Klasifikasi rekomendasi bidang ilmu untuk masuk Perguruan Tinggi menggunakan metode Naive Bayes (studi kasus : Pusat Pelayanan Tes Konsultasi dan Psikologi Universitas Sanata Dharma)
Bebas
90
0
0
Teks penuh
(2) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. CLASSIFICATION OF KNOWLEDGE FIELD RECOMMENDATIONS FOR HIGHER EDUCATION ENTRANCE USING NAÏVE BAYES METHOD (Case Study: Pusat Pelayanan Tes Konsultasi dan Psikologi Universitas Sanata Dharma). A THESIS Submitted in Partial Fulfillment of The Requirements For The Degree of Sarjana Komputer In Informatics Study Program. By : Caroline Asteria Caezar Aryani 165314086 INFORMATICS STUDY PROGRAM FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY YOGYAKARTA 2020 ii.
(3) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. HALAMAN PERSEMBAHAN. Jadilah kuat dan penuh keberanian, janganlah takut, dan janganlah gentar akan mereka: karena TUHANmu, Dialah yang berjalan bersamamu; Dia tidak akan mengecwakanmu atau meninggalkanmu (Ulangan 31:6). v.
(4) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. ABSTRAK Tes potensi akademik adalah suatu tes yang diadakan untuk untuk mengukur kemampuan seseorang, maupun mengukur keberhasilan seseorang dalam melakukan seleksi pada suatu instansi. Pusat Pelayanan Tes dan Konsultasi (P2TKP) adalah salah satu lembaga di Universitas Sanata Dharma yang menyediakan pelayanan tes kepada pihak yang membutuhkan yang membutuhkan di bidang pendidikan, organisasi, perusahaan, lembaga maupun instansi lainnya. Salah satu tes yang diadakan P2TKP adalah tes pengarahan bidang ilmu untuk masuk perguruan tinggi yang menggunakan tes potensi akademik. Pengarahan bidang ilmu dapat dikategorikan menjadi 4 bidang yaitu bidang ilmu fisik, ilmu sosial kuantitatif, ilmu sosial non kuantiatif, dan bahasa. Klasifikasi bidang ilmu dapat dilakukan dengan menggunakan penambangan data. Penambangan data yang dilakukan dalam pengarahan masuk perguruan tinggi untuk mengklasifikasikan bidang ilmu. dapat menghasilkan akurasi dengan. menggunakan metode Naïve Bayes. Penelitian dilakukan dengan menggunakan 400 recorddata menggunakan 5-fold cross validation. Pengujian dilakukan menggunakan 6 atribut yaitu Hubungan Ruang (HR), Berpikir Matematis Tipe A (BMA), Berpikir Matematis Tipe B (BMB), Berpikir Verbal Tipe A (BVA), Berpikir Verbal Tipe B (BVB), dan Perbendaharaan Kata (VOK) dengan menghasilkan akurasi rata-rata yaitu 60.25%. Kata kunci : klasifikasi, pengarahan bidang ilmu, Naïve Bayes, cross validation. viii.
(5) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. ABSTRACT. Academic Potential Test, is a test that organized to measure the ability of a person or someone, it measures the successful rate of a person in doing a selection pass test in an institution. Pusat Pelayanan Tes dan Konsultasi or P2TKP is one of the institution that giving a test consultation to those who need a consultation in the educational field, organizations, companies and other institutions in Sanata Dharma University. One of the test that organized or held by the P2TKP is field knowledge analysis, this kind of test is to measure the person’s ability when he or she wants to join an university that require an academic potential test. Field knowledge analysis can be categorized in 4 other fields, there are Physic field, Quantity field, Non quantitative social field and language. Science field classification could be done by data mining. The data mining in preparing the self to join the course or lecture for classifying science field could resulting an accuracy by using the Naive Bayes method. The research undergo by using 400 records data with 5-fold cross validation. The test is done using 6 attributes, those are Space relation, Sequence of numbers, Numerical analysis, Verbal Thinking Analogy, Verbal Thinking Classify and Words bank with resulting average accuracy measure in 60.25%. Key Words : Classification, Field Knowledge Analysis, Naïve Bayes, cross validation.. ix.
(6) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. KATA PENGANTAR Puji syukur penulis panjatkan kepada Tuhan Yesus Kristus yang telah melimpahkan berkat dan karunia-Nya, sehingga penulis dapat menyelesaikan skripsi dengan judul “Klasifikasi Rekomendasi Bidang Ilmu untuk Masuk Perguruan Tinggi Menggunakan Metode Naïve Bayes”. Penulis menyadari bahwa selama pengerjaan skripsi ini dapat berjalan dengan baik dan lancar karena bimbingan dan bantuan dari berbagai pihak. Maka dalam kesempatan ini, penulis ingin mengucapkan rasa syukur dan terimakasih kepada : 1. Tuhan Yesus Kristus, Bunda Maria, dan para malaikat Tuhan yang telah memberikan berkat dan karunia untuk membimbing dan menolong dalam penyelesaian skripsi. 2. Ibu Agnes Maria Polina, S.Kom., M.Sc. selaku dosen pembimbing skripsi yang dengan sabar membimbing dan meluangkan waktu dalam pengerjaan skripsi. Selain itu, Ibu Agnes Maria Polina, S.Kom., M.Sc. selaku dosen pembimbing akademik yang dengan sabar memberikan bimbingan dan nasehat dari awal semester hingga akhir semester. 3. Kedua orang tua, adik, serta keluarga besar yang selalu memberikan doa, dukungan dan motivasi untuk menyelesaiakan skripsi. 4. Bapak Eduardus Hardika Sandy Atmaja S.Kom., M.Cs. selaku dosen pembimbing metode penelitian yang dengan sabar membimbing dan meluangkan waktu selama pengerjaan metode penelitian. 5. Bapak Robertus Adi Nugroho, ST., M.Eng. selaku Ketua Program Studi Informatika yang selalu memberikan dukungan. dan saran dalam. perkuliahan. 6. Seluruh dosen program studi informatika yang telah membimbing dan memberikan ilmu selama masa kuliah dari awal semester hingga akhir semester. 7. Lembaga P2TKP yang telah membantu kelancaran dalam penyusunan skripsi.. x.
(7) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 8. Thomas Mario dan Galuh Pingkan yang selalu ada dalam keadaan darurat dan memberikan dukungan dalam segala hal. 9. Maria, Dewi, Yogi, Norbert, Vincent, Andhika, Bagus rekan Yudha 40 yang merupakan rekan seperjuangan dalam berorganisasi. 10. Dian, Via, Arsa, Evelin, Clara, Desi, Hady, Husor, William serta temanteman informatika angkatan 2016 lainnya yang menjadi teman seperjuangan dan teman yang dapat menghibur selama 4 tahun masa perkuliahan. 11. Yiyin, Indah, Dodi, Alfri, Alva, Valen merupakan teman seperjuangan dalam pengerjaan skripsi yang dapat saling membantu dan bertukar pikiran. 12. Keluarga besar Satuan Ignatian baik senior maupun junior yang telah banyak mengajarkan banyak hal dan saling membantu dalam. hidup. berdinamika bersama selama 4 tahun. 13. Semua pihak yang tidak dapat disebutkan satu persatu yang telah banyak membantu penulis dalam pembuatan skripsi ini.. xi.
(8) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. DAFTAR ISI. HALAMAN PERSETUJUAN ............................................................................ iii HALAMAN PENGESAHAN .............................................................................. iv HALAMAN PERSEMBAHAN ........................................................................... v PERNYATAAN KEASLIAN KARYA .............................................................. vi LEMBAR PERNYATAAN PERSETUJUAN .................................................. vii ABSTRAK .......................................................................................................... viii ABSTRACT ........................................................................................................... ix KATA PENGANTAR ........................................................................................... x DAFTAR ISI ........................................................................................................ xii DAFTAR GAMBAR ........................................................................................... xv DAFTAR TABEL ............................................................................................. xvii BAB I PENDAHULUAN ...................................................................................... 1 1.1 Latar Belakang .............................................................................................. 1 1.2 Rumusan Masalah ......................................................................................... 2 1.3 Tujuan ............................................................................................................ 2 1.4 Manfaat .......................................................................................................... 3 1.5 Batasan Masalah ............................................................................................ 3 1.6 Sistematika Penulisan .................................................................................... 3 BAB II LANDASAN TEORI ............................................................................... 5 2.1. Tes Potensi Akademik .............................................................................. 5. 2.2. Data Mining ............................................................................................. 6. 2.2.1. Pengertian Data Mining .................................................................... 6. 2.2.2. Tahapan KDD ................................................................................... 7. 2.2.3. Pengelompokan Data Mining ........................................................... 8. 2.3. Klasifikasi ................................................................................................. 9. 2.4. Naïve Bayes ............................................................................................ 10. 2.4.1. Persamaan Metode Naïve Bayes .................................................... 10. 2.4.2. Alur Metode Naïve Bayes ............................................................... 12. 2.5. Cross validation ..................................................................................... 14. xii.
(9) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 2.6. Confusion Matrix .................................................................................... 14. 2.7. Information Gain .................................................................................... 15. BAB III METODOLOGI PENELITIAN ......................................................... 16 3.1. Data ........................................................................................................ 16. 3.2. Desain Alat Uji ....................................................................................... 19. 3.3. Spesifikasi Alat Penelitian...................................................................... 23. 3.3.1. Hardware ........................................................................................ 23. 3.3.2. Software .......................................................................................... 23. 3.4.. Desain User Interface ............................................................................. 23. 3.5. Tahap Penelitian ..................................................................................... 25. 3.5.1. Studi Kasus ..................................................................................... 25. 3.5.2. Penelitian Pustaka ........................................................................... 25. 3.5.3. Perancangan Sistem ........................................................................ 25. 3.5.4. Tahap Preprocessing ....................................................................... 25. 3.5.5. Implementasi Sistem ....................................................................... 26. 3.5.6. Tahap Uji Validasi .......................................................................... 26. 3.5.7. Tahap Uji Akurasi ........................................................................... 26. BAB IV IMPLEMENTASI SISTEM ................................................................ 27 4.1. Implementasi Preprocessing ................................................................. 27. 4.1.1. Transformasi Data ........................................................................... 27. 4.1.2. Implementasi Seleksi Data .............................................................. 28. 4.2. Implementasi Naïve Bayes ..................................................................... 29. 4.3. Implementasi 5- Fold Cross Validation ................................................. 30. 4.4. Implementasi Confussion Matrix dan Akurasi ....................................... 32. 4.5. Implementasi Uji Data Kelompok .......................................................... 33. 4.6. Implementasi Uji Data Tunggal ............................................................. 34. 4.7. User Interface Sistem ............................................................................. 35. BAB V ANALISIS HASIL ................................................................................. 36 5.1. Preprocessing ......................................................................................... 36. 5.1.1. Seleksi Data ..................................................................................... 36. 5.1.2. Transformasi Data ........................................................................... 36. 5.2. Uji Validasi............................................................................................. 37. xiii.
