Perancangan dan Implementasi Aplikasi Deteksi
Kemiripan Dokumen Menggunakan Algoritma
Shingling
dan MD5
Fingerprint
ARTIKEL ILMIAH
Diajukan Kepada
Fakultas Teknologi Informasi
Untuk Memperoleh Gelar Sarjana Komputer
Oleh :
Muhamad Yusuf Adiansyah 672008202
Prof. Dr. Ir. Eko Sediyono, M.Kom.
Program Studi Teknik Informatika
Fakultas Teknologi Informasi
Universitas Kristen Satya Wacana
1
Perancangan dan Implementasi Aplikasi Deteksi Kemiripan
Dokumen Menggunakan Algoritma
Shingling dan MD5
Fingerprint
1)Muhamad Yusuf Adiansyah2)Eko Sediyono
Fakultas Teknologi Informasi Universitas Kristen Satya Wacana Jl. Diponegoro 52-60, Salatiga 50711, Indonesia Email:1)[email protected],2)[email protected]
Abstract
Ease of copying information from one document to another document is one of the effects of advances in information technology. This can lead to plagiarism. One way to find out plagiarism between the two documents is the detection of similarity of two documents (near duplicate). Detection of similarity of two documents produced can be made for the value of the similarity of the two documents. Shingling algorithm is an algorithm invented by Andrei Broder, who is used to the process of finding near-duplicate document. MD5 algorithm can be used to generate the fingerprint, which can be used as a comparison in the process of document similarity detection. In this study, both methods are combined, so detection is done by using a document similarity algorithm Shingling and reinforced with the MD5 algorithm to generate the value of the fingerprint, so to avoid a collision. The results of this study is an application of similarity detection of the two documents (.doc and .txt), using a combination Shingling algorithm and MD5.
Keywords:Shingling, MD5 Fingerprint, Near Duplicate Detection
Abstrak
Kemudahan dalam menyalin informasi dari satu dokumen ke dokumen yang lain merupakan salah satu efek dari kemajuan teknologi informasi. Hal ini dapat mengarah ke plagiasi. Salah satu cara untuk mengetahui plagiasi antara dua dokumen adalah dengan deteksi kemiripan dua dokumen (nearduplicate). Deteksi kemiripan dua dokumen dapat dilakukan untuk mengetahui nilai kemiripan kedua dokumen tersebut. Algoritma
Shingling merupakan algoritma yang ditemukan oleh Andrei Broder, yang digunakan untuk proses pencariannear-duplicatedocument. Algoritma MD5 dapat digunakan untuk membangkitkan fingerprint, yang dapat digunakan sebagai pembanding dalam proses deteksi kemiripan dokumen. Pada penelitian ini digabungkan kedua metode tersebut, sehingga deteksi kemiripan dokumen dilakukan dengan menggunakan algorimaShingling
dan diperkuat dengan algoritma MD5 untuk membangkitkan nilai fingerprint, sehingga terhindar daricollision. Hasil dari penelitian ini adalah sebuah aplikasi deteksi kemiripan dua dokumen (doc & txt), dengan menggunakan gabungan algoritmaShinglingdan MD5.
Kata Kunci:Shingling, MD5Fingerprint, Deteksi Kemiripan Dokumen
1)Mahasiswa Program Studi Teknik Informatika, Fakultas Teknologi Informasi,
Universitas Kristen Satya Wacana
1 1. Pendahuluan
Kemudahan dalam menyalin informasi dari satu dokumen ke dokumen yang lain merupakan salah satu efek dari kemajuan teknologi informasi. Hal ini dapat mengarah ke plagiasi. Plagiasi adalah proses meniru atau menyalin hasil karya milik orang lain yang diklaim sebagai hasil karya sendiri [1]. Plagiasi dokumen digital dapat dilakukan semudah melakukan copy dan paste.
Salah satu cara untuk mengetahui plagiasi antara dua dokumen adalah dengan deteksi kemiripan dua dokumen (near duplicate). Deteksi kemiripan dua dokumen dapat dilakukan untuk mengetahui nilai kemiripan kedua dokumen tersebut [2].
