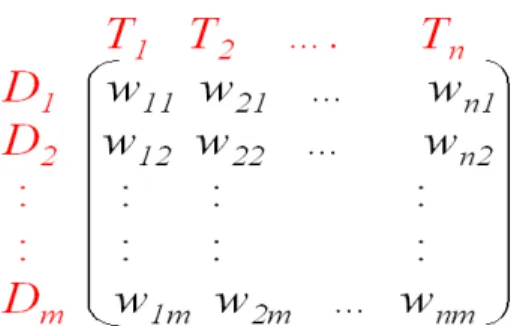BAB 2
LANDASAN TEORI
2.1 Sistem Temu Kembali Informasi
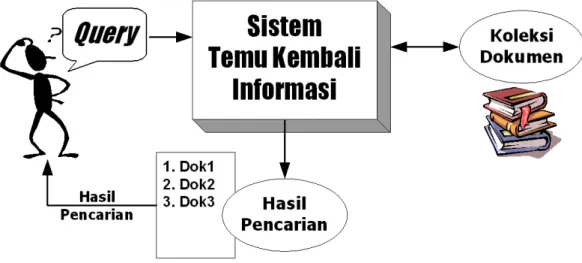
Sistem temu kembali informasi (information retrieval system) digunakan untuk menemukan kembali (retrieve) informasi-informasi yang relevan terhadap kebutuhan pengguna dari suatu kumpulan informasi secara otomatis (Mandala,2004).
Gambar 2.1 Ilustrasi Sistem Temu Kembali Informasi
Salah satu aplikasi umum dari sistem temu kembali informasi adalah search engine atau mesin pencarian yang terdapat pada jaringan internet. Pengguna dapat mencari halaman-halaman web yang dibutuhkannya melalui
search engine. Contoh lain dari sistem temu kembali informasi adalah sistem informasi perpustakaan dan pada mesin ATM (Anjungan Tunai Mandiri).
Mandala (2002, hal: 2) menyatakan bahwa sistem temu kembali informasi terutama berhubungan dengan pencarian informasi yang isinya tidak memiliki struktur. Demikian pula ekspresi kebutuhan pengguna yang disebut query, juga tidak memiliki struktur. Hal ini yang membedakan sistem temu kembali informasi dengan sistem basis data. Dokumen adalah contoh informasi yang tidak terstruktur. Isi dari suatu dokumen sangat tergantung pada pembuat dokumen tersebut.
Sistem Temu Kembali Informasi sebagai sistem yang berfungsi untuk menemukan informasi yang relevan dengan kebutuhan pemakai, merupakan salah satu tipe sistem informasi. Salah satu hal yang perlu diingat adalah bahwa informasi yang diproses terkandung dalam sebuah dokumen yang bersifat tekstual.
Dalam konteks ini, temu kembali informasi berkaitan dengan representasi, penyimpanan, dan akses terhadap dokumen representasi dokumen. Dokumen yang ditemukan tidak dapat dipastikan apakah relevan dengan kebutuhan informasi pengguna yang dinyatakan dalam query. Pengguna Sistem Temu Kembali informasi sangat bervariasi dengan kebutuhan informasi yang berbeda-beda.
Dokumen sebagai objek data dalam Sistem Temu Kembali Informasi merupakan sumber informasi. Dokumen biasanya dinyatakan dalam bentuk indeks atau kata kunci. Kata kunci dapat diekstrak secara langsung dari teks dokumen atau ditentukan secara khusus oleh spesialis subjek dalam proses pengindeksan yang pada dasarnya terdiri dari proses analisis dan representasi dokumen (Lancaster, 1979).
Pengindeksan dilakukan dengan menggunakan sistem pengindeksan tertentu, yaitu himpunan kosa kata yang dapat dijadikan sebagai bahasa indeks
sehingga diperoleh informasi yang terorganisasi. Sementara itu, pencarian diawali dengan adanya kebutuhan informasi pengguna.
Dalam hal ini Sistem Temu Kembali Informasi berfungsi untuk menganalisis pertanyaan (query) pengguna yang merupakan representasi dari kebutuhan informasi untuk mendapatkan pernyataan-pernyataan pencarian yang tepat. Selanjutnya pernyataan-pernyataan pencarian tersebut dipertemukan dengan informasi yang telah terorganisasi dengan suatu fungsi penyesuaian (matching function) tertentu sehingga ditemukan dokumen atau sekumpulan dokumen.
