BAB 2 LANDASAN TEORI
2.1 Graph
Graph merupakan suatu alat bantu untuk merepresentasikan objek-objek diskrit dan hubungan antara objek-objek tersebut. Graph G didefinisikan sebagai pasangan himpunan (V, E), ditulis dengan notasi G = (V, E). V (node) merupakan
merupakan himpunan tidak kosong dari simpul. E (edge) merupakan himpunan sisi
yang menghubungkan sepasang simpul. Dan jika suatu edge berasal dari suatu simpul dan ujungnya kembali ke simpul yang sama, maka edge tersebut dinamakan loop. Simpul pada graph umumnya dinomori dengan huruf atau angka. Sedangkan sisi pada
graph umumnya dinamai dengan himpunan simpul yang dihubungkan oleh sisi tersebut [10].
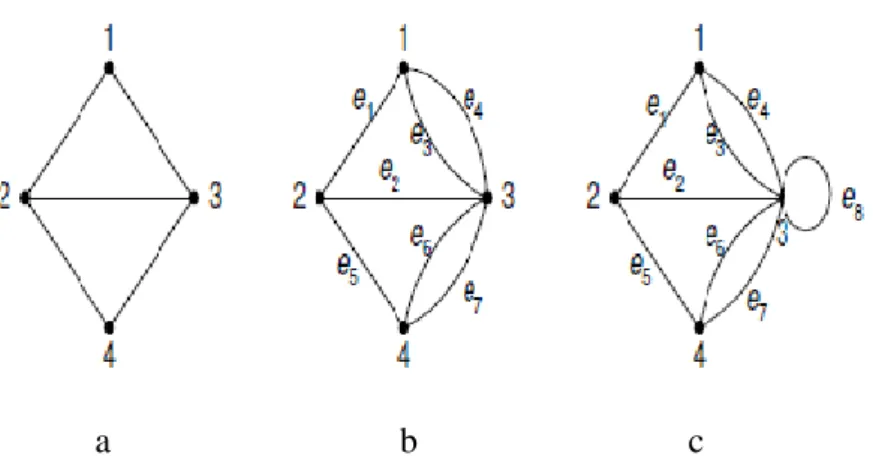
Graph dapat dikelompokkan berdasarkan ada tidaknya edge-nya yang paralel atau loop, jumlah node, berdasarkan ada tidaknya arah pada edge-nya, atau ada tidaknya bobot pada edge-nya.
Berdasarkan ada tidaknya edge yang paralel atau loop graph terdiri dari graph
sederhana dan graph tak sederhana. Graph sederhana adalah graph yang tidak memiliki sisi ganda dan juga loop. Sisi ganda merupakan kondisi ketika dua buah simpul memiliki lebih dari satu sisi. Sedangkan graph tak sederhana adalah graph
yang memiliki sisi ganda dan atau loop. Graph tak sederhana dapat dibagi dua, yaitu
graph semu (pseudograph) dan multiplegraph. Graph semu adalah graph yang mempunyai loop dan edge ganda sedangkan multiplegraph adalah hanya mempunyai
a b c Gambar 2.1 a. Graph Sederhana b. Multiplegraph
c. Graph Semu (Pseudograph)
Berdasarkan orientasi arah atau panah graph dibedakan atas graph tak berarah dan graph berarah. Graph tak berarah adalah graph yang edge-nya tidak mempunyai orientasi arah atau panah sedangkan graph berarah adalah graph yang setiap sisinya memiliki orientasi arah dari suatu simpul ke simpul lainnya.
a b
Gambar 2.2 a. Graph Tak Berarah b. Graph Berarah
Graph berbobot adalah graph yang memiliki nilai pada setiap sisinya. Bobot pada setiap sisi dapat menyatakan jarak antara dua buah kota, biaya perjalanan, waktu tempuh, ongkos produksi, dan sebagainya.
2.1.1 Sirkuit dan Lintasan
Walk (perjalanan) pada suatu graph adalah barisan node dan edge secara
bergantian, yakni : , , , , ,…, , . Dimana adalah edge yang
menghubungkan dengan . Walk dengan panjang n dari ke dapat
dinotasikan dengan : , , , … , .
