Big Data
Management
and Processing
Edited by
Kuan-Ching Li
Hai Jiang
Albert Y. Zomaya
Big Data Management and
Processing
Edited by
Kuan-Ching Li
Guangzhou University, China
Providence University, Taiwan
Hai Jiang
Arkansas State University, USA
Albert Y. Zomaya
CRC Press
Taylor & Francis Group
6000 Broken Sound Parkway NW, Suite 300 Boca Raton, FL 33487-2742
c
2017 by Taylor & Francis Group, LLC
CRC Press is an imprint of Taylor & Francis Group, an Informa business
No claim to original U.S. Government works
Printed on acid-free paper
International Standard Book Number-13: 978-1-4987-6807-8 (Hardback)
This book contains information obtained from authentic and highly regarded sources. Reasonable efforts have been made to publish reliable data and information, but the author and publisher cannot assume responsibility for the validity of all materials or the consequences of their use. The authors and publishers have attempted to trace the copyright holders of all material reproduced in this publication and apologize to copyright holders if permission to publish in this form has not been obtained. If any copyright material has not been acknowledged please write and let us know so we may rectify in any future reprint.
Except as permitted under U.S. Copyright Law, no part of this book may be reprinted, reproduced, transmitted, or utilized in any form by any electronic, mechanical, or other means, now known or hereafter invented, including pho-tocopying, microfilming, and recording, or in any information storage or retrieval system, without written permission from the publishers.
For permission to photocopy or use material electronically from this work, please access www.copyright.com (http://www.copyright.com/) or contact the Copyright Clearance Center, Inc. (CCC), 222 Rosewood Drive, Danvers, MA 01923, 978-750-8400. CCC is a not-for-profit organization that provides licenses and registration for a variety of users. For organizations that have been granted a photocopy license by the CCC, a separate system of payment has been arranged.
Trademark Notice:Product or corporate names may be trademarks or registered trademarks, and are used only for identification and explanation without intent to infringe.
Contents
Foreword . . . .vii
Preface . . . .ix
Acknowledgments . . . .xi
Editors . . . .xiii
Contributors. . . .xv
Chapter 1 Big Data: Legal Compliance and Quality Management . . . .1
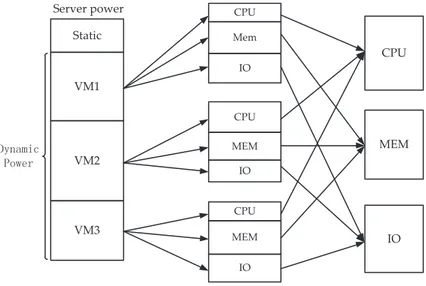
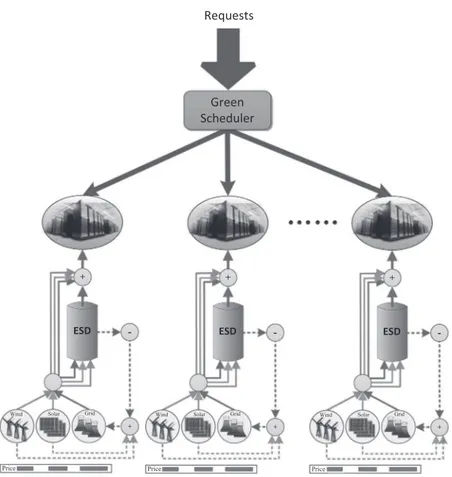
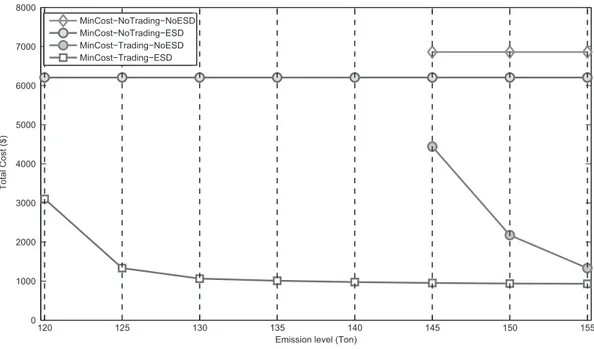
Paolo Balboni and Theodora Dragan Chapter 2 Energy Management for Green Big Data Centers . . . .17
Chonglin Gu, Hejiao Huang, and Xiaohua Jia Chapter 3 The Art of In-Memory Computing for Big Data Processing . . . .45
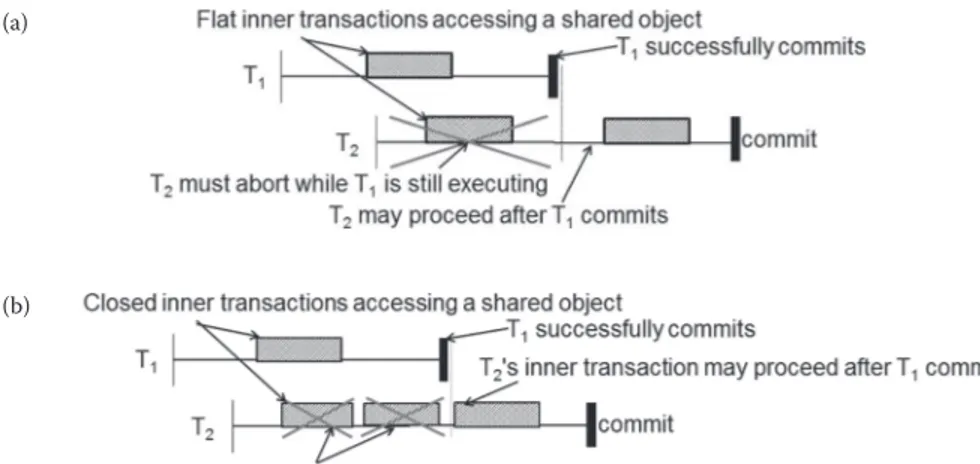
Mihaela-Andreea Vasile and Florin Pop Chapter 4 Scheduling Nested Transactions on In-Memory Data Grids . . . .61
Junwhan Kim, Roberto Palmieri, and Binoy Ravindran Chapter 5 Co-Scheduling High-Performance Computing Applications. . . .81
Guillaume Aupy, Anne Benoit, Loic Pottier, Padma Raghavan, Yves Robert, and Manu Shantharam Chapter 6 Resource Management for MapReduce Jobs Performing Big Data Analytics . . . . .105
Norman Lim and Shikharesh Majumdar Chapter 7 Tyche: An Efficient Ethernet-Based Protocol for Converged Networked Storage . . . .135
Pilar Gonz´alez-F´erez and Angelos Bilas Chapter 8 Parallel Backpropagation Neural Network for Big Data Processing on Many-Core Platform . . . .159
Boyang Li and Chen Liu Chapter 9 SQL-on-Hadoop Systems: State-of-the-Art Exploration, Models, Performances, Issues, and Recommendations . . . .173
Alfredo Cuzzocrea, Rim Moussa, and Soror Sahri Chapter 10 One Platform Rules All: From Hadoop 1.0 to Hadoop 2.0 and Spark . . . .191
Xiongpai Qin and Keqin Li
vi Contents
Chapter 11 Security, Privacy, and Trust for User-Generated Content: The Challenges and
Solutions . . . .215
Yuhong Liu, Yu Wang, and Nam Ling
Chapter 12 Role of Real-Time Big Data Processing in the Internet of Things . . . .239
Miyuru Dayarathna, Paul Fremantle, Srinath Perera, and Sriskandarajah Suhothayan
Chapter 13 End-to-End Security Framework for Big Sensing Data Streams . . . .263
Deepak Puthal, Surya Nepal, Rajiv Ranjan, and Jinjun Chen
Chapter 14 Considerations on the Use of Custom Accelerators for Big Data Analytics . . . .279
Vito Giovanni Castellana, Antonino Tumeo, Marco Minutoli, Marco Lattuada, and Fabrizio Ferrandi
Chapter 15 Complex Mining from Uncertain Big Data in Distributed Environments:
Problems, Definitions, and Two Effective and Efficient Algorithms . . . .297
Alfredo Cuzzocrea, Carson Kai-Sang Leung, Fan Jiang, and Richard Kyle MacKinnon
Chapter 16 Clustering in Big Data . . . .333
Min Chen, Simone A. Ludwig, and Keqin Li
Chapter 17 Large Graph Computing Systems . . . .347
Chengwen Wu, Guangyan Zhang, Keqin Li, and Weimin Zheng
Chapter 18 Big Data in Genomics . . . .363
Huaming Chen, Jiangning Song, Jun Shen, and Lei Wang
Chapter 19 Maximizing the Return on Investment in Big Data Projects: An Approach
Based upon the Incremental Funding of Project Development. . . .385
Antonio Juarez Alencar, Mauro Penha Bastos, Eber Assis Schmitz, Monica Ferreira da Silva, and Petros Sotirios Stefaneas
Chapter 20 Parallel Data Mining and Applications in Hospital Big Data Processing. . . .403
Jianguo Chen, Zhuo Tang, Kenli Li, and Keqin Li
Chapter 21 Big Data in the Parking Lot . . . .425
Ryan Florin, Syedmeysam Abolghasemi, Aida Ghazi Zadeh, and Stephan Olariu
Foreword
Big Data Management and Processing(edited by Li, Jiang, and Zomaya) is a state-of-the-art book that deals with a wide range of topical themes in the field of Big Data. The book, which probes many issues related to this exciting and rapidly growing field, covers processing, management, analytics, and applications.
The many advances in Big Data research that we witness today are brought about because of the many developments we see in algorithms, high-performance computing, databases, datamining, machine learning, and so on. These developments are discussed in this book. The book also show-cases some of the interesting applications and technologies that are still evolving and that will lead to some serious breakthroughs in the coming few years.
