APLIKASI PEMILIHAN MODEL TERBAIK
MENGGUNAKAN BEST SUBSET
REGRESSION DAN REGRESI RIDGE
Serlyana, Margaretha Ohyver, Bayu Kanigoro
Universitas Bina Nusantara, Jl. K.H Syahdan No. 9, Jakarta 11480, 021-5345830,ABSTRAK
Dalam pembuatan model regresi linier, tidak tertutup kemungkinan model awal yang diperoleh masih kurang optimal. Best Subset Regression merupakan salah satu metode yang digunakan untuk menyeleksi variabel penjelas agar memperoleh model yang tebaik. Evaluasi pemilihan model, memerlukan kriteria statistik C-p Mallow. Tujuan dari penelitian ini yaitu memperoleh variabel-variabel penjelas yang terpilih serta memperoleh model regresi yang dapat digunakan untuk mengestimasi jumlah tamu hotel di kota Kendari. Hasil penelitian ini menunjukkan bahwa dengan menggunakan Best Subset Regression diperoleh 5 variabel yang digunakan dalam pemodelan regresi linier ganda. Pada pengujian asumsi klasik, terjadi pelanggaran ketika membuat pemodelan dengan menggunakan 5 variabel penjelas. Pelanggaran-pelanggaran tersebut yaitu residual tidak berdistribusi normal, terjadi heteroskedastisitas dan terjadi multikolinearitas. Untuk mengatasi pelanggaran tersebut digunakan transformasi logaritma natural dan regresi ridge. Model yang diperoleh adalah model yang telah memenuhi asumsi klasik. Model tersebut melibatkan variabel jumlah kamar, jumlah tempat tidur, tarif minimal, tarif maksimal dan jumlah tenaga kerja. (SR)
Kata Kunci :
Best Subset Regression, C-p Mallow, Hotel, Regresi Ridge.
ABSTRACT
In the making linear regression model, it is possible the initial model obtained is still less than optimal. best subset regression is one of the methods used for selecting explonatory variables in order obtain the best model. Model selection evaluation using statistic C-p mallow. The purpose of the research is to obtain explanatory variables are selected as well as obtain the regression model can be used to predict the number of hotel guests in Kendari. Results of this study indicate that by using the Best Subset Regression obtained 5 variables that are used in multiple linear regression modeling. In testing assumption classical, there is violations when making modeling by using 5 variable explanatory. These violations are no residual in distribution normal, no heterogeneous and there is multicolinearitas. To overcome the violations used natural logarithm transformation and ridge regresssion. The model was involving variable number of rooms, the number of the bed, minimum cost, maximum cost and the amount of labors. (SR)
Key Words :
Best Subset Regression, C-p Mallow, Hotel, Ridge Regression.
Pendahuluan
Dalam pembuatan model regresi linier, tidak tertutup kemungkinan model awal yang diperoleh masih kurang optimal. Hal ini dilatar belakangi oleh 3 alasan. Alasan pertama adalah terjadinya overspecified, yaitu terlalu banyak variabel yang dimasukan ke dalam model. Alasan kedua, model tidak mengandung variabel yang tepat. Dan alasan ketiga, model tidak memiliki hubungan matematis yang benar (Freund, Wilson, and Sa, 2006: 227). Terdapat beberapa metode untuk menyeleksi variabel penjelas yang layak
masuk dalam model sehingga diperoleh model terbaik. Salah satu diantaranya yaitu Best Subset Regression (Hanum, 2011).
Best Subset Regression memulai pemilihan dengan model paling sederhana yaitu model dengan satu variabel. Selanjutnya dilanjutkan dengan variabel lain satu per satu sampai didapat model yang memenuhi kriteria terbaik. Terdapat beberapa kriteria untuk mengevaluasi pemilihan model terbaik dalam Best Subset Regrression. Salah satu diantaranya dapat menggunakan statistik C-p Mallow (Hanum, 2011).
Statistik C-p Mallow dikembangkan oleh Colin Mallows sebagai alat dalam mengestimasi jumlah variabel penjelas regresi. Statistik C-p Mallow membandingkan ketepatan dan bias dari model penuh dengan model subset terbaik dari jumlah variabel penjelas. Sebuah model dengan terlalu banyak variabel penjelas dapat menghasilkan model yang tidak tepat (Nirmalraj dan Malliga, 2011). Pada statistik C-p Mallow, model yang baik memiliki nilai statistik C-p Mallow mendekati jumlah parameter. Selain itu, diketahui juga model dengan nilai C-p Mallow yang kecil yang akan digunakan (Lindsey dan Sheather, 2010).
