ANALISIS CENTROID CLUSTERING MENGGUNAKAN METODE X-MEANS
TESIS
SARDO PARDINGOTAN SIPAYUNG 177038048
PROGRAM STUDI S2 TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN
2019
ANALISIS CENTROID CLUSTERING MENGGUNAKAN METODE X-MEANS
TESIS
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Magister Teknik Informatika
SARDO PARDINGOTAN SIPAYUNG 177038048
PROGRAM STUDI S2 TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN
2019
PERSETUJUAN
Judul : ANALISIS CENTROID CLUSTERING MENGGUNAKAN METODE X-MEANS Nama : SARDO PARDINGOTAN SIPAYUNG Nomor Induk Mahasiswa : 177038048
Program Studi : MAGISTER TEKNIK INFORMATIKA
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
Komisi Pembimbing :
Pembimbing 2
Dr. Poltak Sihombing, M.Kom
Pembimbing 1
Dr. Sutarman, M.Sc
Diketahui/disetujui oleh
Program Studi S2 Teknik Informatika Ketua,
Prof. Dr. Muhammad Zarlis 19570701 198601 1003
PERNYATAAN
ANALISIS CENTROID CLUSTERING MENGGUNAKAN METODE X-MEANS
TESIS
Saya mengakui bahwa tesis ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, 13 Agustus 2019
Sardo Pardingotan Sipayung 177038048
PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN
AKADEMIS
Sebagai civitas akademika Universitas Sumatera Utara, saya yang bertanda tangan dibawah ini :
Nama : Sardo Pardingotan Sipayung NIM : 177038048
Program Studi : S2 Teknik Informatika Jenis Karya Ilmiah : Tesis
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Sumatera Utara Hak Bebas Royalti Non-Eksklusif (Non-Exclusive Royalti Free Right) atas tesis saya yang berjudul:
ANALISIS CENTROID CLUSTERING MENGGUNAKAN METODE X-MEANS
Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti Non- Eksklusif ini, Universitas Sumatera Utara berhak menyimpan, mengalih media, memformat, mengelola dalam bentuk database, merawat dan mempublikasikan tesis saya tanpa meminta izin dari saya selama tetap mencantumkan nama saya sebagai penulis dan sebagai pemegang dan/atau sebagai pemilik hak cipta.
Demikian pernyataan ini dibuat dengan sebenarnya.
Medan, 13 Agustus 2019
Sardo Pardingotan Sipayung 177038048
RIWAYAT HIDUP
DATA PRIBADI
Nama Lengkap (berikut gelar) : Sardo Pardingotan Sipayung, S.Kom Tempat dan Tanggal Lahir : Purba Hinalang, 11 Februari 1983 Alamat Rumah : Perum. Griya Permata IV Blok L-06
Tanjung Anom , Kec. Pancur Batu,
Kab. Deli Serdang
Telepon/Faks/HP : 0813-7734-4034
Email : [email protected]
Instansi Tempat Kerja : SMK Methodist-8 Medan
Alamat Kantor : Jl. KL. Yosudarso No. 166-A Medan
DATA PENDIDIKAN
SD : SD Negeri 154023, Purba Hinalang. TAMAT : tahun 1996 SLTP : SLTP Negeri 2 Simpang Haranggaol. TAMAT : tahun 1999 STM : STM GKPS 2 Pematang Siantar. TAMAT : tahun 2002 S1 : Universitas Katolik ST. Thomas Medan. TAMAT : tahun 2007 S2 : Teknik Informatika USU Medan. TAMAT : tahun 2019
UCAPAN TERIMAKASIH
Puji syukur kepada Tuhan Yang Maha Esa, atas segala limpahan berkat dan rahmat- Nya sehingga penulis bisa menyelesaikan Tesis ini yang berjudul : Analisis Centroid Clustering Menggunakan Metode X-Means.
Penyusunan Tesis ini merupakan syarat untuk menyelesaikan studi pada jenjang magister (S2) yang dalam penyusunannya tidak terlepas dari dukungan berbagai pihak, baik secara moril maupun materil. Pada kesempatan yang sangat berbahagia saat ini dan dalam ruang ucapan terima kasih ini, kami menyampaikan rasa terima kasih dan penghargaan yang setinggi-tingginya dengan tulus dan ikhlas kepada :
1. Bapak Prof. Dr. Runtung Sitepu, S.H., M.Hum., selaku Rektor Universitas Sumatera Utara Medan.
2. Bapak Prof. Dr. Opim Salim Sitompul, M.Sc, selaku Dekan Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara Medan.
3. Bapak Prof. Dr. Muhammad Zarlis, M.Sc, selaku Ketua Program Studi S2 Teknik Informatika, Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara Medan.
4. Bapak Dr. Sutarman, M.Sc, sebagai Dosen Pembimbing I yang telah memberikan bimbingan dan arahan dalam penyelesaian tesis ini.
5. Bapak Dr. Poltak Sihombing, M.Kom sebagai Dosen Pembimbing II yang telah memberikan bimbingan dan arahan dalam penyelesaian tesis ini.
6. Bapak Prof. Dr. Saib Suwilo selaku Dosen Pembanding/Penguji I yang telah memberikan saran dan masukan untuk perbaikan dan penyelesaian tesis ini.
7. Bapak Suherman, ST, M.Comp. Ph.D selaku Dosen Pembanding/Penguji II yang telah memberikan saran dan masukan untuk perbaikan dan penyelesaian tesis ini.
8. Orangtua tercinta, Ibunda serta saudara-saudaraku atas ketulusan doa, motivasi dan nasihat-nasehat sepanjang waktu sehingga dapat menyelesaikan pendidikan.
9. Istri tercinta Pininta Sondang Lumbantoruan, atas ketulusan doa, motivasi- motivasi yang diberikan kepada penulis sepanjang waktu sehingga dapat menyelesaikan penidikan.
10. Teman-teman seangkatan di MTI-Kom-A-2017 dan MTI-Kom B yang telah bersama-sama menempuh pendidikan pada Program Studi S2 Teknik Informatika Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara Medan.
Penulis menyadari bahwa penelitian ini masih jauh dari kata sempurna, ini dikarenakan oleh keterbatasan, kemampuan dan pengetahuan penulis.
Harapan penulis, semoga penelitian ini bermanfaat bagi penulis khususnya dan pembaca pada umumnya. Sekali lagi penulis mengucapkan terima kasih, semoga Tuhan Yang Maha Kuasa membalas kebaikan yang telah diberikan. Amin.
Medan, 13 Agustus 2019
Sardo Pardingotan Sipayung 177038048
Centroid merupakan titik pusat data dalam proses pengelompokan, maka perlu dilakukan analisa terhadap centroid dalam menentukan pemberian nilai awal dalam melakukan proses awal clustering. Sehingga digunakan sebagai titik pusat cluster pada proses clustering algoritma X-Means. Menentukan titik pusat cluster atau centroid, mengukur performansi algoritma X-Means dengan parameter range cluster dengan mengukur jarak antar centroid untuk cara yang cepat dan efisien untuk mengelompokkan data yang tidak terstruktur, dan untuk mempercepat proses konstruksi model dan membagi beberapa centroid menjadi dua untuk mencocokkan data sebagai alat uji proses analisa terhadap metode X-Means. Dari pengujian menggunakan algoritma X-Means dengan penentuan jumlah Centroid cluster dilakukan dengan memodifikasi metode X-Means melakukan beberapa penentuan centroid hingga mendapatkan hasil sebanyak 11 iterasi. Dari hasil pengujian tersebut menghasilkan anggota cluster yang baik tingkat kemiripan datanya dengan data lain dan dalam menentukan jumlah cluster, menggunakan modifikasi metode euclidean distance, mendapatkan hasil yang lebih baik tingkat kemiripan setiap anggotanya dibandingkan dengan menentukan jumlah cluster secara acak dengan beberapa kali iterasi.
Kata Kunci: Clustering, Centroid, X-Means, Iterasi, dan Akurasi.
ABSTRACT
Centroid is the data center point in the grouping process, it is necessary to analyze the centroid in determining the initial value in the initial process of clustering. So that it is used as a cluster center point in the X-Means algorithm clustering process.
