IMPUTASI MISSING DATA DENGAN K-NEAREST NEIGHBOR DAN
ALGORITMA GENETIKA
Ucik Mawarsari1, Irhamah2 1
Mahasiswa Pascasarjana Jurusan Statistika, FMIPA-ITS, Surabaya 2
Jurusan Statistika, FMIPA-ITS, Surabaya
E-mail: 1 [email protected], 2 [email protected]
Abstract
Most large-scale surveys are subject to the presence of nonresponse, either in the form of units or items nonresponse. Nonresponse causes the data to be missing. Imputation is a method that can be used to deal with missing data. The purpose of this study is to compare K-Nearest Neighbor Imputation (KNNI) and hybrid KNNI-Genetic Algorithm (KNNI-GA). The hybrid method is using genetic algorithm for variable selection and variable weighting to optimize the KNNI accuracy. This study also compare KNNI and hybrid KNNI-GA with other imputation method, i.e hybrid Artificial Neural Network and Genetic Algorithm (ANN-GA). The imputation methods will be applied to estimate missing values in Large and Medium Manufacturing Industry Survey Data 2008. The best estimation results are measured by the minimum Root Mean Square Error (RMSE). The results show that hybrid KNNI-GA for variable weighting has good estimation ability on the dataset with smaller RMSE than KNNI and hybrid KNNI-GA for variable selection. The hybrid KNNI-GA for variable weighting can be used as an alternative method of hybrid ANN-GA, because generally it can produce small RMSE and faster running time.
Keywords : Imputation, KNNI, Genetic Algorithm Abstrak
Permasalahan yang sering muncul pada sebagian survei skala besar adalah adanya nonrespon, baik pada unit maupun item. Nonrespon merupakan salah satu penyebab
missing data. Untuk menangani missing data, salah satu cara yang dapat digunakan
adalah dengan melakukan imputasi. Tujuan dari penelitian ini adalah mengkaji metode
K-Nearest Neighbor Imputation (KNNI) dan metode hibrida KNNI-Algoritma
Genetika (KNNI-GA) yang digunakan untuk mengestimasi nilai missing. Pada metode hibrida, algoritma genetika digunakan untuk melakukan seleksi dan pembobotan variabel untuk meningkatkan akurasi KNNI. Penelitian ini juga membandingkan hasil imputasi dari metode KNNI dan hibrida KNNI-GA dengan metode imputasi lain, yaitu hibrida Artificial Neural Network dan Algoritma Genetika (ANN-GA). Data yang digunakan adalah data Survei Industri Besar dan Sedang 2008. Hasil estimasi terbaik diukur dengan menggunakan nilai Root Mean Square Error (RMSE) minimum. Imputasi missing data dengan metode hibrida KNNI-GA untuk
pembobotan variabel memberikan hasil yang lebih baik daripada metode KNNI dan hibrida KNNI-GA untuk seleksi variabel karena menghasilkan RMSE yang lebih kecil. Metode hibrida KNNI-GA untuk pembobotan variabel dapat digunakan sebagai alternatif metode hibrida ANN-GA karena secara umum dapat menghasilkan nilai imputasi dengan RMSE yang kecil dan waktu running program yang jauh lebih cepat.
Kata kunci : Imputasi, KNNI, Algoritma Genetika 1. Pendahuluan
Permasalahan yang sering muncul pada sebagian survei skala besar adalah adanya nonrespon, baik pada unit maupun item. Nonrespon merupakan salah satu penyebab missing
data. Nonrespon pada unit terjadi ketika responden sebuah survei menolak atau tidak
menjawab sama sekali pertanyaan-pertanyaan di dalam survei, sedangkan nonrespon pada item terjadi ketika responden tidak menjawab hanya sebagian dari pertanyaan survei. Nonrespon dapat mengakibatkan estimasi yang bias dan standar error yang semakin besar sehingga menyebabkan tidak efisiennya penggunaan data [14].
Salah satu metode yang sering digunakan pada masalah imputasi adalah metode
-Nearest Neighbor Imputation (KNNI). KNNI merupakan salah satu metode imputasi real-donor [3]. Metode ini merupakan metode yang sederhana dan fleksibel karena dapat
digunakan baik pada variabel dengan data kontinu maupun data diskrit [2]. Pada penelitian oleh Batista dan Monard [2] dilakukan analisa penggunaan K-Nearest Neighbor (KNN) sebagai sebuah metode imputasi dengan melakukan simulasi missing data sebanyak 10 hingga 60 persen dari total data. Penelitiannya menunjukkan bahwa metode imputasi KNN memberikan hasil yang sangat baik, bahkan pada saat data memiliki jumlah missing yang besar. Kemudian pada Jerez dan Molina [6], dalam penelitiannya membandingkan beberapa metode imputasi dan hasilnya menunjukkan KNNI lebih unggul diantara metode imputasi berbasis machine learning lain yang diiteliti.
Dalam perkembangannya, optimasi sering dilakukan pada sebuah metode untuk memperoleh hasil yang lebih optimal. Optimasi pada metode KNN dilakukan oleh Siedlecky dan Sklansky [11] dengan mengkombinasikan KNN dengan Algoritma Genetika untuk melakukan seleksi pada variabel yang digunakan pada klasifikasi. Kemudian Analoui dan Amiri [1] mengkombinasikan Algoritma Genetika dan KNN untuk memberikan bobot yang optimal pada setiap variabel yang digunakan untuk meningkatkan akurasi klasifikasi KNN.