Dalam model regresi linier terdapat asumsi klasik yang diperlukan untuk mendapatkan estimator Ordinary Least Squared (OLS) yang bersifat Best Linear Unbiased Estimator (BLUE). Terdapat empat asumsi klasik yang harus terpenuhi yaitu uji normalitas residual, uji autokorelasi residual, uji heteroskedastisitas residual dan uji multikolinearitas (Rosadi, 2011:71-75).
Terdapat penelitian yang berhubungan dengan penelitian ini. Pada tahun 2013 terdapat penelitian tentang penerapan metode transformasi logaritma natural dan partial least squares untuk memperoleh model bebas multikolinieritas dan outlier. Kasus yang terjadi pada penelitian tersebut yaitu terdapat multikolinieritas dan outlier pada data tingkat penghunian kamar hotel di Kendari. Dengan menggunakan gabungan antara transformasi logaritma natural dan partial least squares diperoleh model yang bebas multikolinieitasr dan outlier, dan model yang diperoleh masih mempunyai nilai R2 yang kecil (Ohyver, 2013). Pada tahun 2011 terdapat penelitian tentang faktor konsumsi bahan bakar yang dianalisis secara statistik dan menghasilkan model regresi yang optimal. Hasil analisis dari Best Subset Regression yaitu diperoleh lima variabel penjelas yang menunjukkan bahwa model memiliki nilai adjusted R2 yang tinggi serta nilai C-p Mallow dan kuadrat residual (S2) terendah (Nirmalraj and Malliga, 2011). Pada tahun 2010, terdapat penelitian mengenai pengaruh kualitas pelayanan, fasilitas dan lokasi terhadap keputusan menginap. Hasil penelitian ini menunjukkan bahwa variabel-variabel tersebut signifikan mempengaruhi keputusan tamu dalam menginap. Selain itu, sebesar 47,3% variabel keputusan menginap dapat dijelaskan melalui variabel penjelas. Sedangkan sisanya 52,7% dijelaskan oleh variabel lain diluar ketiga variabel yang digunakan dalam penelitian tersebut.
Sulawesi Tenggara (Sultra) merupakan salah satu provinsi di Indonesia. Sultra ditetapkan sebagai daerah otonom berdasarkan Perpu No. 2 tahun 1964 Jungto UU No. 13 Tahun 1964. Pada awalnya terdiri atas empat kabupaten dan kini setelah pemekaran Sultra telah mempunyai sepuluh kabupaten dan dua kota, di mana ibukotanya terletak di kota Kendari. Salah satu komponen utama yang penting dalam pembangunan ekonomi nasional maupun regional dan merupakan bagian dari industri pariwisata yaitu jasa perhotelan. Jasa perhotelan mendapat perhatian khusus dari pemerintah karena selain merupakan salah satu sumber pendapatan, juga dapat menciptakan lapangan kerja baru untuk masyarakat (BPS Provinsi Sultra, 2011). Berdasarkan data yang terdapat di BPS, diperoleh jumlah sampel hotel di kota Kendari sebanyak 90 hotel dengan jumlah kamar 471 buah, dan jumlah tempat tidur 673 buah. Jumlah tamu yang berkunjung selama tahun 2010, sebanyak 157.537 orang. Banyaknya jumlah hotel yang terdapat di kota Kendari, membuat setiap perusahaan perhotelan tentu ingin menaikkan jumlah pengunjung hotel. Untuk itu, perusahaan perhotelan perlu mengetahui variabel-variabel yang mempengaruhi jumlah tamu hotel.
