CROSS LANGUAGE QUESTION ANSWERING SYSTEM
MENGGUNAKAN PEMBOBOTAN HEURISTIC DAN
MULTIDOKUMEN
FADILA ANDRE MULYANTO
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2013
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Cross LanguageQuestion Answering System Menggunakan Pembobotan Heuristic dan
Multidokumen adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Agustus 2013
Fadila Andre Mulyanto
ABSTRAK
FADILA ANDRE MULYANTO. Cross Language Question Answering System Menggunakan Pembobotan Heuristic dan Multidokumen. Dibimbing oleh SONY HARTONO WIJAYA.
Manusia cenderung bertanya ketika ingin mendapatkan suatu informasi dan terkadang mengalami kendala saat informasi yang ada berbeda dengan bahasa yang dikuasai. Cross Language Question Answering System (CL-QAS) adalah suatu sistem temu kembali informasi yang menggunakan pertanyaan sebagai query dan jawaban sebagai output dengan fitur alih bahasa. Pada penelitian ini, dikembangkan sebuah CL-QAS dengan dokumen bahasa Inggris dan query bahasa Indonesia. Keluaran dari sistem berupa sebuah jawaban yang akan dihitung dengan metode pembobotan heuristic dan multidokumen. Waktu rata-rata yang diperlukan oleh sistem untuk memperoleh jawaban relatif kecil yakni sebesar 3.03 detik. Akurasi ketepatan jawaban yang diperoleh juga cukup baik untuk kata tanya SIAPA (100%), KAPAN (100%), DIMANA (100%), dan BERAPA (90%).
Kata Kunci: multidokumen, Question Answering System, temu kembali informasi
ABSTRACT
FADILA ANDRE MULYANTO. Cross Language Question Answering System
Using Heuristic and Multi-Document Weighting Method. Supervised by SONY
HARTONO WIJAYA.
People tend to ask when they need to get some information. This often raises a difficulty whenever available information is not in same the language with the person understands or speaks. Cross Language Question Answering System (CL-QAS) is an information retrieval system that is able to handle this kind of situation. It accepts a question query as the input and outputs the answer in the translated language. In this study, CL-QAS is developed that takes query in Indonesian language and answers in English. The system output is calculated by weighting heuristic and multi-documents. The average time to produce answer is quite fast, i.e. 3.03 seconds. The system accuracy is good considering for the following queries: SIAPA (100%), KAPAN (100%), DIMANA (100%), and BERAPA
(90%).
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
CROSS LANGUAGE QUESTION ANSWERING SYSTEM
MENGGUNAKAN PEMBOBOTAN HEURISTIC DAN
MULTIDOKUMEN
FADILA ANDRE MULYANTO
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2013
Penguji: Ir Julio Adisantoso, MKomp Aziz Kustiyo, SSi, MKomp
Judul Skripsi: Cross Language Question Answering System Menggunakan Pernbobotan Heuristic dan Multidokurnen
Nama : Fadila Andre Mulyanto NIM : G64090033
Disetujui oleh
Sony Hartono Wijaya, SKorn MKorn Pernbirnbing
Diketahui oleh
Judul Skripsi : Cross Language Question Answering System Menggunakan Pembobotan Heuristic dan Multidokumen
Nama : Fadila Andre Mulyanto NIM : G64090033
Disetujui oleh
Sony Hartono Wijaya, SKom MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Alhamdulillahirobbil’alamin, segala puji dan syukur penulis panjatkan ke
hadirat Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga penulis dapat menyelesaikan tugas akhir yang berjudul Cross Language Question Answering
System Menggunakan Pembobotan Heuristic dan Multidokumen.
Penulis menyadari bahwa tugas akhir ini tidak akan terselesaikan tanpa bantuan dari berbagai pihak. Pada kesempatan ini penulis ingin mengucapkan terima kasih kepada:
1 Ayah dan Ibu tercinta, Bapak Putut dan Ibu Sri, adikku yang saya sayangi Gita, yang selalu memberikan doa, nasihat, semangat, dukungan, dan kasih sayang yang luar biasa kepada penulis sehingga dapat menyelesaikan perkuliahan. 2 Bapak Sony Hartono Wijaya, MKomp selaku dosen pembimbing tugas akhir.
Terima kasih atas kesabaran, bimbingan serta dukungan dalam penyelesaian tugas akhir.
3 Bapak Hendra Rahmawan, MT selaku dosen pembimbing akademik. Terima kasih atas bimbingan yang telah diberikan selama penulis melakukan kegiatan perkuliahan.
4 Teman-teman satu bimbingan skripsi Sapariansyah, Yuzar Marsyah, Ozi Priawadi, Ginanjar dan Ramadhan terima kasih atas kebersamaan dan semangatnya dalam menyelesaikan tugas akhir.
5 Teman-teman satu bimbingan akademik Rizkia Hanna, Iswarawati, Noer Fitria, Anisaul Muawwanah dan rekan-rekan Ilkomerz 46 terima kasih atas bantuannya dalam menjalani kegiatan perkuliahan.
6 Taufik Hidayat, Tommy Sepadinata, Benedictus Adi, Jajang Somantri, Wayan Sumerta, Bryan Dwi, dan sahabat Lorong 2 C2, terima kasih atas untuk dukungan semangat dan motivasi bagi penulis.
7 Khasi Asmarani Lestari yang senantiasa memberikan semangat dan doa kepada penulis selama kegiatan perkuliahan.
8 Bu Rahma, Bu Okta, Pak Ridwan, Pak Syaiful, dan seluruh staf Departemen Ilmu Komputer IPB yang telah banyak membantu baik selama penulis melaksanakan penelitian dan perkuliahan.
Penulis menyadari bahwa dalam penulisan tugas akhir ini masih terdapat banyak kekurangan dan kelemahan dalam berbagai hal karena keterbatasan kemampuan penulis. Penulis berharap adanya masukkan berupa saran atau kritik yang bersifat membangun dari pembaca demi kesempurnaan tugas akhir ini. Semoga karya ilmiah ini bermanfaat.
