KONSEP DAN IMPLEMENTASI PARSING DENGAN
MENGGUNAKAN METODE BRUTE FORCE
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Sains (S.Si)
Program Studi Matematika
Oleh:
Vinsentia Asri Budiarti NIM : 003114035
PROGRAM STUDI MATEMATIKA
JURUSAN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
2006
HALAMAN PERSEMBAHAN
Kebanggaan terbesar adalah bukan tidak pernah gagal, tetapi bangkit
kembali setiap kali kita jatuh.
Kebanyakan dari kita tidak menyukai apa yang sudah kita miliki,
tetapi kita selalu menyesali apa yang belum kita capai.
Seorang pesimis melihat kesulitan dalam setiap kesempatan, seorang
optimis melihat kesempatan dalam setiap kesulitan.
Kupersembahkan Karyaku ini Kepada:
Yesus Kristus Sang Juru Slamatku, Kedua orangtuaku tercinta JB Tukidjo,
Kakaku tersayang mas Bowo, Kekasihku dr Aloysius Sulistyanto, M.D.,
PERNYATAAN KEASLIAN KARYA
Saya menyatakan dengan sesungguhnya bahwa skripsi yang saya tulis ini tidak memuat karya atau bagian karya orang lain, kecuali yang telah disebutkan dalam kutipan dan daftar pustaka, sebagaimana layaknya karya ilmiah.
Yogyakarta, Juli 2006 Penulis
Vinsentia Asri Budiarti
ABSTRAK
Parsing dengan metode Brute Force adalah parsing yang memilih aturan produksi mulai dari paling kiri, dan melakukan expand semua non terminal pada aturan produksi sampai yang tertinggal adalah simbol terminal. Kemungkinan pertama string masukan sukses di-parsing, bisa juga bila terjadi expansi yang salah untuk suatu simbol variabel maka akan dilakukan backtrack. Algoritma ini membangun pohon parsing yang top down, yaitu mencoba segala kemungkinan untuk setiap simbol non terminal.
ABSTRACT
The Brute Force Parsing method is a method which choosing left most symbol on a production rule and expanding all of non terminal symbol on it until only a terminal symbol left. The first possibility is input string parsed successfully, otherwise it will perform backtracking when expansion have an error. This algorithm create a top-down parse tree which will trying all possibilities for each non terminal symbol.
KATA PENGANTAR
Allah mencipatakan manusia diberi akal dan pikiran. Dengan tidak meninggalkanNya kita mampu melewati segala rintangan dan kesulitan yang kita hadapi. Akan tetapi kita sering lupa bahwa kasih dan cintaNya senantiasa menyertai kita sepanjang hidup. Dan dengan campur tangan Allah semua dapat terselesaikan dengan mudah. Bunda Maria perawan suci yang telah mengajarkan kepada kita untuk tidak pernah berhenti memohon dalam kesulitan apapun yang kita hadapi, dengan perantaraanNya maka akan dikabulkanNya.
Puji syukur penulis panjatkan kepadaMu Bapa di surga yang telah mengabulkan doa-doaku dengan perantaraan Bunda Maria, Ibu sejati dan Ratu surgawi. KepadaMu semua pengharapanku yang besar kucurahkan sehingga dapat menyelesaikan tugas dan tanggungjawabku selama ini dengan baik.
Dalam menyusun skripsi ini penulis memperoleh banyak bantuan, petunjuk serta bimbingan yang sangat berharga dari berbagai pihak.. Oleh karena itu dengan ketulusan hati ijinkan penulis secara pribadi menyampaikan ucapan terima kasih sebesar-besarnya kepada:
1. Bpk Ir. Ig. Aris Dwiatmoko, M.Sc. selaku Dekan FMIPA Universitas Sanata Dharma, terima kasih atas saran dan motivasi yang diberikan kepada penulis. 2. Bpk Y.G. Hartono, S.Si., M.Sc. selaku Ketua Program Studi Matematika,
terima kasih atas semangat yang diberikan kepada penulis hingga penulis dapat menyelesaikan skripsi ini.
3. Ibu M.V. Any Herawati, S.Si., M.Si. selaku Dosen Pembimbing Akademik, terima kasih atas saran dan motivasinya.
4. Bpk Iwan Binanto, S.Si. selaku dosen pembimbing skripsi, terima kasih buanyak atas kesabaran, perhatian, motivasi dan kepercayaan yang diberikan kepada penulis hingga selesainya penulisan skripsi ini. Penulis tidak akan pernah melupakan semua bantuan, kesabaran, saran serta kebaikan bapak. 5. Terima kepada semua dosen pengajar serta staff FMIPA atas kerjasamanya
selama ini kepada penulis.
6. Bapak dan ibu tercinta JB. Tukidjo, serta kakakku tersayang Mas Bowo, terima kasih atas kasih sayang, perhatian, semangat, kesabaran dan kebaikan yang diberikan kepada penulis.
7. Tak lupa ucapan terima kasih kepada calon suamiku, dr. Aloysius Sulistyanto, M.D., Akp, terima kasih buanyak atas kesabaran, kesetian, cinta, kasih sayang, motivasi, pengertian, ketulusannya hingga saat ini. Sekali lagi terima kasih telah membangkitkan semangat hidupku.
8. Sahabatku Tatik, terima kasih atas semangat yang diberikan, terima kasih juga atas pinjaman kamusnya.
9. Teman-teman kampus angkatan 2000: Tatik, Ayu, Bunga, Pras, Felix, Willy, Tony, Niza, Eros, Tildy, Sinta, Megi, Eros, Tika, Elin, Sunarto, Deny, Wiwid ndut, Dewi, Susi, Wiwid, Andy, Lia, Nety, Heri, Jeng-jeng, polo, Mira, Ferry, Wahyu, Heru. Terima aksih atas persahabatnnya selama ini.
10.Teman kostku Ana, terima kasih atas persahabatannya ini. 11.Mas Koko, terima kasih atas bantuannya.
12.Semua pihak yang secara langsung maupun tidak langsung yang turut membantu dalam penulisan skripsi ini, maaf tidak dapat disebutkan satu persatu.
Penulis menyadari bahwa skripsi ini masih jauh dari kata sempurna, oleh karena itu segala kritik dan saran yang bersifat membangun dari semua pihak akan penulis terima dengan senang hati. Akhir kata penulis mohon maaf atas segala kekurangan dan penulis berharap smoga skripsi ini dapat bermanfaat bagi kita semua.
Yogyakarta, Juli 2006 Penulis
Vinsentia Asri Budiarti
DAFTAR ISI
HALAMAN JUDUL... i
HALAMAN PERSETUJUAN PEMBIMBING... ii
HALAMAN PENGESAHAN... iii
HALAMAN PERSEMBAHAN... iv
PERNYATAAN KEASLIAN KARYA... v
ABSTRAK... vi
ABSTRACT...vii
KATA PENGANTAR...viii
DAFTAR ISI... .xi
BAB I PENDAHULUAN……..………1
A. Latar Belakang……….1
B. Perumusan Masalah……….3
C. Pembatasan Masalah………... 3
D. Tujuan Penulisan………..………4
E. Manfaat Penulisan………4
F. Metode Penulisan……….4
G. Sistematika Penulisan....………...4
BAB II DASAR TEORI………...6
A. Finite State Automata………..6
A.1. Penerapan Finite State Automata……….6
A.2. Deterministic Finite State Automata………....9
A.3. Non Deterministic Finite State Automata………...12
B. Bahasa – bahasa Reguler………...15
B.1. Bahasa-bahasa Reguler dan Ekspresi-ekspresi Reguler………15
B.2. Aturan Produksi Bahasa Reguler………...18
C. Tata Bahasa Bebas Konteks………..21
C.1. Bahasa – bahasa Bebas Konteks………21
C.2. Penyederhanaan Tata Bahasa Bebas Konteks………....24
D. Parsing………...33
D.1. Parsing Dengan Brute Force………..38
D.2. Ambiguitas……….39
E. Pointer Di Pascal………43
E.1. Deklarasi Variabel Pointer……….45
E.2. Proses Variabel Pointer………..49
BAB III PERANCANGAN DAN DIAGRAM ALUR PROGRAM PARSING..52
A. Perancangan Struktur Data……….52
B. Diagram Alur Program Parsing………..53
BAB IV PENUTUP………63
A. Kesimpulan……….63
B. Saran………...63
DAFTAR PUSTAKA ………64
LAMPIRAN………...65
BAB I
KONSEP DAN IMPLEMENTASI PARSING DENGAN MENGGUNAKAN
METODE BRUTE FORCE
A. Latar Belakang Masalah
Dalam bidang komputer dikenal sebuah bahasa yaitu bahasa otomata berhinggan (finite automata). Sebuah otomata berhingga menguraikan sebuah bahasa sebagai himpunan semua untai yang menggerakkan untai dari state awal ke salah satu state yang diterimanya (himpunan state akhir). Dalam skripsi ini digunakan tata bahasa reguler dan tata bahasa bebas konteks sebagai dasarnya. Bila pada tata bahasa reguler terdapat pembatasan pada ruas kanan atau hasil produksi maka pada tata bahasa bebas konteks tidak terdapat pambatasan hasil produksinya.
