IDENTIFIKASI TINGKAT KELULUSAN MAHASISWA
MENGGUNAKAN METODE
CLUSTERING
ALGORITMA K-MEANS
SKRIPSI
Disusun Oleh:
DISKA RENATA PUTRI 1032010066
J URUSAN TEKNIK INDUSTRI FAKULTAS TEKNOLOGI INDUSTRI
UNIVERSITAS PEMBANGUNAN NASIONAL “ VETERAN “ J AWA TIMUR
SKRIPSI
Telah dipertahankan dihadapan dan diterima oleh Tim Penguji Skr ipsi J ur usan Teknik Industri Fakultas Teknologi Industr i
Univer sitas Pembangunan Nasional “Veteran” J awa Timur Pada Tanggal 30 Desember 2013
Univer sitas Pembangunan Nasional “Veteran” J awa Timur Sur abaya
SKRIPSI
Telah dipertahankan dihadapan dan diterima oleh Tim Penguji Skr ipsi J ur usan Teknik Industri Fakultas Teknologi Industr i
Univer sitas Pembangunan Nasional “Veteran” J awa Timur Pada Tanggal 30 Desember 2013 NIP. 19561205 198703 1 001
Mengetahui
Ketua J ur usan Teknik Industri Fakultas Teknologi Industri
Univer sitas Pembangunan Nasional “Veteran” J awa Timur Sur abaya
KATA PENGANTAR
Puji syukur kehadirat Allah SWT atas segala karunia dan anugerah-Nya sehingga penulis dapat menyelesaikan penyusunan Tugas Akhir ini.
Tugas Akhir ini disusun untuk memenuhi persyaratan kelulusan Program Sarjana Strata-1 (S-1) di Jurusan Teknik Industri Fakultas Teknologi Industri Universitas Pembangunan Nasional “Veteran” Jawa Timur dengan judul :
“Identifikasi Tingkat Kelulusan Mahasiswa Menggunakan Metode Cluster ing Algor itma K-Means”
Penyelesaian penyusunan Tugas Akhir ini tentunya tidak terlepas dari peran serta berbagai pihak yang telah memberikan bimbingan dan bantuan baik secara langsung maupun tidak langsung. Oleh karena itu tidak berlebihan bila pada kesempatan kali ini penulis mengucapkan terima kasih kepada :
1. Kedua orang tua yang telah memberikan banyak dukungan secara moril, materil serta doa, sehingga penyelesaian laporan ini dapat segera terselesaiakan.
2. Bapak Ir. Sutiyono, MT, selaku Dekan Fakultas Teknologi Industri Universitas Pembangunan Nasional “Veteran” Jawa Timur.
3. Bapak Dr. Minto Waluyo, MM, selaku Ketua Jurusan Teknik Industri Universitas Pembangunan Nasional “Veteran” Jawa Timur.
4. Bapak Ir. Rr. Rochmoeljati, MMT, selaku Dosen Pembimbing Utama Skripsi. 5. Bapak Dwi Sukma.D, ST, MT, selaku Dosen Pembimbing Pendamping Skripsi. 6. Ibu Ir. Nisa Masruroh, MT, selaku Dosen Penguji Skripsi.
7. Ibu Enny Ariyani, ST, MT, selaku Dosen Penguji Skripsi 8. Bapak Ir. Handoyo, MT, selaku Dosen Penguji Skripsi. 9. Ibu Ir. Iriani, MMT, selaku Dosen Penguji Skripsi.
11. Untuk Adek dan ‘Agek’ yang telah memberikan banyak dukungan secara serta doa, sehingga penyelesaian laporan ini dapat segera terselesaiakan.
12. Teman-teman angkatan 2010 khususnya asisten laboratorium Optimasi dan Pemrograman Komputer yang telah memberikan semangat dalam penyelesaian Tugas Akhir ini. Serta untuk Citra dan Intan yang bersedia menemani dan selalu membantu ketika penulis mengalami kendala selama perkuliahan hingga penyelesaian Tugas Akhir.
13. Pihak-pihak lain yang terkait baik secara langsung maupun tidak langsung dalam penyelesaian Tugas Akhir ini yang tidak dapat disebutkan satu per satu.
Penulis menyadari sepenuhnya bahwa penyusunan Tugas Akhir ini terdapat kekurangan, maka dengan segala kerendahan hati penulis mengharapkan saran dan kritik yang bersifat membangun.
Akhir kata semoga Tugas Akhir ini dapat bermanfaat bagi semua pihak yang membaca. Terima Kasih.
Surabaya, Desember 2013
KATA PENGANTAR ... i
DAFTAR ISI ... ii
DAFTAR TABEL ... iii
DAFTAR GAMBAR ... iv
DAFTAR LAMPIRAN ... v
ABSTRAKSI ... vi
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang... 1
1.2 Rumusan Masalah ... 2
1.3 Batsan Masalah ... 2
1.4 Asumsi ... 3
1.5 Tujuan ... 3
1.6 Manfaat ... 3
1.7 Sistematika Penulisan ... 4
BAB II TINJAUAN PUSTAKA ... 6
2.1 Data ... 6
2.1.1 Data Menurut Sifatnya ... 7
2.1.2 Data Menurut Sumbernya ... 7
2.1.3 Data Menurut Cara Memperolehnya ... 7
2.2 Variabel ... 8
2.3 Data Mining ... 9
2.4.1 Persyaratan Clustering ... 18
2.4.2 Klasifikasi Clustering ... 19
2.5 Algoritma K-means... 20
2.6 Contoh Penerapan Algoritma K-means ... 26
2.7 Populasi Penelitian... 32
2.8 Peneliti Terdahulu ... 33
BAB III METODOLOGI PENELITIAN... 36
3.1 Lokasi dan Waktu Penelitian ... 36
3.2 Identifikasi dan Definisi Operasional Variabel ... 36
3.3 Langkah-langkah Pemecahan Masalah ... 38
3.4 Metode Pengumpulan Data ... 4 2 3.5 Metode Pengolahan Data ... 42
BAB IV HASIL DAN PEMBAHASAN ... 44
4.1 Pengumpulan Data ... 44
4.2 Pengolahan Data ... 47
4.3 Hasil dan Pembahasan ... 56
BAB V KESIMPULAN DAN SARAN... 59
5.1 Kesimpulan... 59
5.2 Saran ... 59 DAFTAR PUSTAKA
Gambar 2.1 Decision Tree ... 13
Gambar 2.2 Contoh Clustering ... 15
Gambar 2.3 Cluster berdasarkan Definisi Well-Separated-Cluster ... 16
Gambar 2.4 Cluster berdasarkan Definisi Center-Based-Cluster ... 17
Gambar 2.5 Ilustrasi Pengelompokan ... 17
Gambar 2.6 Partitional Clustering ... 19
Gambar 2.7 Dendogram HierarchicalClustering ... 20
Gambar 2.8 K-means Clustering (2 dimensi) ... 21
Gambar 2.9 Ilustrasi Langkah-langkah Algoritma K-means ... 22
Lampiran I Data Mahasiswa Teknik Industri 2010 Lampiran II Data Mahasiswa Aktif Teknik Industri 2010 Lampiran III Jarak Iterasi 1
ABSTRAKSI
Dalam dunia pendidikan saat ini, khususnya di UPN “Veteran” Jawa Timur dituntut untuk memiliki keunggulan bersaing dengan memanfaatkan sumberdaya yang dimiliki. Seperti halnya informasi untuk mengetahui tingkat kelulusan mahasiswa, selama ini jurusan Teknik Industri telah menetapkan standard 3,5 tahun sebagai tolak ukur kelulusan mahasiswa. Namun belum diketahui apakah batas standard tersebut telah dapat dipenuhi oleh mahasiswa.
Oleh karena itu penelitian ini menggunakan metode Clustering Algoritma K-means yang bertujuan melakukan pengelompokkan mahasiswa untuk mengidentifikasi tingkat kelulusan mahasiswa Teknik Industri UPN “Veteran” Jawa Timur, khususnya angkatan 2010.
Dari hasil penelitian menggunakan Clustering Algoritma K-means diketahui dari 76 mahasiswa Teknik Industri UPN “Veteran” Jawa Timur dapat diidentifikasi bahwa kelulusan tepat waktu yaitu 3,5 tahun adalah sebesar 34% mahasiswa. Sedangkan kelulusan 4 hingga 7 tahun sebesar 66% mahasiswa.
