Pengelompokan Penyakit Hepatitis dengan Menggunakan Metode Fuzzy C-Means
( Studi Kasus Data Penyakit hepatitis di Rumah Sakit Panti Rapih Yogyakarta )
SKRIPSI
Ditujukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Jurusan Teknik Informatika
Disusun Oleh :
RAFAELA ROSI PRIHANINGRUM (095314012)
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
Clustering Hepatitis Disease Using Fuzzy C-Means
(Case Study HepatitisDataat Panti Rapih Hospital Yogyakarta)
A Thesis
Presented as Partial Fulfillment of the Requirements
To Obtain the Sarjana Komputer Degree
In Study Program of Informatics Engineering
By
Rafaela Rosi Prihaningrum
095314012
INFORMATICS ENGINEERING STUDY PROGRAM
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
HALAMAN PERSEMBAHAN
Be faithful i s all thi gs e ause it’s i the that your stre gth lies
-Mother Theresa-
Skripsi ini saya persembahkan untuk : Tuhan Yesus Kristus, Keluarga tercinta dan Sahabat terkasih
PERNYATAAN KEASLIAN KARYA
Saya menyatakan dengan sesungguhnya bahwa tugas akhir yang saya tulis tidakmemuat
karya atau bagian karya orang lain, kecuali yang telah disebutkan dalamkutipan dan daftar
pustaka, sebagaimana layaknya karya ilmiah.
Yogyakarta, 23 Agustus 2013
Penulis
LEMBAR PERNYATAAN PERSETUJUAN
PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan dibawah ini, saya mahasiswa Univer sitas Sanata Dharma :
Nama :Rafaela Rosi Prihaningrum
NIM :095314012
Demi pengembangan pengetahuan, saya memberikan kepada perpustakaanUniversitas Sanata
Dharma karya ilmiah yang berjudul :
Pengelompokan Penyakit Hepatitis
dengan Menggunakan Metode Fuzzy C-Means
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikankepada
perpustakaan Universitas Sanata Dharma hak untuk menyimpan,mengalihkan dalam bentuk
media lain, mengelolanya dalam bentuk pangkalandata mendistribusikan secara terbatas, dan
mempublikasikan di internet ataumedia lain untuk kepentingan akademis tanpa perlu
meminta ijin dari sayamaupun memberikan royalti kepada saya selama tetap mencantumkan
nama sayasebagai penulis.
Demikian pernyataan ini saya buat dengan sebenarnya.
Yogyakarta, 23 Agustus 2013
Yang menyatakan,
Pengelompokan Penyakit Hepatitis dengan Menggunakan Metode Fuzzy C-Means
ABSTRAK
Kesehatan merupakan faktor terpenting dalam kehidupan seseorang. Jika kesehatan telah
terganggu maka aktivitas seseorang akan terganggu. Saat ini terdapat banyak penyakit yang
dapat mengakibatkan kematian. Penyakit hepatitis dapat meningkatkan risiko kematian bagi
penderita dan dapat juga menjadi pemicu timbulnya penyakit lain yang menyebabkan
kematian. Analisis pengelompokkan atau cluster analysis adalah salah satu analisis data yang
bertujuan untuk menentukan kelompok atau group dari sekelompok data berdasarkan
kesamaan karakteristik.
Dalam penelitian ini, proses pengelompokkan penyakit hepatitis menggunakanFuzzy
C-Means dalam proses pengujian sistem yang dilakukan dengan empatpercobaan yaitu
percobaan dengan data anamnesa dokter menghasilkan akurasi sebe sar50% , percobaan
yang kedua yaitu percobaan dengan data laboratorium menghasilkan akurasi sebesar
83.871%, yang ketiga yaitu percobaan dengan data anamnesa dokter yang telah di PCA (
Principal Component Analysis ) menghasilkan akurasi sebesar 40.6504% dan yang terakhir
adalah percobaan dengan data anamnesa yang telah digabung dengan data laboratorium
ABSTRACT
Health is the most important factor in a person's life. If health has disrupted the activities
of a person will be disturbed. Currently, there are many diseases that can lead to death. Liver
disease can increase the risk of death for patients and can also be triggers of other diseases
that cause death. Grouping analysis or cluster analysis is one of the data analysis that aims to
determine which group or groups from a group of data based on similar characteristics.
In the research, the process of grouping hepatitis disease using Fuzzy C-Means in the
process of testing the system four experiments conducted, first experiments with the
anamnesa the data which produce an accuracy of 50%, a second trial is an experiment with
laboratory data which produced 83.871% accuracy, the third experiment with anamnesa the
data that has been in the PCA (Principal Component Analysis) produces an accuracy of
40.6504% and the last experiment is anamnesa which has been in the pca combined with
KATA PENGANTAR
Puji dan syukur penulis panjatkan kepada Tuhan Yesus Kristus, karena atas kebaikan dan
kehendak-Nya saya dapat menyelesaikan tugas akhir yang berjudul“Pengelompokan Penyakit Hepatitis dengan Menggunakan Metode Fuzzy C-Means”. Tugas akhir ini ditulis sebagai salah satu syarat memperoleh gelarsarjana program studi Teknik Informatika,
Fakultas Sains dan TeknologiUniversitas Sanata Dharma.
Dalam proses penulisan tugas akhir ini , penulis mengucapkan terima kasihyang
sebesar-besarnya kepada :
1. Ibu PH.Prima Rosa, S.Si., M.Sc., selaku Dekan Fakultas Sains dan Teknologi
Universitas Sanata Dharma Yogyakarta.
2. Ibu Ridowati Gunawan, S.Kom.,M.T., selaku Dosen Pembimbing sekaligus ketua
program studi Teknik Informatika Fakultas Sains dan Teknologi Universitas Sanata
Dharma Yogyakarta, terimakasih atas segala bimbingan, kesabaran dan mengarahkan
serta membimbing penulis dalam menyelesaikan tugas akhir ini.
3. Ibu Sri Hartati Wijono, S.Si.,M.Kom.dan Bapak Albert Agung Hadhiatma,S.T.,M.T.
selaku dosen penguji yang telah memberikan banyak kritik dansaran untuk tugas akhir
saya.
4. Bapak Iwan Binanto, M.Cs., selaku Dosen Pembimbing Akademik Teknik
Informatika Tahun 2009.
5. Seluruh staff dosen Teknik Informatika Universitas Sanata Dharma yang telah banyak
memberikan bekal ilmu, arahan dan pengalaman selama sayamenempuh studi.
6. Seluruh staff Sekretariat Teknik, yang banyak membantu saya dalam
urusanadministrasi akademik terutama menjelang ujian tugas akhir.
7. Kedua orang tua dan kakak saya, terima kasih atas semua yang telah dilakukan
untukku, doa, semangat,dukungan dan cintanya sehingga saya bisa menyelesaikan
studi denganlancar.
8. Estu Karunianingtyas, terimakasih atas bantuan yang diberikan dalam penyusunan
tugas akhir ini.
9. Teman-teman Teknik Informatika : Mirella Tri Ratnasari, Christina Wienda Asrini,
10. Seluruh pihak yang telah ambil bagian dalam proses penulisan tugas akhirini yang
tidak bisa saya sebutkan satu per satu.
Dengan rendah hati penulis menyadari bahwa tugas akhir ini masih jauh
darisempurna, oleh karena itu berbagai kritik dan saran untuk perbaikan tugas akhir ini sangat
penulis harapkan.Akhir kata, semoga tugas akhir ini bermanfaat bagi semua pihak.Terima
kasih.
Yogyakarta, 23 Agustus 2013
Penulis
Daftar Isi
HALAMAN PERSETUJUAN ... ERROR! BOOKMARK NOT DEFINED. HALAMAN PERSEMBAHAN ... IV PERNYATAAN KEASLIAN KARYA ... VI LEMBAR PERNYATAAN PERSETUJUAN ... VII PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS ... VII ABSTRAK ... VIII
2.2.1 Himpunan Tegas (Crisp) ... 7
2.1.1 Himpunanfuzzy ... 7
2.8.1 Penyebab Hepatitis ... 15
2.8.2 Jenis dan Gejala Hepatitis ... 15
2.8 CONTOH PENGGUNAAN FUZZY C-MEANS ... 17
ANALISIS DAN DESAIN SISTEM ... 24
3.1 DATA ... 24
3.2 GAMBARAN UMUM SISTEM ... 25
3.4 PERANCANGAN ANTARMUKA ... 26
3.5 SPESIFIKASI PERANGKAT LUNAK DAN PERANGKAT KERAS ... 27
IMPLEMENTASI DAN ANALISIS HASIL ... 28
4.1HASIL PENGUMPULAN DATA ... 28
4.2PERANCANGAN FUZZY C-MEANS ... 29
4.2.1 Pembersihan Data ... 30
4.2.2 Normalisasi data laboratorium ... 30
4.2.3 PCA ( Principal Component Analysis) ... 30
4.2.4Membentuk derajat Keanggotaan ( Matriks Uik) ... 34
5.3 IMPLEMENTASI USER INTERFACE ... 35
5.4 HASIL PENGUJIAN ... 38
5.5 ANALISIS ... 41
PENUTUP ... 43
5.1KESIMPULAN ... 43
5.2SARAN ... 44
DAFTAR PUSTAKA ... 45
DAFTAR GAMBAR
Gambar Keterangan Halaman
2.1 (Kohavi&Provost,1998) : Confusion Matrix 10
3.1 Flowchart Sistem 25
3.2 Use Case Diagram 26
3.3 Perancangan Antarmuka 26
4.1 Halaman Pengelompokkan Penyakit Hepatitis 35
4.2 dialog box untuk memilih data 36
4.3 Data awal 36
4.4 inisialisasi data 36
4.5 Nilai derajat keanggotaan iterasi terakhir 37
4.6 Fungsi Objektif 37
DAFTAR TABEL
Tabel Keterangan Halaman
2.1 Nilai normal pemeriksaan laboratorium 14
2.2 Kegunaan pemeriksaan labratorium 14
2.3 Jenis Hepatitis 15
4.1 Deskripsi data gejala anamnesis 28
4.2 Deskripsi data gejala Laboratorium 29
4.3 KMO and Bartlett;s Test 31
4.4 Communalities 31
4.5 Total Variance Explained 32
4.6 Conponent Matrix 33
4.7 Score Faktor 34
4.8 Component Score Coefficient Matrix 34
4.9 Fungsi FFCM_InitV 34
4.11 Hasil Pengujian data laboratorium 39
4.12 Hasil Pengujian data anamnesa dokter(PCA) 40
4.13 Hasil Pengujian data anamnesa dokter(PCA) dan data laboratorium
BAB I
PENDAHULUAN
Bab pendahuluan ini berisi tentang hal-hal yang mendasari dilakukannya penelitian serta
pengidentifikasian masalah penelitian. Komponen-komponen yang terdapat dalam bab
pendahuluan ini meliputi latar belakang masalah, perumusan masalah, tujuan penelitian,
batasan masalah, manfaat penelitian, metodologi penelitian dan sistematika penulisan.
