BAB 2
LANDASAN TEORI
Bab ini membahas teori penunjang dan penelitian sebelumnya yang berhubungan dengan penerapan algoritma Shannon-Fano untuk kompresi file audio.
2.1 Kompresi
Data tidak hanya disajikan dalam bentuk teks ataupun citra, tetapi juga dapat berupa audio (bunyi, suara, musik) dan video. Keempat macam data tersebut sering disebut dengan multimedia. Pada umumnya representasi data digital membutuhkan memori yang besar, di sisi lain kebanyakan data mengandung duplikasi atau redundansi.
Duplikasi (redundansi) ini dapat berarti suatu data mengandung bagian yang sama sehingga setiap bagian yang sama ini tidak perlu dikodekan berulang kali. Kompresi dapat dikatakan sebagai proses untuk menghilangkan berbagai redundansi, karena itu langkah pertama yang dilakukan adalah menemukan sumber redundansi pada setiap data (Salomon, 2008). Penghilangan redundansi pada data menggunakan algoritma.
Algoritma
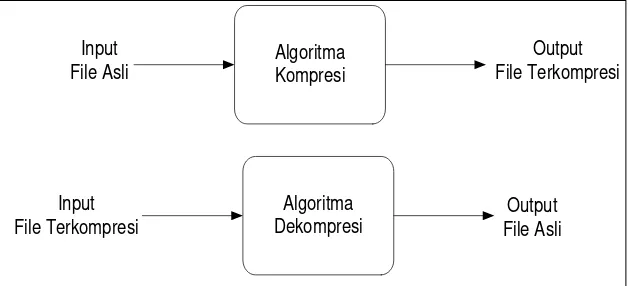
Gambar 2.1 Proses Kompresi dan Dekompresi (Pu, 2006)
2.1.1 Metode kompresi
Metode kompresi data dapat dikelompokkan dalam dua kelompok besar yaitu metode lossless dan lossy (Sayood, 2005) seperti berikut ini:
1. Metode lossless
Metode lossless merupakan metode kompresi dimana data hasil kompresi dapat dikembalikan ke data semula tanpa menghilangkan informasi pada data. Algoritma metode lossless yaitu Run-Length-Encoding, Shannon-Fano, Huffman Encoding, Arithmatic Coding dan Lempel Ziv Welch.
2. Metode lossy
2.1.2 Compression Ratio
Compression Ratio atau rasio kompresi adalah rasio atau perbandingan antara ukuran data yang dikompresi dengan ukuran data asli. Misalkan rasio kompresi suatu data adalah 30%, maka 30% data semula telah berhasil dikompres. Secara matematis rasio kompresi dapat ditulis sebagai berikut (Salomon, 2008) :
Rasio Kompresi = 100% − (Hasil KompresiAudio Asli x 100%) (2.1)
Sedangkan untuk menghitung laju dari data yang dikompresi (rate of compression) dapat dihitung :
Laju Kompresi = Rasio Kompresi (2.2)1
2.1.3 Redundansi
Redundansi atau duplikasi merupakan suatu keadaan dimana representasi suatu elemen data tidak bernilai signifikan dalam merepresentasikan keseluruhan data. Keadaan ini menyebabkan data keseluruhan dapat direpresentasikan secara lebih kompak dengan cara menghilangkan representasi dari sebuah elemen data yang redundan.
2.2 Pengertian Audio
Benda
Gambar 2.2 Alur Gelombang Suara (Mukhlis, 2012)
2.2.1 Representasi Audio Digital
Setiap citra dilakukan proses digitasi dan diubah ke bentuk piksel-piksel, dimana tiap-tiap piksel merupakan gabungan dari angka. Sama seperti citra, audio juga dilakukan proses digitasi dan diubah ke dalam bentuk angka atau dikatakan dengan tahap kuantisasi (Salomon, et al, 2010).
Gelombang suara analog tidak dapat lansung direpresentasikan pada komputer. Komputer hanya mampu mengenal sinyal dalam bentuk digital. Bentuk digital yang dimaksud adalah tegangan yang diterjemahkan dalam angka 0 dan 1, yang disebut dengan istilah bit. Dengan kecepatan perhitungan yang dimiliki komputer, komputer mampu melihat angka 0 dan 1 ini menjadi kumpulan bit dan menerjemahkan bit-bit tersebut menjadi sebuah informasi yang bernilai.
