CLUSTERING TRAFFIC ACCIDENT PRONE AREA IN
SEMARANG USING CHEBYSHEV DISTANCE K-MEANS
Diajukan untuk memenuhi salah satu syarat Memperoleh gelar Sarjana Teknik Informatika
Disusun Oleh :
Nama
: M. Abdillah Luthfi
NIM
: A11.2012.07225
Program Studi : Teknik Informatika-S1
FAKULTAS ILMU KOMPUTER
UNIVERSITAS DIAN NUSWANTORO
SEMARANG
2016
ii
PERSETUJUAN SKRIPSI
Nama : M. Abdillah Luthfi
NIM : A11.2012.07225
Program Studi : Teknik Informatika-S1 Fakultas : Ilmu Komputer
Judul Tugas Akhir : Klasterisasi Daerah Rawan Kecelakaan Lalu Lintas di Kota Semarang Menggunakan Chebychev Distance K-Means.
Tugas Akhir ini telah diperiksa dan disetujui, Semarang, Oktober 2016 Menyetujui : Pembimbing Purwanto, Ph.D NPP.0686.11.1994.051 Menyetujui :
Dekan Fakultas Ilmu Komputer
Dr. Abdul Syukur NPP.0686.11.1992.017
iii
PENGESAHAN DEWAN PENGUJI
Nama : M. Abdillah Luthfi
NIM : A11.2012.07225
Program Studi : Teknik Informatika-S1 Fakultas : Ilmu Komputer
Judul Tugas Akhir : KLASTERISASI DAERAH RAWAN KECELAKAAN
LALU LINTAS DI KOTA SEMARANG
MENGGUNAKAN CHEBYSHEV DISTANCE K-MEANS
Tugas Akhir ini telah diujikan dan dipertahankan dihadapan Dewan Penguji pada Sidang tugas akhir pada Oktober 2016. Menurut pandangan kami, tugas akhir ini memadai dari segi kualitas maupun kuantitas untuk tujuan penganugrahan gelar Sarjana Komputer (S.Kom).
Semarang, Oktober 2016 Dewan Penguji :
Penguji 3 Ketua Penguji
Setia Astuti, S.Si, M.Kom NPP. 0686.11.1994.058 Penguji 1 Anggota Hanny Haryanto,S.Kom,M.T NPP. 0686.11.2009.371 Penguji 2 Anggota
Edy Mulyanto, S.Si, M.Kom NPP.0686.11.1993.040
iv
PERNYATAAN KEASLIAN SKRIPSI
Sebagai mahasiswa Universitas Dian Nuswantoro, yang bertanda tangan di bawah ini, saya :
Nama : M. Abdillah Luthfi NIM : A11.2012.07225
Menyatakan bahwa karya ilmiah saya yang berjudul :
KLASTERISASI DAERAH RAWAN KECELAKAAN LALU LINTAS DI KOTA SEMARANG MENGGUNAKAN CHEBYSHEV DISTANCE
K-MEANS
merupakan karya asli saya (kecuali cuplikan dan ringkasan yang masing-masing telah saya jelaskan sumbernya dan perangkat pendukung seperti web cam dll). Apabila di kemudian hari, karya saya disinyalir bukan merupakan karya asli saya, dan disertai dengan bukti bukti yang cukup, maka saya bersedia untuk dibatalkan gelar saya beserta hak dan kewajiban yang melekat pada gelar tersebut. Demikian surat pernyataan ini saya buat dengan sebenarnya.
Dibuat di : Semarang Pada tanggal : Oktober 2016
Yang menyatakan
v
PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH
UNTUK KEPENTINGAN AKADEMIS
Sebagai mahasiswa Universitas Dian Nuswantoro, yang bertanda tangan di bawah ini, saya :
Nama : M. Abdillah Luthfi NIM : A11.2012.07225
Demi mengembangkan Ilmu Pengetahuan, menyetujui untuk memberikan kepada Universitas Dian Nuswantoro Hak Bebas Royalti Non-Eksklusif (Non-Exclusive
Royalty-Free Right) atas karya ilmiah saya yang berjudul :
KLASTERISASI DAERAH RAWAN KECELAKAAN LALU LINTAS DI KOTA SEMARANG MENGGUNAKAN CHEBYSHEV DISTANCE
K-MEANS
Beserta perangkat yang diperlukan (bila ada). Dengan Hak Bebas Royalti Non-Eksklusif ini Universitas Dian Nuswantoro berhak untuk menyimpan, mengcopy, ulang (memperbanyak), menggunakan, mengelolanya dalam bentuk pangkalan data (database), mendistribusikannya dan menampilkan/ mempublikasikannya di internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya selama tetap mencantumkan nama saya sebagai penulis/ pencipta.
Saya bersedia untuk menanggung secara pribadi, tanpa melibatkan pihak Universitas Dian Nuswantoro, segala bentuk tuntutan hukum yang timbul atas pelanggaran Hak Cipta dalam karya ilmiah saya ini.
Demikian surat pernyataan ini saya buat dengan sebenarnya.
Dibuat di : Semarang Pada tanggal : Oktober 2016
Yang menyatakan
(M. Abdillah Luthfi)
vi
KATA PENGANTAR
Alhamdulillah, puji syukur kehadirat Allah SWT yang telah melimpahkan rahmat dan hidayah-Nya. Sholawat dan salam kepada Rasulullah Muhammad SAW, sehingga penulis dapat menyelesaikan Tugas Akhir ini dengan judul “Klasterisasi Daerah Rawan Kecelakaan Lalu Lintas di Kota Semarang Menggunakan Chebyshev Distance K-Means” dengan baik tanpa suatu halangan yang berarti. Tugas Akhir ini disusun untuk memenuhi syarat kelulusan akademik.
Penulis menyadari bahwa tanpa bimbingan, bantuan, dan doa dari berbagai pihak, Tugas Akhir ini tidak akan dapat diselesaikan tepat pada waktunya. Oleh karena itu, penulis mengucapkan terimakasih yang sebesar-besarnya kepada semua pihak yang telah membantu dalam proses penyusunan Tugas Akhir ini, yaitu kepada :
1. Allah SWT atas kehendak-Nya penulis dapat melaksanakan dan menyelesaikan Tugas Akhir ini.
2. Dr. Ir. Edi Noersasongko, M.Kom selaku Rektor Universitas Dian Nuswantoro.
3. Dr. Drs. Abdul Syukur, MM selaku Dekan Fakultas Ilmu Komputer Universitas Dian Nuswantoro.
4. Heru Agus Santoso, Ph.D selaku Ketua Program Studi Teknik Informatika Fakultas Ilmu Komputer Universitas Dian Nuswantoro.
5. Purwanto, Ph.D selaku dosen pembimbing dan akademik yang dengan sabar selalu memberikan arahan, bimbingan dan motivasi dalam penyusunan Tugas Akhir ini.
6. Dosen-dosen pengampu di fakultas Ilmu Komputer Teknik Informatika Universitas Dian Nuswantoro Semarang yang telah memberikan ilmu dan pengalamannya masing-masing, sehingga penulis dapat mengimplementasikan ilmu yang telah disampaikan.
vii
7. Kedua Orang Tua yang selalu saya cintai dan banggakan. 8. Semua pihak yang namanya tidak dapat disebutkan satu per
satu.
Akhir kata, penulis ingin menyampaikan bahwa penyusunan Tugas Akhir ini masih sangat jauh dari kesempurnaan. Oleh karena itu, penulis sangat mengharapkan berbagai masukan dari semua pihak, baik berupa saran maupun kritik yang sekiranya bisa memperbaiki kekurangan-kekurangan yang ada dalam Tugas Akhir ini. Semoga Tugas Akhir ini dapat bermanfaat bagi semua pihak. Amin
Semarang, Oktober 2016
viii
ABSTRAK
Kecelakaan lalu lintas merupakan salah satu masalah kesehatan yang menjadi penyebab serius kematian didunia dan menempati peringkat 9 dunia. Indonesia sendiri merupakan penyumbang tingkat kecelakaan lalu lintas tertinggi di dunia dengan menempati peringkat ke 5. Selain itu kecelakaan lalu lintas merupakan salah satu topik pembahasan yang senantiasa menjadi bahan utama pembicaraan di masyarakat. Badan Pusat Statistik mencatat bahwa angka kecelakaan lalu lintas yang terjadi di Indonesia masih sangat tinggi. Tingginya angka kecelakaan lalu lintas terjadi karena masyarakat modern menempatkan transportasi sebagai kebutuhan hidup, akibat aktivitas ekonomi, sosial dan sebagainya. Maka dilakukan penelitian terhadap daerah rawan kecelakaan lalu lintas untuk menghasilkan status daerah rawan kecelakaan yang berasal dari rekaman data kecelakaan lalu lintas Polrestabes Kota Semarang selama dua tahun dengan menggunakan algoritma K-Means klastering, dimana daerah (jalan) akan di kelompokkan menjadi 3 klaster berdasarkan kemiripan karakteristik yang ditinjau dari nilai indikator daerah rawan kecelakaan lalu lintas seperti jumlah kecelakaan, jumlah kendaraan yang terlibat dan jumlah korban untuk menunjukkan tingkat kerawanan kecelakaan lalu lintas.
Dalam penelitian ini dilakukan pengelompokkan data menggunakan Chebychev Distance K-Means dan Euclidean Distance K-Means, dimana dalam kasus ini untuk pengklasteran menggunakan Chebychev Distance K-Means lebih optimal dibandingkan Euclidean Distance K-Means. Hal ini disebabkan karena nilai DBI (Davies Bouldin Index) dari Chebychev Distance K-Means sebesar 0.416 lebih rendah dibandingkan Euclidean Distance K-Means yang memiliki nilai 0.426.
