BAB 2
TINJAUAN PUSTAKA
2.1 Data Mining
Data mining adalah eksplorasi dan analisis data dalam jumlah besar untuk menemukan pola yang berarti dan beraturan. Tujuan data mining adalah untuk meningkatkan pemasaran, penjualan, dan operasi dukungan pelanggan melalui teknik data mining, Berry & Linoff (2004).Berdasarkan tugas yang dapat dilakukan Data Mining dibagi menjadi beberapa kelompok, Berry & Linoff (2004):
a. Klasifikasi
Merupakan salah satu proses data mining yang paling umum, untuk memahami database kita harus mengklasifikasikan, mengekategorikan, dan grading dengan tujuan untuk membangun model dari beberapa jenis yang dapat diterapkan pada data unclassified mis:
Menentukan apakah suatu transaksi kartu kredit merupakan transaksi yang curang atau bukan
Memperkirakan apakah suatu pengajuan hipotek oleh nasabah merupakan suatu kredit yang baik atau buruk.
Mendiagnosis penyakit seorang pasien untuk mendapatkan termasuk kategori penyakit apa
b. Estimasi
Estimasi sama dengan klasifikasi, hanya estimasi sering digunakan untuk melakukan tugas klasifikasi nilai variabel yang bertujuan untuk membangun model untuk menyediakan nilai dari variabel target sebagai nilai prediksi.
Contoh:
Memperkirakan jumlah anak dalam keluarga Memperkirakan total pendapatan rumah tangga Memperkirakan nilai seumur hidup pelanggan
c. Prediksi
Prediksi adalah sama dengan klasifikasi atau estimasi, kecuali bahwa catatan diklasifikasi menurut beberapa prilaku masa depan diprediksi atau diperkirakan nilai masa depan.Tugas prediksi memeriksa akurasi klasifikasi dalam pemodelan prediktif, masalah tambahan mengenai hubungan temporal (data historis) variabel masukan atau prediktor terhadap variabel sasaran.contoh:
Data historis digunakan untuk membangun sebuah model yang menjelaskan saat ini perilaku yang diamati
Memprediksi ukuran keseimbangan yang akan ditransfer jika prospek kartu kredit menerima keseimbangan mentransfer menawarkan, memprediksi pelanggan yang akan meninggalkan dalam 6 bulan kedepan.
d. Clustering
Culstering adalah tugas segmentasi populasi yang heterogen menjadi
berapa subkelompok yang lebih homogen disebut dengan cluster, yang membedakan pengelompokan dari klasifikasi. Pengelompokan tidak bergantung pada kelas yang telah ditetapkan. Inclassification, setiap record diberikan kelas yang telah ditetapkan berdasarkan model yang dikembangkan melalui preclassified.clustering sering dilakukan sebagai awal untuk bentuk dari data mining atau modeling.contoh:
Membagi basis pelanggan ke cluster atau orang-orang dengan kebiasaan membeli yang sama, dan kemudian timbul pertanyaan apa jenis promosi yang terbaik untuk setiap cluster
e. Profile
profile adalah merupakan gambaran yang sedang terjadi di database. Contoh:
Deskripsi sederhana: “perempuan mendukung demokrat dalam jumlah yang lebih besar daripada laki-laki” dapat
sosiolog, ekonom, dan ilmuwan politik. Belum lagi calon untuk jabatan publik. Deskripsi dari pola ini kecendrungan sering memberikan kemungkinan penjelasan untuk suatu pola atau kecendrungan.
2.2 Algoritma Apriori
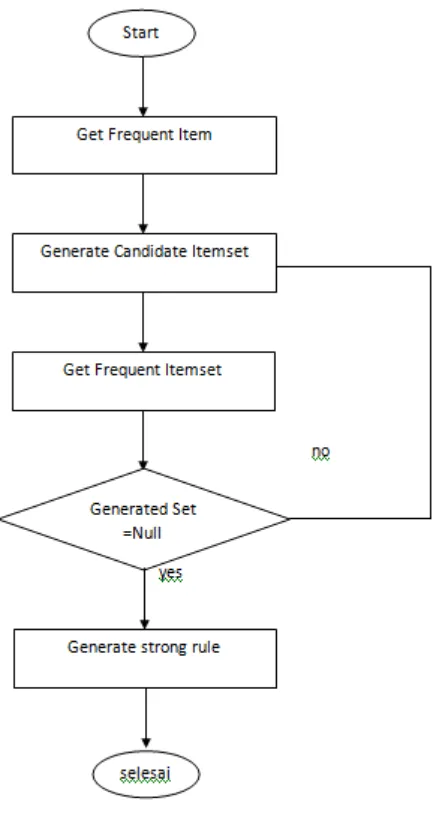
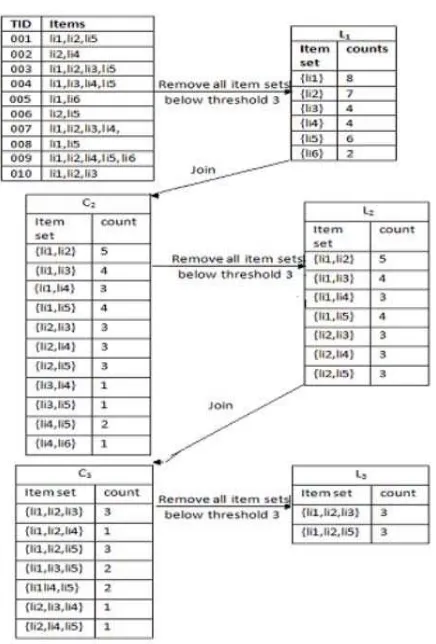
Algoritma Apriori adalah salah satu algoritma pada data mining untuk mencari frequent item/itemset pada transaksional database. Algoritma apriori pertama kali diperkenalkan oleh R.Agarwal dan R Srikant untuk mencari frequent tertinggi dari suatu database, Kaur et al (2014). Penggunaan bottom-up pendekatan berulang. Untuk menentukan asosiasi rule mining sebuah transaksi database, diperlukan waktu dalam melakukan proses frequent item set, menghasilkan kombinasi data yang cukup t banyak, Abdullah (2011). Proses ini dilakukan untuk mencari minimum nilai support dan minimum nilai confidence .
