ANALISIS PERBANDINGAN KINERJA ALGORITMA SHANNON-FANO, ARITHMETIC CODING, DAN HUFFMAN PADA KOMPRESI
BERKAS TEKS DAN BERKASCITRA DIGITAL
SKRIPSI
SYARIFAH KEUMALA ANDRIATY 091401084
PROGRAM STUDI S1 ILMU KOMPUTER
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
ANALISIS PERBANDINGAN KINERJA ALGORITMA SHANNON-FANO, ARITHMETIC CODING, DAN HUFFMAN PADA KOMPRESI
BERKAS TEKS DAN BERKASCITRA DIGITAL
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Sarjana Ilmu Komputer
SYARIFAH KEUMALA ANDRIATY 091401084
PROGRAM STUDI S1 ILMU KOMPUTER
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : ANALISIS PERBANDINGAN KINERJA
ALGORITMA SHANNON-FANO, ARITHMETIC CODING, DAN HUFFMAN PADA KOMPRESI BERKAS TEKS DAN BERKAS CITRA DIGITAL
Kategori : SKRIPSI
Nama : SYARIFAH KEUMALA ANDRIATY
Nomor Induk Mahasiswa : 091401084
Program Studi : S1 ILMU KOMPUTER
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA Diluluskan di
Medan, 24 Juli 2013 Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Syahriol Sitorus, S.SI, MIT Drs. James Pieter Marbun, M.Kom NIP. 19710310 199703 1 004 NIP. 19580611 198603 1 002
Diketahui/disetujui oleh
Program Studi S1 Ilmu Komputer Ketua,
PERNYATAAN
ANALISIS PERBANDINGAN KINERJA ALGORITMA SHANNON-FANO, ARITHMETIC CODING, DAN HUFFMAN PADA KOMPRESI
BERKAS TEKS DAN BERKAS CITRA DIGITAL
SKRIPSI
Saya menyatakan bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, Juli 2013
PENGHARGAAN
Puji dan syukur penulis panjatkan ke hadirat Allah SWT, yang telah memberikan rahmat dan hidayah-Nya, serta segala sesuatu dalam hidup, sehingga penulis dapat menyelesaikan penyusunan skripsi ini, sebagai syarat untuk memperoleh gelar Sarjana Komputer, Program Studi S1 Ilmu Komputer, Fakultas Ilmu Komputer dan Teknologi Informasi (Fasilkom-TI), Universitas Sumatera Utara.
Ucapan terima kasih penulis sampaikan kepada semua pihak yang telah membantu penulis dalam menyelesaikan skripsi ini baik secara langsung maupun tidak langsung. Pada kesempatan ini penulis ingin mengucapkan terima kasih yang sebesar-besarnya kepada:
1. Bapak Prof. Dr. dr. Syahril Pasaribu, DTM&H, M.Sc.(CTM). Sp.A(K) selaku Rektor Universitas Sumatera Utara.
2. Bapak Prof. Dr. Muhammad Zarlis selaku Dekan Fasilkom-TI Universitas Sumatera Utara.
3. Bapak Dr. Poltak Sihombing, M. Kom. selaku Ketua Program Studi S1 Ilmu Komputer dan Dosen Penguji I.
4. Ibu Maya Silvi Lydia, B.Sc. M.Sc. selaku Sekretaris Program Studi S1 Ilmu Komputer dan Dosen Penguji II.
5. Bapak Drs. James Pieter Marbun, M. Kom. selaku Dosen Pembimbing I. 6. Bapak Syahriol Sitorus, S.Si., MIT. selaku Dosen Pembimbing II.
7. Seluruh dosen serta pegawai di Program Studi S1 Ilmu Komputer Fasilkom-TI USU.
8. Ayahanda Said Adnan dan Ibunda Darmiaty yang selalu memberikan dukungan, perhatian, dan doa tanpa henti kepada penulis.
9. Kakanda penulis Syarifah Dian Andriaty, SE, Ak., dr. Syarifah Nora Andriaty, Syarifah Lisa Andriati, SH, M.Hum., dan Syarifah Lia Andriaty, S.Hut. yang telah memberikan motivasi dan dukungan tanpa henti kepada penulis.
10.Muhammad Aidil Akbar, S.Kom. yang telah memberikan bimbingan, dukungan, dan perhatian kepada penulis.
11.Teman-teman sekaligus keluarga besar Program Studi S1 Ilmu Komputer Fasilkom-TI USU.
Medan, Juli 2013 Penulis,
ABSTRAK
Kompresi data merupakan proses mereduksi ukuran suatu data untuk menghasilkan representasi digital yang padat atau mampat (compact) namun tetap dapat mewakili
kuantitas informasi yang terkandung pada data tersebut. Proses kompresi data sangat diperlukan pada dunia komputerisasi, yaitu pada proses pengiriman data, dan pada penyimpanan data tersebut. Kompresi data dapat dilakukan secara lossy dan lossless.
Pada kompresi data yang bersifat lossy, data dapat dimampatkan dan didekompresi
dengan perubahan informasi di dalamnya, sehingga data asli berbeda dengan data hasil. Pada kompresi data yang bersifat lossless, data dapat dimampatkan dan
didekompresi tanpa kehilangan informasi, sehingga metode kompresi dengan sifat
lossless dapat diterapkan pada keperluan medis dan lain sebagainya. Pada penelitian ini dilakukan implementasi beberapa algoritma kompresi yang bersifat lossless, yaitu Shannon-Fano, Arithmetic Coding dan Huffman yang bertujuan untuk mengetahui algoritma paling optimal di antara ketiga algoritma tersebut. Parameter perbandingan kinerja algoritma yang digunakan adalah waktu kompresi, rasio kompresi, faktor kompresi, saving percentage, dan kompleksitas algoritma (Big-O). Aplikasi
pendukung yang dibangun pada penelitian ini adalah suatu aplikasi kompresi dengan berkas teks dengan format *.txt dan berkas citra digital dengan format *.bmp. Berdasarkan percobaan pada lima buah berkas teks dan lima buah berkas citra digital, diketahui bahwa algoritma Shannon-Fano merupakan algoritma teroptimal dibandingkan Arithmetic Coding dan Huffman, notasi Big-O dari algoritma Shannon-Fano dan Arithmetic Coding adalah O(n), sedangkan nilai notasi Big-O dari algoritma Huffman adalah O(n2).
COMPARATIVE PERFORMANCE ANALYSIS OF COMPRESSION ALGORITHMS SHANNON-FANO, ARITHMETIC CODING, AND
HUFFMAN IN TEXT FILE AND DIGITAL FILE IMAGE
ABSTRACT
Data compression is process of reducing the size of data to produce a digital representation of a compressed or compact but still be able to represent the quantity of information that contained in the data. Data compression is required in computerization, which in the process of data sending, and in data storage. Data compression can be implemented in lossy method or lossles method. In lossy data compression, data can be compressed and decompressed with some differences of information between original data and result data. In lossless data compression, data can be compressed and decompressed without lossing any information, so that nature of lossless compression method can be applied to medical purposes and so on. In this research, algorithms of compression data implemented with lossless method, which are Shannon-Fano, Arithmetic Coding, and Huffman that aims to find the most optimal algorithm between them. The comparison parameters of the performance of the algorithms used are compression time, compression ratio, compression factor, saving percentage of memory, and algorithmic complexity (Big-O). Supporting application that built in this research is a compression application with text file formatted in *.txt and digital image file formatted in *.bmp. Based on experiments on five text files and five image files, concluded that Shannon-Fano algorithm is the most optimal algorithm compared to Arithmetic Coding and Huffman, Big-O notation from Shannon-Fano and Arithmetic Coding algorithm is O(n), and Big-O notation from Huffman algorithm is O(n2).
DAFTAR ISI
Hal.
Persetujuan ii
Pernyataan iii
Penghargaan iv
Abstrak vi
Abstract vii
Daftar Isi viii
Daftar Tabel xi
Daftar Gambar xiii
Bab 1 Pendahuluan
1.1 Latar Belakang Masalah 1
1.2 Rumusan Masalah 2
1.3 Batasan Masalah 2
1.4 Tujuan Penelitian 2
1.5 Manfaat Penelitian 3
1.6 Metodologi Penelitian 3
1.7 Sistematika Penulisan 4
Bab 2 Landasan Teori
2.1 Definisi Data 5
2.2 Kompresi Data 6
2.3 Data Berlebihan (Data Redundancy) 7
2.4 Teknik Kompresi Citra 8
2.5 Berkas Teks 9
2.6 Citra Digital 10
2.7 Pengolahan Citra Digital 10
2.8 Format Berkas Bitmap (*.bmp) 11
2.9 Informasi Teori dan Entropi 11
2.10 Algoritma Shannon-Fano 12
2.11 Algoritma Arithmetic Coding 12
2.12 Algoritma Huffman 13
2.13 Kompleksitas Algoritma (Notasi Big-O) 14
2.14 Evaluasi Kinerja Algoritma 15
2.15 Penelitian yang Relevan 16
2.15.1 Studi perbandingan kinerja algoritma kompresi 16 Shannon-Fano dan Huffman pada citra digital
2.15.2 Analisis kinerja dan implementasi algoritma kompresi 16 Arithmetic Coding pada file teks dan citra digital
2.15.3 Implementasi Algoritma Huffman pada Kompresi Citra BMP
Hal. 2.15.4 Analisis Perbandingan Teknik Kompresi Menggunakan
Algoritma Shannon-Fano, dan Run Length Encoding pada Citra Berformat BMP dan PNG
17
Bab 3 Analisis Dan Perancangan Sistem
3.1 Analisis Sistem 18
3.1.1 Ruang lingkup masalah 18
3.1.2 Analisis masalah 18
3.1.3 Analisis kebutuhan 20
3.1.4 Desain logis 20
3.2 Pseudocode 28
3.2.1 Pseudocode pembacaan berkas 28
3.2.2 Pseudocode pengurutan frekuensi 29 3.2.3 Pseudocode kompresi algoritma Shannon-Fano 31 3.2.4 Pseudocode dekompresi algoritma Shannon-Fano 34
3.2.5 Pseudocode kompresi algoritma Arithmetic Coding 36
3.2.6 Pseudocode dekompresi algoritma Arithmetic Coding 41 3.2.7 Pseudocode kompresi algoritma Huffman 43
3.2.8 Pseudocode dekompresi algoritma Huffman 49
3.3 Perancangan Antarmuka 51
3.3.1 Struktur menu 51
3.3.2 Perancangan grafis antarmuka 51 Bab 4 Implementasi Dan Pengujian
4.1 Implementasi Algoritma Shannon-Fano 54
4.1.1 Kompresi algoritma Shannon-Fano 54
4.1.2 Dekompresi algoritma Shannon-Fano 57 4.1.3 Kompleksitas waktu algoritma Shannon-Fano 57 4.2 Implementasi Algoritma Arithmetic Coding 61 4.2.1 Kompresi algoritma Arithmetic Coding 61 4.2.2 Dekompresi algoritma Arithmetic Coding 64 4.2.3 Kompleksitas waktu algoritma Arithmetic Coding 68
4.3 Implementasi Algoritma Huffman 73
4.3.1 Kompresi algoritma Huffman 73 4.3.2 Dekompresi algoritma Huffman 77 4.3.3 Kompleksitas waktu algoritma Huffman 78
4.4 Implementasi Perangkat Lunak 82
4.4.1 Konfigurasi perangkat keras 82 4.4.2 Konfigurasi perangkat lunak 82 4.4.3 Hasil eksekusi aplikasi 82
4.5 Pengujian Sistem 93
4.5.1 Skenario pengujian 93
4.5.2 Pengujian kompresi berkas teks 95
4.5.3 Pengujian kompresi berkas citra 114
Bab 5 Kesimpulan dan Saran 131
5.1 Kesimpulan 131
Hal.
