BAB 2
LANDASAN TEORI
2.1Definisi Data
Data merupakan bahan baku informasi, dapat didefinisikan sebagai kelompok teratur simbol-simbol yang mewakili kuantitas, fakta, tindakan, benda dan sebagainya (Supriyanto & Muhsin, 2008: 69). Data terbentuk dari karakter, dapat berupa alfabet, angka, maupun simbol khusus seperti *,$ dan /. Data disusun mulai dari bits, bytes, fields, records, file dan database.
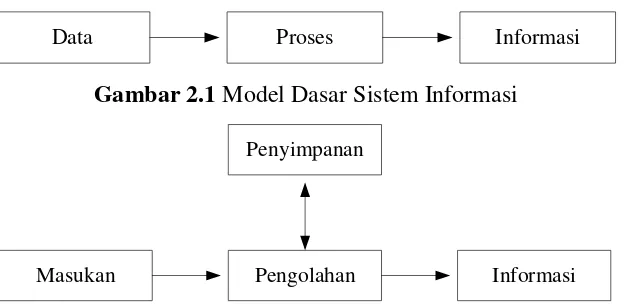
Sistem informasi menerima masukan data dan instruksi, mengolah data tersebut sesuai instruksi, dan mengeluarkan hasilnya. Fungsi pengolahan informasi sering membutuhkan data yang telah dikumpulkan dan diolah dalam periode sebelumnya, karena itu ditambahkan sebuah penyimpanan data file (data file storage) ke dalam model sistem informasi. Dengan begitu, kegiatan pengolahan tersedia, baik bagi data baru maupun data yang telah dikumpulkan dan disimpan sebelumnya.
Data Proses Informasi
Gambar 2.1 Model Dasar Sistem Informasi
Masukan Pengolahan Informasi Penyimpanan
Tablespace
SYSTEM Tablespace 1 Tablespace 2
Database
Segment 1 Segment 2
Segment 3
Extend 1
Extend 2
Data Block
Tablespace
Segment
Gambar 2.3 Susunan Data
Sistem di komputer akan mengorganisasi data dalam sebuah hirarki yang terdiri dari satuan-satuan bit, byte, field, record, file, dan database.Bit merupakan unit data yang terkecil, tingkatan terendah; singkatan dari binary digit (Joos et al, 2009: 12). Byte adalah kumpulan dari kombinasi bits, biasanya terdiri 8 bit yang menjadi unit terkecil dalam storage dan mempunyai alamat, sering kali menjadi bagian dari
word (Supriyanto et al, 2008: 71). Field merupakan karakter-karakter yang membentuk arti tertentu, misalnya field untuk nomor mahasiswa, dan sebagainya
Record adalah kumpulan dari fields yang membentuk sebuah arti yang saling berhubungan. (Noersasongko, 2010: 36). File adalah kumpulan dari records yang sejenis, contoh file tentang kepegawaian di berbagai departemen di sebuah instansi (Supriyanto et al, 2008: 71). Database adalah sekumpulan data yang berhubungan secara logika dan memiliki beberapa arti yang saling berpautan (Mata-Toledo, 2007: 1).
2.2 Kompresi Data
lebih kecil dan lebih ringan dalam proses transmisi dan menghemat ruang memori dalam penyimpanan data (Putra, 2010: 261).
Ada beberapa faktor yang memunculkan data berlebihan sehingga harus diperlukan proses kompresi. Faktor-faktor tersebut antara lain sebagai berikut:
1. pada suatu citra tunggal atau pada frame tunggal video dapat terjadi korelasi yang signifikan antara suatu piksel dengan piksel tetangga. Korelasi ini disebut dengan korelasi spasial (spatial correlation),
2. pada data yang diambil dari beberapa sensor (multi sensor), terdapat korelasi yang signifikan antarsampel yang diambil oleh sensor-sensor tersebut. Korealasi ini disebut dengan korelasi spektral (spectral correlation),
3. pada data temporal seperti video, terdapat korelasi yang signifikan antara sampel data pada segmen waktu yang berbeda. Korelasi ini disebut sebagai korelasi temporal (temporal correlation),
4. pada suatu data terdapat informasi yang tidak relevan dengan sudut pandang persepsi mata.
