1 PERFORMA METODE K NEAREST NEIGHBOR IMPUTATION (KNNI)
UNTUK MENANGANI MULTIVARIATE MISSING DATA
Sartika Y Siregar,S.ST1, Dr. Toni Toharudin2, Bertho Tantular, S.Si, M.Si3
1
Mahasiswa Pascasarjana Statistika Terapan, FMIPA Unpad, Bandung
2
Departemen Statistika, FMIPA Universitas Padjadjaran, Bandung
3
Departemen Statistika, FMIPA Universitas Padjadjaran, Bandung
ABSTRAK
Salah satu hal yang sangat diharapkan ketika melakukan pengumpulan data pada sensus atau survei adalah menghasilkan data yang lengkap. Ketika terdapat data yang tidak lengkap maka harus diklarifikasi penyebabnya. Secara umum, ketidak lengkapan data terjadi karena adanya non observational yaitu kegagalan dalam memperoleh data sebagai bagian dari pendefinisian populasi target. Non observational dapat berupa non coverage dan non response. Non coverage terjadi pada saat elemen dari target populasi tidak mempunyai kesempatan untuk terpilih karena tidak tercantum dalam kerangka sampel. Nonrespon merupakan suatu kegagalan untuk memperoleh data baik secara keseluruhan (nonrespon unit) maupun sebagian dari karakteristik yang ingin diukur (nonrespon item). Nonrespon item masih dapat diatasi dengan berbagai metode. Salah satu caranya adalah dengan metode imputasi. Tujuan dari penelitian ini adalah mengkaji metode K-Nearest Neighbor Imputation
(KNNI) untuk menangani multivariate missing data dengan simulasi data hilang sebanyak 10,20,30,dan 40 persen dari total sampel sehingga dapat dibandingkan performa metode ini pada tiap simulasi data hilang. Data yang digunakan pada penelitian ini adalah data Survei Produktivitas Tanaman Pangan Komoditi Ubi Kayu Provinsi Lampung tahun 2013. Berdasarkan hasil pengolahan pada metode KNNI bahwa semakin besar missing data yang terjadi pada data produktivitas ubi kayu maka rata-rata nilai RMSE nya juga semakin besar pada setiap nilai K yang digunakan. Artinya bahwa semakin sedikit data yang hilang maka tingkat akurasinya pun semakin baik.
Kata Kunci : Nonrespon, Imputasi, KNNI, Nearest Neighbor
1. Pendahuluan
Salah satu hal yang sangat diharapkan ketika melakukan pengumpulan data baik secara sensus atau survei adalah menghasilkan data yang lengkap. Namun ketika terdapat data tidak lengkap/data hilang di dalamnya, maka sebelumnya harus diklarifikasi penyebabnya. Secara umum, ketidak lengkapan data terjadi karena adanya
2
komoditi ini lebih tinggi dari tingkat non observational pada seluruh komoditi (34,06 persen).
Permasalahan data hilang (missing data) akibat adanya nonrespon juga terjadi pada survei yang dilakukan oleh Badan Pusat Statistik (BPS). Salah satunya yaitu pada Survei Produktivitas Tanaman Pangan (Ubinan). Data diperoleh dengan dua cara yaitu dengan metode wawancara dan pengukuran langsung. Ketika pengukuran langsung tidak dapat dilakukan karena waktu survey yang tidak tepat maka akan muncul nonrespon unit. Sebenarnya nonrespon unit pada survei ini dapat dikurangi dengan tetap melakukan metode wawancara untuk item pertanyaan yang lain, namun pada isian item pertanyaan banyaknya hasil ubinan dan jumlah batang/rumpun dalam plot ubinan akan kosong (missing data) karena mensyaratkan metode pengumpulan data untuk kedua item ini dengan metode pengukuran langsung sehingga terjadi nonrespon item pada kedua item pertanyaan tersebut.
