recalldanf1-ScoreMasing-masing Label pada Model CNN
Label True Positive True Negative False Positive False
Negative Precision Recall f1-score
Negatif 82 655.2 71.8 44.8 0.53316 0.64669 0.58446
Netral 487.8 140.4 89.4 136.2 0.84511 0.78173 0.81219
Positif 46.8 674.8 76 56.2 0.38111 0.45437 0.41453
Rendahnya nilai f1-score pada label positif dikarenakan model kurang baik dalam melakukan proses generalisasi pada teks label positif, dimana baik nilaiFalse PositivemaupunFalse Negative
pada label positif melebihi nilaiTrue Positive. Jika melihatconfusion matrixpada Gambar 4.6, dari 131 teks yang diprediksi model sebagai label positif, hanya 43 teks (33%) yang merupakan teks positif, dimana 78 teks tersebut (60%) adalah teks label netral.
label positif, yang ditunjukkan dengan nilaiprecision,recall, danf1-scoreyang lebih tinggi dari label positif. Pada label negatif, model CNN mencatat nilaiFalse Positivelebih tinggi dariFalse Negative, walaupun keduanya masih lebih rendah dari nilaiTrue Positive.
4.3.2 Model LSTM
Sama seperti model CNN, model LSTM pada penelitian ini menggunakanembedding layer seba-gaiinput layer. Untuk memprosesinputyang diterima, model LSTM pada penelitian ini mengguna-kan 2layerLSTM, dengan 256 node pada setiaplayer. Untuk mencegah terjadinyaoverfit, digunakan dropout padalayerLSTM dengan nilai 0.4.
Gambar 4.11. Struktur Model LSTM
Model LSTM kemudian di-training dengan teknik stratified 5-fold cross validation. Hasil dari prosestrainingtersebut dapat dilihat pada Gambar 4.12-4.16
Gambar 4.12. Hasil ProsesTraining,Confusion Matrix, danLearning Curvedari Model LSTM pada Fold 1
Gambar 4.13. Hasil Prosestraining,Confusion Matrix, danLearning Curvedari Model LSTM pada Fold 2
Gambar 4.14. Hasil ProsesTraining,Confusion Matrix, danLearning Curvedari Model LSTM pada Fold 3
Gambar 4.15. Hasil ProsesTraining,Confusion Matrix, danLearning Curvedari Model LSTM pada Fold 4
Gambar 4.16. Hasil ProsesTraining,Confusion Matrix, danLearning Curvedari Model LSTM pada Fold 5
Serupa dengan prosestrainingpada model CNN, prosestraining pada model LSTM dihentikan sebelum nilai epoch mencapai 200, dimana proses training dihentikan lebih awal (early stopping) dikarenakan performa model tidak mengalami peningkatan setelah melewati 5 epoch. Tabel 4.6 me-nunjukkan rata-rata prosestrainingdihentikan setelah melewati 17 epoch.
Selain itu,learning curvejuga menunjukkan adanya jarak (gap) yang cukup besar antara kurva
trainingdanaccuracy, dimana Tabel 4.6 menunjukkan adanya jarak sebesar 0.39742 antaratraining lossdanvalidation losssecara rata-rata . Hal ini menunjukkan bahwa dataset yang digunakan dalam prosestrainingkurang representatif untuk masalah yang ingin diselesaikan.
Tabel 4.6 Data Epoch,Loss, danTrainingdari Setiap Fold pada ProsesTrainingModel LSTM dengan 5-Fold Cross Validation Beserta Rata-rata (mean)
1 2 3 4 5 Mean Epoch 16 17 19 16 18 17.2 Training loss 0.415 0.3481 0.3332 0.4119 0.3442 0.37048 Training Accuracy 0.8086 0.8419 0.8232 0.8049 0.8353 0.82278 Validation loss 0.981 0.6322 0.8744 0.7606 0.6863 0.7869 Validation accuracy 0.5813 0.7526 0.6384 0.6676 0.7295 0.67388
Hal yang berbeda dari prosestrainingpada model LSTM dengan model CNN adalah kurva val-idationcenderung fluktuatif. Hal ini dapat menandakan bahwa dataset yang digunakan untuk proses
validationkurang representatif.
Gambar 4.17. HasilWeighted f1,AccuracydanBalanced Accuracydari Model LSTM Model LSTM mencatat nilaiweighted f1danaccuracysebesar 0.7344 dan 0.7208, sementara pada
balanced accuracy, sama seperti model CNN, model LSTM juga mendapat nilaibalanced accuracy
yang lebih rendah dari nilaiaccuracy, yaitu sebesar 0.6605. Hal ini berarti model LSTM, sama seperti model CNN, juga dapat mengenali salah satu label pada dataset lebih baik dari label lainnya, seperti ditunjukkan pada Tabel 4.7, dimana nilaif1-scorepada label netral, yang merupakan label mayoritas pada dataset, jauh lebih tinggi dibanding nilaif1-scorepada label negatif maupun positif.
Tabel 4.7 Rata-rata nilaiTrue Positive,True Negative,False Positive,False Negative,Precision,
Recalldanf1-ScoreMasing-masing Label pada Model LSTM
Label True Positive True Negative False Positive False
Negative Precision Recall f1-score
Negatif 90.8 627.4 99.6 36 0.47689 0.71609 0.57251
Netral 472.2 165.2 64.6 151.8 0.87966 0.75673 0.81358
Positif 52.4 676.6 74.2 50.6 0.41390 0.50874 0.45645
Berdasarkan Tabel 4.7, pada label negatif model mengalamioverfitting, dimana model cenderung mengenali label lain sebagai label negatif. Berdasarkanconfusion matrix pada Gambar 4.12-4.16, terlihat bahwa beberapa teks label netral dikenali oleh model sebagai teks label negatif. Sebagai contoh, pada prosestraining fold1 (Gambar 4.5), dari 181 teks yang dikenali model sebagai teks label negatif, hanya 80 teks (44%) dari 181 teks tersebut yang merupakan teks label negatif, sedangkan 89 teks (49%) lainnya adalah teks label netral.
oleh model sebagai teks label positif. Padatraining fold1, dari 151 teks yang dikenali sebagai teks label positif, hanya 59 teks (39%) yang merupakan teks label positif, dimana 83 teks (55%) lainnya adalah teks label netral.