Permasalahan missing data akibat nonrespon juga ditemui pada data Survei Industri
Besar dan Sedang (IBS) yang dilaksanakan oleh Badan Pusat Statistik (BPS). Survei IBS merupakan salah satu survei yang memiliki tingkat nonrespon yang cukup tinggi. Dari tahun 2000 sampai 2008 tingkat nonrespon pada unit semakin meningkat, yaitu dari 23,86 persen menjadi 27,20 persen. Dari perusahaan yang respon, ternyata masih terdapat perusahaan yang tidak mengisi kuesioner dengan lengkap. Salah satunya adalah adanya missing pada isian nilai bahan baku dan penolong yang digunakan. Kasus ini terjadi khususnya pada perusahaan industri yang melakukan jasa industri. Pada survei tahun 2008, di Provinsi DKI Jakarta perusahaan yang respon adalah sebesar 73,09 persen. Dari perusahaan yang respon tersebut, ternyata 10 persen terdapat missing data pada variabel bahan baku dan penolong.
Penelitian mengenai imputasi missing data pada Survei IBS telah beberapa kali
dilakukan, diantaranya oleh Wardani [13] yang membandingkan metode Artificial Neural
Network (ANN) dan hibrida ANN dan Algoritma Genetika (ANN-GA). Pada ANN digunakan
arsitektur 1 hidden layer dengan jumlah neuron maksimal sebanyak 8 neuron. Fungsi aktivasi yang digunakan adalah sigmoid logistic pada hidden layer dan identitas pada output layer. Hasilnya, kedua metode tersebut merujuk pada arsitektur yang sama yaitu (3-8-1), namun imputasi dengan metode ANN-GA menghasilkan nilai Mean Square Error (MSE) yang lebih kecil dan waktu running program yang lebih cepat daripada metode ANN.
Seperti yang telah disebutkan oleh Batista dan Monard [2], KNN dapat digunakan pada variabel dengan data kontinu dan data kategorik. Klasifikasi merupakan penerapan metode KNN pada data kategorik. Pada permasalahan imputasi, KNN disebut juga dengan KNNI. Berdasarkan uraian di atas, penelitian ini akan menerapkan metode KNNI dan hibrida KNNI-Algoritma Genetika (KNNI-GA) pada data kontinu yaitu untuk imputasi missing data Survei IBS, dimana algoritma genetika digunakan untuk seleksi variabel dan pembobotan variabel. Kemudian membandingkan hasil imputasi dari metode KNNI dan hibrida KNNI-GA dengan metode imputasi lain, yaitu hibrida ANN-GA yang merupakan metode imputasi
missing data Survei IBS pada penelitian sebelumnya. 2. Metode
Pada metode hibrida KNNI-GA, terdapat dua alternatif metode yang akan dilakukan. Metode pertama berdasarkan Siedlecky dan Sklansky [11], yaitu algoritma genetika digunakan untuk seleksi variabel yang digunakan dalam menentukan observasi terdekat pada KNNI. Sedangkan metode kedua berdasarkan Analoui dan Amiri [1], yaitu algoritma genetika digunakan untuk mencari bobot optimal dari setiap variabel yang digunakan dalam menentukan observasi terdekat pada KNNI. Langkah pertama dalam metode hibrida KNNI-GA adalah kodifikasi, yaitu:
a. Metode pertama : KNNI-GA untuk seleksi variabel.
Permasalahan yang dihadapi melibatkan sebanyak 5 variabel. Maka sebuah vektor biner berukuran 5 1 yang berunsurkan nilai 1 dan 0 dapat diartikan sebagai vektor indikator yang menunjukkan variabel-variabel yang diikutsertakan, kode 1 menunjukkan keikutsertaan variabel. Sebagai contoh kromosom individu yang terbentuk adalah:
[1 1 0 1 1]
String tersebut akan dikodekan ke dalam metode KNNI menjadi, variabel yang berkontribusi dalam proses imputasi dengan KNNI adalah variabel pertama, kedua, keempat, dan kelima. Variabel ketiga tidak diikutsertakan karena berkode 0.
b. Metode kedua : KNNI-GA untuk pembobotan variabel.
Permasalahan yang dihadapi melibatkan sebanyak 5 variabel. Bobot tiap variabel dinyatakan dalam 5 gen biner, maka akan terbentuk sebuah vektor berukuran 5 5 yang berunsurkan bilangan biner. Karena bobot variabel yang akan dibentuk bernilai desimal, maka bilangan biner tersebut harus ditransformasi menjadi bilangan desimal sebelum digunakan. Setelah ditransformasi, maka semua nilai bobot desimal tersebut dinormalisasi ke dalam interval [0,1] dengan rumus Li, Xie, dan Goh [7]:
(4)
dimana adalah konversi desimal dari bobot biner variabel ke-j, dan adalah bobot
variabel ke-j. Sebagai contoh kromosom individu yang terbentuk adalah: [10001 00110 01100 10101 01011]
Kromosom tersebut akan dikodekan ke dalam metode KNNI menjadi, bobot biner untuk
variabel pertama adalah 10001 , nilai desimalnya adalah 17 , sehingga
sesuai persamaan (4) bobot variabel pertama adalah 17 31⁄ 0,5484. Langkah yang
sama dilakukan untuk variabel kedua, ketiga, keempat dan kelima.