(10) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 5.2.1. Perhitungan Manual Naïve Bayes ................................................... 37. 5.2.2. Pengujian Sistem ............................................................................. 50. 5.2.3. Pengujian Menggunakan Function Matlab ..................................... 52. 5.2.4 Evaluasi Hasil Perhitungan Manual, Pengujian Sistem dan Pengujian Menggunakan Matlab ................................................................... 53 5.3. Uji Akurasi ............................................................................................. 54. 5.4. Prediksi ................................................................................................... 58. 5.4.1. Uji Data Tunggal ............................................................................. 58. 5.4.1.1 Uji Data Tunggal 1 ...................................................................... 59 5.4.1.2 Uji Data Tunggal 2 ...................................................................... 59 5.4.1.3 Uji Data Tunggal 3 ...................................................................... 60 5.4.1.4 Uji Data Tunggal 4 ...................................................................... 60 5.4.2. Uji Data Kelompok ......................................................................... 61. BAB VI PENUTUP ............................................................................................. 63 6.1. Kesimpulan ............................................................................................. 63. 6.2. Saran ....................................................................................................... 63. DAFTAR PUSTAKA .......................................................................................... 64 LAMPIRAN ......................................................................................................... 66. xiv.
(11) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. DAFTAR GAMBAR Gambar 2. 1 Pembagian data Training dan Testing .............................................. 14 Gambar 2. 2 Confusion Matrix.............................................................................. 15 Gambar 3. 1 Persentase Setiap Atribut ................................................................. 18 Gambar 3. 2 Diagram Blok Sistem ....................................................................... 19 Gambar 3. 3Flowchart Perhitungan Naïve Bayes................................................ 20 Gambar 3. 4 Diagram Flowchart Uji Data Tunggal ............................................. 21 Gambar 3. 5Flowchart Uji Data Kelompok .......................................................... 22 Gambar 3. 6 Desain User Interface....................................................................... 23 Gambar 4. 1User Interface Sistem ........................................................................ 35 Gambar 5. 1 Hasil Akurasi Uji Validasi Pengujian Sistem .................................. 51 Gambar 5. 2 Confusion Matrix 1 Uji Validasi Pengujian Sistem ......................... 51 Gambar 5. 3 Confusion Matrix 2 Uji Validasi Pengujian Sistem ......................... 51 Gambar 5. 4 Confusion Matrix 3 Uji Validasi Pengujian Sistem ......................... 52 Gambar 5. 5 Confusion Matrix 4 Uji Validasi Pengujian Sistem ......................... 52 Gambar 5. 6 Confusion Matrix 5 Uji Validasi Pengujian Sistem ......................... 52 Gambar 5. 7 Function Naïve Bayes Matlab ......................................................... 53 Gambar 5. 8 Hasil Akurasi Function Matlab ........................................................ 53 Gambar 5. 9 5-fold cross validation ..................................................................... 54 Gambar 5. 10 Confusion Matrix 1......................................................................... 55 Gambar 5. 11 Confusion Matrix 2......................................................................... 55 Gambar 5. 12Confusion Matrix 3.......................................................................... 55 Gambar 5. 13 ConfusionMatrix 4.......................................................................... 55 Gambar 5. 14 ConfusionMatrix 5.......................................................................... 56 Gambar 5. 15 Hasil Akurasi Total ........................................................................ 56 Gambar 5. 16 Grafik Akurasi Setiap Fold ............................................................ 57 Gambar 5. 17 Akurasi Sistem ............................................................................... 58 Gambar 5. 18 Uji Data Tunggal Bidang Ilmu IF .................................................. 59 Gambar 5. 19 Uji Data Tunggal Bidang Ilmu ISK ............................................... 59 Gambar 5. 20 Uji Data Tunggal Bidang Ilmu ISNK ............................................ 60. xv.
(12) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Gambar 5. 21 Uji Data Tunggal Bidang Ilmu Bahasa .......................................... 60 Gambar 5. 22 Uji Data Kelompok ........................................................................ 61 Gambar 5. 23 Hasil Klasifikasi Uji Data Kelompok............................................. 61. xvi.
(13) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. DAFTAR TABEL Tabel 3. 1 Contoh Data Pengarahan Bidang Ilmu ................................................ 16 Tabel 3. 2 Penjelasan Atribut ................................................................................ 17 Tabel 3. 3 Penjelasan Label .................................................................................. 17 Tabel 3. 4 Perbandingan Jumlah Setiap Label ...................................................... 18 Tabel 5. 1 Perangkingan Atribut Berdasarkan Information Gain ......................... 36 Tabel 5. 2 Transformasi Label Pengarahan........................................................... 37 Tabel 5. 3 Contoh Data Training .......................................................................... 37 Tabel 5. 4 Hasil Mean dan Standar Deviasi HR ................................................... 38 Tabel 5. 5 Hasil Mean dan Standar Deviasi BMA ............................................... 38 Tabel 5. 6 Hasil Mean dan Standar Deviasi BMB ............................................... 38 Tabel 5. 7 Hasil Mean dan Standar Deviasi BVA ................................................ 38 Tabel 5. 8 Hasil Mean dan Standar Deviasi BVB................................................. 39 Tabel 5. 9 Hasil Mean dan Standar Deviasi VOK ................................................ 39 Tabel 5. 10 Probabilitas Prior Setiap Kelas .......................................................... 39 Tabel 5. 11 Tabel Contoh Data Testing ................................................................ 39 Tabel 5. 12 Posterior Fold Pertama ...................................................................... 46 Tabel 5. 13 Posterior Fold Kedua ......................................................................... 46 Tabel 5. 14 Posterior Fold Ketiga ......................................................................... 46 Tabel 5. 15 Posterior Fold Keempat ..................................................................... 47 Tabel 5. 16 Posterior Fold Kelima ........................................................................ 47 Tabel 5. 17 Hasil Klasifikasi Fold Pertama .......................................................... 47 Tabel 5. 18 Hasil Klasifikasi Fold Kedua ............................................................. 48 Tabel 5. 19 Hasil Klasifikasi Fold Ketiga............................................................. 48 Tabel 5. 20 Hasil Klasifikasi Fold Keempat ......................................................... 48 Tabel 5. 21 Hasil Klasifikasi Fold Kelima............................................................ 48 Tabel 5. 22 Confusion Matrix Hitung Manual 1 ................................................... 49 Tabel 5. 23 Confusion Matrix Hitung Manual 2 ................................................... 49 Tabel 5. 24 Confusion Matrix Hitung Manual 3 ................................................... 49 Tabel 5. 25 Confusion Matrix Hitung Manual 4 ................................................... 50 xvii.
(14) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Tabel 5. 26 Confusion Matrix Hitung Manual 5 ................................................... 50 Tabel 5. 27 Akurasi Setiap Fold ............................................................................ 56. xviii.
(15) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. BAB I PENDAHULUAN. 1.1. Latar Belakang Pusat Pelayanan Tes dan Konsultasi Psikologi (P2TKP) adalah salah satu lembaga di Universitas Sanata Dharmayang memfokuskan diri pada pelayanan pengembangan Sumber Daya Manusia yang meliputi tes, konsultasi, dan konseling psikologi. Untuk keperluan internal, lembaga ini bertugas menyelenggarakan tes seleksi mahasiswa baru dan dosen-dosen USD, sedangkan untuk pelayanan eksternal, lembaga ini banyak memberikan pelayanan tes kepada pihak-pihak yang membutuhkan di bidang pendidikan, organisasi, perusahaan, lembaga maupun instansi lainnya. Terdapat berbagai macam jenis tes yang dimiliki lembaga P2TKP, salah satunya adalah tes pengarahan sebelum masuk kuliah untuk siswa Sekolah Menengah Atas (SMA) kelas XII untuk mengetahui ketepatan dan kesesuaian peminatan bidang ilmu yang dipilih dengan kemampuan dan bakat yang mereka miliki. Terdapat 6 jenis soal, yaitu Hubungan Ruang (HR), Berpikir Matematis Tipe A (BMA), Berpikir Matematis Tipe B (BMB), Berpikir Verbal Tipe A (BVA), Berpikir Verbal Tipe B (BVB), dan Perbendaharaan Kata (VOK). Dalam menghitung hasil tes pengarahan bidang ilmu untuk masuk pergutruan tinggi, stafdi P2TKPmenggunakan cara manual, yaitu dengan menghitung total jawaban benar dari setiap jenis yang nantinya akan menghasilkan skor untuk masing-masing jenis tes. Dari hasil perhitungan TPA untuk pengarahan masuk perguruan tinggi akan diketahui kesesuaian bidang ilmu di bidang Ilmu Fisik (IF), Ilmu Sosial Kuantitatif (ISK), Ilmu Sosial Non Kuantitatif (ISNK), dan Bahasa (BHS). Cara manual seperti ini. 1.
(16) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 2. dianggap kurang efisien karena lamanya pemeriksaan dan pemerolehan hasil, sehingga hasil tes tidak dapat diketahui secara langsung. Metode Naïve Bayes telah digunakan dalam penelitian dengan topik penjurusan siswa kelas X SMA untuk mengarahkan peserta didik mengetahui kemampuan dan minat yang dimiliki. Hasil akurasi klasifikasi jurusan siswa SMA N 1 Subah dengan menggunakan Naïve Bayes memiliki akurasi sebesar 98,00%. Hal ini menunjukkan bahwa algoritma Naïve Bayesmemiliki akurasi yang baik dalam klasifikasi penjurusan siswa SMA N 1 Subah (Hidayah, 2014). Berdasarkan hal di atas, maka penulis tertarik untuk membuat sistem klasifikasi pengarahan bidang ilmu untuk masuk perguruan tinggi dengan metodeNaïve Bayes, karena metode Naïve Bayesmemiliki nilai akurasi yang tinggi.. 1.2. Rumusan Masalah Dari Latar belakang di atas, dapat dirumuskan masalah yaitu : 1. Bagaimana. mengimplementasikan. metode. Naïve. Bayes. untuk. pengarahan klasifikasi bidang ilmu bagi siswa masuk perguruan tinggi? 2. Berapakah hasil akurasi klasifikasi pengarahan bidang ilmu untuk siswa masuk perguruan tinggi dengan menggunakan metode Naïve Bayes?. 1.3. Tujuan Beberapa tujuan dengan adanya penelitian adalah sebagai berikut : 1. Mengimplementasikan metode Naïve Bayesuntuk klasifikasi pengarahan bidang ilmu masuk perguruan tinggi. 2. Mengetahui akurasi dari hasil klasifikasi bidang ilmu untuk masuk perguruan tinggi dengan menggunakan metode Naïve Bayes..
(17) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 3. 1.4. Manfaat Dengan adanya penelitian ini maka diharapkan dapat bermanfaat bagi semua pihak. Manfaat penelitian ini yaitu: 1. Membantu Lembaga P2TKP USD dalam melakukan klasifikasi pengarahan bidang ilmu masuk perguruan tinggi dengan metode Naïve Bayesagar mempermudah dan mempercepat perhitungan. 2. Hasil penelitian ini dapat menjadi rujukan maupun refrensi bagi penelitian lain yang menggunakan metode Naïve Bayes.. 1.5. Batasan Masalah Dalam penelitian yang dilakukan terdapat batasan masalah sebagai berikut: 1. Data yang digunakan adalah 400 data siswa SMA yang melakukan tes pengarahan bidang ilmu untuk masuk perguruan tinggi di lembaga P2TKP pada periode 2016- 2020. 2. Sistem dibangun untuk lembaga P2TKP Universitas Sanata Dharma 3. Metode klasifikasi yang digunakan adalah Naïve Bayes.. 1.6. Sistematika Penulisan Untuk memberikan gambaran dan kerangka yang jelas pada tiap bab dalam penelitian ini, maka diperlukan sistematika penulisan. Berikut gambaran sistematika penulisan masing-masing bab: 1. BAB I PENDAHULUAN Pada bab ini menguraikan latar belakang, rumusan masalah, tujuan,batasan masalah, dan sistematika penulisan. 2. BAB II LANDASAN TEORI Pada bab ini berisikanteori – teori yang digunakan..