Suatu walk yang edge-nya dalam barisan semua berbeda disebut sebuah trail
(lintasan). Trail dari node u ke node v dinotasikan dengan (u,v) trail. Walk dari suatu
graph disebut tertutup jika dan hanya jika node awal sama dengan node akhirnya ( = ) dan walk dikatakan tidak tertutup jika tidak terhubung dengan .
Path (jalur) adalah walk yang semua node-nya dalam barisan berbeda. Untuk menotasikan path dari u ke v ditulis dengan (u,v) – path. Karena path mempunyai
node yang berbeda, maka pasti edge-nya juga berbeda, sehingga sebuah path juga pasti trail. Sebuah path p pada graph G dengan node awal dan node akhir adalah sebuah barisan bergantian dari node dan edge yang berbentuk : , , , , , , … , , , dimana setiap edge incident (bersisian) pada node-node dan dan jumlah p={ , , , …, }; dimana p adalah jumlah edge dalam G.
Path sederhana (simple path) adalah path yang semua node-nya berbeda. Sebuah path dikatakan tertutup jika node awal dan node akhirnya sama, yakni
= . Sebuah path dikatakan cycle jika path tersebut tertutup dan semua degree node-nya dua.
Sirkuit adalah path tertutup dimana setiap node-nya dapat dilalui lebih dari satu kali dan cycle adalah sirkuit yang tiap node-nya dilalui hanya satu kali kecuali
node awal dan node akhirnya. Sebuah cycle pada sebuah graph harus mempunyai panjang sedikitnya tiga edge.
Lintasan Euler adalah lintasan yang melalui masing-masing edge di dalam
graph tepat satu kali. Sirkuit Euler adalah lintasan Euler tertutup dimana node awal lintasan sama dengan node akhir lintasan. Graph yang mempunyai sirkuit Euler
disebut graph Euler (Eulerian Graph) dan graph yang mempunyai lintasan Euler disebut graph semi-Euler (semi-Eulerian Graph).
Berbeda dengan lintasan dan sirkuit Euler yang melalui edge-edge pada graph
tepat satu kali, maka lintasan dan sirkuit Hamilton melalui node-node pada graph tepat satu kali. Lintasan Hamilton ialah lintasan yang melalui tiap node di dalam graph
tepat satu kali. Sirkuit Hamilton ialah sirkuit yang melalui tiap node di dalam graph
tepat satu kali, kecuali node asal (sekaligus node akhir) yang dilalui dua kali. Graph
yang memiliki sirkuit Hamilton dinamakan graph Hamilton, sedangkan graph yang hanya memiliki lintasan Hamilton disebut graph semi-Hamilton.
2.2 Algoritma A*
Algoritma A* pertama kali dikemukakan oleh Peter Hart, Nils Nilson dan Bertram Raphael pada tahun 1968. Algoritma A* merupakan salah satu algoritma pencarian
graph terbaik yang mampu menemukan jalur dengan biaya pengeluaran paling sedikit dari titik permulaan yang diberikan sampai ke titik tujuan yang diharapkan. Algoritma
A* dapat diimplementasikan lebih efisien karena tidak ada node yang diproses
berulang-ulang.
Algoritma A* merupakan algoritma Best First Search (BFS) yang paling
banyak dikenal [18]. Algoritma ini memeriksa node dengan menggabungkan g(n),
yaitu cost yang dibutuhkan untuk mencapai sebuah node dan h(n) yaitu cost yang didapat dari node ke tujuan. Sehingga dapat dirumuskan sebagai :
f(n) = g(n) + h(n) Keterangan :
f(n) adalah estimasi total biaya (cost) sebuah jalur (path) dari node awal ke node
tujuan (goal) melalui node n.
g(n) adalah biaya (cost) yang dibutuhkan oleh sebuah jalur (path) untuk mencapai
node n dari node awal.
Beberapa terminologi yang terdapat pada algoritma A* adalah : 1. Starting point merupakan terminologi untuk posis awal sebuah benda.
2. Simpul (node) merupakan petak-petak kecil sebagai representasi dari pathfinding. Bentuknya dapat berupa persegi, lingkaran maupun segitiga.
3. A merupakan simpul yang sedang dijalankan dalam algoritma pencarian jalur
terpendek.
4. Open list merupakan tempat menyimpan data simpul yang mungkin diakses dari
starting point maupun simbol yang sedang dijalankan.
