Analisis Kinerja Kombinasi Metode Berbasis Lexicon dan Metode Berbasis
Learning pada Analisis Sentimen Twitter
Imam Syafei dan Hendri Murfi
Departemen Matematika, Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas Indonesia, Depok, 16425, Indonesia
E-mail: [email protected], [email protected]
Abstrak
Analisis sentimen merupakan kegiatan untuk mencari pendapat atau sentimen seorang penulis tentang suatu entitas atau objek tertentu yang dapat berupa pendapat positif atau pendapat negatif. Analisis sentimen pada data yang sangat besar tidak dapat dilakukan secara manual sehingga membutuhkan bantuan metode non-manual. Terdapat dua metode non-manual dasar, yaitu metode berbasis lexicon dan metode berbasis learning. Pada penelitian ini, akan dibahas kombinasi metode berbasis lexicon dan metode berbasis learning. Metode kombinasi ini akan digunakan untuk melakukan analisis sentimen dengan data teks yang berasal dari media sosial Twitter atau biasa disebut tweets. Data yang dikumpulkan berupa tweets yang membicarakan seputar tokoh kandidat calon presiden Republik Indonesia periode 2014-2019.
Performance Analysis on Combination Lexicon Based Method and Learning Based Method in Twitter Sentiment Analysis
Abstract
Sentiment Analysis is an activity to find author’s opinion or sentiment about an entity or object, which can be positive or negative opinion. Sentiment Analysis in big size of data can’t be done manually so that it needs hand from non-manual method. There are two basic non-manual methods, that is lexicon-based method and learning-based method. In this research, will be explained combination lexicon-learning-based method and learning-learning-based method. This method of combination will be used to do sentiment analysis on text data, which from social media Twitter or so called tweets. The collection of data is tweets that contain chatting about the presidential candidate of Republic of Indonesia period 2014-2019.
Keywords: learning-based method; lexicon-based method; method of combination; presidential candidate; sentiment analysis; Twitter.
1. Pendahuluan 1.1 Latar Belakang
Dengan seiring perkembangan dunia internet yang begitu cepat, berbagai hal yang terkait dengan dunia internet ikut merasakan dampak perkembangan ini juga dan salah satu
diantaranya adalah media sosial online. Media sosial online adalah web generasi terkini yang memungkinkan pengguna atau pemilik akun untuk saling berkomunikasi satu sama lain dengan pemilik akun yang lain secara online. Bukti pesatnya perkembangan media sosial
terlihat dari besarnya antusiasme masyarakat untuk membuat akun media sosial dan ikut berpartisipasi di dalam perbincangan yang bersifat global. Bukan hanya pertumbuhan pengguna media sosial yang meningkat dengan cepat akibat perkembangan dunia internet, tetapi juga maraknya kemunculan media sosial yang baru dan menawarkan cara
berkomunikasi yang berbeda-beda antara satu dengan lainnya. Beberapa media sosial yang terkenal adalah Facebook, Twitter, Instagram, Path, dan lainnya. Media sosial tersebut memiliki hingga jutaan pemilik akun yang tersebar hampir diseluruh pelosok dunia, terutama Twitter yang perkembangannya sangat cepat di Indonesia. Twitter sendiri merupakan media sosial dan layanan microblogging yang memungkinkan pengguna untuk mengirim dan membaca pesan berbasis teks hingga 140 karakter, yang dikenal sebagai tweets. Jumlah akun pengguna Twitter di Indonesia menduduki posisi kelima sebagai negara dengan jumlah akun terbanyak dengan jumlah akun mencapai hampir 30 juta terhitung Juli 20121 dan pastinya telah tumbuh lebih banyak lagi di tahun ini. Bukan hanya memiliki jumlah akun yang banyak, tetapi Indonesia ikut menyumbang Ibu Kota Jakarta sebagai kota penghasil tweets terbanyak di dunia dan Bandung sebagai kota kelima penghasil tweets terbanyak di dunia.Keduanya menyumbang setidaknya 2.5% dan 1.2% dari keseluruhan tweets publik2.
Para pengguna Twitter dapat membicarakan apapun yang ada di pikiran mereka sehingga banyak sekali variasi topik pembicaraan yang ada di Twitter. Topik-topik tersebut dapat berupa tanggapan terhadap suatu produk, musik, film, organisasi, tokoh, pandangan politik, dan lainnya. Sehingga banyak sekali informasi yang menggelembung di Twitter dan
merupakan ladang emas informasi yang sangat berharga jika dapat diolah dengan baik. Salah satu cara mendapatkan informasi yang ada di dalam Twitter adalah dengan melakukan analisis sentimen entitas atau objek tertentu pada tweets. Analisis sentimen didefinisikan sebagai kegiatan mencari pendapat penulis tentang suatu entitas tertentu (Feldman, 2013), dimana dalam kasus Twitter ini bertujuan untuk mendapatkan opini publik tentang suatu entitas atau objek tertentu, seperti opini publik terhadap produk yang dikeluarkan suatu perusahaan tertentu atau opini publik tentang seorang tokoh masyarakat. Pada dasarnya, analisis sentimen digunakan untuk mengklasifikasikan data tekstual, seperti tweets, menjadi dua kelas yang berkaitan dengan subjektivitas, yaitu positif dan negatif. Dimana dalam kasus produk perusahaan, perusahaan terkait dapat mengetahui tanggapan atau umpan balik dari para pengguna produk mereka, apakah itu positif atau negatif. Namun dalam penerapannya, analisis sentimen pada tweets tidaklah mudah karena data yang tersimpan dalam server
Twitter sangatlah besar dan tidak akan mungkin dapat dilakukan secara manual, baik dalam akuisisi data ataupun analisisnya. Sehingga dibutuhkan suatu metode non-manual untuk melakukan akuisisi data dan analisis sentimen pada tweets.
Metode analisis sentimen yang dikenal saat ini dapat dibagi dua, yaitu metode berbasis lexicon dan metode berbasis learning. Metode berbasis lexicon umumnya menggunakan kamus yang berisi kata-kata opini untuk menentukan suatu sentimen atau polaritas (positif atau negatif) dari suatu data teks, sedangkan metode berbasis learning adalah metode yang melatih sentiment classifier dengan menggunakan metode - metode machine learning untuk menentukan sentimen positif atau negatif dari suatu data teks. Namun dalam penerapannya, kedua metode ini memiliki beberapa kelemahan sehingga diperkenalkanlah kombinasi metode berbasis lexicon dan learning untuk mengatasi kelemahan-kelemahan tersebut. 1.2 Perumusan Masalah dan Ruang Lingkup
Apakah metode kombinasi dapat meningkatkan kinerja metode berbasis lexicon dalam analisis sentimen Twitter?