Untuk mencari nilai optimum pada metode hibrida KNNI-GA, nilai direpresentasikan dalam 4 gen biner. Sebagai contoh kromosom individu yang terbentuk adalah: [1 0 1 0]. String biner tersebut dikodekan ke dalam metode KNNI menjadi, nilai
yang digunakan adalah 1010 , nilai desimalnya adalah 10 , sehingga nilai
yang digunakan pada KNNI adalah 10. Dengan demikian, 4 string biner pertama dalam
algortima genetika merepresentasikan nilai , dan string biner selanjutnya merepresentasikan kromosom untuk seleksi variabel atau pembobotan variabel. Langkah-langkah dalam algoritma genetika selanjutnya dapat diuraikan sebagai berikut:
1. Membangkitkan secara random sebanyak 50 individu dalam populasi.
2. Menghitung nilai fitness untuk setiap individu dalam populasi sesuai dengan persamaan (5). Dengan RMSE diperoleh dari proses imputasi dengan KNNI.
, dimana 0 1 (5)
3. Membentuk individu baru dengan melakukan seleksi roullete wheel, crossover satu titik
dengan probabilitas ( ) sebesar 0.8, dan mutasi dengan probabilitas ( ) sebesar 0.2.
Kemudian melakukan elitism dan replacement sehingga diperoleh populasi baru.
4. Memilih individu terbaik dari populasi yang merupakan solusi terbaik setelah kriteria yang ditentukan terpenuhi, yaitu ketika mencapai generasi maksimum 50 generasi atau selisih nilai fitness terbaik dalam 5 generasi terakhir tidak lebih dari 1 10 .
Pada penelitian ini, sumber data yang digunakan diperoleh dari hasil Survei IBS tahun 2008 yang diselenggarakan oleh Badan Pusat Statistik. Data yang digunakan meliputi data perusahaan industri sedang Provinsi DKI Jakarta pada KBLI 18 yaitu industri pakaian jadi. Pada tahun 2008, terdapat sebanyak 334 perusahaan yang mengembalikan kuesioner (respon), yang terdiri 267 perusahaan industri sedang dan 67 perusahaan industri besar. Dari 267 perusahaan industri sedang, sepuluh persen diantaranya tidak mengisi data secara lengkap, yaitu terdapat missing pada isian nilai bahan baku dan penolong. Variabel yang digunakan adalah nilai pendapatan ( ), nilai upah/gaji pekerja ( ), nilai bahan bakar dan pelumas ( ), nilai tenaga listrik yang digunakan ( ), nilai pengeluaran lain ( ), dan nilai bahan baku dan
penolong ( ).
Sebelum menerapkan metode imputasi pada data Survei IBS, terlebih dahulu dilakukan studi simulasi untuk mengetahui kinerja dari masing-masing metode, yaitu untuk melihat konsistensi hasil dari setiap metode apabila diterapkan pada data dengan pola yang berbeda. Pembangkitan data simulasi disesuaikan dengan pola dari data Survei IBS yang ada. Data simulasi dibangkitkan dari distribusi normal multivariat sebanyak 100 observasi yang terdiri dari 6 variabel, yaitu , , , , dan dengan aturan sebagai berikut:
a. Data Simulasi 1: variabel dan berkorelasi dengan variabel .
b. Data Simulasi 2: variabel , , , , berkorelasi dengan variabel .
Tahapan penelitian pada data simulasi dan data Survei IBS adalah sama, yaitu: 1. Menggunakan dataset lengkap (data yang tidak memuat nilai missing).
2. Menghilangkan nilai pada variabel X secara random untuk mendapatkan nilai missing sebanyak 10 persen dari jumlah total data dengan asumsi MCAR. Banyaknya nilai pada
variabel X yang dihilangkan adalah sebesar 10 persen dari jumlah total data karena
disesuaikan dengan permasalahan pada studi kasus yaitu terdapat missing data pada variabel nilai bahan baku dan penolong (X ) sebesar 10 persen.
3. Melakukan imputasi missing data dengan menggunakan metode KNNI, hibrida KNNI-GA untuk seleksi dan pembobotan variabel, dan hibrida ANN-GA sebanyak 5 kali percobaan. Berdasarkan penelitian yang dilakukan oleh Hartono (2011), percobaan dilakukan sebanyak 5 kali bertujuan untuk memperoleh rata-rata nilai RMSE dan waktu running dari masing-masing metode. Hal ini dilakukan karena pada metode hibrida KNNI-GA untuk pembobotan variabel dan metode hibrida ANN-GA diperoleh hasil yang tidak sama pada setiap percobaan.
4. Menghitung rata-rata nilai RMSE dan waktu running program yang dihasilkan dari masing-masing metode. Metode yang menghasilkan rata-rata nilai RMSE atau waktu running program yang lebih kecil adalah metode yang lebih baik.