Algoritma Shingling merupakan algoritma yang ditemukan oleh Andrei Broder [2], yang digunakan untuk proses pencarian near-duplicate document. Algoritma Shingling bekerja dengan cara memotong-motong teks menjadi kumpulan kata, dan membangkitkan suatu nilai unik (fingerprint) untuk tiap kumpulan kata Algoritma hash dapat digunakan untuk membangkitkan fingerprint
[3]. Pada penelitian ini dipilih algoritma MD5 yang merupakan salah satu algoritma hash, karena MD5 memiliki performa cepat dan spesifik.Terlebih lagi MD5 telah banyak diintegrasikan dalam berbagai macam bahasa pemrograman, salah satunya adalah C# pada library .Net Framework. Dengan menggabungkan metode ini dapat dibuat sebuah aplikasi untuk membangkitkan nilai kemiripan dua dokumen.
Berdasarkan latar belakang masalah yang ada, maka dilakukan penelitian yang bertujuan untuk merancang aplikasi deteksi kemiripan dokumen teks dengan mengimplementasikan algoritma Shingling, dan MD5 Fingerprint.
2. Tinjauan Pustaka
Penelitian tentang deteksi kemiripan yang pernah dilakukan adalah "A Digest and Pattern Matching-Based Intrusion Detection Engine" [4]. Pada penelitian tersebut dipaparkan suatu masalah yaitu intrusion detection/preventation system (IDS/IPS) pada jaringan komputer. IDS/IPS bekerja dengan bergantung pada signature database dan pattern matching (PM). Untuk melakukan pencocokan pola (PM) dengan data yang lewat pada jaringan komputer digunakan algoritma Boyer-Moore. Hasil ekperimen menghasilkan kesimpulan bahwa dengan membangkitkan nilai fingerprint, proses pencocokan pola menjadi lebih cepat. Pada penelitian tersebut nilai fingerprint dibangkitkan dengan menggunakan teknik Rabin-Fingerprint Perbedaan antara penelitian tersebut dengan penelitian yang dilakukan ini adalah pada penelitian ini bertujuan untuk mencari kemiripan antara dua dokumen, bukan paket data jaringan komputer, dan algoritma MD5 digunakan untuk membangkitkan nilai fingerprint.
2
menyaring near-duplicate documents, dan sukses diimplementasikan selama kurang lebih tiga tahun pada AltaVista. Dokumen yang dibandingkan disederhanakan dalam bentuk set, melalui proses shingling. Pada penelitian tersebut, satu shingle terdiri dari 4 kata, sehingga disebut 4-shingling. Setiap
shingle dibangkitkan sebuah fingerprint kemudian dibandingkan dengan nilai
fingerprint dari shingle pada dokumen kedua. Algoritma yang digunakan untuk membangkitkan nilai fingerprint adalah Rabin's fingerprint. Rabin's membangkitkan nilai fingerprint sebesar 64 bit (8 byte). Berbeda dengan penelitian yang dilakukan ini, nilai fingerprint diperoleh dengan cara membangkitkan nilai hash dari tiap shingle. Algoritma yang digunakan adalah MD5. MD5 membangkitkan nilai hash sebesar 128 bit, bukan 64 bit. Nilai yang lebih panjang ini dimaksudkan untuk menghindari nilai hash yang sama dari dua
shingle yang berbeda.
Pada penelitian yang berjudul "Deteksi Plagiat Dokumen Menggunakan Algoritma Rabin-Karp", dibahas tentang masalah penjiplakan yang banyak terjadi di sekolah dan universitas [6]. Hal plagiat yang biasanya dilakukan terhadap konten digital adalah melakukan copy-paste, quote, dan revisi terhadap dokumen asli. Untuk mengantisipasinya, dibutuhkan suatu cara yang dapat menganalisis teknik-teknik plagiasi yang dilakukan. Ada beberapa pendekatan yang bisa diambil, salah satunya dengan mempergunakan algoritma pencarian string Rabin-Karp. Penelitian tersebut hanya membahas secara skematis bagaimana algoritma Rabin-Karp bekerja dalam mendeteksi plagiasi pada suatu dokumen, bukan implementasinya dalam sebuah program atau aplikasi. Perbedaan antara penelitian tersebut dengan penelitian yang dilakukan ini adalah pada penelitian tersebut digunakan algoritma Rabin-Karp untuk melakukan pencarian string dalam mendeteksi plagiasi, sedangkan pada penelitian ini digunakan algoritma
Shingling.
