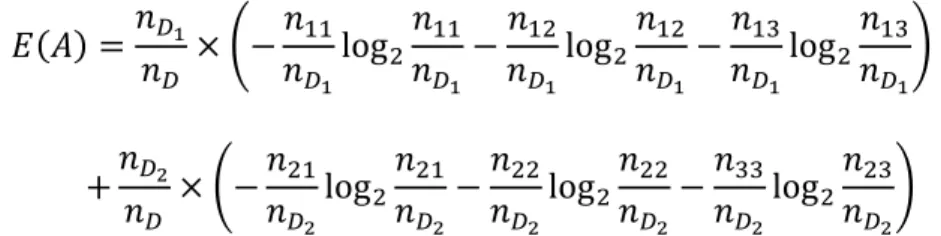BAB II KAJIAN TEORI
Pada bab ini berisi tentang teori-teori dasar mengenai kredit, database, penambangan data (data mining), aturan klasifikasi, decision tree C4.5, naïve bayes, metode evaluasi model, WEKA, dan penelitian yang relevan sebagai landasan pelaksanaan penelitian.
A. Kredit
Kredit adalah kemampuan untuk melaksanakan suatu pembelian atau mengadakan suatu pinjaman dengan suatu janji pembayarannya akan dilakukan ditangguhkan pada suatu jangka waktu yang disepakati (Teguh Pudjo Muljono, 2000: 9).
Menurut Undang-Undang Perbankan No.12 Tahun 1992 pasal 1, kredit adalah penyediaan uang atau tagihan yang dapat dipersamakan dengan itu, berdasarkan persetujuan atau kesepakatan pinjam-meminjam antara pihak bank dengan pihak lain, yang mewajibkan pihak peminjam untuk melunasi hutangnya setelah jangka waktu tertentu dengan bunga, imbalan, atau pembagian hasil keuntungan.
Kegiatan perkreditan mempunyai prinsip-prinsip yang disebut juga sebagai konsep 5C. Pada dasarnya konsep 5C dapat memberikan beberapa informasi mengenai seberapa baik nasabah akan melunasi pinjaman. Konsep 5C tersebut adalah sebagai berikut (Kasmir, 2012: 136):
1. Character
Sifat atau watak dari orang-orang yang akan diberikan kredit benar-benar harus dapat dipercaya. Manfaat dari penilaian character yaitu untuk mengetahui sejauh mana tingkat kejujuran dan integritas serta tekad baik yaitu kemauan untuk memenuhi kewajiban-kewajibannya dari calon debitur.
2. Capacity
Kemampuan melunasi kewajiban-kewajibannya dari kegiatan usaha yang dilakukannya atau kegiatan usaha yang akan dilakukan dengan biaya kredit bank.
3. Capital
Besar atau kecilnya modal seorang calon debitur, serta analisis dari sumber mana saja modal saat ini, termasuk banyaknya modal yang digunakan untuk membiayai usaha yang akan dijalankan.
4. Collateral
Barang-barang jaminan yang diserahkan oleh peminjam/ debitur sebagai jaminan atas kredit yang diterimanya. Manfaat collateral yaitu sebagai alat pengamanan apabila usaha yang dibiayai dengan kredit tersebut gagal atau sebab-sebab lain dimana debitur tidak mampu melunasi kreditnya dari hasil usahanya yang normal.
5. Condition of Economy
Situasi dan kondisi politik, sosial, ekonomi, budaya, dan lain-lain yang mempengaruhi keadaan perekonomian pada suatu saat maupun untuk suatu
kurun waktu tertentu yang kemungkinannya akan dapat mempengaruhi kelancaran usaha dari perusahaan yang memperoleh kredit.
Jumlah kredit yang disalurkan sangat berpengaruh terhadap hidup matinya lembaga keuangan. Banyaknya jumlah kredit yang disalurkan juga harus memperhatikan kualitas kredit tersebut. Bank Indonesia menggolongkan kualitas kredit menurut ketentuan sebagai berikut (Kasmir, 2013: 107-108):
1. Lancar
Suatu kredit dikatakan lancar apabila:
a. pembayaran angsuran pokok dan/ atau bunga tepat waktu; dan b. memiliki mutasi rekening yang aktif; atau
c. bagian dari kerdit yang dijamin dengan agunan tunai. 2. Dalam perhatian khusus
Dikatakan dalam perhatian khusus apabila memenuhi kriteria antara lain: a. terdapat tunggakan pembayaran angsuran pokok dan/ bunga yang
belum melampaui 90 hari; atau
b. kadang-kadang terjadi cerukan atau jumlah penarikan yang melebihi dana yang tersedia pada akun giro atau rekening negatif yang disebabkan oleh nasabah yang menulis cek melebihi jumlah dana yang ada direkeningnya; atau
c. jarang terjadi pelanggaran terhadap kontrak yang diperjanjikan; atau d. mutasi rekening relatif aktif; atau
3. Kurang lancar
Dikatakan kurang lancar apabila memiliki kriteria diantaranya:
a. terdapat tunggakan angsuran pokok dan/ atau bunga yang telah melampaui 90 hari; atau
b. sering terjadi cerukan; atau
c. terjadi pelanggaran terhadap kontrak yang diperjanjikan lebih dari 90 hari; atau
d. frekuensi mutasi rekening relatif rendah; atau
e. terdapat indikasi masalah keuangan yang dihadapi debitur; atau f. dokumen pinjaman yang lemah.
4. Diragukan
Dikatakan diragukan apabila memenuhi kriteria diantaranya:
a. terdapat tunggakan pembayaran angsuran pokok dan/ atau bunga yang melampaui 180 hari; atau
b. terjadi cerukan bersifat permanen; atau c. terjadi wanprestasi lebih dari 180 hari; atau d. terjadi kapitalisasi bunga; atau
e. dokumen hukum yang lemah, baik untuk perjanjian kredit maupun peningkatan jaminian.
5. Macet
Dikatakan macet apabila memenuhi kriteria antara lain:
a. terdapat tunggakan pembayaran angsuran pokok dan/ atau bunga yang telah melampaui 270 hari; atau
b. kerugian operasional ditutup dengan pinjaman baru; atau
c. dari segi hukum dan kondisi pasar, jaminan tidak dapat dicairkan pada nilai yang wajar.
Penggolongan kualitas kredit di atas digunakan untuk mengantisipasi resiko kredit bermasalah secara dini. Kredit bermasalah atau problem loan dapat diartikan sebagai pinjaman yang mengalami kesulitan pelunasan akibat adanya faktor kesengajaan dan atau karena faktor eksternal di luar kemampuan kendali debitur. Apabila kredit dikaitkan dengan tingkat kolektibilitasnya, maka yang digolongkan kredit bermasalah adalah kredit yang memiliki kualitas dalam perhatian khusus, kurang lancar, diragukan, dan macet (Dahlan Siamat 2004: 174).
B. Basis Data (Database)
Menurut Connolly & Begg (2002: 15) database merupakan suatu kumpulan data yang terhubung secara logic, dan deskripsi dari data tersebut yang dirancang untuk memenuhi kebutuhan informasi dari suatu organisasi. Database merupakan tempat penyimpanan data yang besar, dimana dapat digunakan secara simultan oleh banyak pengguna.
Database terdiri dari beberapa objek antara lain yaitu: 1. Field
Field adalah kumpulan dari beberapa karakteristik dari objek-objek yang ada.
2. Record
3. File
File atau berkas adalah kumpulan dari beberapa record yang berhubungan membentuk saling ketergantungan satu dengan yang lainnya.
4. Entity
Entity adalah satu kesatuan yang terdiri dari informasi yang disimpan. 5. Attribute
Atribut adalah nama dari suatu kolom relasi yang menjelaskan suatu entity. 6. Primary Key
Primary Key adalah sebuah field yang mempunyai nilai unik yang tidak memiliki kesamaan antara record yang satu dengan record yang lain. 7. Foreign Key
Foreign Key adalah satu atribut atau kumpulan atribut dalam satu relasi yang berguna untuk menghubungkan primary key lain yang berbeda dalam tabel lain.
Menurut Han, et al (2012: 9) jenis-jenis database adalah sebagai berikut: 1. Relational database
Relational database atau basis data relasional adalah sebuah kumpulan tabel dengan nama khusus dan setiap tabel terdiri atas kumpulan atribut (kolom atau field) dan biasanya menyimpan data dalam jumah yang besar pada data (baris atau record). Setiap data dalam tabel relasi menunjukkan sebuah objek yang diidentifikasi oleh sebuah unique key dan digambarkan oleh nilai dari atribut tersebut.
2. Data Warehouse
Data warehouse adalah tempat penyimpanan informasi dari berbagai sumber data dan disimpan pada satu tempat. Data warehouse dibangun melalui sebuah proses dari pembersihan data dari data-data yang tidak lengkap, menganalisis data, perubahan bentuk data, pemuatan ulang data-data yang baru, dan pembaharuan data-data secara periodik.
