1
BAB I PENDAHULUAN
A. Latar Belakang
Kanker adalah pertumbuhan yang tidak normal dari sel-sel jaringan tubuh dan bersifat ganas. Sel-sel tersebut dapat tumbuh lebih lanjut serta menyebar ke bagian tubuh lainnya serta dapat menyebabkan kematian. Sel kanker tidak mati setelah usianya cukup melainkan tumbuh terus dan bersifat menyerang sehingga sel tubuh yang normal dapat terdesak atau mati (Pusat Data dan Informasi Kementerian Kesehatan RI, 2016). Kanker menjadi penyebab kematian nomor 2 di dunia yaitu sebesar 13% (WHO, 2016). Berdasarkan data GLOBOCAN, International Agency for Research on Cancer (IARC) pada tahun 2008 sampai tahun 2012 terdapat 14,1 juta kasus kanker baru, 8,2 juta kematian akibat kanker dan 32,6 juta orang yang hidup dengan kanker. Sedangkan menurut National Cancer Institute pada tahun 2016, diperkirakan terdapat sebanyak 1.685.210 kasus baru untuk penderita kanker di seluruh dunia dan diperkirakan sebanyak 595.690 orang meninggal akibat kanker. Ancaman kanker di dunia semakin meningkat seiring dengan perubahan pola hidup masyarakat. Menurut Organisasi Penanggulangan Kanker Dunia dan Badan Kesehatan Dunia, diperkirakan terjadi peningkatan kejadian kanker di dunia 300 persen pada tahun 2030 dan mayoritas terjadi di negara-negara berkembang termasuk Indonesia.
2
dari sel-sel di payudara yang mulai tumbuh di luar kendali. Sel-sel ini biasanya berbentuk benjolan. Tumor ganas (kanker) terjadi jika sel-sel dapat tumbuh (menyerang) sekitar jaringan atau menyebar (bermetastasis) ke daerah-daerah yang jauh dari tubuh. Sel di hampir setiap bagian dari tubuh dapat menjadi kanker dan dapat menyebar ke area lain dari tubuh. Kanker payudara terjadi hampir seluruhnya pada wanita, tetapi pria juga dapat mengalaminya. Kanker payudara pada pria lebih jarang terjadi daripada kanker payudara pada wanita. Perbandingannya yaitu 1 dari 150 kasus kanker payudara. (Gejala dan Tanda dalam Kedokteran Klinis, 2012: 337).
3
tahunnya, proporsi kanker payudara sekitar 40% dari seluruh kasus kanker di rumah sakit tersebut (Kementerian Kesehatan RI, 2016).
Masalah terbesar dalam penanggulangan kanker saat ini adalah banyaknya informasi yang kurang dapat dipertanggungjawabkan tersebar di masyarakat sehingga pasien tidak melakukan pengobatan secara benar dan baru datang ke fasilitas pelayanan kesehatan setelah terlambat ditangani (Kementerian Kesehatan RI, 2016). Oleh karena itu, pengenalan kanker merupakan hal yang paling penting untuk dilakukan guna meningkatkan kewaspadaan dan pengetahuan mengenai kanker payudara, serta menggerakkan individu untuk melakukan upaya pencegahan, deteksi dini dan pengobatan terhadap kanker payudara, sehingga resiko terkena kanker payudara dapat dikurangi.
4
Breast Cancer (WDBC) merupakan data set yang diperoleh dari hasil FNA biopsi payudara dari pasien di University of Wisconsin Hospitals. Berdasarkan hasil sampel FNA yang diambil, ditetapkan sembilan parameter berdasarkan karakteristik sel, yaitu clump thickness, uniformity of cell size, uniformity of cell shape, marginal adhesion, single epithelial cell size, bare nuclei, bland chromatin, normal nucleoli dan mitoses. Kesembilan parameter tersebut merupakan isi dari data set Wisconsin Breast Cancer Database (WBCD). Sedangkan untuk data Wisconsin Diagnostic Breast Cancer (WDBC) diperoleh dari karakteristik inti sel dari sebuah gambar digital massa payudara, sehingga berdasarkan hasil sampel FNA yang telah diambil diperoleh sepuluh parameter untuk data WDBC, yaitu radius, texture, perimeter, area, compactness, smoothness, concavity, concave points, symmetry dan fractal dimension. Kedua jenis data tersebut mengklasifikasikan tumor payudara menjadi dua kelas, yaitu tumor jinak (benign) dan tumor ganas (malignant) (Salama et al, 2012: 36-38).
5
masing-masing metode tersebut diterapkan pada ketiga jenis data Wisconsin yang berbeda. Klasifikasi kanker payudara perlu dilakukan untuk menelusuri sebaran dan karakteristik hasil pemeriksaan diagnosa. Klasifikasi dapat diselesaikan dengan teknik-teknik pendekatan secara fungsional yang dikenal dengan istilah soft computing.
Soft computing merupakan suatu model pendekatan untuk melakukan komputasi dengan meniru kemampuan akal manusia yang luar biasa untuk menalar dan belajar pada lingkungan yang memiliki ketidakpastian dan ketidaktepatan (Jang et al, 1997). Beberapa teknik dalam soft computing antara lain sistem fuzzy, Artificial Neural Network (ANN), algoritma evolusioner, dan probabilistic reasoning. Salah satu karakteristik dari soft computing yaitu model komputasi yang berbasis biologis yang mampu menangani permasalahan yang berkaitan dengan persepsi, pengenalan pola, regresi non linier dan klasifikasi.
6
dapat diklasifikasikan lebih lanjut menjadi tiga kategori yaitu, supervised learning, reinforcement learning dan unsupervised learning.
Penelitian terkait neural network untuk klasifikasi telah dilakukan, diantaranya oleh Paulin dan Santhakumaran (2010) yang menggunakan metode backpropagation untuk klasifikasi kanker payudara berdasarkan data Wisconsin Breast Cancer (WBC) ke dalam kriteria benign dan malignant dengan tingkat akurasi 99,28%. Sedangkan pada tahun 2015, Apriani membandingkan model Recurrent Neural Network, Fuzzy Sugeno dan Recurrent Neuro Fuzzy untuk klasifikasi stadium kanker payudara dengan menggunakan data citra mamografi. Hasil dari penelitian tersebut diperoleh model Recurrent Neural Network memiliki nilai sensitivitas, spesifisitas dan akurasi yang lebih baik daripada model Fuzzy Sugeno dan Recurrent Neuro Fuzzy.
7
yang tepat dan menentukan bobot masing-masing neuron (Zakharov et al, 2014: 714).
Penelitian terkait dengan Radial Basis Function (RBF) salah satunya dilakukan oleh Masala, Golosio, dan Pola (2013) yang menggunakan
pengklasifikasian dua layer berdasarkan metode Radial Basis Function (RBF) untuk skrining Talasemia. Sedangkan pada tahun 2005, Soelaiman, Purwitasari & Hayati menggunakan metode pengklasifikasian hybrid berbasis Radial Basis Function (RBF) dan pohon keputusan induktif untuk pengembangan sistem pengenalan wajah.
Penelitian-penelitian lainnnya terkait Radial Basis Function (RBF) juga dilakukan pada kasus pengklasifikasian dan diagnosa kanker payudara.
Diantaranya yaitu penelitian yang dilakukan oleh Kumala (2016) yang
membandingkan 2 metode clustering yang berbeda yaitu K Means dan C Means pada model Radial Basis Function Neural Network (RBFNN) untuk klasifikasi stadium kanker payudara. Hasil yang diperoleh dari penelitian tersebut
menunjukkan bahwa metode K Means clustering lebih baik dibandingkan C Means dengan nilai sensitivitas, spesifisitas, dan akurasi pada metode K Means clustering secara berurutan adalah 75%, 93,75%, dan 80,21% untuk data training dan 81,25%, 75%, dan 79,17% untuk data testing.
8
Function). Penelitian tersebut menggunakan data dari Wisconsin Diagnostic and Prognostic Breast Cancer dengan 9 variabel dan menggunakan algoritma pembelajaran backpropagation. Sedangkan output yang dihasilkan terdiri dari 2 kelas, yaitu benign (tumor) dan malignant (kanker). Hasil akurasi yang diperoleh dari penelitian tersebut menunjukkan bahwa metode RBF lebih baik dibandingkan dengan metode MLP.
Komponen pembentuk soft computing berikutnya yaitu logika fuzzy. Logika fuzzy digunakan sebagai suatu cara untuk memetakan permasalahan dari input menuju ke output yang diharapkan (Kusumadewi & Purnomo, 2010). Menurut Roujas (1996), logika fuzzy dapat dikonseptualisasikan sebagai generalisasi dari logika klasik dimana metode-metode pada logika fuzzy dapat digunakan untuk memberikan interprestasi dari suatu nilai output pada unit yang tidak terbatas dari 0 sampai 1.
9
FNN sering digunakan untuk sistem kendali, penyelesaian masalah prediksi yang bersifat runtun waktu, dan klasifikasi pola.
Penelitian-penelitian sebelumnya yang menggunakan FNN telah dilakukan antara lain penelitian oleh Rahmawati (2016) menggunakan Fuzzy Neural Network (FNN) dengan model Feedforward Neural Network dengan input berupa variabel-variabel fuzzy dan output berupa klasifikasi stadium kanker kolorektal. Penelitian lainnya dilakukan oleh Mohammed (2014) dengan mengkombinasikan metode fuzzy logic system dan fuzzy neural network (FNN) pada sistem kesalahan diagnosa.
