LAB MANAJEMEN DASAR
MODUL RISET AKUNTANSI
PRAKTIKUM I LAB KAMPUS H
Nama :
NPM/Kelas :
Fakultas/Jurusan :
Fakultas Ekonomi
Universitas Gunadarma
UJI VALIDITAS DAN RELIABILITAS INSTRUMEN PENGUMPULAN DATA
I. UJI VALIDITAS
Sebelum instrument/alat ukur digunakan untuk mengumpulkan data penelitian, maka perlu dilakukan uji coba kuesioner untuk mencari kevalidan dan reliabilitas alat ukur tersebut. Uji validitas berguna untuk mengetahui apakah alat ukur tersebut valid, valid artinya ketepatan mengukur atau alat ukur tersebut tepat untuk mengukur sebuah variable yang akan diukur.
Kerlinger (1990) membagi validitas menjadi tiga, yaitu content validity (validitas isi), construct validity (validitas konstruk), dan criterion-related validity (validitas berdasar kriteria). Uji validitas dan realibilitas digunakan untuk menguji data yang berasal dari daftar pertanyaan atau kuesioner responden, validitas dan reliabilitas dapat membuktikan bahwa daftar pertanyaan dalam kuesioner yang diisi oleh responden sudah mewakili populasi atau belum.
Ada dua syarat penting yang berlaku pada sebuah kuesioner yaitu keharusan sebuah kuesioner untuk valid dan reliabel. Suatu kuesioner dikatakan valid jika pertanyaan pada suatu kuesioner mampu untuk mengungkapkan sesuatu yang akan diukur oleh kuesioner tersebut. Sedangkan suatu kuisioner dikatakan reliabel (andal) jika jawaban seseorang terhadap pertanyaan adalah konsisten atau stabil dari waktu ke waktu.
Uji validitas digunakan untuk mengetahui kelayakan butir-butir pertanyaan dalam suatu daftar (konstruk) pertanyaan dalam mendefinisikan suatu variabel. Daftar pertanyaan ini pada umumnya mendukung suatu kelompok variabel tertentu. Uji validitas dilakukan pada setiap butir pertanyaan, dan hasilnya dapat dilihat melalui hasil r-hitung yang dibandingkan dengan r-tabel, dimana r-tabel dapat diperoleh melalui df (degree of freedom) = n-2 (signifikan 5%, n = jumlah sampel).
Jika r-tabel < r-hitung maka valid Jika r-tabel > r-hitung maka tidak valid Tipe – tipe umum pengukuran validitas :
1. Validitas Isi
Validitas isi merupakan validitas yang diperhitungkan melalui pengujian terhadap isi alat ukur dengan analisis rasional. Pertanyaan yang dicari jawabannya dalam validasi ini adalah “ sejauh mana item-item dalam suatu alat ukur mencakup keseluruhan kawasan isi objek yang hendak diukur dari keseluruhan kawasan. Pengertian validitas “ mencakup keseluruhan kawasan isi “, tidak saja menunjukkan bahwa alat ukur tersebut harus komprehensif isinya, tetapi harus pula memuat hanya isi yang relevan dan tidak keluar dari batasan tujuan ukur.
Walaupun isi atau kandungannya komprehensif tetapi bila suatu alat ukur mengikutsertakan pula item-item yang tidak relevan dan berkaitan dengan hal-hal di luar tujuan ukurnya, maka validitas alat ukur tersebut tidak dapat dikatakan memenuhi ciri-ciri validitas yang sesungguhnya.
Validitas isi terbagi menjadi dua tipe, yaitu face validity (validitas muka) dan logical validity (validitas logis).
a. Face Validity (Validitas Muka)
Validitas muka adalah tipe validitas yang paling rendah signifikasinya karena hanya didasarkan pada penilaian selintas mengenai isi alat ukur. Apabila isi alat ukur telah tampak sesuai dengan apa yang ingin diukur, maka dapat dikatakan validitas muka telah terpenuhi. Dengan alasan kepraktisan banyak alat ukur yang pemakaiannya terbatas hanya mengandalkan validitas muka.
b. Logical Validity (Validitas Logis)
Validitas logis disebut juga sebagai validitas sampling. Validitas tipe ini menunjuk pada sejauhmana isi alat ukur merupakan representasi dari aspek yang hendak diukur. Untuk mempeoleh validitas logis yang tinggi suatu alat ukur harus dirancang sedemikian rupa sehingga benar-benar berisi hanya item yang relevan dan perlu menjadi bagian alat ukur secara keseluruhan. Suatu objek ukur yang hendak diungkap oleh alat ukur hendaknya harus dibatasi lebih dahulu kawasan perilakunya secara seksama dan konkrit. Validitas logis memang sangat penting peranannya dalam penyusunan tes presentasi dan penyusunan skala, yaitu dengan memanfaatkan blue-print atau table spesifikasi.
yang terus berlanjut sejalan dengan perkembangan konsep mengenai trait yang diukur. Walaupun pengujian validitas konstruk biasanya memerlukan teknik analisis statistic yang lenih kompleks daripada teknik yang dipakai pada pengujian validitas empiris lainnya, tetapi validitas konstruk tidaklah dinyatakan dalam bentuk koefisien validitas tunggal.
3. Validitas Berdasar Kriteria
Pendekatan validitas berdasarkan kriteria menghendaki tersedianya criteria eksternal yang dapat dijadikan dasar pengujian suatu alat ukur. Suatu kriteria adalah variabel perilaku yang akan diprediksikan oleh suatu alat skor. Untuk melihat tingginya validitas berdasar kriteria, maka dilakukan komputasi korelasi antara skor alat ukur dengan skor kriteria. Validitas berdasar criteria menghasilkan dua macam validitas, yaitu validitas prediktif (predictive validity) dan validitas konkruen (concurrent validity).
Dalam praktiknya, validitas berdasarkan krteria yang sering dilakukan oleh praktisi peneliti, yaitu dengan melakukan korelasi Pearson Product Moment antar item kuesioner dengan jumlah skor kuesioner. Akan tetapi, jika uji ini tidak dapat menganalisis hubungan antar item dalam instrument secara simultan sebagaimana metode multivariat.
Saat ini telah dikembangkan bermacam teknik analisis multivariat, salah satu diantaranya adalah analisis faktor konfirmatori yang sangat berguna untuk pengujian validitas dan reliabilitas instrument yang digunakan dalam penelitian.
a. Validitas Prediktif
Validitas prediktif sangat penting artinya bila alat ukur dimaksudkan untuk berfungsi sebagai prediktor bagi kinerja di masa yang akan datang. Contoh validitas prediktif yaitu : - Seleksi penerimaan karyawan baru
- Bimbingan karir - Penempatan karyawan
- Seleksi penerimaan mahasiswa baru
Contohnya adalah pada saat kita melakukan pengujian validitas alat ukur kemampuan yang digunakan dalam penempatan karyawan. Kriteria yang terbaik antara lain adalah kinerjanya setelah karyawan tersebut betul-betul ditempatkan sebagai karyawan dan melaksanakan tugasnya selama beberapa waktu. Skor tersebut dapat diperoleh dengan cara menggunakan indeks produktivitas dan rating yang dilakukan oleh atasan.
b. Validitas Konkruen
Validitas konkruen tepat digunakan apabila skor alat ukur kriterianya dapat diperoleh dalam waktu yang sama, maka korelasi antara kedua skor tersebut merupakan koefisien validitas konkruen. Untuk menguji validitas skala, maka dapat menggunakan skala kecemasan yang telah lebih dahulu teruji validitasnya, seperti alat ukur TMAS (Tylor Manifest Anxiety Scale). Validitas konkruen merupakan indikasi validitas yang memadai apabila alat ukur tidak digunakan sebagai suatu prediktor dan merupakan validitas yang sangat penting dalam situasi diagnostik. Bila alat ukur dimaksudkan sebagai prediktor, maka validitas konkruen tidak cukup memuaskan dan validitas prediktif merupakan keharusan.