1.1 Latar Belakang
Kesehatan merupakan faktor terpenting dalam kehidupan seseorang. Jika kesehatan
telah terganggu maka aktivitas seseorang akan terganggu. Saat ini terdapat banyak penyakit
yang dapat mengakibatkan kematian.Salah satunya adalah penyakit hepatitis.Indonesia
merupakan Negara ketiga dengan penderita hepatitis terbanyak setelah China dan
India.Penderita hepatitis B dan C di Indonesia diperkirakan mencapai 30 juta orang.(
Dimyati, Vien, 2011).
Hepatitis merupakan salah satu penyakit yang membahayakan jika tidak segera
ditangani.Penyakit yang menyerang hati atau liver ini semakin berbahaya karena gejalanya
yang tidak selalu tampak.Fungsi utama dari hati atau liver adalah menyaring racun-racun
yang ada pada darah. Selain itu, masih ada sekitar 500 fungsi lain dari hati. Jika seseorang
menderita hepatitis, yang merupakan peradangan pada hati atau liver ini, dapat
menghancurkan kesehatan orang tersebut secara keseluruhan karena racun tetap mengendap
pada darah dan merusak atau mengganggu kerja organ lain. Akibat lainnya adalah hati
menolak darah yang mengalir sehingga tekanan darah menjadi tinggi dan pecahnya pembuluh
darah.
Ada 5 macam virushepatitis yang dinamai sesuai abjad. Kelima virus itu adalah
virushepatitis A (VHA), virus hepatitis B (VHB), virus hepatitis C (VHC), virus hepatitis D
(VHD) dan virus hepatitis E (VHE). Virus-virus ini terus berkembang dan bahkan
Penyakit hepatitisdipilih dalam penelitian ini karena banyaknya orang tidak sadar jika sudah terkena penyakit hepatitissehingga menyebabkan keterlambatan penanganan dan dapat
berakibat fatal.Di harapkan dengan adanya penelitian ini dapat membantu dalam
pendeteksian penyakit hepatitis agar dapat di lakukan penanganan lebih lanjut dan supaya
orang mengenal status kesehatan lebih dini.
Analisis pengelompokkan atau cluster analysis adalah salah satu analisis data yang
bertujuan untuk menentukan kelompok atau group dari sekelompok data berdasarkan
kesamaan karakteristik. Analisis ini sudah banyak digunakan untuk menyelesaikan
permasalahan dan penelitian dalam beberapa disiplin ilmu, seperti bidang akademik, bidang
kesehatan,bidang kewilayahan dan bidang marketing.
Perkembangan analisis kelompok dimulai dari metode hirarki yang secara garis besar
membentuk sebuah tree diagram yang biasa disebut dendogram. Sedangkan metode
nonhirarki lebih dikenal dengan cara partisi, contohnya K-means, metode ini menentukan
terlebih dahulu jumlah kelompok yang akan dibentuk. Perkembangan lebih lanjut dari analisa
kelompok adalah dengan mempertimbangkan tingkat keanggotaan yang mencangkup
himpunan fuzzy sebagai dasar pembobotan bagi pengelompokkan yang disebut dengan fuzzy
clustering.
Dalam teknik fuzzy clustering, terdapat beberapa algoritma salah satunya adalah Fuzzy
C-Means.Fuzzy C-Meansadalah salah satu teknik pengelompokkan data yang mana
keberadaan tiap titik data dalam suatu kelompok (cluster) ditentukan oleh derajat keanggotan.
Metode Fuzzy C-Meanstermasuk metode supervised clusteringdimana jumlah pusat
clusterditentukan di dalam proses clustering.
Konsep dasar Fuzzy C-Means adalah menentukan pusat cluster, yang akan menandai
lokasi rata-rata untuk tiap-tiap cluster. Pada kondisi awal, pusat cluster ini masih belum
akurat.Tiap-tiap titik data memiliki derajat keanggotaan untuk tiap-tiap cluster. Dengan cara
memperbaiki pusat cluster dan derajat keanggotaan tiap-tiap titik data secara berulang, maka
akan dapat dilihat bahwa pusat cluster akan bergerak menuju lokasi yang tepat. Perulangan
ini didasarkan pada minimalisasi fungsi obyektif yang menggambarkan jarak dari titik data
yang diberikan ke pusat cluster yang terbobot oleh derajat keanggotaan titik data tersebut.
Output dari Fuzzy C-Means merupakan deretan pusat cluster dan beberapa derajat
Algoritma Fuzzy C-Means sering dipakai dalam berbagai bidang baik bisnis,kesehatan
atau pendidikan. Beberapa penelitian yang menggunakan algoritma Fuzzy C-Means misalnya
penelitian dalam pengelompokkan wilayah kecamatan menurut partisipasi sekolah,
pengembangan algoritma Fuzzy C-means untuk brain medical image analysis, dan penelitian
lainnya.
Pada penelitian ini algoritma Fuzzy C-means digunakan untuk mengelompokan orang
yang terkena penyakit hepatitis A, hepatitis B, hepatitis C. Algoritma Fuzzy C-means ini di
pilih karena metode ini dapat memberikan hasil yang cukup baik dalam hal meningkatkan
homogenitas tiap kelompok yang dihasilkan.
Pendeteksian penyakit hepatitis sudah pernah dilakukan oleh Estu Karunianingtyas
(Karunianingtyas,2011) menggunakan metode naïve Bayesiandengan 26 atribut dari data
anamnesis dokter, namun tingkat keakuratan yang didapat masih rendah karena hanya
mencapai 51.11% maka dari itu penulis ingin melanjutkan penelitian dengan menggunakan
metode Fuzzy C-means.
1.2 Rumusan Masalah
Dari uraian diatas maka permasalahan yang dicoba untuk diselesaikan adalah :
1. Apakah metode Fuzzy C-means dapat dipergunakan untuk mengelompokkan
orang berpenyakit hepatitis dengan memberikan keakuratan yang baik ?
1.3 Tujuan
Tujuan yang ingin dicapai dalam penelitian ini adalah :
1. Menganalisis, mendisain, mengimplementasikan metode Fuzzy C-Means untuk
mengelompokkan penyakit hepatitis.
2. Mengetahui tingkat keakuratan metode Fuzzy C-Means dalam mengelompokkan
1.4 Batasan Masalah
Batasan masalah dalam penelitian ini adalah :
1. Data set yang di gunakan adalah data hasil pemeriksaan laboratorium rumah sakit
dan data hasil anamnesa.
2. Jenis hepatitis yang akan diteliti hanya 3 jenis yaitu hepatitis A, hepatitis B, dan
hepatitis C karena jenis hepatitis D dan hepatitis E jarang ditemukan.
1.5 Manfaat
Manfaat yang diproleh dalam penelitian ini antara lain :
1. Memberikan gambaran tentang langkah – langkah analisis, design dan implementasi metodeFuzzy C-means dalam mengelompokkan orang yang
berpenyakit hepatitis.
2. Sebagai referensi untuk penelitian yang berhubungan dengan clustering penyakit
hepatitis yang lebih lanjut lagi.
1.6 Metodologi Penelitian
Metodologi yang digunakan adalah sebagai berikut:
1. Melakukan pengumpulan data.
2. Melakukan normalisasi pada data laboratorium.
3. Mengekstrak data anamnesis dokter menggunakan metode PCA ( Principal
Component Analysis).
4. Menggabungkan data laboratorium yang sudah di normalisasi dengan data anamnesis
yang sudah di ekstraks.