Kata Kunci : kecelakaan lalu lintas, k-means, chebyshev distance, clustering, Prone
ix
DAFTAR ISI
HALAMAN JUDUL ... i
PERSETUJUAN SKRIPSI ... ii
PENGESAHAN DEWAN PENGUJI ... iii
PERNYATAAN KEASLIAN SKRIPSI ... iv
PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS ... v
KATA PENGANTAR ... vi
ABSTRAK ... viii
DAFTAR ISI ... ix
DAFTAR TABEL ... xi
DAFTAR GAMBAR ... xii
BAB I PENDAHULUAN ... 1 1.1 Latar Belakang ... 1 1.2 Rumusan Masalah ... 4 1.3 Batasan Masalah ... 4 1.4 Tujuan Penelitian ... 5 1.5 Manfaat Penelitian ... 5 BAB II ... 6
TINJAUAN PUSTAKA DAN LANDASAN TEORI ... 6
2.1 Penelitian Terkait ... 6
2.2 Landasan Teori ... 12
2.2.1 Kecelakaan Lalu Lintas ... 12
2.2.2 Penentuan Lokasi Rawan Kecelakaan Lalu Lintas ... 12
2.2.3 Pengertian Jalan ... 13
2.2.4 Data Mining ... 14
2.2.5 CRISP-DM ... 16
2.2.6 Clustering ... 19
2.2.7 Algoritma K-Means ... 19
2.2.8 Davies Bouldin Index ... 21
x BAB III ... 23 METODE PENELITIAN ... 23 3.1 Data Penelitian ... 23 3.2 Tahapan Penelitian ... 25 BAB IV ... 29 4.1 Pengolahan Data ... 29 4.1.1 Persiapan Data ... 29 4.1.2 Preprocessing ... 29 4.2 Proses Klastering ... 30
4.2.1 Chebychev Distance K-Means ... 31
4.2.2 Euclidean K-Means ... 39
4.3 Proses Menggunakan Rapidminer ... 44
4.4 Pengujian Klastering ... 54 4.5 Hasil Pengujian ... 58 BAB V ... 59 5.1 Kesimpulan ... 59 5.2 Saran ... 59 DAFTAR PUSTAKA ... 60
xi
DAFTAR TABEL
Tabel 2. 1 Penelitian Terkait ... 8
Tabel 2. 2 Klasifikasi Kelas Jalan ... 13
Tabel 3. 1 Keterangan Rekaman Data Kecelakaan Lalu Lintas ... 24
Tabel 3. 2 Hasil simplikasi dan generalisasi data kecelakaan lalu lintas ... 24
Tabel 4. 1 Pemilihan Atribut ... 29
Tabel 4. 2 Data Awal ... 30
Tabel 4. 3 Iterasi 1 ... 32
Tabel 4. 4 Centroid baru untuk iterasi 2 ... 33
Tabel 4. 5 Iterasi ke-2... 33
Tabel 4. 6 Centroid baru untuk iterasi 3 ... 35
Tabel 4. 7 Iterasi ke-3... 35
Tabel 4. 8 Centroid baru untuk iterasi 4 ... 37
Tabel 4. 9 Informasi Centroid akhir ... 37
Tabel 4. 10 Iterasi ke-10... 37
Tabel 4. 11 Iterasi 1 ... 40
Tabel 4. 12 Centroid baru untuk iterasi 2 ... 42
Tabel 4. 13 Iterasi 2 ... 42
Tabel 4. 14 Informasi centroid akhir Euclidean Distance ... 43
Tabel 4. 15 Iterasi ke-11... 43
Tabel 4. 16 Data yang diimport ke Rapidminer ... 44
Tabel 4. 17 Centroid Table Chebychev K-Means ... 45
Tabel 4. 18 Hasil Klastering Chebychev K-Means ... 45
Tabel 4. 19 Tabel Centroid Euclidean K-Means ... 49
Tabel 4. 20 Hasil Klastering Euclidean K-Means ... 49
Tabel 4. 21 Daftar Daerah Rawan Kecelakaan Lalu Lintas ... 53
Tabel 4. 22 Contoh hasil klaster untuk pengujian DBI pada Chebychev K-Means ... 55
Tabel 4. 23 Contoh hasil klaster untuk pengujian DBI pada Euclidean K-Means 56 Tabel 4. 24 Perbandingan Nilai DBI Sample ... 57
xii
DAFTAR GAMBAR
Gambar 2. 1 Tahap-Tahap Data mining [17] ... 15
Gambar 2. 2 Gambar siklus hidup CRISP-DM [12] ... 17
Gambar 2. 3 Flowchart Algoritma K-Means ... 20
Gambar 2. 4 Kerangka Pemikiran ... 22
1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Kecelakaan lalu lintas merupakan salah satu masalah kesehatan yang menjadi penyebab serius kematian didunia dan menempati peringkat 9 dunia. Indonesia sendiri merupakan penyumbang tingkat kecelakaan lalu lintas tertinggi di dunia dengan menempati peringkat ke 5 [1].
Selain itu kecelakaan lalu lintas merupakan salah satu topik pembahasan yang senantiasa menjadi bahan utama pembicaraan di masyarakat. Badan Pusat Statistik mencatat bahwa angka kecelakaan lalu lintas yang terjadi di Indonesia masih sangat tinggi [2]. Tingginya angka kecelakaan lalu lintas terjadi karena masyarakat modern menempatkan transportasi sebagai kebutuhan hidup, akibat aktivitas ekonomi, sosial dan sebagainya. Oleh karena itu, kecelakaan dalam dunia transportasi memiliki dampak signifikan dalam berbagai bidang kehidupan masyarakat.
Kecelakaan lalu lintas yang terjadi, terdiri dari berbagai jenis kecelakaan lalu lintas dan melibatkan pelaku atau korban dari berbagai usia dan profesi. Kecelakaan yang selama ini terjadi secara kontinu membuat semua pihak perlu melakukan langkah-langkah pencegahan untuk mengurangi terjadinya kecelakaan [3]. Hal ini jelas perlu mendapatkan perhatian dan penanganan efektif dari pemerintah khususnya Direktur Lalu Lintas (Ditlantas), diantaranya manajemen dan rekayasa lalu lintas (ketepatan dalam menentukan peserta edukasi atau sosialisasi tentang keselamatan di jalan raya atau rekomendasi pemasangan alat perlengkapan jalan yang menjadi prioritas) [4]. Namun masalah tersebut tidak dapat terselesaikan dengan mudah karena kecelakaan lalu lintas membutuhkan perhatian dan penanganan serius mengingat besarnya kerugian yang ditimbulkan.
2
Berdasarkan studi yang dilakukan terhadap 75.000 kasus kecelakaan, diperoleh rasio sebesar 88:10:2 dengan rincian 88% dari seluruh kecelakaan yang diakibatkan oleh tindakan tidak aman, 10% kondisi tidak aman, dan 2% akibat kondisi yang tidak dapat dicegah. Sesungguhnya kecelakaan merupakan akibat dari beberapa faktor yang saling tergantung satu sama lain [5].
Undang-undang Nomor 22 Tahun 2009 tentang Lalu Lintas dan Angkutan Jalan, mengungkapkan kecelakaan lalu lintas adalah suatu peristiwa di jalan yang tidak diduga dan tidak disengaja melibatkan kendaraan dengan atau tanpa pengguna jalan lain yang mengakibatkan korban manusia dan/atau kerugian harta benda [6]. Timbulnya kecelakaan lalu lintas dijalan raya yang meningkat semakin tinggi, sebagian besar diakibatkan atau diawali dengan perilaku pengendara yang melanggar aturan perundang-undangan lalu lintas yang ada seperti mengemudikan kendaraan dengan kecepatan tinggi atau tidak dengan hati-hati, mengendarai kendaraan bermotor tidak memiliki surat izin mengemudi, melanggar lalu lintas dan marka jalan serta berbagai bentuk pelanggaran lainnya [7].
Meningkatnya jumlah pengguna kendaraan bermotor setiap tahunnya, dapat meningkatkan terjadinya kecelakaan lalu lintas karena beberapa faktor antara lain faktor pemakai jalan (pengemudi, pejalan kaki), faktor kendaraan dan faktor lingkungan. Kecelakaan juga diakibatkan oleh kombinasi antara beberapa faktor perilaku buruk dari pengemudi ataupun pejalan kaki,jalan, kendaraan, pengemudi ataupun pejalan kaki, cuaca buruk ataupun pandangan yang buruk dan masih banyak lagi faktor yang menyebabkan kecelakaan lalu lintas [8].
Penggalian data ditujukan untuk mengelompokkan ruas jalan di Kota Semarang berdasarkan faktor kesamaan karakteristik yang ada di dataset yaitu jumlah kecelakaan, jumlah kendaraan yang terlibat, serta jumlah korban akibat kecelakaan yang terjadi dalam suatu rentan waktu tertentu. Dengan menggunakan data mining, dapat diperoleh tingkat kerawanan suatu wilayah terhadap kecelakaan lalu lintas melalui clustering data kecelakaan di Kota Semarang. Data mining merupakan metode pengolahan data berskala besar,
oleh karena itu data mining memiliki peranan penting dalam berbagai bidang. Secara umum kajian data mining membahas metode-metode seperti clustering, klasifikasi, regresi, seleksi variable, dan market basket analisis [9]. Clustering merupakan suatu metode untuk mencari dan mengelompokkan data yang memiliki kemiripan karakteristik antara satu data dengan data yang lain [11].
Salah satu ciri clustering yang baik atau optimal adalah menghasilkan cluster yang berisi data dengan tingkat kemiripan (similarity) yang tinggi pada cluster yang sama dan tingkat kemiripan yang rendah pada cluster yang berbeda. Untuk mengukur kemiripan data dalam suatu cluster menggunakan distance measure. Jika menggunakan distance measure yang berbeda maka hasil dari proses clustering akan menghasilkan hasil yang berbeda juga [10]. Dalam perkembangan clustering terdapat berbagai algoritma yang salah satunya adalah K-Means.
K-Means clustering merupakan salah satu metode data clustering non-hirarki yang mengelompokkan data dalam bentuk satu atau lebih cluster/kelompok. Data yang memiliki karakteristik yang sama dikelompokkan dalam satu cluster/kelompok dan data yang memiliki karakteristik yang berbeda dikelompokkan dengan cluster/kelompok yang lain sehingga data yang berada dalam satu cluster/kelompok memiliki tingkat variasi yang kecil [9].
Silvi Agustina, Dhimas Yhudo, Hadi Santoso, Nofiandi Marnasusanto, Arif Tirtana, Fakhris Khusnu [15] dalam penelitiannya menggunakan algoritma k-means pada clustering kualitas beras berdasarkan ciri fisik menghasilkan akurasi sebesar 92,8%. Selanjutnya Erga Aprina Sari [14] meneliti tentang Penerapan Algoritma K-Means Untuk Menentukan Tingkat Kesehatan Bayi dan Balita Pada Kabupaten dan Kota di Jawa Tengah. Penelitian ini menggunakan teknik data mining dengan algoritma K-Means untuk mengelompokkan atau mengklaster kabupaten-kabupaten yang ada di Provinsi Jawa Tengah berdasarkan kemiripan karakteristik daerah yang ditinjau dari nilai indikator kesehatan yaitu angka kematian bayi dan balita, angka kesakitan bayi dan balita, dan status gizi bayi dan balita.
