BAB 2
LANDASAN TEORI
Bab ini akan membahas tentang teori-teori pendukung dan penelitian sebelumnya yang berhubungan dengan prediksi produksi kelapa sawit dan penerapan jaringan saraf Radial Basis Function (RBF).
2.1. Produksi Kelapa Sawit
Kelapa sawit terdiri daripada dua spesies Arecaceae atau famili palma yang digunakan untuk pertanian komersil dalam pengeluaran minyak kelapa sawit. Pohon Kelapa Sawit Afrika, Elaeis guineensis, berasal dari Afrika barat di antara Angola dan Gambia, manakala pohon kelapa sawit Amerika, Elaeis oleifera, berasal dari Amerika Tengah dan Amerika Selatan.
Bagian yang paling utama pada industry kelapa sawit adalah buah dari kelapa sawit. Bagian daging buah menghasilkan minyak kelapa sawit mentah yang diolah menjadi bahan baku minyak goreng. Untuk memenuhi permintaan minyak kelapa sawit diperlukan produksi kelapa sawit pada industri kelapa sawit.
Beberapa faktor yang mempengaruhi produksi kelapa sawit menurut Septianita (2009) yaitu luas produksi, tenaga kerja, bibit, pupuk urea dan herbisida. Dari penelitian tersebut diketahui bahwa luas produksi berpengaruh secara signifikan terhadap produksi terlihat bahwa tingkat penggunaan lahan pada usaha tani kelapa sawit menunjukkan adanya penambahan faktor tersebut terhadap peningkatan faktor produksi. Faktor lain seperti tenaga kerja juga berpengaruh terhadap produksi namun tidak signifikan karena faktor produksi sudah maksimal jika ditambah satu persen maka hanya akan menurunkan tingkat produksi.
2.2. Data Mining
Data mining merupakan proses kegiatan yang meliputi pengumpulan, pemakaian data historis untuk menemukan keteraturan pola atau hubungan dalam set data berukuran besar. Pengenalan pola merupakan bagian dari data mining. Pengenalan pola melakukan pengelompokkan objek ke berbagai kelas dan dari data tersebut dapat diketahui kecendrungan pola. Pengenalan pola mengacu kepada kasus klasifikasi dan regresi (Santosa, 2007).
Tugas utama dari data mining dibagi menjadi dua yaitu descriptive dan
predictive. Descriptive merupakan kemampuan untuk mengidentifikasi keunikan data, pola, trend, hubungan dan anomaly pada data. Descriptive dibagi menjadi asosiasi, segmentasi dan clustering. Predictive merupakan pengembangan model dari beberapa fenomena yang memungkinkan dilakukan estimasi nilai dan prediksi untuk masa depan. Predictive dibagi menjadi klasifikasi dan regresi. Regresi termasuk kepada estimasi dan peramalan atau prediksi (Myatt & Johnson, 2009).
Atribut dibutuhkan untuk proses data mining. Atribut disebut sebagai variabel dan ada juga yang menyebutnya dengan fitur. Variabel-variabel yang akan digunakan, akan dikelompokkan menjadi input dan output. Format data akan dinyatakan dalam bentuk matrik dimana baris menyatakan objek atau observasi dan kolom dinyatakan variabel (Santosa, 2007).
Metode dalam data mining untuk memproses data-data yang ada dibagi menjadi dua pendekatan yaitu supervised dan unsupervised. Supervised learning
dan pengujian. Unsupervised learning merupakan pembelajaran yang tidak terawasi sehingga metode yang diterapkan tanpa ada proses pelatihan.
2.2.1 Data Cleaning
Menurut Myatt dan Johnson (2009) sebelum memproses data diperlukan cleaning data pada data tabel untuk mengidentifikasi data. Tujuannya adalah untuk menghindari data error, tidak ada entri data dan data yang hilang. Nilai pada data sering hilang pada tabel data, tetapi pendekatan data mining tidak dapat diproses sampai kasus ini diselesaikan. Ada lima pilihan untuk melakukan cleaning data yaitu menghapus data yang memiliki nilai kosong pada tabel data, menghapus variabel yang memiliki data kosong pada tabel data, mengganti nilai data dengan nilai komputasi, mengganti nilai data dengan nilai secara prediksi pada model yang umum menggunakan field yang lain pada data tabel.
