BAB 2
TINJAUAN PUSTAKA
2.1. Data Mining
Data Mining adalah proses pencarian pengetahuan dari suatu data berukuran besar melalui metode statistik, machine learning, dan artificial algorithm. Hal yang paling utama dari suatu proses dengan data mining adalah feature selection dan proses pengenalan pola dari suatu sistem database (Fayyad et al., 1996).
Data mining merupakan salah satu tahapan penting di dalam proses Knowledge Discover in Database (KDD). Terminologi dari KDD dan data mining adalah berbeda. KDD adalah keseluruhan proses di dalam menemukan pengetahuan yang berguna dari
suatu kumpulan data sedangkan data mining adalah salah satu tahapan pada KDD dan
fokus pada upaya untuk menemukan pengetahuan yang berguna dengan menggunakan
algoritma (Fayyad et al., 1996). Istilah KDD pertama kali dikenal pada KDD Workshop
yang diadakan pada tahun 1989 (Shapiro, 1991).
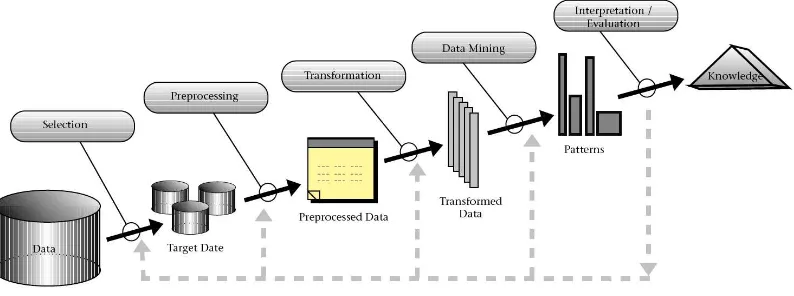
Adapun tahapan proses dari KDD dapat dilihat pada Gambar 2.1.
Gambar 2.1. Proses di dalam Knowledge Discovery in Database(Fayyad et al., 1996)
Berdasarkan Gambar 2.1. dapat terlihat bahwa proses KDD terdiri atas sejumlah
proses iterasi berurutan, yang dapat dijabarkan sebagai berikut.
2. Prepocessing : menghilangkan noise dan inkosistensi data; menggabungkan data yang bersumber dari banyak sumber.
3. Transformation : Mentransformasi data ke dalam bentuk yang sesuai untuk proses data mining.
4. Data Mining : Memilih algoritma data mining yang sesuai dengan pattern data; Ekstraksi pola dari data.
5. Interpretation / Evaluation : menginterpretasi pola menjadi pengetahuan dengan menghilangkan pola yang redundant dan tidak relevan; Mentranslasi pola ke dalam bentuk yang dapat dimengerti oleh manusia.
2.2. Metode pada Data Mining
Fayyad et al. (1996) mengemukakan bahwa terdapat beberapa metode data mining yang
dapat digunakan untuk memprediksi dan mendiskripsikan pengetahuan dari
sekumpulan data adalah sebagai berikut.
1. Classfication (Klasifikasi): Fungsi pembelajaran yang memetakan item data ke dalam satu dari beberapaclass yang telah ditetapkan(predefined class).
2. Regression: Fungsi pembelajaran yang memetakan item data ke dalam bentuk nilai asli dari variabel yang dapat diprediksi.
3. Clustering: Tugas deskriptif untuk mengidentifikasi himpunan berhingga (finite set) dari kategori atau cluster untuk data yang sudah ditentukan.
4. Summarization: Penggunaan metode untuk menemukan deskripsi yang utuh dari suatu subset data.
5. Dependency Modelling: sering juga disebut sebagai Association Rule Learning atau pembelajaran aturan asosiasi yang menghasilkan model yang menyatakan
tingkat signifikansi ketergantungan antar variabel.
6. Change and Deviation Detection: sering juga disebut sebagai anomaly detection, yang menemukan perubahan yang signifikan dari suatu data.