(18) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 4. 3. BAB III METODOLOGI PENELITIAN Pada bab ini menguraikan tentang langkah – langkah umum penelitian dan metode yang digunakan serta tahap – tahap dalam dalam merancang sistem untuk menyelesaikan permasalahan tersebut dengan menggunakan algoritma Naïve Bayes. 4. BAB IV IMPLEMENTASI SISTEM Pada bab ini berisi hal – hal yang berkaitan dengan implementasi sistem dari proses pengolahan data sampai dengan proses pengujian. 5. BAB VANALISIS HASIL Pada bab ini berisi hal – hal yang berkaitan dengan pengujian sistem dan menganalisis hasil implementasi sistem dari proses pengolahan data sampai dengan proses pengujian. 6. BAB VI PENUTUP Bab ini berisi kesimpulan yang terdiri dari rangkuman keseluruhan isi yang telah dibahas dan saran yang berisi saran penelitian untuk pengembangan penelitian..
(19) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. BAB II LANDASAN TEORI Bab ini akan menjelaskan secara singkat teori-teori yang digunakan pada penelitian,teori-teori tersebut antara lain: 2.1. Tes Potensi Akademik Tes potensi akademik adalah suatu tes yang dilakukan untuk mengukur kemungkinan keberhasilan siswa dalam menjalani mata pelajaran yang akan di pelajari di kelas. Materi yang terdapat pada tes potensi akademik terdiri atas 3 (tiga) subtes yaitu tes verbal, kuantitatif dan penalaran. Tes verbal berisi tes persamaan kata, tes lawan kata, dan analogi verbal, untuk tes kuantitatif berisi tes angka, tes seri, tes aritmatika, dan logika aritmatika, sedangkan untuk tes penalaran berisi tes logika formal, analitis, keruangan/spasial, dan penalaran logis (Riswanto,2013). Dengan adanya tes potensi akademik ini jika siswa mampu dengan baik mengerjakan tes potensi akademik yang terdiri dari tes verbal, kuantitatif, dan penalaran maka dapat memprediksi tingkat keberhasilan. Hal ini disebabkan konten soal-soal dalam tes potensi akademik dikembangkan sedemikian rupa sehingga peluang keberhasilan untuk menjawab dengan benar lebih bergantung pada penggunaan daya nalar baik logis ataupun analitik (menghitung) (Azwar, Kualitas Tes Potensi Akademik (TPA) 07A, 2008). Manfaat tes potensi akademik ini adalah sebagai gambaran siswa untuk mencapai kesuksesan dalam mata pelajaran yang ditempuh disekolah, menilai kemampuan siswa dalam menganalisis dan menyelesaikan sebuah persoalan, dan sebagai prediktor kesuksesan siswa dalam belajar di sekolah (Widhiarso, 2016). Tes Potensi Akademik memiliki berbagai macam jenis tes, salah satunya adalah tes pengarahan bidang ilmu untuk masuk. 5.
(20) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 6. perguruan tinggi. Tes pengarahan bidang ilmu untuk masuk perguruan tinggi ini memiliki tujuan untuk mengetahui kesesuaian bakat siswa pada program studi ilmu alam yaitu di bidang Ilmu-ilmu Fisik (IF), Ilmu Sosial Kuantitatif (ISK), Ilmu Sosial Non Kuantitatif (ISNK), dan Bahasa (BHS). Tes pengarahan bidang ilmu untuk masuk perguruan tinggi terdapat beberapa subtestyang dilakukan, yaitu: Hubungan Ruang (HR), Berpikir Matematis Tipe A (BMA), Berpikir Matematis Tipe B (BMB), Berpikir Verbal Tipe A (BVA), Berpikir Verbal Tipe B (BVB), dan Perbendaharaan Kata (VOK). 2.2. Data Mining 2.2.1. Pengertian Data Mining Data miningadalah kegiatan yang meliputi pengumpilan,. pemakaian data, historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar (Santoso,2007). Data mining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan di dalam database. Data mining adalah proses yang menggunakan teknik statistik, matematika, kecerdasan buatan,. dan. machine. learning. untuk. mengekstraksi. dan. mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database besar (Turban, dkk. 2005). Definisi umum dari data mining itu sendiri adalah proses pencarian pola-pola yang tersembunyi (hiddenpatern) berupa pengetahuan (knowledge) yang tidak diketahui sebelumnya dari suatu sekumpulan data yang mana data tersebut dapat berada di dalam database, data warehouse, atau media penyimpanan informasi yang lain. Hal penting yang terkait di dalam data mining adalah: 1. Data mining merupakan suatu proses otomatis terhadap data yang sudah ada. 2. Data yang akan diproses berupa data yang sangat besar..
(21) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 7. 3. Tujuan data mining adalah mendapatkan hubungan atau pola yang mungkin memberikan indikasi yang bermanfaat (Kusrini dan Emha Taufiq, 2009). 2.2.2. Tahapan KDD Proses KDD terdiri dari tahapan – tahapan (Han dan Kamber, 2006), sebagai berikut : 1. Pembersihan Data (Data Cleaning) Proses menghilangkan noise dan data yang tidak konsisten atau tidak relevan. 2. Integrasi Data (Data Integration) Penggabungan data dari berbagai basis data ke dalam satu basis data baru. 3. Pemilihan Data (Data Selection) Pemilihan data relevan yang didapat dari basis data. 4. Transformasi Data (Data Transformation) Data diubah ke dalam format yang sesuai untuk diproses dalam data mining. 5. Data Mining Suatu. proses. dimana. metode. diterapkan. untuk. menemukan pengetahuan berharga dan tersembunyi dari data. 6. Evaluasi Pola (Pattern Recognition) Untuk mengidentifikasi pola – pola menarik untuk direpresentasikan ke dalam knowledge based. 7. Representasi Pengetahuan (Knowledge Presentation) Visualisasi dan penyajian pengetahuan mengenai teknik yang digunakan untuk memperoleh pegetahuan yang diperoleh oleh user..
(22) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 8. 2.2.3. Pengelompokan Data Mining Data mining dibagi menjadi beberapa kelompok berdasarkan. tugas yang dapat dilakukan (Larose, 2006), yaitu : 1. Deskripsi Terkadang peneliti dan analis secara sederhana ingin mencoba mencari cara untuk menggambarkan pola dan kecenderungan yang terdapat dalam data. Sebagai contoh, petugas. pengumpulan. suara. mungkin. tidak. dapat. mengumpulkan keterangan atau fakta bahwa siapa yang tidak cukup profesional akan sedikit didukung dalam pemilihan presiden. Deskripsi dari pola dan kecenderungan sering memberikan kemungkinan penjelesan untuk suatu pola atau kecenderungan. 2. Estimasi Estimasi hampir sama dengan klasifikasi, kecuali variabel target estimasi lebih kearah numerik daripada ke arah kategori. Model dibangun dengan record lengkap yang menyediakan nilai dari variabel target sebagai nilai prediksi. Sebagai contoh, akan dilakukan estimasi tekanan darah sistolik pada pasien rumah sakit berdasarkan umur pasien, jenis kelamin, indeks berat badan, dan level sodium darah. Hubungan antara tekanan darah sistolik dan nilai variabel prediksi dalam proses pembelajaran akan menghasilkan model estimasi. Model estimasi yang dihasilkan dapat digunakan untuk kasus baru lainnya.. 3. Prediksi Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil akan ada dimasa mendatang.Beberapa metode dan teknik yang digunakan dalam klasifikasi dan estimasi dapat pula digunakan (untuk keadaan yang tepat) untuk prediksi..
(23) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 9. 4. Klasifikasi Dalam klasifikasi, terdapat target variabel kategori. sebagai contoh, penggolongan pendapatan dapat dipisahkan dalam tiga kategori yaitu: pendapatan tinggi, pendapatan sedang, dan pendapatan rendah. 5. Pengklusteran Pengklusteran merupakan pengelompokan record, pengamatan, atau memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan. Kluster adalah kumpulan record yang memiliki kemiripan satu dengan yang lainnya dan tidak memiliki kemiripan dengan record-record dalam kluster lain. Pengklusteran berbeda dengan klasifikasi yaitu tidak adanya variabel target dalam pengklusteran. pengklusteran tidak mencoba untuk melakukan klasifikasi, mengestimasi, atau memprediksi nilai dari variabel target. Akan tetapi, algoritma pengklusteran mencoba untuk melakukan pembagian terhadap keselurahan data menjadi kelompok-kelompok yang memiliki kemiripan (homogen), yang mana kemiripan record dalam suatu kelompok akan bernilai maksimal, sedangkan kemiripan dengan record dalam kelompok lain akan bernilai minimal. 6. Asosiasi Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul dalam satu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang pasar.. 2.3. Klasifikasi Salah satu tugas utama dari data mining adalah klasifikasi. Klasifikasi digunakan untuk menempatkan bagian yang tidak diketahui pada data ke dalam kelompok yang sudah diketahui. Klasifikasi menggunakan variabel target dengan nilai nominal. Dalam satu set pelatihan, variabel target sudah diketahui. Dengan pembelajaran(learning).
(24) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 10. dapat ditemukan hubungan antara fitur dengan variabel target. Ada dua langkah dalam proses klasifikasi (Han and Kamber, 2006): a. Pembelajaran (learning) : pelatihan data dianalisis oleh algoritma klasifikasi. b. Klasifikasi: data yang diujikan digunakan untuk mengkalkulasi akurasi dari aturan klasifikasi. Jika akurasi dianggap dapat diterima, aturan dapat diterapkan pada klasifikasi data tuple yang baru.. 2.4. Naïve Bayes Naïve bayes merupakan salah satu metode yang digunakan untuk pengklasifikasian sebuah data dengan berdasarkan teorema bayes dengan mengasumsikan bahwa suatu data memiliki sifat tidak saling terkait antar satu dengan yang lain atau disebut independent. Teknik penggunaan Naïve Bayes sangat sederhana dan cepat dengan penggunaan probabilistik. Algoritma ini menggunakan metode probabilitas dan statistik yang dikemukakan oleh ilmuan Inggris Thomas Bayes yaitu memprediksi peluang di masa depan berdasarkan pengalaman sebelumnya (Tan & Kumar, 2006). 2.4.1. Persamaan Metode Naïve Bayes Persamaan dari teorema Naïve Bayes adalah:. 𝑃(H|X) =. 𝑃(𝑋|𝐻). 𝑃(𝐻) 𝑃(𝑋). Dimana: X. :Data dengan class yang belum diketahui.. H. :Hipotesis data merupakan suatu class spesifik.. P(H|X). :Probabilitas hipotesis H berdasar kondisi X. (2.1).