Algoritma apriori sangat mudah dipahami, tetapi ada beberapa kekurangan pada algortima tersebut:
1. Database Scanning: Database transaksi perlu dipindai berulang kali untuk menemukan frequent itemset. Jika ada n item dalam database, membutuhkan minimal n kali memindai database.
2. Pengaturan minimal frequent item/itemset untuk menentukan nilai support minimum.
3. Aturan Asosiasi rule mining dalam mendapatkan nilai minimum confidence
Langkah-langkah algoritma apriori sebagai berikut: 1. Join(penggabungan).
Pada proses ini setiap item dikombinasikan dengan item yang lainnya sampai tidak terbentuk kombinasi lagi.
2. Prune(pemangkasan).
Gambar 2.2 Generasi proses frequent item/itemset Sumber : Kaur (2014)
2.2.1 Analisis Asosiasi Rule Mining
a. Support
Analisis asosiasi didefenisikan suatu proses untuk menemukan semua aturan asosiasi yang memenuhi syarat minimum untuk support (minimum support) dan syarat minimum untuk confidence (minimum confidence).
2.3 FP-Growth
Frequent Pattern Growth (FP-Growth) adalah salah satu algoritma alternatif untuk mengatasi Frequent Pattern pada algoritma apriori. FP-growth berfungsi untuk menentukan item/itemset yang sering muncul (frequent item/itemset) dalam sebuah database, Moriwal (2014).
Mining tanpa melakukan candidate generation adalah teknik FP-Growth dengan menggunakan struktur data FP-tree, Han et al (2000). Dengan menggunakan cara ini scan database hanya dilakukan dua kali saja, tidak perlu berulang-ulang. Data akan direpresentasekan dalam bentuk FP-Tree. Setelah FP-Tree terbentuk, maka struktur data yang baik sekali untuk Frequent itemset akan diperoleh. FP-Tree merupakan struktur data yang baik sekali untuk frequent Pattern mining, Han et al (2000.) Struktur ini memberikan informasi yang lengkap untuk membentuk Frequent
Pattern. Item-item yang tidak frequent (infrequent) sudah tidak ada dalam penggunaan FP-tree, Han et al (2000).
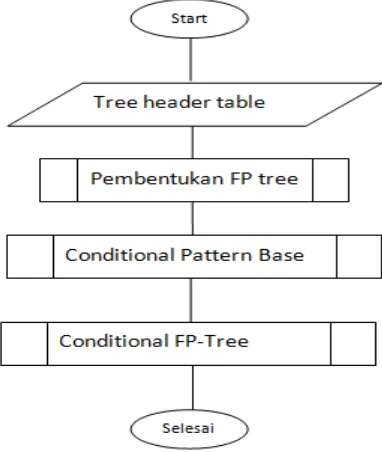
Pembangunan FP-Tree dari sekumpulan data transaksi, akan diterapkan algoritma FP-Growth untuk mencari Frequent itemset yang signifikan, Han et al (2000). Algoritma FP-tree dibagi menjadi tiga langkah utama, yaitu:
Tahap Pembangkitan Conditional Pattern Base Conditional Pattern Base merupakan subdatabase yang berisi prefix path (linasan e:1 prefix) dan pattern
2. Tahap Pembangkitan Conditional FP-tree pada tahap ini, support count dari setiap item pada setiap conditional pattern base dijumlahkan, lalu setiap item yang memiliki jumlah support count lebih besar sama dengan minimum support count akan dibangkitkan dengan conditional FP-tree.