2.3. Clustering
Clustering adalah proses memisahkan sekumpulan data atau objek ke dalam kelompok atau cluster yang lebih kecil berdasarkan kesamaan ciri yang dimiliki (Serapiao et al.,
Terdapat berbagai algoritma clustering yang dapat digunakan, tetapi secara umum dapat dikelompokkan menjadi beberapa kategori sebagai berikut (Rokach and
Maimon, 2005).
1. Partitioning Methods. Diberikan himpunan dari n objek. Metode partisi akan mengelompokkan k partisi dari data. Dimana setiap partisi merepresentasikan sebuah cluster dan k ≤ n. Setiap objek yang ada merupakan bagian dari sebuah clusterk. Beberapa algoritma yang sering dipakai, yang termasuk dalam kategori partitioning methods adalah algoritma K-Means dan K-Medoids.
2. Hierarchical Methods. Pada metode berbasis hirarki ini akan dibangkitkan hierarchical decomposition (dekomposisi berurutan) dari himpunan data objek. Berbeda dengan metode partitioning yang mengelompokkan data ke dalam kelompok-kelompok. Metode hierarchical mengelompokkan data ke dalam hirarki atau tree dari cluster. Representasi data dalam bentuk hirarki adalah diperlukan untuk keperluan penyajiandan visualisasi data. Strategi
pengembangan dari metode ini dapat dibagi menjadi 2 jenis yaitu Agglomerative
(Bottom-Up) dan Devisive (Top-Down). Metode Agglomerativemerupakan metode yang sering digunakan dan terdiri atas metode: Single Linkage, Complete Linkage, dan Average Linkage.
3. Density-Based Methods. Metode Density-Based merupakan metode yang dikembangkan berdasarkan density (kepadatan) tertentu. Metode ini menganggap cluster sebagai suatu area yang berisi objek-objek yang padat/sesak, yang dipisahkan oleh area yang memiliki kepadatan rendah
(merepresentasikan noise). Beberapa algoritma yang termasuk di dalam Density-Based adalah DBSCAN (Density Based Spatial Clustering of Application with Noise) dan OPTICS (Ordering Points to Identify the Clustering Structure).
4. Grid-Based Methods. Pendekatan Grid-Based Methods menempatkan ruang objek ke dalam jumlah berhingga sel yang membentuk struktur grid, sehingga
2.4. K-Means
K-Means adalah salah satu jenis algoritma pembelajaran unsupervised untuk menyelesaikan permasalahan clustering, yang berbasis pada schema iteratif sederhana
untuk menemuka solusi yang bersifat local minimal (Serapiao et al., 2016).
Algoritma K-Means dimulai dengan pemilihan secara acak k, k disini merupakan banyaknya cluster yang ingin dibentuk. Kemudian tetapkan nilai-nilai k secara random,
untuk sementara nilai tersebut menjadi pusat dari cluster, atau biasa disebut dengan istilah centroid, mean, atau means. Hitung jarak setiap data yang ada terhadap
masing-masing centroid dengan menggunakan salah satu rumus perhitungan jarak hingga ditentukan jarak yang paling dekat dari setiap data dengan centroid (Steinbach et al., 2014).
Adapun perhitungan jarak yang umum digunakan adalah Euclidean Distance,
dimana tujuan dari algoritma adalah mengoptimisasi perhitungan jarak yang dinyatakan
dengan fungsi objektif (f) (Serapiao et al., 2016).
i
Di mana K adalah jumlah dari cluster, N adalah jumlah dari object, xj adalah koordinat
dari objek j, ci adalah koordinat dari cluster i dan Gi adalah kelompok dari objek yang
menjadi anggota cluster i.
Untuk tiap cluster, posisi centroid yang baru dihitung kempali berdasarkan posisi rata-rata koordinat dari seluruh objek yang ditempatkan di dalam cluster tersebut.