Situasi yang sama jika terjadi hilang data ketika variabel yang dimaksudkan diperlakukan sebagai variabel angka berisi nilai teks, atau angka spesifik yang memiliki arti khusus. Teks atau angka spesifik kemungkinan akan dijadikan nilai angka untuk menggantikan teks dan angka spesifik. Masalah lain muncul ketika nilai dengan data tabel salah. Nilai mungkin menjadi salah sebagai hasil dari data entri yang error. Keluaran pada data mungkin error dan dapat ditemukan menggunakan metode yang berbeda berdasarkan variabel, sebagai contohnya menghitung nilai score
a-z untuk nilai masing-masing yang merepresentasikan nilai standar deviasi dari nilai mean.
2.2.2 Data Selecting
Data selecting dilakukan untuk memilih variabel data yang akan digunakan dan membagi data menjadi data latih dan data uji. Menurut Kaastra dan Boyd (1996) ada dua tipe pemilihan variabel yaitu teknikal input dan fundamental input. Teknikal input
adalah penetapan nilai variabel yang berpengaruh atau indikator perhitungan dari nilai yang lalu, sedangkan fundamental input adalah penetapan variabel ekonomis yang dipercaya mempengaruhi variabel output dan mungkin membantu peningkatan prediksi.
Pembagian data dalam data mining menurut Kaastra dan Boyd (1996) dibagi menjadi tiga yaitu
a. Training data (data latih)
Data latih terdiri dari data set yang banyak. Biasanya digunakan oleh jaringan saraf untuk melakukan pengenalan pola.
b. Testing data (data uji)
Data uji berjumlah 10-30% data dari training set. Data Uji digunakan untuk mengevaluasi kemampuan jaringan saraf setelah dilatih.
c. Validation data (data validasi)
Data validasi digunakan untuk pengecekan akhir kemampuan jaringan saraf yang telah dilatih.
2.2.3 Tranformasi Data
Transformasi data dibutuhkan untuk membuat variabel baru dari kolom data yang sudah ada untuk merefleksikan lebih dekat tujuan dari projek atau pendekatan kualitas prediksi. Sebuah data ditransformasi agar dapat digunakan untuk beberapa analisis teknik terutama pada bidang analisis data. Transformasi data digunakan untuk mengatur nilai yang diukur pada suatu skala menjadi nilai yang lebih kecil sehingga seluruh atribut data memiliki jangkauan yang lebih kecil dalam jangkauan nilai 0 sampai 1 (Siang, 2012).
1. Transformasi polinomial
𝑥′ = ln 𝑥 (2.1)
Dengan,
𝑥′ = nilai data setelah transformasi polynomial
𝑥 = nilai data pada data aktual
2. Transformasi normal
𝑥′= 𝑥0− 𝑥𝑚𝑖𝑛
𝑥𝑚𝑎𝑥− 𝑥𝑚𝑖𝑛 (2.2)
Dengan,
𝑥′ = nilai data setelah transformasi normal
𝑥0 = nilai data pada data aktual
𝑥𝑚𝑖𝑛 = nilai minimum pada data aktual
𝑥𝑚𝑎𝑥 = nilai maksimum pada data aktual
3. Transformasi linear
Transformasi nilai data pada interval [0.1,0.9]
𝑥′ = 0.8 ( 𝑥−𝑎)
𝑏−𝑎 + 0.1 (2.3)
Dengan,
𝑥′ = nilai data setelah transformasi linear
𝑥 = nilai data pada data aktual
𝑎 = nilai minimum data aktual
𝑏 = nilai maksimum data aktual
2.2.4 Peramalan
Menurut Gaspersz (2010), langkah-langkah yang harus dilakukan dalam menjamin efisiensi untuk melakukan peramalan. Langkah-langkah tersebut adalah sebagai berikut.
1. Menentukan tujuan peramalan 2. Memilih item yang akan diramalkan 3. Menentukan rentang waktu peramalan 4. Memilih model peramalan
5. Mengumpulkan dan menganalisis data 6. Validasi model peramalan
7. Membuat peramalan
8. Implementasi hasil peramalan
9. Memantau keandalan hasil peramalan
Peramalan dilakukan berdasarkan jangka waktu yang diperlukan. Peramalan ini dilakukan untuk mengambil keputusan sehingga peramalan ini menghasilkan suatu kemungkinan keadaan yang akan terjadi. Berdasarkan horison waktu, peramalan dapat dikelompokkan dalam tiga bagian (Herjanto, 2006), yaitu:
1. Peramalan jangka pendek, jangka waktu kurang dari tiga bulan. Misalnya, peramalan yang berhubungan dengan perencanaan pembelian material, penjadwalan kerja dan penugasan karyawan.
