CROSS-PROJECT DEFECT PREDICTION FOR WEB APPLICATION USING NAIVE BAYES
(STUDI KASUS: APLIKASI PETSTORE)
Skripsi
Sebagai Salah Satu Syarat untuk
Memperoleh Gelar Sarjana Komputer (S.Kom)
Oleh:
PUJA AHMAD HABIBI 1113091000112
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI SYARIF HIDAYATULLAH JAKARTA
2018 / 1439 H
CROSS-PROJECT DEFECT PREDICTION FOR WEB APPLICATION USING NAIVE BAYES
(STUDI KASUS: APLIKASI PETSTORE)
Skripsi
Sebagai Salah Satu Syarat untuk
Memperoleh Gelar Sarjana Komputer (S.Kom)
Oleh:
PUJA AHMAD HABIBI 1113091000112
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI SYARIF HIDAYATULLAH JAKARTA
2018 / 1439 H
ii
iii
iv
v tangan dibawah ini:
Nama : Puja Ahmad Habibi NIM : 1113091000112 Program Studi : Teknik Informatika Fakultas : Sains dan Teknologi Jenis Karya : Skripsi
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Islam Negeri Syarif Hidatullah Jakarta Hak Bebas Royalti Noneksklusif (Non-exclusive Royalty Free Right) atas karya ilmiah saya yang berjudul:
CROSS-PROJECT DEFECT PREDICTION FOR WEB APPLICATION USING NAIVE BAYES (CASE STUDY: PETSTORE APPLICATION) Beserta perangkat yang ada (jika diperlukan). Dengan hak Bebas Royalti Noneksklusif ini Universitas Islam Negeri Syarif Hidayatullah Jakarta berhak menyimpan, mengalihmedia/formatkan, merawat, dan mempubikasikan tugas akhir saya selama tetap mencantumkan nama saya sebagai penulis/pencipta dan sebagai pemilik Hak Cipta. Demikian pernyataan ini saya buat dengan sebenarnya.
Ciputat, Maret 2018
(Puja Ahmad Habibi)
vi
Naive Bayes (Studi Kasus: Aplikasi Petstore)
ABSTRAK
Prediksi cacat (defect) pada perangkat lunak merupakan hal yang rumit dan memakan banyak waktu. AI-Based software defect predictor dapat memprediksi sekitar 75% defect pada perangkat lunak dan dapat membantu tim pengembang untuk mendeteksi dan memperbaiki modul pada perangkat lunak yang cacat sebelum dilakukannya unit testing/system testing yang dilakukan oleh tim quality assurance. Beberapa penelitian telah mencoba untuk membuat model prediksi menggunakan dataset dari proyek lain, yang disebut dengan cross-project defect prediction. Namun, dataset proyek tersebut harus memiliki atribut software metric yang sama dengan dataset proyek yang akan di prediksi. Dewasa ini, aplikasi web mengambil peran penting pada kehidupan manusia, oleh karena itu, menjamin kualitas dari aplikasi web merupakan hal yang sangat penting.
Penelitian ini akan menerapkan prediksi cacat pada aplikasi web petstore dengan menggunakan dataset dari proyek lain. Penelitian ini menggunakan CK OO metrik sebagai parameter atau atribut. Algoritma naive bayes merupakan algoritma yang mudah digunakan dan merupakan algoritma yang bagus dalam memprediksi cacat pada perangkat lunak. Tujuan dari penelitian ini adalah menerapkan algoritma naive bayes pada prediksi cacat aplikasi web dengan data lintas proyek (cross-project) menggunakan bantuan library pandas dan scikit- learn. Hasil dari penelitian ini adalah algoritma naive bayes memiliki tingkat akurasi sebesar 75%-89% dan tingkat false alarm yang sedikit rendah sekitar 5% - 26.67%. Namun, naive bayes juga memiliki tingkat precision dan recall yang cukup rendah, sekitar 12.5% - 25% dan 20% - 60%. Algoritma naive bayes juga memprediksi lebih banyak defect dibandingkan dengan code review.
Keyword : Cross-Project, Defect Prediction, Naïve Bayes, CK OO Metrics, Pandas, Scikit-Learn, Python
Jumlah Pustaka : 47 (tahun 2003 – 2017)
Jumlah Halaman : VI BAB + xv Halaman + 79 Halaman + 14 Lampiran
vii
Naive Bayes (Study Case : Petstore Application)
ABSTRACT
Predicting defect in software is a complicated process and time- consuming. AI-Based software defect predictor can predict 75% defect in software and help developer team to detect and to fix defect module before performing unit testing/system testing by quality assurance. Some research tried to construct prediction model using other project datasets, which is called cross-project defect prediction. Nevertheless, the project should have the same software metric attribute. Recently, web application takes a crucial part in human life, for that reason assuring the quality of web application is very serious. This research will implement defect prediction on the petstore web application with other project datasets. CK OO metric is employed as the parameter. Naive bayes algorithm is an effortless and successful algorithm for predicting defect on software. The objective of this research is to apply naive bayes algorithm in cross-project defect prediction for the web application using pandas and scikit-learn. The outcome of this research is naive bayes algorithm has an accuracy level of 72.30%-89.30%
and slightly low false alarm around by 5% - 26.67%/. However, it has low precision and recall score, 12,5% - 25% and 20% - 60%. Then, naive bayes algorithm predicting more defect module on software than code review.
Keyword : Cross-Project, Defect Prediction, Naïve Bayes, CK OO Metrics, Pandas, Scikit-Learn, Python
Number of Reference : 47 (tahun 2003 – 2017)
Number of Page : VI BAB + xv Pages + 79 Pages + 14 Attachment
viii
telah melimpahkan karunia, nikmat dan anugerah-Nya sehingga penulis dapat menyelesaikan penelitian sampai akhir proses penulisan skripsi ini. Tak lupa shalawat serta salam senantiasa dihaturkan kepada junjungan kita baginda Nabi Muhammad SAW beserta keluarga dan para sahabatnya. Penyusunan skripsi ini adalah salah satu syarat untuk memperoleh gelar Sarjana Komputer (S.Kom) pada program studi Teknik Informatika, Fakultas Sains dan Teknologi, Universitas Islam Negeri Syarif Hidayatullah Jakarta.
Dalam proses penulisan skripsi ini, tidak terlepas dari bimbingan, bantuan, dukungan, saran, dan motivasi yang penulis terima dari berbagai pihak. Oleh karena itu, penulis ingin mengucapkan terima kasih banyak kepada :
1. Bapak Dr. Agus Salim, M.Si selaku dekan Fakultas Sains dan Teknologi.
2. Ibu Arini, MT. selaku Ketua Program Studi Teknik Informatika serta Bapak Feri Fahrianto, M.Sc. selaku sekretaris Program Studi Informatika;
3. Bapak Rizal Broer Bahaweres, S.Si, M.Kom, selaku Dosen Pembimbing I dan Victor Amrizal, M.Kom, selaku Dosen Pembimbing II yang telah meluangkan waktu untuk membimbing, memotivasi, memberikan saran dan mendukung penulis dalam menyelesaikan skripsi ini dengan baik.
4. Seluruh Dosen, Staf Karyawan Fakultas Sains dan Teknologi, khusunya Program Studi Teknik Informatika yang telah memberikan bantuan dan ilmu sejak awal perkuliahan.
5. Kedua orangtua tercinta, Bapak Zainuddin dan Ibu Lizawati yang tidak henti-hentinya memberikan doa, kasih sayang, dukungan, dan motivasi kepada penulis dalam menyelesaikan skripsi ini.
6. Teman sekaligus mentor penulis, Bang Kiki Rizky Arpiandi yang telah meluangkan waktunya untuk memberikan saran dan memberikan semangat dalam mengerjakan skripsi ini, terutama dalam mengajari penulis memahami machine learning.
ix
8. Seluruh teman-teman TI angkatan 2013, khususnya teman-teman TI C yang telah memberikan masukan, dorongan, dan motivasi kepada penulis 9. Seluruh teman-teman HMI Komfastek yang telah memberikan penulis
pengalaman, pelajaran, dan kenangan yang berharga dan tidak akan penulis lupakan
10. Seluruh pihak yang tidak dapat disebutkan satu persatu yang secara langsung maupun tidak langsung telah membantu dalam menyelesaikan skripsi ini.
Penulis berharap semoga skripsi ini dapat membawa manfaat serta wawasan bagi pembaca. Penulis menyadari bahwa skripsi ini masih jauh dari sempurna, maka dari itu, penulis menerima saran dan kritik yang membangun untuk perbaikan kedepannya.
Wassalamualaikum, Wr. Wb
Ciputat, Januari 2018 Penulis
Puja Ahmad Habibi
x
PERNYATAAN ORISINALITAS ... Error! Bookmark not defined.