Analisis data perhotelan kota Kendari tentu akan menjadi sumbangan untuk perusahaan perhotelan dalam hal meningkatkan jumlah tamu. Berdasarkan data, dicurigai terdapat korelasi tinggi antar variabel penjelas yang dapat menyebabkan terjadinya multikolinearitas. Misalnya, variabel jumlah fasilitas dan tarif maksimal dimana semakin banyak jumlah fasilitas suatu hotel maka tarif maksimal hotel tersebut akan meningkat. Selain itu, semakin banyak jumlah kamar maka jumlah tenaga kerja akan semakin banyak juga. Terdapat beberapa cara yang dapat digunakan dalam mengatasi korelasi antar variabel penjelas. Salah satu diantaranya menggunakan regresi ridge. Seperti yang disebutkan sebelumnya, tidak menutup kemungkinan model yang diperoleh untuk mengetahui variabel-variabel yang mempengaruhi jumlah tamu tidak optimal. Hal ini yang melatarbelakangi penelitian tentang aplikasi pemilihan model terbaik menggunakan Best Subset Regression dan regresi ridge. Penelitian ini bertujuan untuk memperoleh variabel-variabel yang terpilih untuk pemodelan regresi serta memperoleh model regresi yang dapat digunakan untuk mengestimasi jumlah tamu hotel di kota Kendari.
Metode Penelitian
Data yang digunakan dalam penelitian ini adalah data sekunder. Oleh karena itu, penelitian akan dilakukan di lingkup Universitas Bina Nusantara, Jakarta. Penelitian ini dilakukan dari bulan Februari hingga Juli 2013.
Populasi pada penelitian ini adalah seluruh hotel yang ada di kota Kendari. Sedangkan sampel pada penelitian ini adalah 90 hotel yang ada di kota Kendari. Variabel yang terlibat dalam penelitian ini adalah variabel jumlah tamu sebagai variabel dependen (y) sedangkan jumlah kamar ( ), jumlah tempat tidur ( ), umur hotel ( ), tarif minimal ( ), tarif maksimal ( ), jumlah tenaga kerja ( ) dan jumlah fasilitas ( ) digunakan sebagai variabel penjelas (x).
Langkah-langkah penelitian ini adalah: 1. Mempersiapkan data untuk dianalisis.
2. Memilih penjelas menggunakan Best Subset Regression dengan kriteria Statistik C-p Mallow. 3. Membuat model dengan variabel yang terpilih.
4. Melakukan pengujian asumsi klasik. Diketahui asumsi yang dilanggar adalah residual tidak berdistribusi normal, terdapat heteroskedastisitas dan terjadi multikolinearitas.
5. Melakukan transformasi logaritma natural.
6. Setelah dilakukan transformasi logaritma natural, dilakukan kembali pengecekan uji asumsi klasik. 7. Membuat pemodelan dengan menggunakan regresi ridge untuk mengatasi multikolinearitas. 8. Mengecek nilai VIF untuk memastikan bahwa multikolinearitas telah teratasi.
9. Membuat pembahasan mengenai hasil yang telah diperoleh. 10. Membuat aplikasi.
Best Subset Regression
Best Subset Regression mengidentifikasi model regresi terbaik yang dapat dibentuk dengan variabel penjelas. Selain itu, Best Subset Regression digunakan untuk mengklasifikasi model terbaik (Asadi, Raoufar and Nassiri, 2012). Metode ini merupakan cara yang efisien untuk mengidentifikasi model dalam mengestimasi variabel dependen dengan beberapa variabel penjelas (Nirmalraj dan Malliga, 2011). Best Subset Regression memulai pemilihan dengan model yang paling sederhana yaitu dengan satu variabel penjelas. Selanjutnya dilanjutkan dengan variabel penjelas lain satu per satu sampai didapat model yang memenuhi kriteria terbaik.
Statistik C-p Mallow
Statistik C-p Mallow dikembangkan oleh Colin Mallows sebagai alat dalam menentukan estimasi untuk pengunaan jumlah variabel penjelas regresi. Statistik C-p Mallow membandingkan ketepatan dan bias dari model penuh dengan model subset terbaik dari jumlah variabel penjelas. Pada statistik C-p Mallow, model yang baik memiliki nilai statistik C-p Mallow mendekati jumlah parameter. Selain itu, diketahui juga model dengan nilai statistik C-p Mallow yang kecil yang akan digunakan (Lindsey dan Sheather, 2010:650-669).
Untuk menilai kebaikan model, digunakan mean squared error (MSE) dengan varian dan biasnya. Persamaan (2.15) merupakan statistik C-p Mallow yang disarankan oleh Colin Mallow.
C-p = –
Dimana:
MSE adalah rata-rata kuadrat residual untuk model penuh, SSE (p) adalah jumlah kesalahan kuadrat untuk model bagian yang mengandung p variabel penjelas, n adalah ukuran sampel.