3. Hasil dan Pembahasan Imputasi Missing Data pada Data Simulasi
Data Simulasi 1
Simulasi pertama dilakukan dengan membangkitkan data berdistribusi normal multivariat sebanyak 100 observasi yang terdiri dari 6 variabel, dimana dan berkorelasi dengan . Besarnya nilai rata-rata pada setiap variabel disesuaikan dengan data Survei IBS
yang digunakan sebagai studi kasus. Secara berturut-turut variabel , , , , dan
mempunyai rata-rata 1.000, 300, 20, 25, 30 dan 500 dengan matrik varians-kovarian ( ) sebagai berikut: 30.000 0 0 0 0 10.000 0 2.000 0 0 0 0 0 0 30 0 0 300 0 0 0 75 0 0 0 0 0 0 100 0 10.000 0 300 0 0 8.000
Matrik korelasi dari data yang dibangkitan dengan menggunakan rata-rata dan varian-kovarian di atas adalah: 1 0,0447 0,0889 0,1252 0,0978 0,6888 0,0447 1 0,1293 0,0597 0,1619 0,1827 0,0889 0,1293 1 0,0910 0,0371 0,6275 0,1252 0,0597 0,0910 1 0,0766 0,1318 0,0978 0,1619 0,0371 0,0766 1 0,0336 0,6888 0,1827 0,6275 0,1318 0,0336 1
Dari 100 observasi pada data simulasi 1, nilai pada variabel dihilangkan sebanyak 10 persen dari jumlah total data. Hasil imputasi missing data pada data simulasi 1 dapat dilihat pada Tabel 1. Dari 5 kali percobaan yang dilakukan, metode KNNI dan hibrida KNNI-GA
untuk seleksi variabel memberikan hasil terbaik yang sama, yaitu pada nilai 8 dan
kombinasi variabel 1 0 1 0 0 . Hasil tersebut menunjukkan bahwa variabel dan adalah variabel-variabel yang berkontribusi dalam proses imputasi dengan KNNI. Nilai RMSE yang dihasilkan adalah 51,6616. Rata-rata waktu running program dengan metode KNNI adalah 0,9551 detik, sedangkan dengan metode hibrida KNNI-GA untuk seleksi variabel adalah 1,0981 detik.
Tabel 1. Hasil Imputasi Missing Data pada Data Simulasi 1 dari 5 Kali Percobaan
Metode Hasil Terbaik Rata-rata RMSE Rata-rata Waktu Running (detik) Seleksi/
Bobot Variabel Nilai RMSE
KNNI [1 0 1 0 0] 8 51,6616 51,6616 0,9551
KNNI-GA Seleksi Variabel [1 0 1 0 0] 8 51,6616 51,6616 1,0981 KNNI-GA Bobot Variabel [0,1290 0,0323
0,6129 0,1935 0,4194]
3 29,1031 31,5285 2,9265
ANN-GA 25,3905 30,7505 1.215,1973
Sumber: Hasil Pengolahan Data Simulasi 1
Pada data simulasi 1, variabel memiliki korelasi yang kuat dengan variabel dan . Dengan demikian, hasil seleksi variabel yang diperoleh dengan metode KNNI maupun hibrida KNNI-GA dapat mengidentifikasi variabel yang berkorelasi dengan baik.
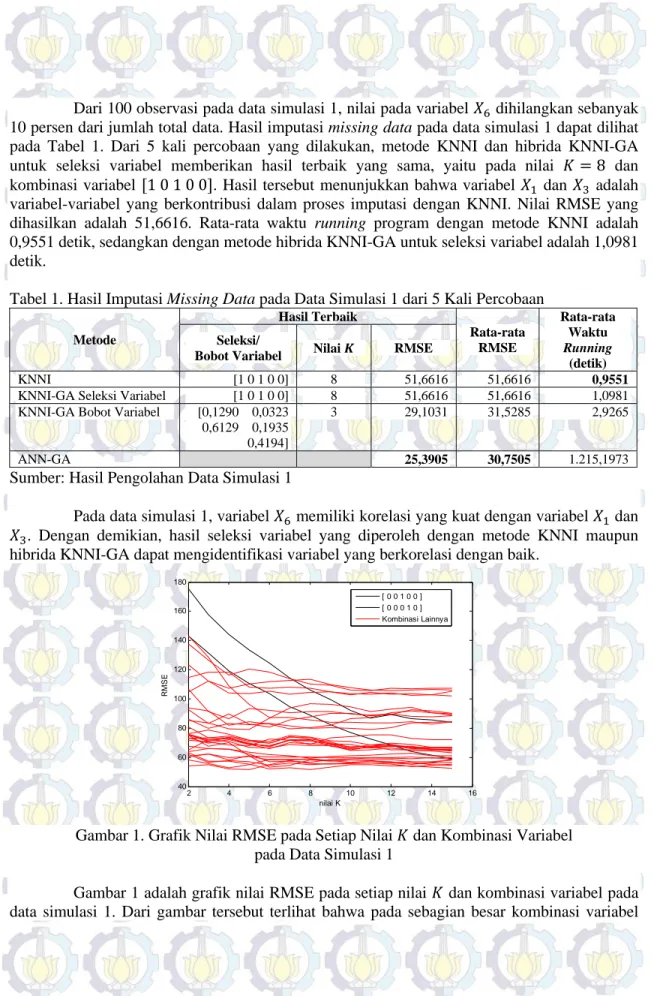
Gambar 1. Grafik Nilai RMSE pada Setiap Nilai dan Kombinasi Variabel pada Data Simulasi 1
Gambar 1 adalah grafik nilai RMSE pada setiap nilai dan kombinasi variabel pada data simulasi 1. Dari gambar tersebut terlihat bahwa pada sebagian besar kombinasi variabel
2 4 6 8 10 12 14 16 40 60 80 100 120 140 160 180 nilai K RM S E [ 0 0 1 0 0 ] [ 0 0 0 1 0 ] Kombinasi Lainnya
(warna merah), nilai RMSE yang dihasilkan cenderung sama pada semua nilai . Namun pada kombinasi variabel tertentu (warna hitam), yaitu 0 0 1 0 0 dan 0 0 0 1 0 , menunjukkan bahwa semakin besar nilai dapat menghasilkan nilai RMSE yang lebih kecil.