2.3 Data Berlebihan (Data Redundancy)
Terdapat beberapa faktor yang memunculkan data berlebihan (data redundancy). Data berlebihan ini dapat dinyatakan secara sistematis. Bila n1 dan n2 menyatakan jumlah
satuan (unit) informasi dalam dua himpunan data (data set) yang mewakili data yang sama maka data berlebihan relatif (relative data redundancy) RD dari himpunan data
pertama dinyatakan sebagai berikut: 𝑅𝑅𝐷𝐷 = 1−𝐶𝐶1
𝑅𝑅 ... (1) Dimana RD merupakan redundansi, dan CR merupakan rasio kompresi.
Rasio kompresi (CR ) dinyatakan sebagai berikut:
𝐶𝐶𝑅𝑅 =𝑛𝑛𝑛𝑛1
2 ... (2) Dimana n1 merupakan nilai dari data hasil kompresi, dan n2 merupakan nilai dari data
asli.
Bila n1 = n2 maka CR = 1 dan RD = 0, berarti bahwa data set pertama tidak
mengandung data berlebihan. Bila n2 < n1 (n2 jauh lebih kecil dari n1) maka CR
mendekati 1 tak terhingga, sehingga RD mendekati 1. Ini berarti terjadi kandungan
mendekati 0, sehingga RD mendekati minus tak terhingga. Ini berarti data set kedua
mengandung informasi jauh lebih banyak dibandingkan data set pertama. Secara umum, CR dan RD berturut-turut beada dalam interval (1,∞) dan (-∞,1). Dalam
praktik, rasio kompresi 20 (atau 20:1) berarti data set pertama mengandung 20 satuan (unit) informasi untuk setiap 1 unit pada data set kedua (atau pada data terkompresi). Dengan kata lain, untuk kasus citra, citra asli (citra belum termampatkan) mengandung 20 bit informasi untuk setiap 1 bit pada data terkompresi. Redundansi 0.8 berarti 80% data pada data set pertama adalah berlebihan.
2.4 Teknik Kompresi Citra
Menurut Putra (2010), ada dua teknik yang dapat dilakukan dalam memampatkan citra digital.
1. Kompresi Lossless
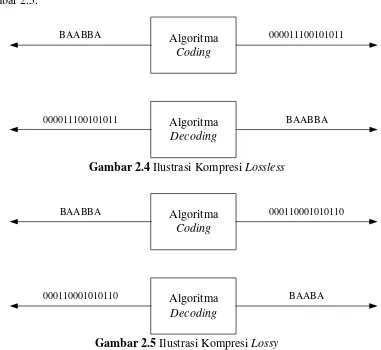
Pada kompresi jenis ini informasi yang terkandung pada berkas hasil sama dengan informasi pada berkas asli. Berkas hasil proses kompresi dapat dikembalikan secara sempurna menjadi berkas asli, tidak terjadi kehilangan informasi, tidak terjadi kesalahan informasi. Oleh karena itu metode ini disebut juga error free compression.
Pada kompresi lossless, karena harus mempertahankan kesempurnaan informasi, sehingga hanya terdapat proses coding dan decoding, tidak terdapat proses kuantitasi. Kompresi tipe ini cocok diterapkan pada berkas basis data (database), spread sheet, berkas word processing, citra biomedis dan lain sebagainya.
2. Kompresi Lossy
pada penyimpanan data analog yang didigitasi seperti gambar, video, dan suara.
Ilustrasi kompresi lossless dan lossy dapat dilihat pada Gambar 2.4 dan Gambar 2.5.
Algoritma Coding
Algoritma Decoding
000011100101011
000011100101011 BAABBA
BAABBA
Gambar 2.4 Ilustrasi Kompresi Lossless
Algoritma Coding
Algoritma Decoding
000110001010110 BAABBA
BAABA 000110001010110
Gambar 2.5 Ilustrasi Kompresi Lossy
2.5 Berkas Teks
2.6 Citra Digital
Citra digital merupakan obyek nyata yang direpresentasi secara elektronis (Mulyanta, 2006: 5). Obyek dapat bersumber dari dokumen, foto, barang cetakan, hingga lukisan. Unsur utama citra digital adalah grid berisi elemen obyek yang sangat dasar, yaitu
picture element (piksel). Setiap piksel mempunyai tingkatan nilai tertentu, sehingga menghasilkan representasi data yang ditangkap oleh mata manusia sebagai bentuk tingkatan warna hitam, putih, abu-abu, hingga penuh dengan warna.
