BAB 2
TINJAUAN PUSTAKA
Pada bab ini akan membahas landasan teori-teori yang bersifat ilmiah untuk mendukung penulisan skripsi ini. Teknik-teknik yang dibahas mengenai pengenalan pola, prapengolahan citra, jaringan saraf tiruan propagasi balik dan beberapa sub pokok pembahasan lainnya yang menjadi landasan teori dalam penulisan skripsi ini.
2.1. Pra-Pengolahan Citra
Citra disebut sebagai gambaran dari objek yang telah mengalami perubahan dalam pengolahan
2.1.1. Citra Digital
Citra digital didefenisikan sebagai representasi diskrit dari data spasial (tata letak) dan intensitas (warna) informasi (Solomon & Breckon, 2011). Citra digital dapat diproses secara langsung oleh komputer.
Ada banyak cara untuk menyimpan citra digital kedalam memori. Seperti:
1. Citra biner hanya memiliki 2 warna, yaitu warna hitam dan warna putih. Satu piksel membutuhkan satu bit memori untuk menyimpan kedua warna ini yaitu hitam dan putih. piksel-piksel objek bernilai 1 yaitu berwarna hitam dan piksel-piksel latar belakang bernilai 0 yaitu berwarna putih.
2. Citra keabuan adalah citra yang setiap pikselnya mengandung satu layer di mana nilai intensitasnya berada pada interval 0 (hitam) – 255 (putih). Untukmenghitung citra grayscale (keabuan) digunakan rumus:
( )
dengan I(x,y) adalah level keabuan pada suatu koordinat yang diperoleh dengan mengatur warna R (merah), G (hijau), B (biru) yang ditunjukkan oleh nilai parameter α, β dan γ. Secara umum nilai α, β dan γ adalah 0.33. Nilai yang lain juga dapat diberikan untuk ketiga parameter tersbut asalkan total keseluruhannya adalah 1 (Putra, 2009).
3. Citra warna adalah setiap piksel pada citra warna yang merupakan kombinasi dari tiga warna dasar RGB (Red Green Blue). Setiap warna dasar menggunakan penyimpanan 8 bit = 1 byte yang berarti setiap warna mempunyai tingkatan sebanyak 255 warna.
2.2. Pengolahan Citra
Tujuan dari pengolahan citra adalah untuk mendapatkan informasi dari citra dan menghasilkan citra yang diinginkan. Terlebih dahulu citra harus diolah sebelum masuk ke proses jaringan saraf tiruan
a. Pembentukan Matriks Biner (Binarization)
Proses ini akan menghasilkan citra hitam putih yang bersih dari tingkat keabun (grayscale), atau dengan kata lain metode ini mengonversi citra gray-level ke citra bilevel (binary image). Pada tahap ini setiap nilai pixel RGB akan diambil nilai rata-ratanya untuk kemudian dicek, jika nilai yang dihasilkan kurang dari nilai threshold yang dihasilkan maka nilai pixel tersebut diubah menjadi warna hitam, sebaliknya jika lebih besar dari nilai konstan maka akan diubah menjadi warna putih (Khairunnisa, 2012).
b. Normalisasi
Normalisasi adalah proses mengubah ukuran citra, baik menambah atau mengurangi, menjadi ukuran yang ditentukan tanpa menghilangkan informasi penting dari citra tersebut (Sharma, dkk, 2012). Dengan adanya proses normalisasi maka ukuran semua citra yang akan diproses menjadi seragam.
c. Thinning
Thinning adalah proses pengurangan data yang mengikis (erode) sebuah objek hingga menjadi ukuran 1 piksel dan menghasilkan kerangka (skeleton) dari objek tersebut. Objek seperti huruf atau silhouettes dapat lebih mudah dikenali dengan melihat kepada kerangkanya saja (Phillips, 2000). Pada penelitian ini digunakan algoritma thinning Zhang-Suen.
