JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 2, No. 1, Januari-Maret 2017 ISSN: 2541-5093
1 Jurnal Nasional JMII 2017
ANALISIS SENTIMEN BERBAHASA INDONESIA
DENGAN PENDEKATAN LEXICON-BASED PADA MEDIA SOSIAL
Adiyasa Nurfalah, Adiwijaya, Arie Ardiyanti Suryani Telkom University
St. Telekomunikasi No. 1, Bandung, Indonesia
E-mail : [email protected] 1), [email protected] 2), [email protected] 3)
Abstrak
Indonesia merupakan salah satu negara pengguna media sosial paling banyak di dunia, bahkan setiap trending topic sering berasal dari Indonesia. Media sosial saat ini digunakan untuk berinteraksi dengan keluarga, teman, bahkan dengan orang yang mungkin tidak dikenal sama sekali.
Selain itu, media sosial juga dipergunakan sebagai alat bantu e – commerce untuk meningkatkan penjualan suatu produk.
Tidak jarang juga, suatu posting pada media sosial dapat menimbulkan keresahan, namun dapat juga suatu posting itu bermanfaat untuk semua orang.
Misalnya posting tentang suatu produk makanan yang mungkin terdapat komentar positif dan negatif didalamnya. Pada penelitian ini akan menggunakan pendekanan Lexicon – based untuk melihat apakah suatu komentar atau posting dari media sosial memiliki sentimen positif atau negatif atau dapat pula netral. Penelitian ini mendapatkan hasil akurasi 66%
untuk prediksi komentar positif, negatif dan juga netral.
Kata Kunci : media sosial, lexicon-based, prediksi , sentimen
Abstract
Indonesia is one of the most media social access in the world, therefor every world trending topic is from Indonesia. Social media are using for interaction and communication with our family, friends, even the stranger. For e – commerce, social media are using for product marketing to the customer.
Posting on social media can cause resslessness, but it can be usefull for people. For example, a posting about food product that may have sentiment positive ,negative, or neutral comments from user. In this research used Lexicon – based methods to classified comments going to positive or negative or even neutral way. This research also have 66% of accuracy for prediction.
Keywords : social media, lexicon – based, prediction,
sentiment
I. P
ENDAHULUANSaat ini media sosial tidak hanya digunakan
sebagai sarana untuk aktualisasi diri dan sarana
pergaulan, tetapi juga sebagai sarana untuk
menyampaikan informasi yang sedang hangat
dibicarakan. Menurut Bing Liu [3], informasi dapat
dikategorikan menjadi 2, yaitu: pengetahuan (fakta),
atau opini (pendapat). Fakta atau pengetahuan
bersifat obyektif terhadap suatu topik pembahasan.
JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 2, No. 1, Januari-Maret 2017 ISSN: 2541-5093
Jurnal Nasional JMII 2017 2 Sedangkan opini biasanya merupakan ekspresi
subyektif yang mendeskripsikan sentimen ataupun perasaan seseorang terhadap suatu topik pembahasan.
Sejak maraknya jejaring sosial, blog, forum, dsb, indonesia selalu masuk dalam 10 besar pengguna terbanyak. Menurut data yang dilansir oleh Socialbakers [1], Indonesia menjadi Negara dengan pengguna Facebook ke-4 terbesar didunia dengan total 47 juta akun lebih setelah Amerika Serikat, Brazil, dan India. Maraknya media sosial ini dapat dimanfaatkan salahsatunya untuk meningkatkan penjualan suatu produk dari perusahaan. Perusahaan melemparkan topik tentang ulasan suatu produk atau fitur dari suatu produk, kemudian pengguna media sosial yang mungkin saja calon pembeli atau yang sudah membeli produk akan memberikan tanggapan tentang produk tersebut dalam bentuk opini berupa pengalaman baik maupun buruk, saran, atau tanggapan netral. Media sosial juga dapat dimanfaatkan untuk mengetahui tanggapan masyarakat umum mengenai kebijakan publik yang dikeluarkan pemerintah atau wacana dari suatu lembaga pemerintah.
Melalui berbagai opini yang diberikan oleh pembaca, maka sang pembuat topik (perusahaan, pemerintah) dapat mengetahui sentimen setuju atau tidak setuju dari pembaca terhadap topik yang disajikan, hasil ini akan berguna sebagai salahsatu parameter analisis, misalnya untuk menentukan jumlah produksi dan menilai kualitas dari suatu produk dari sisi pengguna. Namun, dengan banyaknya informasi yang tersedia di internet, pembuat topik maupun pembaca mungkin akan kewalahan untuk membaca dan menganalisis satu- persatu opini yang diberikan pembaca.