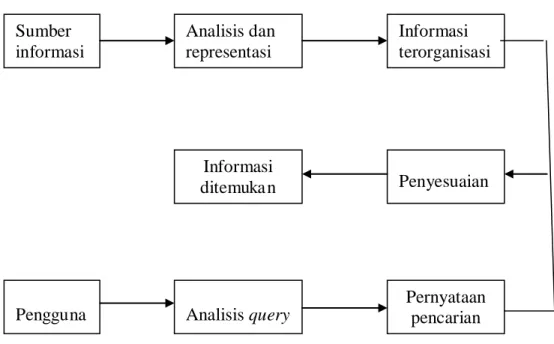
Proses tersebut di atas dapat diilustrasikan seperti gambar berikut:
Gambar 2.2 Outline Sistem Temu Kembali Informasi (Lancaster,1979)
Sebagai suatu sistem, sistem temu kembali informasi memiliki beberapa bagian yang membangun sistem secara keseluruhan. Gambaran bagian-bagian yang terdapat pada suatu sistem temu kembali informasi digambarkan pada Gambar 2.3. Sumber informasi Analisis dan representasi Informasi terorganisasi Informasi ditemuka n Penyesuaian
Pengguna Analisis query
Pernyataan pencarian
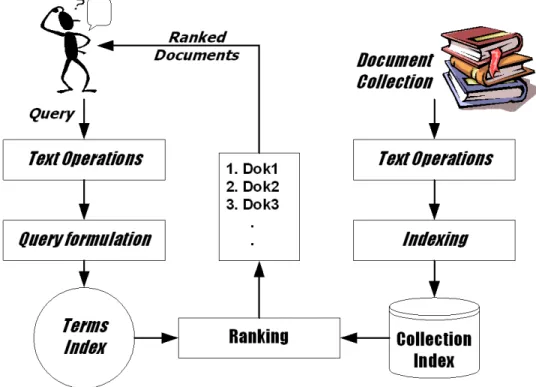
Gambar 2.3 Bagian-bagian Sistem Temu Kembali Informasi (Mandala, 2002)
Gambar 2.3 memperlihatkan bahwa terdapat dua buah alur operasi pada sistem temu kembali informasi. Alur pertama dimulai dari koleksi dokumen dan alur kedua dimulai dari query pengguna. Alur pertama yaitu pemrosesan terhadap koleksi dokumen menjadi basis data indeks tidak tergantung pada alur kedua. Sedangkan alur kedua tergantung dari keberadaan basis data indeks yang dihasilkan pada alur pertama (Mandala, 2002).
Bagian-bagian dari sistem temu kembali informasi menurut gambar 2.3 meliputi :
1. Text Operations (operasi terhadap teks) yang meliputi pemilihan kata-kata dalam query maupun dokumen (term selection) dalam pentransformasian dokumen atau query menjadi terms index (indeks dari kata-kata).
2. Query formulation (formulasi terhadap query) yaitu memberi bobot pada indeks kata-kata query.
3. Ranking (perangkingan), mencari dokumen-dokumen yang relevan terhadap query dan mengurutkan dokumen tersebut berdasarkan kesesuaiannya dengan query.
4. Indexing (pengindeksan), membangun basis data indeks dari koleksi dokumen. Dilakukan terlebih dahulu sebelum pencarian dokumen dilakukan.
Sistem Temu Kembali Informasi menerima query dari pengguna, kemudian melakukan perangkingan terhadap dokumen pada koleksi berdasarkan kesesuaiannya dengan query. Hasil perangkingan yang diberikan kepada pengguna merupakan dokumen yang menurut sistem relevan dengan query. Namun relevansi dokumen terhadap suatu query merupakan penilaian pengguna yang subjektif dan dipengaruhi banyak faktor seperti topik, pewaktuan, sumber informasi maupun tujuan pengguna.
Menurut Lancaster (1979) Sistem Temu Kembali Informasi terdiri dari 6 (enam) subsistem, yaitu:
1. Subsistem dokumen 2. Subsistem pengindeksan 3. Subsistem kosa kata 4. Subsistem pencarian
5. Subsistem antarmuka pengguna-sistem 6. Subsistem penyesuaian.
Sementara itu Tague-Sutcliffe (1996) melihat Sistem Temu Kembali Informasi sebagai suatu proses yang terdiri dari 6 (enam) komponen utama yaitu:
1. Kumpulan dokumen 2. Pengindeksan
3. Kebutuhan informasi pemakai 4. Strategi pencarian
5. Kumpulan dokumen yang ditemukan 6. Penilaian relevansi
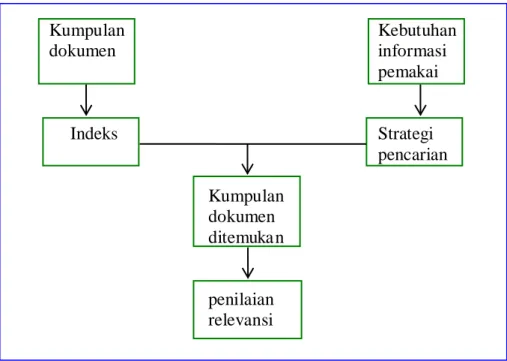
Bila diperhatikan dengan seksama, perbedaan komponen Sistem Temu Kembali Informasi menurut Lancaster (1979) dan menurut Tague-Sutcliffe (1996) terletak pada penilaian relevansi, yaitu suatu tahap dalam temu kembali untuk menentukan dokumen yang relevan dengan kebutuhan informasi pemakai. Secara garis besar komponen-komponen Sistem Temu Kembali dapat diilustrasikan seperti pada Gambar 2.4
Kumpulan Kebutuhan dokumen informasi pemakai Indeks Strategi pencarian Kumpulan dokumen ditemuka n penilaian relevansi
Gambar 2.4 Komponen Sistem Temu-Kembali Informasi (Tarto, 2008)
Dalam proses pencarian informasi terjadi interaksi antara pengguna dengan sistem (mesin) baik secara langsung maupun tidak langsung. Secara umum interaksi antara pengguna dengan sistem dalam proses pencarian informasi dapat dinyatakan seperti pada Gambar 2.5
Gambar 2.5 Interaksi antara pengguna dengan sistem (Tarto, 2008)
Sistem Temu Kembali Informasi didisain untuk menemukan dokumen atau informasi yang diperlukan oleh masyarakat pengguna. Sistem Temu Kembali Informasi bertujuan untuk menjembatani kebutuhan informasi pengguna dengan sumber informasi yang tersedia dalam situasi seperti dikemukakan oleh Belkin (1980) sebagai berikut:
1. Penulis mempresentasikan sekumpulan ide dalam sebuah dokumen menggunakan sekumpulan konsep.
2. Terdapat beberapa pengguna yang memerlukan ide yang dikemukakan oleh penulis tersebut, tapi mereka tidak dapat mengidentifikasikan dan menemukannya dengan baik.
3. Sistem temu kembali informasi bertujuan untuk mempertemukan ide yang dikemukakan oleh penulis dalam dokumen dengan kebutuhan informasi pengguna yang dinyatakan dalam bentuk pertanyaan (query).
Berkaitan dengan sumber informasi di satu sisi dan kebutuhan informasi pengguna di sisi yang lain, Sistem Temu Kembali Informasi berperan untuk:
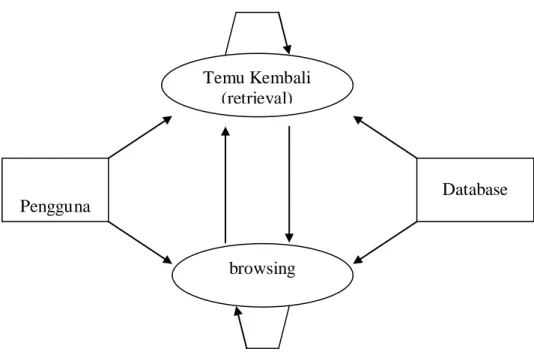
Temu Kembali (retrieval)
Pengguna
browsing
1. Menganalisis isi sumber informasi dan pertanyaan pengguna.
2. Mempertemukan pertanyaan pengguna dengan sumber informasi untuk mendapatkan dokumen yang relevan.
Adapun fungsi utama Sistem Temu Kembali Informasi seperti dikemukakan oleh Lancaster (1979) dan Kent (1971) adalah sebagai berikut:
1. Mengidentifikasi sumber informasi yang relevan dengan minat masyarakat pengguna yang ditargetkan.
2. Menganalisis isi sumber informasi (dokumen)
3. Merepresentasikan isi sumber informasi dengan cara tertentu yang memungkinkan untuk dipertemukan dengan pertanyaan (query) pengguna. 4. Merepresentasikan pertanyaan (query) pengguna dengan cara tertentu yang
memungkinkan untuk dipertemukan sumber informasi yang terdapat dalam basis data.
5. Mempertemukan pernyataan pencarian dengan data yang tersimpan dalam basis data.
6. Menemu-kembalikan informasi yang relevan.
7. Menyempurnakan unjuk kerja sistem berdasarkan umpan balik yang diberikan oleh pengguna.
2.2 Model Ruang Vektor
Mandala (2002, hal: 3) menyatakan bahwa model sistem temu kembali informasi menentukan detail sistem temu kembali informasi yaitu meliputi representasi dokumen maupun query, fungsi pencarian (retrieval function) dan notasi kesesuaian (relevance notation) dokumen terhadap query.
Salah satu model sistem temu kembali informasi yang paling awal digunakan adalah model boolean. Model boolean merepresentasikan dokumen sebagai suatu himpunan kata-kunci (set of keywords). Sedangkan query direpresentasikan sebagai ekspresi boolean. Query dalam ekspresi boolean
merupakan kumpulan kata kunci yang saling dihubungkan melalui operator boolean seperti AND, OR dan NOT serta menggunakan tanda kurung untuk menentukan scope operator. Hasil pencarian dokumen dari model boolean adalah himpunan dokumen yang relevan.
Kekurangan dari model boolean ini antara lain:
1. Hasil pencarian dokumen berupa himpunan, sehingga tidak dapat dikenali dokumen-dokumen yang paling relevan atau agak relevan (partial match). 2. Query dalam ekspresi boolean dapat menyulitkan pengguna yang tidak
mengerti tentang ekpresi boolean.
Kekurangan dari model boolean diperbaiki oleh model ruang vektor yang mampu menghasilkan dokumen-dokumen terurut berdasarkan tingkat kerelevanannya dengan query pengguna. Selain itu, pada model ruang vektor, query dapat berupa sekumpulan kata-kata dari penguna dalam ekspresi bebas, dengan kata lain query juga dinyatakan sebagai himpunan kata-kata atau istilah dengan bahasa sehari-hari (Mandala, 2004).
Metode Ruang Vektor adalah suatu metode untuk merepresentasikan sistem temu kembali informasi. Suatu sistem temu kembali informasi terdiri atas dua bagian, yaitu penyimpanan dokumen dan pemrosesan query. Untuk mengimplementasikan metode ruang vektor, diasumsikan sudah tersedia sekumpulan term yang dapat mendeskripsikan kumpulan dokumen yang tersimpan dalam suatu sistem temu-kembali informasi. Baik query maupun dokumen-dokumen yang disimpan, dinyatakan dalam bentuk vector (Salton, 1989).