Pada metode hibrida KNNI-GA untuk pembobotan variabel, dari 5 kali percobaan yang dilakukan diperoleh nilai rata-rata RMSE yang jauh lebih kecil daripada metode KNNI dan hibrida KNNI-GA untuk seleksi variabel, yaitu sebesar 31,5285. Nilai RMSE terkecil yaitu sebesar 29,1031 dihasilkan pada nilai 3 dengan bobot variabel [0,1290 0,0323 0,6129
0,1935 0,4194]. Hasil tersebut menunjukkan bahwa bobot untuk variabel dalam proses
imputasi dengan KNNI adalah sebesar 0,1290, kemudian bobot untuk variabel adalah
sebesar 0,0323, variabel sebesar 0,6129, variabel sebesar 0,1935, dan variabel sebesar 0,4194. Rata-rata waktu running program dengan metode hibrida KNNI-GA untuk pembobotan variabel adalah 2,9265 detik.
Pada metode hibrida ANN-GA, dari 5 kali percobaan yang dilakukan, diperoleh nilai rata-rata RMSE sebesar 30,7505. Sedangkan hasil RMSE terbaik yang diperoleh adalah 25,3905. Pada data simulasi 1, metode hibrida ANN-GA dapat menghasilkan nilai RMSE yang lebih kecil daripada metode imputasi KNNI dan hibrida KNNI-GA untuk seleksi maupun pembobotan variabel, namun metode ini memiliki rata-rata waktu running program yang lebih besar yaitu 1.215,1973 detik
Data Simulasi 2
Simulasi kedua dilakukan dengan membangkitkan data berdistribusi normal
multivariat sebanyak 100 observasi yang terdiri dari 6 variabel, dimana , , , dan
berkorelasi dengan . Besarnya nilai rata-rata pada setiap variabel disesuaikan dengan data Survei IBS yang digunakan sebagai studi kasus. Secara berturut-turut, variabel
, , , , dan mempunyai rata-rata 1.000, 300, 20, 25, 30 dan 500 dengan matrik
varian-kovarian ( ) sebagai berikut:
23.500 900 150 300 450 5.400 900 1.800 150 300 450 1.800 150 150 30 50 75 160 300 300 50 115 150 340 450 450 75 150 250 525 5.400 1.800 160 340 525 3.050
Matrik korelasi dari data yang dibangkitan dengan menggunakan rata-rata dan varian-kovarian di atas adalah: 1 0,2404 0,0946 0,0867 0,1855 0,6399 0,2404 1 0,6349 0,6741 0,6965 0,8271 0,0946 0,6349 1 0,8527 0,8468 0,5218 0,0867 0,6741 0,8527 1 0,8854 0,5726 0,1855 0,6965 0,8468 0,8854 1 0,6561 0,6399 0,8271 0,5218 0,5726 0,6561 1
Dari data tersebut, nilai pada variabel dihilangkan sebanyak 10 persen dari jumlah total data. Hasil imputasi missing data pada data simulasi 2 dapat dilihat pada Tabel 2. Dari 5 kali percobaan yang dilakukan, metode KNNI dan hibrida KNNI-GA untuk seleksi variabel
memberikan hasil terbaik yang sama, yaitu pada nilai 10 dan kombinasi variabel
yang berkontribusi dalam proses imputasi dengan KNNI. Nilai RMSE yang dihasilkan adalah 14,1711. Rata-rata waktu running program dengan metode KNNI adalah 0,9509 detik, sedangkan dengan metode hibrida KNNI-GA untuk seleksi variabel adalah 1,0987 detik.
Tabel 2. Hasil Imputasi Missing Data pada Data Simulasi 2 dari 5 Kali Percobaan
Metode Hasil Terbaik Rata-rata RMSE Rata-rata Waktu Running (detik) Seleksi/
Bobot Variabel Nilai RMSE
KNNI [0 1 0 0 1] 10 14,1711 14,1711 0,9509
KNNI-GA Seleksi Variabel [0 1 0 0 1] 10 14,1711 14,1711 1,0987 KNNI-GA Bobot Variabel [0,0323 0,4839
0,0968 0,4194 0,5161]
7 8,0263 8,9048 2,7230
ANN-GA 10,7611 11,8223 1.890,6804
Sumber: Hasil Pengolahan Data Simulasi 2
Pada data simulasi 2, variabel memiliki korelasi yang kuat dengan variabel
, , , dan . Selain itu, terdapat multikolinearitas antara variabel , , dan .
Adanya multikolinearitas antar variabel menyebabkan hasil seleksi variabel optimal yang diperoleh dengan metode KNNI maupun hibrida KNNI-GA tidak mengikutsertakan semua variabel dalam proses imputasi.