3. Transactional Data
Transactional data pada setiap record dikumpulkan berdasarkan sebuah transaksi (dalam dunia bisnis). Sebuah transaksi memiliki nomor identitas transaksi yang unik (trans_ID). Transactional data yang mempunyai tabel tambahan yang berisi informasi lain direlasikan pada hubungan yang mungkin terjadi, seperti deskripsi barang, informasi dari pelayan toko, dan lain-lain.
C. Penambangan Data (Data Mining)
Data mining adalah proses menentukan pola dan informasi dari data yang berjumlah besar. Sumber data dapat berupa database, data warehouse, Web, tempat penyimpanan informasi lainnya atau data yang mengalir ke dalam sistem yang dinamis (Han, et al, 2012: 8).
Menurut Grup Gartner (dalam Larose, 2005: 2) data mining adalah suatu proses menemukan hubungan yang berarti, pola, dan kecenderungan dengan memeriksa dalam sekumpulan besar data yang tersimpan dalam penyimpanan dengan menggunakan teknik pengenalan pola seperti statistik dan matematika.
Menurut Turban, dkk (dalam Kusrini & Emha, 2009: 3) Data mining adalah proses yang menggunakan teknik statistik, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengindentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database besar.
Data mining merupakan salah satu langkah penting dalam menemukan sebuah pengetahuan pada proses Knowledge Discovery in Data (KDD). KDD adalah proses menentukan informasi yang berguna serta pola-pola yang ada dalam data. Tahapan proses KDD ditunjukkan pada Gambar 2.1.
Menurut Han, et al (2006: 7 ) tahapan dalam KDD dapat dijelaskan sebagai berikut:
1. Pembersihan Data (Data Cleaning)
Pembersihan data merupakan proses menghilangkan noise dan data yang tidak konsisten. Pada tahap ini data-data yang memiliki isian tidak sempurna seperti data yang tidak memiliki kelengkapan atribut yang dibutuhkan dan data yang tidak valid dihapus dari database.
2. Integrasi Data (Data Integration)
Integrasi data merupakan proses kombinasi beberapa sumber data ke dalam database. Pada tahap ini dilakukan penggabungan data dari berbagai sumber untuk dibentuk penyimpanan data yang koheren.
3. Seleksi Data (Data Selection)
Seleksi data merupakan pemilihan data yang digunakan untuk proses data mining. Data hasil seleksi yang akan digunakan untuk proses data mining, disimpan suatu berkas dan terpisah dari basis data operasional. 4. Transformasi Data (Data Transformation)
Transformasi data merupakan proses mentransformasikan dan mengkonsolidasikan data yang digunakan untuk proses mining. Pada tahap ini dilakukan pengubahan format data menjadi format yang sesuai dengan teknik data mining yang digunakan.
5. Penambangan Data (Data Mining)
Penambangan data merupakan proses utama mencari pengetahuan dari informasi tersembunyi. Penambangan data adalah proses mencari pola
atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik dalam data mining sangat bervariasi, pemilihan teknik yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
6. Evaluasi Pola (Pattern Evaluation)
Evaluasi pola ialah proses mengidentifikasi kebenaran pola yang telah didapat. Pada tahap ini pola yang telah didapat dari proses data mining dievaluasi apakah pola yang ditemukan bertentangan dengan fakta atau hipotesis yang ada sebelumnya.
7. Representasi Pengetahuan (Knowledge Presentation)
Representasi pengetahuan merupakan visualisasi dan presentasi pengetahuan yang telah didapat kepada pengguna. Pada tahap terakhir ini disajikan pengetahuan dan metode yang digunakan untuk memperoleh pengetahuan yang dapat dipahami oleh pengguna atau semua orang.
Data mining mempunyai beberapa metode yang dilakukan pengguna untuk meningkatkan proses mining supaya lebih efektif. Oleh karena itu, data mining dibagi menjadi beberapa kelompok berdasarkan metodenya, yaitu (Larose, 2005: 11):
1. Deskripsi
Deskripsi digunakan untuk memberikan gambaran secara ringkas berupa pola dan tren bagi data yang jumlahnya sangat besar dan jenisnya beragam. Metode dalam data mining yang dapat digunakan untuk deskripsi contohnya neural network dan exploratory data analysis.
2. Klasifikasi
Pada klasifikasi terdapat variabel target yang berupa nilai kategori. Contoh dari klasifikasi adalah penggolongan pendapatan masyarakat ke dalam tiga kelompok, yaitu pendapatan tinggi, pendapatan sedang, dan pendapatan rendah. Algoritma klasifikasi yang biasa digunakan adalah Naïve Bayes, K-Nearest Neighbor, dan C4.5.
3. Estimasi
Estimasi mirip dengan klasifikasi namun variabel target pada proses estimasi lebih condong ke arah numerik daripada ke arah kategori. Model dibangun menggunakan record lengkap yang menyediakan nilai dari variabel target sebagai nilai prediksi, kemudian nilai estimasi dari variabel target dibuat berdasarkan pada nilai prediksi. Contoh algoritma estimasi adalah linear regression dan neural network.
4. Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi, namun pada prediksi data yang digunakan adalah data runtun waktu (data time series) dan nilai pada hasil akhir digunakan untuk beberapa waktu mendatang. Contoh prediksi dalam bisnis dan penelitian adalah prediksi harga beras dalam tiga bulan kedepan.
5. Pengelompokan
Pengelompokan data atau pembentukan data ke dalam jenis yang sama. Pengelompokan tidak untuk mengklasifikasi, mengestimasi, atau memprediksi nilai, tetapi membagi seluruh data menjadi
kelompok-kelompok yang relatif sama (homogen). Perbedaan algoritma pengelompokan dengan algoritma klasifikasi adalah pengelompokan tidak memiliki target/ class/ label. Contoh algoritma pengelompokan adalah K-Means dan Fuzzy C-Means.
6. Asosiasi
Asosiasi digunakan untuk menemukan atribut yang muncul dalam waktu yang bersamaan dan untuk mencari hubungan antara dua atau lebih data dalam sekumpulan data. Contoh penggunaan aturan asosiasi adalah analisis kemungkinan seorang pelanggan membeli roti dan susu dalam waktu yang bersamaan di suatu pasar swalayan. Contoh algoritma aturan asosiasi yang sering digunakan adalah Apriori dan FP-Growth.
D. Klasifikasi
Klasifikasi adalah proses penemuan model (atau fungsi) yang membedakan kelas data atau konsep yang bertujuan agar dapat digunakan untuk memprediksi kelas dari objek yang label kelasnya tidak diketahui. Model ditemukan berdasarkan analisis data training (objek data yang kelasnya diketahui) (Han, et al, 2006: 24). Algoritma-algoritma yang sering digunakan untuk proses klasifikasi sangat banyak, yaitu k-nearest neighbor, rough set, algoritma genetika, metode rule based, C4.5, naive bayes, analisis statistik, memory based reasoning, dan support vector machines (SVM).
Klasifikasi data terdiri dari 2 langkah proses. Pertama adalah learning (fase training), dimana algoritma klasifikasi dibuat untuk menganalisa data training lalu direpresentasikan dalam bentuk aturan klasifikasi. Proses kedua adalah klasifikasi,
dimana data tes digunakan untuk memperkirakan akurasi dari aturan klasifikasi (Han, et al, 2006: 286).
Proses klasifikasi didasarkan pada empat komponen (Gorunescu, 2011: 15): 1. Kelas
Variabel dependen berupa kategori yang merepresentasikan “label” yang terdapat pada objek. Contohnya: risiko penyakit jantung, risiko kredit, dan jenis gempa.
2. Predictor
Variabel independen yang direpresentasikan oleh karakteristik (atribut) data. Contohnya: merokok atau tidak, minum alkohol atau tidak, besar tekanan darah, jumlah tabungan, jumlah aset, jumlah gaji.
3. Training dataset
Satu set data yang berisi nilai dari kedua komponen di atas yang digunakan untuk menentukan kelas yang cocok berdasarkan predictor.
4. Testing dataset
Berisi data baru yang akan diklasifikasikan oleh model yang telah dibuat dan akurasi klasifikasi dievaluasi.
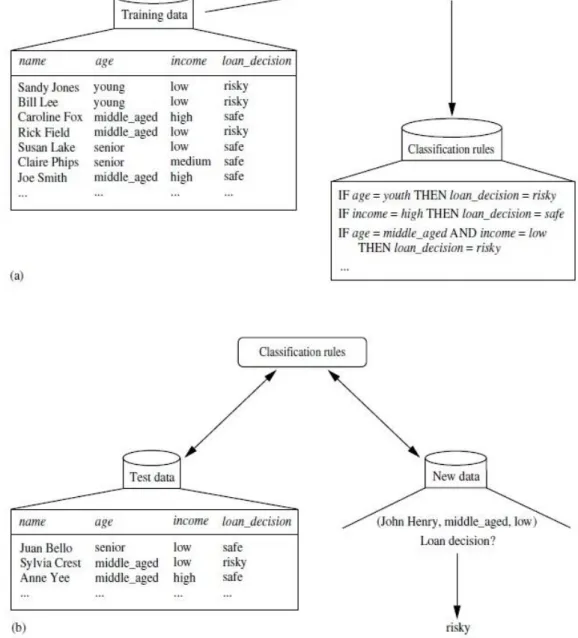
Proses klasifikasi dapat dicontohkan seperti yang ditunjukkan pada Gambar 2.2.