Untuk menghitung centroid tersebut dapat dilakukan dengan menggunakan persamaan
2.2 (Serapiao et al., 2016).
∑
Di mana |Gi| adalah jumlah dari objek yang terdapat di dalam cluster i.
2.5. Algoritma Genetika
Algoritma genetika adalah suatu algoritma stokastik yang memodelkan proses evolusi
dari spesies biologi melalui seleksi alam (Konar, 2005). Secara umum, populasi ini
konsekutif dari proses crossover dan mutasi. Setiap individu dari populasi memiliki nilai yang diasosiasikan kedalam suatu nilai fitness, di dalam kaitannya untuk menyelesaikan suatu permasalahan (Rabunal, 2006). Adapun diagram blok dari
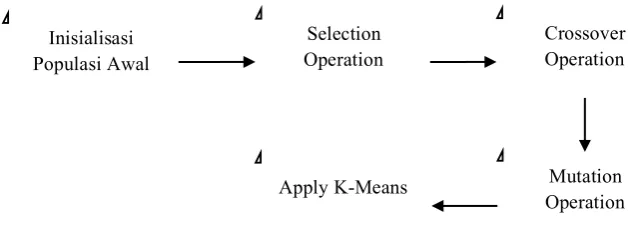
algoritma genetika klasik dapat dilihat pada Gambar 2.2.
Gambar 2.2. Diagram Blok dari Algoritma Genetika(Negnevitsky, 2005)
2.6. GenClust
Algoritma GenClust merupakan jenis Hybrid Clustering yang menggabungkan algoritma genetika dengan K-Means. Penelitian mengenai GenClust pertama kali dilakukan oleh Rahman dan Islam (2014). Kolaborasi antara Algoritma Genetika
dengan K-Means dapat mencegah K-Means terjebak di dalam kondisi Local Minima dan dapat mencapai kondisi Global Optima.
Metode GenClust dipandang cukup baik untuk menentukan jumlah cluster dan
juga centroid dari tiap cluster karena memungkinkan terjadinya peningkatan performa
clustering untuk tiap generasi.
Adapun tahapan proses dari Algoritma GenClust dapat dilihat pada Gambar 2.3.
Inisialisasi Populasi Awal
Perhitungan
Fitness Seleksi Crossover
Mutasi
Gambar 2.3. Tahapan Proses dari Algoritma GenClust
Ide dasar dari penentuan jumlah cluster adalah menggunakan bilangan acak yang
dibangkitkan dengan range jumlah cluster adalah sebanyak 2 sampai dengan √�, di mana n adalah jumlah dari object pada dataset. Posisi centroid yang dibangkitkan dalam
bentuk kromosom adalah 50% kromosom diperoleh melalui perhitungan deterministic dan 50% kromosom diperoleh melalui bilangan acak, misalkan jumlah kromosom
adalah 60, maka 30 kromosom diperoleh dari perhitungan deterministic dan 30 kromosom diperoleh secara random. Adapun langkah-langkah di dalam memperoleh kromosom melalui perhitungan deterministic adalah sebagai berikut (Rahmad dan Islam, 2014).
1. Tentukan koordinat bilangan rx secara random yang menyatakan koordinat centroid yang dijadikan sebagai acuan.
2. Ambil koordinat posisi dari tiap object yang ada pada dataset.
3. Hitung jarak dari tiap object ke bilangan random rx dengan menggunakan euclidean distance.
4. Ambil 30 object dengan jarak terkecil ke bilangan random rx (misalkan dibutuhkan 30 kromosom).
5. Koordinat posisi dari 30 object yang terpilih mengisi koromosom yang diperoleh melalui perhitungan deterministic.
Adapun 50% kromosom lain yang akan diperoleh secara random, koordinat yang akan
mengisi gen pada kromosom diperoleh dengan cara membangkitkan bilangan random
yang berada di antara koordinat posisi terkecil dan koordinat posisi yang terbesar.
