METODE NAÏVE BAYES DENGAN K-NEAREST NEIGHBOR
Cahyo DarujatiFakultas Ilmu Komputer, Universitas Narotama [email protected]
Abstrak
Klasifikasi dokumen teks sebenarnya adalah permasalahan yang mendasar dan penting. Didalam dokumen teks, tulisan yang terkandung adalah bahasa alami manusia, yang merupakan bahasa dengan struktur yang kompleks dan jumlah kata yang sangat banyak. Oleh karena itu, permasalahan ini sangat menantang dikarenakan penggunaan bahasa alami tersebut Setelah melewati beberapa penelitian, ternyata dengan mengesampingkan pemrosesan bahasa natural dan menggunakan pendekatan statistik yaitu dengan hanya menganggap dokumen tersebut merupakan bag of word didapat performa yang cukup memuaskan. Oleh karena itu, dikembangkannya berbagai metode klasifikasi yang tidak memperhitungkan semantik dari dokumen tersebut.Didalam makalah ini, dibahas metode klasifikasi dokumen teks dengan menggunakan konsep pohon, yaitu dengan memperhitungkan jumlah kemunculan semua kata yang muncul dalam dokumen teks tersebut. Sebagai pembanding untuk metode tersebut, dibahas juga metode seperti metode Naive Bayes, yaitu metode dengan menghitung probabilitas kemunculan kata dan metode K-Nearest Neighbor (KNN), yaitu metode yang memperhitungkan kemiripan jumlah kemunculan kata antara satu dokumen dengan dokumen lain, Setelah membahas metode-metode yang ada, dilakukan percobaan terhadap data untuk mengetahui performa masing-masing metode untuk diketahui sebenarnya metode mana yang paling baik untuk digunakan dalam permasalahan klasifikasi teks.
I. Pendahuluan
Pengklasifikasian teks sangat dibutuhkan dalam berbagai macam aplikasi, terutama aplikasi yang jumlah dokumennya bertambah dengan cepat. Ada dua cara dalam penggolongan teks, yaitu clustering teks dan klasifikasi teks. Clustering teks berhubungan dengan menemukan sebuah struktur kelompok yang belum kelihatan (tak terpandu atau unsupervised) dari sekumpulan dokumen. Sedangkan pengklasifikasian teks dapat dianggap sebagai proses untuk membentuk golongan-golongan (kelas-kelas) dari dokumen berdasarkan pada kelas kelompok yang sudah diketahui sebelumnya (terpandu atau supervised).
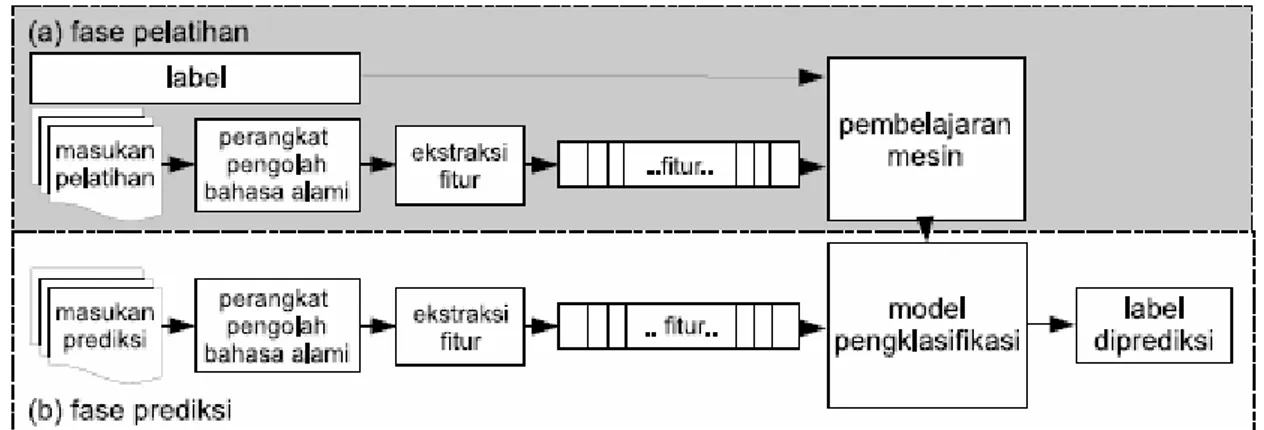
Gambar 1. Pembelajaran mesin dengan klasifikasi terpadu
Gambar 1 menunjukkan proses dari klasifikasi teks secara terpandu menggunakan pembelajaran mesin. Input mengalami pre-processing yaitu bisa berupa stop word atau stemming. Selama pelatihan seperti ditunjukkan pada Gambar 1, ekstraksi fitur diterapkan untuk mengkonversi setiap nilai masukan ke himpunan fitur. Pasangan himpunan fitur dan label kemudian diumpankan ke algoritma pembelajaran mesin untuk membangkitkan sebuah model. Selama prediksi ekstraksi fitur yang sama diterapkan untuk mengkonversi masukan-masukan baru ke himpunan fitur. Himpunan fitur ini lalu diumpankan ke model, yang akan membangkitkan perkiraan (prediksi) label. Sewaktu pengujian, prediksi-prediksi label ini dicocokkan dengan label sebenarnya untuk mengevaluasi kinerja pengklasifikasi teks terpandu.