Seiring dengan perkembangan kemampuan intelektual manusia untuk menciptakan penelitian baru dan mengembangkan penelitian-penelitian terdahulu agar dapat memperoleh hasil yang lebih akurat, maka munculah berbagai macam metode dan penelitian baru terkait klasifikasi stadium kanker payudara yaitu metode Fuzzy Radial Basis Function Neural Network (FRBFNN). Fuzzy Radial Basis Function Neural Network (FRBFNN) merupakan gabungan dari sistem fuzzy, Radial Basis Function (RBF) dan Neural Network (NN).
10
Penggunaan metode Fuzzy Radial Basis Function Neural Network (FRBFNN) telah dilakukan dalam berbagai penelitian sebelumnya. Pada tahun 2008, Pehlivan dan Apaydin melakukan penelitian untuk membandingkan antara Fuzzy Kernel Regression (FNPR) dengan FRBFNN dimana nilai input, output dan bobot pada metode FRBFNN merupakan bilangan fuzzy. Penelitian tersebut menggunakan data percobaan analisis kimia, mikrobiologi serta organoleptik. Hasil dari penelitian tersebut menunjukkan bahwa metode FNPR lebih baik dibandingkan dengan FRBFNN. Penelitian lainnya dilakukan oleh Karthikeyeni dan Ramya (2014) yang membandingkan antara metode Artificial Neuro Fuzzy Inference System (ANFIS) dengan FRBFNN pada prediksi waktu survival pasien kanker paru-paru. Hasilnya yaitu bahwa teknik FRBFNN memiliki tingkat akurasi yang lebih tinggi dari pada metode ANFIS. Pada tahun yang sama, Ayunda, Irawan dan Karnaningroem menggunakan model Fuzzy Radial Basis Function untuk peramalan nilai Biochemical Oxygen Demand(BOD) pada kali Surabaya.
11
pada tugas akhir ini, estimasi bobot dilakukan dengan menggunakan metode global ridge regression.
Berdasarkan hal-hal yang telah diuraikan di atas, melatarbelakangi penulis untuk melakukan penelitian mengenai klasifikasi stadium kanker payudara menggunakan model Fuzzy Radial Basis Function Neural Network (FRBFNN). Oleh karena itu, penelitian yang berjudul “Penerapan Model Fuzzy Radial Basis Function Neural Network (FRBFNN) untuk Klasifikasi Stadium Kanker Payudara” pada tugas akhir ini diharapkan dapat memberikan hasil yang baik dan
bermanfaat di bidang matematika maupun kesehatan.
B. Rumusan Masalah
Berdasarkan latar belakang di atas maka permasalahan dalam penelitian ini dapat dirumuskan sebagai berikut:
1. Bagaimana prosedur klasifikasi stadium kanker payudara pada model Fuzzy Radial Basis Function Neural Network (FRBFNN) dengan menggunakan data Wisconsin Breast Cancer Database (WBCD) dan data Wisconsin Diagnostic Breast Cancer (WDBC)?
2. Bagaimana hasil klasifikasi stadium kanker payudara pada model Fuzzy Radial Basis Function Neural Network (FRBFNN) dengan menggunakan data Wisconsin Breast Cancer Database (WBCD) dan data Wisconsin Diagnostic Breast Cancer (WDBC)?
C. Tujuan Penelitian
12
1. Mendeskripsikan prosedur klasifikasi stadium kanker payudara pada model Fuzzy Radial Basis Function Neural Network (FRBFNN) dengan menggunakan data Wisconsin Breast Cancer Database (WBCD) dan data Wisconsin Diagnostic Breast Cancer (WDBC).
2. Mendeskripsikan hasil klasifikasi stadium kanker payudara pada model Fuzzy Radial Basis Function Neural Network (FRBFNN) dengan menggunakan data Wisconsin Breast Cancer Database (WBCD) dan data Wisconsin Diagnostic Breast Cancer (WDBC).
D. Manfaat Penelitian
Manfaat yang dapat diperoleh dari penelitian ini adalah: 1. Bagi penulis
Bagi penulis sendiri, penulisan skripsi ini dapat menambah pengetahuan dan wawasan tentang aplikasi model FRBFNN dalam kehidupan sehari-hari, khususnya dalam bidang kesehatan.
2. Bagi para pembaca
Sebagai salah satu bahan dalam mempelajari model FRBFNN dan MATLAB serta diharapkan penelitian ini dapat dijadikan sebagai referensi untuk penelitian selanjutnya.
3. Bagi perpustakaan Universitas Negeri Yogyakarta
13
BAB II KAJIAN TEORI A. Kanker Payudara
1. Pengertian Kanker Payudara
Kanker payudara adalah tumor ganas yang terbentuk dari sel-sel payudara yang tumbuh dan berkembang tanpa terkendali sehingga dapat menyebar di antara jaringan atau organ di dekat payudara atau ke bagian tubuh lainnya (Kementrian Kesehatan RI, 2016). Sedangkan menurut National Breast Cancer Foundation, kanker payudara dimulai dalam sel-sel lobulus, yang merupakan kelenjar penghasil susu, atau dapat juga dimulai dari saluran yang mengalirkan susu dari lobulus ke puting. Selain itu kanker payudara juga dapat dimulai di jaringan stroma, yang meliputi lemak dan jaringan ikat fibrosa payudara.
2. Jenis-jenis Kanker Payudara
Ada beberapa jenis kanker payudara yaitu sebagai berikut (Gejala dan Tanda dalam Kedokteran Klinis, 2012: 332-333):
a. Karsinoma duktus invasif
Karsinoma ini merupakan jenis yang paling umum (75%). Dilihat melalui mikroskop, sel ganas tersusun dalam berbagai bentuk mikro arsitektur, termasuk struktur kelenjar. Banyak tumor mengandung komponen stroma jarngan ikat yang menonjol (skirus). Perilaku biologisnya bermacam-macam, dari prognosis baik sampai buruk. Sistem penentuan penentuan stadium kanker (1 sampai 3) dilakukan berdasarkan:
14
2) Perbedaan ukuran, bentuk dan penodaan nukleus 3) Frekuensi mitosis
b. Kanker lobulus invasif
Kanker ini merupakan jenis kedua yang paling umum (10%). Dilihat melalui mikroskop, sel tumor monomorfik tersusun secara berderet, dengan pola alveolus dan targetoid. Kanker ini sering kali memiliki banyak pusat dan bisa terjadi di kedua payudara. Kanker ini tidak berkaitan dengan mikroklasifikasi, dan bisa sulit dideteksi dengan mamografi atau ultrasonografi. Magnetic resonance mammography direkomendasikan untuk mengevaluasi kanker jenis ini.
c. Karsinoma tubulus
Kanker ini mencakup 5 % dari semua penyakit ganas payudar dan semakin mudah dideteksi melalui pengamatn. Kanker ini biasanya merupakan tumor kecil dan secara histologi mengandung kelenjar berbentuk jelas yang dipisahkan oleh stroma berserat. Sel ganas mengandung proyeksi sitoplasma. yang memanjang dari puncak sel ke lumen duktus. Kanker tbulus cenderung tetap berada di suatu tempat dan sebenarnya tidak pernah bermetastasis ke nodus limfa di wilayah yang sama. Sampai 95 % pasien mampu bertahan hidup selama 5 tahun.
d. Kanker payudara inflamasi
15
limfatik ke kult oleh sel ganas, edeam jaringan dan perembesan sel inflamasi dengan tingkat keparahan berbeda-beda. Kanker ini cenderung dialami wanita muda pra-menopause dan secara biologi dengan hasil klinis yang kurang memuaskan.
e. Karsinoma in situ
Karsinoma in situ berasal dari unit duktus-lobulus terminal, dengan karsinoma in situ (DCIS) hanya ada di duktus/duktulus, dan karsinoma lobulusin situ (LCIS) hanya ada di lobulus. Sebelum pemantauan payudara, insidensi DCIS adalah 1 sampai 3 persen dari specimen yang diambil dan 3 sampai 6 persen dari semua kanker payudar. Sejak pemantauan diperkenalkan, DCIS telah didokumentasikan dalam 15 sampai 20 persen semua kanker payudara yang telah diangkat dan dalam 20 sampai 40 persen semua kanker payudar sama (tidak bisa diraba) ang dikeluarkan. Frekuensi LCIS juga meningkat dalma biopsy/specimen yang telah dikeluarkan. LCIS digolongkan sebagai neoplasia lobulus. Dalam DCIS, terdapat poliferasi lapisan sel kuboid dalam menuju lumen dan hilangnya lapisan luar sel mioepitelium, namun membrane alasnya masih utuh.
3. Klasifikasi Kanker Payudara
16
kanker. Berikut adalah penjelasan masing-masing klasifikasi kanker payudara (National Breast Cancer Foundation, 2017):
a. Diagnosis normal
Payudara normal merupakan payudara dengan pertumbuhan sel normal, dimana sel-sel payudara yang tumbuh sama dengan sel-sel payudara yang rusak atau mati.
b. Diagnosis tumor (benign)
Tumor merupakan pertumbuhan sel yang abnormal dimana pembelahan sel pada payudara lebih cepat dari pada sel yang rusak atau mati. Jenis-jenis dari tumor yaitu:
1) Tumor Jinak
Meskipun tumor ini pada umumnya tidak agresif terhadap jaringan sekitarnya, tetapi terkadang tumor ini dapat terus tumbuh, menekan pada organ-organ dan menyebabkan sakit atau masalah lain. Dalam situasi ini, perlu dilakukan pengangkatan tumor agar komplikasinya mereda.
