Fakultas Ilmu Komputer
Universitas Brawijaya
1652
Optimasi K-Means untuk Clustering Kinerja Akademik Dosen
Menggunakan Algoritme Genetika
Budi Santoso1, Imam Cholissodin2, Budi Darma Setiawan3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya
Email: 1[email protected],2[email protected], 3[email protected]
Abstrak
Dosen merupakan pengajar mahasiswa, selain mengajar dosen juga memiliki banyak kegiatan lain dengan memanfaatkan keahlian yang dimiliki untuk mengembangkan potensi dari dosen tersebut. Beberapa karakter yang dimiliki oleh setiap dosen sangat berbeda, diantaranya yaitu pendidikan, penelitian, pengabdian, administrasi, dan penunjang. Kesulitan yang dihadapi oleh kampus salah satunya yaitu terkait pengelompokkan penugasan terhadap dosen. Penugasan tersebut berhubungan dengan studi lanjut, rekomendasi, jabatan terkait structural, mengisi suatu acara, kepanitian, dan lain lain. Sehingga dibutuhkan suatu sistem yang bisa mengkelompokan kinerja akademik dosen secara optimal. Pada penelitian ini untuk mengelompokkan kinerja akademik dosen mneggunakan metode K-Means yang dioptimasi dengan algoritme genetika. Algoritme genetika berperan untuk mengoptimasi
pusat awal cluster pada algoritme K-Means. Data yang digunakan dalam penelitian ini merupakan data
dosen yang ada di fakultas ilmu Komputer Universitas Brawijaya pada tahun 2016. Data tersebut
diperoleh dari GJM fakultas ilmu komputer universitas brawijaya. Hasil pengujian pada clustering
kinerja akademik dosen menggunakan algoritme GA-Kmeans memiliki kualitas cluster lebih tinggi
yaitu sebesar 2,74% dibandingkan dengan algoritme K-Means tanpa algoritme genetika, dimana kualitas cluster yang diperoleh menggunakan metode Silhouette Coefficient.
Kata kunci: Kinerja akademik dosen, GA-Kmeans, silhouett coefficient Abstract
Lecturers are teacher for students, besides teaching, lecturers also have many other activities by utilizing the expertise they have to develop the potential of the lecturer. Some of the characters that each lecturer are so different, such as education, research, dedication, administration, and support. The difficulties faced by the campus, one of them is related to the grouping of assignments to lecturers. The assignment is related to further studies, recommendations, structural related positions, filling an event, commission, etc.So that required a system that can classify the academic performance of lecturers optimally. In this study to classify the academic performance of lecturers using K-Means method is optimized with genetic algorithm. Genetic algorithm acts to optimize the cluster's initial center on K-Means.Data algorithm used in this research is the data of lecturers in UB's Computer Science faculty in 2016. The data obtained from GJM faculty of computer science of Universitas Brawijaya. The result of clustering test of academic performance of lecturer using GA-Kmeans algorithm has higher cluster quality that is 2,74% compared to K-Means algorithm without genetic algorithm, where the cluster quality obtained using Silhouette Coefficient method.
Keywords: Academic performance of lecturers, GA-Kmeans, Silhouett Coefficient
1. PENDAHULUAN
Dosen adalah tenaga pengajar untuk Mahasiswa, tetapi bisa sering memiliki tugas lain yang berkaitan dengan keahlian yang dimiliki dosen tersebut. Dilihat dari sudut pandang pemerintah tepatnya dalam bidang pendidikan telah memberikan syarat untuk gelar
minimum yang harus ditempuh oleh Dosen yaitu Master (S2/SP1) serta harus memiliki biaya yang cukup jika harus melanjutkan studi lanjut. Terdapat pengelompokan kualitas Perguruan Tinggi (PT) yang sangat penting untuk mengetahui penghargaan kualitas dosen, bahwa lulus dari PT dalam negeri ataupun luar negeri.
Untuk menata manajemen perguruan tinggi harus bisa memperbaiki kemampuan mahasiswa baik dalam hal akademik maupun non akademik serta moral di butuhkan kinerja dosen sebagai pengajar yang sangat optimal agar bisa mewujudkan keinginan tersebut. Beberapa hal yang mempengaruhi kinerja dosen diantaranya
yaitu motivasi berprestasi serta
kedisipilan,prosentase motivasi berprestasi
memiliki 42,2% sedangkan disiplin memiliki 37,9%, sedangkan kalau dibandingkan dengan variabel lain motivasi berprestasi dan disiplin memiliki pengaruh terhadap kinerja dosen sebanyak 47,6% dan 52,4% dimiliki oleh variabel lainnya (Sulastri, 2007).