Daftar Pustaka 133
Lampiran Listing Program A-1
DAFTAR TABEL
Nomor
Tabel Nama Tabel Halaman
3.1 Penyebab dan Akibat 19
3.2 Dokumentasi Naratif Use Case Kompresi 22 3.3 Dokumentasi Naratif Use Case Dekompresi 23
3.4 Dokumentasi Naratif Use Case Tentang Aplikasi 24
4.1 Pendataan Karakter Shannon-Fano 54
4.2 Pengurutan Frekuensi Shannon-Fano 55
4.3 Pembagian Bobot Frekuensi I 55
4.4 Pembagian Bobot Frekuensi II 55
4.5 Pembagian Bobot Frekuensi III 56
4.6 Pembagian Bobot Frekuensi IV 56
4.7 Codebook Shannon-Fano 56
4.8 Kompleksitas Waktu Kompresi Algoritma Shannon-Fano 58 4.9 Kompleksitas Waktu Dekompresi Algoritma Shannon-Fano 60
4.10 Pendataan Karakter Arithmetic Coding 61
4.11 Probabilitas Frekuensi Kemunculan Setiap Karakter 61
4.12 Jangkauan Setiap Karakter 62
4.13 Kompresi Arithmetic Coding 62
4.14 Library Arithmetic Coding 65
4.15 Kompleksitas Waktu Kompresi Algoritma Arithmetic Coding 69 4.16 Kompleksitas Waktu Dekompresi Algoritma Arithmetic
Coding
71
4.17 Pendataan Karakter Huffman 73
4.18 Pengurutan Frekuensi Huffman I 73
4.19 Frekuensi Huffman I 74
4.20 Pengurutan Frekuensi Huffman II 74
4.21 Frekuensi Huffman II 74
4.22 Pengurutan Frekuensi Huffman III 75
4.23 Frekuensi Huffman III 75
4.24 Pengurutan Frekuensi Huffman IV 75
4.25 Codebook Huffman 76
4.26 Kompleksitas Waktu Kompresi Algoritma Huffman 78 4.27 Kompleksitas Waktu Dekompresi Algoritma Huffman 81
4.28 Berkas Teks Uji 94
4.29 Berkas Citra Uji 94
4.30 Properties Berkas Teks satu.txt 96
4.31 Properties Berkas Teks bab4.txt 97
4.32 Properties Berkas Teks excel.txt 98
4.33 Properties Berkas Teks data.txt 99
4.34 Properties Berkas Teks flower.txt 100
Nomor
Tabel Nama Tabel Halaman
4.36 Analisis Kompresi Berkas Teks Algoritma Arithmetic Coding 103 4.37 Analisis Kompresi Berkas Teks Algoritma Huffman 105
4.38 Analisis Algoritma Kompresi pada Berkas Teks 107 4.39 Kompleksitas Waktu Algoritma Shannon-Fano pada Berkas
Teks
109 4.40 Kompleksitas Waktu Algoritma Arithmetic Coding pada
Berkas Teks
110 4.41 Kompleksitas Waktu Algoritma Huffman pada Berkas Teks 111 4.42 Kompleksitas Waktu Algoritma Shannon-Fano, Arithmetic
Coding, dan Huffman pada Berkas Teks
112
4.43 Properties Berkas Citra bee.bmp 114
4.44 Properties Berkas Citra bow.bmp 115
4.45 Properties Berkas Citra butterfly.bmp 116
4.46 Properties Berkas Citra flower.bmp 117 4.47 Properties Berkas Citra rainbow.bmp 118
4.48 Analisis Kompresi Berkas Citra Algoritma Shannon-Fano 119
4.49 Analisis Kompresi Berkas Citra Algoritma Arithmetic Coding 121 4.50 Analisis Kompresi Berkas Citra Algoritma Huffman 123 4.51 Analisis Algoritma Kompresi pada Berkas Citra 125 4.52 Kompleksitas Waktu Algoritma Shannon-Fano pada Berkas
Citra
127 4.53 Kompleksitas Waktu Algoritma Arithmetic Coding pada
Berkas Citra
128 4.54 Kompleksitas Waktu Algoritma Huffman pada Berkas Citra 129 4.55 Kompleksitas Waktu Algoritma Shannon-Fano, Arithmetic
Coding, dan Huffman pada Berkas Citra
DAFTAR GAMBAR
Nomor
Gambar Nama Gambar Halaman
2.1 Model Dasar Sistem Informasi 5
2.2 Model Pengembangan Sistem Informasi 5
2.3 Susunan Data 6
2.4 Ilustrasi Kompresi Lossless 9
2.5 Ilustrasi Kompresi Lossy 9
2.6 Nilai-nilai pada Piksel 10
3.1 Diagram Ishikawa 19
3.2 Use Case Diagram pada Aplikasi Kompresi 21
3.3 Diagram Aktivitaspada Aplikasi Kompresi 25
3.4 Diagram SekuensialProses Kompresi 27
3.5 Diagram SekuensialProses Dekompresi 27
3.6 Flowchart Pembacaan Berkas 29
3.7 Flowchart Pengurutan Frekuensi Karakter 30
3.8 Flowchart Kompresi Algoritma Shannon-Fano 1 32
3.9 Flowchart Kompresi Algoritma Shannon-Fano 2 33
3.10 Flowchart Dekompresi Algoritma Shannon-Fano 35
3.11 Flowchart Kompresi Algoritma Arithmetic Coding 1 38
3.12 Flowchart Kompresi Algoritma Arithmetic Coding 2 39 3.13 Gambar 3.13 Flowchart Method FindDecimal() 39
3.14 Flowchart Method FindBinary() 40
3.15 Flowchart Dekompresi Algoritma Arithmetic Coding 1 42 3.16 Flowchart Dekompresi Algoritma Arithmetic Coding 2 43
3.17 Flowchart Method FindLowest() 1 46
3.18 Flowchart Method FindLowest() 2 47
3.19 Flowchart Kompresi Algoritma Huffman 48
3.20 Flowchart Dekompresi Algoritma Huffman 50
3.21 Struktur Menu Aplikasi Kompresi 51
3.22 Rancangan Halaman Utama 52
3.23 Rancangan Halaman Kompresi 52
3.24 Rancangan Halaman Dekompresi 53
3.25 Rancangan Halaman About 53
4.1 Rescaling Bilangan Desimal I 63
4.2 Rescaling Bilangan Desimal II 63
4.3 Rescaling Bilangan Desimal III 64
4.4 Rescaling Library Arithmetic Coding 66
4.5 Pencarian Bilangan Biner I 66
4.6 Pencarian Bilangan Biner II 67
4.7 Pencarian Bilangan Biner III 68
4.8 Treeα 73
4.9 Treeβ 74
No
Gambar Nama Gambar Halaman
4.11 Treeδ 76
4.12 Huffman’s Tree 76
4.13 Tampilan Halaman Utama 83
4.14 Tampilan Halaman Kompresi 83
4.15 Tampilan Dialog Pilih Berkas Kompresi 84
4.16 Tampilan Properties Berkas I 84
4.17 Tampilan Berkas “bab4.txt” 85
4.18 Tampilan Kompresi Algoritma Shannon-Fano 85
4.19 Tampilan Berkas “bab4.sh” 86
4.20 Tampilan Kompresi Algoritma Arithmetic Coding 87
4.21 Tampilan Berkas “bab4.ar” 88
4.22 Tampilan Kompresi Algoritma Huffman 89
4.23 Tampilan Berkas “bab4.hf” 89
4.24 Tampilan Halaman Dekompresi 90
4.25 Tampilan Dialog Pilih Berkas Dekompresi 91
4.26 Tampilan Properties Berkas II 91
4.27 Tampilan Dekompresi Algoritma 92
4.28 Tampilan Halaman Tentang Aplikasi 93
4.29 Pengujian Berkas Teks satu.txt 96
4.30 Pengujian Berkas Teks bab4.txt 97
4.31 Pengujian Berkas Teks excel.txt 98
4.32 Pengujian Berkas Teks data.txt 99
4.33 Pengujian Berkas Teks flower.txt 100
4.34 Grafik Analisis Algoritma Shannon-Fano pada Berkas Teks 102 4.35 Grafik Analisis Algoritma Arithmetic Coding pada Berkas
Teks
104 4.36 Grafik Analisis Algoritma Huffman pada Berkas Teks 106 4.37 Grafik Analisis Algoritma Shannon-Fano, Arithmetic
Coding, dan Huffman pada Berkas Teks
108
4.38 Pengujian Berkas Citra bee.bmp 114
4.39 Pengujian Berkas Citra bow.bmp 115
4.40 Pengujian Berkas Citra butterfly.bmp 116
4.41 Pengujian Berkas Citra flower.bmp 117
4.42 Pengujian Berkas Citra rainbow.bmp 118 4.43 Grafik Analisis Algoritma Shannon-Fano pada Berkas Citra 120 4.44 Grafik Analisis Algoritma Arithmetic Coding pada Berkas
Citra
122 4.45 Grafik Analisis Algoritma Huffman pada Berkas Citra 124 4.46 Grafik Analisis Algoritma Shannon-Fano, Arithmetic
Coding, dan Huffman pada Berkas Citra
ABSTRAK
Kompresi data merupakan proses mereduksi ukuran suatu data untuk menghasilkan representasi digital yang padat atau mampat (compact) namun tetap dapat mewakili
kuantitas informasi yang terkandung pada data tersebut. Proses kompresi data sangat diperlukan pada dunia komputerisasi, yaitu pada proses pengiriman data, dan pada penyimpanan data tersebut. Kompresi data dapat dilakukan secara lossy dan lossless.