Berdasarkan penelitian-penelitian yang telah dilakukan tentang deteksi kemiripan dokumen teks, plagiasi, algoritma pencarian string dan teknik
fingerprint, maka dilakukan penelitian yang bertujuan untuk merancang aplikasi deteksi kemiripan dokumen teks dengan mengimplementasikan algoritma
Shingling dan MD5 Fingerprint.
Penelitian yang dilakukan membahas tentang near-duplicate. Near-duplicate adalah kondisi ketika dua dokumen memiliki isi yang hampir sama, berbeda pada berberapa kata atau susunan kata [8].
Algoritma Shingling merupakan algoritma yang ditemukan oleh Andrei Broder[5]. Algoritma ini bekerja dengan cara membuat sebuah shingle yang berisi beberapa kata dengan jumlah yang tetap. Angka yang menentukan jumlah kata dalam satu shingle ini disebut gram. Pada tiap shingle dibangkitkan nilai
3
r(A,B)= | S
! ∩ S!|
|S
! ∪S!|
(1)
Persamaan 1 Rumus Nilai Kemiripan [5]
Algoritma Shinglingdilakukan melalui beberapa langkah berikut [5]: 1. Hilangkan tanda baca pada dokumen.
2. Dimulai dengan kata pertama, buat satu shingle berisi kata pertama tersebut sampai 3 kata berikutnya.
3. Pindah ke kata kedua, buat shingle berisi kata kedua dan 3 kata berikutnya. 4. Lakukan pembentukan shingle sampai dengan 4 kata terakhir dari
dokumen tersebut.
5. Untuk tiap shingle, bangkitkan nilai fingerprint.
6. Lakukan langkah 1 sampai dengan 5 untuk dokumen kedua.
7. Gunakan rumus nilai kemiripan dokumen (Persamaan 1) untuk menghitung nilai kemiripan dokumen.
Dalam kriptografi, MD5 (Message-Digest Algorithm 5) ialah fungsi hash
kriptografi yang digunakan secara luas dengan hashvalue 128-bit[3]. MD5 telah dimanfaatkan secara bermacam-macam pada aplikasi keamanan, dan MD5 juga umum digunakan untuk melakukan pengujian integritas (fingerprint) sebuah
file.MD5 didesain oleh Ronald Rivest pada tahun 1991 untuk menggantikan
hashfunction sebelumnya, yaitu MD4.
Gambar 1Hash Value dari Beberapa Input yang Berbeda [9]
Hashvalue yang dihasilkan oleh MD5 memiliki panjang 128-bit (16 byte), sekalipun input (pesan) yang digunakan memiliki panjang yang bervariasi.
Hashvalue berubah signifikan sekalipun perubahan yang terjadi pada input hanya 1 byte (1 kata).
4
a. Pesan ditambah dengan sejumlah bit pengganjal sedemikian sehingga panjang pesan (dalam satuan bit) kongruen dengan 448 (mod 512). b. Jika panjang pesan 448 bit, maka pesan tersebut ditambah dengan 512
bit menjadi 960 bit. Jadi, panjang bit-bit pengganjal adalah antara 1 sampai 512.
c. Bit-bit pengganjal terdiri dari sebuah bit 1 diikuti dengan sisanya bit 0. 2. Penambahan nilai panjang pesan semula.
a. Pesan yang telah diberi bit-bit pengganjal selanjutnya ditambah lagi dengan 64 bit yang menyatakan panjang pesan semula.
b. Jika panjang pesan >264 maka yang diambil adalah panjangnya dalam modulo 264. Dengan kata lain, jika panjang pesan semula adalah K bit, maka 64 bit yang ditambahkan menyatakan K modulo 264.
c. Setelah ditambah dengan 64 bit, panjang pesan sekarang menjadi kelipatan 512 bit.
3. Inisialisasi penyangga (buffer) MD.
a. MD5 membutuhkan 4 buah penyangga (buffer) yang masing-masing panjangnya 32 bit. Total panjang penyangga adalah 4 x 32 = 128 bit. Keempat penyangga ini menampung hasil antara dan hasil akhir.
b. Keempat penyangga ini diberi nama A, B, C, dan D. Setiap penyangga diinisialisasi dengan nilai-nilai (dalam notasi HEX) sebagai berikut: A = 01234567
B = 89ABCDEF C = FEDCBA98 c. D = 76543210
4. Pengolahan pesan dalam blok berukuran 512 bit.
Algoritma Shingling yang ditemukan oleh Broder, menggunakan
fingerprint dengan panjang 64 bit. Panjang fingerprint64 bit untuk tiap shingle
memiliki resiko yaitu dihasilkannya fingerprint yang sama untuk shingle yang berbeda. Hal ini disebut dengan collision vulnerabilities [10]. Untuk menghindari kemungkinan collision, maka digunakan fingerprint dengan panjang yang lebih dari 64 bit. Berdasarkan tujuan tersebut maka algoritma MD5 digunakan untuk menghasilkan fingerprint dengan panjang 128 bit.