Determining the center point of the cluster or centroid, measures the performance of the X-Means algorithm with cluster range parameters by measuring the distance between centroids for a fast and efficient way to group unstructured data, and to speed up the model construction process and divide some centroids into two data sets as a test tool for analyzing the X-Means method. From testing using the X-Means algorithm with the determination of the number of Centroid clusters performed by modifying the X-Means method do some determination of the centroid to get the results of 11 iterations. From the test results it produces cluster members that have a good level of data similarity with other data and in determining the number of clusters, using the modification of the euclidean distance method, getting better results for each member compared to determining the number of clusters randomly with several iterations.
Keywords: Clustering, Centroid, X-Means, Iteration, and Accuracy.
Hal
HALAMAN JUDUL i
PERSETUJUAN ii
PERNYATAAN ORISINALITAS iii
PERSETUJUAN PUBLIKASI iv
PANITIA PENGUJI v
RIWAYAT HIDUP vi
UCAPAN TERIMA KASIH vii
ABSTRAK ix
ABSTRACT x
DAFTAR ISI xi
DAFTAR TABEL xiii
DAFTAR GAMBAR xiv
BAB I PENDAHULUAN 1
1.1 Latar Belakang Masalah 1
1.2 Rumusan Masalah 2
1.3 Batasan Masalah 3
1.4 Tujuan Penelitian 3
1.5 Manfaat Penelitian 3
BAB II LANDASAN TEORI 4
2.1 Data Mining 4
2.2 Clustering 5
2.3 X-Means Clustering 7
2.4 Euclidean Distance 8
2.5 Davies-Bouldin Index 8
2.6 Penelitian Terdahulu 10
2.7 Perbedaan Dengan Peneliti Terdahulu 11
BAB III METODE PENELITIAN 12
3.3.1 Observasi 13
3.3.2 Data Yang Digunakan 13
3.4 Desain Sistem 16
BAB IV HASIL DAN PEMBAHASAN 18
4.1 Hasil Pengujian 18
4.1.1 Model Yang Digunakan 18
4.1.2 Pengujian Data 19
4.1.3 Proses X-means Clustering 20
4.1.4 Perhitungan Evaluasi Clustering 23
4.1.5 Grafik Jarak Antar Centroid 25
4.1.6 Hasil Evaluasi Clustering 26
BAB V KESIMPULAN DAN SARAN 27
5.1 Kesimpulan 27
5.2 Saran 27
DAFTAR PUSTAKA 28
LAMPIRAN
Hal
Table 3.1 Tabel Data yang digunakan 14
Tabel 3.2 Data set yang digunakan 15
Tabel 4.1 Rincian Data Penjurusan Siswa SMA 19
Tabel 4.2 Inisialisasi Pusat Cluster Awal (Iterasi ke-1) 20 Tabel 4.3 Jarak Data terhadap Pusat Cluster (Iterasi 1) 21 Tabel 4.4 Inisialisasi Pusat Cluster Baru (Iterasi ke-2) 22 Tabel 4.5 Inisialisasi Pusat Cluster Akhir (Iterasi ke-11) 22 Tabel 4.6 Illustrasi data sample yang telah selesai di clustering 23 Tabel 4.7 Titik pusat cluster akhir dari proses clustering 24
Tabel 4.8 Nilai rasio dari setiap cluster 25
Tabel 4.9 Hasil Davies-Bouldin Index 26
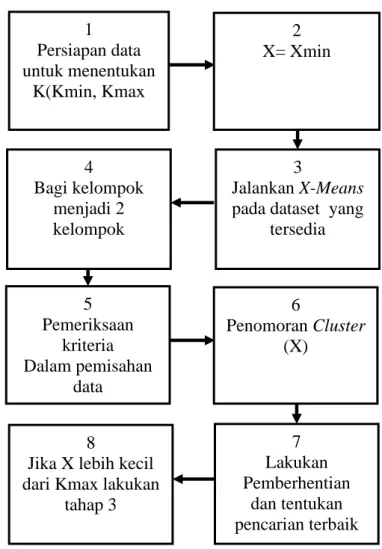
Hal Gambar 2.1. Langkah-Langkah Umum dalam Pengelompokan X-Means 7
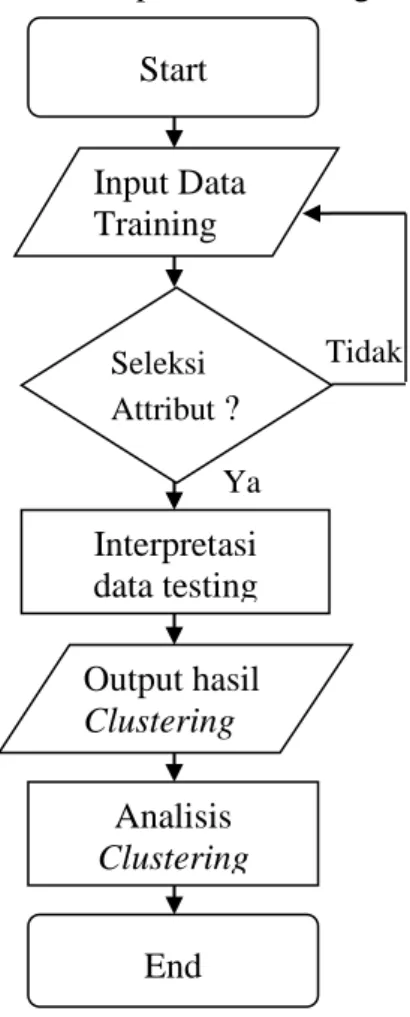
Gambar 3.1. Flowchart Rancangan Penelitian 12
Gambar 4.1 Rancangan Model X-Means 19
Gambar 4.2 Nilai pusat cluster akhir dengan Rapidminer 23
Gambar 4.3 Jarak Antar Centroid 25
BAB 1 PENDAHULUAN
1.1. Latar Belakang
Clustering adalah proses pengelompokan objek data menjadi beberapa cluster yang terpisah sehingga data yang ada di dalam masing-masing cluster tersebut menjadi sebuah kelompok data yang memiliki kemiripan yang relatif sama. Clustering data akan mengelompokkan objek yang paling dekat dimana terdapat kesamaan dengan objek lain, serta data yang akan dicluster diambil secara acak atau random. Data yang dikelompokkan dengan memiliki karakteristik sama mempergunakan metode clustering.
Saat ini perusahaan mulai menyadari pentingnya penggunaan data yang lebih besar untuk menjadi sebuah pendukung keputusan dalam melakukan strategi.
Dikatakan dalam sebuah studi kasus bahwa “Algoritma yang baik akan dikalahkan oleh data yang lebih banyak”. Dengan pernyataan ini perusahaan mulai menyadari bahwa mereka dapat memilih untuk berinvestasi lebih banyak dalam memproses set data yang lebih besar dari pada berinvestasi dalam algoritma yang mahal. Jumlah data yang besar lebih baik digunakan secara keseluruhan karena kemungkinan korelasi pada jumlah yang lebih besar, korelasi yang tidak pernah dapat ditemukan jika data dianalisis pada set terpisah atau pada set yang lebih kecil. Jumlah data yang lebih besar memberikan output yang lebih baik tetapi juga bekerja dengan proses yang terbatas, (Ularu, 2012).
Centroid cluster dipilih secara acak melalui sejumlah K-cluster. Algoritma membagi data yang diberikan ke dalam K-cluster, masing-masing memiliki keanggotaan cluster sendiri dan menetapkan setiap titik data ke pusat massa terdekat.
Kemudian mengkompilasi ulang centroid menggunakan asosiasi cluster saat ini dan
jika pengelompokan tidak menyatu, proses akan diulangi sampai beberapa kali.
X-means clustering adalah variasi dari K-means clustering yang memperlakukan alokasi cluster dengan mencoba partisi berulang dan menjaga pemisahan hasil yang optimal, sampai beberapa kriteria tercapai. Tujuan dari X-means cluster dengan melakukan pengelompokan intrinsik dalam satu set data yang tidak berlabel.
Memberikan cara yang cepat dan efisien untuk mengelompokkan data yang tidak terstruktur, penggunaan concurrency dengan mempercepat proses konstruksi model dan penggunaan.
Titik pusat cluster atau centroid merupakan titik awal dimulainya pengelompokan didalam cluster pada algoritma K-Means. Pengelompokan data dilakukan dengan menghitung jarak terdekat dengan titik pusat cluster awal sebagai titik sentral dalam pembentukan setiap kelompok atau cluster. Namun pada penerapannya, penentuan titik pusat cluster awal inilah yang menjadi kelemahan dari algoritma K-Means. Ini disebabkan karena tidak ada pendekatan yang digunakan dalam memilih dan menentukan titik pusat cluster. Titik pusat cluster dipilih secara sembarang atau acak dari sekumpulan data. Akibatnya hasil clustering dari algoritma K-Means sering kurang optimal dan tidak maksimal dalam setiap percobaan yang dilakukan. Oleh karena itu, dapat dikatakan bahwa baik buruknya hasil clustering, sangat bergantung pada titik pusat cluster atau centroid awal (Baswade, 2013).