Sebuah tata bahasa bebas konteks adalah suatu cara yang menunjukkan bagaimana menghasilkan untai-untai dalam sebuah bahasa. Tata bahasa bebas konteks telah banyak memberikan bantuan pada pemrograman dan perancangan parsing. Tata bahasa bebas konteks menjadi dasar dalam pembentukan suatui
proses parsing. Penyederhanaan tata bahasa bebas konteks bertujuan untuk melakukan pembatasan posisi munculnya terminal-terminal dan variabel-variabel sehingga tidak menghasilkan pohon penurunan yang memiliki kerumitan yang tidak perlu atau aturan produksi yang tidak berarti.
Dengan diturunkannya sebuah untai dari tata bahasa bebas konteks, simbol awal diganti oleh suatu untai. Setiap nonterminal dalam untai ini, secara bergantian digantikan oleh untai yang lain, dan seterusnya sampai tinggal tersisa
untai yang hanya terdiri dari simbol-simbol terminal. Selanjutnya tidak ada lagi penggantian karena tidak ada lagi nonterminal untuk digantikan. Kadang-kadang sangat berguna untuk menggambarkan penurunan itu, yaitu yang menunjukkan kontribusi dari masing-masing non terminal pada untai akhir dari terminal-terminal. Gambar seperti ini dinamakan pohon penurunan atau pohon penguraian (derivation tree atau pharse tree).
Metode parsing ada dua, pertama Top Down dan yang kedua Bottom Up. Top Down sendiri meliputi Backtrack: Brute Force dan No Backtrack: Recursive
Descent Parser. Dalam skripsi ini penulis hanya membahas parsing dengan menggunakan metode Top Down Brute Force. Metode ini akan memilih aturan produksi mulai dari paling kiri dan melakukan expand semua non terminal pada aturan produksi sampai yang tertinggal adalah simbol terminal.
Skripsi ini hanya membahas parsing dengan menggunakan metode Brute Force karena penulis merasa bahwa dasar teori untuk membahas parsing dengan metode Brute Force pernah penulis terima selama kuliah. Sedangkan parsing dengan metode Recursive Desent Parser dasar teori untuk membahasnya belum pernah penulis terima karena ini tentang compiler (dasar teorinya misal membahas analisis leksikal dan analisis semantik). Sehingga penulis memutuskan untuk menulis skripsi tentang parsing yang menggunakan metode Brute Force.
menunjuk ke data dengan tipe khusus. Variabel pointer mengandung alamat dari data dalam memori
B
.
Perumusan MasalahPokok permasalahan yang akan dibahas dalam tulisan ini dapat
dirumuskan sebagai berikut:
1. Apa yang dimaksud dengan parsing dengan menggunakan metodeBrute Force itu?
2. Bagaimana mengimplementasikan parsing dengan menggunakan metode Brute Force?
C.
Pembatasan MasalahDalam pembahasan tentang parsing dalam konsep dan implementasinya penulis membatasi masalah hanya pada proses parsing dengan menggunakan metode Brute Force dengan aturan produksi tata bahasa sebagai berikut:
S → Ba | Ab A → Sa | AAb | a B → Sb | BBa | b
D. Tujuan Penulisan
Tujuan yang ingin dicapai adalah ingin lebih memahami dan mendalami tentang konsep parsing dengan metode Brute Force yang di implementasikan dalam bahasa pemrograman Turbo Pascal.
E. Manfaat Penulisan
Manfaat yang diperoleh dari mempelajari topik ini adalah supaya semakin memahami dan mengerti tentang konsep parsing dengan metode Brute Force dan implementasinya dengan menggunakan bahasa pemrograman Turbo Pascal.
F. Metode Penulisan
Metode yang digunakan penulis adalah studi pustaka yaitu dengan membaca dan mempelajari buku-buku yang berkaitan dengan bahan yang telah dipilih.
G
.
Sistematika PenulisanPada bab I penulis pembahas tentang latar belakang masalah, rumusan
masalah, pembatasan masalah, tujuan penulisan, manfaat penulisan, metode penulisan, sistematika penulisan.meliputi bahasa-bahasa regular dan ekspresi-ekspresi regular, aturan produksi bahasa regular, Tata bahasa bebas kontrks yang meliputi bahasa-bahasa bebas konteks, penyederhanaan tata bahasa bebas konteks, Parsing meliputi parsing dengan metode brute force, ambiguitas, Pointer meliputi deklarasi variable pointer, proses variable pointer.
Pada Bab III membahas tentang perancangan dan diagram alur program parsing yang berisi tentang perancangan dengan menggunakan struktur data, diagram alur program parsing.
BAB II
DASAR TEORI
A. Finite State Automata
A.1 Penerapan Finite State Automata
Finite State Automata / otomata berhingga state, selanjutnya disingkat
dengan FSA, bukanlah mesin fisik tetapi suatu model matematika dari suatu
sistem yang menerima input dan output diskrit. Finite State Automata merupakan
mesin otomata dari bahasa reguler. Suatu finite state automata memiliki state
yang banyaknya berhingga, dan dapat berpindah-pindah dari suatu state ke state
yang lain. Perubahan state ini dinyatakan oleh fungsi transisi. Jenis otomata ini
tidak memiliki tempat penyimpanan, sehingga kemampuan mengingatnya
terbatas. Teori mengenai finite state automata adalah suatu tool yang berguna
untuk merancang sistem.
Contoh, pada pemeriksa pariti ganjil pengirim akan menambahkan bit
paritas sehingga jumlah bit 1 adalah ganjil. Misal terdapat data:
0110
maka pengirim akan menambahkan bit 1, sehingga penerima akan memperoleh
01101
bila data:
0111
maka pengirim akan menambahkan bit 0, sehingga penerima akan memperoleh
01110
bila suatu saat penerima memperoleh jumlah bit 1 yang genap, misal
10010
maka penerima akan memutuskan bahwa telah terjadi kesalahan dalam
pengiriman.
Bisa dibuat sebuah otomata yang akan memeriksa apakah suatu barisan
input memiliki bit 1 dalam jumlah ganjil atau genap. Mesin ini akan mempunyai
dua state, sebut saja sebagai state EVEN (genap) dan state ODD (ganjil).
0 0
1
1 ODD EVEN
gambar 1.1 mesin otomata untuk pemeriksa pariti ganjil
Pada finite state automata, arti dari bentuk-bentuk seperti yang ada pada
gambar diatas adalah:
• Lingkaran menyatakan state/kedudukan
• Label pada lingkaran adalah nama state tersebut
• Bususr menyatakan transisi yaitu perpindahan kefudukan/state
• Label pada bususr adalah simbol input
• Lingkaran didahului sebuah bususr tanpa label menyatakan state awal
• Lingkaran ganda menyatakan state akhir/final
Gambar seperti diatas biasa disebut sebagai graph transisi atau diagram
keadaan (state). Pada gambar diatas state awalnya adalah EVEN. Karena mesin ini
merupakan pemeriksa pariti ganjil, maka himpunan state akhir yang menyatakan
input diterima adalah ODD. Simbol input yang ada {0,1}. Jika mesin
1101
urutan state yang terjadi
EVEN 1 ODD 1 EVEN 0 EVEN 1 ODD
Berakhir dengan state ODD sehingga “1101” diterima oleh mesin
Bila mesin mendapatkan input:
101
urutan state yang terjadi
EVEN 1 ODD 0 ODD 1 EVEN
Berakhir dengan state EVEN maka “101” ditolak oleh mesin.
Meskipun pada contoh diatas state akhirnya hanya satu, pada umumnya
bisa terdapat sejumlah state akhir. Istilah state akhir tidak berarti komputasi (disini
berupa perpindahan/transisi) berhenti (halt) begitu state akhir tercapai. State akhir
hanya menyatakan kedudukan-kedudukan tertentu sebagai kedudukan-kedudukan
yang diterima.
Secara formal finite state automata dinyatakan oleh 5 tupel atau
M=(Q,Σ,δ,S,F), dimana:
Q = himpunan state/kedudukan
Σ = himpunan simbol input/masukan/abjad
δ = fungsi transisi
S = state awal/kesusukan awal, S ∈Q
F = himpunan state akhir
F adalah jumlah state akhir, jadi jumlah state akhir pada suatu finite state
Maka contoh diatas bisa dinyatakan sebagai berikut:
Q = {ODD,EVEN}
Σ = {0,1}
S = EVEN
F = {ODD}
Finite state automata berdasarkan pada pendefinisian kemampuan
berubah state-statenya bisa dikelompokkan ke dalam deterministik maupun non
deterministik,.