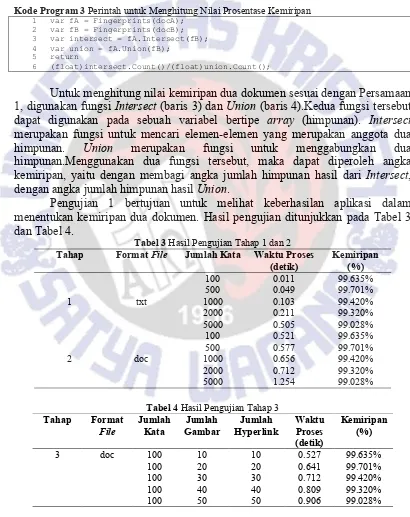
Kombinasi antara algoritma Shingling dengan algoritma MD5 ditunjukkan dengan contoh dibawah. Pada Tabel 1 dan Tabel 2 ditunjukkan fingerprint dengan nilai yang sama (cetak miring), yang berarti ada beberapa shingle yang sama dari kedua dokumen.
Shingle dan fingerprint yang dihasilkan dari dokumen A ditunjukkan pada Tabel 1. Terlihat bahwa panjang fingerprint konsisten sekalipun panjang shingle
5
Tabel 1 Shingle dan Fingerprint dari Dokumen A
Shingle Fingerprint dari MD5
1. Ibu kita Kartini Putri 920b65bb1be56ed6ba69497709ccc28c
2. kita Kartini Putri sejati d1cbd2da3c88dbd67d2088fa54dd7d7b
3. Kartini Putri sejati Putri cb59d3af40a15f4ed16982c73bd70c7c
4. Putri sejati Putri Indonesia b9faba71f188a68d040adaf09d531027
5. sejati Putri Indonesia Harum daaaea0ac17673f9c75631053ec571d2
6. Putri Indonesia Harum namanya b15ffd7a9a40923c1936157eb2339592
Contoh 2 Dokumen B
Ibu kita Kartini Putri sejati Putri Nusantara Wangi namanya
Shingle dan fingerprint yang dihasilkan dari dokumen B ditunjukkan pada Tabel 2. Fingerprint pada Tabel 1 yang bernilai sama dengan yang ada di Tabel 2, ditunjukkan dengan cetak miring.
Tabel 2 Shingle dan Fingerprint dari Dokumen B
Shingle Fingerprint dari MD5
1. Ibu kita Kartini Putri 920b65bb1be56ed6ba69497709ccc28c
2. kita Kartini Putri sejati d1cbd2da3c88dbd67d2088fa54dd7d7b
3. Kartini Putri sejati Putri cb59d3af40a15f4ed16982c73bd70c7c
4. Putri sejati Putri Nusantara c0cbee00191cccad4745e28d1a7f6a6b
5. sejati Putri Nusantara Wangi d44bd649fc0f3dcad13fe18cc35ebda7
6. Putri Nusantara Wangi namanya da9978b7eb3c56adbad6596d39e611cf
3. Metode dan Perancangan Sistem
Sistem yang dikembangkan, memiliki desain yang ditunjukkan pada Gambar 2. Sistem terdiri dari dua input yaitu dokumen A dan dokumen B. Hasil deteksi kedua dokumen tersebut adalah berupa angka prosentase kemiripan.
Dokumen A
Gambar 2 Desain Sistem
6
DESKRIPTIF
menghimpun data tentang kondisi yang ada
EVALUATIF
mengevaluasi proses ujicoba pengembangan suatu produk
EKSPERIMEN
menguji keampuhan dari produk yang dihasilkan.