Misalkan terdapat sejumlah n kata yang berbeda sebagai kamus kata (vocabulary) atau indeks kata (terms index). Kata-kata ini akan membentuk ruang vektor yang memiliki dimensi sebesar n. Setiap kata i dalam dokumen atau query diberikan bobot sebesar wi. Baik dokumen maupun query direpresentasikan sebagai vektor berdimensi n.
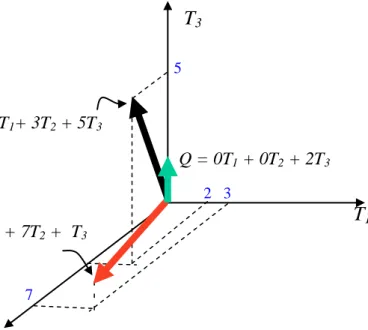
Sebagai contoh terdapat 3 buah kata (T1, T2 dan T3), 2 buah dokumen (D1 dan D2
D
) serta sebuah query Q. Masing-masing bernilai : 1 = 2T1+3T2+5T D 3 2 = 3T1+7T2+0T Q = 0T 3 1+0T2+2T
Maka representasi grafis dari ketiga vektor ini adalah 3
Gambar 2.6 Representasi dokumen dan query pada ruang vektor (Mandala, 2002)
Koleksi dokumen direpresentasi pula dalam ruang vektor sebagai matriks kata-dokumen (terms-documents matrix). Nilai dari elemen matriks wij adalah bobot kata i dalam dokumen j. Permasalahan pembobotan kata (terms weighting) dalam dokumen akan dibahas pada bagian selanjutnya.
Misalkan terdapat sekumpulan kata T sejumlah n, yaitu T = (T1, T2, … , Tn) dan sekumpulan dokumen D sejumlah m, yaitu D = (D1, D2, … , Dm) serta wij
T
3adalah bobot kata i pada dokumen j. Maka gambar 2.7 adalah representasi matriks kata-dokumen (Mandala, 2002).
T
1T
2 D1 = 2T1+ 3T2 + 5T3 D2 = 3T1 + 7T2 + T3 Q = 0T1 + 0T2 + 2T3 7 3 2 5Gambar 2.7 Representasi matriks kata-dokumen
Beberapa karakteristik dari model ruang vektor dalam sistem temu kembali informasi adalah
1. model ruang vektor berdasarkan pada term 2. mendukung penentuan peringkat dokumen 3. model ruang vector memiliki prinsip dasar:
a) dokumen direpresentasikan dengan menggunakan vektor term b) ruang dimensi ditentukan oleh term- term
c) query direpresentasikan dengan menggunakan vektor term 4. model ruang vektor memerlukan
a) bobot term (term weight) untuk vektor dokumen b) bobot term untuk query
5. kinerja model sistem temu kembali informasi ini a) efisien
b) mudah dalam representasi
c) dapat diimplementasikan pada document-matching
Prosedur model ruang vektor dapat dikelompokkan menjadi tiga tahap yaitu :
1. Pengideks-an dokumen
3. Memberikan peringkat dokumen berdasarkan ukuran kesamaan (similarity measure)
2.2.1 Pengindeksan Dokumen
1. Parsing
mengambil term-term dari dokumen dan query dengan cara memotong string input berdasarkan tiap kata yang menyusunnya (Lusiana et al, 2008).
Elemen teks (string input) dipisahkan dengan teknik parsing menggunakan fungsi split dimana pemisahan string dilakukan berdasarkan white space (spasi dan tab) untuk kemudian diletakkan pada array
2. Stopword removing
menghilangkan stopword pada string input yang menyusun dokumen dan query, contoh:
User could find relevant information by using search engine. Dilakukan parsing:
- user - user
- could - could
- find - find
- relevant - relevant
- information hasil stopword removing - information
- by - using
- using - search
- search - engine
Dalam proses ini digunakan sebuah daftar kata buang (stoplist) yaitu daftar kata-kata yang tidak digunakan (dibuang) karena tidak signifikan dalam membedakan dokumen atau query. Stoplist ini terdiri atas 658 kata, umumnya berupa kata tugas, kata hubung, kata bantu, yang mempunyai fungsi dalam kalimat penyusun dokumen tetapi tidak memiliki arti. Daftar stopword terlampir bersama dengan listing program
Proses yang dilakukan dalam tahap penghilangan stopword ini adalah:
- string input yang telah di pisah melalui proses parsing pada tahap pengindeksan sebelumnya dimasukkan dalam array
- array yang berisi string tersebut kemudian melalui proses penyaringan stopword.