Untuk mengatasi missing data tersebut, dapat digunakan beberapa metode yaitu mengabaikan atau membuang data yang hilang, estimasi parameter dan metode imputasi [13]. Pada penelitian ini difokuskan pada metode imputasi untuk mengatasi missing data yang terdapat pada Survei Produktivitas Ubinan.
Berdasarkan teknik imputasinya, metode imputasi terdiri dari dua jenis yaitu teknik machine learning dan teknik statistik. Salah satu metode dengan teknik machine learning adalah metode K-Nearest Neighbor Imputation (KNNI) [10]. Metode KNNI adalah metode yang paling terkenal yang digunakan untuk mengatasi missing data. Metode ini tidak perlu memprediksi model seperti halnya pada prosedur EM Algorithm, hanya menggunakan ukuran jarak. Metode KNNI juga memberikan hasil imputasi yang sangat baik bahkan ketika data yang digunakan memiliki missing data yang cukup besar [5].
Oleh karena itu, pada penelitian ini akan dikaji performa metode KNNI untuk menangani masalah missing data pada item banyaknya hasil ubinan dan jumlah batang/rumpun dalam plot ubinan guna mengurangi nonrespon unit pada Survei Produktivitas Tanaman Pangan Komoditi Ubi Kayu Provinsi Lampung Tahun 2013.
2.Metode
Missing data adalah suatu keadaan dimana beberapa nilai atribut dalam suatu dataset kosong /tidak ada nilainya [18]. Artinya terdapat isian yang tidak lengkap pada variabel tertentu pada suatu observasi.
Keacakan missing data dapat dibagi ke dalam tiga tipe [5] yaitu : (1) Missing Completely at Random (MCAR), yaitu terjadinya missing data tidak bergantung pada nilai seluruh variabel, baik variabel yang terisi (diketahui) maupun variabel yang mengandung missing values ; (2) Missing at Random (MAR), yaitu terjadinya missing data bergantung pada variabel yang terisi (diketahui) namun tidak bergantung pada variabel yang mengandung missing values itu sendiri ; (3) Not Missing at Random (NMAR), yaitu terjadinya missing data pada suatu variabel bergantung pada variabel itu sendiri sehingga tidak dapat diprediksi dari variabel yang lain.
3
data [13]. Metode imputasi tidak hanya mengurangi bias nonrespon tetapi juga dapat menghasilkan data yang lengkap [16]. Beberapa metode imputasi akan dipaparkan pada bagian ini, yaitu :
1. Metode imputasi dengan ukuran pemusatan
Metode imputasi ini menggunakan ukuran pemusatan data untuk mengisikan data yang hilang. Jika tipe data atributnya kontinu maka digunakan nilai mean dan jika tipe data atributnya diskret maka digunakan nilai modus [5]. Metode imputasi ini termasuk ke dalam model-donor imputation yaitu nilai imputasi yang diambil dari model [6].
2. Metode imputasi regresi
Metode imputasi ini termasuk ke dalam model-donor imputation [6]. Metode imputasi ini akan mengisikan nilai yang missing dengan nilai prediksi dari regresi yang berasal dari unit observasi [14].
3. Metode imputasi Hot Deck
Metode imputasi ini termasuk ke dalam real-donor imputation yaitu nilai imputasi diambil dari himpunan nilai observasi [6]. Dengan metode ini, missing data diganti dengan nilai dari observasi yang respon yang memiliki kemiripan dengan observasi yang mempunyai missing data [14].
4. Metode imputasi ColdDeck
Pada metode imputasi ini, missing data pada suatu observasi diisikan dengan hasil survei pada periode sebelumnya atau berdasarkan informasi lain, misal data historis atau series data. Sumber data imputasi bukan berasal dari data set yang sama dengan observasi yang lengkap sehingga tidak memerlukan perhitungan atau algoritma komputer dalam proses imputasinya [16].
