6.1 Pendahuluan
Seperti telah diketahui, terdapat banyak sekali model jaringan saraf tiruan (JST) (Fauset, 1994; Lawrence, 1992). Model-model JST secara garis besar oleh Lawrence (1992) dikelompokkan menjadi JST umpan balik (feedback) dan umpan maju (feedforward). Saat ini JST umpan balik adalah JST yang paling populer digunakan dan dari sekian banyak model JST umpan balik, model JST Perambatan Balik (Backpropagation Neural Network) selanjutnya disingkat JSTPB, adalah model yang paling banyak digunakan.
JSTPB secara bersamaan ditemukan oleh 3 kelompok peneliti yaitu; kelompok Rumelhart, Hinton, Williams, kelompok Cun, dan kelompok Parker antara tahun 1985-1986 (Lawrence, 1992). Jaringan ini adalah jaringan umpan maju yang bekerja dengan aturan perambatan balik delta yang terampat (generalized delta rule). Jaringan ini pada dasarnya merupakan hasil pengembangan Jaringan Saraf Percepteron. Dibandingkan dengan jaringan saraf percepteron, arsitektur jaringan saraf percepteron hanya tersusun dari lapisan tunggal (1 lapisan masukan dan 1 lapisan keluaran tanpa lapisan tersembunyi), sedangkan arsitektur JSTPB tersusun dari lapisan masukan, satu atau beberapa lapisan tersembunyi, dan lapisan keluaran. Kelenturan dalam menentukan jumlah lapisan menurut Fausett (1994) menyebabkan kemampuan JSTPB dalam menyelesaikan masalah yang lebih kompleks menjadi lebih baik dibandingkan dengan percepteron.
Saat ini JSTPB telah banyak digunakan di berbagai bidang seperti pada pemrosesan sinyal, kontrol sistem, pengenalan pola (klasifikasi dan identifikasi), kesehatan, bisnis dsb. Dalam bidang perikanan JSTPB telah digunakan untuk identifikasi dan klasifikasi kawanan ikan dengan beberapa pendekatan yang berbeda antara lain; identifikasi dan klasifikasi spesies kawanan anchovy, sardine, dan horse mackerel dengan pendekatan deskriptor akustik (Haralabous &
Georgakarakos, 1996), identifikasi dan klasifikasi spesies kawanan mackarel, horse mackarel, saithe, haddock, dan cod dengan pendekatan perbedaan sinyal akustik hamburan balik dengan frekwensi akustik yang berbeda (Simmonds et al., 1996)
Walaupun telah banyak digunakan diberbagai bidang, tetapi seperti JST lainnya, JSTPB juga memiliki permasalahan dalam hal kecepatan mencapai kondisi konvergen yaitu kondisi dimana nilai Mean Square Error jaringan sudah tetap atau tidak berfluktuasi lagi. Menurut Fausett (1994), kecepatan dalam pencapaian kondisi konvergen berkaitan dengan kemampuan jaringan dalam mengingat, dan merampat pola-pola masukan yang kesemuanya berkaitan dengan arsitektur, algoritma, dan fungsi aktivasi jaringan.
Dalam bab ini akan dibahas langkah-langkah pemodelan JSTPB dengan memperhatikan arsitektur, algoritma, dan fungsi aktivasi jaringan untuk membangun JSTPB yang dapat digunakan secara optimal untuk identifikasi dan klasifikasi kawanan ikan pelagis.
6.2 Metode Penelitian
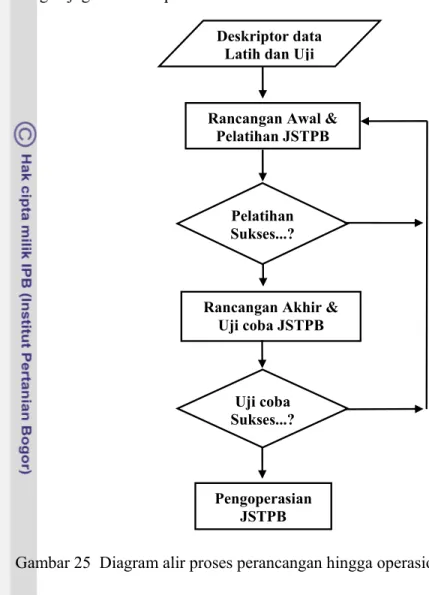
Untuk mendapatkan model JSTPB yang dapat bekerja secara optimal maka perancangan model JSTPB dilakukan dalam dua tahap yaitu: (1) Merancang dan melatih model JSTPB, (2) Menguji rancangan model JSTPB yang dipilih. Untuk kedua tahapan yang dimaksud dibutuhkan dua kelompok data yaitu; kelompok data untuk pelatihan dan perancangan model JSTPB (data latih) serta kelompok data untuk menguji model JSTPB (data uji). Secara garis besar tahapan perancangan awal model JSTPB hingga pengoperasiannya dapat dilihat pada Gambar 25.
Data latih yang dimaksud pada Gambar 25, sebagaimana dijelaskan dalam Bab 5, adalah data tambahan atau data B yang digunakan sebagai data pembimbing dalam mengidentifikasi dan mengklasifikasi secara statistik data asli atau data A. Dalam bab ini data latih digunakan sebagai data masukan untuk perancangan awal dan pelatihan model JSTPB, sedangkan data A dikelompokkan sebagai data uji dan digunakan untuk menguji coba model JSTPB yang dihasilkan pada tahap rancangan awal. Data latih terdiri dari 58 pola kawanan ikan dengan
15 deskriptor hidroakustik sedangkan data uji terdiri dari 56 pola kawanan ikan dengan juga 15 deskriptor akustik.
Gambar 25 Diagram alir proses perancangan hingga operasional JSTPB.
Pada Gambar 25 tampak bahwa keberhasilan pelatihan dan uji coba jaringan ditentukan oleh kemampuan jaringan dalam mencapai kondisi batas tertentu. Dalam penelitian ini kondisi batas yang digunakan untuk pelatihan JSTPB adalah pencapaian fungsi tujuan yang dilakukan dengan jumlah iterasi minimal, dan dengan tingkat ketepatan tertentu. Fungsi tujuan yang digunakan dalam disertasi ini adalah Mean Squre Error (MSE), dengan
( )
∑
(
)
∑
= = − = = n 1 i 2 i i n 1 i 2 i n1 t y e n 1MSE , i=iterasi ke-i, t=nilai target yang diinginkan, yi=nilai target keluaran fungsi aktivasi pada iterasi ke-i, dan ei nilai galat pada
iterasi ke-i. Jika nilai MSE lebih kecil dari nilai batas maka hitungan dihentikan.
Deskriptor data Latih dan Uji
Rancangan Awal & Pelatihan JSTPB
Pelatihan Sukses...?
Rancangan Akhir & Uji coba JSTPB
Uji coba Sukses...?
Pengoperasian JSTPB
Dalam disertasi ini nilai batas MSE ditetapkan sebesar 0,001 dengan maksimum hitungan iterasi sebesar 1500 dan tingkat ketepatan identifikasi 70%, karenanya fungsi tujuan disebut tercapai jika MSE<0,001 dengan Jumlah Iterasi<1500 dengan tingkat ketepatan >70%.
6.2.1 Perancangan awal dan pelatihan JSTPB
Perancangan awal dilakukan untuk menentukan kisaran jumlah sel masukan, lapisan tersembunyi, dan keluaran; jumlah lapisan tersembunyi dan keluaran; dan metode pelatihan yang tepat untuk mendapatkan model JSTPB awal yang ideal. Dalam melakukan perancangan awal, selain dipertimbangkan pola data masukan dan fungsi tujuan yang harus dicapai, juga dipertimbangkan 1) arsitektur jaringan, 2) fungsi aktivasi yang digunakan, dan 3) algoritma jaringan (Fausett, 1994).
1) Arsitektur Jaringan
Arsitektur jaringan menggambarkan banyaknya lapisan dan jumlah unit sel pada sebuah jaringan. Untuk menyelesaikan suatu masalah dibutuhkan jaringan dengan minimal 1 lapisan masukan, 1 lapisan tersembunyi dan 1 lapisan keluaran (Mynsky & Papert, 1969 yang diacu Storbeck & Daan, 2001). Arsitektur jaringan berkaitan dengan (1) jumlah unit sel dan pola masukan, (2) jumlah lapisan dan unit sel tersembunyi, serta (3) jumlah unit sel keluaran (Siang, 2005; Kusumadewi, 2004). Berikut ini penjelasan tentang ketiga hal tersebut.
(1) Jumlah unit sel dan pola masukan
Jumlah unit sel masukan menyatakan banyaknya variabel masukan yang digunakan agar obyek yang diamati dapat dengan mudah diidentifikasi dan diklasifikasi. Menurut Fausett (1994) semakin banyak jumlah unit sel masukan semakin besar peluang untuk meningkatkan ketelitian tetapi dengan akibat bertambah panjangnya proses pelatihan.