PERNYATAAN PERSETUJUAN PUBLIKASI SKRIPSI ... v
ABSTRAK ... vi
ABSTRACT ... vii
KATA PENGANTAR ... viii
DAFTAR ISI ... x
DAFTAR GAMBAR ... xii
DAFTAR TABEL ... xiii
DAFTAR GRAFIK ... xiv
DAFTAR LAMPIRAN ... xv
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 5
1.3 Batasan Masalah ... 6
1.4 Tujuan Penelitian ... 6
1.5 Manfaat Penelitian ... 7
1.6 Metodologi Penelitian ... 7
1.6.1 Metode Pengumpulan Data ... 8
1.6.2 Metode Implementasi ... 8
1.7 Sistematika Penulisan ... 8
BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI ... 10
2.1 Prediksi Cacat Perangkat Lunak ... 10
2.2 Cross-Project Defect Prediction (CPDP) ... 10
2.3 Software Metrics ... 10
2.4 CK OO Metrics Suite ...11
2.4.1 Weighted Method per Class (WMC) ... 11
2.4.2 Depth of Inheritance Tree (DIT) ... 12
2.4.3 Number Of Children (NOC) ... 12
2.4.4 Coupling Between Objects (CBO) ... 12
2.4.5 Response For a Class (RFC) ... 12
xi
2.8 Code Review ... 16
2.9 Proses Ektraksi Metrik Program ... 17
2.10 MetricReloaded ... 17
2.11 Pandas ... 17
2.12 Scikit-Learn ... 18
2.13 Perhitungan Performa Klasifikasi ... 18
2.13 Tinjauan Pustaka... 19
BAB III METODE PENELITIAN ... 25
3.1 Kerangka Berpikir ... 25
3.2 Metode Pengumpulan Data ... 26
3.3 Metode Implementasi ... 27
BAB IV IMPLEMENTASI EKSPERIMEN ... 33
4.1 Proses Pengumpulan Dataset ... 34
4.2 Proses Ekstraksi Metrik Program ... 36
4.3 Proses Pembelajaran Data Menggunakan Naive Bayes ... 39
4.4 Proses Prediksi Dataset Petstore (Test Data) ... 45
4.5 Proses Perhitungan Perfoma Klasifikasi ... 46
BAB V HASIL DAN PEMBAHASAN ... 47
5.1 Proses dan Hasil Prediksi Dataset Petstore ... 47
5.1.1 Prediksi Dataset Petstore ... 47
5.1.2 Hasil Prediksi ... 52
5.2 Perhitungan Performa Klasifikasi... 58
BAB VI KESIMPULAN DAN SARAN ... 61
6.1 Kesimpulan ... 61
6.2 Saran ... 62
DAFTAR PUSTAKA ... 63
LAMPIRAN ... 69
xii
Gambar 1.2. Alur Kerja Cross-Project Defect Prediction ... 3
Gambar 2.1. Software Test Life Cycle Activity ... 16
Gambar 3.1 Metodologi Penelitian ... 25
Gambar 4.1. Tabel Dataset Ant ... 34
Gambar 4.2. Tabel Dataset Log4j... 34
Gambar 4.3. Tabel Dataset Lucene ... 35
Gambar 4.4. Tabel CK OO Metric Dataset Log4j-1.2 ... 35
Gambar 4.5. Tabel CK OO Metric Dataset Ant-1.7 ... 36
Gambar 4.6. Tabel CK OO Metric Dataset Lucene-2.4 ... 36
Gambar 4.7. Panel MetricReloaded ... 37
Gambar 4.8. Hasil Ekstraksi Metrik Petstore ... 38
Gambar 4.9. Tabel Metrik Petstore ... 39
Gambar 4.10. Source code membaca data dengan library pandas ... 40
Gambar 4.11. Source Code Menghitung Peluang Per Kelas ... 41
Gambar 4.12. Source Code Menampilkan Hasil Mean Dan Varians Dataset ... 41
Gambar 4.13. Ouput Mean Dan Varians Setiap Atribut Dataset Ant-1.7 ... 42
Gambar 4.14. Ouput Mean Dan Varians Setiap Atribut Dataset Lucene-2.4 ... 42
Gambar 4.15. Ouput Mean Dan Varians Setiap Atribut Dataset Log4j-1.2 ... 43
Gambar 4.16. Source Code Memilih Atribut Dataset Dan Atribut Target ... 43
Gambar 4.17. Source Code Memanggil Library Sciki-Learn ... 44
Gambar 4.18. Source Code Memanggil Class GaussianNB ... 44
Gambar 4.19. Source Code Training Data Ant-1.7 Dan Prediksi Petstore ... 44
Gambar 4.20. Source Code Training Data Lucene-2.4 Dan Prediksi Petstore ... 45
Gambar 4.21. Source Code Training Data Log4j-1.2 Dan Prediksi Petstore ... 45
Gambar 5.1. Output Prediksi Cacat Petstore Dengan Dataset Ant-1.7 ... 52
Gambar 5.2. Output Prediksi Petstore Dengan Dataset Ant-1.7 (Lanjutan) ... 52
Gambar 5.3. Output Prediksi Petstore Dengan Dataset Lucene-2.4 ... 53
Gambar 5.4. Output Prediksi Petstore Dengan Dataset Lucene-2.4 (Lanjutan) ... 53
Gambar 5.5. Output Prediksi Petstore Dengan Dataset Log4j-1.2 ... 54
Gambar 5.6. Output Prediksi Petstore Dengan Dataset Log4j-1.2 (Lanjutan) ... 54
xiii
Tabel 2.3. Studi Literature ... 20
Tabel 3.1. Korelasi Antara Metode, Perangkat, Parameter dan Hasil ... 27
Tabel.4.1. Spesifikasi Perangkat Lunak ... 33
Tabel 4.2. Dataset Yang Digunakan ... 33
Tabel 5.1. Nilai Atribut Contoh 1 Dataset Petstore ... 47
Tabel.5.2. Hasil Prediksi Cacat Petstore ... 55
Tabel 5.3. Confusion Matrix Menggunakan Dataset Ant-1.7 ... 58
Tabel 5.4. Confusion Matrix Menggunakan Dataset Lucene-2.4 ... 58
Tabel.5.5. Confusion Matrix Menggunakan Dataset Log4j-1.2 ... 59
Tabel 5.6. Hasil Performa Prediksi Yang Di Hasilkan ... 60
xiv
Grafik 1.2. Algoritma Machine Learning Pada Penelitian SDP ... 4 Grafik 1.3. Jenis Algoritma Bayesian Learner Pada Penelitian SDP ... 4
xv
Lampiran 3- Dataset Petstore ... 73
Lampiran 4- Dataset Ant-1.2 ... 75
Lampiran 5- Dataset Lucene-2.4 ... 76
Lampiran 6- Dataset Log4j-1.2 ... 77
Lampiran 7- Tampilan Home Petstore ... 79
Lampiran 8- Tampilan Kategori Birds ... 79
Lampiran 9- Tampilan Login ... 80
Lampiran 10- Tampilan Register ... 80
Lampiran 11- Tampilan Rincian Binatang ... 81
Lampiran 12- Tampilan Cart ... 81
Lampiran 13- Tampilan Confirm Order ... 82
Lampiran 14- Tampilan Help ... 82
UIN Syarif Hidayatullah Jakarta
BAB I
PENDAHULUAN
1.1. Latar Belakang
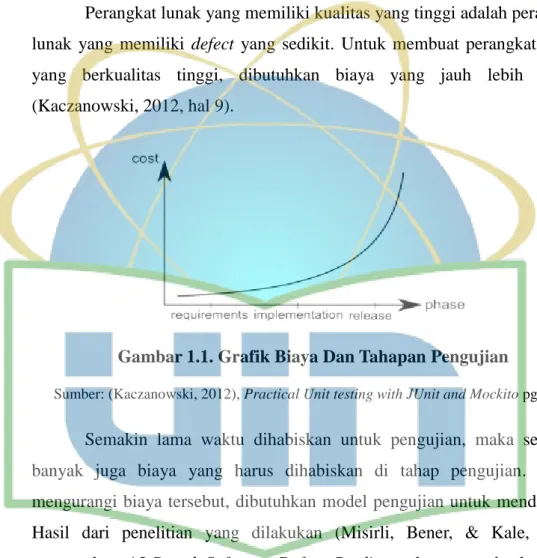
Perangkat lunak yang memiliki kualitas yang tinggi adalah perangkat lunak yang memiliki defect yang sedikit. Untuk membuat perangkat lunak yang berkualitas tinggi, dibutuhkan biaya yang jauh lebih mahal (Kaczanowski, 2012, hal 9).
Gambar 1.1. Grafik Biaya Dan Tahapan Pengujian
Sumber: (Kaczanowski, 2012), Practical Unit testing with JUnit and Mockito pg. 9
Semakin lama waktu dihabiskan untuk pengujian, maka semakin banyak juga biaya yang harus dihabiskan di tahap pengujian. Untuk mengurangi biaya tersebut, dibutuhkan model pengujian untuk mendeteksi.
Hasil dari penelitian yang dilakukan (Misirli, Bener, & Kale, 2011) mengatakan AI-Based Software Defect Predictor dapat mendeteksi 75%
defect pada code dan dapat mengurangi waktu yang dihabiskan pada pengujian perangkat lunak sebesar 25%.
Belakangan ini, aplikasi web berkembang sangat cepat dan menjadi bagian terpenting dalam membantu pekerjaan manusia. Disamping itu, banyak aktivitas manusia sehari-hari terjadi di internet. Oleh karena itu, menjamin kualitas suatu web merupakan hal yang sangat penting, karena hal
UIN Syarif Hidayatullah Jakarta
tersebut dapat mempengaruhi banyak pengguna dan menyebabkan kerugian secara finansia (Giang, Kang, & Bae, 2010).