(R. Dela Arundina, 2010), di dalam penelitiannya menggunakan Silhouette Coefficient pada algoritma X-Means memperoleh tingkat akurasi yang lebih baik dibandingkan dengan K-Means .
Pada Penelitian ini, jumlah centroid cluster ditentukan dengan menghitung nilai Davies-Bouldin Index (DBI). Data yang memperoleh nilai DBI terendah akan digunakan sebagai titik centroid untuk proses clustering algoritma X-Means.
1.2. Rumusan Masalah
Centroid merupakan titik pusat data dalam proses pengelompokan, maka perlu dilakukan analisa terhadap centroid dalam menentukan pemberian nilai awal dalam melakukan proses awal clustering. Sehingga digunakan sebagai titik pusat cluster pada proses clustering algoritma X-Means.
1.3. Batasan Masalah
Beberapa batasan masalah pada penelitian ini adalah sebagai berikut : 1. Dataset yang digunakan dalam penelitian ini yaitu
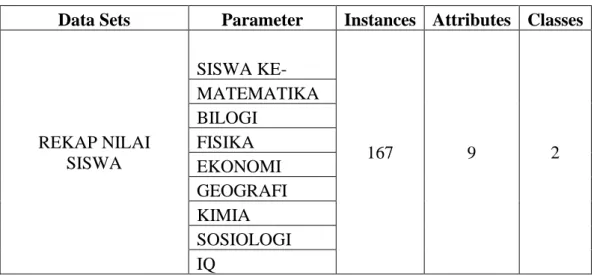
Dataset Penjurusan SMA Methodist-8 Medan, yang berjumlah 167 data dengan 8 atrribut numerik yang diperoleh dari Perguruan Methodist-8 Medan
2. Jumlah cluster pada penelitian ini yaitu 2 cluster dan batas iterasi dari proses clustering adalah 11 iterasi.
1.4. Tujuan Penelitian
Tujuan penelitian ini adalah untuk menentukan titik pusat cluster atau centroid, mengukur performansi algoritma X-Means dan mengukur jarak antar centroid untuk cara yang cepat dan efisien untuk mengelompokkan data yang tidak terstruktur, dan melakukan pengelompokan data terbaik pada metode X-Means dengan melakukan beberapa pengujian terhadap data yang diuji.
1.5. Manfaat Penelitian
Melalui penulisan dalam penelitian ini penulis lebih memahami pengelompokan data, cara kerjanya serta pengaplikasiannya pada komputer. Penulis juga mengharapkan manfaat penelitian ini untuk membantu para pelaku pekerjaan di bidang data mining atau clustering data lainnya. Juga menambah wawasan dan kemampuan dalam mengaplikasikan ilmu-ilmu Teknik Informatika, khususnya clustering untuk proses pengelompokan data.
BAB 2
LANDASAN TEORI
Bab ini akan diuraikan seluruh landasan teori yang berhubungan dengan penelitian.
Konsep-konsep yang akan di jelaskan dalam penelitian ini seperti data mining, clustering, dan algoritma x-means. Pada bagian data mining membahas tentang teknik data mining, tahapan data mining dan macam-macam data mining. Pada clustering membahas tentang pengertian clustering. Pada bagian X-Means membahas tentang kelemahan dan keuntungan dari X-Means serta cara kerjanya.
2.1. Data Mining
Data mining adalah teknologi yang mengkombinasikan metode analisis tradisional dan algoritma yang canggih agar proses data besar lebih cepat diproses. Data mining biasa disebut dengan sebutan yang sering digunakan untuk mencari pengetahuan yang tersembunyi didalam database. Data mining menggunakan teknik statistika, matematika, kecerdasan buatan, dan machine learining untuk mengekstraksi dan menganalisa informasi yang terdapat dalam database besar (Turban et al, 2005).
Analisis yang dilakukan data mining lebih maksimum dibandingkan sistem pendukung keputusan tradisional yang banyak digunakan. Data mining mengatasi masalah-masalah bisnis dengan cara tradisional yang menggunakan banyak waktu dan biaya yang tinggi. Data mining menjelajahi basisdata untuk mengetahui pola yang tersembunyi, serta mencari informasi agar dapat memprediksi yang bisa saja dilupakan oleh pembisnis karena kemungkinan besar mereka tidak menduganya.
Pada perkembangan teknologi saat ini, proses pengumpulan data serta penyimpanannya telah mudah dijalankan walaupun data tersebut berukuran besar,
sehingga data mining melakukan proses pencarian secara mudah dan otomatis mencari informasi yang berguna dalam penyimpanan data yang mempunyai ukuran yang besar. Istilah ini biasa disebut dengan knowledge discovery in database (KDD) yang digunakan secara bergantian untuk memberikan penjelasan tentang proses pencarian informasi yang tersembunyi dalam suatu basis data yang besar. Sebenarnya konsep ini berkaitan satu sama lain walaupun konsepnya berbeda.
2.2. Clustering
Clustering adalah metode mengelompokkan atau mempartisi data dalam suatu data set. Pada dasarnya clustering merupakan suatu metode untuk mencari dan mengelompokkan data yang memiliki kemiripan karakteriktik (similarity) antara satu data dengan data yang lain (Bhusare, 2014).
Cluster merupakan sekumpulan objek-objek data yang memiliki kemiripan satu sama lain didalam cluster yang sama dan yang tidak memiliki kemiripan terhadap objek- objek yang berbeda cluster. Objek akan dikelompokkan ke dalam satu atau lebih cluster sehingga objek-objek yang berada dalam satu cluster akan mempunyai kesamaan yang tinggi antara satu dengan lainnya. Objek-objek dikelompokkan berdasarkan prinsip memaksimalkan kesamaan objek pada cluster yang sama dan memaksimalkan ketidaksamaan pada cluster yang berbeda. Kesamaan objek biasanya diperoleh dari nilai-nilai atribut yang menjelaskan objek data, sedangkan objek-objek data biasanya direpresentasikan sebagai sebuah titik dalam ruang multidimensi.
Karakteristik dari setiap cluster tidak ditentukan sebelumnya, namun tergambar dari kemiripan data yang terkelompok di dalamnya.
Metode clustering terdiri dari dua jenis, yaitu Partitioning clustering dan Hierarchical clustering (Malki, 2016). Partitioning clustering merupakan metode pengelompokan data yang dimulai dengan menentukan terlebih dahulu jumlah cluster yang diinginkan (dua cluster, tiga cluster, atau lain sebagainya). Setelah jumlah cluster diketahui, kemudian dilakukan proses cluster tanpa mengikuti proses hierarki Hierachical clustering adalah suatu metode pengelompokan data yang dimulai dengan mengelompokkan dua atau lebih objek yang memiliki kesamaan paling dekat.
Kemudian proses diteruskan ke objek lain yang memiliki kedekatan kedua. Demikian seterusnya sehingga cluster akan membentuk seperti pohon, dimana ada hirarki yang jelas antar objek, dari yang paling mirip sampai yang paling tidak mirip (Rose, 2016).
Analisis kelompok (cluster analysis) adalah mengelompokkan data (objek) yang didasarkan hanya pada informasi yang ditemukan dalam data yang menggambarkan objek tersebut dan hubungan diantaranya (Prasetyo, Eko. 2012).
Analisis kelompok tersebut dimana objek-objek yang bergabung dalam sebuah kelompok merupakan objek-objek yang mirip satu sama lain dan berbeda dalam kelompok dan lebih besar perbedaannya diantara kelompok lain.
Untuk pemberian data set ada beberapa cara untuk menemukan kesamaan antara data untuk menghasilkan cluster. Karakteristik clustering telah menyebabkan pengembangan beberapa algoritma clustering. Masing-masing algoritma menggunakan kriteria yang berbeda untuk membentuk cluster dari data. Diantara algoritma yang paling banyak digunakan untuk clustering adalah K-Means dan DBSCAN (Prasetyo, Eko. 2014).