Sementara itu, jumlah pola masukan pada dasarnya tidak berkaitan langsung dengan arsitektur jaringan tetapi berkaitan dengan tingkat keakuratan jaringan dalam mencapai fungsi tujuan. Hect-Nielsen (1990) yang diacu Fausett (1994), mengusulkan agar digunakan dua kumpulan pola data yang terpisah selama proses pembelajaran dilakukan. Satu dari kedua kumpulan pola tersebut
digunakan untuk melatih jaringan sedangkan kumpulan lainnya digunakan untuk menguji hasil pelatihan tersebut. Sementara itu Simmonds et al. (1996) mengemukakan bahwa pengurangan jumlah pola dapat secara signifikan menurunkan tingkat keakuratan hasil identifikasi.
(2) Jumlah lapisan dan unit sel tersembunyi
Dengan menambah jumlah lapisan tersembunyi berarti secara teoritis memperlambat proses pencapaian nilai konvergen. Hal ini terjadi karena jumlah lapisan tersembunyi yang lebih banyak berakibat pada proses hitungan umpan maju dan balik dari lapisan tersembunyi satu ke lapisan tersembunyi yang diatasnya hingga lapisan keluaran akan bertambah panjang.
Dalam disertasi ini, penentuan jumlah lapisan dan unit sel tersembunyi dilakukan dengan menggunakan Metode Trial and Error seperti yang dilakukan Simmonds et al. (1996). Sejalan dengan itu, Kusumadewi (Komunikasi pribadi, 2005) menyarankan agar rancangan model JSTPB dimulai dari minimal satu lapisan tersembunyi, sedangkan Lawrence (1992) menyarankan agar jumlah awal unit sel tersembunyi dimulai dengan minimal setengah jumlah unit sel masukan.
(3) Jumlah unit sel keluaran
Penentuan jumlah unit sel keluaran bergantung pada berapa banyak keluaran yang diharapkan. Sebagai nilai awal, ditetapkan jumlah unit sel keluaran sebanyak 1 unit sel keluaran. Identifikasi dilakukan dengan cara membandingkan nilai indeks kawanan ikan (nilai target) dengan nilai target hasil hitungan. Kusumadewi (Komunikasi pribadi, 2005) mengungkapkan bahwa jumlah unit sel keluaran bergantung pada seberapa banyak alternatif keluaran yang diharapkan, semakin kompleks permasalahan yang dihadapi semakin banyak alternatif keluaran yang diberikan.
2) Fungsi aktivasi
Fungsi aktivasi adalah fungsi yang digunakan untuk memutuskan apakah sinyal masukan yang diterima oleh suatu unit sel berada di atas atau dibawah nilai batas (threshold). Jika berada di atas nilai batas maka sinyal tersebut akan diaktifkan atau diteruskan ke unit sel yang lebih diatasnya, sedangkan jika tidak maka sinyal tidak akan diteruskan ke unit sel yang diatasnya.
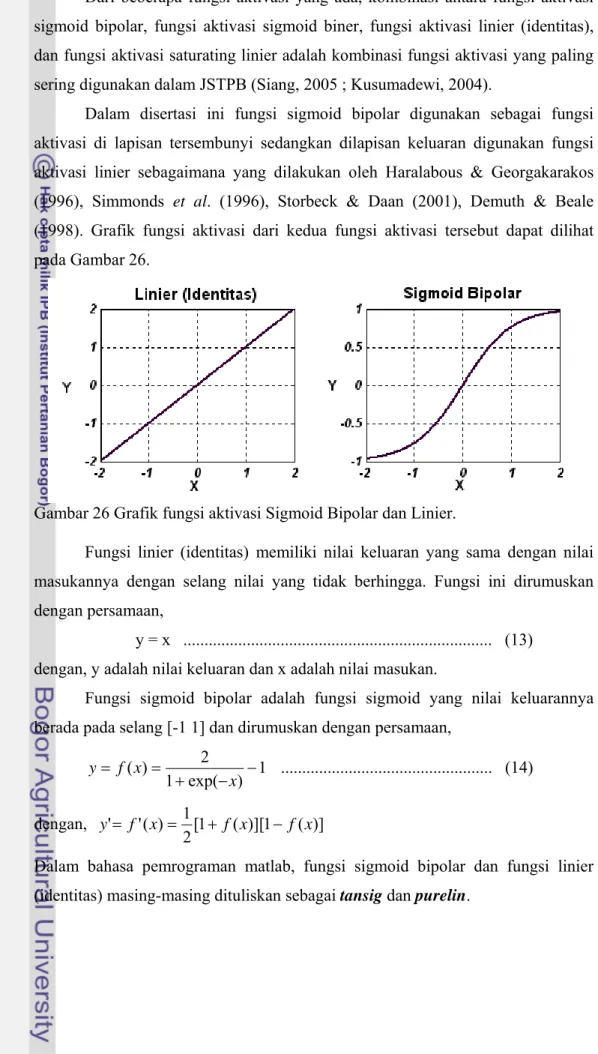
Dari beberapa fungsi aktivasi yang ada, kombinasi antara fungsi aktivasi sigmoid bipolar, fungsi aktivasi sigmoid biner, fungsi aktivasi linier (identitas), dan fungsi aktivasi saturating linier adalah kombinasi fungsi aktivasi yang paling sering digunakan dalam JSTPB (Siang, 2005 ; Kusumadewi, 2004).
Dalam disertasi ini fungsi sigmoid bipolar digunakan sebagai fungsi aktivasi di lapisan tersembunyi sedangkan dilapisan keluaran digunakan fungsi aktivasi linier sebagaimana yang dilakukan oleh Haralabous & Georgakarakos (1996), Simmonds et al. (1996), Storbeck & Daan (2001), Demuth & Beale (1998). Grafik fungsi aktivasi dari kedua fungsi aktivasi tersebut dapat dilihat pada Gambar 26.
Gambar 26 Grafik fungsi aktivasi Sigmoid Bipolar dan Linier.
Fungsi linier (identitas) memiliki nilai keluaran yang sama dengan nilai masukannya dengan selang nilai yang tidak berhingga. Fungsi ini dirumuskan dengan persamaan,
y = x ... (13) dengan, y adalah nilai keluaran dan x adalah nilai masukan.
Fungsi sigmoid bipolar adalah fungsi sigmoid yang nilai keluarannya berada pada selang [-1 1] dan dirumuskan dengan persamaan,
1 ) exp( 1 2 ) ( − − + = = x x f y ... (14) dengan, [1 ( )][1 ( )] 2 1 ) ( ' ' f x f x f x y= = + −
Dalam bahasa pemrograman matlab, fungsi sigmoid bipolar dan fungsi linier (identitas) masing-masing dituliskan sebagai tansig dan purelin.
3) Algoritma jaringan
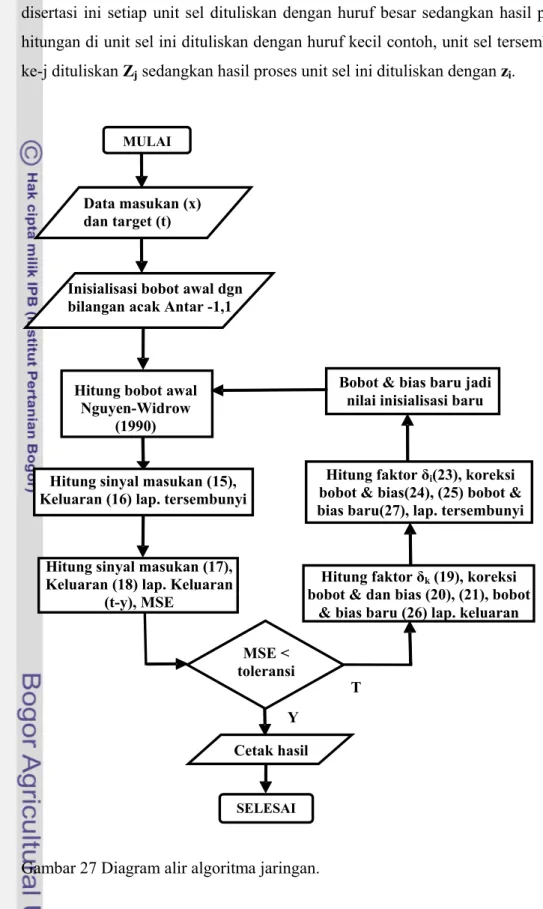
Seperti telah diketahui, ketika JSTPB digunakan maka pada setiap unit sel dalam jaringan tersebut terjadi tiga proses pengolahan data yaitu: proses membaca dan meneruskan informasi pola masukan, proses perambatan balik galat yang berkaitan dengan hasil pelatihan, dan proses penghitungan nilai bobot (Fausett, 1994). Dalam disertasi ini setiap unit sel dituliskan dengan huruf besar sedangkan hasil proses dari unit sel tersebut ditulis dengan huruf kecil contoh, unit sel tersembunyi ke-i dituliskan Zi sedangkan hasil proses unit sel ini dituliskan dengan zi.
Selama proses umpan maju (feedforward), setiap unit sel masukan (Xi)
menerima sebuah sinyal masukan dan meneruskan sinyal tersebut ke unit-unit tersembunyi diatasnya (Z1,…,Zp). Setiap unit sel tersembunyi selanjutnya
menghitung fungsi aktivasinya dan jika memenuhi syarat hasilnya di kirimkan kesetiap unit sel keluaran. Setiap unit sel keluaran (Yk) menghitung fungsi
aktivasinya untuk menentukan reaksi jaringan terhadap pola masukan yang diberikan.