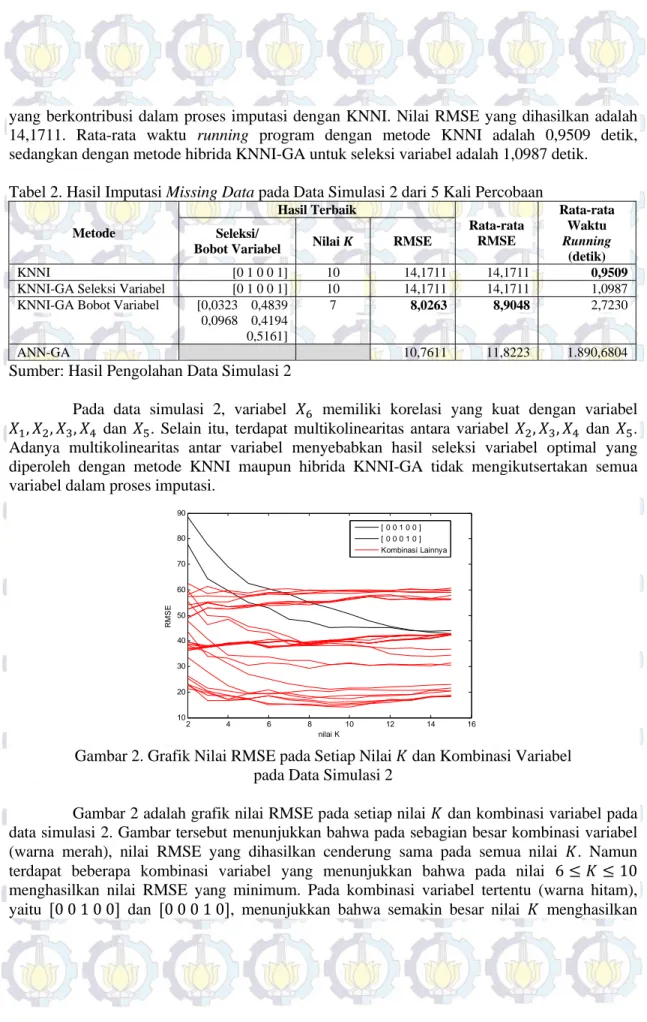
Gambar 2. Grafik Nilai RMSE pada Setiap Nilai dan Kombinasi Variabel pada Data Simulasi 2
Gambar 2 adalah grafik nilai RMSE pada setiap nilai dan kombinasi variabel pada data simulasi 2. Gambar tersebut menunjukkan bahwa pada sebagian besar kombinasi variabel (warna merah), nilai RMSE yang dihasilkan cenderung sama pada semua nilai . Namun
terdapat beberapa kombinasi variabel yang menunjukkan bahwa pada nilai 6 10
menghasilkan nilai RMSE yang minimum. Pada kombinasi variabel tertentu (warna hitam), yaitu 0 0 1 0 0 dan 0 0 0 1 0 , menunjukkan bahwa semakin besar nilai menghasilkan
2 4 6 8 10 12 14 16 10 20 30 40 50 60 70 80 90 nilai K RM S E [ 0 0 1 0 0 ] [ 0 0 0 1 0 ] Kombinasi Lainnya
nilai RMSE yang lebih kecil.
Pada metode hibrida KNNI-GA untuk pembobotan variabel, dari 5 kali percobaan yang dilakukan diperoleh nilai rata-rata RMSE lebih kecil daripada metode KNNI dan hibrida KNNI-GA untuk seleksi variabel, yaitu 8,9048. Nilai RMSE terkecil yaitu 8,0263 dihasilkan
pada nilai 7 dengan bobot variabel [0,0323 0,4839 0,0968 0,4194 0,5161]. Hasil
tersebut menunjukkan bahwa bobot untuk variabel dalam proses imputasi dengan KNNI
adalah sebesar 0,0323, kemudian bobot untuk variabel adalah sebesar 0,4839, variabel sebesar 0,0968, variabel sebesar 0,4194, dan variabel sebesar 0,5161. Rata-rata waktu
running program dengan metode hibrida KNNI-GA untuk pembobotan variabel adalah 2,7230
detik.
Pada metode hibrida ANN-GA, dari 5 kali percobaan yang dilakukan, diperoleh nilai rata-rata RMSE lebih besar daripada metode imputasi hibrida KNNI-GA untuk pembobotan variabel, yaitu 11,8223. Sedangkan hasil RMSE terbaik yang diperoleh adalah 10,7611. Rata-rata waktu running program pada metode hibrida ANN-GA adalah 1.890,6804 detik
Imputasi Missing Data pada Data Survei IBS
Data yang digunakan adalah data perusahaan industri sedang KBLI 18 dari hasil Survei IBS Provinsi DKI Jakarta 2008, dimana imputasi missing data dilakukan pada variabel nilai bahan baku dan penolong. Variabel yang digunakan adalah nilai pendapatan ( ), nilai upah/gaji pekerja ( ), nilai bahan bakar dan pelumas ( ), nilai tenaga listrik yang digunakan ( ), nilai pengeluaran lain ( ), dan nilai bahan baku dan penolong ( ).
Untuk mengetahui kuat atau lemahnya hubungan atau korelasi antar variabel yang digunakan dapat dilihat pada matrik korelasi sebagai berikut:
1 0,3892 0,4302 0,2634 0,8307 0,9723 0,3892 1 0,3358 0,4020 0,1385 0,3563 0,4302 0,3358 1 0,4946 0,3369 0,4130 0,2634 0,4020 0,4946 1 0,1485 0,2685 0,8307 0,1385 0,3369 0,1485 1 0,7755 0,9723 0,3563 0,4130 0,2685 0,7755 1
Dari matrik korelasi tersebut dapat diketahui bahwa terdapat korelasi kuat antara
variabel nilai bahan baku dan penolong dengan nilai pendapatan ( 0,9723) dan nilai
pengeluaran lain ( 0,7755). Selain itu antara variabel nilai pendapatan dengan nilai
pengeluaran lain juga memiliki korelasi yang kuat ( 0,8307), hal ini mengindikasikan
adanya multikolinearitas antara variabel nilai pendapatan dengan nilai pengeluaran lain. Dilihat dari matrik korelasi, data yang digunakan sebagai studi kasus memiliki karakteristik yang mirip dengan data simulasi 2.