Algoritma ini untuk citra biner, dimana piksel background citra bernilai 0, dan piksel foreground (region) bernilai 1. Algoritma ini cocok untuk aplikasi OCR (Optical Character Recognition), yang digunakan untuk bentuk yang diperpanjang (elongated). Algoritma ini terdiri dari beberapa penelusuran, dimana setiap penelusurannya terdiri dari 2 langkah dasar yang diaplikasikan terhadap titik yang pikselnya bernilai 1, dan memiliki paling sedikit 1 piksel dari 8-tetangganya yang bernilai 0.
2.3. Ekstraksi Fitur (Feature Extraction)
Feature extraction adalah proses pengukuran terhadap data yang telah dinormalisasi untuk membentuk sebuah nilai fitur. Nilai fitur digunakan oleh pengklasifikasi untuk mengenali unit masukan dengan unit target keluaran dan memudahkan pengklasifikasian karena nilai ini mudah untuk dibedakan (Pradeep, dkk, 2011).
Secara luas, fitur adalah semua hasil pengukuran yang bisa diperoleh. Fitur juga bisa menggambarkan karakteristik objek yang dipantau (Putra, 2009). Contoh dari fitur level rendah adalah intensitas sinyal. Fitur bisa berupa simbol, numerik atau keduanya. Contoh dari fitur simbol adalah warna. Contoh dari fitur numerik adalah berat. Fitur bisa diperoleh dengan mengaplikasikan algoritma pencari fitur pada data masukan. Fitur dapat dinyatakan dengan variabel kontinu, diskret atau diskret-biner. Fitur biner dapat digunakan untuk menyatakan ada tidaknya suatu fitur tertentu (Putra, 2012).
Fitur yang baik memiliki syarat berikut, yaitu mudah dalam komputasi, memiliki tingkat keberhasilan yang tinggi dan besarnya data dapat diperkecil tanpa menghilangkan informasi penting (Putra, 2009).
2.3.1. Zoning
Zoning adalah salah satu ekstraksi fitur yang paling popular dan sederhana untuk diimplementasikan (Sharma, dkk, 2012). Sistem optical character recognition (OCR) komersil yang dikembangkan oleh CALERA menggunakan metode zoning pada citra biner (Bosker, 1992). Setiap citra dibagi menjadi NxM zona dan dari setiap zona tersebut dihitung nilai fitur sehingga didapatkan fitur dengan panjang NxM. Salah satu cara menghitung nilai fitur setiap zona adalah dengan menghitung jumlah piksel hitam setiap zona dan membaginya dengan jumlah piksel hitam terbanyak yang terdapat pada salah satu zona (Putra, 2012).
2.4. Jaringan Saraf Tiruan
Jaringan Saraf Tiruan adalah jaringan komputasional yang mensimulasikan jaringan sel saraf (neuron) dari pusat sistem saraf makhluk hidup (manusia atau hewan) (Graupe, 2007). Jaringan saraf tiruan pertama kali didesain oleh Warren Mc-Culloh dan Walter Pitts pada tahun 1943.Mc Cullah-Pitts menemukan bahwa dengan mengkombinasikan banyak neuron sederhana sehingga menjadi sebuah sistem saraf merupakan peningkatan tenaga komputasional.
Jaringan saraf tiruan disusun dengan asumsi yang sama seperti jaringan saraf biologi (Puspitaningrum, 2006):
1. Pengolahan informasi terjadi pada elemen-elemen pemrosesan (neuron). 2. Sinyal antara dua buah neuron diteruskan melalui link-link koneksi. 3. Setiap link koneksi memiliki bobot terasosiasi.
4. Setiap neuron menerapkan sebuah fungsi aktivasi terhadap input jaringan (jumlah sinyal input berbobot). Tujuannya adalah untuk menentukan sinyal output.
2.5. Algoritma Propagasi Balik
Algoritma propagasi balik (Back Propagation) pertama dikembangkan pada tahun 1986 oleh Rumelhart, Hinton dan Williams untuk menentukan bobot dan digunakan untuk pelatihan perceptron multi lapis (Graupe, 2007). Metode propagasi balik
merupakan metode yang sangat baik dalam menangani masalah pengelanan pola-pola kompleks. Metode ini merupakan metode jaringan saraf tiruan yang populer. Beberapa contoh aplikasi yang melibatkan metode ini adalah pengompresian data, pendeteksian virus komputer, pengidentifikasian objek, sintesis suara dari teks, dan lain lain (Puspitaningrum, 2006).