Uji Validitas dengan Korelasi Parson Product-Moment
Dalam praktiknya penggunaan uji validitas dengan rumus rxy, yaitu Pearson Product
Moment merupakan uji beda dari alat ukur tersebut, yaitu uji yang membedakan antara kelompok atas dengan kelompok bawah, dalam arti bahwa jawaban kelompok atas seharusnya mampu menjawab (nilai skor 1) dan kelompok bawah seharusnya tidak mampu menjawab (nilai skor 0).
Kelemahan menggunakan uji ini adalah apabila jumlah responden (sampel) yang digunakan cukup besar, maka akan berdampak pada tingginya koefisien korelasi rxy,
sehingga berdampak pada tingginya koefisien korelsi rxy dan berdampak pada
kecenderungan untuk menjadi valid pada item tersebut. Parameter dari hasil uji rxy adalah
besarnya koefien korelasi pearson prduct moment antara 0,0 sampai 1 dikatakan valid bila besarnya rxy hitung lebih besar rxy tabel, koefisien korelasi > dari 0,50. Uji korelasi
dilakukan dengan cara mengkorelasikan item alat ukur dengan jumlah keseluruhan item alat ukur yang ada.
Rumus umum koefisien korelasi Pearson product Moment adalah sebagai berikut : r = (N ΣX.Y – ΣX. ΣY) / (√ { N ΣX2 - (ΣX)2 } { N ΣY2 - (ΣY)2 })
II. UJI RELIABILITAS
Reliabilitas adalah keandalan/konsistensi alat ukur (keajegan alat ukur), sehingga reliabilitas merupakan ukuran suatu kestabilan dan konsistensi responden dalam menjawab hal yang berkaitan dengan konstruk-konstruk pertanyaan yang merupakan dimensi suatu variabel dan disusun dalam suatu bentuk kuesioner. Setelah dilakukan uji validitas, maka harus dilanjutkan dengan menggunakan uji reliabilitas data. Alat ukur yang reliabel pasti terdiri dari item-item alat ukur yang valid. Sehingga, setiap reliabel pasti valid, namun setiap yang valid belum tentu reliabel. Rumus yang sering digunakan untuk uji reliabilitas adalah Alpha Cronbach, Spearman Brown, Kristoff, Angoff, dan Rullon
Uji reliabilitas dapat dilakukan secara bersama-sama terhadap seluruh butir pertanyaan. Jika nilai Cronbach’s Alpha > 0,60 maka reliabel
Jika nilai Cronbach’s Alpha < 0,60 maka tidak reliabel
Pengujian validitas dan reliabilitas adalah proses menguji butir-butir pertanyaan yang ada dalam sebuah angket, apakah isi dari butir pertanyaan tersebut sudah valid dan reliabel. Analisis dimulai dengan menguji validitas terlebih dahulu, baru diikuti oleh uji reliabilitas. Jadi jika sebuah butir tidak valid, baru otomatis ia dibuang. Butir-butir yang sudah valid baru kemudian secara bersama diukur reliabilitasnya.
Pengukuran reliabilitas pada dasarnya bisa dilakukan dengan cara :
1. Repeated Measure atau ukur ulang. Disini seseorang akan disodori pertanyaan yang sama pada waktu berbeda, dan kemudian dilihat apakah dia tetap konsisten dengan jawabannya. 2. One short atau sekali saja. Di sini pengukuran hanya sekali dan kemudian hasilnya
dibandingkan dengan hasil pertanyaan lain.
III. CONTOH KASUS
Seorang mahasiswa bernama Andi melakukan penelitian dengan menggunakan skala untuk mengetahui atau mengungkap prestasi belajar seseorang. Andi membuat 10 butir pertanyaan dengan menggunakan skala likert, yaitu :
Angka 1 = sangat tidak setuju Angka 2 = tidak setuju
Angka 3 = setuju
Angka 4 = sangat setuju
Setelah membagikan skala kepada 12 responden didapatlah tabulasi data-data sebagai berikut :
Subjek Skor Item
1 2 3 4 5 6 7 8 9 10 1 3 4 3 4 4 3 3 3 3 3 2 4 3 3 4 3 3 3 3 3 3 3 2 2 1 3 2 2 3 1 2 3 4 3 4 4 3 3 3 4 3 3 4 5 3 4 3 3 3 4 3 4 4 3 6 3 2 4 4 3 4 4 3 4 4 7 2 3 3 4 4 4 3 4 2 3 8 1 2 2 1 2 2 1 3 4 3 9 4 2 3 3 4 2 1 1 4 4 10 3 3 3 4 4 4 4 4 3 3 11 4 4 3 4 4 3 4 4 4 2 12 3 2 1 2 3 1 1 2 3 3 Langkah-langkah pada program R-Commander :
Untuk mencari nilai-nilai Validitas data tersebut dengan menggunakan program R, ikutilah langkah-langkah berikut :
1. Tekan icon R Commander pada desktop kemudian akan muncul tampilan seperti gambar di bawah ini.
Gambar 1. Tampilan menu awal R commander
2. Pilih menu Data, New data set. Masukkan nama dari data set adalah validitas kemudian tekan tombol OK
Gambar 2. Tampilan menu New data set
Kemudian akan muncul Data Editor
Gambar 4. Tampilan Data Editor
3. Masukkan data dengan var1 untuk skor 1, var2 untuk skor 2 … var 10 untuk skor10. Jika Data Editor tidak aktif maka dapat diaktifkan dengan menekan RGui di Taskbar windows pada bagian bawah layar monitor. Jika sudah selesai dalam pengisian data tekan tombol Close. Untuk mengubah nama dan tipe variabel, dapat dilakukan dengan cara double click pada variable yang ingin di setting. Pemilihan type, dipilih numeric pada semua variabel.
Gambar 5. Tampilan Variabel editor skor1 Untuk type data pilih sesuai dengan data soal
a. numeric, jika data yang dimasukkan berupa angka b. character, jika data yang dimasukkan berupa huruf
Kemudian Isi masing-masing variabel sesuai dengan data soal setelah selesai isi data kemudian tekan tombol X (close)
Selanjutnya, pilih window R-commander akan muncul tampilan :
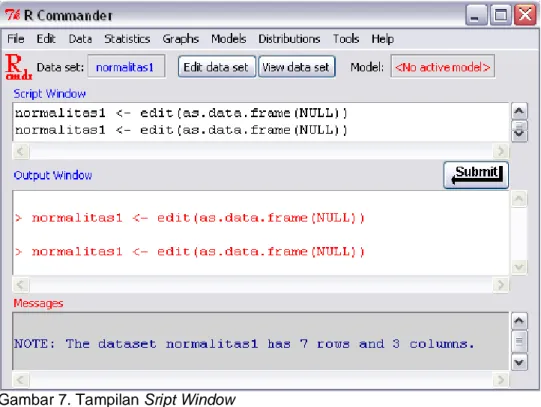
Gambar 7. Tampilan Sript Window
4. Untuk mengecek kebenaran data yang sudah dimasukkan, tekan tombol View data set maka akan muncul tampilan seperti gambar di bawah ini. Jika ada data yang salah, tekan tombol edit data set, lalu perbaiki data yang salah.