5. Closed list merupakan tempat menyimpan data simpul sebelum A yang juga merupakan bagian dari jalur terpendek yang telah dihasilkan didapatkan.
6. Harga (cost) merupakan nilai dari f(n).
7. Halangan (unwalked) merupakan sebuah atribut yang menyatakan bahwa sebuah
simpul tidak dapat dilalui oleh A.
2.2.1 Sifat Algoritma A*
Seperti BFS, A* akan selalu menemukan sebuah solusi, jika memang ada. Apabila fungsi heuristik h dapat diterima, yang berarti nilai h tidak akan pernah melebihi ongkos minimal untuk meraih tujuan yang sebenarnya, maka A* sendiri akan dapat diterima (atau dapat disebut optimal) apabila himpunan tertutup tidak digunakan.
Apabila digunakan sebuah himpunan tertutup, maka h harus monoton (atau konsisten) agar A* dapat menjadi optimal. Ini berarti fungsi heuristik tidak akan pernah berlebihan dalam menghitung ongkos dari sebuah titik ke titik tetangganya. Secara formal, untuk semua jalur x, y dimana y adalah suksesor dari x: h(x) ≤ g(y) - g(x) + h(y).
A* juga dapat dijamin keoptimalannya untuk sembarang heuristik, yang berarti bahwa tidak ada satupun algoritma lain yang mempergunakan heuristik yang sama akan mengecek lebih sedikit titik dari A*, kecuali ketika ada beberapa solusi parsial dimana h dapat dengan tepat memprediksi ongkos jalur minimal.
2.2.2 Kompleksitas Algortima A*
Kompleksitas waktu dari A* sangat bergantung dari heuristik yang digunakannya. Pada kasus terburuk, jumlah titik yang diperiksa berjumlah eksponensial terhadap panjang solusi (jalur terpendek), tetapi A* akan memiliki kompleksitas waktu polinomial apabila fungsi memenuhi kondisi berikut:
|h(x) - h*(x)| ≤ O(log h*(x)
dimana h* adalah heuristik optimal, yaitu ongkos sebenarnya dari jalur x ke tujuan. Dengan kata lain, galat dari h tidak akan melaju lebih cepat dari algoritma dari heuristik optimal h* yang memberikan jarak sebenarnya dari x ke tujuan. Penggunaan memori dari A* bahkan lebih bermasalah dari kompleksitas waktunya. Beberapa varian dari A* telah dikembangkan untuk mengatasi masalah ini, termasuk diantaranya Iterative Deepening-A*, Memory Bounded- A* (MA*) dan Simplified Memory Bounded-A* (SMA*) dan Recursive Best First Search (RBFS). RBFS juga akan memberikan hasil yang optimal apabila heuristiknya dapat diterima.
2.2.3 Jarak dalam Algoritma A*
Algoritma A* adalah algoritma pencarian yang menggunakan fungsi heuristik untuk
menuntun pencarian rute, khususnya dalam hal pengembangan dan pemeriksaan
node-node pada peta [18].
Ada beberapa penghitungan jarak yang sering digunakan dalam algoritma A, yaitu :
1. Jarak Manhattan
Fungsi ini merupakan fungsi heuristik yang paling umum digunakan. Fungsi ini hanya akan menjumlahkan selisih nilai x dan y dari dua buah titik. Fungsi ini dinamakan Manhattan karena di kota Manhattan, Amerika, jarak dari dua lokasi umumnya dihitung dari blok-blok yang harus dilalui saja dan tentunya tidak bisa dilalui secara diagonal. Perhitungannya dapat ditulis sebagai berikut :
h(n) = abs ( - ) + abs ( - )
Dimana h(n) merupakan perkiraan cost dari node n ke node tujuan yang dihitung dengan fungsi heuristik. Variable merupakan koordinat x dari node asal,
sedangkan variabel merupakan koordinat y dari node asal. Variabel merupakan koordinat x dari node tujuan dan merupakan koordinat y dari node
tujuan. Nilai dari h(n) akan selalu bernilai positif.