Gambar 3 Langkah Pelaksanaan R&D [11]
Dalam pelaksanaan R&D, ada beberapa metode yang digunakan yaitu metode deskriptif, evaluatif dan eksperimental.Metode penelitian deskriptif digunakan dalam penelitian awal untuk menghimpun data tentang kondisi yang ada. Metode evaluatif digunakan untuk mengevaluasi proses ujicoba pengembangan suatu produk. Dan metode eksperimen digunakan untuk menguji keampuhan dari produk yang dihasilkan.
Langkah-langkah merancang sistem pada Gambar 3, dapat dijelaskan sebagai berikut.Tahap Deskriptif: dilakukan pengumpulan data dengan memperhatikan kebutuhan deteksi plagiasi dokumen dan algoritma yang dapat digunakan untuk melakukan deteksi kemiripan dokumen; Tahap Evaluatif:dilakukan evaluasi proses ujicoba perancangan aplikasi yang meliputi perancangan proses aplikasidan perancangan antarmuka. Perancangan proses dibuat dengan menggunakan flowchart; Tahap Eksperimen: Produk yang dihasilkan pada tahap sebelumnya kemudian diuji dan dilakukan analisa berdasarkan hasil pengujian tersebut, untuk mengetahui apakah aplikasi yang dihasilkan, telah memenuhi tujuan dan kebutuhan.
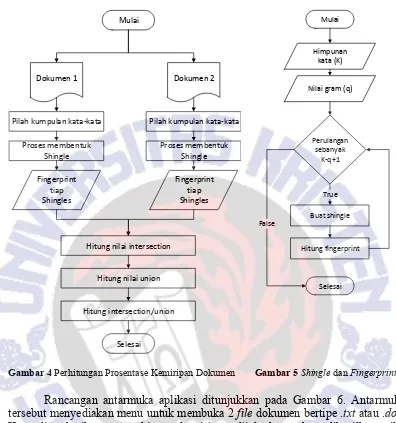
Proses perhitungan prosentase kemiripan dokumen secara garis besar ditunjukkan pada Gambar 4. Pada Gambar 4, proses dimulai dengan memecah dokumen menjadi kumpulan kata-kata. Pada proses ini semua tanda baca dan karakter non-alphanumeric diabaikan. Selanjutnya adalah membentuk shingle
-shingle, tiap shingle berisi berberapa kata. Untuk tiap shingle dihitung nilai
fingerprint. Angka kemiripan diperoleh dengan cara menghitung jumlah
fingerprint yang sama dari dua dokumen yang dibandingkan, kemudian angka tersebut dibagi dengan gabungan fingerprint kedua dokumen (lihat rumus pada Persamaan 1).
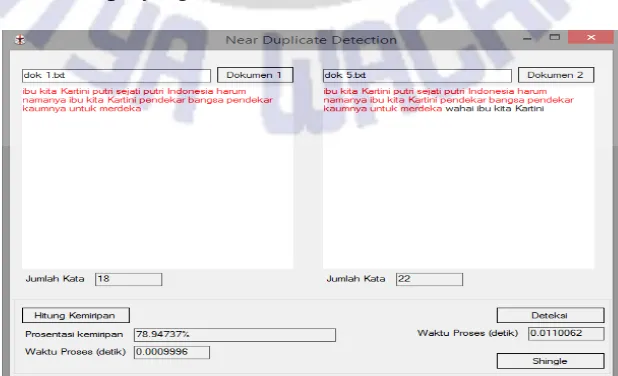
Proses pembuatan shingle dan fingerprint lebih jelasnya ditunjukkan pada Gambar 5. Satu shingle dibentuk dari sejumlah kata (q). Jika nilai q=4, maka satu
shingle terdiri dari 4 kata. Jika suatu dokumen terdiri dari K kata, maka jumlah
shingle yang terbentuk (S) adalah S = K - q + 1. Untuk tiap shingle, dilakukan proses hashing dengan menggunakan algoritma MD5 untuk mendapatkan nilai
7 Mulai
Dokumen 1 Dokumen 2
Proses membentuk Shingle
Proses membentuk Shingle
Fingerprint tiap Shingles
Fingerprint tiap Shingles
Hitung intersection/union
Selesai Hitung nilai intersection
Hitung nilai union
Pilah kumpulan kata-‐kata Pilah kumpulan kata-‐kata
Mulai
Himpunan kata (K)
Nilai gram (q)
Perulangan sebanyak
K-‐q+1
Buat shingle
Hitung fingerprint
Selesai True
False
Gambar 4 Perhitungan Prosentase Kemiripan Dokumen Gambar 5 Shingle dan Fingerprint
8
Gambar 6 Rancangan Antarmuka Aplikasi
Untuk mencapai tujuan perancangan sistem, maka perlu dilakukan pengujian.Pengujian dilakukan dengan menggunakan beberapa dokumen txt dan doc.