5. Menghitung data dengan menggunakan metode FCM ( Fuzzy C-Means).
6. Menghitung nilai keakuratan hasil pengelompokkan dengan menggunakan Confusion
1.7 Sistematika Penulisan
Penulisan tugas akhir ini tersusun dari 5 (lima) bab dengan sistematikapenulisan
sebagai berikut :
BAB I PENDAHULUAN
Bab pendahuluan ini berisi tentang hal-hal yang mendasari dilakukannya
penelitian serta pengidentifikasian masalah penelitian. Komponen-komponen yang
terdapat dalam bab pendahuluan ini meliputi latar belakang masalah, perumusan
masalah, tujuan penelitian, batasan masalah, manfaat penelitian, metodologi penelitian
dan sistematika penulisan.
BAB II LANDASAN TEORI
Bab ini menjelaskan tentang dasar teori yang digunakan dalam penyusunan
tugas akhir ini untuk memperjelas materi-materi yang sudah sedikit dijelaskan pada
bab 1. Penjelasan yang diberikan mulai dari Fuzzy logic dan dilanjutkan dengan Fuzzy
clustering dan Fuzzy C-means. Kemudian menjelaskan tentang permasalahan penyakit
hepatitis dan yang terakhir mengenai pengujian keakuratan metode
BAB III Desain dan Analisis SISTEM
Bab ini berisi tentang desain dan analisis system meliputi contoh perhitungan,
perancangan antarmuka, dan usecase.
BAB IV IMPLEMENTASI SISTEM DAN HASIL
Bab ini berisi implementasi program dari sistem yang akan dibuat, pembahasan
penerapan algoritma Fuzzy C-Means, implemantasi antarmuka dan hasil implementasi.
BAB V PENUTUP
Bab ini berisi kesimpulan dari sistem yang telah dibuat, serta saran untuk
BAB II
TINJAUAN PUSTAKA
Bab ini menjelaskan tentang dasar teori yang digunakan dalam penyusunan tugas akhir ini
untuk memperjelas materi-materi yang sudah sedikit dijelaskan pada bab 1. Penjelasan yang
diberikan mulai dari Fuzzy logic dan dilanjutkan dengan Fuzzy clustering dan Fuzzy
C-means.Kemudian menjelaskan tentang permasalahan penyakit hepatitis dan yang terakhir
mengenai pengujian keakuratan metode.
2.1 Fuzzy Logic
Teori Himpunan Fuzzyakan memberikan jawaban terhadap suatu masalah
yangmengandung ketidak pastian. Aplikasi logika fuzzy untuk mendukung keputusan
semakindiperlukan ketika semakin banyak kondisi yang menuntut adanya keputusan yang
tidakhanya bisa dijawab dengan „Ya‟ atau „Tidak‟.Fuzzy Logic memberikan rata-rata dariperhitungan angka, yang terletak antara nilai benar mutlak dan nilai salah mutlak,
yangberupa range antara 0.0 dan 1.0. Dengan Fuzzy Logic, pengguna dimungkinkan
untukmenghitung derajat keanggotaan dari sebuah data. Fuzzy Logic berurusan dengan
kondisiyang tidak pasti, dimana benar dan salah tidak dapat ditentukan secara mutlak.
Konsep dari Fuzzy Logic diperkenalkan oleh Professor Lotfi A. Zadeh, di Barkley pada
Universitas California (University of California) pada 1960an.Logika Fuzzy dikatakan
sebagai logika baru yang lama, sebab ilmu tentang logika Fuzzy modern dan metodis baru
ditemukan beberapa tahun yang lalu, padahal sebenarnya konsep tentang logika fuzzy itu
sendiri sudah ada sejak lama.
Ada beberapa alasan mengapa orang menggunakan logika Fuzzy, antara lain :
1. Konsep logika Fuzzy mudah dimengerti. Konsep matematis yang mendasari
penalaran Fuzzy sangat sederhana dan mudah dimengerti.
2. Logika Fuzzy sangat fleksibel.
3. Logika Fuzzy memiliki toleransi terhadap data-data yang tidak tepat.
4. Logika Fuzzy mampu memodelkan fungsi-fungsi non-linear yang sangat
2.2 Himpunan Fuzzy
2.2.1 Himpunan Tegas (Crisp)
Pada himpunan tegas, nilai keanggotaan suatu item (x) dalam suatu himpunan
A, sering ditulis dengan µA(x), memiliki dua kemungkinan yaitu :
a. 1 (satu), yang bearti suatu item menjadi anggota dalam suatu himpunan
b. 0 (nol), yang bearti suatu item tidak menjadi anggota himpunan tersebut.
2.1.1 Himpunanfuzzy
Pada himpunan fuzzy nilai keanggotaan terletak pada rentang 0 sampai 1.
Apabila x memiliki nilai keanggotaan fuzzy µA(x)=0 bearti x tidak menjadi
anggota himpunan A. demikian pula, apabila x memiliki nilai keanggotaan
µA(x)=1 bearti x menjadi anggota penuh himpunan A.
2.3 Fuzzy Clustering
Fuzzy clustering adalah salah satu teknik menentukan cluster optimal dalam suatu ruang
vektor yang didasarkan pada bentuk normal euclidean untuk jarak antar vektor
(Kusumadewi,2004).
Metode ini merupakan pengembangan dari metode partitioning data dengan
pembobotan fuzzy. Keunggulan utama fuzzy clustering adalah dapat memberikan hasil
pengelompokkan objek – objek yang tersebar tidak teratur, karena jika terdapat suatu data yang penyebarannya tidak teratur maka terdapat kemungkinan suatu titik data mempunyai
sifat atau karakteristik dari cluster lain sehingga diperlukan pembobotan kecenderungan titik
data terhadap suatu cluster.
Dalam teori logika fuzzy suatu nilai bisa bernilai benar atau salah secara
bersama.Namun berapa besar keberadaan dan kesalahan suatu tergantung pada bobot
keanggotaan yang dimilikinya.Logika fuzzy memiliki derajat keanggotaan dalam rentang 0
hingga 1.
Logika fuzzy adalah suatu cara yang tepat untuk memetakan suatu ruang input kedalam
keanggotaan dan derajat dari kebenaran. Oleh sebab itu sesuatu dapat dikatakan sebagian
benar dan sebagian salah pada waktu yang sama (Kusumadewi. 2004).
1.4 Fuzzy C-Means
Dalam teknik clustering data terdapat beberapa algoritma, salah satunya adalah Fuzzy
C-means. Fuzzy C-means merupakan pengembangan dari metode K-mean clustering karena
pada awalnya ditentukan dulu jumlah kelompok atau cluster yang akan dibentuk. Kemudian
dilakukan iterasi sampai mendapatkan keanggotaan kelompok tersebut.
Konsep dasar Fuzzy C-means, pertama kali adalah menentukan pusat cluster, yang akan
menandai lokasi rata-rata untuk tiap-tiap cluster. Pada kondisi awal, pusat cluster ini masih
belum akurat.Tiap-tiap titik data memiliki derajat keanggotaan untuk tiap-tiap cluster.
Dengan cara memperbaiki pusat cluster dan derajat keanggotaan tiap-tiap titik data secara
berulang, maka akan dapat dilihat bahwa pusat cluster akan bergerak menuju lokasi yang
tepat. Perulangan ini didasarkan pada minimasi fungsi objektif yang menggambarkan jarak
dari titik data yang diberikan ke pusat cluster yang terbobot oleh derajat keanggotaan titik
data tersebut.
Algoritma pengelompokan Fuzzy C-means menurut Kusumadewi diberikan sebagai
berikut :
i. Tentukan :
1. Matriks X berukuran n x m dengan n = jumlah data yang akan di cluster dan
m= jumlah variabel (criteria)
2. Jumlah cluter yang akan di bentuk = C
3. w> 1 adalah tingkat ke fuzzy-an dari hasil pengelompokkan. Parameter ini
disebut dengan fuzzier, nilai dari w yang sering dipakai dan dianggap paling
halus adalah w=2 (Klawoon dan Hopper,2001)
4. Iterasi tertinggi
5. Kriteria penghentian = e (nilai positif yang sangat kecil)
6. Iterasi awal t=1,dan ∆=1
ii. Bentuk matriks partisi awal Uik seperti rumus (2,1) sebagai berikut
Matrik partisi Uik mempunyai komponen i= banyaknya data, k = banyaknya
cluster. Matrik ini random dengan kisaran nilai 0 sampai 1.
iii. Hitung pusat cluster dengan menggunakan rumus (2,2) :
iv. Hitung fungsi objektif pada iterasi ke –i dengan menggunakan rumus (2,3)
dik merupakan ukuran jarak untuk jarak Euclidean antara pusat cluster ke-i
dengan data ke-k. untuk menghitung dik digunakan rumus (2,4) :
v. Perbaiki drajat keanggotaan tiap data pada tiap cluster dengan menggunakan
rumus (2,5)
vi. Cek kondisi berhenti jika :
a) Jika: (|Pi-Pi-1 |<e) atau (t>MaxIter) maka berhenti.
b) Jika tidak: t=t+1, ulangi langkah iii.
Dari algoritma tersebut dapat disimpulkan bahwa langkah pertama yang dilakukan
adalah menentukan matriks derajat keanggotaan secara acak yang kemudian dijadikan acuan
terhadap perhitungan pusat cluster. Pada kondisi awal pusat cluster masih belum akurat, yang
ditunjukkan dengan besarnya selisih nilai objektif, sehingga dilakukan langkah iteratif
cluster bergerak menuju lokasi yang tepat. Langkah ini dilakukan berdasarkan minimisasi
fungsi objektif.