ABSTRACT
In education today, especially UPN “Veteran” East Java required to have a competitive eminence by utilizing their resources. As well as information to find out the graduation rates of the students, during the Industrial Engineering department has set the standard as a benchmark 3.5 year of student graduation. But it has not known whether the limit of the standard has been filled.
Therefore, this research applies the K-means clustering algorithm aimed at grouping the students to identify for student’s graduation rate of Industrial Engineering UPN "Veteran" East Java, especially the class of 2010.
From the results of research using the K-means clustering algorithm is known the 76 students of Industrial Engineering UPN "Veteran" East Java that can be identified in a timely graduation is 3.5 years was 34% of students. While passing 4 to 7 years of graduation by 66% of students.
BAB I
PENDAHULUAN
1.1 Latar Belakang
Ketersediaan akan informasi bukan hal yang sulit diperoleh dewasa ini, sehingga informasi akan menjadi suatu elemen penting dalam perkembangan kehidupan saat ini. Seringkali data ini hanya disimpan dalam penyimpanan data tanpa pengolahan lebih lanjut sehingga tidak memiliki nilai guna lebih. Padahal, tidak sedikit biaya yang harus dikeluarkan untuk mengumpulkan dan menyusun data tersebut. Oleh karena itu, diperlukan konsep data mining agar data memiliki guna lebih untuk keperluan di masa akan datang.
Dalam dunia pendidikan saat ini, khususnya di UPN “Veteran” Jawa Timur dituntut untuk memiliki keunggulan bersaing dengan memanfaatkan sumberdaya yang dimiliki. Seperti halnya informasi untuk mengetahui tingkat kelulusan mahasiswa, selama ini jurusan Teknik Industri telah menetapkan standard 3,5 tahun sebagai tolak ukur kelulusan mahasiswa. Namun belum diketahui apakah batas standard tersebut telah dapat dipenuhi oleh mahasiswa.
Clustering merupakan salah satu teknik yang dikenal dalam data mining. Algoritma K-means memiliki kemampuan mengelompokkan data dalam jumlah yang cukup besar dengan waktu komputasi yang relatif cepat dan efisien. Sehingga dengan metode algoritma K-Means pada penelitian ini diharapkan dapat digunakan untuk mengidentifikasi tingkat kelulusan mahasiswa program studi Teknik Industri angkatan 2010 di UPN “Veteran” Jawa Timur.
1.2 Rumusan Masalah
Berdasarkan latar belakang masalah diatas, maka permasalahan yang bisa dirumuskan dalam penelitian ini adalah bagaimana pengelompokkan mahasiswa agar dapat mengidentifikasi tingkat kelulusan mahasiswa Teknik Industri UPN “Veteran” Jawa Timur.
1.3 Batasan Masalah
Batasan-batasan yang digunakan dalam penelitian adalah sebagai berikut: 1. Data yang digunakan adalah data mahasiswa Teknik Industri UPN
“Veteran” Jawa Timur angkatan 2010 yang masih aktif berdasarkan IPK dan SKS saat ini.
1.4 Asumsi
Asumsi yang digunakan dalam penelitian ini adalah sebagai berikut: 1. Semua data yang digunakan tidak berubah selama penelitian ini dilakukan. 2. Data mahasiswa yang digunakan sesuai dengan kebutuhan penelitian.
1.5 Tujuan
Adapun tujuan dari penelitian ini adalah melakukan pengelompokkan mahasiswa untuk mengidentifikasi tingkat kelulusan mahasiswa Teknik Industri UPN “Veteran” Jawa Timur.
1.6 Manfaat
Manfaat yang diperoleh dari hasil penelitian tersebut adalah:
1. Memberikan informasi sebagai dasar pertimbangan pengambilan keputusan dalam melakukan evaluasi tingkat kelulusan mahasiswa.
2. Menambah wawasan ilmu pengetahuan tentang konsep data mining dengan teknik clustering, khususnya algoritma K-means. Selain itu dapat digunakan sebagai acuan penelitian berikutnya.
1.7 Sistematika Penulisan
Adapun sistematika penulisan dari penelitian ini adalah sebagai berikut:
BAB I PENDAHULUAN
BAB II TINJ AUAN PUSTAKA
Bab ini berisi landasan-landasan teori yang digunakan untuk mendukung terlaksananya penelitian ini. Adapun tinjauan pustaka yang diangkat dalam bab ini adalah pengertian data mining, teknik data mining, pengertian dan metode clustering, khususnya mengenai algoritma K-means.
BAB III METODOLOGI PENELITIAN
Bab ini berisi langkah-langkah dalam melakukan penelitian yaitu hal-hal yang dilakukan untuk mencapai tujuan dari penelitian atau urutan kerja menyeluruh selama pelaksanaan penelitian. Didalamnya terdapat tempat dan waktu penelitian, identifikasi dan definisi operasional variable, langkah-langkah pemecahan masalah, metode pengumpulan data, serta metode pengolahan data.
BAB IV HASIL PENELITIAN DAN PEMBAHASAN
Bab ini berisi pengolahan dari data yang telah dikumpulkan, langkah-langkah pemecahan masalah dan metode analisis serta pembahasan penelitian.
BAB V KESIMPULAN DAN SARAN
Bab ini berisi kesimpulan dan saran dari hasil penelitian yang telah dilakukan yang didapatkan dari tujuan dan permasalahan yang ada. DAFTAR PUSTAKA
BAB II
TINJ AUAN PUSTAKA
2.1 Data
Pengertian data menurut Webster New World Dictionary, Data adalah things known or assumed, yang berarti bahwa data itu sesuatu yang diketahui atau dasumsi artinya yang sudah terjadi merupakan fakta (bukti). Data dapat memberikan gambaran tentang suatu keadaan atau persoalan.
Data bisa juga didefenisikan sekumpulan informasi atau nilai yang diperoleh dari pengamatan (observasi) suatu objek, data dapat berupa angka dan dapat pula merupakan lambang atau sifat. Beberapa macam data antara lain: data populasi dan sampel, data observasi, data primer, dan data sekunder.
Pada dasarnya kegunaan data (setelah diolah dan dianalisis) ialah sebagai dasar yang objektif di dalam proses pembuatan keputusan-keputusan (kebijaksanaan–kebijaksanaan) dalam rangka untuk memecahkan persoalan oleh pengambilan keputusan. Keputusan yang baik hanya bisa diperoleh dari pengambilan keputusan yang objektif, dan didasarkan atas datayang baik.
2.1.1 Data Menur ut Sifatnya
(Sugiono, 2005) Data menurut sifatnya dibagi menjadi 2, yaitu:
a. Data kualitatif yaitu data yang tidak berbentuk angka, misalnya: kuesioner pertanyaan tentang suasana kerja, kualitas pelayanan sebuah restoran atau gaya kepemimpinan, dan sebagainya.
b. Data kuantitatif yaitu data yang berbentuk angka, misalnya: harga saham, besarnya pendapatan, dan sebagainya.
2.1.2 Data Menur ut Sumbernya
Menurut sumber data, yang selanjutnya dibagi dua (Sugiono, 2005):
a. Data internal yaitu data dari dalam suatu organisasi yang menggambarkan organisasi tersebut. Misalnya: jumlah karyawan suatu perusahaan, jumlah modalnya, dan jumlah produksinya
b. Data eksternal yaitu data dari luar suatu organisasi yang dapat menggambarkan faktor–faktor yang mungkin mempengaruhi hasil kerja suatu organisasi. Misalnya: daya beli masyarakat mempengaruhi hasil penjualan suatu perusahaan.
2.1.3 Data Menur ut Cara Memperolehnya
(Sugiono, 2005) Menurut cara memperolehnya, data bisa dibagi dua:
a. Data primer (primery data) yaitu data yang dikumpulan sendiri oleh perorangan/ suatu organisasi secara langsung dari obyek yang diteliti dan untuk studi yang bersangkutan dan dapat berupa interview, observasi. b. Data sekunderi (secondary data) yaitu data yang diperoleh/ dikumpulkan
instansi lain. Biasanya sumber tidak langsung berupa data dokumentasi dan arsip–arsip resmi.