2. Peramalan jangka menengah, mencakup waktu antara 3 bulan sampai 18 bulan. Misalnya, peramalan perencanaan penjualan, perencanaan produksi dan perencanaan tenaga kerja tidak tetap.
1. Teknik peramalan kualitatif
Teknik kualitatif merupakan teknik peramalan yang bersifat subjektif berdasarkan pendapat dari suatu pihak atau berdasarkan hasil penelitian
questioner yang telah dilakukan. Data pada teknik ini tidak dapat direpresentasikan secara tegas ke dalam suatu angka atau nilai.
2. Teknik peramalan kuantitatif
Teknik kuantitatif merupakan teknik peramalan berdasarkan data masa lalu atau data historis dan dapat dibuat dalam bentuk angka.
Dalam peramalan dikenal istilah prediksi. Prediksi merupakan suatu usaha untuk meramalkan keadaan di masa mendatang melalui pengujian keadaan di masa lalu (Rambe, 2002). Data historis diolah secara sistematik dan digabungkan dengan suatu metode tertentu akan memperoleh prediksi keadaan pada masa datang. Prediksi ini menggunakan data kuantitatif sebagai pelengkap informasi melakukan peramalan (Herjanto, 2006). Peramalan menurut Heizer (2005) dapat dikelompokkan berdasarkan sumber peramalannya sebagai berikut.
1. Model data time series atau runtun waktu
Model data time series merupakan suatu jenis peramalan secara kuantitatif. Model ini sering disebut model kuantitatif intrinsik. Tujuannya adalah menemukan pola dalam deret data historis dan mengekstrapolasikan pola dalam deret data tersebut ke pola data masa depan.
2. Model data causal
Model data causal merupakan suatu jenis peralaman yang menggunakan hubungan sebab-akibat sebagai asumsi dari apa yang terjadi di masa lalu akan terulang kembali. Model ini disebut dengan peramalan kuantitatif ekstrasik, sesuai digunakan untuk pengambilan keputusan dan kebijakan.
3. Model data judgemental
Model data time series dan causal digunakan sebagai metode peramalan kuantitatif. Pada umumnya metode peramalan causal meliputi faktor-faktor yang berhubungan dengan variabel yang diprediksi seperti analisi regresi sedangkan metode peramalan time series menggunakan data masa lalu yang telah dikumpulkan untuk dianalisis secara teratur dengan menggunakan teknik yang tepat (Sani, 2013). Hasilnya dapat dijadikan acuan untuk peramalan nilai di masa yang akan datang. Peramalan harus mendasarkan analisisnya pada pola data yang ada. Empat pola data yang lazim ditemui dalam peramalannya adalah sebagai berikut (Aryanto, 2012).
1. Pola data horizontal
Pola ini terjadi bila data berfluktuasi di sekitar rata-ratanya. Produk yang penjualannya tidak meningkat atau menurun selama waktu tertentu termasuk jenis ini. Struktur datanya dapat digambarkan sebagai berikut ini.
Gambar 2.1 Pola Data Horizontal
2. Pola data musiman
Pola musiman terjadi bila nilai data dipengaruhi oleh faktor musiman (misalnya kuartal tahun tertentu, bulanan atau hari-hari pada minggu tertentu). Struktur datanya dapat digambarkan sebagai berikut ini.
Gambar 2.2 Pola Data Musiman
Jumlah
Data
Waktu
Jumlah
Data
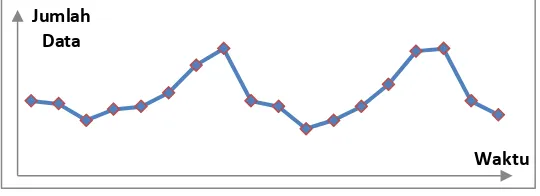
3. Pola data siklis
Pola ini terjadi bila data dipengaruhi oleh fluktuasi ekonomi jangka panjang seperti yang berhubungan dengan siklus bisnis. Struktur datanya dapat digambarkan sebagai berikut.
Gambar 2.3 Pola Data Siklis
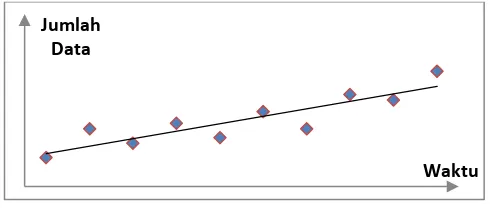
4. Pola data trend
Pola trend terjadi bila ada kenaikan atau penurunan sekuler jangka panjang dalam data. Struktur datanya dapat digambarkan sebagai berikut.