Output dari Fuzzy C-means merupakan matriks pusat cluster berukuran c x p dan
matriks derajat keanggotaan untuk tiap – tiap data berbentuk n x c. Pengelompokkan cluster
dapat dilihat dari kedua output ini. Matriks pusat cluster menunjukkan pusat cluster untuk
tiap – tiap variabel yang diamati dalam setiap cluster-nya. Matriks derajat keanggotaan menunjukkan kecenderungan suatu data untuk masuk kedalam cluster tertentu. Semakin
besar nilai derajat keanggotaannya, maka semakin besar peluang data tersebut masuk
kedalamclustertertentu.
2.5 Confusion Matrix
Validasi merupakan proses untuk menilai hasil metode cluster. Oleh karena itu,
proses ini bertujuan untuk menjamin bahwa solusi cluster yang di hasilkan dalam analisis
cluster dapat menggambarkan populasi sebenarnya.
Confusion Matrix merupakan bagian dari uji validasi dengan metode external test.Uji
validasi external test ini digunakan untuk mengukur sejauh mana label pada cluster dengan
label pada class yang disediakan.
Menurut Kohavi dan Provost (Kohavi dan Provost,1998) confusion Matrix berisi
informasi tentang actual (fakta)dan predicted (prediksi). Confusion matrix pada gambar 2.1
berbentuk matrix 2 x 2 yang digunakan untuk mendapatkan jumlah ketepatan yang didapat
dengan menggunakan algoritma tertentu
Predicted
Negative Positif
Actual
Negative A B
Gambar 2.1 (Kohavi&Provost,1998) : Confusion Matrix
Keterangan :
A, jikaactual dan predicted bernilai negative.
B, jika actual bernilai negative dan predicted bernilai positive.
C, jika actual bernilai positive dan predicted bernilai negative
D, jika actual dan predicted bernilai positive.
Rumus yang digunakan untuk menghitung akurasi dengan confusion
matrix,yaitu :
2.6 Data Preparation
Proses preparasi ini dilakukan sehingga data dapat lebih mudah untuk diolah. Terdapat 3 hal dalam data preparationyaitu :
1. Data Selection: Memilih data yang akan digunakan dalam proses data mining. Dalam proses ini dilakukan juga pemilihan atribut-atribut yang disesuaikan dengan proses
data mining.
2. Data Preprocessing: Memastikan kualitas data yang telah dipilih pada tahap
dataselection, pada tahap ini masalah yang harus dihadapi adalah noisy data dan
missing values. Proses pembersihan data (cleansing) dilakukan dengan melakukan
metode-metode query sederhana untuk menemukan anomali-anomali data yang bisa
saja masih terdapat pada sistem.
3. Data Transformation: Mengelompokkan atribut-atribut atau field-yang telah terpilih
menjadi 1 tabel dengan cara melakukan denormalisasi.
2.7
PCA (Principal Component Analysis)
Terdapat dua metode Dimensionality Reduction yang paling sering digunakan yaitu
Feature Selection dan Feature Extraction.Feature selection merupakan sebuah proses
pemilihan subset feature dari feature asli, sedangkan feature extraction adalah proses
mengekstrak feature baru dari feature asli melalui pemetaan fungsional.
Salah satu metode feature extraction adalah PCA ( Principal Component Analysis ).
Prosedur PCA pada dasarnya adalah bertujuan untuk menyederhanakan variabel dengan cara
menyusutkan (mereduksi) dimensinya. Hal ini dilakukan dengan cara menghilangkan korelasi
diantara variabel bebas melalui transformasi variabel bebas asal ke variabel baru yang tidak
berkorelasi sama sekali atau yang biasa disebut dengan principal component
Analisis Komponen Utama (Principal Component Analysis) atau PCA adalah suatu
metodeyang melibatkan prosedur matematika yangmengubah dan mentransformasikan
sejumlah besarvariabel yang berkorelasi menjadi sejumlah kecilvariabel yang tidak
berkorelasi, tanpa menghilangkaninformasi penting di dalamnya
2.8 Hepatitis
Hepatitis telah menjadi masalah global. Saat ini diperkirakan 400 juta orang di dunia
terinfeksi hepatitis B kronis, bahkan sekitar 1 juta orang meninggal setiap tahun karena
penyakit ini (Wening,2008).
Hepatitis adalah istilah umum yang berarti radang hati.“Hepa” berarti kaitan dengan
hati, sementara “itis” berarti radang.Hepatitis atau peradangan hati dapat diartikan sebagai suatu proses peradangan yang menimpa sel-sel hati (Cahyono,2008). Secara objektif, adanya
hepatitis dibuktikan melalui biopsi jaringan hati (pengambilan sedikit jaringan hati
menggunankan jarum).Namun, secara sederhana pemeriksaan dapat digantikan dengan
pemeriksaan darah.
Hepatitismerupakan salah satu penyakit yang membayakan jika tidak segera
ditangani.Penyakit yang menyerang hati atau liver ini semakin berbahaya karena gejalanya
Hati adalah organ yang terbesar dalam tubuh. Kurang lebih sama besar dengan buah
pepaya, dan terletak di perut kanan-atas.Fungsi utama dari hatiatau liver adalah menyaring
racun-racun yang ada pada darah. Selain itu, masih ada sekitar 500 fungsi lain dari hati. Jika
seseorang menderita hepatitis, yang merupakan peradangan pada hati atau liver ini, dapat menghancurkan kesehatan orang tersebut secara keseluruhan karena racun tetap mengendap
pada darah dan merusak atau mengganggu kerja organ lain. Akibat lainnya adalah hati
menolak darah yang mengalir sehingga tekanan darah menjadi tinggi dan pecahnya pembuluh
darah.
Ada 5 macam virus hepatitis yang dinamai sesuai abjad. Kelima virus itu adalah virus
hepatitis A (VHA), virus hepatitis B (VHB), virus hepatitis C (VHC), virus hepatitis D(VHD), virus hepatitis E (VHE).
Diagnosis hepatitis dapat dipastikan melalui anamnesis dengan dokter serta
pemeriksaan fisik dan laboratorium. Dokter akan menanyakan hal – hal yang terkait dengan penularan hepatitis karena hepatitis jenis A, B, C, dan jenis lainnya memberikan gejala yang
hampir sama.
Pemeriksaan laboratorium pada pasien yang diduga mengidap penyakit hepatitis
dilakukan untuk memastikan diagnosis, mengetahui penyebab dan menilai fungsi hati.Secara
garis besar, pemeriksaan laboratorium dibadakan menjadi dua yaitu, tes seralogi dan biokimia
hati.
Tes seralogi dilakukan dengan cara memeriksa kadar antigen maupun antibodi
terhadap virus penyebab hepatitis. Tes ini bertujuan untuk memastikan diagnosis serta
mengetahui jenis virus penyebabnya. Tes biokimia hati dilakukan dengan cara memeriksa
parameter zat – zat kimia maupun enzim yang dihasilkan atau diproses oleh jaringan hati. Tes biokimia hati dapat dipergunakan untuk mengetahui derajat keparahan atau kerusakan sel
sehingga dapat menilai fungsi hati.
Penderita penyakit hati secara umum termasuk hepatitis, akan diperiksa darahnya
untuk beberapa jenis pemeriksaan parameter biokimia, seperti AST, ALT (alanin
aminotransferase), alkaline fosfatase,bilirubin, albumin, dan protombin (Wening, 2008).
Adapun nilai normal untuk pemeriksaan laboratorium disajikan dalam tabel 2.1 dan kegunaan
Tabel 2.1 : Nilai normal pemeriksaan laboratorium
Parameter Biokimia Hati Rentang Nilai Normal
AST / SGOT ≥ 37 U/L (Pria) | ≥ 31 U/L (wanita)
ALT / SGPT ≥ 42 U/L (Pria) | ≥ 32 U/L (wanita)
HBsAg
NEGATIF : < 1,0 S/CO atau < 1,0 COI (ECLIA)
Anti HAV
NEGATIF : < 1,0 COI POSITIF : >= 1,0 COI (EIA)
Anti HCV
NEGATIF : < 1,0 S/CO atau < 1,0 COI (EIA)
Tabel 2.2 : Kegunaan Pemeriksaan Laboratorium
Jenis Pemeriksaan Kegunaan
SGOT Untuk mengetahui fungsi hati , membantu mendiagnosis kelainan hati
SPGT Untuk mengetahui fungsi hati, membantu mendiagnosis kelainan hati
HBsAg Untuk mengetahui adanya infeksi virus Hepatitis B. Jika HBsAg
positif maka terinfeksi virus hepatitis B. Jika HBsAg positif selama
lebih dari 6 bulan, berarti pasien menderita Hepatitis B kronis dan
disarankan untuk rutin memeriksakan fungsi hati (SGOT, SGPT,
Protein Total, Albumin, AFP) paling tidak 6 bulan – 1 tahun sekali
Anti HAV/ IgM
Anti HAV
Untuk mengetahui adanya antibody terhadap virus Hepatitis A
Anti HCV Untuk mengetahui adanya antibody terhadap virus Hepatitis C. Anti
2.8.1 Penyebab Hepatitis
Penyebab hepatitis sendiri sangat banyak,misalnya hepatitis akibat virus, bahan kimia,
obat – obatan, alkohol, dan lain – lain. Pada saat ini penyakit hepatitis yang sering menjadi masalah adalah hepatitis virus, terutama akibat virus hepatitis B dan C sebab kedua jenis
hepatitis ini sering menimbulkan hepatitis kronis yang dapat berakhir menjadi sironishati dan
kanker hati (Cahyono,2008).