Berdasarkan permasalahan tersebut maka dalam penelitian ini akan dilakukan analisis sentimen pada media sosial berbahasa Indonesia menggunakan pendekatan Lexicon-Based. Berdasarkan penelitian sebelumnya [2][4], analisis sentimen merujuk pada analisis klasifikasi dari opini kedalam 3 kelas, yaitu:
positif, negatif, dan netral.
II. D
ESKRIPSIU
MUMS
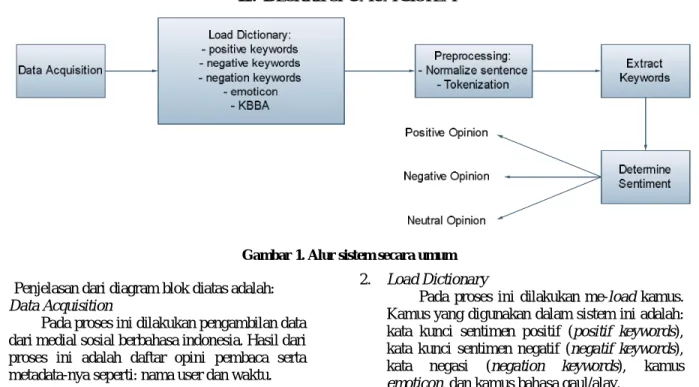
ISTEMGambar 1. Alur sistem secara umum
Penjelasan dari diagram blok diatas adalah:
1. Data Acquisition
Pada proses ini dilakukan pengambilan data dari medial sosial berbahasa indonesia. Hasil dari proses ini adalah daftar opini pembaca serta metadata-nya seperti: nama user dan waktu.
2. Load Dictionary
Pada proses ini dilakukan me-load kamus.
Kamus yang digunakan dalam sistem ini adalah:
kata kunci sentimen positif (positif keywords),
kata kunci sentimen negatif (negatif keywords),
kata negasi (negation keywords), kamus
emoticon, dan kamus bahasa gaul/alay.
JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 2, No. 1, Januari-Maret 2017 ISSN: 2541-5093
Jurnal Nasional JMII 2017 3 3. Preprocessing
Preprocessing bertujuan untuk menyiapkan kalimat sebelum dilakukan ekstraksi kata kunci dan penentuan sentimen. Proses yang dilakukan adalah:
- Normalisasi kalimat
Bertujuan untuk menormalkan kalimat sehingga kalimat gaul menjadi normal.
- Tokenisasi
Bertujuan untuk memecah kalimat menjadi token-token yang merupakan calon keyword.
4. Extract keywords
Proses ini bertujuan untuk mengekstraksi kata kunci penentu sentimen positif dan negatif.
5. Determine sentiment
Proses ini bertujuan untuk menentukan sentimen suatu kalimat opini, penentuan sentimen dilakukan dengan menghitung probabilitas kemunculan kata kunci positif dan kata kunci negatif.
III. I
MPLEMENTASIS
ISTEMDataset
Dataset yang digunakan adalah kumpulan opini pelanggan layanan pasti pas pertamina, yang didapat dari kolom pendapat pada web Pertamina Pasti Pas [6]. Seluruh opini berjumlah 150. Tiap opini diberi label kelas: positif/negatif/netral secara manual.
Penentuan label ini dilakukan untuk menghitung performa sistem yang dibangun. Komposisi kalimat dalam dataset adalah sebagai berikut:
Tabel 1. Komposisi Kalimat Dalam Dataset
Sentimen Jumlah Kalimat
Positif 94
Negatif 44
Netral 12
Kamus
Kamus adalah komponen penting dalam sistem yang menggunakan pendekatan lexicon-based.
Kamus digunakan dalam proses normalisasi kalimat dan ekstraksi kata kunci. Dalam penelitian ini kamus merujuk pada kamus yang disusun oleh PT. EbDesk [5], dimana PT EbDesk menggunakan kamus tersebut dalam membangun sistem analisis sentimen untuk isu-isu politik di Indonesia.
