PROSES
DATA MINING
DALAM MENINGKATKAN
SISTEM PEMBELAJARAN PADA PENDIDIKAN
SEKOLAH MENENGAH PERTAMA
Fatayat
1, Joko Risanto
2 FMIPA Matematika - Universitas RiauE-mail : [email protected]
Abstrak. Dunia Pendidikan memiliki data yang berlimpah dan berkesinambungan mengenai sistem Pembelajaran dan Pendidikan, siswa yang di bina dan alumni yang dihasilkan. Hal ini membuka peluang diterapkannya data mining untuk mengolah Pendidikan lebih baik. Kumpulan dari data tersebut dapat diproses lebih lanjut dengan
data mining, untuk memperoleh pola baru yang dapat digunakan untuk meningkatkan efektifitas dalam proses pembelajaran, semua data yang dikelola pada bagian Administrasi merupakan sebuah sumber informasi yang bisa diekstrak kembali untuk mendapatkan suatu pengetahuan yang bisa digunakan untuk meningkatkan mutu dunia Pendidikan pada umumnya dan disekolah khususnya. Metode yang digunakan dalam penelitian ini adalah menggunakan metode Decision Tree. Dalam proses pembelajaran selama jangka waktu tertentu, maka akan terkumpul sejumlah data yang bisa dikelola disekolah untuk proses data mining .
Kata Kunci : Data Mining, sistem pembelajaran pada Pendidikan Sekolah menengah Pertama
PENDAHULUAN
Dalam proses pembelajaran selama jangka waktu tertentu, maka akan terkumpul sejumlah besar data. Kumpulan data tersebut dapat diproses lebih lanjut dengan data mining untuk memperoleh pola baru yang dapat digunakan untuk meningkatkan efektifitas dalam proses pembelajaran.. Hal ini tentu saja sangat berpengaruh pada peningkatan mutu siswa yang dihasilkan oleh sekolah, dan pada sekala yang lebih besar lagi akan meningkatkan kecerdasan dan intelektual bangsa. Aspek-aspek yang bisa digunakan untuk data mining adalah latar belakang siswa antara lain, Pekerjaan orang tua, pendidikan orang tua, lingkungan tempat tinggal,jarak tempat tinggal, jumlah saudara, nilai siswa dan lain-lain. Hal tersebuat bisa dijadikan sebagai suatu kelompok data yang bisa diolah dan diekstrak kembali untuk mendapat suatu informasi tersembunyi dengan algoritma data mining.
Banyak data yang bisa dikelola disekolah untuk proses data mining maka diperlukan batasan masalah agar penelitian ini bisa lebih terfokus dan tidak mengambang, adapun yang menjadi pembatasan masalah adalah proses nilai-nilai siswa yang meliputi nilai-nilai kognitif, psikomotorik, afektif, kehadiran dan remedi. Data-data yang diambil dari nilai siswa yang ada disekolah yang diambil dari beberapa kelas dan metode yang digunakan adalah Decision Tree.
Data Mining
transformation), data mining,evaluasi pola (pattern evaluation) dan penyajian pengetahuan (knowledge presentation). Kerangka proses data mining yang akan dibahas tersusun atas tiga tahapan, yaitu pengumpulan data (data collection),
transformasi data (data
transformation),dan analisis data (data analysis) [ Nilakant].
Proses tersebut diwakili dengan preprocessing yang terdidri atas pengumpulan data untuk menghasilkan data mentah (raw data) yang dibutuhkan oleh data mining, yang kemudian dilanjutkan dengan transformasi data untuk mengubah data mentah menjadi format yang dapat diproses oleh data mining, misalnya melalui filtrasi atau agregasi. Hasil transformasi data akan digunakan oleh analisis data untuk membangkitkan pengetahuan dengan menggunakan teknik seperti analisis statistik, machine learning, dan visualisasi informasi seperti terlihat pada gambar 2.1
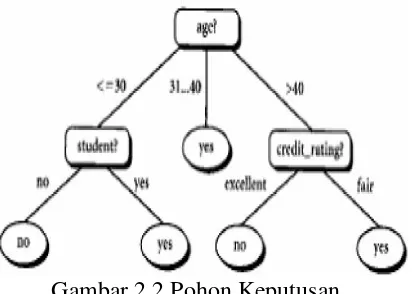
Pohon Keputusan
Gambar 2.2 Pohon keputusan adalah model prediksi menggunakan struktur pohon atau struktur berhirarki. Contoh dari pohon keputusan dapat dilihat di Gambar 2.2. Disini setiap percabangan menyatakan kondisi yang harus dipenuhi dan tiap ujung pohon menyatakan kelas data. Contoh di Gambar 2.2 adalah identifikasi pembeli komputer, dari pohon keputusan tersebut diketahui bahwa salah satu kelompok yang potensial membeli komputer adalah orang yang berusia dibawah 30 tahun dan juga pelajar.