Menurut (Prasetyo, Eko, 2014), ada saatnya di mana set data yang akan diproses dalam data mining belum diketahui label kelasnya. Pengelompokan data dilakukan dengan menggunakan algoritma yang sudah ditentukan dan selanjutnya data akan diproses oleh algoritma untuk dikelompokkan menurut karakteristik alaminya. Tidak unsur pembimbingan (dengan pemberian label kelas), melainkan algoritma akan berjalan dengan sendirinya untuk mengelompokkan data tersebut. Data yang lebih dekat (mirip) dengan data yang lain akan berkelompok dalam satu cluster, sedangkan data yang lebih jauh (berbeda) dari data yang lain akan berpisah dalam kelompok yang berbeda.
Menurut kategori kekompakan, clustering terbagi menjadi dua, yaitu komplet dan parsial. Jika semua data dapat bergabung menjadi satu (dalam konteks partisi) maka dapat dikatakan semua data kompak menjadi satu cluster, tetapi jika ada satu atau dua data yang tidak ikut bergabung dalam cluster mayoritas maka data tersebut dikatakan data yang mempunyai perilaku yang menyimpang. Data yang menyimpang ini disebut outlier, noise atau uninterested background. Maka dari itu, metode yang tangguh untuk melakukan deteksi outlier adalah DBSCAN. Akan tetapi metode lain seperti K-Means juga dapat melakukan deteksi outlier dengan sejumlah komputasi tambahan.
2.3. X-Means Clustering
X-Means clustering digunakan untuk menyelesaikan salah satunya kelemahan utama dari K-means clustering, yaitu perlunya pengetahuan sebelumnya tentang jumlah cluster (K). Dalam metode ini, nilai sebenarnya dari K diperkirakan dalam suatu yang tidak diawasi cara dan hanya berdasarkan set data itu sendiri.
Gambar 2.1. Langkah-Langkah Umum dalam Pengelompokan X-Means
Kmax dan Kmin sebagai batas atas dan bawah untuk nilai yang mungkin dari X. Pada langkah pertama X-Means pengelompokan, mengetahui bahwa saat ini X = Xmin, X-berarti menemukan struktur awal dan centroid. Di langkah selanjutnya, setiap cluster dalam struktur yang diperkirakan diperlakukan sebagai induk cluster, yang dapat dibagi menjadi dua kelompok.
1 Persiapan data untuk menentukan
K(Kmin, Kmax
2 X= Xmin
3
Jalankan X-Means pada dataset yang
tersedia 4
Bagi kelompok menjadi 2 kelompok
5 Pemeriksaan
kriteria Dalam pemisahan
data
6
Penomoran Cluster (X)
7 Lakukan Pemberhentian
dan tentukan pencarian terbaik 8
Jika X lebih kecil dari Kmax lakukan
tahap 3
2.4 Euclidean Distance
Euclidean Distance adalah metric yang paling sering digunakan untuk menghitung kesamaan dua vector. Misalkan ada dua objek yaitu A dengan koordinat (x1,y1) dan B dengan koordinat (x2,y2), maka jarak antar kedua objek tersebut dapat diukur dengan rumus :
Ukuran jarak atau ketidaksamaan antar objek ke-i dengan objek ke-j, disimbolkan dengan dij dan k=1,……, p. Nilai dij diperoleh melalui perhitungan jarak kuadrat Euclidean sebagai berikut:
(2.1)
Keterangan:
: Jarak Kuadrat Euclidean antar objek ke-I dengan objek ke-j n : jumlah variabel cluster
Xik : Nilai atau data dari objek ke-I pada variabel ke-k Xjk : Nilai atau data dari objek ke-j pada variabel ke-k
2.5 Davies-Bouldin Index
David L. Davies dan Donald W. Bouldin memperkenalkan sebuah metode diberi nama dengan nama mereka berdua, yaitu Davies-Bouldin Index (DBI) yang digunakan untuk mengevaluasi cluster . Evaluasi menggunakan Davies-Bouldin Index ini memiliki skema evaluasi internal cluster, dimana baik atau tidaknya hasil cluster dilihat dari kuantitas dan kedekatan antar data hasil cluster . Davies-Bouldin Index merupakan salah satu metode yang digunakan untuk mengukur validitas cluster pada suatu metode pengelompokan, kohesi didefinisikan sebagai jumlah dari kedekatan data terhadap titik pusat cluster dari cluster yang diikuti. Sedangkan separasi didasarkan pada jarak antar titik pusat cluster terhadap clusternya. Pengukuran dengan Davies-Bouldin Index ini memaksimalkan jarak inter-cluster antara cluster Ci dan Cj
dan pada waktu yang sama mencoba untuk meminimalkan jarak antar titik dalam sebuah cluster. Jika jarak inter-cluster maksimal, berarti kesamaan karakteristik antar
Jika jarak intra-cluster minimal berarti masing-masing objek dalam cluster tersebut memiliki tingkat kesamaan karakteristik yang tinggi (Wani & Riyaz. 2017). Tahapan dari perhitungan Davies-Bouldin Index adalah sebagai berikut :
1. Sum of square within cluster (SSW)
Untuk mengetahui kohesi dalam sebuah cluster ke-i adalah dengan menghitung nilai dari Sum of square within cluster (SSW). Kohesi didefinisikan sebagai jumlah dari kedekatan data terhadap titik pusat cluster dari sebuah cluster yang diikuti. Persamaan yang digunakan untuk memperoleh nilai Sum of square within cluster adalah sebagai berikut :
(2,2)
Dari persamaan tersebut, mi merupakan jumlah data dalam cluster ke-i, ci adalah centroid cluster ke-i, dan d() merupakan jarak setiap ke centroid yang dihitung menggunakan jarak euclidean.
2. Sum of Square Between-cluster (SSB)
Perhitungan Sum of Square Between-cluster (SSB) berjutuan untuk mengetahui separasi antar cluster. Persamaan yang digunakan untuk menghitung nilai Sum of Square Between-cluster adalah sebagai berikut :
(2.3)
3. Ratio (Rasio)
Ratio bertujuan untuk untuk mengetahui nilai perbandingan antara cluster ke-i dan cluster ke-j . Cluster yang baik adalah cluster yang memiliki nilai kohesi sekecil mungkin dan separasi yang sebesar mungkin. Nilai rasio dihitung menggunakan persamaan sebagai berikut :
(2.4)
SSBij = d (ci,cj)
Nilai rasio yang diperoleh tersebut digunakan untuk mencari davies-bouldin index (DBI) dari persamaan berikut :
(2.5)
Dari persamaan tersebut, k merupakan jumlah cluster yang digunakan. Semakin kecil nilai DBI yang diperoleh ( non negatif) >=0, maka semakin baik cluster yang diperoleh dari pengelompokan X-means yang digunakan.
2.6 Penelitian Terdahulu
Dalam penelitian ini terdapat penelitian terdahulu yang berkaitan dengan penelitian ini. Adapun summary dari penelitian tersebut adalah sebagai berikut:
Nama Peneliti dan Tahun
Metode yang
digunakan Keterangan
R. Dela Arundina, 2010 X-Means, Silhouette Coefficient
Diperoleh Nilai jarak antar objek dalam cluster namun tidak dijelaskan nilai DBI yang diperoleh untuk setiap iterasi pada proses clustering.
Bartosz Krawczyk, Micha_l Wo´zniak, 2013
One-Class Classifiers with X-means Clustering
Hasil dari penelitian tersebut diperoleh peningkatan waktu eksekusi pengelompokan untuk data dalam satu kelas tetapi tidak dijelaskan untuk beda kelas Mahdi Shahbaba, Soosan
Beheshti. 2012
X-Means, MNDL (Minimum Noiseless Description Length)
Hasil penelitian tersebut menunjukkan metode tersebut mampu memprediksi jumlah cluster, namun tidak dijelaskan korelasi antar iterasi pada proses clustering pada penelitian tersebut.
2.7 Perbedaan Dengan Peneliti Terdahulu
Berdasarkan penelitian yang telah dilakukan, peneliti membuat perbedaan dalam penelitian ini yaitu :
1. Algoritma X-Means yang digunakan dalam penentuan jumlah titik Centroid cluster adalah jumlah nilai terendah dari davies-bouldin index (DBI)
2. Untuk menghitung jarak (distance) antara data dengan centroid menggunakan Euclidean Distance Space.
Ya
Tidak BAB 3
METODE PENELITIAN
3.1. Pendahuluan
Proses clustering pada penelitian ini untuk mencari titik centroid dilakukan dengan menggunakan Algoritma X-Means menghasilkan hasil yang lebih tepat dan optimal.