Setiap dosen pada masing – masing perguruan tinggi pasti memiliki karakteristik yang berbeda mulai dari pendidikan, penelitian,
pengabdian, administrasi, dan penunjang
merupakan beberapa hal yang menjadi karakter setiap dosen. Terkait dengan hal tersebut untuk menentukan penugasan terhadap dosen sangat sulit. Penugasan tersebut berhubungan dengan studi lanjut, rekomendasi, jabatan terkait structural, mengisi suatu acara, kepanitian, dan lain lain. Jadi sangat penting untuk melakukan pengelompokan terhadap dosen yang ada pada
suatu perguruan tinggi tertentu untuk
menghindari kesimpangsiuran pada tugas- tugas yang diberikan terhadap dosen. Sehingga
dibutuhkan suatu sistem yang bisa
mengkelompokan kinerja akademik dosen secara optimal.
K-Means sangat sensitif pada inisialisasi
pusat cluster diawal, serta jatuh optimal lokal
pada suatu cluster. Sehingga algoritme genetika
sangat baik digunakan untuk menemukan
optimal global pada pusat cluster awal (Anusha
& Sathiaseelan, 2014). Hybrid GA-K-Means berbasis genetic dapat mengahasilkan solusi yang lebih optimal daripada GA-K-Means
berbasis K-Means. Dan juga pemilihan
crossover dan mutasi yang tepat dapat meningkatkan kualitas hasil pengklusteran (Wijaya & Badriyah, 2005). GA-K-Means mampu menghasilkan pengelompokan dengan tingkat variasi di dalam klaster yang lebih baik
dibandingkan dengan algoritme K-Means
sederhana. Dengan nilai total 7553.459
dibandingkan dengan nilai yang diperoleh K-Means sebesar 8896.303 (Wardhani, et al., 2012).
Algoritme genetika menghasilkan
himpunan solusi optimal yang sangat berguna pada penyelesaian masalah dengan banyak
obyektif (Mahmudy & Rahman, 2011).
Algoritme genetika dapat digunakan untuk menyelesaikan masalah yang kompleks dengan banyak variabel. Variabel tersebut bisa kontinyu, diskrit atau campuran keduanya (Haupt & Haupt, 2004).
Dari beberapa penelitian yang dilakukan
sebelumnya dapat disimpulkan bahwa clustering
dapat dilakukan dengan metode k-means serta dalam optimasi penentuan centroid dalam proses k-means dapat dilakukan dengan menggunakan algoritme genetika. Oleh karena itu saya akan melakukan penelitian dengan judul “Optimasi K-mean untuk clustering kinerja akademik dosen menggunakan algoritme genetika”. 2. KINERJA DOSEN
Definisi dari Kinerja yaitu seorang karyawan dalam menyelesaikan pekerjaan dengan sukses, segala sesuatu yang dilakukan karyawan merupakan Kinerja. Sedangkan definisi dari Kinerja karyawan adalah seberapa besar pengaruh karyawan dalam memberikan
kontribusinya kepada organisasi meliputi
kuantitas dan kualitas out put, jangka waktu out put. Kehadiran ditempat kerja dan sikap kooperatif. Motivasi berprestasi memberikan pengaruh lebih daripada disiplin terhadap kinerja akademik dosen (Sulastri, 2007).