Gambar 8. Tampilan View Data Set validitas
5. Jika data sudah benar, pilih menu Statistics, Dimensional analysis, Scale reliability, maka akan muncul tampilan seperti gambar di bawah ini
Gambar 9. Tampilan menu olah data
Kemudian akan muncul window scale reliability
Pada window scale reliability, terdapat kumpulan variabel yang telah diinput sebelumnya. Block seluruh variabel, kemudian tekan tombol OK
Gambar 10. Tampilan Scale Reliability
Gambar 11. Tampilan Output Tahap-tahap Analisis :
1. Dari out window, terdapat tampilan r(item,total)
2. Untuk menganalisis uji validitas hanya dibutuhkan nilai dari r(item,total) atau “corrected item total correlation” yang dinyatakan sebagai r-hitung
3. Analisis Validitas :
a. Untuk mendapatkan nilai r-tabel diperoleh melalui df (degree of freedom) df = n – 2, dimana n adalah jumlah sampel
b. df = 12-2 = 10, dengan tingkat signifikansi 0,05 dan uji 2 sisi maka diperoleh r-tabel = 0,576 c. analisis butir pertanyaan (setiap nilai r-hitung)
pada skor 1, (r-hitung = 0,4113) < (r-tabel = 0,576), maka tidak valid pada skor 2, (r-hitung = 0,6151) > (r-tabel = 0,576), maka valid pada skor 3, (r-hitung = 0,8217) > (r-tabel = 0,576), maka valid pada skor 4, (r-hitung = 0,7162) > (r-tabel = 0,576), maka valid pada skor 5, (r-hitung = 0,5603) < (r-tabel = 0,576), maka tidak valid pada skor 6, (r-hitung = 0,7764) > (r-tabel = 0,576), maka valid pada skor 7, (r-hitung = 0,6784) > (r-tabel = 0,576), maka valid pada skor 8, (r-hitung = 0,5679) < (r-tabel = 0,576), maka tidak valid pada skor 9, (r-hitung = 0,0887) < (r-tabel = 0,576), maka tidak valid pada skor 10, (r-hitung = - 0,0800) < (r-tabel = 0,576), maka tidak valid c. Dari hasil analisis di atas, didapat bahwa :
2) Sedangkan skor 1, skor 5, skor 8, skor 9 dan skor 10 tidak valid, sehingga diperlukan perbaikan pada item-item skor tersebut.
Analisis Reliabilitas :
a. Untuk uji reliabilitas, pada output window
Perlu diingat bahwa skor yang valid hanya skor 2, skor 3, skor 4, skor 6 serta skor 7 saja, maka skor yang akan diuji hanya skor tesebut saja, sedangkan untuk skor yang tidak valid, maka diabaikan saja dan sampelnya menjadi 5 saja.
b. Jika nilai Alpha reliability > dari 0,6 maka keseluruhan butir pertanyaan dinyatakan reliabel c. Contoh : Alpha reliability = 0,837 > 0,6 maka dinyatakan reliabel
d. Kesimpulan :
Setelah dilakukan uji Reliabilitas dengan menggunakan Alpha Cronbach, maka ke-5 skor pertanyaan tersebut adalah reliabel, sehingga dapat digunakan untuk alat ukur pengujian selanjutnya.
UJI NORMALITAS I. PENDAHULUAN
Uji normalitas adalah suatu bentuk pengujian tentang kenormalan distribusi data. Tujuan dari uji ini adalah untuk mengetahui apakah data yang diambil adalah data yang terdistribusi normal. Maksud dari data terdistribusi normal adalah bahwa data akan mengikuti bentuk distribusi normal dimana datanya memusat pada nilai rata-rata dan median. Uji ini sering dilakukan untuk analisis statistik parametrik. Uji dapat dilakukan setelah menentukan tipe data dari data penelitian yang diambil.
II. ANALISIS YANG DIPERLUKAN
Yang perlu dilihat dari output R programming adalah nilai signifikan dari Shapiro-Wilk Test of Normality. Dalam hal ini nilai signifikan Shapiro-Wilk Test of Normality harus lebih besar dari (>) 0,05. Namun, sebenarnya dalam menguji kenormalam suatu data ada banyak hal yang perlu diketahui, seperti nilai perbandingan antara nilai skewness dengan standar error skewness yang menghasilkan rasio skewness dan perbandingan antara nilai kurtosis dengan nilai standar error kurtosis yang akan mengahasilkan rasio kurtosis. Dari kedua rasio perbandingan tersebut dapat dikatakan normal bila mempunyai nilai antara -2 sampai dengan 2. Selain hal tersebut masih ada satu lagi alat uji untuk melihat kenormalan data yaitu dengan nilai K-S dengan syarat bila nilai probabilitas lebih besar dari (>) 0,05 maka data tersebut dikatakan normal.
III. CONTOH KASUS
Berikut ini disajikan data mengenai penjualan tiket bus antar kota antar propinsi di terminal Lebak Bulus selama hari raya Idul Fitri. Berdasarkan data di bawah ini, ujilah apakah data tersebut terdistribusi normal !
Hari Lorena Kramat Jati Safari
1 250 280 150 2 190 275 180 3 311 299 188 4 340 300 175 5 322 314 199 6 363 312 205 7 344 311 206
IV. LANGKAH-LANGKAH PENGERJAAN
Untuk mencari nilai-nilai normalitas data tersebut dengan menggunakan program R, ikutilah langkah-langkah berikut :
1. Tekan icon R Commander pada desktop kemudian akan muncul tampilan seperti gambar di bawah ini.
Gambar 1. Tampilan menu awal R commander
2. Pilih menu Data, New data set. Masukkan nama dari data set adalah normalitas1 (tanpa spasi) kemudian tekan tombol OK
Gambar 2. Tampilan menu New data set
Kemudian akan muncul Data Editor
Gambar 4. Tampilan Data Editor
3. Masukkan data bus dengan var1 untuk lorena, var2 untuk kramat jati dan var3 untuk safari. Jika Data Editor tidak aktif maka dapat diaktifkan dengan menekan RGui di Taskbar windows pada bagian bawah layar monitor. Jika sudah selesai dalam pengisian data tekan tombol Close. Untuk mengubah nama dan tipe variabel, dapat dilakukan dengan cara double click pada variable yang ingin di setting. Pemilihan type, dipilih numeric pada semua variabel.
Gambar 5. Tampilan Variabel editor lorena
Kemudian Isi masing-masing variabel sesuai dengan data soal setelah selesai isi data kemudian tekan tombol X (close)
Gambar 6. Tampilan isi Data Editor
Gambar 7. Tampilan Sript Window
4. Untuk mengecek kebenaran data yang sudah dimasukkan, tekan tombol View data set maka akan muncul tampilan seperti gambar di bawah ini. Jika ada data yang salah, tekan tombol edit data set, lalu perbaiki data yang salah.