Selama pelatihan, nilai galat (e) hasil identifikasi pola masukan dihitung disetiap unit sel keluaran dengan cara membandingkan hasil hitungan unit sel keluaran (yk) dengan nilai target yang telah ditetapkan sebelumnya (tk) dan
dirumuskan dengan (e=tk-yk). Berdasarkan nilai galat ini, faktor δk ditentukan.
Faktor δk adalah faktor pengali yang digunakan untuk mendistribusikan galat yang
ada pada unit sel keluaran ke seluruh unit sel pada lapisan sebelumnya (unit-unit lapisan tersembunyi yang tersambung ke unit sel keluaran Yk). Selain itu, faktor δk
digunakan juga untuk memperbaharui bobot antara lapisan keluaran dan lapisan tersembunyi. Selanjutnya, dengan cara yang sama, faktor δj dihitung pada setiap
unit sel tersembunyi Zj untuk mendistribusikan galat pada unit sel tersembunyi ke
seluruh unit sel pada lapisan masukan (unit-unit lapisan masukan Xi yang
tersambung ke unit sel tersembunyi Zj).
Setelah seluruh faktor δ ditentukan, bobot-bobot pada setiap lapisan dihitung secara bersamaan. Hitungan bobot dari lapisan unit-unit tersembunyi ke unit-unit keluaran didasarkan pada faktor δk dan fungsi aktivasi dari unit sel
Zj didasarkan pada faktor δj dan aktivasi Xi dari unit-unit masukan. Dalam
disertasi ini setiap unit sel dituliskan dengan huruf besar sedangkan hasil proses hitungan di unit sel ini dituliskan dengan huruf kecil contoh, unit sel tersembunyi ke-j dituliskan Zj sedangkan hasil proses unit sel ini dituliskan dengan zi.
Gambar 27 Diagram alir algoritma jaringan.
Hitung bobot awal
Nguyen-Widrow (1990)
MSE < toleransi Hitung sinyal masukan (15),
Keluaran (16) lap. tersembunyi Inisialisasi bobot awal dgn bilangan acak Antar -1,1
Hitung sinyal masukan (17), Keluaran (18) lap. Keluaran
(t-y), MSE
,
Data masukan (x) dan target (t)
Hitung faktor δk (19), koreksi
bobot & dan bias (20), (21), bobot & bias baru (26) lap. keluaran
Hitung faktor δi(23), koreksi
bobot & bias(24), (25) bobot & bias baru(27), lap. tersembunyi
Bobot & bias baru jadi nilai inisialisasi baru
Cetak hasil
SELESAI MULAI
T Y
Algoritma JSTPB;
Langkah 0. Inisialisasi bobot dari Xi ke Zj dan dari Zj ke Yk dengan nilai acak
yang kecil.
Langkah 1. Selama kondisi stop belum dilalui maka lakukan langkah 2-9 dan hitung bobot awal JSTPB dengan Metode Nguyen-Widrow.
Langkah 2. Untuk setiap pasang data masukan lakukan langkah 3-8 berikut: Umpan maju (feedforward)
Langkah 3. Setiap unit sel masukan (Xi, i=1,...,n) menerima sinyal xi dan
meneruskannya ke semua unit sel di lapisan diatasnya.
Langkah 4. Setiap unit sel tersembunyi (Zj, j=1,...,p) menjumlahkan setiap
sinyal masukan yang telah diberi bobot,
∑
= + = n 1 i ij i oj j v x v in _ z , ... (15) sinyal keluaran dihitung dengan fungsi aktivasi,) in _ z ( f zj= j , ... (16)
dan mengirimkan hasilnya ke setiap unit sel di lapisan diatasnya (unit-unit keluaran).
Langkah 5. Setiap unit sel keluaran (Yk, k=1,...,m) menjumlahkan setiap sinyal
yang telah diberi bobot yang diterimanya,
∑
= + = m 1 j j jk ok k w z w in _ y , ... (17) dengan fungsi aktivasi sinyal keluaran dihitung dengan,) in _ y ( f yk = k , ... (18) Perambatan balik nilai galat (backpropagation of error)
Langkah 6. Setiap unit sel keluaran (Yk, k=1,...,m) menerima pola target (tk)
yang sesuai dengan pola masukan pelatihan, hitung faktor δ, ) in _ y ( ' f ) y t ( k k k k = − δ , ... (19) hitung koreksi bobot dengan,
j k
jk z
w =αδ
Δ , ... (20) hitung koreksi bias dengan,
k k 0
w =αδ
selanjutnya nilai δk digunakan di lapisan bawah.
Langkah 7. Setiap unit sel tersembunyi (Zj, j=1,...,k) menjumlahkan nilai δ
yang telah diberi bobot dari lapisan diatasnya,
∑
= δ = δ m 1 k k jk j w in _ , ... (22) Selanjutnya hitung nilai δj dengan,) in _ z ( ' f in _ j j j=δ δ , ... (23) hitung koreksi bobot dengan,
i j
ij x
w =αδ
Δ , ... (24) hitung koreksi bias dengan,
j j 0
v =αδ
Δ , ... (25) Perbaharui nilai bobot jaringan dan bobot bias,
Langkah 8. Setiap unit sel keluaran (Yk, k=1,...,m) memperbaharui bobot bias
dan lapisan dengan,
jk jk
jk(baru) w (lama) w
w = +Δ ... (26) Setiap unit sel tersembunyi (Zj, j=1,...,p) memperbaharui bobot
bias dan lapisan dengan,
ij ij
ij(baru) v (lama) v
v = +Δ ... (27) Langkah 9. Test kondisi stop.
6.2.2 Perancangan akhir dan uji coba JSTPB
Perancangan akhir dilakukan untuk menentukan apakah model awal JSTPB yang dihasilkan pada tahap rancangan awal dapat digunakan untuk mengidentifikasi dan mengklasifikasi data uji yang diberikan dengan ketepatan, jumlah iterasi, dan pencapaian fungsi tujuan seperti yang disyaratkan sebelumnya dan dengan komposisi awal data latih dan uji 58:56.
Jika dalam proses pengujian didapatkan bahwa model awal JSTPB tidak dapat mencapai fungsi tujuannya maka dilakukan pemodelan ulang dengan mengubah jumlah unit sel dan lapisan tersembunyi. Perubahan model dilakukan hingga dicapai jumlah maksimum unit sel dan lapisan seperti yang dihasilkan saat perancangan awal. Haralabous & Georgakarakos (1996) menyarankan untuk
menggunakan 12 hingga 18 unit sel tersembunyi untuk 140 data uji atau 9% hingga 12% dari total data uji.
Jika fungsi tujuan tetap tidak dapat dicapai dengan model terakhir maka jumlah pola masukan data latih ditambah secara acak per n pola masukan, sehingga setiap penambahan n pola masukan ke data latih akan mengurangi n pola data uji. Nilai n menyatakan jumlah pola data yang ditambahkan atau dikurangkan dari data latih dan data uji. Haralabous & Georgakarakos (1996) mengemukakan bahwa dengan jumlah pola data uji sebanyak 5-35% dari total data yang tersedia dapat dicapai tingkat ketepatan identifikasi hingga 80%, tergantung spesies kawanan ikan. Dengan demikian, berdasarkan prosentase data uji seperti yang dikemukakan di atas maka perubahan komposisi jumlah pola data latih (58 pola) dan data uji (56 pola) hanya dapat dilakukan hingga jumlah pola data uji berkisar antara 6 hingga 40 pola.
Karena keluaran yang diinginkan berjumlah 5 kawanan ikan yang berbeda maka jumlah unit sel lapisan tersembunyi dari setiap rancangan model yang baru akan selalu dimulai dengan jumlah 5 unit sel tersembunyi dengan tetap menggunakan fungsi aktivasi sigmoid bipolar (tansig) pada lapisan tersembunyi, fungsi linier (purelin) pada lapisan keluaran, dan menggunakan metode pelatihan Levenberg-Marquardt (trainlm).
Sebagaimana disebutkan sebelumnya, ada 3 arsitektur JSTPB yang akan dibangun yang dibedakan berdasarkan jumlah dan tipe deskriptor akustik yang digunakan sebagai masukannya. Ketiga JSTPB tersebut adalah:
(1) JSTPB tipe 1 (JSTPB1) dengan unit sel masukan sebanyak 8 deskriptor hasil analisis statistik.
(2) JSTPB tipe 2 (JSTPB2) dengan jumlah unit sel masukan sebanyak jumlah deskriptor yang digunakan dalam analisis diskriminan yaitu sebanyak 15 deskriptor.
(3) JSTPB tipe 3 (JSTPB3) adalah JSTPB dengan jumlah unit sel masukan yang sama dengan jumlah unit sel masukan JSTPB1 yaitu 8 unit sel masukan tetapi deskriptor yang digunakan adalah deskriptor hasil analisis tingkat kontribusi yang dilakukan dengan JSTPB2.
JSTPB2 digunakan sebagai pembanding Metode Statistik sedangkan JSTPB3 digunakan sebagai pembanding JSTPB1, perhatikan posisi JSTPB2 terhadap metode statistik dan posisi JSTPB3 terhadap JSTPB1 yang sejajar pada Gambar 14.