3. ALGORITME GENETIKA
Algoritme Genetika menghasilkan solusi yang optimal dengan berbagai variasi obyektif serti memiliki banyak kelebihan dibandingkan dengan algoritme lainnya dilihat dari segi
kemampuannya untuk menghasilkan
(Mahmudy, 2013). Algoritme genetika dapat digunakan untuk menyelesaikan masalah yang kompleks dengan banyak variabel. Variabel tersebut bisa kontinyu, diskrit atau campuran keduanya (Haupt & Haupt, 2004). Pada penelitian ini algoritme gentika digunakan untuk
mengoptimasi pusat awal cluster pada algoritme
K-Means. Diagram alir proses optimasi pusat cluster ditunjukkan pada Gambar 3. Langkah-langkah algoritme genetika pada penelitian ini adalah sebagai berikut:
1. Inisialisasi chromosome
2. Untuk setiap chromosome, lakukan langkah
berikut:
a. Mengelompokkan setiap objek data ke
dalam cluster yang memiliki jarak
ditunjukkan pada persamaan (1) sebagai berikut:
𝐷𝑖𝑗= √∑𝑝𝑘=1{𝑥𝑖𝑘− 𝑥𝑗𝑘} (1)
Keterangan :
𝐷𝑖𝑗: jarak data ke-i terhadap pusat cluster
𝑥𝑖𝑘 : data i pada attribute data ke-k
𝑥𝑗𝑘 : Titik pusat ke-j pada attribute ke-k
b. Menghitung nilai fitness pada
persamaan (2) sebagai berikut:
𝑓 = 𝑁𝑐 ∑ { ∑𝑝𝑖𝑗=1𝑑(𝑜𝑖,𝑚𝑖𝑗) 𝑝𝑖 𝑁𝑐 𝑗=1 (2) Keterangan : 𝐶𝑖 : Cluster ke-i 𝑁𝑐 : Jumlah Cluster
𝑃𝑖 : Jumlah data pada
cluster𝐶𝑖
𝑜𝑖 : Pusat cluster𝐶𝑖
𝑚𝑖𝑗 : Data ke - j dan merupakan
anggota dari cluster𝐶𝑖
𝑑(𝑜𝑖, 𝑚𝑖𝑗) : Jarak antara 𝑜𝑖 dan
𝑚𝑖𝑗
c. Reproduksi chromosome dengan
menggunakan crossover one cut point
yaitu dengan cara memilih 2 parent
secara acak kemudian menentukan cut
point serta menyilangkan gen setelah cut
point tersebut. Contoh crossover one cut
point ditunjukkan pada Gambar 1.
𝑃𝑎𝑟𝑒𝑛𝑡1 1 0 1 1 0
𝑃𝑎𝑟𝑒𝑛𝑡2 1 1 0 0 0
𝐶ℎ𝑖𝑙𝑑1 1 0 1 0 0
Gambar 1 Crossover one cut point
d. Reproduksi chromosome dengan
menggunakan mutasi dengan
menggunakan metode reciprocal
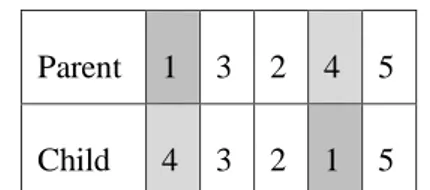
exchange mutation yaitu menukan 2 gen yang dipilih secara acak pada 1 parent yang dipilih secara acak. Contoh reciprocal exchange mutation ditunjukkan pada Gambar 2.
Parent 1 3 2 4 5
Child 4 3 2 1 5
Gambar 2 Reciprocal exchange mutation
e. Evaluasi seleksi untuk menentukan
individu yang lolos ke generasi
berikutnya yaitu menggunakan Elitism
Selection pada 20% individu tertinggi selebihnya memilih secara random dari populasi kecuali individu dengan nilai fitness 20% tertinggi. Elitism Selection merupakan seleksi yang didasarkan pada pemilihan fitness tertinggi yang lolos ke generasi berikutnya.
3. Lakukan langkah 2 sampai kondisi berhenti
yaitu sampai iterasi maksimal.
Gambar 3 Diagram alir proses optimasi pusat cluster 4. K-MEANS
K-mean merupakan teknik klastering yang paling umum dan sederhana. Tujuan klastering ini adalah mengelompokkan obyek ke dalam k cluster atau kelompok. Nilai k harus ditentukan terlebih dahulu (berbeda dengan hierarchical clustering). Pada penelitian ini Untuk
mempebaiki cluster lebih lanjut yaitu dengan
menggunakan metode K-Means. Inisialisasi
pusat cluster awal diperoleh dari proses
pencarian pusat cluster awal dengan
menggunakan algoritme genetika. Diagram alir Mulai
Data normalisasi, jumlah
cluster, jumlah iterasi, cr,mr
Inisialisasi
Chromosome
for a=0 to iterasi maksimal -1
Crossover
Mutasi
Perhitungan nilai fitness
Seleksi elitism
a Pusat – pusat cluster
proses clustering ditunjukkan pada Gambar 4.