Gambar 8. Tampilan View normalitas1
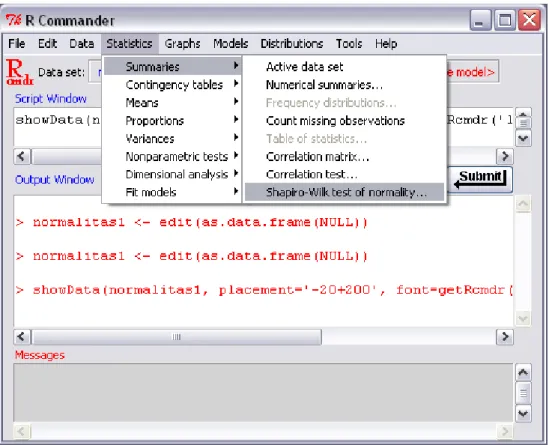
5. Jika data sudah benar, pilih menu Statistic, Summaries, Shapiro-Wilk test of normality. Pilih lorena kemudian tekan tombol OK. Begitu juga dengan kramat jati dan safari. Karena data yang keluar hanya satu persatu tidak dapat langsung keluar dalam satu kali pengolahan.
Gambar 9. Tampilan menu olah data Kemudian akan muncul
a. Tampilan Scale Reliabity kramatjati
Gambar 10. Tampilan Scale Reliability kramatjati b. Tampilan Scale Reliabity lorena
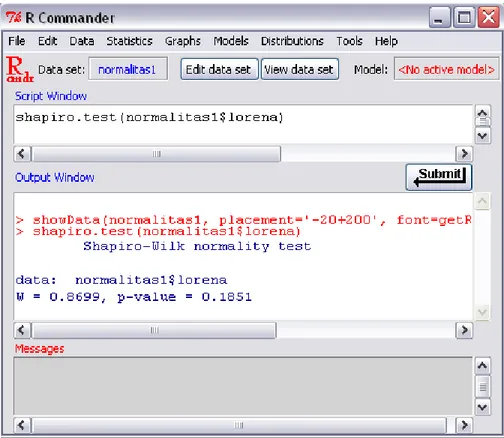
Gambar 11. Tampilan Scale Reliabity lorena c. Tampilan Scale Reliability safari
Gambar 12. Tampilan Scale Reliabity safari
6. Kemudian tekan tampilan R Commander akan muncul output :
Gambar 13. Tampilan Output kramatjati
*Nilai probabilitas Shapiro-Wilk sebesar 0,1623 berarti probabilitas lebih dari 0,05; maka data untuk bus kramat jati tersebut terdistribusi normal
Gambar 14. Tampilan Output lorena
*Nilai probabilitas Shapiro-Wilk sebesar 0,1851 berarti probabilitas lebih dari 0,05; maka data untuk bus lorena tersebut terdistribusi normal.
Gambar 15. Tampilan Output safari
*Nilai probabilitas Shapiro-Wilk sebesar 0,4126 berarti probabilitas lebih dari 0,05; maka data untuk bus safari tersebut terdistribusi normal
Untuk membersihkan Script Window pada R Commander, lakukan langkah berikut : 1. Letakkan kursor pada Script window
2. Kilik Kanan
3. Klik kiri pada Clear window
Untuk membersihkan Output Window pada R Commander, lakukan langkah berikut : 1. Letakkan kursor pada Output window
2. Kilik Kanan
UJI T SAMPEL BEBAS
(INDEPENDENT SAMPLE T-TEST) I. PENDAHULUAN
Pengujian hipotesis dengan distribusi t adalah pengujian hipotesis yang menggunakan distribusi t sebagai uji statistik. Tabel pengujian disebut tabel t-student. Distribusi t pertama kali diterbitkan pada tahun 1908 dalam suatu makalah oleh W.S Gosset. Pada waktu itu Gosset bekerja pada perusahaan bir Irlandia yang melarang penerbitan penelitian oleh karyawannya. Untuk mengelakkan larangan ini dia menerbitkan karyanya secara rahasia dibawah nama ‘student’. Karena itulah distribusi t biasanya disebut Distribusi Student. Hasil uji statistiknya kemudian dibandingkan dengan nilai yang ada pada tabel untuk kemudian menerima atau menolak hipotesis observasi (HO) yang dikemukakan.
Ciri-ciri Uji t
1. Penentuan nilai tabel dilihat dari besarnya tingkat signifikan (α) dan besarnya drajat bebas (db).
2. Kasus yang diuji bersifat acak. Fungsi Pengujian Uji t
1. Untuk memperkirakan interval rata-rata.
2. Untuk menguji hipotesis tentang rata-rata suatu sampel. 3. Menunjukkan batas penerimaan suatu hipotesis.
4. Untuk menguji suatu pernyataan apakah sudah layak untuk dipercaya.
II. ANALISIS YANG DIPERLUKAN
Menentukan rata-ratanya : Xi = (∑x) / n
Menentukan standar deviasi : S2 = ∑ (X1-X)2 / n – 1 dan S = √S2
Rumus umum Uji T Sampel Bebas : To = (X1-X2) – do / √(S12 / n1) + (S22 / n2)
III. CONTOH KASUS
Menjelang tahun ajaran baru ook buku Saputra menjual berbagai macam merk buku tulis. Dari berbagai merk yang ada, ada 2 merk yang sangat laris, yaitu merk Cerdas dan Ganteng. Pemilik took ingin menguji apakah antara kedua merk tersebut sama larisnya atau salah satu lebih laris dari yang lain. Dari catatan penjualan yang ada selama sebulan diperoleh data jumlah buku yang terjual sebagai berikut :
Hari ke Merk Cerdas Merk Ganteng
1 255 250 2 240 248 3 238 240 4 225 215 5 195 200 6 200 205 7 203 198 8 208 190 9 214 199 10 216 225
IV. LANGKAH-LANGKAH PENGERJAAN
Untuk mencari nilai-nilai uji 2 sample bebas data tersebut dengan menggunakan program R, ikutilah langkah-langkah berikut :
1. Tekan icon R Commander pada desktop kemudian akan muncul tampilan seperti gambar di bawah ini.
Gambar 1. Tampilan menu awal R commander
2. Pilih menu Data, New data set. Masukkan nama dari data set adalah normalitas1 (tanpa spasi) kemudian tekan tombol OK
Gambar 2. Tampilan menu New data set
Gambar 3. Tampilan New Data Set
Kemudian akan muncul Data Editor
Gambar 4. Tampilan Data Editor
3. Masukkan data bus dengan var1 untuk skor, var2 untuk buku. Jika Data Editor tidak aktif maka dapat diaktifkan dengan menekan RGui di Taskbar windows pada bagian bawah layar monitor. Jika sudah selesai dalam pengisian data tekan tombol Close. Untuk mengubah nama dan tipe variabel, dapat dilakukan dengan cara double click pada variable yang ingin di setting. Pemilihan type, dipilih numeric pada semua variabel.
Gambar 5. Tampilan Variabel editor skor
Gambar 6. Tampilan Variabel editor buku
Kemudian Isi masing-masing variabel sesuai dengan data soal setelah selesai isi data kemudian tekan tombol X (close)
Gambar 7. Tampilan isi Data Editor
Selanjutnya, pilih window R-commander akan muncul tampilan :
Gambar 8. Tampilan Sript Window
Gambar 9. Tampilan View bebas
Untuk merubah variabel numerik buku pada tampilan R commander pilih : Manage variables in active data set kemudian pilih Bin numeric variable.