Pada kompresi data yang bersifat lossy, data dapat dimampatkan dan didekompresi
dengan perubahan informasi di dalamnya, sehingga data asli berbeda dengan data hasil. Pada kompresi data yang bersifat lossless, data dapat dimampatkan dan
didekompresi tanpa kehilangan informasi, sehingga metode kompresi dengan sifat
lossless dapat diterapkan pada keperluan medis dan lain sebagainya. Pada penelitian ini dilakukan implementasi beberapa algoritma kompresi yang bersifat lossless, yaitu Shannon-Fano, Arithmetic Coding dan Huffman yang bertujuan untuk mengetahui algoritma paling optimal di antara ketiga algoritma tersebut. Parameter perbandingan kinerja algoritma yang digunakan adalah waktu kompresi, rasio kompresi, faktor kompresi, saving percentage, dan kompleksitas algoritma (Big-O). Aplikasi
pendukung yang dibangun pada penelitian ini adalah suatu aplikasi kompresi dengan berkas teks dengan format *.txt dan berkas citra digital dengan format *.bmp. Berdasarkan percobaan pada lima buah berkas teks dan lima buah berkas citra digital, diketahui bahwa algoritma Shannon-Fano merupakan algoritma teroptimal dibandingkan Arithmetic Coding dan Huffman, notasi Big-O dari algoritma Shannon-Fano dan Arithmetic Coding adalah O(n), sedangkan nilai notasi Big-O dari algoritma Huffman adalah O(n2).
COMPARATIVE PERFORMANCE ANALYSIS OF COMPRESSION ALGORITHMS SHANNON-FANO, ARITHMETIC CODING, AND
HUFFMAN IN TEXT FILE AND DIGITAL FILE IMAGE
ABSTRACT
Data compression is process of reducing the size of data to produce a digital representation of a compressed or compact but still be able to represent the quantity of information that contained in the data. Data compression is required in computerization, which in the process of data sending, and in data storage. Data compression can be implemented in lossy method or lossles method. In lossy data compression, data can be compressed and decompressed with some differences of information between original data and result data. In lossless data compression, data can be compressed and decompressed without lossing any information, so that nature of lossless compression method can be applied to medical purposes and so on. In this research, algorithms of compression data implemented with lossless method, which are Shannon-Fano, Arithmetic Coding, and Huffman that aims to find the most optimal algorithm between them. The comparison parameters of the performance of the algorithms used are compression time, compression ratio, compression factor, saving percentage of memory, and algorithmic complexity (Big-O). Supporting application that built in this research is a compression application with text file formatted in *.txt and digital image file formatted in *.bmp. Based on experiments on five text files and five image files, concluded that Shannon-Fano algorithm is the most optimal algorithm compared to Arithmetic Coding and Huffman, Big-O notation from Shannon-Fano and Arithmetic Coding algorithm is O(n), and Big-O notation from Huffman algorithm is O(n2).
BAB 1 PENDAHULUAN
1.1 Latar Belakang Masalah
Kompresi data erat kaitannya dengan representasi informasi. Namun representasi informasi berisi banyak redundansi. Pengobralan kata dalam penulisan berita akan mengakibatkan kelimpahan kata atau redundansi. Dengan kata lain, redundansi merupakan penggandaan dari simbol yang sama dalam suatu string (Kridalaksana, 1993).
Hal yang penting dalam kompresi data adalah penghapusan dari redundansi. Setelah redundansi dihilangkan, informasi harus dienkode menjadi kode biner. Pada tahap implementasi, digunakan code word yang lebih pendek untuk merepresentasikan
huruf yang muncul lebih sering agar dapat mengurangi angka dari bit yang dibutuhkan untuk merepresentasi setiap huruf.
Situasi yang sama terdapat dalam komunikasi digital. Kecepatan dalam saluran komunikasi, baik melalui kabel atau nirkabel meningkat perlahan, maka dari itu data yang terkirim antara saluran telepon, mesin faksimile, telepon genggam, bahkan setelit dapat dimampatkan. Gambar-gambar yang diunggah ke suatu situs internet juga mengalami proses kompresi sebelum gambar tersebut ditampilkan.
Ada terdapat banyak metode untuk memampatkan data. Metode-metode ini berdasarkan dari berbagai ide yang disesuaikan dengan beberapa tipe data dan menghasilkan kompresi yang sedikit berbeda, namun tetap memampatkan data tersebut dengan menghilangkan redundansi dari data aslinya. Beberapa metode kompresi data ini antara lain adalah algoritma Shannon-Fano, Arithmetic Coding, dan Huffman.
ditinjau dari kecepatan proses kompresi dan dekompresinya, memori yang dibutuhkan rasio atau ukuran berkas hasil kompresi terhadap berkas asli) dan kualitas citra hasil kompresi yang dihasilkan.
Pada penelitian ini dilakukan analisis statistik dan perbandingan kinerja dari algoritma Shannon-Fano, Arithmetic Coding, dan Huffman pada kompresi berkas teks dan berkas citra digital.
1.2 Rumusan Masalah
Permasalahan yang diteliti dan diuraikan dalam penelitian ini adalah :
1. bagaimana membandingkan kinerja algoritma Shannon-Fano, Arithmetic Coding, dan Huffman agar proses pengiriman data menjadi lebih cepat dan menghemat memori penyimpanannya,
2. bagaimana kompleksitas (notasi Big-O) pada algoritma Shannon-Fano, Arithmetic Coding, dan Huffman, dan
3. bagaimana kompleksitas waktu kompresi dan dekompresi terbaik dan terburuk di antara algoritma Shannon-Fano, Arithmetic Coding, dan Huffman.
1.3 Batasan Masalah
Ruang lingkup penelitian ini dibatasi pada:
1. jenis berkas yang dikompresi adalah teks dengan format *.txt dan citra digital dengan format *.bmp,
2. kinerja algoritma dianalisis berdasarkan waktu kompresi, rasio kompresi, faktor kompresi, saving percentage, panjang karakter, waktu dekompresi, dan kompleksitas algoritma (notasi Big-O), dan
3. bahasa pemrograman yang digunakan adalah Java dengan editor Netbeans IDE 7.0.1.
1.4 Tujuan Penelitian
Tujuan dari penelitian ini adalah:
2. mengetahui kompleksitas algoritma (notasi Big-O) pada algoritma
Shannon-Fano, Arithmetic Coding, dan Huffman, dan
3. mengetahui kompleksitas waktu kompresi dan dekompresi terbaik dan terburuk di antara algoritma Shannon-Fano, Arithmetic Coding, dan Huffman.
1.5 Manfaat Penelitian
Manfaat yang diharapkan dari penelitian ini adalah menentukan algoritma yang optimal dalam proses kompresi teks dan citra digital sehingga dapat meminimalkan pemakaian memori ataupun bandwidth, mempercepat proses pengiriman data, serta sebagai bahan referensi mengenai algoritma Shannon-Fano, Arithmetic Coding, dan Huffman.
1.6 Metode Penelitian
Adapun tahapan-tahapan yang dilakukan dalam merancang dan mengembangkan penelitian ini adalah sebagai berikut:
1. Studi Literatur
Pada tahap ini dipelajari teori tentang berkas teks, berkas citra digital, dan algoritma kompresi.
2. Analisis sistem.
Pada tahap ini dianalisis proses kerja kompresi menggunakan algoritma Shannon-Fano, Arithmetic Coding, dan Huffman.
3. Perancangan sistem.
Pada tahap ini dilakukan perancangan sistem yang meliputi perancangan proses kerja sistem, perancangan interface, serta algoritma pemrograman.
4. Implementasi sistem.
Pada tahap ini dilakukan implementasi hasil analisis dan perancangan sistem ke dalam bahasa pemrograman.
5. Pengujian sistem.
Pada tahap ini dilakukan pengujian aplikasi untuk mengetahui apakah aplikasi sudah berjalan sesuai dengan tujuan penelitian atau tidak, dan mengevaluasi hasil analisis masing-masing algoritma.
Pada tahap ini dilakukan dokumentasi hasil analisis dan perancangan yang digunakan untuk menuangkan hasil penelitian tersebut ke dalam laporan akhir dalam bentuk skripsi.
1.7 Sistematika Penulisan BAB 1: PENDAHULUAN
Bab ini membahas konsep dasar penyusunan skripsi, yaitu mengenai latar belakang pemilihan judul “Analisis Perbandingan Kinerja Algoritma Shannon-Fano, Arithmetic Coding, dan Huffman pada Kompresi Berkas Teks dan BerkasCitra Digital”, rumusan masalah, batasan masalah, tujuan penulisan, manfaat penulisan, metode penelitian dan sistematika penulisan.