Gambar 2.2 Pohon Keputusan Pohon keputusan merupakan metode klasifikasi metode klasifikasi dan prediksi yang sangat kuwat dan terkenal. Metode pohon keputusan mengubah fakta yang sangat besar menjadi pohon keputusan yang mempersentasikan aturan. Pohon keputusan juga berguna untuk mengeksplorasi data, menemukan hubungan tersembunyi antara jumlah calon variabel input dengan variabel target. Pohon keputusan adalah sebuah struktur yang dapat digunakan untuk membagi kumpulan data yang besar menjadi himpunan-himpunan record yang lebih kecil dengan menerapkan serangkaian aturan keputusan. Dengan masing-masing rangkaian pembagian, anggota himpunan hasil mirip satu dengan yang lain ( Berry dan Linoff, 2004)
METODE PENELITIAN
Salah satu Algoritma induksi keputusan yaitu ID3 (Iterative Dichotomister 3). ID3 dikembangkan oleh J. Ross Quinlan. Dalam prosedur algoritma ID3, input berupa sampel training, label training dan atribut.
Algoritma C4.5 merupakan
perkembangan dari ID3. Sedangkan pada perangkat lunak open source WEKA mempunyai versi sendiri C4.5 yang dikenal sebagai J48.
yang digunakan untuk membagi data tergantung dari jenis atribut yang digunakan dalam split. Algoritma C4.5 dapat menangani data numerik (kontinyu) dan diskret. Split untuk atribut numerik yaitu mengurutkan contoh berdasarkan atribut kontiyu A, kemudian membentuk minimum permulaan (threshold) M dari contoh-contoh yang ada dari kelas mayoritas pada setiap partisi yang bersebelahan, lalu menggabungkan partisi-partisi yang bersebelahan tersebut dengan kelas mayoritas yang sama. Split untuk atribut disket A mempunyai bentuk value
ε X dimana X ⊂ domain(A).
Untuk melakukan pemisahan obyek (split) dilakukan tes terhadap atribut dengan mengukur tingkat ketidakmurnian pada sebuah simpul (node). Pada algoritma C4.5 menggunakan rasio perolehan (gain ratio). Sebelum menghitung rasio perolehan, perlu menghitung dulu nilai informasi dalam satuan bits dari suatu kumpulan objek. Cara menghitungnya dilakukan dengan menggunakan konsep entropi
E (S) = -P+ log2 P+ - P-log2 P-
S adalah ruang (data) sampel yang digunakan untuk pelatihan, p+ adalah jumlah yang bersolusi positif atau mendukung pada data sampel untuk kriteria tertentu dan p- adalah jumlah yang bersolusi negatif atau tidak mendukung pada data sampel untuk kriteria tertentu. Entropi(S) sama dengan 0, jika sama contoh pada S berada dalam kelas yamg sama. Entropi(S) sama dengan 1, jika jumlah contoh positf sama negative dalam S tidak sama [Mitchell,1997].
Entropi split yang membagi S dengan n record memjadi himpunan-himpunan S1 dengan n l baris dan S2 dengan n2 baris adalah :
Entropi split yang membagi S dengan n record memjadi himpunan-himpunan S1
dengan n l baris dan S2 dengan n2 baris adalah :
Kemudian menghitung perolehan informasi dari output data atau variabel dependent y yang dikelompokkan berdasarkan atribut A, dinotasikan dengan gain (S,A). Perolehan informasi, gain (S,A), dari atribut A relative terhadap output data S adalah:
Dengan:
S :Himpunan Kasus A :Atribut
n :Jumlah partisi atribut A IsiI :Jumlah kasus pada partisi ke i ISI :Jumlah kasus dalam S adalah entropy sesudah dilakukan pemisahan data berdasarkan atribut A. Untuk menghitung rasio perolehan perlu diketahui suatu term baru yang disebut pemisahan informasi (Split Info).Pemisahan info dihitung dengan cara:
Bahwa S1 sampai Sc adalah n subset yang dihasilkan dari pemecahan S dengan menggunakan atribut A yang mempunyai sebanyak n nilai. Selanjutnya rasio perolehan (gaain ratio) dihitung dengan cara:
Metode Penelitian
Dalam penelitian ini digunakan data hasil evaluasi Siswa,sofware WEKA,Nilai Kognitif, Nilai Psikomotorik,N ilai Afektif, Kehadiran dan Remedi.