Gambar 2.2 poin (a) adalah proses pembelajaran dimana data training dianalisis menggunakan algoritma klasifikasi. Atribut keputusan kredit sebagai label kelas, dan model pembelajaran atau pengklasifikasian dipresentasikan dalam bentuk aturan klasifikasi (classification rule). Gambar 2.2 poin (b) adalah proses
klasifikasi. Proses klasifikasi digunakan untuk mengestimasi keakurasian dari classification rule yang dihasilkan. Apabila akurasi dapat diterima maka aturan yang diperoleh dapat digunakan pada klasifikasi data baru (Han, et al, 2006: 287).
1. Pohon Keputusan (Decision Tree)
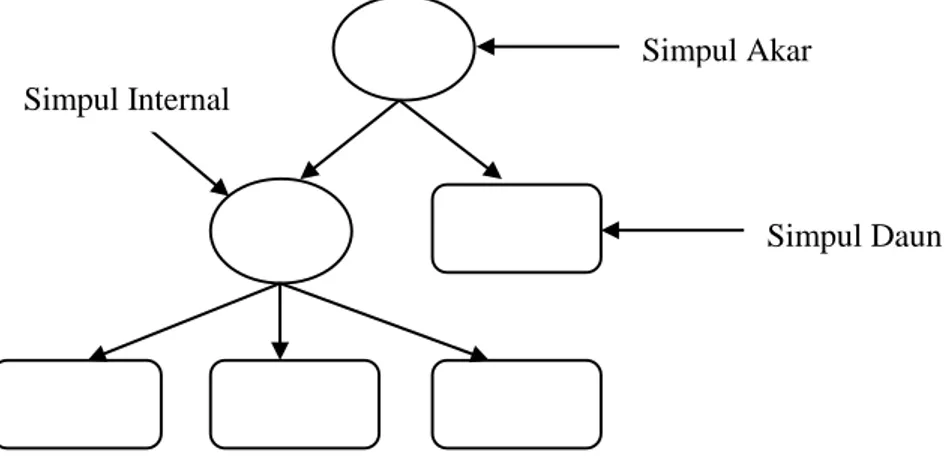
Pohon keputusan merupakan salah satu metode klasifikasi yang menggunakan representasi struktur pohon (tree) dimana setiap simpul internal (internal node) merupakan sebuah atribut, setiap cabang merupakan nilai atribut, dan setiap simpul daun (leaf node) atau simpul terminal merupakan label class, serta simpul yang paling atas adalah simpul akar (root node) (Han, et al, 2006: 291).
Gambar 2.3 Bentuk Pohon Keputusan
Berikut penjelasan mengenai 3 jenis simpul yang terdapat pada pohon keputusan:
a. Simpul Akar
Simpul akar merupakan simpul yang paling atas, pada simpul ini tidak mempunyai input dan bisa tidak mempunyai output atau mempunyai output lebih dari satu.
b. Simpul Internal
Simpul internal merupakan simpul percabangan dari simpul akar, pada Simpul Internal
Simpul Akar
c. Simpul Daun
Simpul daun merupakan simpul terakhir, pada simpul ini hanya terdapat satu input dan tidak mempunyai output, simpul ini sering disebut simpul terminalserta merupakan suatukeputusan.
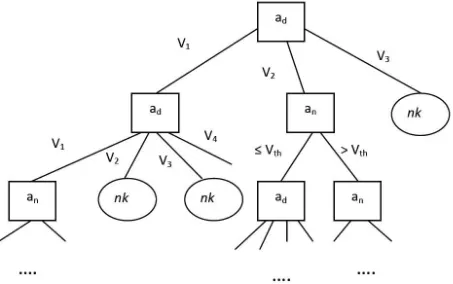
Dalam kaitannya dengan sebuah basis data, himpunan data dapat berupa tabel, sedangkan sampel adalah record. Himpunan data dapat memiliki atribut yang dapat bertipe diskrit maupun kontinu. Ilustrasi dari pohon keputusan berdasarkan tipe atributnya dapat dijelaskan pada Gambar 2.4 (Han, et al, 2001).
Gambar 2.4 Ilustrasi Model Pohon Keputusan Berdasarkan Tipe Atributnya
Berdasarkan Gambar 2.4 jika atribut prediktor bertipe diskret (𝑎𝑑), maka cabang simpul dibuat untuk setiap nilai pada atribut diskrit tersebut (𝑣1, 𝑣2, … 𝑣𝑚). Sedangkan jika atribut prediktor bertipe kontinu atau numerik (𝑎𝑛), maka cabang simpul dibuat untuk dua buah nilai yaitu 𝑎𝑛 ≤ 𝑣𝑡ℎ dan 𝑎𝑛 ≥ 𝑣𝑡ℎ, dimana 𝑣𝑡ℎ adalah nilai ambang dari 𝑎𝑛. Konsep dasar pohon keputusan ditunjukkan pada Gambar 2.5.
Algoritma: Pembentukan_Pohon_Keputusan, Pembentukan pohon keputusan dari tupel pelatih pada partisi data, 𝐷.
Masukan:
Partisi data, 𝐷, yang merupakan satu set data tupel pelatihan dan label kelas yang berkaitan;
Daftar_atribut, kumpulan beberapa atribut;
Metode_seleksi_atribut, sebuah prosedur untuk menentukan kriteria terbaik pemecahan data tupel ke dalam kelas masing-masing. Kriteria ini terdiri dari pemecahan_atribut dan kemungkinannya, baik pemecahan simpul atau pemecahan bagian.
Hasil: pohon keputusan Metode:
(1) Bentuk sebuah simpul 𝑁;
(2) jika tupel di 𝐷 ada pada kelas yang sama, 𝐶, maka
(3) kembali 𝑁 sebagai simpul daun yang diberi label kelas 𝐶; (4) jika daftar_atribut kosong maka
(5) kembali 𝑁 sebagai simpul yang diberi label dengan kelas terbanyak di 𝐷; // kelas terbanyak
(6) berlaku metode_seleksi_atribut (𝐷, daftar_atribut) untuk menemukan pemecahan kriteria terbaik;
(7) beri label 𝑁 dengan kriteria_pemecahan; (8) jika pemecahan_atribut bernilai diskrit dan
beberapa pemecahan diperbolehkan maka // tidak terbatas untuk pohon biner (9) daftar_atribut daftar_atribut – pemecahan_atribut; // hapus
pemecahan_atribut
(10) Untuksetiap j dari pemecahan_kriteria
(11) kemudian 𝐷𝑗 menjadi kumpulan data tupel di 𝐷 dengan hasil 𝑗; // partisi
(12) jika 𝐷𝑗 kosong maka
(13) Lampirkan sebuah simpul daun dengan label kelas terbanyak di 𝐷 untuk simpul 𝑁;
(14) Untuk lainnya lampirkan simpul kembali dengan pembentukan _pohon_keputusan (𝐷𝑗, daftar _atribut) pada 𝑁; berakhir untuk (15)kembali 𝑁;
Berdasarkan Gambar 2.5, input algoritma dasar terdiri dari partisi data 𝐷, daftar atribut (attribute list), dan metode seleksi atribut (attribute selection method). Proses untuk membangun sebuah pohon keputusan seperti yang ditunjukkan pada Gambar 2.5 di atas adalah sebagai berikut:
1. Pohon dimulai dengan simpul tunggal 𝑁 yang merepresentasikan tupel training pada 𝐷 (langkah 1).
2. Jika semua tupel di 𝐷 berasal dari kelas yang sama, maka simpul 𝑁 menjadi daun dan diberi label kelas tersebut (langkah 2 dan 3). Langkah 4 dan 5 merupakan kondisi akhir. Semua kondisi akhir dijelaskan pada akhir algoritma. 3. Jika tidak, maka metode seleksi atribut digunakan untuk memilih atribut split, yaitu atribut terbaik dalam memisahkan tupel ke dalam kelas masing-masing (langkah 6). Atribut tersebut menjadi atribut tes pada simpul 𝑁 (langkah 7). 4. Terdapat dua kemungkinan yang dapat mempartisi 𝐷. Apabila 𝐴 atribut split
pada simpul 𝑁 dan 𝐴 memiliki sejumlah 𝑣 nilai yang berbeda {𝑎1, 𝑎2, … 𝑎𝑣} maka pada data training dapat terjadi (langkah 8 dan 9):
a. Jika 𝐴 memiliki nilai-nilai bersifat diskrit, maka sebuah cabang dibentuk untuk setiap nilai 𝐴. Nilai total cabang yang akan dibentuk sebanyak 𝑣 cabang. Partisi 𝐷𝑗 terdiri dari record yang terdapat pada 𝐷 yang memiliki nilai 𝑎𝑗 untuk atribut 𝐴. Selanjutnya atribut 𝐴 dihapus dari daftar atribut. b. Jika 𝐴 memiliki nilai yang bersifat kontinu, maka hasil pengujian simpul
𝑁 akan menghasilkan dua cabang. Kedua cabang tersebut adalah 𝐴 < split point dan 𝐴 ≥ split point. Split point merupakan keluaran metode seleksi atribut sebagai bagian dari kriteria untuk melakukan partisi. Selanjutnya 𝐷
dipartisi, sehingga 𝐷1 terdiri dari record dimana 𝐴 < split point dan 𝐷2 adalah sisanya.
