Fakultas Teknik Universitas Muhammadiyah Sidoarjo
B-59
Membaca berita telah menjadi kebutuhan sehari-hari semua orang. Kebutuhan dalam mencari dan menemukan berita dalam sekumpulan dokumen berita menjadi sangatlah penting. Dalam sebuah pencarian yang dilakukan, diharapkan dapat menemukan dokumen berita yang terkait dengan dokumen yang telah ditemukan. Association rule mining pada umumnya dimanfaatkan untuk mencari keterkaitan antar barang, dengan menganalisa transaksi penjualan sehari-hari yang selalu dilakukan pada sebuah badan usaha yang bergerak dalam bidang usaha penjualan barang. Pemahaman terhadap metode tersebut, sebagai ide awal dalam meneliti pencarian dokumen-dokumen berita yang saling terkait. Sehingga dengan adanya keterkaitan tersebut, maka dapat membantu dalam memberikan infomasi berita yang dibutuhkan. Penelitian yang dilakukan telah dapat menghasilkan keterkaitan antar dokumen, dimana hubungan antar dokumen dapat direpresentasikan berupa rule yang berasosiasi. Penelitian didukung dengan adanya software yang dibuat, sehingga dapat membantu dalam pembuktian tingkat keberhasilan dari penelitian ini. Dimana keberhasilan dari penelitian ini dihitung dengan menggunakan recall & precision. Hasil dari penelitian yang dilakukan cukup relevant dalam menghasilkan dokumen terkait, dengan mengacu pada uji coba yang telah dilakukan pada penelitian.
KATA KUNCI
Dokumen berita, pencarian, keterkaitan, association rule mining.
1. Pendahuluan
Dalam sekumpulan dokumen sangatlah mudah mencari dokumen yang disesuaikan dengan kata kunci yang dicari, namun jadi tidaklah mudah jika diinginkan untuk mencari dokumen-dokumen yang saling berkaitan. Terdapat penelitian yang dilakukan oleh Iis Siti Darawaty dan Siti Syarah dengan judul “Intelligent Searching using Association Analysis for Law Documents of Indonesian Government”, dimana pada penelitian ini proses pencarian dilakukan dalam menemukan keterkaitan antar dokumen hukum. Tujuan dan maksud dari penelitian yang dilakukan adalah untuk membantu mencari keterkaitan antar berita yang diambil dari sekumpulan dokumen pada surabaya.detik.com, sehingga kontribusi yang dihasilkan akan dapat membantu dalam memberikan infomasi yang lebih (jika diperlukan) terhadap berita yang ditemukan [2].
2. Metode
2.1. Konsep Association Rule Mining
B-
60
Fakultas Teknik Universitas Muhammadiyah Sidoarjo
Gambar 1. Arsitektur SmartRuleTerdapat tiga fungsi dalam sistem smart rule, yaitu: MaxMiner, InvertCount, dan RuleTree. Beberapa langkah yang diperlukan sampai akhirnya didapatkan rule-rule yang diinginkan:
1. Proses pengolahan data dari database dengan mencari sekumpulan maximal frequent itemset. 2. Proses penyimpanan maximal frequent itemset kedalam database.
3. User melakukan seleksi maximal frequent itemset yang diperlukan untuk diubah kedalam frequent itemset, hasil dari seleksi disimpan kedalam config.
4. Proses pengolahan maximal frequent itemset yang telah diseleksi untuk selanjutnya diubah kedalam frequent itemset dengan menghitung nilai support masing-masing frequent itemset.
5. Proses generate rules degan mengolah frequent itemset yang dihasilkan sebelumnya. Rules yang dihasilkan kemudian di-organize dengan maksud untuk menyusun rule secara hirarki (tree) dan selanjutnya disimpan kedalam database.
6. User melakukan seleksi terhadap rule-rule yang dibutuhkan dalam pengambilan keputusan.
Gambar 2. Max Miner
2.2. Max Miner
MaxMiner menggunakan teknik breadth-first search dalam proses pengolahan data dan menghasilkan rule dengan frequent itemset yang maximal, sehingga rule yang dihasilkan lebih sedikit namun dengan pola pattern yang maximal [3,4].