I believe thatBig Data Management and Processingis a very valuable addition to the literature. It will serve as a source of up-to-date research in this continuously developing area. The book also provides an opportunity for researchers to explore the use of advanced computing technologies and their impact on enhancing our capabilities to conduct more sophisticated studies.
I expect thatBig Data Management and Processingwill be well received by the research and development community. It should prove very beneficial for researchers and graduate students focusing on Big Data and will serve as a very useful reference for practitioners and application developers.
Sartaj Sahni University of Florida
Preface
The scope ofBig Datatoday spans many aspects and it is not limited to main computing components (e.g., processors, storage devices, and visualization facilities) alone, but it expands into a much larger range of issues related to management and policy. Also, “Big Data” can mean “Big Energy,” because of the pressure that data places on a variety of infrastructures needed to host, manage, and transport data. This in turn raises various monetary, environmental, and system performance concerns.
Recent advances in software hardware technologies have improved the handling of big data. How-ever, there still remain many issues that are pertinent to the overloading that happens due to the processing of massive amounts of data, which calls for the development of various software and hardware solutions as well as new algorithms that are more capable of processing of data.
This book,Big Data Management and Processing, seeks to provide an opportunity for researchers to explore a range of big data-related issues and their impact on the design of new computing systems. The book is quite timely, since the field of big data computing as a whole is undergoing rapid changes on a daily basis. Vast literature exists today on such data processing paradigms and frameworks and their implications for a wide range of distributed platforms.
The book is intended to be a virtual roundtable of several outstanding researchers that one might invite to attend a conference on big data computing systems. Of course, the list of topics that is explored here is by no means exhaustive, but most of the conclusions provided here should be extended to the other computing platforms that are not covered here. There was a decision to limit the number of chapters while providing more pages for contributed authors to express their ideas, so that the book remains manageable within a single volume.
It is also hoped that the topics covered will get the readers to think of the implications of such new ideas on the developments in their own fields. The book endeavors to strike a balance between theoretical and practical coverage of innovative problem-solving techniques for a range of platforms. The book is intended to be a repository of paradigms, technologies, and applications that target the different facets of big data computing systems.
The 21 chapters are carefully selected to provide a wide scope with minimal overlap between the chapters so as to reduce duplications. Each contributor was asked that his/her chapter should cover review material as well as current developments. In addition, the choice of authors was made so as to select authors who are leaders in the respective disciplines.
Acknowledgments
First and foremost we would like to thank and acknowledge the contributors to this volume for their support and patience, and the reviewers for their useful comments and suggestions that helped in improving the earlier outline of the book and presentation of the material. Also, we extend our deepest thanks to Randi Cohen from CRC Press (USA) for his collaboration, guidance, and most importantly, patience in finalizing this handbook. Finally, we would like to acknowledge the efforts of the team from CRC Press’s production department for their extensive efforts during the many phases of this project and the timely fashion in which the book was produced.
Editors
Kuan-Ching Li is a professor with appointments at the Guangzhou University, China and Providence University, Taiwan. He is a recipient of awards from Nvidia and support from a num-ber of industrial companies. He has also received guest and distinguished chair professorships from universities in China and other countries. He has been actively involved in numerous conferences and workshops in program/general/steering conference chairman positions and as a program com-mittee member, and has organized numerous conferences related to high-performance computing and computational science and engineering.
Professor Li is the Editor-in-Chief of technical publications such as International Journal of Computational Science and Engineering (IJCSE), International Journal of Embedded Systems (IJES), and International Journal of High Performance Computing and Networking (IJHPCN), all published by Inderscience. He also serves as an editorial board member and a guest editor for a number of journals. In addition, he is the author or editor of several technical professional books published by CRC Press, Springer, McGraw-Hill, and IGI Global. His topics of interest include GPU/manycore computing, big data, and cloud. He is a Member of the AAAS, a Senior Member of the IEEE, and a Fellow of the IET.
Hai Jiangis a professor in the Department of Computer Science at Arkansas State University, USA. He received his BS degree from Beijing University of Posts and Telecommunications, China, and his MA and PhD degrees from Wayne State University, Detroit, Michigan, USA. His current research interests include parallel and distributed systems, computer and network security, high-performance computing and communication, big data, and modeling and simulation. He has published one book and several research papers in major international journals and conference proceedings. He has served as a U.S. National Science Foundation proposal review panelist and a U.S. DoE (Department of Energy) Smart Grid Investment Grant (SGIG) reviewer multiple times.