- apabila string dalam array sama dengan string dalam array stopword maka string tersebut akan dieliminasi
- jika tidak sama, maka string tersebut akan diteruskan ke tahap pengindeksan selanjutnya yaitu stemming
Penggunaan stopword removing dalam proses pengindeksan dokumen dan query akan dapat meningkatkan kinerja mesin pencari. Jika stopword terdapat pada masukan query yang diberikan pengguna, dan stopword tersebut tidak dihilangkan, hal ini akan menyebabkan hampir semua dokumen dalam koleksi akan di-retrieve, karena sebahagian besar term penyusun dokumen adalah berupa kata hubung, kata bantu, maupun kata ganti, yang merupakan bagian dari stopword. Dengan demikian akan semakin jauh dari fungsi utama suatu sistem temu kembali informasi karena tidak dapat memberikan dokumen yang relevan dengan permintaan pengguna. Penghilangan stopword setelah proses parsing pada pengindeksan dokumen akan dapat mempercepat proses mesin pencari karena dapat mengurangi jumlah term yang akan di-matching-kan antara dokumen dan query serta yang akan dicari
bobotnya dalam proses perankingan dokumen, dapat menghemat ruang memori dan menghasilkan dokumen yang relevan berdasarkan hasil perhitungan bobot term query pada dokumen (Jones-Willet, 1997).
3. Stemming
Menurut Peter Willet (1997) stemming adalah proses untuk menggabungkan atau memecahkan setiap varian-varian suatu kata menjadi kata dasar.
Stem (akar kata) adalah bagian dari kata yang tersisa setelah dihilangkan
imbuhannya (awalan dan akhiran), contohnya kata connect adalah stem dari connected, connecting, connection, dan connections.
Metode stemming memerlukan input berupa term yang terdapat dalam dokumen. Sedangkan outputnya berupa stem.
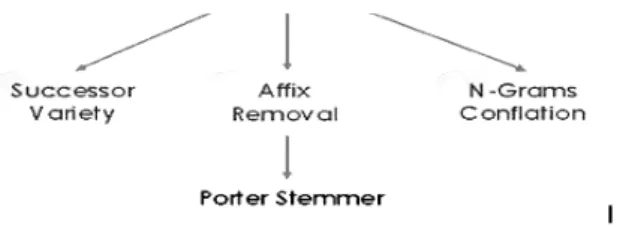
Ada tiga jenis metode stemming
I.
, antara lain :
Successor Variety (SV) : lebih mengutamakan penyusunan huruf dalam
kata dibandingkan dengan pertimbangan atas fonem. Contoh untuk kata-kata : corpus, able, axle, accident, ape, about menghasilkan SV untuk kata apple
a. Karena huruf pertama dari kata “ :
apple
b. Karena dua huruf pertama dari kata “
” adalah “a”, maka kumpulan kata yang ada substring “a” diikuti “b”, “x”, “c”, “p” disebut SV dari “a” sehingga “a” memiliki 4 SV.
apple
II.
” adalah “ap”, maka kumpulan kata yang ada substring “ap” hanya diikuti “e” disebut SV dari “ap” sehingga “ap” memiliki 1 SV.
N-Gram Conflation : ide dasarnya adalah pengelompokan kata-kata
secara bersama berdasarkan karakter-karakter (substring
III.
) yang teridentifikasi sepanjang N karakter.
Affix Removal (penghilangan imbuhan) : membuang prefix (awalan) dan
digunakan adalah algoritma Porter Stemmer karena modelnya sederhana dan effisien.
a. Jika suatu kata diakhiri dengan “ies” tetapi bukan “eies” atau “aies”, maka “ies” di-replace dengan “y”
b. Jika suatu kata diakhiri dengan “es” tetapi bukan “aes” atau “ees” atau “oes”, maka “es” di-replace dengan “e”
c. Jika suatu kata diakhiri dengan “s” tetapi bukan “us” atau “ss”, maka “s” di-replace dengan “NULL”
Gambar 2.8 Jenis-jenis Metode Stemming (Jones-Willet, 1997)
Porter stemmer merupakan algoritma penghilangan
akhiran morphological dan infleksional yang umum dari bahasa Inggris. Algoritma ini terdiri dari himpunan kondisi atau action rules
I.
.
Kondisi dikelompokkan menjadi tiga kelas, yakni :
Kondisi pada stem
Ukuran (
measure), dinotasikan dengan m, dari sebuah stem berdasarkan pada urutan vokal-konsonan.
m = 0, contoh : TR, EE, TREE, Y, BY
m = 1, contoh : TROUBLE, OATS, TREES, IVY
m = 2, contoh : TROUBLES, PRIVATE, OATEN
*<X> berarti stem berakhir dengan huruf x
*v* berarti stem mengandung sebuah vokal
*d berarti stem diakhiri dengan konsonan dobel
*o berarti stem diakhiri dengan konsonan – vokal – konsonan,
berurutan, di mana konsonan akhir bukan w, x, atau y.
II. III.
Kondisi pada suffix (akhiran) Kondisi pada rule
{
step1a(word); step1b(stem);
if (the second or third rule of step 1b was used) step1b1(stem); step1c(stem); step2(stem); step3(stem); step4(stem); step5a(stem); step5b(stem); }
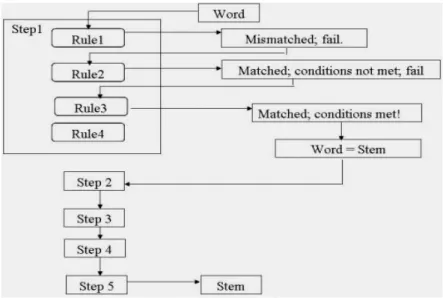
: rule-rule dibagi menjadi step-step. Rule-rule dalam sebuah step diuji secara berurutan, dan hanya 1 rule dari suatu step yang diterapkan.