2.2 Variabel
Dalam melakukan observasi tentunya perlu ditentukan karakter yang akan diobservasi dari unit amatan yang disebut variabel. Variabel dalam penelitian merupakan suatu atribut dari sekelompok objek yang diteliti yang memiliki variasi antara satu objek dengan objek lain dalam kelompok tersebut.
Variabel penelitian adalah sesuatu yang digunakan sebagai ciri, sifat dan ukuran yang dimiliki atau didapatkan oleh satuan penelitian tentang suatu konsep pengertian tertentu (Sugiono, 2005). Variabel dalam penelitian ini terdiri dari variabel independen (bebas) dan variabel dependen (terikat) dijelaskan sebagai berikut:
1. Variabel independen (bebas) adalah variabel yang menjadi sebab timbulnya atau berubahnya variabel terikat.
2. Variabel dependen (terikat) adalah variabel yang dipengaruhi atau menjadi akibat karena adanya variabel bebas, dan variabel ini sering disebut variabel respon.
2.3 Data mining
Seiring dengan perkembangan teknologi, semakin berkembang pula kemampuan kita dalam menggumpulkan dan mengolah data. Penggunaan sistem komputerisasi dalam berbagai bidang baik itu dalam transaksi-transaksi bisnis, maupun untuk kalangan pemerintah dan sosial, telah menghasilkan data yang berukuran sangat besar.
Data-data yang terkumpul ini merupakan suatu tambang emas yang dapat digunakan sebagai informasi. Akibatnya data yang dihasilkan oleh bidang-bidang tersebut sangatlah besar dan berkembang dengan cepat. Hal ini menyebabkan timbulnya kebutuhan terhadap teknik-teknik yang dapat melakukan pengolahan data sehingga dari data-data yang ada dapat diperoleh informasi penting yang dapat digunakan untuk perkembangan masing-masing bidang tersebut.
2.3.1 Pengertian Data mining
Santosa (2007) menyatakan bahwa data mining merupakan suatu kegiatan yang meliputi pengumpulan, pemakaian data historis untuk menentukan keteraturan, pola atau hubungan dalam set data berukuran besar. Salah satu tugas utama dari data mining adalah pengelompokan Clustering dimana data yang dikelompokkan belum mempunyai contoh kelompok.
2.3.2 Teknik Data mining
Perkembangan bidang data mining yang semakin pesat, menimbulkan banyak tantangan baru, aplikasi-aplikasi dari metode dan teknik, statistik serta sistem basis data yang ada tidak dapat secara langsung menyelesaikan masalah-masalah yang ada dalam data mining.
Oleh karena itu maka perlu dilakukan studi-studi terkait untuk menemukan metode data mining baru atau suatu teknik terintegrasi untuk sebuah sistem data mining yang efektif dan efisien. Telah banyak kemajuan dalam hal riset dan pengembangan dari data mining, juga banyak teknik data mining dan sistem baru yang akhir-akhir ini dikembangkan.
Kata mining mempunyai arti yaitu usaha untuk mendapatkan sedikit barang berharga dari sejumlah besar material dasar. Data mining memiliki akar yang panjang dari bidang ilmu seperti kecerdasan buatan (artificial intelegent), machine learning, statistik dan database. Beberapa metode yang sering disebut-sebut dalam literatur data mining antara lain clustering, association rules mining, decision tree, neural network, classification, genetic algorithm dan lain-lain.
Dalam melakukan analisis data mining secara umum teknik-teknik pengolahan data terbagi menjadi 2 pendekatan yaitu Supervised learning dan Unsupervised learning. Dalam pendekatan unsupervised learning metode analisis dilakukan dengan dengan tanpa adanya latihan (training) dan tanpa adanya label (output) dari data. Dalam kategori ini adalah clustering dan association rule analysis.
menemukan fungsi keputusan, fungsi pemisah atau fungsi regresi digunakan beberapa contoh data yang mempunyai output atau label selama proses training. Data untuk training terdiri dari vector/ matrik input dan output (label). Matrik/ vektor input biasa diberi symbol X dan output diberi symbol Y.
(Saepulloh, 2010)
Menurut Han Jiawei (2011) ada beberapa teknik data mining yang digunakan, diantaranya adalah:
1. Association Rule Mining/ Market Basket Analsysis
Aturan asosiasi (Association rules) atau analisis afinitas (affinity analysis) berkenaan dengan studi tentang ’apa bersama apa’. Ini bisa berupa studi transaksi di supermarket, misalnya seseorang yang membeli kopi juga membeli gula. Di sini berarti kopi bersama dengan gula. Karena awalnya berasal dari studi tentang database transaksi pelanggan untuk menentukan kebiasaan suatu produk dibeli bersama produk apa, maka aturan asosiasi juga sering dinamakan market basket analysis.
Market Basket Analysis adalah analisis dari kebiasaan membeli customer dengan mencari asosiasi dan korelasi antara item-item berbeda yang diletakkan customer dalam keranjang belanjaannya.
yang memuat antecedent dan consequent dengan jumlah transaksi. Confidence adalah rasio antara jumlah transaksi yang meliputi semua item dalam antecedent dan consequent dengan jumlah transaksi yang meliputi semua item dalam antecedent.
……… (2.1) Dimana :
S = Support
Σ(Ta+Tc) = Jumlah transaksi yang mengandung antencendent dan consequencent
Σ(T) = Jumlah transaksi
…………..(2.2) Dimana :
C = Confidence
Σ(Ta+Tc) =Jumlah transaksi yang mengandung antencendent dan consequencent
Σ(Ta) = Jumlah transaksi yang mengandung antencendent
tersebut, pemilik pasar swalayan dapat mengatur penempatan barangnya. Penting tidaknya suatu aturan asosiatif dapat diketahui dengan dua parameter support yaitu persentase kombinasi item tersebut dalam database dan confidence yaitu kuatnya hubungan antar item dalam aturan asosiatif.
2. Decision tree
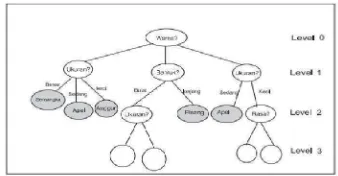
Decision tree adalah salah satu metode classification yang paling populer karena mudah untuk diinterpretasi oleh manusia. pada dasarnya konsep decision tree yaitu mengubah data menjadi pohon keputusan dan aturan-aturan keputusan.
Dalam decision tree kita tidak menggunakan vektor jarak untuk mengklasifikasikan obyek. Seringkali kita mempunyai data observasi dengan atribut-atribut yang bernilai nominal. Misalkan obyek kita adalah sekumpulan buah-buahan yang bisa dibedakan berdasarkan atribut bentuk, warna, ukuran dan rasa. Dalam kumpulan buah itu mungkin ada semangka dan pisang yang bisa dibedakan berdasarkan bentuk, warna, ukuran dan rasa. Bentuk, warna, ukuran dan rasa adalah besaran nominal, yaitu bersifat kategoris dan tiap nilai tidak bisa dijumlahkan atau dikurangkan.disini didasarkan pada pengelompokan objek berdasarkan atribut dan nilainya.
Dalam gambar diatas akan nampak di situ ada 4 level pertanyaan. Dalam setiap level ditanyakan nilai atribut melalui sebuah simpul. Jawaban dari pertanyaan itu dikemukakan lewat cabang-cabang. Langkah ini akan berakhir di suatu simpul jika di situ sudah jelas kelas atau jenis obyek yang kita cari. Kalau dalam satu tingkat suatu obyek sudah diketahui termasuk dalam jenis buah apa, maka kita berhenti di level tersebut. Jika tidak, kita susul dengan pertanyaan di level berikutnya hingga jelas ciri-cirinya dan kita bisa menentukan jenis buahnya. Dengan cara ini akan mudah mengelompokkan obyek ke dalam beberapa kelompok. Dalam decision tree setiap atribut ditanyakan di simpul. Jawaban dari atribut ini dinyatakan dalam cabang sampai akhirnya ditemukan kategori/jenis dari suatu obyek di simpul terakhir. Konsep entropi digunakan untuk penentuan pada atribut mana sebuah pohon akan terbagi. Semakin tinggi entropy sebuah sampel, semakin tidak murni sampel tersebut. Rumus yang digunakan untuk menghitung entropy sampel S adalah sebagai berikut :
Entropy (S) = -p1 log2 p1 – p2 log2 p2 ……….. (2.3)
Dimana p1, p2, ....,pn masing-masing menyatakan proposi kelas 1, kelas 2, ...,
kelas n dalam output.