2. Jarak Euclid
Heuristik ini akan menghitung jarak berdasarkan panjang garis yang dapat ditarik dari dua buah titik. Perhitungannya dapat dituliskan sebagai berikut :
h(n) =
Dalam kasus ini, skala relatif nilai g mungkin akan tidak sesuai lagi dengan nilai fungsi heuristik h. Karena jarak Euclidian selalu lebih pendek dari jarak Manhattan, maka dapat dipastikan selalu akan didapatkan jalur terpendek, walaupun secara komputansi lebih berat.
3. Jarak Euclidian Kuadrat
Dalam beberapa literatur juga disebutkan jika nilai g adalah 0, maka lebih baik jika ongkos komputansi operasi pengakaran pada heuristik jarak Euclidian dihilangkan saja, menghasilkan rumus sebagai berikut :
h(n) =
Fungsi heuristik sangat berpengaruh terhadap kelakuan algoritma A* , yaitu: 1. Apabila h(n) selalu bernilai 0, maka hanya g(n) yang akan berperan, dan A*
berubah menjadi Algoritma Dijkstra, yang menjamin selalu akan menemukan jalur terpendek.
2. Apabila h(n) selalu lebih rendah atau sama dengan ongkos perpindahan dari titik n ke tujuan, maka A* dijamin akan selalu menemukan jalur terpendek. Semakin rendah nilai h(n), semakin banyak titik-titik yang diperiksa A*, membuatnya semakin lambat.
3. Apabila h(n) tepat sama dengan ongkos perpindahan dari n ke tujuan, maka A* hanya akan mengikuti jalur terbaik dan tidak pernah memeriksa satupun titik lainnya, membuatnya sangat cepat. Walaupun hal ini belum tentu bisa diaplikasikan ke semua kasus, ada beberapa kasus khusus yang dapat menggunakannya.
4. Apabila h(n) kadangkala lebih besar dari ongkos perpindahan dari n ke tujuan, maka A* tidak menjamin ditemukannya jalur terpendek, tapi prosesnya cepat. 5. Apabila h(n) secara relatif jauh lebih besar dari g(n), maka hanya h(n) yang
memainkan peran, dan A* berubah menjadi BFS.
Dalam mengaplikasikan Algoritma A* pada aplikasi ini, fungsi heuristik yang digunakan adalah jarak Euclid.
2.2.4 Cara Kerja Algoritma A* Mencari Rute Terpendek
Prinsip algoritma ini adalah mencari jalur terpendek dari sebuah simpul awal (starting point) menuju simpul tujuan dengan memperhatikan harga (f) terkecil. Algoritma ini mempertimbangkan jarak yang telah ditempuh selama ini dari initial state ke current state. Jadi bila jalan yang telah ditempuh sudah terlalu panjang dan ada jalan lain yang lebih kecil jaraknya namun memberikan posisi yang sama dilihat dari goal, jalan baru yang lebih pendek itulah yang akan dipilih [1].
Dengan fungsi heuristik algoritma ini membangkitkan node yang paling
mendekati solusi. Node ini kemudian disimpan suksesornya ke dalam list sesuai dengan urutan yang paling mendekati solusi terbaik. Kemudian, node pertama pada
list diambil, dibangkitkan suksesornya dan kemudian suksesor ini disimpan ke dalam
list sesuai dengan urutan yang terbaik untuk solusi. Listnode ini disebut dengan node terbuka (opennode).
Node pada list bisa berasal dari kedalaman berapapun dari graph. Algoritma
ini akan mengunjungi secara mendalam (mirip Depth First Search (DFS)) selama
node tersebut merupakan node yang terbaik. Jika node yang sedang dikunjungi
ternyata tidak mengarah kepada solusi yang diinginkan, maka akan melakukan runut
balik ke arah node awal untuk mencari node lainnya yang lebih menjanjikandari pada
node yang terakhir dikunjungi. Bila tidak ditemukan juga, maka akan terus mengulang
mencari ke arah node awal sampai ditemukan node yang lebih baik untuk
dibangkitkan suksesornya. Strategi ini berkebalikan dengan algoritma DFS yang
dibangkitkan sebelum melakukan runut balik, dan BFS yang tidak akan melakukan pencarian secara mendalam sebelum pencarian secara melebar selesai. Algoritma A* baru berhenti ketika mendapatkan solusi yang dianggap solusi terbaik.
Adapun langkah-langkah dalam algoritma A* adalah sebagai berikut: 1. Letakkan simpul awal s pada OPEN.