Inisialisasi Populasi Awal
Selection Operation
Crossover Operation
2.7. UCI Machine Learning Repository
UCI Machine Learning Repository adalah sebuah koleksi database, domain teori, dan data generator yang digunakan oleh komunitas yang mempelajari mesin pembelajaran (machine learning), untuk keperluan analisis empiris dari algoritma machine learning.
Dataset yang tersedia pada UCI Machine Learning Repository digunakan oleh pelajar, pendidik, dan peneliti diseluruh dunia sebagai sumber utama dari data set pada machine
learning. Jumlah data set yang tersedia pada UCI Machine Learning Repository pada saat ini sudah berjumlah 320 data set yang dapat digunakan sesuai dengan kebutuhan
pada pembelajaran machine learning. Salah satu data set dari UCI Machine Learning Repository yang umum digunakan adalah Iris Data set.
Iris Data set merupakan data set yang banyak digunakan di dalam permasalahan pengenalan pola. Atribut informasi yang ada pada Iris Data Set adalah terdiri-dari: Sepal Length, Sepal Width, Petal Length, dan Petal Width. Iris Data Set memiliki 3 class yaitu: Iris Setosa, Iris Versicolour, dan Iris Virginica.
2.8. Pengukuran Kinerja pada Algoritma K-Means
Penelitian ini akan mengkaji kinerja dari algoritma K-Means di dalam kaitannya dengan
penentuan centroid. Centroid merupakan pusat dari masing-masing cluster. Centroid ini akan sangat berpengaruh terhadap kinerja dari algoritma K-Means karena penempatan suatu data di dalam suatu dataset pada algoritma K-Means didasarkan pada
kedekatan data tersebut dengan centroid dari tiap cluster, sehingga nilai centroid sangat
berpengaruh terhadap hasil clustering dengan menggunakan algoritma K-Means.
Pengukuran kinerja algoritma K-Means akan dilakukan terhadap penentuan centroid secara acak pada algoritma K-Means klasik, penentuan centroid dengan menggunakan algoritma GenClust dan penentuan centroid dengan menggunakan algoritma GenClust yang dimodifikasi.
Algoritma GenClust mendasarkan penentuan centroid dengan menggunakan algoritma genetika yang dilakukan dengan membangkitkan sejumlah kromosom sesuai
maka berarti jumlah kromosom untuk metode GenClust adalah sebanyak 6 kromosom.
Kromosom yang ditentukan adalah 50% dari pembangkitan bilangan acak sedangkan
50% dari perhitungan deterministik. Jumlah gen yang dibangkitkan adalah sejumlah
jumlah atribut yang ada pada data set. Sebagai contoh, Iris Data set memili 4 (empat)
atribut yaitu: Sepal Length, Sepal Width, Petal Length, dan Petal Width maka berarti jumlah gen yang dibangkitkan adalah sebesar 4 (empat) gen. Kemudian akan dihitung
nilai fitness tiap kromosom, kemudian akan dilakukan proses seleksi, crossover, dan mutasi hingga dihasilkan kromosom terbaik yang kemudian nilai centroid akan didasarkan pada kromosom tersebut. Peneliti akan memodifikasi algoritma GenClust
dimana kromosom yang digunakan adalah 100% berasal dari perhitungan deterministik.
Pengukuran kinerja di dalam Algoritma K-Means dapat diukur berdasarkan pada
keberhasilan algoritma K-Means di dalam mengenali pola yang ada yang dinyatakan di
dalam nilai Mean Square Error (MSE). Nilai MSE menyatakan tingkat kesalahan dari
pengenalan pola yang ada dengan menggunakan algoritma K-Means. Nilai MSEyang
kecil menunjukkan bahwa hasil proses clustering dengan menggunakan K-Means Clustering telah berhasil mengenali pola yang ada, sebaliknya nilai MSE yang besar menunjukkan bahwa hasil clustering dengan menggunakan K-Means Clustering masih
belum mencapai hasil yang diinginkan.