Ruang lingkup permasalahan yang dibahas dalam penelitian ini adalah analisis sentimen untuk kandidat calon Presiden Republik Indonesia periode 2014-2019. Data yang digunakan berupa data teks yang isinya membicarakan tentang kandidat-kandidat tersebut. Data teks diambil dari media sosial Twitter.
1.3 Tujuan Penelitian
Menganalisa kinerja kombinasi metode berbasis lexicon dan metode berbasis learning dalam analisis sentimen kandidat calon Presiden Republik Indonesia periode 2014-2019 pada data Twitter.
2. Tinjauan Teoritis 2.1 Analisis Sentimen
Sentimen dapat didefinisikan sebagai perasaan positif atau negatif individu dan analisis sentimen dapat didefinisikan sebagai kegiatan mencari pendapat penulis tentang suatu entitas
data tekstual menjadi dua kelas yang berkaitan dengan subjektivitas, yaitu positif dan negatif. Namun, dalam penerapannya dapat pula dikelompokan ke dalam suatu kelas yang lain, yaitu netral. Data teks yang mengandung opini positif dikatakan memiliki polaritas positif dan dimasukan ke dalam kelas positif, begitu pula untuk kelas negatif dan netral. Dalam
perkembangannya, analisis sentimen dapat dilakukan dalam beberapa level data teks, yaitu : • Analisis Sentimen Level Dokumen
Ini merupakan bentuk paling sederhana dari sentimen analisis. Level ini dikatakan sederhana karena diasumsikan bahwa di dalam sebuah dokumen hanya terdapat sebuah pendapat penulis mengenai objek utama yang diekspresikan dalam dokumen tersebut.
• Analisis Sentimen Level Kalimat
Dalam level ini tidak ada asumsi bahwa hanya terdapat satu pendapat. Karena dalam sebuah dokumen bisa saja terdapat beberapa pendapat di dalamnya bahkan tentang entitas/objek yang sama. Oleh karena itu, diasumsikan bahwa setiap kalimat dalam dokumen tersebut memiliki sebuah pendapat. Sehingga akan didapatkan beberapa opini berbeda mengenai suatu entitas dalam sebuah dokumen.
• Analisis Sentimen Level Aspek
Level ini sangat berbeda dengan dua level sebelumnya dimana analisis sentimen dilakukan terhadap keseluruhan dokumen atau setiap kalimat. Dalam level ini, analisis sentimen tidak langsung melihat pendapat penulis tentang suatu entitas tertentu
melainkan melihat atribut atau aspek yang dimiliki entitas tersebut. Contohnya
“Handphone android memiliki banyak aplikasi bagus dan dapat diunduh secara gratis, tetapi baterainya tidak tahan lama dan harus sering diisi ulang”. Entitas yang menjadi perhatian adalah Handphone android dan dalam tulisan di atas terdapat beberapa aspek terkait, yaitu aplikasi dan baterai. Dimana aplikasi memiliki polaritas positif dan baterai memiliki polaritas negatif.
2.2 Metode Berbasis Lexicon
Metode berbasis lexicon bergantung pada kata opini atau kata sentimen, yang mana kata-kata tersebut mengekspresikan sentimen positif atau negatif. Metode ini adalah metode untuk menentukan sentimen atau polaritas opini melalui beberapa fungsi kata opini dalam dokumen atau kalimat (Hu dan Liu 2004, Kim dan Hovy 2004; Ding et al. 2008; Taboada, et al. 2010). Pendekatan menggunakan kata opini untuk menentukan sentimen disebut pendekatan
berbasis kamus (lexicon-based aproach) (Ding et al., 2008; Taboada et al., 2010). Kata-kata yang menunjukan keinginan/kesenangan, seperti luar biasa dan bagus, menunjukan sentimen yang positif atau biasa disebut polaritas positif, sedangkan kata-kata yang menunjukkan hal yang tidak diinginkan atau tidak disenangi, seperti buruk dan jahat, memiliki sentimen negatif atau polaritas negatif. Biasanya kata bernilai sentimen ditemukan pada kata sifat dan
keterangan, tetapi ada juga kata kerja dan kata benda yang mengandung nilai sentimen. Sehingga metode ini menggunakan kamus yang berisi kata-kata opini untuk menentukan suatu sentimen positif atau negatif dari suatu data teks. Kamus ini biasa disebut kamus opini (opinion lexicon). Dalam penelitian ini kamus opini yang digunakan untuk memberikan nilai sentimen kepada data teks adalah SentiWordNet 3.0.
2.3 Metode Berbasis Learning
Metode berbasis learning merupakan salah satu metode untuk melakukan analisis sentimen terhadap data teks yang dapat berupa dokumen atau kalimat. Metode ini melatih
pengklasifikasi sentimen (sentiment classifier) dengan menggunakan metode - metode machine learning untuk menentukan sentimen positif atau negatif dari suatu data teks. Pengklasifikasi sentimen merupakan model yang akan digunakan sebagai aturan keputusan suatu data teks bernilai positif atau negatif, atau dengan kata lain pengklasifikasi sentimen berfungsi untuk mengklasifikasi suatu data teks berdasarkan nilai sentimennya.