A.2 Deterministic Finite State Automata
Pada otomata berhingga deterministik/ Deterministic Finite Automata,
selanjutnya disebut dengan DFA, dari suatu state ada tepat satu state berikutnya
untuk setiap simbol masukan yang diterima. Sebagai contoh, misal ada otomata
seperti pada gambar berikut ini:
a a b b b
a
q1 q2
q0
gambar 2.1 mesin DFA
Konfigurasi Deterministic Finite State Automata di atas secara formal
dinyatakan sebagai berikut:
Q = {q0,q1,q2} Σ = {a,b}
S = q0
Fungsi transisi yang ada sebagai berikut:
δ(q0,a) = q0
δ(q0,b) = q1
δ(q1,a) = q1
δ(q1,b) = q2
δ(q2,a) = q1
δ(q2,b) = q2
Biasanya fungsi-fungsi transisi ini disajikan dalam sebuah tabel transisi.
Tabel transisi tersebut menunjukkan state berikutnya untuk kombinasi
state-state dan input. Tabel transisi dari fungsi transisi diatas sebagai berikut:
δ a b
q0 q0 q1
q1 q1 q2
q2 q1 q2
Tabel 1.1
Pada tabel transisi Deterministic Finite Automata diatas, nampak bahwa
sebuah state berikutnya yang unik untuk setiap pasangan state-input. Jadi untuk
sebuah state dan input yang berlaku, bisa ditentukan tepat satu state berikutnya.
Pada Deterministic Finite Automata, δ merupakan sebuah fungsi yang harus
terdefinisi untuk semua pasangan state-input yang ada dalam Q X Σ. Sehingga
berikutnya. State berikutnya itu ditentukan oleh informasi yang ada di dalam
pasangan state-input.
Suatu string x dinyatakan diterima bila δ(S,x) berada pada state akhir.
Biasanya secara formal dikatakan bila M adalah sebuah finite state automata,
M=(Q, Σ, δ, S, F), menerima bahasa yang disebut L(M), yang merupakan
himpunan {x ⏐δ(S,x) didalam F}.
Misal pada contoh gambar 2.1 diberi input string ‘abb’ pada mesin
tersebut. Maka :
δ(q0,abb)= δ(q0,bb)= δ(q1,b)= q2
karena q2 termasuk state akhir, maka ‘abb’ berada dalam L(M)
misal pada ontoh gambar 2.1 di beri input string ‘baba’ pada mesin tersebut,
maka:
δ(q0,baba)= δ(q1,aba) = δ(q1,ba)= δ(q1,a) = q1
karena q1 tidak termasuk state akhir, maka ‘baba’ tidak berada dalam L(M).
Contoh lain, misal terdapat gambar mesin DFA sebagai berikut:
a,b a
b
q0 q1
tabel transisi dari gambar 2.2 adalah :
δ a b
q0 q1 q1
q1 q1 q0
Jadi dari suatu gambar/ diagram transisi dapat dibuat tabel transisinya.
Sebaliknya dapat pula digambar diagram transisi suatu Deterministic Finite
Automata bila diketahuai tabel transisinya.
Contoh terdapat tabel transisi:
δ a b
q0 q0 q1
q1 q0 q0
Tabel 1.3
Dengan S = q0
F = {q1}
Maka diagram transisinya dapat dilihat pada gambar 2.3 berikut ini:
a
b
a,b
q0 q1
gambar 2.3
A.3 Non Deterministic Finite State Automata
Pada Non-deterministic Finite Automata (NFA) dari suatu state bisa
terdapat 0,1, atau lebih busur keluar (transisi) berlabel simbol input yang sama.
Non-deterministic Finite Automata didefinisikan pula dengan lima tupel M = (Q,
Σ, δ, S, F), dengan arti yang serupa pada Deterministic Finite Automata.
Perbedaannya terletak pada fungsi transisinya, dimana untuk setiap pasangan
Contoh:
a,b
a,b
a gambar 2.4 mesin otomata NFA
q0 q1
Dari gambar 2.4, dari state q0 terdapat dua busur keluar yang berlabel
input ‘a’. Dari state q0 bila mendapat input ‘a’ bisa berpindah ke state q0 atau q1,
yang secara formal dinyatakan:
δ(q0,a)= {q0,q1}
maka otomata ini disebut non-deterministik (tidak pasti arahnya). Tabel
transisinya sebagai berikut:
δ a b
q0 {q0,q1} {q1}
q1 {q1} {q1}
Tabel 2.1
Perlu diperhatikan bahwa cara penulisan state hasil transisi pada tabel transisi
untuk Non-deterministic Finite State Automata digunakan kurung kurawal ‘{‘ dan
‘}’, karena hasil transisinya merupakan suatu himpunan state.
Suatu string diterima oleh Non-Deterministic Finite Automata bila
terdapat suatu urutan sehubungan dengan input string tersebut dari state awal
Non-Deterministic Finite Automata pada gambar 2.4. Tentukan apakah string ‘ab’
termasuk dalam L(M)? Untuk Non-Deterministic Finite Automata harus mencoba
semua kemungkinan yang ada sampai terdapat satu yang mencapai state akhir.
Dalam contoh diatas, urutan transisi yang mencapai state akhir:
δ(q0,ab) = δ(q1,b) = q1
Jadi untuk membuktikan suatu string diterima oleh Non-Deterministic
Finite Automata tersebut dibuktikan dulu suatu urutan transisi yang menuju state
akhir .
Contoh lain, misal terdapat gambar 3.2 mesin NFA:
b a
a
q0 q1
gambar 3.2
Terlihat tidak ada busur keluar dari state q1 untuk simbol input ‘b’ atau
secara formal dinyatakan:
tabel transisinya sebagai berikut:
Tabel 2.2
B. Tata Bahasa Reguler
δ a b
q0 {q1} {q0}
q1 {q0} φ
B.1. Bahasa-Bahasa Reguler dan Ekspresi-Ekspresi Reguler
Sebuah bahasa dinyatakan regular jika terdapat finite state automata yang
dapat menerima bahasa-bahasa. Finite state automata sendiri merupakan model
matematika dari suatu sistem yang menerima input dan output diskrit dan juga
merupakan mesin otomata dari bahasa reguler. Bahasa-bahasa yang diterima oleh
suatu finite state automata bisa dinyatakan secara sederhana dengan ekspresi
regular (Regular Ekspression). Ekspresi regular selanjutnya disebut sebagai ER,
yang memberikan cara untuk mendefinisikan bahasa-bahasa. Ekspresi regular
memberikan suatu pola untuk untai dari suatu bahasa. Semua untai yang cocok
dengan sebuah pola tertentu, dan hanya untai-untai itu, yang menyusun bahasa
regular tertentu. Demikian pula sebuah otomata berhingga mendefinisikan sebuah
bahasa sebagai himpunan semua untai yang menggerakkan untai dari kedudukan
awal ke salah satu dari kedudukan-kedudukan yang diterima
Untuk sebuah abjad ∑ tertentu, bahasa-bahasa regular atas ∑ menarik
dari segi teoritis karena membentuk koleksi terkecil dari bahasa-bahasa atas ∑
gabungan bahasa dan memuat bahasa kosong Ø dan bahasa-bahasa singleton { a }
untuk a Є∑.
Definisi 2.2.1 (Kelly, Dean. h 36)
Misalkan ∑ merupakan sebuah abjad. Koleksi dari bahasa-bahasa regular
atas ∑ didefinisikan sebagai berikut:
a. Ø adalah sebuah bahasa regular.
b. { ε } adalah sebuah bahasa regular.
c. Untuk setiap a ∉∑, { a } adalah sebuah bahasa regular.
d. Jika A dan B adalah bahasa-bahasa regular maka A ∪ B, A . B,
dan A* adalah bahasa-bahasa regular.
e. Tidak ada bahasa-bahasa lain atas ∑ yang regular.
Artinya koleksi dari bahasa-bahasa regular atas ∑ terdiri dari bahasa
kosong, semua bahasa singleton, termasuk { ε }, dan semua bahasa yang dibentuk
oleh operasi-operasi bahasa perangkaian, gabungan, dan penutup bintang.
Contoh:
Misalkan ∑ = {a, b} maka yang berikut ini benar:
Ø dan { ε } adalah bahasa-bahasa regular.
{ a } dan { b } adalah bahasa-bahasa regular.
{ a, b} adalah regular, yang merupakan gabungan dari { a } dan { b }.
{ ab } adalah reguler.
{ a, ab, b } adalah regular.
{ ai | i ≥ 0 } adalah regular.
{ (ab)i |i ≥ 0}adalah regular.
Notasi dari ekspresi regular yaitu sebagai berikut: ‘*’, ‘+’, ‘+’, ‘∪’, ‘.’ • * yaitu karakter asterisk, berarti bisa tidak muncul, bisa juga muncul
berhingga kali (0-n)
• +
( pada posisi superscript / di atas) berarti minimal muncul satu kali (1-n)
• + atau ∪ berarti union
• . (titik) berarti konkatenasi, biasanya titik bisa dihilangkan, misal: ab
bermakna sama seperti a.b
Telah disepakati bahwa urutan untuk operator-operator *, ∪ dan . adalah
* pertama, . berikutnya dan ∪ yang terakhir.
