1
Department of Electronic Engineering 2
Department of Electrical Engineering Chung Yuan Christian University
200 Chung Pei Rd., Chung Li, Taiwan, 32023, R.O.C
Email : [email protected], [email protected],[email protected], [email protected]
ABSTRACT
In this paper, we explore various cache memory configurations for a sketch-based application on SimpleScalar simulator. Our goal is to observe the effectiveness of cache memory on network processor for flow-based packet processing. The experiment results demonstrate sufficient amount of temporal locality in the network traffic traces. Due to the randomized property for sketch data structure, it favors the architecture of higher degree of associativity, small line size and least-recently-used replacement policy.
Keywords: Cache memory, Sketch.
1
INTRODUCTION
Recently, sketch data structures gain much attention from researchers in networking community. Sketch is a synopsis data structure and essentially an extension of the random projection technique [1]. It can be used to build compact summaries on the streaming data of network traffic.
There are many advantages to use sketch in the network system design. For example, the data structure is linear and space-efficient. Only a small amount of memory space is needed to achieve certain level of measurement accuracy. Moreover, the data structure can be implemented in distributed fashion and combined using arithmetic operations. As such, it has been proposed and used in many data stream applications such as finding heavy hitter and anomaly detection on network traffic [2, 3].
Sketch can be implemented in hardware [3, 4] matching wire-speed performance or in programmable solution [5-10] on general purpose microprocessor. Augmented with specially design memory hierarchy and parallel processing architecture, network processor is another solution commonly adopted in router line card design for both flexibility and performance requirement.
Recent studies [11, 12] reveal the abundant of temporal locality in network flows where data cache
can be effective for speeding up packet processing time. Data cache implementation is commonly found in network processor architecture used in residential gateway and SOHO routers. Due to ever increasing bandwidth demands, we are motivated to explore the cache memory hierarchy on these types of network processor for sketch application.
The paper is organized as follows: We present a brief survey on different sketch architectures in the related work section. Along with the introduction of network processor, the operation of CM sketch [8] is also provided in the background section. The sketch application is constructed based on the MassDal code bank [13] where CM sketch update and point query procedures are performed. The trace-driven simulation is conducted based on the network traffic trace collections from NLANR [14] by using the SimpleScalar v3.0d simulator [15]. The discussion and simulation results on various cache hierarchies are shown in the final section.
2
BACKGROUND
2.1
Related Work
There are many variants in sketch data structure, for example, FM sketch [5], AMS sketch [6], Count Sketch [7], CM sketch, k-ary sketch [9], and reversible k-ary sketch [4]. FM sketch is used to count distinct number of values in a stream in one pass with minimum memory using randomized algorithm. In network application, FM sketch is used to estimate the number of distinct flows. The AMS sketch is used to approximate frequency moments Fk using randomized algorithm. In
particular, F0 represents the number of distinct
answered very quickly. It can be applied to solve several important problems in data streams such as finding quantiles and frequent items. In network applications, Count-Min sketch can be used to estimate flow size and change in flow size. This sketch is known with its high accuracy in estimating a value.
The k-ary sketch is similar to the Count sketch data structure. However, the most common operations on k-ary sketch use simpler operations and are more efficient than the corresponding operations defined on Count sketch. The k-ary sketch, which is used together with a forecast module and a change detection module, serves as a key component summarizing the streaming network data in sketch-based change detection system. This system is implemented based on two general purpose 400 MHz SGI R12k processor and 900 MHz UltraSPARC III processor, respectively. The system is evaluated in offline with satisfactory performance.
2.2
CM Sketch
Network traffic can be classified into flows based on the attribute specified in the packet header [16]. The operation of several network applications such as usage-based accounting, traffic profiling, traffic engineering, and attack or intrusion detection all depends on this flow information. For example, a network flow can be identified by the following 5-tuple field in the packet header: source address, destination address, source port, destination port, and protocol. All packets belonging to a particular flow have a set of common properties.