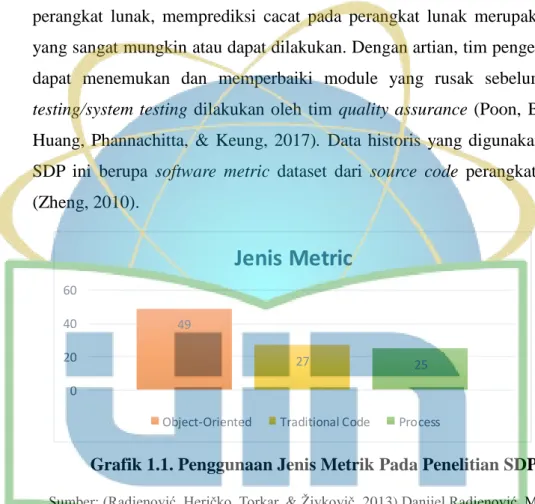
Software defect prediction (SDP) merupakan salah satu aktivitas yang sangat membantu pada fase pengujian di SDLC. SDP mengidentifikasi module yang cacat/defect dan memerlukan pengujian tambahan (Arora, Tetarwal, & Saha, 2015). Dengan menggunakan data historis dari suatu perangkat lunak, memprediksi cacat pada perangkat lunak merupakan hal yang sangat mungkin atau dapat dilakukan. Dengan artian, tim pengembang dapat menemukan dan memperbaiki module yang rusak sebelum unit testing/system testing dilakukan oleh tim quality assurance (Poon, Bennin, Huang, Phannachitta, & Keung, 2017). Data historis yang digunakan pada SDP ini berupa software metric dataset dari source code perangkat lunak (Zheng, 2010).
Grafik 1.1. Penggunaan Jenis Metrik Pada Penelitian SDP
Sumber: (Radjenović, Heričko, Torkar, & Živkovič, 2013) Danijel Radjenović, Marjan Heričko, Richard Torkar, Aleš Živkovič – Software Fault Prediction Metrics: A Systematic
Literature Review
Pada penelitian ini, jenis software metric yang digunakan adalah metric object-oriented, yaitu CK OO metric. Dari hasil peneltian (Radjenović et al., 2013), sekitar 49% penelitian prediksi cacat perangkat lunak menggunakan object-oriented metrics, lalu sekitar 27% menggunakan traditional metrics dan 25% menggunakan process metrics. Disamping itu, (Radjenović et al., 2013) mengemukakan bahwa Object-oriented metric ditemukan lebih bagus untuk digunakan dalam memprediksi cacat pada
49
27 25
0 20 40 60
Jenis Metric
Object-Oriented Traditional Code Process
UIN Syarif Hidayatullah Jakarta
perangkat lunak dibangkan dengan complexity metrics. Object-oriented metric yang paling banyak di pakai adalah CK OO metric.
Umumnya, metode prediksi cacat pada perangkat lunak bertujuan untuk membangun model prediksi berdasarkan data historis (training set) dalam satu proyek, dan kemudian menggunakan model tersebut untuk memprediksi data uji (test set) pada proyek yang sama (Yu, Jiang, & Zhang, 2017). Tetapi, pada proyek perangkat lunak yang baru dikembangkan biasanya tidak memiliki data historis yang cukup untuk membuat model prediksi, sehingga memprediksi cacat pada perangkat lunak yang baru dikembangkan merupakan hal yang hampir tidak mungkin (Poon et al., 2017). Untuk menangani hal tersebut, telah ada beberapa penelitian untuk membuat model prediksi dengan menggunakan data historis/software metric dataset dari proyek lain, atau yang dinamakan dengan cross-project defect prediction (CPDP) (Kawata, Amasaki, & Yokogawa, 2015).
Gambar 1.2. Alur Kerja Cross-Project Defect Prediction
Sumber: (J. Nam, Fu, Kim, Menzies, & Tan, 2017) Jaechang Nam, Wei Fu, Sunghun Kim, Tim Menzies, Lin Tan – Heterogeneous Defect Prediction
Pada CPDP, data latih (training) dan data uji (test set) yang digunakan didapatkan dari proyek yang lain. Hal ini berarti data tersebut memiliki distribusi yang berbeda, tetapi fitur atau atribut dari data proyek yang lain tetap harus sama dengan data yang ingin diuji atau yang dijadikan sebagai data target (Jaechang Nam & Kim, 2015). Teknik pembelajaran mesin dapat diterapkan pada data repositori tersebut untuk mengekstrak dan
UIN Syarif Hidayatullah Jakarta
memprediksi modul yang cacat pada perangkat lunak (Aleem, Capretz, &
Ahmed, 2015).
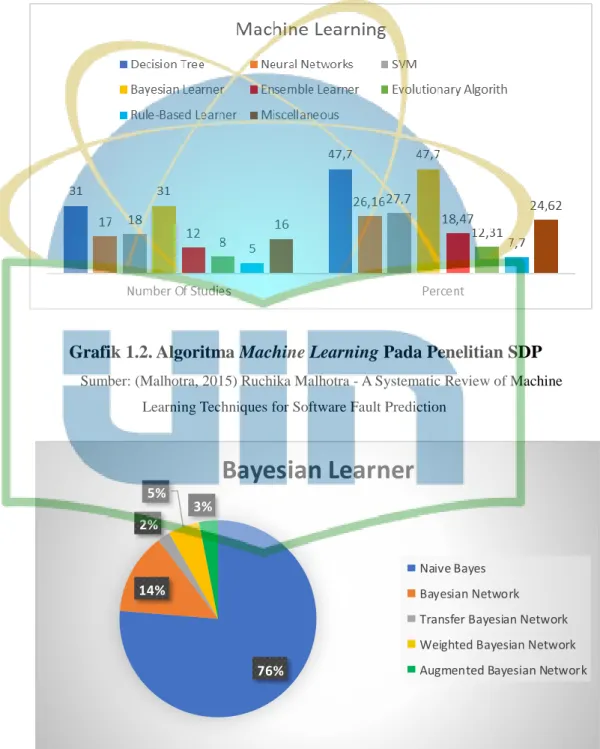
Pada penelitian prediksi cacat perangkat lunak, terdapat banyak algoritma pembelajaran mesin yang digunakan untuk seperti decision tree, bayesian learner (naive bayes dan bayesian networks), ensemble learning, neural networks dan lain-lain.
Grafik 1.2. Algoritma Machine Learning Pada Penelitian SDP
Sumber: (Malhotra, 2015) Ruchika Malhotra - A Systematic Review of Machine Learning Techniques for Software Fault Prediction
76%
14%
2%
5% 3%
Bayesian Learner
Naive Bayes Bayesian Network Transfer Bayesian Network Weighted Bayesian Network Augmented Bayesian Network
UIN Syarif Hidayatullah Jakarta
Grafik 1.3. Jenis Algoritma Bayesian Learner Pada Penelitian SDP
Sumber: (Malhotra, 2015) Ruchika Malhotra - A Systematic Review of Machine Learning Techniques for Software Fault Prediction
Pada penelitian yang dilakukan oleh (Malhotra, 2015), algoritma pembelajaran mesin yang banyak digunakan yaitu Decision Tree (47%), Bayesian Learner (47%), SVM (27,7%), dan Neural Netwoks (26,16%).
Lalu, pada metode bayesian learner, sekitar 74% penelitian yang menggunakan algoritma naive bayes untuk prediksi cacat perangkat lunak.
Kemudian diikuti oleh algoritma bayesian networks sebesar 13%. (Z. He, Peters, Menzies, & Yang, 2013) menyarankan untuk menggunakan algoritma naive bayes ketika diterapkan pada cross-project defect prediction atau prediksi cacat menggunakan lintas data. Karena, naive bayes merupakan algoritma yang sederhana dan mudah untuk digunakan.
Beberapa contoh penelitian yang dilakukan seperti (Kumaresh, R, &
Sivaguru, 2014), (Deep Singh & Chug, 2017), (Aleem et al., 2015), (Singh, Verma, & Vyas, 2013), dan (Wang & Li, 2010) menujukkan bahwa algoritma naive bayes memiliki performa akurasi yang bagus sekitar 80%.
Disamping itu, pada penelitian SDP, algortima naive bayes adalah algortima yang paling banyak digunakan (Malhotra, 2015). Dengan latar belakang tersebut, maka penulis bermaksud untuk melakukan penelitian dengan judul
“CROSS-PROJECT DEFECT PREDICTION FOR APPLICATION USING NAIVE BAYES”.
1.2. Rumusan Masalah
Ditinjau dari latar belakang tersebut, maka dapat dirumuskan permasalahan yang akan dikaji lebih lanjut dalam skripsi ini yaitu :
1. Bagaimana memprediksi modul cacat pada perangkat lunak menggunakan dataset lintas proyek (Ant, Lucene, Log4j) dengan menggunakan metode klasifikasi naive bayes ?
2. Bagaimana cara menganalisa hasil perbandingan pengujian antara code review dan cross-project defect prediction dengan naive bayes ?