2) Tumor Ganas
Tumor ganas/kanker sangat agresif karena menyerang dan merusak jaringan sekitar. Selanjutnya biopsi perlu dilakukan untuk menentukan tingkat keparahan atau agresivitas tumor.
c. Diagnosis kanker (Metastasis kanker)
17
B. Wisconsin Breast Cancer Database (WBCD)
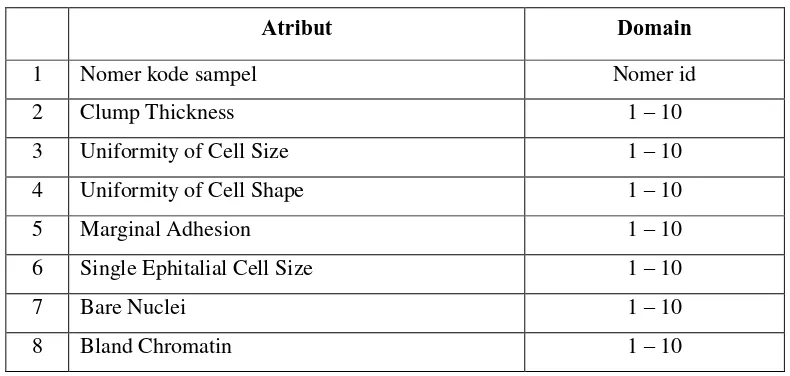
Data medis tentang kanker payudara (breast cancer) dari University of Wisconsin Hospital merupakan data yang diperoleh dari 683 pasien yang telah diklasifikasikan ke dalam 2 (dua) jenis kanker, yaitu kanker jinak/tumor/benign dan kanker ganas/kanker/malignant. Database tersebut berupa 11 atribut yang mewakili data untuk setiap pasien, yang terdiri dari 9 (sembilan) karakteristik dari sel payudara dan 2 (dua) atribut lainnya, yaitu nomer id dari setiap pasien dan kelas label yang sesuai dengan jenis kanker payudara (jinak atau ganas). Nilai-nilai karakteristik sel berada dalam rentang dari 1 sampai 10, dimana 1 menunjukkan nilai terdekat dengan benign sedangkan 10 merupakan nilai tertinggi dan termasuk dikategorikan paling malignant.
Atribut-atribut dari database tersebut selengkapnya ditunjukkan pada tabel 2.1:
Tabel 2. 1 Atribut Wisconsin Breast Cancer Database (WBCD)
Atribut Domain
1 Nomer kode sampel Nomer id
2 Clump Thickness 1 – 10
3 Uniformity of Cell Size 1 – 10
4 Uniformity of Cell Shape 1 – 10
5 Marginal Adhesion 1 – 10
6 Single Ephitalial Cell Size 1 – 10
7 Bare Nuclei 1 – 10
18
Atribut Domain
9 Normal Nucleoli 1 – 10
10 Mitoses 1 – 10
11 Kelas 2 untuk benign
4 untuk malignant
Variabel yang terdapat pada data WBCD diperoleh dari hasil FNA (Fine-Needle Aspirate) Biopsy Cytology yang merupakan salah satu jenis biopsi yang dilakukan dengan cara mengambil sampel sel pada benjolan atau massa payudara yang dicurigai sebagai tumor atau kanker dengan menggunakan jarum halus untuk selanjutnya dilakukan pemeriksaan di laboratorium (Wolberg & Mangasarian, 1990).
Berikut merupakan penjelasan terkait dengan parameter-parameter pada Wisconsin Breast Cancer Database (Salama et al, 2012: 37-38):
1. Clump Thickness
Pada atribut Clump Thickness, sel benign (tumor) cenderung dikelompokkan dalam monolayers (lapisan tunggal), sementara sel-sel kanker sering dikelompokkan dalam multilayer (lapisan yang lebih dari satu).
2. Uniformity of Cell Size/Shape
Pada atribut Uniformity of Cell Size/Shape, sel kanker cenderung bervariasi dalam ukuran dan bentuk.
3. Marginal Adhesion
19 4. Single Ephitalial Cell Size
Single Ephitalial Cell Size terkait dengan keseragaman yang telah dijelaskan sebelumnya. Sel-sel epitel yang membesar secara signifikan kemungkinan dapat menjadi sel kanker.
5. Bare Nuclei
Bare Nuclei adalah istilah yang digunakan untuk inti sel yang tidak dikelilingi oleh sitoplasma. Bare Nuclei biasanya terlihat pada tumor jinak. 6. Bland Cromatin
Bland Cromatin menggambarkan keseragaman 'tekstur' dari inti sel yang terlihat pada sel benign. Sedangkan pada sel-sel kanker, kromatin cenderung bertekstur kasar.
7. Normal Nucleoli
Normal Nucleoli adalah struktur kecil yang terlihat di inti sel. Dalam sel-sel normal, nukleolus biasanya sangat kecil jika terlihat. Sedangkan pada sel kanker nukleolus menjadi lebih menonjol, dan terkadang jumlahnya lebih dari jumlah normal.
8. Mitoses
Ini adalah proses dimana sel membagi dan membelah diri. Kelas kanker dapat ditentukan dengan menghitung jumlah mitosis.
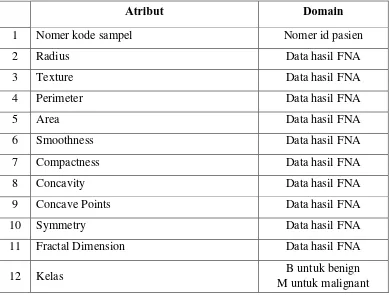
C. Wisconsin Diagnostic Breast Cancer (WDBC)
20
diperoleh dari tes biopsy Fine-needle Aspirate (FNA) pada karakteristik inti sel dari sebuah gambar digital massa payudara (Salama et al, 2012: 38). Atribut-atribut dari data WDBC tersebut selengkapnya ditunjukkan pada tabel 2.2 berikut:
Tabel 2. 2 Atribut Wisconsin Diagnostic Breast Cancer (WDBC)
Atribut Domain
1 Nomer kode sampel Nomer id pasien
2 Radius Data hasil FNA
3 Texture Data hasil FNA
4 Perimeter Data hasil FNA
5 Area Data hasil FNA
6 Smoothness Data hasil FNA
7 Compactness Data hasil FNA
8 Concavity Data hasil FNA
9 Concave Points Data hasil FNA
10 Symmetry Data hasil FNA
11 Fractal Dimension Data hasil FNA
12 Kelas B untuk benign
M untuk malignant Berikut merupakan penjelasan mengenai variabel pada data WDBC (Mu & Nandi, 2008):
1. Radius
Radius dihitung dengan rata-rata panjang segmen garis radial dari pusat massa.
2. Texture
21 3. Perimeter
Perimeter adalah garis keliling inti sel yang diukur sebagai jumlah dari jarak antara titik-titik pada keliling inti sel.
4. Area
Area diukur dengan menghitung jumlah piksel batas bagian dalam batas dan menambahkan satu setengah dari piksel garis keliling.
5. Compactness
Compactness menggabungkan perimeter dan area untuk memberikan ukuran kekompakan sel. Compactness dapat dihitung dengan � /
6. Smoothness
Smoothness diukur dengan menghitung perbedaan antara panjang masing-masing garis radial dan rata-rata panjang dua garis radial yang
mengelilinginya. Smoothness dapat dihitung dengan rumus berikut:
∑ � | � �+ �+1 / |
� � (2.1)
Dimana � adalah panjang garis dari pusat massa ke batas pada masing-masing titik batas.
7. Concavity
Concavity diperoleh dengan mengukur ukuran semua lekukan dalam batas
inti sel.
8. Concave Points
22 9. Symmetry
Symmetry diukur dengan menemukan perbedaan relatif pada panjang antara pasangan segmen garis tegak lurus terhadap sumbu utama kontur inti sel, dapat dihitung dengan:
=∑ |� �− � ℎ�|
∑ |� �+ � ℎ�| (2.2) Dimana �dan ℎ �menunjukkan panjang tegak lurus garis di kiri dan kanan sumbu utama.
10.Fractal Dimension
Fractal Dimension didekati dengan menggunakan “coast-line
approximation” (Mandelbrot, 1997).
D. Himpunan Klasik (Crisp Set)
Himpunan klasik adalah kumpulan objek yang tegas. Pada teori himpunan klasik, keberadaan suatu elemen dalam himpunan A hanya terdapat dua kemungkinan keanggotaan, yaitu menjadi anggota A atau bukan anggota A (Lin & Lee, 1996:12). Suatu nilai yang menunjukkan seberapa besar tingkat keanggotaan suatu elemen (x) dalam suatu himpunan (A), sering dikenal dengan nama nilai keanggotaan atau derajat keanggotaan, yang dinotasikan dengan � . Pada himpunan klasik, hanya ada dua nilai keanggotaan, yaitu � = untuk x menjadi anggota A; dan � = untuk x bukan anggota dari A.
� = { ,, ,, (2.3)
23 Contoh 1
Jika diketahui: S={1, 3, 5, 7, 9} adalah semesta pembicaraan; A={1, 2, 3} dan B={3, 4, 5}, maka dapat dikatakan bahwa:
a. Nilai keanggotaan 1 pada himpunan A, � [ ] = , karena b. Nilai keanggotaan 3 pada himpunan A, � [ ] = , karena
c. Nilai keanggotaan 2 pada himpunan B, � [ ] = , karena d. Nilai keanggotaan 4 pada himpunan A, � [ ] = , karena
E. Himpunan Fuzzy
Menurut Jang et al (1997:13), konsep himpunan fuzzy yang menjadi dasar dari logika fuzzy muncul berdasarkan konsep pemikiran manusia yang cenderung abstrak dan tidak tepat. Teori himpunan fuzzy merupakan perluasan dari teori himpunan klasik. Fungsi keanggotaan dari himpunan klasik, yaitu { , } diperluas menjadi suatu bilangan real dalam interval [ , ] (Lin & Lee, 1996:10).