Untuk memasukkan suara analog sehingga dapat dimanipulasi oleh peralatan elektronik yang ada menggunakan alat. Alat yang diperlukan untuk melakukan ini adalah transducer yaitu sebuah peralatan yang dapat mengubah tekanan udara (yang kita dengar sebagai suara) ke dalam tegangan elektrik yang dapat dimengerti oleh perangkat elektronik, serta sebaliknya. Contoh dari transducer adalah mikrofon dan speaker. Mikrofon dapat mengubah tekanan udara menjadi tegangan elektrik, sementara speaker mengubah tegangan elektrik menjadi tekanan udara.
Tegangan elektrik ini akan diproses menjadi sinyal digital oleh sound card. Ketika suara direkam ke dalam komputer, sound card akan mengubah gelombang suara (bisa dari mikrofon atau stereo set) menjadi data digital, dan ketika suara itu dimainkan kembali, sound card akan mengubah data digital menjadi suara yang kita dengar melalui speaker, atau disebut juga dengan gelombang analog.
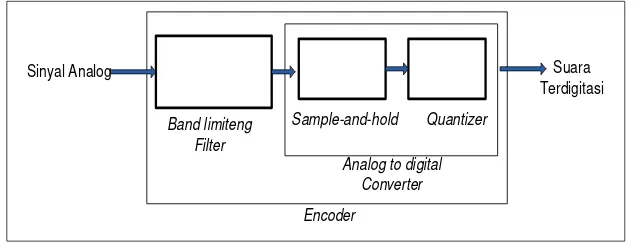
Proses pengubahan gelombang suara menjadi data digital ini dinamakan Analog-to-Digital Conversion (ADC), dan kebalikannya, pengubahan data digital menjadi gelombang suara dinamakan Digital-to-Analog Conversion (DAC).
1. Membuang frekuensi tinggi dari sumber sinyal (Filtering). 2. Mengambil sampel pada interval waktu tertentu (Sampling).
3. Menyimpan amplitudo sampel dan mengubahnya ke dalam bentuk diskrit (kuantisasi).
4. Merubah bentuk menjadi data digital dengan nilai biner.
Band limiteng Filter
Sample-and-hold Quantizer
Sinyal Analog Suara
Terdigitasi
Analog to digital Converter Encoder
Gambar 2.3 Proses Digitasi (Mukhlis, 2012)
Proses pengubahan sinyal analog menjadi digital harus memenuhi sebuah kriteria, yaitu kriteria Nyquist (Salomon, et al, 2010). Kriteria ini mengatakan bahwa untuk memperoleh representasi akurat dari suatu sinyal analog secara lossless, amplitudonya harus diambil sampel setidaknya pada kecepatan (rate) sama atau lebih besar dari 2 kali komponen frekuensi maksimum yang akan didengar. Misalkan, jika frekuensi audio di atas 2000 Hz, maka sampel yang diambil harus lebih dari 4000 Hz.
2.2.2 Kelebihan Audio Digital
Kelebihan audio digital adalah kualitas reproduksi yang sempurna. Kualitas reproduksi yang sempurna yang dimaksud adalah kemampuannya untuk menggandakan sinyal audio secara berulang-ulang tanpa mengalami penurunan kualitas suara.
ada beberapa istilah yaitu sampling rate (laju pencuplikan), bit per sample, bit rate (laju bit), channel (jumlah kanal).
2.2.3 Sampling Rate
Ketika sound card mengubah audio menjadi data digital, sound card akan memecah suara tadi menurut nilai menjadi potongan-potongan sinyal dengan nilai tertentu. Proses sinyal ini bisa terjadi ribuan kali dalam satuan waktu. Banyak pemotongan dalam satu satuan waktu ini dinamakan sampling rate (laju pencuplikan). Satuan sampling rate yang biasa digunakan adalah Hz (Hertz).
Kerapatan laju pencuplikan ini menentukan kualitas sinyal analog yang akan diubah menjadi data digital. Makin rapat sampling rate ini, kualitas suara yang dihasilkan akan makin mendekati suara aslinya. Sebagai contoh, lagu yang disimpan dalam Compact Disc Audio (CDA) memiliki sampling rate 44100 Hz, yang berarti lagu ini dicuplik sebanyak 44100 kali dalam satu detik untuk memastikan kualitas suara yang hampir sama persis dengan aslinya.