These sketches then can be queried to estimate the flow size and changes in flow sizes. We can also doing computation on sketches, such as, compute the moving average of the sketches and subtract two sketches to find their difference, which is useful for sketch-based change detection application. The operations on sketch may vary between different variant of sketches, but in common there are 2 main operations, UPDATE and ESTIMATE. UPDATE operation is used to update the sketch and ESTIMATE operation is used to query the sketch. The result of the query depends on the algorithm implemented for the ESTIMATE operation.
For example, Count-Min sketch is represented by two-dimensional array counters count with width w and depth d. Each entry of the array is initially zero. Count-Min sketch uses d pairwise independent hash functions, h1…hdto map keys to [w]. Let j =
1…d denotes the hash functions use. When an update <key, value> arrives, then value is added to
one count in each row. The UPDATE operation is defined by
count[j, hj(key)] = count[j, hj(key)] + value
The key is hashed using hash function result in 1…w, and entry in count [1, h1[key]]…count[ d,
hd[key]] is updated. Count-Min sketch allows
fundamental queries in data stream summarization such as point query, which return an estimate of the count of an item by taking the minimum, point query median, which return an estimate of the count by taking the median estimate, inner product query, and range query. These queries are approximately answered very quickly. Count-Min sketch has two parameters İ and į, and the accuracy of value estimated by the sketch depends on these two user specified parameters, meaning that the error in answering a query is within a factor of İ with probability į. For point query, the ESTIMATE operation is given by
ai ’
= minj count [j, hj(key)]
The query result, in other words, the estimate value ai’ is guaranteed to be greater or equal than the
exact value ai with probability at least 1-į.
2.3
Network Processor
Network processor is a programmable device optimized for packet processing. Network processors combine the flexibility of general-purpose programmable processors and performance of ASIC chips. The design of network processors span from single-core superscalar processors to system-on-chip designs containing more than 40 execution cores. Their major design methodologies can be grouped in three categories: VLIW-based processors, SMT-based processors, and chip multiprocessors [17]. There are many different internal architecture in network processors, all of them contain many processing units in order to capture the inherent parallelism in network processing tasks. Network processors are capable of processing different tasks efficiently for both header-processing and more complicated payload-processing application.
packet processing applications can be provisioned for worst case and hence data cache that improve only the average case is not required, and also packet processing does not exhibit data locality, hence caching is not effective [18, 19]. These beliefs were refuted in [12]. The result found that a small data cache of 8 KB can reduce packet processing time significantly (50%-90%). Cache can be a solution for many network applications which need various processing requirements because of its fast access time. Cache works based on the principle of locality of reference [20], so caching works well if the data exhibit temporal locality. Previous works on cache memory architectures and algorithms for network processors focusing on how to cache the result of route lookup process [21]. Network traffic has temporal locality, packets that have same destination address appear repeatedly. The idea of caching in network packet processing for routing is to avoid repeated computation of route lookup. The incorporation of cache memory into network processors can significantly improve the overall packet forwarding performance due to a sufficiently high degree of temporal locality in the network traffic [22].
Table 1 lists the cache configuration of some network processors.
Table 1. Cache memory configurations for some off-the-self network processors
No Processor Instruction
Cache Data Cache bytes line size, 2-way set bytes line size, 2-way set bytes line size, 32-way set
3
EXPERIMENTAL SETUP
3.1
Trace Files
Trace files used for the sketch application are collected from the NLANR, and are available in public domain. The traces from NLANR are collected from several sources. For our simulation, the sources are AMP (Americas PATH), MEM (University of Memphis), ODU (Old Dominion University), and PSC (Pittsburgh Supercomputing Center). We use six trace files from every source and all these traces are 90 seconds length. The rate of MEM and ODU is OC-3c, AMP is OC-12c, and PSC is OC-48c. The characteristics of these traces are shown in Figure 1(a), (b), and (c).
(a). Flow throughput of trace files
(c). Total number of packets in trace files
Fig. 1. Characteristics of the traces used in simulation.
Trace files from MEM has the lowest distinct source IP address range from 1,456 to 1,756 IP addresses and trace files from ODU has the highest distinct source IP address range from 19,965 to 28,654 IP addresses. Total packets in trace files used in simulation have range from 69,144 packets to 3,302,360 packets.