Regresi Ridge
Regresi Ridge dapat digunakan untuk mengatasi korelasi yang tinggi antara beberapa variabel penjelas. Regresi Ridge merupakan metode estimasi koefisien regresi yang diperoleh melalui penambahan konstanta bias c pada diagonal X'X. Nilai c untuk koefisien regresi ridge diantara 0 hingga 1. Pada regresi ridge, variabel x dan y merupakan matriks dari koefisien regresi standardized (Freund, Wilson, and Sa, 2011:216). Nilai estimasi regresi ridge dapat diperoleh dari persamaan berikut:
Umumnya sifat dari estimasi ridge memiliki variance yang minimum sehingga diperoleh dari nilai VIF-nya yang merupakan diagonal utama dari matriks pada persamaan berikut:
Pemilihan nilai VIF digunakan dengan memilih nilai VIF yang mendekati nilai satu (Kutner, Nachtsheim, Neter, and Li, 2006:435).
Hasil Dan Bahasan
Dalam penelitian ini,data yang digunakan adalah data perhotelan di kota Kendari provinsi Sultra. Pembentukan model regresi dilakukan menggunakan 90 data. Pemodelan dilakukan dengan menggunakan Best subset regression berdasarkan statistik C-p Mallow dan regresi ridge.
Best Subset Regression
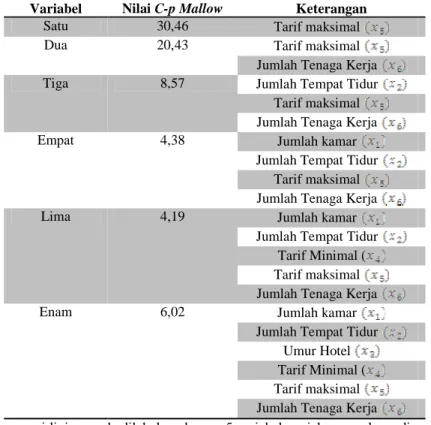
Berdasarkan hasil analisis Best Subset Regression menggunakan statistik C-p Mallow diperoleh nilai sebesar 4,19 yang merupakan nilai terkecil diantara nilai C-p Mallow lainnya dan mendekati jumlah parameter yaitu 5.
Tabel 1 Nilai C-p Mallow
Variabel Nilai C-p Mallow Keterangan
Satu 30,46 Tarif maksimal
Dua 20,43 Tarif maksimal
Jumlah Tenaga Kerja
Tiga 8,57 Jumlah Tempat Tidur
Tarif maksimal Jumlah Tenaga Kerja
Empat 4,38 Jumlah kamar
Jumlah Tempat Tidur Tarif maksimal Jumlah Tenaga Kerja
Lima 4,19 Jumlah kamar
Jumlah Tempat Tidur Tarif Minimal ( Tarif maksimal Jumlah Tenaga Kerja
Enam 6,02 Jumlah kamar
Jumlah Tempat Tidur Umur Hotel Tarif Minimal ( Tarif maksimal Jumlah Tenaga Kerja
Pemodelan regresi linier ganda dilakukan dengan 5 variabel penjelas yang kemudian akan dilakukan uji asumsi klasik terlebih dahulu untuk mendapat estimator Ordinary Least Squared (OLS) yang bersifat Best Linear Unbiased Estimator (BLUE).
Tabel 2. Uji Asumsi Klasik
Uji Hasil Kesimpulan
Normalitas Residual
M = 0,6333 > 0,143 Atau
p-value 6,661e-16 < α=0,05
Residual tidak berdistribusi normal.
Heteroskedastisitas Residual
p-value 3,98e-07 < α=0,05 Residual Variance berubah-ubah
(Heteroskedastisitas)
Autokorelasi Residual
D =1,9257 > Dw Tabel 1,630 Tidak terdapat autokorelasi residual
Multikolinearitas Nilai VIF
X1 = 14,89 X2 = 12.54 X4 = 4.07 X5 = 6.06
X6 = 13.35
Terjadi multikolinearitas karena nilai VIF > 10.
Pada Tabel 2 menunjukkan bahwa terdapat pelanggaran yang terjadi pada pengujian asumsi klasik. Pelanggaran tersebut yaitu residual tidak berdistribusi normal, residual variance berubah-ubah dan terjadi multikolinearitas. Untuk mengatasi pelanggaran tersebut, dilakukan transformasi logaritma natural. Setelah dilakukan transformasi, maka akan dilakukan uji asumsi klasik kembali yang dapat dilihat pada Tabel 3.