Gambar 2.4 Pola Data Trend
2.3. Jaringan Saraf Tiruan
Jaringan saraf tiruan (Artificial Neural Network) adalah pemrosesan suatu informasi yang terinspirasi oleh sistem jaringan saraf biologis (Smith, 2003). Jaringan saraf tiruan juga merupakan cabang ilmu kecerdasan buatan dan alat untuk memecahkan masalah terutama di bidang-bidang yang melibatkan pengelompokan data yang memiliki kecendrungan untuk menyimpan pengetahuan yang bersifat pengalaman dan membuatnya untuk siap digunakan (Sutojo et al, 2011).
Jumlah
Data
Waktu
Jumlah
Data
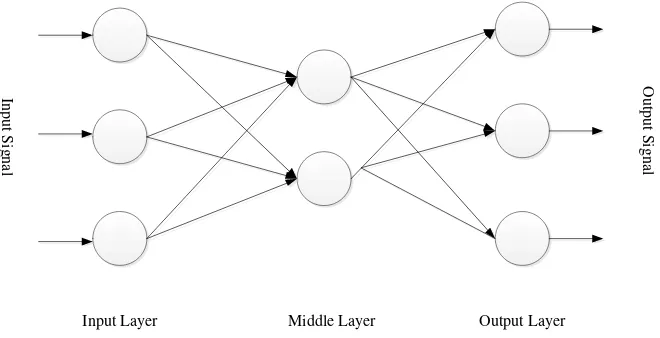
Jaringan saraf tiruan disusun dengan asumsi yang sama dengan jaringan saraf biologis karena pengolahan informasi terjadi pada elemen-elemen pemrosesan (neuron-neuron), sinyal antara dua buah neuron diteruskan melalui link koneksi, setiap link koneksi memiliki weight yang terasosiasi, dan setiap neuron menerapkan sebuah fungsi aktifasi terhadap input jaringan dengan tujuan agar dapat menentukan sinyal output (Puspitaningrum, 2006).
Input Layer Middle Layer Output Layer
Gambar 2.5 Arsitektur Umum Jaringan Saraf Tiruan Multilayer Cara belajar jaringan saraf tiruan dilakukan seperti berikut ini.
1. Pada jaringan saraf tiruan, node atau unit-unit input di-input kan informasi yang sebelumnya telah diketahui hasil keluarannya.
2. Weights antar koneksi dalam suatu arsitektur diberi nilai awal dan kemudian jaringan tersebut dijalankan. Weights ini digunakan untuk belajar dan mengingat suatu informasi.
3. Pengaturan weights dilakukan secara terus-menerus dan menggunakan kriteria tertentu sampai diperoleh keluaran yang diharapkan.
Pada pembelajaran jaringan saraf tiruan, terdapat dua kelompok pembelajaran yaitu sebagai berikut.
1. Jaringan saraf tiruan umpan maju (feed-forward networks), merupakan graf yang tidak mempunyai loop dan bergerak maju. Contoh jaringan umpan maju adalah single-layer perceptron, multilayer perceptron dan radial basis fuction.
2. Jaringan saraf tiruan umpan balik (recurrent-feedback networks), merupakan graf yang memiliki loop koneksi balik. Contoh jaringan ini adalah competitive networks, kohonen’s SOM, hopfield network, dan ART model.
Pada feed-forward networks, diterapkan fungsi aktivasi kedalam weight dan
input dilakukan perhitungan yang hasilnya dianggap sebagai sinyal berbobot yang diteruskan kelapisan di atasnya. Sinyal yang berbobot tersebut menjadi input bagi lapisan selanjutnya. Fungsi aktivasi diterapkan pada lapisan tersebut untuk menghitung output jaringan. Proses ini dilakukan terus menerus sampai kondisi berhenti terpenuhi.
Kelebihan-kelebihan yang diberikan oleh jaringan saraf tiruan adalah sebagai berikut (Sutojo et al, 2011).
1. Belajar Adaptive yang merupakan kemampuan untuk mempelajari bagaimana melakukan pekerjaan berdasarkan data yang diberikan untuk pelatihan dan pengalaman awal.
2. Self-Organisation yang merupakan sebuah jaringan saraf tiruan dapat membuat representasi sendiri dari informasi yang diterimanya selama proses pembelajaran.