Setiap bit dalam piksel akan disimpan dalam urutan tertentu oleh komputer dengan penghitungan matematis agar menghasilkan file yang optimal dibaca oleh media perangkat yang mendukungnya. Setiap informasi bit digital akan diinterpretasikan dan dibaca oleh komputer agar menghasilkan versi analog untuk ditampilkan dan dicetak oleh media lain. Versi yang dilihat oleh mata manusia adalah data bersifat analog yang dirangkat oleh peralatan digital pada media komputer.
1 0 0 1 1 1 1 1 0 0 1
Gambar 2.6 Nilai-nilai pada Piksel
Gambar 2.6 memperlihatkan bahwa bentuk-bentuk obyek dihasilkan dari kombinasi nilai 0 untuk warna hitam dan 1 untuk warna putih, sehingga membentuk
bitonal image. Bitonal image tidak mengenal gradasi warna, sehingga citra yang dihasilkan mempunyai kesan sangat kaku dan tidak alami.
2.7 Pengolahan Citra Digital
tujuan analisis, melakukan proses penarikan informasi atau deskripsi obyek atau pengenalan obyek yang terkandung pada citra, melakukan kompresi atau reduksi data untuk tujuan penyimpanan data, transmisi data, dan waktu proses data. Masukan dari pengolahan citra adalah citra, sedangkan keluarannya adalah citra hasil pengolahan (Sutoyo, 2009: 5).
2.8 Format Berkas Bitmap (*.bmp)
Gambar bitmap adalah citra yang dihasilkan oleh sejumlah titik berwarna-warni yang disebut piksel. Piksel-piksel itu ditempatkan pada suatu bidang matriks. Warna-warna piksel yang sama atau senada yang berada pada suatu area dan berdampingan dengan warna-warna dapat menimbulkan nuansa bentuk. Gabungan dari beberapa nuansa itu ditangkap oleh mata manusia sebagai citra atau gambar (Budijanto, 2006: 253).
Format *.bmp adalah format penyimpanan standar tanpa kompresi umum yang dapat digunakan untuk menyimpan citra biner hingga citra warna. Format ini terdiri dari beberapa jenis yang setiap jenisnya ditentukan dengan jumlah bit yang digunakan untuk menyimpan sebuah nilai piksel (Putra, 2010:58).
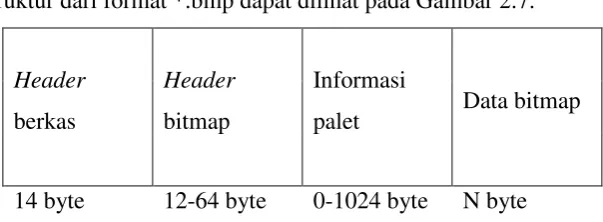
Struktur dari format *.bmp dapat dilihat pada Gambar 2.7.
Header
berkas
Header
bitmap
Informasi
palet Data bitmap
14 byte 12-64 byte 0-1024 byte N byte Gambar 2.7 Struktur Format Berkas *.bmp
Berkas dengan format *.bmp memerlukan memori penyimpanan yang besar, karena berkas ini merupakan format yang belum terkompresi dan menggunakan sistem warna Red, Green, Blue (RGB) dimana masing-masing warna pikselnya terdiri dari 3 komponen yang dicampur menjadi satu.
2.9 Informasi Teori dan Entropi
pada pengkodean. Jika informasi tambahan itu bisa diambil, maka data yang diperlukan tersebut bisa direduksi.
Teori informasi memanfaatkan terminologi entropi sebagai tolak ukur seberapa besar informasi yang dikodekan pada sebuah data. Menurut Adriani (2009),
entropi merupakan suatu ukuran informasi yang dikandung oleh suatu citra dan digunakan sebagai ukuran untuk mengukur kemampuan kompresi dari data. Entropi
memiliki persamaan matematis sebagai berikut:
𝐻𝐻(𝑋𝑋) = − ∑ 𝑝𝑝𝑚𝑚𝑖𝑖=1 𝑖𝑖𝑙𝑙𝑙𝑙𝑙𝑙2𝑝𝑝𝑖𝑖 ... (3) Dimana m merupakan jumlah simbol dan pi merupakan probabilitas simbol ke-i.
Semakin kecil nilai entropi yang dihasilkan, maka kemampuan kompresi lebih baik.