II. Metode Pengklasifikasian Teks
Beberapa metode yang dapat digunakan untuk pengklasifikasian teks [1], antara lain adalah Na¨ıve Bayes [2], k-nearest neighbor [3], Support Vector Machines (SVM), boosting, algoritma pembelajaran aturan (rule learning algorithms) dan Maximum Entropy (MaxEnt). Dalam makalah ini mengggunakan dua metode yaitu :Naïve Bayes dan k-Nearest Neighbor. Metode Naïve Bayes dikenal dengan algoritma klasifikasi simple Bayesian [4]. Algoritma ini banyak digunakan karena terbukti efektif untuk kategorisasi teks, sederhana, cepat dan akurasi tinggi. Sedangkan Metode k-Nearest Neighbor adalah suatu metode untuk mengklasifikasikan data baru berdasarkan similaritas dan labeled data [5]. Similaritas yang dimaksud biasanya menggunakan metric jarak. Satuan jarak yang dipakai biasanya disebut dengan Euclidian [aplikasi of k-nn] Jenis dari metode ini, jika dilihat
Pengklasifikasian dilakukan pada 1 labeled data terdekat, algoritmanya sebagai berikut
- Menghitung jarak antara data baru ke setiap labeled data
- Menentukan 1 labeled data yang mempunyai jarak paling minimal - Klasifikasi data baru ke dalam labeled data tersebut
b. k-NN
Pengklasifikasian dilakukan dengan menentukan nilai pada k labeled data terdekat, dengan syarat nilai k>1, algoritmanya sebagai berikut :
- Menghitung jarak antara data baru ke setiap labeled data
- Menentukan k labeled data yang mempunyai jarak paling minimal - Klasifikasi data baru ke dalam labeled data yang mayoritas
III. Eksperimen
a. Himpunan data eksperimen
Dalam eksperimen ini, himpunan data yang akan diuji adalah kumpulan artikel dari majalah CHIP dan dibagi menurut kelas-kelasnya. Kelas-kelas yang dimaksud adalah pengkategorian jenis artikel, disesuaikan dengan pengkategorian artikel di dalam majalah CHIP, sehingga bisa dibedakan menjadi 5 kelas, yaitu :
1. Game 2. Hardware 3. Software 4. News 5. Tip trik
Jumlah total artikel sangat banyak namun data yang penulis siapkan adalah 3000 data teks yang tersebar pada tiap-tiap kelasnya.
b. Ukuran Evaluasi
Standar ukuran untuk mengevaluasi kinerja sebuah Algoritma dalam pengkategorian teks antara lain adalah recall dan precision. Ukuran untuk mengevaluasi kinerja yang digunakan pada eksperimen adalah accuracy. Accuracy merupakan jumlah rata-rata dari hasil recall pada tiap kelasnya.