3. Real Time Operation yang merupakan perhitungan jaringan saraf tiruan dapat dilakukan secara parallel sehingga perangkat keras yang dirancang dan diproduksi secara khusus agar dapat mengambil keuntungan dan kemampuan ini.
1) Kesulitan memilih arsitektur dari system karena jaringan saraf tiruan memiliki arsitektur yang tetap dengan jumlah neuron serta koneksi yang tetap sehingga akan sulit untuk beradaptasi dengan informasi yang baru. 2) Dalam mempelajari data baru, jaringan akan cenderung melupakan
pengetahuan yang lama.
3) Pelatihan pada jaringan akan memerlukan banyak iterasi serta propagasi data melalui struktur jaringan sehingga perlu waktu yang lama.
4) Kurangnya fasilitas representasi pengetahuan pada jaringan.
2.3.1Radial Basis Function
Radial basis function (RBF) merupakan sebuah fungsi yang dinyatakan dengan nilai yang bergantung pada jarak antar argumen atau jarak antara nilai center (Lukaszyk, 2004). Sama seperti multilayer perceptron (MLP) yang memiliki lapisan hidden
dengan fungsi sigmoid yang dapat belajar dengan fungsi perkiraan, jaringan RBF menggunakan pendekatan yang sedikit berbeda. Menurut Bullinaria (2004) fitur utama RBF adalah sebagai berikut.
1. Terdapat dua layer yang bersifat feed-forward
2. Hidden node mengimplementasikan bagian RBF berupa fungsi Gaussian
3. Output node mengimplementasikan fungsi linear yang sama seperti MLP 4. Jaringan untuk pengujian dibagi menjadi dua bagian, yang pertama weight dari
input ke hidden dan kemudian weight dari hidden ke output
5. Pengujian atau pembelajaran sangat cepat. 6. Interpolasi jaringan sangat baik
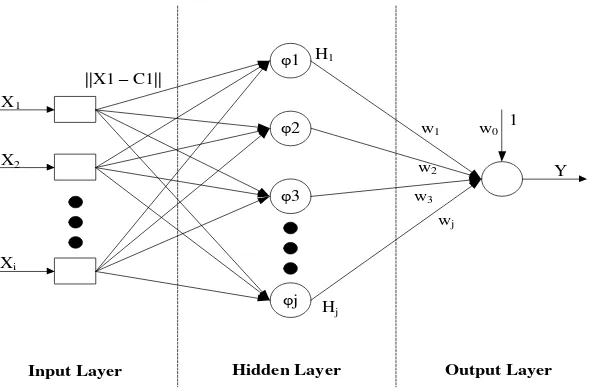
Struktur jaringan RBF terdiri dari tiga layer yaitu input layer, hidden layer, dan
output layer. Pada input layer terdiri dari source node (unit sensor) yang menghubungkan jaringan dengan lingkungannya. Pada layer kedua yang biasa disebut dengan hidden layer mengaplikasikan sebuah transformasi nonlinear dari input ke
φ1
Gambar 2.6 Arsitektur Jaringan Radial Basis Function (Haykin, 2009) Pada jaringan RBF, hidden layer menggunakan biasanya fungsi Gaussian
sebagai radial basis function. Fungsi Gaussian dinyatakan dengan,
𝜑𝑗 = exp {−||𝑋𝑖−𝐶𝑗|| 2
2𝜎2 } (2.4)
dimana φj adalah fungsi Gaussiandan σ adalah standar deviasi dari fungsi Gaussian
ke j dengan nilai center (Cj). Fungsi σ dinyatakan dengan (Zhang & Li, 2012),
σ = 𝑑𝑚𝑎𝑥
√𝑐𝑗 (2.5)
dimana dmax merupakan nilai jarak atau distance terbesar pada hidden j dan Cj merupaka nilai center pada hidden j.
Metode unsupervised learning yang digunakan untuk jaringan RBF biasanya adalah pendekatan K-Means. Pembelajaran dengan metode tersebut dilakukan untuk menentukan nilai center dan standar deviasi dari variabel input pada setiap node di
hidden layer. Setelah mendapatkan nilai pada hidden node tahap selanjutnya hidden layer ke output layer yang menggunakan metode supervised learning dengan pembelajaran yang sama dengan MLP. Pada training set, elemen-elemennya terdiri dari unsur nilai variabel independen (input) dan variabel dependen (output). Sebagai contoh, hubungan variabel independen dengan fungsi aktivasi adalah sebagai berikut.
dengan nilai x merupakan nilai vektor dan nilai y merupakan nilai skalar, dan nilai y bergantung kepada fungsi f dengan komposisi nilai x adalah sebagai berikut(Orr, 1996).