Seperti pada data simulasi, data perusahaan industri sedang KBLI 18 Provinsi DKI Jakarta 2008 yang terdiri dari 243 observasi (dataset lengkap), nilai pada variabel atau nilai bahan baku dan penolong dihilangkan sebanyak 10 persen dari jumlah total data. Langkah selanjutnya adalah melakukan imputasi missing data dengan menggunakan metode KNNI, hibrida KNNI-GA untuk seleksi dan pembobotan variabel, dan hibrida ANN-GA sebanyak 5 kali percobaan, kemudian menghitung rata-rata nilai RMSE dan waktu running program yang dihasilkan dari masing-masing metode tersebut.
dengan nilai RMSE sebesar 415,4998. Nilai tersebut dihasilkan pada 2 dan kombinasi variabel 1 1 1 0 1 . Hasil tersebut menunjukkan bahwa variabel (nilai pendapatan),
(nilai upah/gaji pekerja), (nilai bahan bakar) dan (nilai pengeluaran lain) adalah
variabel-variabel yang berkontribusi dalam proses imputasi missing data pada variabel (nilai bahan baku dan penolong). Rata-rata waktu running program pada metode KNNI adalah 5,3252 detik.
Pada metode hibrida KNNI GA untuk seleksi variabel, dari 5 kali percobaan yang dilakukan diperoleh rata-rata nilai RMSE yang sama dengan metode KNNI, yaitu 415,4998.
Nilai dan kombinasi variabel yang dihasilkan adalah 7 dan kombinasi variabel
1 1 1 0 1 . Rata-rata waktu running program yang diperlukan pada metode hibrida KNNI-GA untuk seleksi variabel adalah 5,3557 detik.
Pada data Survei IBS, variabel nilai bahan baku dan penolong ( ) memiliki korelasi yang kuat dengan variabel nilai pendapatan ( ) dan nilai pengeluaran lain ( ). Selain itu, terdapat multikolinearitas antara variabel nilai pendapatan ( ) dan nilai pengeluaran lain ( ). Adanya multikolinearitas menyebabkan hasil seleksi variabel yang diperoleh dengan metode
KNNI maupun hibrida KNNI-GA mengikutsertakan variabel selain dan yang memiliki
korelasi yang lebih kecil dengan .
Gambar 3 adalah grafik nilai pada semua kombinasi variabel pada data Survei IBS. Pada gambar tersebut terlihat bahwa nilai RMSE yang dihasilkan terbagi ke dalam dua kelompok kombinasi variabel. Kelompok kombinasi variabel bagian atas (warna hitam), diantaranya adalah 0 1 0 0 0 , 0 0 1 0 0 , 0 1 1 0 0 , dan seterusnya, memiliki nilai RMSE yang lebih besar daripada kelompok kombinasi variabel bagian bawah (warna merah). Pada kelompok bagian bawah, pada beberapa kombinasi variabel, nilai minimum RMSE diperoleh
pada nilai 2,6,7, dan 8. Kemudian grafik nilai RMSE cenderung naik pada nilai lebih
besar dari 8.
Gambar 3. Grafik Nilai RMSE pada Setiap Nilai dan Kombinasi Variabel pada Data Survei IBS
Pada metode hibrida KNNI-GA untuk pembobotan variabel diperoleh nilai rata-rata RMSE yang lebih kecil daripada metode KNNI dan hibrida KNNI-GA untuk seleksi variabel,
2 4 6 8 10 12 14 16 0 500 1000 1500 2000 2500 nilai K RM S E [ 0 1 0 0 0 ] [ 0 0 1 0 0 ] [ 0 1 1 0 0 ] [ 0 0 0 1 0 ] [ 0 1 0 1 0 ] [ 0 1 1 1 0 ] [ 0 0 0 0 1 ] [ 0 1 0 0 1 ] [ 0 0 1 0 1 ] [ 0 1 1 0 1 ] [ 0 0 0 1 1 ] [ 0 1 0 1 1 ] [ 0 0 1 1 1 ] [ 0 1 1 1 1 ] Kombinasi Lainnya
yaitu 314,7428. Dari 5 kali percobaan yang dilakukan, hasil terbaik diperoleh pada nilai 2 dengan bobot variabel [0,0968 0,2581 0,7097 0,6129 0,7742]. Hasil tersebut menunjukkan
bahwa bobot untuk variabel dalam proses imputasi dengan KNNI adalah sebesar 0,0968,
kemudian bobot untuk variabel adalah sebesar 0,2581, variabel sebesar 0,7097, variabel
sebesar 0,6129, dan variabel sebesar 0,7742. Nilai RMSE yang dihasilkan adalah
303,3308. Rata-rata waktu running program dengan metode hibrida KNNI-GA untuk pembobotan variabel adalah 10,1921 detik.