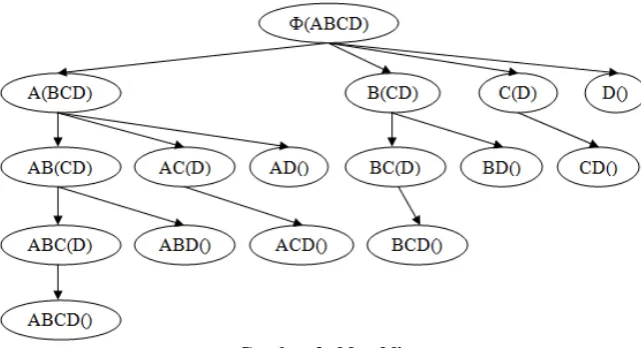
Pada MaxMiner terdapat proses pruning (pemangkasan) dalam mempercepat proses pencarian maximal frequent itemset. Dengan menggunakan representasi tree maxminer mengecek frequency dari ABCD dan AB, AC, AD, dimana terdapat 2 syarat utama dalam melakukan pruning.
1. Jika ABCD frequent (memenuhi nilai support), maka pruning seluruh sub-tree.
2. Jika AC tidak frequent,hapus C dari dalam kurung sebelum diperluas. Contoh: A(BCD), diketahui bahwa AC tidak frequent maka hapus C sehingga menjadi A(BD), dan AC tidak perlu di-expand atau diperluas.
Terdapat hal-hal penting yang perlu diketahui sebelum dilakukan proses pruning, dimana meliputi:
1. Awalnya, generate satu node N = Ф(ABCD), dimana h(N) = Ф (bukan nilai support tapi root yang berisi himpunan kosong) dan t(N) = {A,B,C,D}.
2. Ketika proses menghitung support dari kandidat grup N dilakukan, lakukan juga proses perhitungan support untuk h(N), h(N) t(N) dan h(N) i (dimana i adalah bagian dari t(N)).
3. Hal-hal yang harus dipertimbangkan sebelum memperluas N:
Fakultas Teknik Universitas Muhammadiyah Sidoarjo
B-61
b. Jika untuk sebagian dari i t(N), h(N) i tidak frequent, hapus i dari t(N) sebelum memperluas N.4. Perluas (expand) node N satu demi satu dan lakukan hal yang sama untuk proses berikutnya.
5. Ketika pola maximal teridentifikasi (misalkan ABCD), maka hapus semua node (misalkan B, C dan D) dimana h(N) t(N) adalah sub-set dari pola yang teridentifikasi.
2.3. Inverted Count
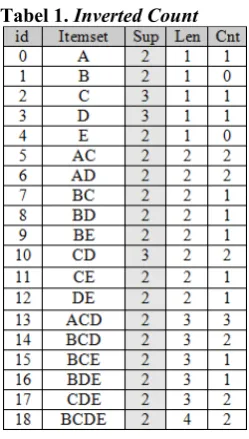
Setelah mendapatkan maximal frequent itemset, proses selanjutnya adalah mencari nilai support untuk seluruh kombinasi dari item (frequent itemset) yang didapat dari proses maximal frequent itemset, yang bertujuan untuk memudahkan dalam melakukan generate strongest association rule dalam menghasilkan rule-rule yang dibutuhkan. Berikut contoh tabel inverted count.
Tabel 1. Inverted Count
2.4. Generate Rule Tree
Generate RuleTree akan diproses setelah proses InvertCount selesai dijalankan. Hasil dari proses ini berupa rule tree, yang dapat ditabelkan, sehingga dengan adanya pentabelan tersebut memudahkan dalam melakukan generate ulang tree tersebut yang berguna dalam penambahan rule baru.
B-
62
Fakultas Teknik Universitas Muhammadiyah Sidoarjo
2.5. Tahap Pemilahan Kata
Tahap pemilahan kata dilakukan dengan tujuan untuk mendapatkan kumpulan kata dari sebuah berita. Diawali dengan proses fetching yang bertujuan untuk mendapatkan berita dari website surabaya.detik.com. Kemudian selanjutnya melakukan proses pengambilan kata yang disebut dengan parsing dokumen (Tokenizing). Hasil dari proses tersebut kemudian diolah dengan menggunakan stop word removal yang bertujuan untuk menghilangkan kata-kata yang tidak diperlukan. Akhir dari proses berupa kata dasar yang diolah dengan menggunakan teknik stemming.
2.5.1. Fetching
Pada penelitian ini data berupa dokumen-dokumen berita yang diambil dari website surabaya.detik.com, dimana proses fetching dilakukan selama satu bulan terakhir. Hasil dari proses fetching kemudian diambil berupa tanggal, judul dan isi berita yang terkadung dalam page yang telah di-fetch. Selanjutnya data-data tersebut disimpan kedalam database yang berguna untuk proses selanjutnya.