Bogor, Agustus 2013
DAFTAR ISI
DAFTAR TABEL vi DAFTAR GAMBAR vi DAFTAR LAMPIRAN vi PENDAHULUAN 1 Latar Belakang 1 Perumusan Masalah 2 Tujuan Penelitian 2 Manfaat Penelitian 2Ruang Lingkup Penelitian 2
METODE 2
Pemrosesan Offline 2
Pemrosesan Online 3
Evaluasi 4
HASIL DAN PEMBAHASAN 4
Koleksi Dokumen (Korpus) Pengujian 4
Praproses dan Indexing Dokumen 5
Pemrosesan Query 6
Perolehan Dokumen Teratas 6
Perolehan Passages 7
Pembobotan Passages 8
Ekstraksi Jawaban dan Perhitungan Jarak 8
Pembobotan Multidokumen 9
Hasil Percobaan 9
SIMPULAN DAN SARAN 13
Kesimpulan 13
Saran 14
DAFTAR PUSTAKA 14
LAMPIRAN 15
DAFTAR TABEL
1 Daftar kata tanya dan named entity 3
2 Contoh hasil pemrosesan query 6
3 Kandidat jawaban sebelum pembobotan multidokumen 9 4 Kandidat jawaban setelah pembobotan multidokumen 9
5 Perbedaan sistem 9
DAFTAR GAMBAR
1 Gambaran umum sistem 3
2 Struktur tag XML dokumen 4
3 Passage yang telah diberikan tag 5
4 Isi konfigurasi Sphinx 5
5 Contoh stopwords dari http://www.ranks.nl.resources/stopwords.html 6
6 Hasil sepuluh dokumen teratas 7
7 Algoritme pembobotan BM25 7
8 Hasil perolehan passage 7
9 Hasil ekstraksi jawaban 8
10 Grafik perbandingan waktu eksekusi 10
11 Grafik hasil percobaan untuk kata SIAPA 11 12 Grafik hasil percobaan untuk kata KAPAN 11 13 Grafik hasil percobaan untuk kata DIMANA 11 14 Grafik hasil percobaan untuk kata BERAPA 12 15 Grafik hasil percobaan semua kata tanya 12 16 Kandidat jawaban dengan metode heuristic 13 17 Kandidat jawaban dengan metode heuristic ditambah multidokumen 13
DAFTAR LAMPIRAN
1 Waktu (detik) eksekusi sistem untuk memperoleh jawaban akhir 15
2 Tabel hasil kata tanya SIAPA 17
3 Tabel hasil kata tanya KAPAN 18
4 Tabel hasil kata tanya DIMANA 19
1
PENDAHULUAN
Latar Belakang
Masalah yang sering terjadi adalah terkadang informasi yang dibutuhkan berasal dari dokumen berbahasa asing (bahasa yang berbeda dengan query yang diberikan). Sedangkan Question Answering System (QAS) pada umumnya bersifat
mono language yang hanya menemukembalikan informasi dari dokumen yang
menggunakan bahasa yang sama dengan query. Cross Language Question
Answering System (CL-QAS) adalah pengembangan QAS yang dapat menutupi
kekurangan sifat mono language dari QAS dengan menambahkan fungsi penerjemah bahasa terhadap query-nya. Kenyataannya banyak pengguna yang tidak memiliki kemampuan khusus untuk menerjemahkan query ke dalam setiap bahasa yang sesuai dengan dokumen yang tersedia. Jika CL-QAS diberikan input query berupa pertanyaan dalam bahasa tertentu (misal, bahasa Indonesia), ia mampu mengembalikan jawaban dari dokumen berbahasa lain (misal, bahasa Inggris). Sehingga informasi dapat diperoleh dari berbagai dokumen beda bahasa dengan menggunakan satu bahasa yang dikuasai oleh pengguna.
Penelitian tentang QAS dalam perkembangannya sudah diimplementasikan oleh Ballesteros dan Li (2007) yang digunakan untuk bahasa Inggris dan Mandarin. Dalam penelitian tersebut digunakan pembobotan heuristic dan syntactic untuk mengidentifikasikan kandidat kalimat yang relevan. Cidhy (2009) mengimplementasikan penggunaan pembobotan heuristic yang dilakukan Ballesteros dan Li (2007) dalam dokumen berbahasa Indonesia. Subu (2012) mengimplementasikan CL-QAS menggunakan pembobotan heuristic dan
rule-based untuk bahasa Indonesia dan Inggris.
Informasi baru muncul setiap saat, jika sebuah website berita dapat menerbitkan lebih dari satu artikel setiap hari, tentunya jumlah dokumen/artikel saat ini sangat banyak dan sangat memungkinkan informasi yang dikandung dalam suatu dokumen memiliki kesamaan dengan dokumen lainnya. Semakin banyak dokumen yang memiliki informasi serupa menunjukkan informasi tersebut semakin penting karena keberadaannya disampaikan secara terus menerus pada dokumen yang berbeda. Murata et al. (2005) mengembangkan metode pembobotan yang menggunakan dokumen lain sebagai bukti informasi tersebut sangat kuat. Diharapkan metode ini mampu meningkatkan akurasi jawaban dari QAS itu sendiri. Mengacu pada penelitian tersebut, penelitian ini akan mengimplementasikan metode heuristic dengan pembobotan multidokumen pada CL-QAS berbahasa Indonesia dan Inggris. Metode heuristic dipilih karena menurut Subu (2012) memberikan hasil lebih baik dibandingkan dengan metode rule-based. Tantangannya adalah mengidentifikasi jawaban dari pertanyaan bahasa Indonesia dengan menggunakan koleksi dokumen berbahasa Inggris serta pemilihan jawaban akhir berdasarkan kemiripan jawaban antar-dokumen. Fokus penelitian ini adalah bagaimana menemukan jawaban sehingga penerjemahan jawaban dari bahasa Inggris ke bahasa Indonesia tidak diperlukan.
2
Perumusan Masalah
Semakin banyak informasi yang sama dari berbagai dokumen yang berbeda menunjukkan informasi tersebut semakin penting dan valid. Inilah yang menjadi fokus masalah dari penelitian ini, yakni mencoba menerapkan metode pembobotan yang dikembangkan oleh Murata et al. (2005) pada dokumen bahasa Jepang untuk dokumen bahasa Indonesia. Metode pembobotan multidokumen yang menggunakan dokumen lain sebagai bukti untuk memperkuat sebuah informasi diharapkan mampu meningkatkan akurasi jawaban dari QAS.
Tujuan Penelitian
Tujuan dari penelitian ini ialah:
1 Mengimplementasikan metode pembobotan heuristic dan multidokumen pada CL-QAS.
2 Mengevaluasi kinerja sistem dalam menemukembalikan jawaban yang benar dari setiap kueri pertanyaan
Manfaat Penelitian
Penelitian ini diharapkan dapat memberikan kemudahan bagi pengguna dalam memperoleh informasi dan memberikan informasi yang tepat untuk setiap pertanyaan yang diberikan oleh pengguna.
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini ialah:
1 Korpus terdiri atas kumpulan dokumen berita berbahasa Inggris dari website IPB (http://news.ipb.ac.id).
2 Kata tanya yang digunakan adalah siapa, di mana, kapan, dan berapa.
3 Kueri pertanyaan dibatasi pada tipe factoid question, yaitu pertanyaan yang memiliki jawaban tunggal.
METODE
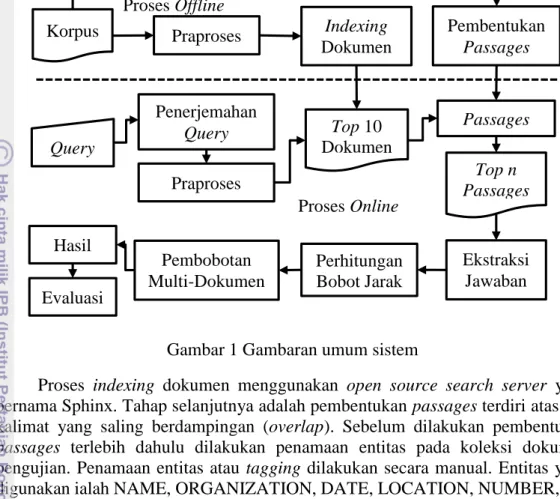
Metode penelitian yang digunakan dalam penelitian ini disajikan pada Gambar 1. Penelitian ini dilakukan dalam tiga tahap, yaitu pemrosesan offline, pemrosesan online, dan evaluasi hasil percobaan.