Sketch application used in our simulations is written in C. The application implements the Count-Min sketch based on code from MassDal implementation [22] with some modifications. It first read a trace file as the input stream, hashes the key, updates the sketch, and then estimate flow of a particular key at the end of 90 seconds interval. We define the flow using source IP address, and use the <source IP address, total length> pair as the <key, value> update for the sketch. The parameters of Count-Min sketch are d = 3 and w =2048 (İ = 0.0013 and į = 0.049), so the probability that the error is within a factor of 0.0013 is 1-į = 0.951.
3.2
Accuracy
To measure the accuracy of estimation using CM sketch, we take the exact value of packet length of top-10 flow, based on source IP address from each trace file, then compare it with the result of the estimation using CM sketch. Table 2 shows the result for AMP trace. The average error of top-10 flow for AMP, PSC, and ODU is 0.04985, 0.12772, and 0.80642 respectively.
Table 2. Result of Count-Min sketch point query estimation for AMP trace 10.0.0.1 5693869 5686792 0.12445 10.0.0.11 8048874 8048586 0.00358 10.0.0.13 1216437 1216309 0.01052 10.0.0.197 1735321 1734664 0.03787 10.0.0.3 20436451 20389249 0.23150
10.0.0.41 4222324 4219985 0.05543 10.0.0.5 1478880 1478752 0.00866 10.0.0.70 1126482 1126198 0.02522 10.0.0.86 2463029 2463029 0 10.0.0.9 7319729 7319633 0.00131
3.3
Simulation Environment
In order to compare the cache miss behavior of the sketch application on network processors, we run the simulation using SimpleScalar simulator v3.0d on a Linux-based PC using dual processor Intel Pentium D CPU 2.80 GHz. We simulate several cache memory configurations based on Table 1, varying the set associative, number of set, and cache line size.
4
RESULT AND DISCUSSION
In this section, we present cache miss behavior of the sketch application. The performance of cache memory is dominated by two factors, miss rate and miss penalty. The miss rate depends on cache line size, number of cache lines (cache size), set associativity, and replacement policy. We discuss the effect of these parameters on cache memory performance for the sketch application.
4.1
Execution Time
To see the effect of increasing cache size to execution time, Figure 2 shows the execution time for varying cache size, with 16 bytes cache line size and 2-way set associative. We can see that if the cache size is changed from 1 KB to 2 KB, the difference on execution time is small, within a range of 6%.
Execution Time VS Cache Size (ODU Trace) 16 bytes line size, 2-way set associative
1
Fig. 2. Execution time vs. cache size for ODU trace.
4.2
Cache Line Size
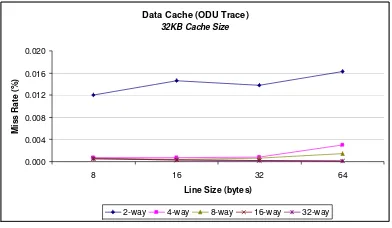
cache entry is usually holds a certain number of words, known as a cache line or cache block. Typically a whole line is read and cached at once. The effectiveness of the line size depends on the application. We simulate the sketch application with different cache line size while keeping the cache size fixed. Figure 3 and 4 presents the result of the simulations.
Data Cache (ODU Trace) 32KB Cache Size
2-way 4-way 8-way 16-way 32-way
Fig. 3. Data cache miss rate with various cache line size.
The miss rate is reduced as the line size increased while keeping the cache size fixed. This is because of spatial locality. However, if the line size is increased to a particular value, the miss rate will increase. This is because larger cache line size causes higher miss penalty. Memory access time also increases because of the additional time required to transfer large lines of data from the main memory to the cache.
Data Cache (ODU Trace) 32-way set associative
1KB 2KB 4KB 8KB 16KB 32KB
Fig. 4. Data cache miss rate with various cache line size.
4.3
Set Associativity
Set-associative scheme is a compromise between a fully associative cache and direct mapped cache. Figure 5 shows the comparison of cache miss rate for different set associativity, with 16 bytes cache line size. Table 3 lists the result of the simulations.
Data Cache (ODU Trace) 16bytes line size
1KB 2KB 4KB 8KB 16KB 32KB
Fig. 5. Data cache miss rate with various set associative.