Bahan/Materi Penelitian
manual tool yang digunakan dalam pengembangan perangkat lunak.sistem data mining yang mengumpulkan semua data hasil evaluasi belajar siswa dan di ekstrak
Uji Coba
Penelitian dan pengujian yang dilakukan pada metode sarana pendukung yaitu berupa peralatan yang sangat berperan dalam menunjang penggunaan aplikasi dalam mengolah data. Pengujian apalikasi ada dua, yaitu lingkungan perangkat keras komputer dn perangkat lunak komputer.
1. Microsoft Excel 2007. 2. WEKA pengujian dengan menggunakan aplikasi WEKA disimpan dalam file Microsoft Excel simpan dengan format CVS ( Comman Separated Value),kemudian buka di Notepad, kemudian ambil Replace pada menu edit, ganti titik koma dengan koma lalu tekan Replace All dan kemudian simpan fail tersebut.
Data Hasil Evaluasi
DATA HASIL EVALUASI SISWA
NAMA KOGNITIF PSIKOMOTORIK AFEKTIF KEHADIRAN REMEDI NAIK
Andi Firmasari 43 47 Baik Kurang Hadir Tidak
Analisa Data Mining Metode C$.5
Sistem yang dirancang adalah untuk menentukan kenaikan siswa ketingkat yang lebih tinggi. Data awal baik numberik atau non numberik akan dibagi perkelas supaya memudahkan dalam proses analisa selanjutnya. Setelah semua data yang akan dimasukan dibagi perkelas, maka akan dilakukan proses klasifikasi untuk kenaikan siswa dengan membuat sebuah pohon keputusan untuk menghasilkan output.
Proses pengambilan keputusan dalam klasifikasi kenaikan siswa dibagi menjadi beberapa kriteria penilaian yaitu:
K= 6.606601
Dengan jumlah data 50 kelas yang didapat 7 kelas, tapi yang memakai 7 kelas ini adalah data-data yang berupa nilai angka yaitu nilai Kognitif, nilai Psikometrik. Nilai-nilai tersebut dikelompokkan berdasarkan atribut sebagai berikut:
Mengelompokan Nilai Kognitif
Mengelompokkan Nilai Kognitif, pengelomokan nilai berdasarkan dari hasil ujian yang didapat oleh siswa. Dan nilai tersebut dikelompokkan kedalam 7 kelas pada Tabel 1.1
Tabel 1.1 Klasifikasi Nilai Kognitif Nilai Kongnitif Klasifikasi
0-13 1
Tabel 1.2 Klasifikasi Nilai Psikomotorik Nilai Psikomotorik Klasifikasi
0-13 1
Mengelompokan nilai Psikomotorik berdasarkan hasil ujian Praktek atau pun karya yang dibuat dan nilai tersebut dikelompokan kedalam 7 kelas seperti terlihat pada tabel 1.2
Mengelompokan Nilai efektif berdasarkan tingkah laku, kesopanan, kerajinan, dan lain-lain. Nilai efektif
tersebut dikelompokan kedalam 3 kelas seperti terlihat pada Tabel 1.3
Tabel 1.3 Klasifikasi Nilai Afektif NilEfektif
Baik Cukup Buruk
Mengelompokan Nilai kehadiran berdasarkan persentase kehadiran siswa. Nilai kehadiran tersebut dikelompokan kedalam 3 kelas seperti terlihat pada tabel 1.4
Tabel 1.4 Klasifikasi Nilai kehadiran Kehadiran
Tinggi Sedang Kurang
Mengelompokan Nilai Remedi atau nilai perbaikan berdasarkan hadir tidak hadirnya siswa pada saat remedi . Nilai remedi tersebut dikelompokan kedalam 2 kelas seperti terlihat pada Tabel 1.5 Tabel 1.5 Klasifikasi Nilai Remedi
Nilai Remedi Hadir Tidak Hadir
Mengelompokan atribut Kenaikan berdasarkan atribut-atribut sebelumnya yang berfungsi sebagai input . Kenaikan merupakan atribut tujuan yang dihasilkan dari proses klasifikasi. Kenaikan dikelompokan kedalam 2 kelas seperti terlihat pada Tabel 1.6
Tabel 1.6 Klasifikasi Nilai Remedi Nilai Kenaikan
Ya
Tidak
Tabel 1.7 Format data akhir setelah dilakukan pra-proses
Kognitif Psikomotorik Afektif Kehadiran Remedi Kenaikan
Pohon Keputusan
Dari format data akhir kenaikan siswa maka akan dilakukan klasifikasi data algoritma C4.5 dengan membuat pohon keputusan. Seperti yang telah dijelaskan sebelumnya, algoritma C4.5 untuk membangun pohon keputusan adalah sebagai berikut;
1. Pilih atribut sebagai akar.
2. Buat cabang untuk tiap-tiap nilai. 3. Bagi kasus dalam cabang.
Ulangi proses untuk setiap cabang sampai semau kasus pada cabang memeiliki kelas yang sama.Dalam kasus yang tertera pada tabel diatas, akan dibuat pohon keputusan untuk menentukan klsaifikasi kenaikan sisiwa baru (ya dan tidak) dengan melihat Nilai Kognitif, Nilai Psikometrik, Nilai Efektif, Kehadiran dan kenaikan.Untuk memilih atribut sebagai akar, didasarkan pada nilai Gain tertinggi dari atribut-atribut yang ada. Untuk menghitung Gain digunakan rumus.