4
Mario Anggara, Henry Sujiani, Helfi Nasution [10] melaporkan bahwa penelitiannya mendapatkan hasil pengujian terhadap pengelompokan member di alvaro fitness menggunakan k-means clustering dengan menggunakan 3 macam distance measure. Didapatkan bahwa dalam pengujian silhouette coefficient clustering, Chebyshev Distance memiliki nilai silhouette coefficient-nya sebesar 0.242821. Sedangkan Euclidean Distance dan
Manhattan Distance memiliki nilai silhouette coefficient sebesar 0.232149 dan
0.240016. Hal itu menunjukan bahwa distance measure paling optimal untuk kasus pengelompokkan member di Alvaro fitness adalah Chebyshev Distance.
Berdasarkan hasil dari latar belakang di atas, penelitian yang akan diambil adalah pemilihan Distance Measure dengan menggunakan Chebyshev
Distance pada K-Means Clustering untuk membantu Ditlantas Polrestabes
Kota Semarang dalam mengindentifikasi dan mengelompokkan daerah rawan kecelakaan lalu lintas di Kota Semarang berdasarkan dataset yang sudah ada agar monitoring terhadap keselamatan pengendara di jalan raya dapat diantisiasi sejak dini.
1.2 Rumusan Masalah
Berdasarkan latar belakang diatas, maka dapat dirumuskan permasalahan yaitu bagaimana mengklaster daerah (jalan) rawan kecelakaan lalu lintas yang ada di Kota Semarang berdasarkan kemiripan karakteristik daerah yang ditinjau dari nilai indikator daerah rawan kecelakaan lalu lintas dengan menggunakan Chebyshev Distance pada K-Means sehingga dapat diketahui status daerah rawan kecelakaan lalu lintas untuk setiap daerah.
1.3 Batasan Masalah
Batasan permasalahan dalam penelitian ini adalah :
1. Data yang digunakan dalam penelitian ini adalah data sekunder yang berasal dari Polrestabes Kota Semarang.
3. Dataset yang digunakan adalah data kecelakaan kendaraan bermotor di Kota Semarang dari tahun 2014-2015.
4. Data yang digunakan adalah kejadian kecelakaan lalu lintas, seperti kecelakaan lalu lintas antar kendaraan bermotor, kendaraan bermotor dengan pejalan kaki.
5. Masalah kecelakaan yang dibahas adalah masalah kecelakaan yang terjadi di wilayah ruas jalan kota.
6. Hasil dari penelitian ini adalah penentuan status rawan daerah Kota Semarang terhadap kecelakaan lalu lintas.
7. Tidak membahas penanggulangan kecelakaan.
1.4 Tujuan Penelitian
Berdasarkan rumusan masalah diatas maka tujuan dari penelitian ini adalah untuk menghasilkan status daerah rawan kecelakaan lalu lintas dengan menggunakan Chebyshev Distance pada algoritma K-Means yang dapat mengklaster daerah (jalan) rawan kecelakaan lalu lintas di Kota Semarang berdasarkan kemiripan karakteristik daerah yang ditinjau dari nilai indikator daerah rawan kecelakaan lalu lintas.
1.5 Manfaat Penelitian
Dengan adanya penelitian ini diharapkan dapat :
1. Dengan menggunakan algoritma K-Means dapat mengelompokkan daerah rawan kecelakaan lalu lintas di Kota Semarang.
2. Dapat digunakan sebagai refrensi dalam melakukan penelitian yang sama dengan menggunakan algoritma K-Means.
3. Dapat meningkatkan kesadaran akan pentingnya keselamatan dalam berkendara.
4. Dapat membantu kepolisian dalam mengkelompokkan daerah di Kota Semarang yang rawan terhadap kecelakaan.
6
BAB II
TINJAUAN PUSTAKA DAN LANDASAN TEORI
2.1 Penelitian Terkait
Tinjauan studi yang menjadi sumber referensi dari penelitian yang penulis buat ini berasal dari beberapa penelitian sejenis sebelumnya. Dari beberapa penelitian tersebut didapatkan berbagai hasil pandangan tentang penerapan klusterisasi data dari masing-masing jurnal. Berikut merupakan beberapa penelitian yang terkait dan relevan dengan penelitian ini.
Penelitian pertama dilakukan oleh Lizda Iswari dan Ervina Gita Ayu yang membuat penelitian tentang Pemanfaatan Algoritma K-Means Untuk Pemetaan Hasil Klasterisasi Data Kecelakaan Lalu Lintas. Dimana dalam penelitian ini, peneliti menggunakan metode clustering untuk mengelompokkan daerah rawan kecelakaan lalu lintas berdasarkan ruas-ruas jalan yang memiliki kesamaan karakteristik dan visualisasi hasil clustering dalam bentuk peta dua dimensi. Dalam penelitian ini masih terbatas pada penggunaan data temporal dalam periode bulanan. Sedangkan dalam penentuan parameter klasterisasi yang digunakan dalam penelitian ini masih bersumber pada deskripsi kejadian dan belum melibatkan data geometri (kondisi fisik) jalan raya [2].
Penelitian kedua dilakukan oleh Silvi Agustina, Dhimas Yhudo, Hadi Santoso, Nofiandi Marnasusanto, Arif Tirtana, Fakhris Khusnu tentang Clustering Kualitas Beras Berdasarkan Ciri Fisik Menggunakan Metode K-Means. Dalam penelitian ini penulis menggunakan metode k-means dan manhattan distance sebagai distance measure (perhitungan jarak). Penelitian ini menggunakan 20 data uji, dimana ke-20 data tersebut dibagi menjadi 3
cluster dengan cluster 1 merupakan beras kualitas buruk, cluster 2 beras
kualitas sedang, dan cluster 3 beras kualitas baik. Dari hasil penelitian, didapatkan 3 pusat cluster akhir yaitu pusat cluster 1 (5,89333;2,05), pusat
cluster 2 (6,28199;2,546), dan pusat cluster 3 (6,96583;2,999167) serta
dihasilkan validasi sebesar 92,8% yang menunjukan bahwa program ini dapat dijadikan sebagai acuan dalam klasterisasi kualitas beras [15].
Selanjutnya penelitian dilakukan oleh Erga Aprina Sari [14] meneliti tentang Penerapan Algoritma K-Means Untuk Menentukan Tingkat Kesehatan Bayi dan Balita Pada Kabupaten dan Kota di Jawa Tengah. Penelitian ini menggunakan teknik data mining dengan algoritma K-Means untuk mengelompokkan atau mengklaster kabupaten-kabupaten yang ada di Provinsi Jawa Tengah berdasarkan kemiripan karakteristik daerah yang ditinjau dari nilai indikator kesehatan yaitu angka kematian bayi dan balita, angka kesakitan bayi dan balita, dan status gizi bayi dan balita.
Dari hasil uji coba didapat kabupaten/kota yang memiliki hasil analisa indikator kesehatan tinggi yang tingkat kesehatan pada indikator tersebut buruk karena jumlah penderitanya banyak. Penanganan masalah dapat difokuskan pada kabupaten/kota dengan indikator kesehatan tinggi.
Penelitian keempat dilakukan oleh Firli Irhamni, Fitri Damayanti, Bain Khusnul K, Mifftachul A tentang Optimalisasi Pengelompokan Kecamatan Berdasarkan Indikator Pendidikan Menggunakan Metode Clustering dan Davies Bouldin Index. Penelitian ini tentang pengelompokan kecamatan untuk pemerataan pendidikan menggunakan indicator pendidikan yang terdapat pasa suatu kecamatan sebagai salah satu organisasi pemerintah. Parameter penyebab keberhasilan pendidikan dapat dilihat dariindikator pendidikan di suatu daerah, salah satu tolak ukurnya adalah rendahnya nilai Angka Partisipasi Murni (APM) dan nilai Angka Partisipasi Kasar (APK). Indikator lain yang mempengaruhi pemerataan pendidikan adalah sarana dan prasarana pendidikan yang meliputi jumlah sekolah, ruang kelas, dan tenaga pengajar. Pengelompokan kecamatan berdasarkan tingkat pendidikan SMA/SMK/MA tersebut menggunakan metode clustering yaitu Self Organizing Map (SOM) dan hasil clustering tersebut kemudian diolah dengan metode Davies Bouldin Index(DBI) untuk menunjukkan seberapa baik cluster yang diperoleh.
8
Penelitian ini memberikan kontribusi terhadap pengambilan kebijakan dari pihak berwenang[16].
Penelitian kelima dilakukan oleh Mario Anggara, Henry Sujiani, Helfi Nasution [10] melaporkan bahwa penelitiannya mendapatkan hasil pengujian terhadap pengelompokan member di alvaro fitness menggunakan k-means
clustering dengan menggunakan 3 macam distance measure. Didapatkan
bahwa dalam pengujian silhouette coefficient clustering, Chebyshev Distance memiliki nilai silhouette coefficient-nya sebesar 0.242821. Sedangkan
Euclidean Distance dan Manhattan Distance memiliki nilai silhouette
coefficient sebesar 0.232149 dan 0.240016. Hal itu menunjukan bahwa distance measure paling optimal untuk kasus pengelompokkan member di Alvaro fitness adalah Chebyshev Distance.
Tabel 2. 1 Penelitian Terkait
No Peneliti Pembahasan Metode Hasil
1 Lizda Iswari dan Ervina Gita Ayu
Pemanfaatan Algoritma K-Means Untuk Pemetaan Hasil Klasterisasi Data Kecelakaan Lalu Lintas
K-Means Dalam penelitian ini masih terbatas pada penggunaan data temporal dalam periode bulanan. Sedangkan dalam penentuan parameter klasterisasi yang digunakan dalam penelitian ini masih bersumber pada deskripsi kejadian dan belum melibatkan data geometri (kondisi fisik) jalan raya.
2 Silvi Agustina, Dhimas
Clustering Kualitas Beras Berdasarkan Ciri Fisik
K-Means Penelitian ini menggunakan 20 data uji, dimana ke-20 data tersebut dibagi menjadi
Yhudo, Hadi Santoso, Nofiandi Marnasusanto, Arif Tirtana, Fakhris Khusnu Menggunakan Metode K-Means
3 cluster dengan cluster 1 merupakan beras kualitas buruk, cluster 2 beras kualitas sedang, dan cluster
3 beras kualitas baik. Dari
hasil penelitian, didapatkan 3 pusat cluster akhir yaitu pusat cluster 1 (5,89333;2,05), pusat cluster 2 (6,28199;2,546), dan pusat
cluster 3
(6,96583;2,999167) serta dihasilkan validasi sebesar 92,8% yang menunjukan bahwa program ini dapat dijadikan sebagai acuan dalam klasterisasi kualitas beras.