Entropi juga didefinisikan sebagai limit kemampuan kompresi citra yang tidak dapat dilampau oleh algoritma manapun.
2.10 Algoritma Shannon-Fano
Algoritma Shannon-Fano dinamai berdasarkan nama pengembangnya yaitu Claude Shannon dan Robert Fano. Metode ini dimulai dengan deretan dari simbol n dengan kemunculan frekuensi yang diketahui. Mula-mula simbol disusun secara menaik (ascending order) berdasarkan frekuensi kemunculannya. Lalu set simbol tersebut dibagi menjadi dua bagian yang berbobot sama atau hampir sama. Seluruh simbol yang berada pada subset I diberi biner 0, sedangkan simbol yang berada pada subset II diberi biner 1. Setiap subset dibagi lagi menjadi dua subsubset dengan bobot kemunculan frekuensi yang kira-kira sama, dan biner kedua diberikan seperti subset I dan subset II. Ketika subset hanya berisi dua simbol, biner diberikan pada setiap simbol. Proses akan berlanjut sampai tidak ada subset yang tersisa (Salomon: 2010).
Algoritma Shannon-Fano merupakan kompresi yang bersifat lossless, dimana metode ini harus mendekompresi berkas agar dapat direkonstruksikan menjadi berkas semula tanpa kehilangan informasi.
2.11 Algoritma Arithmetic Coding
namun pada saat itu metode ini belum memenuhi solusi yang pantas untuk masalah yang akan dihadapi, yaitu keakurasian Arithmetic Coding harus ditingkatkan dengan panjang dari pesan yang dimasukkan. Untungnya, pada tahun 1976 Pasco dan Rissanen membuktikan bahwa panjang angka yang terbatas sebenarnya memadai untuk encoding, tanpa mengurangi akurasinya. Pada tahun 1979 – 1980, Rubin, Guazzo, Rissanen, dan Langdon mempublikasikan algoritma dasar encoding yang masih digunakan sampai sekarang. Algoritma ini berdasarkan ketelitian aritmatik yang terbatas (Bodden et al, 2007)
Arithmetic Coding menggantikan satu deretan simbol input dengan sebuah bilangan floating point. Semakin panjang dan semakin kompleks pesan yang dikodekan, semakin banyak bit yang diperlukan untuk keperluan tersebut. Output dari metode ini adalah satu angka yang lebih kecil dari 1 dan lebih besar atau sama dengan 0. Angka ini secara unik dapat di-encode sehingga menghasilkan deretan simbol yang dipakai untuk menghasilkan angka tersebut (Salomon, 2010).
2.12 Algoritma Huffman
Metode ini dikembangkan oleh David Huffman sebagai bagian dari tugas kuliahnya. Kelas tersebut merupakan bagian dari teori informasi dan diajarkan oleh Robert Fano di MIT. Kode yang dihasilkan menggunakan metode ini dinamakan Huffman Codes. Kode ini merupakan kode prefiks dan optimal untuk model yang diberikan.
Menurut Sayood (2012), prosedur algoritma Huffman berdasarkan dua penelitian mengenai kode prefix yang optimum, yaitu:
1. Simbol yang mempunyai frekuensi kemunculan lebih sering akan memiliki
code word yang lebih pendek dari simbol lainnya.
2. Dua simbol yang mempunyai frekuensi kemunculan paling sedikit akan memiliki code word dengan panjang yang sama.
2.13 Kompleksitas Algoritma (Notasi Big-O)
Dalam aplikasinya, setiap algoritma memiliki dua buah ciri yang khas yang dapat digunakan sebagai parameter pembanding, yaitu jumlah proses yang dilakukan dan jumlah memori yang digunakan untuk melakukan proses. Jumlah proses ini dikenal sebagai kompleksitas waktu yang disimbolkan dengan T(n), sedangkan jumlah memori ini dikenal sebagai kompleksitas ruang yang disimbolkan dengan S(n).
Kenyataannya, jarang sekali dibutuhkan kompleksitas waktu yang detail dari suatu algoritma. Biasanya yang dibutuhkan hanyalah bagian paling signifikan dari kompleksitas waktu yang sebenarnya. Kompleksitas waktu ini dinamakan kompleksitas waktu asimptotik yang dinotasikan dengan O (O-besar atau Big-O). Kompleksitas waktu asimptotik ini diperoleh dengan mengambil term terbesar dari suatu persamaan kompleksitas waktu.