𝑥 =
[ 𝑥1
𝑥2
. . . 𝑥𝑛]
(2.7)
2.3.1.1Tahap Data Pre-processing
Menurut Kaastra dan Boyd (1996) data pre-processing merupakan proses menganalisis dan mentransformasikan variabel input dan output untuk membantu jaringan mempelajari pola data. Data pre-processing dilakukan untuk:
a. Meminimalisasikan data noise
b. Menyoroti hubungan yang penting c. Mendeteksi tren
d. Meratakan distribusi variabel
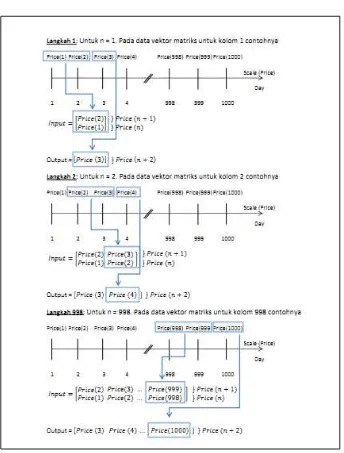
Pada tahap pelatihan, data dikumpulkan untuk melakukan proses pelatihan. Data-data tersebut dirakit sebagai pra-proses time series data. Pada penelitian Hussein
et al (2011), data tersebut direpresentasikan seperti Gambar 2.7.
Gambar 2.7 Data Time Series Prediksi Harga Emas Pada Tahap Pelatihanuntuk Merepresentasikan Form Baris Waktu (Timeline) Hussein et al (2011) melakukan prediksi harga emas hari esok dengan menggunakan harga emas hari kemarin dan hari ini. Sehingga harga emas hari esok adalah output dan harga emas hari kemarin dan hari ini merupakan input. Misalkan
Tabel 2.1 Variabel Data yang digunakan
Harga Penjelasan Variabel
Harga kemarin Harga (n) dengan n = 1,2,3….
Harga hari ini Harga (n+1) dengan n = 1,2,3…. Harga esok hari Harga (n+2) dengan n = 1,2,3….
Dan tahapan prediksi harga emas dapat dilihat pada Gambar 2.8
Pada gambar 2.11, vector matriks input terdiri dari baris dan kolom. Pada baris
input, data yang ditunjukkan merupakan data yang digunakan untuk mencari nilai prediksi sedangkan untuk kolom (sama seperti pada vector matriksoutput) merupakan data yang akan digunakan untuk proses jaringan selanjutnya.
2.3.1.2Tahap I: Input Layer ke Hidden Layer
Dalam mendesain jaringan RBF, dibutuhkan suatu metode untuk menghitung nilai parameter dari unit Gaussian yang diperlukan di hidden layer dengan data yang tidak berlabel. Oleh karena itu diperlukan sebuah metode unsupervised learning yang berupa metode K-Means. Metode K-Means merupakan salah satu bentuk metode pemetaan pada dirinya sendiri (Self Organizing Map) yang juga dikembangkan dalam permodelan NN.
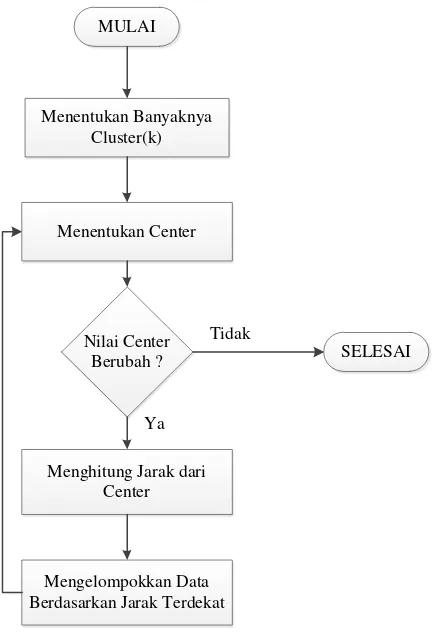
Tahapan algoritma K-means clustering dapat dilakukan seperti yang di Gambar 2.9.
MULAI
Menentukan Banyaknya Cluster(k)
Menentukan Center
Nilai Center Berubah ?
