BAB II
LANDASAN TEORI
2.1. Data
Data adalah bentuk jamak dari datum. Data merupakan keterangan-keterangan tentang suatu hal, dapat berupa sesuatu yang diketahui atau dianggap. Jadi, data dapat diartikan sebagai sesuatu yang diketahui atau yang dianggap atau anggapan. Data juga merupakan sejumlah informasi yang dapat memberikan gambaran tentang suatu keadaan, atau masalah baik yang berbentuk angka-angka maupun yang berbentuk kategori atau keterangan (Supardi, 2013).
Sesuai dengan macam atau jenis variabel, maka data atau hasil pencatatannya juga mempunyai jenis sebanyak variabel. Data dapat dibagi dalam kelompok tertentu berdasarkan kriteria yang menyertainya, misalnya menurut susunan, sifat, waktu pengumpulan, sumber pengambilan dan skala pengukurannya (Supardi, 2013).
a. Pembagian Data Menurut Susunannya 1) Data Acak atau Data Tunggal
Data acak atau data tunggal adalah data yang belum tersusun atau dikelompokkan kedalam kelas-kelas interval.
2) Data Berkelompok
b. Pembagian Data Menurut Sifatnya 1) Data Kualitatif
Data kualitatif adalah data yang tidak berbentuk bilangan. Data kualitatif berbentuk pernyataan verbal, simbol, atau gambar.
Contoh data kualitatif adalah data gender, data golongan darah, data tempat tinggal atau data jenis pekerjaan. Agar dapat dilakukan proses pada data kualitatif atau non metric, data tersebut harus diubah ke dalam bentuk angka, proses ini dinamakan kategorisasi. Data kualitatif dibedakan menjadi dua jenis, yaitu data nominal dan data ordinal.
2) Data Kuantitatif
Data kuantitatif adalah data yang berbentuk bilangan, atau data kualitatif yang diangkakan.
Data kuantitatif dapat disebut sebagai data berupa angka dalam arti sebenarnya. Jadi, berbagai jenis operasi matematika dapat dilakukan pada data kuantitatif. Data kuantitatif merupakan data yang didapat dengan jalan mengukur sehingga bisa mempunyai nilai desimal. Contoh data kuantitatif adalah tinggi badan, usia, penjualan barang, dan sebagainya. Sebagai contoh, tinggi badan seseorang bisa bernilai 165 cm atau 165.5 cm. Seperti pada jenis data kualitatif, jenis data kuantitatif juga terbagi menjadi dua, yaitu data interval dan data rasio.
Data berkala adalah data yang terkumpul dari waktu ke waktu untuk memberikan gambaran perkembangan suatu kegiatan.
2) Data Cross Section
Data cross section adalah data yang terkumpul pada suatu waktu tertentu untuk memberikan gambaran perkembangan keadaan atau kegiatan pada waktu itu.
d. Pembagian Data Menurut Sumber Pengambilannya 1) Data Primer
Data primer adalah data yang diperoleh atau dikumpulkan oleh orang yang melakukan penelitian atau yang bersangkutan yang melakukannya. Data primer disebut juga data asli atau data baru.
2) Data Sekunder
Data sekunder adalah data yang diperoleh atau dikumpulkan dari sumber-sumber yang telah ada. Data itu biasanya diperoleh dari perpustakaan atau dari laporan-laporan/dokumen peneliti yang terdahulu. Data sekunder disebut juga data tersedia.
e. Pembagian Data Menurut Skala Pengukurannya 1) Data Nominal
lainnya dan tidak bisa diurutkan/dibandingkan. Data ini memiliki ciri yaitu kategori data bersifat saling lepas dan kategori data tidak disusun secara logis.
2) Data Ordinal
Data ordinal adalah data yang penomoran objek atau kategori disusun menurut besarnya, yaitu dari tingkat terendah ke tingkat tertinggi atau sebaliknya dengan jarak/rentang yang tidak harus sama. Data ini memiliki ciri seperti ciri data nominal ditambah satu ciri lagi, yaitu kategori data dapat disusun/diurutkan berdasarkan urutan logis dan sesuai dengan besarnya karakteristik yang dimiliki.