Pemrosesan Offline
Pemrosesan offline terdiri atas tahap pengumpulan dokumen, praproses dokumen, indexing dokumen, dan pembuatan passage. Dokumen yang dikumpulkan adalah dokumen berita yang berasal dari website IPB (http://news.ipb.ac.id). Pada tahap praproses, dilakukan proses parsing dan penghilangan stopwords terhadap koleksi dokumen uji. Daftar stopwords bahasa Inggris diperoleh dari website (http://www.ranks.nl/ resources/stopwords.html).
3
Gambar 1 Gambaran umum sistem
Proses indexing dokumen menggunakan open source search server yang bernama Sphinx. Tahap selanjutnya adalah pembentukan passages terdiri atas dua kalimat yang saling berdampingan (overlap). Sebelum dilakukan pembentukan
passages terlebih dahulu dilakukan penamaan entitas pada koleksi dokumen
pengujian. Penamaan entitas atau tagging dilakukan secara manual. Entitas yang digunakan ialah NAME, ORGANIZATION, DATE, LOCATION, NUMBER, dan CURRENCY. Passages yang terbentuk digunakan pada pemrosesan secara online. Tabel 1 menunjukkan daftar pasangan jenis kata tanya dan named entity yang menjadi penciri dari jawaban yang akan ditemukembalikan. Pemrosesan offline dilakukan agar pemrosesan online dapat lebih cepat.
Tabel 1 Daftar kata tanya dan named entity No Kata Tanya Named Entity Tag
1 Siapa NAME, ORGANIZATION
2 Kapan DATE
3 Dimana LOCATION
4 Berapa NUMBER, CURRENCY
Pemrosesan Online
Pemrosesan online adalah proses interaksi langsung secara realtime antara sistem dan pengguna. Query berupa kalimat pertanyaan dimasukkan secara manual oleh pengguna. Tipe pertanyaan diidentifikasi berdasarkan kata tanya yang digunakan sehingga dapat ditentukan named entity yang akan dicari untuk menemukan kandidat jawaban. Kemudian, query tanpa kata tanya digunakan untuk memperoleh 10 dokumen teratas dengan metode pembobotan BM25 yang terdapat pada Sphinx. Setiap passages diambil dari 10 dokumen tersebut. Passage adalah
Korpus Query Indexing Dokumen Pembentukan Passages Praproses Penerjemahan Query Pembobotan Multi-Dokumen Praproses Top 10 Dokumen Passages Perhitungan Bobot Jarak Hasil Ekstraksi Jawaban Top n Passages Proses Offline Proses Online Evaluasi
4
dua kalimat yang saling berdampingan dan telah dibuat pada pemrosesan offline. Pembobotan terhadap passage menggunakan faktor heuristik seperti yang telah dilakukan oleh Ballesteros dan Li (2007). Langkah selanjutnya adalah proses ekstraksi jawaban dari setiap passages teratas dengan mencari tipe entitas yang sesuai dengan pertanyaan. Kemudian dilakukan perhitungan jarak jawaban pada masing-masing passage berdasarkan query pengguna. Tahap terakhir adalah pembobotan multidokumen seperti yang dilakukan oleh Murata et al. (2005) yakni menghitung ulang bobot jawaban yang sama jika terdapat pada beberapa dokumen berbeda. Jawaban dengan bobot tertinggi akan menjadi jawaban akhir.
Evaluasi
Tahap evaluasi dilakukan secara objektif dari segi: pasangan jawaban dan dokumen serta ketepatan untuk setiap jawaban. Semakin banyak hasil yang benar, tentu kinerja sistem semakin tinggi. Pada query factoid terdapat 4 jenis penilaian, yaitu:
1 Right : jawaban dan dokumen benar. 2 Wrong : jawaban salah.
3 Unsupported : jawaban benar tetapi dokumen tidak mendukung 4 Null : jawaban dan dokumen kosong.
HASIL DAN PEMBAHASAN
Koleksi Dokumen (Korpus) Pengujian
Setiap dokumen memiliki struktur XML yang sama. Cuplikan dokumen terdapat pada Gambar 2. Tag <DOC> yang menjadi root berfungsi membedakan satu dokumen dengan dokumen lainnya. Tag <DOCNO> menunjukkan nama dokumen, tag <TITLE> menunjukkan judul dokumen, tag <AUTHOR> menunjukkan penulis dokumen, dan tag <TEXT> yang menunjukkan isi dokumen.
Penamaan entitas (named entity) yang disebut tagging dilakukan pada 182 dokumen uji dengan cara manual. Hal ini dilakukan untuk proses perolehan kandidat jawaban sesuai dengan jenis pertanyaan. Named entity yang digunakan terdiri atas NAME, ORGANIZATION, LOCATION, DATE, CURRENCY, dan NUMBER. Passage akan dibentuk dari dokumen yang telah diberi tag dan disimpan ke dalam DBMS MySQL untuk keperluan pemrosesan online. Contoh
passage yang dibentuk dapat dilihat pada Gambar 3.
Gambar 2 Struktur tag XML dokumen <DOC>
<DOCNO> newsipb011110-003</DOCNO>
<TITLE> Afternoon Talk: Prospect of Jabon </TITLE> <AUTHOR> admin ipb </AUTHOR>
<DATE November 01 2010 </DATE>
<TEXT> TREE Jabon, relatively unheard of…</TEXT> </DOC>
5
Gambar 3 Passage yang telah diberikan tag
Praproses dan Indexing Dokumen
Langkah pertama yang dilakukan adalah menyimpan korpus ke dalam bentuk DBMS MySQL lalu dilakukan indexing menggunakan Sphinx dengan konfigurasi yang dapat dilihat pada Gambar 4. Hasil indexing digunakan untuk proses pencarian 10 dokumen teratas. Dalam konfigurasi Sphinx, terdapat dua fungsi penting yakni, source dan index. Fungsi source mengatur tipe dokumen yang akan diindeks dan fungsi index mengatur proses indexing itu sendiri. Penjelasan untuk konfigurasi yang digunakan pada Sphinx, yaitu:
type, menunjukkan tipe dokumen yang akan diindeks.
sql_host, sql_user, sql_pass, sql_db, dan sql_port, menunjukkan konfigurasi DBMS MySQL tempat dokumen disimpan.
sql_query, mengatur query yang akan dieksekusi sebagai objek yang akan diindeks.
source, menunjukkan fungsi source yang digunakan.
path, mengatur lokasi file hasil indexing disimpan.
min_word_len, mengatur minimal panjang karakter yang diindeks.
charset_type, menunjukkan tipe karakter yang digunakan.
stopwords, mengatur lokasi file yang berisi daftar kata buang (stopwords). Contoh daftar kata buang lihat Gambar 5.
1 source mysql { 2 type = mysql 3 sql_host = localhost 4 sql_user = root 5 sql_pass = 6 sql_db = skripsi 7 sql_port = 3306 8 sql_port = 3306
9 sql_query = SELECT id_news, docno, title, author,date_published, body, timestamp FROM news } 10 index skripsi { 11 source = mysql 12 path = C:/sphinx/data/skripsi 13 charset_type = utf-8 14 min_word_len = 3 15 stopwords = C:/sphinx/skripsi/stopwords-en.txt } Gambar 4 Isi konfigurasi Sphinx
This was expressed by <ORGANIZATION>Professor of Nutritional Sciences, Bogor Agricultural University </ORGANIZATION> (IPB), <NAME>Prof. Ali Khomsan</NAME> in the Afternoon Dialogue of <ORGANIZATION> RRI </ORGANIZATION>, <DATE>Tuesday (25 / 1)</DATE> in <LOCATION>Bogor</LOCATION>. Many factors cause children to suffer from malnutrition, for example, poverty, eating difficulty/low appetite.