6.3 Hasil
Perancangan awal model JSTPB dilakukan dalam 5 tahap untuk 1) menentukan metode pelatihan yang tepat, 2) menentukan kisaran jumlah unit
sel masukan, 3) menentukan kisaran jumlah unit sel tersembunyi, 4) menentukan kisaran jumlah lapisan tersembunyi, dan 5) menentukan kisaran jumlah pola masukan.
6.3.1 Hasil perancangan awal dan pelatihan JSTPB
Berikut ini hasil rancangan awal model JSTPB yang dilakukan untuk menentukan kelima hal yang telah disebutkan sebelumnya. Hasil perancangan awal ini selanjutnya digunakan sebagai nilai awal dalam pelatihan dan uji coba jaringan.
1) Metode pelatihan
Dalam JSTPB ada beberapa metode pelatihan yang dapat digunakan. Metode pelatihan tersebut pada dasarnya merupakan hasil pengembangan metode pelatihan gradient descent (Fausett, 1994; Lawrence, 1992). Penggunaan metode pelatihan yang tepat dapat mempercepat kerja jaringan saraf tiruan (Demuth & Beale, 1998).
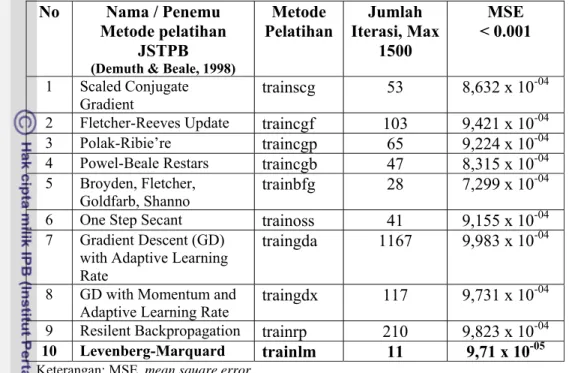
Pada Tabel 17 dapat dilihat bahwa kesepuluh metode pelatihan yang digunakan menghasilkan nilai MSE yang berada dalam batas toleransi (<0,001), walaupun demikian dari kesepuluh metode tersebut, metode pelatihan Levenberg-Marquardt memberikan nilai MSE terkecil yaitu sebesar 9,71 x 10-5 dan hanya dalam 11 kali hitungan iterasi.
Tabel 17 Perbandingan hasil pelatihan beberapa metode pelatihan JSTPB model 8(5-1) dengan menggunakan data pelatihan yang sama
No Nama / Penemu Metode pelatihan
JSTPB (Demuth & Beale, 1998)
Metode
Pelatihan Iterasi, Max Jumlah 1500 MSE < 0.001 1 Scaled Conjugate Gradient trainscg 53 8,632 x 10 -04
2 Fletcher-Reeves Update traincgf 103 9,421 x 10-04
3 Polak-Ribie’re traincgp 65 9,224 x 10-04
4 Powel-Beale Restars traincgb 47 8,315 x 10-04
5 Broyden, Fletcher,
Goldfarb, Shanno trainbfg 28 7,299 x 10
-04
6 One Step Secant trainoss 41 9,155 x 10-04
7 Gradient Descent (GD)
with Adaptive Learning Rate
traingda 1167 9,983 x 10-04
8 GD with Momentum and
Adaptive Learning Rate traingdx 117 9,731 x 10
-04
9 Resilent Backpropagation trainrp 210 9,823 x 10-04
10 Levenberg-Marquard trainlm 11 9,71 x 10-05
Keterangan: MSE, mean square error
Ini berarti bahwa metode pelatihan Levenberg-Marquardt dapat mencapai fungsi tujuannnya lebih cepat dibandingkan dengan metode pelatihan lainnya. Karenanya ditetapkan untuk menggunakan metode pelatihan Levenberq-Marquardt dalam proses perancangan model JSTPB tahap (2) hingga (5).
2) Jumlah unit sel masukan
Jumlah unit sel masukan menyatakan banyaknya variabel yang dapat digunakan untuk membedakan obyek penelitian yang satu dengan obyek penelitian lainnya. Dalam disertasi ini variabel yang dimaksud adalah deskriptor kawanan ikan. Hasil penelitian pada Bab 5 menunjukkan bahwa deskriptor dapat digunakan untuk membedakan spesies kawanan lemuru yang satu dengan lainnya. Dari bab yang sama diketahui bahwa terdapat 8 deskriptor utama yaitu L, H, A, P, E, Trel, Er, dan Dv yang dapat digunakan sebagai pembeda antara kelompok kawanan ikan. Karena itu, pada tahapan ini nilai awal untuk jumlah unit sel masukan ditetapkan sebanyak 8 buah sedangkan jumlah unit sel masukan selanjutnya berjumlah 9, 10, 11 dst. Jumlah deskriptor untuk unit sel masukan diperbanyak hingga 30 deskriptor dengan cara menggandakan secara acak
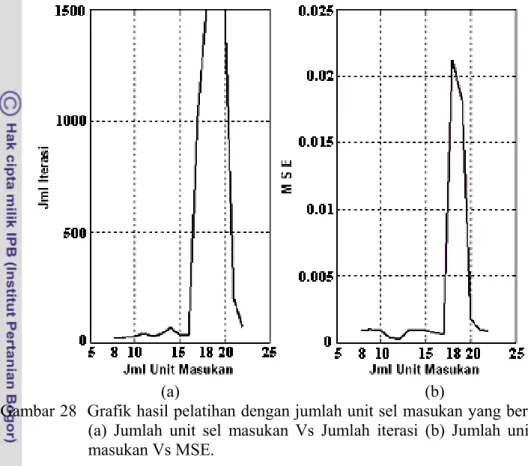
deskriptor yang ada. Hasil pelatihan yang dilakukan dengan jumlah unit sel masukan yang berbeda dapat dilihat pada Gambar 28.
(a) (b)
Gambar 28 Grafik hasil pelatihan dengan jumlah unit sel masukan yang berbeda (a) Jumlah unit sel masukan Vs Jumlah iterasi (b) Jumlah unit sel masukan Vs MSE.
Pada Gambar 28 dapat dilihat bahwa jumlah unit masukan berpengaruh terhadap jumlah iterasi dan nilai MSE. Jika jumlah unit masukan diperbesar maka kondisi konvergen jaringan cenderung akan dicapai lebih lama (jumlah iterasi lebih banyak). Pada kondisi tersebut nilai MSE juga mempunyai kecenderungan membesar, lebih besar dari batas toleransinya.
Gambar tersebut juga menunjukkan bahwa batas toleransi jumlah iterasi yaitu sebanyak maksimum1500 kali iterasi tercapai setelah unit sel masukan berjumlah 17 buah. Pada saat itu nilai MSE sudah melampaui batas toleransinya (MSE > 0,001). Nilai-nilai tersebut tampaknya menurun setelah unit masukan berjumlah 20, tetapi Fausett (1994) menyarankan agar hitungan dihentikan setelah nilai MSE melampaui nilai toleransinya, karena pada saat itu jaringan sudah kehilangan kemampuannya dalam melakukan identifikasi secara umum terhadap data masukan.
Karena kedua hal tersebut di atas maka ditetapkan untuk merancang model JSTPB dengan unit sel masukan berjumlah antara 8 hingga 17 unit sel masukan. Tetapi karena jumlah iterasi terkecil (19 kali iterasi) dicapai ketika unit sel masukan berjumlah 8 unit dengan nilai MSE=0,00056 < toleransi, karenanya nilai awal jumlah masukan jaringan dapat dimulai dengan 8 unit masukan. Jika dengan jumlah ini fungsi tujuan tidak tercapai maka jumlah unit sel masukan ditambah 1 persatu hingga mencapai nilai maksimalnya.
3) Jumlah unit sel tersembunyi
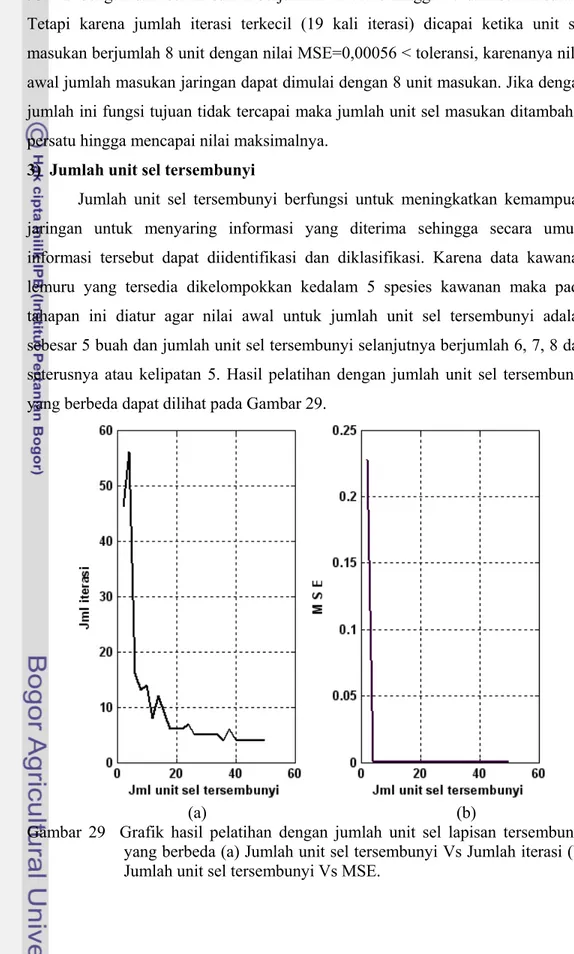
Jumlah unit sel tersembunyi berfungsi untuk meningkatkan kemampuan jaringan untuk menyaring informasi yang diterima sehingga secara umum informasi tersebut dapat diidentifikasi dan diklasifikasi. Karena data kawanan lemuru yang tersedia dikelompokkan kedalam 5 spesies kawanan maka pada tahapan ini diatur agar nilai awal untuk jumlah unit sel tersembunyi adalah sebesar 5 buah dan jumlah unit sel tersembunyi selanjutnya berjumlah 6, 7, 8 dan seterusnya atau kelipatan 5. Hasil pelatihan dengan jumlah unit sel tersembunyi yang berbeda dapat dilihat pada Gambar 29.