UIN Syarif Hidayatullah Jakarta
3. Bagaimana performa klasifikasi cross-project defect prediction pada aplikasi petstore dengan naive bayes ?
1.3. Batasan Masalah
Berdasarkan rumusan masalah yang sudah didapat, maka pada penelitan ini didapat batasan masalah sebagai berikut :
1. Algoritma naive bayes digunakan untuk membuat model prediksi 2. Penelitian ini berfokus kepada implementasi algoritma naive bayes
dalam melakukan cross-project defect prediction pada aplikasi web 3. Aplikasi yang akan diuji pada penelitian ini adalah aplikasi web
petstore
4. Penelitian ini hanya berfokus pada source code java atau file yang berextensi .java
5. CK OO metric digunakan sebagai parameter atau dataset atribut untuk prediksi
6. Penelitian ini menggunakan library Python Scikit-Learn dan Pandas untuk membuat algoritma naive bayes
7. Alat yang digunakan untuk mendapatkan dataset dari aplikasi petstore adalah plugin Intellij IDEA
8. Bahasa pemrograman yang digunakan untuk membuat algoritma naive bayes adalah Python 3.5
9. IDE yang digunakan untuk pemrograman Python adalah PyCharm 10. IDE untuk menjalankan aplikasi petstore dan plugin
MetricReloaded adalah Intellij IDEA 1.4. Tujuan Penelitian
Tujuan dari penelitian skripsi ini antara lain :
UIN Syarif Hidayatullah Jakarta
1. Memprediksi cacat pada perangkat lunak dengan dataset dari proyek lain (Ant-1.7, Lucene-2.4, dan Log4j-1.2) menggunakan algoritma naive bayes
2. Menganalisa hasil perbandingan pengujian antara code review dan cross-project defect prediction dengan algoritma naive bayes 3. Menghitung tingkat akurasi hasil prediksi dari cross-project defect
prediction pada petstore dengan menggunakan algoritma naive bayes
1.5. Manfaat Penelitian
Manfaat yang diharapkan dari penelitian ini adalah sebagai berikut : Bagi penulis:
1. Memperdalam dan memahami ilmu tentang pembelajaran mesin (machine learning) dan penerapannya pada bidang software engineering
2. Dapat menerapkan ilmu yang didapat selama kuliah seperti Kecerdasan Buatan dan Riset Teknologi dan Informasi
Bagi Universitas:
1. Mengetahui kemampuan mahasiswa dalam menguasai materi teori yang telah didapatkan selama kuliah.
2. Mengetahui kemampuan mahasiswa dalam menerapkan ilmunya dan sebagai bahan evaluasi.
3. Memberikan gambaran tentang kesiapan mahasiswa dalam mengahadapi dunia kerja dari hasil yang diperoleh selama belajar atau kuliah.
4. Menambah referensi tentang penggunaan pembelajaran mesin (machine learning) dalam memprediksi modul cacat pada perangkat lunak
UIN Syarif Hidayatullah Jakarta
1.6. Metodologi Penelitian
Pada penyusunan penelitian “Cross-Project Defect Prediction For Web Application Using Naive Bayes” ini, penulis menggunakan pengumpulan data dan proses perancangan dengan metode berikut:
1.6.1. Metode Pengumpulan Data 1.6.1.1. Studi Pustaka 1.6.2. Metode Implementasi
Adapun tahapan-tahapan yang digunakan dalam membuat prediksi cacat software menggunakan algoritma Naive Bayes adalah sebagai berikut:
1.6.2.1. Proses Identifikasi Program
1.6.2.2. Proses Pembuatan Metric Program 1.6.2.3. Proses Pencarian Dataset
1.6.2.4. Proses Training Dataset Dengan Algoritma Naïve Bayes Menggunakan Libary Scikit-learn
1.6.2.5. Proses Prediksi Modul Pada Program Website Petstore
1.6.2.6. Proses Menghitung Tingkat Akurasi Algoritma Naive Bayes
1.7. Sistematika Penulisan
Untuk memudahkan memahami pembahasannya, maka laporan ini secara sistematika terdiri dari enam bab, yaitu sebagai berikut:
BAB I PENDAHULUAN
Bab ini akan diuraikan tentang beberapa hal yang akan dijadikan acuan dalam analisa penerapan algoritma Naive Bayes dalam prediksi cacat pada perangkat lunak yang terdiri dari latar belakang masalah, perumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian serta sistematika penulisan
UIN Syarif Hidayatullah Jakarta
BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI Bab ini akan diuraikan literatur apa saja yang akan dijadikan acuan dalam penelitian ini, serta teori-teori yang berhubungan dan berkenaan dengan topik-topik yang dibahas, antara lain software quality assurance, pengujian perangkat lunak, kecerdasan buatan, machine learning, dan naive bayes classifier.
BAB III METODE PENELITIAN
Bab ini akan diuraikan tentang cara mendapatkan data, data apa saja yang digunakan, bagaimana cara mengolah data tersebut, hasil apa saja yang akan didapat setelah data tersebut diolah serta kerangka berpikir mengenai penelitian ini.
BAB IV IMPLEMENTASI EKSPERIMEN
Bab ini akan diuraikan mengenai penyelesaian permasalahan dengan menggunakan metodologi yang dipilih, serta memuat unsur-unsur pengumpulan data, serta pelaksanaan implementasi.
BAB V HASIL DAN PEMBAHASAN
Bab ini akan diuraikan mengenai hasil analisa yang sudah dilakukan, melakukan pencatatan kekurangan dari hasil analisa yang mungkin harus mendapat perhatian.
BAB VI PENUTUP
Bab ini berisi tentang kesimpulan yang berisi hasil akhir dari pemecahan masalah serta saran untuk perbaikan dari hasil analisa untuk pengembangan selanjutnya.
UIN Syarif Hidayatullah Jakarta
BAB II
TINJAUAN PUSTAKA DAN LANDASAN TEORI
2.1. Prediksi Cacat Perangkat Lunak (Software Defect Prediction)
Pada rekayasa perangkat lunak, error atau fault pada sistem perangkat lunak yang muncul ketika sistem sedang dieksekusi atau dijalankan disebut sebagai defect (atau dikenal sebagai bug) (Mesquita, Rocha, Gomes, & Rocha Neto, 2016). Cacat pada perangkat lunak (software defect) adalah suatu kondisi dimana suatu perangkat lunak tidak sesuai dengan software requirement atau harapan dari end user (Rao &
Kumar, 2016). Software defect prediction (SDP) adalah suatu ilmu atau pembelajaran untuk memprediksi module perangkat lunak yang cacat atau defect. Dalam hal ini, module adalah suatu unit primitif yang menjalankan program atau sistem seperti function atau class (Menzies, Kocagüneli, Minku, Peters, & Turhan, 2015, hal 43).
2.2. Cross-Project Defect Prediction (CPDP)
Cross-Project Defect Prediction (CPDP) adalah suatu seni menggunakan data dari proyek lain untuk memprediksi cacat/defect perangkat lunak terhadap target project yang memiliki sedikit data local (P.
He, Li, Zhang, & Ma, 2014). Pendekatan CPDP selalu membutuhkan dataset proyek yang berlimpah dan set/atribut metrik antara target proyek haruslah sama dengan dataset proyek yang dijadikan data training (Jaechang Nam & Kim, 2015).
2.3. Software Metrics
UIN Syarif Hidayatullah Jakarta
Software metric adalah suatu karakteristik dari suatu sistem perangkat lunak, dokumentasi sistem, atau process development yang dapat diukur (Sommerville, 2016, hal 717). Pada umumnya, software metric atau metrik perangkat lunak digunakan untuk menganalisis kualitas dan efisiensi perangkat lunak. Analisis yang rinci dari data software metric dapat memberikan indikasi yang baik terhadap kemungkinan defect yang terjadi pada perangkat lunak yang sedang dikembangkan (Gayathri &
Sudha, 2014).
Software metrics dapat digunakan untuk berbagai macam hal seperti mengurangi jumlah defect pada source code, memprediksi banyaknya defects yang akan muncul, membantu meningkatkan perawatan perangkat lunak, dan lain-lain (Stephens, 2015, hal 224). Kebanyakan para peneliti hanya berfokus pada 2 jenis metrik umum untuk defect prediction: code metrics, yang digunakan untuk mengukur properti kode (misal, ukuran dan kompleksitas), dan process metrics (misal, jumlah perubahan dan banyaknya pengembang) (Rahman & Devanbu, 2013). CK OO metric merupakan salah satu jenis code metric (Jaechang Nam, 2014).
2.4. CK OO Metrics Suite
CK OO metrics merupakan seperangkat OO metrics yang diusulkan oleh Chidamber dan Kemerer. Terdapat 6 kriteria pengukuran yang terdapat pada CK OO metrics (Suri & Singhani, 2015), yaitu:
1. Weighted Method per Class (WMC) 2. Depth of Inheritance Tree (DIT) 3. Number Of Children (NOC) 4. Coupling Between Objects (CBO) 5. Response For a Class (RFC)
6. Lack of Cohesion in Methods (LCOM) 2.4.1. Weighted Method per Class (WMC)
Weighted method per class (WMC) didapatkan dengan cara menghitung total kompleksitas dari semua method yang terdapat pada suatu class. Asumsikan pada class Ki terdapat method M1, M2,
UIN Syarif Hidayatullah Jakarta
...., Mn. Maka, C1, ..., Cn menjadi kompleksitas suatu method (Singh et al., 2013).