Melatih pengklasifikasi sentimen adalah langkah awal dari metode berbasis learning. Setelah langkah ini selesai, diharapkan pengklasifikasi sentimen akan mampu mengklasifikasikan dengan benar data yang diberikan. Pengklasifikasi sentimen dilatih menggunakan fitur-fitur unigram atau bigram (Pang et al. 2002). Fitur-fitur ini adalah hasil ekstraksi dari data pelatihan yang diberikan. Secara umum, terdapat dua jenis machine learning, yaitu unsupervised learning dan supervised learning. Perbedaan kedua jenis ini terletak pada kebutuhan label pada proses pelatihan. Unsupervised learning tidak membutuhkan label pada proses pelatihan dan biasa digunakan untuk mencari variabel tersembunyi, sebaliknya
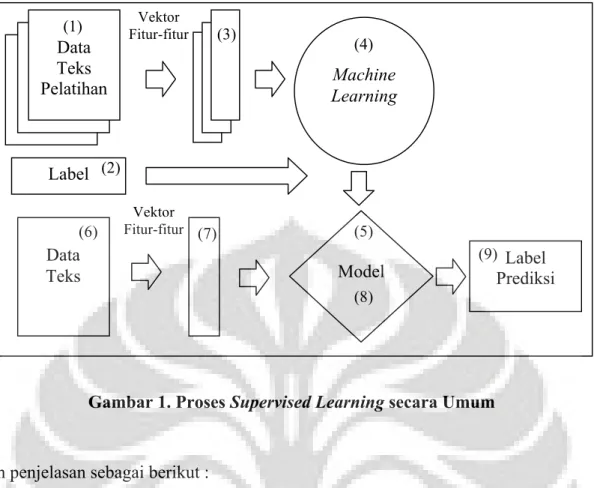
supervised learning membutuhkan label pada proses pelatihan karena biasanya bertujuan untuk melakukan klasifikasi, regresi, atau clustering. Seperti dibahas diawal bahwa akan dilakukan pengklasifikasian data teks berdasarkan nilai sentimennya, maka jenis supervised learning yang akan digunakan dalam penelitian ini. Gambar 1 menunjukan rangkuman proses supervised learning secara umum.
Data Teks Pelatihan Vektor Fitur-fitur Machine Learning Label Vektor Fitur-fitur Model Data
Teks Prediksi Label
(1) (2) (3) (4) (5) (6) (7) (8) (9)
Gambar 1. Proses Supervised Learning secara Umum
dengan penjelasan sebagai berikut :
(1) Pada tahap ini, teks data yang menjadi bahan pelatihan, sebut saja data pelatihan, siap untuk dilatih ke dalam metode machine learning,
(2) Data pelatihan kemudian diberi label secara manual,
(3) Selanjutnya, data pelatihan direpresentasikan ke dalam bentuk vektor dari fitur-fitur hasil ekstraksi dari data pelatihan itu sendiri,
(4) Kemudian, metode machine learning tertentu dilatih dengan menggunakan vektor-vektor data pelatihan bersama dengan label yang sudah diberikan,
(5) Didapatlah model hasil pelatihan machine learning yang akan digunakan menjadi predictive model,
(6) Selanjutnya tahap prediksi label, dimana data baru yang belum dikenal model disiapkan untuk selanjutnya dilakukan prediksi label terhadap data baru tersebut, (7) Kembali data direpresentasikan dalam bentuk vektor dari fitur-fitur,
(8) Kemudian, label dari vektor data baru tersebut diprediksi dengan menggunakan predictive model yang sudah didapatkan sebelumnya,
(9) Dan akhirnya didapatlah label untuk data baru tersebut yang merupakan label hasil prediksi model.
Sejauh ini terdapat beberapa machine learning yang digunakan untuk melakukan analisis sentimen pada data teks, diantaranya Naïve Bayes Classification, Maximum Entropy Classification, dan Support Vector Machine. Ketiganya merupakan supervised learning sehingga membutuhkan pelabelan secara manual.
Pada tahun 1999, Nigam et al. menunjukan bahwa Maximum Entropy Classification terkadang, tetapi tidak selalu, melebihi hasil yang diharapkan dari metode Naïve Bayes Classification dalam pengklasifikasian data teks standar. Sedangkan, Support Vector Machine (SVM) telah ditunjukkan memiliki efektifitas yang tinggi dalam pengkategorian teks traditional dan secara umum melebihi hasil yang diharapkan dari metode Naïve Bayes Classification (Joachims, 1998). Terlebih lagi, SVM menggunakan dasar margin-besar untuk melakukan pengklasifikasian, sedangkan Naïve Bayes dan Maximum Entropy menggunakan probabilitas untuk melakukan pengklasifikasian. Sehingga dalam penelitian ini akan
digunakan Support Vector Machine sebagai metode berbasis learning untuk analisis sentimen pada data Twitter. Pada subbab 2.3.1 akan dibahas mengenai ide dasar Support Vector
Machine.
2.3.1 Support Vector Machine
Support Vector Machine (SVM) adalah algoritma komputer yang belajar melalui sample untuk memberikan label pada objek-objek (Noble, 2006). Tujuan SVM adalah untuk
menghasilkan sebuah model (berdasarkan data pelatihan) yang dapat memeprediksi label dari data pengujian yang diberikan. Model yang digunakan merupakan model linier yang
selanjutnya akan digunakan sebagai hyperplane. Hyperplane merupakan ide dasar dari SVM, dimana akan dicari hyperplane yang dapat memisahkan data berdimensi-n secara sempurna ke dalam dua kelas. Namun, kenyataannya tidak semua data dapat dipisahkan secara linier sehingga SVM menggunakan suatu fungsi yang berfungsi mentransformasi data ke ruang dimensi yang lebih tinggi dimana data tersebut dapat dipisahkan secara linier. Terdapat empat konsep yang perlu diketahui dalam algoritma SVM, konsep ini akan membantu untuk
memahami pengklasifikasian menggunakan SVM. Berikut empat konsep tersebut: • Hyperplane atau Decision Boundary
Hyperplane atau decision boundary digunakan untuk mengklasifikasikan data. Jika data yang digunakan memiliki dua variabel bebas, maka data memiliki bentuk dua dimensi dan bentuk hyperplane berupa garis lurus seperti gambar 2.
!! !! ! !! !! !! !! !!
Gambar 2. Hyperplane yang Memisahkan Dua Himpunan
Jika terdapat tiga variabel bebas, maka hyperplane akan memiliki bentuk bidang. Semakin banyak variabel bebas atau semakin besar dimensi data maka semakin besar pula dimensi hyperplane.
• Hyperplane dengan Margin Maksimum
Hyperplane yang digunakan untuk mengklasifikasikan data tidaklah unik. Misalkan pada contoh kasus dua dimensi seperti gambar 3.