Perhitungan Gain dan Entrophy
Keterangan :
S : Himpunan Kasus A : Atribut
N : Jumlah partisi atribut A ISiI : Jumlah kasus pada partisi ke-i
ISI : Jumlah kasus dalam S
Sedangkan untuk menghitung nilai entrophy dapat dilihat pada rumus
Dengan menggunakan data dua persamaan diatas maka akan didapatkan entrophy dan Gain yang digunakan sebagai akar dalam membuat pohon keputusan.
Menghitung jumlah kasus, jumlah k sus untuk keputus n “Y ”, juml h kasus untk keputus n “Tid k”, d n k sus yang dibagi berdasarkan atribut Nilai Kognitif, Nilai Psikomotorik, Nilai Afektif, Kehadiran dan Kenaikan. Setelah itu, lakukan perhitungan Gain untuk setiap atribut.
Perhitungan Node
Dengan menghitung nilai entrophy dari atribut yang tersisa setelah dihitung entrophy, kemudian menghitung Gain untuk tiap-tiap atribut.
Nilai Entrophy Total
Merupakan Nilai Entrophy yang mewakili dari seluruh jumlah total
Variabel atribut yang ada. Dengan Rumus:
= ( 7 X log2 ( 7 )) + ( 3 log2(3 ))
10 10 10 10 = 0,881290899
Tabel 1.8 Tabel Hasil Perhitungan
KENAIKAN
Atribut Jumlah Ya Tidak Entrophy Gain Total
Kognitif
1 0 0 0 0 0,78419584
2 0 0 0 0
3 0 0 0 0
4 5 3 2 0,970950594
5 1 1 0 0
6 1 0 1 0
7 3 3 0 0
Psikomotorik
1 0 0 0 0
3 1 1 0 0
4 8 6 2 0,8112778124
5 0 0 0 0
6 0 0 0 0
7 1 0 1 0
Afektif
Baik 6 4 2 0,918295834 0,706193149
Cukup 4 3 1 0,811278124
Kehadiran
Tinggi 7 7 0 0
Sedang 3 0 3 0
Remedi
Hadir 0 0 0 0 0,705032719
Tidak Hadir 10 7 3 0,881290899
Total 10 7 3 0,881290899
Dari tabel di atas dapat kita ketahui bahwa atribut yang memiliki Gain paling besar adalah atribut Kognitif, yaitu sebesar 0,78419584. Dengan demikian, atribut Kognitifi bisa menjadi node 4. Ada 3 atribut dari Kognetif yaitu: 5,6,7 Atribut 5 dan 7 sudah mengklasifikasikan kasus menjadi 1 dengan keputusan Tidak naik, sedangkan 6 sudah mengklasifikasikan kasus menjadi 1 dengan keputusan Naik sehingga tidak perlu dilakukan perhitungan lebih lanjut, tetapi untuk nilai atribut lain masih perlu dilakukan perhitungan lain. Dari hasil perhitungan tersebut dapat digambarkan pohon keputusan sementara tampak pada gambar 2.3
KESIMPULAN
Dari penelitian yang penulis lakukan dapat disimpulkan bahwa proses yang dilakukan secara manual dapat juga memberikan keputusan yang diharapkan, tetapi dengan rentang waktu yang lebih lama dalam proses penggalian informasinya dan kapasitas data yang bisa dihitung sangat kecil. Dengan menggunakan metode algoritma
Decision Tree dengan bantuan software WEKA proses pengalian informasi bisa lebih cepat dan bisa dengan kapasitas data yang besar dan pengambilan keputusan lebih optimal dan kesalahan dalam mengambil keputusan dapat dioptimalkan.
DAFTAR PUSTAKA
H n Ji wei “ D t Minig Concept nd Technique‟, Presnt tion
http://www.ilmukomputer.com
Iko Pramudiono. 2003. Pengantar Data Mining : Menambang Permata Pengetahuan di Gunung Data. www.ilmukomputer.com
Kusri & Emh T ufq Luthfi (2009), “ Algoritm D t Mining”,
Andi Yogyakarta, Yogyakarta
Kadarsiah Suryadi, DR dan Ali Ramdhani , M.t, “ Sistem pendukung keputus n”, PT Remaja Rosdakarya, Bandung, 2002