Langkah -langkah proses clustering
menggunakan algoritme K-Means adalah
sebagai berikut:
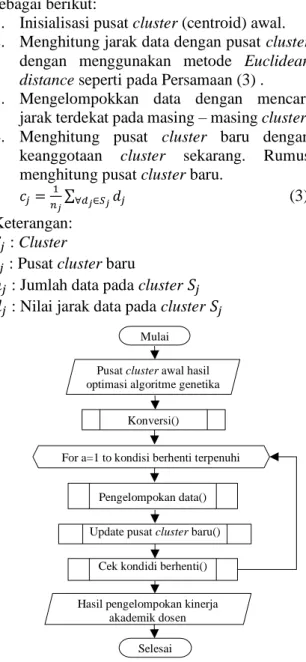
1. Inisialisasi pusat cluster (centroid) awal.
2. Menghitung jarak data dengan pusat cluster
dengan menggunakan metode Euclidean
distance seperti pada Persamaan (3) .
3. Mengelompokkan data dengan mencari
jarak terdekat pada masing – masing cluster.
4. Menghitung pusat cluster baru dengan
keanggotaan cluster sekarang. Rumus
menghitung pusat cluster baru.
𝑐𝑗=𝑛1
𝑗∑∀𝑑𝑗∈𝑆𝑗𝑑𝑗 (3) Keterangan:
𝑆𝑗 : Cluster
𝑐𝑗 : Pusat cluster baru
𝑛𝑗 : Jumlah data pada cluster𝑆𝑗
𝑑𝑗 : Nilai jarak data pada cluster𝑆𝑗
Gambar 4 Diagram alir proses clustering 5. MIN MAX NORMALIZATION
Normalisasi merupakan proses mengubah skala attribute data menjadi lebih kecil yaitu antara rentang 0 sampai 1 atau sebaliknya. Tujuan dari normalisasi data adalah untuk menyetarakan range setiap variabel dengan
variabel lain. Rumus Min-Max Normalization
ditunjukkan pada Persamaan (4) sebagai berikut:
𝑣′= 𝑣−𝑚𝑖𝑛𝐴
𝑚𝑎𝑥𝐴−𝑚𝑖𝑛𝐴(𝑛𝑒𝑤_𝑚𝑎𝑥𝐴− 𝑛𝑒𝑤_𝑚𝑖𝑛𝐴) +
𝑛𝑒𝑤_𝑚𝑖𝑛𝐴 (4)
Keterangan:
𝑣′ : Nilai data yang sudah dinormalisasi
𝑣 : Nilai data yang belum dinormalisasi
𝑚𝑎𝑥𝐴 : Nilai maksimum data dari attribut ke-
A
𝑚𝑖𝑛𝐴 : Nilai minimum data dari attribute ke-
A
𝑛𝑒𝑤_𝑚𝑎𝑥𝐴: Nilai maksimum data baru dari
atribut ke- A
𝑛𝑒𝑤_𝑚𝑖𝑛𝐴 : Nilai minimum data baru dari
atribut ke- A.
6. SILHOUETTE COEFFICIENT
Silhouette Coefficient merupakan salah satu metode intrinsik yang dapat digunakan untuk
mengukur kualitas cluster. Di bawah ini akan
dijelaskan tentang tahapan untuk menghitung
nilai silhoutte coeffisien:
a. Hitung jarak rata- rata data ke – o dengan
semua data yang berada pada satu cluster.
𝑎(𝑜) =∑ 𝑜′∈𝐶𝑖,𝑜≠𝑜′𝑑𝑖𝑠𝑡(𝑜,𝑜′)
|𝐶𝑖|−1 (5)
Keterangan:
𝑜 : Data ke-o pada clusteri
𝑜′ : Data lain pada clusteri selain data
ke-o
𝐶𝑖 : clusteri
|𝐶𝑖| : Jumlah data pada clusteri
𝑑𝑖𝑠𝑡(𝑜. 𝑜′) : Jarak data o dengan data o’
b. Hitung jarak rata-rata jarak data ke-o dengan
semua data yang berada pada cluster lain
kemudian ambil nilai paling minimum.