Gambar 3. Hyperplane-hyperplane yang Memisahkan Himpunan
Terdapat beberapa alternatif yang dapat digunakan sebagai hyperplane contoh di atas. Hal ini tentu saja menyulitkan pemilihan hyperplane, sehingga dibutuhkan cara untuk memilih hyperplane yang terbaik dan unik. Pertama, definisikan margin hyperplane adalah jarak dari hyperplane ke sembarang titik data yang terdekat. Hyperplane yang akan digunakan SVM sebagai decision boundary adalah hyperplane yang
!! !!
!
memaksimalkan kerja SVM karena dengan semakin besarnya margin maka akan semakin kuat pula pemisahan kelas-kelas tersebut.
• Margin Lunak (soft margin)
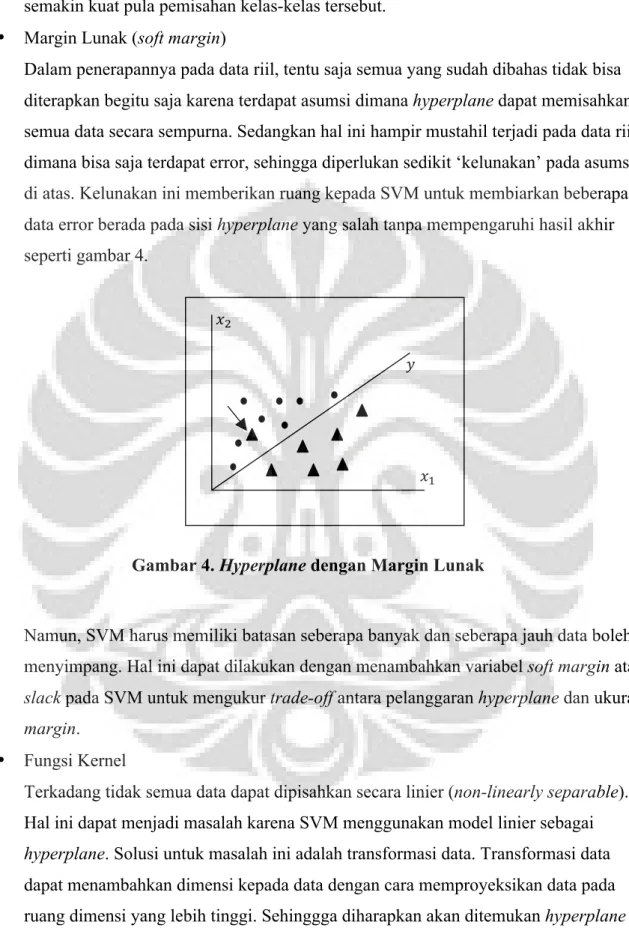
Dalam penerapannya pada data riil, tentu saja semua yang sudah dibahas tidak bisa diterapkan begitu saja karena terdapat asumsi dimana hyperplane dapat memisahkan semua data secara sempurna. Sedangkan hal ini hampir mustahil terjadi pada data riil, dimana bisa saja terdapat error, sehingga diperlukan sedikit ‘kelunakan’ pada asumsi di atas. Kelunakan ini memberikan ruang kepada SVM untuk membiarkan beberapa data error berada pada sisi hyperplane yang salah tanpa mempengaruhi hasil akhir seperti gambar 4.
Gambar 4. Hyperplane dengan Margin Lunak
Namun, SVM harus memiliki batasan seberapa banyak dan seberapa jauh data boleh menyimpang. Hal ini dapat dilakukan dengan menambahkan variabel soft margin atau slack pada SVM untuk mengukur trade-off antara pelanggaran hyperplane dan ukuran margin.
• Fungsi Kernel
Terkadang tidak semua data dapat dipisahkan secara linier (non-linearly separable). Hal ini dapat menjadi masalah karena SVM menggunakan model linier sebagai hyperplane. Solusi untuk masalah ini adalah transformasi data. Transformasi data dapat menambahkan dimensi kepada data dengan cara memproyeksikan data pada ruang dimensi yang lebih tinggi. Sehinggga diharapkan akan ditemukan hyperplane dengan dimensi yang lebih besar yang dapat memisahkan data secara linier (linearly separable). Peran fungsi kernel pada transformasi ini adalah mampu mendefinisikan
hasil kali dalam dari transformasi ini tanpa perlu mengetahui bentuk fungsi transformasi tersebut.
2.4 Kombinasi Metode Berbasis Lexicon dan Metode Berbasis Learning
Pada subbab sebelumnya telah dibahas bahwa terdapat dua metode dasar untuk melakukan analisis sentimen, yaitu metode berbasis lexicon dan metode berbasis learning. Metode berbasis lexicon merupakan metode yang menggunakan kata opini untuk memberikan nilai sentimen suatu data teks. Metode ini efisien dan bisa digunakan untuk menganalisa teks pada level dokumen, kalimat, atau entitas (Zhang, et al., 2011). Sehingga sangat aplikatif dalam analisis sentimen. Meskipun demikian, pada penelitian ini, analisis sentimen diterapkan pada data Twitter atau lebih dikenal dengan nama tweets. Data Twitter tidak seperti data teks pada umumnya karena Twitter telah mengembangkan karakteristiknya sendiri. Beberapa
karakteristik data Twitter dapat mengganggu pendekatan berbasis kamus, seperti kata yang disingkat, bahasa percakapan, emoticon, dan sebagainya. Kemungkinan ekspresi tersebut memiliki nilai sentimen, tetapi ekspresi tersebut tidak ada di dalam kamus opini. Meskipun ekspresi ini dapat ditambahkan secara manual ke dalam kamus opini, ekspresi seperti ini terus berkembang dan muncul ekspresi-ekspresi yang baru seiring dengan berkembangnya trend di internet. Sehingga penambahannya secara manual sangatlah sulit.
Selain menggunakan metode berbasis lexicon, metode berbasis learning juga dapat diterapkan untuk melakukan analisis sentimen pada data Twitter. Machine learning yang digunakan adalah Support Vector Machine. SVM dilatih dengan menggunakan tweets yang menjadi data pelatihan untuk dapat menentukan nilai sentimen. Namun, hal ini juga tidak mudah dilakukan karena pada proses pelatihan SVM juga membutuhkan label disamping data pelatihan dan data Twitter bukan merupakan data dengan jumlah sedikit sehingga pelabelan secara manual akan memakan waktu dan tenaga. Terlebih lagi, SVM yang sudah dilatih pada suatu domain tertentu memiliki performa yang baik pada domain tersebut, tetapi performanya buruk jika digunakan pada domain yang berbeda (Aue dan Gamon, 2005).