6
Gambar 5 Contoh stopwords dari http://www.ranks.nl.resources/stopwords.html
Pemrosesan Query
Query yang digunakan dalam penelitian ini berupa bahasa alami berbentuk
kalimat tanya. Dalam pemrosesan query, proses yang dilakukan adalah menerjemahkan query ke dalam bahasa Inggris menggunakan Microsoft Translator (http://api.microsofttranslator.com/V2/Ajax.svc/Translate). Kemudian mengubah karakter query menjadi huruf kecil, membuang stopwords dalam query, dan melakukan parsing terhadap kalimat tanya dengan memisahkan kata tanya dan kata selain kata tanya (praproses). Hasil pemrosesan dapat dilihat pada Tabel 2.
Kata tanya ini digunakan untuk menentukan tipe jawaban yang ditemukembalikan oleh sistem. Tipe jawaban dicirikan dengan named entity yang terdapat pada dokumen. Pada penelitian ini kata tanya yang digunakan dibatasi dalam empat jenis, yaitu siapa, kapan, di mana, dan berapa, sedangkan query selain kata tanya akan digunakan dalam proses perolehan 10 dokumen teratas dengan menggunakan Sphinx, pembobotan heuristic, dan perhitungan jarak antara query dan jawaban.
Tabel 2 Contoh hasil pemrosesan query
Query Terjemahan (B. Inggris) Kata Tanya Query (praproses) Siapa rektor
ipb
who is the Rector of the University
who rector university
Perolehan Dokumen Teratas
Berdasarkan query yang dimasukkan secara manual oleh pengguna, Sphinx akan melakukan perhitungan untuk menentukan dokumen-dokumen yang terkait dengan query tersebut. Contoh hasil perolehan dokumen dari uji coba query “siapa rektor ipb?” dapat dilihat pada Gambar 6. Pembobotan untuk melakukan pemeringkatan dokumen ialah pembobotan BM25 yang disediakan oleh Sphinx dengan algoritme yang dapat dilihat pada Gambar 7. Setiap token query akan memiliki bobot pada semua dokumen yang akan dijumlahkan untuk mendapatkan keseluruhan nilai BM25 (Fathi 2012). Setelah dijumlahkan, dapat terlihat dokumen yang memiliki bobot relevansi tertinggi berdasarkan query pertanyaan. Sepuluh dokumen teratas akan diambil untuk tahap perolehan passage.
a against any be you’ve
about all are because your
above am aren’t … yours
after an as you’ll yourself
7
Gambar 6 Hasil sepuluh dokumen teratas 1 BM25 = 0
2 Foreach(keyword in matching keywords) { 3 n = total matching documents (keyword) 4 N = total_documents_in_collection 5 k1 = 1.2
6 TF = current_document_occurence_count(keyword) 7 IDF = log((N-n+1)/n) / log(1+N)
8 BM25 = BM25 + TF*IDF/(TF+k1) 9 }
10 BM25 = 0.5 + BM25 / (2*num_keywords(query)) Gambar 7 Algoritme pembobotan BM25
Keterangan :
N : Total dokumen dalam korpus
n : Total dokumen yang memiliki kata dari query
TF : Frekuensi term pada dokumen
IDF : Inverted indeks dokumen k1 : Positif parameter (1.2)
Perolehan Passages
Setiap passage dokumen teratas diperoleh dari database karena passage telah dibuat sebelumnya dalam pemrosesan offline sehingga diharapkan hal ini dapat mengurangi waktu komputasi pada pemrosesan online. Contoh hasil passage yang diperoleh dari uji coba query ”siapa rektor ipb?” dapat dilihat pada Gambar 8.
Passage yang diperoleh akan diboboti pada tahap pembobotan passage. Entity tag
yang terdapat pada passage akan digunakan pada tahap ekstraksi jawaban.
8
Pembobotan Passages
Pembobotan terhadap passage dilakukan dengan metode heuristic yang dikembangkan oleh Ballesteros dan Li (2007). Bobot setiap passages akan disimpan dalam variabel heuristic_score(hs) dengan formula:
hs = count_match + 0.5×Sm + 0.5×Ord + count_match/W
Nilai count_match adalah jumlah hasil pencocokan kata antara query dan
passage (wordmatch). Jika nilai count_match kurang dari threshold (t), count_match = 0. Nilai threshold (t) bergantung pada jumlah kata pada query
(count_query) dan didefinisikan sebagai berikut: a) jika count_query < 4, maka t = count_query.
b) jika 4 <= count_query <= 8, maka t = (count_query/2) + 1. c) jika count_query > 8, maka t = (count_query/3) + 2.
Sm menunjukkan seluruh kata antara query dan passage cocok atau tidak (jika cocok maka Sm=1). Ord menunjukkan kata yang cocok pada query dan
passage memiliki urutan yang sama atau tidak (jika sama maka Ord=1). W adalah
jumlah kata dari passage dengan count_match tertinggi.
Sebuah dokumen tentu memiliki lebih dari satu passage (bentuk passage lihat Gambar 8). Passage yang mendapatkan nilai hs>0 akan dikembalikan sebagai top
passage dan dipertahankan, sedangkan passage yang mendapatkan nilai hs=0 akan
dibuang.
Ekstraksi Jawaban dan Perhitungan Jarak
Ekstraksi jawaban dilakukan terhadap top passages, nilai jarak (d) antara
query dan jawaban diperoleh dengan menghitung selisih antara indeks setiap kata
pada vektor query (q1, q2, … , qn) dan indeks kandidat jawaban (j). Nilai n merupakan
jumlah kata dari query. Berikut formula perhitungan jarak:
d(q, j) = ∑ |qi-j| n n
i=1
Kandidat jawaban yang diperoleh dapat dilihat pada Gambar 9. Kata pada jawaban diperoleh berdasarkan entity tag, dokumen menunjukkan asal dari jawaban tersebut berasal, dan bobot adalah 1/d (1 dibagi nilai jarak). Pengubahan nilai jarak menjadi bobot dilakukan untuk mengubah persepsi nilai jarak yakni semakin kecil semakin baik. Karena pada tahap berikutnya, persepsi yang digunakan adalah semakin besar semakin baik (persepsi bobot).