BAB 2: TINJAUAN PUSTAKA
Bab ini membahas dasar teori yang menunjang penulisan skripsi mengenai teori-teori yang mendukung penelitian.
BAB 3: ANALISIS DAN PERANCANGAN
Bab ini membahas analisis langkah-langkah dalam pembangunan sistem dan pemodelan sistem secara fungsional.
BAB 4: IMPLEMENTASI DAN PENGUJIAN
Bab ini membahas implementasi dan pengujian aplikasi yang telah selesai dibangun dengan algoritma Shannon-Fano, Arithmetic Coding, dan Huffman.
BAB 5: KESIMPULAN DAN SARAN
BAB 2
LANDASAN TEORI
2.1Definisi Data
Data merupakan bahan baku informasi, dapat didefinisikan sebagai kelompok teratur simbol-simbol yang mewakili kuantitas, fakta, tindakan, benda dan sebagainya (Supriyanto & Muhsin, 2008: 69). Data terbentuk dari karakter, dapat berupa alfabet, angka, maupun simbol khusus seperti *,$ dan /. Data disusun mulai dari bits, bytes, fields, records, file dan database.
Sistem informasi menerima masukan data dan instruksi, mengolah data tersebut sesuai instruksi, dan mengeluarkan hasilnya. Fungsi pengolahan informasi sering membutuhkan data yang telah dikumpulkan dan diolah dalam periode sebelumnya, karena itu ditambahkan sebuah penyimpanan data file (data file storage) ke dalam model sistem informasi. Dengan begitu, kegiatan pengolahan tersedia, baik bagi data baru maupun data yang telah dikumpulkan dan disimpan sebelumnya.
Data Proses Informasi
Gambar 2.1 Model Dasar Sistem Informasi
Masukan Pengolahan Informasi Penyimpanan
Tablespace
SYSTEM Tablespace 1 Tablespace 2
Database
Segment 1 Segment 2
Segment 3
Extend 1
Extend 2
Data Block
Tablespace
Segment
Gambar 2.3 Susunan Data
Sistem di komputer akan mengorganisasi data dalam sebuah hirarki yang terdiri dari satuan-satuan bit, byte, field, record, file, dan database.Bit merupakan unit
data yang terkecil, tingkatan terendah; singkatan dari binary digit (Joos et al, 2009:
12). Byte adalah kumpulan dari kombinasi bits, biasanya terdiri 8 bit yang menjadi
unit terkecil dalam storage dan mempunyai alamat, sering kali menjadi bagian dari
word (Supriyanto et al, 2008: 71). Field merupakan karakter-karakter yang
membentuk arti tertentu, misalnya field untuk nomor mahasiswa, dan sebagainya
Record adalah kumpulan dari fields yang membentuk sebuah arti yang saling berhubungan. (Noersasongko, 2010: 36). File adalah kumpulan dari records yang sejenis, contoh file tentang kepegawaian di berbagai departemen di sebuah instansi (Supriyanto et al, 2008: 71). Database adalah sekumpulan data yang berhubungan secara logika dan memiliki beberapa arti yang saling berpautan (Mata-Toledo, 2007: 1).
2.2 Kompresi Data
Proses kompresi merupakan proses mereduksi ukuran suatu data untuk menghasilkan representasi digital yang padat atau mampat (compact) namun tetap dapat mewakili
lebih kecil dan lebih ringan dalam proses transmisi dan menghemat ruang memori dalam penyimpanan data (Putra, 2010: 261).
Ada beberapa faktor yang memunculkan data berlebihan sehingga harus diperlukan proses kompresi. Faktor-faktor tersebut antara lain sebagai berikut:
1. pada suatu citra tunggal atau pada frame tunggal video dapat terjadi korelasi
yang signifikan antara suatu piksel dengan piksel tetangga. Korelasi ini disebut dengan korelasi spasial (spatial correlation),
2. pada data yang diambil dari beberapa sensor (multi sensor), terdapat korelasi yang signifikan antarsampel yang diambil oleh sensor-sensor tersebut. Korealasi ini disebut dengan korelasi spektral (spectral correlation),
3. pada data temporal seperti video, terdapat korelasi yang signifikan antara sampel data pada segmen waktu yang berbeda. Korelasi ini disebut sebagai korelasi temporal (temporal correlation),
4. pada suatu data terdapat informasi yang tidak relevan dengan sudut pandang persepsi mata.
2.3 Data Berlebihan (Data Redundancy)
Terdapat beberapa faktor yang memunculkan data berlebihan (data redundancy). Data
berlebihan ini dapat dinyatakan secara sistematis. Bila n1 dan n2 menyatakan jumlah satuan (unit) informasi dalam dua himpunan data (data set) yang mewakili data yang
sama maka data berlebihan relatif (relative data redundancy) RD dari himpunan data pertama dinyatakan sebagai berikut:
�� = 1−�1
� ... (1)
Dimana RD merupakan redundansi, dan CR merupakan rasio kompresi. Rasio kompresi (CR ) dinyatakan sebagai berikut:
�� =��1
2 ... (2)
Dimana n1 merupakan nilai dari data hasil kompresi, dan n2 merupakan nilai dari data asli.
mendekati 0, sehingga RD mendekati minus tak terhingga. Ini berarti data set kedua mengandung informasi jauh lebih banyak dibandingkan data set pertama. Secara umum, CR dan RD berturut-turut beada dalam interval (1,∞) dan (-∞,1). Dalam praktik, rasio kompresi 20 (atau 20:1) berarti data set pertama mengandung 20 satuan (unit) informasi untuk setiap 1 unit pada data set kedua (atau pada data terkompresi). Dengan kata lain, untuk kasus citra, citra asli (citra belum termampatkan) mengandung 20 bit informasi untuk setiap 1 bit pada data terkompresi. Redundansi
0.8 berarti 80% data pada data set pertama adalah berlebihan.
2.4 Teknik Kompresi Citra
Menurut Putra (2010), ada dua teknik yang dapat dilakukan dalam memampatkan citra digital.
1. Kompresi Lossless
Pada kompresi jenis ini informasi yang terkandung pada berkas hasil sama dengan informasi pada berkas asli. Berkas hasil proses kompresi dapat dikembalikan secara sempurna menjadi berkas asli, tidak terjadi kehilangan informasi, tidak terjadi kesalahan informasi. Oleh karena itu metode ini disebut juga error free compression.
Pada kompresi lossless, karena harus mempertahankan kesempurnaan
informasi, sehingga hanya terdapat proses coding dan decoding, tidak terdapat
proses kuantitasi. Kompresi tipe ini cocok diterapkan pada berkas basis data (database), spread sheet, berkas word processing, citra biomedis dan lain
sebagainya. 2. Kompresi Lossy
Kompresi data yang bersifat lossy mengijinkan terjadinya kehilangan sebagian
pada penyimpanan data analog yang didigitasi seperti gambar, video, dan suara.
Ilustrasi kompresi lossless dan lossy dapat dilihat pada Gambar 2.4 dan Gambar 2.5.
Algoritma Coding
Algoritma Decoding
000011100101011
000011100101011 BAABBA
BAABBA
Gambar 2.4 Ilustrasi Kompresi Lossless
Algoritma Coding
Algoritma Decoding
000110001010110 BAABBA
BAABA 000110001010110
Gambar 2.5 Ilustrasi Kompresi Lossy
2.5 Berkas Teks
2.6 Citra Digital
Citra digital merupakan obyek nyata yang direpresentasi secara elektronis (Mulyanta, 2006: 5). Obyek dapat bersumber dari dokumen, foto, barang cetakan, hingga lukisan. Unsur utama citra digital adalah grid berisi elemen obyek yang sangat dasar, yaitu picture element (piksel). Setiap piksel mempunyai tingkatan nilai tertentu, sehingga
menghasilkan representasi data yang ditangkap oleh mata manusia sebagai bentuk tingkatan warna hitam, putih, abu-abu, hingga penuh dengan warna.
Setiap bit dalam piksel akan disimpan dalam urutan tertentu oleh komputer dengan penghitungan matematis agar menghasilkan file yang optimal dibaca oleh media perangkat yang mendukungnya. Setiap informasi bit digital akan diinterpretasikan dan dibaca oleh komputer agar menghasilkan versi analog untuk ditampilkan dan dicetak oleh media lain. Versi yang dilihat oleh mata manusia adalah data bersifat analog yang dirangkat oleh peralatan digital pada media komputer.
1 0 0 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1
1 0 1 1 0 1 0 1 1 0 1 1 0 1 0 1 1 1 0 1 0 1
1 0 1 1 1 0 1 1 1 0 1 1 0 1 1 1 0 1 1 1 0 1
1 0 1 1 1 1 1 1 1 0 1 1 0 1 1 1 1 1 1 1 0 1
1 0 1 1 1 1 1 1 1 0 1
1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 0 1
Gambar 2.6 Nilai-nilai pada Piksel
Gambar 2.6 memperlihatkan bahwa bentuk-bentuk obyek dihasilkan dari kombinasi nilai 0 untuk warna hitam dan 1 untuk warna putih, sehingga membentuk
bitonal image. Bitonal image tidak mengenal gradasi warna, sehingga citra yang
dihasilkan mempunyai kesan sangat kaku dan tidak alami.
2.7 Pengolahan Citra Digital
tujuan analisis, melakukan proses penarikan informasi atau deskripsi obyek atau pengenalan obyek yang terkandung pada citra, melakukan kompresi atau reduksi data untuk tujuan penyimpanan data, transmisi data, dan waktu proses data. Masukan dari pengolahan citra adalah citra, sedangkan keluarannya adalah citra hasil pengolahan (Sutoyo, 2009: 5).