3) Data Interval
Data interval adalah data dengan objek/kategori yang dapat dibedakan antara data satu dengan lainnya, dapat diurutkan berdasarkan suatu atribut dan memiliki jarak yang memberikan informasi tentang interval antara tiap objek/kategori sama. Besarnya interval dapat ditambah atau dikurangi. Data ini memiliki ciri sama dengan data ordinal ditambah satu ciri lagi, yaitu urutan kategori data mempunyai jarak yang sama.
4) Data Rasio
2.2. Data Mining
Menurut Han & Kamber (2006), data mining adalah kegiatan yang meliputi pengumpulan dan pemakaian data historis yang menemukan keteraturan, pola dan hubungan dalam set data berukuran besar. Maksud dari pengertian ini yaitu proses pencarian informasi yang tidak diketahui sebelumnya dari sekumpulan data besar. Karakteristik Data mining sebagai berikut (Kusrini & Luthfi, 2009) :
a) Data mining berhubungan dengan penemuan sesuatu yang tersembunyi dan pola data tertentu yang tidak diketahui sebelumnya.
b) Data mining biasa menggunakan data yang sangat besar. Biasanya data yang besar digunakan untuk membuat hasil lebih dipercaya.
c) Data mining berguna untuk membuat keputusan yang kritis, terutama dalam strategi.
Secara umum ada dua jenis metode pada data mining (Kusrini & Luthfi, 2009), yaitu:
a) Metode Prediktive
Proses untuk menemukan pola dari data yang menggunakan beberapa variabel untuk memprediksi variabel lain yang tidak diketahui jenis atau nilainya. Teknik yang termasuk dalam predikative mining antara lain klasifikasi, regresi, dan deviasi.
Proses untuk menemukan suatu karakteristik penting dari data dalam suatu basis data. Teknik data mining yang termasuk dalam descriptive mining
adalah clustering, association, dan secuential mining. 2.3. Klasifikasi Data
Klasifikasi data adalah suatu proses yang menemukan properti-properti yang sama pada sebuah himpunan obyek di dalam sebuah basis data, dan mengklasifikasikannya ke dalam kelas-kelas yang berbeda menurut model klasifikasi yang ditetapkan. Tujuan dari klasifikasi adalah untuk menemukan model dari training set yang membedakan atribut ke dalam kategori atau kelas yang sesuai, model tersebut kemudian digunakan untuk mengklasifikasikan atribut yang kelasnya belum diketahui sebelumnya (Zaki & Meira, 2014).
nominal, sedangkan regresi digunakan untuk memprediksi nilai-nilai yang kontinyu. Untuk selanjutnya penggunaan istilah prediction untuk memprediksi kelas yang berlabel disebut classification, dan penggunaan istilah prediksi untuk memprediksi nilai-nilai yang kontinu sebagai prediction (Zaki & Meira, 2014).
a) Model Klasifikasi
Data input untuk klasifikasi adalah koleksi dari record. Setiap record dikenal sebagai instance atau contoh, yang ditentukan oleh sebuah tuple (x,y), dimana x adalah himpunan atribut dan y adalah atribut tertentu, yang dinyatakan sebagai label kelas (juga dikenal sebagai kategori atau atribut target). Klasifikasi adalah tugas pembelajaran sebuah fungsi target f yang memetakan setiap himpunan atribut x ke salah satu label kelas y yang telah didefinisikan sebelumnya. Fungsi target juga dikenal secara informal sebagai model klasifikasi.
b) Pemodelan Deskriptif
Model klasifikasi dapat bertindak sebagai alat penjelas untuk membedakan objek-objek dari kelas-kelas yang berbeda. Sebagai contoh untuk para ahli Biologi, model deskriptif yang meringkas data.
2.4. Teori Graf
noktah, bulatan, atau titik, sedangkan hubungan antara objek dinyatakan dengan garis (Didit Budi Nugroho, 2008).
Secara formal, Graf G didefinisikan sebagai pasangan himpunan (V,E), yang dalam hal ini:
o V = himpunan tidak-kosong dari simpul-simpul (vertices atau node) = { v1 , v2 , ... , vn }
o E = himpunan sisi (edges atau arcs) yang menghubungkan sepasang simpul = {e1 , e2 , ... , en}
atau dapat ditulis singkat notasi G = (V, E).