9
Pembobotan Multidokumen
Pembobotan multidokumen dikembangkan oleh Murata et al. (2005) untuk menentukan jawaban akhir berdasarkan banyaknya dokumen yang menghasilkan jawaban serupa. Berikut formula Murata et al. (2005):
∑ 0.3(i-1)× n
i=1
wt,d
Nilai 0.3 adalah konstanta yang digunakan Murata et al. (2005). Sebagai ilustrasi, misal terdapat pertanyaan “Siapakah rektor IPB?”, kemudian kandidat jawaban yang diperoleh dapat dilihat pada Tabel 3. Jawaban dari pertanyaan ini, yaitu “Herry Suhardiyanto”. Namun sistem mengembalikan kandidat jawaban “Yonny Koesmaryono” dengan bobot tertinggi sehingga berpeluang besar menjadi jawaban akhir yang salah. Padahal kandidat jawaban “Herry Suhardiyanto” muncul pada beberapa dokumen berbeda, yaitu dokumen 578, 154, 32, dan 16. Perhitungan ulang bobot dilakukan dengan mengalikan skor kandidat jawaban menggunakan konstanta 0.3(i-1), nilai i menunjukkan jumlah dokumen berbeda yang merujuk pada kandidat jawaban yang sama. Kemudian dilakukan penjumlahan untuk seluruh skor tiap kandidat (wt,d). Dengan mengaplikasikan metode tersebut, maka skor untuk
“Herry Suhardiyanto” adalah 4.3 (= 3.2 + 2.8×0.3 + 2.5×0.32 + 2.4×0.33). Hasil skor dapat dilihat pada Tabel 4.
Tabel 3 Kandidat jawaban sebelum pembobotan multidokumen
Peringkat Kandidat Jawaban Skor ID Dokumen
1 Yonny Koesmaryono 3.3 42
2 Herry Suhardiyanto 3.2 578
3 Prof. Ir. Herry Suhardiyanto 2.8 154
4 Prof. Ir. Herry Suhardiyanto, MSc 2.5 32
5 Herry Suhardiyanto 2.4 16
Tabel 4 Kandidat jawaban setelah pembobotan multidokumen
Peringkat Kandidat Jawaban Skor ID Dokumen
1 Herry Suhardiyanto 4.3 578, 154, 32, 16
2 Yonny Koesmaryono 3.3 42
Tabel 5 Perbedaan sistem
Fungsi Subu (2012) Sistem Penelitian
Penyimpanan Korpus Berbasis file Berbasis DBMS MySQL
Indexing Dokumen Pembobotan TF-IDF Penggunaan tools Sphinx Penerjemahan Bahasa File kamus Microsoft Translator
Metode Pembobotan Heuristic Heuristic dan multidokumen
Hasil Percobaan
Perbedaan mendasar sistem ini dari sistem Subu (2012) dapat dilihat pada Tabel 5. Penelitian ini menggunakan 182 koleksi dokumen dan diuji menggunakan 40 query pertanyaan yang sama dengan penelitian Subu (2012). Proses evaluasi berdasarkan pada ketepatan pasangan jawaban dan dokumen, penilaian dibedakan
10
menjadi 4 jenis yaitu right, wrong, unsupported, dan null. Hasil percobaan akan dibandingkan dengan penelitian sebelumnya, yakni penelitian Subu (2012).
Penyimpanan korpus untuk sistem baru berbasis DBMS MySQL hanya untuk kemudahan proses indexing dokumen dan pengambilan passage. Indexing dokumen menggunakan tools Sphinx yang memberikan perbedaan waktu yang cukup signifikan untuk proses indexing. Penerjemahan bahasa menggunakan kamus
online Microsoft Translator untuk memastikan terjemahan bahasa Inggris sesuai
dengan query bahasa Indonesia yang diberikan. Metode pembobotan heuristic yang digunakan sama dengan penelitian Subu (2012), sistem baru menambahkan metode pembobotan multidokumen dengan harapan mampu memperbaiki jawaban akhir dari sistem.
1 Perbandingan Waktu Eksekusi Sistem
Setiap pertanyaan diujikan sebanyak 3 kali terhadap sistem agar memperoleh waktu eksekusi yang cukup objektif dalam menghasilkan jawaban akhir. Hasil yang cukup signifikan diperoleh dari perbedaan waktu eksekusi sistem Subu (2012) dan sistem ini. Grafik hasil perbandingan dapat dilihat pada Gambar 10. Hasil waktu eksekusi yang diperoleh dapat dilihat pada Lampiran 1.
Gambar 10 Grafik perbandingan waktu eksekusi
2 Perbandingan Hasil Percobaan Untuk Kata Tanya SIAPA
Pembobotan heuristic untuk kata tanya SIAPA menghasilkan presentase ketepatan jawaban untuk kriteria right sebesar 90%, unsupported 0%, wrong 10%,
null 0%, sedangkan heuristic dan multidokumen menghasilkan kriteria right 100%,
lainnya 0%. Grafik hasil percobaan untuk kata tanya SIAPA dapat dilihat pada Gambar 11. Daftar query dan evaluasinya dapat dilihat pada Lampiran 2.
3 Perbandingan Hasil Percobaan Untuk Kata Tanya KAPAN
Pembobotan heuristic dan heuristic ditambah multidokumen untuk kata tanya KAPAN menghasilkan presentase ketepatan jawaban untuk kriteria right sebesar 100% dan lainnya 0%. Grafik hasil percobaan kata tanya KAPAN dapat dilihat pada Gambar 12. Daftar query dan evaluasinya dapat dilihat pada Lampiran 3.
20.45 3.08 3.03 0.00 5.00 10.00 15.00 20.00 25.00 Heuristic (Subu 2012) Heuristic Heuristic + Multidokumen d etik Metode Pembobotan
11
Gambar 11 Grafik hasil percobaan untuk kata SIAPA
Gambar 12 Grafik hasil percobaan untuk kata KAPAN
Gambar 13 Grafik hasil percobaan untuk kata DIMANA
4 Perbandingan Hasil Percobaan Untuk Kata Tanya DIMANA
Pembobotan heuristic dan heuristic ditambah multidokumen untuk kata tanya DIMANA menghasilkan presentase ketepatan jawaban untuk kriteria right sebesar 100% dan lainnya 0%. Grafik hasil percobaan kata tanya DIMANA dapat dilihat pada Gambar 13. Daftar query dan evaluasinya dapat dilihat pada Lampiran 4.
60 0 30 10 90 0 10 0 100 0 0 0 0 20 40 60 80 100
right unsupported wrong null
Kriteria Jawaban % Heuristic (Subu 2012) Heuristic Heuristic + Multi-Dokumen 100 0 0 0 100 0 0 0 100 0 0 0 0 20 40 60 80 100
right unsupported wrong null
Kriteria Jawaban % Heuristic (Subu 2012) Heuristic Heuristic + Multi-Dokumen 100 0 0 0 100 0 0 0 100 0 0 0 0 20 40 60 80 100
right unsupported wrong null
Kriteria Jawaban %
Heuristic (Subu 2012) Heuristic
12
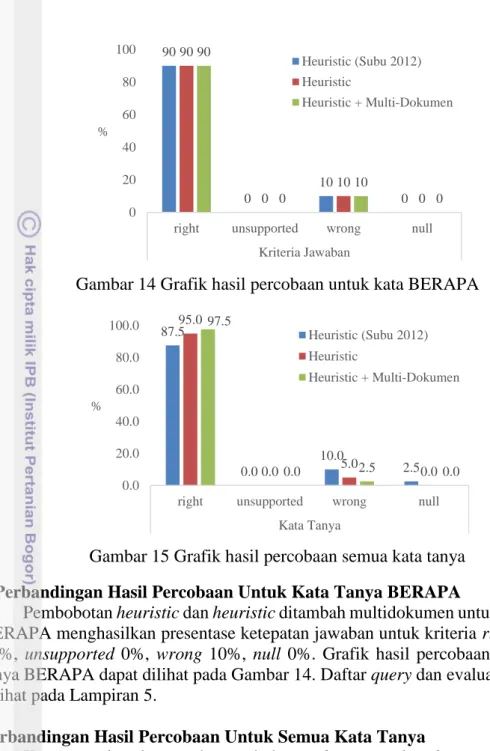
Gambar 14 Grafik hasil percobaan untuk kata BERAPA
Gambar 15 Grafik hasil percobaan semua kata tanya
5 Perbandingan Hasil Percobaan Untuk Kata Tanya BERAPA
Pembobotan heuristic dan heuristic ditambah multidokumen untuk kata tanya BERAPA menghasilkan presentase ketepatan jawaban untuk kriteria right sebesar 90%, unsupported 0%, wrong 10%, null 0%. Grafik hasil percobaan untuk kata tanya BERAPA dapat dilihat pada Gambar 14. Daftar query dan evaluasinya dapat dilihat pada Lampiran 5.