Teori himpunan fuzzy dapat digunakan untuk menetapkan suatu pernyataan yang memiliki tingkat ketidakpastian berdasarkan konsep pemikiran manusia yang tidak pasti dan cenderung beragam antara pemikiran manusia yang satu dengan yang lainnya, misal terdapat suatu pernyataan seperti berikut:
“Orang adalah orang dewasa”
24
Contoh lainnya yang dapat diterapkan pada konsep teori fuzzy, yaitu seperti pada pernyataan untuk menetapkan “tua” dan “muda” atau “cepat” dan “lambat”
dimana pernyataan-pernyataan tersebut merupakan suatu ketidakpastian yang dapat ditafsirkan dalam konteks tertentu.
Menurut Zimmermann (1991:11-12) jika X adalah kumpulan dari objek-objek yang dinotasikan oleh x, maka himpunan fuzzy dalam X adalah suatu himpunan pasangan berurutan:
= { , � | } (2.4) Dimana � adalah derajat keanggotaan x untuk himpunan fuzzy yang memetakkan setiap anggota X ke nilai keanggotaan yang terletak di interval [0, 1]. Berikut ini merupakan contoh dari himpunan fuzzy, fungsi keanggotaan pada himpunan fuzzy dan derajat keanggotaannya:
Contoh 2
Misalkan A adalah himpunan umur dalam satuan tahun dengan interval [0,100]. Anggota A adalah:
= { , , , , , }
Fungsi keanggotaan pada variabel umur diberikan sebagai berikut:
� = {
; −
; < ; >
� = {
; −
25
Berdasarkan fungsi keanggotaan tersebut diperoleh derajat keanggotaan variabel umur pada Tabel 2.3 berikut:
Tabel 2. 3 Derajat Keanggotaan pada Variabel Umur Umur
(Tahun)
Muda μ a A
Tua μ a A
9 1 0
18 0.92 0.08
22 0.53 0.38
28 0.15 0.85
55 0 1
70 0 1
Berikut merupakan bagian-bagian dari himpunan fuzzy:
1. Fungsi Keanggotaan
Fungsi keanggotaan adalah suatu fungsi yang memetakan setiap elemen x dari himpunan semesta X ke dalam suatu nilai yaitu A(x), dalam interval tertutup [0,1] yang menggolongkan derajat keanggotaan x dalam A. Dalam hal ini, fungsi keanggotaan adalah fungsi yang berbentuk.
: [ , ]
Dalam mendefinisikan fungsi keanggotaan, himpunan semesta X selalu diasumsikan sebagai himpunan klasik (Klir & Yuan, 1995:75).
26
Gambar 2.1 Representasi Kurva Segitiga
Berikut adalah fungsi keanggotaan kurva segitiga (Sri Kusumadewi, 2010:155):
� =
{ ; − − ; − − ;
> <
<
(2.5)
2. Operator-operator Fuzzy
Menurut Rojas (1996: 296), operator pada himpunan fuzzy secara umum memiliki kesamaan jenis operator dengan teori himpunan klasik, yaitu operator fuzzy AND, OR, NOT. Melalui pendekatan yang sederhana, operator OR ̃ diidentifikasi sebagai fungsi maksimum, operator AND ̃ sebagai fungsi minimum dan operator NOT atau komplemen ¬̃ diidentifikasi sebagai fungsi
→ – .
Operator gabungan pada teori himpunan klasik dapat dinyatakan dalam operator OR. Jika dan adalah dua himpunan fuzzy, sehingga � , � : → [ , ]. Fungsi keanggotaan pada � dari himpunan gabungan adalah
� = � ̃� ∀ , (2.6)
Pada operator irisan juga berlaku hal yang sama sehingga dapat dinyatakan dalam operator AND pada himpunan dan , sehingga berlaku persamaan seperti berikut
b c domain 0
1
a Derajat
27
� = � ̃ � ∀ , (2.7)
Untuk komplemen pada himpunan , diperoleh persamaannya seperti berikut:
� � = ¬̃ � ∀ , (2.8)
F. Neural Network (NN)
Neural network (NN) merupakan sistem pemrosesan informasi yang memiliki karakteristik mirip dengan jaringan syaraf biologis (Fausett, 1994: 3). Neural network dibentuk sebagai generalisasi model matematika dari jaringan syaraf biologi. Struktur jaringan syaraf pada otak manusia sangat kompleks dan memiliki kemampuan luar biasa yang terdiri dari neuron-neuron dan penghubung yang disebut sinapsis. Neuron bekerja berdasarkan impuls/sinyal yang diberikan pada neuron. Kemudian neuron tersebut meneruskannya kepada neuron yang lain (Siang, 2009:1-2).
Neuron memiliki 3 komponen penting, yaitu dendrit, soma dan axon. Dendrit menerima sinyal dari neuron lain. Sinyal tersebut berupa impuls elektrik yang dikirim melalui celah sinaptik melalui proses kimiawi. Sinyal tersebut dimodifikasi (diperkuat/diperlemah) di celah sinaptik. Berikutnya, soma menjumlahkan semua sinyal-sinyal yang masuk. Kalau jumlahan tersebut cukup kuat dan melebihi batas ambang (threshold), maka sinyal tersebut akan diteruskan ke sel lain melalui axon. Frekuensi penerusan sinyal berbeda-beda antara satu sel dengan yang lain (Siang, 2009:2).
28
Gambar 2.2 Jaringan Syaraf Secara Biologi
Seperti halnya otak manusia, neural network juga terdiri dari beberapa neuron, dan ada hubungan antara neuron-neuron tersebut. Neural network pada awalnya diperkenalkan oleh McCulloch dan Pitts di tahun 1943 yang menyimpulkan bahwa kombinasi beberapa neuron sederhana menjadi sebuah sistem neural akan meningkatkan kemampuan komputasinya. Bobot dalam jaringan yang diusulkan oleh McCulloch dan Pitts diatur untuk melakukan fungsi logika sederhana (Siang, 2009:4).
Neural network dibentuk dengan asumsi sebagai berikut (Fausett, 1994:3). a. Pemrosesan informasi terjadi pada banyak elemen sederhana yang disebut
neuron.
b. Sinyal dikirimkan di antara neuron-neuron melalui penghubung-penghubung. c. Setiap penghubung antar neuron memiliki bobot yang dapat mengalikan
sinyal yang ditransmisikan.
29
Menurut Siang (2009:3), neural network ditentukan oleh 3 hal, yaitu: a. Pola hubungan antar neuron (disebut arsitektur jaringan)
b. Metode untuk menentukan bobot penghubung (disebut metode training/learning/algoritma)
c. Fungsi aktivasi
Berikut merupakan tiga hal penting pembentuk neural network:
1. Arsitektur Jaringan Syaraf
Hubungan antar neuron dalam neural network mengikuti pola tertentu tergantung pada arsitektur jaringan syarafnya. Menurut Fausett (1994: 12-15) terdapat 3 arsitektur dalam neural network, antara lain:
a. Jaringan Layar Tunggal (single layer network)
Dalam jaringan ini, sekumpulan input neuron dihubungkan langsung dengan sekumpulan outputnya. Dalam beberapa model (misal perceptron), hanya ada sebuah neuron output. Pada gambar 2.3 berikut merupakan contoh arsitektur jaringan layar tunggal.
Gambar 2. 3 Jaringan Layar Tunggal �
�
� ⋮
⋮ �
Lapisan input
bobot Lapisan
30
Gambar 2.3 menunjukkan arsitektur jaringan dengan � neuron input , , … , � dan m neuron output , , … , . � adalah bobot yang menghubungkan neuron input ke-p dengan neuron output ke-m. Dalam jaringan ini, semua neuron input dihubungkan dengan semua neuron output, meskipun dengan bobot yang berbeda-beda. Tidak ada neuron input yang dihubungkan dengan neuron input lainnya. Demikian pula dengan neuron output.
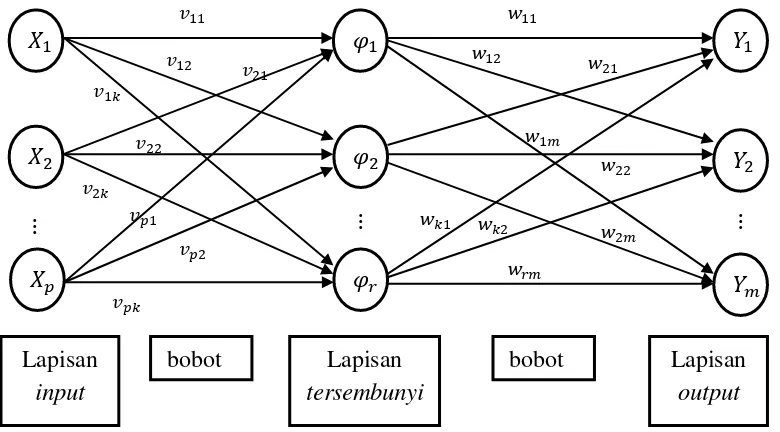
b. Jaringan Layar Jamak (multilayer network)
Jaringan layar jamak merupakan jaringan dengan satu layar simpul atau lebih (disebut hidden neuron/ neuron tersembunyi) antara neuron input dan neuron output. Terdapat layar bobot antara dua tingkat neuron yang berdekatan (input, hidden, output). Pada gambar 2.4 berikut merupakan contoh arsitektur jaringan layar jamak.
[image:30.595.120.510.461.677.2].