Tahap 1. Menggunakan dokumen txt.
- File 1 dan 2 menggunakan dokumen txt yang berisi 100 kata. Dicatat prosentase kecocokan dan waktu proses.
- File 3 dan 4 menggunakan dokumen txt yang berisi 500 kata. Dicatat prosentase kecocokan dan waktu proses.
- File 5 dan 6 menggunakan dokumen txt yang berisi 1000 kata. Dicatat prosentase kecocokan dan waktu proses.
- File 7 dan 8 menggunakan dokumen txt yang berisi 2000 kata. Dicatat prosentase kecocokan dan waktu proses.
- File 9 dan 10 menggunakan dokumen txt yang berisi 5000 kata. Dicatat prosentase kecocokan dan waktu proses.
Tahap 2. Menggunakan dokumen doc.
- File 1 dan 2 menggunakan dokumen doc yang berisi 100 kata. Dicatat prosentase kecocokan dan waktu proses.
- File 3 dan 4 menggunakan dokumen doc yang berisi 500 kata. Dicatat prosentase kecocokan dan waktu proses.
- File 5 dan 6 menggunakan dokumen doc yang berisi 1000 kata. Dicatat prosentase kecocokan dan waktu proses.
- File 7 dan 8 menggunakan dokumen doc yang berisi 2000 kata. Dicatat prosentase kecocokan dan waktu proses.
9
Tahap 3. Menggunakan dokumen doc yang memuat gambar dan hyperlink.
- File 1 dan 2 menggunakan dokumen doc yang berisi 100 kata, 10 gambar dan 10 hyperlink. Dicatat prosentase kecocokan dan waktu proses.
- File 3 dan 4 menggunakan dokumen doc yang berisi 100 kata, 20 gambar dan 20 hyperlink. Dicatat prosentase kecocokan dan waktu proses.
- File 5 dan 6 menggunakan dokumen doc yang berisi 100 kata, 30 gambar dan 30 hyperlink. Dicatat prosentase kecocokan dan waktu proses.
- File 7 dan 8 menggunakan dokumen doc yang berisi 100 kata, 40 gambar dan 40 hyperlink. Dicatat prosentase kecocokan dan waktu proses.
- File 9 dan 10 menggunakan dokumen doc yang berisi 100 kata, 50 gambar dan 50 hyperlink. Dicatat prosentase kecocokan dan waktu proses.
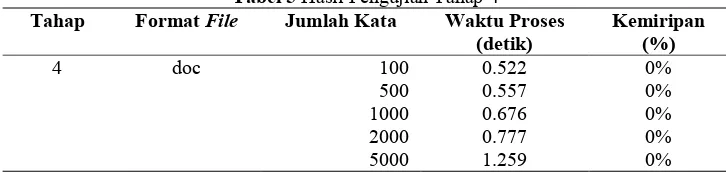
Tahap 4. Menggunakan dokumen doc yang memiliki jumlah kata sama namun memiliki isi yang berbeda.
- File 1 dan 2 menggunakan dokumen doc yang berisi 100 kata. Dicatat prosentase kecocokan dan waktu proses.
- File 3 dan 4 menggunakan dokumen doc yang berisi 1000 kata. Dicatat prosentase kecocokan dan waktu proses.
- File 5 dan 6 menggunakan dokumen doc yang berisi 10000 kata. Dicatat prosentase kecocokan dan waktu proses.
- File 7 dan 8 menggunakan dokumen doc yang berisi 100000 kata. Dicatat prosentase kecocokan dan waktu proses.
File 9 dan 10 menggunakan dokumen doc yang berisi 1000000 kata. Dicatat prosentase kecocokan dan waktu proses.