(25) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 11. (Posteriori Probabilitas). P(H). :Probabilitas hipotesis H (prior probabilitas).. P(X|H). :Probabilitas X berdaasarkan kondisi pada hipotesis H.. P(X). :Probabilitas X.. Untuk menjelaskan metode Naïve Bayes, perlu diketahui bahwa proses. klasifikasi. memerlukan. sejumlah. petunjuk. untuk. menentukan kelas apa yang cocok bagi sampel yang di analisis tersebut. Karena itu, metode Naïve Bayesdi atas disesuaikan sebagai berikut (Saleh, 2015) :. 𝑃(𝐶|𝐹1 … . 𝐹𝑛) =. 𝑃(𝐶)𝑃(𝐹1 … 𝐹𝑛|𝐶) 𝑃(𝐹1 … 𝐹𝑛). (2.2). Di mana variabel C mempresentasikan kelas, sementara variabel F1...Fn mempresentasikan karakteristik petunjuk yang dibutuhkan untuk menentukan klasifikasi. Maka rumus tersebut menjelaskan bahwa peluang masuknya sampel karakteristik tertentu dalam kelas C (Posterior) adalah peluang munculnya kelas C (sebelum masuknya sampel tersebut, seringkali disebut prior), dikali dengan peluang kemunculan karakteristik – karakteristik sampel pada kelas C (disebut likelihood), dibagi dengan peluang kemunculan karakteristik – karakteristik secara global (disebut juga evidence). Karena itu, rumus di atas dapat pula ditulis secara sederhana sebagai berikut (Saleh, 2015):.
(26) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 12. 𝑝𝑜𝑠𝑡𝑒𝑟𝑖𝑜𝑟𝑦 =. 𝑙𝑖𝑘𝑒𝑙𝑖ℎ𝑜𝑜𝑑 𝑥 𝑝𝑟𝑖𝑜𝑟 𝑒𝑣𝑖𝑑𝑒𝑛𝑐𝑒. (2.3). Nilai Evidence selalu tetap untuk setiap kelas pada satu sampel. Nilai dari Posterior tersebut nantinya akan dibandingkan dengan nilai – nilai posterior kelas lainnya untuk menentukan ke kelas apa suatu sampel akan diklasifikasikan. Untuk klasifikasi data kontinu digunakan rumus densitas gauss :. 𝑃(𝑋𝑖 = 𝑥𝑖 |𝑌 = 𝑦𝑖 ) =. 1 √2𝜋(𝜎). 𝑒. 2 −(𝑥𝑖 −µ) 2 2(𝜎). (2.4). Dimana : P = Peluang Xi = Atribut ke-i xi = Nilai Atribut ke-i Y= Kelas yang dicari µ = Mean 𝜎 = Standar Deviasi 2.4.2. Alur Metode Naïve Bayes Alur metode Naïve Bayes dapat dijelaskan sebagai berikut (Saleh, 2015) : 1. Baca data traning. 2.. Hitung jumlah dan probabilitas, namun apabila data numerik maka : a. Cari nilai mean dan standar deviasi dari masing –masing parameter yang merupakan data numerik. Adapun.
(27) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 13. persamaan yang digunakan untuk menghitung nilai rata – rata (mean) dapat dilihat sebagai berikut :. µ=. ∑𝑛𝑖=1 𝑥𝑖 𝑛. (2.5). Di mana : µ : rata – rata hitung (mean) xi : nilai sampel ke-i n : jumlah sampel Dan persamaan untuk menghitung nilai simpangan baku (standar deviasi) dapat dilihat sebagai berikut :. 𝑛. 𝜎=. √∑𝑖=1(𝑥𝑖 − µ)2. (2.6). 𝑛−1. Dimana : σ : standar deviasi xi : nilai x ke- i µ : rata – rata hitung n : jumlah sampel b. Cari nilai probabilistik dengan cara menghitung jumlah data yang sesuai dari kategori yang sama dibagi dengan jumlah data pada kategori tersebut. 3. Mendapatkan nilaidalam tabel mean, standar deviasi dan probabilitas. 4.. Solusi yang dihasilkan.
(28) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 14. 2.5. Cross validation Pada pendekatan ini, setiap data digunakan dalam jumlah yang sama untuk pelatihan dan tepat satu kali untuk pengujian. Bentuk umum pendekatan ini disebut dengan k-fold cross validation, yang memecah set data menjadi k bagian set data dengan ukuran yang sama. Setiap kali berjalan, satu pecahan berperan sebagai data set data latih sedangkan pecahan lainnya menjadi set data latih. Prosedur tersebut dilakukan sebanyak k kali sehingga setiap data kesempatan menjadi data uji tepat satu kali dan menjadi data latih sebanyakk-1 kali. Total error didapatkan dengan menjumlahkan semua. error. yang. didapatkan. dari. k. kali. proses. (Prasetyo,2014).Ketika pengujian dilakukan sebanyak k kali iterasi, maka rata-rata akurasi tiap pengujian akan dihitung untuk mendapatkan tingkat akurasi keseluruhan. Tingkat akurasi dapat dihasilkan dari perhitungan metode confusion matrix.. Gambar 2. 1 Pembagian data Training dan Testing 2.6. Confusion Matrix Confusion matrix adalah suatu metode yang digunakan untuk melakukan perhitungan akurasi pada konsep data mining. Evaluasi dengan confusion matrix 1menghasilkan nilai akurasi, presisi dan recall. Akurasi dalam klasifikasi adalah persentase ketepatan record data yang diklasifikasikan secara benar setelah dilakukan pengujian pada hasil klasifikasi (Jiawei, Kamber, & Pei, 2006)..
(29) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 15. Dalam penelitian ini, pengukuran akurasi dilakukan dengan metode pengujian confusion matrix yang dapat dilihat pada tabel berikut:. Gambar 2. 2Confusion Matrix Keterangan: TP :. Klasifikasi bernilai benar menurut prediksi dan benar menurut nilai sebenarnya. FP :. Klasifikasi bernilai benar menurut prediksi dan salah menurut nilai Sebenarnya. FN :. Klasifikasi bernilai salah menurut prediksi dan benar menurut nilai sebenarnya. TN :. Klasifikasi bernilai salah menurut prediksi dan salah menurut nilai sebenarnya. Untuk menghitung tingkat akurasi digunakan rumus perhitungan. sebagai berikut:. 𝐴𝑘𝑢𝑟𝑎𝑠𝑖 =. 2.7. 𝑇𝑃 + 𝑇𝑁 𝑥 100% 𝑇𝑃 + 𝑇𝑁 + 𝐹𝑃 + 𝐹𝑁. (2.7). Information Gain Information Gainmerupakan metode seleksi fitur paling sederhana dengan. melakukan perangkingan atribut dan banyak digunakan dalam aplikasi kategorisasi teks, analisis data microarray dan analisis data citra (Chormunge & Jena, 2016). Information gaindigunakan pada tahap preprocessinguntuk mengurangi noise yang disebabkan oleh atribut-atribut yang tidak sesuai..
(30) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. BAB III METODOLOGI PENELITIAN. Bagian ini menguraikan mengenai langkah-langkah yang dilakukan dalam penelitian. Termasuk bagaimana cara mendapatkan data, cara mengolah data, cara membuat desain alat uji,spesifikasi alat penelitiandesain user interface dari alat uji yang dibangun, dan tahap penelitian. 3.1. Data Data yang digunakan merupakan data siswa SMA yang mengikuti pengarahan bidang ilmuuntuk masuk perguruan tinggi dalam periode 20162020 berdasarkan hasil tes TPA yang didapatkan dari Lembaga P2TKP. Data pengarahan ini terdapat 6 atribut dan 1 label kelas dengan jumlah 400 data. Pengumpulan data dilakukan dengan cara pengambilan data yang telah dipersiapkan dan wawancara dengan kepala dan staf Lembaga P2TKP. Berikut merupakan contoh data pengarahan bidang ilmu untuk masuk perguruan tinggi. Tabel 3.1 merupakan contoh data pengarahan bidang ilmu. Tabel 3. 1 Contoh DataPengarahan Bidang Ilmu Untuk Masuk Perguruan Tinggi. NO 1 2 3 4 5 6 7 8 9. HR. BMA. BMB. BVA. BVB. VOK. 6 4,5 1 4 5,5 3 6 6,5 4,5. 6 4,5 2 6,5 7,5 1 6 4,5 3. 4,5 4 2 4 4,5 3 5 4,5 4. 3 5 3 4,5 5,5 2 3 3,5 4. 3 6 4 6 6 2 4,5 4,5 5. 6 4,5 2 6 5 4,5 6 5 5,5. 16. PENGARAHA N IF ISNK ISK BHS ISK BHS IF IF BHS.
(31) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 17. 10 11 12 13 14 15 16 17 18 19 20. 7 8 8 7 3 1 4,5 4 2 2 9. 5,5 5 6 4,5 4 3 6,5 2 4,5 3 5,5. 6,5 6,5 6,5 2,5 5 2 3,5 5 4 3 6,5. 6,5 5,5 7 4 3 2 4,5 3 3 3,5 6,5. 7 5 5,5 3,5 4,5 4 5 3 4 4 6. 7 1 6 5 6 2 4 4,5 3 3 7. ISNK ISK IF IF BHS ISK ISNK BHS ISK ISNK IF. Tabel 3.2 merupakan penjelasan dari setiap atribut pada data pengarahan bidang ilmu yang terdiri dari 6 atribut dengan skala nilai 1 - 10. Tabel 3. 2 Penjelasan Atribut No 1 2 3 4 5 6. Atribut HR BMA BMB BVA BVB VOK. Keterangan Nilai Hubungan Ruang Nilai Berpikir Matematis A Nilai Berpikir Matematis B Nilai Berpikir Verbal A Nilai Berpikir Verbal B Nilai Perbendaharaan Kata. Tabel 3.3 merupakan penjelasan dari setiap label pada data pengarahan bidang ilmu yang terdiri dari 4 label. Tabel 3. 3 Penjelasan Label No 1 2 3 4. Label IF ISK ISNK BHS. Keterangan Ilmu Fisik Ilmu Sosial Kuantitatif Ilmu Sosial Non Kuantitatif Bahasa.
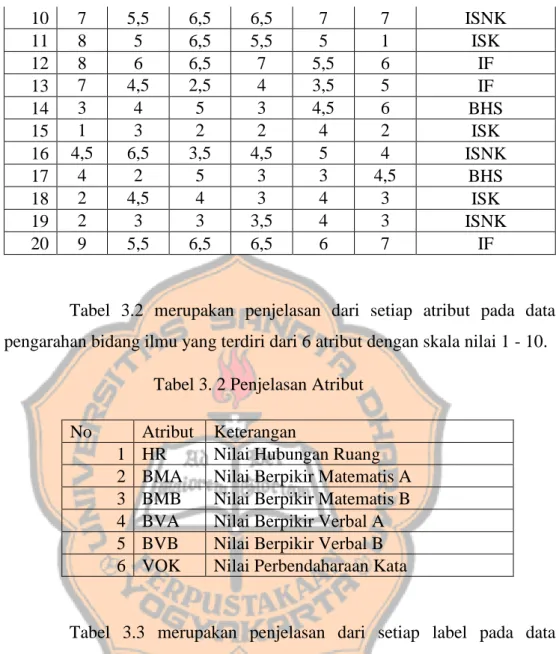
(32) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 18. Tabel 3.4merupakan perbandingan jumlah setiap label pada data pengarahan bidang ilmu yang terdiri dari 4 label. Tabel 3. 4 Perbandingan Jumlah Setiap Label Label. Jumlah. IF ISK. 183 47. ISNK. 75. BHS. 97. Persentase Setiap Label IF. 24% 45%. ISK ISNK. 19% 12%. BHS. Gambar 3. 1 Persentase Setiap Atribut Gambar 3.1 merupakan perbandingan persentase jumlah setiap label pada data pengarahan bidang ilmu yang terdiri dari 4 label. Urutan presentase setiap label yang tertinggi menuju terendah yaitu IF, BHS, ISNK, ISK..