Contoh ekspresi regular ( selanjutnya disingkat sebagai ER):
ER: ab*cc
Contoh string yang dibangkitkan: abcc, abbcc, abbbcc, abbbbcc, acc
( b bisa tidak muncul atau muncul sejumlah berhingga kali )
ER: 010*
Contoh string yang dibangkitkan: 01, 010, 0100, 01000
( jumlah 0 di ujung bisa tidak muncul, bisa muncul berhingga kali )
ER: a + d
Contoh string yang dibangkitkan: ad, aad, aaad
( a minimal muncul sekali )
ER: a * ∪ b *
ER: ( a ∪ b )
Contoh string yang dibangkitkan: a, b
ER: ( a ∪ b )*
Contoh string yang dibangkitkan: a, b, ab, ba, abb, bba, aaaa, bbbb
( untai yang memuat a atau b)
ER: 01 * 0
Contoh string yang dibangkitkan: 0, 01, 011, 0111, 01111
( string yang berawalan dengan 0, dan selanjutnya boleh diikuti deretan1)
B.2. Aturan Produksi Bahasa Reguler
Sebuah otomata berhingga mendefinisikan sebuah bahasa sebagai
himpunan semua untai yang menggerakkan dari state awal ke salah satu state
yang diterima ( himpunan state akhir). Sebagai contoh, pandang otomata
berhingga yang diterima oleh transisi dalam gambar dibawah ini.
a
Otomata berhingga diatas menerima bahasa regular a(a* ∪ b*)b. Bilamana
sebuah lintasan diambil dari kedudukan awal ke yang lain, “keluaran” simbol itu
Untai yang dipakai dalam bahasa regular a(a* ∪ b*)b terdiri dari sebuah
a yang diikuti oleh suatu “bagian akhir”. Misal E dianggap bagian akhir, secara
simbolis observasi ini menyajikan S→ aE. Anak panah (→) bisa dibaca seperti
“dapat ” atau “terdiri dari”. Bagian akhir dari sebuah untai demikian terdiri dari
satu dari dua susunan para a dan para b. Jadi bisa ditulis E → A dan E → B untuk
menunjukkan kemungkinan ganda untuk E. Dua susunan dari para a dan para b
bisa dinyatakan sebagai A → aA bersama dengan A → b untuk menunjukkan
sebuah untai dari para a diikuti oleh sebuah b atau sebagai B → bB bersama
dengan B → b, yang menunjukkan sebuah untai para b diikuti oleh b yang lain.
Ekspresi-ekspresi tersebut dapat diringkas sebagai berikut:
S → aE
E → A
E → B
A → b
A → aA
B → b
B → bB
Ekspresi-ekspresi tersebut dapat dipandang sebagai aturan-aturan
pengganti sewaktu membangkitkan untai-untai. Simbol di sebelah kiri anak panah
bisa diganti oleh untai di sebelah kanan.
Sebagai contoh, untai aab bisa dihasilkan melalui permulaan S,
mengganti S dengan aE, mengganti E dengan aA, dan akhirnya A dengan b.
Diperkenalkan simbol | yang di baca “atau”. Dengan menggunakan simbol ini,
dua aturan E → A dan E → B dapat dikombinasikan sebagai E → A | B,
membangkitkan untai-untai tadi kemungkinan bisa ditulis kembali sebagai
berikut:
1. S → aE
2. E → A | B
3. A → aA | b
4. B → bB | b
Untai a3b bisa dibangkitkan dari S dengan pertama kali menerapkan
aturan 1 untuk mandapatkan aE, kemudian aturan 2 untuk mendapatkan aA, dan
kemudian aturan 3 untuk mendapatkan aaA dan aaaA; akhirnya bagian kedua dari
aturan 3 dapat diterapkan untuk mendapatkan aaab. Uraian dari proses
pembangkitan ini dapat ditulis seperti berikut:
S => aE => aA => aaA => aaaA => aaab
Untuk anak panah ganda =>Dibaca sebagai “menurunkan”, “menghasilkan”, atau
“membangkitkan”.
Definisi (Kelly, Dean. h 81)
Sebuah tata bahasa regular G didefinisikan dengan 4-tupel G = ( ∑, N,
S, P), dimana:
∑ = sebuah abjad
N = sebuah koleksi simbol nonterminal
S = suatu nonterminal tertentu yang dinamakan simbol awal (start
simbol)
P = sebuah koleksi aturan-aturan pengganti, dinamakan
produksi-produksi, yang berbentuk A → w, untuk A ЄN dan w adalah suatu
1. w memuat paling banyak satu nonterminal
2. jika w memuat sebuah nonterminal, maka ia muncul sebagai
simbol terkanan dari w.
Bahasa yang dihasilkan oleh tata bahasa regular G dinotasikan L (G).
Contoh:
Sebuah tata bahasa regular G = ( ∑, N, S, P), untuk
∑ = { a, b }
N = { S, A }
P : S → bA
A→ aaA| b |ε
L (G) memuat semua untai yang berbentuk ba2nb dan ba2n. yaitu L (G) =
b (a2)*(b ∪ε).
C. Tata Bahasa Bebas Konteks
C.1. Bahasa-Bahasa Bebas Konteks
Definisi 3.3.1 ( Kelly, Dean. Otomata Dan Bahasa-Bahasa Formal. h.86)
Sebuah tata bahasa bebas konteks atau Context-Free Grammer (CFG)
adalah sebuah 4-tupel,
G = ( N, ∑, S, P )
Untuk: N adalah sebuah koleksi berhingga dari nonterminal-nonterminal
∑ adalah sebuah abjad ( juga dikenal sebagai sebuah himpunan dari
terminal-terminal )
S adalah sebuah nonterminal spesifik yang dinamakan simbol permulaan
Bahasa yang dihasilkan oleh CFG G dinotasikan L ( G ) dan dinamakan
bahasa bebas konteks ( Context-Free Language ) disingkat CFL. Karena suatu
tata bahasa regular adalah sebuah CFG, didapatkan juga bahwa suatu tata bahasa
regular adalah sebuah CFL.
Seperti sebuah tata bahasa regular, sebuah CFG adalah sebuah cara yang
menunjukkan bagaimana menghasilkan untai-untai dalam sebuah bahasa. Di CFG
juga menggunakan notasi => untuk menunjukkan aksi dari generasi itu sebagai
lawan pada →, yang merupakan bagian dari sebuah aturan produksi. Ketika
menurunkan sebuah untai, nonterminal-nonterminal itu masih mewakili
bagian-bagian tak terturunkan dari untai itu. Dalam hal tata bahasa-tata bahasa regular,
bagian tak terturunkan itu selalu terjadi pada salah satu ujung. Dalam CFG yang
tidak merupakan tata bahasa-tata bahasa regular bisa terdapat lebih banyak dari
satu bagian tak terturunkan dan bisa terjadi dimana saja dalam untai itu. Ketika
penurunan itu telah lengkap, semua bagian tak terturunkan telah diganti oleh
untai-untai ( mungkin kosong ) dari simbol-simbol terminal.
Misal CFG yang ditentukan oleh:
S → aSb |ε
Terdapat bahasa-bahasa bebas konteks yang bukan bahasa-bahasa
regular. Artinya koleksi bahasa-bahasa bebas konteks sepatutnya memuat koleksi
bahasa-bahasa regular.
Dalam generalisasi ke tata bahasa-tata bahasa bebas konteks, semua
pembatasan pada ruas kanan dari aturan-aturan produksi dihapus, dengan
Satu-satunya tempat yang tersisa untuk generalisasi pada ruas kiri dari
aturan-aturan produksi itu. Tata bahasa frasa-tersruktur ( phrase-structured grammer )
adalah salah satu tata bahasa yang ruas kiri aturan-aturan produksinya itu bisa
dibentuk dari suatu untai tak kosong atas N∪∑, yang memuat suatu nonterminal.
Jadi untuk sebuah tata bahasa frasa-terstruktur, koleksi dari aturan-aturan produksi
P memenuhi:
P⊆ ( N∪∑ )* N ( N∪∑ )* × ( N∪∑ )*
Tata tata bahasa frasa tersruktur juga dikenal sebagai tata
bahasa-tata bahasa tipe 0 atau tak dibatasi.
Istilah bebas konteks, apabila diterapkan pada tata bahasa-tata bahasa
mengingatkan akan adanya tata bahasa-tata bahasa yang terhadapnya konteks
bersifat sensitif. Tata bahasa-tata bahasa konteks sensitif ( context-sensitive
grammer ) adalah tata bahasa-tata bahasa frasa terstruktur yang disini dibatasi
oleh produksi-produksi α → β sedemikian sehingga | α | → | β |. Terdapat
sebuah bentuk normal untuk tata bahasa-tata bahasa ini yang setiap produksinya
berbentuk α1Aα2 → α1βα2 dengan β ≠ ε. Produksi-produksi demikian
mengizinkan penggantian nonterminal A dengan untai β hanya bila A terjadi
dalam “konteks” dari α1 dan α2.