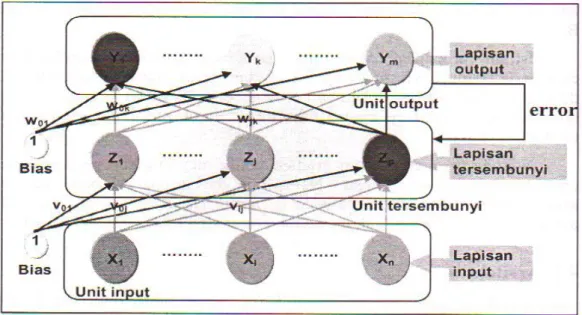
Istilah ―propagasi balik‖ diambil dari cara kerja jaringan ini, yaitu bahwa gradient error unit-unit tersembunyi diturunkan dari penyiaran kembali error-error yang diasosiasikan dengan unit-unit output. Hal ini karena nilai target untuk unit-unti tersembunyi tidak diberikan (Puspitaningrum, 2006). Propagasi balik adalah metode pembelajaran terawasi (supervised learning). Metode ini membutuhkan nilai yang sudah ditentukan sebelumnya untuk mendapatkan output yang diinginkan pada proses pembelajaran. Contoh jaringan propagasi balik dengan satu buah lapisan tersembunyi dapat dilihat pada Gambar 2.1
Gambar 2.1 Jaringan propagasi balik dengan satu buah lapisan tersembunyi (Puspitaningrum, 2006)
Algoritma propagasi balik dapat dibagi ke dalam 2 bagian (Puspitaningrum, 2006):
1. Algoritma pelatihan
Terdiri dari 3 tahap: tahap umpan maju pola pelatihan input, tahap pemropagasian
2. Algoritma aplikasi
Yang digunakan hanyalah tahap umpan maju saja. 1. Algoritma Pelatihan
Inisialisasi bobot-bobot.
Tentukan pula nilai toleransi error atau nilai ambang (bila menggunakan nilai ambang sebagai kondisi berhenti); atau set maksimal epoch (bila menggunakan banyaknya epoch sebagai kondisi berhenti).
1. While kondisi berhenti tidak terpenuhi do langkah ke-2 sampai langkah ke-9. 2. Untuk setiap pasangan pola pelatihan, lakukan langkah ke-3 sampai langkah
ke-8.
A. Tahap Umpan Maju
3. Setiap unit input xi (dari unit ke-1 sampai unit ke-n pada lapisan input) mengirimkan sinyal input ke semua unit yang ada di lapisan atasnya (ke lapisan tersembunyi)
4. Pada setiap unit di lapisan tersembunyi zj (dari unit ke-1 sampai unit ke-p; i=i,…,n; j=,...,p) sinyal output lapisan tersembunyinya dihitung dengan menerapkan fungsi ativasi terhadap penjumlahan sinyal-sinyal input berbobot xi:
( ∑
) ( )
kemudian dikirim ke semua unit di lapisan atasnya.