Aplikasi klasifikasi decision tree telah digunakan dalam banyak area seperti kedokteran, manufaktur dan produksi, dan astronomi.
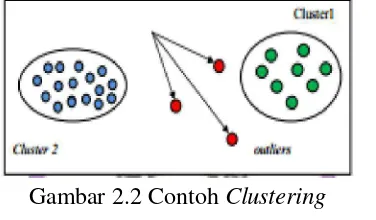
3. Clustering
sendiri juga disebut unsupervised learning, karena Clustering lebih bersifat untuk dipelajari dengan diperhatikan. Cluster analysis merupakan proses partisi satu set objek data ke dalam himpunan bagian. Setiap himpunan bagian adalah cluster, sehingga objek yang di dalam cluster mirip satu sama dengan lainnya, dan mempunyai perbedaan dengan objek dari cluster yang lain.
Gambar 2.2 Contoh Clustering
Sumber: (Baskoro dalam Novianti, 2012)
Cluster analysis banyak digunakan dalam berbagai aplikasi seperti business inteligence, image pattern recognition, web search, biology, dan security. Di dalam business inteligence, Clustering bisa mengatur banyak customer ke dalam banyak group. Clustering juga dapat digunakan sebagai outlier detection, di mana outliers bisa menjadi menarik daripada kasus yang biasa. Contoh aplikasi yang digunakan adalah outlier detection berfungsi untuk mendeteksi dan memonitori aktifitas kriminal dalam e-commerce.
2.4 Clustering
untuk menemukan kelompok atau identifikasi kelompok obyek yang hampir sama.
Secara umum cluster didefiniskan sebagai “sejumlah objek yang mirip yang dikelompokan secara bersama”, namun definisi dari cluster bisa beragam tergantung dari sudut pandang yang digunakan, beberapa definisi cluster berdasarkan sudut pandang adalah sebagai berikut (Saepulloh, 2010):
1. Definisi Well-Separated Cluster
Berdasarkan definisi ini cluster adalah sekelompok titik (objek) dimana sebuah titik pada kelompok itu lebih dekat atau mirip dengan semua titik (objek) yang ada pada kelompok tersebut dari pada titik-titik (objek-objek) lain yang tidak terdapat pada kelompok itu. Biasanya digunakan sebuah nilai batas (threshold) untuk menentukan titik-titik (objek-objek) yang dianggap cukup dekat satu sama lainnya.
Sumber: (Saepulloh, 2010)
Gambar 2.3 Cluster berdasarkan definisi Well-Separated-Cluster 2. Definisi Center-Based Cluster
Umumnya pusat cluster adalah centroid, yaitu rata-rata dari semua titik pada cluster tersebut, namun dapat juga digunakan medoid, yaitu titik yang paling mewakili pada sebuah cluster.
Sumber: (Saepulloh, 2010)
Gambar 2.4 Cluster berdasarkan definisi Center-Based Cluster
Clustering digunakan untuk menganalisis pengelompokkan berbeda terhadap data. Prinsip dari Clustering adalah memaksimalkan kesamaan antar anggota satu kelas dan meminimumkan kesamaan antar cluster. Clustering dapat dilakukan pada data yang memiliki beberapa atribut yang dipetakan sebagai ruang multidimensi. Ilustrasi dari Clustering dapat dilihat pada gambar dibawah ini. Singkatnya, Clustering berusaha untuk menemukan komponen kelompok secara natural berdasarkan pada kedekatan data.
2.4.1 Persyar atan Clustering
(Wakhidah, 2007) menyatakan bahwa syarat untuk melakukan analisa Clustering adalah sebagai berikut:
1. Scalability
Mampu menangani data dalam jumlah yang besar. Karena database yang besar berisi lebih dari jutaan objek bukan hanya ratusan objek, maka dari itu diperlukan algoritma dengan Clustering yang scalable.
2. Kemampuan untuk menangani berbagai jenis tipe
Banyak algoritma Clustering yang hanya dibuat untuk menganalisa data bersifat numeric. Namun sekarang ini, aplikasi data mining harus dapat menangani berbagai macam bentuk data seperti biner, data nominal, data ordinal, ataupun campuran.
3. Kemampuan untuk menangani data yang rusak
Pada kenyataannya, data pasti ada yang rusak, error, tidak dimengerti, ataupun menghilang. Beberapa algoritma Clustering sangat sensitif terhadap data yang rusak, sehingga menyebabkan cluster dengan kualitas rendah. Maka dari itu diperlukan Clustering yang mampu menangani data yang rusak.
4. Usability
2.4.2 Klasifikasi Clustering
Metode Clustering pada dasarnya ada dua jenis, yaitu hierarichal Clustering method dan partitional Clustering method, seperti penjelasan berikut ini (Baskoro, 2010):
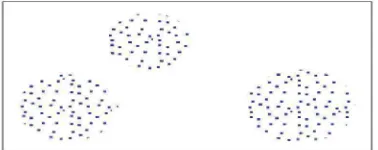
1. Partitional Clustering
Metode partitional Clustering atau biasa disebut non-hierarichal Clustering bertujuan untuk mengelompokkan n objek kedalam k cluster, dimana nilai k sudah ditentukan sebelumnya. Ini bias dilakukan dengan menentukan pusat cluster awal, lalu dilakukan realokasi objek berdasarkan criteria tertentu sampai dicapai pengelompokkan yang optimum.
Gambar 2.6 Partitional Clustering Sumber: (Baskoro, 2010)
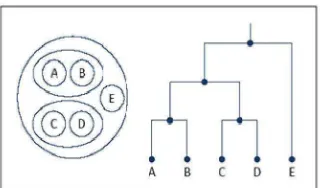
2. Hierarchical Clustering
cluster beranggotakan satu obyek dan berakhir dengan satu cluster dimana anggotanya adalah m obyek. Pada setiap tahap dalam prosedurnya, satu cluster digabung dengan satu cluster yang lain.
Gambar 2.7 Dendogram Hierarchical Clustering Sumber : (Saepulloh, 2010)
2.5 Algoritma K-means
Clustering Algoritma K-means merupakan teknik Clustering yang paling umum dikenal karena sederhana dan mudah diimplementasikan. K-means merupakan metode pengklasteran secara partitioning yang memisahkan data ke dalam kelompok yang berbeda. Dalam teknik ini kita ingin mengelompokkan obyek ke dalam k kelompok atau cluster.
Untuk melakukan Clustering ini, nilai k harus ditentukan terlebih dahulu. Biasanya user atau pemakai sudah mempunyai informasi awal tentang obyek yang sedang dipelajari termasuk berapa jumlah cluster yang paling tepat.
Agusta dalam Novianti (2012) menyatakan bahwa K-means merupakan salah satu metode data Clustering non hirarki yang berusaha mempartisi data yang ada ke dalam bentuk satu atau lebih cluster atau kelompok. Metode ini mempartisi data ke dalam cluster atau kelompok sehingga data yang memiliki karakteristik sama dikelompokkan ke dalam satu cluster yang sama.
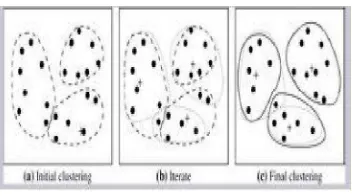
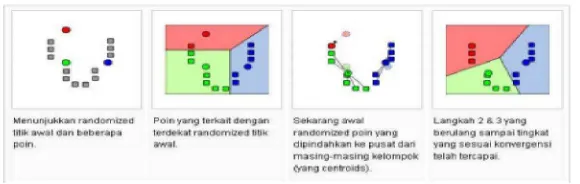
K-Means merupakan algoritma untuk cluster n objek berdasarkan atribut menjadi k partisi, dimana k < n. Gambar berikut ini menunjukkan k-means Clustering algoritma dalam tindakan, untuk kasus dua dimensi. Pusat awal yang dihasilkan secara acak untuk menunjukkan tahapan lebih rinci. Background ruang partisi hanya untuk ilustrasi dan tidak dihasilkan oleh algoritma k-means.