3 Erga Aprina Sari
Penerapan Algoritma K-Means Untuk Menentukan Tingkat Kesehatan Bayi dan Balita Pada Kabupaten dan Kota di Jawa Tengah
K-Means Dari hasil uji coba didapat kabupaten/kota yang memiliki hasil analisa indikator kesehatan tinggi yang tingkat kesehatan pada indikator tersebut buruk karena jumlah penderitanya banyak. Penanganan masalah dapat difokuskan pada kabupaten/kota dengan indikator kesehatan tinggi.
10 4. Firli Irhamni, Fitri Damayanti, Bain Khusnul K, Mifftachul A Optimalisasi Pengelompokan Kecamatan Berdasarkan Indikator Pendidikan Menggunakan Metode Clustering dan Davies Bouldin Index
SOM dan Davies Bouldin
Penelitian ini tentang pengelompokan kecamatan untuk pemerataan pendidikan menggunakan indicator pendidikan yang terdapat pasa suatu kecamatan sebagai salah satu organisasi pemerintah. Parameter penyebab keberhasilan pendidikan dapat dilihat dariindikator pendidikan di suatu daerah, salah satu tolak ukurnya adalah rendahnya nilai Angka Partisipasi Murni (APM) dan nilai Angka Partisipasi Kasar (APK). Indikator lain yang mempengaruhi pemerataan pendidikan adalah sarana dan prasarana pendidikan yang meliputi jumlah sekolah, ruang kelas, dan tenaga pengajar. Pengelompokan kecamatan berdasarkan tingkat pendidikan SMA/SMK/MA tersebut menggunakan metode clustering yaitu Self Organizing Map (SOM) dan hasil clustering tersebut
kemudian diolah dengan metode Davies Bouldin Index(DBI) untuk menunjukkan seberapa baik cluster yang diperoleh. Penelitian ini memberikan kontribusi terhadap pengambilan kebijakan dari pihak berwenang 5 Mario Anggara, Henry Sujiani, Helfi Nasution Pemilihan Distance Measure Pada K-Means
Clustering Untuk Pengelompokkan Member Di Alvaro Fitness
K-Means penelitiannya mendapatkan hasil pengujian terhadap pengelompokan member di alvaro fitness menggunakan
k-means clustering dengan
menggunakan 3 macam
distance measure.
Didapatkan bahwa dalam pengujian silhouette coefficient clustering,
Chebyshev Distance
memiliki nilai silhouette coefficient-nya sebesar 0.242821. Sedangkan
Euclidean Distance dan
Manhattan Distance
memiliki nilai silhouette coefficient sebesar 0.232149 dan 0.240016. Hal itu menunjukan bahwa distance
measure paling optimal
12
pengelompokkan member di Alvaro fitness adalah
Chebyshev Distance.
2.2 Landasan Teori
2.2.1 Kecelakaan Lalu Lintas
Kecelakaan lalu lintas adalah suatu peristiwa dijalan yang tidak disangka-sangka dan tidak disengaja melibatkan kendaraan dengan atau tanpa pemakai jalan lainnya mengakibatkan korban manusia atau kerugian harta benda [6].
2.2.2 Penentuan Lokasi Rawan Kecelakaan Lalu Lintas
Suatu tempat dikatakan “daerah” atau “lokasi” apabila diketahui letak dan batas-batasnya. Antara Direktorat Keselamatan Transportasi Darat dengan Departemen Pemukiman dan Prasana Wilayah terdapat perbedaan dalam penyebutan tempat yang tergolong rawan kecelakaan lalu lintas. Direktorat Keselamatan Transportasi Darat menyebutnya dengan “daerah rawan kecelakaan”, sedangkan Departemen Pemukiman dan Prasana Wilayah menyebutnya dengan “lokasi rawan kecelakaan”.
Daerah yang memiliki angka kecelakaan tinggi, resiko kecelakaan tinggi serta potensi kecelakaan tinggi pada suatu ruas jalan dapat disebut juga dengan daerah rawan kecelakaan [18].
Suatu lokasi dapat dinyatakan sebagai lokasi rawan kecelakaan apabila [19] :
1. Memiliki angka kecelakaan yang tinggi. 2. Lokasi kejadian kecelakaan relatif bertumpuk.
3. Lokasi kecelakaan berupa persimpangan, atau segmen ruas jalan sepanjang 100 – 300 m untuk jalan perkotaan, atau segmen ruas jalan sepanjang 1 km utnuk jalan antar kota.
4. Kecelakaan terjadi dalam ruang dan rentan waktu yang relatif sama.
5. Memiliki penyebab kecelakaan dengan factor yang spesifik.
2.2.3 Pengertian Jalan
Jalan adalah seluruh bagian jalan, termasuk bangunan pelengkap dan perlengkapannya yang diperuntukan bagi lalu lintas umum, yang berada pada permukaan tanah, diatas permukaan tanah, dibawah permukaan tanah dan/atau air, serta diatas permukaan air, kecuali jalan rel dan jalan kabel [6].
Jalan dibagi kedalam kelas – kelas bukan hanya didasarkan pada fungsinya tetapi juga dipertimbangkan pada besarnya volume serta sifat lalu lintas. Adapun klasifikasi jalan dijelaskan dalam table dibawah ini :
Tabel 2. 2 Klasifikasi Kelas Jalan Tipe Klasifikasi Keterangan
Tipe I Klas I Jalan dengan standar tinggi untuk melayani antar wilayah atau antar kota untuk kecepatan tinggi dengan pembatasan jalan masuk.
Klas II Jalan dengan standar tinggi untuk melayani antar wilayah atau didalam metropolitan untuk kecepatan tinggi dengan pembatasan jalan masuk.
Tipe II Klas I Jalan dengan standar tinggi, 2 jalur atau lebih untuk antar kota atau dalam kota, kecepatan tinggi, volume lalu lintas tinggi dengan masih ada beberapa pembatas jalan masuk.
Klas II Jalan dengan standar tinggi, 2 lajur atau lebih untuk melayani antar /dalam kota, kecepatan tinggi, volume lalu lintas sedang dengan/ tanpa pembatas jalan masuk.
Klas III Jalan dengan standar menengah, 2 lajur atau lebih melayani antas distrik, kecepatan sedang, volume lalu lintas tinggi, tanpa pembatas jalan masuk.
14
Klas IV Jalan dengan standar rendah, I lajur dua arah sebagai jalan penghubung.
2.2.4 Data Mining
Data mining merupakan analisis dari peninjauan kumpulan data untuk menemukan hubungan yang tidak diduga dan meringkas data dengan cara yang berbeda dengan sebelumnya, yang dapat dipahamidan bermanfaat bagi pemilik data.
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat dilakukan, yaitu [12] :
a. Description (Deskripsi)
Peneliti dan analis secara sederhana ingin mencoba mencari cara untuk menggambarkan pola dan kecenderungan yang terdapat dalam data.
b. Estimation (Estimasi)
Estimasi hampir sama dengan klasifikasi, dimana variabel tujuan yang lebih kearah numerik daripada ke arah kategori.
c. Prediction (Prediksi)
Prediksi hampir sama dengan klasfikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil akan ada di masa mendatang (sesuatu yang belum terjadi).
d. Association (Asosiasi)
Asosiasi dalam data mining adalah menemukan atribut yang muncul dalam satu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang belanja.
e. Clustering
Clustering merupakan pengelompokan record, pengamatan, atau
memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan.
f. Classification (Klasifikasi)
Penyusunan data menjadi beberapa kelompok yang ditentukan.
2.2.4.1 Tahap-Tahap Data mining
Rangkaian proses data mining dibagi menjadi beberapa tahap yang bersifat interaktif seperti pada gambar 2.1.
Gambar 2. 1 Tahap-Tahap Data mining [17]
a. Data Selection
Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang akan digunakan untuk proses data mining, disimpan dalam suatu berkas, terpisah dari basis data operasional.
b. Cleaning
Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data, seperti kesalahan ketik (tipografi).
Data WareHouse Knowledge
Cleaning and Integration
Selection and Transformation
Data Mining Evaluation and Presentation
16
c. Transformation
Pengubahan data ke dalam format yang sesuai untuk dapat diproses dalam data mining. Misal, beberapa metode standar seperti analisis asosiasi dan clustering hanya bisa menerima input data kategorikal, maka data berupa angka numerik yang berlanjut perlu dibagi menjadi beberapa interval.
d. Data mining
Proses pencarian pola atau informasi yang menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu.
e. Pattern Evaluation
Tahap ini mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesis yang ada sebelumnya.
2.2.5 CRISP-DM
Cross-Industry Standard Process for Data Mining (CRISP-DM)
yang dikembangkan tahun 1996 oleh analis dari beberapa industri seperti DaimlerChrysler, SPSS dan NCR. CRISP-DM menyediakan standarproses data mining sebagai strategi pemecahan masalah secara umumdari bisnis atau unit penelitian.
Gambar 2. 2 Gambar siklus hidup CRISP-DM [12]
Berdasarkan CRISP-DM, proses data mining terdiri dari 6 fase [12] yaitu :
1. Fase Pemahaman Bisnis (Business Understanding)
a. Penentuan tujuan proyek dan kebutuhan secara detail dalam lingkup bisnis atau unit penelitian secara keseluruhan.
b. Menerjemahkan tujuan dan batasan menjadi formula dari permasalahan data mining.
c. Menyiapkan strategi awal untuk mencapai tujuan. 2. Fase Pemahaman Data (Data Understanding Phase)
a. Mengumpulkan data.
b. Menggunakan analisis penyelidikan data untuk mengenali lebih lanjut data dan pencarian pengetahuan awal.
18
d. Jika diinginkan, pilih sebagian kecil grup data yang mungkin mengandung pola dari permasalahan.
3. Fase Pengolahan Data (Data Preparation Phase)
a. Siapkan data dari awal, kumpulan data yang akan digunakan untuk keseluruhan fase berikutnya. Fase ini merupakan pekerjaan berat yang perlu dilaksanakan secara intensif.
b. Pilih kasus dan variable yang ingin dianalisis dan yang sesuai analisis yang akan dilakukan.
c. Lakukan perubahan pada beberapa variabel jika dibutuhkan. d. Siapkan data awal sehingga siap untuk perangkat pemodelan. 4. Fase Pemodelan (Modelling Phase)
a. Pilih dan aplikasikan teknik pemodelan yang sesuai. b. Kalibrasi aturan model untuk mengoptimalkan hasil.
c. Perlu diperhatikan bahwa beberapa teknik mungkin untuk digunakan pada permasalahan data mining yang sama.
d. Jika diperlukan, proses dapat kembali ke fase pengolahan data untuk menjadikan data ke dalam bentuk yang sesuai dengan spesifikasi kebutuhan teknik data mining tertentu.