Professor Jiang serves as the executive editor of International Journal of High Performance Computing and Networking(IJHPCN). He is an editorial board member ofInternational Journal of Big Data Intelligence(IJBDI),The Scientific World Journal(TSWJ),Open Journal of Internet of Things(OJIOT), andGSTF Journal on Social Computing(JSC) and a guest editor ofIEEE Sys-tems Journal,International Journal of Ad Hoc and Ubiquitous Computing,Cluster Computing, and The Scientific World Journal for multiple special issues. He has also served as a general or pro-gram chair for some major conferences/workshops (CSE, HPCC, ISPA, GPC, ScaleCom, ESCAPE, GPU-Cloud, FutureTech, GPUTA, FC, SGC). He has been involved in more than 90 conferences and workshops as a session chair or program committee member, including major conferences such as AINA, ICPP, IUCC, ICPADS, TrustCom, HPCC, GPC, EUC, ICIS, SNPD, TSP, PDSEC, SECRUPT, and ScalCom. He is a professional member of ACM and IEEE Computer Society and a representa-tive of the U.S. NSF XSEDE (Extreme Science and Engineering Discovery Environment) Campus Champion for Arkansas State University.
Albert Y. Zomayais the chair professor of high-performance computing and networking in the School of Information Technologies, University of Sydney, Australia and also serves as the director of the Centre for Distributed and High Performance Computing. He has published more than 600 scientific papers and articles and is the author, coauthor, or editor of more than 20 books. He is the founding editor-in-chief ofIEEE Transactions on Sustainable Computingand serves as an associate editor for more than 20 leading journals. He served as the editor-in-chief ofIEEE Transactions on Computersfrom 2011 to 2014.
xiv Editors
1
Big Data
∗
Legal Compliance and Quality
Management
Paolo Balboni and Theodora Dragan
CONTENTS
Abstract . . . .1
1.1 Introduction . . . .2
1.1.1 Topic, Approach, and Methodology . . . .2
1.1.2 Structure and Arguments . . . .4
1.2 Business of Big Data . . . .4
1.2.1 Connection between Big Data and Personal Data . . . .5
1.2.1.1 Any Information . . . .5
1.2.1.2 Relating to . . . .6
1.2.1.3 Identified or Identifiable . . . .6
1.2.1.4 Natural Person . . . .6
1.2.2 Competition Aspects . . . .7
1.3 Reconciling Traditional and Modern Data Protection Principles . . . .8
1.3.1 Traditional Data Protection Principles . . . .9
1.3.1.1 Transparency . . . .9
1.3.1.2 Proportionality and Purpose Limitation . . . ..10
1.3.2 Modern Data Protection Principles. . . ..12
1.3.2.1 Accountability . . . ..12
1.3.2.2 Privacy by Design and by Default. . . ..13
1.3.2.3 Users’ Control of Their Own Data . . . ..14
1.4 Conclusions and Recommendations . . . ..15
ABSTRACT
The overlap between big data and personal data is becoming increasingly relevant in today’s society, in light of the technological developments and, in particular, of the increased use of personal data as currency for purchasing “free” services. The global nature of big data, coupled with recently devel-oped data analytics and the interest of companies in predicting trends and consumer preferences, makes it necessary to analyze how personal data and big data are connected. With a focus on the quality of data as fundamental prerequisite for ensuring that outcomes are accurate and relevant, the authors explore the ways in which traditional and modern personal data protection principles apply to the big data context.
It is not about the quantity of the data, but about the quality of it!
*All websites were last accessed on August 19, 2016.
2 Big Data Management and Processing
1.1 INTRODUCTION
It is 2016 and big data is everywhere: in the newspapers, on TV, in research papers, and on the lips of every IT specialist. This is not only due to its catchy name, but also due to the sheer quantity of data available—according to IBM, we create 2.5 quintillion (2.5 times 1018)bytes of data every day.*
But what is the big deal with big data and, in particular, to what extent does it affect, or overlap with, personal data?
1.1.1 TOPIC, APPROACH, ANDMETHODOLOGY
By way of introduction, the first step is to provide a definition of the concept that runs through this chapter. Various attempts at defining big data have been made in recent years, but no universal definition has been agreed upon yet. This is likely due to the constant evolution of this concept, which makes it difficult to describe without risking that the definition is either too generic or that it becomes inadequate within a short period of time.
One attempt at a universal definition was made by Gartner, a leading information technology research and advisory company, that defines big data as “volume, velocity and/or high-variety information assets that demand cost-effective, innovative forms of information processing that enable enhanced insight, decision making, and process automation.”† In this case, data are
regarded as assets, which attaches an intrinsic value to it. On the other hand, the Article 29 Data Pro-tection Working Party defines big data as “the exponential growth both in the availability and in the automated use of information: it refers to gigantic digital datasets held by corporations, governments and other large organisations, which are then extensively analysed using computer algorithms.”‡This
definition regards big data as a phenomenon composed of both the process of collecting information and the subsequent step of analyzing it. The common elements of the different definitions are there-fore the size of the database and the analytical aspect, which together are expected to lead to better, more focused services and products, as well as more efficient business operations and more targeted approaches.
Big data can be (and has been) used in an incredibly diverse range of situations. It was employed to help athletes of Great Britain’s rowing team achieve superior performance levels at the 2016 Olympic Games in Rio de Janeiro, by analyzing relevant information about their predecessors’ performance.§
Predictive analytics were used in order to deal with traffic in highly congested cities, paving the way for the creation of the smart cities of the future.¶Further, big data can have a great impact on medical
sciences, and has already helped boost obesity research results by enabling researchers to identify links between obesity and depression that were previously unknown.**
Although big data does not always consist of personal data and could, for example, relate to techni-cal information or to information about objects or natural phenomena, the European Data Protection Supervisor (EDPS) pointed out in its Opinion 7/2015 that “one of the greatest values of big data for businesses and governments is derived from the monitoring ofhumanbehaviour, collectively and
*IBM—What Is Big Data? 2016. IBM—Bringing Big Data to the Enterprise. https://www-01.ibm.com/software/ data/bigdata/what-is-big-data.html.
†What Is Big Data?—Gartner IT Glossary—Big Data. 2012.Gartner IT Glossary.
http://www.gartner.com/it-glossary/big-data/.
‡Article 29 Data Protection Working Party. 2013.Opinion 03/2013 on Purpose Limitation.
§Marr, Bernard. 2016. How Can Big Data and Analytics Help Athletes Win Olympic Gold in Rio 2016?Forbes.com.
http://www.forbes.com/sites/bernardmarr/2016/08/09/how-big-data-and-analytics-help-athletes-win-olympic-gold-in-rio-2016/#12bedc444205.
¶Toesland, Finbarr. 2016. Smart-from-the-Start Cities Is the Way Forward.Raconteur.
http://raconteur.net/technology/smart-from-the-start-cities-is-the-way-forward.
Big Data 3
individually.”*Analyzing and predicting human behavior enables decision makers in many areas to make decisions that are more accurate, consistent, and economical, thereby enhancing the efficiency of society as a whole. A few fields of application that immediately come to mind when thinking of big data analytics based on personal data are university admissions, job recruitment, customer profiling, targeted marketing, or health services. Analyzing the information about millions of previ-ous applicants, candidates, customers, or patients makes it easy to establish common threads and to predict all sorts of things, such as whether a specific person is fit for the job or is likely to develop a certain disease in the future.