Rancangan Penelitian
Adapun rancangan dari penelitian ini dapat dilihat sebagai berikut:
Gambar 3.1. Flowchart Rancangan Penelitian Input Data
Training
Seleksi Attribut ?
Interpretasi data testing Output hasil Clustering
Analisis Clustering
End Start
3.2. Teknik Pengumpulan Data
Pada penelitian ini dilakukan teknik pengumpulan data yang digunakan peneliti adalah sebagai berikut:
1. Mengumpulkan dari literature, jurnal, paper, dan bacaan-bacaan lainnya yang berhubungan dengan algoritma klasifikasi data mining.
2. Peneliti melakukan pengumpulan data penelitian yang diperoleh dengan mengambil dataset dari Sekolah SMA Methodist-8 Medan.
3.3. Pelaksanaan Penelitian
Proses penelitian ini terdapat beberapa kegiatan, yaitu kegiatan-kegiatan yang terdapat pada penelitian, yaitu observasi lapangan, pengumpulan data dan analisa data.
3.3.1. Observasi
Observasi yang dilakukan pada penelitian ini adalah hal yang paling penting. Karena penulis dapat mengetahui tingkat visibilitas yang digunakan. Data-data yang telah dikumpulkan telah menjadi titik pantauan dalam observasi ini sehingga mendapatkan hasil yang diinginkan.
3.3.2. Data yang Digunakan
Pada langkah awal dalam analisis data ini akan ditentukan beberapa atribut yang digunakan sebagai parameter dalam pengelompokkan data sampel. Atribut menyatakan suatu parameter yang dibuat sebagai kriteria dalam pembentukan atribut.
Pada ilmu statistik khususnya pada sampel terdapat penjelasan mengenai beberapa metode pengambilan sampel. Sampel yang baik yaitu yang dapat menggambarkan (mewakili) populasinya. Untuk memperoleh sampel yang baik diperlukan metode yang baik dalam pemilihan anggota sampel. Sampel nonrandom merupakan salah satu metode pengambilan sampel dimana pemilihan sampel dengan cara ini menggunakan pengetahuan dan opini dari peneliti terhadap obyek yang akan diteliti. Penelitian ini diperlukan beberapa langkah pre-processing guna mengolah raw data yang didapat
sehingga menjadi data yang siap di training, adapun langkah-langkahnya sebagai berikut:
1. Membuat rancangan data input dan output yang akan dimasukkan sebagai data penelitian.
2. Memisahkan data penelitian menjadi dua bagian, yaitu data pelatihan dan data pengujian. Data pelatihan digunakan untuk mengamati proses pengenalan pola (memorisasi), sedangkan data pengujian digunakan untuk mengamati kemampuan algoritma dalam mengenali pola pada sample yang belum dipelajari oleh algoritma X-Means
3. Pada Data Set yang akan diuji terdiri dari beberapa tipe data, yaitu: integer, float, numeric, Boolean sehingga pada masing masing kolom memiliki karakteristik tersendiri apakah itu nilai mean, fungsi distribusinya, nilai maksimum dan minimumnya.
Adapun data yang digunakan adalah sebagai berikut:
Table 3.1 Tabel Data yang digunakan
Data Sets Parameter Instances Attributes Classes
REKAP NILAI SISWA
SISWA KE-
167 9 2
MATEMATIKA BILOGI
FISIKA EKONOMI GEOGRAFI KIMIA SOSIOLOGI IQ
1. Instance : data itu sendiri, setiap instance akan memiliki atribut dan class
2. Atribut : atribut adalah keterangan yang dikandung dalam data itu sendiri, setiap data bisa memiliki lebih dari 1 atribut. Biasanya atribut menggunakan variabel diskrit
3. Class : class adalah status dari setiap instance, class adalah kesimpulan dari setiap data, setiap data biasanya hanya memiliki 1 class, biasanya class menggunakan variable diskrit
Pada data set yang digunakan memliki 167 data, dan memiliki 9 atributs serta memiliki 2 class yang merupakan nama jurusan yaitu IPA dan IPS.
Adapun data yang digunakan adalah sebagai berikut:
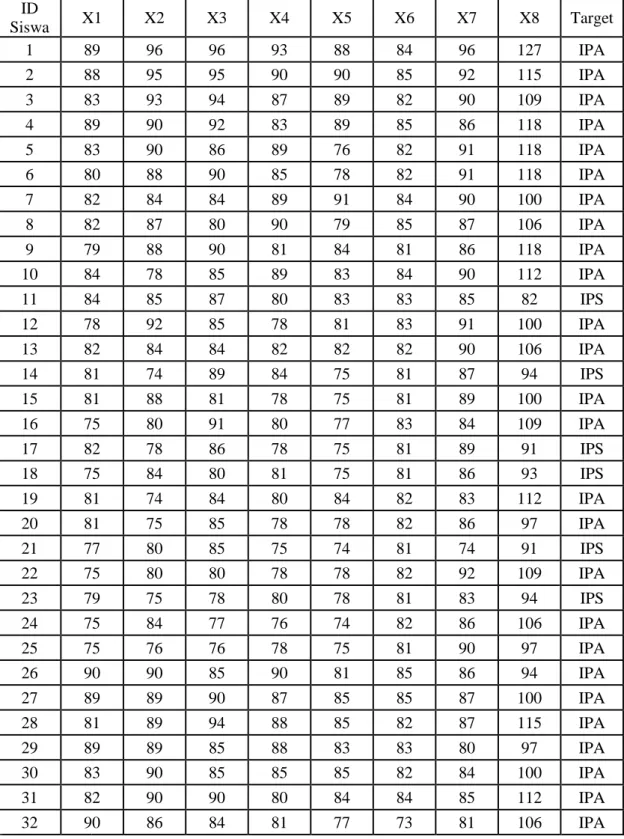
Tabel 3.2 Data sets yang digunakan ID
Siswa X1 X2 X3 X4 X5 X6 X7 X8 Target
1 89 96 96 93 88 84 96 127 IPA
2 88 95 95 90 90 85 92 115 IPA
3 83 93 94 87 89 82 90 109 IPA
4 89 90 92 83 89 85 86 118 IPA
5 83 90 86 89 76 82 91 118 IPA
6 80 88 90 85 78 82 91 118 IPA
7 82 84 84 89 91 84 90 100 IPA
8 82 87 80 90 79 85 87 106 IPA
9 79 88 90 81 84 81 86 118 IPA
10 84 78 85 89 83 84 90 112 IPA
11 84 85 87 80 83 83 85 82 IPS
12 78 92 85 78 81 83 91 100 IPA
13 82 84 84 82 82 82 90 106 IPA
14 81 74 89 84 75 81 87 94 IPS
15 81 88 81 78 75 81 89 100 IPA
16 75 80 91 80 77 83 84 109 IPA
17 82 78 86 78 75 81 89 91 IPS
18 75 84 80 81 75 81 86 93 IPS
19 81 74 84 80 84 82 83 112 IPA
20 81 75 85 78 78 82 86 97 IPA
21 77 80 85 75 74 81 74 91 IPS
22 75 80 80 78 78 82 92 109 IPA
23 79 75 78 80 78 81 83 94 IPS
24 75 84 77 76 74 82 86 106 IPA
25 75 76 76 78 75 81 90 97 IPA
26 90 90 85 90 81 85 86 94 IPA
27 89 89 90 87 85 85 87 100 IPA
28 81 89 94 88 85 82 87 115 IPA
29 89 89 85 88 83 83 80 97 IPA
30 83 90 85 85 85 82 84 100 IPA
31 82 90 90 80 84 84 85 112 IPA
32 90 86 84 81 77 73 81 106 IPA
ID
Siswa X1 X2 X3 X4 X5 X6 X7 X8 Target
33 87 80 86 81 75 73 78 100 IPA
34 91 85 75 82 76 72 90 94 IPS
35 83 84 81 80 70 76 75 97 IPS
36 87 84 74 81 80 79 87 106 IPA
37 79 83 78 80 76 80 82 97 IPA
38 82 82 77 77 74 78 81 94 IPA
39 85 80 73 79 74 78 79 100 IPA
40 72 65 69 72 75 72 73 97 IPA
41 70 70 70 72 70 71 80 97 IPS
42 70 70 70 76 70 76 70 82 IPS
43 72 72 75 72 70 72 76 85 IPS
44 80 70 75 72 70 76 77 82 IPS
45 77 70 70 77 71 74 85 85 IPS
46 70 70 74 72 70 75 73 96 IPS
47 70 70 70 71 70 70 74 85 IPS
48 70 70 70 72 70 71 72 82 IPS
49 75 70 70 73 70 74 72 82 IPS
50 70 70 70 72 72 73 76 82 IPS
… … … … … … … … … …
167 70 76 70 76 75 78 78 93 IPS
3.4. Desain Sistem
Pada penelitian ini, keperluan hardware dan software sebagai bagian dari proses desain sistem meliputi:
a. Perangkat Keras (Hardware) 1. Noteboon Acer
2. Processor Intel AtomTM N570 @1.66GHz 1.67 GHz 3. RAM 2 GB DDR3
4. Harddisk 500 GB
5. Monitor dengan reolusi 1024 x 600 pixel (32 bit true color) 6. Mouse dan keyboard
b. Perangkat Lunak (Software)
1. Sistem Operasi Windows 7Sistem Operasi Windows 7 merupakan sistem operasi berbasis grafis yang dirancang oleh Microsoft berfingsi pada
sebagainya. Windows 7 merupakan sistem dasar yang mendukung pada setiap proses penelitian ini.