(a) (b)
Gambar 29 Grafik hasil pelatihan dengan jumlah unit sel lapisan tersembunyi yang berbeda (a) Jumlah unit sel tersembunyi Vs Jumlah iterasi (b) Jumlah unit sel tersembunyi Vs MSE.
Pada Gambar 29 dapat dilihat bahwa banyaknya unit sel tersembunyi pada lapisan tersembunyi menentukan jumlah iterasi dan nilai MSE. Gambar tersebut menunjukkan kecenderungan penurunan jumlah iterasi dan nilai MSE. Ketika jumlah unit sel lapisan tersembunyi lebih sedikit, jumlah iterasi tampak lebih tinggi dan ketika jumlah unit sel lapisan tersembunyi bertambah banyak maka jumlah iterasi semakin mengecil. Hal ini berarti bahwa peningkatan kecepatan jaringan untuk mencapai kondisi konvergen dapat dilakukan dengan penambahan jumlah unit sel tersembunyi.
Gambar yang sama juga menunjukkan bahwa nilai MSE cenderung bergerak mengecil ketika jumlah unit sel tersembunyi diperbanyak. Tampak bahwa nilai MSE masih berada di atas batas toleransi (>0,001) ketika unit sel tersembunyi masih berjumlah 5 buah dengan jumlah iterasi masih cukup besar (56 iterasi).
Berdasarkan kedua hal di atas maka ditetapkan untuk menggunakan unit sel tersembunyi minimal sebanyak 5 buah unit sel dan akan ditambah satu atau hingga kelipatan lima untuk setiap pengulangan hitungan.
4) Jumlah lapisan tersembunyi
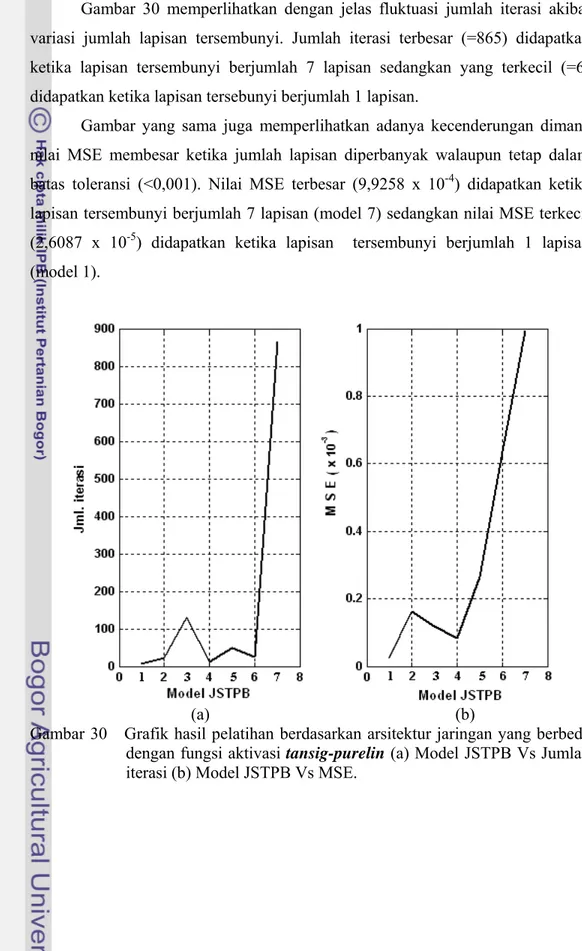
Sebagaimana jumlah unit sel tersembunyi, secara teoritis jika lapisan tersembunyi diperbanyak maka kemampuan jaringan untuk mencapai fungsi tujuannya (MSE<0,001) menjadi lebih lambat mengingat jumlah lapisan tersembunyi menentukan jumlah langkah kerja jaringan seperti tampak pada algoritma JSTPB. Kusumadewi (komunikasi pribadi, Januari 2006) menyarankan agar jumlah lapisan tersembunyi tidak lebih dari 7 lapisan karena dengan jumlah lapisan lebih dari itu ketidakstabilan jaringan akan mudah sekali terjadi. Hasil pelatihan JSTPB dengan jumlah lapisan tersembunyi yang berbeda dapat dilihat pada Gambar 30.
Sebagaimana dijelaskan sebelumnya, fungsi aktivasi yang digunakan pada seluruh model ini adalah fungsi sigmoid bipolar (tansig) pada setiap lapisan tersembunyi sedangkan pada lapisan keluarannya digunakan fungsi linier (purelin). Tabel 18 dan Gambar 30 menunjukkan bahwa jumlah lapisan dalam JSTPB menentukan jumlah iterasi dan nilai MSE. Susunan angka pada Tabel 18 kolom 2 seperti pada baris 4 (model jaringan ke-3) adalah 5-5-5-1 artinya, lapisan
tersembunyi pada model jaringan ke-3 berjumlah 3 lapisan dengan 5 buah unit sel tersembunyi pada setiap lapisannya.
Gambar 30 memperlihatkan dengan jelas fluktuasi jumlah iterasi akibat variasi jumlah lapisan tersembunyi. Jumlah iterasi terbesar (=865) didapatkan ketika lapisan tersembunyi berjumlah 7 lapisan sedangkan yang terkecil (=6) didapatkan ketika lapisan tersebunyi berjumlah 1 lapisan.
Gambar yang sama juga memperlihatkan adanya kecenderungan dimana nilai MSE membesar ketika jumlah lapisan diperbanyak walaupun tetap dalam batas toleransi (<0,001). Nilai MSE terbesar (9,9258 x 10-4) didapatkan ketika lapisan tersembunyi berjumlah 7 lapisan (model 7) sedangkan nilai MSE terkecil (2,6087 x 10-5) didapatkan ketika lapisan tersembunyi berjumlah 1 lapisan (model 1).
(a) (b)
Gambar 30 Grafik hasil pelatihan berdasarkan arsitektur jaringan yang berbeda dengan fungsi aktivasi tansig-purelin (a) Model JSTPB Vs Jumlah iterasi (b) Model JSTPB Vs MSE.
Tabel 18 Perbandingan hasil pelatihan berdasarkan arsitektur jaringan yang berbeda dengan fungsi aktivasi tansig-purelin
.
Model
Jaringan Arsitektur Jaringan Jumlah Iterasi <0.001 M S E
1 (5-1) 6 2,6087 x 10-5 2 (5-5-1) 23 1,6288 x 10-4 3 (5-5-5-1) 131 1,1706 x 10-4 4 (5-5-5-5-1) 13 8,3708 x 10-5 5 (5-5-5-5-5-1) 50 2,6559 x 10-4 6 (5-5-5-5-5-5-1) 26 6,3735 x 10-4 7 (5-5-5-5-5-5-5-1) 865 9.9258 x 10-4
Dari penjelasan di atas ditetapkan bahwa jumlah lapisan tersembunyi berpengaruh terhadap kecepatan kerja jaringan JSTPB. Dalam disertasi ini jumlah awal lapisan tersembunyi adalah sebanyak 1 lapisan dengan 5 unit sel tersembunyi. Jika dengan arsitektur seperti ini fungsi tujuan tidak dapat dicapai maka jumlahnya dapat ditambah hingga jumlah maksimal 7 lapisan.
5) Jumlah pola pelatihan
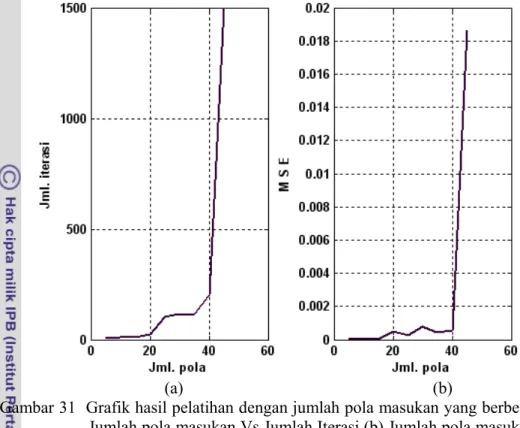
Tahapan ini dilakukan untuk menentukan jumlah minimal data pelatihan yang diperlukan agar kerja jaringan dapat dioptimalkan. Dalam disertasi ini kawanan ikan yang akan diidentifikasi adalah 4 spesies kawanan lemuru dan 1 kawanan non-lemuru, karenanya secara teoritis diperlukan minimal 5 pola masukan untuk dapat melakukan identifikasi sedangkan jumlah pola selanjutnya adalah 6, 7, 8 atau sebanyak kelipatan dari 5. Hal ini sejalan dengan Hecht-Nielsen (1990) yang diacu Haralabous & Georgakarakos (1996) yang menyarankan agar penentuan jumlah minimum data yang diperlukan ditentukan dengan Metode Leaving-one-out. Hasil pelatihan JSTPB dengan junlah pola masukan yang berbeda dapat dilihat pada Gambar 31.