Sampling rate yang umumnya digunakan antara lain 8000 Hz, 11000 Hz, 16000 Hz, 22000 Hz, 24000 Hz, 44000 Hz, 88000 Hz. Makin tinggi sampling rate, semakin baik kualitas audio. Teori Nyquist menyatakan bahwa sampling rate yang diperlukan minimal 2 kali bandwidth sinyal. Hal ini berkaitan dengan kemampuan untuk merekonstruksi ulang sinyal audio.
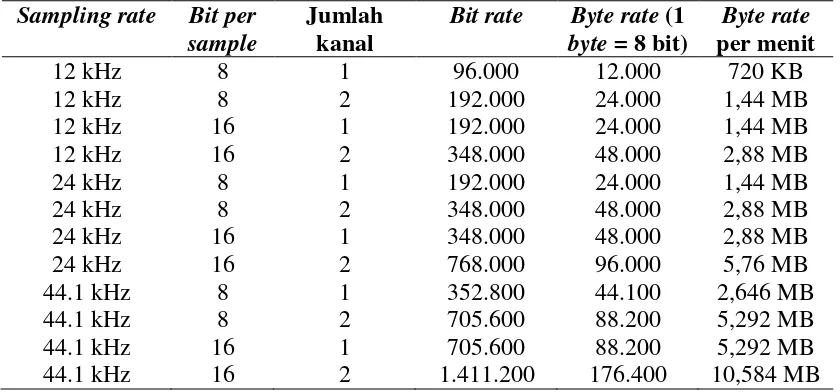
Tabel 2.1 Tabel Frekuensi Sampling dan Kualitas Suara yang Dihasilkan
Sampling Rate Aplikasi
per sample akan ada 256 level pilihan sedangkan 16 bit per sample akan ada 65.536 level pilihan. Makin tinggi bit per sample makin teliti proses kuantisasi. Dalam contoh ini, penggunaan 16 bit per sample dibandingkan penggunaan 8 bit per sample akan mempertinggi ketelitian kualitas kuantisasi sebanyak 256 kali.
2.2.5 Bit Rate
Istilah bit rate merupakan gabungan dari istilah sampling rate dan bit per sample. Bit rate menyatakan banyaknya bit yang diperlukan untuk menyimpan audio selama satu detik, satuannya adalah bit per detik. Bit rate (dengan satuan bit per detik) diperoleh dengan rumus yang sederhana yaitu perkalian antara jumlah kanal, sampling rate (dengan satuan Hertz) dan bit per sample (dengan satuan bit).
Tabel 2.2 Tabel Penyimpanan Berbagai Konfigurasi Audio Digital Sampling rate Bit per
Audio sekualitas CD Audio menggunakan sampling rate 44,1 kHz, 16 bit per sample, 2 kanal. Total media yang diperlukan untuk menyimpan data audio ini perdetik adalah 176.400 byte, untuk durasi 1 menit diperlukan 10,584 MB. Jika rata-rata durasi satu lagu selama 5 menit, maka dibutuhkan tempat lebih dari 50 MB untuk menyimpan data audio lagu tersebut jika diasumsikan 1 KB = 1.000 byte dan 1 MB = 1.000 KB = 1.000.000 byte.
2.2.6 MP3 (MPEG-1 Layer 3)
(Digital Audio Broadcast). Produk mereka Musicam (yang dikenal dengan Layer 2) terpilih karena kesederhanaan, ketahanan terhadap kesalahan, dan perhitungan komputasi yang sederhana untuk melakukan pengkodean yang menghasilkan keluaran yang memiliki kualitas tinggi. Pada akhirnya ide dan teknologi yang dikembangkan menjadi MPEG-1 Layer 3.
Mp3 merupakan salah satu format audio digital yang memiliki teknik kompresi sendiri yang bersifat lossy yaitu menghilangkan beberapa bagian audio yang tidak dapat dideteksi pendengaran manusia. Mp3 dibuat dengan mengambil data audio dari file Wav dan diproses dengan sebuah algoritma untuk mengurangi besarnya ukuran audio. Oleh karena itu, mp3 lebih popular dan banyak dipakai untuk perdagangan musik di internet dibanding file Wav yang berukuran besar.