4.3.3 Model CNN-LSTM
Struktur model CNN-LSTM pada penelitian ini menyerupai model CNN di sub-bab 4.3.1 jika di-gabungkan dengan model LSTM pada sub-bab 4.3.2, dimana terdapatconvolutional layerdanpooling layeryang merupakan bagian dari model CNN dan LSTMlayerdari model LSTM. Agar jumlahlayer
yang digunakan sama dengan jumlahlayerpada model CNN dan LSTM, model CNN-LSTM pada penelitian ini hanya menggunakan 1convolutional layerdanpooling layer, serta 1layerLSTM.
Gambar 4.18. Struktur Model CNN-LSTM
Hasil dari prosestrainingdanlearning curvedari setiap fold dengan teknik stratified 5-fold cross
Gambar 4.19. Hasil ProsesTraining,Confusion Matrix, danLearning Curvedari Model CNN-LSTM pada Fold 1
Gambar 4.20. Hasil ProsesTraining,Confusion Matrix, danLearning Curvedari Model CNN-LSTM pada Fold 2
Gambar 4.21. Hasil ProsesTraining,Confusion Matrix, danLearning Curvedari Model CNN-LSTM pada Fold 3
Gambar 4.22. Hasil ProsesTraining,Confusion Matrix, danLearning Curvedari Model CNN-LSTM pada Fold 4
Gambar 4.23. Hasil ProsesTraining,Confusion Matrix, danLearning Curvedari Model CNN-LSTM pada Fold 5
Learning curve menunjukkan proses training pada model CNN-LSTM juga mengalami early stopping, dimana Tabel 4.8 menunjukkan rata-rata prosestrainingdihentikan setelah 23 epoch. Tidak sepertilearning curvepada model CNN,learning curveuntukvalidation accuracymaupunvalidation losspada model CNN-LSTM terlihat lebih fluktuatif dibandingkan denganlearning curvepada model CNN. Hal ini dapat berarti dataset yang digunakan sebagai dataset untuk prosesvalidation kurang
representatif untuk digunakan pada model CNN-LSTM.
Selain itu, padalearning curveuntuk i juga terdapat jarak antara kurvatraining danvalidation, dimana Tabel 9 menunjukkan selisih antara training loss danvalidation loss secara rata-rata men-capai 0.71924. Hal ini menunjukkan bahwa dataset yang digunakan pada proses training kurang representatif secara statistik.
Tabel 4.8 Data Epoch,Loss, danTrainingdari Setiap Fold pada ProsesTrainingModel CNN-LSTM dengan 5-FoldCross ValidationBeserta Rata-rata (mean)
1 2 3 4 5 Mean Epoch 26 25 21 26 19 23.4 Training loss 0.2507 0.3005 0.3804 0.2900 0.4173 0.32778 Training Accuracy 0.9590 0.9531 0.9253 0.9557 0.9198 0.94258 Validation loss 0.9400 1.0472 0.9875 1.3021 0.9583 1.04702 Validation accuracy 0.7804 0.6999 0.7452 0.6794 0.7325 0.72748
Gambar 4.24. HasilWeighted f1,AccuracydanBalanced accuracydari Model CNN-LSTM
Model CNN-LSTM mendapatkan nilaiweighted f1danaccuracymasing-masing sebesar 0.76916 dan 0.76785. Serupa dengan model CNN dan model LSTM, model CNN-LSTM mendapatkan nilai
balanced accuracyyang lebih rendah dibandingweighted f1danaccuracy, yaitu sebesar 0.6551, lebih rendah 0.11 dariweighted f1maupunaccuracy.
Tabel 4.9 Rata-rata nilaiTrue Positive,True Negative,False Positive,False Negative,Precision,
Recalldanf1-ScoreMasing-masing Label pada Model CNN-LSTM
Label True Positive True Negative False Positive False
Negative Precision Recall f1-score
Negatif 85.2 671.8 55.2 39.6 0.60684 0.68269 0.64254
Netral 523.6 143.2 84.6 97.6 0.86090 0.83910 0.84986
Positif 46.8 692.4 56.4 56.2 0.45349 0.45437 0.45392
Berdasarkan Tabel 4.9, sama seperti model CNN maupun model LSTM, model CNN-LSTM men-catat performa yang jauh lebih baik untuk mengenali data dengan label netral. Selain itu, model CNN-LSTM juga mencatat performa yang kurang baik pada label positif, dimana baik nilaiprecisiondan
recallpada kelas positif berada dibawah 0.5, dimana baik nilaiFalse PositivemaupunFalse Negative
pada label positif lebih tinggi dariTrue Positive. Jika melihat hasil confusion matrixpada Gambar 4.19-4.23, terlihat bahwa banyak teks yang dikenali oleh model sebagai label positif merupakan teks label netral, dan banyak teks yang merupakan label positif dikenali oleh model sebagai teks label netral.
Pada teks label negatif, terdapat selisih yang cukup besar antaraprecisiondanrecalljika diband-ingkan dengan selisih serupa di label netral maupun positif, karena nilaiFalse Positive yang jauh lebih besar dari nilaiFalse Negative, yang berarti model mengenali teks label lain sebagai teks label