An interesting study was recently conducted by the University of Cambridge Psychometrics Cen-tre: by analyzing the social networking “likes” of 58,000 users, researchers found that they were able to predict ethnic origin with an accuracy of 95% and religious or political orientation with an accu-racy of over 80%.†Even more dramatically perhaps, they were able to predict psychological traits
such as intelligence or emotional stability. The research was conducted using openly available data provided by the study subjects themselves (Facebook likes). Its results can be fine-tuned even fur-ther when cross-referencing them with data about the same subjects drawn from ofur-ther sources, such as other social networking profiles or Internet usage habits. This is the point where big data starts overlapping with personal data, being separated only by a blurry border: “liking” a specific rock band does not constitute personal data as such, but the ability of linking this information directly to an individual or to other information makes it possible to identify what the person actually likes; furthermore, it enables to draw inferences about their personality, possibly revealing even sensitive political or religious preference (as was the case in the Cambridge study). “Companies may consider most of their data to be non personal data sets, but in reality it is now rare for data generated by user activity to be completely and irreversibly anonymised,” stated the EDPS in a recent Opinion.‡The
availability of massive amounts of data from different sources combined with the desire to learn more about people’s habits therefore poses a serious challenge regarding the right to privacy of the individual and requires that the data protection principles are carefully taken into consideration.
A fundamental part of big data analytics, however, is that the raw data must be accurate in order to lead to accurate results; massive quantities of inaccurate data can lead to skewed results and poor decision making. Bruce Schneier, an internationally renowned security technologist, refers to this as the “pollution problem of the information age.”§There is a risk that analytical applications find
patterns in cases where the individual facts are not directly correlated, which may lead to unfair conclusions and may adversely affect the persons involved. Another risk is that of being trapped in an “information bubble,” with people only being shown certain information that has been predicted to be of interest to them (but may not be in reality). In an article published in 2015 byTIMEmagazine, Facebook’s newsfeed algorithm was explained: whereas users have access to an average of 1,500 posts per day, they only see about 300 of them, which have been preselected by an algorithm in order to correspond as much as possible with the interests and preferences of each user.¶The author
of the article concludes that “by structuring the environment, Facebook is training people implicitly to behave in a particular way in that algorithmic environment.” Therefore, data quality is paramount
*European Data Protection Supervisor. 2015.Opinion 7/2015—Meeting the Challenges of Big Data: A Call for Transparency, User Control, Data Protection by Design and Accountability. Available at: https://secure.edps.europa.eu/EDPSWEB/ webdav/site/mySite/shared/Documents/Consultation/Opinions/2015/15-11-19_Big_Data_EN.pdf.
†Kosinski, M., D. Stillwell, and T. Graepel. 2013. Private Traits and Attributes Are Predictable from Digital Records of
Human Behavior.Proceedings of the National Academy of Sciences110 (15): 5802–5805. doi: 10.1073/pnas.1218772110.
‡European Data Protection Supervisor. 2014. Preliminary Opinion of the European Data Protection Supervisor
Privacy and Competitiveness in the Age of Big Data: The Interplay between Data Protection, Competition Law and Consumer Protection in the Digital Economy.https://secure.edps.europa.eu/EDPSWEB/webdav/site/mySite/ shared/Documents/Consultation/Opinions/2014/14-03-26_competitition_law_big_data_EN.pdf.
§Schneier, Bruce. 2015.Data and Goliath. New York: W.W. Norton.
¶Here’s How Your Facebook News Feed Actually Works. 2015.TIME.Com.
4 Big Data Management and Processing
to ensuring that the algorithms and analytical procedures are carried out successfully and that the predicted results correspond with the reality.
This chapter is aimed at analyzing the personal data protection legal compliance aspects of big data from a modern perspective, in order to identify the main challenges and to make adequate rec-ommendations for the more efficient and lawful use of data as an asset. Few considerations are also made on the connection between big personal data analytics and competition law. The methodology is straightforward: the observations made throughout the chapter are based on the research conducted by regulatory and advisory bodies, as well as on the empirical research and practical experience of the authors. One of the chapter’s focal points is data quality. Owing to the nature of big data, raw data that are not of adequate quality (accurate, relevant, consistent, and complete) represent an obstacle in harnessing the value of the data. It is hoped that the chapter will enable the reader to gain a bet-ter understanding that a correct legal compliance management can make a fundamental difference between simply collecting vast amount of data, on the one hand, and effectively using the power of big data, on the other hand.
1.1.2 STRUCTURE ANDARGUMENTS
This chapter is organized into two main sections: the first one addresses the personal data aspects of big data from a business perspective and is aimed at identifying the benefits and challenges of using big data analytics on massive personal datasets. The second part deals in detail with how the tradi-tional data protection principles should be applied to big data analytics, while also tackling modern data protection principles. Overall, the chapter aims to serve as a good basis for understanding both the positive and the negative implications of deploying big data analytics on personal datasets. In addition, the chapter will focus on the importance of the quality of the data analyzed, on the different ways in which good levels of data quality can be achieved, and on the negative consequences that may ensue when they are not.
1.2 BUSINESS OF BIG DATA
It is by now clear: big data means big business. Data are frequently called “the oil of the 21st century” or “the fuel of the digital economy,” and the era we live in has been referred to as the “data gold rush” by Neelie Kroes, the vice president of the European Commission responsible for the Digital Agenda.*This is true not only at the theoretical level but also in practice. A report by the leading consulting firm McKinsey found that “the intensity of big data varies across sectors but has reached critical mass in every sector” and that “we are on the cusp of a tremendous wave of innovation, productivity, and growth, as well as new modes of competition and value capture—all driven by big data as consumers, companies, and economic sectors exploit its potential.”†
With so much importance being given to data, it is not surprising that new business models are emerging, companies are being created, and apps and games are being designed with data collection as one of the main purposes. The most recent and compelling example is that of the Pok´emon Go mobile game, which was designed to allow users to collect characters in specific places around the city.‡Niantic Labs, the developer of the game that has practically gone viral in only a couple of
weeks, has access to data about the whereabouts of players, their connections, and other data such as area, climate, time of the day, and so on. It collects data from roughly 9.5 million daily active
*European Commission—Press Release—Speech: The Data Gold Rush. 2014.Europa.Eu. http://europa.eu/rapid/press-release_SPEECH-14-229_en.htm.
†McKinsey Global Institute. 2011. Big Data: The Next Frontier for Innovation, Competition, and Productivity.
http://file:///Users/theodoradragan/Downloads/MGI_big_data_full_report%20(1).pdf.
‡See, Hautala, Laura. 2016.Pokemon Go: Gotta Catch All Your Personal Data. CNET.