Gambar 2. 4 Jaringan Layar Jamak
� � �
⋮
Lapisan input
bobot Lapisan
tersembunyi �
�
� ⋮
⋮
�
�
�
�
bobot Lapisan
31
Gambar 2.4 adalah jaringan dengan neuron input , , … , � , layar tersembunyi yang terdiri dari r neuron � , � , … , � dan m neuron output , , … , . Jaringan ini dapat menyelesaikan masalah yang lebih kompleks dibandingkan dengan layar tunggal, meskipun kadangkala proses pelatihan lebih kompleks dan lama.
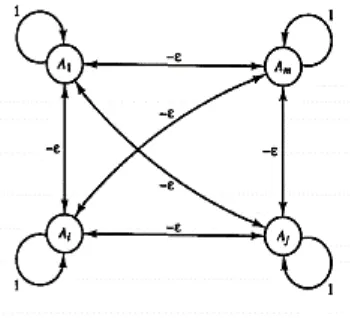
c. Jaringan Layar Kompetitif (competitive layer network)
[image:31.595.242.417.370.529.2]Arsitektur ini memiliki bentuk yang berbeda, dimana antar neuron dapat saling dihubungkan. Jaringan layar kompetitif memiliki bobot – �. Gambar 2.5 merupakan salah satu contoh arsitektur ini.
Gambar 2. 5 Jaringan Layar Kompetitif
2. Fungsi Aktivasi
32
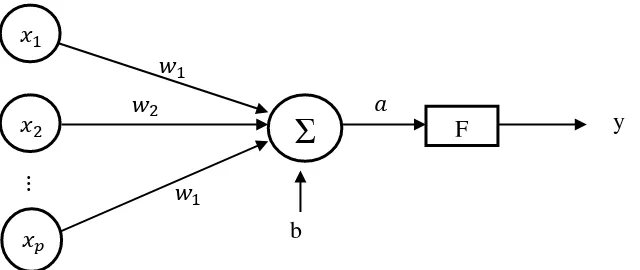
Gambar 2. 6 Fungsi Aktivasi pada Neural Network Sederhana
, , … , � adalah neuron yang masing-masing memiliki bobot , , … , � dan bobot bias pada lapisan input.
Berikut merupakan beberapa fungsi aktivasi Neural Network menurut Fausett (1994: 17-19):
a. Fungsi Linear
Fungsi Linear dirumuskan sebagai: = + , �. Jika = dan = , maka
= , � (2.9)
Persamaan 2.9 disebut fungsi identitas. Pada fungsi identitas, nilai output yang dihasilkan sama dengan nilai inputnya. Berikut merupakan gambar untuk fungsi aktivasi identitas.
Gambar 2. 7 Fungsi Aktivasi Identitas b
y ⋮
�
[image:32.595.254.413.573.704.2]33 b. Fungsi Undak Biner (Binary Step)
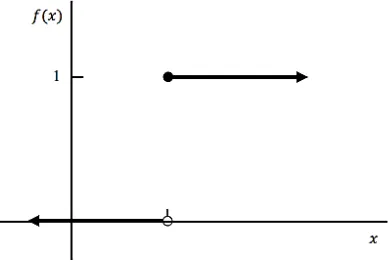
Jaringan dengan lapisan tunggal sering menggunakan fungsi undak biner (step function) untuk mengkonversikan input dari suatu variabel yang bernilai kontinu ke suatu output biner (0 atau 1). Fungsi undak biner dirumuskan sebagai berikut.
= { ,, < (2.10)
[image:33.595.216.412.323.455.2]Fungsi aktivasi undak biner ditunjukkan pada Gambar 2.8 berikut.
Gambar 2. 8 Fungsi Aktivasi Undak Biner c. Fungsi Sigmoid Biner
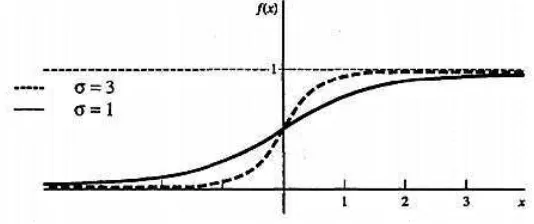
Fungsi ini digunakan untuk neural network yang dilatih dengan menggunakan metode backpropagation. Fungsi sigmoid biner memiliki nilai pada range 0 sampai 1, sehingga sering digunakan untuk neural network yang membutuhkan nilai output yang terletak pada interval 0 sampai 1. Namun, fungsi ini bisa juga digunakan oleh neural network yang nilai outputnya 0 atau 1. Fungsi sigmoid biner dirumuskan sebagai berikut:
= = + −�� (2.11)
dengan
34
[image:34.595.177.444.146.258.2]Fungsi aktivasi sigmoid biner ditunjukkan pada Gambar 2.9 berikut.
Gambar 2. 9 Fungsi Aktivasi Sigmoid Biner d. Fungsi Sigmoid Bipolar
Fungsi sigmoid bipolar berkaitan dengan fungsi tangen hiperbolik yang sering digunakan sebagai fungsi aktivasi ketika nilai output yang dibutuhkan terletak pada interval -1 sampai 1. Fungsi sigmoid bipolar dirumuskan sebagai berikut.
= = −+ −��−�� (2.12)
dengan
′ =�[ + ][ − ]
Fungsi aktivasi sigmoid bipolar dengan � = ditunjukkan pada Gambar 2.10 berikut.
[image:34.595.231.393.583.695.2]35
3. Algoritma Pembelajaran
Algoritma pembelajaran adalah prosedur untuk menentukan bobot pada lapisan yang berhubungan dalam neural network (Fausett, 1994: 429). Tujuan utama dari proses pembelajaran adalah melakukan pengaturan terhadap bobot-bobot yang ada pada neural network sehingga diperoleh bobot akhir yang tepat sesuai dengan pola data yang dilatih (Kusumadewi & Hartati, 2010: 84). Secara garis besar ada dua jenis pembelajaran pada neural network, yaitu pembelajaran yang menyangkut pengaturan bobot koneksi pada neural network dan struktur belajar, yang berfokus pada perubahan struktur jaringan, termasuk jumlah neuron dan jenis hubungan antar neuron. Kedua jenis pembelajaran dapat dilakukan secara bersamaan atau terpisah. Setiap jenis pembelajaran dapat diklasifikasikan menjadi tiga kategori, yaitu Supervised Learning, Reinforcement Learning, dan Unsupervised Learning (Lin & Lee, 1995:5). Berikut merupakan ketiga kategori algoritma pembelajaran (Lin & Lee, 1995:213-214):
a. Pembelajaran terawasi (supervised learning)
36
[image:36.595.124.453.145.234.2]pembelajaran lagi. Gambar 2.11 berikut merupakan diagram alur dari supervised learning:
Gambar 2. 11 Supervised Learning (Pembelajaran Terawasi) b. Pembelajaran Penguatan (Reinforcement Learning)
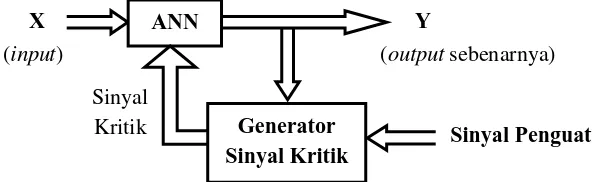
Reinforcement learning adalah bentuk dari supervised learning karena jaringan masih menerima beberapa umpan balik dari lingkungannya. Tapi umpan balik (penguat sinyal) hanya sebagai evaluatif yaitu hanya menyatakan seberapa baik atau seberapa buruk output tertentu dan menyediakan petunjuk mengenai apa yang seharusnya menjadi jawaban yang tepat. Output dari penguat sinyal biasanya diproses oleh sinyal generator untuk menghasilkan sinyal evaluative yang lebih informatif untuk neural network dalam menyesuaikan bobot yang benar dengan harapan mendapatkan umpan balik yang lebih baik. Gambar 2.12 berikut merupakan diagram alur dari reinforcement learning.
Gambar 2. 12 Reinforcement Learning (Pembelajaran Penguatan) c. Pembelajaran Tak Terawasi (Unsupervised Learning)
Dalam Unsupervised Learning, tidak ada pasangan data (input-target output) yang dipakai untuk melatih jaringan hingga diperoleh bobot yang
Sinyal Error
X ANN
Generator Sinyal Error (input)
Y
(output sebenarnya)
d
(output yang diharapkan)
Sinyal Kritik
X ANN
Generator Sinyal Kritik (input)
Y
(output sebenarnya)
[image:36.595.151.451.547.638.2]37
diinginkan, sehingga tidak ada yang memberikan umpan balik informasi. Jaringan harus menemukan sendiri pola, fitur, keteraturan, korelasi, atau kategori pada data input dan kode dalam output. Sementara dalam menemukan fitur ini, jaringan mengalami perubahan bobot; proses ini disebut mengorganisasikan diri. Proses pembelajaran bertujuan untuk mengelompokkan unit-unit yang hampir sama ke dalam suatu area tertentu sehingga algoritma pembelajaran ini sangat cocok untuk klasifikasi. Gambar 2.13 berikut merupakan diagram alur dari unsupervised learning.
Gambar 2. 13 Unsupervised Learning (Pembelajaran Tak Terawasi)
G. Ketepatan Hasil Klasifikasi
Keputusan medis mengenai tindakan medis yang harus dilakukan bergantung pada hasil klasifikasi (diagnosa). Tingkat ketelitian diagnosa dapat diukur dengan akurasi. Nilai akurasi juga dapat digunakan untuk mengetahui seberapa bagus dan terpercaya hasil klasifikasi yang telah dilakukan.