(2.1) Untuk mencari nilai kompleksitasnya, kita menggunakan rumus cyclometic complexity yaitu:
(2.2) 2.4.2. Depth of Inheritance Tree (DIT)
Metrik DIT adalah metrik inheritance yang pengukurannya menemukan tingkat pewarisan kelas dalam perancangan sistem.
Dengan kata lain, metrik ini menghitung panjang jalur maksimum dari simpul suatu kelas ke akar pohon pada hierarchy. Metrik ini membantu untuk memahami perilaku kelas dan mengukur kompleksitas desain hubungan antar kelas (Suri & Singhani, 2015).
2.4.3. Number Of Children (NOC)
Metrik NOC adalah metrik yang digunakan untuk menghitung jumlah keturunan atau subclass yang berada di bawah suatu kelas pada hirarki dan terhubung secara langsung, atau disebut sebagai anak class atau children (Singh et al., 2013).
2.4.4. Coupling Between Objects (CBO)
Metrik CBO mengacu pada jumlah gabungan antar 2 kelas.
Ketika class1 memanggil suatu fungsi atau method dari class2, maka class1 dan class2 saling berhubungan atau coupling (Suri &
Singhani, 2015).
2.4.5. Response For a Class (RFC)
Metrik RFC berfungsi untuk menghitung berapa banyak metode yang diterapkan atau di panggil di dalam suatu kelas (Suri
& Singhani, 2015).
2.4.6. Lack of Cohesion in Methods (LCOM)
Metrik LCOM ini digunakan untuk menghitung ketidaksamaan metode di suatu Class dengan melihat variabel atau atribut yang digunakan oleh suatu metode pada Class tersebut.
UIN Syarif Hidayatullah Jakarta
Misalkan ada Class C dengan n method M1, M2,..., Mn dan Ij
merupakan kumpulan variabel atau atribut yang digunakan pada
method Mi. Maka, dan
. Jika adalah 0, maka P = 0 (Aggarwal, Singh, Kaur, & Malhotra, 2006).
(2.3)
jika sebaliknya 2.5. Machine Learning
Machine learning merupakan cabang dari kecerdasan buatan dimana algoritma tersebut dapat mempelajari data dengan sendirinya dan mendapatkan pengetahuan dari data tersebut. Pengetahuan tersebut kemudian digunakan untuk membuat prediksi dan keputusan tanpa campur tangan manusia (Raschka & Mirjalili, 2017, hal 39).
Menurut (Raschka & Mirjalili, 2017, hal 40), machine learning dapat dibedakan menjadi 3 jenis, yaitu supervised learning, unsupervised learning, dan reinforcement learning. Umumnya, prediksi cacat perangkat lunak merupakan jenis machine learning yang menggunakan pendekatan supervised learning (Gayathri & Sudha, 2014).
Tujuan utama dalam pembelajaran diawasi (supervised learning) adalah belajar model dari data pelatihan berlabel yang memungkinkan untuk membuat prediksi tentang data tak terlihat atau masa depan.
Klasifikasi merupakan salah satu teknik dari supervised learning. Tujuan dari klasifikasi adalah untuk memprediksi label yang berkategori dari suatu data atau instance (Raschka & Mirjalili, 2017, hal 41-42).
Pada dataset, ada nilai pada atribut tertentu yang tidak dapat di ukur.
Hal ini dinamakan dengan missing value. Dengan adanya missing value pada dataset dapat mempersulit dalam membuat model prediksi. Pada dataset, missing value muncul atau ditandai dengan kolom kosong, NaN (not a number), atau N/A (Brink, Richards, & Fetherolf, 2017, hal 61).
Sehingga, ada baiknya untuk mengatasi missing value pada dataset
UIN Syarif Hidayatullah Jakarta
sebelum membuat atau melakukan prediksi. Ada beberpa cara yang dapat digunakan untuk mengatasi missing value. Salah satu cara termudah untuk mengatasi hal tersebut adalah dengan cara menghilangkan fitur (kolom) atau sample (baris) (Raschka & Mirjalili, 2017).
2.6. Naive Bayes
Pengklasifikasian Naïve Bayes berasumsi bahwa dampak dari nilai atribut pada kelas tertentu merupakan independen dari nilai-nilai atribut lainnya. Asumsi ini disebut kelas independen bersyarat (Jain & Richariya, 2012). Misal, terdapat vektor yang merepresentasikan atribut n dari suatu contoh pada dataset. C merepresentasikan class label pada suatu contoh x. Untuk dapat menghitung probabilitas contoh x masuk ke suatu class dapat di hitung sebagai berikut:
(2.4)
Dimana, p(C) merupakan nilai probabilitas suatu kelas dan p(Xn | C) adalah nilai probabilitas suatu atribut Xn terhadap suatu kelas. Jika attribut ke i bernilai kontinyu, maka nilai tersebut diasumsikan memiliki distribusi gaussian terhadap suatu kelas. Maka, hitung nilai mean dan variance dari atribut tersebut terhadap suatu kelas, direpresentasikan sebagai µc,i dan σ2c,i. Maka, untuk mencari nilai xi pada atribut ke n dengan class label c, di hitung dengan persamaan (2.5) atau disebut dengan distribusi normal (Haghpanah & Taheri, 2017)
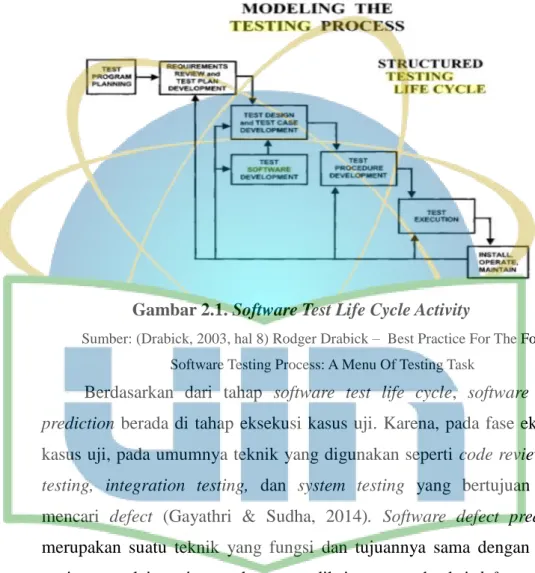
(2.5) 2.7. Software Testing Life Cycle
Software Testing Life Cycle adalah proses pengujian yang dilakukan secara sistematis dan terencana. Menurut (Jamil, Arif, Sham, Abubakar, &
Ahmad, 2016), STLC terdiri dari 6 aktivitas, yaitu:
1) Analisis kebutuhan
UIN Syarif Hidayatullah Jakarta
Selama tahap pertama STLC, peninjauan persyaratan perangkat lunak dilakukan oleh tim Quality Assurance di mana mereka memahami persyaratan inti dari perangkat lunak yang akan diuji. Jika dalam kasus analisa terdapat konflik yang muncul (contoh: tidak memahami kebutuhan dari perangkat lunak yang akan diuji), tim Quality Assurance harus berkoordinasi dengan tim developer untuk lebih memahami perangkat lunak yang akan diuji dan menyelesaikan konflik yang terjadi.
2) Perencanaan pengujian
Perencanaan uji adalah fase kedua dan terpenting dari STLC, karena ini adalah tahap dimana semua strategi pengujian didefinisikan. Tahap ini berkaitan dengan persiapan rencana uji, yang akan menjadi penyampaian akhir fase ini. Test Plan adalah dokumen wajib yang bias terhadap pengujian fungsional aplikasi, yang tanpanya proses pengujiannya tidak akan mungkin terjadi
3) Pengembangan kasus uji
Pengembangan kasus uji adalah fase dimana kasus uji/test case dikembangkan, Kasus Uji yang sesuai ditulis oleh tim QA secara manual atau kasus uji dihasilkan secara otomatis. Uji kasus menentukan satu set input tes atau data, kondisi eksekusi, dan hasil yang diharapkan. Kumpulan data uji yang ditentukan harus dipilih sehingga menghasilkan hasil yang diharapkan dan juga input data yang salah yang akan menghasilkan kesalahan selama pengujian.
4) Eksekusi kasus uji
Tahap Uji Eksekusi terdiri dari pelaksanaan uji kasus berdasarkan rencana uji yang dihasilkan sebelum tahap eksekusi. Jika fungsionalitas melewati fase eksekusi tanpa adanya laporan bug, tes dikatakan telah dihapus atau dilewati, dan setiap uji coba yang gagal akan dikaitkan dengan bug atau kesalahan yang ditemukan. Dari fase ini, maka akan didapatkan laporan bug atau defect pada program atau kasus uji yang telah di uji
UIN Syarif Hidayatullah Jakarta
5) Laporan pengujian.
Uji Pelaporan adalah pelaporan hasil yang dihasilkan setelah pelaksanaan uji kasus yang juga melibatkan pelaporan bug yang kemudian diteruskan ke tim pengembang sehingga dapat diperbaiki
Gambar 2.1. Software Test Life Cycle Activity
Sumber: (Drabick, 2003, hal 8) Rodger Drabick – Best Practice For The Formal Software Testing Process: A Menu Of Testing Task
Berdasarkan dari tahap software test life cycle, software defect prediction berada di tahap eksekusi kasus uji. Karena, pada fase eksekusi kasus uji, pada umumnya teknik yang digunakan seperti code review, unit testing, integration testing, dan system testing yang bertujuan untuk mencari defect (Gayathri & Sudha, 2014). Software defect prediction merupakan suatu teknik yang fungsi dan tujuannya sama dengan teknik testing yang lain, yaitu untuk memprediksi atau mendeteksi defect.