2. Jika OPEN kosong maka pencarian berakhir.
3. Pindahkan simpul n yang memiliki nilai minimum f dari OPEN ke CLOSED. 4. Jika n adalah simpul tujuan, pencarian berhasil dan berakhir dengan menelusuri
kembali pointer dari n ke s.
5. Ekspansikan n, bangkitkan semua suksesor dari simpul n, dan tambahkan ke
pointer tersebut kembali ke n. Untuk setiap suksesor n’ dari simpul n :
a. Jika n’ tidak ada pada OPEN atau CLOSED, estimasi h(n’) (sebuah perkiraan dari biaya perjalanan terbaik dari n’ ke beberapa simpul tujuan), dan hitung f(n’) = g(n’) + h(n’), dimana g(n’) = g(n) +c(n,n) dan g(s) = 0.
b. Jika n’ sudah berada pada OPEN atau CLOSED, letakkan pointer perjalanan pada hasil g(n’) yang terendah.
c. Jika n’ membutuhkan penyesuaian pointer dan ditemukan pada CLOSED, buka
kembali n’.
6. Kembali ke langkah 2.
2.3 Sistem Informasi Geografis
Geographic Information System (GIS) merupakan sistem yang dirancang untuk bekerja dengan data yang tereferensi secara spasial atau koordinat-koordinat geografis. Sistem ini terdiri dari perangkat keras, perangkat lunak, data, manusia (brainware), organisasi dan lembaga yang digunakan untuk mengumpulkan, menyimpan, menganalisis dan menyebarkan informasi-informasi mengenai daerah-daerah di permukaan bumi [5]. Aplikasi GIS saat ini tumbuh tidak hanya secara jumlah, namun juga bertambah dari jenis keragaman aplikasinya.
Seiring dengan perkembangan tersebut, para pakar pun banyak memberikan definisi mengenai SIG sehingga defenisi SIG selalu berubah. Adapun beberapa definisi dari SIG, yaitu [4] :
1. Sistem informasi geografis adalah sistem yang dapat mendukung pengambilan
keputusan spasial dan mampu mengintegrasikan deskripsi-deskripsi lokasi dengan karakteristik-karakteristik fenomena yang ditemuka n di suatu lokasi.
2. Sistem informasi geografis adalah sistem komputer yang digunakan untuk
memasukkan, menyimpan, memeriksa, mengintegrasikan, memanipulasi, menganalisa, dan menampilkan data yang berhubungan dengan posisi-posisi di muka bumi.
3. Sistem informasi geografis merupakan kombinasi perangkat keras dan
perangkat lunak computer yang memungkinkan untuk mengelola, memetakan informasi spasial berikut data atributnya dengan akurasi kartografi.
SIG merupakan produk dari beberapa komponen. Komponen-komponen yang terdapat dalam SIG yaitu :
1. Perangkat keras (Hardware)
Data yang terdapat dalam SIG diolah melalui perangkat keras. Perangkat keras dalam SIG terbagi menjadi tiga kelompok yaitu:
a. Alat masukan (input) sebagai alat untuk memasukkan data ke dalam
jaringan komputer. Contoh: scanner, digitizer, CD-ROM.
b. Alat pemrosesan, merupakan sistem dalam komputer yang berfungsi
mengolah, menganalisis dan menyimpan data yang masuk sesuai kebutuhan, contoh: CPU, tape drive, disk drive.
c. Alat keluaran (ouput) yang berfungsi menayangkan informasi geografi
sebagai datadalam proses SIG, contoh: VDU, plotter, printer. 2. Perangkat lunak (Software)
Perangkat lunak merupakan sistem modul yang berfungsi untuk memasukkan, menyimpan dan mengeluarkan data yang diperlukan. Data hasil penginderaan jauh dan tambahan (data lapangan, peta) dijadikan satu menjadi data dasar geografi. Data dasar tersebut dapat disimpan, ditampilkan pada monitor maupun dicetak sebagai laporan.
3. Intelegensi manusia (Brainware)
Brainware merupakan kemampuan manusia dalam pengelolaan dan pemanfaatan SIG secara efektif. Adanya koordinasi dalam pengelolaan SIG sangat diperlukan agar informasi yang diperoleh tidak simpang siur, tetapi tepat dan akurat.