Tata bahasa-tata bahasa konteks sensitif tidak dapat menurunkan bahasa
yang sama banyak dengan tata bahasa-tata bahasa frasa terstruktur, tetapi tata
bahasa-tata bahasa konteks sensitif mengizinkan terjadinya penurunan-penurunan
didalam cara yang dapat diduga. Walaupun demikian, perhatikan bahwa karena
dalam sebuah tata bahasa konteks sensitif yang benar. Bahasa-bahasa
pemrograman sering kali dirancang agar konteks sensitif sebagai sebuah cara
untuk menyederhanakan proses kompilasi.
Contoh :
Untuk tata bahasa bebas konteks yang ditentukan oleh
S → AA
A → AAA | a | bA | Ab
Tata bahasa bebas konteks diatas dapat menurunkan untai b2aba2ba sebagai
berikut:
S => AA => AAAA => bAAAA => bbAAAA => bbaAAA
=> bbabAAA => bbabaAA => bbabaAbA => bbabaabA =>
bbabaaba => b2aba2ba.
C.2. Penyederhanaan Tata Bahasa Bebas Konteks
Penyederhanaan tata bahasa bebas konteks bertujuan untuk melakukan
pembatasan sehingga tidak menghasilkan pohon penurunan yang memiliki
kerumitan yang tidak perlu atau aturan produksi yang tidak berarti.
Misalkan terdapat tata bahasa bebas konteks ( dengan simbol awal S ):
S → A A → B B → C C → D D → a | A
Tata bahasa bebas konteks tersebut memiliki kelemahan terlalu panjang jalannya
Suatu tata bahasa bebas konteks dapat disederhanakan dengan tiga cara
sebagai berikut:
1. Penghilangan produksi useless ( tidak berguna )
2. Penghilangan produksi unit
3. Penghilangan produksi ε.
Selanjutnya akan dibahas satu persatu cara penyederhanaan tata bahasa bebas
konteks tersebut.
1. Penghilangan Produksi Useless
Produksi useless adalah:
• Produksi yang memuat simbol variabel yang tidak memiliki
penurunan yang akan menghasilkan terminal-terminal seluruhnya
( maksudnya menuju terminal ), produksi ini tidak berguna karena
bila diturunkan tidak akan pernah selesai ( masih ada simbol
variabel yang tersisa ).
• Produksi yang tidak akan pernah dicapai dengan penurunan
apapun dari simbol awal, sehingga produksi itu redundan
(berlebihan).
Contoh :
1. Terdapat tata bahasa bebas konteks:
S → aAb | cEB A → dBE | eeC B → ff
Dari tata bahasa bebas konteks diatas dapat diterangkan bahwa:
1). Aturan produksi S → cEB, A → dBE, E tidak memiliki
penurunan
2). Aturan produksi B → ff , D → h, redundan
maka dari tata bahasa bebas konteks diatas, produksi yang useless:
S → cEB
A → dBE
B → ff
D → h
Jadi tata bahasa bebas konteks setelah disederhanakan menjadi:
S → aAb
A → eeC
C → ae
2. Terdapat tata bahasa bebas konteks:
S → aBD
B → cD | Ab
D → ef
A → Ed
F → dc
Dari tata bahasa bebas konteks diatas dapat diterangkan sebagai berikut:
1). Aturan produksi A → Ed, E tidak memiliki penurunan
2). Aturan produksi F → dc, redundan
maka dari tata bahasa bebas konteks tersebut yang useless yaitu:
B → Ab A → Ed F → dc
Jadi aturan produksi untuk tata bahasa bebas konteks tersebut setelah
disederhanakan menjadi:
S → aBD B → cD D → ef
Pada prinsipnya setiap kali melakukan penyederhanaan harus diperiksa
lagi aturan produksi yang tersisa, apakah semua produksi yang useless sudah
dihilangkan.
2. Penghilangan Produksi Unit
Produksi unit adalah produksi dimana ruas kiri dan ruas kanan aturan
produksinya hanya berupa satu simbol variabel, misalkan A → B, C → D.
Keberadaan produksi unit membuat tata bahasa bebas konteks memiliki kerumitan
yang tidak perlu atau menambah panjang penurunan. Penyederhanaan ini
dilakukan dengan melakukan penggantian aturan produksi unit.
Contoh:
1. Tata bahasa bebas konteks:
S → Cba | D
A → bbC
B → Sc | ddd C → eA | f | C D → E | SABC
Penggantian yang dilakukan dari tata bahasa bebas konteks diatas adalah:
D →E menjadi D → gh C → C dihapus
S → D menjadi S → gh | SABC
Sehingga aturan produksi setelah penyederhanaan menjadi:
S → Cba | gh | SABC A → bbC
B → Sc | ddd C → eA | f D → gh | SABC E → gh
2. Tata bahasa bebas konteks:
S → A S → Aa A → B B → C B → b C → D C → ab D → b
Penggantian yang dilakukan dari tata bahasa bebas konteks diatas adalah:
1). C → D menjadi C → b
2). B → C menjadi B → b | ab, karena B → b sudah
ada maka cukup dituliskan B → ab
3). A → B menjadi A → ab | b
4). S → A menjadi S → ab | b
S → ab | b S →Aa A → ab | b B → ab B → b C → b C → ab D → b
3. Penghilangan Produksi
ε
.Produksi
ε
adalah produksi dalam bentuk α →ε
atau bisa dianggapsebagai produksi kosong ( empty ). Penghilangan produksi
ε
dilakukan denganmelakukan penggantian produksi yang memuat variabel yang bisa menuju
produksi ε, atau biasa disebut nullable. Prinsip penggantiannya bisa dilihat kasus
berikut:
S → bcAd A → ε
Pada kasus diatas A nullable, serta A → ε satu-satunya produksi dari A,
maka variabel A bisa ditiadakan. Hasil penyederhanaan tata bahasa bebas konteks
menjadi:
S → bcd
Tetapi bila kasusnya:
S → bcAd A → bd | ε
Pada kasus diatas A nullable, tapi A → ε bukan satu-satunya produksi
S → bcAd | bcd A → bd
Contoh:
1. Terdapat tata bahasa bebas konteks:
S → AB
A → abB | aCa | ε B → bA | BB | ε C → ε
Variabel yang nullable adalah A, B, C. Dari S → AB maka S juga
nullable, maka dilakukan penggantian:
A → aCa menjadi A → aa B → bA menjadi B → bA | b B → BB menjadi B → BB | B A → abB menjadi A → abB | ab S → AB menjadi S → AB | A | B | ε C →ε, B →ε, A →ε dihapus
Perlu diperhatikan bahwa untuk penggantian S → AB disini tetap
mempertahankan produksi S → ε, karena S merupakan simbol awal. Ini
satu-satunya perkecualian produksi ε yang dihasilkan oleh simbol awal.
Jadi hasil akhir penyederhanaannya menjadi:
S → AB | A | B | ε A → abB | ab | aa B → bA | b | BB | B
2. Tata bahasa bebas konteks:
A → ε B → c
Variabel yang nullable adalah A. A → ε bukan penurunan satu-satunya dari A (terdapat A → bc), maka S → dA diganti menjadi S → dA | d. A → ε dihapus.
Tata bahasa bebas konteks setelah penyederhanaan menjadi: S → dA | d Bd
A → bc B → c
Pada prinsipnya ketiga penyederhanaan penghilangan useless, unit dan
ε
dilakukan bersama pada suatu tata bahasa bebas konteks, yang nantinya
menyiapkan tata bahasa bebas konteks tersebut untuk diubah ke dalam suatu
Bentuk Normal Chomsky . Bentuk Normal Chomsky tidak penulis bahas. Hal yang
memerlukan perhatian dari tata bahasa bebas konteks adalah penghilangan suatu
tipe produksi bisa menghasilkan produksi tipe yang lain, hal ini didasari
kenyataan bahwa penghilangan produksi
ε
bisa menghasilkan produksi unit.Perhatikan juga bahwa penghilangan produksi unit tidak menghasilkan produksi
ε
,dan penghilangan produksi useless tidak menghasilkan produksi unit maupun
ε
.Maka semua produksi yang tidak diinginkan bisa dihapuskan dengan melakukan
urutan sebagai berikut:
• Menghilangkan produksi
ε
• Menghilangkan produksi unit
Hasil yang diperoleh nanti adalah tata bahasa yang sudah bebas dari ketiga jenis
produksi tersebut.