Menghitung Jarak dari Center
Mengelompokkan Data Berdasarkan Jarak Terdekat
SELESAI
Ya
Tidak
Pertama kali yang dilakukan dalam algoritma K-means clustering adalah menentukan kelompok atau cluster dengan syarat jumlah kelompok yang akan dibuat harus lebih kecil dengan jumlah data yang digunakan, kelompok pada jaringan radial basis function yang dimaksud adalah jumlah hidden yang akan digunakan.
Kedua, menentukan nilai center secara acak.
Ketiga, menghitung jarak data ke center digunakan Euclidean norm. Nilai
Euclidean norm dapat dinyatakan dengan (Haykin,2009),
d(Xi, Cj) = ||Xi – Cj||2 (2.8) dengan nilai Xi adalah nilai vector input dari data ke i dan nilai Cj adalah nilai vector dari centerhidden ke j.
Keempat, kelompokkan data sesuai dengan kelompoknya, yaitu data yang memiliki jarak terpendek pada masing-masing hidden (jumlah kelompok = jumlah
hidden). Misalkan jumlah hidden adalah dua sehingga jumlah kelompok dua, ketika d(x1,c1) < d(x1,c2) maka nilai x1 masuk ke kelompok 1 dan lakukan hal yang sama dengan data selanjutnya
Kelima, memperbaharui nilai center dengan cara merata-ratakan nilai anggota kelompok yang dapat dinyatakan sebagai berikut.
𝑐𝑗 = 𝑛1𝑖 × ∑𝑛𝑖=1𝑥𝑖 (2.9)
dengan ni merupakan jumlah anggota kelompok.
Lakukan langkah pertama sampai kelima hingga nilai center tidak berubah lagi.
Metode K-Means memiliki beberapa keuntungan penggunaan pada jaringan RBF ini, yaitu
1. Algoritma K-Means merupakan algoritma dengan komputasi yang efisien karena seluruh yang kompleks dijadikan linear pada angka cluster
2.3.1.2Tahap II: Hidden Layer ke Output Layer
Setelah K-Means digunakan pada input layer ke hidden layer maka proses selanjutnya
hidden layer ke output layer yang merupakan pembelajaran terawasi yang sama seperti penggunaan pada MLP, output layer dilatih dengan menggunakan Least Means Square.
Inisialisasi weight pada hidden layer sampai output layer dilakukan inisialisasi weight
secara acak. Lalu dilakukan penghitungan seluruh output (Yk) pada jaringan yang dinyatakan dengan (Haykin,2009) ,
𝑌𝑘= ∑𝐿𝑗=1𝜑𝑗𝑤𝑘𝑗 (2.10)
dimana,
Yk = nilai node pada output k dari nodehidden ke j L = nomor dari data pelatihan
φj = fungsi Gaussian pada node j
wkj = nilai weightoutput dari node ke j pada hidden layer ke output k
Setelah itu dilakukan langkah selanjutnya untuk menghitung error atau selisih hasil pada output Yk yang dinyatakan dengan,
𝛿𝑘 = (𝑡𝑘− 𝑌𝑘) (2.11)
dimana,
δk = unit kesalahan yang akan dipakai dalam perubahan weight layar tk = hasil normalisasi data dari data input.
Yk = output pada node k
Setelah tingkat kesalahan didapat tidak sesuai dengan yang diinginkan maka dihitung suku perubahan weight wkj (yang akan dipakai nanti pada saat merubah
weight wkj) dengan laju percepatan α yang dinyatakan dengan,
∆𝑤𝑘𝑗= 𝛼𝛿𝑘𝜑𝑘 (2.12)
objektif dari algoritma K-means sehingga nilai yang didapat sudah sesuai. Lalu tahap selanjutnya adalah tahap perubahan weight dengan menghitung semua perubahan
weight wkj yang dinyatakan dengan,
𝑤𝑘𝑗(𝑏𝑎𝑟𝑢) = 𝑤𝑘𝑗(𝑙𝑎𝑚𝑎) + ∆𝑤𝑘𝑗 (2.13)
Proses tersebut terus dilakukan sampai weight(wkj) tidak berubah lagi.
2.3.2. Menghitung Nilai Error
Menghitung nilai error sangat penting untuk melihat hasil pelatihan pada jaringan sarat tiruan. Hal ini dikarenakan pada tahap pelatihan nilai error yang diharapkan adalah nilai yang paling kecil. Outputerror adalah perhitungan error yang merupakan hasil dari perbedaan nilai target dan nilai output yang didapat. Nilai ini akan digunakan untuk menghitung nilai error. The Means Absolute Percentage Error
(MAPE) merupakan metode perhitungan error untuk mengevaluasi metode peramalan. Pendekatan ini menghitung kesalahan peramalan yang besar karena nilai
output error yang didapat dari perbedaan antara target dan output dibagi nilai target. Perhitungan nilai MAPE dapat dinyatakan sebagai berikut.