Secara umum proses SIG terdiri atas empat bagian (subsistem), yaitu : 1. Subsistem masukan data (input data)
Subsistem ini berperan untuk memasukkan data dan mengubah data asli ke bentuk yang dapat diterima dan dipakai dalam SIG. Semua data dasar geografi diubah dulu menjadi data digital, sebelum dimasukkan ke komputer. Data digital memiliki kelebihan dibandingkan dengan peta (garis, area) karena jumlah data yang disimpan lebih banyak dan pengambilan kembali lebih cepat. Ada dua macam data dasar geografi, yaitu data spasial dan data atribut.
a. Data spasial (keruangan), yaitu data yang menunjukkan ruang, lokasi atau tempat tempat di permukaan bumi. Data spasial berasal dari peta analog, foto udara dan penginderaan jauh dalam bentuk cetak kertas.
b. Data atribut (deskriptis), yaitu data yang terdapat pada ruang atau tempat. Atribut menjelaskan suatu informasi. Data atribut diperoleh dari statistik, sensus, catatan lapangan dan tabular (data yang disimpan dalam bentuk tabel) lainnya. Data atribut dapat dilihat dari segi kualitas, misalnya kekuatan pohon. Dan dapat dilihat dari segi kuantitas, misalnya jumlah pohon.
Data dasar yang dimasukkan dalam SIG diperoleh dari tiga sumber, yaitu data lapangan (teristris), data peta dan data penginderaan jauh.
a. Data lapangan (teristris)
Data teristris adalah data yang diperoleh secara langsung melalui hasil pengamatan di lapangan, karena data ini tidak terekam dengan alat penginderaan jauh. Misalnya, batas administrasi, kepadatan penduduk, curah hujan, jenis tanah dan kemiringan lereng.
b. Data peta
Data peta adalah data yang digunakan sebagai masukan dalam SIG yang diperoleh dari peta, kemudian diubah ke dalam bentuk digital.
c. Data penginderaan jauh
Data ini merupakan data dalam bentuk citra dan foto udara. Citra adalah gambar permukaan bumi yang diambil melalui satelit. Sedangkan foto udara adalah gambar permukaan bumi yang diambil melalui pesawat udara.
2. Subsistem manipulasi dan analisis data
Subsistem ini menentukan informasi-informasi yang dihasilkan oleh SIG, melakukan manipulasi dan pemodelan data. Ada beberapa macam analisa data, antara lain:
a. Analisis lebar
Analisis lebar adalah analisis yang dapat menghasilkan gambaran daerah tepian sungai dengan lebar tertentu. Kegunaannya antara lain untuk perencanaan pembangunan bendungan sebagai penang-gulangan banjir. b. Analisis penjumlahan aritmatika (arithmetic addition)
Analisis ini digunakan untuk menangani peta dengan klasifikasi, hasilnya menunjukkan peta dengan klasifikasi baru.
c. Analisis garis dan bidang
Analisis ini dapat digunakan untuk menentukan wilayah dalam radius tertentu. Misalnya, daerah rawan banjir, daerah rawan gempa dan daerah rawan penyakit.
3. Subsistem manajemen
Subsistem ini mengorganisasikan data maupun tabel atribut terkait ke dalam sebuah sistem basis data agar mudah di-retrieve, di-update, dan di-edit.
4. Subsistem penyajian data (output data)
Subsistem output data berfungsi menayangkan informasi geografi sebagai hasil analisis data dalam proses SIG. Informasi tersebut ditayangkan dalam bentuk peta, tabel, bagan, gambar, grafik dan hasil perhitungan.
Selain informasi dapat diperoleh secara cepat, tepat dan akurat, keuntungan SIG dengan menggunakan komputer adalah:
1. Mudah dalam mengolah.
2. Pengumpulan data dan penyimpanannya hemat tempat dan ringkas.
3. Mudah diulang kalau sewaktu-waktu diperlukan.
4. Mudah diubah kalau sewaktu-waktu ada perubahan.
5. Mudah dibawa, dikirim dan ditransformasikan (dipindahkan).
6. Aman, karena dapat dikunci dengan kode atau manual.
7. Relatif lebih murah dibandingkan dengan survei lapangan.
8. Data yang sulit ditampilkan secara manual, dapat diperbesar bahkan dapat
ditampilkan dengan gambar tiga dimensi.