2. RapidMiner
RapidMiner merupakan software untuk pengelolaan data mining.
RapidMiner melakukan pekerjaan text mining berkisar dengan analisis teks, mengekstrak pola-pola dari data set yang besar dan mengkombinasikannya dengan metode statistika, kecerdasan buatan, dan database.
BAB 4
HASIL DAN PEMBAHASAN
Bab ini merupakan penjelasan tentang penggunaan metode X-Means dengan ditetapkannya nilai centroid, serta analisa terhadap beberapa metode yang diterapkan juga yang bisa mendapatkan hasil dalam penelitian dengan cara mengcluster data menjadi beberapa cluster pada data set Penjurusan Siswa SMA.
Pelatihan serta pengujian dalam penelitian ini adalah dengan cara melakukan pengelompokkan data terbaik pada metode X-Means dengan melakukan beberapa pengujian terhadap penentuan nilai centroid.
4.1. Hasil Pengujian
Pengujian yang dilakukan oleh peneliti yaitu menggunakan data set Penjurusan Siswa SMA yang meliputi: ID Siswa, Matematika, Biologi, Fisika, Ekonomi, Geografi, Kimia, Sosiologi, IQ. Pada metode X-Means dengan ditetapkannya nilai centroid, serta analisa terhadap beberapa metode yang diterapkan juga yang bisa mendapatkan hasil dalam penelitian dengan cara clustering data menjadi beberapa cluster pada data set Penjurusan Siswa SMA sebagai langkah awal analisa dengan cara melakukan pengelompokkan data terbaik pada metode X-Means.
4.1.1. Model yang digunakan
Pada dataset yang telah ditentukan diperlukan model dari metode yang akan digunakan yaitu X-Means dengan grafik dari software RapidMiner yang digunakan dapat dilihat sebagai berikut:
Gambar 4.1 Rancangan Model X-Means 4.1.2. Pengujian Data
Pada pengujian data dilakukan analisa clustering yang menggunakan perangkat lunak yaitu RapidMiner. Data set diperoleh dari hasil penelitian yang dilakukan disekolah dengan mendapatkan nilai siswa. Data yang diuji bertujuan agar dapat mempelajari berbagai cluster yang terdapat dalam program serta perbedaan yang dihasilkan dari masing-masing metode yang diuji. Adapun rincian data adalah sebagai berikut :
Tabel 4.1 Rincian Data Penjurusan Siswa SMA ID
Siswa X1 X2 X3 X4 X5 X6 X7 X8 Target
1 89 96 96 93 88 84 96 127 IPA
2 88 95 95 90 90 85 92 115 IPA
3 83 93 94 87 89 82 90 109 IPA
4 89 90 92 83 89 85 86 118 IPA
5 83 90 86 89 76 82 91 118 IPA
6 80 88 90 85 78 82 91 118 IPA
7 82 84 84 89 91 84 90 100 IPA
8 82 87 80 90 79 85 87 106 IPA
9 79 88 90 81 84 81 86 118 IPA
10 84 78 85 89 83 84 90 112 IPA
167 70 76 70 76 75 78 78 93 IPS
Keterangan :
ID siswa : Nomor Urut Siswa, X1 : Nilai Matematika, X2 : Nilai Biologi, X3 : Nilai Fisika, X4 : Nilai Ekonomi, X5 : Nilai Geografi, X6 : Nilai Kimia, X7 :
Nilai Sosiologi, X8 : Nilai Kemapuan Menalar (IQ).
Untuk melihat rincian data penjurusan siswa selengkapnya dapat dilihat pada lampiran 1.
4.1.3. Proses Clustering dengan X-Means
Pengujian ini bertujuan untuk melihat pengaruh jumlah dokumen, jumlah cluster, dan metode clustering dalam mengelompokkan dokumen. Selanjutnya dilakukan proses clustering dengan menggunakan X-Means, adapun tahapannya adalah sebagai berikut:
i. Inisialisasi jumlah cluster (C=2) dengan pusat cluster 1 dan pusat cluster 2 diambil secara random, adapun pusat cluster awal dapat dilihat pada tabel 4.2.
Tabel 4.2 Inisialisasi Pusat Cluster Awal (Iterasi ke-1)
ID Siswa X1 X2 X3 X4 X5 X6 X7 X8 Target
85 75 77 72 73 73 70 85 91 IPA
165 70 80 70 69 70 78 78 90 IPS
ii. Hitung jarak setiap data ke masing-masing pusat cluster awal pada tabel 4.2 dengan persamaan sebagai berikut :
2= 2 (4.1)
Keterangan :
x1 : data ke-i dari atribut ke-j
x2 : pusat cluster ke-i dari atribut ke-j n : jumlah karakteristik data (atribut)
: Euclidean Distance, jarak antara data pada titik
x
1 danx
2Berikut adalah perhitungan jarak antar data ke pusat cluster pada tabel 4.2 adalah : Iterasi 1 :
ID_Siswa ke-1:
C1 =
= 58.06 C2 =
= 62.63
ID_Siswa ke-2:
C1 =
= 49.50 C2 =
= 53.71
ID_Siswa ke-3:
C1 =
= 41.82 C2 =
= 46.06
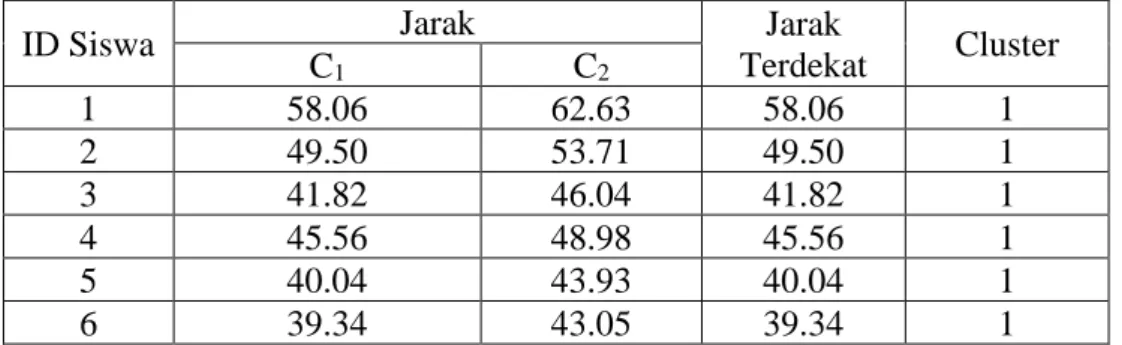
Melakukan hal yang sama sampai seluruh data siswa diperoleh masing-masing jarak terhadap pusat cluster 1 (C1) dan pusat cluster 1 (C2). Adapun hasil perhitungan jarak antar data dapat dilihat pada tabel 4.3.