With cache size of 1 KB and 2-way set associative the miss rate is 6.01%, while with the same cache size and using 64-way set associative, the miss rate is decrease to 1.4%. It means that with fixed cache line size and total cache size, higher associativity results in lower miss rate. From the figure we can also conclude that with fixed cache line size, the miss rate decreases with the increasing of cache size. With 2-way set associative, each location in main memory can be cached by one of 2 cache locations, while in 64-way set associative, it can be cached by one of 64 cache locations. This is the reason why 64-way set associative gives lower miss rate than 2-way set associative with the same cache size.
Table 3. Data cache miss rate (%) with various set associative
Set
associative Cache Size (KB)
1 2 4 8 16 32
2-way 6.01057 2.47777 1.64468 1.28921 0.08600 0.01616
4-way 4.30620 1.65910 0.63327 0.25714 0.05805 0.00080
8-way 3.74993 1.00153 0.61444 0.24603 0.04461 0.00049
16-way 1.71278 0.96281 0.59984 0.24888 0.04347 0.00040
32-way 1.70489 0.89698 0.59798 0.24752 0.04344 0.00041
64-way 1.72232 0.89774 0.59046 0.24765 0.04282 0.00041
4.4
Replacement Policy
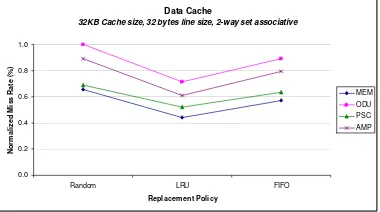
In addition to set associativity and cache line size, the replacement policy is also one of the factors that affect cache performance. Replacement policy is the technique used to replace data in cache line with a new data from main memory when a cache miss occur. There are three replacement policies commonly used, LRU (Least Recently Used), FIFO (First In First Out), random. Using LRU, the cache line containing data with the oldest hit will be chosen for replacement. By using FIFO policy, the cache line chosen for replacement is the cache line with the oldest data. For random replacement, the cache line will be selected randomly.
Cache size
Figure 7 show LRU has the lowest miss rate compared to other replacement policies.
Data Cache
32KB Cache size, 32 bytes line size, 2-way set associative
0.0
(a). Data cache miss rate vs. replacement policy on 32 KB cache size, 32 bytes line size, 2-way set associative
Data Cache
32KB Cache size, 32 bytes line size, 32-way set associative
0.0
(b). Data cache miss rate vs. replacement policy on 32 KB cache size, 32 bytes line size, 32-way set associative
Fig. 7. Data cache miss rate vs. replacement policy for all traces.
Data Cache (MEM trace) Cache line size = 32 bytes
9.
Direct 2-way 4-way 8-way 16-way 32-way
(a). Data cache miss rate for MEM trace
Data Cache (ODU trace) Cache line size = 32 bytes
9.
Direct 2-way 4-way 8-way 16-way 32-way
(b). Data cache miss rate for ODU trace
Fig. 8. Data cache miss rate for all traces.
Figure 8 (a) and (b) shows the data cache miss rate for MEM and ODU traces with 32 bytes cache line size, the set associative and cache size are varying. The experiment results show that increasing the set associative and cache size, while keeping the cache line size fixed results in lower miss rate. As described in Figure 8, with cache size of 16 KB, the miss rate of all set associative is almost as low as cache size of 32 KB. If we see from the set associative, with cache size of 1 KB to 16 KB, using 2-way to 16-way set associative the miss rate decreases about 50% on higher cache size. When the cache size is 16 KB, increase the set associative beyond 2-way have much less effect on miss rate. Thus, using cache size 16 KB with 32 bytes cache line size and 2-way set associative is enough for the sketch application used in our simulation.
5
SUMMARY
We present the evaluation of cache memory performance for the Count-Min sketch application on different cache configurations. As the result shows, there are abundant of temporal localities exist in the Internet traffic traces. Therefore, for a compact sketch data structure, a simple cache memory hierarchy is effective for reducing the total execution cycle. The operation of sketch update and query is based on the randomized property of hashing. Thus, for a same amount of cache size, a lower miss rate can be achieved with higher degree of set associativity and smaller size of line size. The replacement policy also plays an important role in cache with lower degree of set associativity. The LRU policy achieves the lowest miss rate compare to those of FIFO and Random. Our simulation results of evaluating the cache memory performance for sketch applications are preliminary. In the future, we plan to benchmark and explore various sketch-based applications on network processor.