Step (langkah-langkah) tahapan pada algoritma Porter Stemmer :
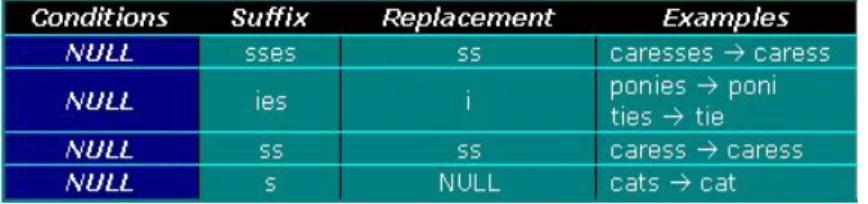
Step 1a : remove plural suffixation, yaitu menghapus/ mengganti akhiran pada kata yang berbentuk jamak, berupa akhiran sses menjadi ss, ies menjadi i, ss (tidak diganti), dan akhiran s hingga didapatkan stem
Step 1b : remove verbal inflection, yaitu menghapus/ mengganti akhiran pada kata yang mengalami modulasi lisan/ pengucapan, berupa akhiran eed (jika terdapat paling kurang sebuah huruf vokal-konsonan berurutan) menjadi ee, serta akhiran ed dan ing (tidak diganti) untuk kata yang hanya memiliki sebuah huruf vokal, dan dihapus untuk yang memiliki lebih dari satu huruf vokal
Step 1b1 : continued for -ed and -ing rules, berupa tahap lanjutan untuk
rule akhiran ed dan ing. Hasil stemming pada akhiran ed dan ing pada step sebelumnya
Tabel 2.1 Remove Plural Suffixation
akan di-stemming lagi yaitu dengan menghapus kata yang berakhiran at (diganti menjadi ate), bl menjadi ble, iz menjadi ize, untuk kata yang diakhiri dengan dobel huruf konsonan dan tidak berakhir dengan huruf l, s, atau z akan diganti menjadi kata yang berakhir satu huruf konsonan saja, jika kata berakhir dengan huruf l, s, atau z maka tidak diganti, dan untuk kata yang diakhiri dengan huruf konsonan–vokal–konsonan berurutan, di
mana konsonan akhir bukan w, x, atau y dan hanya terdapat satu urutan huruf vokal-konsonan di dalamnya maka ditambahkan e
Step 1c : y and i, jika kata mengandung sebuah huruf vokal dan berakhiran y akan diganti dengan i
Step 2 : peel one suffix off for multiple suffixes, dengan kata tersebut
memiliki paling kurang sebuah huruf vokal-konsonan berurutan, yaitu kata berakhiran ational atau ation atau ator (menjadi ate), tional (menjadi tion), enci (menjadi ence), anci (menjadi ance), izer atau ization (menjadi ize), iviti atau iveness (menjadi ive), ality atau alism atau alli (menjadi al), biliti (menjadi ble), abli (menjadi able), ently (menjadi ent), eli (menjadi e), ousli dan ousness (menjadi ous), fulness (menjadi ful)
Tabel 2.3 Continued for -ed and -ing Rules
Step 3 : dengan kata tersebut memiliki paling kurang sebuah huruf
vokal-konsonan berurutan, kata berakhiran ative atau ful atau ness akan dihapus, kata berakhiran icate atau iciti atau ical (menjadi ic), alize (menjadi al)
Step 4 : delete last suffix,
Tabel 2.6 Step 3
dengan kata tersebut memiliki paling kurang dua huruf vocal-konsonan berurutan, kata berakhiran al, ance, ence, er, ic, able, ible, ant, ement, ment, ent, ion, ou, ism, ate, iti, ous, ive, dan ize akan dihapus
Step 5a : remove e, menghapus akhiran e jika kata tersebut paling kurang memiliki dua huruf vocal-konsonan yang berurutan atau memiliki sebuah huruf vocal-konsonan berurutan dan tidak diakhiri dengan huruf konsonan–vokal–konsonan berurutan, di mana konsonan akhir bukan w, x, atau y
Step 5b : reduction, jika kata hanya memiliki sebuah huruf vokal-konsonan berurutan dan tidak berakhir dengan dobel huruf vokal-konsonan dan huruf l maka diganti dengan akhiran satu huruf konsonan saja
4. Term weighting (pembobotan term)
Tabel 2.8 Remove e
Tabel 2.9 Reduction Tabel 2.7 Delete Last Suffix
2.2.2 Pembobotan kata (term weighting)
Sistem Temu Kembali Informasi berhadapan dengan pencarian informasi yang sesuai dengan query pengguna dari koleksi dokumen. Koleksi dokumen tersebut terdiri dari dokumen-dokumen yang beragam panjangnya dengan kandungan term yang berbeda pula. Hal yag perlu diperhatikan dalam pencarian informasi dari koleksi dokumen yang heterogen adalah pembobotan term. Term dapat berupa kata, frase atau unit hasil indexing lainnya dalam suatu dokumen yang dapat digunakan untuk mengetahui konteks dari dokumen tersebut. Karena setiap kata memiliki tingkat kepentingan yang berbeda dalam dokumen, maka untuk setiap kata tersebut diberikan sebuah indikator, yaitu term weight.