Sebuah file Mp3 terdiri dari header dan audio data serta pada akhir dari file biasanya terdapat ID3 Tag yang berisi informasi judul lagu, artis, album, dan lain lain yang tidak diperlukan dalam proses encoding ataupun decoding, dapat dilihat seperti Gambar 2.4.
Header
Data
Audio
Side
Info
Gambar 2.4 Struktur File Mp3
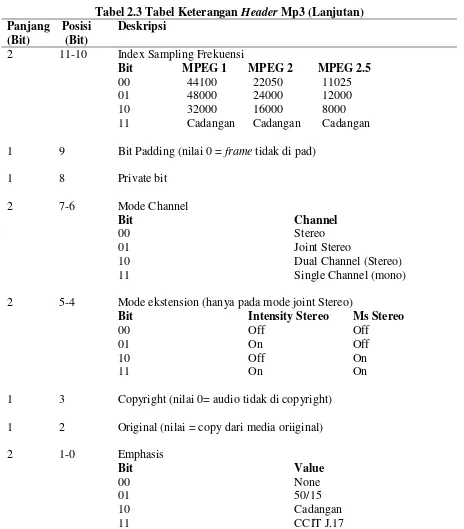
Header Mp3 memegang peranan peranan penting dalam proses decoding. Header terdiri dari 32 bit, dimana bit-bit tersebut merupakan informasi dari tipe audio data.
Informasi yang dapat diperoleh dari header dan keterangan tiap-tiap bit dijelaskan pada Tabel 2.3.
Tabel 2.3 Tabel Keterangan Header Mp3 Panjang
(Bit)
Posisi (Bit)
Deskripsi
11 31-21 Bit untuk sinkronisasi frame
Tabel 2.3 Tabel Keterangan Header Mp3 (Lanjutan)
2 11-10 Index Sampling Frekuensi
Bit MPEG 1 MPEG 2 MPEG 2.5
00 44100 22050 11025
01 48000 24000 12000
10 32000 16000 8000
11 Cadangan Cadangan Cadangan
1 9 Bit Padding (nilai 0 = frame tidak di pad)
2 5-4 Mode ekstension (hanya pada mode joint Stereo)
Bit Intensity Stereo Ms Stereo
00 Off Off
01 On Off
10 Off On
11 On On
1 3 Copyright (nilai 0= audio tidak di copyright) 1 2 Original (nilai = copy dari media oriiginal)
2 1-0 Emphasis
Berikut ilustrasi contoh suatu header 32 bit pada file Mp3. Suatu sampel audio yang bernilai :
FF FB 90 04
Berarti nilai bitnya :
1 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 Bit ke- 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
Dari ilustrasi diatas maka bit ke- 31 sampai 21 adalah sinkronisasi frame. Bit 20 dan 19, keduanya bernilai 1 yang menunjukkan versi MPEG versi 1. Bit ke-18 dan ke-17 bernilai 0 dan 1 sehingga layernya adalah layer 3. Bit ke-16 bernilai 1 berarti tidak ada 16 bit CRC. Bit ke-15 sampai 12 bernilai 1001, menunjukkan bahwa bitrate-nya adalah 128 kbps. Bit ke-11 dan ke-10 bernilai 0 berarti frekuensi samplingnya adalah 44.1 kHz, bit ke-9 bernilai 0 menunjukkan bahwa tidak terdapat padding dan untuk bit ke-8 bernilai 0, untuk kepentingan pribadi serta untuk bit ke-7 dan 6 bernilai 0 berarti mode adalah stereo.
Bit ke-5 dan 4 bernilai 0 yang berarti intensitas stereo dan Ms stereo keduanya off, bit ke-3 bernilai 0 menunjukkan tidak di copyright dan bit ke-2 bernilai 1 berarti file tidak di copy dari media original sedangkan untuk bit ke-1 dan ke-0 bernilai 0 maka emphasis bernilai none.