Definisi diatas menyatakan bahwa V tidak boleh kosong, sedangkan E boleh kosong. Jadi, sebuah graf dimungkinkan tidak mempunyai sisi satu buah pun, tetapi simpulnya harus ada, minimal satu. Graf yang hanya mempunyai satu buah simpul tanpa sebuah sisi pun dinamakan graf trivial. Sedangkan garis yang hanya berhubungan dengan satu simpul disebut loop (Didit Budi Nugroho, 2008). 2.5. Struktur Pohon
a) Misalkan G merupakan suatu graf dengan n buah simpul dan tepat n – 1 buah sisi. Jika G tidak mempunyai sirkuit maka G merupakan pohon. b) Suatu pohon dengan n buah simpul mempunyai n – 1 buah sisi.
c) Setiap pasang simpul di dalam suatu pohon terhubung dengan lintasan tunggal.
d) Misalkan G adalah graf sederhana dengan jumlah simpul n, jika G tidak mengandung sirkuit maka penambahan satu sisi pada graf hanya akan membuat satu sirkuit.
2.5.1 Pohon Berakar
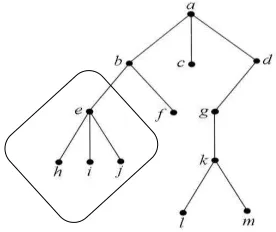
Pada suatu pohon, yang sisi-sisinya diberi arah sehingga menyerupai graf berarah, maka simpul yang terhubung dengan semua simpul pada pohon tersebut dinamakan akar. Suatu pohon yang satu buah simpulnya diperlakukan sebagai akar maka pohon tersebut dinamakan pohon berakar (rooted tree). Simpul yang berlaku sebagai akar mempunyai derajat masuk sama dengan nol. Sementara itu, simpul yang lain pada pohon itu memiliki derajat masuk sama dengan satu. Pada suatu pohon berakar, Simpul yang memiliki derajat keluar sama dengan nol dinamakan daun. Pada Gambar 1 dibawah, a merupakan akar, c, d, f, g, h, i, dan j
merupakan daun (Adiwijaya, 2014).
2.5.2 Terminologi Pohon Berakar
Gambar 2. Terminologi Pohon Berakar
a. Anak (child atau children) dan Orangtua (parent) b, c, dan d adalah anak-anak simpul a, a adalah orangtua dari anak-anak itu
b. Lintasan (path). Lintasan dari a ke h adalah a, b, e, h. dengan pnjang lintasannya adalah 3. f adalah saudara kandung e, tetapi, g bukan saudara kandung e, karena orangtua mereka berbeda.
c. Subtree
Gambar 3. Subtree Pohon Berakar d. Derajat (degree)
Derajat sebuah simpul adalah jumlah anak pada simpul tersebut. Contohnya :
o Simpul yang berderajat 2 adalah simpul b dan k. o Simpul yang berderajat 3 adalah simpul a dan e.
Jadi, derajat yang dimaksudkan di sini adalah derajat-keluar.
Derajat maksimum dari semua simpul merupakan derajat pohon itu sendiri. Pohon di atas berderajat 3
e. Daun (leaf)
Simpul yang berderajat nol (atau tidak mempunyai anak) disebut daun. Simpul h, i, j, f, c, l, dan m adalah daun.
f. Simpul Dalam (internal nodes)
Simpul yang mempunyai anak disebut simpul dalam. Simpul b, d, e, g, dan k adalah simpul dalam.
g. Aras (level) atau Tingkat
Gambar 4. Level dalam Pohon Berakar h. Tinggi (height) atau Kedalaman (depth)
Aras maksimum dari suatu pohon disebut tinggi atau kedalaman pohon tersebut. Pohon di atas mempunyai tinggi 4.
disebut pohon n-ary. Jika n = 2, pohonnya disebut pohon biner (binary tree) (Adiwijaya, 2014).
2.5.3 Pohon Keputusan (Decision Tree)
Pohon keputusan adalah model prediksi menggunakan struktur pohon atau struktur berhirarki. Decision tree merupakan metode klasifikasi yang paling popular digunakan. Selain karena pembangunannya relatif cepat, hasil dari model yang dibangun mudah untuk dipahami. Pada decision tree terdapat 3 jenis node (Munir, 2009), yaitu :
a. Root Node, merupakan node paling atas, pada node ini tidak ada input dan bisa tidak mempunyai output atau mempunyai output lebih dari satu. b. Internal Node , merupakan node percabangan, pada node ini hanya
terdapat satu input dan mempunyai output minimal dua.
c. Leaf node atau terminal node , merupakan node akhir, pada node ini hanya terdapat satu input dan tidak mempunyai output.