2.5.2. Parsing (Tokenizing)
Tokenizing adalah sebuah proses yang dilakukan seseorang untuk menjadikan sebuah kalimat menjadi lebih bermakna atau berada dengan cara memecah kalimat tersebut menjadi kata-kata atau frase-frase. Tokenizing di dalam pembuatan aplikasi ini merupakan proses penguraian deskripsi yang semula berupa kalimat-kalimat berisi kata-kata dan tanda pemisah antara kata seperti titik(.), koma(,), spasi dan tanda pemisah lain menjadi kata-kata saja baik itu berupa kata-kata penting maupun kata-kata tak penting. Secara sederhana proses tokenizing ini terlihat sebagai proses pengambilan kata jika bertemu dengan tanda pemisah antar kata.
2.5.3. Stop Word Removal
Kebanyakan bahasa resmi di berbagai negara memiliki kata fungsi dan kata sambung seperti partikel dan preposisi yang hampir selalu muncul pada dokumen-dokumen teks. Biasanya kata-kata ini memiliki arti yang lebih di dalam memenuhi kebutuhan seorang searcher di dalam mencari inuntukmasi. Kata-kata tersebut (misalnya a, an, the on pada bahasa inggris) disebut sebagai stopwords. Di dalam bahasa Indonesia stopwords dapat disebut sebagai kata tidak penting misalnya “di”, “oleh”, “pada”, “sebuah”, “karena”. Sebelum proses stopwords removal dilakukan, terlebih dulu dibuat daftar stopwords (stoplist). Preposisi, kata hubung dan partikel biasanya merupakan kandidat stoplist.
2.5.4. Stemming
Stemming adalah proses pemetaan dan penguraian berbagai bentuk (variants) dari suatu kata menjadi bentuk kata dasamya (stem) (Tala ,p.1). Proses ini juga disebut sebagai conflation (Frakes, 1992). Proses stemming secara luas sudah digunakan di dalam Inuntukmation Retrieval (pencarian inuntukmasi) untuk meningkatkan kualitas inuntukmasi yang didapatkan. Kualitas inuntukmasi yang dimaksud misalnya untuk mendapatkan hubungan antar variant kata yang satu dengan yang lainnya. Sebagai contoh kata "diculik", "menculik" (melakukan ti ndaka n menculi k) dan " pencul ik” (orang yang me nculi k) yang se mula mengandung arti yang berbeda dapat di-stem menjadi sebuah kata "culik" yang memiliki arti yang sama sehingga kata-kata di atas dapat saling berhubungan.
2.6.
Tahap Pencarian Dokumen Terkait
Pada tahap pencarian dokumen yang terkait ini menjelaskan mengenai pengolahan data yang telah diproses
pada tahap pemilahan kata dengan mengambil kata dasar yang telah terbentuk. Selanjutnya data tersebut
diindeks terlebih dahulu dan kemudian diolah oleh
association rule mining dengan menggunakan arsitektur
smart rule untuk mendapatkan
rule-rule yang berisi sekumpulan kata yang saling terkait satu sama lain.
Kemudian
rule-rule yang telah didapat diolah menggunakan
vector space model dalam proses pencarian
dokumen yang terkait [1].
2.6.1. Indexing Word
Fakultas Teknik Universitas Muhammadiyah Sidoarjo
B-63
Tabel 2. Contoh Penyimpanan Kata2.6.2. Term Weight
Pada proses pembobotan kata ini menggunakan model pembobotan
tf.idf. Dimana
tf dan idf dikombinasikan
dalam model vector-space, dengan menghitung koordinat document d pada sumbu term t dengan rumus: d
t=
tf(d,t) x idf(t). tf adalah term frequency dalam dokumen, dimana semakin banyak sebuah term muncul dalam
sebuah dokumen, maka dokumen tersebut menjadi semakin penting. Sedangkan idf adalah inverse document
frequency, dimana semakin jarang sebuah
term muncul dalam keseluruhan koleksi dokumen, maka
term
tersebut menjadi penting.
2.6.3. Term Frequency
tf biasanya dihitung dengan tf = fd,t, dimana fd,t adalah frekuensi termt dalam dokumen d. Namun adapun beberapa variasi yang mungkin dalam penjabaran tf. Dalam penelitian ini tf dijabarkan kedalam bentuk Cornel Smart System, dengan rumus sebagai berikut:
………..………. (1)
2.6.4. Inverse Document Frequency
Pemakaian kata inverse menunjukkan pada fakta bahwa, ferkuensi berbanding terbalik dengan nilai idf, dimana frekuensi term yang semakin besar (jumlah term makin banyak), menyebabkan nilai idf semakin kecil. Adapun beberapa variasi yang mungkin dalam penjabaran idf, namun pada penelitian ini idf dijabarkan kedalam bentuk Cornel Smart
System, dengan rumus idf = log(N/ft) + 1.