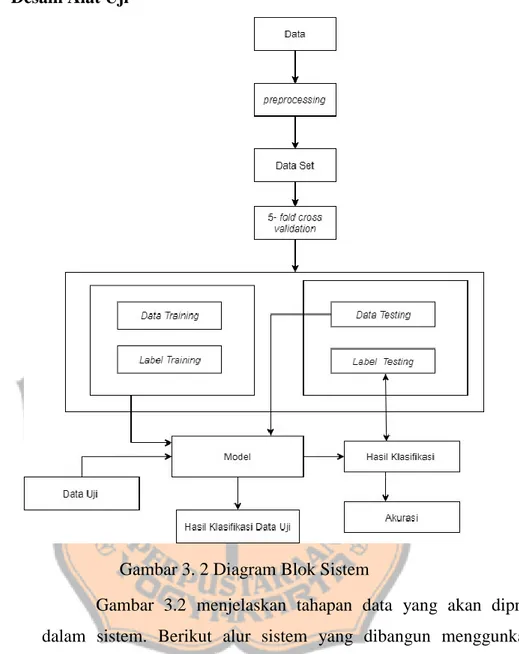
(33) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 19. 3.2. Desain Alat Uji. Gambar 3. 2 Diagram Blok Sistem Gambar 3.2 menjelaskan tahapan data yang akan diproses dalam sistem. Berikut alur sistem yang dibangun menggunkakan metode Naïve Bayes: 1. Sistem membaca file data mentah yang telah di-upload. 2. Data yang telah di-upload selanjutnya akan melalui tahap preprocessinguntuk menghasilkan data siap pakai atau data set. Preprocessing yang digunakan adalah seleksi data dan transformasi data. 3. Pembagian data testing dan data training menggunakan 5–fold cross validation..
(34) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 20. 4. Terdapat model Naïve Bayes untuk melakukan perhitungan yang. digunakan untuk mencari nilai. posterior tiap kelas berdasarkan data testing, lalu hasil posterior tertinggi akan menjadi hasil klasifikasi. 5. Tahap selanjutnya adalah membandingkan label testing dengan. hasil. klasifikasi. yang digunakan. untuk. mendapatkan hasil akurasi dengan menggunakan confusion matrix. 6. Pada sistem ini terdapat uji data dengan memasukkan data baru, lalu dilakukan perhitungan pada model Naïve Bayes sehingga akan menampilkan hasil klasifikasi data uji.. Gambar 3. 3Flowchart Perhitungan Naïve Bayes Gambar 3.3menjelaskan alur perhitungan Naïve Bayes digambarkan dengan flowchart. Berikut merupakan alur perhitungan Naïve Bayes : 1. Hitung mean dan standar deviasi tiap atribut pada semua kelas dengan menggunakan persamaan 2.5 dan 2.6..
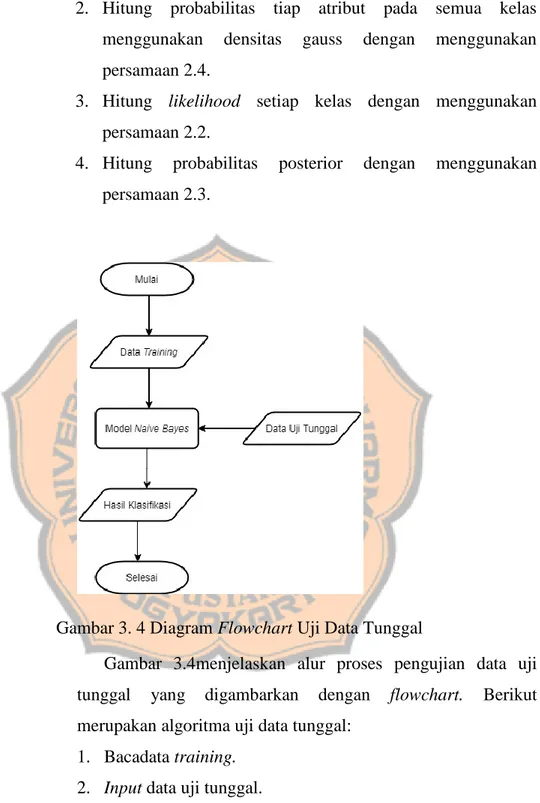
(35) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 21. 2. Hitung. probabilitas. menggunakan. tiap. densitas. atribut gauss. pada. dengan. semua. kelas. menggunakan. persamaan 2.4. 3. Hitung likelihood setiap kelas dengan menggunakan persamaan 2.2. 4. Hitung. probabilitas. posterior. dengan. menggunakan. persamaan 2.3.. Gambar 3. 4 Diagram Flowchart Uji Data Tunggal Gambar 3.4menjelaskan alur proses pengujian data uji tunggal. yang. digambarkan. dengan. flowchart.. Berikut. merupakan algoritma uji data tunggal: 1. Bacadata training. 2. Input data uji tunggal. 3. Hitung mean dan standar deviasi tiap atribut pada semua kelas. 4. Hitung probabilitas tiap atribut pada semua kelas. 5. Hitung likelihood setiap kelas..
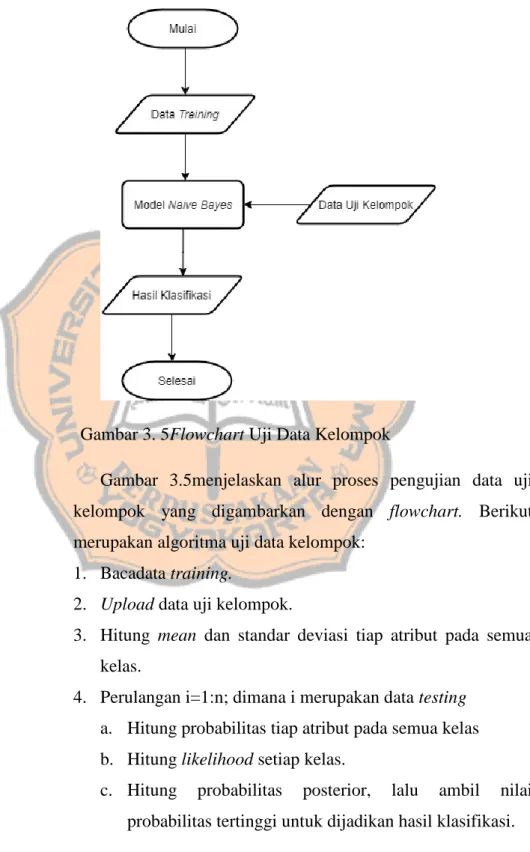
(36) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 22. 6. Hitung probabilitas posterior, lalu ambil nilai probabilitas tertinggi untuk dijadikan hasil klasifikasi.. Gambar 3. 5Flowchart Uji Data Kelompok Gambar 3.5menjelaskan alur proses pengujian data uji kelompok yang digambarkan dengan flowchart. Berikut merupakan algoritma uji data kelompok: 1. Bacadata training. 2. Upload data uji kelompok. 3. Hitung mean dan standar deviasi tiap atribut pada semua kelas. 4. Perulangan i=1:n; dimana i merupakan data testing a. Hitung probabilitas tiap atribut pada semua kelas b. Hitung likelihood setiap kelas. c. Hitung. probabilitas. posterior,. lalu. ambil. nilai. probabilitas tertinggi untuk dijadikan hasil klasifikasi..
(37) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 23. 3.3. Spesifikasi Alat Penelitian 3.3.1. Hardware Hardwareyang digunakan dalam penelitian ini adalah : - Laptop Lenovo ideapad 330 - Processor AMD Ryzen 7 - RAM 8 GB - HDD 1 TB. 3.3.2. Software Softwareyang digunakan dalam penelitian ini adalah : -. Sistem Operasi : Windows 10. -. Matlab 2016b. -. Draw.io. - Weka Tools 3.9 - Microsoft Excel 2013. 3.4.. Desain User Interface. Gambar 3. 6 Desain User Interface.
(38) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 24. Gambar 3.6 merupakan perancangan user interface yang nantinya dipakai untuk pembuatan sistem klasifikasi pengarahan bidang ilmu untuk masuk perguruan tinggi dengan metode Naïve Bayes. Berikut penjelasan setiap area serta fungsinya yang terdapat pada user interface : 1. Area 1 : Tabel yang digunakan untuk menampilkan data pengarahan bidang ilmu yang masih mentah. 2. Area 2 : Tombol yang digunakan untuk memilih dan upload filedata pengarahan bidang ilmu yang masih mentah. 3. Area 3 : Tombol yang digunakan untuk melakukan prepocessing yang didalamnya terdapat proses seleksi data dan transformasi. 4. Area 4 : Tabel yang digunakan untuk menampilkan data yang telah melalui tahap prepocessing. 5. Area 5 : Tombol akurasi terdapat fungsi yang digunakan untuk menghitung akurasi. 6. Area 6 : Area yang digunakan untuk menampilkan hasil akurasi. 7. Area 7 : Tabel untuk menampilkan confusion matrix sebanyak 5 tabel, karena menggunakan 5-fold cross validation. 8. Area 8 : Tabel yang digunakan untuk menampilkan data pengarahan bidang ilmu yang akan diuji secara berkelompok. 9. Area 9: Tombol yang digunakan untuk memilih dan upload filedata pengarahan bidang ilmuyang akan diuji secara berkelompok. Terdapat pula tombol klasifikasi digunakan untuk melakukan klasifikasi. 10. Area 10: Tabel yang digunakan untuk menampilkan hasil uji data kelompok. 11. Area 11: Field yang digunakan untuk memasukkan data untuk uji data tunggal. 12. Area 12: Tombol klasifikasi digunakan untuk melakukan klasifikasi. 13. Area 13: Area yang digunakan untuk menampilkan hasil klasifikasi..
(39) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 25. 3.5. Tahap Penelitian 3.5.1. Studi Kasus Tes potensi akademik adalah suatu tes yang diadakan untuk. untuk mengukur kemampuan seseorang, maupun mengukur keberhasilan seseorang dalam melakukan seleksi pada suatu instansi. Pusat Pelayanan Tes dan Konsultasi (P2TKP) adalah salah satu lembaga di Universitas Sanata Dharma yang menyediakan pelayanan tes kepada pihak yang membutuhkan yang membutuhkan di bidang pendidikan, organisasi, perusahaan, lembaga maupun instansi lainnya. Salah satu tes yang diadakan P2TKP adalah tes pengarahan bidang ilmu untuk masuk perguruan tinggi yang menggunakan tes potensi akademik. Pengarahan bidang ilmu dapat dikategorikan menjadi 4 bidang yaitu bidang ilmu fisik, ilmu sosial kuantitatif, ilmu sosial non kuantiatif, dan bahasa. 3.5.2. Penelitian Pustaka Dalam melakukan penelitian ini, penulis mencari literatur. sebagai refrensi teori – teori yang digunakan. Literatur yang digunakan berasal dari jurnal ilmiah, buku, dan karya ilmiah. Literarur digunakan untuk mendukung proses penelitian. 3.5.3. Perancangan Sistem Pada tahap ini penulis membuat rancangan dan kebutuhan. sistem yaitu dengan membuat diagram blok sistem, flowchart perhitungan Naïve Bayes, flowchart uji data tunggal, flowchart uji data kelompok, dan perancangan user interface. 3.5.4. Tahap Preprocessing Preprocessing yang digunakan pada penelitian ini adalah. seleksi data dan transformasi data. Seleksi data yang digunakan yaitu perangkingan atribut dengan menggunakan information gain. Pada penelitian ini dilakukan transformasi data pada label pengarahan yaitu dengan mengubah label pengarahan dari bentuk kategorikal menjadi bentuk numerik..