5. Metode imputasi berbasis Machine Learning
Metode imputasi berbasis Machine Learning diantaranya yaitu metode C4.5 dan CN2. Kedua metode tersebut merupakan metode yang simpel untuk mengatasi missing data. Namun jika kedua metode tersebut dibandingkan dengan metode K-Nearest Neighbor Imputation (KNNI) untuk mengatasi missing data, metode KNNI memberikan hasil yang lebih baik [5]. Metode imputasi berbasis Machine Learning
yang lain adalah Multi Layer Perceptron (MLP) dan Self Organization Maps
(SOM). Jika dua metode tersebut dibandingkan dengan metode KNNI, maka metode KNNI memberikan performa yang paling baik [10].
Pada penelitian ini akan diterapkan metode K Nearest Neighbor Imputation untuk menangani missing data pada data produktivitas tanaman pangan komoditi ubi kayu.
Metode K Nearest Neighbor Imputation (KNNI)
Metode imputasi KNN merupakan salah satu metode yang paling populer untuk menyelesaikan permasalahan missing data. Keunggulan dari metode imputasi KNN adalah :
(1) Metode imputasi KNN dapat digunakan untuk memprediksi dua tipe data baik data diskret (dengan nilai modus) maupun kontinu (dengan nilai mean)
(2) Metode imputasi KNN tidak membutuhkan pembentukan model prediksi untuk setiap item yang mengalami missing data [5].
4
ketika dataset yang digunakan cukup besar, akan membutuhkan waktu yang cukup lama. Namun walaupun begitu, metode imputasi KNN tetap merupakan metode yang cukup baik untuk imputasi data yang hilang [13].
Tahapan pengerjaan imputasi missing data dengan metode KNNI dapat dijelaskan sebagai berikut :
1. Menentukan nilai K, yaitu berapa jumlah observasi terdekat yang akan digunakan
2. Menghitung jarak antara observasi yang mengandung missing data pada variabel ke-j dengan observasi lainnya yang tidak mengandung missing data pada variabel yang bersesuaian dengan menggunakan rumus
, = − (1)
Dengan :
, = jarak antar observasi target dan observasi
= nilai variabel ke-j pada observasi target , j = 1,2,. , m = nilai variabel ke-j pada observasi lainnya , j = 1,2,., m
3. Mencari K observasi terdekat berdasarkan nilai jarak terkecil. Nilai variabel pada K observasi terdekat ini yang akan digunakan untuk proses imputasi pada observasi yang mengandung nilai missing
4. Menghitung bobot (weight) pada setiap K observasi terdekat. Observasi yang paling dekat akan mendapatkan bobot yang paling besar
5. Menghitung nilai rata-rata pada K observasi terdekat yang tidak mengandung nilai missing dengan prosedur weighted mean estimation yaitu dengan rumusan
=
(2)Dengan adalah nilai variabel ke-j pada observasi ke-k, k= 1,2,…,K dan =
adalah bobot observasi tetangga terdekat ke-k, yang dirumuskan sebagai berikut : =
, !
6. Melakukan proses imputasi missing data pada observasi yang mangandung nilai missing dengan nilai rata-rata yang diperoleh pada tahap 5
3.Hasil dan Pembahasan
Data yang digunakan dalam penelitian ini adalah data survei produktivitas tanaman pangan/ubinan tahun 2013 di Provinsi Lampung pada komoditi ubi kayu. Komoditi ini dipilih karena tingkat nonrespon unitnya lebih tinggi daripada tingkat nonrespon pada seluruh komoditi. Jumlah observasi yang akan digunakan dalam penelitian ini adalah 1427 observasi dengan jumlah variabel yang digunakan sebanyak lima variabel. Variabel yang akan digunakan pada penelitian ini adalah : luas tanaman sejenis (X1), banyaknya pupuk UREA yang digunakan (X2), banyaknya pupuk
NPK/majemuk yang digunakan (X3), berat hasil ubinan (X4), banyaknya batang dalam
plot ubinan (X5).