Berikut adalah kamus yang digunakan dalam penelitian ini dan contoh isi kamusnya:
- Positif keywords: baik, banyak, bangkit - Negatif keywords: bangkrut, banjir, bantah - Negation keywords: belum, bukan, tidak - Emoticon: (nilainya: 1), (nilainya: -1) - Kamus gaul: bgmn = bagaimana, bgs = bagus,
beud = banget
Preprocessing
Proses yang dilakukan dalam tahap preprocessing adalah normalisasi kalimat dan tokenisasi.
Normalisasi kalimat
Proses yang dilakukan untuk menormalisasi kalimat adalah:
1. Meregangkan tanda baca (punctuation) dan symbol selain alphabet
Tujuan dari meregangkan tanda baca adalah agar tanda baca dan symbol selain alphabet tidak masuk menjadi token pada saat proses tokenisasi.
2. Menjadikan huruf kecil semua 3. Normalisasi kata
Tabel 2. Aturan normalisasi kata
Tidak Normal / gaul Normal
Akhiran -ny Akhiran –nya
Akhiran –nk Akhiran –ng
Akhiran –x Akhiran –nya
Akhiran –z Akhiran -s
Akhiran –dh Akhiran –t
JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 2, No. 1, Januari-Maret 2017 ISSN: 2541-5093
Jurnal Nasional JMII 2017 4 Kata berulang: sama2 Kata berulang: sama-
sama
Ejaan: oe Huruf: u
Ejaan: dj Huruf: j
4. Hilangkan huruf yang berulang dalam kata Dalam bahasa tulisan opini bebas, untuk mengekspresikan kekesalan, kesenangan, dan lain-lain biasanya digunakan huruf yang berulang-ulang dalam kata. Contohnya: padattt untuk mengekspresikan keadaan yang sangat padat. Kata berulang seperti “padattt” akan di normalisasi menjadi “padat”.
Tokenisasi
Setelah kalimat dinormalisasi, selanjutnya kalimat dipecah kedalam token-token menggunakan pembatas / delimiter spasi. Terdapat 3 jenis token yang digunakan dalam penelitian ini yaitu:
- Unigram
Yaitu token yang terdiri dari hanya satu kata, contohnya: rumah.
- Bigram
Yaitu token yang terdiri dari dua kata, contohnya: rumah makan.
- Trigram
Yaitu token yang terdiri dari tiga kata, contohnya: rumah makan padang.
Aturan yang digunakan untuk membentuk ketiga jenis token tersebut adalah dengan overlapping token.