Contoh:
1. Tata bahasa bebas konteks:
S → AA | C | bd A → Bb | ε
B → AB | d C → de
• Pertama-tama dilakukan penghilangan produksi
ε
, sehingga aturanproduksinya menjadi :
S → A | AA | C | bd A → Bb
B → B | AB | d C → de
• Selanjutnya penghilangan produksi unit, sehingga aturan produksinya
menjadi:
S → Bb | AA | de | bd A → Bb
B → AB | d C → de
• Penghilangan produksi useless, maka hasilnya menjadi:
S → Bb | AA | de | bd A → Bb
B → AB | de
Jadi hasil akhir aturan produksi tidak lagi memiliki produksi
ε
, produksi unitD. Parsing
Dengan diturunkannya sebuah untai dari tata bahasa bebas konteks,
simbol awal diganti oleh suatu untai. Setiap nonterminal dalam untai ini, secara
bergantian digantikan oleh untai yang lain, dan seterusnya sampai tinggal tersisa
untai yang hanya terdiri dari simbol-simbol terminal. Selanjutnya tidak ada lagi
penggantian karena tidak ada lagi nonterminal untuk digantikan. Kadang-kadang
sangat berguna untuk menggambarkan penurunan itu, yaitu yang menunjukkan
kontribusi dari masing-masing nonterminal pada untai akhir dari
terminal-terminal. Gambar seperti ini dinamakan pohon penurunan atau pohon penguraian
(derivation tree atau pharse tree).
Sebuah pohon (tree) adalah suatu graph terhubung tidak sirkuler, yang
memiliki satu simpul (node)/vertex disebut akar (root) dan dari situ memiliki
lintasan ke setiap simpul. Pohon penurunan (derivation tree/pharse tree) berguna
untuk menggambarkan bagaimana memperoleh suatu string (untai) dengan cara
menurunkan simbol-simbol variabel menjadi simbol-simbol terminal. Setiap
simbol variabel akan diturunkan menjadi terminal, sampai tidak ada simbol
variabel yang belum tergantikan.
Misal terdapat tata bahasa bebas konteks dengan aturan produksi (simbol
awal S, selanjutnya didalam bahasan ini S digunakan sebagai simbol awal untuk
tata bahasa bebas konteks):
S → AA
Dari aturan produksi tata bahasa bebas konteks tersebut akan
digambarkan pohon penurunan untuk memperoleh untai ‘bbabaaba’. Pada pohon
tersebut simbol awal akan menjadi akar (root). Setiap kali penurunan dipilih
aturan produksi yang menuju ke solusi. Simbol-simbol variabel akan menjadi
simpul-simpul yang mempunyai anak. Simpul-simpul yang tidak mempunyai
anak akan menjadi simbol terminal. Jadi gambar dari aturan produksi tersebut
adalah:
S
A A
b A A A A
b A b A a b A
a a a
Proses penurunan atau parsing bisa dilakukan dengan cara :
1. Penurunan terkiri (leftmost derivation) : simbol variabel terkiri yang
diperluas terlebih dulu.
2. Penurunan terkanan (rightmost derivation) : simbol variabel terkanan
yang diperluas terlebih dulu.
Misal terdapat tata bahasa bebas konteks:
S → aAS | a
A → SbA | ba
Untuk memperoleh untai ‘aabbaa’ dari tata bahasa bebas konteks diatas
1. Dengan penurunan terkiri : S => aAS => aSbAS => aabAS =>
aabbaS => aabbaa
2. Dengan penurunan terkanan : S => aAS => aAa => aSbAa =>
aSbbaa => aabbaa
Meskipun proses penurunannya berbeda akan tetapi memiliki pohon
penurunan yang sama, yaitu sebagai berikut:
S
a A S
S b A a
a b a
Biasanya persoalan yang diberikan berkaitan dengan pohon penurunan
adalah untuk mencari penurunan yang hasilnya menuju kepada suatu untai yang
ditentukan. Dalam hal ini, perlu untuk melakukan percobaan pemililihan aturan
produksi yang bisa menuju ke solusi.
Misalkan sebuah tata bahasa bebas konteks memiliki aturan produksi
sebagai berikut:
S → aAd | aB
A → b | c
B → ccd | ddc
Pohon penurunan dari tata bahasa bebas konteks diatas untuk
memperoleh untai ‘accd’ bisa dilihat pada gambar berikut ini:
Contoh:
1. Untuk tata bahasa bebas konteks berikut:
S → Ba | Ab
A → Sa | AAb | a
B → Sb | BBa | b
Dari tata bahasa bebas konteks tersebut diperoleh penurunan untai ‘bbaaaabb’ sebagai
berikut:
S =>Ab => AAbb => SaAbb => BaaAbb =>BBaaaAbb => bBaaaAbb =>
bbaaaAbb => bbaaaabb
Pohon penurunannya sebagai berikut:
S
A b
A A b
S a a
B a
B B a
b b
2. Sebuah tata bahasa bebas konteks memiliki aturan produksi:
S → aB | bA
A → a | aS | bAA
Pohon penurunan untuk memperoleh untai ‘aaabbabbba’ bisa dilihat
pada gambar dibawah ini:
S
a B
a B B
a B B b S
b b S b A
a B a
b
Metode Parsing
Di dalam mengimplementasikan sebuah metode parsing ke dalam
program perlu diperhatikan tiga hal:
1. Rentang waktu eksekusi
2. Penanganan kesalahan
3. Penanganan kode
Metode parsing bisa digolongkan sebagai berikut:
1. Top Down
Kalau dilihat dari terminologi pohon penurunan, metode ini melakukan
penelusuran dari root/puncak menuju ke leaf/daun (simbol awal sampai
simbol terminal). Metode top down sendiri meliputi:
1.Backtrack/backup : Brute Force
2. Bottom Up
Metode ini melakukan penelusuran dari leaf/daun menuju ke root/puncak.
Pada skripsi ini hanya dibahas parsing dengan metode Top Down Brute
Force.
D.1. Parsing Dengan Brute Force
Metode ini memilih aturan produksi mulai dari paling kiri, dan
melakukan expand semua non terminal pada aturan produksi sampai yang
tertinggal adalah simbol terminal. Kemungkinan pertama string masukan sukses
di-parsing, bisa juga bila terjadi expansi yang salah untuk suatu simbol variabel
maka akan dilakukan backtrack. Algoritma ini membangun pohon parsing yang
top down, yaitu mencoba segala kemungkinan untuk setiap simbol non terminal.
Contoh suatu bahasa dengan aturan produksi sebagai berikut:
S → aAd | aB
A → b | c
B → ccd | ddc
Misal ingin dilakukan parsing untuk string: ‘accd’. Tahapan yang terjadi
bisa dilihat pada gambar berikut:
i) S ii) S iii) S
a A d a A d
iv) S v) S vi) S
a A d a B a B
c c c d
Terlihat pada penurunan iii) A → b, terjadi kegagalan, maka dilakukan
backtrack dan penurunan iv) yang dilakukan adalah expansi A → c. karena terjadi
kegagalan maka backtrack lagi, dan ‘naik’ ke atas sampai terjadi penurunan v)
S → aB. Penurunan vi) B → ccd memberikan hasil akhir bahwa ‘accd’ diterima
oleh bahasa tersebut.
D.2. Ambiguitas
Ambiguitas/mendua arti terjadi bila terdapat lebih dari satu pohon
penurunan yang berbeda untuk memperoleh suatu untai. Keduaartian dapat
menjadi sebuah masalah untuk bahasa-bahasa tertentu jika artinya bergantung
dalam bagian pada struktur, seperti halnya dengan bahasa-bahasa asli dan
pemrograman. Jika sebuah struktur bahasa mempunyai lebih dari satu
dekomposisi dan jika kontruksi sebagian menentukan arti, maka arti itu adalah
mendua arti. Sebagai contoh dari hal mendua arti yang mengaburkan arti yaitu
pandang tata bahasa-tata bahasa untuk pernyataan-pernyataan penugasan
sederhana berikut ini:
A → I := E
I → a | b | c
E → E + E | E * E ( E ) | I
Untai a := b + c * a adalah sebuah untai dalam bahasa dari
pernyataan-pernyataan penugasan ini. Ada dua pohon penurunan yang berbeda untuk tata
bahasa tersebut, yaitu:
A A
I := E I := E
a E + E a E * E
I E * E E + E I
b I I I I a
c a b c
Jika dicoba untuk menentukan berapa nilai pada sebelah kanan dari
operator penugasan itu (simbol :=) dihitung, akan terdapat dua hasil yang
mungkin yaitu b + ( c * a ) atau ( b + c ) * a. Pada umumnya hasil-hasil ini
tidaklah sama.
Contoh:
Terdapat tata bahasa bebas konteks:
S → SbS | ScS | a
Terdapat dua cara membangkitkan sebuah untai yaitu penurunan terkiri
dan penurunan terkanan. Dalam sebuah penurunan terkiri (leftmost derivations)
nonterminal terkiri yang selalu diperluas. Begitu juga dalam sebuah penurunan
terkanan (rightmost derivations) nonterminal terkanan yang selalu diperluas.
Jadi untuk tata bahasa bebas konteks diatas, penurunan terkiri untuk untai
S => ScS => SbScS => abScS =>abacS => abaca
Penurunan terkanan untuk untai ‘abaca’ sebagai berikut:
S => ScS => Sca => SbSca => Sbaca => abaca
Diketahui dua penurunan ini mempunyai pohon penurunan yang sama.