REFERENCES
[1] Aggarwal C. C (2007) Data Stream Models and Algorithms, New York: Springer Science. [2] Gilbert A.C, Kotidis Y, Muthukrishnan S,
[3] Schweller R, Gupta A, Parsons E, Chen Y (2004). Reverse Hashing for Sketch-based Change Detection on High-speed Networks. Proceedings of ACM/USENIX Internet Measurement Conference ’04. Taormina, Sicily, Italy, 25-27 October, 2004.
[4] Gao Y, Li Z, Schweller R, Chen Y (2005) Towards a High-speed Router-based Anomaly/Intrusion Detection System (HRAID). ACM SIGCOMM Conference 2005, Philadelphia, USA, 22-26 August 2005. [5] Flajolet P, Martin G.N (1985). Probabilistic
counting algorithms for database applications. Journal of Computer and System Sciences 31(2): 182-209.
[6] Alon N, Matias Y, Szegedy M (1996) The space complexity of approximating the frequency moments. ACM Symposium on Theory of Computing, pp 20-29.
[7] Charikar M, Chen K, Farach-Colton M (2002) Finding frequent items in data streams”, Proceedings of the International Colloqium on Automata, Languages, and Programming (ICALP). Malaga, Spain, 8-13 July 2002. [8] Cormode G, Muthukrishnan S (2005) An
improved data stream summary: The count-min sketch and its application. Journal of Algorithms, 55(1): 58-75.
[9] Krishnamurty B, Sen S, Zhang Y, Chen Y (2003) Sketch-based Change Detection: Methods, Evaluation, and Applications. Proceedings of ACM Internet Measurement Conference ’03. Miami, Florida, USA, 27-29 October 2003.
[10]Barman D, Satapathy P, Ciardo G (2007) Detecting Attacks in Routers using Sketches. Workshop on High Performance Switching and Routing 2007. HPSR '07. New York, 30 May – 1 June 2007.
[11]Liu Z, Zheng K, Liu B (2007) Hybrid Cache Architecture for High Speed Packet Processing [12]Mudigonda J, Vin H.M, Yavatkar R (2005)
Managing Memory Access Latency in Packet
Processing. ACM SIGMETRICS’05. Banff, Alberta, Canada, 6-10 June 2005.
[13]Cormode G. Massive Data Analysis Lab. MassDAL Public Code Bank [Online].
Available at
http://www.cs.rutgers.edu/~muthu/massdal-code-index.html [Accessed: 5 March 2009]. [14]CAIDA. National Laboratory for Applied
Network Research (NLANR) Project traces
[Online]. Available at ftp://pma.nlanr.net/traces/daily/20060430
[Accessed: 19 February 2009].
[15]SimpleScalar LLC. (2003). SimpleScalar v3.0d
[Online]. Available at
http://www.simplescalar.com/ [Accessed: 28
February 2009].
[16]Quittek J, Zseby T, Claise B, Zander S (2004) RFC 3917 Requirements for IP Flow Information Export (IPFIX). The Internet Society.
[17]Memik G, Mangione-Smith W (2006) Evaluating Network Processors using NetBench. ACM Transactions on Embedded Computing Systems (TECS), Vol. 5, Issue 2, 2006: 453-471.
[18]Comer D (2003) Network Systems Design using Network Processors, New Jersey: Prentice Hall.
[19]Lekkas P.C (2003) Network Processors: Architectures, Protocols and Platforms, USA: McGraw-Hill.
[20]Jacob B, Ng S, Wang D (2008) Memory Systems, Cache, DRAM, Disk, Burlington: Morgan Kaufmann.
[21]Chiueh T, Pradan P (1999) High-Performance IP Routing Table Lookup using CPU Caching. Proceedings of IEEE INFOCOM ’99. New York, 21-25 March 1999.