2.6. Probabilitas
Bila suatu percobaan mempunyai N(S) hasil percobaan yang berbeda dan masing-masing mempunyai kemungkinan yang sama untuk terjadi, dan bila tepat n(A) diantara hasil percobaan itu menyusun kejadian A, maka peluang kejadian A adalah
Menurut Walpole dan Myers (1986) kaidah-kaidah probabilitas ada beberapa macam, antara lain :
1. Kaidah penjumlahan
a. Kaidah penjumlahan dua kejadian yang saling terpisah.
b. Kaidah penjumlahan dua kejadian yang tidak saling bebas.
c. Kaidah penjumlahan n buah kejadian yang saling terpisah. Bila 1, 2, ⋯ , kejadian-kejadian yang saling terpisah, maka
d. Bila A dan ′ adalah dua kejadian yang satu merupakan komplemen lainnya maka
2. Kaidah peluang bersyarat
3. Kaidah Penggandaan
a. Kaidah penggandaan khusus
Bila kejadian A dan B saling bebas maka
b. Jika kejadian-kejadian 1, 2, 3, ⋯ , saling bebas, maka
4. Kaidah Bayes
Jika kejadian-kejadian 1, 2, ⋯ , merupakan partisi dari ruang sampel
S dengan ( ) ≠ 0 untuk = 1, 2, ⋯ , maka untuk sembarang kejadian A
yang bersifat ( ) ≠ 0 maka untuk � = 1, 2, ⋯ ,
∑
∑
2.7. Algoritma CART
Algoritma CART termasuk dalam anggota analisis klasifikasi yang disebut
2.7.1. Partisi Berulang Biner (Binary Recursive Partitioning)
Teknik atau proses kerja dari CART dalam membuat sebuah pohon klasifikasi dikenal dengan istilah Binary Recursive Partitioning. Proses disebut binary karena setiap parent node akan selalu mengalami pemecahan ke dalam tepat dua child node. Sedangkan recursive berarti bahwa proses pemecahan tersebut akan diulang kembali pada setiap child nodes hasil pemecahan terdahulu, sehingga child nodes tersebut sekarang menjadi parent nodes. Proses pemecahan ini akan terus dilakukan sampai tidak ada kesempatan lagi untuk melakukan pemecahan berikutnya. Dan istilah partitioning mengartikan bahwa learning sample yang dimiliki dipecah ke dalam bagian-bagian atau partisi-partisi yang lebih kecil (Damayanti, 2011).
Kriteria pemecahan didasarkan pada nilai-nilai dari variabel independen yang dimiliki. Misalkan dimiliki variabel dependen yang bertipe kategorik dan variabel-variabel independen 1, 2, ⋯ , � . Proses binary recursive partitioning
klasifikasi yang paling besar atau maksimal (proses splitting tidak bisa dilakukan lagi) (Damayanti, 2011).
2.7.2. Langkah Kerja CART
Menurut Lewis (2000) pada dasarnya dalam membuat sebuah pohon klasifikasi, CART bekerja dalam empat langkah utama. Langkah pertama adalah tree building process yaitu proses pembentukan dan pembuatan pohon klasifikasi. Terdiri dari proses splitting nodes yaitu proses pemecahan parent nodes menjadi dua buah child node melalui aturan pemecahan tertentu dan dilakukan secara berulang-ulang serta proses pelabelan kelas yaitu proses mengidentifikasi node-node yang terbentuk pada suatu kelas tertentu melalui aturan pengidentifikasian. Langkah kedua adalah proses penghentian pembuatan atau pembentukan pohon klasifikasi (stopping the trees building process). Pada tahap ini pohon terakhir atau maximal tree (��� ) telah terbentuk. Langkah ketiga adalah pruning yaitu proses pemangkasan atau pemotongan ��� menjadi pohon yang lebih kecil (T). Sehingga proses tersebut menghasilkan optimal tree atau pohon klasifikasi yang optimal.