Berikut ilustri pembentukan token-token tersebut:
Opini: rumah makan padang itu jauh
Unigram Rumah, makan, padang, itu, jauh
Bigram Rumah makan, makan padang, padang itu, itu jauh
Trigram Rumah makan padang, makan padang itu, padang itu jauh
Tujuan digunakannya ketiga jenis token ini adalah karena banyak frase bahasa Indonesia yang tidak hanya terdiri dari satu kata. Penulis mengambil hingga 3 kata karena dalam struktur bahasa Indonesia frase dengan satu kesatuan arti memiliki maksimal 3 kata.
Ekstraksi Kata Kunci
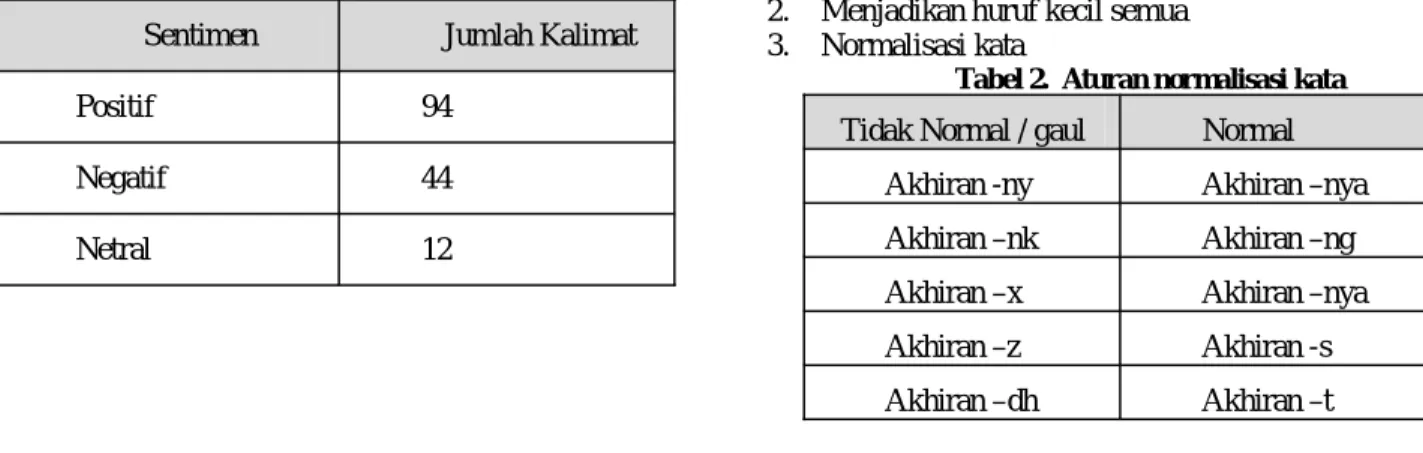
Setelah terbentuk unigram, bigram, dan trigram, selanjutnya di-ekstrak kata kunci dari kalimat menggunakan ketiga jenis token tersebut dicocokkan dengan kamus untuk mendapatkan kata kunci positif dan negatif. Proses yang terjadi dapat dipisahkan menjadi sebagai berikut:
1. Ekstraksi kata kunci positif dan kata kunci negatif
Proses yang terjadi adalah: token-token unigram, bigram, dan trigram dicocokkan dengan kata kunci yang ada dalam kamus kata kunci positif (positif keywords) dan kamus kata kunci negatif (negatif keywords).
2. Evaluasi negasi
Kata kunci positif dan kata kunci negatif hasil ekstraksi kata kunci belum merupakan nilai akhir, selanjutnya dilakukan evaluasi negasi karena kata kunci yang dihasilkan bisa berubah nilainya jika sebelumnya atau sesudahnya diikuti kata negasi. Contohnya kata “berkembang”
adalah kata kunci positif namun jika sebelumnya diikuti kata “tidak” sehingga token menjadi
“tidak berkembang” maka nilainya menjadi negatif. Kata-kata negasi dalam mengevaluasi kata kunci didapatkan dari kamus kata negasi (negation keywords).
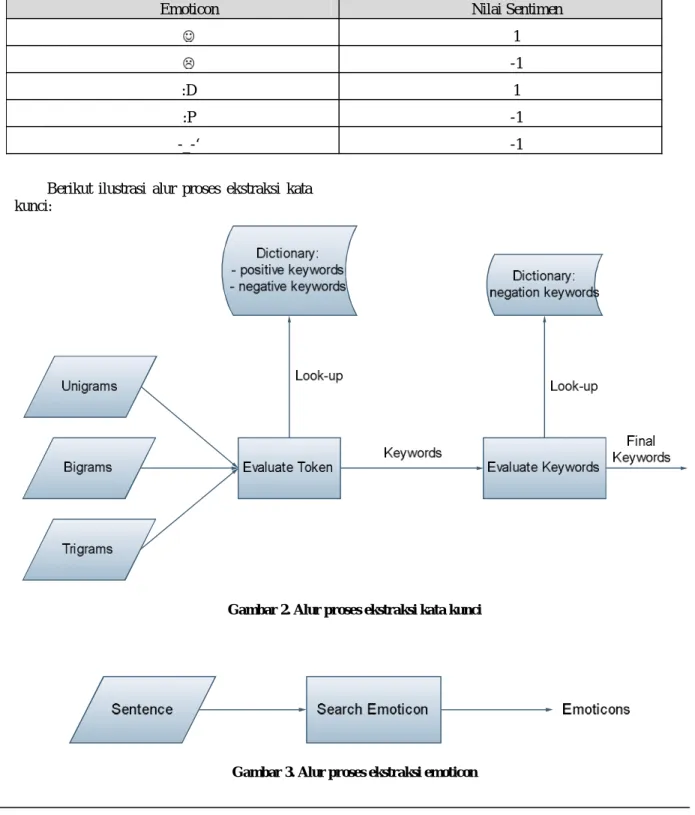
3. Ekstraksi emoticon
Selanjutnya dari kalimat awal dicari emoticonnya. Kita semua mengetahui untuk mengekspresikan persetujuan atau pertidaksetujuan dalam suatu kalimat biasanya digunakan emoticon. Maka dari itu dalam penelitian ini emoticon dalam kalimat dianggap penting dan memiliki kontribusi dalam menentukan nilai sentimen suatu kalimat.