Ketidakmampuan metode berbasis lexicon dalam mengidentifikasi ekspresi, seperti kata singkatan, bahasa percakapan, emoticon, dan sebagainya, serta keharusan memberikan label secara manual pada metode berbasis learning menjadi dasar dibentuknya kombinasi dari kedua metode tersebut. Kombinasi kedua metode dilakukan secara sekuensial, pertama gunakan metode berbasis lexicon untuk menentukan nilai sentimen. Selanjutnya, data hasil
Mulai Selesai Data Twitter (Tweets) Metode Lexicon menentukan nilai sentimen Tweets Data Pelatihan Data Pengujian Menghapus kata opini dari Data Pelatihan Melatih SVM menggunakan Data Pelatihan Model Prediksi untuk Klasifikasi (1) (2) (3) (4) (5) (6) (7)
metode berbasis lexicon digunakan sebagai data pelatihan untuk Support Vector Machine. Sehingga dari proses tersebut tidak membutuhkan pelabelan manual. Dengan kata lain, metode kombinasi ini menjadikan metode berbasis lexicon sebagai batu loncatan dan mentransfer pembelajaran kepada SVM. Metode kombinasi ini juga mampu beradaptasi terhadap gaya baru dalam percakapan. Untuk lebih jelasnya, gambar 5 akan menunjukan flowchart algoritma lengkap kombinasi metode berbasis lexicon dan metode berbasis learning.
Gambar 5. Skema Algoritma Kombinasi
dengan penjelasan sebagai berikut :
(1) Data Twitter (tweets) sudah siap untuk diproses,
(2) Metode berbasis lexicon mengidentifikasi keberadaan kata opini pada setiap tweets dan memberikan nilai sentimen positif atau negatif sesuai dengan kata opini yang ada dalam tweets tersebut,
(3) Data pengujian merupakan tweets yang diidentifikasi tidak memiliki kata opini di dalamnya dan biasa digunakan untuk menganalisa kinerjamodel yang dihasilkan, (4) Data pelatihan merupakan tweets yang diidentifikasi memiliki kata opini di
dalamnya,
(5) Sebelum data pelatihan diberikan kepada SVM, terlebih dahulu kata opini, yang teridentifikasi oleh metode berbasis lexicon, dihapus dari tweets. Penghapusan ini menyebabkan SVM dapat belajar kata singkatan, bahasa percakapan, emoticon, dan lain-lain dari domain yang spesifik (Zhang, et al., 2011),
(6) Selanjutnya, SVM dilatih menggunakan data pelatihan yang sudah melewati proses (5) bersama dengan labelnya,
(7) Hasil proses (6) didapat model prediksi yang akan digunakan untuk melakukan klasifikasi tweets ke dalam kelas positif untuk tweets dengan nilai sentimen positif atau kelas negatif untuk tweets dengan nilai sentimen negatif.
3. Metode Penelitian 3.1 Studi Literatur
Mempelajari kombinasi metode berbasis lexicon dan metode berbasis learning untuk menyelesaikan permasalahan analisis sentimen.
3.2 Akuisis dan Persiapan Data Twitter
Mengumpulkan data Twitter berupa tweets yang berhubungan dengan kandidat calon Presiden Republik Indonesia periode 2014-2019. Pengambilan tweets dilakukan secara otomatis dengan bantuan software online yang bernama DiscoverText dimana software ini mampu untuk menyaring tweets yang ada di Twitter berdasarkan sebuah atau beberapa kata kunci yang diberikan. Kata kunci yang digunakan adalah nama 10 orang kandidat calon Presiden Republik Indonesia 2014. Selanjutnya, dilakukan pembersihan dan persiapan data secara non-manual untuk menjadi input metode yang digunakan.
3.3 Penyusunan Algoritma
Pada tahap ini dilakukan perangakaian algoritma kombinasi metode berbasis lexicon dan metode berbasis learning dalam analisis sentimen kandidat calon Presiden Republik Indonesia periode 2014-2019.
3.4 Implementasi Program
Program yang digunakan untuk menyelesaikan permasalahan analisis sentimen kandidat calon Presiden Republik Indonesia periode 2014-2019 dengan menggunakan kombinasi metode berbasis lexicon dan metode berbasis learning adalah Python 2.7.
3.5 Simulasi dan Evaluasi Hasil
Pada tahap ini dilakukan simulasi program dan mengevaluasi hasil dari kinerja metode yang digunakan.
4. Hasil Penelitian
Pada bab ini akan dijabarkan mengenai hasil metode berbasis lexicon (SentiWordNet) untuk klasifikasi tweets ke kelas positif atau kelas negatif dan hasil metode berbasis learning (SVM) untuk meningkatkan kinerja metode berbasis lexicon dalam pengklasifikasian.
Kinerja dari metode yang digunakan akan diukur berdasarkan ukuran keberhasilan. Tabel 1 akan mempermudah pengertian tentang ukuran keberhasilan.
Tabel 1. Tabel Kontingensi Observasi
Prediksi Benar Positif (BP) Salah Positif (SP)
Salah Negatif (SN) Benar Negatif (BN)
dengan penjelasan sebagai berikut :
• Benar Positif (BP) : banyak tweets yang dilabel dengan benar sebagai kelas positif, • Salah Positif (SP) : banyak tweets yang salah dilabel sebagai kelas positif,
• Salah Negatif (SN) : banyak tweets yang salah dilabel sebagai kelas negatif,
• Benar Negatif (BN) : banyak tweets yang dilabel dengan benar sebagai kelas negatif.
Ukuran keberhasilan yang akan digunakan adalah akurasi, presisi, dan recall (Powers, 2007), dimana ketiganya memiliki definisi sebagai berikut :
!"#$%&' = !" + !" !"#$%ℎ !"##!$
• Presisi adalah kemampuan untuk tidak melabel positif tweets yang negatif. !"#$%$% = !"
!" + !" • Recall adalah kemampuan mencari semua tweets positif.
!"#$%% = !" !" + !"
dimana ketiganya memiliki nilai maksimum 1 dan nilai minimum 0.