a. Proses Pemecahan Node
Proses pemecahan pada masing-masing parent node didasarkan pada goodness of split criterion (kriteria pemecahan terbaik). Kriteria pemecahan terbaik ini dibentuk berdasarkan fungsi impurity (fungsi keragaman). Fungsi impurity adalah sebuah fungsi � yang didefinisikan dengan ⋯ dengan ∑ , dimana
Impurity measure (ukuran impurity) dari beberapa node t sebagai berikut (Breiman, et al., 1993) :
� ⋯
maka Gini Diversity Index (Indeks Keragaman Gini) adalah :
∑
Dalam sebuah node t, andaikan terdapat n kelas (1, 2 ⋯ , ). Untuk
Untuk j = 3 dan i adalah kelas-kelas lainnya maka (2.1) dapat dituliskan :
∑
∑
Sehingga untuk n kelas secara umum, didapatkan :
∑
Sehingga berdasarkan (2.1) Gini Diversity Index dapat dituliskan sebagai berikut (Breiman, et al., 1993) : didefinisikan decrease impurity (pengurangan keragaman) :
Nilai digunakan sebagai uji goodness of split criterion
��
Hal ini berarti splitting (pemecahan) dilakukan untuk membuat dua buah node baru yang keragamannya lebih kecil (homogen) apabila dibandingkan dengan node awalnya (parent node). Misalkan sebuah pohon klasifikasi telah terbentuk dan memiliki sekumpulan atau himpunan
terminal nodes�̃ , didefinisikan impurity node I(t), dengan
Didefinisikan pula tree impurity (�) , dengan
� ∑
̃ ∑ ̃
sehingga didapatkan hasil sebagai berikut
b. Pelabelan Kelas
Pelabelan kelas adalah proses pengidentifikasian tiap nodes pada suatu kelas tertentu. Pelabelan kelas tidak hanya diberlakukan untuk
terminal nodes saja, non-terminal nodes bahkan root node mengalami proses ini. Hal ini dikarenakan setiap non-terminal nodes memiliki kesempatan untuk menjadi terminal nodes. Sehingga proses pelabelan kelas akan terus dilakukan selama proses splitting masih berlanjut (Breiman, et al., 1993).
Misalkan sebuah pohon klasifikasi telah terbentuk dan memiliki
terminal nodes�̃. Class assignment rule mengidentifikasikan sebuah kelas
pelabelan kelas sebagai berikut ; apabila �� maka (Breiman et al, 1993).
c. Proses Penghentian Pemecahan
Menurut Lewis (2000), proses splitting atau pembuatan pohon klasifikasi akan berhenti apabila sudah tidak dimungkinkan lagi dilakukan proses pemecahan. Proses pemecahan akan berhenti apabila hanya tersisa satu objek saja yang ada dalam node terakhir atau semua objek yang berada di dalam sebuah node merupakan anggota kelas yang sama (homogen). Kemudian bernilai 0 atau 1. � , dan resubstitution estimate �(�) untuk nilai misclassification sama dengan 0. Node-node terakhir atau yang tidak mengalami pemecahan lagi sebagai akibat dari kondisi di atas akan menjadi terminal nodes dan diidentifikasikan pada suatu kelas tertentu sesuai dengan class assignment rule yang telah dijelaskan sebelum ini. Pohon klasifikasi yang terbentuk sebagai hasil dari proses ini dinamakan “maximal tree” (��� ).
d. Proses Pemangkasan Pohon
Resubstitution estimate �( ) adalah probabilitas terjadinya
Pohon klasifikasi yang terbentuk dapat berukuran besar dan kompleks dalam mengambarkan struktur data. Sehingga perlu dilakukan suatu pemangkasan, yaitu suatu penilaian ukuran sebuah pohon tanpa mengorbankan kebaikan ketepatan melalui pengurangan simpul pohon sehingga dicapai penghematan gambaran. Pemangkasan dilakukan dengan memangkas bagian pohon yang kurang penting sehingga didapat pohon optimal (Breiman, et al., 1993).
Proses pemangkasan pohon klasifikasi dimulai dengan mengambil � yang merupakan right child node dan � yang merupakan left child node
dari ��� yang dihasilkan dari parent nodet. Jika diperoleh dua child node
dan parent node yang memenuhi persamaan � � � maka
hild node � dan � dipangkas. Dimana � dan
�� . Hasilnya adalah pohon �1 yang memenuhi kriteria �(�1) =
�(��� ). Proses tersebut diulang sampai tidak ada lagi pemangkasan yang mungkin terjadi.