Gambar 2.8 K-meansClustering dalam tindakan (2 dimensi) Sumber: (Wakhidah, 2007)
(Santoso, 2007) Rangkaian gambar dibawah ini menunjukkan ilustrasi bagaimana Algoritma K-means dilakukan sebagai berikut:
Dari gambar diatas dapat dijelaskan mengenai langkah-langkah dari algoritma K-means adalah:
1. Pilih jumlah cluster k
2. Inisialisasi k pusat cluster Ini bisa dilakukan dengan berbagai cara. Yang paling sering dilakukan adalah dengan cara random. Pusat-pusat cluster diberi nilai awal dengan angka-angka random.
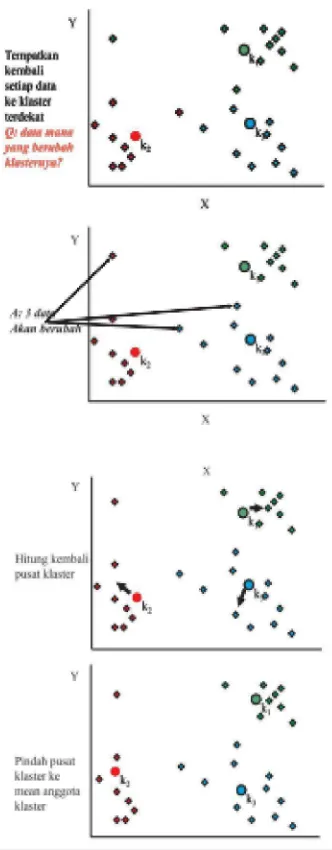
3. Tempatkan setiap data/obyek ke cluster terdekat Kedekatan dua obyek ditentukan berdasar jarak kedua obyek tersebut. Demikian juga kedekatan suatu data ke cluster tertentu ditentukan jarak antara data dengan pusat cluster. Dalam tahap ini perlu dihitung jarak tiap data ke tiap pusat cluster. Jarak paling dekat antara satu data dengan satu cluster tertentu akan menentukan suatu data masuk dalam cluster mana.
4. Hitung kembali pusat cluster dengan keanggotaan cluster yang sekarang Pusat cluster adalah rata-rata dari semua data/obyek dalam cluster tertentu. Jika dikehendaki bisa juga memakai median dari cluster tersebut. Jadi rata-rata (mean) bukan satu-satunya ukuran yang bisa dipakai.
Adapun rumus untuk pengerjaan Algoritma K-means adalah sebagai berikut: a. Me ne nt uka n Ba nya k nya Clu ste r k
Untuk menentukan nilai banyaknya cluster k dilakukan dengan beberapa pertimbangan seperti dibawah ini: (Saepulloh, 2010)
1. Pertimbangan teoritis, konseptual, praktis yang mungkin diusulkan untuk menentukan berapa banyak jumlah cluster.
2. Besarnya relative cluster seharusnya bermanfaat, pemecahan cluster yang menghasilkan 1 objek anggota cluster dikatakan tidak bermanfaat sehingga hal ini perlu untuk dihindari.
b. Me ne nt uka n Cent roid
Penentuan centroid awal dilakukan secara random/ acak dari data/ objek yang tersedia sebanyak jumlah kluster k, kemudian untuk menghitung centroid cluster berikutnya ke i, vidigunakan rumus sebagai berikut: (Saepulloh, 2010)
1
Nk : Banyaknya objek/jumlah data yang menjadi anggota cluster ke k c. Me ng h it u ng J arak Ant ara Dat a De nga n Ce ntroid
……….. (2.5)
Dimana:
De : Euclidean Distance i : Banyaknya Objek (x,y): Koordinat Objek (s,t) : Koordinat Centroid d. Konvergensi
Pengecekan konvergensi dilakukan dengan membandingkan matrik group assignment pada iterasi sebelumnya dengan matrik group assignment pada iterasi yang sedang berjalan. Jika hasilnya sama maka algoritma k-means cluster analysis sudah konvergen, tetapi jika berbeda maka belum konvergen sehingga perlu dilakukan iterasi berikutnya. (Saepulloh, 2010)
2.6 C on t oh P en e r a p a n A lgo r it m a K-M ean s
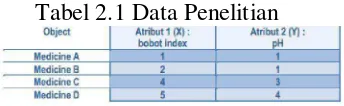
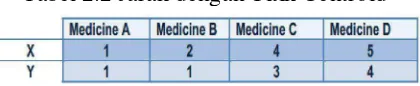
Misalnya kita memiliki 4 objek sebagai titik data pelatihan dan setiap obyek memiliki 2 atribut. Tiap atribut mewakili koordinat dari objek, yaitu:
Objek Atribut 1 (X): bobot indeks Objek Atribut 2 (Y): pH
Tabel 2.1 Data Penelitian
1. Menentukan Jumlah Cluster
Dengan memperhatikan data tersebut, kita dapat mengelompokkan object tersebut ke dalam dua cluster sesuai dengan atributnya (yaitu cluster 1 dan cluster 2). Masalahnya adalah bagaimana menentukan medicine tersebut merupakan anggota dalam cluster 1 atau cluster 2.
2. Menentukan nilai centroid
Untuk menentukan nilai awal centroid dilakukan secara acak. Disini, dimisalkan titik koordinat medicine A adalah cluster 1 (C1) dan medicine B adalah cluster 2 (C2) sebagai nilai centroid awal.
• C1 = (1,1) • C2 = (2,1)
3. Menghitung jarak antara titik centroid dengan tiap titik object.
Untuk menghitung jarak antara titik centroid dengan tiap titik object, kita dapat menggunakan rumus Euclidean Distance yaitu seperti dibawah ini:
dimana :
De adalah Euclidean Distance i adalah banyaknya objek,
Sehingga pada iterasi 0, dengan titik centroid C1 = (1,1) dan C2 = (2,1). Tabel 2.2 Jarak dengan Titik Centroid
Berikut adalah cara untuk menghitung distance dari tiap object : • Medicine A = (1,1) dengan C1=(1, 1)
dengan C2=(2,1)
• Medicine B = (2,1) dengan C1=(1, 1)
dengan C2=(2,1)
• Medicine C = (4,3) dengan C1=(1, 1)
dengan C2=(2,1)
• Medicine D = (5,4) dengan C1=(1, 1)
dari perhitungan diatas, diperoleh distance matriksnya, yaitu:
4. Pengelompokan Object.
Setelah menghitung distance matriks, kita menentukan anggota cluster menurut jarak minimum dari centroid. Dengan merujuk pada distance matriks, medicine A termasuk cluster 1, sedangkan medicine B, C dan D termasuk cluster 2. Hal ini dapat dilihat pada perolehan nilai sebagai berikut:
5. Iterasi 1, menentukan centroid baru.
6. Iterasi 1, menghitung jarak antara titik centroid baru dengan tiap titik object. Pada tahap menghitung jarak antara object dengan centroid baru. Hal ini hampir sama dengan tahap 3, yaitu menghitung jarak dengan
Dengan cara perhitungan yang sama pada tahap 3, maka diperoleh distance matriksnya, yaitu seperti dibawah ini:
7. Iterasi 1, melakukan pengelompokan object
Hampir sama dengan tahap 4, yaitu menentukan anggota cluster dengan menghitung jarak minimum tiap object dengan centroid baru. Hasil yang diperoleh :
8. Iterasi 2, menentukan centroid baru.
9. Iterasi 2, menghitung jarak antara titik centroid baru dengan tiap titik object. Tahap ini juga hampir sama dengan tahap 3, yaitu menghitung jarak dengan Centroid baru seperti dibawah ini:
Dengan cara perhitungan yang sama pada tahap 3, maka diperoleh distance matriksnya, yaitu:
10. Iterasi 2, melakukan pengelompokan object
Hampir sama dengan tahap 4, yaitu menentukan anggota cluster dengan menghitung jarak minimum tiap object dengan centroid baru yang telah dihasilkan. Hasil yang diperoleh seperti dibawah ini:
Berdasarkan hasil anggota cluster yang diperoleh tetap sama antara G1= G2, maka iterasi dihentikan.