Imputasi missing data dengan metode KNNI akan dilakukan pada variabel berat hasil ubinan (X4) dan banyaknya batang dalam plot ubinan (X5) secara bersamaan.
5
plot ubinan (X5) secara bersamaan. Simulasi data hilang akan menggunakan simple random sampling without replacement (SRS WOR) dengan persentase data hilang sebanyak 10, 20, 30, dan 40 persen. Banyaknya persentase data hilang disesuaikan dengan permasalahan yang ada.
Setelah data pada variabel X4 dan X5 dihilangkan sesuai banyaknya persentase
data hilang, maka langkah selanjutnya adalah melakukan imputasi dengan metode KNNI dengan menggunakan nilai K=10,15,20, dan 30. Setiap nilai K pada tiap persentase missing data dicobakan sebanyak 10 kali percobaan sehingga diperoleh nilai RMSE pada tiap percobaannya dan kemudian dihitung rata-rata nilai RMSE nya.
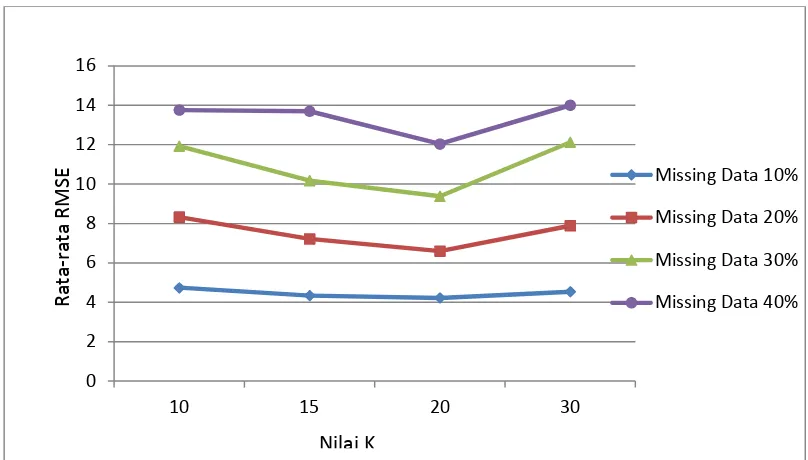
Tabel 1. Nilai Rata-rata RMSE pada Imputasi Variabel X4 dan X5 dengan Metode
KNNI pada Data Produktivitas Ubi Kayu Prov. Lampung 2013
Persentase Missing Data
Rata-rata Nilai RMSE
K=10 K=15 K=20 K=30
10 4.7388014 4.341415 4.2186241 4.5352438
20 8.3209924 7.220235 6.5948563 7.8889096
30 11.9230503 10.17751 9.3844144 12.1286796
40 13.757097 13.6982 12.0325382 14.001417
Sumber : Hasil Pengolahan Data
Dari tabel diatas dapat dilihat hasil pengolahan dari metode KNNI bahwa semakin besar missing data yang terjadi pada data produktivitas ubi kayu maka rata-rata nilai RMSE nya juga semakin besar pada setiap nilai K yang digunakan. Artinya bahwa semakin sedikit data yang hilang maka tingkat akurasinya pun semakin baik. Jika dilihat pada kolom K=10 diperoleh hasil rata-rata nilai RMSE pada missing data 10 persen yaitu 4,7388014; pada missing data 20 persen yaitu 8,3209924; pada missing data 30 persen yaitu 11,9230503; dan pada missing data 40 persen yaitu 13,757097; dan begitu seterusnya pada setiap nilai K yang digunakan. Semakin besar nilai K yang digunakan tidak menunjukkan rata-rata nilai RMSE yang semakin kecil. Nilai K dapat ditentukan oleh peneliti disesuaikan dengan banyaknya observasi yang diteliti.