2.3 Penelitian Sebelumnya
Algoritma Shannon-Fano banyak diterapkan untuk kompresi citra dan teks. Penelitian yang dilakukan sebelumnya untuk kompresi dengan menggunakan algoritma Shannon-Fano yaitu kompresi teks (Saputri, 2011). Saputri (2011) menggunakan algoritma Shannon-Fano untuk kompresi teks, dimana file teks dapat di kompresi dengan hasil rasio kompresi rata-rata mencapai 45% sehingga dikatakan algoritma Shannon-Fano sangat bagus digunakan untuk file teks.
kompresi sebanyak 60%. Untuk pengujian algoritma Shannon-Fano memperoleh hasil rasio kompresi sebanyak 54%. Penelitian ini menunjukkan bahwa algoritma Shannon-Fano cocok digunakan untuk kompresi data teks .
Penggunaan algoritma Shannon-Fano pada kompresi citra (Adriani, 2009). Adriani (2009) menggunakan algoritma Shannon-Fano pada kompresi dan dekompresi citra digital dimana citra dapat dikompresi dengan hasil rasio kompresi rata-rata 27,12%. File citra yang telah dikompres tidak lagi berbentuk citra. Untuk mengembalikannya ke dalam bentuk citra dilakukan proses dekompresi.
Untuk kompresi audio, algoritma yang pernah digunakan adalah algoritma Huffman (Sunarto, 2010). Sunarto (2010) menggunakan algoritma Huffman untuk kompresi audio Wav dengan rasio kompresi rata-rata 19.07%. File hasil kompresi harus di dekompresi lagi untuk bisa memainkan file kembali.
Selain algoritma Huffman, algoritma yang pernah dipakai untuk kompresi audio adalah algoritma Arithmatic Coding (Siregar, 2011). Siregar (2011) menggunakan algoritma Arithmetic Coding untuk kompresi audio file Wav, Mp3 dan Midi. Rata rata rasio kompresi untuk file Wav adalah 15.34 %, Mp3 0.26 %, dan Midi sebesar 18.60 %. Sama seperti penelitian Sunarto (2010), file audio hasil kompresi tidak dapat dimainkan.
Penggunaan algoritma Shannon-Fano juga dipakai pada kompresi audio (Al-laham, et al, 2007). Peneliti ini menggunakan algoritma Shannon-Fano untuk melakukan kompresi pada semua jenis data seperti teks, citra, video dan audio dimana peneliti membandingkan semua algoritma untuk menentukan algoritma mana yang memiliki kualitas kompresi lebih bagus dari antara semua data.
Pada kompresi audio digunakan juga algoritma Run Length Encoding (Rahandi, 2011). Rahandi (2011) mengggunakan algoritma Run Length Encoding untuk kompresi file audio Wav dan Mp3. Rasio kompresi rata-rata untuk audio Wav sebesar 13.83% dan rasio kompresi rata-rata Mp3 sebesar 0.46%. Penelitian ini menunjukkan bahwa file hasil kompresi harus melalui proses dekompresi untuk bisa memainkan kembali audio tersebut.
kembali oleh aplikasi yang dirancang sendiri maupun dengan menggunakan media player lain tanpa harus melalui proses dekompresi.
2.4 Algoritma Shannon-Fano
Algoritma Shannon-Fano ditemukan oleh Claude Shannon dan Robert Fano yang merupakan algoritma pertama yang diperkenalkan untuk kompresi sinyal digital pada makalahnya yang berjudul “A Mathematical Theory of Communication” pada tahun 1948. Shannon dan Fano terus menerus mengembangkan algoritma ini yang menghasilkan kode biner (binary code) untuk setiap karakter yang terdapat pada data dengan redundansi minimum.
Algoritma Shannon-Fano didasarkan pada variable-length code yang berarti beberapa karakter pada data yang dikodekan direpresentasikan dengan kode yang lebih pendek dari karakter yang ada pada data. Jika frekuensi kemunculan karakter semakin tinggi maka kode semakin pendek. Dengan demikian kode yang yang dihasilkan tidak sama panjang sehingga kode tersebut bersifat unik.
Algoritma Shannon-Fano menggunakan struktur data yang sama dengan algoritma Huffman, yaitu struktur data string sebagai data masukan, struktur data binary tree sebagai pembentukan pohon biner dan array sebagai pendeklarasian variabel yang sama.