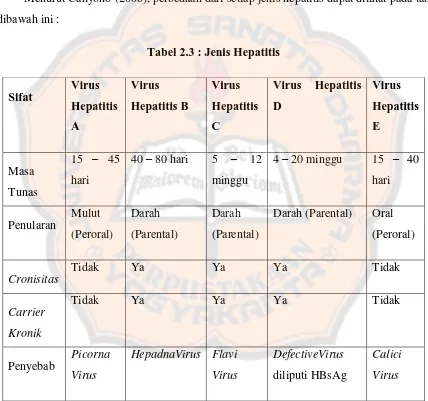
2.8.2 Jenis dan Gejala Hepatitis
Menurut Cahyono (2008), perbedaan dari setiap jenis hepatitis dapat dilihat pada tabel
2 dibawah ini :
Tabel 2.3 : Jenis Hepatitis
Sifat
Darah (Parental) Oral
(Peroral)
Pada fase awal hepatitis, penderita belum merasakan gejala yang spesifik. Keluhan yang
dirasakan antara lain mual, muntah, tidak nafsu makan, badan terasa lemas, dan mudah lelah.
Hepatitis A merupakan jenis hepatitis yang paling ringan. Hal ini disebabkan infeksi
virus hepatitis A (VHA) umumnya tidak sampai menyebabkan kerusakan jaringan hati
(Wening, 2008). Mereka yang terinfeksi virus ini dapat pulih sepenuhnya. Hepatitis A ini
menular melalui makanan atau minuman yang telah terkontaminasi oleh virus VHA.
Hepatitis B merupakan jenis hepatitis yang paling berbahaya.Penyakit ini lebih sering
menular dibandingkan dengan jenis hepatitis lainnya. Hepatitis B menular melalui kontak
darah atau cairan tubuh yang mengandung virus hepatitis B (VHB) maupun material lain
yang terinfeksi, seperti jarum suntik, alat bedah, jarum akupuntur, dan alat – alat yang dapat menimbulkan luka lecet milik individu yang terinfeksi .Hepatitis B kronis memberikan gejala
yang lebih serius yaitu mudah lelah, cemas, tidak nafsu makan, mual, muntah dan merasa
lemas.Hepatitis B kronis dapat membuat penumpukan cairan dalam rongga perut sehingga
perut terlihat membuncit.Seseorang dapat mengidap virus ini tetapi tidak disertai dengan
gejala klinik atau tidak tampak adanya kelainan atau gangguan kesehatan. Orang tersebut
merupakan pembawa atau biasa disebut carrier.
Carrier dapat terjadi karena individu tersebut memiliki pertahanan tubuh yang baik
atau karena virus VHB mengalami perubahan sifat yang tidak aktif (Wening, 2008).Virus
yang tidak aktif ini akan membuat pertahanan tubuh tidak dapat mengenalinya sebagai
“musuh” sehingga sistem imun tidak mengadakan perlawanan, suatu saat ketika pertahanan
tubuh dalam kondisi lemah maka virus akan aktif dan akan muncul gejala hepatitis. Carrier
jumlahnya relatif banyak dan berpotensi menularkan.
Hepatitis C juga menyebabkan peradangan hati yang cukup berat. Hepatitis C menular
melalui darah, biasanya karena transfusi atau jarum suntik yang terkontaminasi virus hepatitis
C (VHC).Pada penderita hepatitis C keluhan yang dirasakan adalah merasalemas, mual,
muntah, hilang nafsu makan, demam, mual, dan nyeri ulu hati. Sebagian dari penderita
mengeluh bahwa urin berwarna gelap, feses berwarna putih, serta kulit, kuku dan bola mata
bagian putih berwarna kuning. Jika diraba, perut bagian atas kanan membesar karena terjadi
2.8 Contoh Penggunaan Fuzzy C-Means
Terdapat data gejala yang telah dirubah kedalam bentuk biner
Pegal NyeriSendi Normal Linu-linu
0 0 1 0
0 0 1 0
0 0 1 0
0 0 1 0
0 0 1 0
0 1 0 0
0 0 1 0
1 0 0 0
0 0 1 0
0 0 1 0
0 0 1 0
0 0 1 0
Data tersebut akan dibagi dalam tiga kelompok. Pertama tentukan :
banyaknya cluster c 3
Pembobot w 2
maksimum iterasi maxiter 5
error e 0.01
fungsi objektif P0 0
Iterasi awal iter 1
i k1 k2 k3
1 0.440986528 0.490279156 0.069
2 0.555826368 0.384816328 0.059
3 0.156206358 0.306739378 0.537
4 0.460986631 0.075301468 0.464
5 0.426768818 0.216412813 0.357
6 0.095909122 0.285092664 0.619
7 0.32906622 0.398552921 0.272
8 0.019634378 0.466853598 0.514
9 0.311402432 0.347649768 0.341
10 0.321789912 0.537765533 0.14
11 0.695747687 0.031368532 0.273
12 0.047758847 0.100471348 0.852
Langkah selanjutnya adalah menghitung pusat kluster Vij dan didapat hasil :
vij 1 2 3 4 5 6 7
1 0.00532574 0.001543791 0.712869 0.280262 0.934722 0 0.161594 2 0.05747037 0.161248551 0.780585 0.000696 0.738046 0 0.118575 3 0.1668799 0.430836171 0.369851 0.032433 0.824529 0 0.106082
8 9 10 11 12 13 14 15 16
0.883904 0.48318 0.933401 0.336406 0.756065 0.123037 0 0.1054 0.001321 0.710058 0.647889 0.730909 0.086154 0.889208 0.004009 0 0.0331 0.007138 0.94078 0.484568 0.508542 0.083062 0.409287 0.093653 0 0.0555 0.315987
17 18 19 20 21 22 23 24 25 26
Lalu hitung fungsi objektif pada iterasi ke-i
Kemudian setelah fungsi objektif diperoleh, yang dilakukan adalah memperbaiki
derajat keanggotaan dan diperoleh derajatkeanggotaan yang baru sebagai berikut :
8 0.39 0.31 0.30
9 0.33 0.30 0.37
10 0.39 0.23 0.38
11 0.21 0.39 0.40
12 0.42 0.39 0.19
Setelah dibentuk derajat keanggotaan yang baru kemudian cek kondisi berhenti
apakah (|Pi-Pi-1 |<e) atau (t>MaxIter) ? Jika tidak: t=t+1, ulangi langkah dari menghitung
pusat kluster.
Setelah mengalami 6 kali iterasi maka diperoleh fungsi objektif sebagai berikut :
Iterasi Fungsi Objektif
1 17.91338887
2 14.52300538
3 14.261227
4 14.23399458
5 14.22633765
Dan derajat keanggotaan yang diperoleh pada iterasi keenam adalah :
K1 K2 K3
0.35 0.33 0.32
0.35 0.32 0.33
0.35 0.33 0.32
0.33 0.34 0.33
0.34 0.33 0.32
0.32 0.34 0.34
0.31 0.35 0.34
0.34 0.33 0.33
0.32 0.34 0.34
0.32 0.34 0.34
0.34 0.33 0.33
dari matriks derajat keanggotaan diatas maka dapat disimpulkan pengelompokkan
data setelah iterasi keenam :
K1 K2 K3
X
X
X
X
X
X
X
X
X X
X X
X
Setelah data dikelompokkan dengan menggunakan Fuzzy C-Means maka hasil
pengelompokkan tersebut dihitung dengan menggunkana confusion matrix sebagai berikut
Hepatitis\Kelompok a b c
K1 3 2 1
K2 1 2 2
K3 0 0 3
BAB III
ANALISIS dan DESAIN SISTEM
Bab ini berisi tentang desain dan analisis sistem meliputi perancangan antarmuka,
flowchartdan usecase.
3.1 Data
Penyakit hepatitis merupakan penyakit peradangan hati. Terdapat beberapa jenis
hepatitis yaitu hepatitis A, B, C, D, E. Hepatitis tipe A dan E masih dapat untuk di
sembuhkan, namun untuk hepatitis tipe B dan C biasanya menjadi penyakit yang
kronis.Dalam penelitian ini penyakit hepatitis yang akan digunakan adalah hepatitis A, B, dan
C karena tipe tersebut yang paling banyak ditemui dibandingkan dengan tipe yang lainnya.
Rumah sakit Panti Rapih Yogyakarta merupakan sebuah rumah sakit besar yang setiap
harinya didatangi pasien hepatitis untuk berobat. Data yang didapat dari Rumah sakit Panti
Rapih merupakan data set yang bertipe record, berupa data hasil laboratorium dan data dari
hasil pemeriksaan dari dokter(anamnesis).Semua keterangan tentang status data pasien
tersebut dikumpulkan dan didokumentasikan oleh pihak rekam medis.