5. Setiap unit di lapisan output yk (dari unit ke-1 sampai unit ke-m; i=1,...,n; k=1,…,m) dihitung sinyal outputnya dengan menerapkan fungsi aktivasi terhadap penjumlahan sinyal-sinyal input berbobot zj bagi lapisan ini:
( ∑
) ( )
B. Tahap Pemropagasibalikan Error
6. Setiap unit output yk (dari unit ke-1 sampai unit ke-m; i=1,…,p; k=1,….,m) menerima pol target tk lalu informasi kesalahan lapisan output (δk) dihitung. δk dikirim ke lapisan di bawahnya dan digunakan untuk mengitung besar koreksi
bobot dan bias (Δwjk dan Δw0k) antara lapisan tersembunyi dengan lapisan output: ( ) ( ∑ ) ( ) Δwjk = α δk zj Δw0k = α δk
7. Pada setiap unit di lapisan tersembunyi (dari unit ke-1 sampai unit ke-p; i=1,…,n; j=1,…,p; k=1,…,m) dilakukan perhitungan informasi kesalahan lapisan tersembunyi (δj). δj kemudian digunakan untuk menghitung besar koreksi bobot dan bias (Δwjk dan Δw0k) antara lapisan input dan lapisan tersembunyi. (∑ ) ) ( ∑ ) ( ) Δvij = α δj xi Δv0j = α δj
C. Tahap Peng-update-an Bobot dan Bias
8. Pada setiap unit output yk (dari unit ke-1 sampai unit ke-m) dilakukan
peng-update-an bias dan bobot (j=0,…,p; k=1,…,m) sehingga bias dan bobot baru menjadi: wjk (baru) = wjk (lama) + Δ wjk
Dari unit ke-1 sampai unit ke-p di lapisan tersembunyi juga dilakukan peng-update-an pada bias dan bobotnya (i=0,…,n; j=1,…,p):
vij (baru) = vij (lama) + Δ vij 9. Tes kondisi berhenti.
2. Algoritma Aplikasi
Inisialisasi bobot.Bobot ini diambil dari bobot-bobot terakhir yang diperoleh dari algoritma pelatihan.
1. Untuk seitap vektor input, lakukanlah langkah ke-2 sampai ke-4.
2. Setiap unit input xi (dari unit ke-1 sampai unit ke-n pada lapisan input; i=1,…,n) menerima sinyal input pengujian xi dan menyiarkan sinyal xi ke semua unikt pada lapisan di atasnya (unit-unit tersembunyi).
3. Setiap unit di lapisaan tersembunyi zj (dari unit ke-1 sampai unit ke-p; i=1,…,n; j=1,….,p) menghitung sinyal outputnya dengan menerapkan fungsi aktivasi terhadap penjumlahan sinyal-sinyal input xi. Sinyal output dari lapisan tersembunyi kemudian dikirim ke semua unit pada lapisan di atasnya:
( ∑
) ( )
4. Setiap unit output yk (dari unit ke-1 sampai unit ke-m; j=1,…,p; k=1,…,m) menghitung sinyal outputnya dengan menerapkan fungsi aktivasi terhadap penjumlahan sinyal-sinyal input bagi lapisan ini, yaitu sinyal-sinyal input zj dari lapisan tersembunyi:
( ∑
) ( )
2.5.1 Fungsi Aktifasi
Pilihan fungsi aktivasi yang dapat digunakan pada metode propagasi balik yaitu fungsi sigmoid biner, sigmoid bipolar dan tangent hiperbolik.Karakteristiki yang harus miliki fungsi aktivasi tersebut adalah kontinu, diferensiabel dan tidak menurun secara monoton.Fungsi aktivasi diharapkan jenuh (mendekati nilai-nilai maksimum dan minimum secara asimtot) (Puspitaningrum, 2006).
1. Fungsi Sigmoid Biner
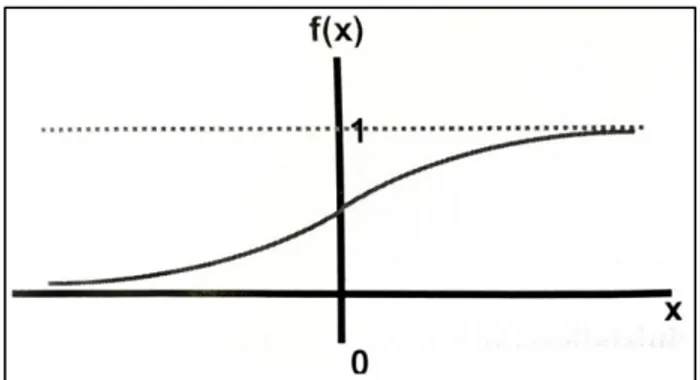
Fungsi ini merupakan fungsi yang umum digunakan. Rentang-nya adalah (0,1) dan didefenisikan sebagai :
( )
( )
dengan turunan :
( ) ( )( ( )) ( )
Fungsi sigmoid biner diilustrasikan pada gambar 2.2.