(a) (b)
Gambar 31 Grafik hasil pelatihan dengan jumlah pola masukan yang berbeda (a) Jumlah pola masukan Vs Jumlah Iterasi (b) Jumlah pola masukan Vs M S E.
Gambar 31 memperlihatkan hasil pelatihan yang dilakukan dengan pola masukan yang berbeda-beda. Pada gambar tersebut tampak terlihat bahwa jumlah iterasi dan nilai MSE cenderung bertambah besar ketika jumlah pola latihan diperbanyak. Jumlah iterasi terkecil (=6) didapatkan ketika pola data pelatihan berjumlah 5 buah, sedangkan nilai maksimumnya (=1500) dicapai ketika pola data pelatihannya berjumlah 50 buah. Dari gambar yang sama tampak terlihat bahwa nilai MSE terkecil (=7,0953 x 10-7) didapatkan ketika pola data pelatihan
berjumlah 5 buah dan nilai terbesarnya (=0,0186) didapatkan ketika pola data pelatihan berjumlah 50 buah. Karenanya, jumlah pola data pelatihan yang digunakan dapat berjumlah antara 5 hingga +50 jumlah pola latihan. Pada kisaran pola data tersebut jumlah iterasi berkisar antara 5 hingga 203 iterasi sedangkan nilai MSE yang dapat dicapai berkisar antara 7,0953 x 10-7 hingga 7.8709 x 10-4
(<0,001).
Peningkatan nilai MSE ketika jumlah pola data ditambah seperti terlihat pada Gambar 31 disebabkan karena galat yang timbul akibat salah melakukan identifikasi pola masukan n juga dibebankan ke proses identifikasi pola
ke-(n+1). Sebagaimana terlihat pada Gambar 27, pembebanan ini dilakukan dengan menjadikan bobot akhir proses identifikasi pola ke-n, yang koreksinya dihitung berdasarkan nilai galat pola n, menjadi bobot awal proses identifikasi pola ke-(n+1). Karenanya, secara teoritis nilai MSE akan membesar ketika jumlah galat hasil identifikasi pola-pola sebelumnya menumpuk pada pola-pola berikutnya.
Berdasarkan hasil pemodelan jaringan yang dilakukan diatas maka model awal yang akan digunakan untuk identifikasi dan klasifikasi kawanan ikan adalah model JSTPB 1 yang terdiri dari 1 lapisan masukan dengan 8 unit sel masukan, sesuai banyaknya deskriptor utama hasil analisis statistik, 1 lapisan tersembunyi dengan 5 unit sel tersembunyi, sesuai banyaknya spesies kawanan ikan hasil analisis statistik, dan 1 lapisan keluaran dengan 1 unit sel keluaran (Yk; k = 1).
Model ini menggunakan fungsi aktivasi sigmoid bipolar di lapisan tersembunyi dan fungsi aktivasi linier di lapisan keluaran dan bekerja dengan metode pelatihan Levenberg-Marquardt dengan pola data masukan berjumlah 56 buah.
6.3.2 Hasil perancangan akhir dan uji coba JSTPB
Pengujian model JSTPB dilakukan untuk mengetahui sampai sejauh mana model JSTPB yang dipilih pada tahap perancangan dapat digunakan untuk mengidentifikasi dan mengklasifikasi kawanan ikan. Komposisi awal data latih dan data uji yang digunakan dalam pengujian ini adalah 56 pola data pada data uji dan 58 pola data pada data latih. Pengujian dilakukan dengan melakukan simulasi data uji pada model JSTPB1, JSTPB2, dan JSTPB3. Sebagaimana dijelaskan sebelumnya, jaringan dinyatakan dapat bekerja secara optimal jika nilai MSE<0,001, jumlah iterasi< 1500, dan ketepatan hasil identifikasi > 70%.
Setelah dilakukan pengujian model JSTPB1 dengan pola data uji dan latih masing-masing sebanyak 56 dan 58 pola dengan berbagai alternatif model jaringan, didapatkan bahwa tingkat ketepatan identifikasi terbaik dihasilkan saat komposisi pola data uji dan latih masing-masing sebanyak 30 dan 84 pola atau jumlah pola data uji sebesar 26,3% dari total data yang tersedia atau 35,7% dari total data latih dengan arsitektur JSTPB sebagai berikut.
1) Uji JSTPB1
Pada Tabel 19 dapat dilihat deskriptor yang digunakan pada unit sel masukan. Deskriptor ini sebagaimana telah dijelaskan sebelumnya adalah deskriptor utama yang didapatkan dari hasil analisis statistik diskriminan.
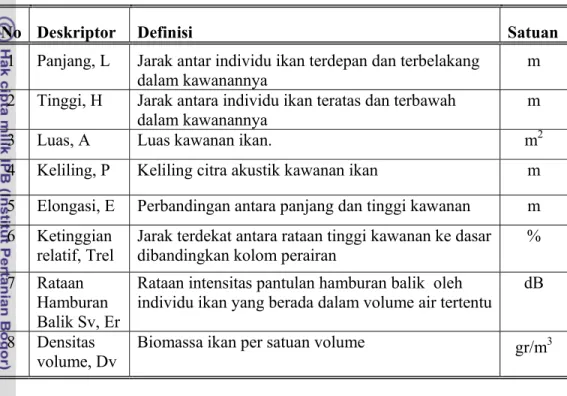
Tabel 19 Deskriptor pada unit sel masukan JSTPB1
No Deskriptor Definisi Satuan
1 Panjang, L Jarak antar individu ikan terdepan dan terbelakang
dalam kawanannya m
2 Tinggi, H Jarak antara individu ikan teratas dan terbawah dalam kawanannya
m
3 Luas, A Luas kawanan ikan. m2
4 Keliling, P Keliling citra akustik kawanan ikan m 5 Elongasi, E Perbandingan antara panjang dan tinggi kawanan m 6 Ketinggian
relatif, Trel
Jarak terdekat antara rataan tinggi kawanan ke dasar dibandingkan kolom perairan
% 7 Rataan
Hamburan Balik Sv, Er
Rataan intensitas pantulan hamburan balik oleh individu ikan yang berada dalam volume air tertentu
dB 8 Densitas
volume, Dv
Biomassa ikan per satuan volume gr/m3
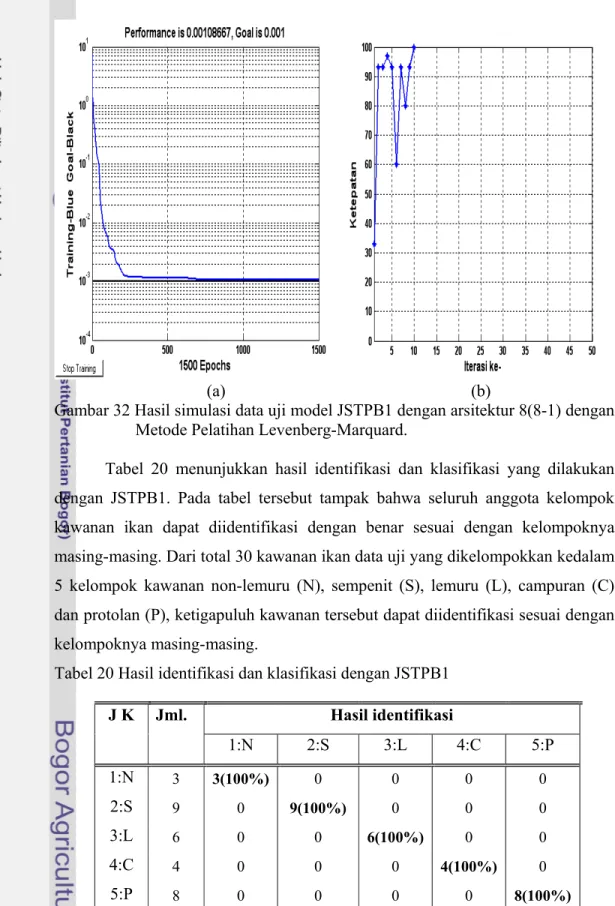
Gambar 32 (a) memperlihatkan banyaknya iterasi (epoch) yang diperlukan untuk mendapatkan hasil pelatihan yang sesuai dengan batas toleransi galat yang telah ditetapkan sebelumnya. Pada gambar tersebut tampak bahwa nilai MSE>1 pada awal hitungan, nilai ini secara konsisten terus mengecil hingga hitungan iterasi ke-218. Pada hitungan iterasi ke-218 didapatkan nilai MSE terkecil yaitu sebesar 0,00099.