……….. (2)
2.6.5. Pembobotan Query
Selain melakukan perhitungan pembobotan term-term terhadap sekumpulan dokumen, term-term pada query juga dapat diberikan pembobotan [5]. Berikut perumusan pembobotan term pada query yang umumnya dipakai:
………..………. (3)
Wi, q = Bobot masing-masing termquery q terhadap seluruh dokumen i. freqi, q = Total kemunculan masing-masing term query pada seluruh dokumen i. max1 freq1, q = Max jumlah masing-masing term query pada seluruh dokumen i. N = Jumlah keseluruhan dokumen disemua term query.
ni = Jumlah keseluruhan dokumen masing-masing term query.
2.6.6. Similarity
B-
64
Fakultas Teknik Universitas Muhammadiyah Sidoarjo
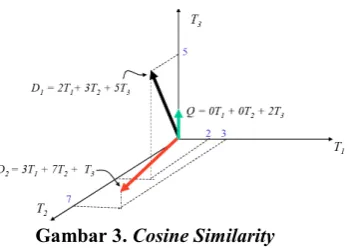
Gambar 3. Cosine SimilarityPada gambar 3 merupakan model vector-space, dimana dokumen-dokumen direpresentasikan dengan vector-vector pada ruang multidimensi Euclidian. Setiap sumbu pada bagian ini berhubungan dengan sebuah term (kata). Untuk jumlah term t, sejumlah t unit vektor v(i) membentuk basis orthonormal untuk sebuah space t-dimensi. Begitulah pengertian dari "space". Dokumen similarity didefinisikan sebagai cosine similarity, berikut perhitungan dari cosine similarity.
……… (4)
3. Hasil
Uji coba dilakukan terhadap rule-rule yang telah dihasilkan pada proses association rule mining dan pencarian dokumen yang relevan pada proses vector space model dalam pencarian dokumen yang terkait. Tingkat keberhasilan diukur dengan menggunakan recall dan precision terhadap dokumen yang diolah dengan menggunakan association rule mining dalam pencarian dokumen terkait dengan dokumen yang diolah tanpa menggunakan association rule mining.
\
Tabel 3. Contoh Rule untuk Pencarian Dokumen Terkait
Tabel 3 menunjukkan bahwa jika dilakukan pencarian terhadap kolom antecedent maka akan memperoleh dokumen yang mengandung kata-kata pada kolom consequent, dengan arti bahwa dokumen yang mengandung kata pada kolom antecedent berkaitan dengan dokumen yang mengandung kata pada kolom consequent.
Tabel 4. Recall Precision Contoh Rule 1
Fakultas Teknik Universitas Muhammadiyah Sidoarjo
B-65
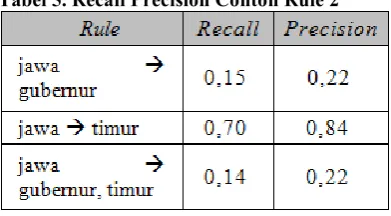
Tabel 5. Recall Precision Contoh Rule 2Dari tabel 5 untuk hasil perhitungan recall dan precision dari rule “jawa gubernur” didapatkan recall dengan nilai 15% dan precision 22%, untuk rule “jawa timur” didapatkan recall dengan nilai 70% dan precision 84%, sedangkan untuk rule “jawa gubernur, timur” didapatkan recall dengan nilai 14% dan precision 22%.
Tabel 6. Recall Precision Contoh Rule 3
Dari tabel 6 untuk hasil perhitungan recall dan precision dari rule “kabupaten rumah” didapatkan recall dengan nilai 12% dan precision dengan nilai 35%, untuk rule “kabupaten desa” didapatkan recall dengan nilai 26% dan precision dengan nilai 51%, untuk rule “kabupaten warga” didapatkan recall dengan nilai 17% dan precision dengan nilai 54%, untuk rule “kabupaten camat” didapatkan recall dengan nilai 30% dan precision dengan nilai 60%, untuk rule “kabupaten korban” didapatkan recall dengan nilai 12% dan precision dengan nilai 36%, sedangkan untuk rule “kabupaten rumah, desa, warga, camat, korban” didapatkan recall dengan nilai 2% dan precision dengan nilai 9%.
Tabel 7. Recall Precision Contoh Rule 4