2.8 Format Berkas Bitmap (*.bmp)
Gambar bitmap adalah citra yang dihasilkan oleh sejumlah titik berwarna-warni yang disebut piksel. Piksel-piksel itu ditempatkan pada suatu bidang matriks. Warna-warna piksel yang sama atau senada yang berada pada suatu area dan berdampingan dengan warna-warna dapat menimbulkan nuansa bentuk. Gabungan dari beberapa nuansa itu ditangkap oleh mata manusia sebagai citra atau gambar (Budijanto, 2006: 253).
Format *.bmp adalah format penyimpanan standar tanpa kompresi umum yang dapat digunakan untuk menyimpan citra biner hingga citra warna. Format ini terdiri dari beberapa jenis yang setiap jenisnya ditentukan dengan jumlah bit yang digunakan untuk menyimpan sebuah nilai piksel (Putra, 2010:58).
Struktur dari format *.bmp dapat dilihat pada Gambar 2.7.
Header
berkas
Header
bitmap
Informasi
palet Data bitmap
14 byte 12-64 byte 0-1024 byte N byte Gambar 2.7 Struktur Format Berkas *.bmp
Berkas dengan format *.bmp memerlukan memori penyimpanan yang besar, karena berkas ini merupakan format yang belum terkompresi dan menggunakan sistem warna Red, Green, Blue (RGB) dimana masing-masing warna pikselnya terdiri dari 3 komponen yang dicampur menjadi satu.
2.9 Informasi Teori dan Entropi
pada pengkodean. Jika informasi tambahan itu bisa diambil, maka data yang diperlukan tersebut bisa direduksi.
Teori informasi memanfaatkan terminologi entropi sebagai tolak ukur
seberapa besar informasi yang dikodekan pada sebuah data. Menurut Adriani (2009),
entropi merupakan suatu ukuran informasi yang dikandung oleh suatu citra dan
digunakan sebagai ukuran untuk mengukur kemampuan kompresi dari data. Entropi
memiliki persamaan matematis sebagai berikut:
�(�) = − ∑ ����=1 ���2�� ... (3) Dimana m merupakan jumlah simbol dan pi merupakan probabilitas simbol ke-i. Semakin kecil nilai entropi yang dihasilkan, maka kemampuan kompresi lebih baik.
Entropi juga didefinisikan sebagai limit kemampuan kompresi citra yang tidak dapat
dilampau oleh algoritma manapun.
2.10 Algoritma Shannon-Fano
Algoritma Shannon-Fano dinamai berdasarkan nama pengembangnya yaitu Claude Shannon dan Robert Fano. Metode ini dimulai dengan deretan dari simbol n dengan kemunculan frekuensi yang diketahui. Mula-mula simbol disusun secara menaik (ascending order) berdasarkan frekuensi kemunculannya. Lalu set simbol tersebut dibagi menjadi dua bagian yang berbobot sama atau hampir sama. Seluruh simbol yang berada pada subset I diberi biner 0, sedangkan simbol yang berada pada subset II diberi biner 1. Setiap subset dibagi lagi menjadi dua subsubset dengan bobot kemunculan frekuensi yang kira-kira sama, dan biner kedua diberikan seperti subset I dan subset II. Ketika subset hanya berisi dua simbol, biner diberikan pada setiap simbol. Proses akan berlanjut sampai tidak ada subset yang tersisa (Salomon: 2010).
Algoritma Shannon-Fano merupakan kompresi yang bersifat lossless, dimana
metode ini harus mendekompresi berkas agar dapat direkonstruksikan menjadi berkas semula tanpa kehilangan informasi.
2.11 Algoritma Arithmetic Coding
namun pada saat itu metode ini belum memenuhi solusi yang pantas untuk masalah yang akan dihadapi, yaitu keakurasian Arithmetic Coding harus ditingkatkan dengan panjang dari pesan yang dimasukkan. Untungnya, pada tahun 1976 Pasco dan Rissanen membuktikan bahwa panjang angka yang terbatas sebenarnya memadai untuk encoding, tanpa mengurangi akurasinya. Pada tahun 1979 – 1980, Rubin,
Guazzo, Rissanen, dan Langdon mempublikasikan algoritma dasar encoding yang
masih digunakan sampai sekarang. Algoritma ini berdasarkan ketelitian aritmatik yang terbatas (Bodden et al, 2007)
Arithmetic Coding menggantikan satu deretan simbol input dengan sebuah
bilangan floating point. Semakin panjang dan semakin kompleks pesan yang
dikodekan, semakin banyak bit yang diperlukan untuk keperluan tersebut. Output dari
metode ini adalah satu angka yang lebih kecil dari 1 dan lebih besar atau sama dengan 0. Angka ini secara unik dapat di-encode sehingga menghasilkan deretan simbol yang dipakai untuk menghasilkan angka tersebut (Salomon, 2010).
2.12 Algoritma Huffman
Metode ini dikembangkan oleh David Huffman sebagai bagian dari tugas kuliahnya. Kelas tersebut merupakan bagian dari teori informasi dan diajarkan oleh Robert Fano di MIT. Kode yang dihasilkan menggunakan metode ini dinamakan Huffman Codes.
Kode ini merupakan kode prefiks dan optimal untuk model yang diberikan.
Menurut Sayood (2012), prosedur algoritma Huffman berdasarkan dua penelitian mengenai kode prefix yang optimum, yaitu:
1. Simbol yang mempunyai frekuensi kemunculan lebih sering akan memiliki
code word yang lebih pendek dari simbol lainnya.
2. Dua simbol yang mempunyai frekuensi kemunculan paling sedikit akan memiliki code word dengan panjang yang sama.
Algoritma Huffman merupakan kompresi yang bersifat lossless, dimana
2.13 Kompleksitas Algoritma (Notasi Big-O)
Dalam aplikasinya, setiap algoritma memiliki dua buah ciri yang khas yang dapat digunakan sebagai parameter pembanding, yaitu jumlah proses yang dilakukan dan jumlah memori yang digunakan untuk melakukan proses. Jumlah proses ini dikenal sebagai kompleksitas waktu yang disimbolkan dengan T(n), sedangkan jumlah memori ini dikenal sebagai kompleksitas ruang yang disimbolkan dengan S(n).
Kenyataannya, jarang sekali dibutuhkan kompleksitas waktu yang detail dari suatu algoritma. Biasanya yang dibutuhkan hanyalah bagian paling signifikan dari kompleksitas waktu yang sebenarnya. Kompleksitas waktu ini dinamakan kompleksitas waktu asimptotik yang dinotasikan dengan O (O-besar atau Big-O). Kompleksitas waktu asimptotik ini diperoleh dengan mengambil term terbesar dari suatu persamaan kompleksitas waktu.
Misalnya jika diperoleh waktu eksekusi dari suatu algoritma T(n) adalah sebanyak 5n3+4n+3 langkah untuk besar input sebesar n, maka akan lebih mudah
untuk menghapus pangkat yang kecil seperti 4n dan 3 karena keduanya tidak terlalu signifikan terhadap input n. Koefisien 5 pada 5n3 juga dihilangkan dengan anggapan
bahwa komputer beberapa tahun kedepan akan menjadi 5 kali lipat lebih cepat dari komputer sekarang, sehingga keberadaan koefisien 5 juga tidak terlalu signifikan. Maka waktu yang diperlukan oleh algoritma tersebut untuk memproses input sebesar
n adalah n3, atau biasa dituliskan Big-O=n3 (Dasgupta et al, 2006).
Notasi Big-O yang sering dijumpai pada algoritma antara lain:
1. O(1) – constant time
Algoritma yang menghasilkan nilai selalu tetap tanpa bergantung kepada banyak masukan.
2. O(2log n) – logarithmic time
Algoritma yang berdasarkan pada binary tree biasanya memiliki kompleksitas O(log n).
3. O(n) – linear time
4. O(n 2log n) – linearithmic time
Algoritma yang memecahkan masalah menjadi masalah yang lebih kecil, lalu menyelesaikan tiap masalah secara independen.
5. O(n2) – quadratic time
Algoritma yang melibatkan proses perulangan bersarang (nested loop).
6. O(n3) – cubic time
Algoritma dengan kompleksitas O(n3) mirip dengan O(n2), namun
menggunakan loop bersarang sebanyak 3 kali. Algoritma sejenis ini hanya
cocok jika n kecil. Jika n besar, waktu yang dibutuhkan akan sangat lama. 7. O(2n) – exponential time
Salah satu algoritma yang mempunyai kompleksitas O(2n) adalah brute force
dalam menebak suatu password. Setiap penambahan karakter, akan melipatgandakan waktu yang dibutuhkan.
8. O(n!) – factorial time
O(n!) merupakan kompleksitas yang sangat cepat pertumbuhan waktu yang diperlukannya. Algoritma ini memproses setiap masukan dan menghubungkannya dengan n-1 masukan lainnya.
2.14 Evaluasi Kinerja Algoritma
Beberapa parameter untuk evaluasi kinerja algoritma, antara lain: 1. Rasio Kompresi
Rasio Kompresi merupakan rasio antara ukuran dari berkas terkompres dan berkas asli.
����������������= ������������������� ���������������������� ... (4) 2. Faktor Kompresi
Faktor kompresi merupakan invers dari rasio kompresi, yaitu hubungan antara berkas asli dan berkas terkompres.
�����������������= ���� ������ �����������
���� ����� ����������� ... (5) 3. Saving Percentage (SP)
Saving percentage menghitung pemampatan dari berkas asli sebagai
��= ���������� ����������� −�������� ������ ���������������� ����������� % .. ... (6)
2.15 Penelitian yang Relevan
2.15.1 Studi Perbandingan Kinerja Algoritma Kompresi Shannon-Fano dan
Arithmetic Coding pada Citra Digital
Pada penelitian Andriani (2009) yang berjudul Studi Perbandingan Kinerja Algoritma Kompresi Shannon-Fano dan Arithmetic Coding pada Citra Digital, perbandingan kinerja algoritma kompresi bertujuan untuk mengetahui performansi masing-masing algoritma terhadap citra digital. Untuk mengetahui performansi hasil proses kompresi dilakukan melalui perhitungan rasio kompresi, ukuran file hasil kompresi, kecepatan proses kompresi dan dekompresi dan nilai PSNR. Berdasarkan seluruh hasil pengujian, sistem kompresi menggunakan Arithmetic Coding Coding memiliki performansi yang baik berdasarkan rasio kompresi serta ukuran file hasil kompresi, sedangkan dari segi kecepatan proses kompresi dan dekompresi algoritma Shannon-Fano lebih baik daripada algoritma Arithmetic Coding.