Misalnya jika diperoleh waktu eksekusi dari suatu algoritma T(n) adalah sebanyak 5n3+4n+3 langkah untuk besar input sebesar n, maka akan lebih mudah untuk menghapus pangkat yang kecil seperti 4n dan 3 karena keduanya tidak terlalu signifikan terhadap input n. Koefisien 5 pada 5n3 juga dihilangkan dengan anggapan bahwa komputer beberapa tahun kedepan akan menjadi 5 kali lipat lebih cepat dari komputer sekarang, sehingga keberadaan koefisien 5 juga tidak terlalu signifikan. Maka waktu yang diperlukan oleh algoritma tersebut untuk memproses input sebesar n adalah n3, atau biasa dituliskan Big-O=n3 (Dasgupta et al, 2006).
Notasi Big-O yang sering dijumpai pada algoritma antara lain: 1. O(1) – constant time
Algoritma yang menghasilkan nilai selalu tetap tanpa bergantung kepada banyak masukan.
2. O(2log n) – logarithmic time
Algoritma yang berdasarkan pada binary tree biasanya memiliki kompleksitas
O(log n).
3. O(n) – linear time
4. O(n 2log n) – linearithmic time
Algoritma yang memecahkan masalah menjadi masalah yang lebih kecil, lalu menyelesaikan tiap masalah secara independen.
5. O(n2) – quadratic time
Algoritma yang melibatkan proses perulangan bersarang (nested loop). 6. O(n3) – cubic time
Algoritma dengan kompleksitas O(n3) mirip dengan O(n2), namun menggunakan loop bersarang sebanyak 3 kali. Algoritma sejenis ini hanya cocok jika n kecil. Jika n besar, waktu yang dibutuhkan akan sangat lama. 7. O(2n) – exponential time
Salah satu algoritma yang mempunyai kompleksitas O(2n) adalah brute force dalam menebak suatu password. Setiap penambahan karakter, akan melipatgandakan waktu yang dibutuhkan.
8. O(n!) – factorial time
O(n!) merupakan kompleksitas yang sangat cepat pertumbuhan waktu yang diperlukannya. Algoritma ini memproses setiap masukan dan menghubungkannya dengan n-1 masukan lainnya.
2.14 Evaluasi Kinerja Algoritma
Beberapa parameter untuk evaluasi kinerja algoritma, antara lain: 1. Rasio Kompresi
Rasio Kompresi merupakan rasio antara ukuran dari berkas terkompres dan berkas asli.
𝐶𝐶𝑙𝑙𝑚𝑚𝑝𝑝𝐶𝐶𝐶𝐶𝐶𝐶𝐶𝐶𝑖𝑖𝑙𝑙𝑛𝑛𝑅𝑅𝑅𝑅𝑅𝑅𝑖𝑖𝑙𝑙= 𝐶𝐶𝑖𝑖𝑠𝑠𝐶𝐶𝐶𝐶𝑖𝑖𝑠𝑠𝐶𝐶𝑏𝑏𝐶𝐶𝑎𝑎𝑙𝑙𝐶𝐶𝐶𝐶𝑅𝑅𝑎𝑎𝑅𝑅𝐶𝐶𝐶𝐶 𝑐𝑐𝑙𝑙𝑚𝑚𝑝𝑝𝐶𝐶𝐶𝐶𝐶𝐶𝐶𝐶𝑖𝑖𝑙𝑙𝑛𝑛𝑐𝑐𝑙𝑙𝑚𝑚𝑝𝑝𝐶𝐶𝐶𝐶𝐶𝐶𝐶𝐶𝑖𝑖𝑙𝑙𝑛𝑛 ... (4)
2. Faktor Kompresi
Faktor kompresi merupakan invers dari rasio kompresi, yaitu hubungan antara berkas asli dan berkas terkompres.