(40) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 26. 3.5.5. Implementasi Sistem Pada tahap ini rancangan sistem yang telah dibuat. sebelumnya diimplementasikan dalam bentuk source code pada matlab. 3.5.6. Tahap Uji Validasi Pada tahap ini melakukan pengujian dengan. menggunakan 20 data. Pengujian yang dilakukan antara lain dengan menggunakan perhitungan manual excel, pengujian pada sistem, dan pengujian menggunankan fungsi matlab. Uji validasi digunakan untuk membandingkan hasil dari setiap pengujian dengan tujuan menghasilkan hasil yang sama. 3.5.7. Tahap Uji Akurasi Pada tahap ini dilakukan analisis dari hasil luaran sistem. yang telah dibuat dengan menggunakan 400 record data. Analisis yang dilakukan adalah pada penggunaan 5-fold cross validation, hasil akurasi setiap fold pada sistem, akurasi rata-rata sistem, dan perbandingan hasil klasifikasi sistem dengan hasil rekomendasi P2TKP..
(41) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. BAB IV IMPLEMENTASI SISTEM Pada bab ini berisi hal – hal yang berkaitan dengan implementasi sistem dari proses pengolahan data sampai dengan proses pengujian. 4.1. Implementasi Preprocessing 4.1.1. Transformasi Data. Transformasi data merupakan salah satu tahapan preprocessingyang digunakan untuk mengubah data bertipe string menjadi numerik. Berikut merupakan contoh implmentasi dari transformasi data. %baca data clc; clear; [num,text raw] = xlsread('ujj.xlsx'); sizeData = raw(:,6); [m,n]= size(sizeData); for i=1:m if (strcmp(raw(i,7),'IF')) num(i,7)=1; elseif (strcmp(raw(i,7),'ISK')) num(i,7)=2; elseif (strcmp(raw(i,7),'ISNK')) num(i,7)=3; else num(i,7)=4; end end transformasi = num; xlswrite('transformasi.xlsx', transformasi);. 27.
(42) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 28. 4.1.2. Implementasi Seleksi Data Pada pengimplementasian sistem terdapat tahap seleksi data. dengan. melakukan. information gain. perangkingan. atribut. berdasarkan. hasil. pada weka tools. Berikut merupakan contoh. implementasi dari seleksi data. clear; clc; rating=[1 2 6 3 4 5 ]; data=xlsread('transformasi.xlsx'); jumlahCiri=6; if jumlahCiri > size(rating,2)-1 jumlahCiri = size(rating,2); end for i=1:jumlahCiri if i==1 datapakai=data(:,rating(i)); else datapakai= [datapakai,data(:,rating(i))]; end end datapakai = [datapakai,data(:,7)]; save 'databaru.mat' 'datapakai';.
(43) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 29. 4.2. Implementasi Naïve Bayes Berikut merupakan contoh implementasi dari Naïve Bayes. function output = NaiveB (DataTraining, LabelTraining, DataTesting) kelas=[1,2,3,4]; IF = find(LabelTraining(:)==1); ISK = find(LabelTraining(:)==2); ISNK = find(LabelTraining(:)==3); BHS = find(LabelTraining(:)==4); %nilai prior prob_IF =length(IF)/length(LabelTraining); prob_ISK =length(ISK)/length(LabelTraining); prob_ISNK =length(ISNK)/length(LabelTraining); prob_BHS =length(BHS)/length(LabelTraining); prob = [prob_IF,prob_ISK, prob_ISNK,prob_BHS]; %nilai likelihood for i=1:length (kelas(1,:)) mn(i,:) = mean(DataTraining(LabelTraining==kelas(1,i),:)); st_dev(i,:)= std(DataTraining(LabelTraining==kelas(1,i),:)); end %nilai posterior for j=1:size(kelas,2) likelihood= normpdf(DataTesting,mn(j,:),st_dev(j,:)); posterior(j)=prod(likelihood)*prob(j); end if posterior(1) > posterior(2)&& posterior(1) > posterior(3)&&posterior(1)> posterior(4) output=1; elseif posterior(2) > posterior(1)&& posterior(2) > posterior(3)&&posterior(2)> posterior(4) output=2; elseif posterior(3) > posterior(1)&& posterior(3) > posterior(2)&&posterior(3)> posterior(4) output=3; else output=4; end end.
(44) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 30. 4.3. Implementasi 5- Fold Cross Validation 5- fold cross validationmerupakan tahapan pembagian data yang dipakai dalam penelitian ini. Berikut merupakan contoh implementasi dari 5- fold cross validation. %pembagian data Data = datapakai; ukurandata= size(Data,2); x= Data(:,1:ukurandata-1); y= Data(:,ukurandata); jumdata= size(x); range =jumdata (1)/5; kel1= kel2= kel3= kel4= kel5=. x(1:range,:); x(range+1:range*2,:); x(range*2+1:range*3,:); x(range*3+1:range*4,:); x(range*4+1:range*5,:);. DataTraining1 = [kel2;kel3;kel4;kel5]; DataTesting1= kel1; DataTraining2= [kel1;kel3;kel4;kel5]; DataTesting2= kel2; DataTraining3 =[kel1;kel2;kel4;kel5]; DataTesting3= kel3; DataTraining4 =[kel1;kel2;kel3;kel5]; DataTesting4= kel4; DataTraining5 =[kel1;kel2;kel3;kel4]; DataTesting5= kel5; LabelKel1 LabelKel2 LabelKel3 LabelKel4 LabelKel5. = = = = =. y(1:range); y(range+1:range*2); y (range*2+1:range*3,:); y (range*3+1:range*4,:); y (range*4+1:range*5,:);.
(45) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 31. LabelTraining1 = [LabelKel2;LabelKel3; LabelKel4;LabelKel5]; LabelTesting1 = LabelKel1; LabelTraining2 = [LabelKel1;LabelKel3; LabelKel4;LabelKel5]; LabelTesting2 = LabelKel2; LabelTraining3 = [LabelKel1;LabelKel2;LabelKel4;LabelKel5]; LabelTesting3 = LabelKel3; LabelTraining4 = [LabelKel1;LabelKel2; LabelKel3;LabelKel5]; LabelTesting4 = LabelKel4; LabelTraining5 = [LabelKel1;LabelKel2;LabelKel3;LabelKel4]; LabelTesting5 = LabelKel5;.
(46) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 32. 4.4. Implementasi Confussion Matrix dan Akurasi Berikut merupakan contoh implementasi dari confusion matrixdengan menggunakan 5-fold cross validationdan akurasi.. for i=1:size(DataTesting1,1) hasil(i,1)= NaiveB(DataTraining1,LabelTraining1,DataTesting1(i,:)); end cf1= confusionmat(LabelTesting1,hasil); output1= (sum(diag(cf1))/sum(sum(cf1))) *100; for i=1:size(DataTesting2,1) hasil(i,1)= NaiveB(DataTraining2,LabelTraining2,DataTesting2(i,:)); end cf2= confusionmat(LabelTesting2,hasil); output2= (sum(diag(cf2))/sum(sum(cf2))) *100; for i=1:size(DataTesting3,1) hasil(i,1)= NaiveB(DataTraining3,LabelTraining3,DataTesting3(i,:)); end cf3= confusionmat(LabelTesting3,hasil); output3= (sum(diag(cf3))/sum(sum(cf3))) *100; for i=1:size(DataTesting4,1) hasil(i,1)= NaiveB(DataTraining4,LabelTraining4,DataTesting4(i,:)); end cf4= confusionmat(LabelTesting4,hasil); output4= (sum(diag(cf4))/sum(sum(cf4))) *100; for i=1:size(DataTesting5,1) hasil(i,1)= NaiveB(DataTraining5,LabelTraining5,DataTesting5(i,:)); end cf5= confusionmat(LabelTesting5,hasil); output5= (sum(diag(cf5))/sum(sum(cf5))) *100; %Akurasi akurasi = (output1+output2+output3+output4+output5)/5;.
(47) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 33. 4.5. Implementasi Uji Data Kelompok Pada penelitian ini terdapat uji data kelompok yang digunakan untuk mencari hasil klasifikasi pada data uji kelompok yang di-upload pada sistem. Berikut merupakan contoh implementasi dari uji data kelompok. global datauji; load DATuj; load LABuj; DataTraining= DATuj ; LabelTraining= LABuj; DataTesting = datauji(:,1:6]); DataTesting= cell2mat(DataTesting); for i=1:size(DataTesting,1) hasil(i)= NaiveB(DataTraining,LabelTraining,DataTesting(i,:)); % assignin('base', 'hasil',hasil) if hasil(i)==1 output(i,1)=1; elseif hasil(i)==2 output(i,1)=2; elseif hasil(i)==3 output(i,1)=3; else output(i,1)=4; end end raw3=[DataTesting,output]; xlswrite ('raw3.xls', raw3); set(handles.tabelKlasifikasiBanyak,'data',raw3);.
(48) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 34. 4.6. Implementasi Uji Data Tunggal Pada penelitian ini terdapat uji data tunggal yang digunakan untuk mencari hasil klasifikasi pada data telah diinputkan pada sistem. Berikut merupakan contoh implementasi dari uji data tunggal.. global datapakai; data= datapakai; input1= str2num(get(handles.hr,'String')); input2= str2num(get(handles.bma,'String')); input3= str2num(get(handles.bmb,'String')); input4= str2num(get(handles.bva,'String')); input5= str2num(get(handles.bvb,'String')); input6= str2num(get(handles.bhs,'String')); inputan=[input1,input2,input6,input3,input4,input5]; load DATuj; load LABuj; DATuj = DATuj(:,[ 1 2 6 3 4 5 ]); hasil= NaiveB(DATuj , LABuj,inputan); if hasil==1 set(handles.klasifikasi, 'String','IF'); elseif hasil==2 set(handles.klasifikasi, 'String','ISK'); elseif hasil==3 set(handles.klasifikasi, 'String','ISNK'); else set(handles.klasifikasi, 'String','BHS'); end.
(49) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 35. 4.7. User Interface Sistem. Gambar 4. 1User Interface Sistem Gambar 4.1 merupakan gambar hasil runuser interface pada sistem. Untuk menjalankan sistem, pertama- tama user melakukan upload file data mentah yang akan diproses. Selanjutnya, input jumlah atribut yang akan diproses lalu tekan tombol preprocessing. Data yang telah melalui tahap preprocessing dimana data telah melalui tahap seleksi data dan transformasiakan ditampilkan pada tabel. Setelah itu, user menekan tombol akurasi untuk menampilkan hasil akurasi beserta confusion matrix. Sistem ini dapat menguji data secara berkelompok dengan cara upload data uji kelompok lalu tekan tombol klasifikasi untuk melakukan klasifikasi secara berkelompok, maka hasil dari klasifikasi tersebut akan ditampilkan pada tabel hasil uji data kelompok. Sistem ini dapat pula menguji data tunggal dengan memasukkan data berupa nilai ke dalam field, selanjutnya user menekan tombol klasifikasi untuk mendapatkan hasil klasifikasi yang akan ditampilkan pada sistem..