2.8. Code Review
Code review adalah pengujian sistematis yang dapat menemukan atau menghilangkan kerenttanan atau kelemahan pada code. Code review menggunakan satu atau lebih dari satu orang untuk mereview code yang telah ditulis oleh anggota kelompok lain. Tahapan yang dilakukan dalam code review, yaitu: menulis code dan meminta untuk di review, mereview
UIN Syarif Hidayatullah Jakarta
code dan mendapatkan feedback dari reviewer, memperbaiki kesalahan yang ditemukan dan memfinalisasikan hasil review, dan terakhir menyatukan hasil code yang telah direview dengan code asal (Lal &
Pahwa, 2017).
2.9. Ektraksi Metrik Program
Ektraksi metrik program bertujuan untuk mendapatkan data software metric. (Tosun, Bener, Turhan, & Menzies, 2010) menyarankan untuk menggunakan automated tools untuk mengektrak metrik suatu program.
Karena hal tersebut dapat mempermudah dan mempercepat proses mendapatkan data metrik. Khususnya ketika akan mengekstrak metrik program yang kompleks dan besar, alat otomatis tersebut dapat membantu untuk mendapatkan nilai metrik yang akurat (Kayarvizhy, 2016). Pada penelitian ini, metric tools yang digunkan adalah MetricReloaded yang merupakan plugin IntellijIDEA.
2.10. MetricReloaded
MetricReloaded adalah plugin automated code metrics untuk Intellij IDEA dan Intellij Platform IDE (JetBrains, 2016). Plugin ini menawarkan banyak jenis metrik dari cyclometic complexity sampai class cohesion.
Setelah terinstal, plugin ini menyediakan pilihan menu di bawah Analyze | Calculate Metrics. Metrik dapat dijalankan untuk keseluruhan proyek, modul khusus, file tidak terikat, file terkini, atau bahkan cakupan khusus, membuatnya sangat fleksibel dalam hal apa yang ingin kita analisis (JetBrains, 2014).
2.11. Pandas
Pandas adalah library dari bahasa pemrograman Python yang menyediakan struktur data yang cepat, fleksibel, dan ekspresif yang dirancang untuk bekerja dengan data relasional atau berlabel. Tujuan dibuatnya library ini adalah untuk analisis data dan manipulasi data (Pandas, 2016). Library Pandas dapat digunakan untuk berbagai macam jenis data seperti, Data tabular dengan kolom yang heterogen, seperti tabel
UIN Syarif Hidayatullah Jakarta
SQL atau spreadsheet Excel, data deret waktu, data matriks dan bentuk data observasional / statistik lainnya. Hal-hal yang dapat dilakukan oleh library Pandas seperti membaca dan menulis data, mengelompokkan suatu data, label-based slicing, dan masih banyak lagi.
2.12. Scikit-Learn
Scikit-learn adalah modul atau library Python yang mengintegrasikan berbagai algoritma pembelajaran mesin mutakhir untuk masalah yang diawasi (supervised) dan tidak diawasi (unsupervised) (Pedregosa et al., 2012). Algoritma pembelajaran mesin yang dapat digunakan dengan menggunakan library Scikit-learn yaitu, Naive Bayes, SVM, Decision Tree, Neural Network, Nearest Neighbor, Feature Selection, Decision Tree, dan lain-lain (Scikit-Learn, 2017).
2.13. Perhitungan Performa Klasifikasi
Untuk mengukur suatu performa yang dilakukan oleh algortima machine learning dalam melakukan klasifikasi, dapat dilakukan dengan memetakkan jumlah kelas yang di prediksi benar dengan menggunakan tabel confusion matrix (Kirk, 2017, hal 92). Berikut merupakan tabel confusion matrix dan terminologi didalamnya (Kumudha & Venkatesan, 2016):
Tabel 2.1. Confusion Matrix
Predicted Positive Predicted Negative Actual Positive True Positive (TP) False Negative (FN) Actual Negative False Positive (FP) True Negative (TN)
True Positive (TP): jumlah module defect yang di prediksi dengan benar
True Negative (TN): jumlah module non-defect yang di prediksi dengan benar
False Positive (FP): jumlah module non-defect yang di prediksi salah atau di prediksi sebagai defect
UIN Syarif Hidayatullah Jakarta
False Negative (FN): jumlah module defect yang di prediksi salah atau di prediksi sebagai non-defect
Semua terminologi yang terdapat pada tabel confusion matrix dapat digunakan untuk menghitung performa klasifikasi seperti akurasi, precision, recall, false alarm, dan lain-lain. Pada penelitian ini, performa klasifikasi yang digunakan adalah akurasi, precision, recall, dan false alarm. Tabel dibawah ini menjelaskan rumus dan fungsi dari masing- masing performa klasifikasi (Kumudha & Venkatesan, 2016):
Tabel 2.2. Perhitungan Performa Performance
Measure
Formula Deskripsi
Akurasi Untuk menghitung jumlah module
yang di prediksi dengan benar
Precision Untuk menghitung jumlah module
yang diklasifikasikan sebagai defect
Recall Untuk menghitung jumlah module
defect di prediksi dengan benar
False Alarm Untuk menghitung jumlah module
non-defect yang di klasifikasikan sebagai defect
2.14. Tinjauan Pustaka
Pada bagian tinjauan pustaka penulis mengumpulkan studi literatur sejenis yang penulis gunakan sebagai acuan penelitian. Tujuannya adalah untuk mendalami materi, mengambil kesimpulan, melihat kekurangan, dan kelebihan dari penelitian sebelumnya untuk dapat menghasilkan penelitian yang lebih baik. Berikut ini adalah pemaparan dari beberapa literatur sejenis (Tabel 2.1):
UIN Syarif Hidayatullah Jakarta
Tabel 2.3. Studi Literatur
Judul Tahun
Prediksi Cacat Perangkat Lunak
Metode Hasil
Cross-Project Data
Code Metric
OO Metric
Lainnya
Software Fault Prediction Models for Web
Applications (Giang et al., 2010)
2010 - - - Machine Learning (Neural
Network, Naive Bayes, Random Forest, Logistic Regression,
Nnge) + Feature Selection
Prediksi cacat perangkat lunak pada web menggunakan model prediksi khusus web berdasarkan karateristik aplikasi web lebih bagus dari pada menggunakan model prediksi yang lain.
Effective multi-objective naïve Bayes learning for cross-project defect prediction (Ryu & Baik, 2016)
2016 - - Multi-Objective Naive Bayes
Prediksi cacat cross-project
menggunakan metode multi-objective naive bayes memperlihatkan performa prediksi yang sama bagus dengan prediksi cacat within-project. Metode multi-objective naive bayes dapat
mengatasi ketidakseimbangan kelas pada cross-project data
UIN Syarif Hidayatullah Jakarta
Cross Company and within Company Fault Prediction using Object Oriented Metrics (Singh et al., 2013)
2013 -- - Machine Learning (J48, Naive
Bayes, SVM, Random Forest, K-NN, Decision Tree)
Metrik OO CK terbukti efektif untuk prediksi cacat menggunakan data cross- project. Secara keselurahan performa J48 memiliki precision, recall, dan F-measure yang bagus. Metrik OO CK pada cross- project defect prediction, memiliki nilai precision yang bagus ketika
menggunakan metode naive bayes dan J48.
Transfer learning for cross- company software defect prediction (Ma, Luo, Zeng,
& Chen, 2012)
2012 - - Transfer Naive Bayes
Prediksi cacat cross-company menggunakan transfer naive bayes memiliki performa yang bagus dan akurasi yang tinggi.
UIN Syarif Hidayatullah Jakarta
Cross-project defect prediction for web application using naive bayes (case study: Petstore web application) (Penulis)
2018 - - Naive Bayes
Algoritma naive bayes memiliki tingkat akurasi sebesar 75%-89% dan tingkat false alarm yang sedikit rendah sekitar 5% - 26.67%. Namun, naive bayes juga memiliki tingkat precision dan recall yang cukup rendah, sekitar 12.5% - 25%
dan 20% - 60%. Algoritma naive bayes juga memprediksi lebih banyak defect dibandingkan dengan code review.
UIN Syarif Hidayatullah Jakarta
Pada tabel diatas, dijelaskan beberapa jurnal yang penulis gunakan sebagai acuan dalam penelitian ini. Giang, Kang, & Bae melakukan penelitian mengenai “Software Fault Prediction Models for Web Applications”. Mereka menggunakan dataset khusus untuk aplikasi web yang atribut atau parameternya terdiri dari LOJ, NOFJ, LOCSS, NOIC, NOH, dan LOC. Metrik yang mereka ajukan berfokus pada user interface.
Mereka menggunakan beberapa metode untuk memprediksi cacat pada aplikasi web yaitu Logisic Regression, metode pembelajaran mesin (NNge, random forest, neural network, Naıve Bayes). Hasil dari penelitian yang mereka lakukan menunjukkan Prediksi cacat perangkat lunak pada web menggunakan model prediksi khusus web berdasarkan karateristik aplikasi web lebih bagus dari pada menggunakan model prediksi yang lain.