Tabel 3. Uji Asumsi Klasik
Uji Hasil Kesimpulan
Normalitas Residual
M = 0,0565 < 0,143 Atau
p-value 0,9204 > α = 0,05
Residual berdistribusi normal.
Heteroskedastisitas Residual
p-value 3,98e-07 < α=0,05 Residual Variance berubah-ubah
(Heteroskedastisitas)
Autokorelasi Residual
D =1,9257 > Dw Tabel 1,630 Tidak terdapat autokorelasi residual
Multikolinearitas Nilai VIF
X1 = 14,89 X2 = 12,54 X4 = 4,07 X5 = 6,06
X6 = 13,35
Terjadi multikolinearitas karena nilai VIF > 10.
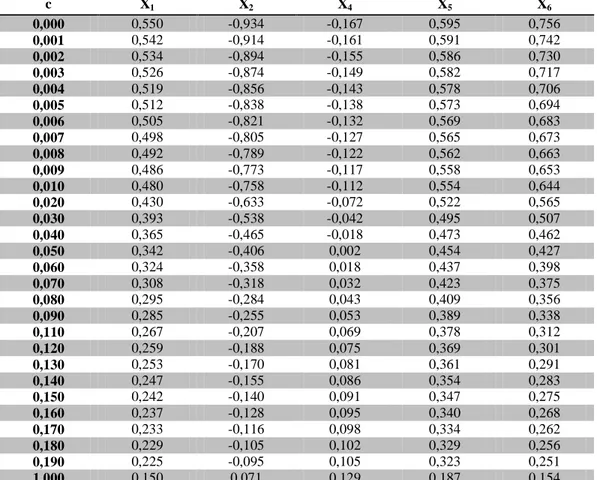
Dari Tabel 3, pada uji multikolinearitas dapat dilihat terdapat nilai VIF lebih besar dari 10 sehingga terjadi multikolinearitas. Langkah yang dilakukan untuk mengatasi kasus multikolinearitas ini adalah dengan menggunakan regresi Ridge. Dan hasilnya dapat dilihat pada Tabel 4. Koefisien koefisien regresi ridge untuk berbagai nilai c dapat dilihat secara lengkap pada Tabel 4.
Tabel 4. Nilai koefisien regresi ridge untuk berbagai nilai c.
c X1 X2 X4 X5 X6 0,000 0,550 -0,934 -0,167 0,595 0,756 0,001 0,542 -0,914 -0,161 0,591 0,742 0,002 0,534 -0,894 -0,155 0,586 0,730 0,003 0,526 -0,874 -0,149 0,582 0,717 0,004 0,519 -0,856 -0,143 0,578 0,706 0,005 0,512 -0,838 -0,138 0,573 0,694 0,006 0,505 -0,821 -0,132 0,569 0,683 0,007 0,498 -0,805 -0,127 0,565 0,673 0,008 0,492 -0,789 -0,122 0,562 0,663 0,009 0,486 -0,773 -0,117 0,558 0,653 0,010 0,480 -0,758 -0,112 0,554 0,644 0,020 0,430 -0,633 -0,072 0,522 0,565 0,030 0,393 -0,538 -0,042 0,495 0,507 0,040 0,365 -0,465 -0,018 0,473 0,462 0,050 0,342 -0,406 0,002 0,454 0,427 0,060 0,324 -0,358 0,018 0,437 0,398 0,070 0,308 -0,318 0,032 0,423 0,375 0,080 0,295 -0,284 0,043 0,409 0,356 0,090 0,285 -0,255 0,053 0,389 0,338 0,110 0,267 -0,207 0,069 0,378 0,312 0,120 0,259 -0,188 0,075 0,369 0,301 0,130 0,253 -0,170 0,081 0,361 0,291 0,140 0,247 -0,155 0,086 0,354 0,283 0,150 0,242 -0,140 0,091 0,347 0,275 0,160 0,237 -0,128 0,095 0,340 0,268 0,170 0,233 -0,116 0,098 0,334 0,262 0,180 0,229 -0,105 0,102 0,329 0,256 0,190 0,225 -0,095 0,105 0,323 0,251 1,000 0.150 0.071 0.129 0.187 0.154
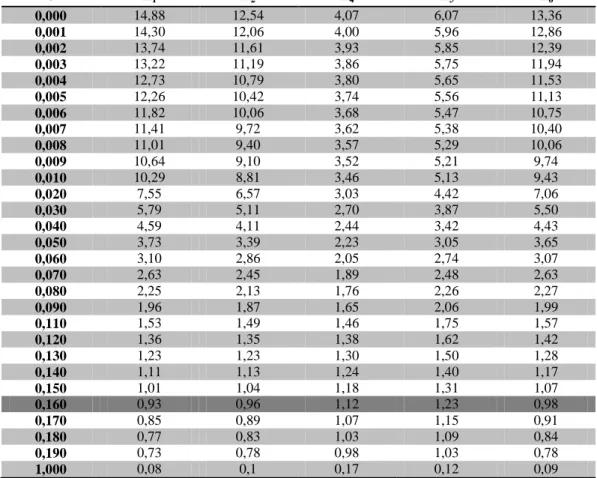
Untuk memilih koefisien regresi yang mana yang akan digunakan, dapat melihat nilai VIF pada Tabel 5. Pada Tabel 5 terlihat bahwa mulai dari c = 0,000 sampai c = 1,000 nilai VIF akan semakin kecil. Nilai VIF yang akan diambil adalah nilai VIF yang relatif mendekati satu. Sehingga koefisien regresi yang akan digunakan adalah koefisien pada nilai c = 0,160.