(50) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. BAB V ANALISIS HASIL Pada bab ini berisi hal – hal yang berkaitan dengan pengujian sistem dan menganalisis hasil implementasi sistem dari proses pengolahan data sampai dengan proses pengujian. 5.1. Preprocessing 5.1.1. Seleksi Data Pada tahap seleksi data ini penulis mencoba menghitung. information gain untuk melakukan perangkingan atribut dengan menggunakan weka tools, penulis mengurutkan atribut berdasarkan hasil perangkinagn information gain yang dapat dilihat pada tabel 5.1 : Tabel 5. 1 Perangkingan Atribut Berdasarkan Information Gain. 5.1.2. Rangking. Atribut. 1. HR. 2. BMA. 3. VOK. 4. BMB. 5. BVA. 6. BVB. Transformasi Data Setelah melakukan tahap seleksi data, selanjutnya dilakukan. transformasi data pada label pengarahan yaitu dengan mengubah label pengarahan dari bentuk kategorikal menjadi bentuk numerik. Tabel 5.2 merupakan contoh transformasi data label pengarahan :. 36.
(51) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 37. Tabel 5. 2 Transformasi Label Pengarahan. 5.2. Data Sebelum. Data Setelah. Transformasi. Transformasi. IF. 1. ISK. 2. ISNK. 3. BHS. 4. Uji Validasi Pada tahap uji validasi dilakukan perbandingan antara perhitungan manual. dan pengujian pada sistem. Data yang digunakan merupakan data klasifikasi bidang ilmu dengan jumlah 20 data dengan menggunakan 5-fold cross validation. 5.2.1. Perhitungan ManualNaïve Bayes. 1. Hitung data training yaitu ambil 16 data untuk dijadikan sebagai training dari 20 data awal dengan menggunakan 5-fold cross validation. Tabel 5.3 merupakan tabel contoh data training. Tabel 5. 3 Contoh Data Training No 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15. HR 6 4,5 1 4 5,5 3 6 6,5 4,5 7 8 8 7 3 1. BMA 6 4,5 2 6,5 7,5 1 6 4,5 3 5,5 5 6 4,5 4 3. BMB 4,5 4 2 4 4,5 3 5 4,5 4 6,5 6,5 6,5 2,5 5 2. BVA 3 5 3 4,5 5,5 2 3 3,5 4 6,5 5,5 7 4 3 2. BVB VOK PENGARAHAN 3 6 IF 6 4,5 ISNK 4 2 ISK 6 6 BHS 6 5 ISK 2 4,5 BHS 4,5 6 IF 4,5 5 IF 5 5,5 BHS 7 7 ISNK 5 1 ISK 5,5 6 IF 3,5 5 IF 4,5 6 BHS 4 2 ISK.
(52) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 38. 16. 4,5. 6,5. 3,5. 4,5. 5. 4. ISNK. 2. Menghitung nilai mean dan standar deviasi untuk setiap data atribut. Tabel 5.4, 5.5, 5.6, 5.7, 5.8, 5.9merupakan hasil dari nilai mean dan standar deviasi dari setiap atribut,sesuai dengan persamaan pada 2.5 dan 2.6: Tabel 5. 4 Hasil Mean dan Standar Deviasi HR HR MEAN. IF 6,625. ISK 3,875. ISNK. BHS. 5,333333333 3,625. STDEV 0,946484724 3,473110997 1,443375673 0,75. Tabel 5. 5 Hasil Mean dan Standar Deviasi BMA BMA MEAN. IF 5,625. STDEV 0,75. ISK 4,375. ISNK 5,5. 2,428133714 1. BHS 3,625 2,286737122. Tabel 5. 6 Hasil Mean dan Standar Deviasi BMB BMB MEAN. IF 5,125. ISK 3,75. STDEV 0,946484724 2,17944947. ISNK 4,66666667. BHS 4. 1,60727513. 0,816496581. Tabel 5. 7 Hasil Mean dan Standar Deviasi BVA BVA MEAN. IF 4,125. ISK 4. STDEV 1,931105038 1,77951304. ISNK BHS 5,33333333 3,375 1,040833. 1,108677891.
(53) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 39. Tabel 5. 8 Hasil Mean dan Standar Deviasi BVB BVB MEAN. IF 4,375. STDEV 1,03078. ISK 4,75. ISNK 6. BHS 4,375. 0,95743. 1. 1,70171. Tabel 5. 9 Hasil Mean dan Standar Deviasi VOK VOK MEAN. IF 5,75. STDEV 0,5. ISK 2,5. ISNK 5,16667. BHS 5,5. 1,73205. 1,60728. 0,70711. 3. Menghitung probabilitas prior kelas. Tabel 5.10 adalah perhitungan probabilitas setiap kelas dengan hasil sebagai berikut : Tabel 5. 10 Probabilitas Prior Setiap Kelas Kelas IF Jumlah 5 Perhitungan 5/16 Probabilitas Kelas 0,3125. ISK 4 4/16 0,25. ISNK 3 3/16. BHS 4 4/16. 0,1875. 0,25. 4. Menghitung probabilitas setiap kategori kelasdengan acuan nilai mean dan standar deviasi untuk setiap atributnya.Tabel 5.11 adalah tabel contoh data testing pada fold kelima yang digunakan untuk perhitungan Naïve Bayes. Tabel 5. 11 Tabel Contoh Data Testing 17 18 19 20. 4 2 2 9. 2 4,5 3 5,5. 5 4 3 6,5. 3 3 3,5 6,5. 3 4 4 6. 4,5 3 3 7. BHS ISK ISNK IF.
(54) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 40. Perhitungan untuk data testing nomor 17. Untuk HR=4, maka hitung berdasarkan persamaan 2.4 sebagai berikut : P(HR=4 | PENGARAHAN= IF) =. 1 √2𝜋(0,946484724). 𝑒. −(4−6,625)2 2(0,946484724)2. = 0.00900596. P(HR=4 | PENGARAHAN= ISK) =. 1 √2𝜋(3.473110997). 𝑒. −(4−3.875)2 2(3.473110997)2. = 0.11479160. P(HR=4 | PENGARAHAN= ISNK) =. 1 √2𝜋(1.443375673). 𝑒. −(4−5.333333333)2 2(1.443375673)2. = 0,18039799. P(HR=4 | PENGARAHAN= BHS) =. 1 √2𝜋(0,75). 𝑒. −(4−3,625)2 2(0,75)2. = 0,46942044. Untuk BMA=2, maka hitung berdasarkan persamaan 2.4 sebagai berikut : P(BMA=2 | PENGARAHAN= IF) =. 1 √2𝜋(0.75). 𝑒. −(2−5.625)2 2(0.75)2. = 0.00000450. P(BMA=2 | PENGARAHAN= ISK).
(55) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 41. =. 1 √2𝜋(2.428133714). 𝑒. −(2−4.375) 2 2(2.428133714)2. = 0.10183327. P(BMA=2 | PENGARAHAN= ISNK) =. 1 √2𝜋(1). 𝑒. −(2−5.5)2 2(1)2. = 0.00087268. P(BMA=2 | PENGARAHAN= BHS) =. 1 √2𝜋(2,286737122). 𝑒. −(2−3,625)2 2(2,286737122)2. = 0.13553105. Untuk BMB=5, maka hitung berdasarkan persamaan 2.4 sebagai berikut : P(BMB=5 | PENGARAHAN= IF) =. −(5−5.125)2. 1 √2𝜋(0.946484724). 𝑒 2(0.946484724)2 = 0.41783903. P(BMB=5 | PENGARAHAN= ISK) =. 1 √2𝜋(2.17944947). 𝑒. −(5−3.75)2 2(2.17944947)2. = 0.15528634. P(BMB=5 | PENGARAHAN= ISNK) =. 1 √2𝜋(1.60727513). 𝑒. −(5−4.66666667)2 2(1.60727513)2. P(BMB=5 | PENGARAHAN= BHS). = 0.2429945.
(56) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 42. =. 1 √2𝜋(0.816496581). 𝑒. −(5−4)2 2(0.816496581)2. = 0.23079948. Untuk BVA=3, maka hitung berdasarkan persamaan 2.4 sebagai berikut : P(BVA=3 | PENGARAHAN= IF) =. 1 √2𝜋(1.931105038). 𝑒. −(3−4.125)2 2(1.931105038)2. = 0.1734422. P(BVA=3 | PENGARAHAN= ISK) 1. =. √2𝜋(1.77951304). 𝑒. −(3−4)2 2(1.77951304)2. = 0.19144150. P(BVA=3 | PENGARAHAN= ISNK) =. 1 √2𝜋(1.040833). 𝑒. −(3−5.3333333)2 2(1.040833)2. = 0.03106168. P(BVA=3 | PENGARAHAN= BHS) =. 1 √2𝜋(1,108677891). 𝑒. −(3−3,375)2 2(1,108677891)2. = 0.33982988. Untuk BVB=3, maka hitung berdasarkan persamaan 2.4 sebagai berikut : P(BVB=3 | PENGARAHAN= IF) =. 1 √2𝜋(1.03078). 𝑒. −(3−4.375)2 2(1.03078)2. = 0.158983202584412.
(57) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 43. P(BVB=3 | PENGARAHAN= ISK) =. −(3−4.75)2. 1 √2𝜋(0.95743). 𝑒 2(0.95743)2 = 0.07840345. P(BVB=3 | PENGARAHAN= ISNK) =. 1 √2𝜋(1). 𝑒. −(3−6)2 2(1)2. = 0.00443185. P(BVB=3 | PENGARAHAN= BHS) =. −(3−4,375)2. 1 √2𝜋(1.70171). 𝑒 2(1.70171)2 = 0,16914248. UntuVOK=4,5, maka hitung berdasarkan persamaan 2.4 sebagai berikut : P(VOK=4,5 | PENGARAHAN= IF) =. 1 √2𝜋(0.5). 𝑒. −(4−5.75)2 2(0.5)2. = 0.03505660. P(VOK=4,5| PENGARAHAN= ISK) =. 1 √2𝜋(1.73205). 𝑒. −(4,5−2.5)2 2(1.73205)2. = 0.11825507. P(VOK=4,5 | PENGARAHAN= ISNK) =. 1 √2𝜋(1.60728). 𝑒. −(4,5−5.16667)2 2(1.60728)2. = 0.22775146.
(58) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 44. P(VOK=4,5 | PENGARAHAN= BHS) =. 1 √2𝜋(0,70711). −(4,5−5.5)2. 𝑒 2(0,70711)2 = 0.20755375. 5. Menghitung nilai likelihood dengan menggunakan hasil dari perhitungan nilai probabilitas. Nilai likelihooddibagi menjadi 5 yaitulikelihood IF, likelihoodISK,likelihood ISNK, dan likelihood BHS. Nilai likelihood dapat dihitung sebagai berikut : Likelihood IF LIF = P(IF)*P(HR) * P(BMA)*P(BMB)*P(BVA)*P(BVB)*P(VOK) = 0.3125*0.00900596*0.00000450*0.41783903*0.17434422 *0.158983202584412*0.03505660 = 0.00000000001644810081 Likelihood ISK LISK = P(ISK)* P(HR) *P(BMA)*P(BMB)*P(BVA)*P(BVB)*P(VOK) = 0,25*0.11479160*0.10183327*0.15528634*0.19144150 *0.07840345*0.11825507 = 0.00000322199 Likelihood ISNK LISNK = P(ISNK)*P(HR) * P(BMA)*P(BMB) *P(BVA)*P(BVB)*P(VOK) = 0,1875* 0.18039799*0.00087268 *0.24292945 *0.03106168*0.00443185*0.22775146 = 0.00000000120 Likelihood BHS LBHS = P(BHS)*P(HR) * P(BMA).