Langkah langkah algoritma kompresi Shannon-Fano pada audio adalah sebagai berikut (Pu, 2006):
1. Menghitung frekuensi kemunculan masing-masing simbol pada sampel data di audio.
2. Mengurutkan frekuensi kemunculan simbol, dari simbol yang terbesar sampai yang terkecil (secara topdown).
4. Berilah label pada setiap sisi pohon biner, sisi kiri dilabeli dengan 0 dan sisi kanan dilabeli dengan 1.
5. Ulangi langkah 3 sampai node tidak dapat dibagi lagi.
6. Telusuri pohon biner dari akar sampai ke daun. Barisan label label pada sisi pohon dari akar ke daun menyatakan kode Shannon-Fano untuk symbol yang bersesuaian.
Jika ingin mengembalikan audio yang terkompresi menjadi audio ukuran asli maka harus dilakukan proses dekompresi.
Langkah-langkah dekompresi menggunakan algoritma Shannon-Fano adalah sebgai berikut:
1. Membaca bit pertama dari kode yang dihasilkan.
2. Jika bit pertama ada dalam tabel kode Shannon-Fano, maka bit tersebut diterjemahkan menjadi simbol yang sesuai dengan bit tersebut.
3. Jika bit tersebut tidak ada dalam tabel kode Shannon-Fano, gabungkan bit tersebut dengan bit selanjutya, kemudian cocokkan dengan tabel hasil pengkodean.
4. Ulangi langkah 3 sampai ada rangkaian bit yang cocok dengan tabel kode Shannon-Fano, terjemahkan rangkaian bit tersebut menjadi simbol yang sesuai. 5. Jika terdapat simbol yang sesuai, maka baca bit selanjutnya dan ulangi langkah 2,
3, dan 4 sampai rangkaian kode habis.
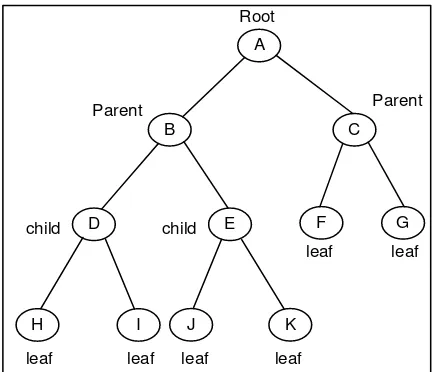
2.5 Binary Tree
Suatu binary tree memiliki ciri ciri sebagi berikut:
a. Sebuah root
b. Terdapat node yang disebut parent atau child
Untuk lebih jelasnya pembuatan contoh binary tree dapat dilihat pada Gambar 2.6
Dilihat dari kepemilikan node pada masing-masing parent dan tinggi tree, maka pohon biner (binary tree) dibedakan menjadi dua yaitu pohon biner lengkap dan pohon biner sempurna. Pohon biner lengkap (completely binary tree), yakni masing-masing node memiliki 2 buah anak atau tidak memiliki anak sama sekali.
A
Sebuah pohon biner sempurna (perfect binary tree) adalah pohon biner yang lengkap yang masing-masing node memiliki 2 buah anak dan mempunyai kedalaman yang sama (jarak dari akar atau biasanya disebut juga dengan height).
A
B C
E
D F G
H I J K L M N O
Gambar 2.8 Contoh Perfect BinaryTree
Berikut ilustrasi untuk memperjelas cara kerja algoritma Shannon-Fano serta pembentukan pohon biner. Diambil suatu sampel data audio yang dinyatakan dalam bentuk heksadesimal.
1. Misalnya file audio dalam bentuk heksadesimal sebagai berikut: FE 3F 02 00 FE 3F 02 FF 7C 3F
2. Langkah awal adalah membentuk tabel distribusi frekuensi seperti terlihat pada Tabel 2.4.
Tabel 2.4 Tabel Distribusi Frekuensi
Karakter Frekuensi
3F 3
FE 2
02 2
00 1
FF 1
3. Kemudian dibentuk node pohon untuk tiap karakter beserta nilai frekuensinya masing-masing. Pengurutan dilakukan secara menurun (descending) dari nilai frekuensi terbesar hingga terkecil dan frekuensi yang sama didahulukan sesuai dengan urutan yang pertama muncul dapat dilihat pada Gambar 2.9.