2.15.2 Analisis Kinerja dan Implementasi Algoritma Kompresi Arithmetic Coding pada File Teks dan Citra Digital
Pada penelitian Sarifah (2010) yang berjudul Analisis Kinerja dan Implementasi Algoritma Kompresi Arithmetic Coding pada File Teks dan Citra Digital, penelitian
diimplementasi menggunakan Matlab 7.5.0. Analisis kinerja algoritma ini bertujuan untuk mengetahui performansi algoritma ini pada file teks dan citra digital. Untuk
mengetahui performansi hasil proses kompresi dilakukan melalui perhitungan rasio kompresi, ukuran file hasil kompresi, kecepatan proses kompresi dan dekompresi dan
2.15.3 Implementasi Algoritma Huffman pada Kompresi Citra BMP
Pada penelitian Ginting (2012) yang berjudul Implementasi Algoritma Huffman pada Kompresi Citra BMP, penelitian diimplementasikan menggunakan Microsoft Visual Basic 2008. Implementasi algoritma Huffman tersebut bertujuan untuk mengkompresi citra bmp sehingga ukuran file hasil kompresi lebih kecil dibandingkan dengan ukuran
citra asli dimana parameter yang digunakan untuk mengukur kinerja algoritma adalah rasio kompresi yang dihasilkan. Berdasarkan dari seluruh hasil pengujian, hasil kompresi citra menggunakan algoritma Huffman hanya mencapai tingkat rasio 2% - 8% untuk citra yang mengandung banyak variasi warna sedangkan untuk citra yang mengandung sedikit variasi warna (duplikasi warna) tingkat rasionya dapat mencapai hingga 80%.
2.15.4 Analisis Perbandingan Teknik Kompresi Menggunakan Algoritma Shannon-Fano, dan Run Length Encoding pada Citra Berformat BMP dan PNG.
BAB 3
ANALISIS DAN PERANCANGAN SISTEM
3.1 Analisis Sistem
Analisis sistem merupakan tahap awal dalam sebuah penelitian yang bertujuan mengetahui masalah terkait dalam pembuatan sebuah sistem dan menggambarkan proses-proses yang ada di dalam sistem untuk menghasilkan keluaran yang sesuai dengan kebutuhan pemakai (user).
3.1.1 Ruang lingkup masalah
Tools yang digunakan untuk membuat aplikasi kompresi Shannon-Fano, Arithmetic Coding, dan Huffman ini adalah NetBeans IDE 7.0.1. Desain interface yang ada
dalam aplikasi ini berupa tampilan form aplikasi untuk proses kompresi dari berkas teks dengan format *.txt atau berkas citra dengan format *.bmp yang dimasukkan secara digital beserta properties dari masing-masing algoritma kompresi dan untuk
proses dekompresi dari berkas dengan format *.sf, *.ar, atau *.hf beserta properties
dari masing-masing algoritma dekompresi. Tujuan dari adanya properties ini adalah
sebagai parameter yang menentukan algoritma optimal pada kompresi berkas teks atau berkas citra digital.
3.1.2 Analisis masalah
Tabel 3.1 Penyebab dan Akibat
Analisis Penyebab dan Akibat Perbaikan Tujuan Sistem Masalah atau
Peluang Masalah
Penyebab dan
Akibat Tujuan Sistem Kendala Sistem 1. Ukuran dari
berkas teks dan berkas citra digital besar. 2. Banyak algoritma yang dapat diterapkan untuk kompresi berkas.
1. Proses transmisi data (berkas teks atau berkas citra digital) lambat.
2. Membutuhkan memori yang besar untuk menyimpan berkas teks atau berkas citra digital. 1. Dibutuhkan aplikasi untuk proses kompresi dan dekompresi berkas.
1. Tidak tersedianya aplikasi kompresi dan dekompresi berkas yang menggunakan algoritma Shannon-Fano, Arithmetic Coding, dan Huffman.
Penyebab dan akibat pada Tabel 3.1 merepresentasikan sejumlah analisis masalah yang mempengaruhi aplikasi kompresi. Selanjutnya, masalah-masalah tersebut didekomposisi untuk mendapatkan rincian masalah yang lebih detil sebagai bahan pertimbangan untuk menghasilkan solusi teknis.
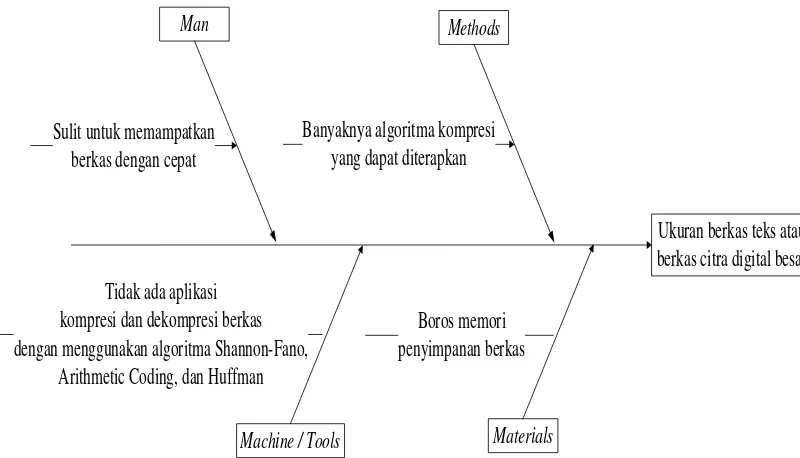
Adapun dekomposisi masalah tersebut digambarkan dengan diagram ishikawa
dan dapat dilihat pada Gambar 3.1.
Ukuran berkas teks atau berkas citra digital besar Sulit untuk memampatkan
berkas dengan cepat
Boros memori penyimpanan berkas Tidak ada aplikasi
kompresi dan dekompresi berkas dengan menggunakan algoritma Shannon-Fano,
Arithmetic Coding, dan Huffman
Machine / Tools Materials Methods Man
Banyaknya algoritma kompresi yang dapat diterapkan
[image:36.595.114.514.467.696.2]3.1.3 Analisis kebutuhan
Analisis kebutuhan suatu sistem dikelompokkan menjadi 2 bagian, yaitu analisis fungsional dan analisis non-fungsional. Fungsional sistem adalah aktivitas dan pelayanan yang harus dimiliki oleh sebuah sistem yang dapat berupa input, output,
proses maupun data yang tersimpan. Terkait dengan tahapan analisis perbandingan kinerja algoritma kompresi, khususnya analisis fungsional, tentunya sistem yang diinginkan dapat:
1. memampatkan berkas teks atau berkas citra digital, 2. menampilkan properties dari kinerja algoritma kompresi,
3. mendekompresi berkas yang telah dimampatkan, dan 4. menampilkan properties dari kinerja algoritma dekompresi.
Non-fungsional sistem adalah karakteristik atau batasan yang menentukan kepuasan sebuah sistem yakni seperti kinerja, kemudahan penggunaan, anggaran, serta tenggat waktu yang mampu bekerja tanpa mengganggu fungsionalitas sistem lainnya. Non-fungsional sistem dari sistem yang dibangun dari segi performance adalah sistem
memiliki kemampuan dalam melakukan kompresi berkas teks dan berkas citra digital dengan baik. Dari segi information adalah kemampuan sistem dalam menyediakan
pesan konfirmasi keberhasilan proses kompresi dan dekompresi berkas. Dari segi
economic adalah kemampuan sistem bekerja dengan baik tanpa biaya (cost) perangkat
lunak dan perangkat keras, sehingga penggunaannya tidak mengeluarkan biaya ekstra.
3.1.4 Desain logis
Model yang dihasilkan berdasarkan analisis di atas menunjukkan apa saja yang ada dalam aplikasi Shannon-Fano, Arithmetic Coding, dan Huffman pada kompresi berkas teks dan berkas citra digital, dan bagaimana bagian-bagian sistem tersebut diintegrasikan sehingga membentuk sistem yang utuh. Hal tersebut merupakan solusi yang memenuhi kebutuhan yang telah dianalisis. Desain logis yang digunakan pada penelitian ini antara lain:
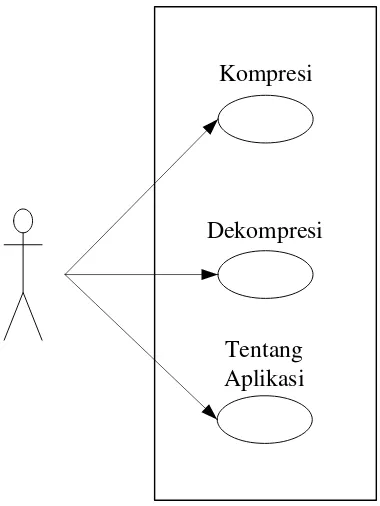
1. Diagram Use case
Pada sistem aplikasi kompresi terdapat satu aktor yaitu user. Untuk
mendapatkan use case dari aktor, maka harus ditentukan hal-hal apa saja yang dapat dilakukan pemain pada sistem. Hal-hal yang dapat dilakukan oleh aktor antara lain:
a. melakukan kompresi berkas, b. melakukan dekompresi berkas, c. melihat halaman Tentang Aplikasi.
Diagram use case yang terjadi berdasarkan aktor dan use case yang telah diperoleh dapat dilihat pada Gambar 3.2.