Tabel 5. Nilai VIF untuk Berbagai Nilai c
c X1 X2 X4 X5 X6 0,000 14,88 12,54 4,07 6,07 13,36 0,001 14,30 12,06 4,00 5,96 12,86 0,002 13,74 11,61 3,93 5,85 12,39 0,003 13,22 11,19 3,86 5,75 11,94 0,004 12,73 10,79 3,80 5,65 11,53 0,005 12,26 10,42 3,74 5,56 11,13 0,006 11,82 10,06 3,68 5,47 10,75 0,007 11,41 9,72 3,62 5,38 10,40 0,008 11,01 9,40 3,57 5,29 10,06 0,009 10,64 9,10 3,52 5,21 9,74 0,010 10,29 8,81 3,46 5,13 9,43 0,020 7,55 6,57 3,03 4,42 7,06 0,030 5,79 5,11 2,70 3,87 5,50 0,040 4,59 4,11 2,44 3,42 4,43 0,050 3,73 3,39 2,23 3,05 3,65 0,060 3,10 2,86 2,05 2,74 3,07 0,070 2,63 2,45 1,89 2,48 2,63 0,080 2,25 2,13 1,76 2,26 2,27 0,090 1,96 1,87 1,65 2,06 1,99 0,110 1,53 1,49 1,46 1,75 1,57 0,120 1,36 1,35 1,38 1,62 1,42 0,130 1,23 1,23 1,30 1,50 1,28 0,140 1,11 1,13 1,24 1,40 1,17 0,150 1,01 1,04 1,18 1,31 1,07 0,160 0,93 0,96 1,12 1,23 0,98 0,170 0,85 0,89 1,07 1,15 0,91 0,180 0,77 0,83 1,03 1,09 0,84 0,190 0,73 0,78 0,98 1,03 0,78 1,000 0,08 0,1 0,17 0,12 0,09
Sehingga persamaan regresi ridge untuk c = 0.160 yaitu sebagai berikut:
Setelah diperoleh koefisien-koefisien regresi ridge, selanjutnya akan dilakukan pengembalian estimasi koefisien regresi. Hasil yang diperoleh setelah dilakukan pengembalian estimasi koefisien regresi yaitu pada persamaan berikut:
Spesifikasi dan Program Aplikasi 1. Spesifikasi Hardware
Spesifikasi kebutuhan hardware yang dianjurkan adalah:
a. Processor : Intel® CoreTM i3
b. RAM : 2GB
c. Mouse
d. keyboard
2. Spesifikasi Software
a. Bahasa pemrograman Java b. NetBeans IDE
c. R-Language versi 3.0.1. dengan menggunakan berbagai Library yaitu 1. library(Runiversal) -> digunakan untuk mengkonversi R ke Java dan XML. 2. library(leaps) -> digunakan untuk C-p Mallow.
3. library(lmtest) -> digunakan untuk regresi. 4. library(car) -> digunakan untuk menghitung VIF.
5. library(ridge)-> digunakan untuk menghitung estimasi regresi ridge. 6. library(stats) -> digunakan untuk menghitung standard deviation.