𝐶𝐶𝑙𝑙𝑚𝑚𝑝𝑝𝐶𝐶𝐶𝐶𝐶𝐶𝐶𝐶𝑖𝑖𝑙𝑙𝑛𝑛𝐹𝐹𝑅𝑅𝑐𝑐𝑅𝑅𝑙𝑙𝐶𝐶= 𝐶𝐶𝑖𝑖𝑠𝑠𝐶𝐶 𝑏𝑏𝐶𝐶𝑎𝑎𝑙𝑙𝐶𝐶𝐶𝐶 𝑐𝑐𝑙𝑙𝑚𝑚𝑝𝑝𝐶𝐶𝐶𝐶𝐶𝐶𝐶𝐶𝑖𝑖𝑙𝑙𝑛𝑛
𝐶𝐶𝑖𝑖𝑠𝑠𝐶𝐶 𝑅𝑅𝑎𝑎𝑅𝑅𝐶𝐶𝐶𝐶 𝑐𝑐𝑙𝑙𝑚𝑚𝑝𝑝𝐶𝐶𝐶𝐶𝐶𝐶𝐶𝐶𝑖𝑖𝑙𝑙𝑛𝑛 ... (5) 3. Saving Percentage (SP)
𝑆𝑆𝑆𝑆= 𝐶𝐶𝑖𝑖𝑠𝑠𝐶𝐶𝑏𝑏𝐶𝐶𝑎𝑎𝑙𝑙𝐶𝐶𝐶𝐶 𝑐𝑐𝑙𝑙𝑚𝑚𝑝𝑝𝐶𝐶𝐶𝐶𝐶𝐶𝐶𝐶𝑖𝑖𝑙𝑙𝑛𝑛 −𝐶𝐶𝑖𝑖𝑠𝑠𝐶𝐶𝐶𝐶𝑖𝑖𝑠𝑠𝐶𝐶 𝑏𝑏𝐶𝐶𝑎𝑎𝑙𝑙𝐶𝐶𝐶𝐶 𝑐𝑐𝑙𝑙𝑚𝑚𝑝𝑝𝐶𝐶𝐶𝐶𝐶𝐶𝐶𝐶𝑖𝑖𝑙𝑙𝑛𝑛𝑅𝑅𝑎𝑎𝑅𝑅𝐶𝐶𝐶𝐶 𝑐𝑐𝑙𝑙𝑚𝑚𝑝𝑝𝐶𝐶𝐶𝐶𝐶𝐶𝐶𝐶𝑖𝑖𝑙𝑙𝑛𝑛 % .. ... (6)
2.15 Penelitian yang Relevan
2.15.1 Studi Perbandingan Kinerja Algoritma Kompresi Shannon-Fano dan
Arithmetic Coding pada Citra Digital
Pada penelitian Andriani (2009) yang berjudul Studi Perbandingan Kinerja Algoritma Kompresi Shannon-Fano dan Arithmetic Coding pada Citra Digital, perbandingan kinerja algoritma kompresi bertujuan untuk mengetahui performansi masing-masing algoritma terhadap citra digital. Untuk mengetahui performansi hasil proses kompresi dilakukan melalui perhitungan rasio kompresi, ukuran file hasil kompresi, kecepatan proses kompresi dan dekompresi dan nilai PSNR. Berdasarkan seluruh hasil pengujian, sistem kompresi menggunakan Arithmetic Coding Coding memiliki performansi yang baik berdasarkan rasio kompresi serta ukuran file hasil kompresi, sedangkan dari segi kecepatan proses kompresi dan dekompresi algoritma Shannon-Fano lebih baik daripada algoritma Arithmetic Coding.
2.15.2 Analisis Kinerja dan Implementasi Algoritma Kompresi Arithmetic Coding
pada File Teks dan Citra Digital
2.15.3 Implementasi Algoritma Huffman pada Kompresi Citra BMP
Pada penelitian Ginting (2012) yang berjudul Implementasi Algoritma Huffman pada Kompresi Citra BMP, penelitian diimplementasikan menggunakan Microsoft Visual Basic 2008. Implementasi algoritma Huffman tersebut bertujuan untuk mengkompresi citra bmp sehingga ukuran file hasil kompresi lebih kecil dibandingkan dengan ukuran citra asli dimana parameter yang digunakan untuk mengukur kinerja algoritma adalah rasio kompresi yang dihasilkan. Berdasarkan dari seluruh hasil pengujian, hasil kompresi citra menggunakan algoritma Huffman hanya mencapai tingkat rasio 2% - 8% untuk citra yang mengandung banyak variasi warna sedangkan untuk citra yang mengandung sedikit variasi warna (duplikasi warna) tingkat rasionya dapat mencapai hingga 80%.
2.15.4 Analisis Perbandingan Teknik Kompresi Menggunakan Algoritma
Shannon-Fano, dan Run Length Encoding pada Citra Berformat BMP dan PNG.