Kemudian akan muncul tampilan :
Gambar 11. Tampilan Bin a Numeric Variable Kemudian akan muncul tampilan rubah nama Bin :
Gambar 12. Tampilan Bin Names
6. Pada Response Variable pilih skor kemudian tekan tombol OK .
Gambar 14. Tampilan Independent Samples t-Test
7. Maka akan muncul hasil pada output window sebagai berikut :
Gambar 15. Tampilan output bagian Analisis
Uji Selisih rata-rata 1. Hipotesis 2. Statistik uji : uji t 3. α = 0.05
4. Daerah Kritis : Ho ditolak jika sig. < α
5. Dari hasil pengolahan R-Programing, diperoleh sign t = 0.255 6. Karena Sign t. > α (0.255>0.05) maka Ho diterima.
Kesimpulan: Ho diterima sehingga rata-rata penjualan buku merk Cerdas = merk Ganteng.
Pada output di atas didapat rata-rata buku cerdas yang terjual sebesar 220 (dibulatkan) dan rata-rata buku ganteng yang terjual sebesar 217.
UJI 2 SAMPLE BERPASANGAN (PAIRED SAMPLE t-TEST) I. PENDAHULUAN
Paired sample t-Test adalah uji t dimana sample saling berhubungan antara satu sample dengan sample yang lain. Pengujian ini biasanya dilakukan pada penelitian dengan menggunakan teknik eksperimen dimana satu sample diberi perlakuan tertentu kemudian dibandingkan dengan kondisi sample sebelum adanya perlakuan. Tujuan dari pengujian ini adalah untuk menguji perbedaan rata-rata antara sample-sampel yang berpasangan.
II. ANALISIS YANG DIPERLUKAN
Hipotesis :
Ho : tidak ada perbedaan antara sebelum dan sesudah adanya perlakuan Ha : ada perbedaan antara sebelum dan sesudah adanya perlakuan Kriteria pengambilan keputusan :
1. Menggunakan nilai signifikan / P-Value
Jika nilai signifikan / P-Value > 0,05 ; maka Ho diterima Jika nilai signifikan / P-Value < 0,05 ; maka Ho ditolak. 2. Menggunakan perbandingan antara t hitung dengan t tabel
Nilai t tabel didapat dari α (taraf nyata / tingkat signifikan) dengan derjat bebas / degree of
freedom (df).
Jika t hitung > t tabel ; maka Ho ditolak Jika t hitung < t tabel ; maka Ho diterima.
III. CONTOH KASUS
Sebuah perusahaan mie instan akan melakukan penelitian terhadap produk mereka sebelum dilakukan promosi dengan setelah dilakukan promosi. Data didapat dari 7 lokasi dengan data sebagai berikut :
No. Sebelum Sesudah
1. 224 255 2. 231 251 3. 223 254 4. 251 225 5. 264 245 6. 222 268 7. 235 215
IV. LANGKAH-LANGKAH PENGERJAAN
Untuk mencari nilai-nilai uji 2 sampel berpasangan data tersebut dengan menggunakan program R, ikutilah langkah-langkah berikut :
1. Tekan icon R Commander pada desktop kemudian akan muncul tampilan seperti gambar di bawah ini.
Gambar 1. Tampilan menu awal R commander
2. Pilih menu Data, New data set. Masukkan nama dari data set adalah datapenjualan (tanpa spasi) kemudian tekan tombol OK
Gambar 2. Tampilan menu New data set
Gambar 3. Tampilan New Data Set Kemudian akan muncul Data Editor
Gambar 4. Tampilan Data Editor
3. Masukkan data dengan var1 untuk sebelum, var2 untuk sesudah. Jika Data Editor tidak aktif maka dapat diaktifkan dengan menekan RGui di Taskbar windows pada bagian bawah layar monitor. Jika sudah selesai dalam pengisian data tekan tombol Close. Untuk mengubah nama dan tipe variabel, dapat dilakukan dengan cara double click pada variable yang ingin di setting. Pemilihan type, dipilih numeric pada semua variabel.
Tekan icon R Commander pada desktop kemudian akan muncul window data editor Data Set : data penjualan .
Gambar 5. Tampilan Variabel editor sebelum
Gambar 6. Tampilan Variabel editor sesudah 4. Kemudian masukan data skor sesuai dengan soal
Selanjutnya, pilih window R-commander akan muncul tampilan :
Gambar 8. Tampilan Sript Window
5. Untuk mengecek kebenaran data yang sudah dimasukkan, tekan tombol View data set maka akan muncul tampilan seperti gambar di bawah ini. Jika ada data yang salah, tekan tombol edit data set, lalu perbaiki data yang salah.
Gambar 9. Tampilan View data penjualan
6. Jika data sudah benar, pilih menu statistika,means, paired t-test maka akan muncul menu seperti gambar di bawah ini
Gambar 10. Tampilan menu olah data
Kemudian akan muncul tampilan seperti di bawah ini :
Gambar 11. Tampilan Paired t-Test
Untuk kolom pertama pilih sebelum dan yang kedua pilih sesudah kemudian tekan tombol OK
Gambar 12. Tampilan Output Analysis
Dari hasil di atas dapat disimpulkan bahwa probabilitas p-value = 0,454. Oleh karena probabilitas > 0,05 maka Ho diterima, atau promosi yang dilakukan manajer untuk melakukan promosi ternyata tidak efektif untuk meningkatkan penjualan mie instan.
Atau bisa menggunakan t table yang didapat dari nilai df dan nilai taraf nyata. Nilai df
sebesar 6 dengan taraf nyata sebesar 5% maka didapat nilai t table sebesar 3,707. Nilai
tersebut lebih besar daripada nilai t hitung yang hanya sebesar -0,8006. Oleh karena nilai t hitung < t table maka Ho diterima, atau promosi yang dilakukan manajer untuk melakukan
UJI NONPARAMETRIK
(CHI SQUARE / X2)
I. PENDAHULUAN
Dalam uji statistika dikenal uji parametrik dan uji nonparametrik. Uji statistika parametrik hanya dapat digunakan jika data menyebar normal atau tidak ditemukannya petunjuk pelanggaran kenormalan dan keragaman atau variasi antara perlakuan-perlakuan/peubah bebas yang dibandingkan dengan homogen.
Untuk data yang tidak memenuhi syarat tersebut dan data dengan satuan pengukuran nominal dan ordinal digunakan uji lain yaitu uji statistika nonparametrika.
Pada modul ini uji statistika nonparametrik yang akan dibahas adalah Chi Square (X2).
Chi square merupakan salah satu alat analisis yang banyak digunakan dalam pengujian hipotesis. Chi square terutama digunakan untuk Uji Homogenitas, uji Independensi, dan Uji Keselarasan (Goodness of Fit Test).
II. ANALISIS YANG DIPERLUKAN
Rumus untuk uji Chi Square yaitu sebagai berikut : X2 = (∑ ( obk – ebk) 2) / ebk
Keterangan :
obk : hasil observasi pada baris b kolom k
ebk : nilai harapan (expected value) pada baris b kolom k
Degree of Fredom (df)/derajat bebas (db) Chi square yaitu Df = (k – 1) * (b – 1)
Keterangan :
k : jumlah kolom observasi b : jumlah baris observasi
III. UJI INDEPENDENSI
Uji ini digunakan untuk menguji ada atau tidaknya interdependensi antara variabel kuantitatif yang satu dengan yang lainnya berdasarkan observasi yang ada.