IV. Hasil Eksperimen 1. Deskripsi Eksperimen
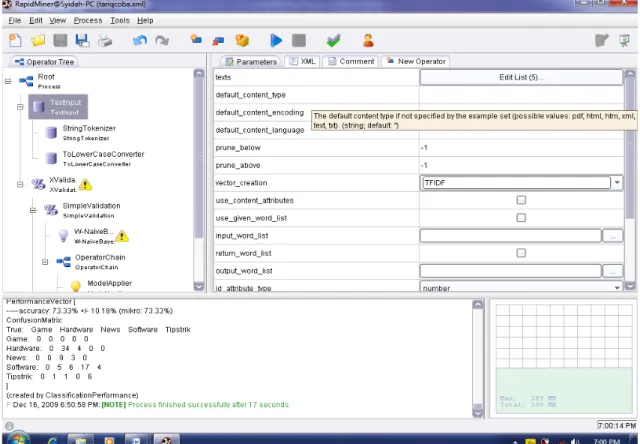
Eksperimen yang akan dilakukan adalah melihat kinerja dari dua Algoritma klasifikasi dokumen teks yaitu algoritma Naïve Bayes dan algoritma k-Nearest Neighbor. Dari kedua Algoritma ini akan diuji dengan 2 masukan yaitu menggunakan stop word removal maupun tanpa stop word removal (sebagaimana adanya). Kedua Algoritma, pengujian dilakukan validasi silang sebanya 10 kali (10 folds validation), yaitu dengan membagi data uji menjadi 10 sub samples, Untuk rasio data uji dimulai dari 10 %, naik 10% setiap kali uji sampai dengan 90 %. Tiap rasio dilakukan 10 kali pengujian dan output yang diinginkan adalah accuracy rata-ratanya. menggunakan software Rapidminner..
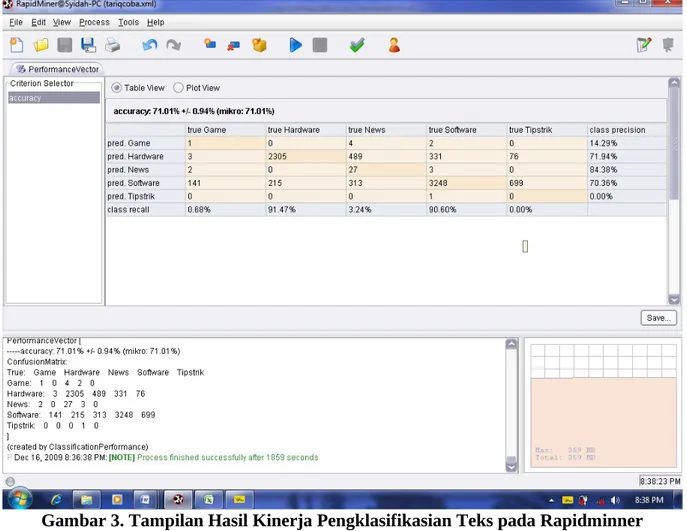
Gambar 3. Tampilan Hasil Kinerja Pengklasifikasian Teks pada Rapidminner 2. Implementasi Algoritma Naïve Bayes
Tabel 1 merupakan hasil implementasi Algoritma Naive Bayes pada dokumen teks sebagaimana adanya (tanpa stop word removal). Terlihat accuracy terbesar terjadi pada data pelatihan (training sample) mencapai 70% dengan nilai accuracy 87.45%
Percentage of Training Sample Accuracy
0.1 61.10 0.2 65.85 0.3 68.19 0.4 69.33 0.5 70.36 0.6 71.62 0.7 73.06 0.8 73.87 0.9 74.2
2.1 Penggunaan Stopword Removal Dalam Algoritma Naïve Bayes
Gambar 4 adalah contoh dokumen teks sebagaimana adanya dan cuplikan stopword yang akan dipakai dalam proses klasifikasi teks.