2.8. Logika Fuzzy
makna pada ungkapan seperti "sering", "kecil" dan "tinggi". Logika fuzzy memperhitungkan bahwa dunia nyata yang kompleks dan ada ketidakpastian, semuanya tidak dapat memiliki nilai absolut dan mengikuti fungsi linear (Godil & Shamim, 2011)
Pada himpunan tegas setiap elemen dalam semestanya selalu ditentukan secara tegas apakah elemen itu merupakan anggota himpunan tersebut atau tidak. Tetapi dalam kenyataanya tidak semua himpunan terdefinisi secara tegas. Oleh karena itu perlu didefinisikan suatu himpunan Fuzzy yang bisa menyatakan kejadian tersebut. Himpunan Fuzzy memiliki dua atribut (Kusumadewi, 2002), yaitu :
a. Linguistik, yaitu penamaan suatu kelompok yang mewakili suatu keadaan atau kondisi tertentu dengan menggunakan bahasa alami, seperti: lambat, sedang, cepat.
b. Numeris, yaitu suatu nilai (angka) yang menunjukkan ukuran dari suatu variabel, seperti: 40, 50, 60, dan sebagainya.
Penerapan logika fuzzy dapat meningkatkan kinerja sistem kendali dengan menekan munculnya fungsi-fungsi liar pada keluaran yang disebabkan oleh fluktasi pada variabel masukan. Pendekatan logika fuzzy secara garis besar diimplementasikan dalam tiga tahapan yaitu :
1. Tahapan pengaburan (fuzzification) yakni pemetaan dari masukan tegas ke himpunan kabur.
3. Tahap penegasan (defuzzification), yakni transformasi keluaran dari nilai kabur ke nilai tegas.
2.8.1. Fungsi Keanggotaan
Fungsi keanggotaan (member function) adalah suatu kurva yang menunjukkan pemetaan titik-titik input data ke dalam nilai keanggotaannya (sering juga disebut dengan derajat keanggotaan) yang memiliki interval 0 sampai 1. Salah satu cara yang dapat digunakan untuk mendapatkan nilai keanggotaan adalah menggunakan pendekatan fungsi (Kusumadewi & Purnomo, 2010). Ada beberapa fungsi yang bisa digunakan. Di antaranya, yaitu:
a. Representasi Linear.
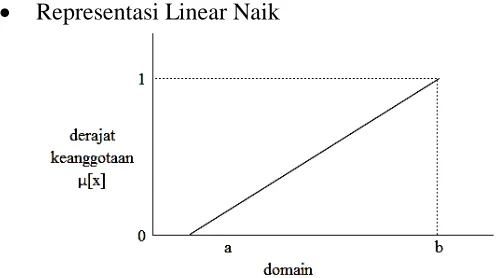
Pada representasi linear, pemetaan input ke derajat keanggotannya digambarkan sebagai suatu garis lurus. Bentuk ini paling sederhana dan menjadi pilihan yang baik untuk mendekati suatu konsep yang kurang jelas. Ada dua keadaan himpunan linear, yaitu :
Representasi Linear Naik
Gambar 6. Representasi Linear Naik Fungsi keanggotaan sebagai berikut :
[ ] {
�
�
Representasi Linear Turun
Gambar 7. Representasi Linear Turun Fungsi keanggotaan sebagai berikut :
[ ] {
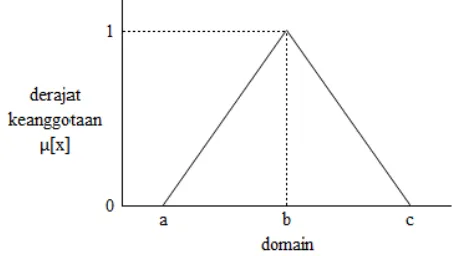
b. Representasi Kurva Segitiga. Kurva Segitiga pada dasarnya merupakan gabungan antara dua garis (linear).