Data anamnesis yang didapat sebanyak 130 data yang merupakan data pasien penyakit
hepatitis tahun 2000 hingga 2010 yang diambil tanggal 10 Januari 2011 oleh Estu
Karunianingtyas. Dari data anamnesis didapat lima gejala yaitu gejala otot, gejala perut,
gejala kulit, gejala mata, dan gejala mirip flu. Masing –masing gejala tersebut memiliki beberapa sub gejala.
Data laboratorium yang didapat sebanyak 66 data pasien hepatitis A, 48 pasien hepatitis
B, dan 30 pasien hepatitis C. Dari data laboratorium didapat lima gejala yaitu SGPT, SGOT,
antiHAV, HbsAg, dan antiHCV.
Gejala otot memiliki sub gejala pegal dan nyeri sendi. Gejala perut memiliki sub gejala
muntah, diare, kencing berwarna gelap, nafsu makan berkurang, mual,nyeri perut sebelah
kanan, Illeus obstructive,Haemotomesis. Gejala kulit memiliki sub gejala kulit berwarna
dan mata berwarna normal. Gejala mirip flu memiliki sub gejala demam, lesu, pusing,
mialgia, lelah, dan menggigil.
Data anamnesispasien yang telah didapat dilakukan binerisasi yaitu konversi sub gejala
menjadi 0 atau 1 dengan ketentuan 0 jika pasien tidak mengalami gejala tersebut dan 1 jika
pasien mengalami gejala tersebut.
3.2 Gambaran Umum Sistem
Sistem ini digunakan untuk melakukan pengelompokkan jenis penyakit hepatitis
berdasarkan dengan gejala anamnesis dan gejala laboratorium dengan menggunakan metode
Fuzzy C-Means.Sistem ini juga digunakan untuk menghitung keakuratan dari metode Fuzzy
C-Means dalam mengelompokkan penyakit hepatitis.Pengelompokkan dilakukan untuk
memberikaninformasi mengenai anggota masing-masing cluster/kelompok.
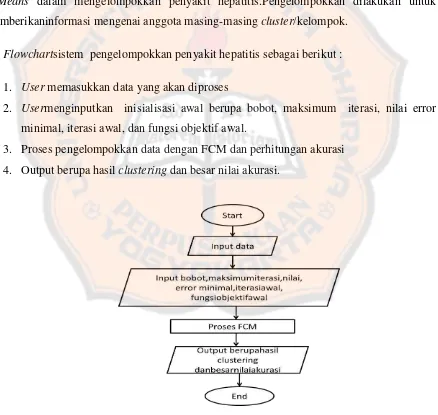
Flowchartsistem pengelompokkan penyakit hepatitis sebagai berikut :
1. User memasukkan data yang akan diproses
2. Usermenginputkan inisialisasi awal berupa bobot, maksimum iterasi, nilai error
minimal, iterasi awal, dan fungsi objektif awal.
3. Proses pengelompokkan data dengan FCM dan perhitungan akurasi
4. Output berupa hasil clustering dan besar nilai akurasi.
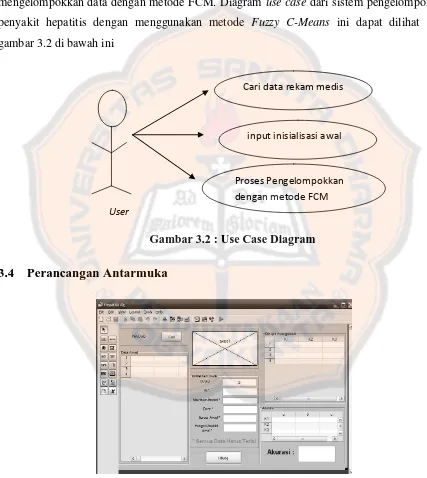
3.3 Use Case Diagram
Diagram use case digunakan untuk menggambarkan interaksi antara pengguna dengan
sistem. Pada system ini yang menjadi actor adalahuser. User dapat memilih data yang akan dikelompokkan dan dapat melakukan pengelompokkan data.Fungsi yang dapat dijalankan oleh pengguna sistem ini adalah fungsi memasukkan data dalam bentuk file .csv. Fungsi
berikutnya adalah fungsi memasukkan data inisialisasi awal.Fungsi terakhir yaitu fungsi
mengelompokkan data dengan metode FCM. Diagram use case dari sistem pengelompokkan
penyakit hepatitis dengan menggunakan metode Fuzzy C-Means ini dapat dilihat pada
gambar 3.2 di bawah ini
Gambar 3.2 : Use Case Diagram
3.4 Perancangan Antarmuka
Gambar 3.3 : Perancangan Antarmuka Cari data rekam medis
Proses Pengelompokkan dengan metode FCM
input inisialisasi awal
Desain Tampilan sistem pengelompokkan penyakit hepatitis dengan metode Fuzzy
C-Means ini hanya mempunyai satu tampilan utama. Pada tampilan ini terdapat fasilitas untuk
mencari data rekam medis yang akan dihitung dan data yang dipilih akan ditampilkan di tabel
“Data Awal” , selain itu juga user harus mengisikan inisialisasi awal pada tampilan ini
sebelum tombol “Hitung” ditekan. Nilai dari tabel “Derajat Keanggotaan” dan tabel “Akurasi” serta nilai akurasi akan otomatis terisi ketika tombol “Hitung” ditekan.
3.5 Spesifikasi Perangkat Lunak dan Perangkat Keras
Spesifikasi software dan hardware yang digunakan dalam implementasi sistem
diagnosa penyakit hepatitis menggunakan Fuzzy C-Meansadalah sebagai berikut:
1. Software :
XP SP 2
2. Hardware :
Processor : Intel(R) Core(TM) i3 CPU M370 @2.40GHz
Memory : 2 GB.
BAB IV
Implementasi dan Analisis Hasil
Pada bab ini dibahas mengenai hasil penelitian dan analisis hasil penelitian dari implementasi
system yang telah dibuat. Hasil penelitian yang terpenting berupa perbandingan akurasi yang
diperoleh dari pengujian metode Fuzzy C-Means. Pada bab ini juga dibahas mengenai user
interface yang dibangun berdasarkan algoritma yang telah dirancang.
4.1 Hasil Pengumpulan Data
Pada penelitian yang telah dilakukan di Rumah Sakit Panti Rapih Yogyakarta,
diperoleh 144 data laboratorium dari pasien yang mengidap penyakit hepatitis A, hepatitis B
dan hepatitis C yang masing – masing 66 data pasien hepatitis A, 48 data pasien hepatitis B, dan 30 data pasien hepatitis C. Dari 130 data anamnesis terdiri dari 50 data hepatitis A, 50
data hepatitis B dan 30 data hepatitis C dan merupakan data pasien penyakit hepatitis tahun
2000 hingga 2010 yang diambil tanggal 10 Januari 2011 oleh Estu Karunianingtyas. Untuk
masing – masing gejala anamnesis terdiri atas beberapa kriteria seperti pada tabel 4.1 dan untuk data laboratorium terdiri atas beberapa feature seperti pada tabel 4.2 dibawah ini :
Tabel 4.1 : Deskripsi data gejala anamnesis
NO Gejala Feature
1 Otot Pegal, nyeri sendi, normal dan linu -linu
2 Perut Muntah, diare, kencing berwarna gelap, mual, nyeri perut
sebelah kanan, nafsu makan berkurang dan perut acites(perut
membuncit)
4 Mata Normal, kuning
5 Mirip Flu Demam, pusing, lesu, mialgia, lelah, menggigil, batuk
Tabel 4.2 : Deskripsi data gejala Laboratorium
NO Feature
1 SGOT
2 SGPT
3 Igm
4 HbsAg
5 Anti HCV
Data anamnesis dan data laboratorium pasien hepatitis digabungkan menjadi satu
berupa teks yang disimpan dalam format excel (.xls), masing-masing disimpan secara
terpisah baik data hepatitis A, B maupun C. Terdiri 40 data hepatitis A, 40 data hepatitis B
dan 30 data hepatitis C.
4.2 Perancangan Fuzzy C- Means
Data yang digunakan dalam penelitian ini adalah data hasil diagnosa akhir dan data
laboratorium pasien hepatitis yang diperoleh dari Rekam Medis Rumah Sakit Panti
Rapih.Data diberikan dalam bentuk manual, yaitu berupa map yang berisi lembaran data
diagnosa keperawatan yang mana pasien telah dirawat inap.Peneliti melakukan pencatatan
data laboratorium pasien dalam format ekstensi xls.
4.2.1 Pembersihan Data
Pembersihan Data (data cleaning) merupakan tahap awal dalam proses
penambangan data. Pada data anamnesisdan data laboratorium yang diperoleh
terdapat beberapa data yang tidak lengkap, seperti misalnya ada beberapa pasien yang
tidak menjalani pemeriksaan laboratorium sehingga tidak didapat data
laborataoriumnya dan terdapat juga pasien yang menjalani pemeriksaan laboratorium
yang tidak menyeluruh sehingga menyebabkan data tidak lengkap.Data yang tidak
lengkap tersebut kemudian dibuang sehingga diperoleh 110 data laboratorium dan 110
data anamnesis.