IV. CONTOH KASUS
Dalam suatu masyarakat akan diteliti apakah terdapat hubungan antara pendapatan terhadap pola belanja bahan makanan yang dikonsumsi. Hasil observasi adalah sebagai berikut.
Perilaku Belanja
Pendapatan Supermarket Pasar Tradisional
Tinggi 3 0
Sedang 3 3
Rendah 0 6
Ujilah data di atas dengan menggunakan R-Commander serta analisislah!
V. LANGKAH-LANGKAH PENGERJAAN
Untuk mencari nilai-nilai data tersebut dengan menggunakan program R, ikutilah langkah-langkah berikut :
1. Tekan icon R Commander pada desktop kemudian akan muncul tampilan seperti gambar di bawah ini.
Gambar 1. Tampilan menu awal R commander
2. Pada R Commander pilih menu bar Statistics, Contingency tables, dan Enter and analyze two-way table seperti tampilan di bawah ini.
Gambar 2. Tampilan menu olah data Kemudian akan tampil seperti di bawah ini.
Gambar 3. Tampilan Enter- Two Way Table
3. Kemudian isi kotak tersebut sesuai contoh kasus, Number of Rows digeser ke kanan sehingga berubah dari 2 menjadi 3. Kemudian isi Enter counts. Tampilan data yang sudah diisi sebagai berikut. Kemudian pilih OK.
4. Kemudian akan tampil output di bawah ini
Gambar 5. Tampilan Output Analisa :
Hipotesis:
Ho : Tidak ada hubungan antara tingkat pendapatan dengan perilaku belanja Ha : Ada hubungan antara tingkat pendapatan dengan perilaku belanja Chi square hitung : X-square = 8,75
Derajat bebas : df = 2 p-value : 0,01259 Probabilitas:
Jika probabilitas (p-value) > 0,05 maka Ho diterima Jika probabilitas (p-value) < 0,05 maka Ho ditolak Keputusan:
Hasil perhitungan menyatakan bahwa besarnya probabilitas (p-value) adalah 0,01259 → 0,013 karena probabilitas lebih kecil daripada taraf uji yang digunakan dalam penelitian atau p-value < α atau 0,000 < 0,05 maka Ho ditolak.
Dengan demikian dapat disimpulkan bahwa tingkat pendapatan seseorang akan mempengaruhi perilaku belanjanya.
5. UJI KESELARASAN (GOODNESS OF FIT)
Uji keselarasan adalah perbandingan antara frekuensi observasi dengan frekuensi harapan. Uji keselarasan pada prinsipnya bertujuan untuk mengetahui apakah sebuah distribusi data dari sampel mengikuti sebuah distribusi teoritis tertentu ataukah tidak.
6. CONTOH KASUS
Seorang Manajer Pemasaran sabun mandi HARUM selama ini menganggap bahwa konsumen sama-sama menyukai tiga warna sabun mandi yang diproduksi, yaitu Putih, Merah, dan Kuning. Untuk mengetahui apakah pendapat Manajer tersebut benar, maka kepada dua belas responden ditanya warna sabun mandi yang paling disukainya.
Berikut adalah data kuesioner tersebut. Responden Warna Pilihan
Nia Putih Vira Merah Jame Kuning Ricky Kuning Kaila Merah Kezia Kuning Rossy Kuning Maia Kuning Nabila Putih Fahri Putih Faisal Merah Guptha Merah
Ujilah data di atas dengan menggunakan R Commander serta analisislah !
7. LANGKAH PENGERJAAN
Untuk mencari nilai-nilai data tersebut dengan menggunakan program R, ikutilah langkah-langkah berikut :
Tekan icon R Commander pada desktop kemudian akan muncul tampilan seperti gambar di bawah ini.
Gambar 6. Tampilan menu awal R commander
Pilih menu Data, New data set. Masukkan nama dari data set adalah responden kemudian tekan tombol OK.
Gambar 7. Tampilan menu New data set
Gambar 8. Tampilan New Data Set responden Kemudian akan muncul Data Editor
Gambar 9. Tampilan Data Editor
Masukkan data dengan var1 untuk responden, var2 untuk kode warna var 3 untuk warna pilihan. Jika Data Editor tidak aktif maka dapat diaktifkan dengan menekan RGui di Taskbar windows pada bagian bawah layar monitor. Jika sudah selesai dalam pengisian data tekan tombol Close. Untuk mengubah nama dan tipe variabel, dapat dilakukan dengan cara double click pada variable yang ingin di setting. Pemilihan type, dipilih numeric pada variable kode warna dan character untuk responden
Tekan icon R Commander pada desktop kemudian akan muncul window data editor Data Set : responden.
Gambar 10. Tampilan Variable editor responden
Gambar 11. Tampilan Variable editor kode warna
Gambar 12. Tampilan Variable editor warna pilihan
Kemudian Isi masing-masing variabel sesuai dengan data soal setelah selesai isi data kemudian tekan tombol X (close)
Gambar 13. Tampilan isi Data Editor
Selanjutnya, pilih window R-commander akan muncul tampilan :
1. Pada R Commander, pilih menu bar data, pilih Manage variables in active data set, pilih
2. Akan tampil sebagai berikut. Kemudian klik OK
3. Akan tampil sebagai berikut dengan mengubah terlebih dahulu 1 : putih
2 : merah 3 : kuning Kemudian klik OK
4. Pada R Commander pilih menu bar pilih Edit data set. Maka akan tampil sebagai berikut. Sebelumnya kolom warna pilihan tidak terisi data. Close Data Editor
5. Pada menu bar pilih Statistics, pilih Frequency distribution
6. Maka akan tampil sebagai berikut, beri tanda check list pada Chi-square goodness of fit
test. Kemudian klik OK
7. Maka akan tampil sebagai berikut, kemudian klik OK
9. Lihat pada Output Window, maka dapat dianalisis. Hipotesis:
Ho : Tidak ada perbedaan kesukaan terhadap warna sabun Ha : Ada perbedaan kesukaan terhadap warna sabun Chi square hitung: X-square = 0,5
Derajat bebas: df = 2 p-value: 0,7788 Probabilitas:
Jika probabilitas (p-value) > 0,05 maka Ho diterima Jika probabilitas (p-value) < 0,05 maka Ho ditolak Keputusan:
Hasil perhitungan menyatakan bahwa besarnya probabilitas (p-value) adalah 0,7788 →
0,779 karena probabilitas lebih besar daripada taraf uji yang digunakan dalam penelitian
atau p-value > α atau 0,7788 > 0,05 maka Ho diterima.
Dengan demikian dapat disimpulkan bahwa tidak ada perbedaan kesukaan terhadap warna sabun yang dikonsumsi.