Big Data 5
users, a number that is growing exponentially by the day at the moment.*This is a clear example of how apps and games are starting to develop around the business of data, but also of how the data can be collected in “fun” ways without the users necessarily being aware of how and what data are gathered—the privacy policy is however very vague on these aspects.†
1.2.1 CONNECTION BETWEENBIGDATA ANDPERSONALDATA
The business of big data requires conducting a careful balancing exercise between the importance of harvesting the value of the data to foster innovation and evolution on the one hand, and the powerful impact that big data can have on many business sectors on the other hand. The manner in which personal data are collected and subsequently analyzed affects competition policy, antitrust policy, and consumer protection. In a paper published by the World Economic Forum, attention has been drawn to the fact that, “as ecosystem players look to use (mobile-generated) data, they face concerns about violating user trust, rights of expression, and confidentiality.”‡Big data and business are very much
intertwined, and even more so when the big data in question is personal data, in particular because “for many online offerings which are presented or perceived as being ‘free’, personal information operates as a sort of indispensable currency used to pay for those services: ‘free’ online services are ‘paid for’ using personal data which have been valued in total at over EUR 300 billion and have been forecast to treble by 2020.”§
The concept of personal data is defined by Regulation 679/2016 as “any information relating to an identified or identifiable natural person (‘data subject’); an identifiable natural person is one who can be identified, directly or indirectly, in particular by reference to an identifier such as a name, an identification number, location data, an online identifier or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person.”¶
While the list of factors specific to the identity of the person has been enriched from the previous definition of personal data that was contained in Directive 95/46/EC, the main elements remain the same. These elements have been discussed and elaborated by the Article 29 Working Party in its Opinion 4/2007, which establishes that there are four fundamental elements to establish whether an information is to be considered personal data.**
According to the Opinion, these elements are: “any information,” “relating to,” “identified or identifiable,” and “natural person.”
1.2.1.1 Any Information
All information relevant to a person is included, regardless of the “position or capacity of those persons (as consumer, patient, employee, customer, etc.).”††In this case, the information can be
objective or subjective and does not necessarily have to be true or proven.
*Wagner, Kurt. 2016. How Many People Are Actually Playing Pokémon Go?Recode.http://www.recode.net/2016/7/13/ 12181614/pokemon-go-number-active-users.
†Pokémon GO Privacy Policy. 2016.Nianticlabs.Com.https://www.nianticlabs.com/privacy/pokemongo/en.
‡World Economic Forum. 2012. Big Data, Big Impact: New Possibilities for International Development.
http://www3.weforum.org/docs/WEF_TC_MFS_BigDataBigImpact_Briefing_2012.pdf.
§European Data Protection Supervisor. 2014. Preliminary Opinion of the European Data Protection Supervisor
Privacy and Competitiveness in the Age of Big Data: The Interplay between Data Protection, Competition Law and Consumer Protection in the Digital Economy.https://secure.edps.europa.eu/EDPSWEB/webdav/site/mySite/ shared/Documents/Consultation/Opinions/2014/14-03-26_competitition_law_big_data_EN.pdf.
¶Article 4(1), Regulation (Eu) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection
of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation),Official Journal of the European Union, L 119/3, 4/5/2016. **Article 29 Data Protection Working Party. 2007. Opinion 4/2007 on the Concept of Personal Data.
http://ec.europa.eu/justice/policies/privacy/docs/wpdocs/2007/wp136_en.pdf.
6 Big Data Management and Processing
The words “any information” also imply information of any form, audio, text, video, images, etc. Importantly, the manner in which the information is stored is irrelevant. The Working Party expressly mentions biometric data as a special case,*as such data can be considered as information content as well as a link between the individual and the information. Because biometric data are unique to an individual, they can also be used as an identifier.
1.2.1.2 Relating to
Information related to an individual is information about that individual. The relationship between data and an individual is often self-evident, an example of which is when the data are stored in an individual employee’s files or in a medical record. This is, however, not always the case, especially when the information regards objects. Such objects belong to individuals, but additional meanings or information are required to create the link to the individual.†
At least one of the following three elements should be present in order to consider information to be related to an individual: “content,” “purpose,” or “result.” An element of “content” is present when the information is in reference to an individual, regardless of the (intended) use of the information. The “purpose” element instead refers to whether the information is used or is likely to be used “with the purpose to evaluate, treat in a certain way or influence the status or behavior of an individual.”‡A
“result” element is present when the use of the data is likely to have an impact on a certain person’s rights and interests.§These elements are alternatives and are not cumulative, implying that one piece
of data can relate to different individuals based on diverse elements.
1.2.1.3 Identified or Identifiable
“A natural person can be ‘identified’ when, within a group of persons, he or she is ‘distinguished’ from all other members of the group.”¶ When identification has not occurred but is possible, the
individual is considered to be “identifiable.”
In order to determine whether those with access to the data are able to identify the individual, all reasonable means likely to be used either by the controller or by any other person should be taken into consideration. The cost of identification, the intended purpose, the way the processing is structured, the advantage expected by the data controller, the interest at stake for the data subjects, and the risk of organizational dysfunctions and technical failures should be taken into account in the evaluation.**
1.2.1.4 Natural Person
Directive 95/46/EC is applicable to the personal data of natural persons, a broad concept that calls for protection wholly independent from the residence or nationality of the data subject.
The concept of personality is understood as “the capacity to be the subject of legal relations, starting with the birth of the individual and ending with his death.”††Personal data thus relate to
identified or identifiable living individuals. Data concerning deceased persons or unborn children falling in principle outside the application of personal data protection legislation (Recital 20 of Reg-ulation (EU) 679/2016) may, however, indirectly be subject to protection in particular cases. When the data relate to other living persons, or when a data controller makes no differentiation in their documentation between living and deceased persons, it may not be possible to ascertain whether the person the data relate to is living or deceased; additionally, some national laws consider deceased or
*Idem, p. 8.
†Idem, p. 9. ‡Idem, p. 10. §Idem, p. 11. ¶Idem, p. 12.
**Idem, p. 15.
Big Data 7
unborn persons to be protected under the scope of Directive 95/46/EC.*Legal persons are excluded from the protection provided under Regulation (EU) 679/2016 and Directive 95/46/EC. However, some provisions of Directive 2002/58/EC†(amended by Directive 2009/136/EC‡) extend the scope
of Directive 95/46/EC to legal persons.§
In conclusion, in some cases, the data may not be personal in nature, but may become personal data as a result of cross-referencing it with other sources and databases containing information about spe-cific users, therefore shrinking the circle of potential persons to “identifiable persons” and ultimately even to specifically identified individuals. The 2013 MIT Technology Review raised the question of whether big data has made anonymity impossible, arguing that “as the amount of data expands exponentially, nearly all of it carries someone’s digital fingerprints.”¶Bigpersonaldata is becoming
more and more the norm, rather than the exception, calling for the adoption of specific safeguarding measures with regard to the individual’s right to privacy.
1.2.2 COMPETITIONASPECTS
The development of the digital market has made it clear that in the business of big data, personal data is a particularly important asset, especially regarding gaining (and maintaining) a strong market position. This is why personal data are also being used as a competitive advantage by some digital businesses. The EDPS addressed the ever-increasing connection between big personal data analytics and competition law in the workshop on “Privacy, Consumers, Competition and Big Data” that it held in 2014 with the aim of discussing the themes explored in its Preliminary Opinion published earlier that same year.**
Given the lack of a “unifying objective” with regard to competition law at the EU level, authorities evaluate each situation (such as mergers between companies having a dominant market position) on a case-by-case basis, based on very specific parameters of competition. The parameters have been established by Commission Guidelines and are the following: price, output, product quality, product variety, and innovation.††However, applying these criteria in relation to companies whose business
model is centered around big data is difficult, especially considering, for example, the challenge of measuring the probability of the merged entity to raise the price in case of services offered “for free” in exchange of the personal data of the users. Therefore, the report recommended increasing vigilance with regard to such issues and monitoring the market to establish whether an abuse of dominant market position is being carried out using personal data as a “weapon.”