Ekstraksi emoticon ini dilakukan dengan menggunakan referensi kamus emoticon yang mengandung nilai sentimen dari setiap emoticon.
Berikut contoh isi kamus emoticon:
JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 2, No. 1, Januari-Maret 2017 ISSN: 2541-5093
Jurnal Nasional JMII 2017 5
Tabel 3. Kamus Emotion
Emoticon Nilai Sentimen
1 -1
:D 1
:P -1
-_-‘ -1
Berikut ilustrasi alur proses ekstraksi kata kunci:
Gambar 2. Alur proses ekstraksi kata kunci
Gambar 3. Alur proses ekstraksi emoticon
JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 2, No. 1, Januari-Maret 2017 ISSN: 2541-5093
Jurnal Nasional JMII 2017 6 Penentuan Sentimen
Setelah diketahui semua kata kunci dan emoticon yang mempunyai nilai sentimen, selanjutnya dihitung probabilitas kemunculan sentimen positif dan negatif mana yang lebih dominan. Jika nilai sentimen positif lebih dominan maka nilai sentimen untuk kalimat tersebut adalah positif, namun jika nilai sentimen negatif lebih dominan maka nilai sentimen untuk kalimat terebut adalah negatif, namun jika nilainya sama antara sentimen negatif dan sentimen positif maka nilai sentimen untuk kalimat tersebut adalah netral.
Berikut formula dalam penentuan sentimen:
IV. P
ENGUJIAN DANA
NALISISS
ISTEMTujuan dilakukan pengujian terhadap sistem yang dibangun adalah untuk mengetahui performa sistem dalam menentukan nilai sentimen suatu kalimat opini. Performa sistem diukur dengan cara menghitung tingkat akurasi deteksi sistem. Akurasi dihitung dengan cara membandingkan hasil deteksi sentimen dari sistem dengan nilai sentimen sebenarnya yang sebelumnya telah ditentukan oleh manusia, dalam hal ini oleh penulis sendiri. Berikut formulasi untuk menghitung akurasi:
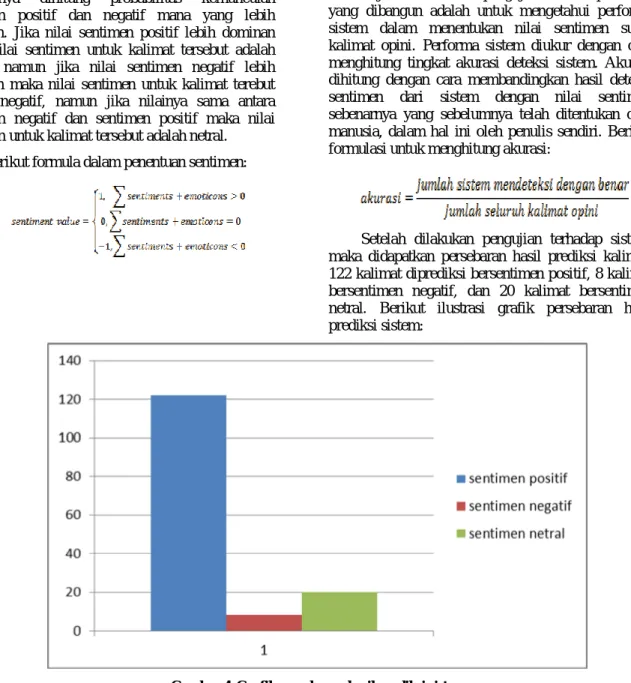
Setelah dilakukan pengujian terhadap sistem, maka didapatkan persebaran hasil prediksi kalimat:
122 kalimat diprediksi bersentimen positif, 8 kalimat bersentimen negatif, dan 20 kalimat bersentimen netral. Berikut ilustrasi grafik persebaran hasil prediksi sistem:
Gambar 4. Grafik persebaran hasil prediksi sistem
JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 2, No. 1, Januari-Maret 2017 ISSN: 2541-5093
Jurnal Nasional JMII 2017 7 Sementara itu, dari hasil pengujian didapatkan
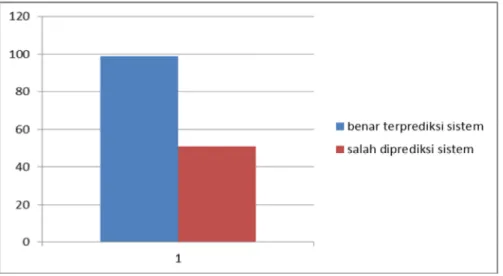
bahwa sistem mempunyai tingkat akurasi sebesar 66
%, dengan 99 kalimat benar diprediksi nilai
sentimennya dan 51 kalimat salah diprediksi nilai sentimennya.