UJI PERBEDAAN LEBIH DARI DUA SAMPEL (ANOVA)
I. PENDAHULUAN
Uji perbedaan lebih dari dua sampel disebut juga analisis varians, dipopulerkan oleh Sir Donald Fisher, seorang pendiri modern. Analisis ini digunakan untuk :
1. Menguji hipotesis kesamaan rata-rata antara dua grup atau lebih (tidak berbeda secara signifikan).
2. Menguji apakah varians populasinya sama ataukah tidak. Asumsi :
1. Populasi-populasi yang akan diuji terdistribusi normal 2. Varians dari populasi-populasi tersebut adalah sama 3. Sampel tidak berhubungan satu dengan yang lain
II. ANALISIS YANG DIPERLUKAN
Uji Kesamaan Varians
Lihat output livene’s test of homogeneity of varians 1. Hipotesis :
Ho : Varians ketiga sampel identik Ha : Varians ketiga sampel tidak identik 2. Pengambilan keputusan
Jika Probabilitas > 0.05, maka Ho di terima Jika Probabilitas < 0.05, maka Ho di tolak Uji Anova
Lihat output analysis of varians 1. Hipotesis :
Ho : ke-3 Rata-rata populasi adalah identik Ha : ke-3 Rata-rata populasi adalah tidak identik 2. Pengambilan keputusan
Jika Probabilitas > 0.05, maka Ho di terima Jika Probabilitas < 0.05, maka Ho di tolak
III. CONTOH KASUS
Seorang pengusaha persewaan becak ingin membeli ban. Di toko ternyata ada 3 ban becak yang harganya sama, yaitu ban merk A, ban merk B, ban merk C. Pengusaha tersebut ingin membeli satu dari 3 ban tersebut. Untuk itu ia akan mengadakan percobaan terhadap daya tahan ban (hari). Hasil percobaannya adalah sebagai berikut :
Sampel Ban A Ban B Ban C
1 110 100 110
2 100 100 110
3 110 120 90
4 120 120 80
IV. LANGKAH-LANGKAH PENGERJAAN
Untuk mencari nilai-nilai anova data tersebut dengan menggunakan program R, ikutilah langkah-langkah berikut :
1. Tekan icon R Commander pada desktop kemudian akan muncul tampilan seperti gambar di bawah ini.
Gambar 1. Tampilan menu awal R commander
2. Pilih menu Data, New data set. Masukkan nama dari data set adalah anova kemudian tekan tombol OK
Gambar 2. Tampilan menu New data set
Kemudian akan muncul Data Editor
Gambar 4. Tampilan Data Editor
3. Masukkan data dengan var1 merk.ban dan var2 daya tahan. Jika Data Editor tidak aktif maka dapat diaktifkan dengan menekan RGui di Taskbar windows pada bagian bawah layar monitor. Jika sudah selesai dalam pengisian data tekan tombol Close. Untuk mengubah nama dan tipe variabel, dapat dilakukan dengan cara double click pada variable yang ingin di setting.
Gambar 5. Tampilan Variabel editor merk.ban
Gambar 6. Tampilan Variabel editor dayatahan
Kemudian Isi masing-masing variabel sesuai dengan data soal setelah selesai isi data kemudian tekan tombol X (close)
Gambar 7. Tampilan isi Data Editor
Selanjutnya, pilih window R-commander akan muncul tampilan :
Gambar 8. Tampilan Sript Window
4. Untuk mengecek kebenaran data yang sudah dimasukkan, tekan tombol View data set maka akan muncul tampilan. Jika ada data yang salah, tekan tombol edit data set, lalu perbaiki data yang salah.
Gambar 9. Tampilan View anova
Untuk merubah variabel numerik ban pada tampilan R commander pilih : Manage variables in active data set kemudian pilih Bin numeric variable.
Kemudian akan muncul tampilan :
Gambar 11. Tampilan Bin a Numeric Variable Kemudian akan muncul tampilan rubah nama Bin :
Gambar 12. Tampilan Bin Names
6. Pada Response Variable pilih variabel daya tahan (numerik) kemudian tekan tombol OK .
Gambar 14. Tampilan Levene’s Test
7. Pilih menu R commander untuk mencari nilai Anova. Pilih menu Statistics, Means, One-way ANOVA
Gambar 15. Tampilan menu olah data 2 Kemudian akan muncul tampilan :
Gambar 16. Tampilan One-Way Analysis of Variance
8. Maka akan muncul hasil pada output window sebagai berikut : Output bagian 1
Gambar 17. Tampilan output bagian 1
Analisa : Output di atas menunjukan nilai f probabilitas 0,1004 > 0,05 maka Ho diterima atau ketiga varians sampel identik
Analisa ; Output di atas menunjukan f probabilitas 0,2801>0,05, maka Ho diterima atau daya tahan ke tiga merk ban adalah identik (sama). Rata-rata daya tahan ban A adalah 110,0, ban B110,0, ban C 97,5
Output bagian 3 :
Gambar 19 Tampilan output bagian 3
Analisa : Standar deviasi ban merk A 8,16, merk B 11,54, merk C 15,00
Jumlah sampel masing-masing merk ban adalah 4 dan tidak ada data yang hilang Output bagian 4 :
Gambar 20. Tampilan output bagian 4 Analisa : 95% family-wise confidence level
Lihat nilai estimate paling besar adalah Ban C-ban A = -1,25 dan ban C-Ban B= -1,25, maka ini menunjukan rata-rata daya tahan antara ketiga merk ban berbeda, dengan selang kepercayaan 95 %
REGRESI LINIER BERGANDA
I. PENDAHULUAN
Program R menu regresi merupakan alat yang digunakan untuk menentukan persamaan regresi yang menunjukkan hubungan antara variabel terikat yang ditentukan dengan dua atau lebih variabel bebas. Tujuan utama analisis regresi adalah untuk perkiraan nilai suatu variabel (terikat) jika nilai variabel lain yang berhubungan dengannya (variabel bebas) sudah ditentukan.
Regresi linier (liniear regression) digunakan untuk melakukan pengujian hubungan antara sebuah variabel dependent (tergantung) dengan satu variabel atau beberapa variabel independent (bebas) yang ditampilkan dalam bentuk persamaan regresi.
Jika variabel dependent yang dihubungkan hanya dengan satu variabel independent saja, maka persamaan regresi yang dihasilkan adalah regresi linier sederhana (liniear regresssion). Jika variabel dependent yang dihubungkan dengan lebih dari satu variabel independent, maka persamaan regresinya adalah regresi linier berganda (multiple liniear regression).
II. ANALISIS YANG DIPERLUKAN
Persamaan Umum : Y = α + b1 X1+ b2 X2 + b3 X3 + ...+bn Xn Keterangan : Y = variabel dependent α = konstanta X1 ...Xn = variabel independent b1 bn = koefisien regresi
Tiga asumsi dasar yang tidak boleh dilanggar oleh regresi linier berganda yaitu 1) Tidak boleh ada autokorelasi,
Untuk menguji variabel-variabel yang diteliti, apakah terjadi autokorelasi atau tidak, bila uji nilai Durbin Watson mendekati angka dua, maka dapat dinyatakan tidak ada korelasi.
2) Tidak boleh ada multikolinieritas
Cara yang paling mudah untuk menguji ada atau tidaknya gejala multikolinieritas adalah melihat korelasi (hubungan) antar variabel bebas. Jika nilai korelasi dibawah angka 1, maka tidak terjadi multikolinieritas.
3) Tidak boleh ada heterokeditas.