Perbandingan Hasil Percobaan Untuk Semua Kata Tanya
Ketepatan jawaban pada pembobotan heuristic dan heuristic ditambah multidokumen untuk semua kata tanya dapat dilihat pada Gambar 15. Pembobotan
heuristic menghasilkan presentase tertinggi untuk kriteria right dan wrong sebesar
95% dan 5%, sedangkan heuristic yang ditambah multidokumen menghasilkan kriteria right dan wrong sebesar 97.5% dan 2.5%.
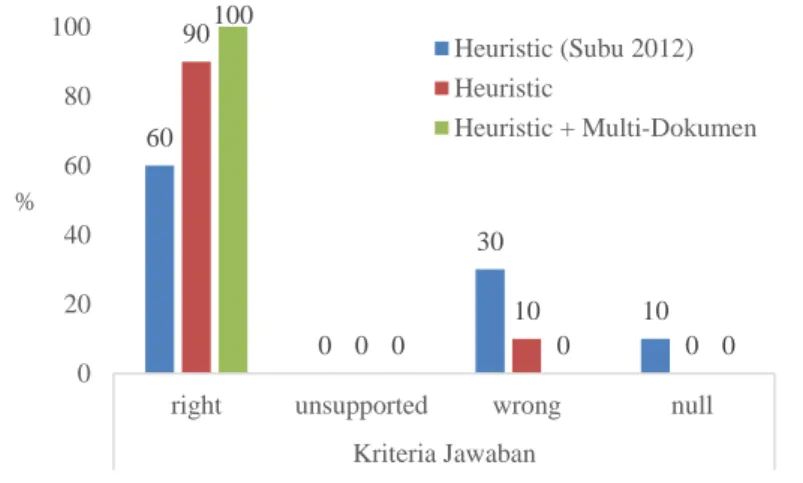
Berdasarkan hasil evaluasi yang diperoleh, sistem ini mampu memperoleh jawaban hampir 10 kali lebih cepat dan peningkatan akurasi rata-rata jawaban right sebesar 10% dari Subu (2012) untuk seluruh kata tanya. Hasil yang diperoleh tidak berbeda jauh dengan sistem sebelumnya yakni sistem Subu (2012), terlihat hasil yang akurasi yang diperoleh pada kata tanya KAPAN, DIMANA, dan BERAPA menunjukkan nilai yang sama. Namun, pada kata tanya SIAPA terjadi peningkatan akurasi dari sistem sebelumnya yakni sebesar 60% menjadi 90% untuk sistem baru dengan metode heuristic dan menjadi 100% untuk sistem baru dengan metode
heuristic ditambah multidokumen.
90 0 10 0 90 0 10 0 90 0 10 0 0 20 40 60 80 100
right unsupported wrong null
Kriteria Jawaban % Heuristic (Subu 2012) Heuristic Heuristic + Multi-Dokumen 87.5 0.0 10.0 2.5 95.0 0.0 5.0 0.0 97.5 0.0 2.5 0.0 0.0 20.0 40.0 60.0 80.0 100.0
right unsupported wrong null
Kata Tanya %
Heuristic (Subu 2012) Heuristic
13 Peningkatan akurasi dari sistem Subu (2012) dapat dikarenakan perbedaan proses indexing yang merupakan proses untuk memperoleh dokumen relevan terkait query yang diberikan. Struktur kode sistem yang dibuat pada penelitian ini juga berbeda karena perbedaan proses indexing namun memiliki konsep metode yang sama. Percobaan menggunakan metode tambahan yakni pembobotan multidokumen menunjukkan hasil yang positif, hal tersebut dapat dilihat pada hasil kata tanya SIAPA. Metode heuristic dan metode heuristic ditambah multidokumen memperoleh nilai right sebesar 90% dan 100%. Perbedaan ini terjadi pada uji coba
query “Siapa Presiden BEM IPB?”, kandidat jawaban yang diperoleh menggunakan
metode heuristic dan heuristic ditambah multidokumen dapat dilihat pada Gambar 16 dan Gambar 17.
Metode heuristic menghasilkan “Dr. drh. Moh. Agil M. Agr.” sebagai jawaban akhir karena memiliki nilai bobot tertinggi padahal jawaban ini adalah jawaban yang salah (wrong). Pada metode heuristic ditambah multidokumen, pembobotan multidokumen menghitung ulang hasil bobot dari metode heuristic karena terdapat salah satu kandidat jawaban yang sama namun berasal dari dokumen yang berbeda yakni kandidat jawaban “Reza Pahlevi” (lihat Gambar 16). Bobot “Reza Pahlevi” dihitung ulang sehingga hasil yang diperoleh seperti pada Gambar 17. Dengan demikian, sistem memberikan jawaban yang benar (right) untuk kasus query “Siapa Presiden BEM IPB”.
Gambar 16 Kandidat jawaban dengan metode heuristic
Gambar 17 Kandidat jawaban dengan metode heuristic ditambah multidokumen
SIMPULAN DAN SARAN
Kesimpulan
Hasil dari penelitian ini adalah sebuah Cross Language Question Answering
System menggunakan pembobotan heuristic dan multidokumen. Kinerja terbaik
diperoleh pada pembobotan heuristic ditambah multidokumen untuk pengujian
query pertanyaan menggunakan kata tanya SIAPA, DIMANA, KAPAN dan kurang
14
dan waktu eksekusi yang diperlukan untuk memperoleh jawaban juga lebih baik dibandingkan sistem yang dikembangkan oleh Subu (2012).
Saran
Saran perbaikan untuk penelitian berikutnya adalah:
1 Penggunaan metode ekstraksi kalimat yang lebih baik untuk kasus nama gelar, singkatan, dan nama situs.
2 Penggunaan kamus penerjemah (translator) lebih dari satu.
3 Penambahan jumlah dokumen dan penggunaan Named Entity Tagger otomatis untuk dokumen bahasa Inggris.
4 Penggunaan metode pembentukan passage yang berbeda (Fathi 2012).
DAFTAR PUSTAKA
Ballesteros LA, Li X. 2007. Heuristic and syntactic scoring for cross-language question answering system. Di dalam: Proceedings of NTCIR-6 Workshop
Meeting; 2007 Mei 15-18; Tokyo, Jepang. Tokyo (JP): National Institute of
Informatics. hlm 230-233.