Selanjutnya, akan ditunjukkan hasil simulasi program. Pertama, tabel 2 menunjukan hasil kinerja metode berbasis lexicon (SentiWordNet) mengidentifikasi seluruh data tweets (data pelatihan dan data pengujian).
Tabel 2. Hasil Simulasi SentiWordNet
Jumlah Tweets 1888
Akurasi 31,6%
Presisi 59,2%
Recall 60,5%
Berdasarkan hasil akurasi, SentiWordNet berhasil mengidentifikasi nilai sentimen atau melabel tweets dengan benar sebanyak 596 dari 1888 tweets, dimana 984 dari 1888 tweets berhasil dilabel (dilabel dengan benar dan salah) dan sisanya sebanyak 904 tidak berhasil diberi label. Selanjutnya berdasarkan hasil presisi, dari keseluruhan tweets yang dilabel positif, sebanyak 59,2% diantaranya benar berasal dari kelas positif. Terakhir berdasarkan hasil recall, dari keseluruhan tweets yang berasal dari kelas positif, sebanyak 60,5% diantaranya berhasil dilabel dengan benar sebagai kelas positif.
Kedua, tabel 3 menunjukan hasil kinerja SVM melabel data pengujian yang merupakan tweets yang tidak berhasil dilabel oleh SentiWordNet.
Tabel 3. Hasil Simulasi SVM
Jumlah Tweets 904
Akurasi 59,3%
Presisi 60,6%
Berdasarkan hasil akurasi, dari 904 tweets yang diidentifikasi tidak memiliki kata opini oleh SentiWordNet, SVM mampu mengklasifikasikan 536 tweets dengan benar. Sehingga SVM mampu meningkatkan sebanyak 536 pengklasifikasiaan secara benar dari total 1888 tweets. Jadi, SVM mampu miningkatkan akurasi SentiWordNet sebesar 0.2838983051 atau sekitar 28%.
Selanjutnya berdasarkan hasil presisi, dari keseluruhan tweets yang dilabel positif, sebanyak 60,6% diantaranya benar berasal dari kelas positif. Terakhir berdasarkan hasil recall, dari keseluruhan tweets yang berasal dari kelas positif, sebanyak 93,1% diantaranya berhasil dilabel dengan benar sebagai kelas positif.
Untuk kebutuhan analisis kinerja, dijalankan pula analisis sentimen Twitter dengan hanya menggunakan metode berbasis learning, yaitu Support Vector Machine. Hal ini dilakukan untuk melihat seberapa baik kinerja SVM tanpa menggunakan bantuan SentiWordNet. Data input yang digunakan merupakan data pelatihan dan untuk melihat hasil kinerja SVM digunakan metode Cross-Validation. Setelah dilakukan eksekusi program didapat rata-rata akurasi SVM, yaitu 90%. Namun, perlu dicatat bahwa penggunaan metode berbasis learning sendiri membutuhkan pelabelan manual yang sangat menguras tenaga dan waktu.
5. Pembahasan
Pada bab ini, akan dilakukan implementasi kombinasi metode berbasis lexicon dan metode berbasis learning untuk melakukan analisis sentimen kandidat calon Presiden Republik Indonesia periode 2014-2019. Implementasi menggunakan bahasa pemrograman Python dan package Microsoft Translator, Scikit-Learn 0.14, dan Pattern 2.5.
5.1 Deskripsi dan Persiapan Data
Data teks yang akan digunakan adalah data dari media sosial Twitter atau yang lebih dikenal dengan nama tweets. Akuisisi tweets dilakukan dengan bantuan software online, yaitu DiscoverText, dimana akuisisi data dilakukan secara otomatis. Periode Pengambilan data dilakukan sejak Agustus 2013 s.d. Februari 2014 dan telah terkumpul sebanyak 11731 tweets.
presiden Republik Indonesia periode 2014-2019. Berikut nama-nama kandidat calon yang menjadi perhatian dalam penelitian ini:
1. Aburizal Bakrie 6. Mahfud M.D.
2. Dahlan Iskan 7. Megawati Soekarno Putri
3. Hatta Rajasa 8. Prabowo Subianto
4. Jusuf Kalla 9. Surya Paloh
5. Joko Widodo 10. Wiranto
Berikut adalah beberapa contoh tweets yang diakuisisi menggunakan DiscoverText: Tabel 4. Contoh Hasil Akuisisi Tweets
Kalau memang baik tak salah rakyat pilih JOKOWI@Tri Risma: Kalau dipercaya jadi presiden, Jokowi bisa - Yahoo! News Indonesia
Jika jd capres Jokowi hrs dicarikan tandingnya yg sepadan. Jgn capres yg 4L. Basiiii n pasti pecundang.
SBY mantan TNI, dan Calon Presiden Prabowo subianto adalah Mantan KOPASSUS.. Krn anggoto TNI disiplin.. Maka dari itu, smw presiden TEGAS!!!
You Are The Next Presiden : Prabowo Subianto, Pemimpin yang Murah senyum, Lemah Lembut, dan Berani Tegas Dalam Aturan Dan Keputusan. Donjon
@kompascom Prabowo dgn 6 Program Aksinya cukup bagus sbg Presiden. Jokowi jangan diganggu sbg Gubernur DKI. DKi semrawut Indonesia hanyut! Presiden Jokowi wakilnya Abraham Samad tiada pasangan lebih mintilihir / dahsyat
Sebelum data dapat digunakan perlu dilakukan beberapa tahap persiapan data. Pertama, dilakukan penyaringan data meliputi penghapusan tweets yang sama dan penghapusan link dari isi tweets. Setelah itu, dilakukan pembangunan stopwords. Stopwords adalah kata atau fitur yang tidak relevan dengan isi tweets. Kata atau fitur yang tidak relevan tersebut
diantaranya, ID pengguna Twitter dan nama kandidat calon Presiden. Tahap terakhir adalah penerjemahan tweets ke dalam bahasa Inggris. Penerjemahan dilakukan karena kamus opini yang digunakan pada metode berbasis lexicon, yaitu SentiWordNet, hanya mengenal kata-kata yang berasal dari bahasa Inggris. Penerjemahan dilakukan secara non-manual dengan bantuan Python dan package Microsoft Translator. Berikut adalah beberapa contoh hasil penerjemahan tweets ke dalam bahasa Inggris dengan menggunakan bantuan Microsoft Translator.