Dengan melihat grafik plot antara nilai variabel terikat (SRESID) dengan residual (ZPRED). Jika ada pola tertentu, seperti titik-titik yang ada membentuk pola tertentu yang teratur (bergelombang, melebar, kemudian menyempit), maka mengidentifikasikan telah terjadi heterokeditas. Jika tidak ada pola yang jelas, serta titik-titik menyebar di atas dan di bawah angka 0 pada sumbu Y, maka tidak terjadi heterokeditas.
Koefisien Korelasi (r/R)
Adalah koefisien yang digunakan untuk mengetahui hubungan antara variabel X dan Y, syaratnya adalah : r = (n (ΣXY) – (ΣX) (ΣY)) / [n(ΣX2) – ((ΣX)2)½ [n(ΣY2) – (ΣY)2 ] ½
Jika r = 0 atau mendekati 0, maka hubunganya sangat lemah atau bahkan tidak ada hubungan sama sekali.
Jika r = +1 atau mendekati +1, maka hubunganya kuat dan searah. Jika r = -1 atau mendekati -1, maka hubunganya kuat dan tidak searah. Koefisien Determinasi (r2/R2)
Adalah koefisien yang digunakan untuk mengetahui seberapa besar variabel bebas (X) mempengaruhi variabel terikat (Y). Nilai koefisien determinasi berkisar antara 0 sampai dengan 1. Kesalahan Standar Estimasi
Digunakan untuk mengetahui ketepatan persamaan estimasi. Dapat digunakan dengan mengukur besar kecilnya kesalahan standar estimasi (semakin kecil nilai kesalahannya, maka semakin tinggi ketepatannya).
III. CONTOH KASUS
Seorang dosen statistika sedang melakukan penelitian terhadap beberapa mahasiswa. Ia ingin mengetahui bagaimana hubungan antara frekuensi belajar dalam satu minggu dan lamanya belajar per hari terhadap IPK yang didapat seorang mahasiswa. Berikut data hasil penelitian : Nama IPK Frekuensi Belajar (hari) Lama Belajar (Jam)
Suci 4,00 6 3 Ratna 3,50 5 2 Febrin 3,25 4 2,5 Kamal 3,32 4 2 Yessi 2,80 5 1 Dennis 2,98 5 1,5 Dedy 2,30 3 1 Susi 3,48 4 2 Anthon 2,55 2 2 Adhy 2,75 4 1,5
Analisalah data di atas !!!
1V. LANGKAH-LANGKAH PENGERJAAN
Untuk mencari nilai-nilai regresi data tersebut dengan menggunakan program R, ikutilah langkah-langkah berikut :
1. Tekan icon R Commander pada desktop kemudian akan muncul tampilan seperti gambar di bawah ini.
Gambar 1. Tampilan menu awal R commander
2. Pilih menu Data, New data set. Masukkan nama dari data set adalah regresi kemudian tekan tombol OK
Gambar 2. Tampilan menu New data set
Gambar 3. Tampilan New Data Set Kemudian akan muncul Data Editor
Gambar 4. Tampilan Data Editor
3. Masukkan data dengan var1 untuk ipk, var2 untuk frek.belajar dan var3 untuk lama.belajar. Jika Data Editor tidak aktif maka dapat diaktifkan dengan menekan RGui di Taskbar windows pada bagian bawah layar monitor. Jika sudah selesai dalam pengisian data tekan tombol Close. Untuk mengubah nama dan tipe variabel, dapat dilakukan dengan cara double click pada variable yang ingin di setting. Pemilihan type, dipilih numeric pada semua variabel.
Gambar 5. Tampilan Variabel editor ipk
Gambar 6. Tampilan Variabel editor frek.belajar
Gambar 7. Tampilan Variabel editor lama.belajar
Kemudian Isi masing-masing variabel sesuai dengan data soal setelah selesai isi data kemudian tekan tombol X (close)
Selanjutnya, pilih window R-commander akan muncul tampilan :
Gambar 9. Tampilan Sript Window
4. Untuk mengecek kebenaran data yang sudah dimasukkan, tekan tombol View data set maka akan muncul tampilan seperti gambar di bawah ini. Jika ada data yang salah, tekan tombol edit data set, lalu perbaiki data yang salah.
Gambar 10. Tampilan View regresi
5. Jika data sudah benar, pilih menu Statistics, Fit models, Linear regression, maka akan muncul menu seperti gambar di bawah ini
Gambar 11. Tampilan menu olah data
6. Pada Response Variable pilih variabel yang termasuk variabel terikat misalnya IPK dan pada Explanatory Variable pilih yang termasuk variabel bebas misalnya variabel frek..belajar dan lama belajar, untuk memilih 2 variabel sekaligus tekan ctrl lalu pilih frek..belajar dan lama.belajar kemudian tekan tombol OK
Gambar 12. Tampilan Response variable
7. Maka akan muncul hasil pada output window sebagai berikut : Output bagian 1:
Gambar 13. Tampilan Output 1 Analisa output bagian 1 :
Pada bagian ini dikemukakan nilai koefisien a dan b serta harga t hitung dan tingkat signifikan. Persamaan regresi : Y= 1.11819 +0.23592 X1 + 0.53187X2
Harga 1.11819 merupakan nilai konstanta (a) yang menunjukkan bahwa jika tidak ada frekuensi dan lama belajar yang dilakukan maka IPK yang akan dicapai 1.11819 sedang harga 0.23592 merupakan koefisien regresi yang menunjukan bahwa setiap penambahan 1 hari belajar maka akan ada penambahan IPK sebesar 0.23592.serta untuk harga 0.53187 merupakan koefisien regresi yang menunjukan bahwa setiap penambahan 1 jam belajar maka akan ada penambahan IPK sebesar 0.53187.
Uji t : Dilakukan untuk mengetahui masing-masing variabel bebas mempengaruhi atau tidak variabel terikat.
Langkah – langkah :
a. Ho : Frekuensi belajar tidak berpengaruh terhadap IPK Ha : Frekuensi belajar berpengaruh terhadap IPK Syarat : > 0.05 Ho diterima
< 0.05 Ho ditolak
Frekuensi belajar = 0.00517< 0.05, Ho ditolak
Kesimpulan : Frekuensi belajar berpengaruh terhadap IPK b. Ho : Lama belajar tidak berpengaruh terhadap IPK
Ha : Lama belajar tidak berpengaruh terhadap IPK Lama belajar = 0.00161 < 0.05, Ho ditolak
Kesimpulan : Lama belajar mempengaruhi IPK.
Dapat dilihat di atas terdapat tanda dua bintang pada baris Frekuensi belajar dan Lama belajar itu berarti kedua variabel mempengaruhi IPK.
Output bagian 2 :
Gambar 14. Tampilan Output 2 Analisa output bagian 2
Pada bagian ini ditampilkan R2 adalah sebesar 0.8897.
Uji f : Dilakukan untuk mengetahui pengaruh secara bersama-sama.
Ho : Frekuensi belajar dan Lama belajar tidak berpengaruh secara bersama-sama terhadap IPK.
Ha : Frekuensi belajar dan Lama belajar berpengaruh secara bersama-sama terhadap IPK.
Syarat : > 0.05 Ho diterima dan < 0.05 Ho ditolak Didapat p-value = 0.0004458 < 0.05, Ho ditolak
Kesimpulan : Frekuensi belajar& Lama belajar berpengaruh secara bersama-sama terhadap IPK.