3. Tahap Pencarian frequent itemset apabila conditional FP-tree merupakan lintasan tunggal(single path), maka didapatkan frequent itemset dengan melakukan kombinasi item untuk setiap conditonal FP-tree. Jika bukan lintasan tunggal, maka dilakukan pembangkitan FP-growth secara rekursif. Ketiga tahap tersebut merupakan langkah yang akan dilakukan untuk mendapatkan frequent itemset.
Dengan menggunakan FP-Growth, kita dapat melakukan Pettern Frequent itemset dengan tidak membutuhkan waktu yang cukup lama.
Gambar 2.3 Proses FP_Growth
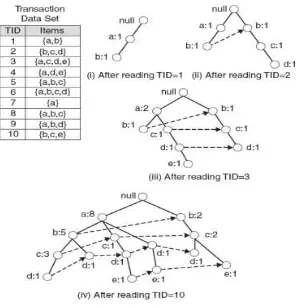
Gambar 2.4 Deskripsi FP-Growth Sumber: Han (2000)
Pada gambar 2.4 proses FP-Growth untuk pembacaan TID = 1 yaitu {a,b} dimulai mengerjakan fp-tree a1,b2, dilanjutkan dengan pembacaan TID=2 yaitu {b,c,d} yang dihasilkan a1,b2,c1,d1, dilanjutkan kemudian pembacaan TID =3 yaitu {a,c,d,e} yang
dihasilkan a2,b2,c2,d2,e1, dilanjutkan dengan pembacaan sampai dengan proses TID = 10 yaitu {b,c,e} yang dihasilkan a2,b7,c5,d5,e3 sehingga perolehan frequent item/itemset untuk keseluruhan TID pada gambar 2.4 diatas adalah a=8, b=7, c=6, d=5 dan e = 3
Pada tebel 2.1 di atas memperlihatkan jumlah setiap frequent item yang muncul untuk setiap transaksinya adalah I2, I3, dan I5
2.4 Grafik Mining
Grafik Mining menjadi semakin penting dalam pemodelan rumit struktur, seperti: sirkuit, gambar, senyawa kimia, struktur protein, jaringan biologis, sosial jaringan, Web, alur kerja, dan dokumen XML, Kavi & Joshi (2014) Banyak algoritma pencarian grafik telah dikembangkan dalam informatika kimia, visi komputer, video pengindeksan, dan pengambilan teks. Dengan meningkatnya permintaan pada analisis data dalam jumlah besar dan terstruktur, graph data mining selalu digunakan, Kumar &Rukmani(2010). Di antara berbagai jenis pola grafik, grafik adalah pola yang sangat
dasar yang dapat ditemukan di koleksi grafik, yang berguna untuk mengklasifikasi dan klastering grafik, membangun indeks grafik, dan memfasilitasi pencarian kesamaan dalam database grafik. Penelitian terbaru telah mengembangkan beberapa metode graph mining dan diterapkan ke penemuan pola yang menarik dalam berbagai aplikasi, Kavi & Joshi (2014) Misalnya, ada laporan tentang penemuan struktur kimia aktif dalam dataset HIV-screening oleh con-trasting dukungan sering grafik antara kelas yang berbeda. Ada pejantan-ies pada penggunaan struktur sering seperti fitur untuk mengklasifikasikan senyawa kimia, teknik pertambangan grafik sering untuk mempelajari keluarga struktural protein, pada deteksi subpathways cukup besar sering terjadi di jaringan metabolisme, dan pada penggunaan grafik, pola grafik pengindeksan dan pencarian kesamaan dalam database grafik.
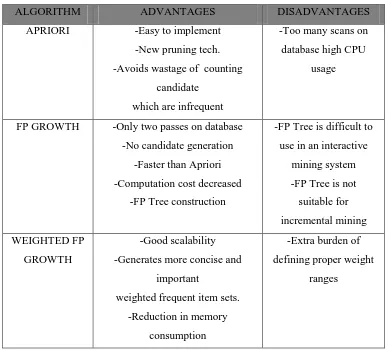
(2014) menganalisis frequent pattern dalam perpindahan objek pada algoritma apriori dan Penelitian Kavi & Joshi (2014) telah mencoba A Survey on Enhancing Data Processing of Positive and Negative Association Rule Mining hasil penelitian yang dilakukan dapat dilihat pada tabel 2.2 di bawah ini:
Tabel 2.2 Algoritma Apriori dengan FP-Growth
Kavi & Joshi (2014)
ALGORITHM ADVANTAGES DISADVANTAGES
APRIORI -Easy to implement
-New pruning tech.
-Avoids wastage of counting
candidate
which are infrequent
-Too many scans on
database high CPU
usage
FP GROWTH -Only two passes on database
-No candidate generation
weighted frequent item sets.
-Reduction in memory
consumption
-Extra burden of
defining proper weight
ranges
Berdasarkan penelitian diatas, maka perlu dilakukan penelitian pada algoritma
apriori untuk menemukan teknik baru dalam mengatasi masalah frequent item/itemset dalam pembentukan asosiasi rule mining untuk mendapatakan nilai support dan nilai