S
S c S
S b S a
a a
Dalam tata bahasa berikut ini yang juga menurunkan untai ‘abaca’ :
S => SbS => abS => abScS => abacS => abaca dan
S => SbS => SbScS => SbSca => Sbaca => abaca
Penurunan terkiri berbeda dari penurunan sebelumnya begitu juga
dengan penurunan terkanan juga berbeda dengan penurunan sebelumnya.
Kehadiran dari dua penurunan terkiri dan terkanan yang berbeda ada
hubungannya dengan keberadaan dua pohon penurunan yang berbeda. Jadi sebuah
tata bahasa yang mendua arti dapat dicirikan sebagai salah satu tata bahasa yang
mempunyai dua atau lebih penurunan terkiri dan terkanan yang berbeda untuk
Pohon penurunan yang satunya sebagai berikut:
S
S b S
a S c S
a a
Contoh lain dari tata bahasa bebas konteks yang ambigu adalah:
S → aB | bA
A → a | aS | bAA
B → b | bS | aBB
Tata bahasa bebas konteks diatas dapat menurunkan untai ‘aabbaabb’,
penurunannya sebagai berikut:
S => aB => aaBB => aabB => aabbS => aabbaB => aabbaaBB =>
aabbaabB => aabbaabb
S => aB => aaBB => aabSB => aabbAB => aabbaB => aabbaaBB
=>aabbaabB => aabbaabb
Pohon penurunannya:
S S
a B a B
a B B a B B
b b S b S a B B
a B b A b b
a B B a
Jadi untuk menunjukkan bahwa suatu tata bahasa bebas konteks ambigu,
bias dilakukan dengan menemukan untai yang memungkinkan pembentukan lebih
dari satu pohon penurunan. Ambiguitas dapat menimbulkan masalah pada
bahasa-bahasa tertentu, baik bahasa-bahasa alami maupun pada bahasa-bahasa pemrograman. Bila suatu
struktur bahasa memiliki lebih dari suatu dekomposisi (penurunan), dan
susunannya akan menentukan arti, maka artinya menjadi ambigu.
E. Pointer Di Pascal
Nama perubah, yang digunakan untuk mewakili suatu nilai data,
sebenarnya merupakan atau menunjukkan suatu lokasi tertentu dalam pengingat
komputer dimana data yang diwakili oleh nama perubah tersebut disimpan. Pada
saat sebuah program dikompilasi, kompiler akan melihat pada bagian deklarasi
perubah (var) untuk mengetahui nama-nama perubah apa saja yang akan
digunakan, sekaligus mengalokasikan atau menyediakan tempat dalam pengingat
untuk menyimpan nilai data tersebut. Perubah-perubah yang demikian ini
dinamakan dengan perubah satatis.
Dari pengertian diatas, bahwa sesudah suatu lokasi pengingat ditentukan
untuk suatu nama perubah, maka dalam program tersebut perubah yang dimaksud
akan tetap menempati lokasi yang telah ditentukan dan tidak mungkin diubah.
Dengan melihat pada sifat-sifat perubah statis maka banyaknya data yang bias
diolah adalah terbatas. Sebagai contoh, missal diketahui perubah dengan deklarasi
Var tabel : array [1..100,1..50] of integer;
Perubah tabel diatas hanya mampu untuk menyimpan data sebanyak
100X50 = 5000 buah data. Jika tetap nekat untuk menambah data pada perubah
tersebut, eksekusi program akan terhenti karena deklarasi lariknya kurang. Jika
ingin mengolah data yang banyaknya tidak bias dipastikan sebelumnya, maka
pascal menyediakan satu fasilitas yang memungkinkan menggunakan suatu
perubah yang disebut dengan perubah dinamis.
Perubah dinamis adalah suatu perubah yang akan dialokasikan hanya
pada saat diperlukan, yaitu setelah program dieksekusi. Dengan kata lain, pada
saat program dikompilasi, lokasi untuk perubah tersebut belum ditentukan.
Kompiler hanya akan mencatat bahwa suatu perubah akan diperlakukan sebagai
perubah dinamis. Hal ini membawa keberuntungan pula, bahwa perubah-perubah
dinamis tersebut bias dihapus pada saat program dieksekusi, sehingga ukuran
pengingat akan selalu berubah. Hal inilah yang menyebabkan perubah dinamakan
sebagai perubah dinamis.
Karena alasan inilah perubah dinamis lebih dikenal dengan sebuatan
pointer yang artinya menunjuk ke sesuatu. Dalam perubah dinamis, nilai data
E.1. Deklarasi Variabel Pointer
Bentuk umum:
Var <Nama Var> : <^TipeData>
Contoh:
Var
P : ^integer;
Pendeklarasian variabel pointer tidak jauh berbeda dengan pendeklarasian biasa,
hanya perlu ditambahkan simbol topi (^) sebelum tipe datanya. Simbol topi
tersebut menandakan bahwa variabel tersebut menunjuk ke lokasi tertentu pada
memori. Dapat digambarkan variable P seperti ditunjukkan pada diagram berikut:
P
Variabel pointer dapat pula dibuat yang tipe record. Pendeklarasiannya
adalah seperti berikut:
Bentuk Umum:
Type
<NamaPointer>= <^NamaRecord>; <NamaRecord> = Record
<item1> : <TipeData1>; <item2> : <TipeData2>;
…..
<itemN> : <TipeDataN>; End;
Var
Contoh:
Pada contoh diatas, P1 dan P2 masing-masing bertipe pointer, sedang
A,B,C perubah statis bertipe string.
Pada saat program dikompilasi, perubah P1 dan P2 akan menempati
lokasi tertentu dalam pengingat. Kedua perubah ini masing-masing belum
menunjuk ke suatu simpul. Pointer yang belum menunjuk ke suatu simpul
nilainya dinyatakan dengan nil.
Untuk mengalokasikan simpul dalam pengingat, statemen yang
digunakan adalah statemen new, yang mempunyai bentuk umum:
New (perubah);
Dengan perubah adalah nama perubah yang bertipe pointer.
Sebagai contoh, dengan deklarasi perubah seperti diatas dan statemen:
New(P1);
New(P2);
Maka sekarang dipunyai dua buah simpul yang ditunjuk oleh P1 dan P2.
P1
P2
Program ini kemudian menyerahkan nilai ke dua item data tersebut
contoh, pernyataan berikut akan menyerahkan nilai 2.0 ke item yang ditunjuk
dengan P1 dan menambah 1 ke nilai tersebut, menyimpan hasilnya ke dalam item
data yang ditunjuk dengan P2:
P1^ := 2.0;
P2^ := P1^ + 1.0;
Isi memori dapat digambarkan sebagai berikut:
2.0 P1
P2 3.0
Variabel pointer dapatr digunakan sebagai argumen ke prosedur new.
Variable pointer dapat dapat digunakan dalam pernyataan penugasan, disediakan
dua variable yang mempunyai tipe sama. Asumsikan P1 dan P2 menunjuk ke item
data, seperti ditunjukkan dalam contoh sebelumnya. Pernyataan tersebut:
P2 := P1;
Akan menyebabkan P1 dan P2 menunjuk ke item data yang sama, seperti
ditunjukkan:
P1
P2
2.0
3.0
Maka isi dari P2 (yang berupa alamat) telah diganti dengan nilai (yang
berupa alamat) yang dikandung dari P1. yang terjadi adalah item data yang
sebelumnya ditunjuk dengan P2 masih ada, tetapi tidak ada cara untuk mengakses
isi tersebut.
Salah satu keistimewaan yang sangat berguna pada tipe data pointer
adalah kemampuan untuk melekatkan pointer ke dalam record. Keistimewan ini
andaikata akan membuat dua record dengan cara seperti itu bahwa satu record
menunjuk ke record berikutnya, seperti ditunjukkan dalam diagram berikut ini:
pertama
Salah satu cara untuk membuat nilai awal (inisialisasi) elemen dengan
menggunakan:
New(Pertama);
Pertama^.Nama:= ’Ina’;
Pada saat ini keadaan bagian memori sebagai berikut:
Pertama Ina ?
Isi pada pertama^.nama sudah didefinisikan, tetapi isi pada pertama^.Berikut
(bagian pointer pada record) belum didefinisikan pada tahap ini. Sekarang dapat
membuat record lain untuk data berikut dengan menggunakan variable Temp:
New(Temp);
Temp^.Nama:=’Ira’; Bagian memori sekarang menjadi
Pertama
Temp
Ina ? Ira ?