Akurasi merupakan kemampuan dalam mengidentifikasi hasil positif maupun hasil negatif secara tepat. Contohnya, jika nilai akurasi = 95%, artinya klasifikasi akurat sebesar 95%, baik untuk pasien yang dinyatakan tidak berpenyakit maupun dinyatakan memiliki penyakit. Rumus untuk menghitung akurasi adalah sebagai berikut:
= a � � ha a a� � % (2.13)
(input) X ANN
38
BAB III PEMBAHASAN
A. Fuzzy Radial Basis Function (FRBFNN)
1. Arsitektur Fuzzy Radial Basis Function Neural Network (FRBFNN)
Fuzzy Radial Basis Function Neural Network (FRBFNN) merupakan gabungan dari sistem fuzzy, Radial Basis Function (RBF) dan Neural Network (NN). FRBFNN adalah model RBFNN dengan input, bobot atau output yang berupa himpunan fuzzy. Pendekatan FRBFNN dibangun atas dasar meminimalkan kuadrat dari total perbedaan antara output pengamatan dan output perkiraan. (Pehlivan & Apaydin, 2016: 61).
39
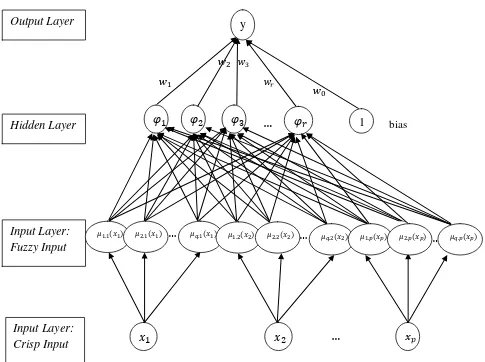
Gambar 3.1 Arsitektur Fuzzy Radial Basis Function Neural Network (FRBFNN)
Berdasarkan Gambar 3.2, , , … , adalah neuron pada lapisan input yang berupa bilangan crisp. . , . , … , . , . . . , . ( )adalah neuron pada lapisan input yang berupa bilangan fuzzy, � , � , … , � adalah neuron pada lapisan tersembunyi dan adalah neuron pada lapisan output, sedangkan adalah bobot pada lapisan tersembunyi dan lapisan output. Dalam arsitektur FRBFNN juga ditambahkan sebuah neuron bias pada lapisan tersembunyi. Bias tersebut berfungsi untuk membantu neural network dalam mengolah informasi dengan lebih baik.
…
Input Layer: Crisp Input Input Layer: Fuzzy Input Hidden Layer Output Layer
bias
� � � … � 1
y
… …
…
…
40
2. Model Fuzzy Radial Basis Function Neural Network (FRBFNN)
Model Fuzzy Radial Basis Function Neural Network (FRBFNN) mengacu pada model Radial Basis Function Neural Network (RBFNN) yang menggunakan fungsi basis sebagai fungsi aktivasi untuk setiap neuron pada lapisan tersembunyi. Beberapa fungsi radial basis adalah sebagai berikut (Andrew, 2002: 74).
a. Fungsi Gaussian
�[ ] = − � − (3.1)
b. Fungsi Multikuadratik
�[ ] = √ − + (3.2)
c. Fungsi Invers Multikuadratik
�[ ] =√ � − +
� (3.3)
d. Fungsi Cauchy
�[ ] =( � − + )− (3.4)
dengan,
= jarak pada neuron tersembunyi dari variabel input ke cluster
� = nilai input himpunan fuzzy
= nilai pusat pada neuron tersembunyi dari variabel input ke cluster
�[� ] = fungsi aktivasi neuron tersembunyi
Hasil output y yang dihasilkan dari model FRBFNN merupakan kombinasi linear dari bobot dengan fungsi aktivasi � [� ] dan bobot bias . Vektor output dirumuskan sebagai berikut (Orr, 1996:11):
41 dengan,
� [� ] = − ∑ ∑ �. − .
=
=
= jarak maksimum pada cluster ke-k
. = pusat cluster ke-k untuk nilai input fuzzy ke-l dan variabel ke-j
= bobot dari neuron lapisan tersembunyi ke-k menuju neuron output
= bobot bias dari neuron lapisan tersembunyi ke-k menuju neuron output
� = fungsi aktivasi bias dimana nilainya adalah 1
� [� ] = fungsi aktivasi neuron tersembunyi ke-k
� = [ . , . , … , . , . . . , . ( )] merupakan vektor input
berupa himpunan fuzzy
= , , … banyaknya variabel X
= , , … banyaknya himpunan fuzzy
= , , … banyaknya neuron pada hidden layer
Karena � = maka persamaan (3.5) dapat ditulis sebagai berikut:
= ∑ = � [� ] + (3.6)
Pada tugas akhir ini, fungsi keanggotaan yang digunakan yaitu fungsi keanggotaan segitiga, sedangkan fungsi basis sebagai fungsi aktivasi pada lapisan tersembunyi menggunakan fungsi basis Gaussian (persamaan 3.1) serta menggunakan fungsi aktivasi linear (persamaan 2.9) pada lapisan output.
3. Algoritma Pembelajaran Fuzzy Radial Basis Function Neural Network
(FRBFNN)
42
jaringan syaraf Radial Basis Function (RBF). Model Fuzzy Radial Basis Function Neural Network (FRBFNN) adalah model unsupervised-supervised learning (Chi & Hsu, 2001: 2808). Metode pembelajaran tidak terawasi (unsupervised learning) digunakan pada proses dari lapisan input menuju lapisan tersembunyi dan metode pembelajaran terawasi (supervised learning) digunakan pada proses yang terjadi dari lapisan tersembunyi menuju lapisan output (Chen et al, 2005: 323).
Algoritma pembelajaran FRBFNN yang pertama adalah melakukan proses fuzzifikasi yaitu mengubah nilai input yang berupa bilangan crisp menjadi bilangan fuzzy. Selanjutnya dilakukan normalisasi terhadap data input hasil fuzzifikasi tersebut. Prosedur pembelajaran FRBFNN selanjutnya mengacu pada algoritma pembelajaran RBFNN yang terbagi menjadi tiga bagian, yaitu (Andrew, 2002: 80):
43
[image:43.595.168.461.211.314.2]Berikut ini adalah ilustrasi penggunaan algoritma K‐means untuk menentukan cluster dari 4 buah obyek dengan 2 atribut, seperti ditunjukkan dalam Tabel 3.1 berikut.
Tabel 3. 1 Tabel Sampel Data Obyek Atribut 1 (X):
indeks berat
Atribut 2 (Y): pH
Obat A 1 1
Obat B 2 1
Obat C 4 3
Obat D 5 4
Clustering akan dilakukan untuk membentuk 2 cluster jenis obat berdasarkan atributnya. Langkah‐langkah algoritma K‐Means clustering adalah sebagai berikut:
1) Penentuan nilai awal titik tengah
Misalkan obat A dan obat B masing‐masing menjadi titik tengah (centroid) dari cluster yang akan dibentuk, sehingga diperoleh koordinat kedua centroid tersebut yaitu = , dan = , .
2) Menghitung jarak obyek ke centroid dengan menggunakan rumus jarak Euclid
Misal akan dihitung jarak obat D ke centroid pertama = , dan centroid kedua = , dengan menggunakan jarak Euclide seperti pada persamaan 2.13. Berikut ini merupakan hasil perhitungannya:
, = √ − + − =
44
Proses perhitungan tersebut juga diterapkan untuk menghitung jarak obat A, B, C ke centroid pertama dan centroid kedua. Hasil perhitungan jarak ini disimpan dalam bentuk matriks �, dengan banyaknya cluster dan
� banyak obyek. Setiap kolom dalam matriks tersebut menunjukkan obyek sedangkan baris pertama menunjukkan jarak ke centroid pertama, baris kedua menunjukkan jarak ke centroid kedua. Matriks jarak setelah iterasi ke‐0 adalah sebagai berikut:
= [ ,, , ]
[image:44.595.190.445.406.600.2]Gambar 3.2 berikut merupakan gambar ilustrasi untuk iterasi ke- 0 pada metode K-Means clustering.
Gambar 3. 2 Gambar Ilustrasi untuk Iterasi 0
3) Clustering obyek: Memasukkan setiap obyek ke dalam cluster berdasarkan jarak minimumnya. Jadi obat A dimasukkan ke cluster 1, dan obat B, C dan D dimasukkan ke cluster 2. Keanggotaan obyek ke dalam cluster dinyatakan dengan matrik, elemen dari matriks bernilai 1 jika sebuah
Atribut 1 (X): indeks berat
A
tr
ib
ut
2
(
Y
):
45
obyek menjadi anggota grup. Berikut adalah matriks keanggotaan yang baru.
� = [ ]
4) Iterasi-1, menentukan centroid: Berdasarkan anggota masing‐masing cluster, selanjutnya ditentukan centroid baru. Cluster 1 hanya berisi 1 obyek, sehingga centroidnya tetap = , . Cluster 2 mempunyai 3 anggota, sehingga centroidnya ditentukan berdasarkan rata‐rata koordinat ketiga anggota tersebut:
= + + , + + = ,
5) Iterasi‐1, menghitung jarak obyek ke centroid: selanjutnya, jarak antara centroid baru dengan seluruh obyek dalam cluster dihitung kembali sehingga diperoleh matriks jarak sebagai berikut:
= [ , , ,, , ]
6) Iterasi‐1, clustering obyek: langkah ke‐3 diulang kembali, menentukan keanggotaan cluster berdasarkan jarak minimumnya. Berdasarkan matriks jarak yang baru, maka obat B harus dipindah ke cluster 2. Berikut adalah matriks keanggotaan yang baru.