Panasonic KX-HCM10 Kamera dengan Web Server Webcam atau Netcam dengan
berat 350 gram ini jika dilihat
selintas tidak jauh berbeda penampilan
dan fungsinya dengan webcam yang telah ada di pasaran.
Namun jika dicermati....
... terlalu lalu akankah akan lama akhirnya akhir lamanya aku selama … (a) (b)
Gambar 4. Contoh Stopword Removal (a)Teks biasa (b) Contoh stop word removal
Setelah digunakannya stopword removal pada klasifikasi teks menggunakan metode Naïve Bayes, tentu saja hasil accuracy yang diperoleh berbeda jika dibandingkan tanpa menggunakan stop word. Lihat Tabel 2 di bawah ini, terlihat accuracy terbesar terjadi pada saat data pelatihan (training sample) mencapai 90 % dengan nilai accuracy 74.2 %
Percentage of Training Sample Accuracy
0.1 61.06 0.2 65.81 0.3 68.15 0.4 69.29 0.5 70.56 0.6 71.58 0.7 73.02 0.8 73.83 0.9 74.2
Tabel 2 Hasil Implementasi Algoritma Naïve Bayes dengan Stopword Removal 2.2 Pengaruh Stopword Removal Dalam Kinerja Algoritma Naïve Bayes
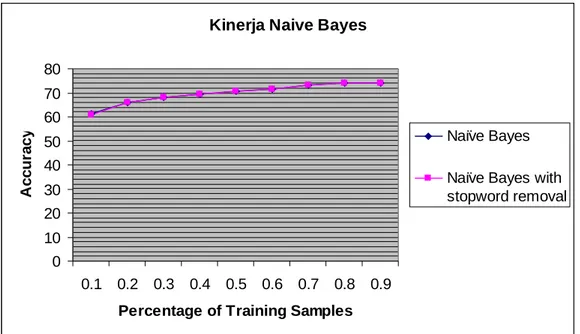
Lihat Gambar 5 di bawah ini, gambar tersebut adalah grafik kinerja dari Naïve Bayes dalam pengklasifikasian teks. Secara visual dapat dilihat bahwa penggunaan stopword hanya berdampak sangat kecil pada kinerja/accuracy. (sehingga diagram terlihat berimpit) Terlihat accuracy terbesar sebesar 74,2% sama-sama diperoleh dengan menggunakan stopword maupun tidak. Keduanya memperoleh kinerja terbesar saat data pelatihan mencapai 90 %
Kinerja Naive Bayes 0 10 20 30 40 50 60 70 80 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
Percentage of Training Samples
A
cc
u
ra
cy Naïve Bayes
Naïve Bayes with stopword removal
Gambar 5 Kinerja Naïve Bayes 3. Implementasi Algoritma k-Nearest Neighbor
Untuk algoritma k-Nearest Neighbor, nilai k ditentukan sama dengan 1.Tabel 3 merupakan hasil implementasi Algoritma k-Nearest Neighbor pada dokumen teks sebagaimana adanya (tanpa stop word removal). Terlihat accuracy terbesar terjadi pada data pelatihan (training sample) 10% dengan nilai accuracy 41,67%
Percentage of Training Sample Accuracy
0.1 41.67 0.2 34.37 0.3 30.64 0.4 31.59 0.5 29.51 0.6 30.61 0.7 31.53 0.8 33 0.9 35
Tabel 3. Hasil Implementasi Algoritma k-NN
3.1. Penggunaan stopword removal dalam Algoritma k-Nearest Neighbor
Setelah digunakannya stopword removal pada klasifikasi teks menggunakan metode k-Nearest Neighbor, tentu saja hasil accuracy yang diperoleh berbeda jika dibandingkan tanpa menggunakan stop word. Lihat Tabel 4 dibawah ini, terlihat accuracy terbesar terjadi pada saat data pelatihan (training sample) 10% dengan nilai accuracy 41,55.