2.7 Populasi Penelitian
Menurut Sugiyono 2011, menyatakan bahwa populasi adalah wilayah generalisasi yang terdiri atas obyek/ subyek yang mempunyai kualitas dan karakteristik tertentu yang ditetapkan oleh peneliti untuk dipelajari dan kemudian ditarik kesimpulannya. Jadi populasi bukan hanya orang, tetapi juga obyek atau benda yang lain. Populasi juga bukan sekedar jumlah yang ada pada obyek/ subyek yang dipelajari tetapi meliputi seluruh karakteristik/ sifat yang dimiliki oleh subyek atau obyek itu.
Populasi adalah seluruh kumpulan elemen yang dapat digunakan untuk membuat beberapa kesimpulan. Kumpulan elemen tersebut pada hakekatnya merupakan objek dimana pengamatan akan dilakukan oleh peneliti. Jika populasi sangat besar maka perlu dilakukan pengambilan sampel (sampling). Ide dasar dari pengambilan sampel adalah dengan memilih bagian dari elemen populasi, sehingga kesimpulan tentang keseluruhan populasi dapat diperoleh.
2.8 Peneliti Terdahulu
Penelitian terdahulu sebagai penunjang metode yang digunakan dalam penelitian ini adalah:
1. Oyelade, O.J , 2010 (Application of K-means Clustering Algorithm for Pr ediction of Students’ Academic Perfor mance), penelitian ini menjelaskan mengenai Clustering Algoritma K-means sebagai metode yang sederhana dan efisien untuk memantau perkembangan akademik mahasiswa. Kemampuan untuk memantau perkembangan prestasi akademik mahasiswa adalah permasalahan yang penting bagi perguruan tinggi. Dalam penelitian ini juga menganalisa mahasiswa lembaga swasta dari hasil implementasi menggunakan Clustering Algoritma K-means yang menjadi tolak ukur yang baik dalam memantau perkembangan akademik mahasiswa di institusi yang lebih tinggi dengan tujuan membuat keputusan yang efektif oleh perencana akademik untuk memantau mahasiswa pada tiap semesternya agar dapat meningkatkan hasil akademik di waktu yang datang.
sekolah, kota mahasiswa, dan program studi. Dari hasil penelitian ini dapat membantu mengetahui sejauh mana tingkat keberhasilan PSSB dan SPMB terhadap tingkat kelulusan mahasiswa. Informasi yang dihasilkan dapat digunakan sebagai dasar analisis dalam pengambilan keputusan.
BAB III
METODOLOGI PENELITIAN
3.1 Lokasi dan Waktu Penelitian
Dalam penelitian ini, pengambilan data dilakukan di UPN “Veteran” Jawa Timur. Sedangkan waktu yang digunakan untuk melakukan pengambilan data dimulai pada bulan September 2013 hingga data yang diperlukan sudah tercukupi.
3.2 Identifikasi dan Definisi Oper asional Variabel
Identifikasi variabel penelitian dilakukan untuk menentukan variabel-variabel yang akan diukur dalam penelitian ini. Variabel dapat diartikan sebagai segala sesuatu yang menjadi obyek pengamatan. Adapun variabel yang digunakan adalah sebagai berikut:
1. Variabel Terikat
Variabel terikat adalah variabel yang nilainya tergantung dari variasi perubahan variabel bebas. Dalam penelitian ini yang termasuk variabel terikat yaitu mengidentifikasi tingkat kelulusan mahasiswa Teknik Industri UPN “Veteran” Jawa Timur.
2. Variabel Bebas
a. Indeks Prestasi Kumulatif (IPK) saat ini
Indeks Prestasi Kumulatif merupakan suatu penghitungan indeks prestasi dengan menggabungkan semua mata kuliah yang telah ditempuh sampai suatu semester tertentu.IPK yang digunakan dalam penelitian ini adalah IPK hingga tujuh semester ini.
b. Satuan Kredit Semester (SKS) saat ini
3.3 Langkah-Langkah Pemecahan Masalah
Gambar 3.1. Langkah – langkah Pemecahan Masalah
Keterangan Langkah-langkah pemecahan masalah: 1. Mulai
Merupakan langkah awal dari suatu penelitian yang akan dilakukan. 2. Studi Lapangan
Merupakan proses untuk mengumpulkan data yang digunakan untuk pengolahan data penelitian. Data penelitian tersebut adalah data mahasiswa berupa IPK dan SKS saat ini yang telah ditempuh.
3. Studi Literatur
Algoritma K-means. Studi literatur tersebut diperoleh dari buku-buku dan skripsi yang ada dalam perpustakaan.
4. Perumusan masalah
Melakukan perumusan masalah yang akan diteliti dalam perusahaan kemudian melakukan suatu pendekatan untuk memecahkan masalah.
5. Penetapan tujuan
Menetapkan tujuan yang ingin dicapai, sehingga dapat menentukan arah sasarannya. Adapun tujuannya adalah dapat mengidentifikasi tingkat kelulusan mahasiswa berdasarkan pengelompokkan golongan mahasiswa. 6. Identifikasi variabel
Setelah menentukan tujuan dari penelitian, kemudian ditentukan variabel-variabel yang akan diidentifikasi menjadi obyek penelitian atau merupakan aspek yang berperan dalam peristiwa yang akan diteliti. Variabel-variabel yang digunakan untuk penelitian meliputi variabel bebas dan variabel terikat. 7. Pengumpulan data
Adapun data-data yang diperlukan dalam penelitian ini adalah populasi data mahasiswa berdasarkan parameter IPK dan SKS saat ini yang telah ditempuh. 8. Menentukan jumlah cluster
Dengan memperhatikan data-data yang telah diketahui, maka dapat ditentukan jumlah cluster.
9. Menentukan nilai pusat cluster
10. Menghitung jarak antara titik pusat cluster dengan titik tiap objek
Setelah ditentukan nilai pusat cluster, kemudian menghitung jarak antara titik centroid dengan titik tiap objek yang nantinya akan dikelompokkan berdasarkan jarak terdekat objek.
11. Mengelompokkan objek berdasarkan jarak terdekat objek
Setelah didapatkan hasilnya, anggota cluster dimasukkan ke dalam cluster yang memiliki jarak yang paling dekat dengan centroidnya.
12. Perubahan cluster baru
Adanya perubahan cluster baru setelah dikelompokkan objeknya berdasarkan jarak terdekat objek.
13. Hitung pusat cluster baru
Dengan adanya objek yang berpindah cluster, maka perlu adanya perhitungan pusat cluster baru. Jika tidak adanya cluster yang berpindah, maka pengelompokkan selesai dan dilanjutkan pembahasan.
14. Pembahasan
Diperlukan untuk mengetahui hasil dari penelitian yang telah dilaksanakan dan melakukan pembahasan terhadap hasil pengolahan data tersebut.
15. Kesimpulan dan saran
Berisi informasi berupa identifikasi tingkat kelulusan berdasarkan pengelompokan mahasiswa. Serta saran yang diberikan untuk penelitian selanjutnya
3.4 Metode Pengumpulan Data
Dalam suatu penelitian, data merupakan kedudukan yang paling tinggi, karena data mempunyai penggambaran variabel yang diteliti dan berfungsi sebagai alat pembuktian hipotesis. Data yang akurat syarat utama bagi terciptanya tujuan penelitian agar dapat memberikan suatu keputusan yang tepat.
Metode pengambilan data yang digunakan pada penelitian ini adalah dengan pengambilan data sekunder. Data sekunder adalah data yang diperoleh peneliti dengan melakukan pengumpulan data yang telah ada di UPN “Veteran” Jawa Timur berupa IPK dan SKS saat ini. Serta studi kepustakaan yang tujuannya untuk memperoleh wawasan serta landasan teori yang akan digunakan untuk pemecahan masalah mengenai Clustering AlgoritmaK-means.
3.5 Metode Pengolahan Data
Setelah pengumpulan data diperoleh, maka selanjutnya adalah melakukan pengolahan data dengan menggunakan metode Clustering Algoritma K-means. Adapun langkah-langkahnya adalah seperti dibawah ini:
1. Menentukan jumlah cluster
Dengan memperhatikan data penelitian yang ada, kita dapat mengelompokkan objek tersebut ke dalam dua cluster atau lebih secara random atau acak.