� = [ ]
46
Gambar 3. 3 Gambar Ilustrasi untuk Iterasi 1
7) Iterasi‐2, menentukan centroid: langkah ke‐4 diulang kembali untuk menentukan centroid baru berdasarkan keanggotaan cluster yang baru. Cluster 1 dan cluster 2 masing‐masing mempunyai 2 anggota, sehingga centroidnya menjadi = + , + = , dan = + , + =
, .
8) Iterasi‐2, menghitung jarak obyek ke centroid : ulangi langkah ke‐2, sehingga diperoleh matriks jarak sebagai berikut:
= [ ,, ,, ,, ,, ]
9) Iterasi‐2, clustering obyek: mengelompokkan tiap‐tiap obyek berdasarkan jarak minimumnya, diperoleh:
� = [ ]
A
tr
ib
ut
2
(
Y
):
pH
47
Atribut 1 (X): indeks berat
[image:47.595.193.449.171.371.2]Gambar 3.4 berikut merupakan gambar ilustrasi untuk iterasi ke- 2 pada metode K-Means clustering.
Gambar 3. 4 Gambar Ilustrasi untuk Iterasi 2
[image:47.595.144.493.532.646.2]Hasil pengelompokkan pada iterasi terakhir dibandingkan dengan hasil sebelumnya, diperoleh � = � . Hasil ini menunjukkan bahwa tidak ada lagi obyek yang berpindah cluster, dan algoritma telah stabil. Hasil akhir clustering ditunjukkan dalam Tabel 3.2 berikut:
Tabel 3. 2 Hasil Clustering Obyek Atribut 1 (X):
indeks berat
Atribut 2 (Y):
pH Hasil cluster
Obat A 1 1 1
Obat B 2 1 1
Obat C 4 3 2
Obat D 5 4 2
b. Menentukan jumlah fungsi basis (neuron pada lapisan tersembunyi) dilakukan dengan metode trial and error.
A
tr
ib
ut
2
(
Y
):
48
c. Menentukan bobot output layer jaringan optimum. Bobot output layer jaringan optimum ditentukan dengan menggunakan metode global ridge regression. Metode global ridge digunakan untuk mengestimasi bobot dengan cara menambahkan parameter regulasi yang bernilai positif pada sum square error (SSE). Estimasi bobot terbaik didapatkan dari hasil akhir dengan SSE terkecil. Untuk mendapatkan SSE terkecil, dilakukan metode untuk meminimalkan SSE yaitu dengan metode kuadrat terkecil (least square) yang bertujuan mempermudah dalam penyelesaian masalah optimum.
Pada tugas akhir ini metode least square yang digunakan untuk menentukan nilai bobot dengan menghasilkan akurasi maksimum. Model linear yang digunakan adalah = ∑ = � [� ] + . Berikut adalah perumusan dari metode least square:
�� = ∑ = − ̂ (3.7)
dengan,
= , , … , � banyaknya data pengamatan
̂ = nilai klasifikasi variabel output ke-i
= target output ke-i
Untuk menentukan nilai optimum bobot , dapat ditentukan dengan cara menurunkan SSE terhadap bobot-bobotnya, sehingga diperoleh:
� �
� = ∑ = − ̂
�
� (3.8)
Berdasarkan persamaan (3.6) diperoleh: �
49
Persamaan (3.9) disubstitusikan ke persamaan (3.8) dengan hasil sama dengan nol, sehingga diperoleh:
∑= − ̂ � [� ] = (3.10)
∑= � [� ] = ∑= ̂ � [� ] (3.11)
∑= � [� ] = ∑= ̂ � [� ] (3.12)
Karena k = 1,2,...,r maka diperoleh r persamaan seperti (3.12) untuk menentukan r bobot. Untuk memperoleh penyelesaian tunggal, persamaan (3.12) ditulis dengan notasi vektor, sehingga diperoleh:
� � = � �̂ (3.13)
dengan,
� = [
� [� ]
� [� ]
� [� ]
] , � = [ ] , �̂ = [ ̂ ̂
̂ ]
Karena terdapat r persamaan untuk setiap nilai k, maka persamaan (3.13) dapat ditulis sebagai berikut:
[ � �
� �
� �] =
[ � �̂
� �̂
� �̂]
� � = � �̂ (3.14)
dengan,
� = [� � … � � � ]
� = [
� [� ] � [� ] … � [� ]
� [� ] � [� ] … � [� ]
� [� ] � [� ] … � [� ]
50
Matriks � merupakan matriks fungsi aktivasi. Komponen ke-i dari y saat bobot pada nilai optimum adalah (Orr, 1994: 43):
�= ∑ = � [� ] = �̅���̂ (3.15)
dengan,
�̅�=
[
�� [�[� ]]
� [� ]
]
Akibat � adalah salah satu kolom dari � dan �̅�� adalah salah satu baris dari
�. Oleh karena itu, berdasarkan persamaan (3.15) diperoleh:
= [ ] = [ � �̂
� �̂
� �̂]
= ��̂ (3.16)
Persamaan (3.16) disubstitusikan ke persamaan (3.14) menjadi:
� � = � �̂ (3.17)
� ��̂ = � �̂ (3.18)
Jika nilai invers dari � � dapat ditentukan, maka nilai bobot optimum dapat dicari dengan:
�̂ = � � − � �̂ (3.19)
�̂ = �− � �̂ (3.20)
�̂ merupakan nilai bobot dan A adalah matriks perkalian � dengan �. Selanjutnya ditambahkan parameter regulasi yang bernilai positif pada SSE sehingga diperoleh fungsi (Orr, 1996: 24):
51 dengan,
̂ = nilai klasifikasi variabel output ke-i
= target output ke-i
= , , … , � banyaknya data pengamatan
= parameter regulasi
= bobot dari neuron lapisan tersembunyi ke-k menuju neuron output Bobot yang optimum diperoleh dengan mendiferensialkan persamaan (3.21) dengan variabel bebas yang kemudian ditentukan penyelesaiannya untuk diferensial sama dengan nol, maka didapatkan (Orr, 1996: 41-43):
��
� = ∑ − ̂�
�
� +
= (3.22)
��
� = ∑
�
� −
= ∑= ̂��� + (3.23)
Substitusikan ��
� = pada persamaan (3.23) sehingga diperoleh:
∑= �� − ∑= ̂��� + = (3.24)
∑= �� −∑= ̂��� + = (3.25)
∑= �� + = ∑= ̂��� (3.26)
Misalkan �
� = � [� ], maka didapatkan:
∑= � [� ] + = ∑= ̂� [�� ] (3.27)
sehingga dalam notasi vektor adalah sebagai berikut:
52 Dengan,
� = [
� [� ]
� [� ]
� [� ]
] , � = [ ] , �̂ = [ ̂ ̂
̂ ]
Terdapat r persamaan untuk setiap nilai k, maka persamaan (3.28) dapat ditulis sebagai berikut:
[ � �
� �
� �] + [
̂ ̂
̂ ] =
[ � �̂
� �̂
� �̂]
� � + �̂ = � �̂ (3.29)
dengan,
= parameter regulasi
�̂ = vektor bobot klasifikasi
�̂ = vektor target klasifikasi
� = Matriks fungsi aktivasi dengan {� } = sebagai kolom
= perkalian matriks fungsi aktivasi dan vektor bobot
Matriks � merupakan matriks fungsi aktivasi. Komponen ke-i dari y saat bobot pada nilai optimum adalah (Orr, 1994: 43):
[� ] = ∑ = ̂ � [� ] = �̅ �̂ (3.30)
dengan,
�̅�=
[
�� [�[� ]]
� [� ]
53
� = [ ] = [ �̅ ̂
�̅ ̂
�̅ ̂]
= ��̂ (3.31)
Berdasarkan definisi-definisi yang telah disebutkan di atas diperoleh:
� �̂ = � � + �̂ (3.32)
= � ��̂ + �̂
= � � + �̂
Jadi diperoleh perasamaan normal untuk bobot pengklasifikasian sebagai berikut:
�̂ = � � + � − � �̂ (3.33)
Metode Global Ridge Regression digunakan untuk menentukan estimasi bobot optimum. Pada tugas akhir ini, kriteria pemilihan model digunakan yaitu kriteria Generalised Cross-Validation (GCV) untuk menghitung prediksi error. Rumus untuk kriteria GCV adalah sebagai berikut (Orr, 1996: 20).
�̂��� = ̂
�� ̂
� (3.34)
dengan,
� = � − � ��� − ��
� = banyak data P = matriks proyeksi
54
B. Prosedur Pemodelan Fuzzy Radial Basis Function Neural Network
(FRBFNN) untuk Klasifikasi Kanker Payudara
Berikut adalah prosedur pemodelan Fuzzy Radial Basis Function Neural Network (FRBFNN) untuk klasifikasi stadium kanker payudara pada data Wisconsin Breast Cancer Database (WBCD) dan data Wisconsin Diagnostic Breast Cancer (WDBC):
1. Menentukan Variabel Input dan Output
Variabel input yang digunakan dalam tugas akhir ini adalah nilai-nilai variabel hasil Fine-needle Aspirate (FNA) biopsy payudara yang diperoleh dari University of Wisconsin Hospital. Banyaknya variabel input menentukan banyaknya neuron pada lapisan input. Sedangkan target jaringan atau output berupa klasifikasi atau diagnosa dari kanker payudara. Klasifikasi kanker payudara pada tugas akhir ini menggunakan target jaringan, yaitu 0 untuk benign (tumor) dan 1 untuk malignant (kanker). Banyaknya variabel output akan menentukan banyaknya neuron pada lapisan output.
2. Pembagian Data Training dan Testing
55
Terdapat beberapa perbandingan dalam pembagian data menjadi data training maupun testing yang sering digunakan, antara lain (Deb Rajib et al, 2015):
a. 60% untuk data training dan 40% untuk data testing. b. 75% untuk data training dan 25% untuk data testing. c. 80% untuk data training dan 20% untuk data testing.