Kompresi
[image:38.595.238.428.280.533.2]Tentang Aplikasi Dekompresi
Gambar 3.2 Diagram Use Case pada Aplikasi Kompresi
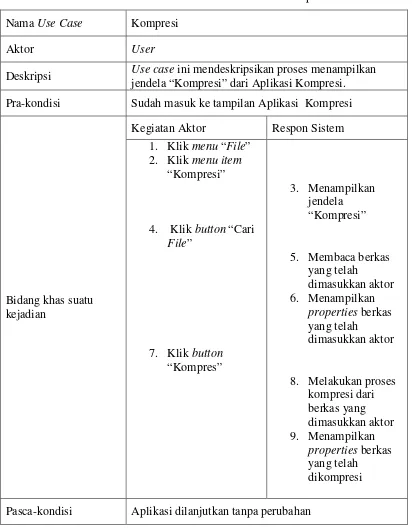
Tabel 3.2 Dokumentasi Naratif Use Case Kompresi
Nama Use Case Kompresi
Aktor User
Deskripsi Use casejendela “Kompresi” dari Aplikasi Kompresi. ini mendeskripsikan proses menampilkan Pra-kondisi Sudah masuk ke tampilan Aplikasi Kompresi
Bidang khas suatu kejadian
Kegiatan Aktor Respon Sistem 1. Klik menu “File”
2. Klik menu item
“Kompresi”
4. Klik button “Cari
File”
7. Klik button
“Kompres”
3. Menampilkan jendela “Kompresi”
5. Membaca berkas yang telah
dimasukkan aktor 6. Menampilkan
properties berkas yang telah
dimasukkan aktor
8. Melakukan proses kompresi dari berkas yang dimasukkan aktor 9. Menampilkan
properties berkas yang telah
dikompresi Pasca-kondisi Aplikasi dilanjutkan tanpa perubahan
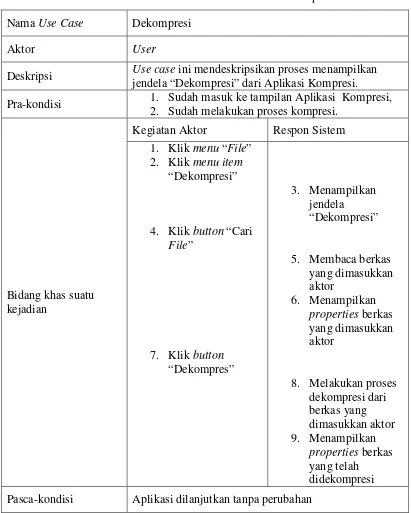
Dokumentasi naratif untuk proses dekompresi yang terdapat dalam diagram
Tabel 3.3 Dokumentasi Naratif Use Case Dekompresi
Nama Use Case Dekompresi
Aktor User
Deskripsi Use casejendela “Dekompresi” dari Aplikasi Kompresi. ini mendeskripsikan proses menampilkan Pra-kondisi 1.2. Sudah masuk ke tampilan Aplikasi Kompresi, Sudah melakukan proses kompresi.
Bidang khas suatu kejadian
Kegiatan Aktor Respon Sistem 1. Klik menu “File”
2. Klik menu item
“Dekompresi”
4. Klik button “Cari File”
7. Klik button
“Dekompres”
3. Menampilkan jendela
“Dekompresi”
5. Membaca berkas yang dimasukkan aktor
6. Menampilkan
properties berkas
yang dimasukkan aktor
8. Melakukan proses dekompresi dari berkas yang dimasukkan aktor 9. Menampilkan
properties berkas
yang telah didekompresi Pasca-kondisi Aplikasi dilanjutkan tanpa perubahan
Tabel 3.4 Dokumentasi Naratif Use Case Tentang Aplikasi
Nama Use Case Tentang Aplikasi
Aktor User
Deskripsi Use casejendela “Tentang Aplikasi” dari Aplikasi Kompresi. ini mendeskripsikan proses menampilkan Pra-kondisi Sudah masuk ke tampilan Aplikasi Kompresi
Bidang khas suatu kejadian
Kegiatan Pemain Respon Sistem 1. Klik menu
“Bantuan” 2. Klik menu item
“Tentang Aplikasi” 3. Menampilkan jendela “Tentang Aplikasi”
Pasca-kondisi Aplikasi dilanjutkan tanpa perubahan
2. Diagram aktivitas
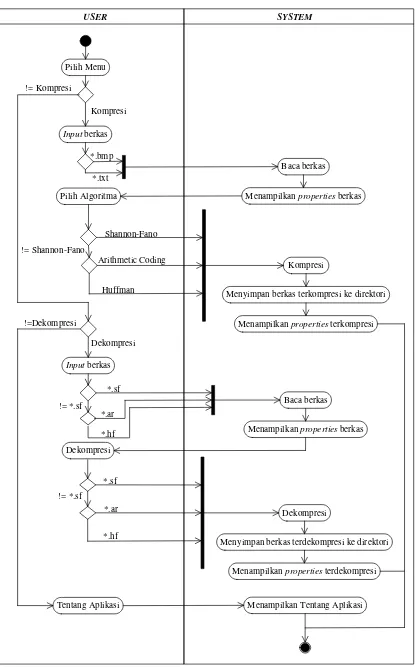
USER SYSTEM
Input berkas
Baca berkas *.bmp
*.txt
Pilih Algoritma
Kompresi Shannon-Fano
Menyimpan berkas terkompresi ke direktori
Menampilkan properties terkompresi Menampilkan properties berkas
!= Shannon-Fano
Huffman Kompresi != Kompresi
Pilih Menu
Arithmetic Coding
Input berkas
*.sf
Baca berkas
Menampilkan properties berkas != *.sf
*.ar
*.hf Dekompresi
Dekompresi
*.sf != *.sf
*.ar
*.hf
Dekompresi
Menyimpan berkas terdekompresi ke direktori
Menampilkan properties terdekompresi
Tentang Aplikasi Menampilkan Tentang Aplikasi
[image:42.595.110.525.81.748.2]!=Dekompresi
3. Diagramsekuensial
Diagram ini menggambarkan hubungan statis antara aktor dan lifeline. Hubungan pada proses kompresi berkas terdiri dari proses sebagai berikut: a. pemanggilan berkas,
b. pembacaan isi berkas, c. pemasukkan algoritma,
d. penyimpanan berkas hasil kompresi, dan e. perhitungan properties kompresi.
Kompresi Berkas Input Berkas
Input berkas *.txt || *.bmp
Baca Isi Berkas
Baca isi berkas
Input Algoritma
Kode ASCII terkompresi
Simpan Berkas Terkompresi Menghitung Properties
Properties Algoritma
Shannon-Fano, Arithmetic Coding, dan Huffman
Gambar 3.4 Diagram Sekuensial Proses Kompresi
Dekompresi Berkas Input berkas *.sh || *.ar || *.hf
Baca isi berkas
Input Berkas Baca Isi Berkas Input Algoritma
Algoritma Shannon-Fano, Arithmetic Coding, dan Huffman
Simpan Berkas Terkompresi Menghitung Properties
Properties Kode ASCII
terdekompresi
3.2 Pseudocode
Pseudocode adalah penjelasan dari algoritma pemrograman komputer yang
menggunakan struktur sederhana dari bahasa pemrograman. Biasanya yang ditulis dari
pseudocode adalah variabel dan fungsi. Tujuan penggunaan utama dari pseudocode
adalah untuk memudahkan dalam memahami prinsip-prinsip dari suatu algoritma.
3.2.1 Pseudocode pembacaan berkas
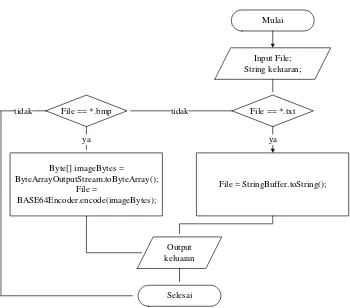
Pada pembacaan berkas, berkas yang dibaca merupakan berkas yang dimasukkan secara digital. Pseudocode pembacaan berkas:
bacafile()
{
input file; String keluaran;
if (file == "*.txt")
{
file = StringBuffer.toString();
}
else if (file == "*.bmp")
{
byte[] imageBytes = ByteArrayOutputStream.toByteArray(); file = BASE64Encoder.encode(imageBytes);
}
output keluaran; }
Input File; String keluaran;
File == *.txt
File = StringBuffer.toString(); File == *.bmp
Output keluaran
Selesai
Mulai
ya ya
tidak tidak
Byte[] imageBytes = ByteArrayOutputStream.toByteArray();
File =
[image:46.595.144.494.76.384.2]BASE64Encoder.encode(imageBytes);
Gambar 3.6 Flowchart Pembacaan Berkas
3.2.2 Pseudocode pengurutan frekuensi
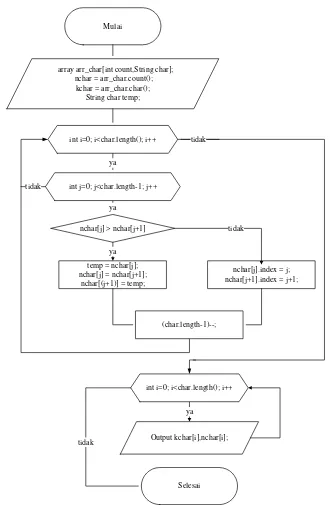
Pada pengurutan frekuensi, pengurutan dilakukan secara menaik. Pseudocode
pengurutan frekuensi: sorting()
{
array arr_char[int count,String char];
nchar = arr_char.count();
kchar = arr_char.char(); String char temp;
for (int i=0; i<char.length(); i++) {
for (int j=0; j<char.length-1; j++)
{
if (nchar[j] > nchar[j+1])
{
temp = nchar[j];
nchar[j] = nchar[j+1];
nchar[(j+1)] = temp; }
nchar[j].index = j;
}
(char.length-1)--;
}
for (int i=0; i<char.length(); i++)
{
output kchar[i],nchar[i]; }
}
Flowchart pengurutan frekuensi karakter dapat dilihat pada Gambar 3.7.