𝑏(𝑜) = 𝐶 𝑚𝑖𝑛
𝑗: 1 ≤ 𝑗 ≤ 𝑘, 𝑗 ≠ 𝑖 {
∑ 𝑜′∈𝐶𝑗𝑑𝑖𝑠𝑡(𝑜,𝑜′)
|𝐶𝑗| } (6)
Keterangan:
𝑜 : Data ke-o pada clusterj
𝑜′ : Data lain pada clusterj selain data
ke-o
𝐶𝑗 : clusterj
|𝐶𝑗| : Jumlah data pada clusterj
𝑑𝑖𝑠𝑡(𝑜. 𝑜′) : Jarak data o dengan data o’
Setelah itu maka untuk objek i memiliki nilai
silhoutte coefisien ditunjukkan pada persamaan (7) sebagai berikut:
𝑆𝑖=max (𝑎(𝑏𝑖−𝑎𝑖)
𝑖,𝑏𝑖) (7)
Keterangan:
𝑆𝑖 : Nilai silhouette coefficient pada data ke i
𝑎𝑖 : Nilai a(o) pada data ke i
𝑏𝑖 : Nilai b(o) pada data ke i
Mulai Pusat cluster awal hasil optimasi algoritme genetika
For a=1 to kondisi berhenti terpenuhi
Hasil pengelompokan kinerja akademik dosen
Selesai Konversi()
Pengelompokan data() Update pusat cluster baru()
7. IMPLEMENTASI
Pada penelitian ini terdiri atas implementasi antarmuka yang memiliki 4 bagian, yaitu
implementasi antarmuka input, implementasi
antarmuka clustering, implementasi antarmuka
optimasi pusat cluster, dan implementasi
antarmuka analisis kualitas cluster.
Implementasi dilakukan pada laptop dengan spesifikasi Intel(R) DualCore(TM) - CPU @ 2.13GHz menggunakan bahasa pemrograman
JAVA. Masing-masing dari implementasi
antarmuka ditunjukkan pada Gambar 5, Gambar 6, Gambar 7, dan Gambar 8 sebagai berikut:
Gambar 5 Antarmuka halaman input
Pada antarmuka halaman input terdiri atas mr,
cr, popsize, iterasi, dan jumlah cluster. Untuk dapat menginputkan variabel harus menekan tombol set.
Gambar 6 Antarmuka halaman clustering
Pada antarmuka halaman clustering teridiri
atas pendidikan, penelitian, pengabdian,
administrasi, penunjang, dan cluster. Pada
kolom terakhir yaitu kolom cluster berfungsi untuk mengelompokkan data tergantung dari inputan jumlah cluster sebelumnya.
Gambar 7 Antarmuka halaman optimasi pusat cluster
Pada antarmuka halaman optimasi pusat cluster merupakan representasi pusat cluster awal yang akan digunakan pada algoritme
K-Means. Pada field nilai fitness merupakan fitness
optimal global yang didapat pada algoritme genetika.
Gambar 8 Antarmuka halaman analisis kualitas cluster
Pada antarmuka halaman analisis kualitas cluster terdiri atas nilai rata-rata fitness dan
kualitas cluster. Nilai rata-rata fitness
merupakan nilai rata-rata silhouette coefficient
pada masing-masing cluster sedangkang kualitas
cluster nilai rata-rata silhouette coefficient pada semua data.
8. HASIL DAN PENGUJIAN
Pengujian yang dilakukan pada penelitian ini terdiri atas pengujian parameter algoritme genetika, pengujian jumlah cluster, serta pengujian perbandingan algoritme. Tujuan dari pengujian adalah untuk mengetahui kombinasi
pada parameter iterasi, cr, mr, popsize, dan
jumlah cluster dalam mendapatkan nilai kualitas
cluster paling optimal. Setiap pengujian dilakukan secara berulang sebanyak 10 kali. 8.1 Pengujian Parameter Algoritme Genetika
Pada pengujian parameter algoritme
genetika memiliki 3 macam, yaitu pengujian
kombinasi nilai cr dan mr, pengujian jumlah
iterasi, dan pengujian ukuran popsize. Pengujian
parameter algoritme genetika bertujuan untuk mengetahui pengaruh parameter algoritme
genetika pada proses clustering.
8.1.1 Pengujian Kombinasi Nilai cr dan mr
Pengujian kombinasi nilai cr dan mr,
bertujuan untuk mengetahui kombinasi nilai cr
dan mr yang tepat guna memperoleh pusat –
pusat cluster yang paling optimal. Nilai cr yang
digunakan adalah 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7,
0.8, dan 0.9, sedangkan nilai mr adalah 0.1, 0.2,
0.3, 0.4, 0.5, 0.6, 0.7, 0.8, dan 0.9. Kombinasi cr
dan mr, dilakukan secara menyilang yaitu jika
nilai mr 0.9 begitu pula sebaliknya. Hasil dari
pengujian kombinasi nilai cr dan mr ditunjukkan
pada Gambar 9.