Pada tugas akhir ini, menggunakan pembagian data 80% untuk data training dan 20% untuk data testing.
3. Pembelajaran Fuzzy Radial Basis Function Neural Network (FRBFNN)
Berikut merupakan langkah-langkah dalam pembelajaran FRBFNN: a. Melakukan proses fuzzifikasi pada nilai input
Variabel input diperoleh dari hasil fuzzifikasi terhadap variabel yang diperoleh dari data Wisconsin Breast Cancer Database (WBCD) dan Wisconsin Diagnostic Breast Cancer (WDBC). Proses fuzzifikasi pada tugas akhir ini menggunakan fungsi keanggotaan segitiga (Persamaan 2.5) dengan 3 himpunan fuzzy. Hasil dari proses fuzzifikasi tersebut selanjutnya disebut sebagai derajat keanggotaan. Derajat keanggotaan digunakan sebagai input pada proses pembelajaran model FRBFNN.
b. Menormalisasi data
56
dibawa ke bentuk normal yang memiliki mean = 0 dan standar deviasi = 1. Menurut Samarasinghe (2007: 53 253), pendekatan sederhana untuk normalisasi data adalah dengan bantuan mean dan standar deviasi sebagai berikut:
1) Perhitungan nilai rata-rata
̅. = ∑ [= . ] (3.38)
dengan
̅ . adalah rata-rata nilai data pada himpunan fuzzy ke-l dan variabel ke-j
[ . ] adalah nilai input fuzzy pada data ke-i, himpunan fuzzy ke-l dan variabel ke-j
= , , … , � banyaknya data.
= , , … banyaknya variabel X
= , , … banyaknya himpunan fuzzy
2) Perhitungan nilai varians
. =n− ∑= [ . ] − ̅. (3.39)
dengan
. adalah nilai varians data pada himpunan fuzzy ke-l dan variabel ke-j
[ . ] adalah nilai input fuzzy pada data ke-i, himpunan fuzzy ke-l dan variabel ke-j
= , , … , � banyaknya data.
= , , … banyaknya variabel X
= , , … banyaknya himpunan fuzzy
3) Perhitungan normalisasi
[ . ] ∗ =[�. ] − ̅.
57 dengan
. adalah nilai standar deviasi data pada himpunan fuzzy ke-l dan variabel ke-j
̅ . adalah rata-rata nilai data pada himpunan fuzzy ke-l dan variabel ke-j
[ . ] adalah nilai input fuzzy pada data ke-i, himpunan fuzzy ke-l dan variabel ke-j
Pada MATLAB, normalisasi dengan mean dan standar deviasi menggunakan perintah prestd yang akan membawa data ke dalam bentuk normal dengan mean = 0 dan standar deviasi =1 dengan syntax:
[Pn,meanp,stdp,Tn,meant,stdt]=prestd(P,T); (3.41) dengan,
P = matriks data input, T = matriks data target,
Pn = matriks data input yang telah dinormalisasi, Tn = matriks data target yang telah dinormalisasi,
Meanp = rata-rata pada matriks data input sebelum dinormalisasi,
Stdp = standar deviasi pada matriks data input sebelum dinormalisasi, Meant = rata-rata pada matriks target sebelum dinormalisasi,
Stdt = standar deviasi pada matriks target sebelum dinormalisasi. c. Menentukan pusat dan jarak dari setiap fungsi basis.
58
suatu jarak untuk mengukur kemiripan dari objek-objek yang diamati. Jarak yang umumnya digunakan yaitu jarak Euclide. Semakin kecil nilai jarak Euclide, semakin tinggi tingkat kemiripan, begitu pula sebaliknya, semakin besar nilai jarak Euclide maka semakin rendah tingkat kemiripannya. Setelah ukuran kemiripan ditemukan, maka dapat dilakukan pengelompokan (Brodjol, 2008).
K-Means merupakan salah satu metode clustering non hierarchy yang berusaha mempartisi data yang ada ke dalam bentuk satu atau lebih cluster/kelompok. Metode ini mempartisi data ke dalam cluster/kelompok sehingga data yang memiliki karakteristik yang sama dikelompokkan ke dalam satu cluster yang sama dan data yang mempunyai karakteristik yang berbeda dikelompokkan ke dalam kelompok yang lain (Agusta, 2007: 47).
Algoritma metode K-Means clustering adalah sebagai berikut (Johnson & Wichern, 2007: 696):
1) Partisi data kedalam K cluster
2) Tempatkan setiap data/obyek ke cluster terdekat. Kedekatan dua obyek ditentukan berdasarkan jarak kedua obyek tersebut. Jarak biasanya dihitung dengan menggunakan jarak Euclide. Persamaan jarak Euclide antara dua titik sebarang P dan Q dengan koordinat P ( , ,… , )dan Q
( , ,… , )adalah sebagai berikut:
, = √ − + − + + − (3.42)
59
3) Ulangi langkah ke-2 sampai nilai pusat lama sama dengan nilai pusat baru (stabil).
Menurut Zhang dan Fang (2013: 194), metode K-Means clustering memiliki beberapa keunggulan antara lain yaitu: algoritma K-Means merupakan algoritma klasik untuk menyelesaikan masalah pengelompokkan sehingga algoritma ini relatif sederhana dan cepat; untuk data yang besar, algoritma ini relatif fleksibel dan efisien; serta dapat memberikan hasil yang relatif baik. Sedangkan kelemahan dari metode K-Means clustering dikemukakan oleh Berkhin (2002: 27) yang menyebutkan bahwa metode K-Means clustering sangat bergantung pada pemilihan nilai awal centroid, tidak jelas berapa banyak cluster K yang terbaik dan hanya bekerja pada atribut numerik.
Metode K-means ini mengelompokkan data input menjadi beberapa kelompok atau kluster sehingga nilai pusat dan varians setiap kluster dapat dihitung. Pusat cluster adalah rata-rata (mean) kluster tersebut. Banyak neuron pada lapisan tersembunyi sesuai dengan banyak cluster yang terdapat pada pengelompokan menggunakan K-means clustering.
d. Menentukan jumlah fungsi basis neuron pada lapisan tersembunyi.
Pada lapisan tersembunyi metode RBFNN, dilakukan aktivasi fungsi basis. Dalam tugas akhir ini, aktivasi fungsi basis dilakukan dengan aplikasi Matlab dengan menggunakan program rbfDesign (Sutijo, 2006:156). Program untuk rbfDesign dilampirkan pada Lampiran 13 halaman 210. Cuplikan dari Program rbfDesign adalah sebagai berikut:
60 dengan,
H = matriks desain RBFNN X = matriks input
C = matriks pusat cluster
R = matriks jarak masing-masing input terhadap pusat cluster Option = tipe aktivasi fungsi basis
Tipe aktivasi yang digunakan pada tugas akhir ini adalah fungsi Gaussian dengan ‘b’ yaitu neuron bias yang ditambahkan pada jaringan, sehingga matriks
� akan mendapatkan satu kolom tambahan.
e. Menentukan bobot dari lapisan tersembunyi ke lapisan output.
Digunakan metode global ridge-regression untuk mendapatkan bobot yang optimum. Pada tugas akhir ini penentuan bobot dengan metode global ridge-regression dilakukan dengan menggunakan aplikasi Matlab menggunakan metode global ridge (Sutijo, 2006:169). Program untuk global ridge dilampirkan pada Lampiran 14 halaman 212. Berikut adalah sebagian fungsi pada program global ridge.
lamb = globalRidge(H,T,0.05) (3.44)
dengan,
lamb = parameter regulasi H = matriks desain RBFNN T = target data input training
61
4. Menentukan Jaringan Optimum
Jaringan optimum pada FRBFNN didapatkan dengan metode trial and error. Metode ini dilakukan dengan cara menentukan hasil klasifikasi yang didapatkan menggunakan beberapa cluster yang berbeda. Model FRBFNN terbaik adalah model dengan suatu cluster tertentu yang memiliki hasil akurasi tertinggi baik pada data training maupun testing.
5. Klasifikasi
62
Gambar 3. 5 Diagram Alur Model FRBFNN
C. Hasil Model Fuzzy Radial Basis Function Neural Network (FRBFNN)
untuk Klasifikasi Stadium Kanker Payudara
Langkah-langkah klasifikasi stadium kanker payudara menggunakan model Fuzzy Radial Basis Function Neural Network dengan menggunakan data Wisconsin Breast Cancer Database (WBCD) dan data Wisconsin Diagnostis Breast Cancer (WDBC) adalah sebagai berikut.
Mulai
Menentukan Variabel Input dan Output
Pembagian Data Training dan Testing
Menentukan Jaringan Optimum
Pembelajaran RBFNN
Jaringan Optimum
Akurasi
Hasil jelek
Hasil baik
Model FRBFNN Terbaik
Hasil Klasifikasi Kanker Payudara
63
1. Menentukan variabel input dan variabel output
Penentuan variabel input pada model FRBFNN didasarkan pada hasil fuzzifikasi terhadap data WBCD dan WDBC yang diperoleh. Sedangkan Variabel output dari model FRBFNN pada tugas akhir ini adalah klasifikasi stadium kanker payudara. Output yang diharapkan pada data WBCD dan WDBC adalah sama yaitu benign (tumor) dan malignant (kanker). Penentuan output model FRBFNN adalah berdasarkan hasil klasifikasi yang didapatkan yang berupa bilangan decimal. Pengklasifikasian dilakukan dengan membulatkan bilangan desimal tersebut dengan kriteria sebagai berikut:
1) Jika -0.5< <