Adapun persamaan untuk mengukur Mean Square Error (MSE) dapat dilihat pada Persamaan 2.3 (Salman et al., 2017).
MSE = (2.3)
Dimana:
X = Nilai aktual atau sebenarnya Y = Nilai yang tercapai
2.9. Penelitian-Penelitian Terkait
2.9.1. Penelitian Terdahulu
Pada algoritma K-Means, penentuan jumlah cluster dan penentuan centroid (pusat) merupakan hal yang cukup sulit untuk dilakukan. Penentuan jumlah cluster dan penentuan centroid (pusat) mempengaruhi secara langsung kualitas dari proses clustering (Maitra, et al., 2010).
Sejumlah peneliti telah tertarik untuk melakukan penelitian mengenai penelitian
centroid pada algoritma K-Means. Ahmad dan Dey (2007) menggunakan konsep fuzzy di dalam penentuan centroid. Proses penentuan centroid akan dilakukan dengan cara membangkitkan bilangan acak untuk centroid tiap cluster. Nilai acak tersebut kemudian
akan masuk ke dalam tahapan inferensi dan kemudian hasil defuzzifikasi akan menjadi
nilai centroid tiap cluster. Cara penentuan centroid ini hampir sama dengan penentuan
centroid dengan cara random dan tingkat keakuratannya belum teruji untuk dataset berukuran besar. Cara penentuan centroid yang sama pernah dilakukan oleh Rahman
dan Islam (2012) di dalam penentuan centroid untuk fuzzy clustering.
Cao et al. (2009) melakukan penentuan centroid berdasarkan nilai frekuensi dari
data. Nilai frekuensi dari data menggambarkan nilai rata-rata dari posisi nilai atribut
dari tiap data yang ada pada suatu cluster. Kelemahan dari metode ini adalah data-data
di dalam suatu cluster harus memiliki nilai atribut yang tidak memiliki perbedaan terlalu
besar. Apabila terdapat perbedaan nilai atribut yang terlalu besar, tentu hasil clustering
tidak memberikan hasil yang baik.
Rahman dan Islam (2014) mengemukakan metode Hybrid Clustering yang dikenal sebagai GenClust yang menggabungkan pemakaian algoritma K-Means dengan
Algoritma Genetika. Algoritma Genetika digunakan untuk menentukan jumlah cluster
dan juga centroid dari tiap cluster. Penggunaan metode GenClust dapat menghindarkan
algoritma K-Means di dalam terjebak di dalam kondisi local optima. Algoritma genetika merupakan salah satu model soft computing yang sering digunakan dalam
menyelesaikan permasalahan optimasi. Dalam algoritma genetika terdapat tiga
parameter penting yang harus didefinisikan yaitu ukuran populasi, probabilitas pindah
silang dan probabilitas mutasi. Ketiga parameter ini harus didefinisikan secara hati-hati
agar tidak terjadi konvergensi dini atau lokal optimum yaitu dimana
individu-individu dalam populasi konvergen pada suatu solusi optimum lokal sehingga hasil
paling optimum tidak dapat ditemukan (Muzid, 2014).
Metode GenClust dipandang cukup baik untuk menentukan jumlah cluster dan
juga centroid dari tiap cluster karena memungkinkan terjadinya peningkatan performa
clustering untuk tiap generasi. Namun, yang perlu menjadi pertimbangan adalah percobaan yang dilakukan oleh Rahman dan Islam (2014) hanya menggunakan sample
dari beberapa dataset dan belum pernah digunakan untuk dataset yang berukuran besar.
GenClust akan menyebabkan kesulitan tersendiri bila dataset yang terlibat berukuran besar.
Adapun rincian penelitian terdahulu dan pengembangannya dapat dilihat pada
Tabel 2.1.