Gambar 8. Representasi Kurva Segitiga Dengan fungsi keanggotaan sebagai berikut :
[ ] {
� � �
�
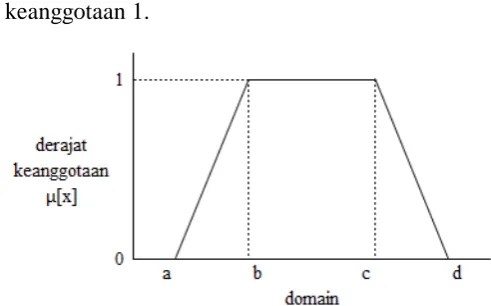
c. Representasi Kurva Trapesium. Kurva Trapesium pada dasarnya seperti bentuk segitiga, hanya saja ada beberapa titik yang memiliki nilai keanggotaan 1.
Gambar 9. Representasi Kurva Trapesium Dengan fungsi keanggotaan sebagai berikut :
[ ]
{
� � �
�
d. Representasi Kurva Bahu
Gambar 10. Representasi Kurva Bahu 2.8.2. Operator Dasar Fuzzy
Ada beberapa operasi yang didefinisikan secara khusus untuk mengkombinasi dan memodifikasi himpunan Fuzzy. Nilai keanggotaan sebagai hasil dari operasi dua himpunan sering dikenal dengan nama fire strength atau α–
predikat. Ada tiga operator dasar yang diciptakan oleh Zadeh (Kusumadewi & Purnomo, 2010), yaitu:
a. Operator AND
Operator ini berhubungan dengan operasi interseksi pada himpunan. α– predikat sebagai hasil operasi dengan operator AND diperoleh dengan mengambil nilai keanggotaan terkecil antar elemen pada himpunan-himpunan yang bersangkutan.
[ ] [ ]
b. Operator NOT
[ ]
c. Operator OR
Operator ini berhubungan dengan operasi union pada himpunan. α–
predikat sebagai hasil operasi dengan operator OR diperoleh dengan mengambil nilai keanggotaan terbesar antar elemen pada himpunanhimpunan yang bersangkutan.
[ ] [ ]
2.8.3. Fungsi Implikasi
Tiap – tiap aturan (proposisi) pada basis pengetahuan Fuzzy akan berhubungan dengan suatu relasi Fuzzy. Bentuk umum dari aturan yang digunakan dalam fungsi implikasi adalah:
IF x is A THEN y is B
Proposisi yang mengikuti IF disebut sebagai anteseden, sedangkan proposisi yang mengikuti THEN disebut sebagai konsekuen. Secara umum, ada dua fungsi implikasi yang dapat digunakan, yaitu :
a. Min. Pengambilan keputusan dengan fungsi min, yaitu dengan cara mencari nilai minimum berdasarkan aturan ke-i dan dapat dinyatakan dengan :
b. Dot. Fungsi ini akan menskala output himpunan Fuzzy. 2.8. Fuzzy Inference System
melakukan penalaran dengan nalurinya (Alavi, et al., 2010). Langkah pertama dari FIS adalah menetapkan nilai keanggotaan untuk data input dan output (Alidoosti, et al., 2012).
Menurut Kusumadewi & Hartati (2010), sistem inferensi fuzzy merupakan suatu kerangka komputasi yang didasarkan pada teori himpunan fuzzy, aturan fuzzy yang berbentuk IF-THEN, dan penalaran fuzzy.
IF (x1 is A1) (x2 is A2) (x is A1) THEN y is B
dengan adalah operator (misal : OR dan AND)
Sistem inferensi fuzzy didasarkan pada konsep penalaran monoton. Pada metode penalaran secara monoton, nilai crisp pada daerah konsekuen dapat diperoleh secara langsung berdasarkan fire strength pada antesedennya. Salah satu syarat yang harus dipenuhi pada metode penalaran ini adalah himpunan fuzzy pada konsekuennya harus bersifat monoton (baik monoton naik maupun monoton turun). Salah satu inferensi fuzzy adalah Fuzzy Logic Controller.
Fuzzy Logic Controller (FLC) adalah pengendali yang mengendalikan sebuah sistem atau proses dengan menggunakan logika fuzzy sebagai cara pengambilan keputusan. Secara garis besar, terdapat empat komponen utama penyusun FLC, yaitu fuzzification, basis aturan (rule base), modul pengambil keputusan (inference engine), dan modul defuzzifikasi.