Term weighting atau pembobotan term sangat dipengaruhi oleh hal-hal berikut ini (Mandala, 2004):
1. Term Frequency (tf) factor, yaitu faktor yang menentukan bobot term pada suatu dokumen berdasarkan jumlah kemunculannya dalam dokumen tersebut. Nilai jumlah kemunculan suatu kata (term frequency) diperhitungkan dalam pemberian bobot terhadap suatu kata. Semakin besar jumlah kemunculan suatu term (tf tinggi) dalam dokumen, semakin besar pula bobotnya dalam dokumen atau akan memberikan nilai kesesuian yang semakin besar.
2. Inverse Document Frequency (idf) factor, yaitu pengurangan dominansi term yang sering muncul di berbagai dokumen. Hal ini diperlukan karena term yang banyak muncul di berbagai dokumen, dapat dianggap sebagai term umum (common term) sehingga tidak penting nilainya. Sebaliknya faktor kejarangmunculan kata (term scarcity) dalam koleksi dokumen harus diperhatikan dalam pemberian bobot. Menurut Mandala (dalam Witten, 1999) ‘Kata yang muncul pada sedikit dokumen harus dipandang sebagai kata yang lebih penting (uncommon tems) daripada kata yang muncul pada banyak dokumen. Pembobotan akan memperhitungkan faktor kebalikan frekuensi
dokumen yang mengandung suatu kata (inverse document frequency). Hal ini merupakan usulan dari George Zipf. Zipf mengamati bahwa frekuensi dari sesuatu cenderung kebalikan secara proposional dengan urutannya.’
Metode TF-IDF merupakan metode pembobotan term yang banyak digunakan sebagai metode pembanding terhadap metode pembobotan baru. Pada metode ini, perhitungan bobot term t dalam sebuah dokumen dilakukan dengan mengalikan nilai Term Frequency dengan Inverse Document Frequency.
Pada Term Frequency (tf), terdapat beberapa jenis formula yang dapat digunakan yaitu (Mandala, 2004):
1. tf biner (binery tf), hanya memperhatikan apakah suatu kata ada atau tidak dalam dokumen, jika ada diberi nilai satu, jika tidak diberi nilai nol
2. tf murni (raw tf), nilai tf diberikan berdasarkan jumlah kemunculan suatu kata di dokumen. Contohnya, jika muncul lima kali maka kata tersebut akan bernilai lima.
3. tf logaritmik, hal ini untuk menghindari dominansi dokumen yang mengandung sedikit kata dalam query, namun mempunyai frekuensi yang tinggi.
tf
= 1 +log (tf)
4. tf normalisasi, menggunakan perbandingan antara frekuensi sebuah kata dengan jumlah keseluruhan kata pada dokumen.
tf
= 0.5 + 0.5 xtf
max tf
Inverse Document Frequency (idf) dihitung dengan menggunakan formula (2.1)
idf
j
= log (D /df
j)
dimana
D adalah jumlah semua dokumen dalam koleksi
df
j adalah jumlah dokumen yang mengandung term
t
w
j
Menurut Defeng (dalam Robertson, 2004) ‘Jenis formula yang akan digunakan untuk perhitungan term frequency (tf) yaitu tf murni (raw tf). Dengan demikian rumus umum untuk TF-IDF adalah penggabungan dari formula perhitungan raw tf dengan formula idf (rumus 2.3) dengan cara mengalikan nilai term frequency (tf) dengan nilai inverse document frequency (idf) :
ij
= tf
ij× idf
jw
ij
= tf
ij× log (D /df
j)
Keterangan :
w
ij adalah bobot term
t
j terhadap dokumend
itf
ij adalah jumlah kemunculan term
t
jdalam dokumend
iD
adalah jumlah semua dokumen yang ada dalam databasedf
j adalah jumlah dokumen yang mengandung term
t
j(minimal ada satu kata yaitu term
t
j)
Berdasarkan rumus 2.4, berapapun besarnya nilai
tf
ij , apabila D =
df
jw
maka akan didapatkan hasil 0 (nol) untuk perhitungan idf. Untuk itu dapat ditambahkan nilai 1 pada sisi idf,’ sehingga perhitungan bobotnya menjadi sebagai berikut:
ij
= tf
ij× ( log (D /df
j) + 1 )
(2.3)
(2.4)
berikut ini diberikan contoh perhitungan bobot dokumen terhadap query yang diberikan pengguna, dengan menggunakan metode pembobotan TF-IDF (rumus 2.5) di atas:
pengguna memberikan query : gold silver truck sehingga didapatkan query terms (Q):
- gold - silver - truck
dalam koleksi dokumen terdapat:
dokumen 1 (d1) = Shipment of gold damaged in a fire. dokumen 2 (d2) = Delivery of silver arrived in a silver truck. dokumen 3 (d3) = Shipment of gold arrived in a truck Jadi total jumlah dokumen dalam koleksi (D) = 3
Untuk setiap query dan dokumen dalam koleksi, dilakukan pemotongan string berdasarkan tiap kata yang menyusunnya, menghilangkan tanda baca, angka dan stopword:
Setelah melalui proses ini, maka kata of, in, dan a pada ketiga dokumen dihapus lalu di-stemming sehingga didapatkan term-term ( documents terms) sebagai berikut:
- ship - gold - damage - fire - deliver - silver - arrive - truck
Pada tahap ini tiap dokumen diwujudkan sebagai sebuah vektor dengan elemen sebanyak term query yang terdapat dalam tiap dokumen yang berhasil
dikenali dari tahap ekstraksi dokumen sebelumnya. Vektor tersebut beranggotakan bobot dari setiap term query yang dihitung berdasarkan metode TF-IDF
Gambar 2.10 Representasi Term Query pada Ruang Vektor
Fungsi metode ini adalah untuk mencari representasi nilai dari tiap dokumen dalam koleksi. Dari sini akan dibentuk suatu vektor antara dokumen dan query yang ditentukan oleh nilai bobot term query dalam dokumen. Semakin besar nilai perhitungan bobot yang diperoleh maka semakin tinggi tingkat similaritas dokumen terhadap query. Contohnya untuk perhitungan bobot (w) term query silver dalam dokumen2 (d2) = Delivery of silver arrived in a silver truck, yaitu: jumlah kemunculan term silver dalam dokumen 2 (d2) adalah sebanyak dua kali (
tf
= 2), total dokumen yang ada di koleksi sebanyak tiga dokumen (D=3), dari ketiga dokumen dalam koleksi, term silver muncul pada dokumen 2 (d2), sehingga total dokumen yang mengandung term silver adalah satu dokumen (d
f
= 1), sehingga dapat diperoleh nilai bobot term silver pada dokumen 2 (d2)w
ij= tf
ij× ( log (D /df
j) + 1 )
w
ij=
2* (
log ( 3 / 1 ) + 1)
w
ij=
2* (
0.477 + 1)
w
ij=
2.954 silver truck goldDengan demikian dapat diperoleh nilai bobot (w) untuk setiap term pada query dalam masing-masing dokumen:
Tabel 2.10 Perhitungan Pembobotan TF-IDF Term Query dalam Setiap Dokumen
tf
df D df
IDF IDF+1 W = tf* (IDF+1)
Q d1 d2 d3 d1 d2 d3
gold 1 0 1 2 1.5 0.176 1.176 1.176 0 1.176
silver 0 2 0 1 3 0.477 1.477 0 2.954 0
truck 1 1 1 2 1.5 0.176 1.176 0 1.176 1.176
sum(d1) sum(d2) sum(d3)
Nilai Bobot setiap Dokumen = 1.176 4.130 2.352
2.2.3 Pemeringkatan (Perankingan) Dokumen
Setelah bobot masing-masing dokumen diketahui, maka dilakukan proses pemeringkatan atau perankingan dokumen berdasarkan besarnya tingkat kerelevanan (kesesuaian) dokumen terhadap query, dimana semakin besar nilai bobot dokumen terhadap query maka semakin besar tingkat similaritas dokumen tersebut terhadap query yang dicari.
Tabel 2.11 Hasil Pembobotan dan Perankingan Dokumen terhadap Query
d1 d2 d3
W 1.176 4.130 2.352
Rank III I II
Dengan demikian dapat dihasilkan daftar dokumen teranking berdasarkan nilai kesesuaian (similarity) antara dokumen dan query masukan yang kemudian akan diberikan kepada pengguna. Dari hasil pembobotan dan perankingan dapat diketahui bahwa dokumen 2 (d2) memiliki tingkat relevansi tertinggi kemudian disusul dengan dokumen 3 (d3) lalu dokumen 1 (d1).
2.3 Evaluasi Sistem Temu Kembali Informasi
Mandala (2002, hal: 7) menyatakan bahwa dalam bidang temu kembali informasi (information retrieval) terdapat berbagai metode yang digunakan dalam pembobotan kata, pengukuran kesesuaian, perangkingan, model sistem temu kembali informasi dan lain-lain. Sehingga diperlukan suatu ukuran sebagai perbandingan keefektifan metode-metode tersebut. Pada gambar 2.11 ditunjukkan bahwa evaluasi dapat dilakukan dengan menggunakan koleksi pengujian.
Gambar 2.11 lustrasi penggunaan koleksi pengujian
2.3.1 Kakas Evaluasi
Berikut adalah penjelasan mengenai beberapa hal-hal berkenaan dengan analisis performansi suatu sistem temu kembali informasi.
2.3.2 Koleksi Pengujian
Performansi sistem temu kembali informasi berhubungan dengan relevansi dokumen-dokumen yang dihasilkannya terhadap suatu query. Pengukuran performansi atau evaluasi sistem temu kembali informasi tidak dapat dilakukan bila seluruh dokumen yang relevan terhadap suatu query tidak diketahui sebelumnya. Seluruh dokumen relevan hampir tidak pernah diketahui, terutama untuk koleksi dokumen yang besar. Untuk mengatasi permasalahan ini maka dibuatlah koleksi pengujian.
Koleksi pengujian merupakan suatu kumpulan dokumen. Dari kumpulan dokumen tersebut ditentukan sekumpulan query mengenai koleksi. Beberapa ahli yang mengenal kumpulan dokumen tersebut menentukan relevansi dokumen-dokumen berdasar query. Sehingga didapatkan koleksi pengujian lengkap dengan sekumpulan query dan dokumen-dokumen yang telah ditentukan relevansinya. Pembentukan koleksi dokumen yang berukuran besar memerlukan kerja keras dari banyak pihak (Mandala, 2002).