5. Fase Evaluasi (Evaluation Phase)
a. Mengevaluasi satu atau lebih model yang digunakan dalam fase pemodelan untuk mendapatkan kualitasdan efektivitas sebelum disebarkan untuk digunakan.
b. Menetapkan apakah terdapat model yang memenuhi tujuan pada fase awal.
c. Menentukan apakah terdapat permasalahan penting dari bisnis atau penelitian yang tidak tertangani dengan baik.
d. Mengambil keputusan berkaitan dengan penggunaan hasil dari
data mining.
6. Fase Penyebaran (Deployment Phase)
a. Menggunakan model yang dihasilkan. Terbentuknya model tidak menandakan telah terselesaikan proyek.
b. Contoh sederhana penyebaran: Pembuatan laporan.
c. Contoh kompleks penyebaran: Penerapan proses data mining secara pararel pada departemen lain.
2.2.6 Clustering
Clustering merupakan salah satu teknik data mining yang
digunakan untuk mendapatkan kelompok-kelompok dari obyek-obyek yang mempunyai karakteristik yang umum di data yang cukup besar. Pengelompokan sejumlah data/obyek ke dalam cluster merupakan tujuan utama dari metode clustering sehingga dalam setiap cluster akan diisi data yang memiliki tingkat kemiripan yang tinggi [13].
Sebuah cluster adalah kumpulan data yang memiliki kemiripan karakteristik satu sama lain dan tidak memiliki kemiripan dengan cluster lain. Clustering bersifat unsupervised learning karena pengelompokan data yang didasarkan pada kesamaan antar objek.
2.2.7 Algoritma K-Means
Beberapa teknik clustering yang paling sederhana diantara teknik lainnya adalah Klastering K-Means. K-means merupakan salah satu metode pengelompokan data (clustering) nonhierarki yang termasuk dalam pendekatan partisi dimana data yang ada dipartisi ke dalam bentuk dua atau lebih kelompok. Metode ini mengelompokan data yang berkarakteristik sama menjadi satu kelompok dan data yang berkaraktersitik berbeda dikelompokkan kedalam kelompok lain.
Algoritma K-means secara umum memiliki tahapan sebagai berikut:
1. Tentukan jumlah kelompok
2. Inisialisasi titik centroid k (pusat cluster) secara acak.
3. Hitung jarak setiap titik pusat cluster, jarak antar satu data dengan satu
cluster akan menentukan data tersebut masuk dalam cluster mana.
20 Chebyshev Distance 𝑑𝑖𝑗 = 𝑘|𝑥𝑖𝑗− 𝑥𝑗𝑘| 𝑚𝑎𝑥 (2.1) Dimana : K = Dimensi data
4. Hitung pusat cluster yang baru dengan keanggotaan cluster yang sekarang, dengan cara mencari rata-rata (mean) dari semua objek atau data dalam cluster tertentu atau dengan menggunakan median dari
cluster tersebut.
5. Ulangi mulai dari langkah ketiga sampai nilai pusat cluster tidak berubah.
START
Jumlah K Inisiasi
Pusat
Hitung jarak data ke pusat
Kelompokkan data berdasarkan
jarak minimum
Pusat cluster baru
Selisih Pusat cluster lama dan
baru
Pusat cluster lama = pusat cluster baru
End
tidak
ada
2.2.8 Davies Bouldin Index
Davies Bouldin Index merupakan metode evaluasi cluster dari hasil clustering. Semakin kecil nilai DBI yang di peroleh (non-negatif ≥ 0) maka semakin baik cluster yang diperoleh dari pengelompokan K-Means yang digunakan [20].
𝑣𝑎𝑟(𝑥) = 1 𝑁 − 1∑(𝑥𝑖 − 𝑥̅) 2 𝑁 𝑖=1 (2.2) 𝑅𝑖 = max 𝑅𝑖𝑗 𝑗 = 1, . . 𝑘, 𝑖 ≠ 𝑗 (2.3) 𝑅𝑖𝑗 𝑖≠𝑗 =𝑣𝑎𝑟(𝐶𝑖) + 𝑣𝑎𝑟(𝐶𝑗) ||𝑐𝑖− 𝑐𝑗|| (2.4) 𝐷𝐵𝐼 =1 𝑘. ∑ 𝑅𝑖 𝑘 𝑖=1 (2.5) Dimana
𝑥̅ : rata-rata dari cluster x dan N adalah jumlah anggota cluster Var : variance dari data
22
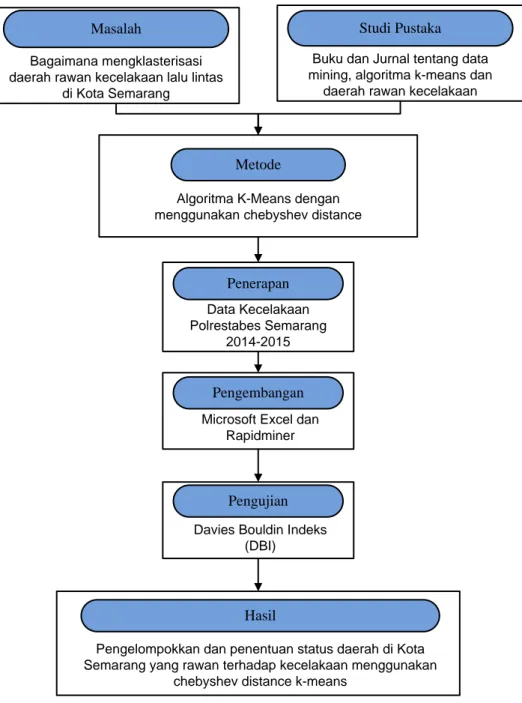
2.3 Kerangka Pemikiran
Gambar 2. 4 Kerangka Pemikiran
Masalah
Bagaimana mengklasterisasi daerah rawan kecelakaan lalu lintas
di Kota Semarang
Studi Pustaka
Buku dan Jurnal tentang data mining, algoritma k-means dan
daerah rawan kecelakaan
Metode
Algoritma K-Means dengan menggunakan chebyshev distance
Penerapan Data Kecelakaan Polrestabes Semarang
2014-2015
Pengembangan Microsoft Excel dan
Rapidminer
Pengujian Davies Bouldin Indeks
(DBI)
Hasil
Pengelompokkan dan penentuan status daerah di Kota Semarang yang rawan terhadap kecelakaan menggunakan
23
BAB III
METODE PENELITIAN
3.1 Data Penelitian
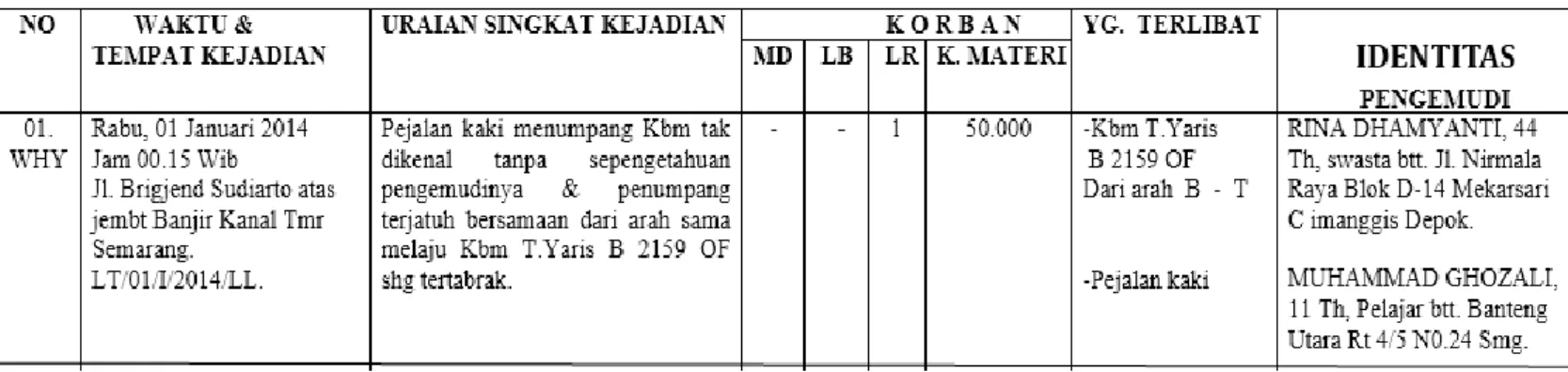
Dalam penelitian tugas akhir ini, objek penelitian dilakukan dengan pengambilan data yang diperoleh dari Satlantas Polrestabes Kota Semarang antara tahun 2014 sampai 2015. Data yang diperoleh merupakan data sekunder melalui dokumentasi Satlantas Polrestabes Kota Semarang. Berikut rekaman data Satlantas Polrestabes Kota Semarang :
Gambar 3. 1 Rekaman Data Kecelakaan Lalu Lintas
Berikut keterangan dari rekaman data di atas akan dijelaskan pada tabel di bawah ini :
24
Tabel 3. 1 Keterangan Rekaman Data Kecelakaan Lalu Lintas
Atribut Keterangan
Waktu & Tempat Kejadian Atribut yang menginformasikan waktu dan tempat kejadian terjadinya kecelakaan Uraian Singkat Kejadian Atribut yang menginformasikan uraian
singkat terjadinya kecelakaan
Korban Atribut yang menginformasikan jumlah korban pada saat terjadinya kecelakaan tersebut baik koban meninggal dunia, luka berat, luka ringan, serta menjelaskan pula kerugiaan materiil yang didapat akibat terjadinya kecelakaan tersebut
Yang terlibat Atribut yang menginformasikan pengguna jalan (kendaraan bermotor, pejalan kaki, dsb.) yang terlibat dalam kecelakaan tersebut Identitas Pengemudi Atribut yang menginformasikan tentang identitas korban yang terlibat dalam kecelakaan tersebut.