Sekarang adalah melengkapi record yang mengandung ‘Ina’ dan record yang
mengandung ‘Ira’. Isi dari pertama^berikut memerlukan penunjuk ke data yang
ditunjuk dengan Temp. Dapat dibuat hubungan tersebut dengan sangat sederhana
sebagai berikut:
Pertama^.Berikut := temp;
Susunan memori tersebut sekarang menjadi :
Pertama
Temp
Sekarang dapat melengkapi struktur tersebut dengan menempatkan nil ke dalam
bagian pointer (berikut) pada lemen terakhir;
Temp^.berikut := nil;
Bagian memori tersebut pada saat ini ditunjukkan struktur yang telah komplit:
Pertama
E.2. Proses Variabel Pointer
Pada pembahasan diatas telah diterangkan bagaimana mendeklarasikan
variabel pointer dan bagaimana menginisialisasikan variabel pointer
menggunakan prosedur new. Cara lain untuk menginisialisasikan variabel pointer
adalah dengan menggunakan konstanta pointer yaitu nil. Jika variabel pointer
diserahi nilai nil, ini berarti bahwa tidak menunjuk dimanapun juga, artinya
pointer tidak menunjuk ke item data. Jika P merupakan variabel pointer,
pernyataan
P := nil;
Menyebabkan nilai P diset ke nil. Nilai nil untuk variabel pointer disimbolkan
dalam memori dengan diagram sebagai berikut:
P
Hal yang penting untuk mengerti perbedaan antara variable pointer yang
belum didefinisikan dan variabel pointer yang mempunyai nilai, isi dari variabel
yang belum didefinisikan (sama dengan dideklarasikan tapi tidak ada nilainya
sebelum diserahi suatu nilai ke variabel tersebut) tidak diketahui. Prosedur new
membuat item data dan menetapkan nilai pada variabel pointer. Penyerahan nilai
nil ke variabel pointer juga menetapkan nilai variabel pointer tersebut, tetapi tidak
demikian jika tanpa mengalokasikan hubungan ke item data.
Sebelumnya dikatakan bahwa memungkinkan untuk menggunakan
memori kembali dalam head yang tidak diperlukan, ini dilakukan dengan
menggunakan prosedur Dispose, yang membebaskan penunjuk item data dengan
parameternya dan mengeset parameter ke nil. Bentuk prosedur Dispose:
Dispose(variable_pointer);
Sebagai contoh, andaikan PtrP1 dan PtrP2 menunjuk item data real,
seperti ditunjukkan:
P1 2.0
P2 3.03.0
Setelah eksekusi pada prosedur dispose untuk PtrP1, seperti”
Dispose (PtrP1);
Nilai PtrP1 akan mnjadi nil, dan ruangan yang telah dialokasikan untuk variable
tersebut akan dikembalikan ke kelompoknya pada ruangan yang dapat digunakan
dan dialokasikan kembali jika diperlukan. Pada penunjuk ini diagram memorinya
sebagai berikut:
P1
3.0 P2
Andaikata ingin mempunyai PtrP1 menunjuk ke item data yang sama
dengan PtrP2 dan membebaskan penunjuk data dengan PtrP1. Hal pertama harus
menggunakan prosedur dispose, seperti ditunjukkan segmen program berikut:
Setelah eksekusi prosedur dispose ini, memori akan kelihatan sebagai berikut:
P1
3.0 P2
Kemudian, setelah eksekusi pada pernyataan penugasan tersebut memori akan
tampak sebagai berikut:
P1
BAB III
PERANCANGAN DAN DIAGRAM ALUR PROGRAM PARSING
A. Perancangan Struktur Data
Program parsing yang akan penulis buat menggunakan senarai berantai (linked list). Senarai berantai adalah kumpulan komponen yang disusun secara berurutan dengan bantuan pointer. Masing-masing komponen dinamakan dengan simpul (node). Dengan demikian setiap simpul dalam suatu senarai berantai terbagi menjadi dua bagian. Bagian pertama disebut medan informasi, yang berisi informasi yang akan disimpan dan diolah. Bagian kedua disebut medan penghubung (link field), yang berisi alamat simpul berikutnya. Penghubung dalam elemen terakhir selalu mempunyai nilai nil. Ini berguna sebab pada elemen tersebut tidak ada data yang melewati elemen ini, sehingga penghubung ini tidak menunjuk kemanapun.
Gambar 3. 1 di bawah ini menunjukkan diagram skematis dari senarai berantai dengan 8 simpul. Setiap simpul digambar dalam dua bagian. Bagian kiri adalah medan informasi dan bagian kanan adalah medan penyambung, sehingga dalam diagram digambarkan sebagai anak panah. Medan penyambung sebenarnya adalah suatu pointer yang menunjuk ke simpul berikutnya, sehingga nilai dari medan adalah alamat suatu lokasi tertentu dalam pengingat.
Dari gambar 3.1., pointer awal, yang bukan merupakan bagian dari senarai menunjuk ke simpul pertama dari senarai tersebut. Medan penyambung
(pointer) dari suatu simpul yang tidak menunjuk simpul lain disebut dengan pointer kosong, yang nilainya dinyatakan sebagai nil.
Awal
Medan penyambung dari simpul kedua Medan informasi dari simpul kedua
Gambar 3. 1. Contoh senarai berantai dengan 8 simpul
Nilai awal pada Temp adalah isi pada kepala. Pada saat nilai pada Temp tidak sama dengan nil, dapat menggunakan bagian data pada bagian ini (menggunakan Temp^.Data) dan kemudian diproses ke elemen berikutnya dengan mengganti Temp dengan nilai pada Temp^.berikut yaitu isi pada bagian penghubung pada elemen sekarang (elemen yang ditunjuk oleh pointer Temp). Teknik untuk menyimpan daftar dari data adalah menggunakan array.
b a a a a b b
b
B. Diagram Alur Program Parsing
Suatu program adalah sederetan perintah yang mengatur apa-apa yang harus dikerjakan komputer, untuk mendapatkan suatu hasil/keluaran yang di harapkan. Sebelum suatu program dibuat, alangkah baiknya kalau dibuat logika/ urut-urutan perintah program dalam suatu diagram yang disebut diagram alur.
Suatu program komputer pada umumnya berisi 3 hal, yaitu: 1. Pembacaan/pemasukan data ke dalam komputer
Diagram alur untuk program parsing yang penulis buat adalah sebagai berikut:
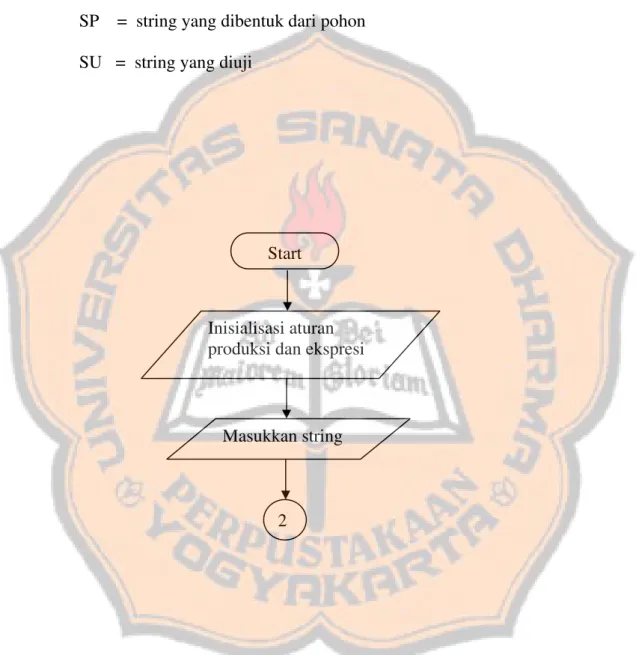
Ket: Nleft = simpul ekspresi terkiri
SP = string yang dibentuk dari pohon SU = string yang diuji
Start
2
2
Buat simpul awal untuk ekspresi S
ya
tidak ya
tidak
tidak
ya
tidak Buat Nleft
SP = SU Valid
SP < SU
Hapus simpul anak dari Nleft terakhir yang diexpand
Adakah aturan produksi untuk Nleft yang belum diuji
Tidak valid
Catatan :
n = banyaknya string
Simbol untuk menyatakan START ataupun BERHENTI
KOTAK MASUKAN, untuk membaca data yang kemudian diberikan sebagai harga suatu variabel
KOTAK PENUGASAN, untuk memberi harga kepada suatu variabel, atau untuk melakukan perhitungan matematika yang hasilnya di berikan sebagai harga suatu variabel
KOTAK KEPUTUSAN, untuk memutuskan arah atau percabangan yang diambil sesuai dengan kondisi yang saat itu terjadi, BENAR atau SALAH
Simpul penghubung, untuk penghubung bila diagram alur terputus disebabkan oleh pergantian halaman (tidak cukup digambar satu halaman).
Sebelum membuat program parsing yang lengkap, maka perlu dibuat algoritmanya terlebih dahulu.
Algoritma cek ekspresi
{digunakan untuk mengecek ekpresi apakah string yang dimasukkan sebuah ekspresi apa tidak }
langkah 0 (Inisialisasi ekspresi dari aturan produksi)
langkah 1 Tentukan: Isekspresi = false
langkah 2 Test, apakah Iseksprei = nil ?