(59) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 45. *P(BMB)*P(BVA)*P(BVB)*P(VOK) = 0,25*0.46942044*0.13553105 *0.230799484 *0.33982988 *0.16914248 *0.207553749 = 0.98193286687 6. Mencari nilai probabilitas posterior dengan menggunakan hasil dari nilai likelihood pada setiap kelas untuk menentukkan kelas klasifikasi dengan nilai probabilitas terbesar. Perhitungan probabilitas posterior dihitung sebagai berikut : PIF. =. 0.00000000001644810081 0.00000000001644810081 +0.00000322199+0.00000000120+0.98193286687. = 0.000000092197066 PISK. =. 0.00000322199 0.00000000001644810081 +0.00000322199+0.00000000120+0.98193286687. = 0.01806031983 PISNK =. 0,00000014705 0,0000000012+0,00000108203+0,00000014705+0,00017517836. = 0.00000672110. PBHS =. 0.00017517836 0.0000000012+0.00000108203+0.00000014705+0.00017517836. = 0,98193286687 Dari hasil tersebut, terlihat bahwa nilai probabilitas tertinggi ada pada kelas BHS, maka hasil klasifikasi pada data testing nomor 17 adalah BHS. Setelah melakukan perhitungan yang sama sampai menemukan probabilitas tertinggi setiap data testing pada fold kesatu, kedua, dan ketiga, maka didapatkan hasil probabilitas posterior sebagai berikut. Tabel 5.12, 5.13, 5.14, 5.15, 5.16 merupakan tabel posterior pada semua fold..
(60) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 46. Tabel 5. 12 Posterior Fold Pertama Posterior Data Testing 1 Data Testing 2 Data Testing 3 Data Testing 4. IF 0,92975973 0,017371251 0,000000000000000000 051 0,010133763. ISK 0,0146979 5 0,2181675 49 0,9031912 28 0,1080858 82. ISNK 0,0531622 4 0,7126098 62 0,0967920 30 0,8679376 1. BHS 0,0023800 9 0,0518513 38 0,0000167 42 0,0138427 45. Tabel 5. 13 Posterior Fold Kedua Posterior Data Testing 5 Data Testing 6 Data Testing 7 Data Testing 8. IF. ISK. ISNK. BHS. 0,0300238. 0,00000017. 0,9496294. 0,0203466. 0,00000000016189. 0,000161935. 0,068304089. 0,931533976. 0,86543296. 0,00000174. 0,11068144. 0,02388385. 0,540546133. 0,001875379. 0,451079458. 0,00649903. Tabel 5. 14 Posterior Fold Ketiga Posterior Data Testing 9 Data Testing 10 Data Testing 11 Data Testing 12. IF. ISK. 0,000236068. 0,05206554. 0,9999985452 0,000000000000 000384 0,99999997087. 0,000000071 3 0,999999992 19 0,000000000 16918. ISNK 0,3812009 69 0,0000000 291 0,0000000 0781 0,0000000 2896. BHS 0,566497423 0,0000013544 0,000000000000 000057 0,000000000001 97.
(61) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 47. Tabel 5. 15 Posterior Fold Keempat Posterior Data Testing 13 Data Testing 14 Data Testing 15 Data Testing 16. IF. ISK 0,2910833 1 0,0540049 98. 0,265851786 0,001315545 0,0000000000000000000 00064 0,00065253. ISNK 0,4430282 09 0,1477305 79. BHS 0,0000367 0,7969488 77. 0,0000000 418 0,4071245 0,1533941 0,4388287 62 26 83 0,9406093 0,0593907. Tabel 5. 16 Posterior Fold Kelima Posterior Data Testing 17 Data Testing 18 Data Testing 19 Data Testing 20. IF 0,0000000922 0,000000000034 5 0,000000000000 047 0,080467130101 6298. ISK 0,01806031 98 0,98667304 566 0,99439554 477 0,00839063 489. ISNK 0,00000672 11 0,00456097 583 0,00060864 483 0,91114223 501. BHS 0,9819328669 0,00876597847 0,0049958104 0,000000000000 0191. Setelah melakukan perhitungan yang sama pada semua data testing fold pertama, kedua, ketiga, keempat, kelima, maka didapatkan hasil klasifikasi. Tabel 5.17, 5.18, 5.19, 5.20, 5.21 merupakan tabel hasil klasifikasi tiap fold sebagai berikut. Tabel 5. 17 Hasil Klasifikasi Fold Pertama Data Testing 1 2 3 4. Label Testing IF ISNK ISK BHS. Hasil Klasifikasi IF ISNK ISK ISNK.
(62) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 48. Tabel 5. 18 Hasil Klasifikasi Fold Kedua Data Testing 5 6 7 8. Label Testing ISK BHS IF IF. Hasil Klasifikasi ISNK BHS IF IF. Tabel 5. 19 Hasil Klasifikasi Fold Ketiga Data Testing 9 10 11 12. Label Testing BHS ISNK ISK IF. Hasil Klasifikasi BHS ISK ISK IF. Tabel 5. 20 Hasil Klasifikasi Fold Keempat Data Testing 13 14 15 16. Label Testing IF BHS ISK ISNK. Hasil Klasifikasi ISNK BHS ISK BHS. Tabel 5. 21 Hasil Klasifikasi Fold Kelima Data Testing 17 18 19 20. Label Testing BHS ISK ISNK IF. Hasil Klasifikasi BHS ISK ISK ISNK. Setelah mendapatkan hasil klasifikasi, selanjutnya mencari hasil akurasi menggunakan confusion matrix dengan persamaan 2.7.. Pengujian. dilakukan dengan menggunakan 5-fold cross validation. Tabel 5.22, 5.23, 5.24, 5.25, 5.26 merupakan confusion matrix hasil dari klasifikasi perhitungan manual..
(63) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 49. Tabel 5. 22Confusion Matrix Hitung Manual 1 IF IF ISK ISNK BHS. ISK 1 0 0 0. Akurasi =. ISNK 0 1 0 0. 1+1+1 4. BHS 0 0 1 1. 0 0 0 0. x 100 % = 75 %. Tabel 5. 23Confusion Matrix Hitung Manual 2 IF ISK ISNK BHS 2 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1. IF ISK ISNK BHS. Akurasi =. 2+1 4. x 100 % = 75 %. Tabel 5. 24Confusion Matrix Hitung Manual 3 IF. ISK. ISNK. BHS. IF. 1. 0. 0. 0. ISK ISNK. 0 1. 1 0. 0 0. 0 0. BHS. 0. 0. 0. 1. Akurasi =. 1+1+1 4. x 100 % = 75 %.
(64) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 50. Tabel 5. 25 Confusion Matrix Hitung Manual 4 IF IF ISK ISNK BHS. ISK 0 0 0 0. Akurasi =. 1+1 4. ISNK 0 1 0 0. BHS 1 0 0 0. 0 0 1 1. x 100 % = 50 %. Tabel 5. 26 Confusion Matrix Hitung Manual 5 IF IF ISK ISNK BHS. Akurasi =. ISK 0 0 0 0 1+1 4. ISNK 0 1 1 0. BHS 1 0 0 0. 0 0 0 1. x 100 % = 50 %. Setelah mendapatkan hasil akurasi setiap pengujian, selanjutnya mencari hasil akurasi total dengan cara menghitung rata – rata dari hasil akurasi setiap pengujian. Untuk menghitung akurasi total dapat menggunakan perhitungan sebagai berikut : Akurasi Rata - Rata 5.2.2. =. 75+75+75+50+50 5. x 100 % = 65 %. Pengujian Sistem Pada pengujian sistem ini data yang digunakan sebanyak 20 record data dengan 6 atribut yaitu HR, BMA,BMB, BVA, BVB, VOK menggunakan 5-fold cross validation yang menghasilkan akurasi rata – rata sebesar 65 %. Gambar 5.1 merupakan hasil akurasi uji validasi pengujian sistem..
(65) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 51. Gambar 5. 1 Hasil Akurasi Uji Validasi Pengujian Sistem Gambar 5.2, 5.3, 5.4, 5.5, 5.6 merupakan tabel confusion matrix uji validasi pengujian sistem yang digunakan untuk mencari hasil akurasi dengan menggunakan 5-fold cross validation yang ditampilkan pada GUI dengan menggunakan tabel.. Gambar 5. 2 Confusion Matrix 1 Uji Validasi Pengujian Sistem Akurasi =. 1+1+1 x 4. 100 % = 75 %. Gambar 5. 3 Confusion Matrix 2 Uji Validasi Pengujian Sistem.
(66) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI 52. Akurasi =. 2+1 x 4. 100 % = 75 %. Gambar 5. 4 Confusion Matrix3 Uji Validasi Pengujian Sistem Akurasi =. 1+1+1 x 4. 100 % = 75 %. Gambar 5. 5 Confusion Matrix4 Uji Validasi Pengujian Sistem Akurasi =. 1+1 x 4. 100 % = 50 %. Gambar 5. 6 Confusion Matrix5 Uji Validasi Pengujian Sistem Akurasi =. 1+1 x 4. 100 % = 50 %. Akurasi Rata- Rata 5.2.3. =. 75+75+75+50+50 5. x 100 % = 65 %. Pengujian Menggunakan Function Matlab Fungsi matlab yang digunakan untuk perhitungan model Naïve Bayes adalah fungsi fitcnb, sedangkan untuk memprediksi.
Gambar




+7

Dokumen terkait
Menurut Gunawan (2014: 265) kepramukaan merupakan proses pendidikan di luar lingkungan sekolah dan di luar lingkungan keluarga dalam bentuk kegiatan menarik,
Dalam pengelolaan pendapatan daerah, sumber pendapatan yang berasal dari Pemerintah melalui desentralisasi fiskal dalam bentuk Dana Alokasi Umum (DAU) saat ini
Budaya organisasi didefinisikan Edgar Schein dalam Luthans (2006:278) sebagai pola asumsi dasar – diciptakan, ditemukan atau dikembangkan oleh kelompok tertentu saat
Vegetarian adalah sebutan bagi orang yang hanya makan tumbuh-tumbuhan dan tidak mengkonsumsi makanan yang berasal dari mahluk hidup seperti daging, unggas, ikan atau hasil
Bila pasien tidak mendapatkan remisi komplit atau parsial terhadap steroid, tidak mempunyai efek samping terhadap steroid, serta remisi telah berjalan lebih dari satu tahun,
Dengan menggunakan media internet ( website ) pengguna dapat langsung mencari dan melihat informasi data spasial yang dibutuhkan tanpa harus mendatangi.. tempat
Kepuasan pemustaka terhadap layanan ETD Perpustakaan UGM berdasarkan perbedaan persepsi, harapan minimum dan harapan ideal terlihat bahwa skor AG yang paling tinggi
Dengan 24 plate ini sudah dapat disimpulkan kondisi orang yang di tes apakah mengalami buta warna total, parsial atau normal.24 gambar pada aplikasi tes buta warna