Tabel 4.3 Jarak Data terhadap Pusat Cluster (Iterasi 1)
ID Siswa Jarak Jarak
Terdekat Cluster
C1 C2
1 58.06 62.63 58.06 1
2 49.50 53.71 49.50 1
3 41.82 46.04 41.82 1
4 45.56 48.98 45.56 1
5 40.04 43.93 40.04 1
6 39.34 43.05 39.34 1
ID Siswa Jarak Jarak
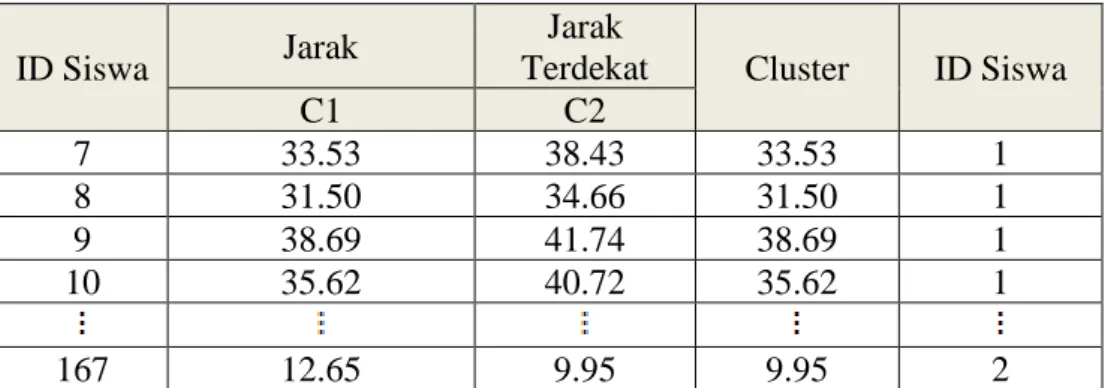
Terdekat Cluster ID Siswa
C1 C2
7 33.53 38.43 33.53 1
8 31.50 34.66 31.50 1
9 38.69 41.74 38.69 1
10 35.62 40.72 35.62 1
167 12.65 9.95 9.95 2
Keterangan :
C1 : Data Siswa Kelompok 1, C2 : Data Siswa Kelompok 2
Untuk melihat rincian Jarak Data terhadap Pusat Cluster (Iterasi 1) selengkapnya dapat dilihat pada lampiran 2.
iii. Tentukan pusat cluster baru dengan cara menghitung rata-rata nilai attribut setiap data yang termasuk kedalam cluster pada tabel 4.3. Adapun nilai cluster yang baru dapat dilihat pada tabel 4.4.
Tabel 4.4 Inisialisasi Pusat Cluster Baru (Iterasi ke-2)
Cluster X1 X2 X3 X4 X5 X6 X7 X8
C1 79.65 79.38 79.14 79.97 77.53 77.84 82.96 100.97 C2 71.02 71.60 68.81 72.35 69.73 75.23 74.48 91.88
iv. Kembali kelangkah ii sampai tidak ada data yang berpindah cluster atau sampai batas maksimal iterasi. Pada penelitian ini, konvergensi atau titik pusat data penjurusan siswa diperoleh pada saat iterasi ke – 11, Adapun nilai pusat cluster akhir yang didapati dapat dilihat pada tabel 4.5.
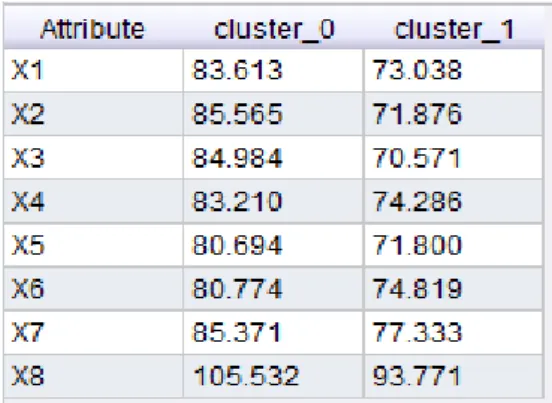
Tabel 4.5 Inisialisasi Pusat Cluster Akhir (Iterasi ke-11)
Cluster X1 X2 X3 X4 X5 X6 X7 X8
C1 83.613 85.565 84.984 83.210 80.694 80.774 85.371 105.532 C2 73.038 71.876 70.571 74.286 71.800 74.819 77.333 93.771
Jika dilakukan pengujian menggunakan aplikasi Rapidminer maka hasil
perhitungan manual dengan Rapidminer menjadi sama seperti tampilan berikut:
Gambar. 4.2 Nilai pusat cluster akhir dengan Rapidminer 4.1.4 Perhitungan Evaluasi Clustering
Evaluasi clustering dilakukan dengan tujuan untuk mengetahui seberapa baik kualitas dari hasil clustering. Pada penelitian ini, evaluasi hasil clustering yang digunakan adalah Davies-Bouldin Index. Untuk mendapatkan nilai Davies-Bouldin Index, terlebih dahulu dihitung nilai Sum of Square Within-cluster (SSW), Sum of Square Between-cluster (SSB) dan Ratio. Untuk memulai perhitungan manual Davies-Bouldin Index, dibutuhkan data yang sudah di clustering. Illustrasi data sample yang telah selesai di-clustering dapat dilihat pada tabel 4.6.
Tabel 4.6 Illustrasi data sample yang telah selesai di-clustering C1
Data
Ke -i X1 X2 X3 X4 X5 X6 X7 X8
1 89 96 96 93 88 84 96 127
2 88 95 95 90 90 85 92 115
3 83 93 94 87 89 82 90 109
4 89 90 92 83 89 85 96 118
5 83 90 86 89 76 82 91 118
C2 Data
Ke -i X1 X2 X3 X4 X5 X6 X7 X8
21 77 80 85 75 74 81 74 91
23 79 75 78 80 78 81 83 94
25 75 76 76 78 75 81 90 97
38 82 82 77 77 74 78 81 94
Untuk melihat rincian Illustrasi data sample C1 dan C2 yang telah selesai di- clustering selengkapnya dapat dilihat pada lampiran 3.
Data yang telah selesai di-clustering diperoleh dari perhitungan jarak data dengan titik pusat cluster akhir. Titik pusat cluster akhir dari proses clustering merupakan nilai rata-rata yang dimiliki oleh masing-masing cluster 1 dan cluster 2. Nilai rata-rata tersebut digunakan sebagai input dalam perhitungan Sum of Square Within-cluster (SSW). Titik pusat cluster akhir dari proses clustering dapat dilihat pada tabel 4.7 berikut ini.
Tabel 4.7 Titik pusat cluster akhir dari proses clustering
mj Atribut1 Atribut2 Atribut3 Atribut4 Atribut5 Atribut6 Atribut7 Atribut8 m1 baru 83.613 85.565 84.984 83.210 80.694 80.774 85.371 105.532 m2 baru 73.038 71.876 70.571 74.286 71.800 74.819 77.333 93.771
Tahap pertama dari evaluasi clustering menggunakan Davies-Bouldin Index adalah menghitung nilai Sum of Square Within-cluster (SSW) menggunakan persamaan (2.2).
Nilai SSW diperoleh dari perhitungan jarak setiap data terhadap titik pusat cluster akhir menggunakan Euclidiean Distane. Nilai SSW yang diperoleh dari keseluruhan perhitungan SSW adalah sebagai berikut.
SSW1 = 15.3517 SSW2 = 13.3528
Setelah nilai SSW diperoleh, selanjutnya adalah menghitung nilai Sum of Square Between-cluster (SSB). Untuk mendapatkan nilai SSB adalah dengan menghitung jarak antar titik pusat cluster dari setiap cluster menggunakan persamaan (2.3)
SSB1,2 = 30.0671
Perhitungan selanjutnya setelah SSW dan nilai SSB diperoleh adalah menghitung nilai Ratio (Rasio). Nilai Rasio diperoleh dengan menghitung jarak antar titik pusat cluster dari setiap cluster menggunakan persamaan (2.4)
Tabel 4.8 Nilai rasio dari setiap cluster
R Data ke -i
R-Max
1 2
1 0 0.9547 0.9547
2 0.9547 0 0.9547
Karena nilai rasio telah diperoleh, maka perhitungan selanjutnya adalah menghitung nilai Davies-Bouldin Index (DBI). Nilai Davies-Bouldin Index (DBI) diperoleh dengan menghitung rata-rata dari rasio terbesar (R-Max) menggunakan persamaan (2.5)
Berdasarkan hasil DBI yang diperoleh, maka dapat disimpulkan hasil evaluasi dari hasil clustering pada tabel 4.3 adalah cukup baik, karena nilai DBI yang diperoleh sudah mendekati nilai 0.