5. Cabang akan dibuat untuk setiap nilai pada atribut tes dan tupel pada data training akan dipartisi lagi (langkah 10 dan langkah 11).
6. Proses pembentukan ini menggunakan proses rekursif untuk membentuk pohon pada setiap data partisi (langkah 14).
7. Proses rekursif akan berhenti jika telah mencapai kondisi sebagai berikut: a. Semua tupel pada simpul berada di dalam satu kelas (langkah 2 dan 3). b. Tidak ada atribut lainnya yang dapat digunakan untuk mempartisi tupel
lebih lanjut (langkah 4). Selanjutnya dalam hal ini, akan diterapkan jumlah terbanyak (langkah 5). Hal tersebut berarti mengubah sebuah simpul menjadi daun dan memberi label dengan kelas pada jumlah terbanyak. Sebagai alternatifnya, distribusi kelas pada simpul ini dapat disimpan. c. Tidak ada tupel yang digunakan untuk mencabang, suatu partisi 𝐷𝑗kosong
(langkah 12). Selanjutnya dalam hal ini, sebuah daun dibuat dan diberi label dengan kelas yang memiliki kelas terbanyak di 𝐷 (langkah 13). 8. Kembali menghasilkan pohon keputusan (langkah 15) (Han, et al,
2012:331-336; Neni Miswaningsih, 2015: 37-39).
Pohon keputusan memiliki beberapa cara dalam menentukan ukuran data dalam bentuk pohon, salah satunya adalah dengan algoritma C4.5. Algoritma C4.5 menggunakan information gain sebagai penentu simpul akar, internal, dan daun.
Misalkan 𝑁 merupakan simpul partisi dari 𝐷. Apabila terdapat nilai information gain tertinggi maka akan terpilih sebagai atribut pemisah untuk simpul
𝑁. Perhitungan informasi yang dibutuhkan untuk mengklasifikasi pada tupel 𝐷 dinyatakan sebagai berikut:
𝐼𝑛𝑓𝑜(𝐷) = − ∑𝑚 𝑝𝑖 log2(𝑝𝑖) 𝑖=1
(2.1)
dimana 𝑚 merupakan banyaknya jenis kategori nilai pada atribut C, 𝑝𝑖 = |𝐶𝑖,𝐷|
|𝐷|
merupakan probabilitas dari tupel 𝐷 yang mempunyai kelas 𝐶𝑖. Info (𝐷) merupakan rata-rata dari informasi yang dibutuhkan untuk mengetahui label kelas dari tupel 𝐷. 𝐼𝑛𝑓𝑜 (𝐷) juga sering dikenal sebagai entropy dari tupel 𝐷. Sebagai ilustrasi diberikan Tabel 2.1.
Tabel 2.1 Banyaknya Kelas pada Tupel 𝐷 Kelas
𝐶1 𝐶2
frekuensi 𝑛𝐶1 𝑛𝐶2
𝑝𝑖 𝑝1 𝑝2
− log2(𝑝𝑖) −log2𝑝1 −log2𝑝2
−𝑝𝑖log2(𝑝𝑖) − p1log2(𝑝1) −𝑝2log2(𝑝2)
Apabila diberikan tupel 𝐷 dengan dua pengklasifikasian yaitu kelas 𝐶1, dan 𝐶2, dengan frekuensi𝑛𝐶1 dan 𝑛𝐶2 serta 𝑝𝑖 adalah proporsi dari setiap kelas, maka
𝑝1 = 𝑛𝐶1
𝑛𝐶1+ 𝑛𝐶 2 untuk 𝑝2 analog dengan perhitungan 𝑝1.
Perhitungan − log2𝑝𝑖 dilakukan untuk mentransformasi masing-masing proporsi kelas menjadi informasi dalam bentuk bit atau bilangan basis 2. Informasi tersebut dapat juga dipandang sebagai jumlah informasi yang dapat dikodekan menjadi satu atau nol.
Nilai −𝑝𝑖log2𝑝𝑖 akan positif bila 𝑝𝑖 lebih besar dari nol dan kurang dari satu. Ketika 𝑝𝑖 = 1 maka nilai dari −𝑝𝑖log2𝑝𝑖 adalah nol, sehingga nilai −𝑝𝑖log2(𝑝𝑖) diantara bilangan positif atau nol pada data training. Nilai 𝐼𝑛𝑓𝑜(𝐷) = − ∑𝑚 𝑝𝑖 log2(𝑝𝑖)
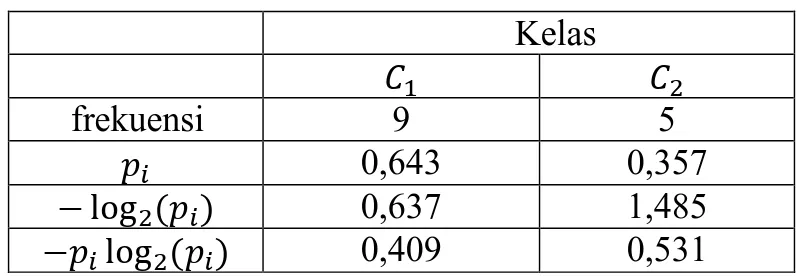
𝑖=1 adalah nol jika dan hanya jika semua data memiliki klasifikasi yang sama dimana probabilitasnya adalah satu. Sebagai contoh diberikan Tabel 2.2.
Tabel 2.2 Contoh Perhitungan 𝐼𝑛𝑓𝑜(𝐷) Kelas 𝐶1 𝐶2 frekuensi 9 5 𝑝𝑖 0,643 0,357 − log2(𝑝𝑖) 0,637 1,485 −𝑝𝑖log2(𝑝𝑖) 0,409 0,531
Tabel 2.2 merupakan data penjualan komputer, dimana 𝐶1 adalah membeli komputer dan 𝐶2 adalah tidak membeli komputer. Berdasarkan Tabel 2.2 𝐼𝑛𝑓𝑜(𝐷) = 0,409 + 0,531 = 0,940, nilai 𝐼𝑛𝑓𝑜(𝐷) ≠ 0, artinya data belum memiliki klasifikasi kelas yang sama, sehingga dibutuhkan perhitungan lanjutan untuk menemukan simpul akar dalam pembentukan pohon keputusan.
Selanjutnya misalkan terdapat atribut 𝐴 yangmemiliki 𝑣 nilai yang berbeda {𝑎1, 𝑎2, … 𝑎𝑣}. Atribut 𝐴 dapat digunakan untuk membagi 𝐷 ke dalam 𝑣 partisi {𝐷1, 𝐷2, … , 𝐷𝑣}, dimana 𝐷𝑗memuat tupel 𝐷 yang memiliki nilai 𝑎𝑗 dari 𝐴. Sebagai ilustrasi perhitungan entropy, diberikan Tabel 2.3.