4. Hasil dan Pembahasan
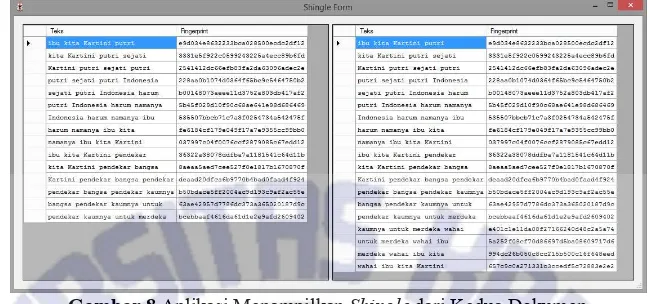
Antarmuka sistem hasil yang dihasilkan ditunjukkan pada Gambar 7 dan Gambar 8. Pada Gambar 7, ditunjukkan tampilan aplikasi pada waktu proses deteksi kemiripan selesai dilakukan. Nilai kemiripan ditunjukkan dalam bentuk prosentase, dan shingle yang sama diberi warna merah.
10
Gambar 8 Aplikasi Menampilkan Shingle dari Kedua Dokumen
Pada bagian ini dibahas mengenai implementasi aplikasi deteksi kemiripan dokumen.Aplikasi diimplementasikan dalam bentuk aplikasi desktop yang ditujukan untuk pengguna sistem operasi Windows. Aplikasi dikembangkan dengan menggunakan teknologi .Net Framework 4.5, bahasa pemrograman C#.
Kode Program 1 Perintah untuk Memecah Menjadi Kumpulan Kata
1 string Delimiter = " ";
2 string WhiteList = @"[^A-Za-z0-9]+";
3 var cleanDoc = Regex.Replace(
4 doc, WhiteList, Delimiter)
.Net Framework menyediakanlibrary untuk melakukan pencarian karakter dalam sebuah string. Regex merupakan class pada library .Net Framework yang salah satunya berfungsi untuk mencari dan mengganti karakter (baris 3).Dalam implementasi aplikasi deteksi kemiripan ini, class Regex digunakan untuk mencari karakter-karakter non-alphanumeric (baris 2), sebagai contohnya adalah karakter tanda baca, kemudian diganti dengan karakter spasi (baris 1).Class Regex memproses tugas tersebut lebih cepat dari pada menggunakan perulangan.
Kode Program 2 Perintah untuk Membentuk Shingle dan Menghitung Fingerprint
1 for (int i = 0; i < jumlahShingle; i++)
2 {
3 string[] shingle = new string[gram];
4 Array.Copy(words, i,
5 shingle, 0, shingle.Length);
6 stringhash = GetMd5Hash(md5,
7 string.Join(" ", shingle));
8 s.Add(hash);
9 }
10 11
12 public static string GetMd5Hash(
13 MD5 md5Hash, string input)
14 {
15 byte[] data = md5Hash.ComputeHash(
16 Encoding.UTF8.GetBytes(input));
17 StringBuilder sBuilder = new StringBuilder();
11
Untuk membangkitkan nilai fingerprint dari suatu shingle, digunakan algoritma MD5 (baris 13). Pada .Net Framework, tersedia class MD5, yang berfungsi untuk membangkitkan nilai hash/fingerprint dari inputstring. Class
MD5 yang tersedia mengakibatkan proses pengembangan aplikasi menjadi lebih cepat karena tidak perlu menulis kode program sendiri. Selain itu, implementasi MD5 pada .Net Framework memberikan jaminan bahwa library tersebut berjalan optimal dalam lingkungan Windows.
Kode Program 3 Perintah untuk Menghitung Nilai Prosentase Kemiripan
1 var fA = Fingerprints(docA);
2 var fB = Fingerprints(docB);
3 var intersect = fA.Intersect(fB);
4 var union = fA.Union(fB);
5 return
6 (float)intersect.Count()/(float)union.Count();
Untuk menghitung nilai kemiripan dua dokumen sesuai dengan Persamaan 1, digunakan fungsi Intersect (baris 3) dan Union (baris 4).Kedua fungsi tersebut dapat digunakan pada sebuah variabel bertipe array (himpunan). Intersect
merupakan fungsi untuk mencari elemen-elemen yang merupakan anggota dua himpunan. Union merupakan fungsi untuk menggabungkan dua himpunan.Menggunakan dua fungsi tersebut, maka dapat diperoleh angka kemiripan, yaitu dengan membagi angka jumlah himpunan hasil dari Intersect, dengan angka jumlah himpunan hasil Union.
Pengujian 1 bertujuan untuk melihat keberhasilan aplikasi dalam menentukan kemiripan dua dokumen. Hasil pengujian ditunjukkan pada Tabel 3 dan Tabel 4.