Tabel 2.1. Penelitian Terdahulu
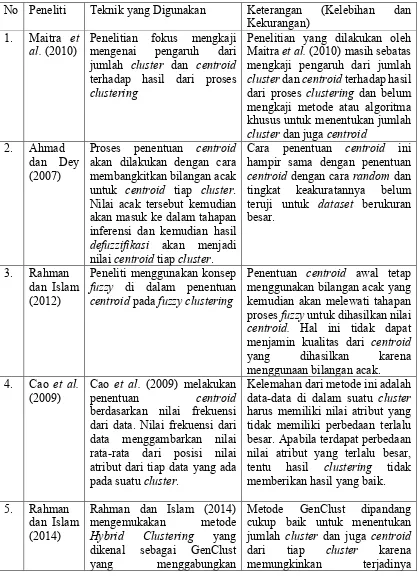
No Peneliti Teknik yang Digunakan Keterangan (Kelebihan dan Kekurangan)
1. Maitra et al. (2010)
Penelitian fokus mengkaji mengenai pengaruh dari jumlah cluster dan centroid terhadap hasil dari proses clustering
Penelitian yang dilakukan oleh Maitra et al. (2010) masih sebatas mengkaji pengaruh dari jumlah cluster dan centroid terhadap hasil dari proses clustering dan belum mengkaji metode atau algoritma khusus untuk menentukan jumlah cluster dan juga centroid
2. Ahmad dan Dey (2007)
Proses penentuan centroid akan dilakukan dengan cara membangkitkan bilangan acak untuk centroid tiap cluster. Nilai acak tersebut kemudian akan masuk ke dalam tahapan inferensi dan kemudian hasil defuzzifikasi akan menjadi nilai centroid tiap cluster.
Cara penentuan centroid ini hampir sama dengan penentuan centroid dengan cara random dan tingkat keakuratannya belum teruji untuk dataset berukuran besar.
3. Rahman dan Islam (2012)
Peneliti menggunakan konsep fuzzy di dalam penentuan centroid pada fuzzy clustering
Penentuan centroid awal tetap menggunakan bilangan acak yang kemudian akan melewati tahapan proses fuzzy untuk dihasilkan nilai centroid. Hal ini tidak dapat menjamin kualitas dari centroid yang dihasilkan karena menggunaan bilangan acak. 4. Cao et al.
(2009)
Cao et al. (2009) melakukan penentuan centroid berdasarkan nilai frekuensi dari data. Nilai frekuensi dari data menggambarkan nilai rata-rata dari posisi nilai atribut dari tiap data yang ada pada suatu cluster.
Kelemahan dari metode ini adalah data-data di dalam suatu cluster harus memiliki nilai atribut yang tidak memiliki perbedaan terlalu besar. Apabila terdapat perbedaan nilai atribut yang terlalu besar, tentu hasil clustering tidak memberikan hasil yang baik. Hybrid Clustering yang dikenal sebagai GenClust yang menggabungkan
No Peneliti Teknik yang Digunakan Keterangan (Kelebihan dan Kekurangan)
pemakaian algoritma K-Means dengan Algoritma Genetika. Algoritma Genetika digunakan untuk menentukan jumlah cluster dan juga centroid dari tiap cluster.
peningkatan performa clustering untuk tiap generasi. Namun, yang perlu menjadi pertimbangan adalah percobaan yang dilakukan oleh Rahman dan Islam (2014) menggunakan 50% kromosom diperoleh melalui perhitungan deterministic dan 50% kromosom diperoleh melalui bilangan acak. Hal ini akan bermasalah pada dataset berukuran besar karena memerlukan proses komputasi yang cukup besar.
2.9.2.. Perbedaan dengan Penelitian Terdahulu
Peneliti di dalam penelitian ini akan menggunakan metode GenClust yang telah dimodifikasi dimana kromosom yang dibangkitkan secara keseluruhan (100%)
diperoleh melalui perhitungan deterministik, kemudian centroid untuk tiap cluster akan