Gambar 9 Grafik pengujian kombinasi nilai cr dan mr
Berdasarkan grafik hasil pengujian
kombinasi nilai cr dan mr yang ditunjukkan pada
Gambar 9 diperoleh kombinasi terbaik pada nilai
cr 0.2 dan nilai mr 0.8. Hasil pencarian optimum
yang beragam dibutuhkan offspring yang
banyak. Hal yang ditunjukkan pada Gambar 9
dimana semakin besar nilai mr dan semakin
sedikit nilai cr semakin baik nilai rata – rata
fitness yang didapat. Hal tersebut membuktikan bahwa level eksplorasi yang dihasilkan tinggi. Kompleksitas ruang pencarian nilai fitness hampir sama, ada indikasi ruang pencarian dan letak global optimalnya banyak.
8.1.2 Pengujian Jumlah Iterasi
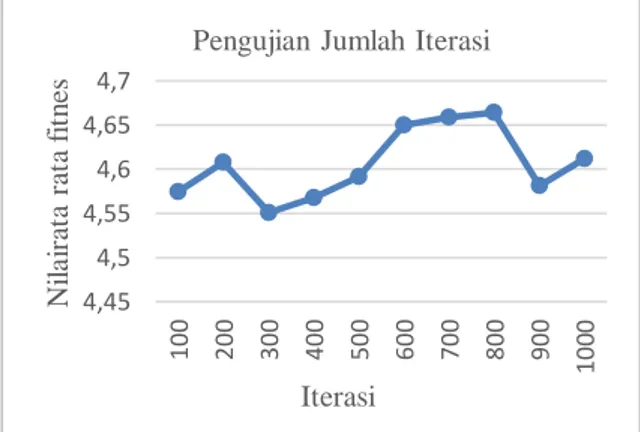
Pengujian jumlah iterasi dibutuhkan untuk memperoleh nilai optimal pada pusat-pusat cluster. Jumlah iterasi yang digunakan adalah kelipatan 100 dimulai dengan 100 iterasi. Hasil dari pengujian jumlah cluster ditunjukkan pada Gambar 10 dan Gambar 11.
Gambar 10 Grafik Pengujian Jumlah Iterasi
Gambar 11 Grafik Waktu Komputasi berdasarkan Jumlah Iterasi
Berdasarkan grafik hasil pada Gambar 10 diperoleh jumlah iterasi terbaik dengan rata-rata nilai fitness terbesar adalah 800. Jumlah iterasi merupakan salah satu hal yang dibutuhkan untuk memperoleh solusi terbaik tetapi juga tergantung pada permasalahan yang dihadapi. Solusi optimum sering kali sulit didapat jika jumlah iterasi terlalu sedikit karena pencarian solusi berhenti sebelum mencapai solusi optimum. Jumlah iterasi yang terlalu banyak bisa mengakibatkan kompleksitas waktu semakin meningkat. Pada Gambar 11 diperoleh bahwa semakin banyak jumlah iterasi waktu yang dibutuhkan juga semakin lama.
8.1.3 Pengujian Ukuran Popsize
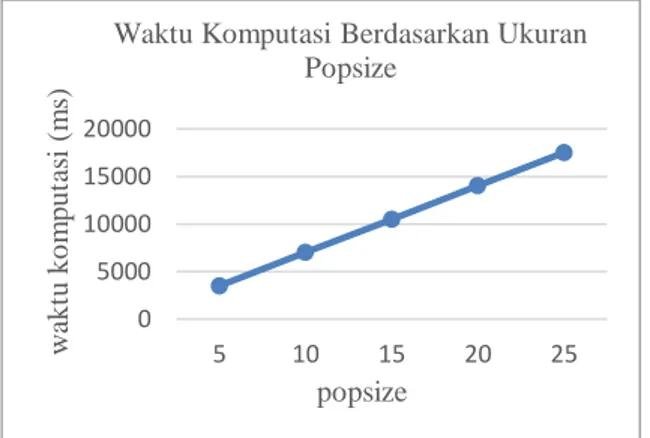
Pengujian ukuran popsize dibutuhkan untuk mengetahui ukuran popsize yang paling optimal yang dibutuhkan sehingga memperoleh pusat-pusat cluster pada cluster terbaik. Popsize yang diuji coba yaitu 5, 10, 15, 20, dan 25. Hasil Pengujian ukuran popsize ditunjukkan pada Gambar 12 dan Gambar 13.