Cidhy DATK. 2009. Implementasi Question Answering System dengan Pembobotan Heuristic [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Fathi S. 2012. Pembentukan Passage dalam Question Answering System untuk Dokumen Bahasa Indonesia [skripsi]. Bogor (ID). Institut Pertanian Bogor. Murata M, Utiyama M, Isahara H. 2005. Japanese-to-english and
english-to-japanese cross-language question-answering system using decreased adding with multiple answers. Di dalam: Proceedings of the Fifth NTCIR Workshop
Meeting on Evaluation of Information Access Technologies: Information Retrieval, Question Answering and Cross-Lingual Information Access; 2005
Dec 6-9; Tokyo, Japan. Tokyo (JP): National Institute of Informatics.
Subu S. 2012. Cross Language Question Answering System Menggunakan Pembobotan Heuristic dan Rule Based [skripsi]. Bogor (ID): Institut Pertanian Bogor.
15 Lampiran 1 Waktu (detik) eksekusi sistem untuk memperoleh jawaban akhir
No Query Heuristic (Subu 2012) Heuristic Heuristic +
Multidokumen
1 Siapa rektor IPB 23.41 22.72 23.26 2.63 2.45 3.55 3.24 2.76 2.43
2 Siapa Herry Suhardiyanto 22.43 21.24 22.00 3.20 3.43 3.10 3.33 3.22 2.91 3 Siapa Menteri Pertanian 22.61 22.56 23.01 2.87 3.11 3.81 2.85 3.12 2.73 4 Siapa Suswono 21.63 22.18 22.5 2.52 3.24 2.84 3.2 3.34 2.89 5 Siapa presiden BEM IPB 21.81 21.52 21.75 2.87 3.51 3.93 3.31 2.8 2.74
6 Siapa Reza Pahlevi 19.03 18.63 19.47 2.29 3.31 3.46 2.94 2.82 2.71
7 Siapa kepala PPSHB IPB 22.73 22.89 22.52 3.13 2.92 3.64 2.7 2.6 2.71 8 Siapa Suharsono 20.3 19.32 20.08 3.27 3.29 3.25 2.52 2.71 2.73 9 Siapa ketua LPPM IPB 23.03 22.99 22.3 2.41 3.31 2.36 2.83 3.2 2.75
10 Siapa ketua HILPI 22.42 22.84 21.85 2.64 3.71 3.20 2.79 3.17 2.56
11 Kapan Agrinex
Expo 2011
19.36 19.26 19.31 3.13 3.34 3.52 3.13 2.39 2.57
12 Kapan IPB merilis
cabai CH3
20.31 19.98 20.38 2.56 3.82 2.76 3.48 4.54 3.02
13 Kapan Diploma
IPB punya Tax Center 19.22 19.95 19.21 2.64 2.65 2.88 3.01 3.38 2.57 14 Kapan registrasi mahasiswa baru pascasarjana 2011 20.1 20.25 20.67 3.55 2.83 2.92 3.15 3.06 2.9 15 Kapan seminar sagu IPB 20.27 20.83 20.5 2.88 3.25 2.61 3.39 3.48 3.1 16 Kapan program menanam 1000 pohon Bintaro 19.73 19.36 20.12 2.67 2.23 3.63 3.16 3.5 3.27 17 Kapan PIMNAS 2011 19.08 19.16 18.57 3.45 2.90 2.24 3.2 2.85 2.98 18 Kapan TPB cup 2011 19.97 19.55 20.06 3.84 3.35 3.85 2.93 2.78 2.33 19 Kapan wisuda Diploma Tahap II 20.39 20.14 20.69 3.84 3.60 2.94 3.03 2.87 3.37 20 Kapan Simposium Temulawak Internasional 20.59 20.22 20.8 3.20 3.10 3.45 3.01 3.42 2.63 21 Dimana kampus IPB 20.14 20.42 19.88 2.98 3.66 2.98 3.62 2.99 2.9 22 Dimana Agrinex Expo 2011 19.5 19.65 19.46 3.36 2.69 3.18 2.58 2.92 2.94 23 Dimana seminar sagu IPB 21.73 21.84 22.18 3.02 3.03 3.30 2.65 3.22 2.74 24 Dimana Seminar Hasil Penelitian IPB Tahun 2011 22.95 22.17 21.93 3.03 2.37 3.28 3.12 3.22 3.37 25 Dimana mahasiswa menanam 1000 pohon Bintaro 22.11 20.89 21.51 3.15 3.53 3.72 3.38 2.79 2.76
16
No Query Heuristic (Subu 2012) Heuristic Heuristic +
Multidokumen 26 Dimana PIMNAS 2011 18.52 18.67 18.44 3.35 2.71 2.64 3.18 2.96 3.13 27 Dimana PIMNAS 2010 18.56 18.51 18.44 3.24 3.31 3.19 3.4 3.41 2.87 28 Dimana Simposium Temulawak Internasional 21.23 20.3 20.2 3.33 2.67 3.77 2.9 3.09 2.71 29 Dimana TPB cup 2011 20.07 19.81 20.12 2.43 3.07 2.21 2.62 2.62 2.47 30 Dimana lomba Anugerah Media Humas 2010 20.01 20.17 19.73 3.52 3.57 2.87 2.59 3.19 3.33
31 Berapa wakil ipb
pada PIMNAS 2011
20.15 19.75 19.71 3.12 3.35 3.11 3.25 2.94 3.12
32 Berapa mahasiswa
yang ikut TPB cup 2011 19.95 19.35 19.57 2.92 2.61 3.08 3.2 2.87 3.45 33 Berapa spesies koleksi sagu BPTP papua 19.91 20.34 19.57 2.11 2.82 3.24 3 3.22 3.13 34 Berapa beasiswa
Bank Mandiri pada mahasiswa IPB 19.58 19.09 19.87 3.43 2.31 3.04 3.39 3.49 3.23 35 Berapa lulusan diploma pada wisuda tahap II 20.22 20.05 19.79 3.47 3.62 3.12 3.21 3.74 2.91 36 Berapa judul penelitian pada Seminar Hasil Penelitian IPB Tahun 2011 20.4 19.52 19.51 3.43 3.04 3.07 2.84 2.93 2.68 37 Berapa pohon yg ditanam Forum Mahasiswa Pascasarjana IPB 20.01 19.19 19.98 2.90 3.35 2.88 3.12 3.68 2.89 38 Berapa total pegawai ipb menerima bantuan pendidikan BNI syariah 20.04 19.13 19.89 2.52 2.46 2.96 2.89 3.02 3.5
39 Berapa orang dari
Soul Women University mengunjungi IPB
19.74 19.17 19.09 3.02 2.79 2.37 3.18 2.67 2.84
40 Berapa mahasiswa
ipb ikut demo memasak dengan kompor sekam
17 Lampiran 2 Tabel hasil kata tanya SIAPA
No Query Hasil yang
diharapkan
Heuristic (Subu
2012) Heuristic
Heuristic +
Multidokumen
Jawaban Ket Jawaban Ket Jawaban Ket
1 Siapa rektor IPB Herry Suhardiyanto Herry Suhardiya nto R Prof. Dr. Ir. Herry Suhardiya nto M.Sc. R Prof. Dr. Ir. Herry Suhardiya nto M.Sc. R 2 Siapa Herry Suhardiyant o
Rector of IPB Rector of
IPB R Rector IPB R Rector IPB R 3 Siapa Menteri Pertanian Suswono Suswono R Mr Suswono R Mr Suswono R 4 Siapa Suswono Minister of Agriculture National Logistic Agency W Minister Agricultur e R Minister Agricultur e R 5 Siapa presiden BEM IPB
Reza Pahlevi PPNSI W Dr. Drh.