Tabel 5. Contoh Hasil Terjemahan Tweets ke Bahasa Inggris
Tweets sebelum diterjemahkan Tweets setelah diterjemahkan Kalau memang baik tak salah rakyat
pilih JOKOWI@Tri Risma: Kalau dipercaya jadi presiden, Jokowi bisa - Yahoo! News Indonesia
If it's not one of the people either choose JOKOWI @ Tri Risma: if believed could be President, Jokowi-Yahoo! News Indonesia
Jika jd capres Jokowi hrs dicarikan tandingnya yg sepadan. Jgn capres yg 4L. Basiiii n pasti pecundang.
If jd Jokowi capres hrs suitable regular partner is worth it. Capres Jgn yg 4 l. Basiiii n sure losers.
SBY mantan TNI, dan Calon Presiden Prabowo subianto adalah Mantan KOPASSUS.. Krn anggoto TNI disiplin.. Maka dari itu, smw presiden TEGAS!!!
YUDHOYONO'S former TNI, and presidential candidate Prabowo subianto is a former KOPASSUS. Krn anggoto TNI discipline.. Thus, the President EMPHATICALLY smw!!!
You Are The Next Presiden : Prabowo Subianto, Pemimpin yang Murah senyum, Lemah Lembut, dan Berani Tegas Dalam Aturan Dan Keputusan. Donjon
You Are The Next President: Prabowo Subianto, the leader of the smile, gentle, Bold and Resolute in the rules and decisions. The Donjon @kompascom Prabowo dgn 6
Program Aksinya cukup bagus sbg Presiden. Jokowi jangan diganggu sbg Gubernur DKI. DKi semrawut
Indonesia hanyut!
@kompascom Prabowo with 6 Program Action is pretty good as President. Jokowi do not disturb as Governor. JAWA semrawut Indonesia drifting!
Presiden Jokowi wakilnya Abraham Samad tiada pasangan lebih mintilihir / dahsyat
President Jokowi his Deputy Abraham Samad no more terrible mintilihir/pair
Setelah melewati serangkaian persiapan data, didapat data bersih yang siap untuk dijadikan data input pada simulasi program sebanyak 1888 tweets.
5.2 Simulasi Program
Setelah melalui persiapan data, maka data telah siap untuk diolah ke dalam kombinasi metode berbasis lexicon dan metode berbasis learning. Tahapan simulasi meliputi :
1. Identifikasi tweets dengan menggunakan SentiWordNet, 2. Pemberian label dan penghapusan kata opini pada tweets, dan 3. Pelatihan Support Vector Machine (SVM).
Pertama, tweets akan diidentifikasi dengan menggunakan SentiWordNet untuk mendapatkan nilai sentimen dari tweets tersebut. Berikut adalah beberapa contoh hasil identifikasi dengan
Tabel 6. Contoh Hasil Identifikasi Nilai Sentimen
Tweets yang diidentifikasi Nilai sentimen
If it's not one of the people either choose JOKOWI @ Tri Risma: if believed could be President, Jokowi-Yahoo! News Indonesia
0 If jd Jokowi capres hrs suitable regular partner is worth it.
Capres Jgn yg 4 l. Basiiii n sure losers.
0.3375 YUDHOYONO'S former TNI, and presidential candidate
Prabowo subianto is a former KOPASSUS. Krn anggoto TNI discipline.. Thus, the President EMPHATICALLY smw!!!
0 You Are The Next President: Prabowo Subianto, the leader
of the smile, gentle, Bold and Resolute in the rules and decisions. The Donjon
0.2083 @kompascom Prabowo with 6 Program Action is pretty
good as President. Jokowi do not disturb as Governor. JAWA semrawut Indonesia drifting!
0.4167 President Jokowi his Deputy Abraham Samad no more
terrible mintilihir/pair
-0.25
Berdasarkan hasil identifikasi di atas, terlihat bahwa terdapat tweets dengan nilai sentimen positif, negatif, dan nol. Nilai sentimen didapat dari kata opini yang ada pada tweets tersebut, kata opini yang negatif akan memberikan nilai sentimen yang negatif begitu pula dengan kata opini positif akan memeberikan nilai sentimen positif pada tweets. Sedangkan sentimen yang bernilai nol menunjukkan bahwa tidak terdapat kata opini positif ataupun negatif pada tweets tersebut sehingga tweets tersebut dianggap netral. Nilai sentimen hasil identifikasi
SentiWordNet berupa bilangan real dengan interval -1 sampai 1. Jika tweets memiliki nilai sentimen yang semakin mendekati nilai 1, maka tweets tersebut memiliki sentimen yang semakin positif. Sebaliknya, jika tweets memiliki nilai sentimen yang semakin mendekati nilai -1, maka tweets tersebut memiliki sentimen yang semakin negatif.
Setelah proses identifikasi tweets oleh SentiWordNet, data akan dibagi menjadi dua buah kelompok data, yaitu data pelatihan dan data pengujian. Data pelatihan adalah tweets-tweets yang diidentifikasi oleh SentiWordNet memiliki kata opini di dalamnya, sedangkan data pengujian adalah tweets-tweets yang diidentifikasi oleh SentiWordNet tidak memiliki kata opini di dalamnya. Berdasarkan hasil simulasi didapat data pelatihan dengan jumlah data sebanyak 984 tweets dan data pengujian dengan jumlah data sebanyak 904 tweets.
Selanjutnya, data pelatihan yang sudah dibentuk akan diberi label terlebih dahulu sebelum digunakan untuk proses pelatihan oleh SVM. Pemberian label dilakukan secara non-manual,
dimana tweets dengan nilai sentimen positif diberi label 1 dan tweets dengan nilai sentimen negatif diberi label -1. Setelah pemberian label, maka data pelatihan akan masuk tahap selanjutnya, yaitu penghapusan kata opini dari tweets. Kata opini yang dihapus adalah kata opini yang teridentifikasi oleh SentiWordNet. Tujuan penghapusan ini agar SVM dapat mempelajari kata singkatan, bahasa percakapan, emoticon, dan lain-lain dari domain yang spesifik (Zhang, et al., 2011). Tabel 7 menunjukan contoh hasil pelabelan dan penghapusan kata opini dari tweets.