Gambar 12 Grafik Pengujian Ukuran Popsize
4,3 4,35 4,4 4,45 4,5 4,55 4,6 4,65 4,7 '0.1 0.9' '0.2 0.8' '0.3 0.7' '0.4 0.6' '0.5 0.5' '0.6 0.4' '0.7 0.3' '0.8 0.2' '0.9 0.1' Ni la i ra ta -r at a fi tn es s Mr dan Cr
Pengujian Kombinasi nilai cr dan mr
4,45 4,5 4,55 4,6 4,65 4,7 100 200 300 400 500 600 700 800 900 1000 N il a ir at a ra ta f it n es Iterasi
Pengujian Jumlah Iterasi
0 10000 20000 30000 40000 100 200 300 400 500 600 700 800 900 1000 wa kt u ko m put as i (m s) Iterasi
Waktu Komputasi Berdasarkan Jumlah Iterasi 4,4 4,5 4,6 4,7 4,8 5 10 15 20 25 ra ta -r at a fi it n es s Popsize Pengujian Jumlah Popsize
Gambar 13 Grafik Waktu Komputasi Berdasarkan Ukuran Popsize
Berdasarkan hasil pengujian ukuran popsize
pada Gambar 12 diperoleh rata-rata fitness
terbaik pada popsize 25. Pada grafik yang ditunjukkan pada Gambar 12 juga diperoleh kesimpulan bahwa semakin banyak popsize
yang digunakan maka nilai rata-rata fitness yang
diperoleh juga semakin baik. Ukuran popsize
pada algoritme genetika sangat berpengaruh dalam proses pencarian agar semakin besar dalam memperoleh solusi yang paling optimal.
Akan tetapi, jumlah popsize yang semakin
banyak menyebab waktu komputasi yang diperlukan juga semakin lama seperti yang ditunjukkan pada Gambar 13.
8.2 Pengujian Jumlah Cluster
Pengujian jumlah cluster dilakukan untuk
mengetahui jumlah dengan tingkat validasi data
tertinggi pada penyelesaian clustering data
kinerja akademik dosen. Metode yang
digunakan untuk mengetahui kualitas dari cluster menggunakan metode analisis cluster Silhouette Coefficient. Jumlah cluster yang diuji coba yaitu 2, 3, 4, dan 5. Hasil pengujian jumlah cluster ditunjukkan pada Gambar 14.
Gambar 14 Pengujian Jumlah Cluster
Nilai Silhouette Coefficient memiliki range
-1 sampai dengan -1, jika nilai yang dihasilkan oleh Silhouette Coefficient mendekati 1 maka kualitas cluster yang dihasilkan akan semakin baik, tetapi jika nilai yang dihasilkan oleh Silhouette Coefficient mendekati -1 maka
kualitas cluster akan semakin buruk. Nilai
kualitas yang baik dalam metode Silhouette
Coefficient adalah jika jarak data terhadap satu cluster yang sama semakin dekat dan jarak antar
data terhadap cluster yang berbeda semakin
jauh. Sehingga, dalam Gambar 14 menunjukkan bahwa dalam mengelompokkan data kinerja
akademik dosen yang memiliki tingkat
kemiripan yang tinggi terhadap satu cluster yang
sama dan semakin rendah tingkat kemiripan
pada cluster yang berbeda terjadi pada 3 cluster
hasil pengelompokkan data yang semakin tepat. 8.3 Pengujian Perbandingan Algoritme
Pengujian perbandingan algoritme
merupakan pengujian yang dilakukan untuk
mengetahui kinerja dari masing-masing
algoritme yang dihasilkan. Dalam melakukan
clustering data kinerja akademik dosen
dibutuhkan pengujian untuk membandingkan algoritme K-Means yang dioptimasi dengan
algoritme genetika dengan algoritme K-Means
tanpa algoritme genetika. Evaluasi cluster yang
dilakukan menggunakan metode Silhouette
Coefficient dengan range -1 sampai dengan 1
dimana jika kualitas cluster mendekati 1 maka
kualitas cluster akan semakin baik. Hasil
pengujian perbandingan algoritme ditunjukkan pada Tabel 1.