Moh. Agil M. Agr. W Reza Pahlevi R 6 Siapa Reza Pahlevi President of BEM KM IPB - N President BEM KM IPB R President BEM KM IPB R 7 Siapa kepala PPSHB IPB Suharsono Suharson o R Dr Suharsono R Dr Suharsono R 8 Siapa Suharsono Head of PPSHB IPB Head of PPSHB R Head of PPSHB IPB R Head PPSHB IPB R 9 Siapa ketua LPPM IPB Prof. Dr. Bambang Pramudya Bambang Pramudya R Prof. Dr. Bambang Pramudya R Prof. Dr. Bambang Pramudya R 10 Siapa ketua HILPI Prof Dr Ir Muladno MSA Dr. Ir. Hashim, DEA Prof Dr Ir Muladno MSA R Prof Dr Ir Muladno MSA R
18
Lampiran 3 Tabel hasil kata tanya KAPAN
No Query Hasil yang
diharapkan
Heuristic (Subu
2012) Heuristic
Heuristic +
Multidokumen
Jawaban Ket Jawaban Ket Jawaban Ket
1 Kapan Agrinex Expo 2011 Friday, 4 March 2011 Friday, 4 March 2011 R Friday 4 March 2011 R Friday 4 March 2011 R 2 Kapan IPB merilis cabai CH3 October 2010 October 2010 R October 2010 R October 2010 R 3 Kapan Diploma IPB punya Tax Center Tuesday 5 April 2011 Tuesday 5 April 2011 R Tuesday 5 April 2011 R Tuesday 5 April 2011 R 4 Kapan registrasi mahasiswa baru pascasarjana 2011 January 19, 2011 January 19, 2011 R January 19 2011 R January 19 2011 R 5 Kapan seminar sagu IPB 14 /10 14 /10 R 14 /10 R 14 /10 R 6 Kapan program menanam 1000 pohon Bintaro Saturday, 19 February 2011 Saturday, 19 February 2011 R Saturday, 19 February 2011 R Saturday, 19 February 2011 R 7 Kapan PIMNAS 2011 18-22 Juli 2011 18-22 Juli 2011 R 18-22 Juli 2011 R 18-22 Juli 2011 R 8 Kapan TPB cup 2011 14-17 April 2011 14-17 April 2011 R 14-17 April 2011 R 14-17 April 2011 R 9 Kapan wisuda Diploma Tahap II 18-19 October 18-19 October R 18-19 October R 18-19 October R 10 Kapan Simposium Temulawak Internasional 27 May 2011 27 May 2011 R 27 May 2011 R 27 May 2011 N
19 Lampiran 4 Tabel hasil kata tanya DIMANA
No Query Hasil yang
diharapkan
Heuristic (Subu
2012) Heuristic
Heuristic +
Multidokumen
Jawaban Ket Jawaban Ket Jawaban Ket
1 Dimana
kampus IPB
Darmaga Darmaga R Darmaga R Darmaga R
2 Dimana Agrinex Expo 2011 Jakarta Convention Center Jakarta Convention Center R Jakarta Convention Center R Jakarta Convention Center R 3 Dimana seminar sagu IPB IPB International Convention Center IPB International Convention Center R IPB International Convention Center IICC R IPB International Convention Center IICC R 4 Dimana Seminar Hasil Penelitian IPB Tahun 2011 Auditorium of the Faculty of Fisheries and Marine Sciences Auditorium of the Faculty of Fisheries and Marine Sciences R Auditorium of the Faculty of Fisheries and Marine Sciences R Auditorium of the Faculty of Fisheries and Marine Sciences R 5 Dimana mahasiswa menanam 1000 pohon Bintaro
Darmaga Darmaga R Darmaga R Darmaga R
6 Dimana PIMNAS 2011 Makassar, South Sulawesi Makassar, South Sulawesi R Makassar, South Sulawesi R Makassar South Sulawesi R 7 Dimana PIMNAS 2010
Denpasar Denpasar R Denpasar R Denpasar R
8 Dimana Simposium Temulawak Internasional IPB International Convention Center IPB International Convention Center R IPB International Convention Center R IPB International Convention Center R 9 Dimana TPB cup 2011
Gymnasium Gymnasium R Gymnasium R Gymnasium R
10 Dimana lomba Anugerah Media Humas 2010 West Nusa Tenggara West Nusa Tenggara R West Nusa Tenggara R West Nusa Tenggara R
20
Lampiran 5 Tabel hasil kata tanya BERAPA
No Query Hasil yang
diharapkan
Heuristic (Subu
2012) Heuristic
Heuristic +
Multidokumen
Jawaban Ket Jawaban Ket Jawaban Ket
1 Berapa wakil ipb
pada PIMNAS 2011
141 141 R 1 W 1 W
2 Berapa mahasiswa
yang ikut TPB cup 2011 1,400 1,400 R 1,400 R 1400 R 3 Berapa spesies koleksi sagu BPTP papua 60 60 R 60 R 60 R 4 Berapa beasiswa
Bank Mandiri pada mahasiswa IPB Rp 1,2 billion 3 W Rp 1,2 billion R Rp 1,2 billion R 5 Berapa lulusan diploma pada wisuda tahap II 1160 1160 R 1160 R 1160 R 6 Berapa judul penelitian pada Seminar Hasil Penelitian IPB Tahun 2011 225 225 R 225 R 225 R 7 Berapa pohon yg ditanam Forum Mahasiswa Pascasarjana IPB 1000 1000 R 1000 R 1000 R 8 Berapa total pegawai ipb menerima bantuan pendidikan BNI syariah 80 80 R 80 R 80 R
9 Berapa orang dari
Soul Women University mengunjungi IPB
10 10 R 10 R 10 R
10 Berapa mahasiswa
ipb ikut demo memasak dengan kompor sekam
150 150 R 150 R 150 R
21
RIWAYAT HIDUP
Penulis lahir di Serang pada tanggal 27 April 1991. Penulis merupakan sulung dari dua bersaudara dari pasangan Bapak Putut Irianto dan Ibu Sri Mulyani. Penulis menghabiskan masa pendidikan dasar, menengah, dan atas di kota Cilegon. Tahun 2009 menjadi tahun kelulusan penulis dari SMA Negeri 1 Cilegon. Di tahun yang sama pula penulis diterima sebagai mahasiswa Institut Pertanian Bogor di departemen Ilmu Komputer melalui jalur USMI.
Selama menjalani kuliah di IPB penulis berorganisasi di Divisi Edukasi Himpunan Mahasiswa Ilmu Komputer sebagai penanggung jawab komunitas
Networking pada periode 2010/2011. Penulis melaksanakan kegiatan Praktik Kerja
Lapang (PKL) selama 2 bulan di Divisi Informtaion Technology (IT) dan
Networking Berita Satu Media Holdings sebagai Web Developer pada tahun 2012.
Penulis juga pernah meraih prestasi seperti: Proposal Didanai Program Kreativitas Mahasiswa DIKTI pada tahun 2012, Proposal Didanai Sobat Bumi Pertamina pada tahun 2013, dan Semifinalis Acer International Green Contest pada tahun 2013.