9. Berdasarkan data SIG dapat dilakukan pengambilan keputusan dengan tepat dan
cepat.
2.3.1 Sistem Proyeksi Peta
Proyeksi peta merupakan suatu fungsi yang merelasikan koordinat titik-titik yang terletak di atas permukaan suatu kurva ke koordinat titik-titk yang terletak di bidang datar [16]. Proyeksi peta bertujuan untuk memindahkan unsure-unsur titik, garis, dan sudut dari permukaan bumi ke suatu bidang datar dengan menggunakan rumus-rumus proyeksi peta sehingga tercapai kondisi yang diinginkan. Kondisi tersebut meliputi jarak, sudut atau arah dan luas unsur di atas peta akan tetap sama sebagaimana di permukaan bumi.
Salah satu system proyeksi peta yang sering digunakan adalah UTM (Universal Transverse Mercator). Pada sistem proyeksi ini, posisi horizontal dua
dimensi (x,y)utm didefinisikan dengan menggunakan bidang proyeksi selinder,
horizontal, seluruh permukaan bumi dibagi menjadi 60 bagian yang disebut zone UTM. Setiap zone dibatasi oleh dua meridian selebar 60. Secara vertical setiap derajat memiliki lebar 80 yang pembagiannya dimulai dari 800 LS ke arah utara. Sedangkan dibawah 800 LS, notasinya dimulai dari C, D, E, F, hingga X (tetapi huruf I dan O tidak digunakan).
Setiap zone UTM memiliki sistem koo rdinat sendiri dengan titik nol sejati pada perpotongan antara meridian sentralnya dengan ekuator. Dan, untuk menghindari nilai koordinat negatif, maka meridian tengahnya diberi nilai awal absis (x) 500.000 meter. Sementara untuk zone yang terletak di bagian selatan ekuator, juga untuk menghindari nilai koordinat yang negative, bidang ekuator diberi nilai awal ordinat (y) 10.000.000 meter.
Wilayah Indonesia terbagi ke dalam 9 zone UTM, mulai dari meridian 900 BT
hingga meridian 1440 BT dengan batas lintang 110 LS hingga 60 LU. Dengan
demikian, wilayah Indonesia dimulai dari zone 46 (meridian sentral 930 BT) hingga zone 54 (meridian sentral 1410 BT).
2.4 ArcView
ArcView merupakan salah satu perangkat lunak sistem infrmasi geografi yang
di keluarkan oleh ESRI (Environmental Systems Research Intitute). Dengan
menggunakan ArcView kita dapat melakukan pertukaran data, operasi-operasi matematik, menampilkan informasi spasial maupun atribut secara bersamaan,
membuat peta tematik, menyediakan bahasa pemograman (script) serta melakukan
fungsi-fungsi khusus lainnya dengan bantuan extensions seperti spasial analyst dan
image analyst (ESRI).
ArcView dalam operasinya menggunakan, membaca dan mengolah data dalam format Shapefile, selain itu ArcView juga dapat memanggil data-data dengan format BSQ, BIL, BIP, JPEG, TIFF, BMP, GeoTIFF atau data grid yang berasal dari ARC/INFO serta banyak lagi data-data lainnya. Setiap data spasial yang dipanggil
akan tampak sebagai sebuah theme dan gabungan dari theme-theme ini akan tampil
dalam sebuah view. ArcView mengorganisasikan komponen-komponen programnya
(view, theme, table, chart, layout dan script) dalam sebuah project. Project merupakan suatu unit organisasi tertinggi di dalam ArcView.
Salah satu kelebihan dari ArcView adalah kemampaunnya berhubungan dan berkerja dengan bantuan extensions. Extensions (dalam konteks perangkat lunak SIG
ArcView) merupakan suatu perangkat lunak yang bersifat “plug-in” dan dapat
diaktifkan ketika penggunanya memerlukan kemampuan fungsionalitas tambahan [14]. Extensions bekerja atau berperan sebagai perangkat lunak yang dapat dibuat sendiri, telah ada atau dimasukkan (di-instal) ke dalam perangkat lunak ArcView untuk memperluas kemampuan-kemampuan kerja dari ArcView itu sendiri.