2. Menentukan nilai pusat cluster
3. Menempatkan setiap objek ke cluster terdekat
Dalam tahap ini, dilakukan perhitungan jarak tiap data ke tiap pusat cluster. Yang nantinya akan masuk ke suatu cluster dengan jarak paling dekat antara satu objek dengan satu cluster tertentu.
4. Pengelompokan objek
Setelah diketahuinya keanggotaan clusternya, hitung kembali pusat cluster dengan anggota cluster yang sekarang. Nilai pusat cluster adalah rata-rata dari semua objek dalam cluster tertentu.
BAB IV
HASIL DAN PEMBAHASAN
Pada bab ini akan dijelaskan secara rinci mengenai pengumpulan data-data yang diperlukan dalam penelitian dan juga proses pengolahan data hingga diperoleh hasil yang diinginkan sesuai kerangka kerja yang telah ditetapkan. Bab ini juga berisikan mengenai analisa dan pembahasan dari hasil pengolahan data yang telah dilakukan sebelumnya.
4.1 Pengumpulan Data
Dalam melakukan Clustering Algoritma K-means pengelompokan mahasiswa Teknik Industri UPN “Veteran” Jawa Timur, maka dilakukan pengumpulan data yang diperoleh dari data historis mahasiswa berupa Indeks Prestasi Kumulatif (IPK) dan Satuan Kredit Semester (SKS) yang telah ditempuh.
No NPM SKS
Sumber: Biro Admik UPN “Veteran” Jawa Timur
4.2 Pengolahan Data
A. Iterasi 1
1. Penentuan jumlah cluster
Dengan memperhatikan data penelitian yang ada, dapat ditentukan pengelompokkan yang bertujuan membagi obyek ke dalam tiga cluster (k=3). Dan akan terbentuk 3 pusat cluster (centroid).
2. Penentuan nilai pusat cluster
Untuk menentukan nilai awal centroid dilakukan secara acak. Disini ditentukan pusat cluster nya adalah sebagai berikut:
C1= (130 ; 2,88) C2= (140 ; 3,43) C3= (130 ; 2,88)
3. Penempatan tiap obyek ke cluster terdekat
Menempatkan setiap obyek ke dalam cluster terdekat ditentukan berdasarkan perhitungan jarak antara tiap obyek dan tiap pusat cluster. Rumus yang digunakan untuk menghitung jarak terdekat adalah rumus (2.5) pada BAB II sebelumnya
Hitung jarak terdekat tiap obyek ke semua pusat cluster C1, C2, C3. Dimisalkan data pertama (Mahasiswa dengan Npm 1032010001) adalah A dan data kedua (Mahasiswa dengan Npm 1032010003) adalah B. Berikut contoh perhitungannya:
• Jarak terdekat A ke C1
= 0
• Jarak terdekat A ke C2
• Jarak terdekat A ke C3
= 0
• Jarak terdekat B ke C1
= 10,0151
• Jarak terdekat B ke C2
= 0
• Jarak terdekat B ke C3
= 10,0151
Kedekatan suatu obyek ke cluster tertentu ditentukan oleh jarak antara obyek dengan pusat cluster. Dari hasil perhitungan diatas dapat diketahui hasil dari perhitungan jarak antara A dan pusat cluster 1 sebesar 0. Hasil perhitungan jarak A dan pusat cluster 2 adalah 10,0151. Sedangkan jarak antara A dengan pusat cluster 3 sebesar 0. Dan untuk jarak antara B dan pusat cluster 1 adalah 10,0151, jarak B dan pusat cluster 2 sebesar 0, dan jarak antara B dan pusat cluster 3 adalah 10,0151.
Jadi, jarak paling dekat antara A dengan ketiga pusat cluster tersebut akan menentukan A masuk ke dalam cluster mana. Begitu pula dengan hasil perhitungan jarak B.
Untuk hasil dari perhitungan jarak antara obyek dan pusat cluster lainnya dapat dilihat pada lampiran III.
4. Pengelompokan obyek berdasar jarak minimum
maka semakin besar kedekatannya. Oleh karena itu, dari hasil perhitungan jarak diatas dapat dikelompokkan obyek tersebut ke dalam cluster tertentu. Mahasiswa A : Dilihat dari jarak antara A dan pusat cluster C1, C2, C3 dapat diketahui bahwa A bergabung ke cluster 1.
Mahasiswa B : Dilihat dari jarak antara B dan pusat cluster C1, C2, C3 dapat diketahui bahwa B bergabung ke cluster 2.
Dari hasil perhitungan jarak pada langkah sebelumnya, diketahui bahwa jarak antara A dengan pusat cluster 1 merupakan jarak paling minimum sehingga A bergabung ke dalam cluster 1. Begitu pula dengan B dimana diketahui bahwa jarak minimum B adalah dengan pusat cluster 2, maka B bergabung ke dalam cluster 2.
Untuk pengelompokan obyek yang lainnya dapat dilihat pada lampiran III. Hasil dari pengelompokan obyek-obyek ini merupakan keanggotaan cluster yang sekarang (cluster iterasi 1) terbentuk dari 2 cluster, kemudian dilakukan iterasi 2 dengan menentukan pusat cluster baru (pusat cluster kedua).
B. Iterasi 2
1. Penentuan pusat cluster baru
Pada iterasi ini, dengan adanya dua cluster yang terbentuk dari iterasi sebelumnya, maka nilai pusat cluster baru didapat dari nilai rata-rata semua anggota masing-masing cluster pada iterasi sebelumnya sebanyak dua pusat cluster dapat dilihat sebagai berikut:
Centroid (pusat cluster) C1 didapat dari rata-rata semua anggota cluster 1, sedangkan centroid 2 didapat dari rata-rata semua anggota cluster 2. 2. Penempatan tiap obyek dengan pusat cluster baru
Menempatkan setiap obyek ke dalam cluster terdekat ditentukan berdasarkan perhitungan jarak antara tiap obyek dan tiap pusat cluster. Rumus yang digunakan untuk menghitung jarak terdekat adalah rumus (2.5) pada BAB II.
Hitung jarak terdekat tiap obyek ke semua pusat cluster baru C1, C2. Berikut contoh perhitungannya:
• Jarak terdekat A ke C1
= 8,1002
• Jarak terdekat A ke C2
= 9,5509
• Jarak terdekat B ke C1
= 18,1102
• Jarak terdekat B ke C2
= 0,4659
Jadi, jarak paling dekat antara A dengan ketiga pusat cluster tersebut akan menentukan A masuk ke dalam cluster mana. Begitu pula dengan hasil perhitungan jarak B.
Untuk hasil dari perhitungan jarak antara obyek dan pusat cluster lainnya dapat dilihat pada lampiran IV.
3. Pengelompokan objek berdasar jarak minimum
Dari perhitungan sebelumnya dapat diketahui hasil dari jarak masing-masing obyek ke dalam tiap pusat cluster. Semakin kecil nilai jaraknya, maka semakin besar kedekatannya. Oleh karena itu, dari hasil perhitungan jarak diatas dapat dikelompokkan obyek tersebut ke dalam cluster tertentu. Mahasiswa A: Dilihat dari jarak antara A dan pusat cluster C1, C2 dapat diketahui bahwa A bergabung ke cluster 1.
Mahasiswa B: Dilihat dari jarak antara B dan pusat cluster C1, C2 dapat diketahui bahwa B bergabung ke cluster 2.
Dari hasil perhitungan jarak pada langkah sebelumnya, diketahui bahwa jarak antara A dengan pusat cluster 1 merupakan jarak paling minimum sehingga A bergabung ke dalam cluster 1. Begitu pula dengan B dimana diketahui bahwa jarak minimum B adalah dengan pusat cluster 2, maka B bergabung ke dalam cluster 2.
C. Iterasi 3
1. Penentuan pusat cluster baru
Pada iterasi ini, dengan adanya dua cluster yang terbentuk dari iterasi sebelumnya, maka nilai pusat cluster baru didapat dari nilai rata-rata semua anggota masing-masing cluster pada iterasi sebelumnya sebanyak dua pusat cluster dapat dilihat sebagai berikut:
C1 = (121,900 ; 2,8224) C2 = (139,538 ; 3,3662)
Pusat cluster C1 didapat dari rata-rata semua anggota cluster 1, sedangkan pusat cluster C2 didapat dari rata-rata semua anggota cluster 2.