4.2.2 Normalisasi data laboratorium
Pada data hasil pemeriksaan laboratorium didapat nilai hasil pemeriksaan yang
mempunyai satuan yang berbeda – beda. Hal ini disebabkan karena alat pemeriksaanyang digunakan untuk memeriksa penyakit hepatitis berbeda antara
pasien satu dengan pasien yang lain sehingga menyebabkan rentang nilai normal yang
berbeda.Perbedaan jenis kelamin juga berpengaruh pada rentang nilai normal
pemeriksaan laboratorium.Data pemeriksaan laboratorium dinormalisasi dengan
menggunakan nilai rentang normal dari pemeriksaan laboratorium sesuai dengan jenis
alat yang digunakan dan jenis kelamin pasien.
4.2.3 PCA ( Principal Component Analysis)
PCA merupakan salah satu dari metode dimensional reduction yang
digunakan untuk menyederhanakan variabel.Pada penelitian ini, data yang diolah
dengan menggunakan metode PCA adalah data anamnesa yang mempunyai 26
variabel.
Data anamnesa ini akan diolah dengan bantuan SPSS 17untuk mereduksi
variabel bebas yang berkorelasi tinggi sehingga dapat diketahui variabel mana saja
Langkah – langkah yang dilakukan dalam prosedur PCA dengan menggunakan SPSS 17 pada data anamnesa pasien penyakit hepatitis adalah sebagai
berikut :
a. Barlett Test
Tabel 4.3: KMO and Bartlett;s Test
.236
Barlett Test merupakan tes statistik untuk menguji apakah betul
variabel-variabel bebas yang dilibatkan berkorelasi.
Ho :Tidak ada korelasi antarvariabel bebas
H1 :Ada korelasi antarvariabel bebas
Kriteria uji dengan melihat p-value (signifikansi) : Terima Ho jika Sig. > 0,05
atau tolak Ho jika Sig. < 0,05. Pada tabel 4.3 di atas dapat dilihat bahwa nilai
Chi-Square adalah 1168.660, dengan derajat bebas sebesar 325, dan p-value (sig) sebesar
0,000. Karena p-value (0,000) < 0,05 maka Ho di tolak. Artinya, benar-benar terdapat
Communalities menunjukkan berapa varians yang dapat dijelaskan oleh factor
yang diekstrak (faktor yang terbentuk).Cara memperolehnya adalah dengan
mengkuadratkan nilai korelasi yang terdapat pada tabel 4.6Component Matrix.Setiap
variabel berkorelasi dengan faktor-faktor yang terbentuk.Misalkan untuk variabel
pegal diperoleh nilai sebesar 0.715. Hal ini berarti sekitar 71,5% variabel pegal dapat
dijelaskan oleh faktor yang terbentuk. Untuk variabel nyeri sendi, diperoleh nilai
sebesar 0,867. Hal ini berarti sekitar 86,7% variabel nyeri sendi dapat dijelaskan oleh
faktor yang terbentuk.
c. Total Variance Explained
Tabel 4.5: Total Variance Explained
Total
1 2.978 11.454 11.454 2.978 11.454 11.454
2 2.414 9.284 20.739 2.414 9.284 20.739
3 2.255 8.672 29.410 2.255 8.672 29.410
4 1.692 6.508 35.919 1.692 6.508 35.919
5 1.551 5.967 41.885 1.551 5.967 41.885
6 1.450 5.578 47.464 1.450 5.578 47.464
7 1.320 5.077 52.540 1.320 5.077 52.540
8 1.168 4.493 57.033 1.168 4.493 57.033
9 1.121 4.313 61.346 1.121 4.313 61.346
10 1.070 4.115 65.461 1.070 4.115 65.461
11 1.028 3.954 69.415 1.028 3.954 69.415
12 .987 3.796 73.211
13 .927 3.564 76.775
Compone nt
Initial Eigenvalues
Extraction Sums of Squared Loadings
Kemampuan setiap factor mewakili variabel-variabel yang dianalisis
ditunjukkan oleh besarnya varians yang dijelaskan, yang disebut dengan
eigenvalue.Varians yang dimaksud adalah varians variabel-variabel yang sudah
distandardisasi.Dengan standardisasi, nilai rata-rata setiap variabel menjadi nol dan
variansnya menjadi satu.Karena varians setiap variabel adalah satu, maka varians
totalnya ada 26 karena dalam kasus ini ada 26 variabel bebas.
Eigenvalues menunjukkan kepentingan relatif masing-masing factor dalam
menghitung varians ketiga variabel yang dianalisis. Susunan eigenvalues selalu
diurutkan dari yang terbesar sampai ke yang terkecil, dengan kriteria bahwa angka
eigenvalues di bawah 1 tidak digunakan dalam menghitung jumlah faktor yang
angka eigenvalues memiliki nilai di atas 1. Sehingga proses factoring seharusnya
berhenti pada 11 faktor saja. Faktor 1 memiliki eigenvalue sebesar 2,978 artinya
faktor 1 ini dapat menjelaskan 2,978 atau 11,454% dari total communalities
d. Component Matrix
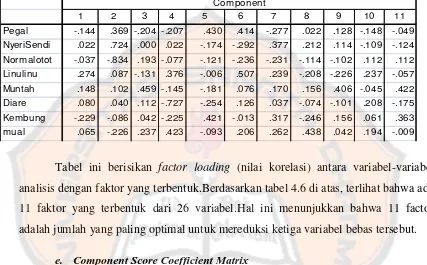
Tabel 4.6: Conponent Matrix
1 2 3 4 5 6 7 8 9 10 11
Pegal -.144 .369 -.204 -.207 .430 .414 -.277 .022 .128 -.148 -.049
NyeriSendi .022 .724 .000 .022 -.174 -.292 .377 .212 .114 -.109 -.124
Normalotot -.037 -.834 .193 -.077 -.121 -.236 -.231 -.114 -.102 .112 .112 Linulinu .274 .087 -.131 .376 -.006 .507 .239 -.208 -.226 .237 -.057
Muntah .148 .102 .459 -.145 -.181 .076 .170 .156 .406 -.045 .422
Diare .080 .040 .112 -.727 -.254 .126 .037 -.074 -.101 .208 -.175
Kembung -.229 -.086 .042 -.225 .421 -.013 .317 -.246 .156 .061 .363
mual .065 -.226 .237 .423 -.093 .206 .262 .438 .042 .194 -.009
Component
Tabel ini berisikan factor loading (nilai korelasi) antara variabel-variabel
analisis dengan faktor yang terbentuk.Berdasarkan tabel 4.6 di atas, terlihat bahwa ada
11 faktor yang terbentuk dari 26 variabel.Hal ini menunjukkan bahwa 11 factor
adalah jumlah yang paling optimal untuk mereduksi ketiga variabel bebas tersebut.
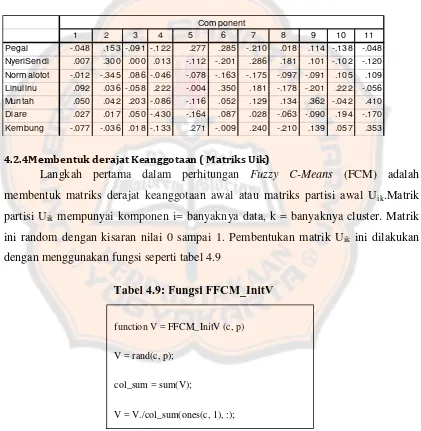
e. Component Score Coefficient Matrix
Setelah mendapatkan faktor yang terbentuk melalui proses reduksi, maka perlu
dicari persamannya. Dengan persaman tersebut, dapat diperoleh skor setiap faktor
secara manual.Persamaan yang dibuat mirip dengan regresi linier berganda, hanya
dalam persamaan faktornya tidak terdapat konstanta.Skor-skor faktor yang dihasilkan
dapat digunakan untuk menggantikan skor-skor pada varibel bebas yang asli. Hasil
skor faktor yang diperoleh ditunjukkan pada tabel 4.7 dan hasilComponent Score
Tabel 4.7: Score Faktor
FC1 FC2 FC3 FC4 FC5 FC6 FC7 FC8 FC9 FC10 FC11
-0.0649 -0.11 1.665 0.12 0.4 0.1013 -0.13 0.183 1.005 0.48 -0
1.07655 0.051 1.419 0.55 -0.4 0.3197 -0.46 -0.21 0.129 0.51 0.22
-1.04707 -0.9 1.1 0.21 0.03 -1.239 1.115 -1.97 1.861 2.49 -0.5
-1.16246 -0.99 0.862 0.17 0.35 0.6079 0.022 1.279 0.035 -0.53 0.26
1.11325 0.918 0.687 0.71 0.04 -0.571 0.845 0.457 0.124 -1.12 0.35
0.83123 -0.55 0.624 0.09 0.65 -0.531 0.143 -0.76 0.512 -0 0.54
0.98196 -0.05 1.311 0.73 0.47 -0.469 -0.81 -0.63 -0.78 0.31 -0.5
-1.40938 -0.44 0.474 0.17 -0.8 -0.249 -0.57 0.108 -0.47 -0.18 -0.8
Tabel 4.8: Component Score Coefficient Matrix
1 2 3 4 5 6 7 8 9 10 11
Pegal -.048 .153 -.091 -.122 .277 .285 -.210 .018 .114 -.138 -.048
NyeriSendi .007 .300 .000 .013 -.112 -.201 .286 .181 .101 -.102 -.120
Normalotot -.012 -.345 .086 -.046 -.078 -.163 -.175 -.097 -.091 .105 .109
Linulinu .092 .036 -.058 .222 -.004 .350 .181 -.178 -.201 .222 -.056
Muntah .050 .042 .203 -.086 -.116 .052 .129 .134 .362 -.042 .410
Diare .027 .017 .050 -.430 -.164 .087 .028 -.063 -.090 .194 -.170
Kembung -.077 -.036 .018 -.133 .271 -.009 .240 -.210 .139 .057 .353
Component
4.2.4Membentuk derajat Keanggotaan ( Matriks Uik)
Langkah pertama dalam perhitungan Fuzzy C-Means (FCM) adalah
membentuk matriks derajat keanggotaan awal atau matriks partisi awal Uik.Matrik
partisi Uik mempunyai komponen i= banyaknya data, k = banyaknya cluster. Matrik
ini random dengan kisaran nilai 0 sampai 1. Pembentukan matrik Uik ini dilakukan
dengan menggunakan fungsi seperti tabel 4.9
Tabel 4.9: Fungsi FFCM_InitV
function V = FFCM_InitV (c, p)
V = rand(c, p);
col_sum = sum(V);
Matriks Uik yang terbentuk dari fungsi FFCM_initV disimpan ke dalam
hepatitis.mat.Jika dijumlahkan maka nilai perbaris dari matriks Uik yang terbentuk
tidak lebih dari 1. Setelah nilai matriks partisi awal disimpan maka proses FCM
dilakukan pertama kali dengan memilih data yang akan diolah, kemudian data
tersebut akan dihitung dengan menggunakan fungsi FFCM yang terdapat pada
halaman lampiran. Perhitungan FCM ini akan dilakukan berulang kali untuk
memperbaiki lokasi pusat cluster. Langkah iterative ini akan dilakukan berdasarkan
minimisasi fungsi objektif.