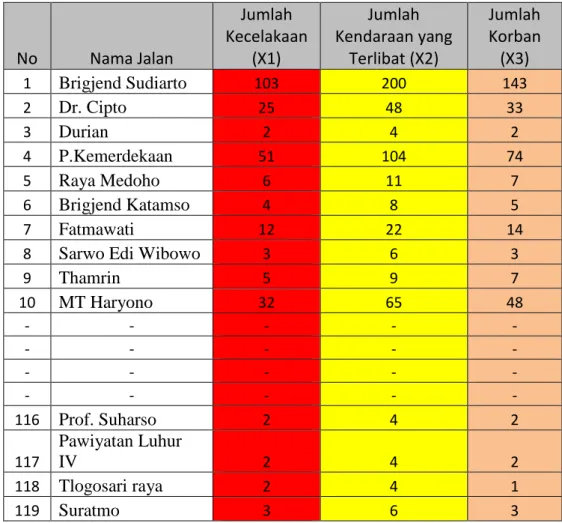
Hasil rekapitulasi data rekaman kecelakaan lalu intas pada 10 segmen jalan dapat di lihat pada table . Setiap jalan memiliki tiga parameter, yaitu jumlah kecelakaan, jumlah kendaraan yang terlibat, dan jumlah korban
Tabel 3. 2 Hasil simplikasi dan generalisasi data kecelakaan lalu lintas DATA LAKA LANTAS POLRESTABES
SEMARANG
BULAN JANUARI S/D DESEMBER 2014
NO Nama Jalan Jumlah Kecelakaan Jumlah Kendaraan yang terlibat Jumlah Korban 1 Brigjend Sudiarto 59 116 80 2 Dr. Cipto 18 34 25 3 Durian 1 2 1 4 P.Kemerdekaan 26 55 41 5 Medoho 2 4 2
6 Brigjend Katamso 3 6 4
7 Fatmawati 5 10 6
8 Sarwo Edi Wibowo 2 4 2
9 Thamrin 2 3 4
10 MT Haryono 16 32 25
3.2 Tahapan Penelitian
Tahapan analisis data pada penelitian ini menggunakan data kecelakaan lalu lintas Kota Semarang tahun 2014 dan 2015, diperoleh dari pengumpulan data sebanyak 1549 record. Namun tidak semua data digunakan dan tidak semua atribut digunakan karena banyak data yang tidak memenuhi syarat dan data tersebut harus melalui beberapa tahap pengolahan awal data. Agar mendapatkan data yang berkualitas yaitu dengan teknik data cleaning.
Tahapan penelitian menggunakan metode Cross Industry Standard
Process- Data Mining (CRISP-DM).
1. Tahap Pemahaman Bisnis (Bussines Understanding Phase)
Penelitian ini mempunyai tujuan bisnis yaitu menentukan daerah atau wilayah di Kota Semarang yang rawan terhadap kecelakaan lalu lintas karena dengan penelitian ini nantinya dapat digunakan oleh pihak kepolisian untuk lebih memperhatikan daerah yang sering terjadi atau rawan terhadap kecelakaan.
2. Tahap Pemahaman Data (Data Understanding Phase)
Pengumpulan data sekunder dilakukan dengan cara mengambil data kecelakaan lalu lintas di Satlantas Polrestabes Semarang tahun 2014 dan 2015. Dari proses pengambilan data, data yang diperoleh pada tahun 2014 sebanyak 801 kasus kecelakaan lalu lintas dan tahun 2015 data yang diambil dari bulan januari hingga bulan november yaitu sebanyak 748 kasus kecelakaan yang terjadi. Sehingga total dari data yang mentah yang didapatkan untuk data training sebanyak 1549 data. Data tersebut meliputi waktu dan tempat kejadian kecelakaan, uraian singkat kejadian, korban yang terlibat dalam kecelakaan, kendaraan yang terlibat kecelakaan, dan identitas korban.
26
3. Tahapan Pengolahan Data (Data Preparation Phase)
Dari 1549 data mentah yang diperoleh dari rekaman data kecelakaan lalu lintas dilakukan simplikasi dan generalisasi, karena dengan data asli seperti gambar 3.1 belum bisa diolah dan setelah dilakukan simplikasi dan generalisasi data tersebut dapat diolah seperti tabel 3.2. Namun tidak semua data dan atribut dapat digunakan, karena masih ada data yang mengandung missing value (memiliki keterangan yang kurang lengkap) oleh karena itu dilakukan cleaning data dan selection data, data reduksi. Cleaning data dan selection data merupakan tahap awal dalam processing data mining. Pembersihan ini dilakukan untuk membuang data-data yang informasi terter, seperti tidak adanya informasi identitas korban, umur, pekerjaan.
Data reduksi adalah data yang informative, data dengan record dan jumlah atribut yang sesuai dengan kebutuhan. Ada beberapa field yang dihilangkan karena data tidak lengkap. 1549 data yang digunakan yang terdiri dari 3 atribut yang akan diolah.
4. Fase pemodelan (Modeling Phase)
Tahap pemodelan merupakan tahap pengolahan dataset yang dimodelkan dengan algoritma k-means sehingga perhitungan dan Pengelompokan data.
Algoritma K-Means
Algoritma K-means secara umum memiliki tahapan sebagai berikut:
1. Tentukan jumlah kelompok
2. Inisialisasi titik centroid k (pusat cluster) secara acak.
3. Hitung jarak setiap titik pusat cluster, jarak antar satu data dengan satu
cluster akan menentukan data tersebut masuk dalam cluster mana.
Chebyshev Distance 𝑑𝑖𝑗 = 𝑘|𝑥𝑖𝑗− 𝑥𝑗𝑘| 𝑚𝑎𝑥 (3.1) Dimana : K = Dimensi data
𝑥𝑖𝑗 = Data dari jumlah kecelakaan, jumlah kendaraan yang
terlibat, jumlah korban
𝑥𝑗𝑘 = Centroid
𝑑𝑖𝑗 = Jarak antara 𝑥𝑖𝑗 dan 𝑥𝑗𝑘dan || adalah nilai mutlak.
4. Hitung pusat cluster yang baru dengan keanggotaan cluster yang sekarang, dengan cara mencari rata-rata (mean) dari semua objek atau data dalam cluster tertentu atau dengan menggunakan median dari
cluster tersebut.
5. Ulangi mulai dari langkah ketiga sampai nilai pusat cluster tidak berubah.
5. Fase Evaluasi (Evaluation Phase)
Pada fase ini dilakukan penilaian menggunakan Davies Bouldin
Index (DBI) untuk menentukan jumlah cluster paling optimal dalam proses clustering tersebut, dengan membandingkan pengelompokan sebanyak 3
klaster menggunakan Chebychev K-Means dengan Euclidean K-Means yang telah digunakan pada penelitian sebelumnya. Dimana dalam penentuannya nilai DBI yang paling rendah diantara keduanya dianggap paling optimal dalam menghasilkan cluster set sebanyak 3 klaster.
6. Fase Penyebaran
Fase yang terakhir adalah fase penyebaran dimana data yang telah dievaluasi diimplementasikan sehingga dapat digunakan untuk menentukan daerah rawan kecelakaan lalu lintas di Kota Semarang. Data diuji dengan menggunakan tool rapidminer. Dengan menggunakan pemodelan dalam rapidminer maka dapat diketahui kemiripan hasil clustering yang dilakukan menggunakan perhitungan pada Microsoft
28
Excel dengan Rapidminer dalam penentuan status daerah terhadap kecelakaan lalu lintas di Kota Semarang.
29
BAB IV
ANALISA DAN PEMBAHASAN
4.1
Pengolahan Data
4.1.1 Persiapan Data
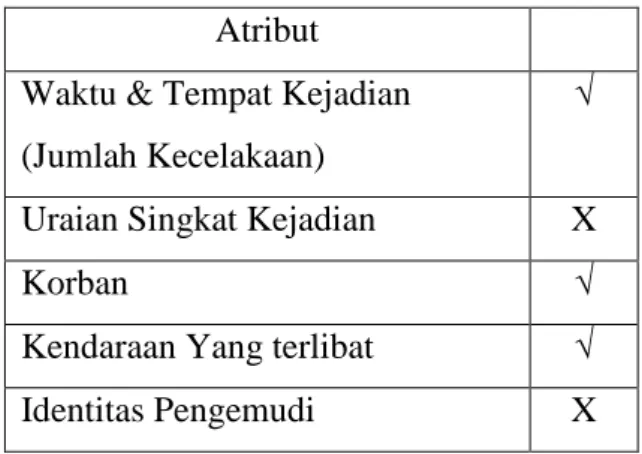
Dalam penelitian ini data yang digunakan merupakan data sekunder melalui dokumentasi Satlantas Polrestabes Kota Semarang antara tahun 2014 sampai 2015 dengan atribut Waktu & Tempat kejadian, Uraian Singkat Kejadian, Korban (MD, LB, LR, Kerugian Materi), yang terlibat, Identitas Pengemudi. Rekaman data Satlantas Polrestabes Kota Semarang seperti yang sudah dijelaskan pada Gambar 3.1, dipilih atribut yang akan digunakan dalam penelitian:
Tabel 4. 1 Pemilihan Atribut Atribut
Waktu & Tempat Kejadian (Jumlah Kecelakaan)
√
Uraian Singkat Kejadian X
Korban √
Kendaraan Yang terlibat √
Identitas Pengemudi X
4.1.2 Preprocessing
Preprocessing yang dilakukan adalah penghapusan data
missing value (memiliki keterangan yang kurang lengkap) Pada
tahap ini rekaman data kecelakaan lalu lintas suatu jalan yang tidak memiliki keterangan yang kurang lengkap seperti kejadian kecelakaan lalu lintas yang kurang dari 2 tahun, tidak adanya keterangan identitas korban, umur, pekerjaan, maka jalan tersebut tidak digunakan.