2.9.1. Komposisi Aturan
a) Metode Max (Maximum). Pada metode ini, solusi himpunan fuzzy diperoleh dengan cara mengambil nilai maksimum aturan, kemudian menggunakannya untuk memodifikasi daerah fuzzy, dan mengaplikasikannya ke output dengan menggunakan operator OR (union). Jika semua proposisi telah dievaluasi, maka output akan berisi suatu himpunan fuzzy yang merefleksikan kontribusi dari tiap-tiap proposisi. Secara umum dapat dituliskan :
[ ] �� [ ] [ ]
dengan :
[ ] = nilai keanggotaan solusi fuzzy sampai aturan ke – i. [ ] = nilai keanggotaan konsekuen fuzzy aturan ke – i.
b) Metode Additive (Sum). Pada metode ini, solusi himpunan fuzzy diperoleh dengan cara melakukan boundedsum terhadap semua output daerah fuzzy. Secara umum dapat dituliskan :
[ ] � [ ] [ ]
dengan :
[ ] = nilai keanggotaan solusi fuzzy sampai aturan ke – i. [ ] = nilai keanggotaan konsekuen fuzzy aturan ke – i.
c) Metode OR (Probor). Pada metode ini, solusi himpunan fuzzy diperoleh dengan cara melakukan product terhadap semua output daerah fuzzy. Secara umum dituliskan :
[ ] [ ] [ ] [ ] [ ]
[ ] = nilai keanggotaan solusi fuzzy sampai aturan ke – i. [ ] = nilai keanggotaan konsekuen fuzzy aturan ke – i. 2.9.2. Metode Mamdani
Salah satu metode FLC yang dapat digunakan untuk pengambilan keputusan adalah metode Mamdani. Metode Mamdani sering juga dikenal dengan nama metode Max-Min. metode ini diperkenalkan oleh Ebrahim Mamdani pada tahun 1975 (Kusumadewi, 2002). Untuk medapatkan output diperlukan beberapa tahapan, antara lain:
a) Pembentukan himpunan fuzzy. Pada metode Mamdani, baik variabel input maupun variabel output dibagi menjadi satu atau lebih himpunan fuzzy. b) Aplikasi fungsi implikasi (aturan). Fungsi implikasi yang digunakan
adalah min.
c) Komposisi aturan. Metode yang digunakan dalam melakukan inferensi sistem fuzzy pada Mamdani adalah max.
2.9.3. Defuzzifikasi
Ada beberapa metode defuzzifikasi pada komposisi aturan Mamdani (Kusumadewi, 2002), antara lain:
a) Metode Centroid (Composite Moment). Pada metode centroid solusi crisp diperoleh dengan cara mengambil titik pusat daerah fuzzy. Secara umum dapat dituliskan:
∫
∫ atau
b) Metode Bisektor. Pada metode bisektor solusi crisp diperoleh dengan cara mengambil nilai pada domain yang memiliki nilai keanggotaan separo dari jumlah total nilai keanggotaan pada daerah fuzzy. Dapat dituliskan :
zp sedemikian hingga ∫ ∫
c) Metode Mean of Maximum (MOM). Pada metode mean of maximum solusi crisp diperoleh dengan cara mengambil nilai rata-rata domain yang memiliki nilai keanggotaan maksimum.
d) Metode Largest of Maximum (LOM). Pada metode largest of maximumsolusi crisp diperoleh dengan cara mengambil nilai terbesar dari domain yang memiliki nilai keanggotaan maksimum.
e) Metode Smallest of Maximum (SOM). Pada metode smallest of maximumsolusi crisp diperoleh dengan cara mengambil nilai terkecil dari domain yang memiliki nilai keanggotaan maksimum.
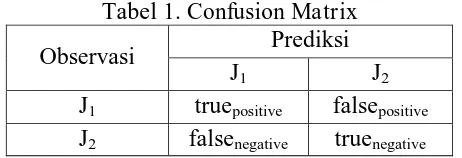
2.10. Akurasi Klasifikasi
positif yang diberi label dengan tidak tepat. Istilah-istilah ini berguna ketika menganalisis kemampuan classifier dan diringkas dalam tabel berikut.
Tabel 1. Confusion Matrix
Observasi Prediksi
J1 J2
J1 truepositive falsepositive
J2 falsenegative truenegative
Misalkan terdapat confusion matrix 2×2 seperti pada tabel di atas, maka rumus yang akan digunakan untuk menghitung akurasi adalah sebagai berikut :
� �
� �
Rumus di atas dapat juga didefenisikan seperti pada rumus berikut :