array arr_char[int count,String char]; nchar = arr_char.count();
kchar = arr_char.char(); String char temp;
Mulai
nchar[j] > nchar[j+1]
temp = nchar[j]; nchar[j] = nchar[j+1];
nchar[(j+1)] = temp; ya ya ya
nchar[j].index = j; nchar[j+1].index = j+1;
tidak
Output kchar[i],nchar[i];
Selesai ya int i=0; i<char.length(); i++
int j=0; j<char.length-1; j++
int i=0; i<char.length(); i++ tidak
tidak
tidak
[image:47.595.150.480.235.740.2](char.length-1)--;
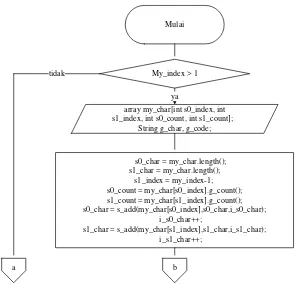
3.2.3 Pseudocode kompresi algoritma Shannon-Fano Pseudocode proses kompresi algoritma Shannon-Fano:
split(int my_index) {
if(my_index > 1)
{
array my_char[int s0_index, int s1_index, int s0_count, int s1_count];
String g_char, g_code;
s0_char = my_char.length()];
s1_char = my_char.length()]; int i_s0_char = 0;
int i_s1_char = 0;
s0_index = 0;
s1_index = my_index-1;
s0_count = my_char[s0_index].g_count();
s1_count = my_char[s1_index].g_count();
s0_char = s_add(my_char[s0_index],s0_char,i_s0_char); i_s0_char++;
s1_char = s_add(my_char[s1_index],s1_char,i_s1_char); i_s1_char++;
karakter_s0 = my_char[s0_index].g_char();
kode_s0 = my_char[s0_index].g_code();
karakter_s1 = my_char[s1_index].g_char();
kode_s1 = my_char[s1_index].g_code();
my_char[s0_index].add_code("1");
output(karakter_s0+" , "+kode_s0); my_char[s1_index].add_code("0");
output(karakter_s1+" , "+kode_s1);
for(int i=0; i<my_index; i++)
{
if(!((s1_index-s0_index == 1) || (s1_index-s0_index == - 1)))
{
if(s0_count < s1_count)
{
s0_index++;
my_char[s0_index].add_code("1"); s0_char =
s_add(my_char[s0_index],s0_char,i_s0_char); i_s0_char++;
output(karakter_s0+" , "+kode_s0);
}
else {
s1_index--;
s1_count += my_char[s1_index].g_count();
my_char[s1_index].add_code("0"); s1_char =
s_add(my_char[s1_index],s1_char,i_s1_char); i_s1_char++;
output(karakter_s1+" , "+kode_s1); } } } split(s0_char, i_s0_char); split(s1_char, i_s1_char); } }
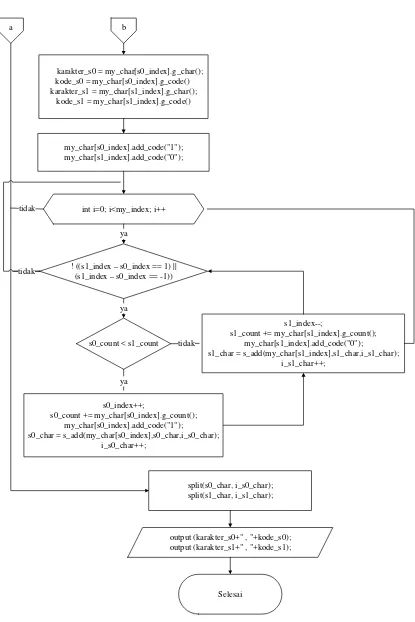
[image:49.595.172.467.459.743.2]Flowchart proses kompresi algoritma Shannon-Fano dapat dilihat pada Gambar 3.8 dan Gambar 3.9.
Mulai
My_index > 1
array my_char[int s0_index, int s1_index, int s0_count, int s1_count];
String g_char, g_code;
s0_char = my_char.length(); s1_char = my_char.length();
s1_index = my_index-1; s0_count = my_char[s0_index].g_count(); s1_count = my_char[s1_index].g_count(); s0_char = s_add(my_char[s0_index],s0_char,i_s0_char);
i_s0_char++;
s1_char = s_add(my_char[s1_index],s1_char,i_s1_char); i_s1_char++;
ya tidak
a b
int i=0; i<my_index; i++
karakter_s0 = my_char[s0_index].g_char(); kode_s0 = my_char[s0_index].g_code() karakter_s1 = my_char[s1_index].g_char();
kode_s1 = my_char[s1_index].g_code()
my_char[s0_index].add_code("1"); my_char[s1_index].add_code("0");
s0_count < s1_count ya
ya
tidak
split(s0_char, i_s0_char); split(s1_char, i_s1_char); ya
output (karakter_s0+" , "+kode_s0); output (karakter_s1+" , "+kode_s1);
Selesai s0_index++;
s0_count += my_char[s0_index].g_count(); my_char[s0_index].add_code("1");
s0_char = s_add(my_char[s0_index],s0_char,i_s0_char); i_s0_char++;
s1_index--;
s1_count += my_char[s1_index].g_count(); my_char[s1_index].add_code("0");
s1_char = s_add(my_char[s1_index],s1_char,i_s1_char); i_s1_char++;
! ((s1_index – s0_index == 1) || (s1_index – s0_index == -1)) tidak
tidak
[image:50.595.126.541.68.690.2]a b
3.2.4 Pseudocode dekompresi algoritma Shannon-Fano Pseudocode proses dekompresi algoritma Shannon-Fano:
decode() {
String bin, biner;
array tree[String g_char, String g_code]; int binLength = bin.length();
char[] binCharAt = bin.toCharArray();
Stringbuffer bf;
biner = "";
for (int i=0; i<binLength; i++)
{
biner += binCharAt[i];
for (int j=0; j<tree.length; j++)
{
output (biner+" , "+tree[j].g_code()); if (biner.equals(tree[j].g_code()))
{
output ("karakter : "+tree[j].g_char()); bf.append(tree[j].g_char());
output ("string : "+bf); biner = "";
}
} } }
Flowchart proses dekompresi algoritma Shannon-Fano dapat dilihat pada
String bin, biner;
array tree[String g_char, String g_code]; int binLength = bin.length(); char[]
binCharAt = bin.toCharArray(); Mulai
int i=0; i<binLength; i++
biner += binCharAt[i];
int j=0; i<treeLength; j++
biner.equals(tree[j].g_code())
bf.append(tree[j].g_char()); biner;
Output tree[j].g_char()+bf; ya
ya
ya
tidak
tidak tidak
[image:52.595.174.446.80.607.2]Selesai
3.2.5 Pseudocode kompresi algoritma Arithmetic Coding Pseudocode proses kompresi algoritma Arithmetic Coding:
findDecimal(double low, double high, String text) {
array header[symbol,range_min,range_max];
double min,max;
if(text.length() > 0)
{
int i = 0;
while(text.charAt(0) != header.symbol[i] )
{
i++;
}
min = low+(high-low)*header.range_min[i];
max = low+(high-low)*header.range_max[i];
text =removeFirstChar(text);
findDecimal(min, max, text); }
}
final String findBinary(double a,double b, String result){ if(a<0.5 && b<0.5){
result = findBinary(2*a, 2*b, result+"0"); }else if(a>0.5 && b>0.5){
result = findBinary((a-0.5)*2, (b-0.5)*2, result+"1");
}else if(a==0 && b>=0.5){ result = result+"0";
}else if(a<=0.5 && b==1){
result = result+"1"; }else if(a<=0.5 && b>= 0.5){
String buff,bin;
ifLength = inputfile.length(); ifCharAt = inputfile.toCharArray();
buff = "";
for (int i=0; i<ifLength; i++)
{
buff += ifCharAt[i];
if (buff.length() == 2) {
findDecimal(0,1,buff);
bin = findBinary(min,max,"");
output (buff+ " : " + min + " - " + max + " bin : "+bin);
sb.append(bin);
buff = ""; }
}
if (buff.length() == 1)
{
findDecimal(0,1,buff);
bin = findBinary(min,max,"");
output (buff+ " : " + min + " - " + max + " bin : "+bin);
sb.append(bin); }
Output sb; }
Flowchart proses kompresi Arithmetic Coding dapat dilihat pada Gambar
Mulai
Double ifLength; Char[] ifCharAt; StringBuffer sb;
String buff,bin;
ifLength = inputFile.length(); ifCharAt = inputFile.toCharArray();
buff = “”;
int i=0; i<ifLength; i++;
buff += ifCharAt[i];
buff.length() == 2
findDecimal(0,1,buff);
bin = findBinary(min,max,””);
sb.append(bin); buff = “”;
ya ya
tidak
tidak
output (buff+ " : " + min + " - " + max + " bin : "+bin);
[image:55.595.183.458.80.746.2]a
buff.length() == 1
findDecimal(0,1,buff);
bin = findBinary(min,max,””);
sb.append(bin); ya tidak
Selesai
a
Output sb;
Gambar 3.12 Flowchart Kompresi Algoritma Arithmetic Coding 2
double low,high; String text;
array
header[symbol,range_min,range_max]; double min,max;
int i = 0; Mulai findDecimal()
text.length() > 0
text.charAt(0) != header.symbol[i]
i++; tidak
ya ya
min = low+(high-low)*header.range_min[i]; max = low+(high-low)*header.range_max[i];
text =removeFirstChar(text); findDecimal(min, max, text);
Selesai tidak
[image:56.595.212.465.80.352.2] [image:56.595.202.469.388.734.2]Mulai findBinary()
Double a,b; String result;
a<0.5 && b<0.5
result = findBinary(2*a, 2*b, result +”0");
a>0.5 && b>0.5
result = findBinary((a-0.5)*2, (b-0.5)*2, result +”1");
ya
ya tidak
a==0 && b>=0.5
result = result +”0"; ya tidak
a<=0.5 && b==1
result = result +”1"; ya
tidak
a<=0.5 && b>= 0.5
re