Percentage of Training Sample Accuracy 0.1 41.55 0.2 34.43 0.3 30.64 0.4 31.63 0.5 29.49 0.6 30.61 0.7 31.46 0.8 32.89 0.9 34.77
Tabel 4. Hasil Implementasi Algoritma k-NN dengan Stopword Removal 3.2. Pengaruh Stopword Removal Dalam Kinerja Algoritma k-Nearest
Neighbor
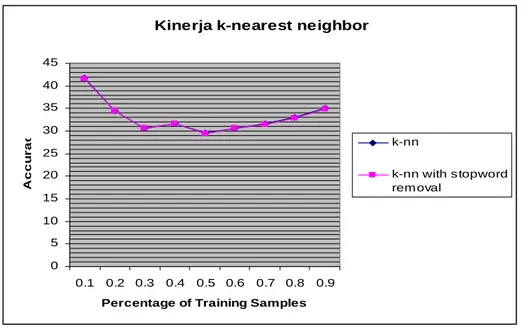
Lihat gambar 5 dibawah ini, gambar tersebut adalah grafik kinerja dari k-Nearest Neighbor dalam pengklasifikasian teks. Cukup menarik, terlihat accuracy terbesar sebesar 41,67 % Accuracy terbesar tersebut dicapai tanpa menggunakan stopword. Uniknya akurasi terbesar dicapai saat data training hanya 10%, padahal idealnya semakin besar data training akurasinya akan semakin meningkat. Penggunaan stopword juga tidak berpengaruh besar terhadap hasil kinerja, selisih akurasinya dengan k-nearest neighbor tanpa menggunakan stopword cukup tipis, sehingga pada gambar 5 diagramnya berimpit.
Kinerja k-nearest neighbor
0 5 10 15 20 25 30 35 40 45 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Percentage of Training Samples
A c c u ra c y k-nn k-nn with stopword removal
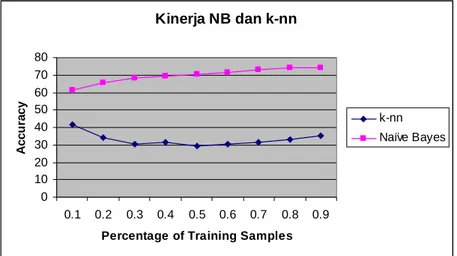
Kinerja NB dan k-nn 0 10 20 30 40 50 60 70 80 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
Percentage of Training Samples
A cc u ra cy k-nn Naïve Bayes
Gambar 6. Kinerja terbaik dari Naïve Bayes dank-Nearest Neighbor
V. Kesimpulan dari eksperimen yang dilakukan
Setelah algoritma Naïve Bayes dan algoritma k-Nearest Neighbor diimplementasikan dalam pengklasifikasian dokumen teks, ternyata penggunaan stopword hanya berdampak kecil. Dari kedua algoritma tersebut kinerja terbaik diperoleh jika tanpa menggunakan stopword. Gambar 6 menunjukkan secara umum algoritma yang terbaik. Terlihat bahwa kinerja terbaik diperoleh oleh algoritma Naïve Bayes.
Penghargaan
Rekan-rekan Common Computing Research Group - Electrical Engineering ITS: Bimo Gumelar, Medika Himura, Heru Arwoko, Meidya Koeshardianto, Mursyidah, dll.
Referensi
[1] Yiming Yang. An evaluation of statistical approaches to text categorization. Journal of Information Retrieval, 1:67–88, 1999.
[2] David D. Lewis. Naive (bayes) at forty: The independence assumption in Information retrieval. pages 4–15. Springer Verlag, 1998.
[3] Tuba Yavuz and H. Altay Guvenir. Application of k-Nearest Neighbor on Fearure Projection Classifier to Text Categorization, 1998
Tuba Yavuz and H Altay Guvenir�
[4] Wenyuan Dai, et all. Transferring Naïve Bayes Classifiers for Text Classifications, 1997