Pada metode hibrida ANN-GA, dari 5 kali percobaan yang dilakukan, diperoleh nilai rata-rata RMSE yang lebih besar daripada metode imputasi hibrida KNNI-GA untuk pembobotan variabel, yaitu 357,2930 dengan rata-rata waktu running program selama 1.272,3939 detik. Hasil RMSE terbaik yang diperoleh adalah 330,3085. Selain memiliki waktu
running program yang lebih besar daripada metode imputasi sebelumnya, imputasi pada data
Survei IBS dengan metode hibrida ANN-GA menghasilkan nilai imputasi yang bernilai negatif. Hal ini disebabkan oleh karena fungsi aktivasi pada hidden layer yang digunakan pada hibrida ANN-GA berbasis fungsi non linier, yaitu sigmoid logistic, sehingga menyebabkan estimasi yang kurang tepat ketika diterapkan pada data studi kasus yang memiliki pola hubungan linier.
Secara ringkas hasil imputasi missing data dengan menggunakan metode KNNI, hibrida KNNI-GA untuk seleksi dan pembobotan variabel, dan hibrida ANN-GA pada data Survei IBS dapat dilihat pada Tabel 3.
Tabel 3. Hasil Imputasi Missing Data pada Data Perusahaan Industri Sedang KBLI 18 Provinsi DKI Jakarta 2008
Metode Hasil Terbaik Rata-rata RMSE Rata-rata Waktu Running (detik) Seleksi/
Bobot Variabel Nilai RMSE
KNNI [1 1 1 0 1] 7 415,4998 415,4998 5,3252
KNNI-GA Seleksi Variabel [1 1 1 0 1] 7 415,4998 415,4998 5,3557 KNNI-GA Bobot Variabel [0,0968 0,2581
0,7097 0,6129 0,7742]
2 303,3308 314,7428 10,1921
ANN-GA 330,3085 357,2930 1.272,3939
Sumber: Hasil Pengolahan Data Survei Industri Besar dan Sedang
4. Kesimpulan
Berdasarkan hasil penelitian yang telah dilakukan, dapat diambil beberapa kesimpulan sebagai berikut:
1. Imputasi missing data dengan metode KNNI memiliki rata-rata waktu running program yang cepat.
2. Imputasi missing data dengan metode hibrida KNNI-GA untuk pembobotan variabel menghasilkan nilai RMSE yang lebih kecil daripada metode hibrida KNNI-GA untuk seleksi variabel. Akan tetapi dilihat dari rata-rata waktu running program, metode hibrida
KNNI-GA untuk seleksi variabel lebih efisien karena memiliki waktu running program yang lebih cepat.
3. Metode KNNI dan hibrida KNNI-GA untuk seleksi variabel menghasilkan rata-rata nilai RMSE yang sama karena variabel yang terseleksi sama.
4. Metode hibrida KNNI-GA untuk pembobotan variabel dapat digunakan sebagai alternatif metode hibrida ANN-GA, karena secara umum dapat menghasilkan nilai imputasi dengan nilai RMSE yang kecil dan waktu running program yang lebih cepat.
Daftar Pustaka
[1] Analoui, M. dan Amiri, M.F., 2006, "Feature Reduction of Nearest Neigbor Classifier using Genetic Algorithm", World Academy of Science, Engineering and Technology 17, 36-39.
[2] Batista G. dan Monard M.C., 2003, A Study of K-Nearest Neighbour as an Imputation
Method, Working Paper, University Sao Paulo, Brazil.
[3] Chaimongkol, W. dan Suwattee, P., 2004, Weighted Nearest Neighbor and Regression
Imputation, Working Paper, National Institute of Development Administration.
[4] Engelbrecht, A.P., 2002, Computational Intelligence: An Introduction, John Wiley & Sons, Inc, England.
[5] Gen, M. dan Cheng, R., 1999, Genetic Algorithm and Optimization Engineering, John Wiley & Sons, Inc, Japan.
[6] Jerez, J.M., dan Molina, I., 2010, "Missing Data Imputation Using Statistical And Machine Learning Methods In A Real Breast Cancer Problem", Artificial Intelligence in
Medicine 50, 105-115.
[7] Li, Y., Xie, M., dan Goh, T., 2009, "A Study of Project Selection and Feature Weighting for Analogy Based Software Cost Estimation", The Journal of System and Software 82, 241-252.
[8] Little, R.J., dan Rubin, D.B., 1987, Statistical Analysis with Missing Data, John Wiley & Sons, Inc, New York.
[9] Meesad, P. dan Hengpraprohm, K., 2008, "Combination of KNN-Based Feature Selection and KNN Based Missing Value Imputation of Microarray Data", International
Conference on Innovative Computing Information and Control.
[10] Saekhoo, J. 2008. Simple Linear Regression Analysis for Incomplete Longitudinal Data, Disertasi Ph.D, National Institute of Development Administration.
[11] Siedlecki,W. dan Sklansky, J., 1989, "A Note on Genetic Algorithms for Large-Scale Feature Selection", Pattern Recognition Letters 10, 335-347.
[12] Wasito, I. dan Mirkin, B., 2005, "Nearest Neighbor Approach in the Least Square Data Imputation Algorithms", Information Sciences 169, 1-25.
[13] Wardani, S., 2011, Metode Jaringan Syaraf Tiruan-Algoritma Genetika untuk Imputasi, Tesis Magister, Institut Teknologi Sepuluh Nopember, Surabaya.
[14] Zarnoch, S.J., Cordell, H.K., Bets, C., dan Bergstrom, J.C., 2010, Multiple Imputation: An
Application to Income Nonresponse in the National Survey on Recreation and the Environment, Research Paper, United States Department of Agriculture.