6
Gambar 1. Rata-rata nilai RMSE pada setiap Persentase Missing Data dan Nilai K yang Digunakan dengan Metode KNNI
4. Kesimpulan
Berdasarkan penelitian yang telah dilakukan pada metode KNNI dapat diambil kesimpulan bahwa :
1. Semakin besar missing data yang terdapat pada data maka rata-rata nilai RMSE nya juga semakin besar
2. Semakin besar nilai K yang digunakan tidak menunjukkan rata-rata nilai RMSE yang semakin kecil.
DAFTAR PUSTAKA
[1] Alfarisi, A.R., Tjandrasa, H, dan Arieshanti, I. 2013. Perbandingan Performa antara Imputasi Metode Konvensional dan Imputasi dengan Algoritma Mutual Nearest Neighbor. Jurnal Teknik Pomits, 2. Surabaya : Institut Teknologi Sepuluh November.
[2] Andridge, A. dan Little, R.J.A. 2010. A Review of Hot Deck Imputation for Survey Non-response.NIH Public Access, 78, 40–64.
[3] Babich, G.A. dan Sibul, L.H. 1994. Weighted Parzen Windows for Pattern Classification. Technical Report. Applied Research Laboratory The Pennsylvania State University.
[4] Badan Pusat Statistik. 2012. Buku Pedoman Pengumpulan Data Tanaman Pangan. Jakarta : BPS.
7
[6] Chaimongkol, W. dan Suwattee, P. 2004. Weighted Nearest Neighbor and Regression Imputation. Working Paper. National Institute of Development Administration.
[7] Cover, T.M. dan Thomas, J.A. 2006. Elements of Information Theory, Second Edition. New York : John Wiley & Sons, Inc.
[8] Doquire, G. dan Verleysen, M. 2012. Feature Selection with Missing Data Using Mutual Information Estimators. Neurocomputing, 90, 3-11. Elsevier.
[9] Francois, D., Rossi, F., Wertz, V., dan Verleysen, M. 2007. Resampling Methods for Parameter-Free and Robust Feature Selection with Mutual Information.
Neurocomputing, 70, 1276-1288. Elsevier.
[10] Jerez, J.M., Molina, I, Laencina, P.J.G., Alba, E., dan Ribelles, N. 2010. Missing Data Imputation Using Statistical and Machine Learning Methods in a Real Breast Cancer Problem. Artificial Intelligence in Medicine, 50, 105-115. Elsevier.
[11] Kwak, N. dan Choi, C-H. 2002. Input Feature Selection by Mutual Information Based on Parzen Window. IEEE Transactions on Pattern Analysis and Machine Intelligence, 24, 1667-1671.
[12] Laencina, P.J.G., Gomez, J-L.S., Vidal, A.R.F., dan Verleysen, M. 2008. K-Nearest Neighbours Based on Mutual Information for Incomplete Data Classification.
ESANN’2008 Proceedings. European Symposium on Artificial Neural Networks-Advances in Computational Intelligence and Learning Bruges.
[13] Laencina, P.J.G., Gomez, J-L.S., Vidal, A.R.F., dan Verleysen, M. 2009. K Nearest Neighbours with Mutual Information for Simultaneous Classification and Missing Data Imputation. Neurocomputing, 72, 1483-1493. Elsevier.
[14] Little, R.J. dan Rubin, D.B. 1987. Statistical Analysis with Missing Data. New York: John Wiley & Sons, Inc.
[15] Liu, H. dan Zhang, S. 2012. Noisy Data Elimination Using Mutual K-Nearest Neighbor for Classification Mining. The Journal of System and Software, 85, 1067-1074. Elsevier.
[16] Lohr, S.L. 1999. Sampling : Design and Analysis. Pacific Grove,CA : Duxbury Press.
[17] Mawarsari, U. 2012. Imputasi Missing Data dengan K-Nearest Neighbor dan Algoritma Genetika (Studi Kasus pada Data Survei Industri Besar dan Sedang 2008). Tesis. Surabaya : Institut Sepuluh November.
[18] Tan, P.N., Steinbach, M., dan Kumar, V. 2006. Introduction to Data Mining (4th ed.). Boston : Pearson Addison Wesley.