2. Penempatan tiap obyek dengan pusat cluster baru
Menempatkan setiap obyek ke dalam cluster terdekat ditentukan berdasarkan perhitungan jarak antara tiap obyek dan tiap pusat cluster. Rumus yang digunakan untuk menghitung jarak terdekat adalah rumus (2.5) Pada BAB II sebelumnya
Hitung jarak terdekat tiap obyek ke semua pusat cluster baru C1, C2. Berikut contoh perhitungannya:
• Jarak terdekat A ke C1
= 8,1002
• Jarak terdekat A ke C2
= 9,5509
• Jarak terdekat B ke C1
• Jarak terdekat B ke C2
= 0,4659
Kedekatan suatu obyek ke cluster tertentu ditentukan oleh jarak antara obyek dengan pusat cluster. Dari hasil perhitungan diatas dapat diketahui hasil dari perhitungan jarak antara A dan C1 sebesar 8,1002. Hasil perhitungan jarak A dan C2 adalah 9,5509. Hasil perhitungan jarak antara B dan C1 adalah 18,1102, sedangkan jarak antara B dengan C2 sebesar 0,4659.
Jadi, jarak paling dekat antara A dengan ketiga pusat cluster tersebut akan menentukan A masuk ke dalam cluster mana. Begitu pula dengan hasil perhitungan jarak B.
Untuk hasil dari perhitungan jarak antara obyek dan pusat cluster lainnya dapat dilihat pada lampiran V.
3. Pengelompokan objek berdasar jarak minimum
Dari perhitungan sebelumnya dapat diketahui hasil dari jarak masing-masing obyek ke dalam tiap pusat cluster. Semakin kecil nilai jaraknya, maka semakin besar kedekatannya. Oleh karena itu, dari hasil perhitungan jarak diatas dapat dikelompokkan obyek tersebut ke dalam cluster tertentu. Mahasiswa A: Dilihat dari jarak antara A dan pusat cluster C1, C2 dapat diketahui bahwa A bergabung ke cluster 1.
Dari hasil perhitungan jarak pada langkah sebelumnya, diketahui bahwa jarak antara A dengan pusat cluster 1 merupakan jarak paling minimum sehingga A bergabung ke dalam cluster 1. Begitu pula dengan B dimana diketahui bahwa jarak minimum B adalah dengan pusat cluster 2, maka B bergabung ke dalam cluster 2.
Untuk pengelompokan obyek yang lainnya dapat dilihat pada lampiran V. Hasil dari pengelompokan obyek-obyek ini merupakan keanggotaan cluster yang sekarang (cluster iterasi 3).
Dalam pusat cluster iterasi 2 dan iterasi 3 diketahui sudah sama (tidak berubah) dan anggota cluster pada iterasi 2 sama dengan pengelompokan anggota cluster pada iterasi 3. Jadi pada iterasi 3 ini sudah konvergen sehingga tidak perlu dilakukan iterasi kembali.
Dari tabel diatas didapatkan hasil Clustering Algoritma K-means yang diketahui bahwa terdapat dua cluster yang terbentuk. Dalam Cluster I terdapat 50 anggota cluster yang saat ini memiliki SKS kurang dari 138 dan IPK kurang dari 3,5. Sedangkan dalam Cluster II diketahui memiliki 138 - 140 SKS saat ini dan IPK saat ini rata-rata diatas 3,0 dengan jumlah 26 anggota cluster dari total 76 anggota cluster.
4.3 Hasil dan Pembahasan
Dapat diketahui Satuan Kredit Semester (SKS) saat ini dan Indeks Prestasi Kumulatif mahasiswa (IPK) saat ini yang terbagi dalam masing-masing cluster. Sistem satuan kredit semester digunakan sebagai besarnya beban studi mahasiswa yang diperlukan mahasiswa untuk menyelesaikan suatu program perkuliahan. Seorang mahasiswa dapat dinyatakan lulus apabila telah menyelesaikan jumlah SKS tertentu. Kelulusan program sarjana (S1), khususnya jurusan Teknik Industri UPN “Veteran” Jawa Timur mempersyaratkan mahasiswanya untuk menyelesaikan 144 - 160 SKS. Sedangkan untuk standard kelulusan, jurusan Teknik Industri UPN “Veteran” Jawa Timur memiliki standard tingkat kelulusan yaitu minimal 3,5 tahun hingga 7 tahun. Sehingga dalam penelitian ini, identifikasi tingkat kelulusan diketahui berdasarkan hasil cluster yang terbentuk.
kelulusan 4 tahun atau lebih, yaitu dalam jangka waktu 4 hingga 7 tahun kelulusan.
Dari hasil yang didapatkan dalam pengolahan data Clustering Algoritma K-means mahasiswa Teknik Industri UPN “Veteran” Jawa Timur angkatan 2010, dapat diketahui bahwa yang termasuk dalam Cluster I terdapat mahasiswa dengan jumlah SKS saat ini kurang dari 138 SKS dan IPK saat ini rata-rata dibawah 3,6. Sehingga dari hasil pengklasteran tersebut dapat diidentifikasi bahwa mahasiswa akan lulus 4 hingga 7 tahun dengan jumlah mahasiswa sebanyak 50 mahasiswa atau sebesar 66% dari 76 mahasiswa.
BAB V
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Adapun kesimpulan yang didapat dari penelitian ini adalah dari hasil penelitian dengan menggunakan metode Clustering Algoritma K-means diketahui dari 76 mahasiswa Teknik Industri UPN “Veteran” Jawa Timur angkatan 2010 dapat diidentifikasi bahwa kelulusan tepat waktu yaitu 3,5 tahun adalah sebesar 34% mahasiswa. Sedangkan prediksi kelulusan 4 hingga 7 tahun sebesar 66% mahasiswa.
5.2 Sar an
Saran yang dapat diberikan dari hasil penelitian ini adalah sebagai berikut: 1. Diharapkan bagi pihak jurusan dapat menggunakan penelitian ini sebagai
acuan untuk menentukan tingkat kelulusan mahasiswa pada periode mendatang.
DAFTAR PUSTAKA
Albar, 2010, “Identifikasi Dengan Menggunakan Algoritma K-Means Pada Plat Kendaraan”, Poli Rekayasa Vol 6, Politeknik Negeri Padang.
Amaliah, Bilqis, 2012, “Penentuan Jenis Fumigasi Dengan Menggunakan Metode Decision Tree ID3”, paper Institut Teknologi Sepuluh Nopember (ITS). Larose DT, 2004, “Discovering Knowledge in Data: An Introduction to Data
mining”, New Jersey.
Nango, Dwi, 2012, “Penerapan Algoritma K-Means Untuk Clustering Data Anggaran Pendapatan Belanja Daerah Di Kabupaten XYZ”, Jurusan Teknik Informatika, Fakultas Teknik, Universitas Negeri Gorontalo. Narwati, “Pengelompokan Mahasiswa Menggunakan Algoritma K-Means”,
Fakultas Teknologi Informasi.
Noranita, Beta, 2010, “Implementasi Data mining Untuk Menemukan Pola Hubungan Tingkat Kelulusan Mahasiswa Dengan Data Induk Mahasiswa”, Seminar dan Call for Paper Munas Aptikom, Politeknik Telkom, Bandung.
Oyelade, O.J, 2010, “Application of K-Means Clustering Algorithm for Prediction of Students’ Academic Performance”, Internasional Journal of Computer Science and Information Security Vol 7.
Saepulloh, Dadan, 2010, “Analisis Data mining K-Means Cluster Untuk Data Berjenis Biner”, Pasca Sarjana, Fakultas Matematika, Universitas Padjadjaran, Bandung.
Santosa, Budi, 2007, “Data mining Teknik Pemanfaatan Data Untuk Keperluan Bisnis”, Surabaya.
Santosa, Budi, 2012, “Analisa Perbandingan Metode Hierarchical Clustering, K-Means Dan Gabungan Keduanya Dalam Membentuk Cluster Data”, Jurnal Teknik POMITS Vol 1, Surabaya.
LAMPIRAN I
DATA MAHASISWA TEKNIK INDUSTRI ANGKATAN 2010
LAMPIRAN II
DATA MAHASISWA AKTIF TEKNIK INDUSTRI ANGKATAN 2010