30
Dari rekaman data yang diperoleh, semua data terisi sesuai dengan ketentuan tidak ada yang kosong, sehingga semua data yang diperoleh dapat digunakan pada proses selanjutnya. Setelah data yang terkumpul dan telah diseleksi, data diolah dalam Ms. Excel sehingga diperoleh hasil simplikasi dan generalisasi seperti yang terlihat dibawah ini :
Tabel 4. 2 Data Awal
No Nama Jalan Jumlah Kecelakaan (X1) Jumlah Kendaraan yang Terlibat (X2) Jumlah Korban (X3) 1 Brigjend Sudiarto 103 200 143 2 Dr. Cipto 25 48 33 3 Durian 2 4 2 4 P.Kemerdekaan 51 104 74 5 Raya Medoho 6 11 7 6 Brigjend Katamso 4 8 5 7 Fatmawati 12 22 14
8 Sarwo Edi Wibowo 3 6 3
9 Thamrin 5 9 7 10 MT Haryono 32 65 48 - - - - - - - - - - - - - - - - - - - - 116 Prof. Suharso 2 4 2 117 Pawiyatan Luhur IV 2 4 2 118 Tlogosari raya 2 4 1 119 Suratmo 3 6 3 4.2 Proses Klastering
Proses klastering yaitu proses pengelompokan data berdasarkan kemiripan karakteristiknya. Pada penelitian ini, penulis menggunakan algoritma k-means yang digunakan untuk mengklasterisasi daerah rawan kecelakaan lalu lintas dengan Chebyshev distance dan Euclidean distance sebagai perhitungan jarak setiap data terhadap pusat klaster. Dalam
menentukan daerah rawan kecelakaan lalu lintas, dilakukan klastering dengan perhitungan algoritma k-mean sebagai berikut :
4.2.1 Chebychev Distance K-Means
Berikut merupakan proses klasterisasi daerah rawan kecelakaan lalu lintas dengan menggunakan algoritma k-means dan Chebychev Distance sebagai perhitungan jarak setiap data terhadap pusat klaster:
1. Menentukan jumlah klaster, berapa banyak klaster yang akan dibuat, k=3.
2. Menentukan pusat klaster awal secara acak, missal ditentukan C1=(2,2,2); C2=(3,3,3); C3=(4,4,4).
3. Menghitung jarak setiap data terhadap pusat klaster, misalkan untuk menghitung jarak data pertama dengan pusat klaster pertama yaitu : Chebyshev Distance 𝑑𝑖𝑗 = 𝑘|𝑥𝑖𝑗− 𝑥𝑗𝑘| 𝑚𝑎𝑥 (4.1) Dimana : K = Dimensi data 𝑑11= max( |103 − 2|, |200 − 2|, |143 − 2|) = 198
Jarak data pertama dengan pusat klaster kedua: 𝑑12= max( |103 − 3|, |200 − 3|, |143 − 3|)
= 197
Jarak data pertama dengan pusat klaster ketiga:
𝑑13= max( |103 − 4|, |200 − 4|, |143 − 4|) = 196
32
Hasil perhitungan terdapat pada table berikut: Tabel 4. 3 Iterasi 1 Data ke- Jumlah Kecelakaan (X1) Jumlah Kendaraan yang terlibat (X2) Jumlah Korban (X3) C1 C2 C3 Anggota klaster 1 103 200 143 198 197 196 C3 2 25 48 33 46 45 44 C3 3 2 4 2 2 1 2 C2 4 51 104 74 102 101 100 C3 5 6 11 7 9 8 7 C3 6 4 8 5 6 5 4 C3 7 12 22 14 20 19 18 C3 8 3 6 3 4 3 2 C3 9 5 9 7 7 6 5 C3 10 32 65 48 63 62 61 C3 . . . . . . . . . . . . . . . . 116 2 4 2 2 1 2 C2 117 2 4 2 2 1 2 C2 118 2 4 1 2 2 3 C1 119 3 6 3 4 3 2 C3
4. Suatu data akan menjadi bagian anggota klaster dengan jarak terkecil dari pusat klaster. Misalkan untuk data pada tabel 4.3 diatas, jarak terkecil terdapat pada klaster ketiga sehingga data pertama masuk dalam anggota data klaster ketiga. Begitu pula untuk data ketiga, jarak terkecil terdapat pada klaster kedua sehingga data tersebut masuk dalam anggota klaster kedua. 5. Menghitung pusat klaster baru dengan mencari rata-rata dari
semua data dalam klaster tertentu. Untuk klaster pertama terdapat 3 data, sehingga:
𝐶11= 2 + 2 + 2
3 = 2
𝐶12= 3 + 2 + 4
𝐶13 =1 + 2 + 1
3 = 1.33333333 Untuk klaster dua ada 20 data, sehingga:
𝐶
21=
2+2+3+2+2+2+2+2+2+2+2+2+2+2+2+2+2+2+2+2 20= 2.05
𝐶
22=
4+4+4+4+4+4+4+4+4+4+4+4+4+4+4+4+4+4+4+4 20= 4
𝐶
23=
2+2+2+2+2+4+2+2+2+4+3+2+2+3+5+4+2+3+2+2 20= 2.6
Untuk klaster ketiga ada 96 data, sehingga:
𝐶31= 103 + 25 + 51 + ⋯ + 4 + 3 + 3 96 = 13.55208 𝐶32= 200 + 48 + 104 + ⋯ + 8 + 5 + 6 96 = 27.6875 𝐶33= 143 + 33 + 74 + ⋯ + 4 + 4 + 3 96 = 18.38542
Tabel 4. 4 Centroid baru untuk iterasi 2 Jumlah Kecelakaan (x1) Jumlah Kendaraan yang Terlibat (x2) Jumlah Korban (x3) C1 2 3 1.33333 C2 2.05 4 2.6 C3 13.55208 27.6875 18.38542
6. Ulangi langkah ke-3 dengan titik pusat baru sampai posisi klaster tidak berubah.
Tabel 4. 5 Iterasi ke-2
Data ke- Jumlah Kecelakaan (X1) Jumlah Kendaraan yang terlibat (X2) Jumlah Korban (X3) Claster ke-1 (C1) Claster ke-2 (C2) Claster ke-3 (C3) Anggota klaster 1 103 200 143 197 196 172.3125 C3 2 25 48 33 45 44 20.3125 C3 3 2 4 2 1 0.6 23.6875 C2 4 51 104 74 100.2 98.53846 75.21978 C3
34 5 6 11 7 7.2 5.538462 17.78022 C2 6 4 8 5 4.2 2.538462 20.78022 C2 7 12 22 14 18.2 16.53846 6.78022 C3 8 3 6 3 2.2 0.538462 22.78022 C2 9 5 9 7 5.2 4.153846 19.78022 C2 10 32 65 48 61.2 59.53846 36.21978 C3 . . . . . . . . . . . . . . . . 116 2 4 2 0.2 1.461538 24.78022 C1 117 2 4 2 0.2 1.461538 24.78022 C1 118 2 4 1 0.866667 1.846154 24.78022 C1 119 3 6 3 2.2 0.538462 22.78022 C2
Karena pada iterasi pertama dan kedua (table 4.3 dan 4.5) posisi klaster berubah, maka dilakukan iterasi ke-3 dengan terlebih dahulu menghitung titik pusat klaster baru.
Untuk klaster pertama terdapat 18 data, sehingga:
𝐶
11=
2+2+3+2+2+2+2+2+2+2+2+2+2+2+2+2+2+2+2+2 18= 2.055556
𝐶
12=
4+3+4+4+4+4+4+4+4+4+4+4+2+4+4+4+4+4 18= 3.833333
𝐶
13=
2+1+2+2+2+2+2+2+3+2+2+3+2+2+3+2+2+1 18= 2.055556
Untuk klaster kedua terdapat 63 data, sehingga:
𝐶21 =2 + 6 + 4 + ⋯ + 4 + 3 + 3 63 = 4.539683 𝐶22 =4 + 11 + 8 + ⋯ + 8 + 5 + 6 63 = 9.142857 𝐶232 + 7 + 5 + ⋯ + 4 + 4 + 3 63 = 5.936508
Untuk klaster ketiga terdapat 38 data, sehingga: 𝐶31 = 103 + 25 + 51 + ⋯ + 9 + 12 + 9 38 = 26.97368 𝐶32 =200 + 48 + 104 + ⋯ + 18 + 25 + 20 38 = 55.31579 𝐶33=143 + 33 + 74 + ⋯ + 12 + 18 + 11 38 = 37.10526
Tabel 4. 6 Centroid baru untuk iterasi 3 Jumlah Kecelakaan (x1) Jumlah Kendaraan yang Terlibat (x2) Jumlah Korban (x3) C1 2.055556 3.833333 2.055556 C2 4.539683 9.142857 5.936508 C3 26.97368 55.31579 37.10526
Tabel 4. 7 Iterasi ke-3
Data ke- Jumlah Kecelakaan (X1) Jumlah Kendaraan yang terlibat (X2) Jumlah Korban (X3) Claster ke-1 (C1) Claster ke-2 (C2) Claster ke-3 (C3) Anggota klaster 1 103 200 143 196.1667 190.8571 144.6842 C3 2 25 48 33 44.16667 38.85714 7.315789 C3 3 2 4 2 0.166667 5.142857 51.31579 C1 4 51 104 74 100.1304 94.41379 48.68421 C3 5 6 11 7 7.130435 1.413793 44.31579 C2 6 4 8 5 4.130435 1.586207 47.31579 C2 7 12 22 14 18.13043 12.41379 33.31579 C2 8 3 6 3 2.130435 3.586207 49.31579 C1 9 5 9 7 5.130435 0.87931 46.31579 C2 10 32 65 48 61.13043 55.41379 10.89474 C3 . . . . . . . . . . . .
36 . . . . 116 2 4 2 0.434783 5.586207 51.31579 C1 117 2 4 2 0.434783 5.586207 51.31579 C1 118 2 4 1 1.434783 5.586207 51.31579 C1 119 3 6 3 2.130435 3.586207 49.31579 C1
Karena pada iterasi kedua dan ketiga (table 4.5 dan 4.7) posisi klaster berubah, maka dilakukan iterasi ke-4 dengan terlebih dahulu menghitung titik pusat klaster baru.
Untuk klaster pertama terdapat 39 data, sehingga:
𝐶11 = 2 + 3 + 2 + ⋯ + 2 + 2 + 3 39 = 2.435897 𝐶12= 4 + 6 + 4 + ⋯ + 4 + 4 + 6 39 = 4.74359 𝐶13 =2 + 3 + 2 + ⋯ + 2 + 1 + 3 39 = 2.948718
Untuk klaster kedua terdapat 57 data, sehingga:
𝐶21 =6 + 4 + 12 + ⋯ + 4 + 6 + 4 57 = 6.894737 𝐶22 =11 + 8 + 22 + ⋯ + 8 + 12 + 8 57 = 14.07018 𝐶23 = 7 + 5 + 14 + ⋯ + 4 + 8 + 4 57 = 8.929825
Untuk klaster ketiga terdapat 23 data, sehingga:
𝐶31= 103+25+51+32+58+16+45+25+28+19+52+55+30+48+61+28+18+16+76+16+19+21 23 = 37.3913 𝐶32= 200+48+104+65+102+35+34+96+60+56+39+107+119+68+100+123+56+42+34+154+35+40+43 23 = 76.52174
𝐶33=
143+33+74+48+77+24+43+59+38+32+21+73+101+44+50+86+39+16+18+99+20+27+32
23 =
52.04348
Tabel 4. 8 Centroid baru untuk iterasi 4 Jumlah Kecelakaan (x1) Jumlah Kendaraan yang Terlibat (x2) Jumlah Korban (x3) C1 2.055556 3.833333 2.055556 C2 4.539683 9.142857 5.936508 C3 26.97368 55.31579 37.10526
Tabel 4. 9 Informasi Centroid akhir Jumlah Kecelakaan (x1) Jumlah Kendaraan yang Terlibat (x2) Jumlah Korban (x3) C1 4.795699 9.655914 6.16129 C2 20.76471 43.76471 28.58824 C3 61 122.7778 84.66667
Tabel 4. 10 Iterasi ke-10
Data ke- Jumlah Kecelakaan (X1) Jumlah Kendaraan yang terlibat (X2) Jumlah Korban (X3) Claster ke-1 (C1) Claster ke-2 (C2) Claster ke-3 (C3) Anggota klaster 1 103 200 143 190.3441 156.2353 77.22222 C3 2 25 48 33 38.34409 4.411765 74.77778 C2 3 2 4 2 5.655914 39.76471 118.7778 C1 4 51 104 74 94.34409 60.23529 18.77778 C3 5 6 11 7 1.344086 32.76471 111.7778 C1 6 4 8 5 1.655914 35.76471 114.7778 C1 7 12 22 14 12.34409 21.76471 100.7778 C1 8 3 6 3 3.655914 37.76471 116.7778 C1
38 9 5 9 7 0.83871 34.76471 113.7778 C1 10 32 65 48 55.34409 21.23529 57.77778 C2 . . . . . . . . . . . . . . . . 116 2 4 2 5.655914 39.76471 118.7778 C1 117 2 4 2 5.655914 39.76471 118.7778 C1 118 2 4 1 5.655914 39.76471 118.7778 C1 119 3 6 3 3.655914 37.76471 116.7778 C1
Iterasi akan berhenti jika posisi klaster tidak mengalami perubahan. Untuk data kecelakaan yang terjadi di 119 segmen jalan dibutuhkan iterasi sebanyak 10 kali untuk mendapatkan hasil klasterisasi akhir.