𝑀𝐴𝑃𝐸 = 𝑛1 ∑ 𝑦𝑡−𝑦̂𝑡
𝑦𝑡 × 100% 𝑛
𝑡=1 (2.14)
2.4. Penelitian Terdahulu
Berikut ini adalah penjelasan mengenai penelitian terdahulu dari kasus penelitian kelapa sawit dan jaringan saraf radial basis function.
2.4.1 Penelitian kasus prediksi produksi kelapa sawit
Penelitian mengenai prediksi produksi kelapa sawit sudah pernah dilakukan. Metode prediksi yang dilakukan pada penelitian-penelitian tersebut menggunakan metode
time-series dan juga menggunakan metode statistik.
hujan, ketinggian dari permukaan laut, kelerengan, umur tanaman, batuan, solium, dan keasaman tanah. Percobaan dengan beberapa layer untuk mendapatkan hasil terbaik yaitu 3 layer, 4 layer dan 5 layer. Hasil terbaik didapat pada percobaan 3 layer pada iterasi ke 30000, dengan laju pembelajaran sebesar 0.9, dan momentum sebesar 0.9. Hasil pelatihan yang didapat dengan R2=0.9998 dan RMSE = 0.0709 dan hasil pengujian dengan R2 = 0.8901 dan RMSE = 2.2196.
Penelitian lain dilakukan Bando (2012) menggunakan metode ARIMA untuk memprediksi curah hujan dengan produksi kelapa sawit. Tahapan yang dilakukannya sebagai berikut.
1. Tahap identifikasi
Pada tahap identifikasi dilakukan perumusan kelompok model-model yang umum. Kemudian melakukan penetapan model untuk sementara.
2. Penaksiran parameter dan pengujian
Tahap ini dilakukan penaksiran parameter sementara. Kemudian diperiksa apakah model tersebut memadai. Jika ya, maka tahap lanjut ke penerapan. Namun, jika tidak maka tahapan mengulang ke penaksiran parameter.
3. Penerapan
Pada tahap ini dilakukan model untuk peramalan. Data yang digunakan ada dua yaitu data curah hujan dan data produksi. Lalu data-data tersebut digunakan dengan metode ARIMA untuk mendapatkan hasil peramalan selanjutnya.
Kacaribu (2013) menggunakan dua metode untuk membandingkan prediksi produksi kelapa sawit yaitu menggunakan metode causal berupa regresi ganda dan metode time-series berupa exponential smoothing. Adapun tahapan-tahapan yang dilakukannya sebagai berikut.
1. Identifikasi masalah
2. Mengumpulkan dan mempersiapkan data untuk dianalisis
3. Mengolah data (dengan menggunakan regresi ganda dan exponential smoothing)
6. Menentukan metode yang cocok untuk peramalan
Backpropagation Melakukan percobaan sebanyak 3 kali dengan layer yang berbeda dan banyak iterasi untuk
ARIMA Hanya meneliti untuk memeriksa keterhubungan curah hujan dengan
2.4.2 Penelitian kasus prediksi dengan menggunakan Radial Basis Function
Pada penelitian Jayawerdana et al (1997), RBF digunakan untuk memprediksi level air saat terjadi musim hujan. Hasil prediksi dinyatakan jaringan RBF yang menggunakan metode K-Means lebih baik daripada MLP dengan algoritma
backpropagation. Jaringan RBF berbasis linear dalam parameter dan menjamin nilai-nilai optimal. Pengembangan model jaringan RBF memerlukan sedikit trial and error
sehingga peramalan yang dilakukan hanya memerlukan sedikit waktu dan usaha dari pada penggunaan jaringan MLP dengan pendekatan bacpropagation.
Pada penelitian Husein et al (2011), peneliti menampilkan pemakaian data untuk jaringan saraf RBF dan juga membandingkan nilai yang didapat dengan menggunakan tiga metode yaitu Single Radial Basis Function Network, Multiple Radial Basis Function Network dan Auto Regressive Model. Dari ketiga metode tersebut performa terbaik dihasilkan pada metode Auto Regressive Model lalu Multiple Radial Basis Function Network.