Ryu & Baik melakukan penelitian prediksi cacat pada cross-project data menggunakan metode multi-objective naive bayes. Dataset yang digunakan yaitu dataset metrik object-oriented. Hasil dari penelitian mereka menunjukkan bahwa metode multi-objective naive bayes memperlihatkan performa prediksi yang sama bagus dengan prediksi cacat within-project. Metode multi-objective naive bayes dapat mengatasi ketidakseimbangan kelas pada cross-project data. Penelitian yang dilakukan Singh et al untuk prediksi cacat perangkat lunak menggunakan metrik CK Object-Oriented cross-project menunjukkan bahwa, metrik OO CK terbukti efektif untuk prediksi cacat menggunakan data cross-project.
UIN Syarif Hidayatullah Jakarta
Secara keselurahan performa J48 memiliki precision, recall, dan F- measure yang bagus. Metrik OO CK memiliki nilai precision yang bagus ketika menggunakan metode naive bayes dan J48. Ma, Luo, Zeng, & Chen menggunakan metode transfer naive bayes untuk memprediksi cacat perangkat lunak pada data cross-project. Dataset yang digunakan merupakan dataset pemrograman konvensional. Hasil dari penelitian mereka menunjukkan bahwa, Prediksi cacat cross-company menggunakan transfer naive bayes memiliki performa yang bagus dan akurasi yang tinggi. Dari beberapa penelitian diatas, penulis ingin menerapkan algoritma naive bayes untuk memprediksi cacat pada aplikasi web petstore dengan menggunakan dataset dari proyek lain atau cross-project. Software metric yang akan digunakan yaitu CK OO metric
UIN Syarif Hidayatullah Jakarta
BAB III
METODE PENELITIAN
3.1. Kerangka Berpikir
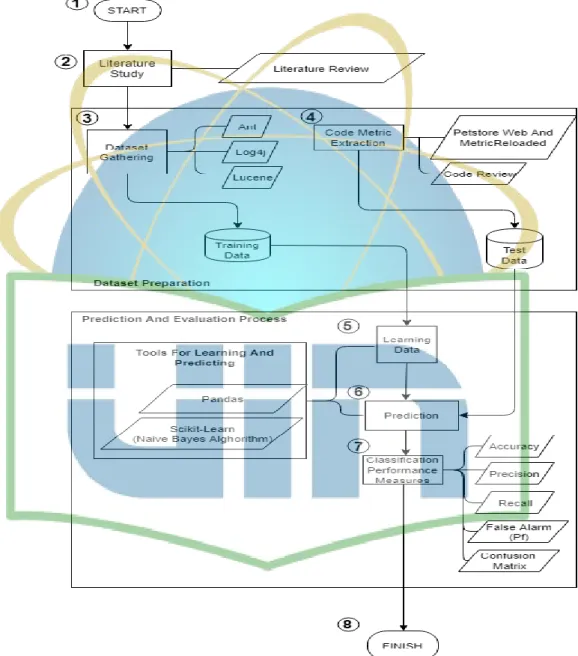
Gambar 3.1 Metodologi Penelitian
UIN Syarif Hidayatullah Jakarta
3.2. Metode Pengumpulan Data (Nomor 2 Pada Gambar 3.1)
Pengumpulan data bertujuan untuk mencari dan mengumpulkan data yang terkait dengan penelitian seperti landasan teori, metodologi penulisan, metodologi proses, dan acuan penelitian sejenis. Pada penelitian ini, metode pengumpulan data yang dilakukan adalah studi literatur dan studi pustaka.
Studi literatur yang dilakukan diharapkan dapat memberikan gambaran secara lengkap dan dapat memberikan dasar kontribusi tentang identifikasi pola dan prediksi cacat perangkat lunak yang akan dilakukan pada penelitian ini.
Pada tahapan pengumpulan data dengan studi pustaka dan studi literatur, penulis mencari referensi-referensi yang berhubungan dengan topik dan objek yang akan di teliti. Pencarian referensi dilakukan di perpustakaan, toko buku, dan di internet. Setelah mendapatkan referensi-referensi tersebut, penulis lalu mencari berbagai informasi yang dibutuhkan untuk penelitian ini. Informasi yang didapatkan, penulis gunakan untuk landasan teori, metode penelitian, serta penelitian ini secara langsung. Studi literatur yang dilakukan adalah mempelajari beberapa referensi sebagai berikut:
1. Penelitian terdahulu yang telah melakukan prediksi cacat perangkat lunak dengan menggunakan dataset proyek yang berbeda.
2. Dasar teori tentang dataset metrik Chidamber dan Kemerer (CK)
3. Dasar teori tentang machine learning
UIN Syarif Hidayatullah Jakarta
4. Penelitian terdahulu yang menggunakan metode Naïve Bayes untuk prediksi cacat pada perangkat lunak.
1.3. Metode Implementasi
Tabel 3.1. Korelasi Antara Metode, Perangkat, Parameter dan Hasil
No Metode/Teknik Perangkat Parameter Hasil
1 Pengumpulan Training Dataset (3)
http://openscience.us/repo/defect/ck/, Dataset : Lucene, Ant, Log4j
WMC, DIT,NOC, CBO, LCOM, RFC, Bug
Training Data
2 Ekstraksi metrik program (4)
MetricReloaded, Java, Intellij IDEA, Source code petstore, Code Review
WMC, DIT, NOC, CBO, LCOM, RFC, Bug
Test Data
3 Learning Data (5)
Python3.5, Pandas, Scikit-Learn, PyCharm, Training Data
WMC, DIT, NOC, CBO, LCOM, RFC, Bug
Model
Pembelajaran
4 Prediksi (6) Python3.5, Scikit-Learn, PyCharm, Model Pembelajaran
WMC, DIT, NOC, CBO, LCOM, RFC, Bug
Hasil prediksi dataset petstore 5 Perhitungan
Performa Klasifikasi (7)
Hasil Prediksi Dataset Petstore, Test Data
Bug Hasil
Performa Klasifikasi dari Algoritma Naive Bayes Adapun untuk tahapan implementasi dalam penelitian ini, penulis akan menjelaskan cara kerja algoritma Naive Bayes dalam melakukan prediksi cacat pada perangkat lunak.
1. Proses Pengumpulan Dataset (Nomor 3
pada gambar 3.1)
UIN Syarif Hidayatullah Jakarta
Pengumpulan dataset bertujuan untuk mencari dan mengumpulkan dataset metric dari proyek atau program lain yang kemudian digunakan untuk membuat model prediksi cacat pada perangkat lunak. Kriteria yang penulis cari dalam mencari dataset metric program adalah dataset yang memiliki atribut atau fitur yang sama dengan metric program yang akan di prediksi. Pencarian dataset dilakukan dengan mencari di internet yang terdapat pada website http://openscience.us/repo/defect/ck. Model software metric yang penulis gunakan yaitu Chidamber dan Kemerer (CK) metric desain, yang merupakan metric untuk program atau aplikasi berorientasi objek. Setelah melakukan pecarian, penulis menggunakan dataset Ant, Log4J, dan Lucene. Pemilihan dataset dilakukan secara acak.
Lalu, dataset tersebut akan dijadikan sebagai data latih atau training data yang akan digunakan untuk membuat model prediksi cacat pada perangkat lunak. Setelah itu, penulis hanya mengambil atribut CK metric pada setiap dataset dan membuang atribut yang tidak digunakan. Label atau atribut target pada dataset tersebut berupa jumlah banyaknya bug yang ditemukan pada setiap module. Karena pada penelitian ini hanya melakukan klasifikasi, maka penulis mengganti nilai pada atribut target menjadi 1 dan 0. Jika pada module tersebut memiliki nilai atribut bug lebih besar dari (>) 0, maka nilai pada atribut target, yakni “bug”, diberi nilai 1.
UIN Syarif Hidayatullah Jakarta
Sebaliknya, jika nilai atribut bug sama dengan 0, maka nilai pada atribut target tersebut diberi nilai 0.
2. Proses Ekstraksi Metric Program (Nomor 4 pada gambar 3.1)
Proses ekstraksi metric program bertujuan untuk menganalisa dan mendapatkan data Chidamber dan Kemerer (CK) metric dari program yang akan dijadikan target prediksi. Data metric program ini kemudian akan digunakan sebagai target dataset. Untuk mengekstrak data metric dari program yang akan dijadikan target, penulis menggunakan plugin dari IDE Java, yang bernama Intellij IDEA, yaitu MetricReloaded. Plugin ini dapat menganalisa dan mendapatkan data Chidamber dan Kemerer (CK) metric dari semua module Java yang terdapat pada file directory program yang dituju.
Setelah itu, penulis melakukan code review terhadap semua file berektensi java. Tujuan dilakukannya code review adalah untuk memberikan label pada dataset petstore. Jika suatu module ketika di review terdapat code yang dicurigai bug, maka module tersebut akan dilabeli dengan angka 1 yang berarti module tersebut defect.
Sebaliknya, jika module tersebut tidak terdapat bug, maka akan dilabeli dengan angka 0 yang berarti module tersebut non-defective.
Dataset petstore memiliki 76 module. Tetapi, terdapat 11 module yang memiliki missing data. Untuk mengatasi hal tesebut, 11 module yang memiliki missing data tersebut di buang dari dataset petstore.