Berdasarkan pada titik pusat centroid terakhir dalam tabel 4.9 diatas, dapat dikategorikan bahwa C1 merupakan kategori jalan yang tidak rawan kecelakaan, sedangkan C2 merupakan kategori jalan rawan kecelakaan dan C3 merupakan kategori jalan yang sangat rawan kecelakaan.
Hasil analisis klastering dari table 4.10 :
a. Klaster pertama (C1) mempunyai titik pusat klaster (4.795699, 9.655914, 6.16129) dan nilainya lebih rendah dari titik pusat klaster kedua dan ketiga, sehingga dapat disimpulkan bahwa C1 merupakan kelompok jalan yang tidak rawan kecelakaan lintas sebanyak 93. b. Klaster kedua (C2) mempunyai titik pusat klaster (20.76471, 43.76471,
28.58824) dan nilainya lebih besar dibandingkan dengan titik pusat klaster pertama tetapi lebih rendah dibandingkan dengan titik pusat klaster ketiga, sehingga dapat disimpulkan bahwa C2 merupakan kelompok jalan yang rawan kecelakaan lalu lintas sebanyak 17.
c. Klaster ketiga (C3) mempunyai titikpusat klaster (61, 122.7778, 84.66667) dan nilainya lebih besar dibandingkan titik pusat klaster
pertama dan kedua, sehingga dapat disimpulkan bahwa C3 merupakan kelompok jalan yang sangat rawan kecelakaan lalu lintas sebanyak 9.
4.2.2 Euclidean K-Means
Berikut merupakan proses klasterisasi daerah rawan kecelakaan lalu lintas dengan menggunakan algoritma k-means dan Euclidean Distance sebagai perhitungan jarak setiap data terhadap pusat klaster:
1. Menentukan jumlah klaster, berapa banyak klaster yang akan dibuat, k=3.
2. Menentukan pusat klaster awal secara acak, missal ditentukan C1=(2,2,2); C2=(3,3,3); C3=(4,4,4).
3. Menghitung jarak setiap data terhadap pusat klaster, misalkan untuk menghitung jarak data pertama dengan pusat klaster pertama yaitu : Euclidean Distance 𝐷(𝑖,𝑗)= √(𝑋1𝑖− 𝑋1𝑗) 2 + (𝑋2𝑖− 𝑋2𝑗) 2 + ⋯ + (𝑋𝑘𝑖− 𝑋𝑘𝑗) 2 (4.2) dimana:
D (i,j) = Jarak data ke i ke pusat cluster j Xki = Data ke i pada atribut data ke k
Xkj = Titik pusat ke j pada atribut ke k
𝐷11= √(103 − 2)2+ (200 − 2)2+ (143 − 2)2 = 263.222
Jarak data pertama dengan pusat klaster kedua:
𝐷12= √(103 − 3)2+ (200 − 3)2+ (143 − 3)2 = 261.551
Jarak data pertama dengan pusat klaster ketiga:
40
Hasil perhitungan terdapat pada table berikut: Tabel 4. 11 Iterasi 1 Data ke- Jumlah Kecelakaan (X1) Jumlah Kendaraan yang terlibat (X2) Jumlah Korban (X3) C1 C2 C3 Anggota klaster 1 103 200 143 263.2223 261.5511 259.8807 C3 2 25 48 33 60.04998 58.38664 56.72742 C3 3 2 4 2 2 1.732051 2.828427 C2 4 51 104 74 134.1231 132.4613 130.8014 C3 5 6 11 7 11.04536 9.433981 7.874008 C3 6 4 8 5 7 5.477226 4.123106 C3 7 12 22 14 25.37716 23.72762 22.09072 C3 8 3 6 3 4.242641 3 2.44949 C3 9 5 9 7 9.110434 7.483315 5.91608 C3 10 32 65 48 83.57631 81.91459 80.25584 C3 . . . . . . . . . . . . . . . . 116 2 4 2 2 1.732051 2.828427 C2 117 2 4 2 2 1.732051 2.828427 C2 118 2 4 1 2.236068 2.44949 3.605551 C1 119 3 6 3 4.242641 3 2.44949 C3
4. Suatu data akan menjadi bagian anggota klaster dengan jarak terkecil dari pusat klaster. Misalkan untuk data pada tabel 4.11 diatas, jarak terkecil terdapat pada klaster ketiga sehingga data pertama masuk dalam anggota data klaster ketiga. Begitu pula untuk data ketiga, jarak terkecil terdapat pada klaster kedua sehingga data tersebut masuk dalam anggota klaster kedua.
5. Menghitung pusat klaster baru dengan mencari rata-rata dari semua data dalam klaster tertentu. Untuk klaster pertama terdapat 3 data, sehingga: 𝐶11= 2 + 2 + 2 3 = 2 𝐶12= 3 + 2 + 4 3 = 3 𝐶13 =1 + 2 + 1 3 = 1.333333
Untuk klaster kedua terdapat 19 data, sehingga: 𝐶21 =2 + 2 + 3 + 2 + 2 + 2 + 2 + 2 + 2 + 2 + 2 + 2 + 2 + 2 + 2 + 2 … + 2 + 2 + 2 19 = 2.052632 𝐶22 =4 + 4 + 4 + 4 + 4 + 4 + 4 + 4 + 4 + 4 + 4 + 4 + 4 + 4 + 4 + 4 + 4 + 4 + 4 19 = 4 𝐶23 =2 + 2 + 2 + 2 + 2 + 4 + 2 + 2 + 2 + 4 + 3 + 2 + 2 + 3 + 4 + 2 + 3 + 2 + 2 19 = 2.473684
Untuk klaster ketiga terdapat 97 data, sehingga:
𝐶31 = 103 + 25 + 51 + ⋯ + 4 + 3 + 3 97 = 13.43299 𝐶32 =200 + 48 + 104 + ⋯ + 8 + 5 + 6 97 = 27.4433 𝐶32 = 143 + 33 + 74 + ⋯ + 4 + 4 + 3 97 = 18.24742
42
Tabel 4. 12 Centroid baru untuk iterasi 2 Jumlah Kecelakaan (x1) Jumlah Kendaraan yang Terlibat (x2) Jumlah Korban (x3) C1 2 3 1.33333 C2 2.052632 4 2.473684 C3 13.43299 27.4433 18.24742 Tabel 4. 13 Iterasi 2 Data ke- Jumlah Kecelakaan (X1) Jumlah Kendaraan yang terlibat (X2) Jumlah Korban (X3) C1 C2 C3 Anggota klaster 1 103 200 143 262.8297 261.446 231.0006 C3 2 25 48 33 59.63873 58.2618 27.82108 C3 3 2 4 2 1.20185 0.476599 30.72914 C2 4 51 104 74 133.7253 132.3324 101.885 C3 5 6 11 7 10.58825 9.223299 21.26349 C2 6 4 8 5 6.51494 5.116104 25.34793 C2 7 12 22 14 24.92879 23.57554 7.051494 C3 8 3 6 3 3.574602 2.274756 28.30453 C2 9 5 9 7 8.781293 7.360334 23.18998 C2 10 32 65 48 83.19722 81.79542 51.38536 C3 . . . . . . . . . . . . . . . . 116 2 4 2 1.20185 0.476599 30.72914 C2 117 2 4 2 1.20185 0.476599 30.72914 C2 118 2 4 1 1.054093 1.474624 31.2694 C1 119 3 6 3 3.574602 2.274756 28.30453 C2
Tabel 4. 14 Informasi centroid akhir Euclidean Distance Jumlah Kecelakaan (x1) Jumlah Kendaraan yang Terlibat (x2) Jumlah Korban (x3) C1 4.795699 9.655914 6.16129 C2 20.76471 43.76471 28.58824 C3 61 122.7778 84.66667
Tabel 4. 15 Iterasi ke-11
Data ke- Jumlah Kecelakaan (X1) Jumlah Kendaraan yang terlibat (X2) Jumlah Korban (X3) Claster ke-1 (C1) Claster ke-2 (C2) Claster ke-3 (C3) Anggota klaster 1 103 200 143 254.1649 210.3857 105.499 C3 2 25 48 33 50.97842 7.439025 97.76073 C2 3 2 4 2 7.557885 51.38366 156.2784 C1 4 51 104 74 125.0509 81.26926 23.7988 C3 5 6 11 7 1.990061 41.92343 146.8039 C1 6 4 8 5 2.173427 46.00624 150.8964 C1 7 12 22 14 16.30104 27.62859 132.48 C1 8 3 6 3 5.155967 48.95422 153.8522 C1 9 5 9 7 1.084157 43.85388 148.7061 C1 10 32 65 48 74.52194 30.88667 74.32171 C2 . . . . . . . . . . . . . . . . 116 2 4 2 7.557885 51.38366 156.2784 C1 117 2 4 2 7.557885 51.38366 156.2784 C1 118 2 4 1 8.151332 51.90816 156.8097 C1 119 3 6 3 5.155967 48.95422 153.8522 C1
![Gambar 2. 2 Gambar siklus hidup CRISP-DM [12]](https://thumb-ap.123doks.com/thumbv2/123dok/4515268.3271237/29.892.281.693.228.642/gambar-gambar-siklus-hidup-crisp-dm.webp)