Tabel 7. Contoh Hasil Pelabelan Data Pelatihan dan Penghapusan Kata Opini
Tweets yang diidentifikasi
(sebelum kata opini dihapus) (setelah kata opini Tweets dihapus)
Kata
opini sentimen Nilai Label If jd Jokowi capres hrs suitable
regular partner is worth it. Capres Jgn yg 4 l. Basiiii n sure losers.
If jd Jokowi capres hrs partner is it. Capres Jgn yg 4 l. Basiiii n losers. ['suitable', 'regular', 'worth', 'sure'] 0.3375 1
You Are The Next President: Prabowo Subianto, the leader of the smile, gentle, Bold and Resolute in the rules and decisions. The Donjon
You Are The President: Prabowo Subianto, the leader of the, , and Resolute in the rules and decisions. The Donjon
['next', 'smile', 'gentle', 'bold']
0.2083 1
@kompascom Prabowo with 6 Program Action is pretty good as President. Jokowi do not disturb as Governor. JAWA semrawut Indonesia drifting!
@kompascom Prabowo with 6 Program is as President. Jokowi do not disturb as Governor. JAWA semrawut Indonesia drifting! ['action', 'pretty', 'good'] 0.4167 1
President Jokowi his Deputy Abraham Samad no more terrible mintilihir/pair
President Jokowi his Deputy Abraham Samad no mintilihir/pair
['more', 'terrible']
-0.25 -1
Data pelatihan yang sudah tidak memiliki kata opini beserta labelnya akan digunakan untuk proses pelatihan oleh SVM. SVM akan dilatih menggunakan data pelatihan agar dapat mengklasifikasikan data dengan benar. Proses pelatihan bertujuan untuk mencari parameter model yang akan digunakan untuk mengklasifikasikan data secara benar. Strategi yang biasa digunakan untuk mencari parameter adalah grid-search dengan menggunakan metode Cross-Validation (Lin, et al., 2010).
Berdasarkan hasil simulasi program analisis sentimen Twitter dengan menggunakan kombinasi metode berbasis lexicon dan metode berbasis learning pada studi kasus calon presiden Republik Indonesia periode 2014-2019, maka dapat ditarik beberapa kesimpulan, yaitu :
1. Akurasi metode berbasis lexicon masih belum cukup baik. Hal ini terjadi sebagian besar karena dua kemungkinan. Pertama, ketidakmampuan alat penerjemah
(Microsoft Translator) untuk menerjemahkan kata singkatan dan bahasa percakapan. Kedua, ketidakmampuan metode lexicon untuk mendeteksi kata (bukan kata sifat) yang kemungkinan memiliki nilai sentimen. Begitu pula dengan presisi dan recall yang nilainya tidak begitu baik.
2. SVM mampu meningkatkan akurasi metode berbasis lexicon dengan peningkatan akurasi sebesar 28%. Hal ini didukung dalam paper Zhang, et al. di tahun 2011, dimana disebutkan bahwa SVM meningkatkan metode berbasis lexicon sebesar 5%. 3. Kinerja SVM dalam memprediksi data-data yang tidak dapat dilabel (data pelatihan)
oleh metode berbasis lexicon belum optimal. Hal ini terjadi karena berbagai kemungkinan. Pertama, kesalahan metode lexicon dalam memberi label pada data pelatihan sehingga menyebabkan transfer pembelajaran yang salah pula. Kedua, perbedaan kuantitas antara data yang memiliki label positif dan data dengan label negatif. Selain akurasi, hal serupa juga terjadi pada presisi, dimana nilainya tidak begitu berbeda dengan metode berbasis lexicon. Namun, lain halnya dengan recall dimana nilai recall jauh lebih tinggi dibandingkan metode berbasis lexicon.
7. Saran
Sebagai pengembangan pemahaman atas kombinasi metode berbasis lexicon dan metode berbasis learning dan aplikasinya pada data Twitter, penulis menyarankan agar beberapa hal berikut dapat dibahas lebih mendalam, yaitu :
1. Penggunaan metode yang dapat mengubah kata yang disingkat menjadi kata yang sebenarnya agar dapat mengurangi kesalahan dalam penerjemahan ke bahasa Inggris. 2. Pemanfaatan metode active learning yang dapat memilih data pelatihan sehingga
8. Daftar Referensi
[1] Bazaraa, M. S., Sherali, H. D., dan Shetty, C. M. (1993). Nonlinear Programming Theory and Algorithms (2nd ed.). USA: John Wiley & Sons.
[2] Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Singapore: Springer. [3] Chang, C. C. dan Lin, C. J. (2011). LIBSVM : A Library For Support Vector Machines.
ACM Transactions on Intelligent Systems and Technology, 27(2), 1-27.
[4] Chen, P. H., Fan, R. E., dan Lin, C. J. (2006). A Study on SMO-type Decomposition Methods for Support Vector Machines. IEEE Transactions On Neural Networks, 17(4), 893-908.
[5] Feldman, R. (2013). Techniques and Applications for Sentiment Analysis. Communication of the ACM, 56(4), 82-89.
[6] Hsu, C. W., Chang, C. C., and Lin, C. J. (2010). A Practical Guide to Support Vector Classification. Diakses pada 1 Mei 2014 dari
www.csie.ntu.edu.tw/~cjlin/papers/guide/guide.pdf.
[7] Noble, William S. (2006). What is A Support Vector Machine? Nature biotechnology. ISSN 1087-0156, 24(12), 1565 – 1567.
[8] Pang, B., Vaithyanathan, S., dan Lee, L. (2002). Thumbs up? Sentiment Classification using Machine Learning Techniques. Proceedings of EMNLP, 79–86.
[9] Pedregosa, F., et al. (2011). Scikit-learn: Machine Learning in Python. Journal of Machine Learning Research, 12, 2825-2830.
[10] Powers, D. M. W. (2007). Evaluation: From Precision, Recall and F-Factor to ROC, Informedness, Markedness & Correlation. Journal of Machine Learning Technologies, 2(1), 37–63.
[11] Robertson, S. (2008). Understanding Inverse Document Frequency: On Theoretical Arguments for IDF. Journal of Documentation, 60(5), 503–520.
[12] Zhang, L., et al. (2011). Combining Lexicon-based and Learning-based Methods for Twitter Sentiment Analysis. Technical Report, HP Laboratories.