3F 3 FE 2 02 2 00 1 FF 1 7C 1
Gambar 2.9 Contoh Pengurutan Frekuensi Secara Descending
4. Setelah itu, dibagi menjadi dua buah bagian node dengan jumlah frekuensi kemunculan simbol yang sama atau hampir mendekati sama antara node yang satu dengan node yang lainnya seperti Gambar 2.10.
3F FE 5 02 00 FF 7C 5
Gambar 2.10 Contoh Pembagian Menjadi Dua Node
5. Berikutnya dengan mengulangi langkah 4, yaitu membagi menjadi dua buah node dengan jumlah frekuensi kemunculan simbol yang sama atau hampir mendekati sama pada salah satu node di node sebelah kiri.
3F FE 5
3F 3 FE 2
02 00 FF 7C 5
Gambar 2.11 Contoh Pembagian Menjadi Dua Node Kedua
3F FE 5
3F 3 FE 2
02 00 FF 7C 5
02 2 00 FF 7C 3
Gambar 2.12 Contoh Pembagian Menjadi Dua Node Ketiga
7. Node sebelah kanan dapat dibagi lagi maka lakukan langkah seperti langkah 6, dapat dilihat pada Gambar 2.13.
3F FE 5
3F 3 FE 2
02 00 FF 7C 5
02 2 00 FF 7C 3
00 FF 2 7C 1
Gambar 2.13 Contoh Pembagian Menjadi Dua Node Keempat
8. Kemudian lakukan langkah langkah seperti diatas sampai semua node tidak dapat dibagi lagi. Hasil dari perulangan dapat dilihat pada Gambar 2.14.
3F FE 5
3F 3 FE 2
02 00 FF 7C 5
02 2 00 FF 7C 3
00 FF 2 7C 1
00 1 FF 1
9. Setelah semua node tidak dapat dibagi lagi dan membentuk pohon biner, maka tambahkan label pada setiap sisi pohon biner, sisi kiri dilabeli dengan 0 dan sisi kanan dilabeli dengan 1. Kemudian telusuri pohon biner dari akar hingga ke daun. Barisan label label pada sisi pohon dari akar ke daun menyatakan kode Shannon-Fano untuk simbol yang bersesuaian dapat dilihat pada Gambar 2.15.
3F FE 5
Gambar 2.15 Contoh Pembagian Menjadi Dua Node Keenam
10. Pada Gambar 2.15 dapat dilihat tiap karakter telah memiliki kode Shannon-Fano Penelusuran dari akar ke daun (dari atas ke bawah) menghasilkan kode Shannon-Fano dengan kode bit untuk tiap karakter seperti pada Tabel 2.5.
Tabel 2.5 Tabel Hasil Kode Shannon-Fano
11. Maka file audio untuk FE 3F 02 00 FE 3F 02 FF 7C 3F hasil kode bit adalah 0100101100100101110111100 dengan jumlah bit hasil kompresi 25 bit dan jumlah sebelum dikompresi yaitu jumlah karakter dalam byte 8 bit = 10 8 bit = 80 bit.
Jika ingin mengembalikan audio yang terkompresi menjadi audio ukuran asli maka harus dilakukan proses dekompresi.
Sebagai contoh untuk menulis kembali file audio asli dari bilangan heksa pengganti 4B 25 DE 00 maka hal pertama yang perlu dilakukan adalah mengubahnya kembali ke kode bit.
Tabel 2.6 Tabel Pengubahan Heksadesimal ke Biner
Kode Heksadesimal Kode Biner
4B 01001011
25 00100101
DE 11011110
00 00000000
Setelah didapat kode bit pengganti seperti gambar di atas, kemudian diambil informasi dari header audio untuk mengecek apakah sebelumnya dilakukan penambahan bit. Jika dilakukan adanya penambahan bit, maka kode pengganti tersebut harus dikurangi sebanyak bit yang ditambah pada bit belakang. Misalkan sebelumnya kode bit 01001011001001011101111000000000 ditambah 7 bit maka kode bit ini juga harus dikurangi sebanyak tujuh bit dari belakang menjadi 0100101100100101110111100.
Tabel 2.7 Tabel Kode Shannon-Fano
Simbol Frekuensi Kode Bit
3F 3 00 (2 bit)
FE 2 01 (2 bit)
02 2 10 (2 bit)
00 1 110 (3 bit)
FF 1 1110 (4 bit)
7C 1 1111 (4 bit)