Gambar 2.2 Fungsi sigmoid biner dengan rentang (0,1) (Puspitaningrum, 2006)
2.5.2 Inisialisasi Bobot dan Bias
Cepat atau tidaknya pembelajaran pada pelatihan jaringan propagasi balik salah satunya dipengaruhi oleh nilai bobot antar neuron dan nilai bias. Semakin baik inisialisasi bobot dan bias semakin cepat pula pembelajaran jaringan propagasi balik. Bobot dan bias pada jaringan propagasi balik dapat dinisialisasi dengan berbagai cara seperti inisialisasi acak, nguyen-widrow dan lain-lain (Putra, 2012).
1. Inisialisasi Acak
Prosedur yang umum dilakukan adalah menginisialisasi bias dan bobot, baik dari unit input ke unit tersembunyi maupun dari unit tersembunyi ke unit output secara acak dalam sebuah interval tertentu (γ dan γ), misalnya antara -0.4 sampai -0.4, -0.5 sampai 0.5, dan -1 sampai 1 (Puspitaningrum, 2006).
2. Inisialisasi Nguyen Windrow
Waktu pembelajaran jaringan propagasi balik yang bobot dan biasnya diinisalisasi dengan inisialisasi Nguyen-Widrow lebih cepat dibandingkan bila diinisialisasi dengan inisialisasi acak. Pada inisialisasi Nguyen-Widrow, inisialisasi acak tetap terpakai tetapi digunakan untuk menginisialisasi bias dan bobot dari unit tersembunyi ke unit output saja. Untuk bias dan bobot dari unit-unit input ke unit-unit-unit-unit tersembuyi digunakan bias dan bobot yang khusus diskala agar jatuh pada range tertentu. Dengan penskalaan maka diharapkan kemampuan belajar dari unit-unit tersembunyi dapat meningkat.
Faktor skala Nguyen-Widrow (β) didefenisikan sebagai : ( ) ⁄
di mana :
n = banyak unit input
p = banyak unit tersembunyi β = faktor skala
Prosedur inisialisasi Nguyen-Widrow
Untuk setiap unit tersembunyi dari unit ke-1 sampai unit ke-p :
1. Inisialisasi vektor bobot dari unit-unit input ke unit-unit tersembunyi (j = 1, …, p) dengan cara :
a. Menentukan bobot-bobot antara unit input ke unit tersembunyi (vij) : vij(lama) = bilangan acak antara -β dan β
di mana i = 1, …, n. b. Menghitung ||vij ||.
c. Menginisialisasi kembali vij :
( ) ‖ ‖
2. Menentukan bias antara unit input ke unit tersembuni (j = 1, …, p). voj diset dengan bilangan acak yang terletak pada skala antara -β dan β.
Penambahan parameter momentum dalam mengupdate bobot seringkali bisa mempercepat proses pelatihan. Ini disebabkan karena momentum memaksa proses perubahan bobot terus bergerak sehingga tidak terperangkap dalam minimum-minimum lokal. Pengupdatean bobot pada proses pelatihan jaringan yang biasa adalah sebagai berikut :
Δwjk = α δk zj Δvij = α δjxi
Jika error tidak terjadi (output actual telah sama dengan output target) maka δk menjadi nol dan hal ini akan menyebabkan koreksi bobot Δwjk = 0, atau dengan kata lain pengupdatean bobot berlanjut dalam arah yang sama seperti sebelumnya.
Jika parameter momentum digunakan maka persamaan-persamaan pengupdatean bobot dengan langkah pelatihan t, dan t+1 untuk langkah pelatihan selajutnya, mengalami modifikasi sebagai berikut :
Δwjk(t + 1) = α δk zj + µ Δwjk(t) Δvij(t + 1) = α δj xi + µ Δvij(t)