Tabel 2.3 Kelas Tupel D Berdasarkan Partisi Atribut 𝐴
𝐴 Kelas Total 𝐶1 𝐶2 𝑎1 𝑛11 𝑛12 𝑛𝐷1 𝑎2 𝑛21 𝑛22 𝑛𝐷2 𝑎3 𝑛31 𝑛32 𝑛𝐷3 Total 𝑛 𝑛 𝑛
Tabel 2.3 menunjukkan jumlah tupel 𝐷 dengan partisi atribut 𝐴 yang mempunyai nilai kategori 𝑎1, 𝑎2 serta pengklasifikasian sebanyak dua kelas yaitu 𝐶1, 𝐶2. Dimana 𝑛11, … , 𝑛32 merupakan jumlah sampel pada subset yang mempunyai nilai 𝑎1, 𝑎2 yang berada pada kelas 𝐶1, 𝐶2 kemudian 𝑛𝐷1, 𝑛𝐷2merupakan jumlah sampel yang mempunyai nilai 𝑎1, 𝑎2, dan 𝑛𝐶1, 𝑛𝐶2 merupakan jumlah sampel
kategori kelas 𝐶1, 𝐶2, maka nilai dari entropy atribut 𝐴 dapat dihitung sebagai berikut: 𝐸(𝐴) =𝑛𝐷1 𝑛𝐷 × (− 𝑛11 𝑛𝐷1log2 𝑛11 𝑛𝐷1 − 𝑛12 𝑛𝐷1log2 𝑛12 𝑛𝐷1 − 𝑛13 𝑛𝐷1log2 𝑛13 𝑛𝐷1) +𝑛𝐷2 𝑛𝐷 × (−𝑛21 𝑛𝐷2 log2 𝑛21 𝑛𝐷2 −𝑛22 𝑛𝐷2 log2 𝑛22 𝑛𝐷2 −𝑛33 𝑛𝐷2 log2 𝑛23 𝑛𝐷2 )
Rumus secara umum dalam mencari nilai entropy dari subset 𝐴 sebagai berikut: 𝐼𝑛𝑓𝑜𝐴(𝐷) = 𝐸(𝐴) = ∑ |𝐷𝑗| |𝐷| 𝑣 𝑗=1 × 𝐼𝑛𝑓𝑜 (𝐷𝑗) (2.2) dimana 𝐸(𝐴) adalah entropy dari subset 𝐴, v merupakan banyaknya jenis kategori nilai pada subset 𝐴, |𝐷𝑗|
|𝐷| merupakan bobot dari subset 𝑗 dan jumlah sampel pada subset yang mempunyai nilai 𝑎𝑗dari 𝐴, dibagi dengan jumlah tupel dari 𝐷. Entropy dari subset 𝐴 merupakan informasi harapan yang dibutuhkan untuk mengklasifikasi suatu tupel dari 𝐷 berdasarkan partisi dari atribut 𝐴.
Menurut Han, et al (2012: 337), nilai information gain dari atribut 𝐴 pada subset 𝐷 dapat dihitung dengan persamaan berikut:
Information gain didefinisikan sebagai perbedaan diantara informasi asli yang dibutuhkan dengan jumlah informasi baru yang didapatkan dari partisi 𝐴. Atribut 𝐴 yang memiliki nilai information gain tertinggi dipilih sebagai pemisah atribut pada simpul 𝑁
Proses untuk menghitung nilai 𝐸(𝐴) bergantung dari nilai suatu atribut. Jika 𝑎𝑑 adalah atribut diskrit, maka tupel 𝐷 dibagi menjadi sub tupel 𝐷1… 𝐷𝑛, dimana 𝑛 jumlah nilai pada atribut 𝑎𝑑 dan 𝐷𝑖 adalah sub tupel yang memiliki nilai atribut 𝑎𝑖. Jika 𝑎𝑛 adalah atribut kontinu, maka sub tupel 𝐷 dibagi menjadi duasub tupel 𝐷𝑣1 dan 𝐷𝑣2 dengan 𝐷1 = {𝑣𝑗|𝑣𝑗 ≤ 𝑠𝑝} dan 𝐷2 = {𝑣𝑗|𝑣𝑗 > 𝑠𝑝}, dimana 𝑠𝑝 merupakan sebuah nilai ambang (split point).
Nilai split information digunakan pada pencarian nilai gain ratio untuk mengatasi bias terhadap atribut yang memiliki banyak nilai unik. Persamaan split information dan gain ratio dinyatakan sebagai berikut:
𝑆𝑝𝑙𝑖𝑡 𝐼𝑛𝑓𝑜𝐴(𝐷) = − ∑ |𝐷𝑗| |𝐷|× 𝑙𝑜𝑔2 |𝐷𝑗| |𝐷| 𝑣 𝑗=1 (2.4) 𝐺𝑎𝑖𝑛 𝑅𝑎𝑡𝑖𝑜 (𝐴) = 𝐺𝑎𝑖𝑛(𝐴) 𝑆𝑝𝑙𝑖𝑡 𝐼𝑛𝑓𝑜 (𝐴) (2.5)
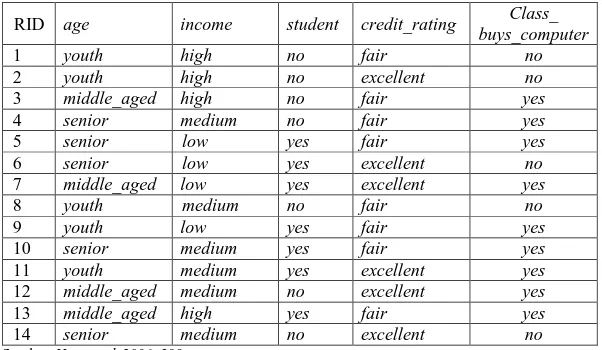
Apabila atribut tersebut memiliki nilai gain ratio terbesar maka atribut tersebut terpilih sebagai atribut split pada konstruksi pohon keputusan (Han, et al, 2012: 337-339). Sebagai contoh penerapan decision tree C4.5 dengan perhitungan manual pada sebuah kasus pelanggan AllElectronic. Tabel 2.4 merupakan data training dari database pelanggan AllElectronic atau disebut dengan partisi tupel 𝐷.
Tabel 2.4 Keputusan Membeli Komputer
RID age income student credit_rating Class_
buys_computer
1 youth high no fair no
2 youth high no excellent no
3 middle_aged high no fair yes
4 senior medium no fair yes
5 senior low yes fair yes
6 senior low yes excellent no
7 middle_aged low yes excellent yes
8 youth medium no fair no
9 youth low yes fair yes
10 senior medium yes fair yes
11 youth medium yes excellent yes
12 middle_aged medium no excellent yes
13 middle_aged high yes fair yes
14 senior medium no excellent no
Sumber: Han, et al, 2006: 299
Kasus yang tertera pada Tabel 2.4 akan dibuat pohon keputusan untuk menentukan membeli komputer atau tidak dengan melihat umur, pendapatan, status pelajar, dan peringkat kredit.
Pertama menghitung informasi yang dibutuhkan untuk mengklasifikasikan partisi data 𝐷 menggunakan persamaan (2.1) dengan 𝑖 = 1, 2 adalah banyaknya kategori nilai pada kelas membeli komputer. Tabel 2.5 merupakan total kasus pelanggan yang berada pada kelas yes dan no.
Tabel 2.5 Kelas Membeli Komputer Class_buys_computer yes no 9 5 𝐼𝑛𝑓𝑜(𝐷) = − 9 14log2( 9 14) − 5 14log2( 5 14) = 0,940
Selanjutnya menghitung informasi harapan yang dibutuhkan untuk klasifikasi data berdasarkan partisi dari setiap atribut. Sebagai contoh partisi pada
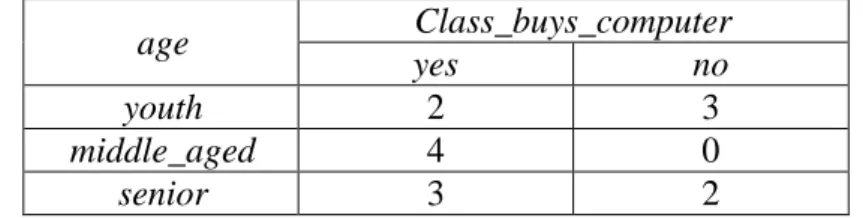
atribut age. Banyaknya data yang berada dalam kelas yes atau no berdasarkan atribut age dapat dilihat pada Tabel 2.6.
Tabel 2.6 Kelas Membeli Komputer Berdasarkan Partisi Atribut Age
age Class_buys_computer
yes no
youth 2 3
middle_aged 4 0
senior 3 2
Digunakan persamaan (2.2) untuk menghitung informasi harapan yang dibutuhkan untuk klasifikasi data berdasarkan partisi dari atribut age dengan 𝑗 adalah banyaknya kategori pada atribut age.
𝐼𝑛𝑓𝑜𝑎𝑔𝑒(𝐷) = 5 14× (− 2 5log2 2 5− 3 5log2 3 5) + 4 14× (− 4 4log2 4 4− 0 4log2 0 4) + 5 14 × (3 5log2 3 5− 2 5log2 2 5) = 0,694
Oleh karena itu didapatkan information gain yang dihitung menggunakan persamaan (2.3).
𝐺𝑎𝑖𝑛(𝑎𝑔𝑒) = 𝐼𝑛𝑓𝑜(𝐷) − 𝐼𝑛𝑓𝑜𝑎𝑔𝑒(𝐷) = 0,940 − 0,694 = 0,246
Pergitungan gain ratio atribut age dapat dihitung menggunakan persamaan (2.5) namun terlebih dahulu perlu dihitung nilai split information menggunakan persamaan (2.4) dengan 𝑗 adalah banyaknya jenis kategori nilai pada atribut age.