*Idem, pp. 22–23.
†Directive 2002/58/EC of the European Parliament and of the Council of 12 July 2002 concerning the processing of
per-sonal data and the protection of privacy in the electronic communications sector (Directive on privacy and electronic communications) [2002] OJL 201, 31/07/2002 P. 0037–0047.
‡Directive 2009/136/EC of the European Parliament and of the Council of 25 November 2009 amending Directive
2002/22/EC on universal service and users’ rights relating to electronic communications networks and services, Direc-tive 2002/58/EC concerning the processing of personal data and the protection of privacy in the electronic communications sector and Regulation (EC) No. 2006/2004 on cooperation between national authorities responsible for the enforcement of consumer protection laws (Text with EEA relevance). [2006] OJ L 337, 18/12/2009 P. 0011–0036.
§In the EDPS Preliminary Opinion on Big Data, it is also expected that: “[c]ertain national jurisdictions (Austria, Denmark,
Italy and Luxembourg) extend some protection to legal persons.” European Data Protection Supervisor. 2014.Preliminary Opinion of the European Data Protection Supervisor Privacy and Competitiveness in the Age of Big Data: The Interplay between Data Protection, Competition Law and Consumer Protection in the Digital Economy, p. 13, footnote 31. Avail-able at https://secure.edps.europa.eu/EDPSWEB/webdav/site/mySite/shared/Documents/Consultation/Opinions/2014/14-03-26_competitition_law_big_data_EN.pdf.
¶MIT Technology Review. 2013.Big Data Gets Personal.
https://www.technologyreview.com/business-report/big-data-gets-personal/.
**European Data Protection Supervisor. 2014.Report of Workshop of Privacy, Consumers, Competition and Big Data. https://secure.edps.europa.eu/EDPSWEB/webdav/site/mySite/shared/Documents/Consultation/Big%20data/14-07-11_EDPS_Report_Workshop_Big_data_EN.pdf.
8 Big Data Management and Processing
Given these market conditions, it appears useful to consider using privacy and personal data pro-tection compliance as a competitive advantage in order to harness the full value of the data held by a company. Privacy and personal data protection compliance can ensure that the data, even when it is massive in quantity, is collected, stored, and processed according to the relevant rules. As mentioned earlier in the chapter, the principle of data quality plays a particularly important role in this matter, as it helps ensure that only accurate, relevant, and up-to-date data are processed, helping with com-pliance but also with making sure that the outcomes of the data analysis are relevant and useful. A research conducted by the consulting firm Deloitte points out the “epistemological fallacy that more bytes yield more benefits,” arguing that it is “an example of what philosophers call a ‘category error’. Decisions are not based on raw data; they are based on relevant information. And data volume is at best a rough proxy for the value and relevance of the underlying information.”*Therefore, it is not about the quantity of data collected, but about the quality of the information contained in it.
The best approach to ensure consistent data quality within a database is to start from the point of collection and to implement measures or procedures along the chain of processing. When data are collected responsibly, consumer trust could improve and users could therefore provide more accurate data. In a recent survey by SDL, 79% of respondents said they are more likely to provide personal information to brands that they “trust.”†Having an adequate, transparent, and easy-to-understand
privacy policy is the first step in that direction, as it would contribute to balance out the information asymmetry between companies and consumers. Another step would be the implementation of regular reviewing procedures, aimed at identifying the data that are still relevant, rectifying the data that are out of use or incorrect, and deleting the data that are no longer of use. It would also constitute an opportunity for “cleaning up” the database periodically, in order to ensure that there is no “dead data” from so-called zombie accounts.‡
Taking such steps would ensure that the database consists of reliable, good-quality data that not only comply with the relevant laws and regulations, but whose analysis can provide more detailed and accurate outcomes. Companies that care about the quality of the data they process are therefore more likely to have a real market advantage over the ones that do not take any steps in this respect. Academic research corroborates the theoretical assumptions and the practical observations: Erik Brynjolfsson, the director of the MIT Initiative on the Digital Economy studied a sample of publicly traded firms and concluded that the firms in the sample that had adopted a data-driven decision-making approach enjoyed 5%–6% higher output and productivity than would be expected given their other investments and level of information technology usage.§
1.3 RECONCILING TRADITIONAL AND MODERN DATA PROTECTION PRINCIPLES
The most recent Opinion on topics related to big data issued by the EDPS discussed whether, and how, traditional data protection principles should be applied to big data analytics that involve
*Guszcza, James and Bryan Richardson. 2014. Two Dogmas of Big Data: Understanding the Power of Analytics for Predict-ing Human Behavior.Deloitte Review, 15.http://dupress.com/articles/behavioral-data-driven-decision-making/#end-notes.
†SDL. 2014. New Privacy Study Finds 79 Percent of Customers Are Willing to Provide Personal Information to
a ‘Trusted Brand’. http://www.sdl.com/about/news-media/press/2014/new-privacy-study-finds-customers-are-willing-to-provide-personal-information-to-trusted-brands.html.
‡European Data Protection Supervisor. 2014. Report of Workshop of Privacy, Consumers, Competition and Big
Data. https://secure.edps.europa.eu/EDPSWEB/webdav/site/mySite/shared/Documents/Consultation/Big%20data/14-07-11_EDPS_Report_Workshop_Big_data_EN.pdf.
§Brynjolfsson, Erik, Lorin M. Hitt, and Heekyung Hellen Kim. Strength in Numbers: How Does Data-Driven
Big Data 9
personal data.*The underlying consideration that transpired from the document was that “we need to protect more dynamically our fundamental rights in the world of big data.” It was argued that the “traditional” data protection principles (i.e., those established before the era of big data) such astransparency,proportionality, andpurpose limitationhave to be modernized and strengthened, but also complemented by “new principles,” that have been developed more recently in response to the challenges brought about by big data itself—accountability,privacy by design, andprivacy by default. In the following sections, the application of these principles will be discussed with ref-erence to the overarching principle ofdata qualitythat the authors have advocated throughout the chapter. Data quality is considered to be closely linked to each of these principles. Ensuring that the data are relevant, accurate, and up-to-date is fundamental for the successful application of the principles, while also representing the bridge between compliance and revenue, enabling thus the return of investment(ROI).
1.3.1 TRADITIONALDATAPROTECTIONPRINCIPLES
The EDPS refers to transparency, proportionality, and purpose limitation as “traditional” data protec-tion principles. Although these principles were identified since before the era of big data analytics, they remain just as essential nowadays. They have been upgraded to fit the context, so it is important to gain an understanding of how big data has changed the way that they are applied.