Gambar 5. Grafik jumlah yang benar dideteksi dan salah dideteksi oleh sistem
Berikut contoh kalimat-kalimat hasil pengujian terhadap sistem:
Table 4. Contoh hasil pengujian sistem
Kalimat Kata
kunci Positif
Kata kunci Negatif
Sentimen Ha
sil
Sebenar nya
ane sangat puas dengan pelayanannya karna lebih aman, nyaman, pas takarannya, pas kembaliannya, pas semuanya
puas,am an,nyaman
1 1
kok pom bensinya sering tutup atau habis bensin ya ??
kok,tutup -1 -1
di jalan raya pamulang dan sawangan kapan ada spbu pastipas-nya?
0 0
kalau melihat gencarnya perubahan yang dilakukan oleh Pertamina sih boleh juga, tapi buat saya bukan hanya perubahannya namun bagaimana konsistensi atas perubahan itu...jangan-jangan hanya sebentar saja....
bukan hanya,konsist ensi,boleh juga
jangan- jangan,hanya
1 -1
Pelayanan cukup baik, hanya akhir akhir ini para operator pengisi bensin, sering bercanda dengan sesama operator, apalagi saat pagi hari, yng antrainnya cukup panjang.Tingkatkan kembali mutu anda.
jangan- jangan,hanya
hanya 1 -1
JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 2, No. 1, Januari-Maret 2017 ISSN: 2541-5093
Jurnal Nasional JMII 2017 8 V. K
ESIMPULAN DANS
ARANBerbeda dengan pendekatan berbasis machine learning [2], pada lexicon-based tidak diperlukan training terhadap data sehingga sangat bergantung kapada kamus. Jika kamus lengkap maka performa sistem akan baik, sebaliknya jika kamus tidak lengkap maka performa sistem akan buruk. Dari pengujian yang dilakukan terhadap sistem menghasilkan tingkat akurasi sebesar 66 %, ini berarti kamus belum cukup mewakili kata kunci – kata kunci yang ada dalam kalimat pada kasus opini Pertamina Pasti Pas. Kesulitan yang terjadi pada metode lexicon-based terletak pada penentuan atau pembaharuan kamus oleh manusia. Untuk itu, pada penelitian-penelitian selanjutnya mungkin bisa dilakukan peng-update-an kamus secara otomatis dengan cara mengkombinasikan lexicon-based dengan machine learning.
Selain itu, secara umum kesulitan yang dihadapi dalam natural language processing adalah tidak terstrukturnya kalimat sesuai dengan kaidah tata bahasa yang baku, untuk itu diperlukan pre- processing yang sangat beragam diantaranya:
mengubah simbol-simbol atau angka-angka tertentu menjadi huruf (untuk mengatasi tulisan gaul).
Kemudian langkah lain untuk preprocessing adalah melabeli tiap token dengan jenis katanya (kata
kerja, kata benda, kata keterangan waktu, kata sifat, dll). Tujuannya adalah untuk membedakan mana kalimat opini dan mana kalimat yang bukan opini.
D
AFTARP
USTAKA[1] Social Bakers:
http://www.socialbakers.com,diunduh pada tanggal 20 Oktober 2012.
[2] Yusuf Nur, Muhamad. Santika, Diaz. 2011.
Analisis Sentimen pada Dokumen Berbahasa Indonesia. Konferensi Nasional Sistem dan Informatika 2011. Bali, Indonesia.
[3] Liu, Bing. Sentimen Analysis and Subjectivity. Department of Computer Science University of Illinois at Chicago.
Chichago, USA.
[4] Vidya, Nur Azizah. 2011. Opinion Mining dengan Menggunakan Multinomial Naive Bayes Classifier pada Blog. Tugas Akhir Teknik Informatika, Institut Teknologi Telkom. Bandung, Indonesia.
[5] P.T. EbDesk:
http://www.ebdesk.com,diunduh pada tanggal 20 Oktober 2012.
[6] Pertamina Pasti Pas:
http://pastipas.pertamina.com/pendapat.asp,