𝑆𝑝𝑙𝑖𝑡𝐼𝑛𝑓𝑜𝑎𝑔𝑒(𝐷) = − 5 14× log2( 5 14) − 4 14× log2( 4 14) − 5 14× log2( 5 14) = 1,577 𝐺𝑎𝑖𝑛𝑅𝑎𝑡𝑖𝑜(𝑎𝑔𝑒) =0,246 1,577= 0,1559
Setelah perhitungan gain ratio dari setiap atribut maka akan dipilih nilai yang terbesar sebagai atribut yang menjadi simpul akar dari pohon keputusan dan nilai dari atribut tersebut menjadi cabang. Perhitungan lanjutan yang analog dengan perhitungan simpul akar perlu dilakukan apabila setiap cabang belum menunjukkan keputusan akhir.
Pada saat pembangunan pohon keputusan, akan banyak ditemukan adanya cabang yang noise atau outlier pada data training. Pemangkasan pohon dapat dilakukan untuk menghapus cabang-cabang tersebut sehingga dapat mempercepat proses klasifikasi. Pohon yang dipangkas akan menjadi lebih kecil dan lebih mudah dipahami. Pemangkasan pohon dilakukan selain untuk pengurangan ukuran pohon, juga bertujuan untuk mengurangi tingkat kesalahan klasifikasi pada kasus baru. Contoh pemangkasan pohon keputusan ditunjukkan Gambar 2.6 dan Gambar 2.7.
Setelah pemangkasan pohon, kemudian dilakukan pembentukan aturan keputusan, yaitu membuat aturan keputusan dari pohon yang telah dibentuk. Aturan tersebut dapat dalam bentuk if-then diturunkan dari pohon keputusan dengan melakukan penelusuran dari akar sampai ke daun. Setiap simpul dan percabangan akan diberikan if, sedangkan nilai pada daun akan ditulis then. Setelah semua aturan dibuat, maka aturan dapat disederhanakan (digabungkan).
2. Naïve Bayes
Sebelum membahas mengenai naïve bayes, perlunya pengetahuan tentang peluang bersyarat. Peluang bersyarat adalah peluang terjadinya kejadian 𝑋 bila diketahui bahwa suatu kejadian 𝐻 telah terjadi. Peluang bersyarat dilambangkan denagn 𝑃(𝑋|𝐻) dibaca “peluang 𝑋 bila 𝐻 terjadi”. Persamaan untuk peluang bersyarat sebagai berikut (Walpole, 1995: 97-98).
𝑃(𝑋|𝐻) =𝑃(𝑋 ∩ 𝐻)
𝑃(𝐻) 𝑗𝑖𝑘𝑎 𝑃(𝐴) > 0 (2.6) Sama halnya dengan peluang terjadinya kejadian 𝐻 bila diketahui bahwa suatu kejadian 𝑋 telah terjadi.
𝑃(𝐻|𝑋) =𝑃(𝑋 ∩ 𝐻)
𝑃(𝑋) 𝑗𝑖𝑘𝑎 𝑃(𝐻) > 0 (2.7) Dengan mengkombinasikan persamaan (2.6) dan (2.7) maka diperoleh
𝑃(𝐻|𝑋)𝑃(𝑋) = 𝑃(𝑋 ∩ 𝐻) = 𝑃(𝑋|𝐻)𝑃(𝐻) sehingga persamaan (2.7) menjadi:
(𝐻|𝑋) =𝑃(𝑋 ∩ 𝐻)
𝑃(𝑋)
𝑃(𝐻|𝑋) = 𝑃(𝑋|𝐻)𝑃(𝐻)
Teorema Bayes memprediksi peluang di masa depan berdasarkan pengalaman di masa sebelumnya. Pada teorema Bayes, 𝑋 dijabarkan oleh kumpulan 𝑛 atribut dengan 𝐻 adalah beberapa hipotesis, sehingga data 𝑋 termasuk sebuah kelas 𝐶 (Han, et al, 2012: 350). Persamaan dari teorema Bayes adalah
𝑃(𝐻|𝑋) = 𝑃(𝑋|𝐻)𝑃(𝐻)
𝑃(𝑋) (2.8) Keterangan :
𝑋 : Data dengan kelas yang belum diketahui
𝐻 : Hipotesis data 𝑋 merupakan suatu kelas khusus
𝑃(𝐻|𝑋) : Probabilitas hipotesis 𝐻 berdasarkan kondisi 𝑋 (posterior probability) 𝑃(𝐻) : Probabilitas hipotesis 𝐻 (prior probability)
𝑃(𝑋|𝐻) : Probabilitas 𝑋 berdasarkan kondisi pada hipotesis 𝐻 𝑃(𝑋) : Probabilitas 𝑋
Naïve Bayes adalah pengklasifikasian statistik yang dapat digunakan untuk memprediksi probabilitas keanggotaan suatu class. Bayes merupakan teknik berbasis probabilistik sederhana yang berdasar pada penerapan teorema Bayes dengan asumsi independensi yang kuat. Dengan kata lain, dalam naïve bayes, model yang digunakan adalah “model fitur independen” (Eko Prasetyo, 2012: 59).
Klasifikasi naïve bayes yang mengacu pada teorema Bayes di atas mempunyai persamaan sebagai berikut
𝑃(𝐶𝑖|𝑋) =
𝑃(𝑋|𝐶𝑖)𝑃(𝐶𝑖)
Keterangan :
𝑃(𝐶𝑖|𝑋) : Probabilitas hipotesis 𝐶𝑖 jika diberikan fakta atau record 𝑋 (posterior probability)
𝑃(𝑋|𝐶𝑖) : Nilai parameter yang memberikan kemungkinan yang paling besar (likelihood)
𝑃(𝐶𝑖) : Probabilitas kelas 𝐶𝑖 (Prior probability) 𝑃(𝑋) : Probabilitas 𝑋
Menurut Han, et al (2012: 351) proses dari pengklasifikasian naïve bayes adalah sebagai berikut:
a. Variabel 𝐷 adalah kumpulan dari data dan label yang terkait dengan class. Setiap data diwakili oleh vektor atribut 𝑛-dimensi, 𝑋 = (𝑥1, 𝑥2, … , 𝑥𝑛) dengan 𝑛 dibuat dari data 𝑛 atribut, berturut-turut, 𝐴1, 𝐴2, … , 𝐴𝑛.
b. Misalkan terdapat 𝑖 class, 𝐶1, 𝐶2, … , 𝐶𝑖. Diberikan sebuah data 𝑋, kemudian pengklasifikasian akan memprediksi 𝑋 ke dalam kelompok yang memiliki probabilitas posterior tertinggi berdasarkan kondisi 𝑋. Artinya klasifikasi naïve bayes memprediksi bahwa 𝑋 termasuk class𝐶𝑖 jika dan hanya jika:
𝑃(𝐶𝑖|𝑋) > 𝑃(𝐶𝑗|𝑋) untuk 1 ≤ 𝑗 ≤ 𝑚, 𝑗 ≠ 𝑖 (2.10) Maka nilai 𝑃(𝐶𝑖|𝑋) harus lebih dari 𝑃(𝐶𝑗|𝑋) supaya diperoleh hasil akhir 𝑃(𝐶𝑖|𝑋).
c. Ketika 𝑃(𝑋) konstan untuk semua class maka hanya 𝑃(𝑋|𝐶𝑖)𝑃(𝐶𝑖) yang dihitung. Jika probabilitas class prior sebelumnya tidak diketahui, maka diasumsikan bahwa class-nya sama, yaitu 𝑃(𝐶1) = 𝑃(𝐶2) = ⋯ = 𝑃(𝐶𝑚),
untuk menghitung 𝑃(𝑋|𝐶𝑖) dan 𝑃(𝑋|𝐶𝑖)𝑃(𝐶𝑖). Perhatikan bahwa probabilitas class prior dapat diperkirakan oleh
𝑃(𝐶𝑖) =
(|𝐶𝑖,𝐷|)
|𝐷| (2.11) dimana |𝐶𝑖,𝐷| adalah jumlah data training dari kelas 𝐶𝑖 dan 𝐷 adalah jumlah total data training yang digunakan.