1.3.1.1 Transparency
The principle of transparency regards the information given to the data subject about the use made of the data by the data controller. Transparency is one of the basic principles of data protection and lies at the core of data quality: if the practices of the data controller are transparent, then the users know what they can expect and are more likely to provide accurate data about themselves; therefore, the dataset created is more likely to be relevant. One way to ensure transparency used to be by giving information notices to users to let them know how their data are processed. However, in the era of big data, more proactivity on the part of the data controller is required, so that it can be ensured that the information given to the users is easy to read and understand.
Too often, privacy policies consist of texts written in “legalese” that are not understood by users. A study conducted by Pew Research Center found that 52% of respondents did not know what a privacy policy was, erroneously believing that it meant an assurance that their data would be kept confidential by the company.†This could also be the result of the fact that privacy policies are often
long and complex texts that would simply take too much time to read carefully. According to a study carried out by two researchers from Carnegie Mellon, it would take a person an average of 76 work days to read the privacy policy of every website visited throughout a year.‡The study was
conducted in 2008 and, considering the dynamic expansion of the use of Internet, it may well be that nowadays an individual would not even have enough time in a year to read all the privacy policies of the websites visited within that same year.
Privacy policies are, at the moment, the main tool that is considered to ensure transparency and yet, they are inefficient at achieving that purpose. Some options for improving privacy policies were
*European Data Protection Supervisor. 2015.Opinion 7/2015—Meeting the Challenges of Big Data: A Call for Trans-parency, User Control, Data Protection by Design and Accountability.https://secure.edps.europa.eu/EDPSWEB/webdav/ site/mySite/shared/Documents/Consultation/Opinions/2015/15-11-19_Big_Data_EN.pdf.
†Pew Research Center. 2014. Half of Online Americans Don’t Know What a Privacy Policy Is.
http://www.pewresearch.org/fact-tank/2014/12/04/half-of-americans-dont-know-what-a-privacy-policy-is/.
‡Cranor, Lorrie Faith and Aleecia McDonald. 2008.Reading the Privacy Policies You Encounter in a Year Would Take
10 Big Data Management and Processing
suggested by a group of professors from Carnegie Mellon at PrivacyCon held in January this year.*
They proposed extracting and highlighting data practices that do not match users’ expectations, using visual formats to display privacy policies, and highlighting in different colors the practices that correspond to common expectations and the ones that do not.
These ideas could help users decipher the privacy policies and understand how their data are being used, increasing transparency and contributing to balancing out the information asymmetry between data controllers and data subjects.
The authors support these suggestions and agree with the idea that visually enhanced privacy policies would be more effective and would transmit information quickly, grabbing users’ attention. Using different colors to identify the privacy-level compliance would render the privacy policy, as a tool, more efficient in communicating the information. As a positive side effect, easier-to-understand privacy policies would enhance user trust in the data controller and contribute to data quality, as users tend to provide more accurate data about themselves when they trust the company that is the controller of that data.
1.3.1.2 Proportionality and Purpose Limitation
The sheer volume of personal data that each single user leaves behind while browsing the Internet or using an app on their mobile phone is enormous. Computational social scientist Alex Pentland refers to these data as “breadcrumbs”: “I believe that the power of big data is that it is information about people’s behaviour instead of information about their beliefs. It’s about the behaviour of customers, employees, and prospects for your new business. It’s not about the things you post on Facebook, and it’s not about your searches on Google, which is what most people think about, and it’s not data from internal company processes and RFIDs. This sort of big data comes from things like location data off of your cell phone or credit card: It’s the little data breadcrumbs that you leave behind you as you move around in the world.”†A real-life example of how these breadcrumbs of data can be used
is that of Netflix, that used big data analytics to find out whether the online series “House of Cards” would be a hit, based on the information it gathered from its customer base of over 30 million users worldwide.‡
The principles of proportionality and purpose limitation are closely tied to the Netflix example. Incredible amounts of data are gathered each day, but it is not always clear how the data will be used in the future, and that is precisely what the value of data resides in: the potential of using it over and over, for different purposes, without diminishing its overall value. Therefore, the traditional data protection principles of proportionality and purpose limitation find application in the big data sector too.
In this respect, on April 2, 2013, the Article 29 Data Protection Working Party published an opinion on the principle of purpose limitation.§The concept of purpose limitation has two primary
building blocks:
• Personal data must be collected for specified, explicit, and legitimate purposes (the
so-called purpose specification).¶
*PrivacyCon Organised by the Federal Trade Commission. 2016. Expecting the Unexpected: Understanding Mismatched Privacy Expectations Online. https://www.ftc.gov/system/files/documents/videos/privacycon-part-2/part_2_privacycon_slides.pdf.
†Edge. 2012. Reinventing Society in the Wake of Big Data—A Conversation with Alex (Sandy) Pentland.
https://www.edge.org/conversation/reinventing-society-in-the-wake-of-big-data.
‡Carr, David. 2014. Giving Viewers What They Want: For ‘House Of Cards,’ Using Big Data to Guarantee Its
Popular-ity. NYTimes.com. http://www.nytimes.com/2013/02/25/business/media/for-house-of-cards-using-big-data-to-guarantee-its-popularity.html?pagewanted=all&_r=0.
§Article 29 Data Protection Working Party. 2013. Opinion 03/2013 on purpose limitation. Adopted on April
2, 2013. Available at:http://ec.europa.eu/justice/data-protection/article-29/documentation/opinion-recommendation/files/ 2013/wp203_en.pdf.
Big Data 11
• Personal data must not be further processed in a way incompatible with those purposes (the
so-called compatible use).*
Compatible or incompatible use needs are to be assessed—“compatibility assessment”—on a case-by-case basis, according to the following key factors (see also Article 6.4 Regulation (EU) 679/2016):
• The relationship between the purposes for which the personal data have been collected and
the purposes of further processing†
• The context in which the personal data have been collected and the reasonable expectations
of the data subjects as to their further use‡
• The nature of the personal data and the impact of the further processing on the data subjects§ • The safeguards adopted by the controller to ensure fair processing and to prevent any undue
impact on the data subjects¶
In this opinion, the Article 29 Data Protection Working Party deals with Big Data.**More pre-cisely, Article 29 Data Protection Working Party specifies that, in order to lawfully process Big Data, in addition to the four key factors of the compatibility assessment to be fulfilled, additional safeguards must be assessed to ensure fair processing and to prevent any undue impact. Article 29 Data Protection Working Party considers two scenarios to identify such additional safeguards:
1. “[i]n the first one, the organizations processing the data want to detect trends and correla-tions in the information.
2. In the second one, the organizations are interested in individuals (. . . ) [as they specifically want] to analyse or predict personal preferences, behaviour and attitudes of individual cus-tomers, which will subsequently inform ‘measures or decisions’ that are taken with regard to those customers.”††
In the first scenario, the so-called functional separation plays a major role in deciding whether further use of data may be considered compatible. Examples of “functional separation” are: “full or partial anonymisation, pseudonymsation, or aggregation of the data, privacy enhancing technologies, as well as other measures to ensure that the data cannot be used to take decisions or other actions with respect to individuals”‡‡
In the second scenario, prior customers/data subjects consent (i.e., free, specific, informed, and unambiguous “opt-in”) would be required for further use to be considered compatible. In this respect, Article 29 Data Protection Working Party specifies that “such consent should be required, for example, for tracking and profiling for purposes of direct marketing, behavioural advertisement, data-brokering, location-based advertising or tracking-based digital market research.”§§
Further-more, access for data subjects: (i) to their “profiles,” (ii) to the algorithm that develops the profiles, and (iii) to the source of data that led to the creation of the profiles is regarded as prerequisite for consent to be informed and to ensure transparency.¶¶Moreover, data subjects should be effectively
granted the right to correct or update their profiles. Last but not least, Article 29 Data Protection
*Ibid. p. 12.