UIN Syarif Hidayatullah Jakarta
Sehingga, terdapat 65 module pada dataset target atau dataset petstore.
3. Proses Pembelajaran Data (Nomor 5 Gambar 3.1)
Proses Pembelajaran dari data bertujuan untuk membuat suatu model yang akan digunakan untuk memprediksi cacat pada perangkat lunak dari dataset yang telah dikumpulkan. Metode pembelajaran yang digunakan adalah klasifikasi Naive Bayes. Output yang dihasilkan dari klasifikasi Naive Bayes berupa tingkat kemungkinan atau probabilitas dari suatu kelas. Rumus yang digunakan yaitu terdapat pada persamaan nomor (2.4). Karena dataset yang digunakan merupakan data kontinyu (continous), maka data tersebut harus di normalisasikan. Untuk menormalisasikannya, penulis menggunakan Gaussian Naive Bayes untuk mencari ). Rumus tersebut terdapat pada persamaan nomor (2.5). Langkah awal pada proses ini yaitu menentukan atribut mana yang dijadikan sebagai input pembelajaran dan menentukan atribut ouputnya. Dalam hal ini, atribut input pembelajarannya yaitu atribut dari 6 CK OO metrik (WMC, DIT, NOC, CBO, LCOM, RFC) dan atribut targetnya atau label yaitu Bug. Sebelum menormalisasikan datasetnya menggunakan Gaussian Naive Bayes, penulis menyortir datasetnya berdasarkan kelasnya (defective atau non-defective) masing – masing. Setelah itu, penulis mencari rata-rata ( ) dan variasi ( ) dari setiap atribut yang ada berdasarkan kelasnya masing-masing.
UIN Syarif Hidayatullah Jakarta
Lalu penulis mencari besarnya kemungkinan atau probabilitas dari setiap kelas .
(3.1)
(3.2)
(3.3) Pada tahapan ini, penulis menggunakan dua library pendukung, yaitu pandas dan scikit-learn. Library Pandas digunakan untuk membaca dataset dan menentukan atribut yang digunakan untuk pembelajaran dan juga untuk membantu mencari nilai mean dan standard deviation pada dataset berdasarkan label/classnya.
Sedangkan library Scikit-learn digunakan untuk memanggil Class GaussianNB(), yang berisi algoritma gaussian naive bayes, yang digunkan untuk melatih data training dan juga untuk menghitung tingkat akurasi dari prediksi yang dihasilkan oleh algoritma gaussian naive bayes.
4. Proses Prediksi Dataset Petstore (Nomor 6 Pada Gambar 3.1)
Setelah menbuat model prediksi dari data training dataset ant, lucene, dan log4j dengan klasifikasi Naive Bayes, Penulis menggunakan dataset web petstore yang di dapatkan dari proses ekstrasi metrik program sebagai input yang akan di prediksi dan menggunakan library scikit-learn untuk melakukan prediksi dari dataset petstore. Output yang dihasilkan berupa hasil prediksi dari
UIN Syarif Hidayatullah Jakarta
semua module pada dataset petstore. Jika modul tersebut diprediksikan cacat, maka ouput yang dihasilkan yaitu 1. Sebaliknya, jika modul tersebut diprediksikan tidak terdapat cacat, maka output yang dihasilkan yaitu 0.Sama halnya pada tahap pembelajaran data, kita harus menentukan atribut yang dijadikan input dan output.
Dalam hal ini, atribut dataset petstore yang dijadikan input adalah 6 dari metrik CK OO (WMC, DIT, NOC, CBO, RFC, LCOM) dan atribut ouputnya yaitu Bug.
5. Proses Perhitungan Performa Klasifikasi (Nomor 7 Pada Gambar 3.1)
Setelah mendapatkan hasil output prediksi semua modul web petstore, kemudian penulis menghitung tingkat performa klasifikasi dari naive bayes seperti akurasi, precision¸recall, dan false alarm.
Untuk melakukan hal tersebut, memetakkan hasil prediksi naive bayes dengan menggunakan tabel confusion matrix. Perhitungan pada tahap ini dilakukan secara manual.
UIN Syarif Hidayatullah Jakarta
BAB IV
IMPLEMENTASI EKSPERIMEN
Pada bab ini akan dibahas tentang cara mengimplementasi penelitian prediksi cacat perangkat lunak menggunakan data lintas proyek. Sebelumnya, spesifikasi perangkat lunak dan tools yang digunakan, dan spesifikasi dataset yang digunakan.
Tabel 4.1. Spesifikasi Perangkat Lunak Spesifikasi Perangkat Lunak
Bahasa Pemrograman - Java 1.8
- Python
3.5.2
IDE - PyCharm
- Intellij
IDEA
Library - Pandas
UIN Syarif Hidayatullah Jakarta
- Scikit-
Learn
Plugin - MetricRelo
ader
Tabel 4.2. Dataset Yang Digunakan Dataset
Training - Log4j-1.2
- Lucene-2.4
- Ant-1.7
Test - Petstore
UIN Syarif Hidayatullah Jakarta
4.1. Proses Pengumpulan Dataset
Pada tahap ini, penulis melakukan pencarian di internet tentang dataset software defect prediction yang menggunakan metric CK OO metrik. Penulis mendapatkan data metrik pada website http://www.openscience.us/repo/defect/ck/. Lalu penulis memilih 3 dataset yang terdapat pada website tersebut secara acak, yaitu dataset ant-1.7, log4j-1.2, dan lucene-2.4.
Ketiga dataset tersebut memiliki 21 atribut, 6 diantaranya merupakan atribut CK OO metrik. Berikut merupakan isi dari ketiga
dataset tersebut:
Gambar 4.1. Tabel Dataset Ant
UIN Syarif Hidayatullah Jakarta
Gambar 4.2. Tabel Dataset Log4j
UIN Syarif Hidayatullah Jakarta
Gambar 4.3. Tabel Dataset Lucene
Karena penulis hanya berfokus menggunakan atribut CK OO metrik, maka penulis hanya mengambil 6 atribut CK OO metrik (WMC, DIT, NOC, CBO, RFC, LCOM) dan 1 atrubut sebagai target prediksi, yang bernama bug. Sisa dari atribut metrik tersebut tidak penulis gunakan atau dihilangkan. Dari ketiga gambar di atas, atribut yang di kotakkan warna merah
adalah atribut yang di ambil. Berikut merupakan hasilnya:
Gambar 4.4. Tabel CK OO Metric Dataset Log4j-1.2
UIN Syarif Hidayatullah Jakarta
Gambar 4.5. Tabel CK OO Metrik Dataset Ant-1.7
Gambar 4.6. Tabel CK OO Metrik Dataset Lucene-2.4
Data dari atribut bug yang terdapat pada ketiga dataset tersebut berisi berapa banyak jumlah bug yang ditemukan pada suatu module di dataset tersebut, bukan berisi tentang apakah module tersebut defect atau non- defective. Untuk mengatasi hal ini, penulis memberikan nilai 1 pada module yang memiliki nilai lebih dari 0 pada atribut bug. Jika module tersebut bernilai 0, maka module tersebut tidak dianggap sebagai defect. Nantinya, ketiga dataset ini akan dijadikan sebagai data latih atau training data.
4.2. Proses Ekstraksi Metrik Program
Tahap ini bertujuan untuk mendapatkan data CK OO metrik dari program yang akan di uji atau di prediksi, yaitu website petstore. Untuk mendapatkan data CK OO metrik tersebut, penulis menggunakan plugin dari Intellij IDEA untuk mengekstrak data metrik dari suatu program. Plugin
UIN Syarif Hidayatullah Jakarta
tersebut yaitu MetricReloaded. MetricReloaded menyediakan beberapa jenis kumpulan /set metrik yang dapat diekstrak, satu diantaranya CK OO metrik.
Pertama, penulis mengimport source code petstore yang didapatkan di github (https://github.com/igor-baiborodine/jpetstore-6-vaadin-spring-boot) dengan menggunakan IDE Jetbrains Intellij IDEA. Setelah itu, penulis menentukkan file directory yang berisi source code dari aplikasi web petstore. Source code tersebut terdapat pada folder src/main
Setelah menemukan target file atau folder yang dituju, penulis membuka plugin MetricReloaded untuk mengektraksi source code. Untuk membuka MetricReloaded klik kanan pada folder yang ingin diekstrak metriknya, dalam hal ini penulis memilih folder main. Lalu, maka akan muncul pop up, pilih Analyze, lalu pilih Calculate Metrics, maka akan muncul panel dari MetricReloaded.
Gambar 4.7. Panel MetricReloaded
UIN Syarif Hidayatullah Jakarta
Metrics scope merupakan target folder atau file directory yang ingin diekstrak. Lalu setelah itu, pada bagian metrics profile, penulis memilih metrik Chidamber-Kemerer metrics suite atau CK OO metrics. Lalu klik OK, maka akan muncul data CK OO metric
Gambar 4.8. Hasil Ekstraksi Metrik Petstore
Setelah itu, data metrik tersebut di export ke dalam file berformat csv dengan cara mengklik tombol export, pilih dimana file tersebut akan
disimpan, lalu klik save. Berikut merupakan tampilan dari metrik petstore.
Gambar 4.9. Tabel Metrik Petstore