d. Apabila diberikan kumpulan data yang mempunyai banyak atribut, maka perhitungan 𝑃(𝑋|𝐶𝑖) dengan penjabaran lebih lanjut rumus Bayes tersebut yaitu menjabarkan 𝑃(𝑥1, . . . , 𝑥𝑛|𝐶𝑖) menggunakan aturan perkalian, menjadi sebagai berikut (Samuel Natalius: 2010):
𝑃(𝑥1, … , 𝑥𝑛|𝐶𝑖) = 𝑃(𝑥1|𝐶𝑖)𝑃(𝑥2, … , 𝑥𝑛|𝐶𝑖, 𝑥1)
= 𝑃(𝑥1|𝐶𝑖)𝑃(𝑥2|𝐶𝑖, 𝑥1)𝑃(𝑥3, … , 𝑥𝑛|𝐶𝑖, 𝑥1, 𝑥2) 𝑃(𝑥1, … , 𝑥𝑛|𝐶𝑖) = 𝑃(𝑥1|𝐶𝑖)𝑃(𝑥2|𝐶𝑖, 𝑥1) … 𝑃(𝑥𝑛|𝐶𝑖, 𝑥1, 𝑥2, … , 𝑥𝑛−1) Dapat dilihat bahwa hasil penjabaran tersebut menyebabkan semakin banyak dan semakin kompleksnya faktor-faktor syarat yang mempengaruhi nilai probabilitas, yang hampir mustahil untuk dianalisa satu-persatu. Akibatnya, perhitungan tersebut menjadi sulit untuk dilakukan. Oleh karena itu digunakan asumsi independensi yang sangat tinggi (naïve), bahwa masing-masing petunjuk (𝑥1, 𝑥2, … , 𝑥𝑛) saling bebas (independen) satu sama lain, maka berlaku suatu kesamaan sebagai berikut (Samuel Natalius: 2010):
𝑃(𝑥𝑖|𝑥𝑗) = 𝑃(𝑥𝑖∩ 𝑥𝑗) 𝑃(𝑥𝑗) =𝑃(𝑥𝑖)𝑃(𝑥𝑗) 𝑃(𝑥𝑗) = 𝑃(𝑥𝑖) untuk 𝑖 ≠ 𝑗, sehingga 𝑃(𝑥𝑖|𝐶, 𝑥𝑗) = 𝑃(𝑥𝑖|𝐶𝑖)
Disimpulkan bahwa asumsi independensi naïve tersebut membuat syarat peluang menjadi sederhana, sehingga perhitungan menjadi mungkin untuk dilakukan. Selanjutnya, penjabaran 𝑃(𝑥1, . . . , 𝑥𝑛|𝐶𝑖) dapat disederhanakan menjadi seperti berikut:
𝑃(𝑋|𝐶𝑖) = ∏ 𝑃(𝑥𝑘|𝐶𝑖) = 𝑃(𝑥1|𝐶𝑖) × 𝑛
𝑘=1
𝑃(𝑥2|𝐶𝑖) × … × 𝑃(𝑥𝑛|𝐶𝑖) (2.12)
Perhitungan 𝑃(𝑋|𝐶𝑖) pada setiap atribut mengikuti hal-hal berikut:
1) jika 𝐴𝑘 adalah kategori, maka 𝑃(𝑥𝑘|𝐶𝑖) adalah jumlah data dari kelas 𝐶𝑖 di 𝐷 yang memiliki nilai 𝑥𝑘 untuk atribut 𝐴𝑘 dibagi dengan |𝐶𝑖,𝐷| yaitu jumlah data dari kelas 𝐶𝑖 di 𝐷,
2) jika 𝐴𝑘 adalah numerik, biasanya diasumsikan memiliki distribusi Gauss dengan rata-rata 𝜇 dan standar deviasi 𝜎, didefinisikan oleh:
𝑔(𝑥, 𝜇, 𝜎) = 1 √2𝜋𝜎𝑒 −(𝑥−𝜇) 2 2𝜎2 (2.13) sehingga diperoleh: 𝑃(𝑥𝑘|𝐶𝑖) = 𝑔(𝑥𝑘, 𝜇𝐶𝑖, 𝜎𝐶𝑖) (2.14) Setelah itu akan dihitung 𝜇𝐶𝑖 dan 𝜎𝐶𝑖 yang merupakan rata-rata dan standar deviasi masing-masing nilai atribut 𝐴𝑘 untuk tupel training kelas 𝐶𝑖. e. 𝑃(𝑋|𝐶𝑖)𝑃(𝐶𝑖) dievaluasi pada setiap kelas 𝐶𝑖 untuk memprediksi
pengklasifikasian label kelas data 𝑋 dengan menggunakan
𝑃(𝑋|𝐶𝑖)𝑃(𝐶𝑖) > 𝑃(𝑋|𝐶𝑗)𝑃(𝐶𝑗) untuk 1 ≤ 𝑗 ≤ 𝑚, 𝑗 ≠ 𝑖 (2.15) label kelas untuk data 𝑋 yang diprediksi adalah kelas 𝐶𝑖 jika nilai 𝑃(𝑋|𝐶𝑖)𝑃(𝐶𝑖) lebih dari nilai 𝑃(𝑋|𝐶𝑗)𝑃(𝐶𝑗).
E. Pengujian dan Evaluasi Model
Model yang didapatkan dari kedua metode decision tree C4.5 dan naïve byes kemudian dilakukan pengujian menggunakan k-fold cross validation. Cross-validation adalah bentuk sederhana dari teknik statistik. Jumlah fold standar untuk memprediksi tingkat error dari data adalah dengan menggunakan 10-fold cross validation (Witten, et al, 2011: 153).
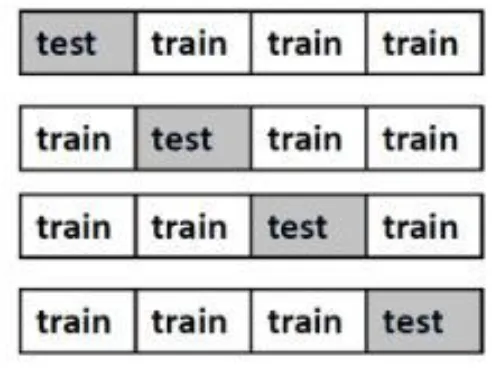
Data yang digunakan dibagi secara acak ke dalam k subset yaitu 𝐷1, 𝐷2, … , 𝐷𝑘 dengan ukuran yang sama. Dataset akan dibagi menjadi data training dan data testing. Proses training dan testing dilakukan sebanyak k kali secara berulang-ulang. Pada iterasi ke-i, partisi 𝐷𝑖 disajikan sebagai data testing dan partisi sisanya digunakan secara bersamaan dan berurutan sebagai data training. Iterasi kedua, subset 𝐷1, 𝐷2, … , 𝐷𝑘 akan dites pada 𝐷2, dan selanjutnya hingga 𝐷𝑘 (Han, et al, 2012: 364). Gambar 2.8 berikut adalah contoh ilustrasi 4-fold cross validation.
Gambar 2.8 Ilustrasi 4-Fold Cross Validation
Berdasarkan Gambar 2.8 ditunjukkan bahwa nilai fold yang digunakan adalah 4-fold cross validation. Berikut diberikan langkah-langkah pengujian data dengan 4-fold cross validation.
a. Dataset yang digunakan dibagi menjadi 4 bagian, yaitu 𝐷1, 𝐷2, 𝐷3, dan 𝐷4. 𝐷𝑡, 𝑡 = (1, 2, 3, 4) digunakan sebagai data testing dan dataset lainnya sebagai data training.
b. Tingkat akurasi dihitung pada setiap iterasi ( iterasi-1, iterasi-2, iterasi-3, iterasi-4), kemudian dihitung rata-rata tingkat akurasi dari seluruh iterasi untuk mendapatkan tingkat akurasi data keseluruhan.
Evaluasi hasil klasifikasi dilakukan dengan metode confusion matrix. Confusion matrix adalah tool yang digunakan sebagai evaluasi model klasifikasi untuk memperkirakan objek yang benar atau salah. Sebuah matrix dari prediksi yang akan dibandingkan dengan kelas sebenarnya atau dengan kata lain berisi informasi nilai sebenarnyadan prediksi pada klasifikasi (Gorunescu, 2011: 319).
Tabel 2.7 Tabel Confusion Matrix Dua Kelas
Clasification Predicted class
Class=Yes Class=No
Class=Yes a (true positive) b (false negative) Class=No c (false positive) d (true negative)
Pada tabel confusion matrix di atas, true positive (TP) adalah jumlah record positif yang diklasifikasikan sebagai positif, false positive (FP) adalah jumlah record negatif yang diklasifikasikan sebagai positif, false negatives (FN) adalah jumlah record positif yang diklasifikasikan sebagai negatif, true negatives (TN) adalah jumlah record negatif yang diklasifikasikan sebagai negatif. Setelah data uji diklasifikasikan maka akan didapatkan confusion matrix sehingga dapat dihitung jumlah sensitivitas, spesifisitas, dan akurasi (Henny Lediyana, 2013: 69).
Sensitivitas adalah proporsi dari class=yes yang teridentifikasi dengan benar. Spesifisitas adalah proporsi dari class=no yang teridentifikasi dengan benar. Contohnya dalam klasifikasi pelanggan komputer dimana class=yes adalah pelanggan yang membeli computer sedangkan class=no adalah pelanggan yang tidak membeli komputer. Dihasilkan sensitivitas sebesar 95%, artinya ketika dilakukan uji klasifikasi pada pelanggan yang membeli, maka pelanggan tersebut berpeluang 95% dinyatakan positive (membeli komputer). Apabila dihasilkan spesifisitas sebesar 85%, artinya ketika dilakukan uji klasifikasi pada pelanggan yang tidak membeli, maka pelanggan tersebut berpeluang 95% dinyatakan negative (tidak membeli).