Gambar 1 Tampilan Program
Tampilan utama program ditunjukkan pada Gambar 1. Pada program aplikasi ini, terdapat dua fungsi tombol Browse, view dan menu utama yaitu Analysis. Tombol Browse pertama berfungsi dalam memilih file R-script yang akan digunakan untuk mengaktifkan software R. Sedangkan tombol Browse kedua digunakan untuk memilih file (data) yang akan digunakan untuk proses perhitungan. Tombol View digunakan untuk melihat file (data) yang telah di import. Pada menu utama Analysis, terdapat 4 sub menu yaitu Best Subset Regression, Multiple Regression, Transformation dan Ridge Regression.
Simpulan Dan Saran
Berdasarkan hasil penelitian yang telah dilakukan, maka dapat disimpulkan bahwa:
1. Dari hasil analisis Best Subset Regression menggunakan kriteria statistik C-p Mallow, diperoleh 5 variabel yang akan digunakan dalam pemodelan regresi linier ganda. Variabel yang terpilih yaitu variabel jumlah kamar, jumlah tempat tidur, tarif minimal, tarif maksimal dan jumlah tenaga kerja. 2. Regresi ridge dilakukan untuk mengatasi masalah multikolinearitas pada data. Persamaan regresi
ridge yang diperoleh dari nilai c=0,16 dengan nilai VIF relatif mendekati nilai 1. Model yang diperoleh dengan menggunakan regresi ridge yaitu:
3. Model yang diperoleh telah memenuhi asumsi klasik sehingga dapat digunakan untuk mengestimasi jumlah tamu hotel di kota Kendari.
Saran atau usulan untuk penelitian selanjutnya adalah mencari variabel-variabel penjelas lain yang mungkin dapat mempengaruhi jumlah tamu hotel. Memerlukan peninjauan yang lebih mendalam atas variabel jumlah kamar tidur yang berpengaruh negatif terhadap jumlah tamu menginap. Pengelola hotel harus memperhatikan variabel-variabel untuk meningkatkan jumlah tamu hotel. Menambahkan fitur regresi ridge dengan variabel dependen tanpa di transformasi logaritma natural.
Asadi, V., Raoufat, M.H., and Nassiri, S.M. (2012). Fresh Egg Mass Estimation Using Machine Vision Technique. International Agrophysics, 26(3). 229.
Badan Pusat Statistik. (2011). Direktori dan Tingkat Penghunian Kamar Hotel Provinsi Sulawesi Tenggara Tahun 2011. Badan Pusat Statistik Provinsi Sulawesi Tenggara.
Freund, R.J., Wilson, W.J., and Sa, Ping. (2006). Regression Analysis Statistical Modeling of a Response Variable. (2nd edition). San Diego: Academic Press.
Hanum, Herlina. (2011). Perbandingan Metode Stepwise, Best Subset Regression dan Fraksi dalam Pemilihan Model Regresi Berganda Terbaik. Jurnal Penelitian Sains. 14(2A): 1-6.
Kutner, M.H., Nachtsheim, C.J., Neter, J., and Li, William. (2005). Applied Linear Statistical Models. (5th edition). New York: McGraw-Hill/Irwin.
Lindsey, C., and Sheather, S. (2010). Variable Selection in Linear Regression. The Stata, Journal. 10(4): 650-669.
Nirmalraj, J., and Malliga., P. (2011). Airline Emission Forecast Through Empirical Analysis of Its Contributing Factors. International Journal of Environmental Science and Develpoment. 2(1). ISSN: 2010-0264.
Ohyver, M. (2013). Penerapan Metode Transformasi Logaritma Natural dan Partial Least Squares untuk Memperoleh Model Bebas Multikolinier dan Outlier. Jurnal Mat Stat. 13(1): 42-51.
Pradipta, Nanang. (2009). Metode Regresi Ridge untuk Mengatasi Model Regresi Linier Berganda yang Mengandung Multikolinieritas. Skripsi S1. Medan: Jurusan Matematika, FMIPA Universitas Sumatra Utara.
Rosadi, Dedi. (2011). Analisis Ekonometrika & Runtun Waktu Terapan dengan R. Yogyakarta: Andi Offset.
Riwayat Penulis
Serlyana lahir di kota Jambi pada tanggal 25 September 1990. Penulis menamatkan pendidikan S1 di Universitas Bina Nusantara dalam bidang Teknologi Komputer dan Statistika pada tahun 2013.