5.3 Implementasi User Interface
Implementasi sistem pengelompokkan penyakit hepatitis dengan menggunakan Fuzzy
C-Meansini dibangun dengan menggunakan program MATLAB R2010a. Source code
program terdapat pada halaman Lampiran.
Gambar 4.1 : Halaman Pengelompokkan Penyakit Hepatitis
Pada gambar 4.1 ditunjukkan halaman pengelompokkan penyakit hepatitis dengan
menggunakan metode FCM. Di halaman ini user memilih data rekam medis yang akan
dihitung dengan menekan tombol cari maka akan muncul dialog box seperti gambar 4.2
Gambar 4.2 :dialog box untuk memilih data
Kemudian user memilih nama file berformat .csv yang akan dihitung.setelah tombol
open ditekan maka data yang dipilih akan tampil pada tabel data awal seperti gambar 4.3
Gambar 4.3 :Data awal
Kemudian user memasukkan inisialisasi awal untuk bobot (w), maximum iterasi, nilai
error, iterasi awal dan fungsi objektif awal pada kolom inisialisasi awal seperti gambar 4.4.
Untuk nilai bobot (w) nilai yang diinputkan tidak boleh kurang dari 1 karena nilai
perhitungan akan menjadi 0 jika menginputkan bobot bernilai 1.
Setelah memasukkan nilai inisialisasi awal tekan tombol “Hitung” untuk menjalankan program. Selanjutnya akan ditampilkan derajat keanggotaan terakhir dan nilai akurasinya.
Ketika tombol “Hitung” ditekan maka secara otomatis nilai derajat keanggotaan terakhir dan nilai fungsi objektif akhir akan tersimpan pada uikAkhir.xls dan FungsiObjektif.xls. Hasil
nilai derajat keanggotaan pada iterasi terakhir yang didapat, nilai fungsi objektif akhir dan
hasil akurasi akan tampak seperti gambar 4.5, gambar 4.6 dan gambar 4.7 dibawah ini
Gambar 4.5 :Nilai derajat keanggotaan iterasi terakhir
1.258421 0.077375 0.030552 0.016056 0.010787 0.00726 0.004815 0.003175 0.002089 0.001373 0.000901 0.000592 0.000389 0.000255 0.000168 0.00011 7.22E-05
Gambar 4.6: Fungsi Objektif
Nilai derajat keanggotaan akhir pada gambar 4.6 merupakan hasil dari perhitungan
metode FCM.Nilai derajat keanggotaan akhir ini yang menentukan pengelompokkan dari
data pasien penyakit hepatitis.Cara mengelompokkan pasien berpenyakit hepatitis ini dengan
melihat nilai tertinggi dari derajat keanggotaan akhir yang didapat.
Fungsi objektif pada gambar 4.6 dapat memberitahu banyak iterasi yang dilakukan untuk mengolah data dengan menggunakan metode FCM dan nilai minimasi fungsi objektif yang didapat.Pada gambar 4.6 dilakukan 17 kali iterasi dengan nilai minimasi fungsi objektif sebesar -3.77768E-05.
Pada gambar 4.7 diatas ditunjukkan hasil pengelompokkan dengan menggunakan
metode FCM, akurasi yang diperoleh dari hasil percobaan tersebut sebesar 46.5517%. Nilai
akurasi tersebut didapatkan dengan cara :
Akurasi=
.
Jika dibandingkan dengan penelitian sebelumnya akurasi yang diperoleh dari
penelitian ini lebih buruk, karena penelitian sebelumnya akurasi yang diperoleh sebesar
51.11%.
5.4 Hasil Pengujian
Pengujian yang dilakukan pada sistem pengelompokkan penyakit hepatitis ini
dilakukan dengan menggunakan data anamnesisyang belum di PCA, data anamnesa sudah di
PCA, data anamnesa sudah di PCA digabungkan dengan data laboratorium dan percobaan
yang terakhir dilakukan pada data laboratorium. Data anamnesa yang digunakan memiliki
110 data dan 26 atribut berbentuk biner, sedangkan data laboratorium yang digunakan
memiliki 110 data dan 5 atribut. Data anamnesa yang sudah dilakukan proses PCA terdiri
dari 110 data dan 11 atribut dan pada data anamnesa yang sudah di PCA dan digabung
dengan data laboratorium terdiri dari 110 data dan 16 atribut.
Tabel 4.10 menunjukkan hasil percobaan pada data anamnesa dokter yang didalamnya
terdiri dari nilai inisialisasi awal yang diinputkan dan nilai akurasi yang didapat dari
percobaan tersebut.Sedangkan tabel 4.11 menunjukkan hasil percobaan pada data
laboratorium yang didalamnya terdiri dari nilai inisialisasi awal yang diinputkan dan nilai
akurasi serta perrcobaan dengan menggunakan data laboratorium yang sudah di normalisasi.
tabel 4.12 dan hasil percobaan pada data anamnesa yang sudah dilakukan proses PCA dan
digabung dengan data laboratorium ditunjukkan pada tabel 4.13
Tabel 4.10 Hasil Pengujian data anamnesa dokter
NO Nilai inisialisasi awal akurasi
1 Bobot(w)=2; maksimum iterasi =100; error = 1e-4;
iterasi awal =1; fungsi objektif awal = 0
46.5517%
2 Bobot(w)=2; maksimum iterasi =10; error = 1e-4;
iterasi awal =1; fungsi objektif awal = 0
45.6897%
3 Bobot(w)=6; maksimum iterasi =18; error = 0.002;
iterasi awal =1; fungsi objektif awal = 0
50%
4 Bobot(w)=8; maksimum iterasi =10; error = 0.5;
iterasi awal =1; fungsi objektif awal = 0
43.1034%
5 Bobot(w)=8; maksimum iterasi =50; error =
0.000005; iterasi awal =1; fungsi objektif awal = 0
47.4138%
Tabel 4.11 Hasil Pengujian data laboratorium
NO Nilai inisialisasi awal akurasi
1 Bobot(w)=2; maksimum iterasi =100; error = 1e-4;
iterasi awal =1; fungsi objektif awal = 0
82.3529%
2 Bobot(w)=2; maksimum iterasi =10; error = 1e-4;
iterasi awal =1; fungsi objektif awal = 0
3 Bobot(w)=5; maksimum iterasi =40; error =
0.00600; iterasi awal =1; fungsi objektif awal = 0
78.1818%
4 Bobot(w)=8; maksimum iterasi =10; error = 0.5;
iterasi awal =1; fungsi objektif awal = 0
83.871%
5 Bobot(w)=8; maksimum iterasi =50; error =
0.000005; iterasi awal =1; fungsi objektif awal = 0
74.5455%
6 Bobot(w)=2; maksimum iterasi =100; error = 1e-4;
iterasi awal =1; fungsi objektif awal = 0 ( dengan
menggunakan data laboratorium yang sudah di
normalisasi ).
100%
Tabel 4.12Hasil Pengujian data anamnesa dokter(PCA)
NO Nilai inisialisasi awal akurasi
1 Bobot(w)=2; maksimum iterasi =100; error = 1e-4;
iterasi awal =1; fungsi objektif awal = 0
38.2114%
2 Bobot(w)=2; maksimum iterasi =10; error = 1e-4;
iterasi awal =1; fungsi objektif awal = 0
39.0244%
3 Bobot(w)=6; maksimum iterasi =18; error = 0.02;
iterasi awal =1; fungsi objektif awal = 0
40.6504%
4 Bobot(w)=8; maksimum iterasi =10; error = 0.5;
iterasi awal =1; fungsi objektif awal = 0