4.1.5 Grafik jarak antar centroid
Pada Gambar 4.1 ditampilkan grafik hasil pencarian nilai jarak antar centroid, dimana untuk setiap jarak centroid cluster adalah 30.067 dengan K=2.
Gambar 4.3 Jarak antar centroid
4.1.6 Hasil Evaluasi Clustering
Hasil clustering telah diperoleh, maka tahap selanjutnya adalah menghitung nilai DBI dari setiap hasil clustering. Untuk kemudian dihitung nilai rata-rata DBI dari seluruh percobaan dan pada setiap jumlah cluster. Hasil nilai Davies-Bouldin Index dari jumlah Cluster dapat dilihat pada tabel 4.9.
Tabel 4.9 Hasil Davies-Bouldin Index
X
Rata-rata dalam jarak
centroid
Rata-rata dalam jarak centroid pada
cluster Davies-
Bouldin Index
C0 C1 C2 C3
Min 2, Max 100 225.891 15.352 13.353 0.955
Min 3, Max 100 187. 973 168.487 216.509 199.225 1.345 Min 4, Max 100 168.562 111.478 167.479 201.492 184.340 1.531 Berdasarkan hasil DBI yang diperoleh, yaitu 2 cluster dengan hasil DBI = 0.955, 3 cluster hasil DBI = 1.345 dan 4 cluster hasil DBI = 1.531, maka dapat disimpulkan hasil evaluasi dari hasil clustering pada tabel 4.9 bahwa hasil yang terbaik berada pada centroid 2 cluster , karena nilai DBI yang diperoleh sudah mendekati nilai 0.
BAB 5
KESIMPULAN DAN SARAN
5.1. Kesimpulan
Pada penelitian yang telah dilakukan, maka penulis menghasilkan beberapa kesimpulan sebagai berikut:
1. Dari pengujian menggunakan algoritma X-Means dengan penentuan jumlah Centroid cluster dilakukan dengan memodifikasi metode X-Means melakukan beberapa penentuan centroid hingga mendapatkan hasil sebanyak 11 iterasi. Dari hasil pengujian tersebut menghasilkan anggota cluster yang baik tingkat kemiripan datanya dengan data lain.
2. Dalam menentukan jumlah cluster, menggunakan modifikasi metode euclidean distance, mendapatkan hasil yang lebih baik tingkat kemiripan setiap anggotanya dibandingkan dengan menentukan jumlah cluster secara acak dengan beberapa kali iterasi.
3. Dalam menentukan jumlah centroid , menggunakan metode Davies-Bouldin Index dimana nilai DBI sudah mendekati 0.
5.2. Saran
Pada penelitian selanjutnya yang diharapkan penulis adalah untuk mengembangkan sistem program dalam memudahkan dalam rekapitulasi kelompok cluster, karena masih ada kekurangan dalam penelitian ini sehingga harus disempurnakan dalam penelitian kedepannya dapat memperoleh hasil lebih baik dari sebelumnya. Maka dari itu penulis mengharapkan penelitian ini dilanjutkan dengan menggunakan algoritma lainnya agar cluster dapat tersusun dengan cepat dan tepat.
DAFTAR PUSTAKA
Baswade, A.M. & Nalwade, P.S. 2013. Selection Of Initial Centroids For K-Means Algorithm. International Journal of Computer Science and Mobile Computing (IJCSM) 2(7): 161-164.
R. Dela Arundina, 2010. Analisis Dan Implementasi Algoritma X-Means Pada Data Pelanggan Telekomunikasi. Universitas Telkom. Bandung.
Turban Efraim, E., Jay, Aronson. & Liang Ting-Peng. 2013. Decision Support System and Intelligent System. Andi Offset.
Bhusare, B.B. & Bansode, S.M. 2014. Centroids Initialization for K-means Clustering using Improved Pillar Algorithm. International Journal of Advanced Research in Computer Engineering & Technology 3(4): 1317–1322.
Al Malki, A., Rizk, M. M., El-Shorbagy, M. A. & Mousa, A. A. 2016. Hybrid Genetic Algorithm with KMeans for Clustering Problems. Open Journal of Optimization, 5, 71-83.
Rose, J.D. 2016. An efficient association rule based hierarchical algorithm for text clustering. International Journal of Advanced Engineering Technology 7(4):
751–753.
Prasetyo, Eko. 2014. Data Mining Mengolah Data menjadi Informasi Menggunakan Matlab. Yogyakarta : CV. ANDI OFFSET
Prasetyo, Eko. 2012. Data Mining Konsep dan Aplikasi Menggunakan Matlab.
Yogyakarta : Andi
Wani, M. A. & Riyaz, R. 2017. A novel point density based validity index for clustering gene expression datasets. International Journal of Data Mining and Bioinformatics 17(1): 66-84.
D. Pelleg & A. Moore. 2014. X-means: Extending K-means with Efficient Estimation of The Number of Clusters. Proceedings of the Seventeenth International Conference on Machine Learning, Palo Alto, CA.
Krawczyk Bartosz & Micha_l Wo´zniak. 2013. Pruning Ensembles of One Class Classifiers with X-means Clustering. Wroc_law University of Technology.
Maimon, O. & Last, M. 2014. Knowledge Discovery and Data Mining, The Fuzzy network (IFN) Methodology. Dordrecht: Kluwer Academik.
Poteras, C.M., Mihӑescu, M.C. & Mocanu, M. 2014. An optimized version of the kmeans clustering algorithm. Proceedings of the 2014 Federated Conference on Computer Science and Information Systems, pp. 695–699.
Rathi, R. & Lohiya, S. 2014. Big Data and Hadoop. International Journal of
Advanced Research in Computer Science & Technology (IJARCST 2014), 2(2), pp. 214 – 217.
Rokach, L. & O. Maimon. 2005. Data Mining and Knowledge Discovery Handbook.
Springer: Tel Aviv.
Serapiao, A.B.S., G.S. Correa, F.B. Goncalves, & V.O. Carvalho. 2016. Combining K-Means and K-Harmonic With Fish School Search Algorithm for Data Clustering Task on Graphics Processing Units. Applied Soft Computing 41: pp.
290-304
Shahbaba Mahdi. & Beheshti Soosan. 2012. Improving X-Means Clustering with MNDL. International Conference on Information Science, Signal Processing and their Applications (ISSPA).
ULARU, Elena Geanina, Florina Camelia PUICAN, Anca APOSTU & a Manole VELICANU. Perspective on Big Data and Big Data Analytics. Database Systems Journal. 2012, II(4), 12.
LAMPIRAN A
Tabel 4.1 Rincian Data Pejurusan Siswa SMA Methodist-8 Medan ID Siswa X1 X2 X3 X4 X5 X6 X7 X8 Target
1 89 96 96 93 88 84 96 127 1
2 88 95 95 90 90 85 92 115 1
3 83 93 94 87 89 82 90 109 1
4 89 90 92 83 89 85 86 118 1
5 83 90 86 89 76 82 91 118 1
6 80 88 90 85 78 82 91 118 1
7 82 84 84 89 91 84 90 100 1
8 82 87 80 90 79 85 87 106 1
9 79 88 90 81 84 81 86 118 1
10 84 78 85 89 83 84 90 112 1
11 84 85 87 80 83 83 85 82 1
12 78 92 85 78 81 83 91 100 1
13 82 84 84 82 82 82 90 106 1
14 81 74 89 84 75 81 87 94 1
15 81 88 81 78 75 81 89 100 1
16 75 80 91 80 77 83 84 109 1
17 82 78 86 78 75 81 89 91 1
18 75 84 80 81 75 81 86 93 1
19 81 74 84 80 84 82 83 112 1
20 81 75 85 78 78 82 86 97 1
21 77 80 85 75 74 81 74 91 2
22 75 80 80 78 78 82 92 109 1
23 79 75 78 80 78 81 83 94 2
24 75 84 77 76 74 82 86 106 1
25 75 76 76 78 75 81 90 97 2
26 90 90 85 90 81 85 86 94 1
27 89 89 90 87 85 85 87 100 1
28 81 89 94 88 85 82 87 115 1
29 89 89 85 88 83 83 80 97 1
30 83 90 85 85 85 82 84 100 1
31 82 90 90 80 84 84 85 112 1
32 90 86 84 81 77 73 81 106 1
33 87 80 86 81 75 73 78 100 1
34 91 85 75 82 76 72 90 94 1
35 83 84 81 80 70 76 75 97 1
36 87 84 74 81 80 79 87 106 1
37 79 83 78 80 76 80 82 97 1