Tabel 3 Hasil Pengujian Tahap 1 dan 2
Tahap Format File Jumlah Kata Waktu Proses (detik)
Tabel 4 Hasil Pengujian Tahap 3
12
Tabel 5 Hasil Pengujian Tahap 4
Tahap Format File Jumlah Kata Waktu Proses (detik)
Kemiripan (%)
4 doc 100 0.522 0%
500 0.557 0%
1000 0.676 0%
2000 0.777 0%
5000 1.259 0%
Berdasarkan hasil pengujian, maka disimpulkan bahwa proses deteksi dipengaruhi oleh banyaknya kata yang terdapat dalam dokumen yang dibandingkan. Dokumen dengan format txt lebih cepat diproses daripada doc. Hal ini dikarenakan untuk dokumen format doc, perlu dilakukan proses konversi ke format txt, kemudian baru dilakukan proses deteksi. Proses ini memberikan selisih waktu sekitar 0.5 detik (diperoleh dari 0.511 detik untuk format doc, dikurangi 0.011 detik untuk format txt). Berdasarkan pengujian Tahap 3, jumlah gambar dan hyperlink dalam dokumen memberikan pengaruh pada lama waktu proses. Hal ini karena adanya gambar menyebabkan ukuran dokumen menjadi lebih besar, dan membutuhkan ruang memori lebih besar juga pada saat proses deteksi. Berdasarkan pengujian Tahap 4, diketahui bahwa lama waktu proses deteksi tidak dipengarui oleh seberapa besar kemiripan dokumen tersebut.
5. Simpulan
Berdasarkan penelitian, pengujian dan analisis terhadap aplikasi, maka dapat diambil kesimpulan sebagai berikut: (1) Deteksi kemiripan dokumen dapat dilakukan dengan menggunakan algorima Shingling dan diperkuat dengan algoritma MD5 untuk membangkitkan nilai fingerprint, sehingga terhindar dari
13 6. Daftar Pustaka
[1]. Hartosujono, H. 2012. Perbedaan Profil Kepribadian Pada Mahasiswa Pelaku dan Bukan Pelaku Plagiat. HUMANITAS (Jurnal Psikologi Indonesia) 2, 119–127.
[2]. Montanari, D. & Puglisi, P. L. 2012. Near duplicate document detection for large information flows. In Multidisciplinary Research and Practice for Information Systems, pp. 203–217. Springer.
[3]. Walia, A. G. N. K. 2014. Cryptography Algorithms: A Review. [4]. Chen, Z., Zhang, Y. & Delis, a. 2009. A Digest and Pattern
Matching-Based Intrusion Detection Engine. The Computer Journal 52, 699–723. (doi:10.1093/comjnl/bxp026)
[5]. Broder, A. 2000. Identifying and filtering near-duplicate documents. Combinatorial pattern matching , 1–10.
[6]. Firdaus, H. B. 2008. Deteksi Plagiat Dokumen Menggunakan Algoritma Rabin-Karp. Program Studi Teknik Informatika Sekolah Teknik Elektro dan Informatika, Institut Teknologi Bandung (ITB). Bandung , 1–5. [7]. Fowler, H. R., Aaron, J. E. & others 2007. The little, brown handbook.
Pearson Longman.
[8]. Stein, B., Koppel, M. & Stamatatos, E. 2007. Plagiarism analysis, authorship identification, and near-duplicate detection PAN’07. In ACM SIGIR Forum, pp. 68–71.
[9]. Rivest, R. 1992. The MD5 message-digest algorithm.
[10]. Wang, G. 2011. Collision attack for the hash function extended MD4. In Information and Communications Security, pp. 228–241. Springer. [11]. Sugiyono 2009. Metode Penelitian Pendidikan Pendekatan Kuantitatif,
![Gambar 1Hash Value dari Beberapa Input yang Berbeda [9]](https://thumb-ap.123doks.com/thumbv2/123dok/3064129.1720681/10.595.100.512.161.670/gambar-hash-value-dari-beberapa-input-yang-berbeda.webp)

![Gambar 3 Langkah Pelaksanaan R&D [11]](https://thumb-ap.123doks.com/thumbv2/123dok/3064129.1720681/13.595.119.448.110.292/gambar-langkah-pelaksanaan-r-d.webp)