Gambar 32 (b) menunjukkan perubahan tingkat ketepatan identifikasi yang dihasilkan jaringan setelah dilakukan hitungan iterasi sebanyak 10 kali. Gambar tersebut menunjukkan tingkat ketepatan dibawah 40% dicapai diawal hitungan sedangkan pada hitungan iterasi ke-10 tingkat ketepatan mencapai 100%. Ini berarti bahwa pada hitungan iterasi ke-10 seluruh data uji dapat diidentifikasi dengan benar. Pada saat itu hitungan iterasi<1500, nilai MSE<0,001, dan tingkat ketepatan hitungan 100%. Hasil identifikasi dapat dilihat pada Tabel 20.
(a) (b)
Gambar 32 Hasil simulasi data uji model JSTPB1 dengan arsitektur 8(8-1) dengan Metode Pelatihan Levenberg-Marquard.
Tabel 20 menunjukkan hasil identifikasi dan klasifikasi yang dilakukan dengan JSTPB1. Pada tabel tersebut tampak bahwa seluruh anggota kelompok kawanan ikan dapat diidentifikasi dengan benar sesuai dengan kelompoknya masing-masing. Dari total 30 kawanan ikan data uji yang dikelompokkan kedalam 5 kelompok kawanan non-lemuru (N), sempenit (S), lemuru (L), campuran (C) dan protolan (P), ketigapuluh kawanan tersebut dapat diidentifikasi sesuai dengan kelompoknya masing-masing.
Tabel 20 Hasil identifikasi dan klasifikasi dengan JSTPB1
J K Jml. Hasil identifikasi 1:N 2:S 3:L 4:C 5:P 1:N 3 3(100%) 0 0 0 0 2:S 9 0 9(100%) 0 0 0 3:L 6 0 0 6(100%) 0 0 4:C 4 0 0 0 4(100%) 0 5:P 8 0 0 0 0 8(100%) Total 30 3 9 6 4 8
Gambar 33 memperlihatkan kontribusi masing-masing deskriptor dalam JSTPB1. Dari kedelapan deskriptor yang digunakan, kelompok deskriptor morfometrik (P, A, L, El, H) berkontribusi paling besar dalam proses identifikasi dan klasifikasi, diikuti kelompok deskriptor batimetrik (Trel) dan kelompok deskriptor energetik (Dv, Er).
H Er Dv Trel E L A P 0 0.2 0.4 0.6 0.8 1 1.2 D e s k ri pt or Tingkat Kontribusi Gambar 33 Diagram Pareto JSTPB1.
Dari penjelasan di atas dapat disimpulkan bahwa model jaringan JSTPB1 dengan 8 unit sel masukan pada lapisan masukan, 8 unit sel tersembunyi pada 1 lapisan tersembunyi, dan 1 unit sel keluaran pada 1 lapisan keluaran dapat digunakan dengan baik untuk mengidentifikasi dan klasifikasi 30 data kawanan ikan uji dengan ketepatan hingga 100%.
2) Uji JSTPB2
Sebagaimana dijelaskan sebelumnya, deskriptor masukan yang digunakan dalam JSTPB2 jumlahnya sama dengan jumlah deskriptor yang digunakan dalam analisis statistik diskriminan yaitu limabelas deskriptor. Deskriptor tersebut digunakan sebagai unit sel masukan pada JSTPB2 dapat dilihat pada Tabel 13.
Gambar 34 (a) memperlihatkan jumlah iterasi (epoch) yang diperlukan JSTPB2 untuk mendapatkan hasil pelatihan yang sesuai dengan batas toleransi galat yang telah ditetapkan sebelumnya. Pada gambar tersebut tampak bahwa nilai MSE>1 pada awal hitungan, nilai ini secara konsisten terus mengecil hingga hitungan iterasi ke-6. Pada hasil hitungan iterasi ke-6 didapatkan nilai MSE terkecil yaitu sebesar 7,73x10-6.
Gambar 34 (b) menunjukkan perubahan tingkat ketepatan identifikasi yang dihasilkan jaringan setelah dilakukan hitungan iterasi sebanyak 32 kali. Gambar tersebut menunjukkan tingkat ketepatan dibawah 70% dicapai diawal hitungan sedangkan pada hitungan iterasi ke-32 tingkat ketepatan mencapai 70%. Ini berarti bahwa setelah hitungan iterasi ke-32, 70% dari total 30 data uji dapat diidentifikasi dengan benar. Pada saat itu hitungan iterasi<1500, nilai MSE<0,001. Hasil identifikasi dapat dilihat pada Tabel 21.
(a) (b)
Gambar 34 Hasil simulasi data uji model JSTPB2 15(15-1) dengan Metode Pelatihan Levenberg-Marquard.
Pada Tabel 21 tampak bahwa seluruh anggota kelompok kawanan Non-lemuru dapat diidentifikasi dengan benar, sedangkan anggota kelompok kawanan ikan lainnya sebagian dapat diidentifikasi dengan benar, sebagian lainnya teridentifikasi sebagai anggota kawanan ikan lain dan 1 anggota kawanan lemuru dan campuran tidak dapat diidentifikasi (Tidak Dikenali, T.D).
Tabel 21 Hasil identifikasi dan klasifikasi dengan JSTPB2 JK Jml. Hasil identifikasi 1:N 2:S 3:L 4:C 5:P T.D 1:N 4 4(100%) 0 0 0 0 0 2:S 7 0 3(42,9%) 3(42,9%) 1(14,2%) 0 0 3:L 5 0 0 4(80%) 0 0 1(20%) 4:C 6 0 0 0 5(83,3%) 0 1(16,7%) 5:P 8 1(12,5%) 1(12,5%) 0 1(12,5%) 5(62,5%) 0 Total 30 5 4 7 7 5 2
Pada Gambar 35 dapat dilihat kontribusi masing-masing deskriptor dalam proses identifikasi dan klasifikasi dengan JSTPB2. Dari ke-15 deskriptor yang digunakan, 8 deskriptor yang menunjukkan kontribusi paling besar adalah deskriptor Er, A, Ku, H, P, Sk, El, dan L. Kedelapan deskriptor tersebut adalah deskriptor dari kelompok deskriptor morfometrik dan energetik. Dari kedelapan deskriptor tersebut, kelompok deskriptor morfometrik adalah kelompok deskriptor yang berpengaruh besar dalam proses identifikasi dan klasifikasi JSTPB2 dengan 5 deskriptor. Kedelapan deskriptor selanjutnya digunakan sebagai deskriptor masukan pada JSTPB3. Dr Tm in Esd Df Dv Dm in Trel L E S P H K A Er 0.0 0.2 0.4 0.6 0.8 1.0 1.2 D e s k ri pt or Tingkat Kontribusi Gambar 35 Diagram Pareto JSTPB2.
Dari penjelasan di atas dapat disimpulkan bahwa model jaringan JSTPB2 dengan 15 unit sel masukan pada 1 lapisan masukan, 15 unit sel tersembunyi pada
1 lapisan tersembunyi, dan 1 unit sel keluaran pada 1 lapisan keluaran dapat digunakan dengan baik untuk identifikasi dan klasifikasi kawanan ikan dengan ketepatan hingga 70%.
3) Uji JSTPB3
Deskriptor yang digunakan sebagai unit sel masukan pada JSTPB3 dapat dilihat pada Tabel 22 berikut ini. Deskriptor-deskriptor ini adalah hasil dari analisis tingkat kontribusi yang dilakukan pada JSTPB2.
Tabel 22 Deskriptor pada unit sel masukan JSTPB3
No Deskriptor Definisi Satuan
1 Panjang, L Jarak antar individu ikan terdepan dan terbelakang dalam kawanannya
m 2 Tinggi, H Jarak antara individu ikan teratas dan terbawah
dalam kawanannya m
3 Luas, A Luas kawanan ikan. m2
4 Keliling, P Keliling citra akustik kawanan ikan m 5 Elongasi, E Perbandingan antara panjang dan tinggi kawanan m 6 Skewness, S Ukuran sebaran data terhadap nilai rataannya
7 Rataan Hamburan Balik Sv, Er
Rataan Intensitas pantulan hamburan balik oleh individu ikan yang berada dalam volume air tertentu
dB 8 Kurtosis, K Ukuran sebaran data terhadap sebaran normalnya
Pada Gambar 36 (a) diperlihatkan banyaknya iterasi (epoch) yang diperlukan untuk mendapatkan hasil pelatihan yang sesuai dengan batas toleransi galat yang telah ditetapkan sebelumnya. Pada gambar tersebut tampak bahwa nilai MSE>1 pada awal hitungan dan nilai ini secara konsisten terus mengecil hingga hitungan iterasi ke-42. Pada hitungan iterasi ke-42 didapatkan nilai MSE terkecil yaitu sebesar 0,00097.
Pada Gambar 36 (b) ditunjukkan perubahan tingkat ketepatan identifikasi yang dihasilkan jaringan setelah dilakukan hitungan iterasi sebanyak 50 kali. Gambar tersebut menunjukkan tingkat ketepatan dibawah 50% dicapai diawal hitungan sedangkan pada hitungan iterasi ke-14 tingkat ketepatan mencapai 73,33%. Ini berarti bahwa setelah hitungan iterasi ke-14, 22 dari 30 data uji dapat
diidentifikasi dengan benar. Pada saat itu hitungan iterasi<1500, nilai MSE<0,001, dan tingkat ketepatan hitungan 73,33%. Hasil identifikasi dapat dilihat pada Tabel 23.