†Ibid. p. 23. ‡Ibid. p. 24. §Ibid. p. 25. ¶Ibid. p. 26.
**Ibid. pp. 45ss.
12 Big Data Management and Processing
Working Party recommends allowing “data portability”: “safeguards such as allowing data sub-jects/customers to have access to their data in a portable, user-friendly and machine readable format [as a way] to enable businesses and data-subjects/consumers to maximise the benefit of big data in a more balanced and transparent way.”*
1.3.2 MODERNDATAPROTECTIONPRINCIPLES
The EDPS has identified “four essential elements for the responsible and sustainable development of big data:
• Organisations must be much more transparent about how they process personal data; • Afford users a higher degree of control over how their data is used;
• Design user friendly data protection into their products and services; and • Become more accountable for what they do.”†
It is evident from the above list that, of the four essential elements, only the first one relates to a traditional data protection principle (transparency). The other three of the four essential elements are all related to modern data protection principles, such as accountability, privacy by default and by design, and increased users’ control of their own data. In that sense, big personal data processing is very different from traditional personal data processing, since it requires additional principles to be followed—principles that have been designed specifically to respond to the challenges of big data.
1.3.2.1 Accountability
The (by nowclich´e) popular saying “with great power comes great responsibility” perfectly captures the essence of accountability in big personal data processing (see also Article 5.2 Regulation (EU) 679/2016). The accountability is related not only to how the data are processed (how transparent the procedures are, how much access the data subject has to its own data, etc.) but also to issues of algorithmic decision making, which is the direct result of big personal data processing in the twenty-first century.‡Processing the personal data at a high level is only a means to an end, the
final purpose being reaching the ability to make informed decisions on a high scale based on the information collected and stored in big databases. As the EDPS points out in its Opinion 7/2015, “one of the most powerful uses of big data is to make predictions about what is likely to happen but has not yet happened.”§This is, again, closely tied to the quality of data that the authors have
been emphasizing throughout this chapter: if data quality is high, related decisions are likely to have positive results, whereas, if the data are of poor quality, decisions are likely to have a negative impact on the affected population, leading to potentially unfair and/or discriminatory conclusions. In any case, data controllers have to take responsibility and be accountable for the decisions they make based on the processing of big datasets of personal data.
Proactive steps, such as disclosing the logic involved in big data analytics or giving clear and easily understandable information notices to the data subjects, are needed to establish accountability. This is so especially since the information contained in the datasets is not always collected directly from
*Ibid. p. 47. For example, access to information about energy consumption in a user-friendly format could make it easier for households to switch tariffs and get the best rates on gas and electricity, as well as enabling them to monitor their energy consumption and modify their lifestyles to reduce their bills as well as their environmental impact.
†European Data Protection Supervisor. 2015.Opinion 7/2015—Meeting the Challenges of Big Data: A Call for Transparency,
User Control, Data Protection by Design and Accountability. Available at: https://secure.edps.europa.eu/EDPSWEB/ webdav/site/mySite/shared/Documents/Consultation/Opinions/2015/15-11-19_Big_Data_EN.pdf.
‡Kubler, Kyle. 2016. The Black Box Society: The Secret Algorithms That Control Money and Information.Information,
Communication & Society, 1–2. doi: 10.1080/1369118x.2016.1160142.
§European Data Protection Supervisor. 2015. Opinion 7/2015—Meeting the Challenges of Big Data: A Call for
Big Data 13
the concerned individual—data can be “volunteered, observed or inferred, or collected from public sources.”*Apart from disclosing the logic involved in decision making based on big data analytics and ensuring that data subjects have access to their own data, as well as to information as to how it is processed, companies should also develop policies for the regular verification of data accuracy, data quality, and compliance with the relevant legislation. As the EDPS points out, “accountability is not a one-off exercise.”†It needs to be undertaken continually, for as long as data are being processed
by the company. The principle of data accountability is closely connected to privacy by design and by default—which, taken together, represent another modern data protection principle.
1.3.2.2 Privacy by Design and by Default
It is not enough anymore for data controllers to regard data privacy as an afterthought. Instead, data controllers should incorporate data protection into the design and architecture of communica-tion systems that are meant for the colleccommunica-tion or processing of personal data. Recitals 78 and 108 of the Regulation (EU) 679/2016 foreshadow the increasing importance of data privacy by design and by default, principles that are also explicitly addressed in Article 25 of the same legislation.‡In
particular, the first comma of Article 25 states that: “the controller shall, both at the time of the deter-mination of the means for processing and at the time of the processing itself, implement appropriate technical and organisational measures, such as pseudonymisation, which are designed to implement data-protection principles, such as data minimisation, in an effective manner and to integrate the necessary safeguards into the processing in order to meet the requirements of this Regulation and protect the rights of data subjects,” whereas comma 2 of the same article requires that “by default, only personal data which are necessary for each specific purpose of the processing are processed.”§
When dealing with big datasets of personal data, taking into account privacy requirements right from the beginning ensures that only the data that is strictly necessary for the processing is being collected and, subsequently, that the data used in the relevant decision making is accurate. Moreover, as mentioned previously in this chapter (under Section 1.2.2), there is a direct connection between how much data subjects trust a data controller and the accuracy of data they choose to share with it. If privacy is embedded right from the very beginning in the collection and processing of personal data, data subjects are more likely to trust the data controller, thereby providing higher-quality data. On the same note, as already mentioned above, the EDPS underlined in its Opinion 7/2015, the concept of “functional separation.”¶ Functional separation requires data controllers to distinguish
between personal data used for a specific purpose, such as “to detect trends or correlations in the information,” from personal data used for another purpose, such as to make decisions based on the trends detected by means of processing the same information. This would allow data controllers to detect and analyze trends based on the collected data, without negatively affecting the data subjects from whom the data were collected in the first place. Such functional separation would ensure that the traditional data protection principle of purpose limitation is respected and that personal data are not processed for a purpose that is not compatible with the purposes for which it was collected, unless specific and informed consent of data subjects has been givena priori.
*European Data Protection Supervisor. 2015.Opinion 7/2015—Meeting the Challenges of Big Data: A Call for Trans-parency, User Control, Data Protection by Design and Accountability. Available at: https://secure.edps.europa.eu/ EDPSWEB/webdav/site/mySite/shared/Documents/Consultation/Opinions/2015/15-11-19_Big_Data_EN.pdf.
†Idem.
‡Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural
persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation) (Text with EEA relevance).
§Idem.
¶European Data Protection Supervisor. 2015.Opinion 7/2015—Meeting the Challenges of Big Data: A Call for