Tabel 1. Hasil Pengujian Perbandingan Algoritme
Waktu Komputasi (ms) interval -1 s.d 1 Dalam (%) K-Means 97.7 0.380336251 69.02 GA-Kmeans 150612 0.435227965 71.76
Berdasarkan hasil pengujian pada masing-masing algoritme telah didapat nilai rata-rata Silhouette Coefficient seperti yang ditunjukkan
pada Tabel 1 bahwa algoritme K-Means yang
dioptimasi dengan algortima genetika memiliki
rata-rata nilai Silhouette Coefficient lebih tinggi
yaitu 71.76% dibandingkan dengan algoritme
K-Means tanpa dioptimasi yang hanya memperoleh 69.02%. Selain itu juga menunjukkan bahwa
untuk menghasilkan cluster yang paling baik dan
stabil membutuhkan waktu komputasi yang cukup lama. 0 5000 10000 15000 20000 5 10 15 20 25 w akt u ko m put as i (m s) popsize
Waktu Komputasi Berdasarkan Ukuran Popsize 0,399598 727 0,435227 965 0,312042 671 0,313025 939 0 0,1 0,2 0,3 0,4 0,5 2 3 4 5 ra ta -r at a Si lh o ue tt e C o ef fi ic ie n t jumlah cluster Pengujian Jumlah Cluster
9. KESIMPULAN
Algoritme genetika dan K-Means dapat
digunakan untuk melakukan clustering data
kinerja akademik dosen ke dalam k kategori.
Chromosome merupakan pendefinisian dari
representasi penyelesaian. Panjang chromosome
terdiri dari jumlah cluster dikali dengan jumlah
dimensi data sehingga jika jumlah dimensi 5
dikelompokkan ke dalam 2 cluster maka 5 sel
pertama merupakan representasi dari cluster
pertama dan 5 sel kedua merepresentasikan dari cluster kedua. Di dalam proses optimasi,
terdapat reproduksi chromosome untuk
memperbarui chromosome. Solusi yang didapat
berupa pusat-pusat cluster yang didapat
merupakan chromosome paling optimum dari
hasil setiap iterasi yang didapat. Pusat cluster tersebut kemudian dijadikan inisialisasi pusat
cluster di awal pada algoritme K-Means.
Nilai optimal yang didapatkan berdasarkan
dari hasil pengujian yaitu kombinasi nilai cr dan
mr adalah 0.2 dan 0.8, jumlah iterasi adalah 800,
ukuran popsize adalah 25. Jumlah cluster
mempengaruhi kualitas hasil clustering.
Berdasarkan hasil pengujian didapatkan jumlah cluster terbaik adalah sebanyak 3 cluster dengan
rata-rata nilai Silhouette Coefficient tertinggi
yaitu 71.76%.
Hasil clustering yang dioptimasi dengan
algoritme genetika memiliki kulitas clustering
data kinerja akademik dosen lebih baik jika
dibandingkan dengan algoritme K-Means tanpa
dioptimasi terlebih dahulu. Berdasarkan hasil pengujian perbandingan algoritme, algoritme
GA-KMeans memiliki kulitas clustering lebih
tinggi yaitu 2.74% dibandingkan dengan
algoritme K-Means. Algoritme GA-KMeans
juga lebih stabil, hal ini terbukti selama 10 kali percobaan nilai kualitas clustering hampir sama. 10. DAFTAR PUSTAKA
Anusha, M. & Sathiaseelan, J. G. R., 2014. An Enhanced K-Means Genetic Algorithm
for Optimal Clustering. IEEE.
Haupt, R. L. & Haupt, S. E., 2004. PRACTICAL
GENETIC ALGORITHMS. In: Second
Edition. s.l.:A JOHN WILEY & SONS, INC.,.
Mahmudy, W. F., 2013. Algoritme Evolusi.
Malang: PTIIK Universitas Brawijaya. Mahmudy, W. F. & Rahman, M. A., 2011.
OPTIMASI FUNGSI
MULTI-OBYEKTIF BERKENDALA
MENGGUNAKAN ALGORITME
GENETIKA ADAPTIF DENGAN
PENGKODEAN REAL. Jurnal Ilmiah
KURSOR, Volume 6.
Sulastri, T., 2007. Hubungan Motivasi
Berprestasidan Disiplin dengan Kinerja
Dosen. Jurnal Optimal, Volume 1.
Wardhani, F. K., Suryani, E. & Mukhlason, A., 2012. Penerapan metode GA-Kmeans untuk pengelompokan pengguna pada
Bapersip Provinsi Jawa Timur. JURNAL
TEKNIK ITS, Volume 1.
Wijaya, N. H. & Badriyah, T., 2005. Segmentasi
Data Pemasaran Menggunakan
Algoritme Genetika. Prosiding Seminar