(a) (b)
Gambar 36 Hasil simulasi data uji model JSTPB3 8(8-1) dengan Metode Pelatihan Levenberg-Marquard.
Tabel 23 menunjukkan hasil identifikasi dan klasifikasi yang dilakukan dengan Metode JSTPB. Pada tabel tersebut tampak bahwa seluruh anggota kelompok kawanan non-lemuru dapat diidentifikasi dengan benar, sedangkan anggota kelompok kawanan ikan lainnya sebagian dapat diidentifikasi dengan benar, sebagian lainnya teridentifikasi sebagai spesies kawanan ikan lain, 1 anggota kawanan sempenit dan lemuru tidak dapat dikenali. Dari kelima spesies kawanan ikan, tingkat ketepatan terendah dalam identifikasi terlihat pada kawanan sempenit dengan 57,1%.
Tabel 23 Hasil identifikasi dan klasifikasi JSTPB3 JK Jml. Hasil identifikasi 1:N 2:S 3:L 4:C 5:P T.D 1:N 4 4(100%) 0 0 0 0 0 2:S 7 0 4(57,1%) 1 (14,3%) 1(14,3%) 0 1(14,3%) 3:L 5 0 1(20%) 3(60%) 0 0 1(20%) 4:C 6 0 0 1(16,7%) 5(83,3%) 0 0 5:P 8 0 1(12,5%) 0 1(12,5%) 6 (75%) 0 Total 30 4 6 5 7 6 2
Pada Gambar 37 ditunjukkan kekuatan pengaruh kedelapan deskriptor dalam proses identifikasi dan klasifikasi JSTPB3. Dengan urutan kekuatan kontribusi seperti pada gambar tersebut maka dapat disimpulkan bahwa kelompok deskriptor morfometrik adalah kelompok deskriptor yang paling berperan dalam JSTPB3. H Er S E K A L P 0 0.2 0.4 0.6 0.8 1 1.2 D e s k ri pt or Tingkat Kontribusi Gambar 37 Diagram Pareto JSTPB3.
Dari penjelasan di atas dapat disimpulkan bahwa model jaringan JSTPB3 dengan 8 unit masukan pada 1 lapisan masukan, 8 unit sel tersembunyi pada 1 lapisan tersembunyi, dan 1 unit sel keluaran pada 1 lapisan keluaran dapat bekerja secara optimal untuk identifikasi dan klasifikasi kawanan ikan dengan ketepatan hingga 73,33%.
Galat hasil identifikasi yang terukur pada JSTPB2 dan JSTPB3 diduga karena beberapa data deskriptor citra akustik dari kelompok kawanan ikan satu dengan lainnya bertampalan atau hampir bertampalan (overlap) sebagaimana terlihat pada Gambar 23. Pada gambar tersebut dapat dilihat bahwa, fungsi diskriminan 1 dan 2 hanya dapat membedakan dengan benar 81,7% data uji, dengan demikian 18,3% sisanya dapat teridentifikasi sebagai anggota kelompok kawanan lain. Kemungkinan lain dikemukakan oleh Simmonds et al.(1996) yang mengatakan bahwa galat hasil identifikasi dapat disebabkan karena kemiripin tingkah laku ikan yang diamati. Hasil hitungan JSTPB1, JSTPB2, dan JSTPB3 dapat dilihat masing-masing pada Lampiran 12, 13, dan 14.
6.4 Pembahasan
Dari hasil perancangan awal dan pelatihan JSTPB serta hasil analisis statistik, didapatkan model awal JSTB yang bekerja dengan metode pelatihan
Levenberg-Marquardt. Model ini tersusun dari 8 unit sel masukan pada lapisan
masukan, 5 unit sel tersembunyi pada lapisan tersembunyi dan 1 unit sel keluaran pada 1 lapisan keluaran, model 8(5-1).
Penggunaan metode pelatihan Levenberg-Marquardt sebagaimana disebutkan di atas didasarkan pada kemampuan metode pelatihan ini untuk mencapai fungsi tujuannya dengan lebih cepat dibandingkan dengan metode pelatihan lainnya (lihat Tabel 17). Hasil ini sejalan dengan hasil penelitian Demuth & Beale (1998) yang juga menemukan hal yang sama. Kecepatan pemrosesan data yang ditunjukkan metode pelatihan Levenberg-Marquardt diduga karena metode ini menggunakan Algoritma Newton yang sudah dikembangkan. Kreyszig (1988) mengemukakan bahwa algoritma Newton adalah algoritma yang efisien yang dapat digunakan untuk menyelesaikan operasi-operasi matriks. Karena itu, penyelesaian Matriks Hesian dapat dilakukan dengan lebih cepat dan dengan penggunaan memori komputer yang lebih sedikit (Demuth & Beale, 1998).
Hasil perancangan awal dan pelatihan JSTPB juga menunjukkan bahwa setelah unit sel masukan berjumlah lebih besar dari 18, nilai MSE dan iterasi hitungan mencapai nilai yang melebihi batas toleransi (lihat Gambar 28). Hal ini
menunjukkan bahwa penambahan jumlah unit sel masukan berpengaruh terhadap kecepatan dan ketepatan pencapaian fungsi tujuan. Fausett (1994) mengemukakan bahwa kecenderungan peningkatan nilai galat selama berlangsungnya proses pelatihan, mengindikasikan bahwa JSTPB telah kehilangan kemampuannya dalam merampat pola-pola masukan yang diberikan, pada kondisi seperti itu proses pelatihan sebaiknya dihentikan. Dengan demikian pencapaian fungsi tujuan dan ketepatan hasil identifikasi yang memadai dapat dilakukan jika unit sel masukan berkisar antar 8 hingga 17deskriptor.
Hasil perancangan awal dan pelatihan JSTPB juga menunjukkan bahwa penambahan jumlah unit sel tersembunyi pada lapisan tersembunyi mengakibatkan proses pencapaian fungsi tujuan dapat dilakukan dengan lebih cepat (jumlah iterasi berkurang) seperti terlihat pada Gambar 29. Hal ini sejalan dengan Fausett (1994) yang juga menemukakan hal yang sama ketika membandingkan kecepatan pemrosesan data yang dilakukan dengan jumlah unit sel tersembunyi yang berbeda. Hal yang sebaliknya terjadi jika jumlah lapisan tersembunyi diperbanyak. Gambar 30 menunjukkan bahwa semakin banyak jumlah lapisan tersembunyi maka semakin lambat proses hitungan dilakukan dan semakin besar nilai MSE yang dihasilkan, dengan kata lain semakin banyak jumlah iterasi hitungan yang diperlukan. Fausett (1994) mengemukakan bahwa pada kondisi tertentu JSTPB hanya memerlukan cukup 1 lapisan tersembunyi untuk mendapatkan hasil identifikasi dengan ketepatan yang memadai, sedangkan pada kondisi lainnya 2 lapisan tersembunyi dapat membuat proses pelatihan jaringan menjadi lebih mudah.
Model hasil rancangan awal selanjutnya diuji coba dengan menggunakan data uji dengan komposisi awal data latih dan data uji 58:56.. Hasil uji coba menunjukkan bahwa model JSTPB 8(5-1) tidak dapat meberikan hasil yang memadai dalam proses identifikasi dan klasifikasi data uji, karenanya dilakukan pemodelan ulang. Dari hasil pemodelan ulang didapatkan 3 model JSTPB yaitu JSTPB1 8(8-1), JSTPB2 15(15-1) dan JSTPB3 8(8-1). Ketiga JSTPB ini dapat mencapai fungsi tujuan dengan jumlah iterasi<1500 dan ketepatan >70%. Hasil pemodelan ulang ini dapat dicapai setelah komposisi data latih dan uji diubah menjadi 84:30.
Hal ini mengindikasikan bahwa ketiga JSTPB layak digunakan untuk mengidentifikasi dan mengklasifikasi kawanan ikan lemuru. Walaupun demikian, Gambar 32(b), 34(b) dan 36(b) menunjukkkan bahwa hanya JSTPB1 yang menunjukkan adanya kecenderungan yang nyata dimana nilai ketepatan akan meningkat ketika jumlah iterasi diperbanyak. Hal sebaliknya terlihat pada Gambar 34(b) dan 36(b). Pada kedua gambar ini, nilai ketepatan tidak mengalami peningkatan seiring dengan penambahan jumlah iterasi hitungan. Dengan demikian peluang untuk mendapatkan hasil identifikasi yang memadai akan lebih besar jika identifikasi dan klasifikasi dilakukan dengan model JSTPB1.
6.5 Kesimpulan
Dari penjelasan di atas disimpulkan bahwa;
(1) JSTPB1 dengan model 8(8-1), JSTPB2 dengan model 15(15-1), dan JSTPB3 dengan model 8(8-1) dan dengan metode pelatihan Levenberg-Merquardt (trainlm), layak digunakan untuk identifikasi dan klasifikasi kawanan lemuru.
(2) Fungsi aktivasi tansig dan purelin pada lapisan tersembunyi dan keluarannya, dapat digunakan dengan baik untuk mengidentifikasi spesies kawanan lemuru dengan ketepatan antara 70-100%.
(3) Untuk mencapai tingkat ketepatan yang demikian, dibutuhkan maksimal 35,7% data uji dari total data latih yang tersedia atau 30 pola data uji dengan 84 pola data latih.