Rumus untuk menghitung akurasi, spesifisitas, dan sensitivitas pada confusion matrix adalah sebagai berikut (Gorunescu, 2011: 319)
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 = 𝑇𝑃 + 𝑇𝑁 𝑇𝑃 + 𝑇𝑁 + 𝐹𝑃 + 𝐹𝑁= 𝑎 + 𝑑 𝑎 + 𝑏 + 𝑐 + 𝑑 (2.16) 𝑆𝑒𝑛𝑠𝑖𝑡𝑖𝑣𝑖𝑡𝑎𝑠 = 𝑇𝑃 𝑇𝑃 + 𝐹𝑁 = 𝑎 𝑎 + 𝑏 (2.17) 𝑆𝑝𝑒𝑠𝑖𝑓𝑖𝑠𝑖𝑡𝑎𝑠 = 𝑇𝑁 𝑇𝑁 + 𝐹𝑃= 𝑑 𝑑 + 𝑐 (2.18) F. Waikato Environment for Knowledge (WEKA)
The Waikato Environment for Knowledge Analysis (WEKA) adalah sebuah sistem data mining open source yang berbasis java. Sistem ini dikembangkan oleh Universitas Waikato di Selandia Baru dan merupakan perangkat lunak free yang tersedia di bawah GNU (General Public License). WEKA menyediakan dukungan yang luas untuk seluruh proses data mining mulai dari menyiapkan data masukkan, evaluasi pembelajaran, skema statistik, visualisasi data input dan hasil
pembelajaran. Metode atau teknik yang digunakan pada WEKA adalah Predictive dan Descriptive karena sistem ini mendukung teknik-teknik data preprocessing, clustering, classification, regression, visualization, dan feature Reduction. (Witten, et all, 2011: 403-404 ).
Gambar 2.9 Tampilan Awal GUI WEKA
WEKA mulai dikembangkan sejak tahun 1994 dan telah menjadi software data mining open source yang paling popular. WEKA mempunyai kelebihan seperti mempunyai banyak algoritma data mining dan machine learning, kemudahan dalam penggunaannya, selalu up-to-date dengan algoritma-algoritma yang baru. Software WEKA tidak hanya digunakan untuk akademik saja namun cukup banyak dipakaioleh perusahaan untuk meramalkan bisnis dari suatu perusahaan.
WEKA mendukung beberapa format file untuk inputnya, yaitu:
1. Comma Separated Values (CSV): Merupakan file teks dengan pemisah tanda koma (,) yang cukup umum digunakan. File ini dapat dibuat dengan menggunakan Microsoft Excel atau membuat sendiri dengan menggunakan notepad.
2. Format C45: Merupakan format file yang dapat diakses dengan menggunakan aplikasi WEKA.
3. Attribute-Relation File Format (ARFF): Merupakan tipe file teks yang berisi berbagai instance data yang berhubungan dengan suatu set atribut data yang dideskripsikan serta di dalam file tersebut.
4. SQL Server/ MySql Server: Dapat mengakses database dengan menggunakan SQL Server/MySql Server.
Beberapa menu dalam tampilan WEKA, diantaranya yaitu
1. Explorer, menu ini memberikan akses untuk semua fasilitas yang menggunakan pilihan menu dan pengisian data. Pada menu ini terdapat enam sub-menu pada bagian atas window, sub-menu tersebut yaitu:
a. Preprocess, proses pemilihan dataset yang akan diolah pemilihan filter, b. Classify, terdapat berbagai macam teknik klasifikasi dan evaluasinya
yang digunakan untuk mengolah data,
c. Cluster, terdapat berbagai macam teknik cluster yang dapat digunakan untuk mengolah data,
d. Associate, terdapat berbagai macam teknik association rules yang dapat digunakan untuk mengolah data,
e. Select Atribut, proses pemilihan aspek yang mempunyai hubungan paling relevan pada data,
f. Visualize, proses menampilan berbagai plot dua dimensi yang dibentuk dari pengolahan data.
2. Experimenter, menu ini digunakan untuk mengatur percobaan dalam skala besar, dimulai dari running, penyelesaian, dan menganalisis data secara statistik.
3. Knowledge Flow, pada tampilan menu ini, pengguna memilih komponen WEKA dari toolbar untuk memproses dan menganalisis data serta memberikan alternatif pada menu Explorer untuk kondisi aliran data yang melewati sistem. Selain itu, Knowledge Flow juga berfungsi untuk memberikan model dan pengaturan untuk mengolahan data yang tidak bisa dilakukan oleh Explorer.
4. Simple CLI, menu yang menggunakan tampilan command-line. Menu ini menggunakan tampilan command-line untuk menjalankan class di weka.jar, dimana langkah pertama variabel Classpath dijelaskan di file Readme. Pada sub-menu klsifikasi WEKA terdapat test options yang digunakan untuk menguji kinerja model klasifikasi. Ada empat model tes yaitu:
1. Use training set
Pengetesan dilakukan dengan menggunakan data training itu sendiri. Akurasi akan sangat tinggi, tetapi tidak memberikan estimasi akurasi yang sebenarnya terhadap data yang lain (data yang tidak dipakai untuk training). 2. Supplied test set
Pengetesan dilakukan dengan menggunakan data lain (file training dan testing tersedia secara terpisah). Dengan menggunakan option inilah bisa dilakukan prediksi pada data tes.
Pada cross-validation, akan ada pilihan banyaknya fold yang akan digunakan. Nilai default-nya yaitu 10.
4. Percentage split
Hasil klasifikasi akan dites menggunakan k% dari data tersebut, dimana k adalah proporsi dari dataset yang digunakan untuk data training. Persentase di kolom adalah bagian dari data yang dipakai sebagai training set. Pada option ini data training dan testing terdapat dalam satu file.
G. Penelitian yang Relevan
Penelitian tentang data mining dengan menggunakan berbagai algoritma pada analisis bidang keuangan telah banyak dilakukan khususnya untuk analisis klasifikasi kredit. Beberapa diantaranya yang mendukung penelitian ini dengan variabel dan metode penelitian yang berkaitan.
Penelitian yang dilakukan oleh Yogi Yusuf, dkk dalam jurnal “Evaluasi Pemohon Kredit Mobil di PT X dengan menggunakan Teknik Data Mining Decision Tree”. Penelitian ini menggunakan model credit scoring dengan algoritma C5.0 kredit mobil dengan teknik decision tree dan bantuan software Celementine. Atribut yang digunakan ada 8 yaitu penghasilan, cicilan per bulan, uang muka, jumlah periode pinjaman, rekening tabungan, umur, rekening tagihan telepon, rekening tagihan listrik, dan atribut label kelas. Jumlah sampel yang digunakan sebanyak 750 record. Data dibagi menjadi 60% sebagai data training dan 40% sebagai data testing. Dari penelitian tersebut dapat diketahui bahwa terdapat 148 record (79,57%) yang memiliki hasil validasi yang benar dari 186 sampel. Sedangkan untuk hasil validasi yang kurang tepat terdapat 20,43 % dimana terdapat 38 record
yang memiliki perbedaan antara hasil prediksi dan aktual. Hasil prediksi juga menunjukkan bahwa sebesar 19,4 % yang semula diprediksi memiliki status kredit lancar ternyata memiliki status kredit macet. Tingkat akurasi keseluruhan dari model yang dibangun sebesar 79,57%.
Penelitian yang dilakukan oleh Claudia Clarentia Ciptohartono dalam jurnal skripsi “Algoritma Klasifikasi Naïve Bayes untuk Menilai Kelayakan Kredit”. Penelitian ini menggunakan algoritma naïve bayes dan software bantu Rapid Miner untuk menentukan nilai kelayakan kredit konsumen dari perusahaan BCA Finance Jakarta 2013. Data awal penelitian berjumlah 682 data dan 20 atribut, setelah tahap preprocessing menjadi 682 data dan 16 atribut. Pada penelitian ini digunakan metode cross validation untuk mengukur kinerja algoritma yang digunakan, diketahui nilai akurasi sebelum preprocessing sebesar 85,57% dan setelah preprocessing sebesar 92,53% .
Penelitian yang dilakukan oleh Rina Fiati dalam jurnal “Model Klasifikasi Kelayakan Kredit Koperasi Karyawan Berbasis Decision Tree”. Pada penelitian ini menggunakan algoritma decision tree dan bantuan software RapidMiner. Atribut yang digunakan ada 6 yaitu nomor anggota, bagian, golongan, masa keanggotaan, status marital, dan status pinjaman. Jumlah data yang digunakan ada 584 record, perhitungan manual nilai gain menggunakan data sampel yaitu 10 record. Tingkat akurasi decision tree untuk data dari koperasi karyawan PT Nojorono Tobacco International sebesar 92,28%. Berdasakan model klasifikasi yang telah diperoleh pada penelitian ini, penentuan kelayakan kredit koperasi karyawan adalah dengan memperhatikan atribut masa keanggotaan, status marital dan nomor anggota.